This study employs online reviews to identify user needs and proposes a multi-attribute decision-making approach to address the sustainable product iteration problem. The approach presented in this paper explores how small and medium-sized manufacturing industries can use online review information to capture user needs and iterate products in a sustainable manner.
The sustainable iterative approach to product design proposed in this study involves the following steps: (1) Obtaining user needs information from a large number of online reviews. (2) Thematically organizing user requirements using the BTM model to establish a product iteration factor information base. (3) Dividing the corresponding products into structural modules to align user requirements with the structural modules as a second screening for user requirements. (4) Introducing the PLTS method to account for expert scoring hesitation and uncertainty. The DEMATEL method is used to consider the interrelatedness of indicators and is reconstructed into a DEMATEL correlation function in the form of exact values using an improved binary semantic approach. This step is a core element of the iterative design. (5) Analyzing the correlation rankings of the importance of the structural modules of interest to the users in order to prioritize the modules for the final iteration. (6) Discussing a sustainable product iteration plan in focus groups with professional product designers, structural engineers, brand owners, and product development technicians. The discussion focuses on the selected critical structural and technical modules; the functional characteristics of the components, user requirements, and the current state of the product are gradually analyzed to ensure the sustainable recycling of most modules and the iterative upgrading of the product.
The entire process of sustainable iterative product design involves an iterative filtered loop, where each horizontal plane clearly depicts the iteration stage, and each stage can be paused, as shown in
Figure 1. This iterative process can be repeated with the original product to meet changing user needs whenever the latest online reviews become available.
3.1. Mining User Needs Based on the BTM Model
Yan et al. [
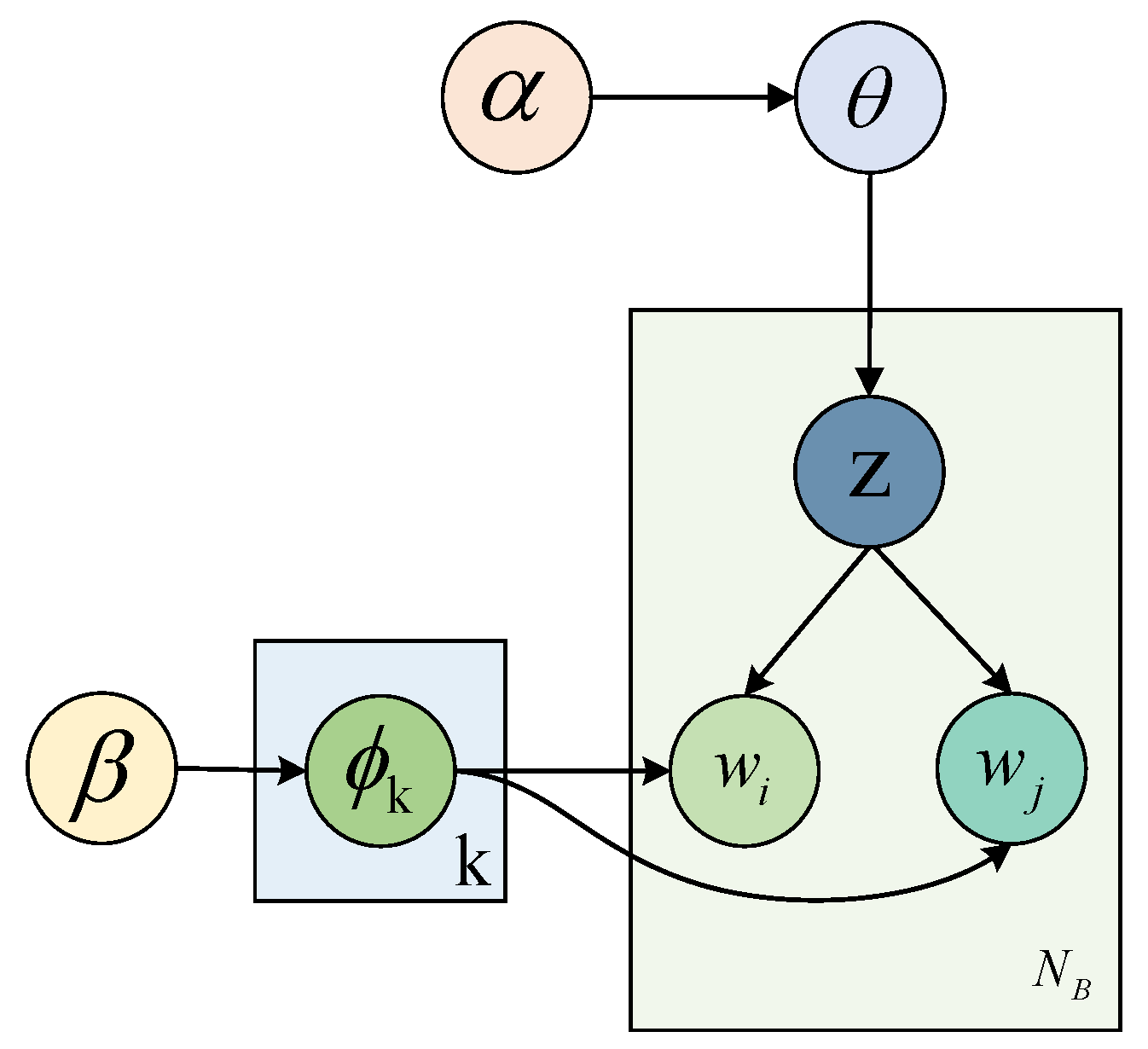
29] proposed a biterm topic model (BTM) to comprehensively explore the topics in a corpus and tackle the issue of sparsity in short texts. BTM posits that two words in a biterm share a common topic, which is derived from a hybrid topic across the corpus. In this framework, a topic is represented as a distribution of words. Unlike most topic models that examine the thematic factors of a corpus by modeling document generation, BTM achieves this objective by modeling the co-occurrence of word pairs. Specifically, if two phrases appear together more frequently, they are more likely to be related to the same topic [
30]. As shown in
Figure 2.
Assuming that a biterm is composed of words wi,1 and wi,2, that is, , the two words in each biterm are sampled from the same topic .
Biterms form a set . In addition, the symmetrical and in the Dirichlet prior are used, which have single-value hyperparameters and , respectively. The BTM is generated as follows:
The topic distribution is generated for with parameters in the Dirichlet prior, ;
For each topic , the topic distribution is generated for with parameters in the Dirichlet prior, ;
For each biterm :
The topic distribution of the biterm in the topic distribution is :. A word is generated according to the topic distribution :.
According to BTM, the probability of
can be calculated by integrating
and
. In addition, by multiplying the probability of each biterm, the entire corpus can be obtained. This can be stated as follows [
30]:
3.2. Evaluating User Requirements and Technical Modules using Probabilistic Semantic Term Sets
Pang et al. [
20] proposed the use of probabilistic linguistic term sets (PLTS) in their work. A PLTS is a semantic collection consisting of a set of semantic terms and their associated probabilistic information. In the case where the expert’s evaluation of the semantic set represented by PLTS is denoted as
L(p), the corresponding definitions can be found.
In Definition 1 [
31], suppose
is a semantic term set,
is called a PLTS on S:
In Equation (2), denotes the number of semantic sets in the PLTS, and represents the likelihood of the semantic set .
When , the semantic information in the experts’ evaluation is complete; when , the semantic information in the experts’ evaluation is an incomplete probability distribution and the PLTS needs to be standardized.
For example, assume that LTS is a semantic terminology set with five levels of granularity, . When the evaluation indicator is the evaluation of the product’s battery life, the user gives “The battery life of the product is good” as S4 with a probability of 0.6, and “I don’t know much about the battery life” as S3 with a probability of 0.3. At this time, . When the evaluation indicator evaluates the quality of the product, the first user gives a very good rating, the second user gives a very good rating, the third user gives a good rating, and the fourth an average rating, then the “quality of the product is very good” is S4 and the probability is 0.5. The probability of a product being of good quality is S3 and the probability is 0.25. The probability of the product being of average quality is S2 and the probability is 0.25, and .
In Definition 2 [
31], suppose
is
the incomplete PLTS in the previous semantic information, it is standardized to:
In Definition 3 [
31],
and
are the K-th semantic sets in
and
,
and
are the probability information of semantic sets
and
, respectively, and the distance between
and
is:
where
and
denote the subscripts of
and
.
In Definition 4 [
31], suppose
is the
of the previous PLTS and
is the subscript of the semantic term set
, then the score function, degree of deviation, and degree of hesitation of
are:
In Equation (8), . If the two PLTSs are and , respectively, and if , then is superior to .
In Definition 5 [
31], suppose
is the S of the previous PLTS, then
is converted to an exact numerical function:
The greater the , the smaller the degree of deviation; the smaller the degree of hesitation, the better is the PLTS .
3.3. Calculating User Requirement Weights Using the Improved Probabilistic Semantic DEMATEL Method
The next step uses the enhanced probabilistic semantic DEMATEL method for calculating the weights of indicators in multi-attribute decision making. In multi-attribute decision making, indicator interactions are typically considered when applying factors to the exact numerical DEMATEL method and to probabilistic semantic improvements. This involves converting the semantic variables into probabilistic semantics and analyzing the indicators’ interactions using the DEMATEL method to determine their importance. Importance calculations are then performed to obtain the weights for each indicator. To calculate the index weight using the improved probabilistic semantic DEMATEL method, the following steps should be followed:
A direct correlation matrix
Xk between the indexes was established. The LTS term collection for the correlation between the evaluation index is
. The evaluation indexes are
. Expert
evaluation of the correlation between indexes, according to the collection Sr, was used to establish a direct correlation matrix between indexes.
where
represents the degree of influence of the use of the LTS evaluation index
Ci by expert Ek on
Cj. It takes a value of 0 if there is no influence.
All expert evaluations of the inter-influence of relationships between the indicators were assembled according to the example in Definition 1 to obtain a direct correlation matrix between the indicators in the form of a probabilistic semantic term set for all experts.
where
represents the PLTS, and the exact numerical calculation is usually adopted during the calculation by the traditional DEMATEL method. The current data are still semantic information, which makes it impossible to calculate, so this study uses binary semantics to convert the semantic information into exact values. This is performed using Equations (5) and (6) to calculate the score function and the deviation degree
of the probabilistic semantic
. Subsequently, binary semantics were used to convert them into exact numerical values.
In Definition 6,
is the result of the semantic term set L after integration, and let
,
.
can be expressed by the following function
as a binary semantic conformance [
31]:
where
denotes the rounding operator,
denotes the transfer value. In contrast, let
be binary semantic information and the information is converted into a real number using a
function.
- 3
The score function and the degree of deviation were calculated and then converted into a direct correlation matrix after obtaining exact values using the
function.
- 4
The directly normalized correlation matrices were then calculated. A common method for normalizing directly correlated matrices is based on the sum of the vector factors of every row of the matrix [
32]. Let the normalization coefficient of
be
, the normalization coefficient is calculated with the score function and the degree of deviation in the PLTS, the calculation form of
is calculated as follows:
The normalized direct correlation matrix
Z is:
- 5
The total correlation matrix was calculated using
T. According to references [
33,
34],
T is calculated as follows:
- 6
Index importance was calculated.
The sum of
i in row
I of matrix
T is defined as
Dj and the sum of
j in column is defined as
Fj.
Let
, the formula for calculating the index importance
is as follows:
The index importance was normalized to obtain the index weight . The index weight set was .
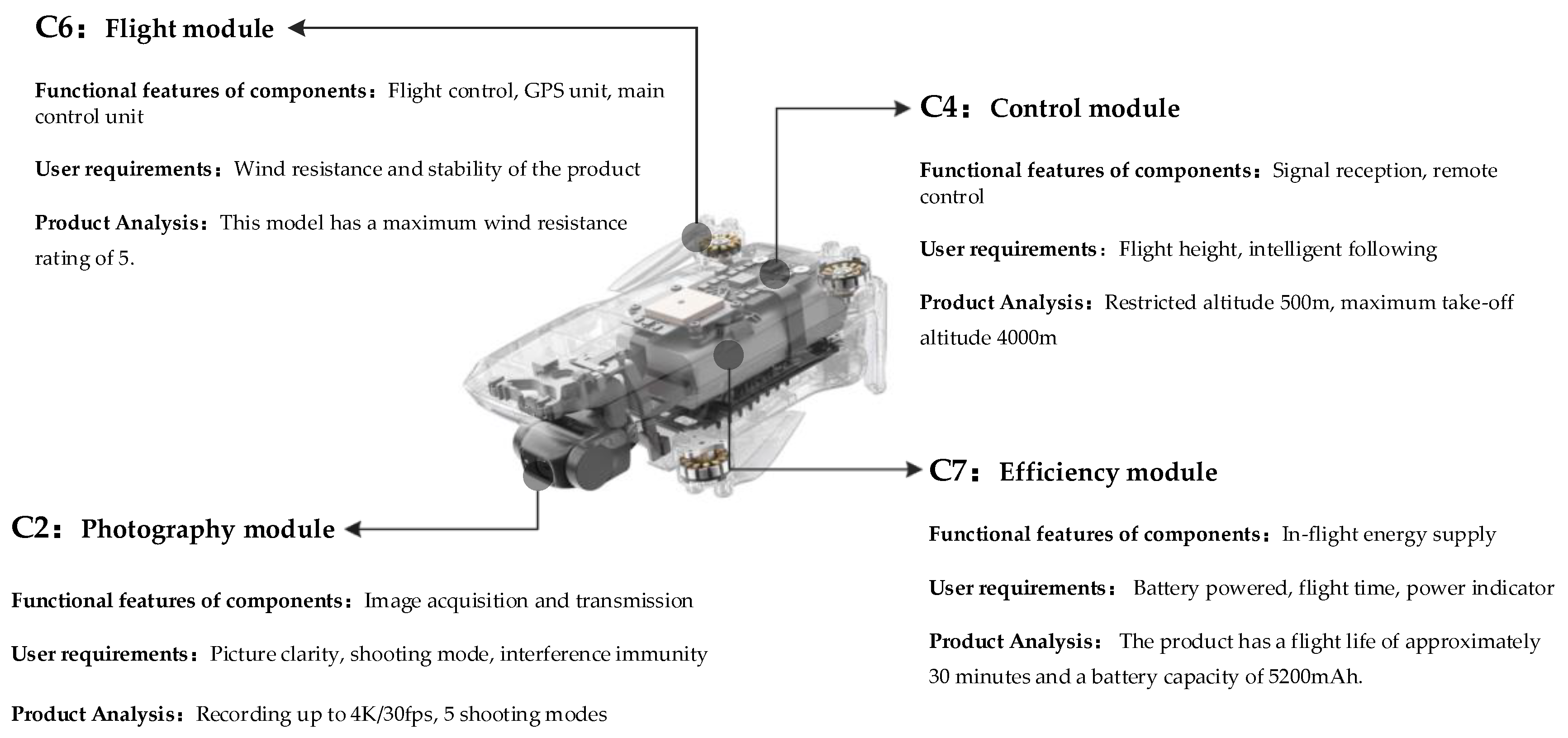
3.4. Sequencing Technology Modules with Consideration of User Requirements Interaction
Suppose that the number of experts is , the expert weight is , the user need is , the technical module is , and the weight of need is .
The correlation between user needs
and technical module
is evaluated by the expert as:
The weight between user need
is evaluated by the expert as:
The importance of technical modules considering the mutual influence between user needs is:









{kind=link}
{kind=link}
{kind=link}
{kind=link}
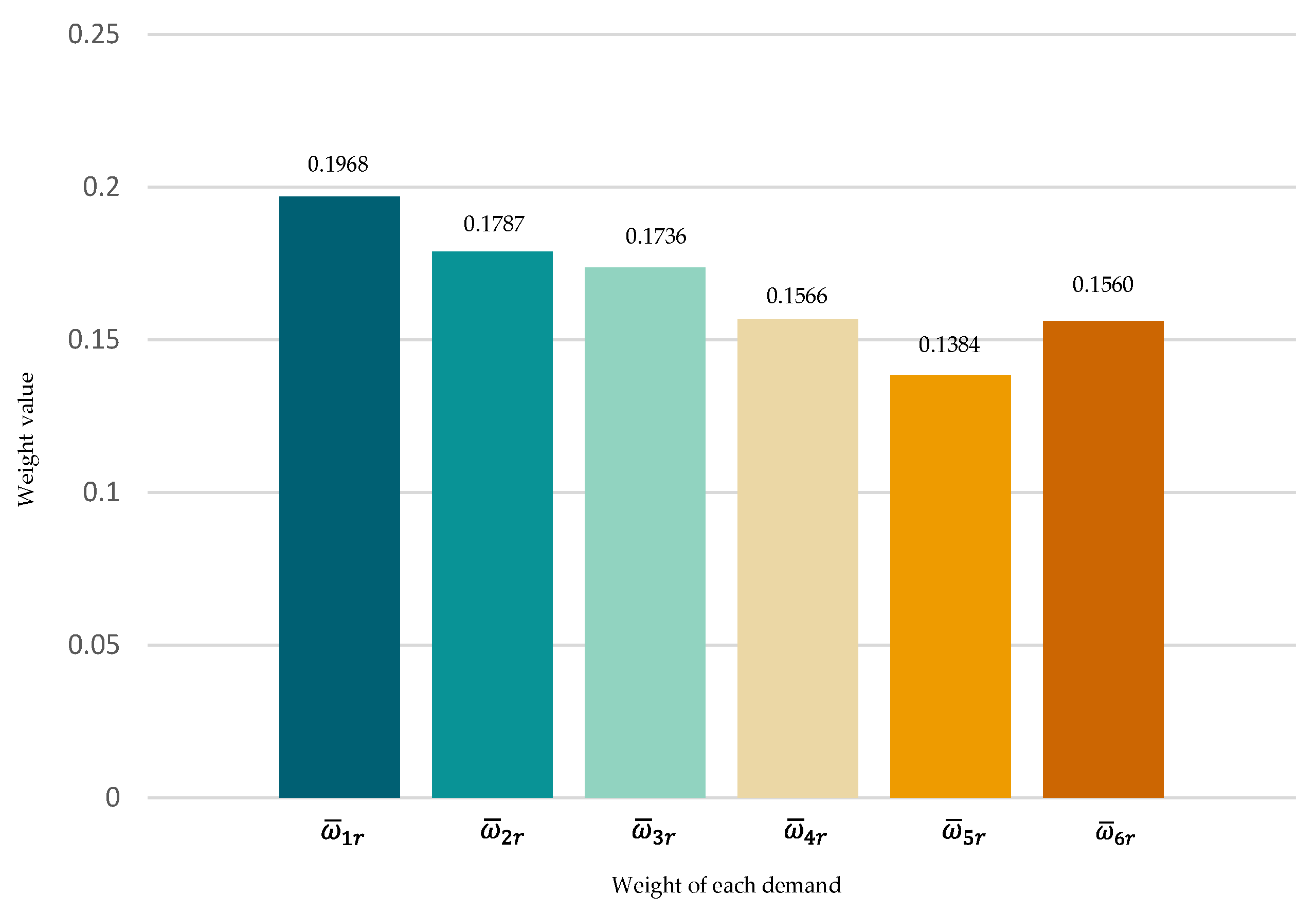{kind=link}
{kind=link}