
A Point-Interval Forecasting Method for Wind Speed Using Improved Wild Horse Optimization Algorithm and Ensemble Learning


Abstract
:1. Introduction
2. Methodology
2.1. Empirical Wavelet Transform
2.2. Gated Recurrent Unit
2.3. Extreme Learning Machine
2.4. Bidirectional Long Short-Term Memory Network
2.5. Improved Wild Horse Optimization Algorithm
2.5.1. Wild Horse Optimization Algorithm
2.5.2. Improvement Strategy
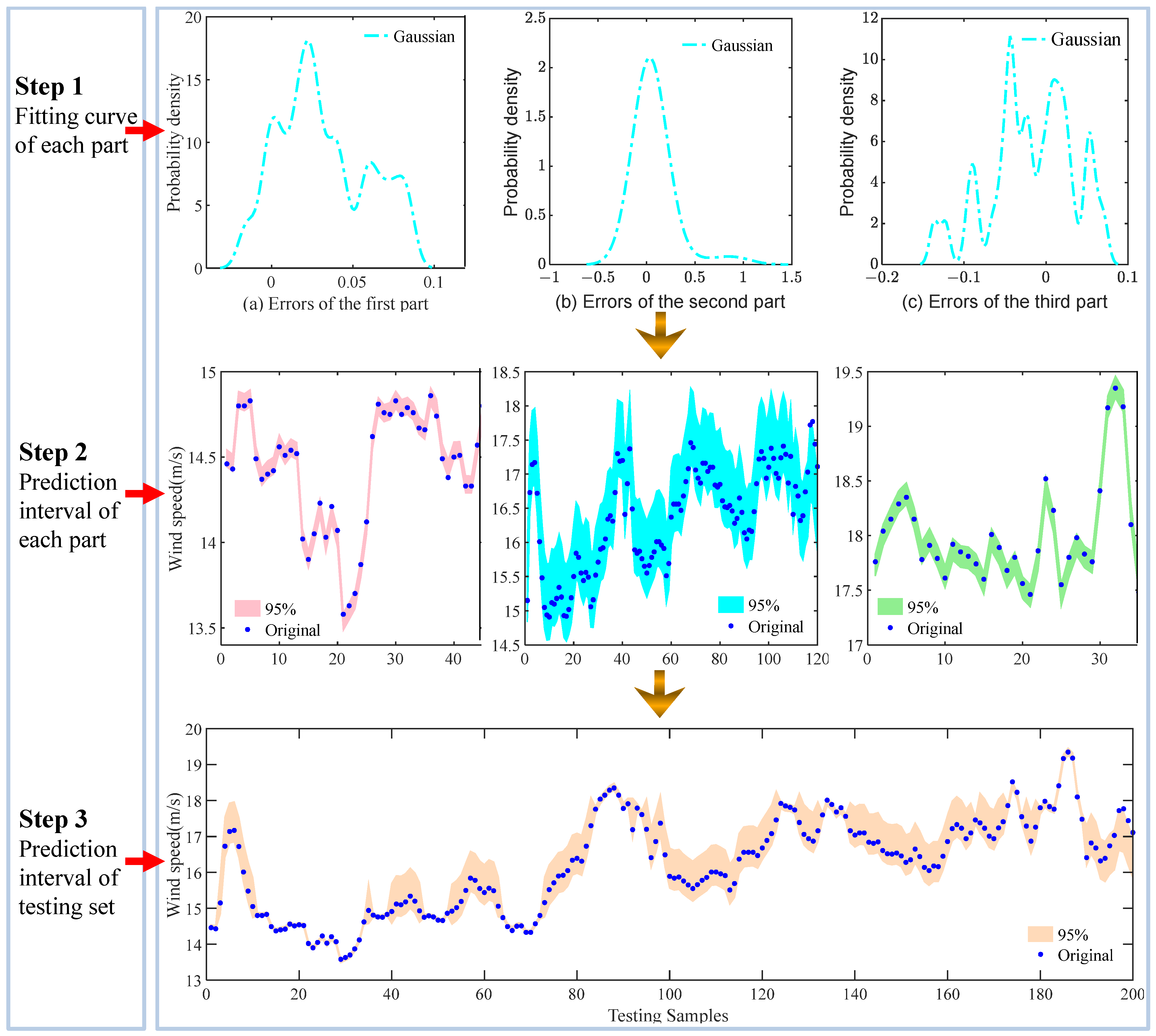
2.6. Improved Kernel Density Estimation
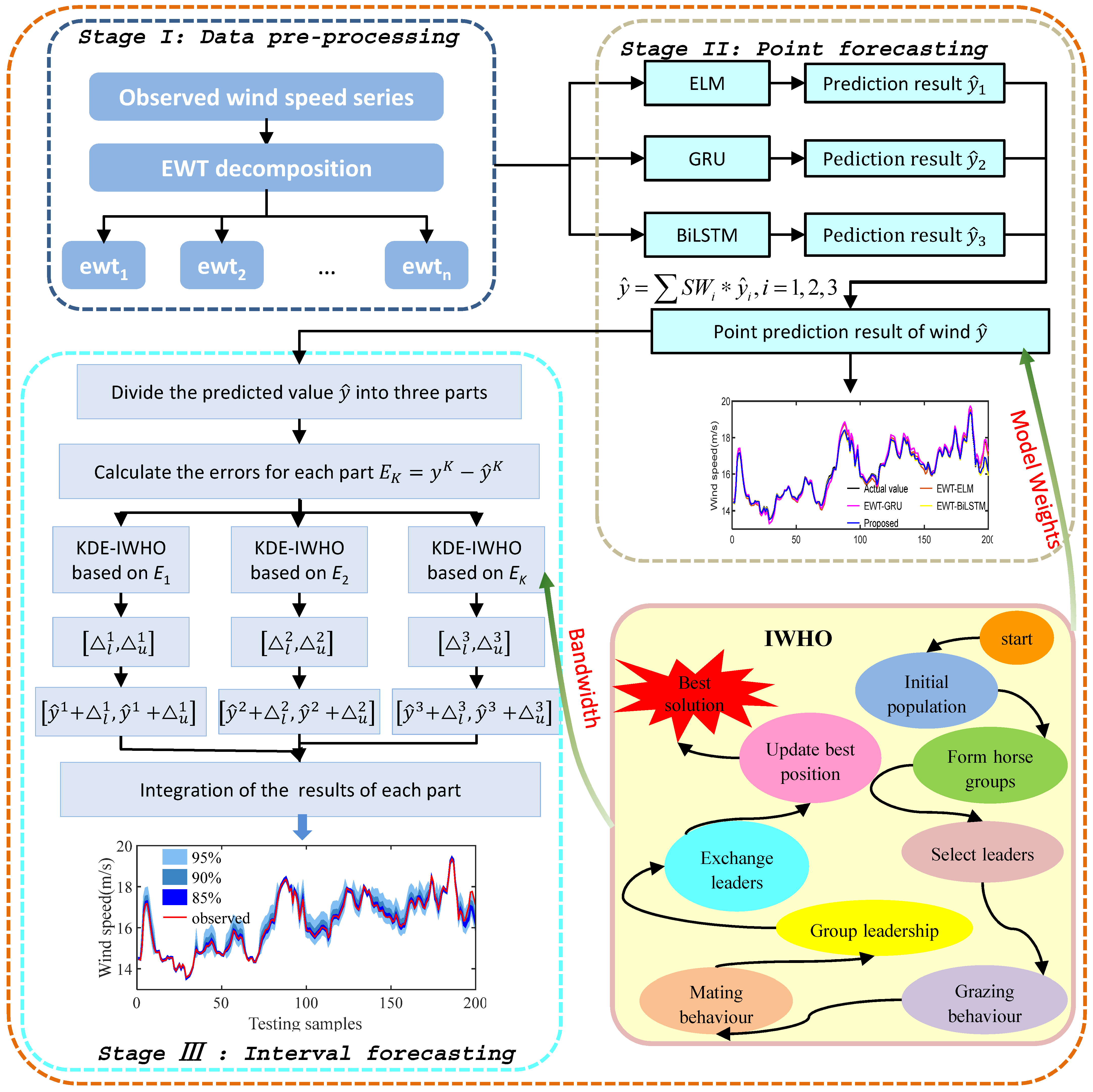
2.7. The Structure and Process of the Proposed Model
3. Case Study
3.1. Data Description
3.2. Evaluation Indicators
3.2.1. Point Prediction
3.2.2. Interval Prediction
3.3. Experimental Analysis
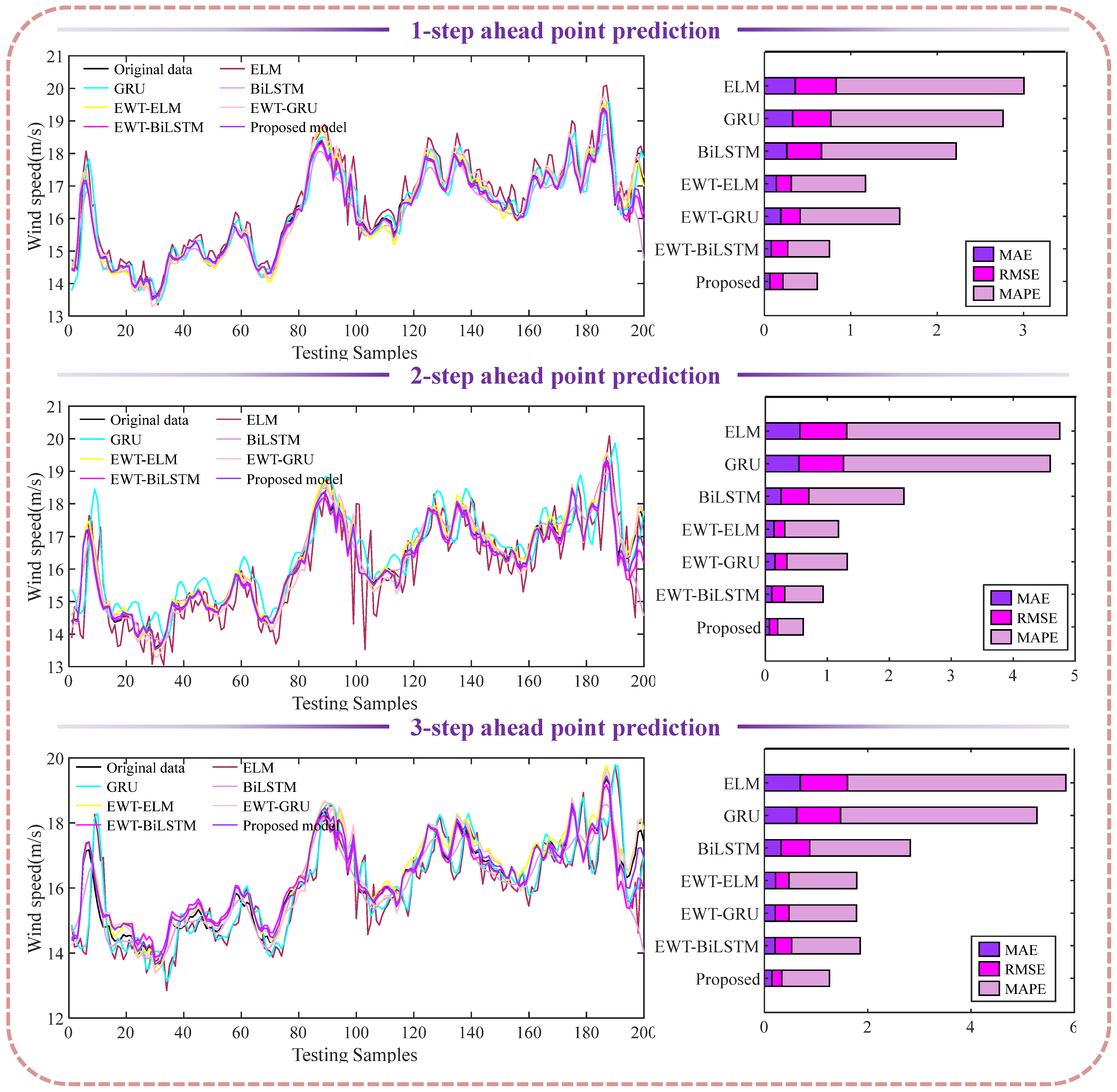
3.3.1. Experiment I: Comparison with Each Module
3.3.2. Experiment II: Comparison with Models Based on Different Decomposition Algorithms
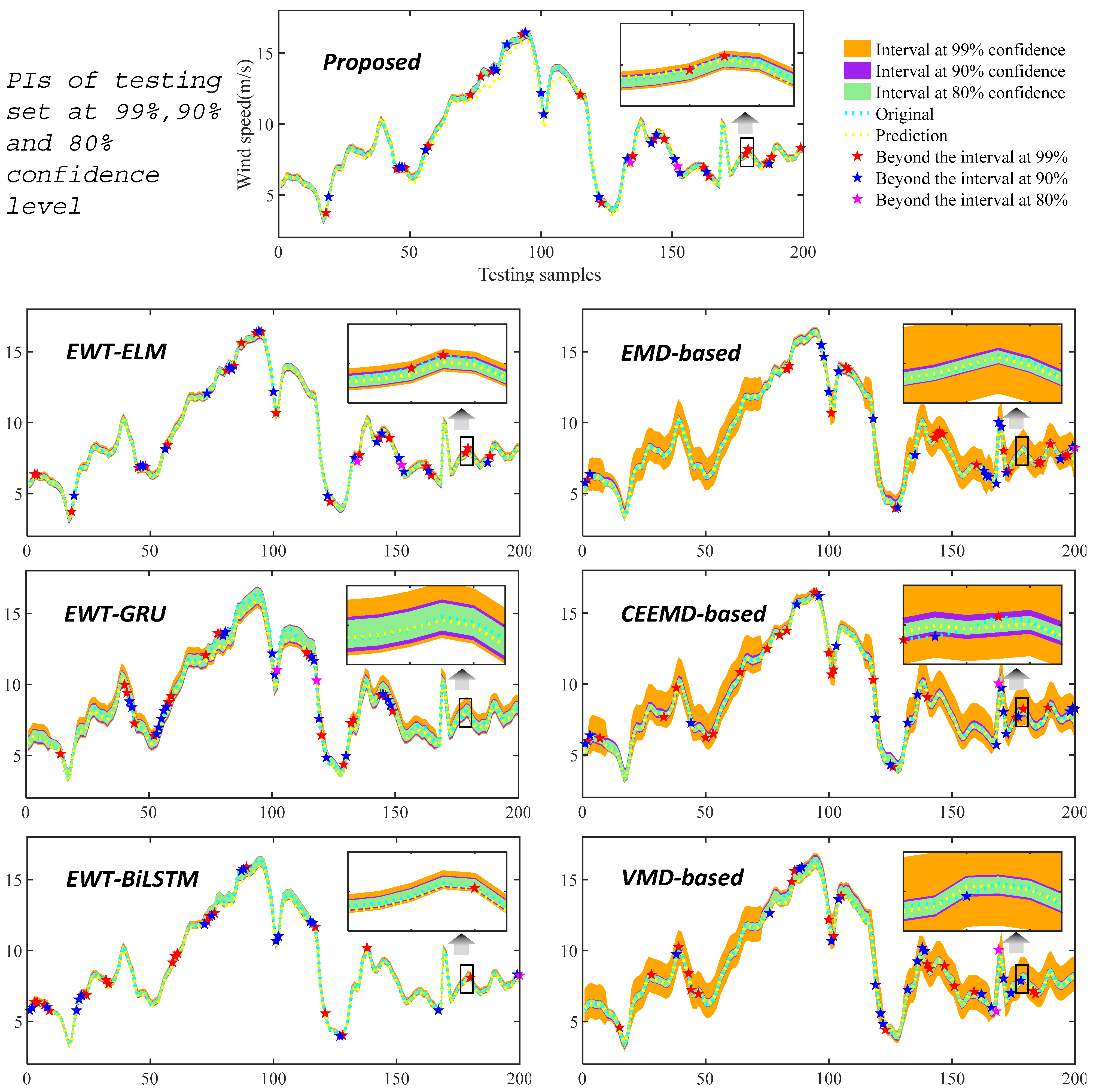
3.3.3. Experiment III: Comparison of Interval Estimates for All Models
4. Discussion
4.1. Significance Test of Point Prediction
4.2. Improvement in Interval Prediction Performance
4.3. Discussion of the IWHO Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bórawski, P.; Bełdycka-Bórawska, A.; Jankowski, K.J.; Dubis, B.; Dunn, J.W. Development of Wind Energy Market in the European Union. Renew. Energy 2020, 161, 691–700. [Google Scholar] [CrossRef]
- Yuan, L.; Xi, J. Review on China’s Wind Power Policy (1986–2017). Environ. Sci. Pollut. Res. 2019, 26, 25387–25398. [Google Scholar] [CrossRef] [PubMed]
- Global Wind Energy Council. Global Wind Report 2022; Global Wind Energy Council: Brussels, Belgium, 2022. [Google Scholar]
- Li, J.; Wang, J.; Li, Z. A Novel Combined Forecasting System Based on Advanced Optimization Algorithm—A Study on Optimal Interval Prediction of Wind Speed. Energy 2023, 264, 126179. [Google Scholar] [CrossRef]
- Alrwashdeh, S.S. Investigation of Wind Energy Production at Different Sites in Jordan Using the Site Effectiveness Method. Energy Eng. 2019, 116, 47–59. [Google Scholar] [CrossRef]
- Alrwashdeh, S.S.; Alsaraireh, F.M. Wind Energy Production Assessment at Different Sites in Jordan Using Probability Distribution Functions. ARPN J. Eng. Appl. Sci. 2018, 13, 8163–8172. [Google Scholar]
- Cui, Y.; Huang, C.; Cui, Y. A Novel Compound Wind Speed Forecasting Model Based on the Back Propagation Neural Network Optimized by Bat Algorithm. Environ. Sci. Pollut. Res. 2020, 27, 7353–7365. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Zhang, L.; Wang, J.; Niu, X. Hybrid System Based on a Multi-Objective Optimization and Kernel Approximation for Multi-Scale Wind Speed Forecasting. Appl. Energy 2020, 277, 115561. [Google Scholar] [CrossRef]
- Misaki, T.; Ohsawa, T.; Konagaya, M.; Shimada, S.; Takeyama, Y.; Nakamura, S. Accuracy Comparison of Coastal Wind Speeds between WRF Simulations Using Different Input Datasets in Japan. Energies 2019, 12, 2754. [Google Scholar] [CrossRef]
- Jia, Z.; Zhou, Z.; Zhang, H.; Li, B.; Zhang, Y. Forecast of Coal Consumption in Gansu Province Based on Grey-Markov Chain Model. Energy 2020, 199, 117444. [Google Scholar] [CrossRef]
- Yang, W.; Wang, J.; Lu, H.; Niu, T.; Du, P. Hybrid Wind Energy Forecasting and Analysis System Based on Divide and Conquer Scheme: A Case Study in China. J. Clean. Prod. 2019, 222, 942–959. [Google Scholar] [CrossRef]
- Fu, W.; Zhang, K.; Wang, K.; Wen, B.; Fang, P.; Zou, F. A Hybrid Approach for Multi-Step Wind Speed Forecasting Based on Two-Layer Decomposition, Improved Hybrid DE-HHO Optimization and KELM. Renew. Energy 2021, 164, 211–229. [Google Scholar] [CrossRef]
- Xie, K.; Yi, H.; Hu, G.; Li, L.; Fan, Z. Short-Term Power Load Forecasting Based on Elman Neural Network with Particle Swarm Optimization. Neurocomputing 2020, 416, 136–142. [Google Scholar] [CrossRef]
- Li, Y.; Yang, P.; Wang, H. Short-Term Wind Speed Forecasting Based on Improved Ant Colony Algorithm for LSSVM. Clust. Comput. 2019, 22, 11575–11581. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, P.; Zhang, L.; Niu, X. A Combined Forecasting Model for Time Series: Application to Short-Term Wind Speed Forecasting. Appl. Energy 2020, 259, 114137. [Google Scholar] [CrossRef]
- Jia, P.; Liu, H.; Wang, S.; Wang, P. Research on a Mine Gas Concentration Forecasting Model Based on a GRU Network. IEEE Access 2020, 8, 38023–38031. [Google Scholar] [CrossRef]
- Wu, C.; Wang, J.; Chen, X.; Du, P.; Yang, W. A Novel Hybrid System Based on Multi-Objective Optimization for Wind Speed Forecasting. Renew. Energy 2020, 146, 149–165. [Google Scholar] [CrossRef]
- Ma, Z.; Chen, H.; Wang, J.; Yang, X.; Yan, R.; Jia, J.; Xu, W. Application of Hybrid Model Based on Double Decomposition, Error Correction and Deep Learning in Short-Term Wind Speed Prediction. Energy Convers. Manag. 2020, 205, 112345. [Google Scholar] [CrossRef]
- Krishna Rayi, V.; Mishra, S.P.; Naik, J.; Dash, P.K. Adaptive VMD Based Optimized Deep Learning Mixed Kernel ELM Autoencoder for Single and Multistep Wind Power Forecasting. Energy 2022, 244, 122585. [Google Scholar] [CrossRef]
- da Silva, R.G.; Ribeiro, M.H.D.M.; Moreno, S.R.; Mariani, V.C.; Coelho, L.d.S. A Novel Decomposition-Ensemble Learning Framework for Multi-Step Ahead Wind Energy Forecasting. Energy 2021, 216, 119174. [Google Scholar] [CrossRef]
- Wang, J.; Heng, J.; Xiao, L.; Wang, C. Research and Application of a Combined Model Based on Multi-Objective Optimization for Multi-Step Ahead Wind Speed Forecasting. Energy 2017, 125, 591–613. [Google Scholar] [CrossRef]
- Wang, K.; Wang, J.; Zeng, B.; Lu, H. An Integrated Power Load Point-Interval Forecasting System Based on Information Entropy and Multi-Objective Optimization. Appl. Energy 2022, 314, 118938. [Google Scholar] [CrossRef]
- Song, J.; Wang, J.; Lu, H. A Novel Combined Model Based on Advanced Optimization Algorithm for Short-Term Wind Speed Forecasting. Appl. Energy 2018, 215, 643–658. [Google Scholar] [CrossRef]
- Wei, Y.; Chen, Z.; Zhao, C.; Chen, X.; Yang, R.; He, J.; Zhang, C.; Wu, S. Deterministic and Probabilistic Ship Pitch Prediction Using a Multi-Predictor Integration Model Based on Hybrid Data Preprocessing, Reinforcement Learning and Improved QRNN. Adv. Eng. Inform. 2022, 54, 101806. [Google Scholar] [CrossRef]
- Wang, Y.; Xue, W.; Wei, B.; Li, K. An Adaptive Wind Power Forecasting Method Based on Wind Speed-Power Trend Enhancement and Ensemble Learning Strategy. J. Renew. Sustain. Energy 2022, 14, 063301. [Google Scholar] [CrossRef]
- Liu, X.; Yang, L.; Zhang, Z. The Attention-Assisted Ordinary Differential Equation Networks for Short-Term Probabilistic Wind Power Predictions. Appl. Energy 2022, 324, 119794. [Google Scholar] [CrossRef]
- Zhang, X. Developing a Hybrid Probabilistic Model for Short-Term Wind Speed Forecasting. Appl. Intell. 2022, 53, 728–745. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, J.; Infield, D.; Liu, Y.; Lien, F. Short-Term Forecasting and Uncertainty Analysis of Wind Turbine Power Based on Long Short-Term Memory Network and Gaussian Mixture Model. Appl. Energy 2019, 241, 229–244. [Google Scholar] [CrossRef]
- Hu, J.; Heng, J.; Wen, J.; Zhao, W. Deterministic and Probabilistic Wind Speed Forecasting with De-Noising-Reconstruction Strategy and Quantile Regression Based Algorithm. Renew. Energy 2020, 162, 1208–1226. [Google Scholar] [CrossRef]
- He, Y.; Wang, Y.; Wang, S.; Yao, X. A Cooperative Ensemble Method for Multistep Wind Speed Probabilistic Forecasting. Chaos Solitons Fractals 2022, 162, 112416. [Google Scholar] [CrossRef]
- Zhu, S.; Yuan, X.; Xu, Z.; Luo, X.; Zhang, H. Gaussian Mixture Model Coupled Recurrent Neural Networks for Wind Speed Interval Forecast. Energy Convers. Manag. 2019, 198, 111772. [Google Scholar] [CrossRef]
- Afrasiabi, M.; Mohammadi, M.; Rastegar, M.; Afrasiabi, S. Advanced Deep Learning Approach for Probabilistic Wind Speed Forecasting. IEEE Trans. Ind. Inform. 2021, 17, 720–727. [Google Scholar] [CrossRef]
- Mahmoud, T.; Dong, Z.Y.; Ma, J. An Advanced Approach for Optimal Wind Power Generation Prediction Intervals by Using Self-Adaptive Evolutionary Extreme Learning Machine. Renew. Energy 2018, 126, 254–269. [Google Scholar] [CrossRef]
- Yu, M.; Niu, D.; Wang, K.; Du, R.; Yu, X.; Sun, L.; Wang, F. Short-Term Photovoltaic Power Point-Interval Forecasting Based on Double-Layer Decomposition and WOA-BiLSTM-Attention and Considering Weather Classification. Energy 2023, 275, 127348. [Google Scholar] [CrossRef]
- Gilles, J. Empirical Wavelet Transform. IEEE Trans. Signal Process. 2013, 61, 3999–4010. [Google Scholar] [CrossRef]
- Liu, H.; Chen, C. Multi-Objective Data-Ensemble Wind Speed Forecasting Model with Stacked Sparse Autoencoder and Adaptive Decomposition-Based Error Correction. Appl. Energy 2019, 254, 113686. [Google Scholar] [CrossRef]
- Li, Y.; Wu, H.; Liu, H. Multi-Step Wind Speed Forecasting Using EWT Decomposition, LSTM Principal Computing, RELM Subordinate Computing and IEWT Reconstruction. Energy Convers. Manag. 2018, 167, 203–219. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme Learning Machine: Theory and Applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, Z.; Wang, Y.; Su, J.; Han, Z.; Zhou, D.; Zhang, K.; Zhao, Y.; Bao, Y. Short-Term Wind Speed Predicting Framework Based on EEMD-GA-LSTM Method under Large Scaled Wind History. Energy Convers. Manag. 2021, 227, 113559. [Google Scholar] [CrossRef]
- Naruei, I.; Keynia, F. Wild Horse Optimizer: A New Meta-Heuristic Algorithm for Solving Engineering Optimization Problems. Eng. Comput. 2022, 38, 3025–3056. [Google Scholar] [CrossRef]
- Hao, J.; Zhu, C.; Guo, X. A New CIGWO-Elman Hybrid Model for Power Load Forecasting. J. Electr. Eng. Technol. 2022, 17, 1319–1333. [Google Scholar] [CrossRef]
- Zhang, C.; Ji, C.; Hua, L.; Ma, H.; Nazir, M.S.; Peng, T. Evolutionary Quantile Regression Gated Recurrent Unit Network Based on Variational Mode Decomposition, Improved Whale Optimization Algorithm for Probabilistic Short-Term Wind Speed Prediction. Renew. Energy 2022, 197, 668–682. [Google Scholar] [CrossRef]
- Li, H.; Yu, Y.; Huang, Z.; Sun, S.; Jia, X. A Multi-Step Ahead Point-Interval Forecasting System for Hourly PM2.5 Concentrations Based on Multivariate Decomposition and Kernel Density Estimation. Expert Syst. Appl. 2023, 226, 120140. [Google Scholar] [CrossRef]
- Gao, T.; Niu, D.; Ji, Z.; Sun, L. Mid-Term Electricity Demand Forecasting Using Improved Variational Mode Decomposition and Extreme Learning Machine Optimized by Sparrow Search Algorithm. Energy 2022, 261, 125328. [Google Scholar] [CrossRef]
- Du, B.; Huang, S.; Guo, J.; Tang, H.; Wang, L.; Zhou, S. Interval Forecasting for Urban Water Demand Using PSO Optimized KDE Distribution and LSTM Neural Networks. Appl. Soft Comput. 2022, 122, 108875. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameter | Value |
|---|---|---|
| ELM | Number of hidden neurons | 6 |
| Transfer function | sig | |
| GRU | Number of hidden neurons | 30 |
| Max epochs | 50 | |
| Initial learning rate | 0.01 | |
| BiLSTM | Number of hidden neurons | 30 |
| Max epochs | 50 | |
| Initial learning rate | 0.01 | |
| IWHO-EGB | Population size | 20 |
| Maximum iterations | 50 | |
| Stallions percentage | 0.2 | |
| Upper limit of weight | 1 | |
| Lower limit of weight | 0 | |
| IKDE | Population size | 10 |
| Maximum iterations | 20 | |
| Stallions percentage | 0.2 | |
| Upper limit of weight | 0.1 | |
| Lower limit of weight | 0.005 |
| Dataset | Sample | Mean (m/s) | Median (m/s) | Max (m/s) | Min (m/s) | Std. (m/s) |
|---|---|---|---|---|---|---|
| Site1 | Training | 12.3907 | 12.6000 | 27.9600 | 0.4100 | 5.4978 |
| Testing | 16.2023 | 16.3800 | 19.3500 | 13.5800 | 1.3068 | |
| Validation | 5.2517 | 2.8350 | 15.1600 | 0.3100 | 5.1152 | |
| All samples | 12.4391 | 13.4050 | 27.9600 | 0.3100 | 5.6648 | |
| Site2 | Training | 11.3606 | 11.3550 | 25.8300 | 0.3600 | 3.9136 |
| Testing | 6.7988 | 5.3450 | 17.3000 | 0.4200 | 5.1558 | |
| Validation | 16.9875 | 17.3700 | 21.9900 | 12.8700 | 2.6959 | |
| All samples | 11.0109 | 11.5350 | 25.8300 | 0.3600 | 4.8934 | |
| Site3 | Training | 5.0691 | 4.5600 | 14.8300 | 0.0900 | 3.6591 |
| Testing | 8.9383 | 8.0300 | 16.4400 | 3.3200 | 3.1747 | |
| Validation | 4.2931 | 4.2750 | 7.6200 | 0.4200 | 1.5805 | |
| All samples | 5.7654 | 5.5300 | 16.4400 | 0.0900 | 3.7677 |
| Metric | Description | Equation |
|---|---|---|
| MAE | Mean absolute error | Refer to Equation (33) |
| RMSE | Root mean square error | |
| MAPE | Mean absolute percentage error | |
| R2 | Coefficient of determination | |
| PICP | PI coverage probability | |
| PINAW | PI normalized average width | |
| AIS | Average interval score |
| 1-Step | 2-Step | 3-Step | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE (m/s) | RMSE (m/s) | MAPE (%) | R2 | MAE (m/s) | RMSE (m/s) | MAPE (%) | R2 | MAE (m/s) | RMSE (m/s) | MAPE (%) | R2 | |
| Site1 | ||||||||||||
| ELM | 0.3570 | 0.4728 | 2.1736 | 0.8675 | 0.5594 | 0.7548 | 3.4388 | 0.6647 | 0.6952 | 0.9119 | 4.2301 | 0.5107 |
| GRU | 0.3277 | 0.4409 | 1.9935 | 0.8848 | 0.5411 | 0.7211 | 3.3338 | 0.6940 | 0.6240 | 0.8496 | 3.8049 | 0.5752 |
| BiLSTM | 0.2598 | 0.4006 | 1.5575 | 0.9049 | 0.2544 | 0.4483 | 1.5357 | 0.8818 | 0.3237 | 0.5540 | 1.9469 | 0.8194 |
| EWT-ELM | 0.1377 | 0.1739 | 0.8589 | 0.9821 | 0.1417 | 0.1730 | 0.8637 | 0.9824 | 0.2154 | 0.2587 | 1.3119 | 0.9606 |
| EWT-GRU | 0.1897 | 0.2246 | 1.1513 | 0.9701 | 0.1551 | 0.1954 | 0.9699 | 0.9775 | 0.2119 | 0.2665 | 1.3048 | 0.9582 |
| EWT-BiLSTM | 0.0808 | 0.1898 | 0.4806 | 0.9787 | 0.1038 | 0.2119 | 0.6162 | 0.9736 | 0.2093 | 0.3200 | 1.3239 | 0.9397 |
| Proposed model | 0.0645 | 0.1501 | 0.3978 | 0.9866 | 0.0669 | 0.1335 | 0.4121 | 0.9895 | 0.1474 | 0.1891 | 0.9226 | 0.9790 |
| Site2 | ||||||||||||
| ELM | 0.6359 | 0.7720 | 30.0916 | 0.9775 | 0.6661 | 0.7979 | 29.2131 | 0.9759 | 0.7201 | 0.9153 | 29.1313 | 0.9683 |
| GRU | 0.6616 | 0.7626 | 29.3708 | 0.9780 | 0.6530 | 0.8087 | 26.6273 | 0.9753 | 0.6325 | 0.8708 | 16.3146 | 0.9713 |
| BiLSTM | 0.4495 | 0.5229 | 19.5257 | 0.9897 | 0.5142 | 0.6002 | 23.0972 | 0.9864 | 0.3426 | 0.4097 | 11.8257 | 0.9937 |
| EWT-ELM | 0.3888 | 0.4969 | 14.4731 | 0.9907 | 0.2000 | 0.2532 | 7.6905 | 0.9976 | 0.2884 | 0.3569 | 10.2520 | 0.9952 |
| EWT-GRU | 0.1362 | 0.1676 | 4.3028 | 0.9989 | 0.4014 | 0.5202 | 11.7996 | 0.9898 | 0.5507 | 0.6689 | 22.9484 | 0.9831 |
| EWT-BiLSTM | 0.1580 | 0.1912 | 6.6465 | 0.9986 | 0.1767 | 0.2120 | 8.0111 | 0.9983 | 0.2862 | 0.3516 | 7.9880 | 0.9953 |
| Proposed model | 0.0960 | 0.1198 | 2.8844 | 0.9995 | 0.1218 | 0.1609 | 3.8680 | 0.9990 | 0.1794 | 0.2370 | 4.8923 | 0.9979 |
| Site3 | ||||||||||||
| ELM | 0.3833 | 0.6166 | 4.5139 | 0.9621 | 0.6948 | 1.0138 | 8.4530 | 0.8975 | 1.0543 | 1.4322 | 12.6841 | 0.7955 |
| GRU | 0.3698 | 0.5745 | 4.5143 | 0.9671 | 0.7781 | 1.0963 | 9.6551 | 0.8802 | 1.2204 | 1.5846 | 14.8457 | 0.7496 |
| BiLSTM | 0.5200 | 0.6508 | 5.4658 | 0.9578 | 0.3108 | 0.4327 | 3.7440 | 0.9813 | 0.3026 | 0.4384 | 3.6605 | 0.9808 |
| EWT-ELM | 0.0898 | 0.1132 | 1.1306 | 0.9987 | 0.2417 | 0.3148 | 2.8992 | 0.9901 | 0.2550 | 0.3148 | 2.9582 | 0.9901 |
| EWT-GRU | 0.2829 | 0.3898 | 2.9384 | 0.9849 | 0.3227 | 0.4222 | 3.6803 | 0.9822 | 0.5071 | 0.6636 | 5.7460 | 0.9561 |
| EWT-BiLSTM | 0.2839 | 0.2441 | 1.8321 | 0.9941 | 0.1434 | 0.1818 | 1.7636 | 0.9967 | 0.1538 | 0.2368 | 1.4846 | 0.9944 |
| Proposed model | 0.0824 | 0.1096 | 0.9897 | 0.9988 | 0.1323 | 0.1598 | 1.7568 | 0.9975 | 0.1200 | 0.1996 | 1.2008 | 0.9960 |
| 1-Step | 2-Step | 3-Step | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE (m/s) | RMSE (m/s) | MAPE (%) | R2 | MAE (m/s) | RMSE (m/s) | MAPE (%) | R2 | MAE (m/s) | RMSE (m/s) | MAPE (%) | R2 | |
| Site1 | ||||||||||||
| EMD-based | 0.1376 | 0.2517 | 0.8450 | 0.9627 | 0.2463 | 0.3765 | 1.5227 | 0.9166 | 0.2654 | 0.3748 | 1.6411 | 0.9173 |
| CEEMD-based | 0.0752 | 0.1458 | 0.4851 | 0.9855 | 0.0900 | 0.1429 | 0.5601 | 0.9880 | 0.1426 | 0.2216 | 0.8894 | 0.9711 |
| VMD-based | 0.1190 | 0.1639 | 0.7284 | 0.9842 | 0.1292 | 0.1791 | 0.7885 | 0.9811 | 0.1768 | 0.2363 | 1.0805 | 0.9671 |
| Proposed model | 0.0645 | 0.1501 | 0.3978 | 0.9866 | 0.0669 | 0.1335 | 0.4121 | 0.9895 | 0.1474 | 0.1891 | 0.9226 | 0.9790 |
| Site2 | ||||||||||||
| EMD-based | 0.2626 | 0.3267 | 9.6082 | 0.9960 | 0.2286 | 0.3118 | 5.6527 | 0.9963 | 0.2909 | 0.3956 | 8.1681 | 0.9941 |
| CEEMD-based | 0.1061 | 0.1475 | 2.9597 | 0.9992 | 0.1529 | 0.2099 | 3.9996 | 0.9983 | 0.2606 | 0.3254 | 9.2805 | 0.9960 |
| VMD-based | 0.2896 | 0.4151 | 9.0222 | 0.9935 | 0.4857 | 0.6518 | 12.642 | 0.9839 | 0.2530 | 0.3318 | 7.5103 | 0.9958 |
| Proposed model | 0.0960 | 0.1198 | 2.8844 | 0.9995 | 0.1218 | 0.1609 | 3.8680 | 0.9990 | 0.1794 | 0.2370 | 4.8923 | 0.9979 |
| Site3 | ||||||||||||
| EMD-based | 0.1072 | 0.1792 | 1.3822 | 0.9968 | 0.3377 | 0.4327 | 4.0238 | 0.9813 | 0.2040 | 0.3133 | 2.4345 | 0.9902 |
| CEEMD-based | 0.1536 | 0.2443 | 1.9178 | 0.9940 | 0.1709 | 0.2545 | 2.1584 | 0.9935 | 0.1954 | 0.2959 | 2.4724 | 0.9913 |
| VMD-based | 0.1740 | 0.2662 | 2.0130 | 0.9929 | 0.2157 | 0.3095 | 2.5698 | 0.9904 | 0.2657 | 0.3730 | 3.0462 | 0.9861 |
| Proposed model | 0.0824 | 0.1096 | 0.9897 | 0.9988 | 0.1323 | 0.1598 | 1.7568 | 0.9975 | 0.1200 | 0.1996 | 1.2008 | 0.9960 |
| 1-Step | 2-Step | 3-Step | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PICP | PINAW | AIS | PICP | PINAW | AIS | PICP | PINAW | AIS | ||
| Site1 | EWT-ELM | 0.9950 | 0.3894 | −0.0459 | 0.9900 | 0.1849 | −0.0198 | 0.9900 | 0.1294 | −0.0157 |
| EWT-GRU | 0.9950 | 0.3760 | −0.0445 | 0.9950 | 0.1383 | −0.0160 | 0.9950 | 0.1824 | −0.0211 | |
| EWT-BiLSTM | 0.9900 | 0.4094 | −0.0473 | 0.9950 | 0.1483 | −0.0172 | 1.0000 | 0.2337 | −0.0270 | |
| EMD-based | 0.9950 | 0.3065 | −0.0362 | 0.9950 | 0.3273 | −0.0380 | 0.9900 | 0.3486 | −0.0410 | |
| CEEMD-based | 0.9950 | 0.2132 | −0.0255 | 0.9900 | 0.1493 | −0.0174 | 0.9950 | 0.2352 | −0.0275 | |
| VMD-based | 0.9900 | 0.1856 | −0.0218 | 0.9900 | 0.1935 | −0.0228 | 0.9900 | 0.2299 | −0.0273 | |
| Proposed model | 0.9950 | 0.1940 | −0.0161 | 0.9900 | 0.0913 | −0.0109 | 0.9950 | 0.1097 | −0.0120 | |
| Site2 | EWT-ELM | 0.9900 | 0.1063 | −0.0360 | 0.9950 | 0.0551 | −0.0186 | 0.9900 | 0.0847 | −0.0287 |
| EWT-GRU | 1.0000 | 0.0361 | −0.0122 | 0.9900 | 0.1195 | −0.0404 | 0.9900 | 0.1566 | −0.0533 | |
| EWT-BiLSTM | 0.9900 | 0.0365 | −0.0124 | 0.9950 | 0.0462 | −0.0162 | 0.9900 | 0.0743 | −0.0184 | |
| EMD-based | 0.9950 | 0.1147 | −0.0397 | 0.9950 | 0.1147 | −0.0394 | 0.9950 | 0.1304 | −0.0449 | |
| CEEMD-based | 0.9900 | 0.0540 | −0.0186 | 0.9950 | 0.0716 | −0.0242 | 0.9900 | 0.0771 | −0.0266 | |
| VMD-based | 0.9950 | 0.0792 | −0.0268 | 0.9950 | 0.0974 | −0.0329 | 0.9900 | 0.0746 | −0.0254 | |
| Proposed model | 0.9900 | 0.0254 | −0.0087 | 0.9900 | 0.0338 | −0.0118 | 0.9950 | 0.0570 | −0.0174 | |
| Site3 | EWT-ELM | 0.9900 | 0.0396 | −0.0107 | 0.9900 | 0.0847 | −0.0287 | 0.9900 | 0.0902 | −0.0239 |
| EWT-GRU | 0.9900 | 0.0986 | −0.0259 | 0.9900 | 0.1566 | −0.0533 | 0.9900 | 0.1540 | −0.0406 | |
| EWT-BiLSTM | 0.9950 | 0.0359 | −0.0096 | 0.9900 | 0.0543 | −0.0194 | 0.9950 | 0.0618 | −0.0163 | |
| EMD-based | 0.9950 | 0.1326 | −0.0374 | 0.9950 | 0.1304 | −0.0449 | 0.9900 | 0.1957 | −0.0565 | |
| CEEMD-based | 0.9950 | 0.1423 | −0.0391 | 0.9900 | 0.1304 | −0.0266 | 0.9900 | 0.1637 | −0.0456 | |
| VMD-based | 0.9900 | 0.1456 | −0.0415 | 0.9900 | 0.0746 | −0.0254 | 0.9950 | 0.1630 | −0.0455 | |
| Proposed model | 0.9900 | 0.0322 | −0.0087 | 0.9950 | 0.0570 | −0.0144 | 0.9900 | 0.0513 | −0.0135 | |
| 1-Step | 2-Step | 3-Step | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PICP | PINAW | AIS | PICP | PINAW | AIS | PICP | PINAW | AIS | ||
| Site1 | EWT-ELM | 0.9000 | 0.1729 | −0.2908 | 0.9100 | 0.0696 | −0.0906 | 0.9000 | 0.0943 | −0.1334 |
| EWT-GRU | 0.9050 | 0.1794 | −0.2824 | 0.8950 | 0.0986 | −0.1334 | 0.9000 | 0.1342 | −0.1802 | |
| EWT-BiLSTM | 0.9000 | 0.1845 | −0.3150 | 0.9100 | 0.0768 | −0.1386 | 0.9050 | 0.1605 | −0.2390 | |
| EMD-based | 0.9100 | 0.1936 | −0.2078 | 0.8950 | 0.1711 | −0.2792 | 0.9000 | 0.2014 | −0.3083 | |
| CEEMD-based | 0.9050 | 0.1562 | −0.2138 | 0.8950 | 0.0699 | −0.1307 | 0.9000 | 0.1005 | −0.1980 | |
| VMD-based | 0.8950 | 0.1881 | −0.1907 | 0.9050 | 0.0930 | −0.1583 | 0.9000 | 0.1271 | −0.1972 | |
| Proposed model | 0.9050 | 0.0836 | −0.1826 | 0.9000 | 0.0607 | −0.0826 | 0.9000 | 0.0842 | −0.1118 | |
| Site2 | EWT-ELM | 0.8950 | 0.0794 | −0.3247 | 0.9000 | 0.0457 | −0.1713 | 0.9050 | 0.0552 | −0.2417 |
| EWT-GRU | 0.8950 | 0.0294 | −0.1118 | 0.9000 | 0.0786 | −0.3350 | 0.9000 | 0.1063 | −0.4491 | |
| EWT-BiLSTM | 0.8950 | 0.0270 | −0.1084 | 0.9050 | 0.0266 | −0.1060 | 0.9000 | 0.0439 | −0.1696 | |
| EMD-based | 0.9050 | 0.0521 | −0.2482 | 0.8950 | 0.0591 | −0.2652 | 0.9100 | 0.0687 | −0.3251 | |
| CEEMD-based | 0.9000 | 0.0269 | −0.1281 | 0.8950 | 0.0356 | −0.1711 | 0.9050 | 0.0435 | −0.1919 | |
| VMD-based | 0.9100 | 0.0554 | −0.2273 | 0.9050 | 0.0805 | −0.3056 | 0.9000 | 0.0397 | −0.2063 | |
| Proposed model | 0.9050 | 0.0190 | −0.0753 | 0.9100 | 0.0426 | −0.1950 | 0.9050 | 0.0454 | −0.1517 | |
| Site3 | EWT-ELM | 0.9050 | 0.0280 | −0.0865 | 0.9050 | 0.0552 | −0.2417 | 0.9000 | 0.0692 | −0.2110 |
| EWT-GRU | 0.8950 | 0.0674 | −0.2156 | 0.9000 | 0.1063 | −0.4491 | 0.9000 | 0.1032 | −0.3549 | |
| EWT-BiLSTM | 0.9100 | 0.0244 | −0.0800 | 0.9000 | 0.0554 | −0.2117 | 0.9050 | 0.0404 | −0.1302 | |
| EMD-based | 0.9050 | 0.0318 | −0.1570 | 0.9100 | 0.0687 | −0.3251 | 0.8950 | 0.0490 | −0.2421 | |
| CEEMD-based | 0.9050 | 0.0420 | −0.2078 | 0.9050 | 0.0435 | −0.1919 | 0.9100 | 0.0530 | −0.2524 | |
| VMD-based | 0.9000 | 0.0429 | −0.2032 | 0.9000 | 0.0512 | −0.2063 | 0.8950 | 0.0605 | −0.2279 | |
| Proposed model | 0.9000 | 0.0232 | −0.0713 | 0.9050 | 0.0439 | −0.1696 | 0.9100 | 0.0314 | −0.1087 | |
| 1-Step | 2-Step | 3-Step | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PICP | PINAW | AIS | PICP | PINAW | AIS | PICP | PINAW | AIS | ||
| Site1 | EWT-ELM | 0.8000 | 0.1286 | −0.4599 | 0.8000 | 0.0556 | −0.1635 | 0.7900 | 0.0698 | −0.2016 |
| EWT-GRU | 0.8100 | 0.1257 | −0.4578 | 0.8000 | 0.0781 | −0.2345 | 0.8100 | 0.1004 | −0.3159 | |
| EWT-BiLSTM | 0.8000 | 0.1341 | −0.4958 | 0.8050 | 0.0297 | −0.1954 | 0.7950 | 0.0673 | −0.3624 | |
| EMD-based | 0.8000 | 0.0641 | −0.2835 | 0.8050 | 0.1105 | −0.4411 | 0.8000 | 0.1305 | −0.4884 | |
| CEEMD-based | 0.8100 | 0.0290 | −0.1550 | 0.7950 | 0.0469 | −0.1983 | 0.8050 | 0.0691 | −0.2930 | |
| VMD-based | 0.8050 | 0.0577 | −0.2318 | 0.7950 | 0.0662 | −0.2479 | 0.8000 | 0.0965 | −0.2930 | |
| Proposed model | 0.8000 | 0.1282 | −0.4787 | 0.8150 | 0.0482 | −0.1453 | 0.8050 | 0.0652 | −0.1943 | |
| Site2 | EWT-ELM | 0.7900 | 0.0584 | −0.5555 | 0.7900 | 0.0370 | −0.3145 | 0.7950 | 0.0442 | −0.4104 |
| EWT-GRU | 0.8100 | 0.0218 | −0.1983 | 0.8050 | 0.0606 | −0.5657 | 0.8050 | 0.0826 | −0.7676 | |
| EWT-BiLSTM | 0.8100 | 0.0227 | −0.1920 | 0.7950 | 0.0298 | −0.2949 | 0.8050 | 0.0340 | −0.3023 | |
| EMD-based | 0.7950 | 0.0458 | −0.4132 | 0.7950 | 0.0413 | −0.4310 | 0.8050 | 0.0483 | −0.5162 | |
| CEEMD-based | 0.8000 | 0.0186 | −0.2046 | 0.7950 | 0.0271 | −0.2766 | 0.7950 | 0.0357 | −0.3248 | |
| VMD-based | 0.7950 | 0.0468 | −0.3974 | 0.7950 | 0.0715 | −0.5625 | 0.8050 | 0.0397 | −0.3582 | |
| Proposed model | 0.8000 | 0.0157 | −0.1352 | 0.8050 | 0.0208 | −0.2199 | 0.8100 | 0.0341 | −0.3008 | |
| Site3 | EWT-ELM | 0.8000 | 0.0214 | −0.1511 | 0.7950 | 0.0442 | −0.4104 | 0.7950 | 0.0562 | −0.3739 |
| EWT-GRU | 0.8000 | 0.0548 | −0.3778 | 0.8050 | 0.0826 | −0.7676 | 0.7950 | 0.0841 | −0.6017 | |
| EWT-BiLSTM | 0.8100 | 0.0202 | −0.1395 | 0.8050 | 0.0441 | −0.3808 | 0.8050 | 0.0334 | −0.2266 | |
| EMD-based | 0.8050 | 0.0232 | −0.2273 | 0.8050 | 0.0483 | −0.5162 | 0.8050 | 0.0373 | −0.3515 | |
| CEEMD-based | 0.8000 | 0.0262 | −0.2896 | 0.7950 | 0.0357 | −0.3248 | 0.8000 | 0.0386 | −0.3728 | |
| VMD-based | 0.8050 | 0.0343 | −0.3055 | 0.8050 | 0.0397 | −0.3582 | 0.8000 | 0.0487 | −0.3703 | |
| Proposed model | 0.8000 | 0.0179 | −0.1247 | 0.8100 | 0.0340 | −0.3023 | 0.8050 | 0.0230 | −0.1798 | |
| Site1 | Site2 | Site3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | |
| ELM | 7.3574 * | 6.5137 * | 7.4031 * | 11.9461 ** | 12.2984 * | 8.6157 * | 3.4739 * | 8.6157 * | 6.6053 * |
| GRU | 6.0446 * | 6.6629 * | 6.6660 * | 14.2987 * | 10.0245 * | 6.2358 * | 3.1618 * | 6.2358 * | 8.9628 * |
| BiLSTM | 4.1084 * | 3.0480 * | 2.9419 * | 15.6143 * | 14.7711 * | 7.9450 * | 9.7314 * | 7.9450 * | 4.2174 * |
| EWT-ELM | 0.8572 | 1.7900 *** | 5.8412 * | 8.8936 * | 5.9151 * | 7.3056 * | 0.9546 | 7.3056 * | 6.5051 * |
| EWT-GRU | 2.9417 * | 2.7935 * | 5.5774 * | 6.2635 * | 8.9593 * | 11.4720 * | 8.4334 * | 11.4720 * | 8.4120 * |
| EWT-BiLSTM | 2.6336 * | 3.1598 * | 3.4036 * | 6.9916 * | 5.4954 * | 7.8462 * | 7.2497 * | 7.8462 * | 5.4131 * |
| EMD-based | 2.4400 ** | 4.7320 * | 4.7581 * | 6.5853 * | 4.3216 * | 3.7923 * | 1.7628 *** | 7.8462 * | 2.4107 ** |
| CEEMD-based | 0.0983 | 0.3405 | 0.9707 | 2.1819 ** | 2.3459 ** | 4.9596 * | 2.8860 * | 4.9596 * | 2.3144 ** |
| VMD-based | 1.1217 | 1.9378 *** | 2.7354 * | 8.1072 * | 9.7279 * | 4.6521 * | 4.1650 * | 4.6521 * | 5.6159 * |
| Improvement (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | ||
| Site1 | EWT-ELM | 64.92 | 44.95 | 23.57 | 37.21 | 8.83 | 16.19 | −4.09 | 11.13 | 3.62 |
| EWT-GRU | 63.82 | 31.88 | 43.13 | 35.34 | 38.08 | 37.96 | −4.57 | 38.04 | 38.49 | |
| EWT-BiLSTM | 65.96 | 36.63 | 55.56 | 42.03 | 40.40 | 53.22 | 3.45 | 25.64 | 46.39 | |
| EMD-based | 55.52 | 71.32 | 70.73 | 12.13 | 70.42 | 63.74 | −68.85 | 67.06 | 60.22 | |
| CEEMD-based | 36.86 | 37.36 | 56.36 | 14.59 | 36.80 | 43.54 | −208.84 | 26.73 | 33.69 | |
| VMD-based | 26.15 | 52.19 | 56.04 | 4.25 | 47.82 | 43.31 | −106.51 | 41.39 | 33.69 | |
| Site2 | EWT-ELM | 75.83 | 36.56 | 39.37 | 76.81 | −13.84 | 37.24 | 75.66 | 30.08 | 26.71 |
| EWT-GRU | 28.69 | 70.79 | 67.35 | 32.65 | 41.79 | 66.22 | 31.82 | 61.13 | 60.81 | |
| EWT-BiLSTM | 29.84 | 27.16 | 5.43 | 30.54 | −83.96 | 10.55 | 29.58 | 25.43 | 0.50 | |
| EMD-based | 78.09 | 70.05 | 61.25 | 69.66 | 26.47 | 53.34 | 67.28 | 48.98 | 41.73 | |
| CEEMD-based | 53.23 | 51.24 | 34.59 | 41.22 | −13.97 | 20.95 | 33.92 | 20.50 | 7.39 | |
| VMD-based | 67.54 | 64.13 | 31.50 | 66.87 | 36.19 | 26.47 | 65.98 | 60.91 | 16.02 | |
| Site3 | EWT-ELM | 18.69 | 49.83 | 43.51 | 17.57 | 29.83 | 48.48 | 17.47 | 26.34 | 51.91 |
| EWT-GRU | 66.41 | 72.98 | 66.75 | 66.93 | 62.24 | 69.37 | 66.99 | 60.62 | 70.12 | |
| EWT-BiLSTM | 9.37 | 25.77 | 17.18 | 10.87 | 19.89 | 16.51 | 10.61 | 20.61 | 20.65 | |
| EMD-based | 76.74 | 67.93 | 76.11 | 54.59 | 47.83 | 55.10 | 45.14 | 41.44 | 48.85 | |
| CEEMD-based | 77.75 | 45.86 | 70.39 | 65.69 | 11.62 | 56.93 | 56.94 | 6.93 | 51.77 | |
| VMD-based | 79.04 | 43.31 | 70.33 | 64.91 | 17.79 | 52.30 | 59.18 | 15.61 | 51.44 | |
| Function Definition | Dim | Range | fmin |
|---|---|---|---|
| 30 | [−100, 100] | 0 | |
| 30 | [−10, 10] | 0 | |
| 30 | [−100, 100] | 0 | |
| 30 | [−5.12, 5.12] | 0 | |
| 30 | [−32, 32] | 0 | |
| 30 | [−600, 600] | 0 |
| Function | IWHO | WHO | GWO | PSO | WOA | MVO | |
|---|---|---|---|---|---|---|---|
| f1 | AVG | 4.58 × 10−97 | 2.20 × 10−17 | 1.42 × 10−10 | 8.81 × 10−2 | 2.74 × 10−32 | 4.33 |
| STD | 2.05 × 10−97 | 4.44 × 10−17 | 1.48 × 10−10 | 5.07 × 10−2 | 7.49 × 10−32 | 1.16 | |
| f2 | AVG | 1.74 × 10−56 | 6.83 × 10−11 | 1.28 × 10−6 | 6.18 × 10−1 | 3.79 × 10−21 | 2.68 × 10 |
| STD | 3.25 × 10−56 | 1.18 × 10−10 | 6.83 × 10−7 | 2.55 × 10−1 | 1.19 × 10−20 | 5.27 × 10 | |
| f3 | AVG | 1.68 × 10−100 | 1.62 × 10−8 | 1.34 | 2.37 × 102 | 5.39 × 104 | 9.29 × 102 |
| STD | 7.50 × 10−100 | 4.27 × 10−8 | 2.29 | 8.23 × 10 | 1.53 × 104 | 3.55 × 102 | |
| f9 | AVG | 0.00 | 7.40 × 10−3 | 6.54 | 9.12 × 10 | 1.24 × 10−14 | 1.15 × 102 |
| STD | 0.00 | 2.28 × 10−2 | 4.79 | 3.44 × 10 | 3.61 × 10−14 | 2.63 × 10 | |
| f10 | AVG | 8.88 × 10−16 | 4.72 × 10−10 | 3.26 × 10−6 | 9.79 × 10−1 | 1.33 × 10−14 | 2.55 |
| STD | 0.00 | 1.01 × 10−9 | 2.37 × 10−6 | 6.04 × 10−1 | 7.78 × 10−15 | 4.31 × 10−1 | |
| f11 | AVG | 0.00 | 1.66 × 10−17 | 8.20 × 10−3 | 2.68 | 1.11 × 10−17 | 1.03 |
| STD | 0.00 | 7.44 × 10−17 | 1.31 × 10−2 | 1.15 | 3.42 × 10−17 | 2.12 × 10−2 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Zhu, C.; Hao, J.; Kong, L.; Zhang, S. A Point-Interval Forecasting Method for Wind Speed Using Improved Wild Horse Optimization Algorithm and Ensemble Learning. Sustainability 2024, 16, 94. https://doi.org/10.3390/su16010094
Guo X, Zhu C, Hao J, Kong L, Zhang S. A Point-Interval Forecasting Method for Wind Speed Using Improved Wild Horse Optimization Algorithm and Ensemble Learning. Sustainability. 2024; 16(1):94. https://doi.org/10.3390/su16010094
Chicago/Turabian StyleGuo, Xiuting, Changsheng Zhu, Jie Hao, Lingjie Kong, and Shengcai Zhang. 2024. "A Point-Interval Forecasting Method for Wind Speed Using Improved Wild Horse Optimization Algorithm and Ensemble Learning" Sustainability 16, no. 1: 94. https://doi.org/10.3390/su16010094
APA StyleGuo, X., Zhu, C., Hao, J., Kong, L., & Zhang, S. (2024). A Point-Interval Forecasting Method for Wind Speed Using Improved Wild Horse Optimization Algorithm and Ensemble Learning. Sustainability, 16(1), 94. https://doi.org/10.3390/su16010094