
Research on Transportation Carbon Emission Peak Prediction and Judgment System in China


Abstract
:1. Introduction
2. Literature Review
2.1. Research on Carbon Peaking
2.2. Research on Transportation Carbon Emission Prediction
2.3. Research on Influencing Factors of Transportation Carbon Emission
3. Methodology and Data
3.1. Methodology
3.1.1. ARIMA Model
3.1.2. Fuzzy Comprehensive Evaluation Method
- Step 1:
- Establish a comprehensive evaluation factor set.
- Step 2:
- Establish an evaluation set of a comprehensive evaluation.
- Step 3:
- Determine the fuzzy comprehensive appraisal matrix.
- Step 4:
- Determine the weight of each factor.
- Step 5:
- Calculate the comprehensive evaluation index.
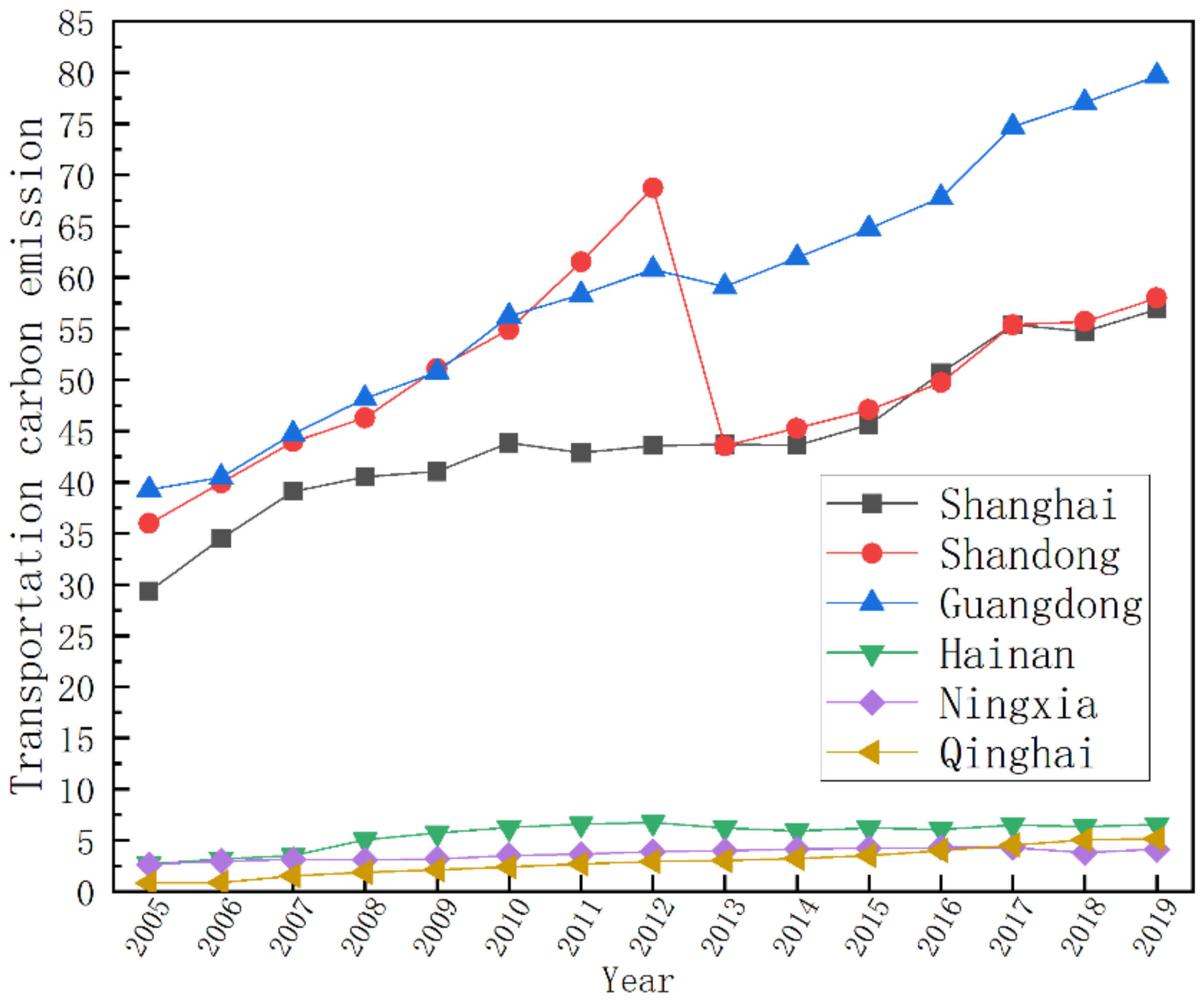
3.2. Data
4. Empirical Analysis
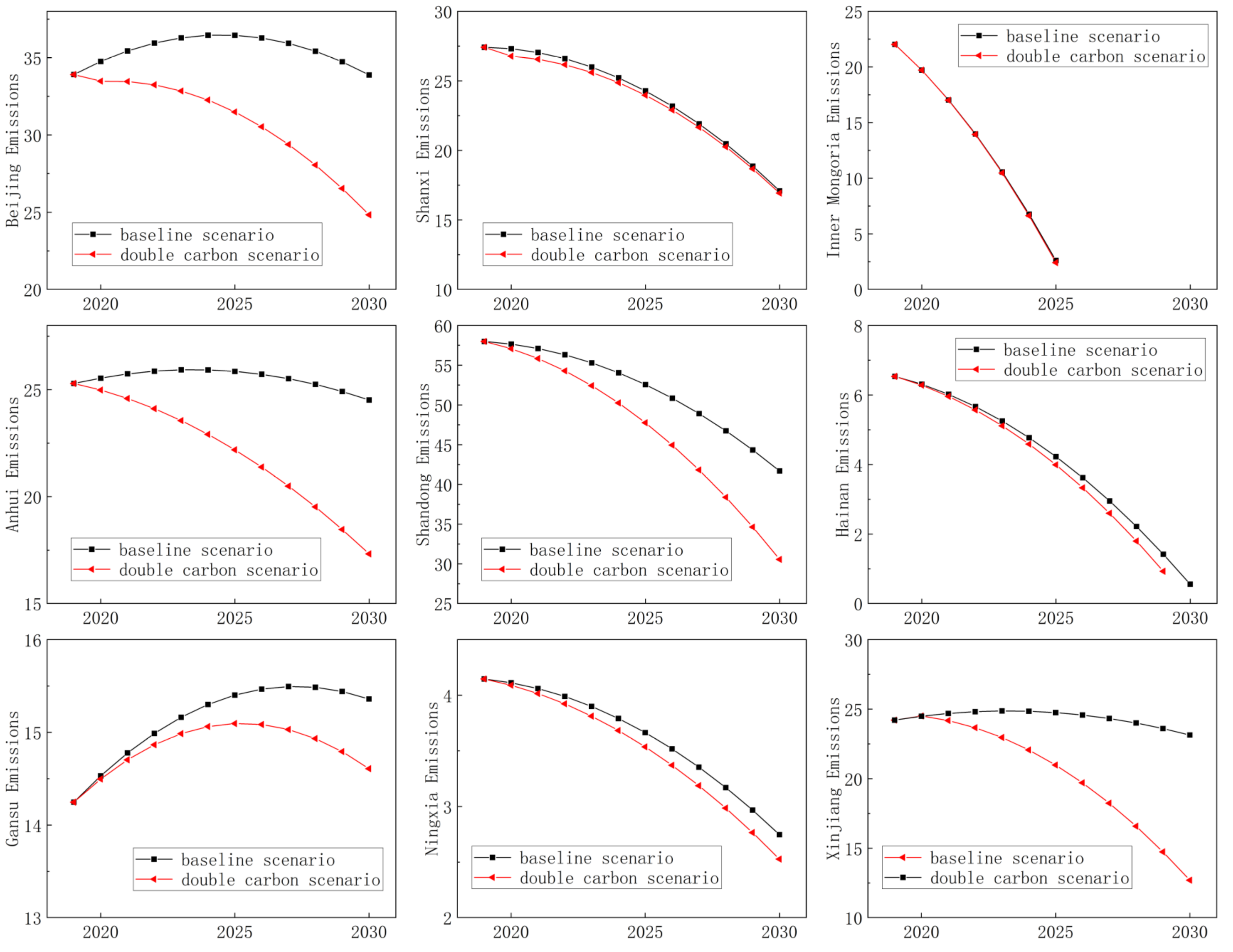
4.1. Carbon Peak Scenario Setting
4.2. Prediction Result Analysis
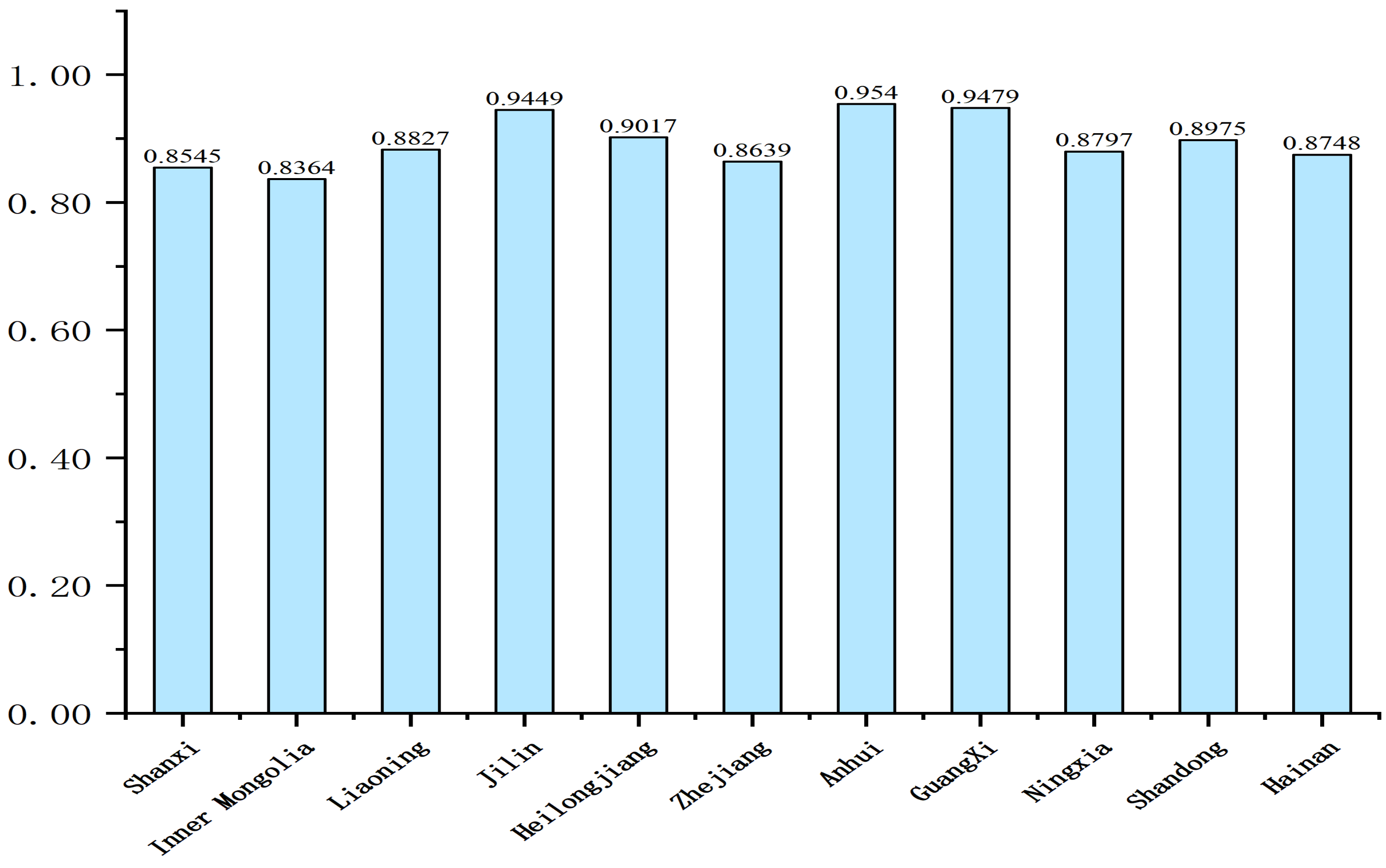
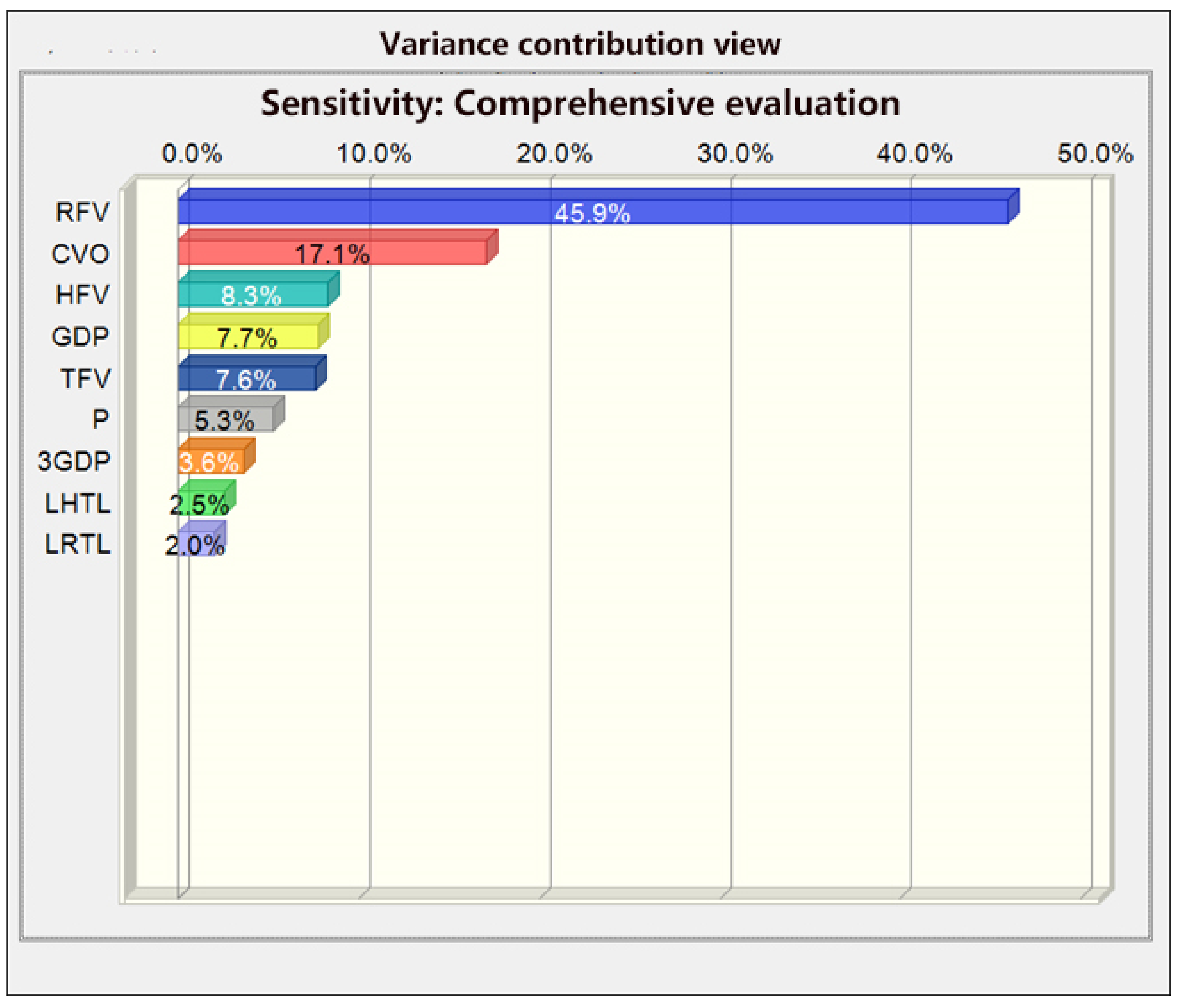
4.3. Comprehensive Evaluation
5. Conclusions, Actions, and Recommendations
5.1. Conclusions
5.2. Actions and Recommendations
5.3. Study Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, Y.; Liu, S.; Li, L. Grey Correlation Analysis of Transportation Carbon Emissions under the Background of Carbon Peak and Carbon Neutrality. Energies 2022, 15, 3064. [Google Scholar] [CrossRef]
- Yu, Y.; Li, S.; Sun, H.; Taghizadeh-Hesary, F. Energy carbon emission reduction of China’s transportation sector: An input–output approach. Econ. Anal. Policy 2021, 69, 378–393. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, Y.; Zhu, L.; Zhang, F.; Zhang, Y. Influencing factors and decoupling elasticity of China’s transportation carbon emissions. Energies 2018, 11, 1157. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Q. Research on carbon emission reduction based on the optimization of transportation structure under VAR model. IOP Conf. Ser. Earth Environ. Sci. 2020, 440, 042008. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, L.; Huang, C. Study on the carbon emission spillover effects of transportation under technological advancements. Sustainability 2022, 14, 10608. [Google Scholar] [CrossRef]
- Prasad, R.D.; Raturi, A. Low-carbon measures for Fiji’s land transport energy system. Util. Policy 2018, 54, 132–147. [Google Scholar] [CrossRef]
- Selvakkumaran, S.; Limmeechokchai, B. Low carbon society scenario analysis of transport sector of an emerging economy—The AIM/Enduse modelling approach. Energy Policy 2015, 81, 199–214. [Google Scholar] [CrossRef]
- Gao, J.; Pan, L. A System Dynamic Analysis of Urban Development Paths under Carbon Peaking and Carbon Neutrality Targets: A Case Study of Shanghai. Sustainability 2022, 14, 15045. [Google Scholar] [CrossRef]
- Zhang, C.; Luo, H. Research on carbon emission peak prediction and path of China’s public buildings: Scenario analysis based on LEAP model. Energy Build. 2023, 289, 113053. [Google Scholar] [CrossRef]
- Gonçalves, D.N.S.; Goes, G.V.; D’Agosto, M.d.A.; La Rovere, E.L. Development of Policy-Relevant Dialogues on Barriers and Enablers for the Transition to Low-Carbon Mobility in Brazil. Sustainability 2022, 14, 16405. [Google Scholar] [CrossRef]
- Liimatainen, H.; Kallionpää, E.; Pöllänen, M.; Stenholm, P.; Tapio, P.; McKinnon, A. Decarbonizing road freight in the future—Detailed scenarios of the carbon emissions of Finnish road freight transport in 2030 using a Delphi method approach. Technol. Forecast. Soc. 2014, 81, 177–191. [Google Scholar] [CrossRef]
- Dhar, S.; Pathak, M.; Shukla, P.R. Transformation of India’s transport sector under global warming of 2 °C and 1.5 °C scenario. J. Clean Prod. 2018, 172, 417–427. [Google Scholar] [CrossRef]
- Wang, X.; Zhou, Y.; Bi, Q.; Cao, Z.; Wang, B. Research on the Low-Carbon Development Path and Policy Options of China’s Transportation Under the Background of Dual Carbon Goals. Front. Environ. Sci. 2022, 10, 905037. [Google Scholar] [CrossRef]
- AlSabbagh, M.; Siu, Y.L.; Guehnemann, A.; Barrett, J. Integrated approach to the assessment of CO2 emitigation measures for the road passenger transport sector in Bahrain. Renew. Sust. Energy Rev. 2017, 71, 203–215. [Google Scholar] [CrossRef]
- Wang, C.; Cai, W.; Lu, X.; Chen, J. CO2 mitigation scenarios in China’s road transport sector. Energy Convers. Manag. 2007, 48, 2110–2118. [Google Scholar] [CrossRef]
- Gao, B.; Sun, X. Analysis on temporal change and grey relation of transportation carbon emissions in Jilin Province. IOP Conf. Ser. Earth Environ. Sci. 2018, 146, 012009. [Google Scholar] [CrossRef]
- Wu, Y.; Zhou, Y.; Liu, Y.; Liu, J. A Race Between Economic Growth and Carbon Emissions: How Will the CO2 Emission Reach the Peak in Transportation Industry? Front. Energy Res. 2022, 9, 778757. [Google Scholar] [CrossRef]
- Byers, E.A.; Gasparatos, A.; Serrenho, A.C. A framework for the exergy analysis of future transport pathways: Application for the United Kingdom transport system 2010–2050. Energy 2015, 88, 849–862. [Google Scholar] [CrossRef]
- Tang, B.-J.; Li, X.-Y.; Yu, B.; Wei, Y.-M. Sustainable development pathway for intercity passenger transport: A case study of China. Appl. Energy 2019, 254, 113632. [Google Scholar] [CrossRef]
- Fernández-Dacosta, C.; Shen, L.; Schakel, W.; Ramirez, A.; Kramer, G.J. Potential and challenges of low-carbon energy options: Comparative assessment of alternative fuels for the transport sector. Appl. Energy 2019, 236, 590–606. [Google Scholar] [CrossRef]
- Zhou, G.; Chung, W.; Zhang, X. A study of carbon dioxide emissions performance of China’s transport sector. Energy 2013, 50, 302–314. [Google Scholar] [CrossRef]
- Talbi, B. CO2 emissions reduction in road transport sector in Tunisia. Renew. Sust. Energy Rev. 2017, 69, 232–238. [Google Scholar] [CrossRef]
- Mattioli, G. Transport needs in a climate-constrained world. A novel framework to reconcile social and environmental sustainability in transport. Energy Res. Soc. Sci. 2016, 18, 118–128. [Google Scholar] [CrossRef]
- Fan, F.; Lei, Y. Decomposition analysis of energy-related carbon emissions from the transportation sector in Beijing. Transp. Res. Part D Transp. Environ. 2016, 42, 135–145. [Google Scholar] [CrossRef]
- Xu, B.; Lin, B. Differences in regional emissions in China’s transport sector: Determinants and reduction strategies. Energy 2016, 95, 459–470. [Google Scholar] [CrossRef]
- Tsita, K.G.; Pilavachi, P.A. Decarbonizing the Greek road transport sector using alternative technologies and fuels. Therm. Sci. Eng. Prog. 2017, 1, 15–24. [Google Scholar] [CrossRef]
- Zhang, Q.; Gu, B.; Zhang, H.; Ji, Q. Emission reduction mode of China’s provincial transportation sector: Based on “Energy+” carbon efficiency evaluation. Energy Policy 2023, 177, 113556. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, Q.; Zhou, D.; Wang, H. Drivers and evolution of low-carbon development in China’s transportation industry: An integrated analytical approach. Energy 2023, 262, 125614. [Google Scholar] [CrossRef]
- Wang, M.; Zhu, C.; Cheng, Y.; Du, W.; Dong, S. The influencing factors of carbon emissions in the railway transportation industry based on extended LMDI decomposition method: Evidence from the BRIC countries. Environ. Sci. Pollut. Res. 2023, 30, 15490–15504. [Google Scholar] [CrossRef] [PubMed]
- Kour, M. Modelling and forecasting of carbon-dioxide emissions in South Africa by using ARIMA model. Int. J. Environ. Sci. Technol. 2023, 20, 11267–11274. [Google Scholar] [CrossRef]
- Du, Y.-W.; Wang, S.-S.; Wang, Y.-M. Group fuzzy comprehensive evaluation method under ignorance. Expert Syst. Appl. 2019, 126, 92–111. [Google Scholar] [CrossRef]
- Eggleston, H.S.; Buendia, L.; Miwa, K.; Ngara, T.; Tanabe, K. 2006 IPCC Guidelines for National Greenhouse Gas Inventories; Chapter 6; Institute for Global Environmental Strategies: Kanagawa, Japan, 2006; Volume 2, pp. 5–7. ISBN 4-88788-032-4. [Google Scholar]
- GB/T2589-2020; General Principles for Calculation of Comprehensive Energy Consumption. Standardization Administration of China: Beijing, China, 2020. (In Chinese)
- Eggleston, H.S.; Buendia, L.; Miwa, K.; Ngara, T.; Tanabe, K. 2006 IPCC Guidelines for National Greenhouse Gas Inventories; Chapter 2; Institute for Global Environmental Strategies: Kanagawa, Japan, 2006; Volume 2, pp. 16–23. ISBN 4-88788-032-4. [Google Scholar]
- DB11/T 1785-2020; Requirements for Carbon Dioxide Emission Accounting and Reporting Power Generation Enterprises. China Beijing Local Standard Press: Beijing, China, 2020. (In Chinese)
- Ye, L.; Yang, D.; Dang, Y.; Wang, J. An Enhanced Multivariable Dynamic Time-Delay Discrete Grey Forecasting Model for Predicting China’s Carbon Emissions. Energy 2022, 249, 123681. [Google Scholar] [CrossRef]
- Garg, N.; Soni, K.; Saxena, T.K.; Maji, S. Applications of AutoRegressive Integrated Moving Average (ARIMA) approach in time-series prediction of traffic noise pollution. Noise Control. Eng. J. 2015, 63, 182–194. [Google Scholar] [CrossRef]
- Zhan, D. Allocation of carbon emission quotas among provinces in China: Efficiency, fairness and balanced allocation. Environ. Sci. Pollut. Res. 2022, 29, 21692–21704. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.; Wang, M.; Yang, Y. Analysis of the Influencing Factors of Regional Carbon Emissions in the Chinese Transportation Industry. Energies 2020, 13, 1100. [Google Scholar] [CrossRef]
- Zhuang, X.; Li, X.; Xu, Y. How Can Resource-Exhausted Cities Get Out of “The Valley of Death”? An Evaluation Index System and Obstacle Degree Analysis of Green Sustainable Development. Int. J. Environ. Res. Public Health 2022, 19, 16976. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Sun, L.; Qin, L. Optimization of China’s provincial carbon emission transfer structure under the dual constraints of economic development and emission reduction goals. Environ. Sci. Pollut. R 2022, 29, 50335–50351. [Google Scholar] [CrossRef]
- Sun, H.; Hu, L.; Geng, Y.; Yang, G. Uncovering impact factors of carbon emissions from transportation sector: Evidence from China’s Yangtze River Delta Area. Mitig. Adapt. Strateg. Glob. Change 2020, 25, 1–15. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Corresponding Formula | S/N |
|---|---|---|
| Mean value | (1) | |
| Variance | (2) | |
| Standard deviation | (3) | |
| Autocovariance (Unbiased) | (4) | |
| Autocovariance (Biased) | (5) |
| Energy | Average Low Calorific Value | Carbon Content per Unit Calorific Value | Carbon Oxidation Rate | Carbon Emission Factor |
|---|---|---|---|---|
| Unit | kJ/kg or kJ/m3 | t-c or TJ | kg-CO2 or kg | |
| raw coal | 20,934 | 27.37 | 0.94 | 1.975 |
| gasoline | 43,124 | 18.9 | 0.98 | 2.929 |
| kerosene | 43,124 | 19.5 | 0.98 | 3.022 |
| diesel | 42,705 | 20.2 | 0.98 | 3.010 |
| fuel oil | 41,868 | 21.1 | 0.98 | 3.174 |
| liquefied petroleum gas | 50,242 | 17.2 | 0.98 | 3.105 |
| natural gas | 32,238 | 15.32 | 0.99 | 1.793 |
| Region | Covering Provinces, Districts, and Cities | CO2 Emission Coefficient (kg/KW·h) |
|---|---|---|
| North China | Beijing, Tianjin, Hebei, Shaanxi, Shandong, Western Inner Mongolia | 1.246 |
| Northeast Region | Liaoning, Jilin, Heilongjiang, Eastern Inner Mongolia | 1.096 |
| East China | Shanghai, Jiangsu, Zhejiang, Anhui, Fujian | 0.928 |
| Central China | Henan, Hubei, Hunan, Jiangxi, Sichuan | 0.801 |
| Northwest Region | Shaanxi, Gansu, Qinghai, Ningxia, Xinjiang | 0.977 |
| Southern region | Guangdong, Guangxi, Yunnan, Guizhou | 0.714 |
| Other areas | Hainan | 0.917 |
| Provinces | 2005–2010 Growth Rate | 2015–2020 Growth Rate | Carbon Peaking and Carbon Neutralization Growth Rate | Provinces | 2005–2010 Growth Rate | 2015–2020 Growth Rate | Carbon Peaking And Carbon Neutralization Growth Rate |
|---|---|---|---|---|---|---|---|
| Beijing | 0.163393 | 0.039929 | 0.019964 | Henan | 0.089542 | 0.086504 | 0.043252 |
| Tianjin | 0.077817 | 0.032453 | 0.016226 | Hubei | 0.062533 | 0.071907 | 0.035953 |
| Hebei | 0.064459 | 0.048132 | 0.024066 | Hunan | 0.085229 | 0.048496 | 0.024248 |
| Shanxi | 0.132255 | 0.020896 | 0.010448 | Guangdong | 0.0743 | 0.0423 | 0.02115 |
| IM | 0.156804 | −0.045 | 0.090007 | Guangxi | 0.103671 | 0.031571 | 0.015785 |
| Liaoning | 0.057878 | 0.011297 | 0.005648 | Hainan | 0.184606 | 0.010589 | 0.005294 |
| Jilin | 0.115844 | −0.02529 | −0.05058 | Chongqing | 0.109648 | 0.095315 | 0.047658 |
| Heilongjiang | 0.026716 | −0.02624 | −0.05247 | Sichuan | 0.112668 | 0.097086 | 0.048543 |
| Shanghai | 0.083376 | 0.045146 | 0.022573 | Guizhou | 0.157019 | 0.028792 | 0.014396 |
| Jiangsu | 0.097621 | 0.045483 | 0.022742 | Yunnan | 0.092279 | 0.060289 | 0.030144 |
| Zhejiang | 0.094741 | 0.00794 | 0.00397 | Shaanxi | 0.145902 | 0.018894 | 0.009447 |
| Anhui | 0.12326 | 0.028159 | 0.014079 | Gansu | 0.078081 | 0.011127 | 0.005564 |
| Fujian | 0.142639 | 0.059667 | 0.029834 | Qinghai | 0.232711 | 0.078224 | 0.039112 |
| Jiangxi | 0.07533 | 0.053902 | 0.026951 | Ningxia | 0.059488 | −0.00463 | −0.00927 |
| Shandong | 0.088311 | 0.042559 | 0.02128 | Xinjiang | 0.044788 | 0.02955 | 0.014775 |
| Total | 0.094699 | 0.038416 | 0.01920 |
| Peak Province | Shanxi | Inner Mongolia | Liaoning | Jilin | Heilongjiang | Zhejiang | Anhui | Guangxi | Ningxia | Shandong | Hainan |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Peak time | 2017 | 2012 | 2017 | 2015 | 2016 | 2017 | 2018 | 2018 | 2017 | 2019 | 2019 |
| Entropy Method | |||
|---|---|---|---|
| Term | Shannon Entropy (e) | Information Utility (d) | Weight (%) |
| Shanxi | 0.701 | 0.299 | 7.989 |
| Inner Mongolia | 0.697 | 0.303 | 8.113 |
| Liaoning | 0.657 | 0.343 | 9.186 |
| Jilin | 0.675 | 0.325 | 8.701 |
| Heilongjiang | 0.635 | 0.365 | 9.778 |
| Zhejiang | 0.663 | 0.337 | 9.03 |
| Anhui | 0.596 | 0.404 | 10.823 |
| Guangxi | 0.641 | 0.359 | 9.61 |
| Ningxia | 0.671 | 0.329 | 8.813 |
| Shandong | 0.695 | 0.305 | 8.154 |
| Hainan | 0.634 | 0.366 | 9.802 |
| Index Item | Membership Degree | Normalization of Membership Degree (Weight) |
|---|---|---|
| GDP | 0.058464345 | 0.113249657 |
| GDP of the tertiary industry | 0.028897378 | 0.129508773 |
| Population | 0.009890318 | 0.075106036 |
| Railway transport line length | 0.011364705 | 0.052662112 |
| Highway transport line Length | 0.333312678 | 0.051549757 |
| Total freight volume | 0.427762786 | 0.104439486 |
| Railway freight volume | 0.046064872 | 0.232147967 |
| Highway freight volume | 0.314856355 | 0.108263984 |
| Civil automobile-owned | 0.001368723 | 0.13307223 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Yang, Y.; Liu, S.; Li, Q. Research on Transportation Carbon Emission Peak Prediction and Judgment System in China. Sustainability 2023, 15, 14880. https://doi.org/10.3390/su152014880
Sun Y, Yang Y, Liu S, Li Q. Research on Transportation Carbon Emission Peak Prediction and Judgment System in China. Sustainability. 2023; 15(20):14880. https://doi.org/10.3390/su152014880
Chicago/Turabian StyleSun, Yanming, Yile Yang, Shixian Liu, and Qingli Li. 2023. "Research on Transportation Carbon Emission Peak Prediction and Judgment System in China" Sustainability 15, no. 20: 14880. https://doi.org/10.3390/su152014880
APA StyleSun, Y., Yang, Y., Liu, S., & Li, Q. (2023). Research on Transportation Carbon Emission Peak Prediction and Judgment System in China. Sustainability, 15(20), 14880. https://doi.org/10.3390/su152014880