1. Introduction
Tumor detection is the challenging and essential task in different medical-image applications as it includes a large amount of data/information. In the medical field, brain tumor detection, either manually or automatically, is vital for clinical diagnosis and treatment to avoid the death rate. Therefore, the novel Iterative Reflect Perceptual Sammon Bagging Classification (IRPS-BAC) Method is useful for medical applications. It provides main advantages in the medical field, especially for early-stage diagnosing and treating brain tumors accurately.
An automatic method was introduced in [
1] for epileptic seizure detection depending on deep metric learning. A one-dimensional convolutional embedding module was employed for single-channel and multichannel EEG signals correspondingly. However, the detection time was not reduced by the designed method. The cell-free DNA (cfDNA) methylome was introduced in [
2] to identify ovarian cancer at the early stage, but the detection accuracy level was not improved by cfDNA methylome.
A new patient-specific seizure prediction technique was introduced in [
3] depending on deep learning with electroencephalogram (EEG) recordings. However, the computational complexity was not reduced by the patient-specific seizure prediction technique. An artificial intelligence system was discussed in [
4] for identifying the epileptic focus based on features that utilized interictal EEGs. An efficient computer-aided solution was obtained for epilepsy focus detection, but the computational time consumption was not reduced by the artificial intelligence system.
A new analysis system was introduced in [
5] for identifying the epileptic seizure from EEG signals. The designed system employed the statistical features depending on optimum allocation technique (OAT) with logistic model trees (LMT), but the space complexity was not minimized by the designed analysis system. The blood samples of DNA methylation profiling were carried out in [
6] for ovarian cancer detection. A supervised machine learning algorithm was used to predict and classify the blood sample as malignant or non-malignant, but the computational cost was not reduced by DNA methylation profiling.
Epithelial ovarian cancer (EOC) was linked in [
7] with the pathogenic variants (PVs) in homologous recombination and/or mismatch repair genes. The women’s testing was carried out with familial EOC. However, the tumor detection accuracy was not improved by EOC. The circulating tumor DNA (ctDNA) utility was carried out in [
8] with biomarker for EOC, but feature selection time was not reduced by ctDNA utility.
An ultrasensitive and selective electrochemical biosensor was employed in [
9] for rapid DNA methylation detection in blood. DNA methylation sensing included hybridization of DNA modified gold-coated magnetic nanoparticles to target DNA and to differentiate methylated DNA. However, computational cost was not reduced by designed biosensor. The signal decomposition and statistical method was discussed in [
10] for epileptic seizure detection. The variational mode decomposition (VMD) was carried out to extract components of intrinsic mode functions (IMFs) through EEG signal decomposition. However, the feature selection accuracy was not improved by signal decomposition and statistical method.
A brain tumor occurs due to the unrestrained and fast expansion of cells. If not treated at an early stage, it may lead to death. Despite numerous important efforts as well as talented results in this domain, accurate feature selection and classification have a challenging duty. Few machine learning brain tumor detection methods are examined to discover brain tumor detection. In previous work, the relevant feature was selected, but the feature selection time was enhanced. The conventional classification process failed to attain accuracy. To address these issues, the Iterative Reflect Perceptual Sammon Bagging Classification (IRPS-BAC) Method is introduced.
The following is a list of our key contributions to this research:
- ➢
This paper presents the proposed IRPS-BAC Method to improve the tumor detection performance with higher accuracy and lesser time complexity;
- ➢
This paper uses the iterative reflect perceptual sammon feature selection process and bagging classification process in the proposed IRPS-BAC Method;
- ➢
This paper applies the iterative reflect perceptual sammon feature selection process for computing divergence between features and objective. The sammon mapping projects the similar and dissimilar features into feature space and also selects the relevant features. In this way, the tumor detection time is said to be minimized;
- ➢
This paper performs the bagging classification process in the IRPS-BAC Method. The internal node process the selected features to take the tumor decision as normal or cancerous based on information gain. This, in turn, helps to improve accuracy and reduce the time complexity and error rate.
The rest of the paper is arranged as follows: the related works of tumor detection is presented in
Section 2. In
Section 3, details of the IRPS-BAC Method are described with a neat diagram.
Section 4 provides the experimental setup. The results and discussions are presented in
Section 5. Finally,
Section 6 concludes the paper.
2. Related Works
An efficient encrypted EEG data classification and recognition system was designed in [
11] through a chaotic baker map and Arnold Transform algorithm with convolutional neural networks (CNNs). A fully automated system depending on the Hybrid Grey Wolf Optimizer Improved Sine Cosine Algorithm (HGWOISCA) was introduced in [
12] for EEG signal classification.
An automated deep learning-enabled brain signal classification for epileptic seizure detection was introduced in [
13] to categorize the brain signals to identify the existence of seizure or not. A new enhanced search ability based on atomic search optimization (ESAASO) was introduced in [
14] for seizure and non-seizure detection. An inertia weight, levy flight, and ranking strategies were combined to increase the performance.
A new epileptic seizure detection method was introduced in [
15] with empirical mode decomposition, the mutual information-based best individual feature (MIBIF) selection algorithm, and the multi-layer perceptron neural network. An autonomously generalized retrospective and patient-specific hybrid model was introduced in [
16] based on convolutional neural network with long short-term memory. An automated learning framework termed Fourier–Bessel series expansion-based empirical wavelet transform (FBSE-EWT) method was introduced in [
17] for identifying epileptic seizures from the EEG signals. A deep long short-term memory (LSTM) network was introduced in [
18] to study high-level representations of EEG patterns. The features were given to softmax layer to attain the predicted labels.
A support vector machine classifier was introduced in [
19] for time series EEG signals mapping to a complex network. Edge weight fluctuation (EWF) was used to extract fluctuation in EEG signals. A new method was introduced in [
20] for time series EEG signals mapping to complex network. A random forest classifier was performed in [
21] to relying contextually on several spatial and temporal features of machine learning used in tumor detection. A segmentation and detection method for brain tumors was developed [
22] by using images from MRI sequence as an input image to identify the tumor area. Deep hybrid learning (DeepTumorNetwork) was introduced in [
23] for categorizing brain cancers. However, the time was not reduced.
3. Methodology
A tumor is the abnormal increase in cells to form an unnatural section with different features from normal cells. Tumor detection is the most challenging task in medical applications [
24]. The tumor classification is a difficult task in the field of medical data analysis. Machine learning technology helps the radiologists to easily detect the tumor without any surgical intervention [
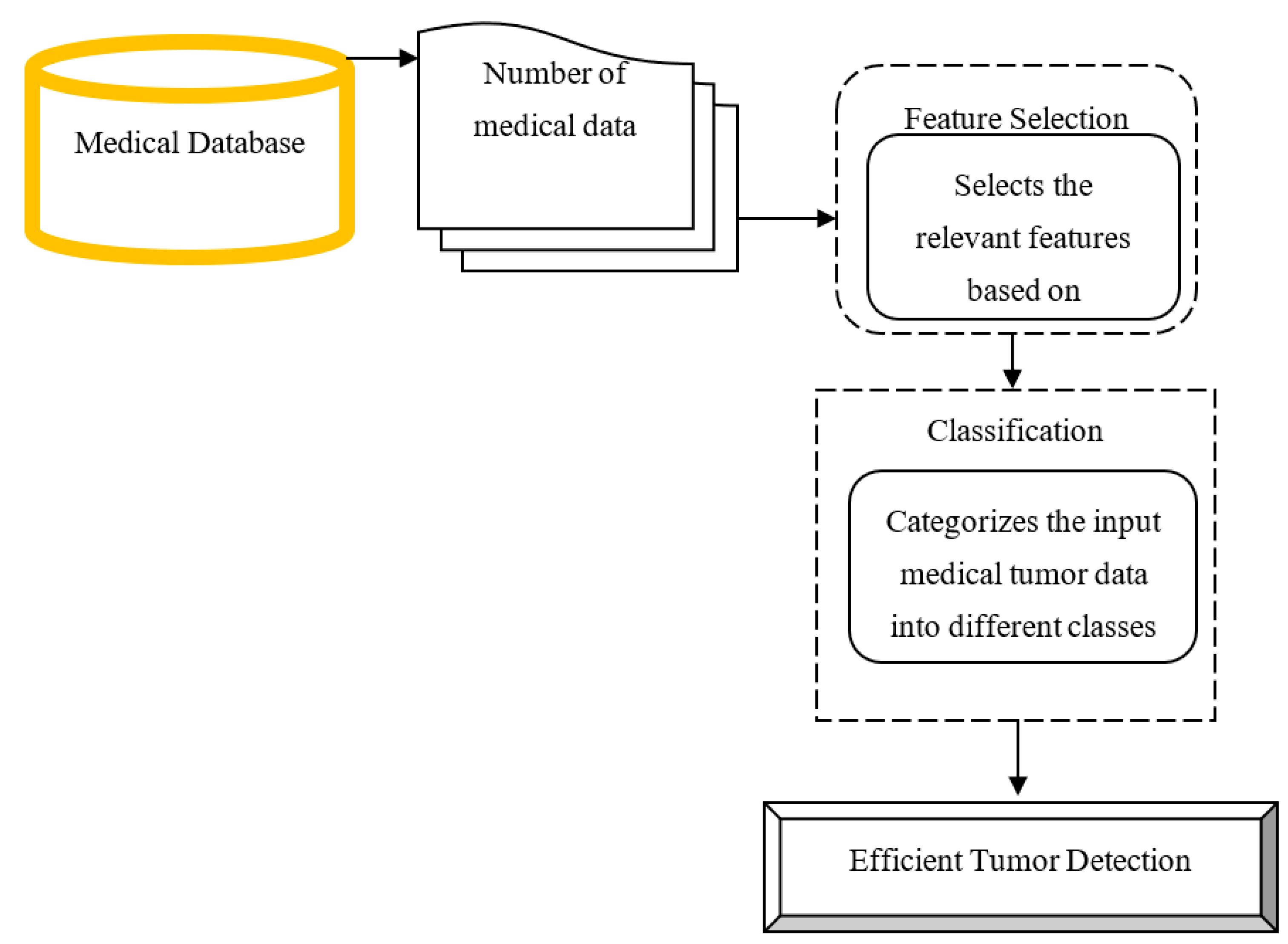
25]. Different classification methods are discussed by the researchers to detect the tumor disease in an effective manner, but the detection accuracy was not improved and detection time consumption was not reduced by conventional methods. In order to address these issues, an efficient method called the Iterative Reflect Perceptual Sammon Bagging Classification (IRPS-BAC) Method is introduced for tumor detection. The structural diagram of the IRPS-BAC Method is illustrated in the
Figure 1.
The above
Figure 1 explains the flow process of the proposed IRPS-BAC Method to perform efficient tumor detection with higher accuracy and lesser time consumption. The input medical data ‘d_1, d_2, d_3…d_m’ are gathered from the database. The collected medical data with features are considered as an input for performing feature selection. Finally, the selected features of tumor classification are carried out with higher accuracy and lesser time consumption. The brief explanation of the iterative reflect perceptual sammon feature extraction and bagging classification is discussed in next sub-section.
3.1. Iterative Reflect Perceptual Sammon Feature Extraction
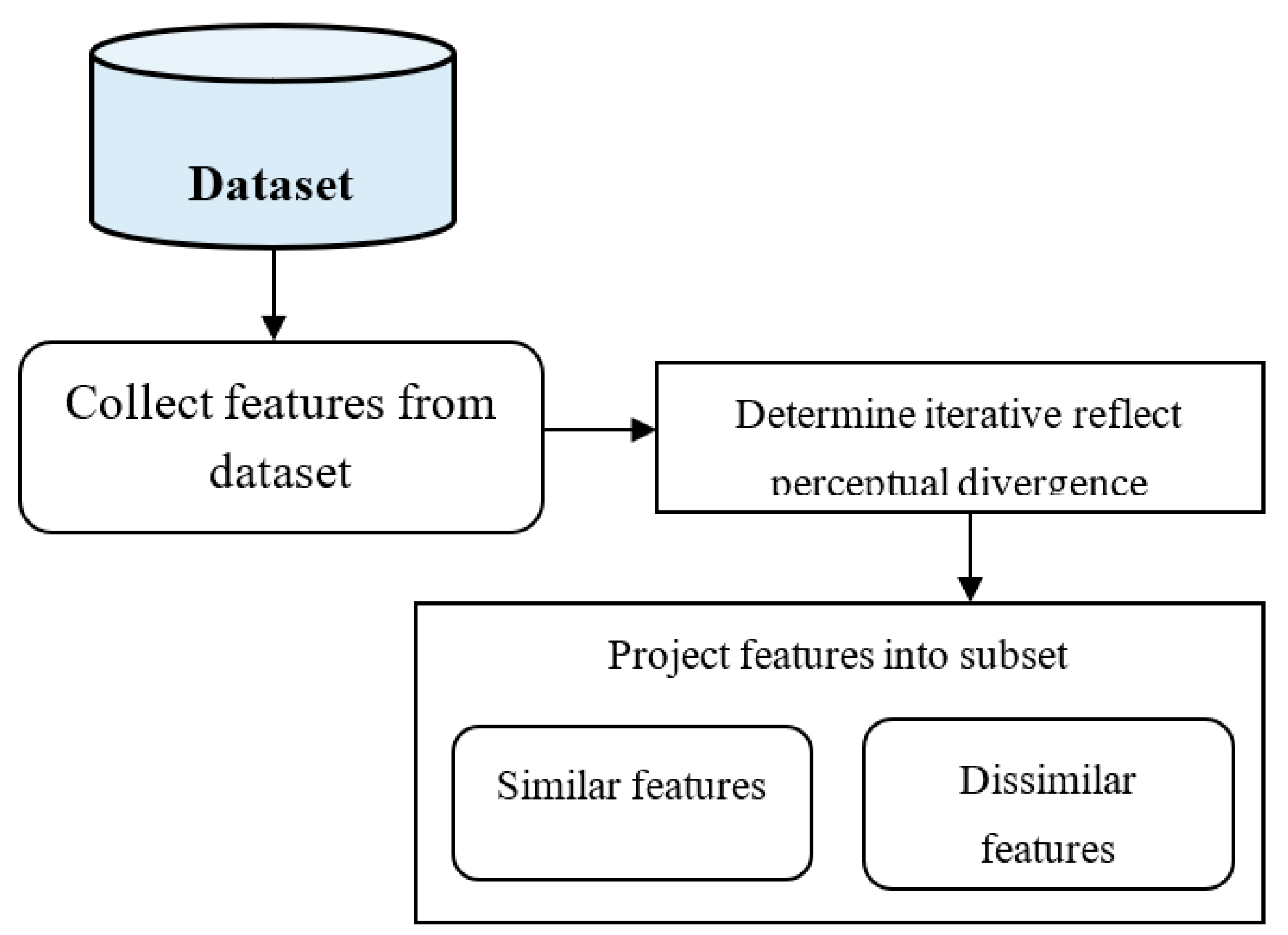
The proposed IRPS-BAC Method performs the feature selection for accurate tumor detection with lesser time consumption. Feature selection is the process that finds the feature subset from the input dataset. Iterative reflect perceptual divergence computes the distance between the two points. In the IRPS-BAC Method, sammon mapping projects the similar and dissimilar features into feature space. The diagrammatic representation of the feature selection is illustrated in
Figure 2.
Figure 2 explains the diagrammatic representation of the feature selection process. Let us consider that the number of features in the database is ‘
’. By applying the iterative reflect perceptual divergence, the distance is determined between feature and objective. It is formulated as
From (1), ‘
’ denotes iterative reflect perceptual divergence. ‘
’ denotes the features of input data. The iterative reflect perceptual divergence value varies from ‘0’ to ‘1’. After that, the threshold value is predefined to map the input features from a database into any of their subsets. Consequently, the sammon mapping result is given as
From (2), ‘
’ symbolizes the sammon mapping function. ‘
’ represent the threshold. The feature that gets more diverged from objective is considered as the dissimilar feature, or else the feature is considered as the relevant feature. By this manner, the similar feature gets mapped into low-dimensional space. The algorithmic process of iterative reflect perceptual sammon feature selection is shown in Algorithm 1.
| Algorithm 1: Iterative Reflect Perceptual Sammon Feature Selection |
| Input: Database, number of features ‘’ |
| Output: Selected features |
1. Begin
2. Number of input features ‘’ taken as an input
3. For each feature ‘’
4. Compute the iterative reflect perceptual divergence
5. Map the features into subsets based on divergence value
6. Select the relevant features from database
7. End for
8. End |
The algorithmic step of the IRPS-BAC Method is described with feature selection process. Initially, the number of features is considered as an input. Then, the divergence value is computed for every feature. Based on the values, the relevant features are selected. Finally, the relevant features are used to perform efficient tumor detection.
3.2. ID3 Ensembled Bagging Classification
In the IRPS-BAC Method, bagging classifier is an ensemble of base classifiers each on random subsets of a dataset and combines their individual predictions. Each base classifier trained random input generated with replacement. Training set for every base classifier is independent of each other. Bagging classifier minimizes the overfitting through voting which resulted in bias compensated by variance reduction. Bootstrap aggregating is a machine learning technique used to improve the stability and accuracy of classification and regression analysis. Let us consider that Bagging classifier construct ‘
’ number of ID3 decision tree results for each medical data in bootstrap samples. The ID3 decision tree is used in the IRPS-BAC Method for categorizing the medical data into normal data or cancerous data (i.e., abnormal data). ID3 decision tree has root node, internal node, and leaf node. The root node has data with selected features. The internal node processes the selected features and the leaf node takes the decision to categorize the tumor as a normal or cancerous one based on information gain. The information gain is given as
From (3), ‘
’ denotes the two classes of ID3 classifier (i.e., normal or abnormal). ‘
’ symbolizes the entropy of total set. ‘
’ symbolizes the input data. ‘
’ symbolizes the entropy of the classes. The information gain is used for data partitioning consistent with selected features. The data with high information gain is categorized as normal. The data with less information gain is categorized as abnormal. The output of classification is attained at the leaf node. Each weak classifier presents the classification results. After that, bagging classifier in the IRPS-BAC Method aggregates all base classifier into strong classifier. It is formulated as
From (4), the strong classifier results are obtained. Subsequently, the IRPS-BAC Method applies vote ‘
’ for each base ID3 classifier results ‘
’. It is computed as
From (5), the majority vote of all base ID3 classifier results is employed to formulate the strong classifier for grouping the medical data. Consequently, the strong classifier result is computed as
From (6), ‘’ designates the final strong clustering result, whereas ‘’ denotes the majority votes of base classifier output. The obtained strong classification results are used to accurately characterize the data as normal data or abnormal data. The algorithmic description of the ID3 Ensembled Bagging Classification in the IRPS-BAC Method is described as follows.
Algorithm 2 describes the algorithmic description of ID3 ensembled bagging classification in the IRPS-BAC Method. The number of medical data with the selected features is considered as an input. With selected features, the ensemble bagging classifier built the number of decision trees to categorize the medical data. The bagging classifier combines the decision tree and assigns the votes to every decision tree result. The decision tree with maximum votes is considered as the final classification results. By this manner, the classification results are improved and minimized the time consumption. The proposed IRPS-BAC Method effectively performs the brain tumor detection with higher accuracy.
| Algorithm 2: ID3 Ensembled Bagging Classification |
| Input: Selected features |
| Output: Classification results |
Begin
1. for each data with selected features
2. Construct base learners with selected features
3. Classifies data based on maximum information gain
4. Combine all weak learners
5. for each weak learners
6. Assign votes to each base learner
7. Find base learner with majority of votes
8. Obtain strong classification results
9. end for
10. end for
End |
4. Experimental Settings
The experimental analysis of the proposed IRPS-BAC Method and existing methods, the automatic method [
1], cfDNA methylome [
2], and Deep Tumor Network [
25], are implemented using JAVA coding for detecting the tumor with minimum time consumption. The medical data is collected from two different datasets, namely the Epileptic Seizure Recognition Data Set and Cervical Cancer Risk Classification. The first dataset [
23] is taken from the UCI machine learning repository (
https://archive.ics.uci.edu/ml/datasets/Epileptic+Seizure+Recognition (accessed on December 2022)). The objective of the dataset is to predict the epileptic seizure which is a symptom due to excessive neuronal activity in brain. The dataset comprises 11,500 instances and 179 attributes. Among 179, 178 attributers are explanatory variables (X1, X2…X178) and last attribute is a class attributes. The second dataset [
26] is taken from Kaggle (
https://www.kaggle.com/datasets/loveall/cervical-cancer-risk-classification (accessed on December 2022)). This file comprises the list of risk factors for cervical cancer leading to biopsy examination. The dataset comprises 858 instances and 36 attributes.
5. Results Analysis
The simulation results of the proposed IRPS-BAC Method and existing methods, the automatic method [
1], cfDNA methylome [
2], and Deep Tumor Network [
25], are illustrated in this section. The efficiency of proposed and existing methods are compared with different parameters, including:
- ➢
Tumor detection time;
- ➢
Tumor detection accuracy;
- ➢
False-positive rate.
The effectiveness of the proposed IRPS-BAC Method and existing methods are discussed in terms of tables and graphical representation.
5.1. Impact on Tumor Detection Accuracy
Tumor detection accuracy is defined as the ratio of number of data points that are correctly identified as tumor or normal through the classification to the total number of data points. The tumor detection accuracy is expressed as
From (7), ‘’ symbolizes the tumor detection accuracy. The tumor detection accuracy is computed in percentages (%).
Table 1 and
Table 2 explain the tumor detection accuracy of three different methods, namely, the automatic method, cfDNA methylome, Deep Tumor Network, and the proposed IRPS-BAC Method for two datasets, namely the Epileptic Seizure Recognition Data Set and Cervical Cancer Risk Classification.
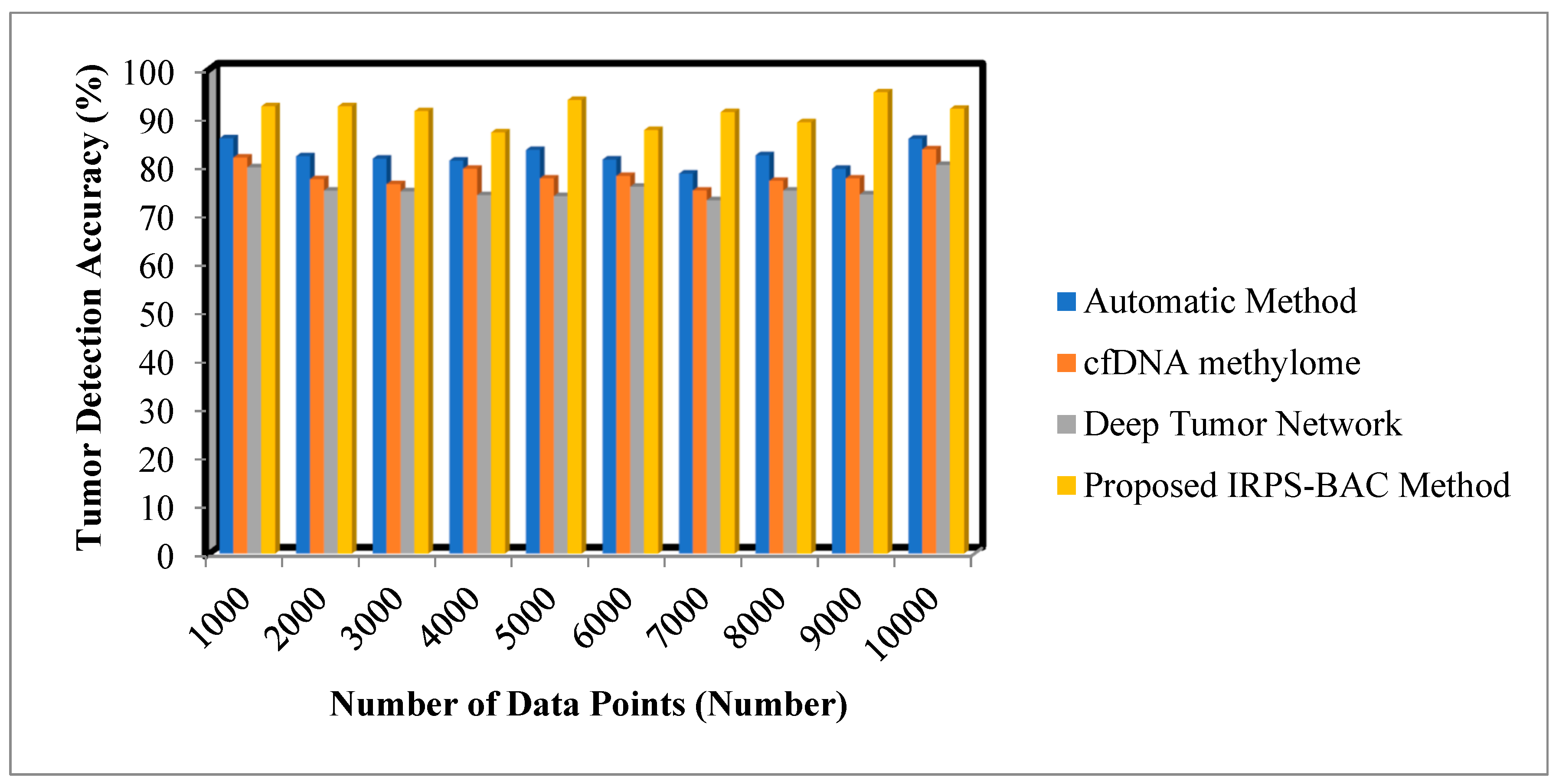
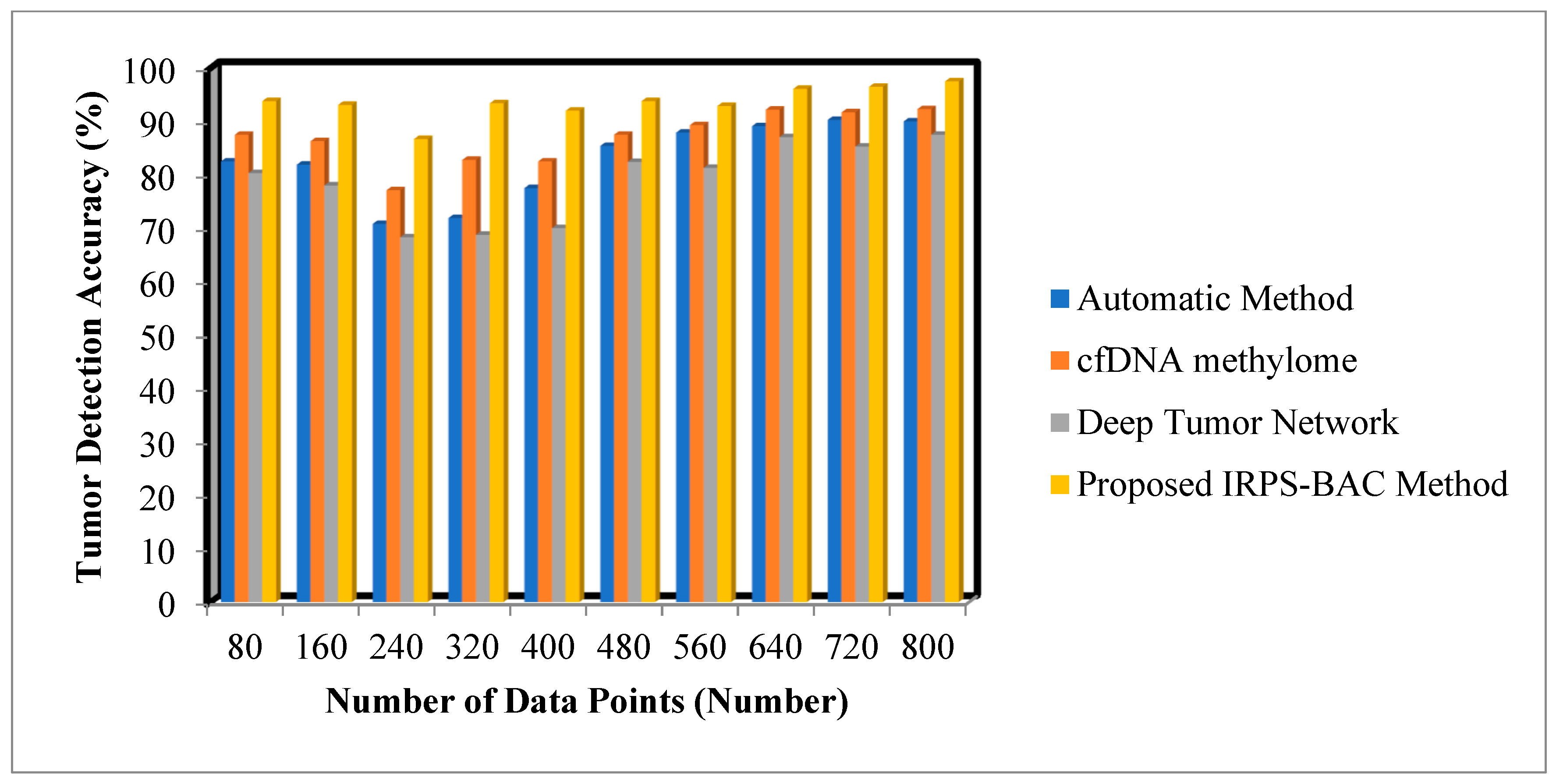
The various medical data points are collected from the database. The performance of the tumor detection accuracy of the proposed IRPS-BAC Method is significantly improved when compared to the existing techniques. The simulation graph with different results is illustrated in
Figure 3 and
Figure 4.
Figure 3 and
Figure 4 provide the simulation results of tumor detection accuracy results for three different methods with respect to different number of data points. With an increase in number of data points, the tumor detection accuracy for three different techniques gets increased or decreased, respectively. Comparatively, the IRPS-BAC Method attained higher tumor detection accuracy than the other three existing methods. This is because of using feature selection and classification process for efficient tumor detection. The divergence is computed for every feature to perform the relevant feature selection process. With relevant feature selection, the ensembled bagging classification is a type of machine learning technique using ID3 for analyzing the medical data into normal data or cancerous data for accurate tumor detection. The bagging classifier integrates decision tree as well as allocates the votes to each decision tree outcome. The decision tree with higher votes is taken as the final classification outcomes. These classification results are used to get precise brain tumor detection. When considering the Epileptic Seizure Recognition Data Set with the ‘5000’ input data points considered for experimentation, the tumor detection accuracy is found to be ’93.7%’ using the IRPS-BAC Method. The tumor detection accuracy is ’83.4%’ when compared to the automatic method [
1], ‘77.5%’ when compared to cfDNA methylome [
2], and ‘73.85%’ when compared to Deep Tumor Network [
25]. The average comparison analysis on tumor detection accuracy using the Epileptic Seizure Recognition Data Set is found to be comparatively enhanced by 11%, 17%, and 21% when compared to [
1,
2,
25]. For Cervical Cancer Risk Classification, the number of data points is considered as 160 in the second iteration for calculating the tumor detection accuracy. By applying the proposed IRPS-BAC Method, the tumor detection accuracy was found to be 93.1% and the tumor detection accuracy of existing models in [
1,
2,
25] are 81.9%, 86.3%, and 78%, respectively. Similarly, different performance results are observed for each method with respect to the number of data points. The average of ten comparison results indicates that the IRPS-BAC Method considerably improves tumor detection accuracy using Cervical Cancer Risk Classification by 14%, 8%, and 19% when compared to the two state-of-the-art algorithms explored by [
1,
2,
25].
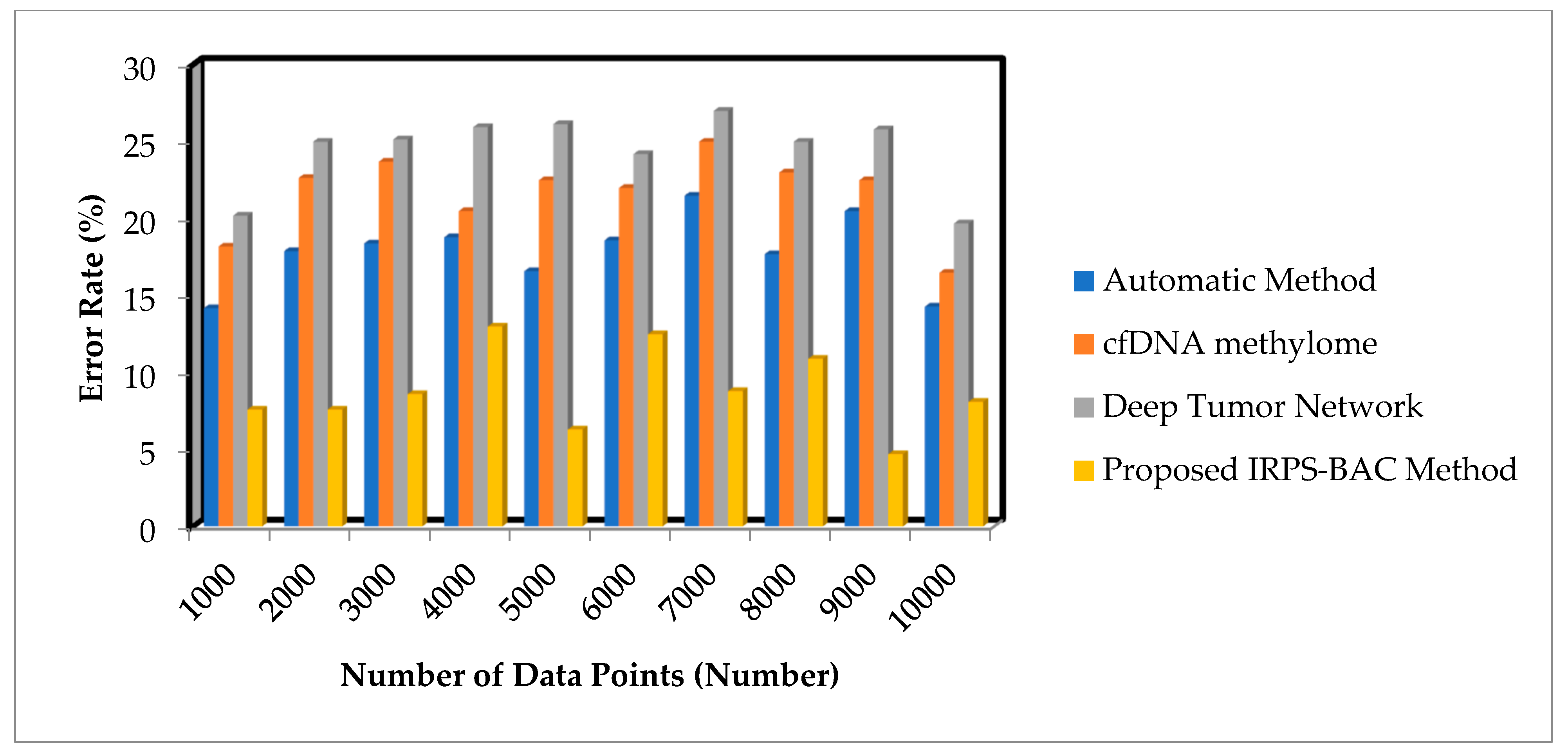
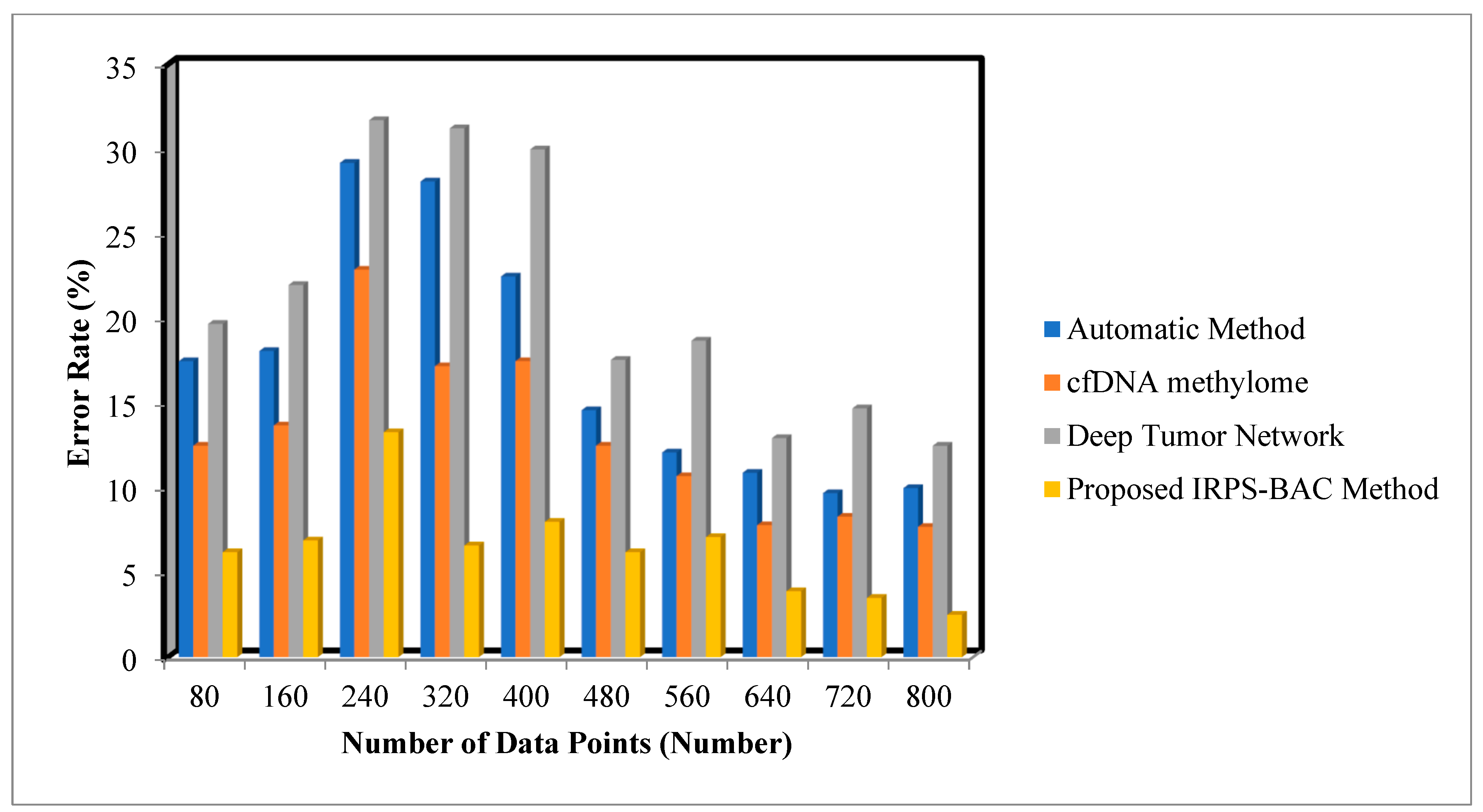
5.2. Impact on Error Rate
Error rate is defined as the ratio of the number of data points that are incorrectly detected as a tumor or normal to the total number of data points. The error rate is calculated as
From (8), ‘’ denotes the error rate. Consequently, the error rate is calculated in terms of percentage (%).
Table 3 and
Table 4 describe the error rate of three different methods, namely the automatic method, cfDNA methylome, Deep Tumor Network, and the proposed IRPS-BAC Method, for two datasets, namely, the Epileptic Seizure Recognition Data Set and Cervical Cancer Risk Classification.
The various medical data points are collected from the database. The performance of the error rate of the proposed IRPS-BAC Method is reduced when compared to the existing techniques. The simulation graph with different error rate results is shown in
Figure 5 and
Figure 6.
Figure 5 and
Figure 6 provide the simulation results of error rate results for three different methods with respect to a number of data points. With an increase in number of data points, the error rate for three different techniques gets increased or decreased, respectively. Comparatively, the IRPS-BAC Method attained a lesser error rate than the other three existing methods. The main reason for minimizing the error rate is to apply feature selection and classification process in the IRPS-BAC Method. The divergence value is determined for every feature. The applicable features are chosen by using the innovation of iterative reflect perceptual sammon feature selection process. Next, by using the bagging classification process, an internal node processes the selected features as well as a leaf node, to consider the tumor decision as normal or cancerous based on information gain. In this manner, error rate is said to be reduced.
When considering the Epileptic Seizure Recognition Data Set with the ‘1000’ input data points considered for experimentation, the error rate is found to be ‘7.6%’ using the IRPS-BAC Method. The error rate is ‘14.2%’ when compared to the automatic method [
1], ‘18.2%’ when compared to cfDNA methylome [
2], and ‘20.2%’ when compared to Deep Tumor Network [
25]. The average comparison analysis on error rate using the Epileptic Seizure Recognition Data Set is found to be comparatively reduced by 50%, 59%, and 64% when compared to [
1,
2,
25]. Let us consider 80 numbers of data points taken in the first iteration and the observed results using the IRPS-BAC Method is
whereas the performance of error rate results of [
1,
2] is
,
and
respectively. The comparison results indicate that the error rate of the IRPS-BAC Method is considerably reduced by 62%, 52%, and 70% when compared to [
1,
2,
25].
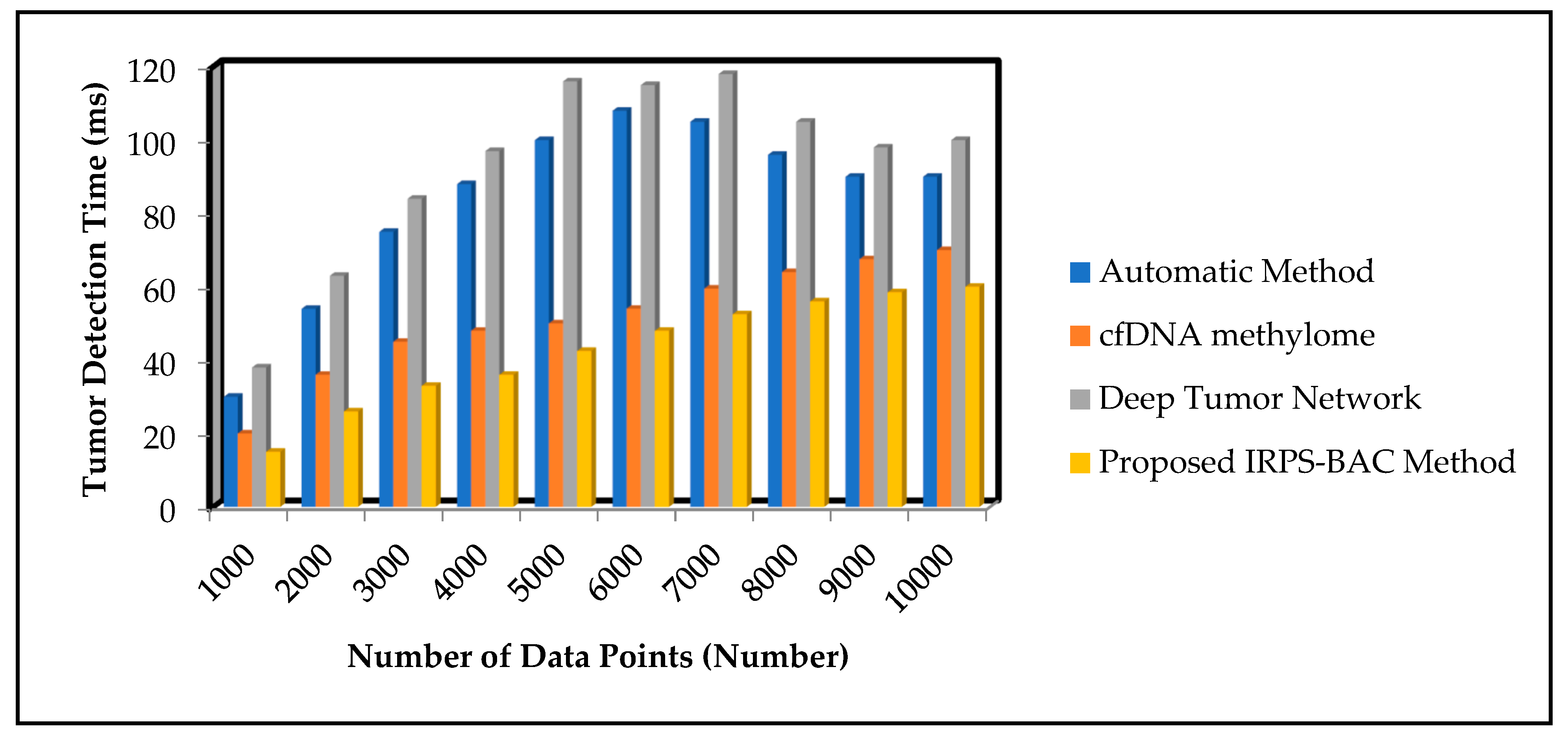
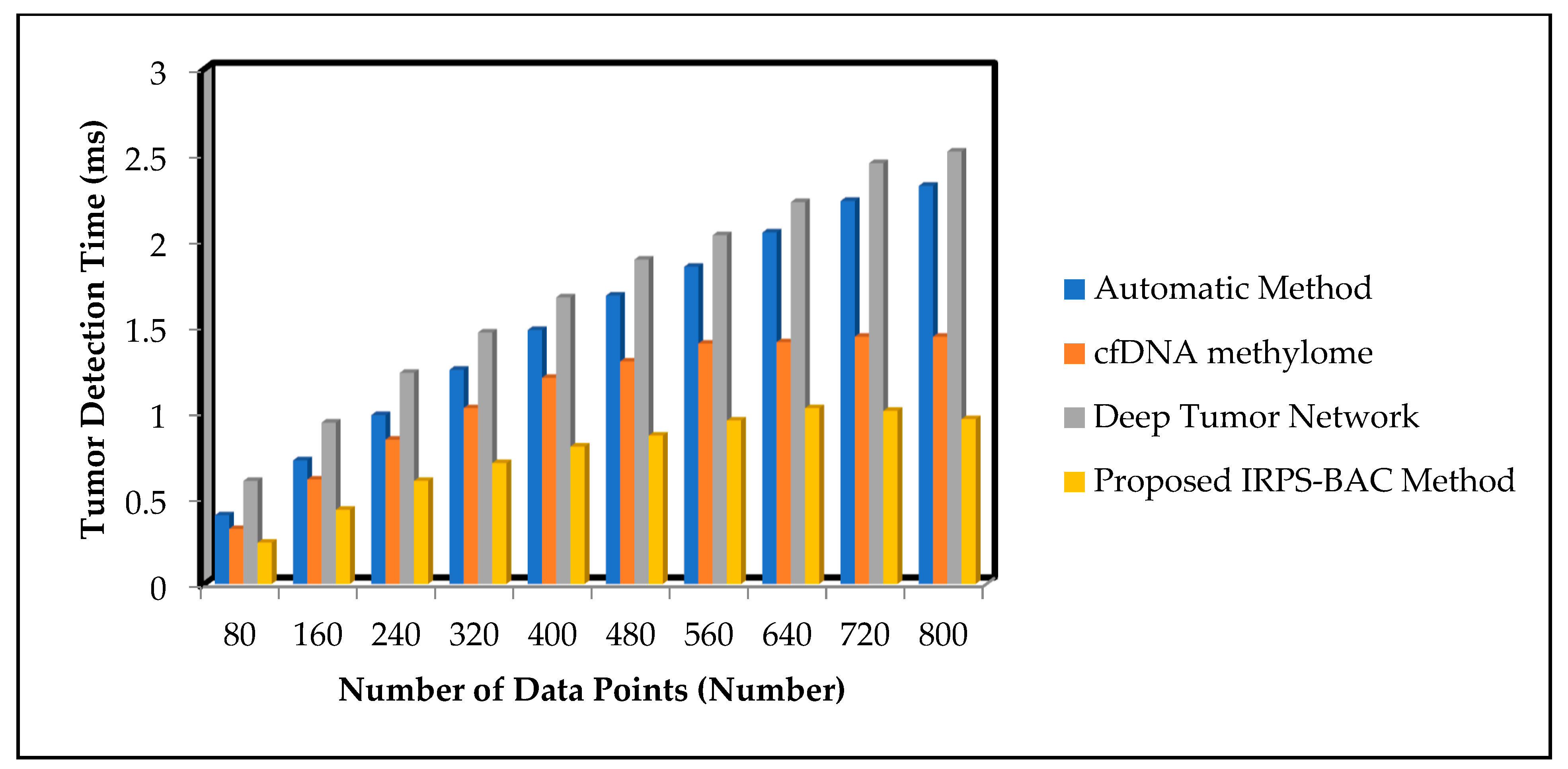
5.3. Impact on Tumor Detection Time
Tumor detection time is defined as the amount of time consumed to detect the tumor from the given input data points through the classification. The time is calculated using the given formula
From (9), ‘’ represents the input number of data points. ‘’ symbolizes the time consumed for detecting the single data point. The tumor detection time is measured in milliseconds (ms).
Table 5 and
Table 6 illustrate the tumor detection time of three different methods, namely automatic method, cfDNA methylome, and Deep Tumor Network, of the proposed IRPS-BAC Method for two datasets, namely Epileptic Seizure Recognition Data Set and Cervical Cancer Risk Classification. The medical data points are gathered from the database. The performance of tumor detection time of the proposed IRPS-BAC Method is reduced when compared to the existing techniques. The simulation graph with different tumor detection time results is illustrated in
Figure 7 and
Figure 8.
Figure 7 and
Figure 8 illustrate the simulation results of tumor detection time results for three different methods with respect to number of data points. With increase in number of data points, the tumor detection time for three different techniques gets increased correspondingly. Comparatively, the IRPS-BAC Method attained lesser tumor detection time than the other three existing methods. This is due to the application of feature selection and classification process in the IRPS-BAC Method. The feature selection is carried out through the divergence value to pick up significant features to perform efficient tumor detection. Further, the bagging classification process is applied to combine every weak learner into a strong one for classifying the normal data or abnormal data. This aid in diminishing the tumor detection time. When considering the Epileptic Seizure Recognition Data Set with the ‘9000’ input data points considered for experimentation, tumor detection time is found to be ‘56 ms’ using the IRPS-BAC Method. The tumor detection time is ‘96 ms’ when compared to the automatic method [
1], ‘64 ms’ when compared to cfDNA methylome [
2], and ‘98 ms’ when compared to the Deep Tumor Network [
25]. The average performance analysis on tumor detection time using the Epileptic Seizure Recognition Data Set is found to be comparatively reduced by 49%, 18%, and 55% when compared, according to [
1,
2,
25]. Let us consider 400 data points for conducting the experiments to calculate the tumor detection time. The overall performance of tumor detection time using the proposed IRPS-BAC Method is
. In addition, the tumor detection time using [
1,
2,
25] was found to be
, 1.2 ms, and
respectively. For each method, various performance results are observed with respect to different counts of input. The comparison result of tumor detection time of the IRPS-BAC Method is considerably reduced by 47%, 30%, and 62% when compared to the two state-of-the-art algorithms, according to [
1,
2,
25].
5.4. Throughput
Throughput is the number of data points being successfully executed in accurate time. This is mathematically expressed as given below:
where
denotes the data points executed time in seconds ‘
’. Throughput is computed by data per second (data/sec).
Table 7 and
Table 8 demonstrate the throughput of three different methods for two datasets. The various medical data points are gathered from the database. The performance of the throughput of the proposed IRPS-BAC Method is enhanced when compared to the obtainable techniques. The simulation graph with different results is illustrated in
Figure 9 and
Figure 10.
Figure 9 and
Figure 10 offer the comparison results of throughput results for three different methods based on number of data points. With increase in number of data points, the throughput for three different techniques gets increased, respectively. Comparatively, the IRPS-BAC Method attained maximum throughput with the two other existing methods. The main reason for higher throughput is to apply feature selection and classification process for efficient tumor detection. The average performance analysis on throughput using the Epileptic Seizure Recognition Data Set is found to be comparatively increased by 14%, 27%, and 44% when compared using [
1,
2,
25]. The throughput of the IRPS-BAC Method using Cervical Cancer Risk Classification is considerably improved by 11%, 22%, and 41% when compared to the two state-of-the-art algorithms [
1,
2,
25].




 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}