_Li.png)
Recommendation Systems for e-Shopping: Review of Techniques for Retail and Sustainable Marketing

 ,
, 
 , ,
, ,
Abstract
1. Introduction
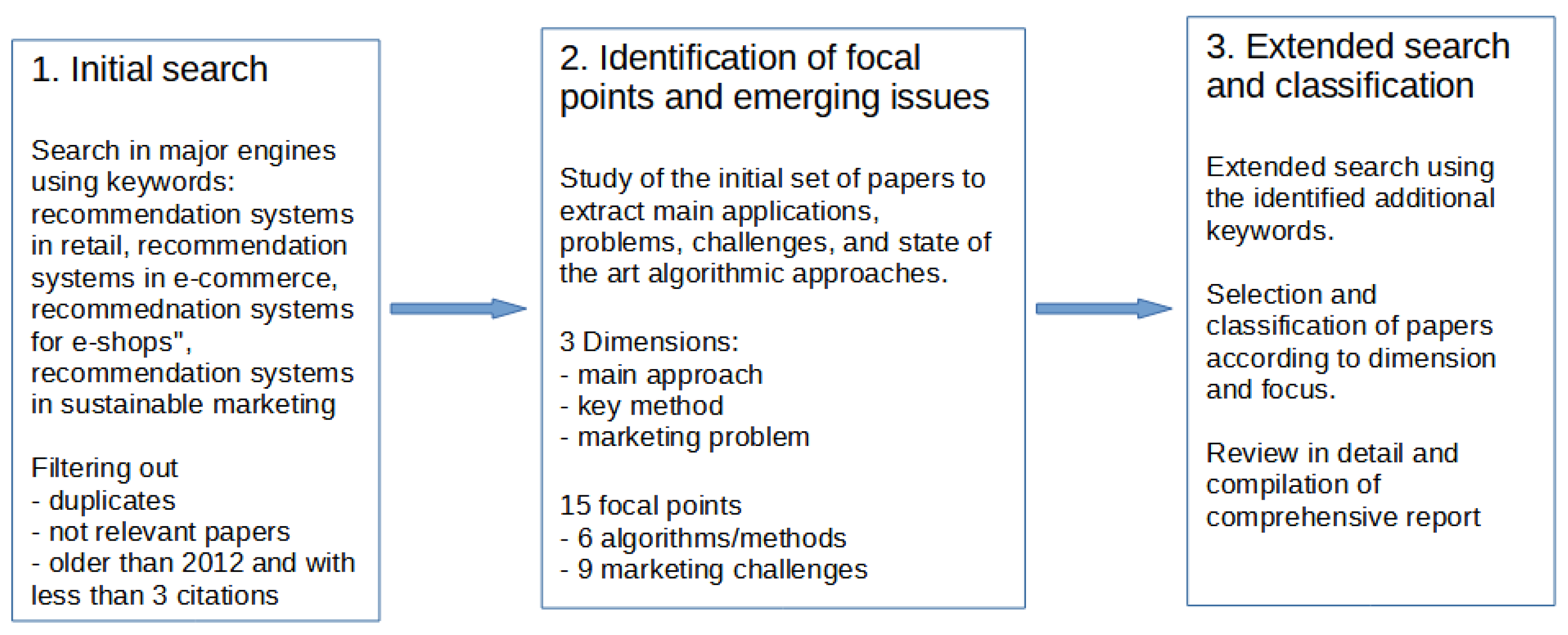
2. Methodology
- (1)
- A wide initial search was performed in Google Scholar and Scopus, using the keywords “recommendation systems in retail”, “recommendation systems in e-commerce”, ”recommendation systems for e-shops”, and ”recommendation systems in sustainable marketing”. The publication year and the number of citations were recorded, and the results were processed by the authors to remove duplicates, papers that were not relevant, and those with minimal impact (i.e., with fewer than three citations). It is noted that additional searches in other major databases did not bring out any additional findings.
- (2)
- The papers returned by the search engines—both review and research papers—were studied in order to extract the main applications, popular problems in retail RS, and challenges addressed, as well as the typical and emerging algorithmic approaches employed in this area. The references of these papers were also tracked to find additional articles of interest. The findings were used to define the focal points of the relevant research, which was mapped on three dimensions: (a) the main approach (e.g., collaborative filtering, content-based, knowledge-based), (b) the key methods (e.g., neural networks, rule-based, matrix factorization), and (c) the particular marketing problem addressed (e.g., user acceptance, contextualization, explainability). In parallel, a set of additional keywords was identified, which reflected more specific and detailed terms in the area of interest.
- (3)
- An extended search using the specific keywords of the previous step was then performed to dig out any missed-out papers addressing specialized problems. All the identified papers were filtered to keep those that were indeed contributing relevant information to the area of interest and demonstrated considerable impact. The selection was based on the citations received in relation to the years since publication, how recent they are, and how closely targeted they are to the narrowed field of our review. The research found was classified according to the dimensions and categories of step 2. Finally, the filtered and classified papers were reviewed by the authors in more detail, in order to compile a comprehensive report on the notable efforts in RS for retail shopping.
3. Prior Reviews of RS in e-Commerce
3.1. Reviews of Recommendation Applications
3.2. Reviews of Recommendation Technologies
4. Goals and Major Challenges of Recommendation Systems in e-Commerce
4.1. Business-Oriented Performance Aspects
4.2. Evaluation Metrics for Recommendation Algorithms
4.2.1. Accuracy Metrics
Evaluating Like/Dislike Predictions
Evaluating Recommendation Lists
4.2.2. Evaluation of Business Aspects of Algorithm Quality
4.2.3. Metrics for Online Evaluation of Business Value
5. Recommendation Types and Methods in e-Retail
5.1. Typical Applications of RS
- An e-shop recommending products to its visitors. Important characteristics of the problem are: (a) Whether the recommendations are produced before or after a sale or an item selection action by the user. A recommendation that precedes the user’s action is based on the general needs of the users, while the one that follows a user’s selection aims at matching the current user’s action. (b) Whether the recommendations are addressed to known or unknown users. When the user is unknown, recommendations can only be based on general knowledge, such as global popularity of items and associations among items. The first recommendations are predefined, while the next ones can be adjusted to the user’s actions by a session-based recommendation algorithm. (c) The need for the RS to be dynamically adjusted by exploiting interactivity/filtering. The problem in this case is not simply to produce a list of items but involves the ability to react with intelligence to the user’s selections.
- Personalizing promotional actions. The problem is to match to a particular user any type of action, such as to send info about a product, show an ad, make a special offer/discount, send coupons, etc., on behalf of stores, either online, offline, or both. The RS may be operating in (a) search engines or metasellers (eBay, BestPrice, etc.) or (b) individual stores, where the RS is typically incorporated into their loyalty program and used to send promotional messages, discounts, gifts, etc. A rapidly growing trend is for companies to offer to their customers mobile apps linked to a customer account. Such apps are inherently personalized bidirectional channels and one of the most promising fields for RS.
5.2. Outline of Main Recommendation Approaches Applied in e-Commerce
5.2.1. Collaborative Filtering (CF)
5.2.2. Content-Based (CBF)
5.2.3. Knowledge-Based (KB)
5.2.4. Demographic (DF)
5.2.5. Hybrid Recommendation Techniques (HR)
5.3. Modeling Methods Most Commonly Used in Retail
5.3.1. Rule-Based and Knowledge-Based Models
5.3.2. Neural Networks and Deep Learning
Shallow Neural Models
Deep Neural Networks
Graph Neural Networks
5.3.3. Markovian Methods
5.3.4. Graph Database Modeling
5.3.5. Matrix Factorization
5.3.6. Natural Language Processing Methods
6. Solutions to Specialized Recommendation Problems
6.1. Context-Aware Recommendations
6.2. Session-Based Recommendations
6.3. Group Recommendations
6.4. Explainable Recommendation Systems
6.5. RS Based on Implicit Information
6.6. Social Networks and Trust-Based Recommendations
7. Discussion
7.1. Summary of Research Landscape
7.2. Remaining Challenges and Future Trends
Author Contributions
Funding
Conflicts of Interest
References
- Kennedyd, S.I.; Marjerison, R.K.; Yu, Y.; Zi, Q.; Tang, X.; Yang, Z. E-commerce engagement: A prerequisite for economic sustainability—An empirical examination of influencing factors. Sustainability 2022, 14, 4554. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Billsus, D.; Pazzani, M.J. Learning collaborative information filters. In Proceedings of the Fifteenth International Conference on Machine Learning (ICML 1998), Madison, WI, USA, 24–27 July 1998; Volume 98, pp. 46–54. [Google Scholar]
- Huang, Z.; Chen, H.; Zeng, D. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM Trans. Inf. Syst. TOIS 2004, 22, 116–142. [Google Scholar] [CrossRef]
- Nilashi, M.; Jannach, D.; bin Ibrahim, O.; Esfahani, M.D.; Ahmadi, H. Recommendation quality, transparency, and website quality for trust-building in recommendation agents. Electron. Commer. Res. Appl. 2016, 19, 70–84. [Google Scholar] [CrossRef]
- Yoon, V.Y.; Hostler, R.E.; Guo, Z.; Guimaraes, T. Assessing the moderating effect of consumer product knowledge and online shopping experience on using recommendation agents for customer loyalty. Decis. Support Syst. 2013, 55, 883–893. [Google Scholar] [CrossRef]
- Linden, G.; Smith, B.; York, J. Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–78. [Google Scholar] [CrossRef]
- Smith, B.; Linden, G. Two decades of recommender systems at Amazon. com. IEEE Internet Comput. 2017, 21, 12–18. [Google Scholar] [CrossRef]
- Li, S.S.; Karahanna, E. Online Recommendation Systems in a B2C E-Commerce Context: A Review and Future Directions. J. Assoc. Inf. Syst. 2015, 16, 72–107. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Alamdari, P.M.; Navimipour, N.J.; Hosseinzadeh, M.; Safaei, A.A.; Darwesh, A. A systematic study on the recommender systems in the E-commerce. IEEE Access 2020, 8, 115694–115716. [Google Scholar] [CrossRef]
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Appl. Sci. 2020, 10, 7748. [Google Scholar] [CrossRef]
- Karimova, F. A survey of e-commerce recommender systems. Eur. Sci. J. 2016, 12, 75–89. [Google Scholar] [CrossRef]
- Xiao, B.; Benbasat, I. Research on the use, characteristics, and impact of e-commerce product recommendation agents: A review and update for 2007–2012. In Handbook of Strategic e-Business Management; Springer: Berlin/Heidelberg, Germany, 2014; pp. 403–431. [Google Scholar]
- Singh, P.K.; Pramanik, P.K.D.; Dey, A.K.; Choudhury, P. Recommender systems: An overview, research trends, and future directions. Int. J. Bus. Syst. Res. 2021, 15, 14–52. [Google Scholar] [CrossRef]
- Almahmood, R.J.K.; Tekerek, A. Issues and Solutions in Deep Learning-Enabled Recommendation Systems within the E-Commerce Field. Appl. Sci. 2022, 12, 11256. [Google Scholar] [CrossRef]
- Zhang, Q.; Lu, J.; Jin, Y. Artificial intelligence in recommender systems. Complex Intell. Syst. 2021, 7, 439–457. [Google Scholar] [CrossRef]
- Bouraga, S.; Jureta, I.; Faulkner, S.; Herssens, C. Knowledge-based recommendation systems: A survey. Int. J. Intell. Inf. Technol. IJIIT 2014, 10, 1–19. [Google Scholar] [CrossRef]
- Kim, M.C.; Chen, C. A scientometric review of emerging trends and new developments in recommendation systems. Scientometrics 2015, 104, 239–263. [Google Scholar] [CrossRef]
- Chen, C. CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 359–377. [Google Scholar] [CrossRef]
- Park, D.H.; Kim, H.K.; Choi, I.Y.; Kim, J.K. A literature review and classification of recommender systems research. Expert Syst. Appl. 2012, 39, 10059–10072. [Google Scholar] [CrossRef]
- McNee, S.; Riedl, J.; Konstan, J. Being accurate is not enough: How accuracy metrics have hurt recommender systems. In CHI ‘06 Extended Abstracts on Human Factors in Computing Systems; ACM Press: New York, NY, USA, 2006; pp. 1097–1101. [Google Scholar]
- Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems Handbook, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Tomkins, S.; Isley, S.; London, B.; Getoor, L. Sustainability at scale: Towards bridging the intention-behavior gap with sustainable recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; pp. 214–218. [Google Scholar]
- Adamopoulos, P.; Tuzhilin, A. On Unexpectedness in Recommender Systems: Or How to Better Expect the Unexpected. ACM Trans. Intell. Syst. Technol. 2015, 5, 1–32. [Google Scholar] [CrossRef]
- Lawrence, R.; Almasi, G.; Kotlyar, V.; Viveros, M.; Duri, S. Personalization of Supermarket Product Recommendations. Data Min. Knowl. Discov. 2001, 5, 11–32. [Google Scholar] [CrossRef]
- Eskandanian, F.; Mobasher, B.; Burke, R. A Clustering Approach for Personalizing Diversity in Collaborative Recommender Systems. In Proceedings of the UMAP ’17, 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017; pp. 280–284. [Google Scholar]
- Kunaver, M.; Požrl, T. Diversity in recommender systems—A survey. Knowl.-Based Syst. 2017, 123, 154–162. [Google Scholar] [CrossRef]
- Jugovac, M.; Jannach, D.; Lerche, L. Efficient optimization of multiple recommendation quality factors according to individual user tendencies. Expert Syst. Appl. 2017, 81, 321–331. [Google Scholar] [CrossRef]
- Shen, A. Recommendations as personalized marketing: Insights from customer experiences. J. Serv. Mark. 2014, 28, 414–427. [Google Scholar] [CrossRef]
- Pappas, I.O.; Kourouthanassis, P.E.; Giannakos, M.N.; Chrissikopoulos, V. Shiny happy people buying: The role of emotions on personalized e-shopping. Electron Mark. 2014, 24, 193–206. [Google Scholar] [CrossRef]
- Chen, Y.C.; Shang, R.A.; Kao, C.Y. The effects of information overload on consumers’ subjective state towards buying decision in the internet shopping environment. Electron. Commer. Res. Appl. 2009, 8, 48–58. [Google Scholar] [CrossRef]
- Gai, P.J.; Klesse, A.K. Making recommendations more effective through framings: Impacts of user-versus item-based framings on recommendation click-throughs. J. Mark. 2019, 83, 61–75. [Google Scholar] [CrossRef]
- Ho, S.Y.; Bodoff, D.; Tam, K.Y. Timing of adaptive web personalization and its effects on online consumer behavior. Inf. Syst. Res. 2011, 22, 660–679. [Google Scholar] [CrossRef]
- Bortko, K.; Bartków, P.; Jankowski, J.; Kuras, D.; Sulikowski, P. Multi-criteria evaluation of recommending interfaces towards habituation reduction and limited negative impact on user experience. Procedia Comput. Sci. 2019, 159, 2240–2248. [Google Scholar] [CrossRef]
- Silveira, T.; Zhang, M.; Lin, X.; Liu, Y.; Ma, S. How good your recommender system is? A survey on evaluations in recommendation. Int. J. Mach. Learn. Cybern. 2019, 10, 813–831. [Google Scholar] [CrossRef]
- Gunawardana, A.; Shani, G. A survey of accuracy evaluation metrics of recommendation tasks. J. Mach. Learn. Res. 2009, 10, 2935–2962. [Google Scholar]
- Stalidis, G.; Siomos, T.; Kaplanoglou, P.I.; Katsalis, A.; Karaveli, I.; Delianidi, M.; Diamantaras, K. Multidimensional Factor and Cluster Analysis Versus Embedding-Based Learning for Personalized Supermarket Offer Recommendations. In Data Analysis and Rationality in a Complex World, Studies in Classification, Data Analysis, and Knowledge Organization; Springer: Berlin/Heidelberg, Germany, 2019; pp. 273–281. [Google Scholar]
- Chen, L.; Yang, Y.; Wang, N.; Yang, K.; Yuan, Q. How serendipity improves user satisfaction with recommendations? a large-scale user evaluation. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 240–250. [Google Scholar]
- Ge, M.; Delgado-Battenfeld, C.; Jannach, D. Beyond accuracy: Evaluating recommender systems by coverage and serendipity. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 257–260. [Google Scholar]
- Bandyopadhyay, S.; Thakur, S.; Mandal, J. Product recommendation for e-commerce business by applying principal component analysis (PCA) and K-means clustering: Benefit for the society. Innov. Syst. Softw. Eng. 2021, 17, 45–52. [Google Scholar] [CrossRef]
- Silva, N.; Carvalho, D.; Pereira, A.C.; Mourão, F.; Rocha, L. Evaluating Different Strategies to Mitigate the Ramp-up Problem in Recommendation Domains. In Proceedings of the 23rd Brazillian Symposium on Multimedia and the Web, Gramado, Brazil, 17–20 October 2017; pp. 333–340. [Google Scholar]
- Aggarwal, C.C. Recommender Systems; Springer: Berlin/Heidelberg, Germany, 2016; Volume 1. [Google Scholar]
- Smyth, B. Case-based recommendation. The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 342–376. [Google Scholar]
- Aïmeur, E.; Brassard, G.; Fernandez, J.M.; Onana, F.M. Privacy-preserving demographic filtering. In Proceedings of the 2006 ACM Symposium on Applied Computing, Dijon, France, 23–27 April 2006; pp. 872–878. [Google Scholar]
- Walek, B.; Fajmon, P. A hybrid recommender system for an online store using a fuzzy expert system. Expert Syst. Appl. 2023, 212, 118565. [Google Scholar] [CrossRef]
- Yan, C.; Chen, Y.; Zhou, L. Differentiated fashion recommendation using knowledge graph and data augmentation. IEEE Access 2019, 7, 102239–102248. [Google Scholar] [CrossRef]
- Ma, M.; Jiang, Y. A Meta-Level Hybrid Recommendation Method Based on User Novelty. In Proceedings of the 3rd International Conference on Information Technologies and Electrical Engineering, Changde, China, 3–5 December 2020; pp. 616–625. [Google Scholar]
- Bandyopadhyay, S.; Thakur, S. Product prediction and recommendation in e-commerce using collaborative filtering and artificial neural networks: A hybrid approach. In Intelligent Computing Paradigm: Recent Trends; Springer: Berlin/Heidelberg, Germany, 2020; pp. 59–67. [Google Scholar]
- Rodrigues, F.; Ferreira, B. Product recommendation based on shared customer’s behaviour. Procedia Comput. Sci. 2016, 100, 136–146. [Google Scholar] [CrossRef][Green Version]
- Choi, K.; Yoo, D.; Kim, G.; Suh, Y. A hybrid online-product recommendation system: Combining implicit rating-based collaborative filtering and sequential pattern analysis. Electron. Commer. Res. Appl. 2012, 11, 309–317. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Analysis of recommendation algorithms for e-commerce. In Proceedings of the 2nd ACM Conference on Electronic Commerce, Minneapolis, MN, USA, 17–20 October 2000; pp. 158–167. [Google Scholar]
- Psaila, G.; Lanzi, P. Hierarchy-based mining of association rules in data warehouses. In Proceedings of the 2000 ACM Symposium on Applied Computing, Como, Italy, 19–21 March 2000; pp. 307–312. [Google Scholar]
- Lin, W.; Ruiz, C. Efficient adaptive-support association rule mining for recommender systems. Data Min. Knowl. Discov. 2002, 6, 83–105. [Google Scholar] [CrossRef]
- Leung, C.W.k.; Chan, S.C.f.; Chung, F.l. A collaborative filtering framework based on fuzzy association rules and multiple-level similarity. Knowl. Inf. Syst. 2006, 10, 357–381. [Google Scholar] [CrossRef]
- Ghafari, S.; Tjortjis, C. A survey on association rules mining using heuristics. WIREs Data Min. Knowl. Discov. 2019, 9, e1307. [Google Scholar] [CrossRef]
- Najafabadi, M.K.; Mahrin, M.N.; Sarkan, H.M. Improving the accuracy of collaborative filtering recommendations using clustering and association rules mining on implicit data. Comput. Hum. Behav. 2017, 67, 113–128. [Google Scholar] [CrossRef]
- Pariserum Perumal, S.; Ganapathy, S.; Kannan, A. An intelligent fuzzy rule-based e-learning recommendation system for dynamic user interests. J. Supercomput. 2019, 75, 5145–5160. [Google Scholar] [CrossRef]
- Nair, B.; Mohandas, V.; Nayanar, N.; Teja, E.; Vigneshwari, S.; Teja, K. A stock trading recommender system based on temporal association rule mining. SAGE Open 2015, 5, 2158244015579941. [Google Scholar] [CrossRef]
- Liao, S.; Chang, H. A rough set-based association rule approach for a recommendation system for online consumers. Inf. Process. Manag. 2016, 52, 1142–1160. [Google Scholar] [CrossRef]
- Kim, J.; Kang, S.; Kim, H. Recommendation algorithm of the app store by using semantic relations between apps. J. Supercomput. 2011, 65, 16–26. [Google Scholar] [CrossRef]
- Aguilar, J.; Valdiviezo-Diaz, P.; Riofrio, G. A general framework for intelligent recommender systems. Appl. Comput. Inform. 2017, 13, 147–160. [Google Scholar] [CrossRef]
- Mikolov, T.; Yih, W.t.; Zweig, G. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 10–12 June 2013; pp. 746–751. [Google Scholar]
- Barkan, O.; Koenigstein, N. Item2vec: Neural item embedding for collaborative filtering. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Barkan, O.; Caciularu, A.; Katz, O.; Koenigstein, N. Attentive item2vec: Neural attentive user representations. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–8 May 2020; pp. 3377–3381. [Google Scholar]
- Barkan, O.; Caciularu, A.; Rejwan, I.; Katz, O.; Weill, J.; Malkiel, I.; Koenigstein, N. Cold item recommendations via hierarchical item2vec. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 912–917. [Google Scholar]
- Hu, L.; Cao, L.; Wang, S.; Xu, G.; Cao, J.; Gu, Z. Diversifying Personalized Recommendation with User-session Context. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 1858–1864. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Shan, Y.; Hoens, T.R.; Jiao, J.; Wang, H.; Yu, D.; Mao, J. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 255–262. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Huang, P.S.; He, X.; Gao, J.; Deng, L.; Acero, A.; Heck, L. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2333–2338. [Google Scholar]
- Wu, C.Y.; Ahmed, A.; Beutel, A.; Smola, A.J.; Jing, H. Recurrent recommender networks. In Proceedings of the Tenth ACM International Conference on Web Search And Data Mining, Cambridge, UK, 6–10 February 2017; pp. 495–503. [Google Scholar]
- Lee, H.I.; Choi, I.Y.; Moon, H.S.; Kim, J.K. A multi-period product recommender system in online food market based on recurrent neural networks. Sustainability 2020, 12, 969. [Google Scholar] [CrossRef]
- Salampasis, M.; Siomos, T.; Katsalis, A.; Diamantaras, K.; Christantonis, K.; Delianidi, M.; Karaveli, I. Comparison of RNN and Embeddings Methods for Next-item and Last-basket Session-based Recommendations. In Proceedings of the 2021 13th International Conference on Machine Learning and Computing, Shenzhen, China, 26 February–1 March 2021; pp. 477–484. [Google Scholar]
- Yuan, F.; Karatzoglou, A.; Arapakis, I.; Jose, J.M.; He, X. A simple convolutional generative network for next item recommendation. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 582–590. [Google Scholar]
- Addagarla, S.K.; Amalanathan, A. e-SimNet: A visual similar product recommender system for E-commerce. Indones. J. Electr. Eng. Comput. Sci. IJEECS 2021, 22, 563–570. [Google Scholar] [CrossRef]
- Latha, Y.M.; Rao, B.S. Product recommendation using enhanced convolutional neural network for e-commerce platform. Clust. Comput. 2023, 1–15. [Google Scholar] [CrossRef]
- Cong, D.; Zhao, Y.; Qin, B.; Han, Y.; Zhang, M.; Liu, A.; Chen, N. Hierarchical attention based neural network for explainable recommendation. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 373–381. [Google Scholar]
- Chen, X.; Xu, H.; Zhang, Y.; Tang, J.; Cao, Y.; Qin, Z.; Zha, H. Sequential recommendation with user memory networks. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 108–116. [Google Scholar]
- Tang, J.; Belletti, F.; Jain, S.; Chen, M.; Beutel, A.; Xu, C.; Chi, E.H. Towards neural mixture recommender for long range dependent user sequences. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1782–1793. [Google Scholar]
- Xue, F.; He, X.; Wang, X.; Xu, J.; Liu, K.; Hong, R. Deep item-based collaborative filtering for top-n recommendation. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 1–25. [Google Scholar] [CrossRef]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Chen, Q.; Zhao, H.; Li, W.; Huang, P.; Ou, W. Behavior sequence transformer for e-commerce recommendation in alibaba. In Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data, Anchorage, AK, USA, 5 August 2019; pp. 1–4. [Google Scholar]
- Khan, Z.; Hussain, M.I.; Iltaf, N.; Kim, J.; Jeon, M. Contextual recommender system for E-commerce applications. Appl. Soft Comput. 2021, 109, 107552. [Google Scholar] [CrossRef]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar]
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-based recommendation with graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 346–353. [Google Scholar]
- Song, W.; Xiao, Z.; Wang, Y.; Charlin, L.; Zhang, M.; Tang, J. Session-based social recommendation via dynamic graph attention networks. In Proceedings of the Twelfth ACM International Conference on Web Search And Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 555–563. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph neural networks for social recommendation. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 417–426. [Google Scholar]
- Liu, P.; Zhang, L.; Gulla, J.A. Real-time social recommendation based on graph embedding and temporal context. Int. J. Hum.-Comput. Stud. 2019, 121, 58–72. [Google Scholar] [CrossRef]
- Wang, D.; Bao, Y.; Yu, G.; Wang, G. Using page classification and association rule mining for personalized recommendation in distance learning. In Proceedings of the International Conference on Web-Based Learning, Hong Kong, China, 17–19 August 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 363–374. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Berg, R.v.d.; Kipf, T.N.; Welling, M. Graph convolutional matrix completion. arXiv 2017, arXiv:1706.02263. [Google Scholar]
- Grad-Gyenge, L.; Kiss, A.; Filzmoser, P. Graph embedding based recommendation techniques on the knowledge graph. In Proceedings of the Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017; pp. 354–359. [Google Scholar]
- Rakkappan, L.; Rajan, V. Context-aware sequential recommendations withstacked recurrent neural networks. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3172–3178. [Google Scholar]
- Unger, M.; Bar, A.; Shapira, B.; Rokach, L. Towards latent context-aware recommendation systems. Knowl.-Based Syst. 2016, 104, 165–178. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, S.; Wang, D.; Li, Z.; Wang, L. Context-aware sequential recommendation. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1053–1058. [Google Scholar]
- Eirinaki, M.; Vazirgiannis, M.; Kapogiannis, D. Web path recommendations based on page ranking and markov models. In Proceedings of the 7th Annual ACM International Workshop on Web Information and Data Management, Bremen, Germany, 5 November 2005; pp. 2–9. [Google Scholar]
- Shani, G.; Heckerman, D.; Brafman, R.I. An MDP-based recommender system. J. Mach. Learn. Res. 2005, 6, 1265–1295. [Google Scholar]
- Zhang, Z.; Nasraoui, O. Efficient hybrid Web recommendations based on Markov clickstream models and implicit search. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI’07), Silicon Valley, CA, USA, 2–5 November 2007; pp. 621–627. [Google Scholar]
- Le, D.T.; Fang, Y.; Lauw, H.W. Modeling sequential preferences with dynamic user and context factors. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 145–161. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Konno, T.; Huang, R.; Ban, T.; Huang, C. Goods recommendation based on retail knowledge in a Neo4j graph database combined with an inference mechanism implemented in jess. In Proceedings of the 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; pp. 1–8. [Google Scholar]
- Sen, S.; Mehta, A.; Ganguli, R.; Sen, S. Recommendation of Influenced Products Using Association Rule Mining: Neo4j as a Case Study. SN Comput. Sci. 2021, 2, 1–17. [Google Scholar] [CrossRef]
- Delianidi, M.; Salampasis, M.; Diamantaras, K.; Siomos, T.; Katsalis, A.; Karaveli, I. A Graph-Based Method for Session-Based Recommendations. In Proceedings of the 24th Pan-Hellenic Conference on Informatics, Athens, Greece, 20–22 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 264–267. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Le, D.T.; Lauw, H.W.; Fang, Y. Basket-sensitive personalized item recommendation. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Srifi, M.; Oussous, A.; Ait Lahcen, A.; Mouline, S. Recommender systems based on collaborative filtering using review texts—A survey. Information 2020, 11, 317. [Google Scholar] [CrossRef]
- Tarnowska, K.A.; Ras, Z. NLP-based customer loyalty improvement recommender system (CLIRS2). Big Data Cogn. Comput. 2021, 5, 4. [Google Scholar] [CrossRef]
- Sharma, A.K.; Bajpai, B.; Adhvaryu, R.; Pankajkumar, S.D.; Gordhanbhai, P.P.; Kumar, A. An Efficient Approach of Product Recommendation System using NLP Technique. Mater. Today Proc. 2021, 80, 3730–3743. [Google Scholar] [CrossRef]
- Shoja, B.M.; Tabrizi, N. Customer reviews analysis with deep neural networks for e-commerce recommender systems. IEEE Access 2019, 7, 119121–119130. [Google Scholar] [CrossRef]
- Karthik, R.; Ganapathy, S. A fuzzy recommendation system for predicting the customers interests using sentiment analysis and ontology in e-commerce. Appl. Soft Comput. 2021, 108, 107396. [Google Scholar] [CrossRef]
- Karn, A.L.; Karna, R.K.; Kondamudi, B.R.; Bagale, G.; Pustokhin, D.A.; Pustokhina, I.V.; Sengan, S. Customer centric hybrid recommendation system for E-Commerce applications by integrating hybrid sentiment analysis. Electron. Commer. Res. 2023, 23, 279–314. [Google Scholar] [CrossRef]
- Sun, Z.; Han, L.; Huang, W.; Wang, X.; Zeng, X.; Wang, M.; Yan, H. Recommender systems based on social networks. J. Syst. Softw. 2015, 99, 109–119. [Google Scholar] [CrossRef]
- Shambour, Q.; Lu, J. A trust-semantic fusion-based recommendation approach for e-business applications. Decis. Support Syst. 2012, 54, 768–780. [Google Scholar] [CrossRef]
- Agrawal, R.; Imielinski, T.; Arun, S. Mining association rules between sets of items in large databases. ACM Sigmond Rec. 1993, 22, 207–216. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Van Esesn, B.C.; Awwal, A.A.S.; Asari, V.K. The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv 2018, arXiv:1803.01164. [Google Scholar]
- Gao, C.; Zheng, Y.; Li, N.; Li, Y.; Qin, Y.; Piao, J.; Quan, Y.; Chang, J.; Jin, D.; He, X.; et al. A survey of graph neural networks for recommender systems: Challenges, methods, and directions. ACM Trans. Recomm. Syst. 2023, 1, 1–51. [Google Scholar] [CrossRef]
- Xu, F.; Lian, J.; Han, Z.; Li, Y.; Xu, Y.; Xie, X. Relation-aware graph convolutional networks for agent-initiated social e-commerce recommendation. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 529–538. [Google Scholar]
- Basharin, G.P.; Langville, A.N.; Naumov, V.A. The life and work of AA Markov. Linear Algebra Its Appl. 2004, 386, 3–26. [Google Scholar] [CrossRef]
- Guia, J.; Soares, V.G.; Bernardino, J. Graph Databases: Neo4j Analysis. In Proceedings of the ICEIS, Porto, Portugal, 26–29 April 2017; pp. 351–356. [Google Scholar]
- Cheng, C.H.; Chen, Y.S. Classifying the segmentation of customer value via RFM model and RS theory. Expert Syst. Appl. 2009, 36, 4176–4184. [Google Scholar] [CrossRef]
- Delianidi, M.; Diamantaras, K.; Tektonidis, D.; Salampasis, M. Session-Based Recommendations for e-Commerce with Graph-Based Data Modeling. Appl. Sci. 2022, 13, 394. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Context-aware recommender systems. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 217–253. [Google Scholar]
- Huang, J.; Zhou, L. Timing of web personalization in mobile shopping: A perspective from Uses and Gratifications Theory. Comput. Hum. Behav. 2018, 88, 103–113. [Google Scholar] [CrossRef]
- Raza, S.; Ding, C. Progress in context-aware recommender systems—An overview. Comput. Sci. Rev. 2019, 31, 84–97. [Google Scholar] [CrossRef]
- Frolov, E.; Oseledets, I. Tensor methods and recommender systems. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1201. [Google Scholar] [CrossRef]
- Fang, B.; Liao, S.; Xu, K.; Cheng, H.; Zhu, C.; Chen, H. A novel mobile recommender system for indoor shopping. Expert Syst. Appl. 2012, 39, 11992–12000. [Google Scholar] [CrossRef]
- Jannach, D.; Ludewig, M.; Lerche, L. Session-based item recommendation in e-commerce: On short-term intents, reminders, trends and discounts. User Model. User-Adapt. Interact. 2017, 27, 351–392. [Google Scholar] [CrossRef]
- Wang, S.; Cao, L.; Wang, Y.; Sheng, Q.Z.; Orgun, M.; Lian, D. A survey on session-based recommender systems. arXiv 2019, arXiv:1902.04864. [Google Scholar] [CrossRef]
- Choi, Y.; Kim, S.K. A Recommendation System for Repetitively Purchasing Items in E-commerce Based on Collaborative Filtering and Association Rules. J. Internet Technol. 2018, 19, 1691–1698. [Google Scholar]
- Lerche, L.; Jannach, D.; Ludewig, M. On the Value of Reminders within E-Commerce Recommendations. In Proceedings of the 2016 Conference on User Modeling Adaptation and Personalization, Halifax, NS, Canada, 13–17 July 2016. [Google Scholar]
- Wang, J.; Sarwar, B.M.; Sundaresan, N. Utilizing related products for post-purchase recommendation in e-commerce. In Proceedings of the RecSys’11, Chicago, IL, USA, 23–27 October 2011. [Google Scholar]
- Jannach, D.; Lerche, L.; Jugovac, M. Adaptation and Evaluation of Recommendations for Short-term Shopping Goals. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015. [Google Scholar]
- Hwangbo, H.; Kim, Y. Session-based recommender system for sustainable digital marketing. Sustainability 2019, 11, 3336. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y. Opportunity model for e-commerce recommendation: Right product; right time. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. arXiv 2015, arXiv:1511.06939. [Google Scholar]
- Tan, Y.K.; Xu, X.; Liu, Y. Improved recurrent neural networks for session-based recommendations. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 17–22. [Google Scholar]
- Jing, H.; Smola, A.J. Neural survival recommender. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 515–524. [Google Scholar]
- Yuan, F.; He, X.; Jiang, H.; Guo, G.; Xiong, J.; Xu, Z.; Xiong, Y. Future Data Helps Training: Modeling Future Contexts for Session-based Recommendation. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 303–313. [Google Scholar]
- Salampasis, M.; Katsalis, A.; Siomos, T.; Delianidi, M.; Tektonidis, D.; Christantonis, K.; Kaplanoglou, P.; Karaveli, I.; Bourlis, C.; Diamantaras, K. A Flexible Session-Based Recommender System for e-Commerce. Appl. Sci. 2023, 13, 3347. [Google Scholar] [CrossRef]
- Pessemier, T.; Dooms, S.; Martens, L. Comparison of group recommendation algorithms. Multimed. Tools Appl. 2014, 72, 2497–2541. [Google Scholar] [CrossRef]
- Masthoff, J.; Gatt, A. In pursuit of satisfaction and the prevention of embarrassment: Affective state in group recommender systems. User Model. User-Adapt. Interact. 2006, 16, 281–319. [Google Scholar] [CrossRef]
- Trang Tran, T.; Atas, M.; Felfernig, A.; Stettinger, M. An overview of recommender systems in the healthy food domain. J. Intell. Inf. Syst. 2018, 50, 501–526. [Google Scholar] [CrossRef]
- Berkovsky, S.; Freyne, J. Group-based recipe recommendations: Analysis of data aggregation strategies. In Proceedings of the RecSys2010, Barcelona, Spain, 26–30 September 2010; pp. 111–118. [Google Scholar]
- Park, J.; Kihwan Nam, k. Group recommender system for store product placement. Data Min. Knowl. Discov. 2019, 33, 204–229. [Google Scholar] [CrossRef]
- Quijano-Sanchez, L.; Belen Diaz-Agudo, B.; Recio-Garcia, J. Development of a group recommender application in a Social Network. Knowl.-Based Syst. 2014, 71, 72–85. [Google Scholar] [CrossRef]
- Beladev, M.; Rokach, L.; Shapira, B. Recommender systems for product bundling. Knowl.-Based Syst. 2016, 111, 193–206. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, X. Explainable recommendation: A survey and new perspectives. arXiv 2018, arXiv:1804.11192. [Google Scholar]
- Ai, Q.; Azizi, V.; Chen, X.; Zhang, Y. Learning heterogeneous knowledge base embeddings for explainable recommendation. Algorithms 2018, 11, 137. [Google Scholar] [CrossRef]
- Fu, Z.; Xian, Y.; Gao, R.; Zhao, J.; Huang, Q.; Ge, Y.; Xu, S.; Geng, S.; Shah, C.; Zhang, Y.; et al. Fairness-aware explainable recommendation over knowledge graphs. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 69–78. [Google Scholar]
- Zhu, Y.; Xian, Y.; Fu, Z.; de Melo, G.; Zhang, Y. Faithfully explainable recommendation via neural logic reasoning. arXiv 2021, arXiv:2104.07869. [Google Scholar]
- Walek, B.; Fajmon, P. A Recommender System for Recommending Suitable Products in E-shop Using Explanations. In Proceedings of the 2022 3rd International Conference on Artificial Intelligence, Robotics and Control (AIRC), Virtual Conference, 20–22 May 2022; pp. 16–20. [Google Scholar]
- Hwangbo, H.; Kim, Y.S.; Cha, K.J. Recommendation system development for fashion retail e-commerce. Electron. Commer. Res. Appl. 2018, 28, 94–101. [Google Scholar] [CrossRef]
- Schoinas, I.; Tjortjis, C. MuSIF: A product recommendation system based on multi-source implicit feedback. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Hersonissos, Greece, 24–26 May 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 660–672. [Google Scholar]
- Guo, Y.; Yin, C.; Li, M.; Ren, X.; Liu, P. Mobile e-commerce recommendation system based on multi-source information fusion for sustainable e-business. Sustainability 2018, 10, 147. [Google Scholar] [CrossRef]
- Peska, L.; Vojtas, P. Towards Complex User Feedback and Presentation Context in Recommender Systems. In Proceedings of the Datenbanksysteme für Business, Technologie und Web (BTW 2017)—Workshopband, Stuttgart, Germany, 6–7 March 2017. [Google Scholar]
- Xue, H.J.; Dai, X.; Zhang, J.; Huang, S.; Chen, J. Deep matrix factorization models for recommender systems. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; Volume 17, pp. 3203–3209. [Google Scholar]
- Seckler, M.; Heinz, S.; Forde, S.; Tuch, A.N.; Opwis, K. Trust and distrust on the web: User experiences and website characteristics. Comput. Hum. Behav. 2015, 45, 39–50. [Google Scholar] [CrossRef]
- Li, Y.M.; Wu, C.T.; Lai, C.Y. A social recommender mechanism for e-commerce: Combining similarity, trust, and relationship. Decis. Support Syst. 2013, 55, 740–752. [Google Scholar] [CrossRef]
- Yin, S.; Luo, X. A survey of learning-based methods for cold-start, social recommendation, and data sparsity in e-commerce recommendation systems. In Proceedings of the 2021 16th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Chengdu, China, 26–28 November 2021; pp. 276–283. [Google Scholar]



{kind=link}
{kind=link}
| Methods | Comments | Related Papers |
|---|---|---|
| Rule-based and knowledge-based models | Methods with long history in RS, suitable for alleviating the cold start, sparse data, and ramp-up problems. Complex models can be used to combine pre-existing domain knowledge with discovered patterns and product features. Recent research utilized semantic web technologies and reasoning engines in order to enhance the intelligence/cognitive abilities. | [24,52,53,54,55,56,57,58,59,60,61,62] |
| Neural networks and deep learning | The most rapidly developing modeling approaches, appearing in a variety of different forms (e.g., deep networks, recurrent, embedding-based, etc.). Their main strengths are in learning complex relations and in capturing semantic, sequencing, and contextual information. Their limitations are their high demands for training data and computational resources. They are the preferred technologies for modeling multiple-step behavior and for extracting features from unstructured data. | [38,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98] |
| Markovian methods | Less popular methods that aim at capturing the sequences of user actions in click stream data and session-based RS. Recent research work was limited. | [99,100,101,102,103] |
| Graph databases | A relatively new and promising framework, which is efficient in capturing logical relations among users and items. It is suitable for both CF and KB approaches. | [104,105,106] |
| Matrix factorization | The most typical approach for early CF recommenders, which is still valid as a powerful core method for reducing the dimensionality problem. Recent research work in e-commerce RS was limited. | [71,107,108] |
| Natural language processing | Particularly useful methods for extracting implicit information about users’ stances, regarding both their personality/behavior and their opinion on specific products. Additionally, NLP has been used for extracting item features from their text description. | [109,110,111,112,113,114,115,116] |
| Challenges | Methods and Proposed Solutions | Related Papers |
|---|---|---|
| Introduction of diversity, novelty, and other properties related to recommendation quality | Formulation of suitable metrics and development of algorithms that optimize multiobjective user–item matching functions. Detection of users’ expectations and personalization of results employing clustering, prefiltering, and item list reranking. | [22,25,27,28,29] |
| Optimization of user satisfaction and acceptance | User requirements and the effects of timing, overload, explanation, and other parameters have been studied through surveys. | [30,31,32,33,34] |
| Alleviate cold start and sparsity | The content-based and knowledge-based approaches are naturally stronger in this perspective. Various types of hybridization have been proposed, employing neural networks, advanced knowledge-based components, rule-based components, and data augmentation. In recent experimental comparisons, the combination of CF with DNN gave the best hit ratio. | [47,48,49,50,51,156,162] |
| Provide explanations for the recommendation | Knowledge-based systems were mainly used to provide the reasoning behind the recommendations. Knowledge graphs were successfully applied, as well as embeddings and specialized neural-network-based methods. | [150,151,152,153] |
| Operation with unknown users | Session-based RSs, being based solely on the current user actions, were applied to serve unregistered or rarely revisiting users. Most of the latest efforts employed deep learning networks. | [106,130,131,135,138,139,140] |
| Contextualization | The most typical approach was to extend matrix factorization (e.g., tensor factorization) to deal with the increased dimensionality. More elaborate solutions were based on specialized deep neural network architectures (e.g., context-aware recurrent neural network). | [86,96,97,98,125,126,127,128,129] |
| Implicit user information | Implicit feedback was derived from the user’s browsing sequence, transaction data, mouse movements, mobile device sensors, using hybrid approaches, and a variety of methods from association rules to deep learning. | [51,97,155,156,157,158,159] |
| Group recommendations | Several approaches were proposed, including weighting, aggregation of profiles, aggregation of item lists, and hybrids. Considerable efforts were focused on introducing user behavior and quality metrics. | [143,144,145,146,147,148,149] |
| Feature extraction from unstructured data | Information was successfully extracted from free text comments, image/video, and sound to enhance recommendation. NLP/sentiment analysis was used to exploit user comments and CNN components in deep networks to extract high-level features from visual or sound data. | [110,111,112,113,115,116,161] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stalidis, G.; Karaveli, I.; Diamantaras, K.; Delianidi, M.; Christantonis, K.; Tektonidis, D.; Katsalis, A.; Salampasis, M. Recommendation Systems for e-Shopping: Review of Techniques for Retail and Sustainable Marketing. Sustainability 2023, 15, 16151. https://doi.org/10.3390/su152316151
Stalidis G, Karaveli I, Diamantaras K, Delianidi M, Christantonis K, Tektonidis D, Katsalis A, Salampasis M. Recommendation Systems for e-Shopping: Review of Techniques for Retail and Sustainable Marketing. Sustainability. 2023; 15(23):16151. https://doi.org/10.3390/su152316151
Chicago/Turabian StyleStalidis, George, Iphigenia Karaveli, Konstantinos Diamantaras, Marina Delianidi, Konstantinos Christantonis, Dimitrios Tektonidis, Alkiviadis Katsalis, and Michail Salampasis. 2023. "Recommendation Systems for e-Shopping: Review of Techniques for Retail and Sustainable Marketing" Sustainability 15, no. 23: 16151. https://doi.org/10.3390/su152316151
APA StyleStalidis, G., Karaveli, I., Diamantaras, K., Delianidi, M., Christantonis, K., Tektonidis, D., Katsalis, A., & Salampasis, M. (2023). Recommendation Systems for e-Shopping: Review of Techniques for Retail and Sustainable Marketing. Sustainability, 15(23), 16151. https://doi.org/10.3390/su152316151