
ERF-XGB: Ensemble Random Forest-Based XG Boost for Accurate Prediction and Classification of E-Commerce Product Review


Abstract
:1. Introduction
- A new ensemble random forest-based XG boost (ERF-XGB) approach is proposed for the accurate and effective prediction and classification of sentiments of online reviews into two categories: positive and negative.
- Selection of more relevant feature information from preprocessed datasets using the Harris hawk optimization (HHO) algorithm.
- Analyzing the proposed ERF-XGB approach performances in terms of evaluation indicators: accuracy, recall, precision, and F1-score.
2. Literature Survey
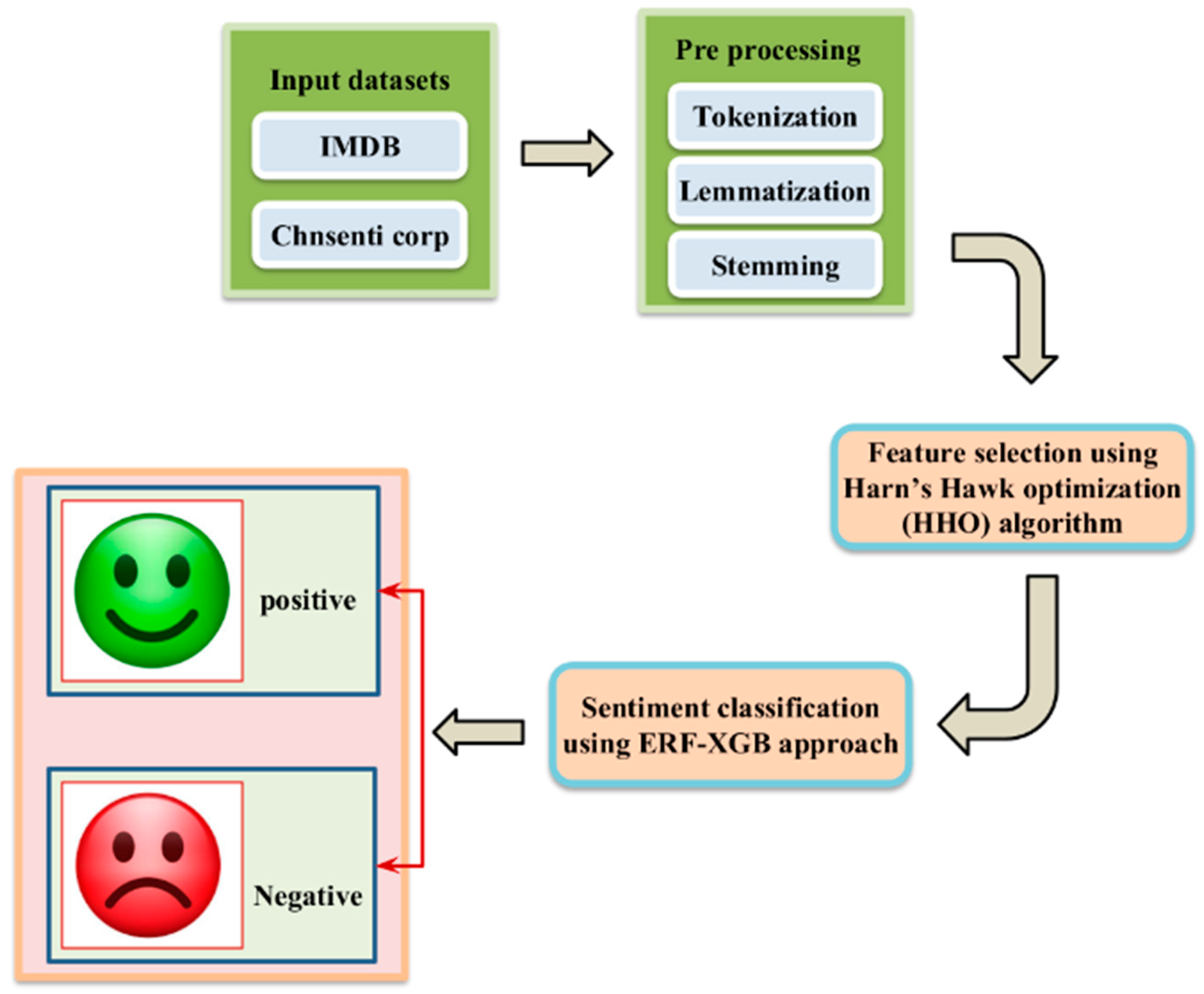
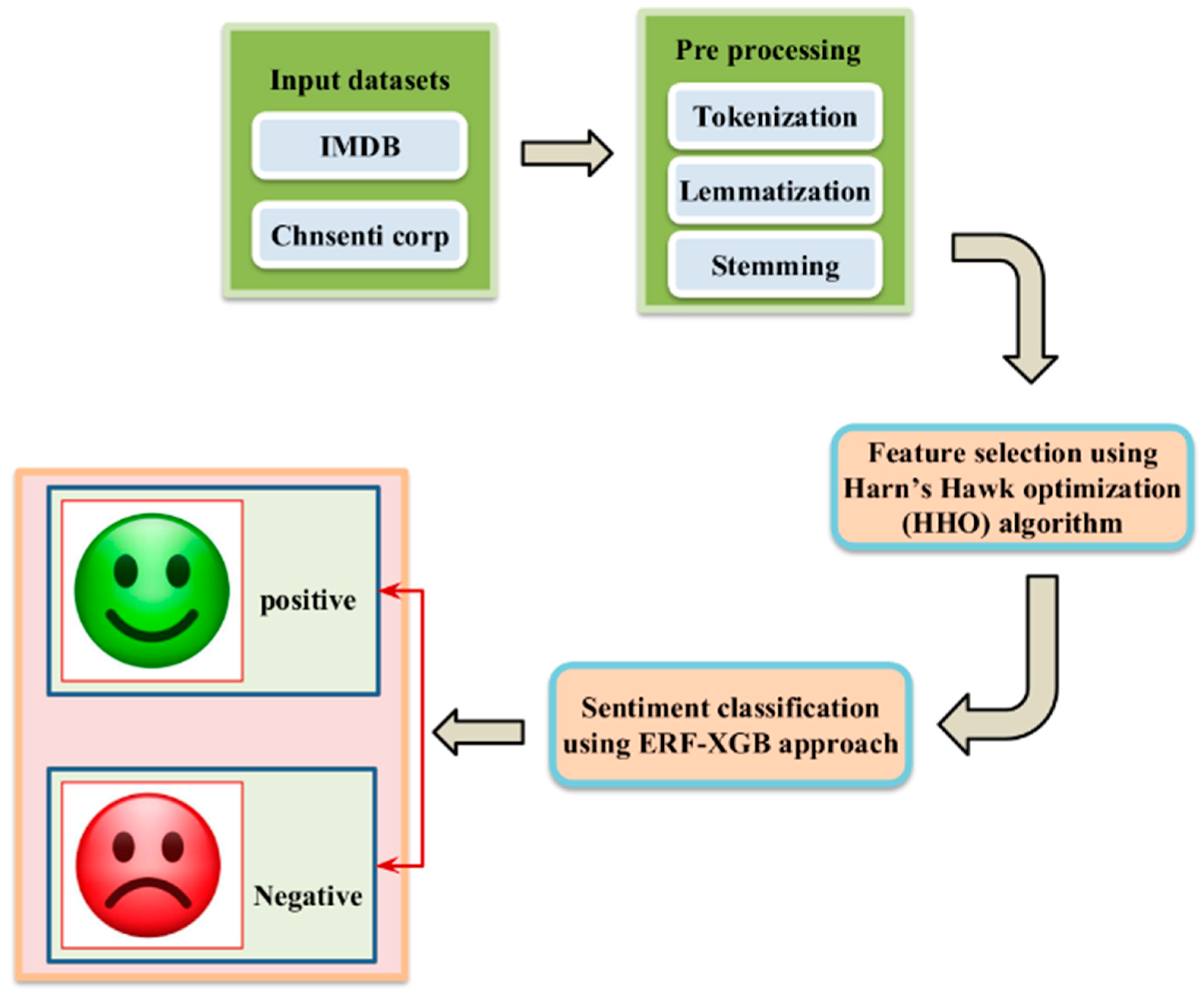
3. Proposed Methodology
3.1. Data Preprocessing
3.1.1. Tokenization
3.1.2. Lemmatization
3.1.3. Stemming
3.2. Feature Selection
- Harris Hawk optimization (HHO)
3.3. Sentiment Classification
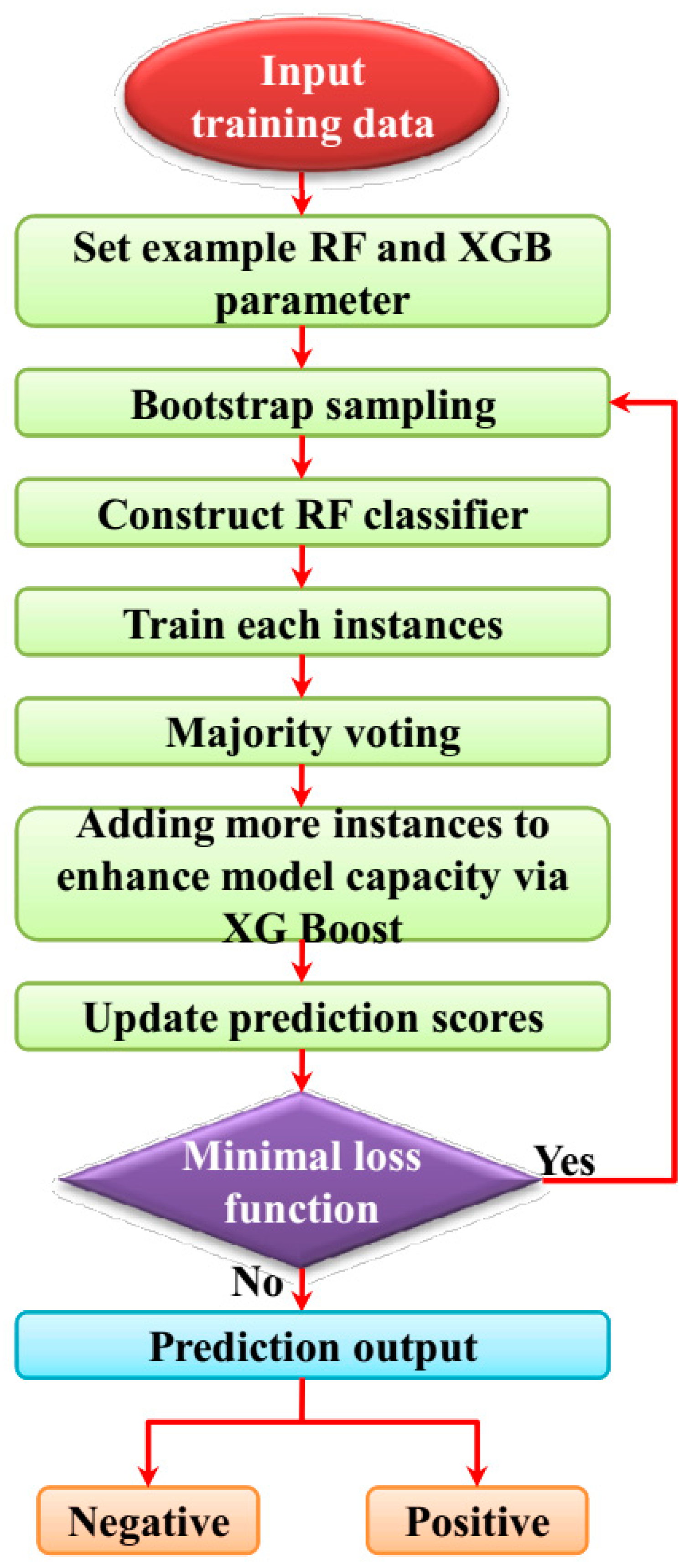
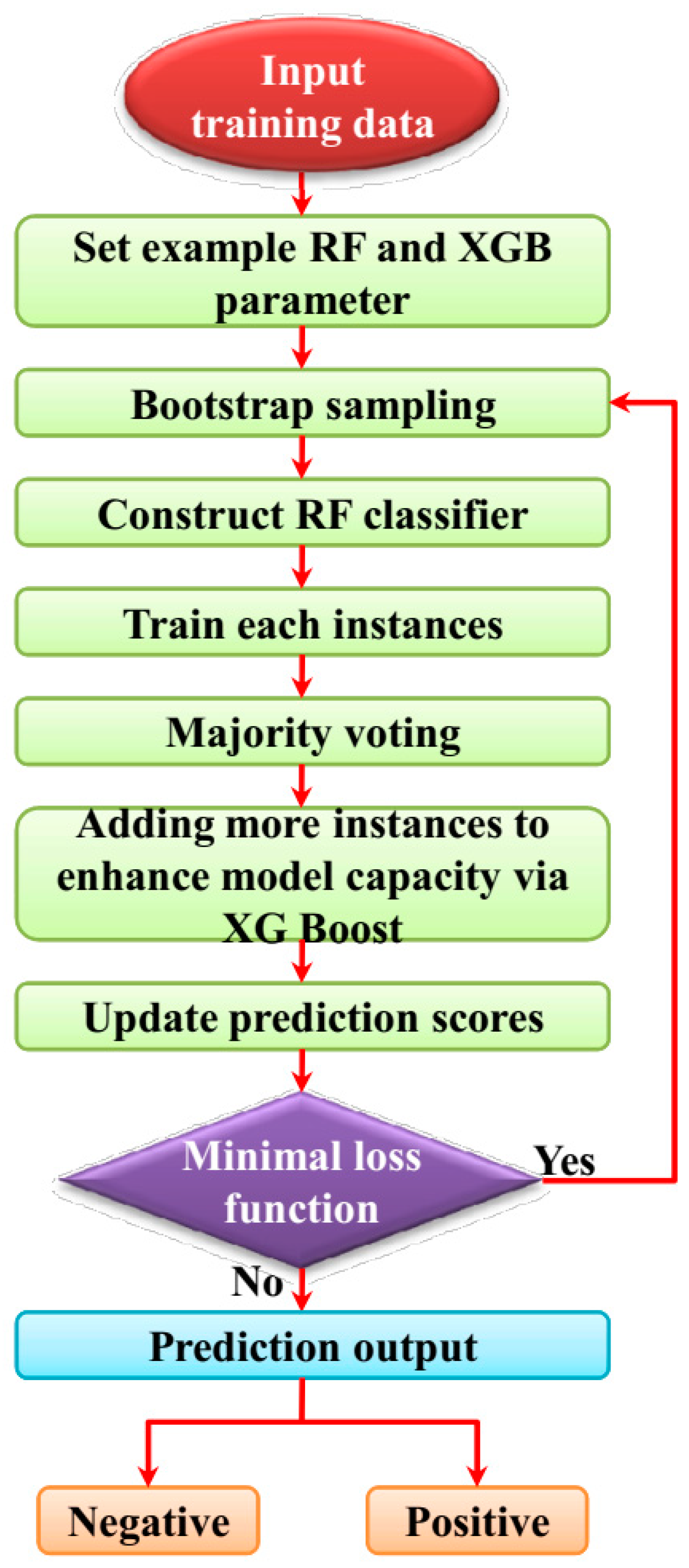
3.3.1. Ensemble Random Forest (ERF)
- Steps for generating ERF
- 1.
- Bagging: The random forest algorithm selects random samples to extract from the initial training dataset for establishing a training subset. For generating decision trees, the bagging algorithm received bootstrap sample sets. Unextracted data are called out-of-bad data (OOB). The calculation of the OOB is more capable compared with cross-validation. OOB contains two-phase to extract the RF feature importance, such as the Gini index and OOB error rate. In the OOB error rate, the phase calculates the decision tree and the Gini index phase calculates the failed classification.
- 2.
- Decision tree construction: From bootstrap sample sets, classification trees are generated. The feature vector samples are represented by . In feature vectors, the original decision tree chooses the optimal feature vector. The results of the classification can finally be received from decision tree models.
3.3.2. XG Boost (XGB) Algorithm
4. Experimental Results and Discussions
4.1. Experimental Setup
4.2. Dataset Description
4.3. Performance Measures
4.4. Hyperparameter Configuration
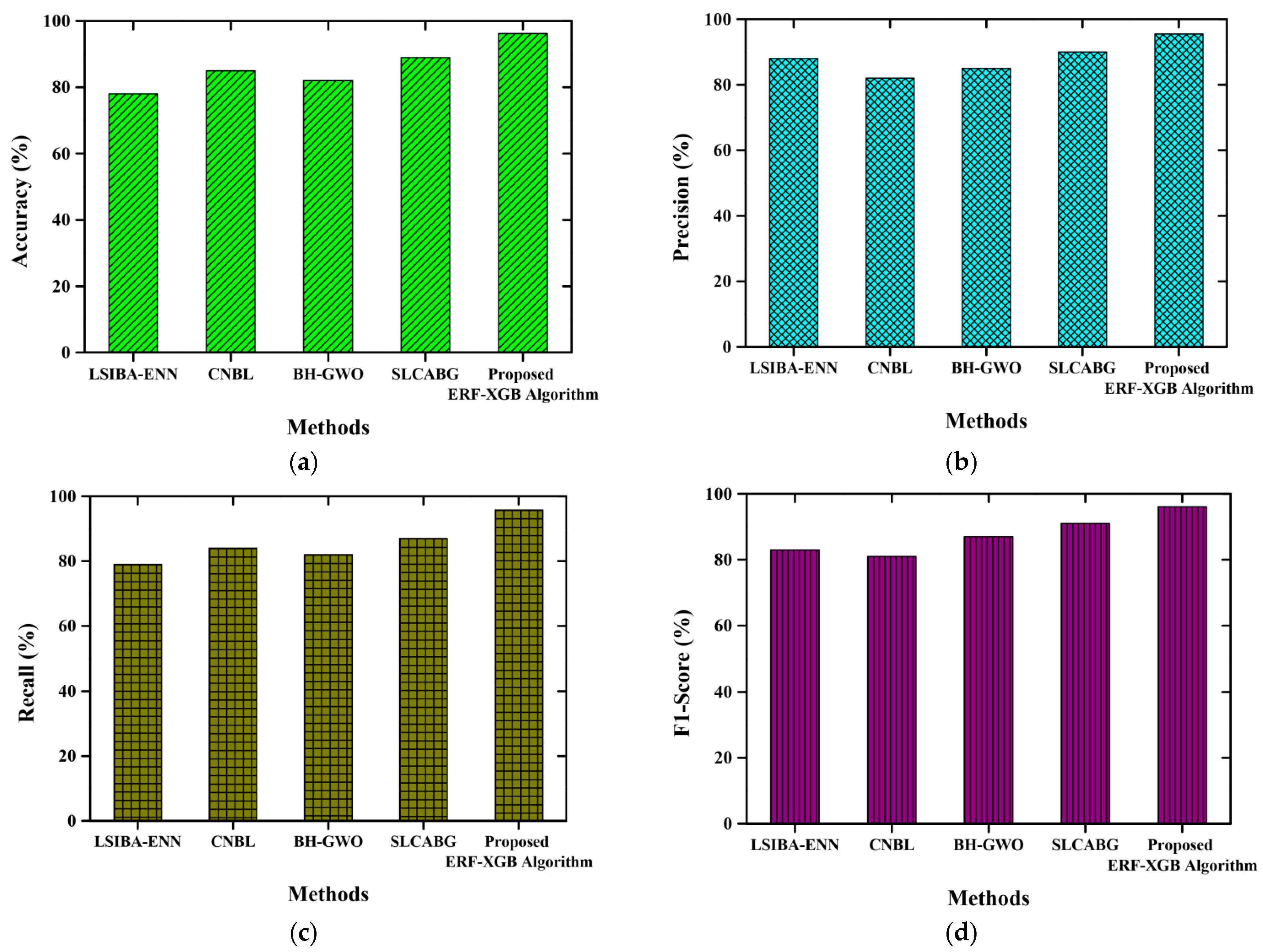
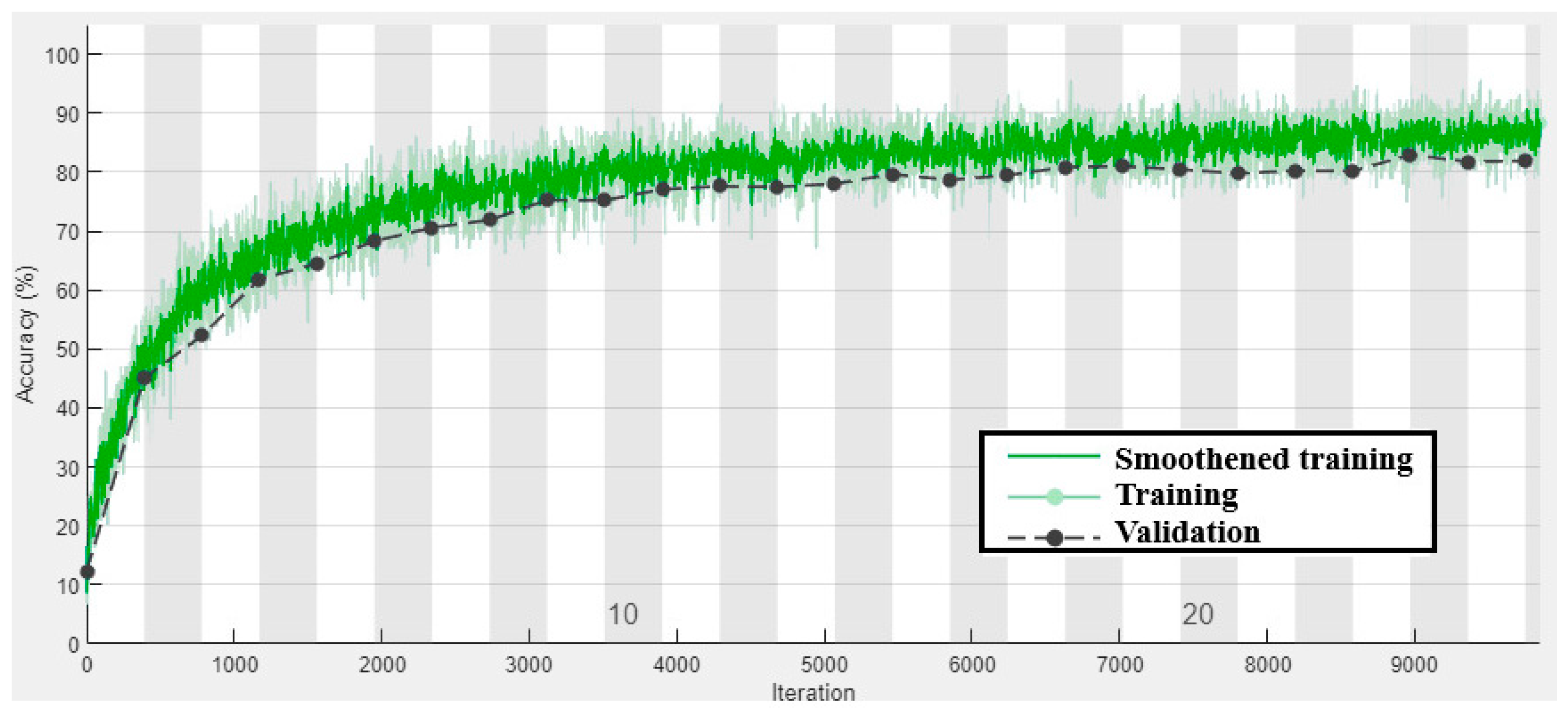
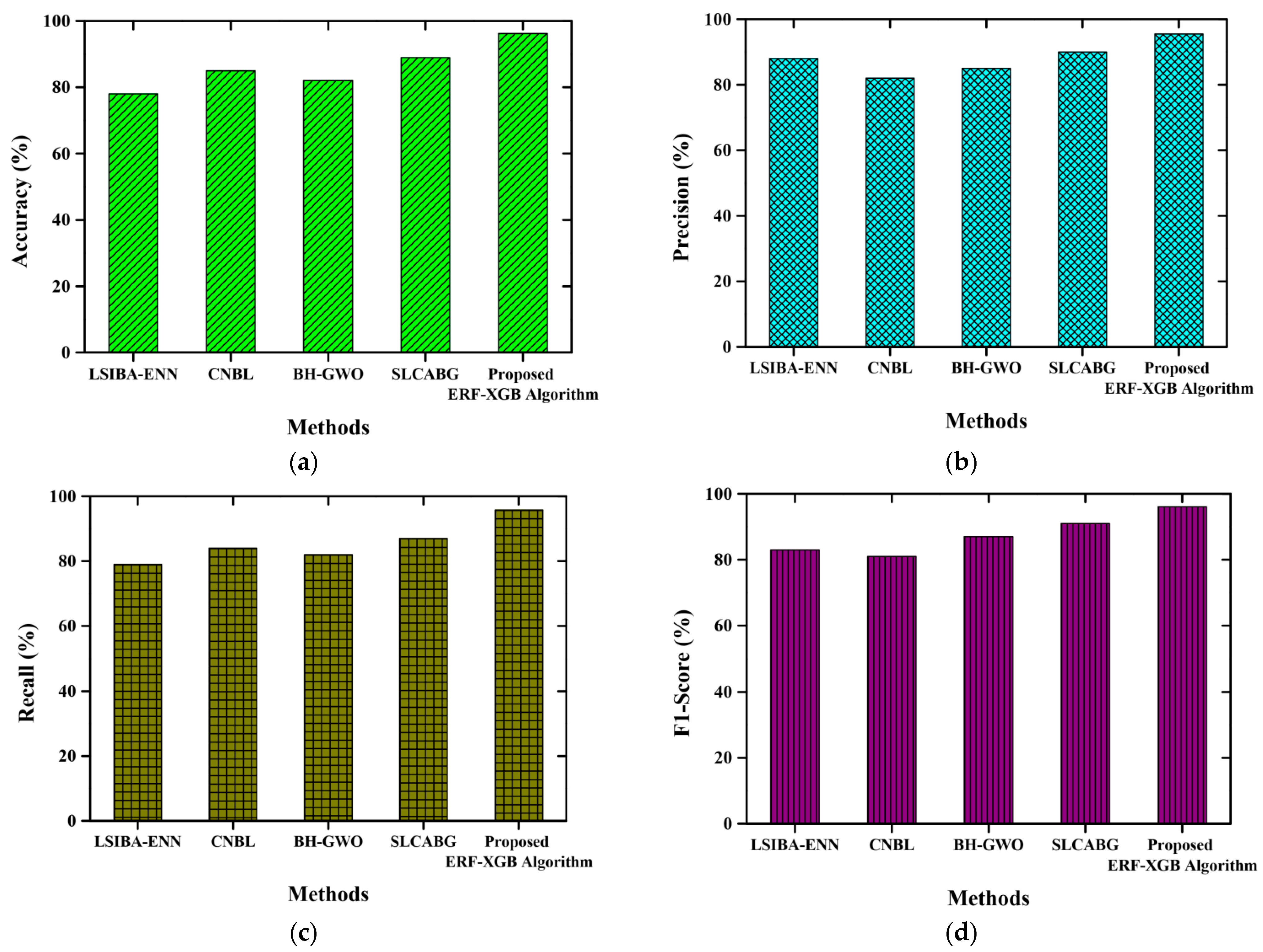
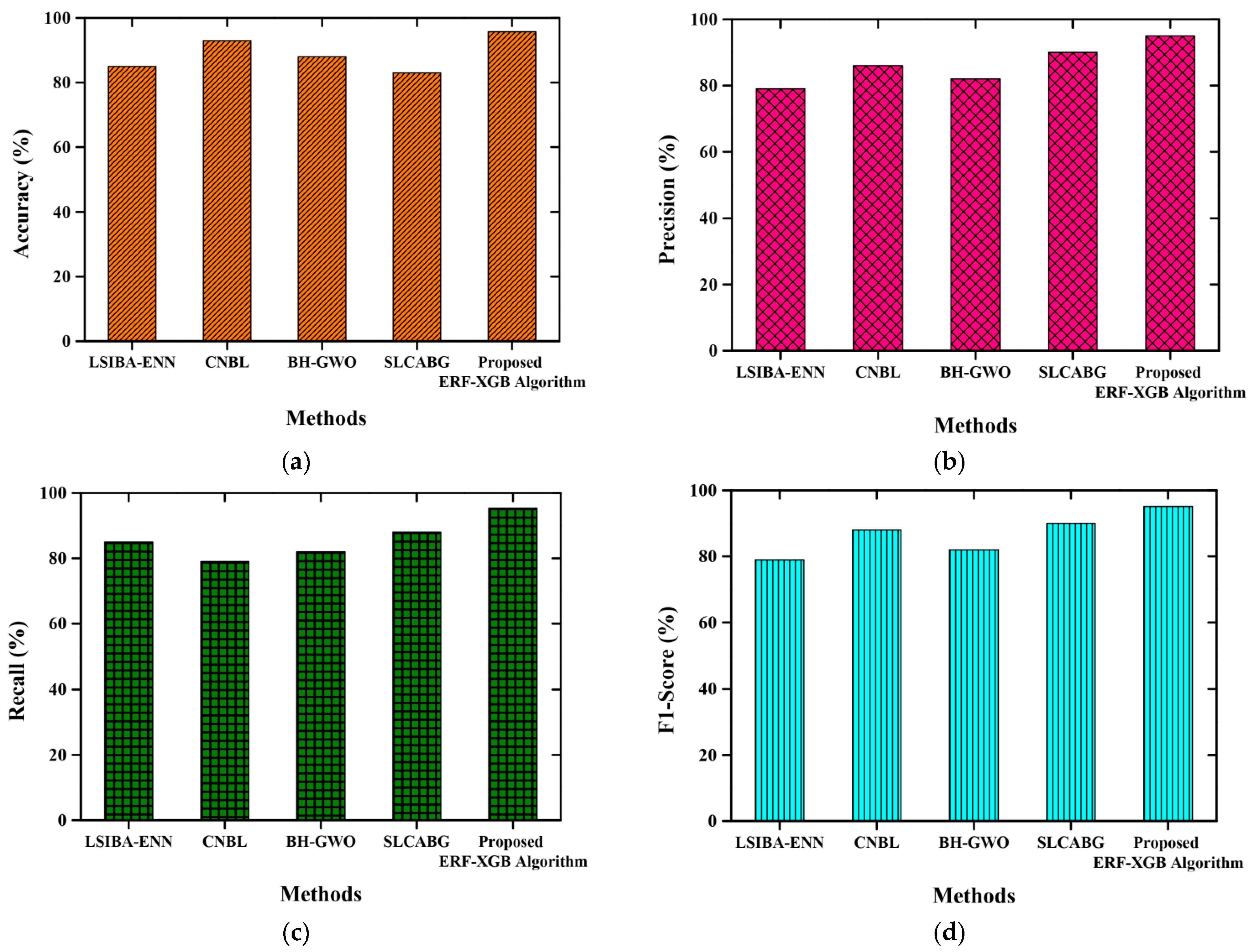
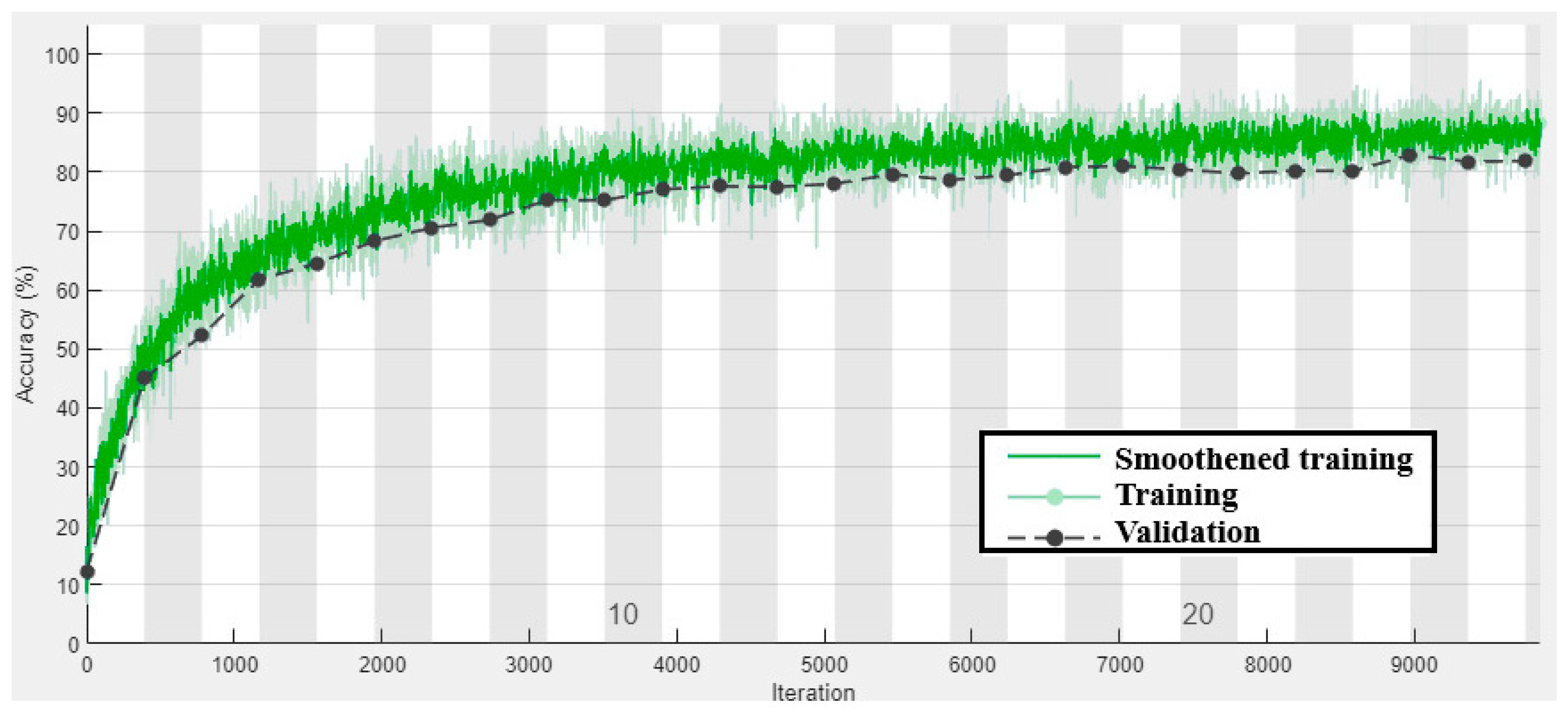
4.5. Performance Analysis
4.6. Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Munna, M.H.; Rifat, M.R.I.; Badrudduza, A.S.M. Sentiment analysis and product review classification in e-commerce platform. In Proceedings of the 2020 23rd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 19–21 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Diwakar, D.; Kumar, R.; Gour, B.; Khan, A.U. Proposed machine learning classifier algorithm for sentiment analysis. In Proceedings of the 2019 Sixteenth International Conference on Wireless and Optical Communication Networks (WOCN), Bhopal, India, 19–21 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Noor, A.; Islam, M. Sentiment Analysis for Women’s E-commerce Reviews using Machine Learning Algorithms. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Singh, S.N.; Sarraf, T. Sentiment analysis of a product based on user reviews using random forests algorithm. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29–31 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 112–116. [Google Scholar]
- Yi, S.; Liu, X. Machine learning based customer sentiment analysis for recommending shoppers, shops based on customers’ review. Complex Intell. Syst. 2020, 6, 621–634. [Google Scholar] [CrossRef]
- Hossain, M.S.; Rahman, M.F.; Uddin, M.K.; Hossain, M.K. Customer sentiment analysis and prediction of halal restaurants using machine learning approaches. J. Islam. Mark. 2022. ahead-of-print. [Google Scholar] [CrossRef]
- Karn, A.L.; Karna, R.K.; Kondamudi, B.R.; Bagale, G.; Pustokhin, D.A.; Pustokhina, I.V.; Sengan, S. Customer centric hybrid recommendation system for E-Commerce applications by integrating hybrid sentiment analysis. Electron. Commer. Res. 2022, 23, 279–314. [Google Scholar] [CrossRef]
- Shrirame, V.; Sabade, J.; Soneta, H.; Vijayalakshmi, M. Consumer Behavior Analytics using Machine Learning Algorithms. In Proceedings of the 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Mehraliyev, F.; Chan, I.C.C.; Kirilenko, A.P. Sentiment analysis in hospitality and tourism: A thematic and methodological review. Int. J. Contemp. Hosp. Manag. 2022, 34, 46–77. [Google Scholar] [CrossRef]
- Li, H.; Bruce, X.B.; Li, G.; Gao, H. Restaurant survival prediction using customer-generated content: An aspect-based sentiment analysis of online reviews. Tour. Manag. 2023, 96, 104707. [Google Scholar] [CrossRef]
- Verma, P.; Dumka, A.; Bhardwaj, A.; Ashok, A. Product Review-Based Customer Sentiment Analysis Using an Ensemble of mRMR and Forest Optimization Algorithm (FOA). Int. J. Appl. Metaheuristic Comput. 2022, 13, 1–21. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, Z.; Yao, X.; Yang, Q. A machine learning-based sentiment analysis of online product reviews with a novel term weighting and feature selection approach. Inf. Process. Manag. 2021, 58, 102656. [Google Scholar] [CrossRef]
- Xu, F.; Pan, Z.; Xia, R. E-commerce product review sentiment classification based on a naïve Bayes continuous learning framework. Inf. Process. Manag. 2020, 57, 102221. [Google Scholar] [CrossRef]
- Kumar, S.; Yadava, M.; Roy, P.P. Fusion of EEG response and sentiment analysis of products review to predict customer satisfaction. Inf. Fusion 2019, 52, 41–52. [Google Scholar] [CrossRef]
- Parimala, M.; Swarna Priya, R.M.; Praveen Kumar Reddy, M.; Lal Chowdhary, C.; Kumar Poluru, R.; Khan, S. Spatiotemporal-based sentiment analysis on tweets for risk assessment of event using deep learning approach. Softw. Pract. Exp. 2021, 51, 550–570. [Google Scholar] [CrossRef]
- Ramshankar, N.; Joe Prathap, P.M. A novel recommendation system enabled by adaptive fuzzy aided sentiment classification for E-commerce sector using black hole-based grey wolf optimization. Sādhanā 2021, 46, 125. [Google Scholar] [CrossRef]
- Gu, T.; Xu, G.; Luo, J. Sentiment analysis via deep multichannel neural networks with variational information bottleneck. IEEE Access 2020, 8, 121014–121021. [Google Scholar] [CrossRef]
- Yang, L.; Li, Y.; Wang, J.; Sherratt, R.S. Sentiment analysis for E-commerce product reviews in Chinese based on sentiment lexicon and deep learning. IEEE Access 2020, 8, 23522–23530. [Google Scholar] [CrossRef]
- Zhao, W. Classification of Customer Reviews on E-commerce Platforms Based on Naive Bayesian Algorithm and Support Vector Machine. J. Phys. Conf. Ser. 2020, 1678, 012081. [Google Scholar] [CrossRef]
- Alzahrani, M.E.; Aldhyani, T.H.; Alsubari, S.N.; Althobaiti, M.M.; Fahad, A. Developing an intelligent system with deep learning algorithms for sentiment analysis of e-commerce product reviews. Comput. Intell. Neurosci. 2022, 2022, 3840071. [Google Scholar] [CrossRef]
- Huang, W.; Lin, M.; Wang, Y. Sentiment Analysis of Chinese E-Commerce Product Reviews Using ERNIE Word Embedding and Attention Mechanism. Appl. Sci. 2022, 12, 7182. [Google Scholar] [CrossRef]
- Zhang, R.; Tran, T.T. Helping e-commerce consumers make good purchase decisions: A user reviews-based approach. In E-Technologies: Innovation in an Open World, Proceedings of the 4th International Conference, MCETECH 2009, Ottawa, Canada, 4–6 May 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–11. [Google Scholar]
- Garg, N.; Sharma, K. Text pre-processing of multilingual for sentiment analysis based on social network data. Int. J. Electr. Comput. Eng. 2022, 12, 776–784. [Google Scholar] [CrossRef]
- Kolajo, T.; Daramola, O.; Adebiyi, A.; Seth, A. A framework for pre-processing of social media feeds based on integrated local knowledge base. Inf. Process. Manag. 2020, 57, 102348. [Google Scholar] [CrossRef]
- Nafis, N.S.M.; Awang, S. The impact of pre-processing and feature selection on text classification. In Advances in Electronics Engineering, Proceedings of the ICCEE 2019, Kuala Lumpur, Malaysia, 29–30 April 2019; Springer: Singapore, 2020; pp. 269–280. [Google Scholar]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Alabool, H.M.; Alarabiat, D.; Abualigah, L.; Heidari, A.A. Harris hawks optimization: A comprehensive review of recent variants and applications. Neural Comput. Appl. 2021, 33, 8939–8980. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, X.; Zhang, J.; Wang, L.; Wang, D.; Zhang, P. Fault diagnosis of silage harvester based on a modified random forest. In Information Processing in Agriculture; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Zhu, X.; Chu, J.; Wang, K.; Wu, S.; Yan, W.; Chiam, K. Prediction of rockhead using a hybrid N-XGBoost machine learning framework. J. Rock Mech. Geotech. Eng. 2021, 13, 1231–1245. [Google Scholar] [CrossRef]
- Luan, Y.; Lin, S. Research on text classification based on CNN and LSTM. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 29–31 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 352–355. [Google Scholar]
- Maas, A.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Maas, A. Large Movie Review Dataset. Sentiment Analysis. Available online: https://ai.stanford.edu/~amaas/data/sentiment (accessed on 6 March 2023).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Base Learner | Tree |
| Gamma | 0 |
| Learning rate | 0.03 |
| Number of pruning after control | 0.2 |
| Regularization | L2 |
| Tree depth | 4 |
| Random sampling decision tree ratio | 0.7 |
| Minimum leaf node sample weight | 2 |
| Sl. No | Performance Measures | Performance Ranges | |||
|---|---|---|---|---|---|
| Proposed ERF-XGB | XG Boost [24] | ||||
| IMDB Dataset | ChnSenti Corp Dataset | IMDB Dataset | ChnSenti Corp Dataset | ||
| 1 | Accuracy | 98.2% | 98.7% | 90.1% | 90.7% |
| 2 | Precision | 98.5% | 98% | 89.3% | 88.6% |
| 3 | Recall | 98.8% | 98.3% | 89.4% | 89.3% |
| 4 | F1-score | 98.1% | 97.1% | 89.0% | 88.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alghazzawi, D.M.; Alquraishee, A.G.A.; Badri, S.K.; Hasan, S.H. ERF-XGB: Ensemble Random Forest-Based XG Boost for Accurate Prediction and Classification of E-Commerce Product Review. Sustainability 2023, 15, 7076. https://doi.org/10.3390/su15097076
Alghazzawi DM, Alquraishee AGA, Badri SK, Hasan SH. ERF-XGB: Ensemble Random Forest-Based XG Boost for Accurate Prediction and Classification of E-Commerce Product Review. Sustainability. 2023; 15(9):7076. https://doi.org/10.3390/su15097076
Chicago/Turabian StyleAlghazzawi, Daniyal M., Anser Ghazal Ali Alquraishee, Sahar K. Badri, and Syed Hamid Hasan. 2023. "ERF-XGB: Ensemble Random Forest-Based XG Boost for Accurate Prediction and Classification of E-Commerce Product Review" Sustainability 15, no. 9: 7076. https://doi.org/10.3390/su15097076
APA StyleAlghazzawi, D. M., Alquraishee, A. G. A., Badri, S. K., & Hasan, S. H. (2023). ERF-XGB: Ensemble Random Forest-Based XG Boost for Accurate Prediction and Classification of E-Commerce Product Review. Sustainability, 15(9), 7076. https://doi.org/10.3390/su15097076