
D2D Communication Network Interference Coordination Scheme Based on Improved Stackelberg

Abstract
1. Introduction
- (1)
- We propose a DQN–Stackelberg model framework, in which the base station is the leader, and both D2D and relay users are the followers.
- (2)
- An interference management algorithm for heterogeneous D2D cellular communication networks is proposed, and a power control and channel allocation scheme is designed to solve the interference problem in D2D communication networks.
- (3)
- The system simulation experiment first proves the effectiveness of the proposed algorithm. At the same time, the comparison of related algorithms shows that the proposed algorithm effectively guarantees the communication quality of cellular users and improves the system throughput and interference management capability.
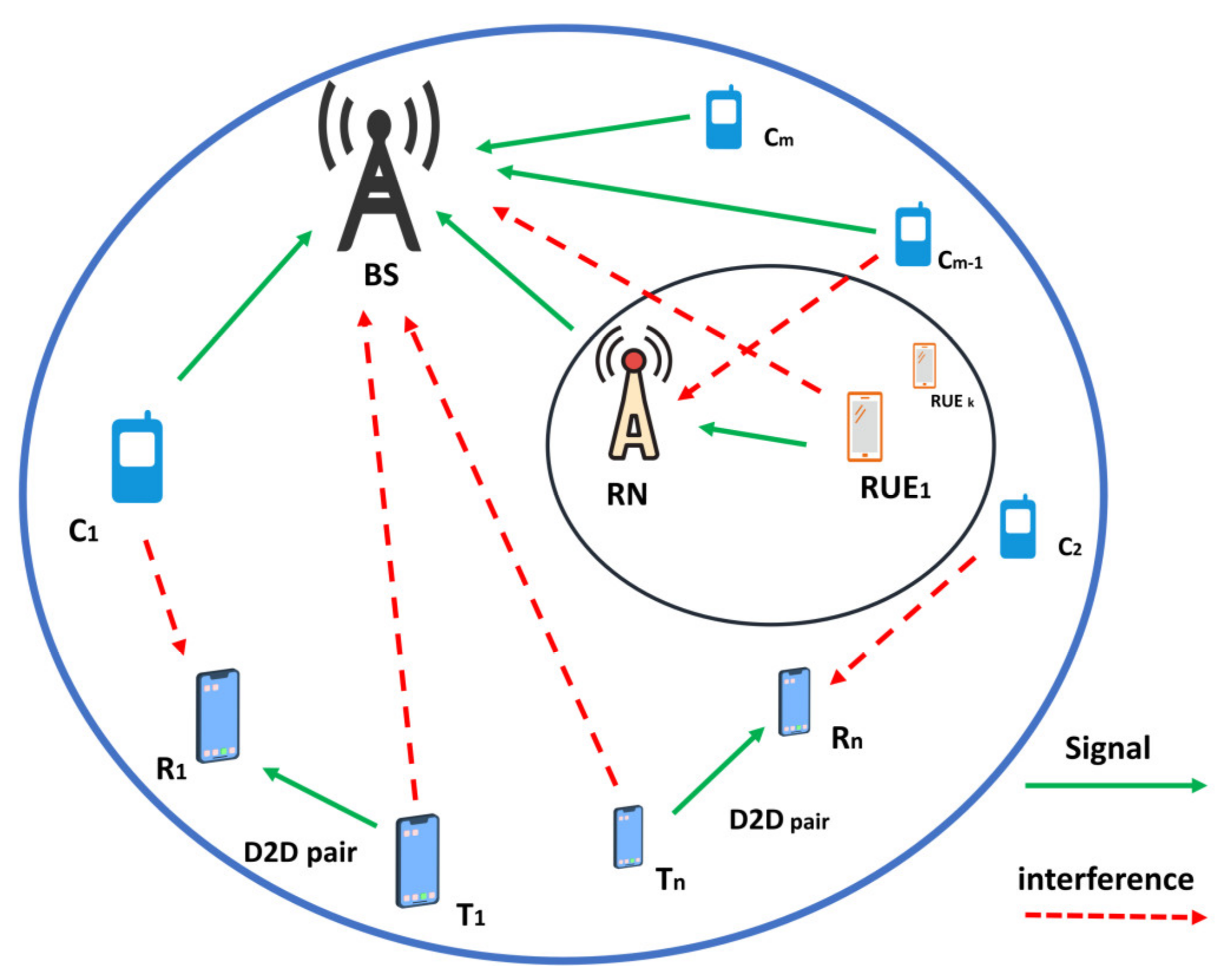
2. System Model
2.1. Establishment of System Model
2.2. Establishment of Problems in System Model
3. Interference Coordination Algorithm Based on Improved Stackelberg Game
- (1)
- Leader (BS) Utility Function
- (2)
- Follower (D2D, RUE) Utility Function
3.1. Reused Resource User Power Control Algorithm
3.2. Resource Allocation Algorithm for Base Station Decision
- (1)
- Traverse all columns in the leader utility function matrix , select the position of the maximum value in the column, and record the row “m” corresponding to the maximum value.
- (2)
- Judge whether the values of each “m” are different. If the values are the same, execute the fourth step; otherwise, continue to execute.
- (3)
- Find out all the rows “m” that do not have duplicate values, record the “n” value of the corresponding D2D user or the “q” value of the corresponding relay user, and remove the leader utility matrix (note: the matrix must not be empty because it should be less than), and repeat the first step.
- (4)
- Output all pairs of and and use the Round Robin algorithm to fairly allocate all resources k to and .
3.3. DQN-Based Stackelberg Model Interference Coordination Algorithm
- (1)
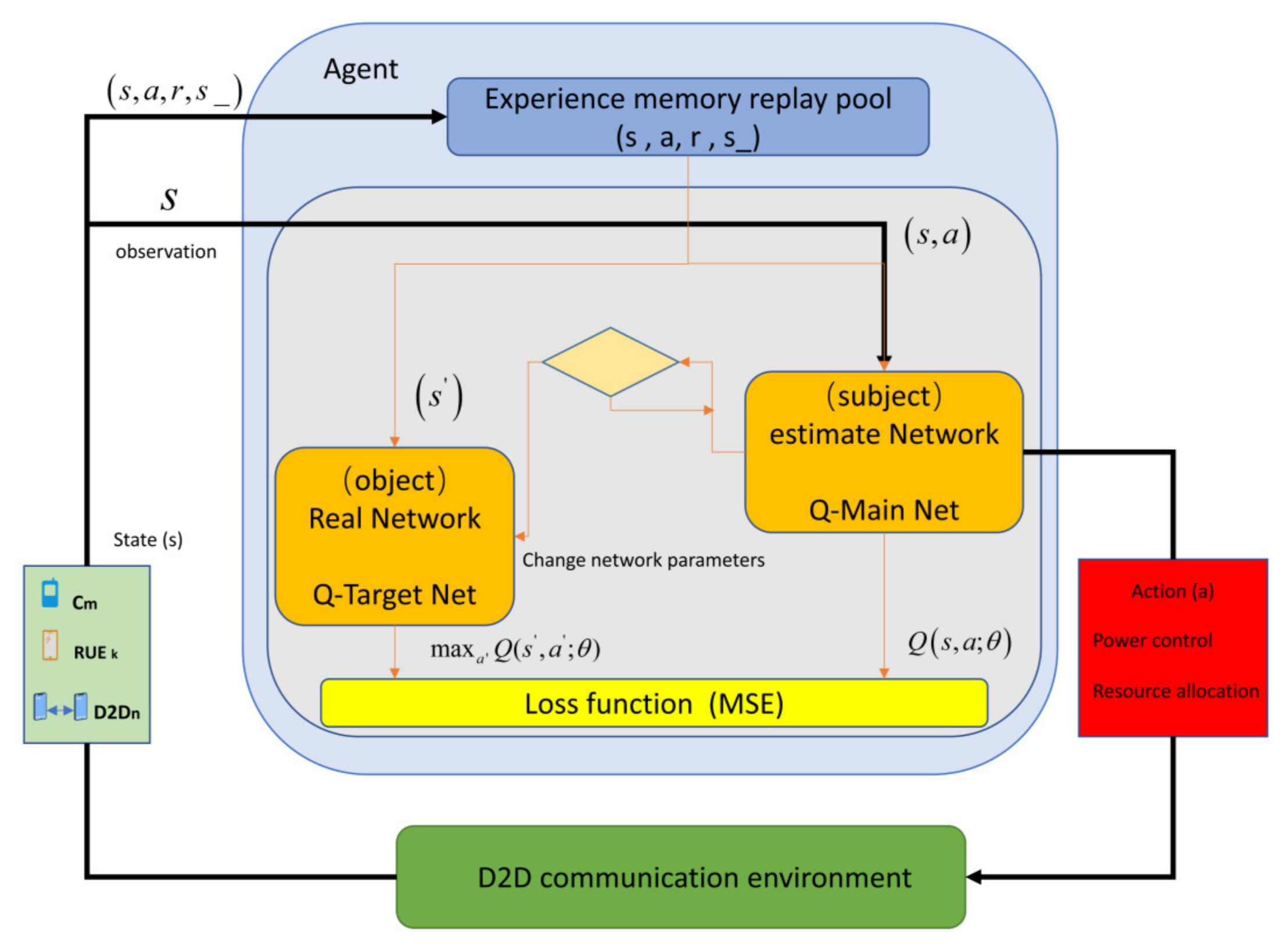
- Model Diagram of D2D Communication Interference Coordination Based on DQNThe interference model diagram proposed in this paper mainly consists of the D2D communication environment, transmit power selection of users of multiplexed cellular resources (D2D, CUE), experience pool, deep neural network, Q-Target net, Q-Main estimation network and loss function .This paper will introduce the D2D communication environment, user action selection and reward and punishment functions in the Stackelberg improved algorithm.
- (1)
- Experience Replay PoolThe proposed DQN model is a combination of deep learning and Q learning models. Q learning is an offline learning method (off policy). On the one hand, it can learn the latest strategies according to the user status in the current D2D communication system in real time, and on the other hand, it can learn the past strategies through the experience replay pool. Adding experience replay pool to the whole model greatly improves the learning efficiency of the deep neural network.The experience replay pool stores multiple transfer learning samples obtained by agents interacting with the environment at each time step and stores them in the playback memory network. When the deep learning network is trained, transfer learning samples are added to the experience replay pool, which greatly improves the diversity of the deep learning sample data and ensures cellular users, D2D users and the reliable extraction of link state characteristics of the relay users.
- (2)
- Deep Neural Network CNN Implementationrefers to the action space from the state of user interference in the current environment of D2D communication to that of the agent based on the current state. In this paper, we use deep learning to fit this mapping efficiently. Specifically, it includes CNN1 (Q-Main Net) and CNN2 (Q-Target Net); the two deep learning network models have the same structure, but their network parameters are completely different. Q-Main Net is used to generate the current Q value; Q-Target Net is used to generate the Target Q value, and this value is used as the reference value of the loss function in depth learning training.
- (3)
- Q-Target NetworkThe role of the Q-Target network is mainly to disrupt the correlation of system training. In the whole model, Q-Target Net uses the parameters with relatively high service time to estimate the Q value, while Q-Main Net uses the latest parameters to evaluate the latest parameters. As shown in Figure 2, represents the output of Q-Target Net, and represents the output of the current network Q-Main Net. The specific process is Q-Target Net and updates the parameters of Q-Main Net according to the loss function. After a certain number of iterations, the network parameters of Q-Main Net are copied to Q-Target Net. After introducing Q-Target Net, the target Q value is kept unchanged during a certain period of training, which reduces the correlation between the current Q value and the target Q value to a certain extent and improves the stability of the algorithm.
- (4)
- Q-Main NetworkThe Q-Main Net is used to train an infinite approximation function that can approach the real optimal value.
- (5)
- Loss Function:Including θ is a network parameter with the following objectives:
- (2)
- Improved Stackelberg AlgorithmDeep reinforcement learning is often used in the process of the continuous interaction between agents and environmental information. After continuous learning, they perform a series of actions in a specific state to maximize the cumulative return. Compared with deep learning, deep reinforcement learning does not require data sets but only needs to define the agent, state S, action A and reward R.In this paper, each cellular user can realize the real-time update of triplet variables through continuous interaction and learning with the D2D communication environment information in each time slot t. The variables are state, action and reward. Each component variable of the reinforcement learning model of cost parameters is defined as follows:Status: defined as the path status of the reusable cellular link on the PRB.Action: define a group of price factors as actions, and set the value space as:in this study.Reward is the reward function: the reward function reflects the learning goal, which is defined as the difference between the logarithmic throughput of the link resources that D2D/RUE reuses CUE and the link resources that D2D/RUE does not reuse CUE, namely:
- (3)
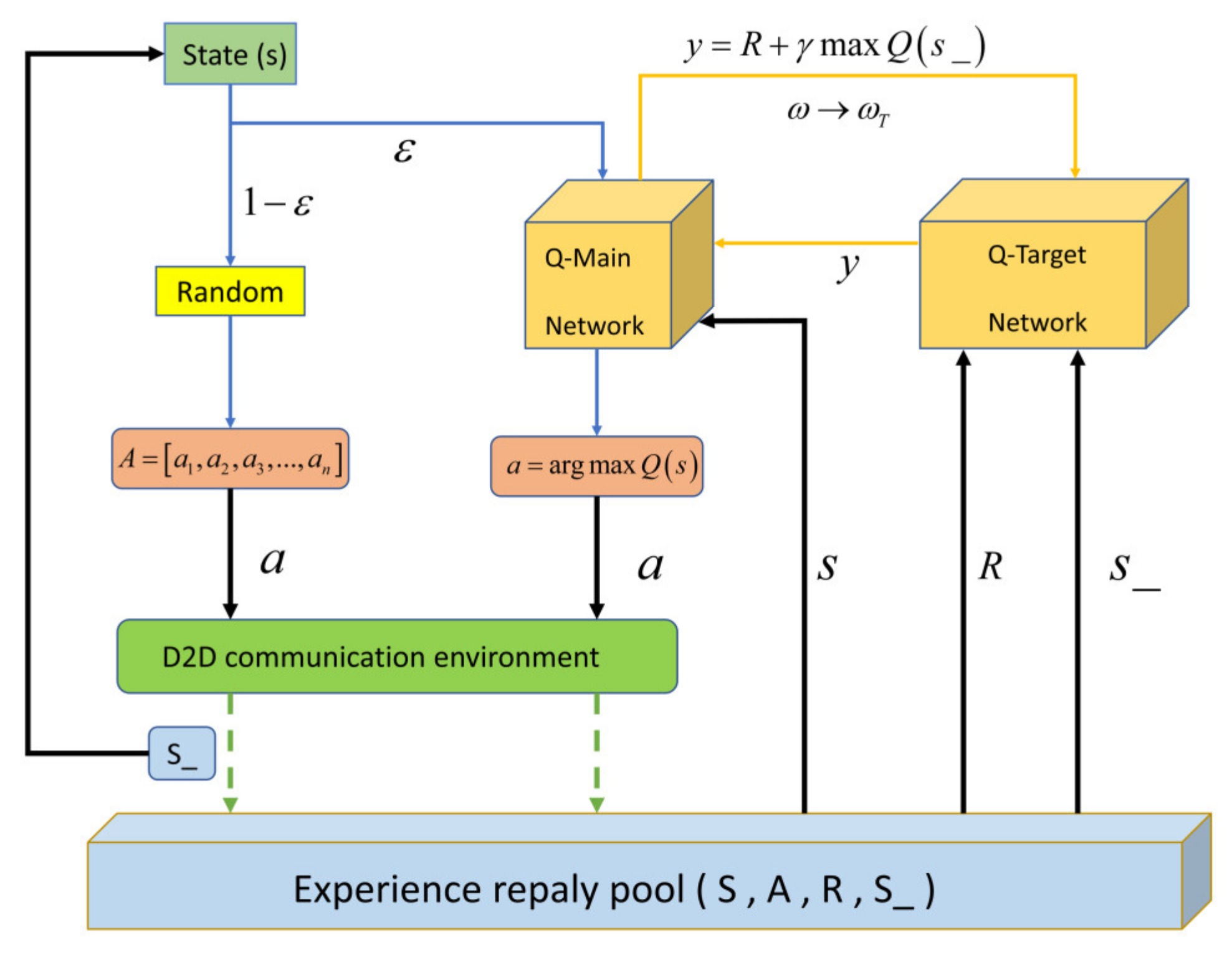
- Updating and Training AlgorithmThe above completed the Q table of the mutual mapping of state, action and reward (i.e., return function), state and action in the D2D communication environment based on improved Stackelberg. Two deep learning networks, namely, the Q-Target network and Q-Main estimation network, were used to fit the Q table. Finally, the algorithm was updated according to the reward value obtained in each iteration of training, and the optimal action selection under different interference states of D2D communication was the output in the experiment. The interference management model based on D2D communication is shown in Figure 3. The detailed algorithm process is explained as follows:
- (1)
- Experience will play back the storage of the poolAccording to the previously determined D2D communication interference environment state parameters, determine the action selection of the agent at this time. There are two kinds of action choices here. One is based on probability , which selects an action corresponding to the maximum Q value through the Q-Network, and the other is based on probability , which randomly selects an action through the action space of the benchmark. (It is worth noting that the value of is set very small from the beginning of training to the time when the experience pool is full, so as to ensure that the previous actions are random and increase the diversity of samples. In addition, the relevant parameters in the Q-Target network are random.) After the action selection, the intelligent agent will execute this action in the D2D communication environment, and then the D2D communication environment will return to the next D2D communication environment state (S_) and reward (R); the new quaternion is (S, A, R, S_), and it is stored in the experience pool. Finally, with the new status (S_) just obtained as the current D2D communication state, repeat the above steps until the experience pool is full.
- (2)
- Update the parameters of Q-Main Net and Q-Target NetAfter the storage of the experience pool is completed, the deep learning model containing the dual deep learning network starts to update. First, the next state (S_) in the D2D communication environment in the experience pool is updated. The reward value (R) after the execution of the action with the current user (D2D user, relay communication user) is brought into the Q-Target network, and the next Q value (y) is calculated. Then, the y value and loss function are used to update the parameters in the Q-Main Net. Then, repeat the above steps. The agent interacts with the D2D communication environment information to generate a new round of (S, A, R, S_). The quads are stored in the experience pool, and the stored samples in the experience pool are used to update the Q-Main Net parameters. With continuous learning, the difference between the two will continue to decrease until the Q-Main Net completes convergence. At this time, the action is the best choice.Figure 3. D2D communication interference management model based on DQN.


| Algorithm 1: Pseudo code |
| Initialize replay memory D to capacity N |
| Initialize action-value function Q with random weights |
| Initialize target action-value function with weights |
| For episode = 1, M do |
| Initialize sequence and preprocessed sequence For t=1, T do |
| With probability select a random action |
| Otherwise select |
| Execute action in emulator and observe reward and sequence |
| Set and preprocess |
| Store transition in D |
| Sample random minibatch of transitions from D |
| Perform a gradient descent step on with respect |
| to the network parameters |
| Every C step reset |
| End For |
| End For |
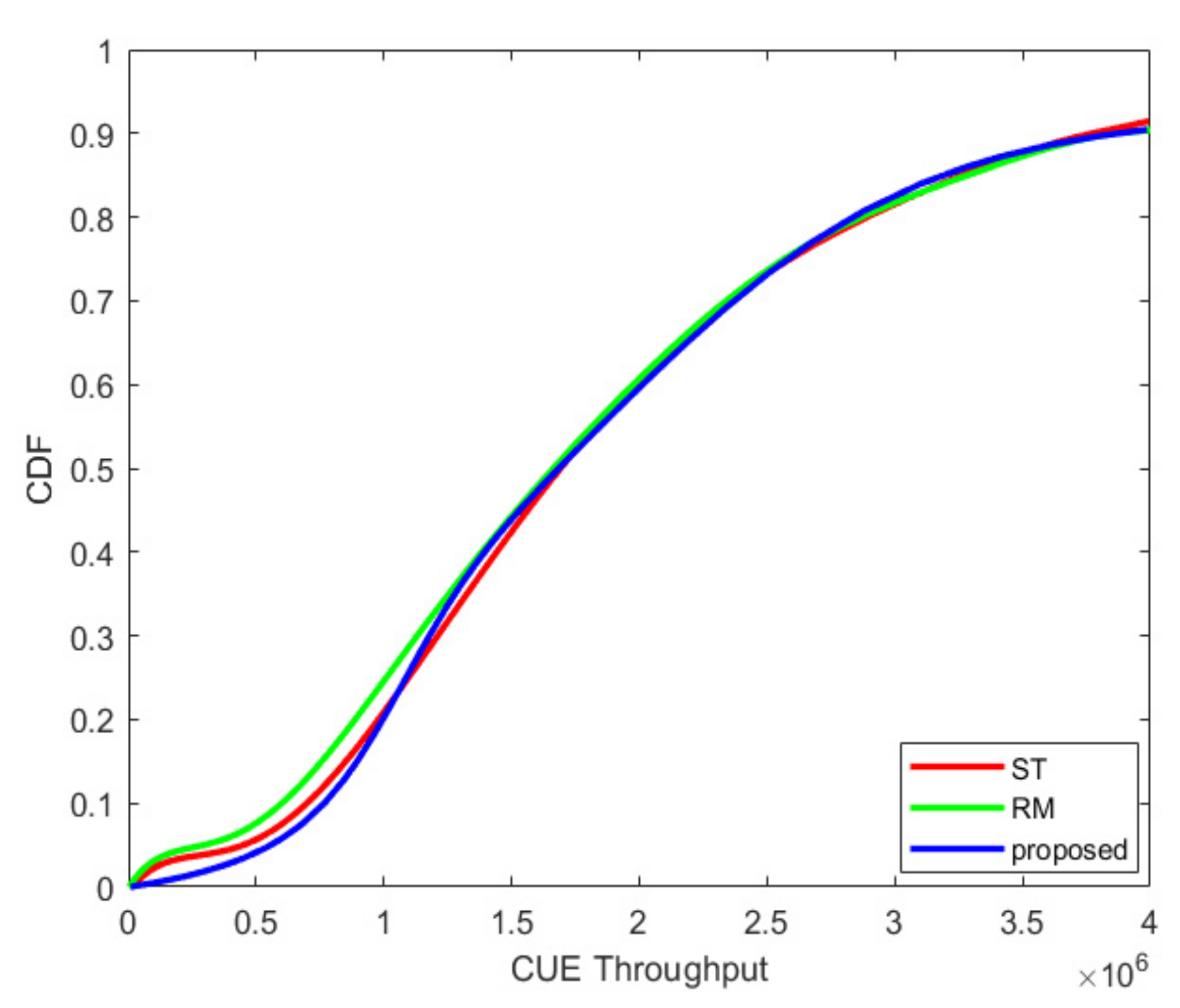
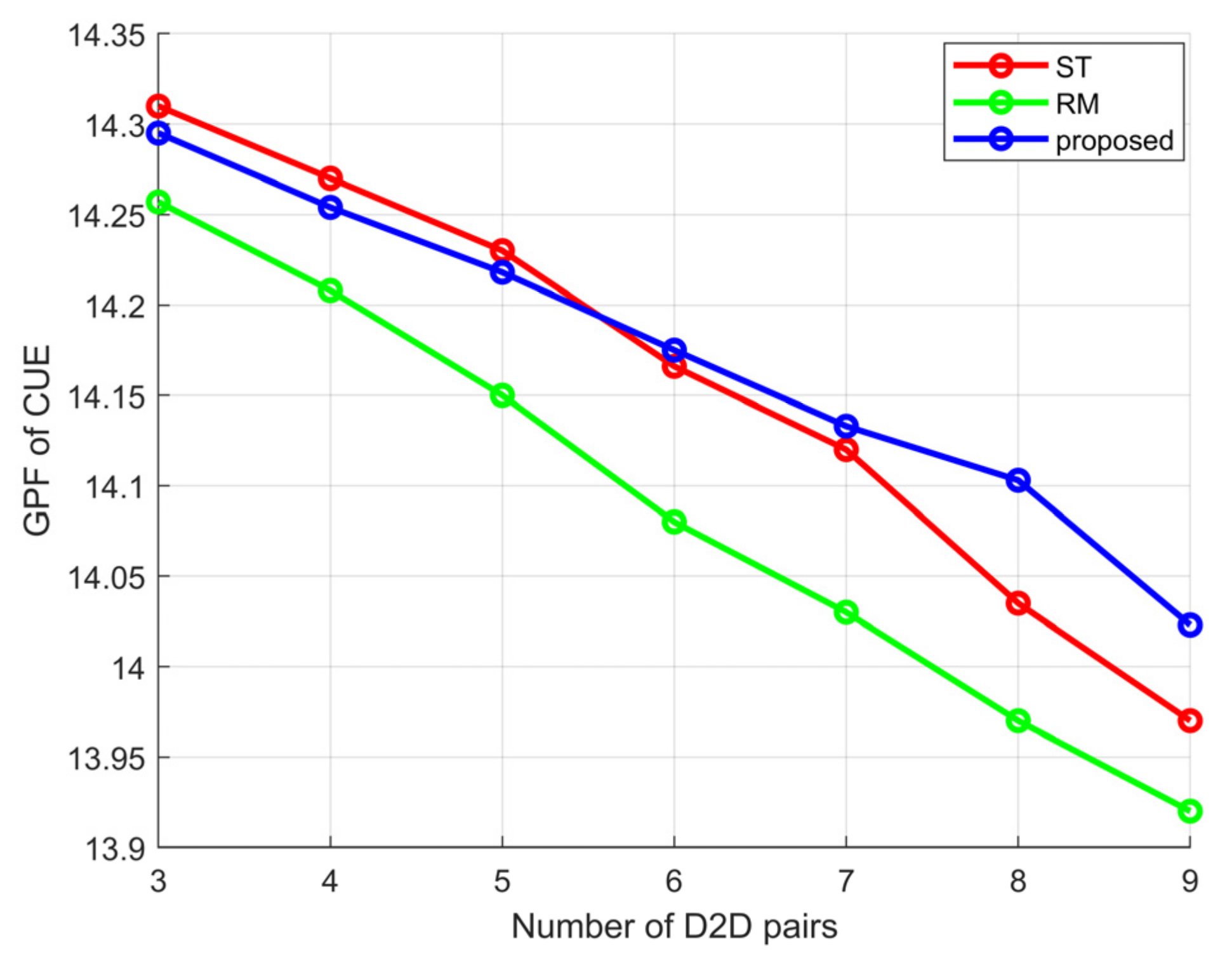
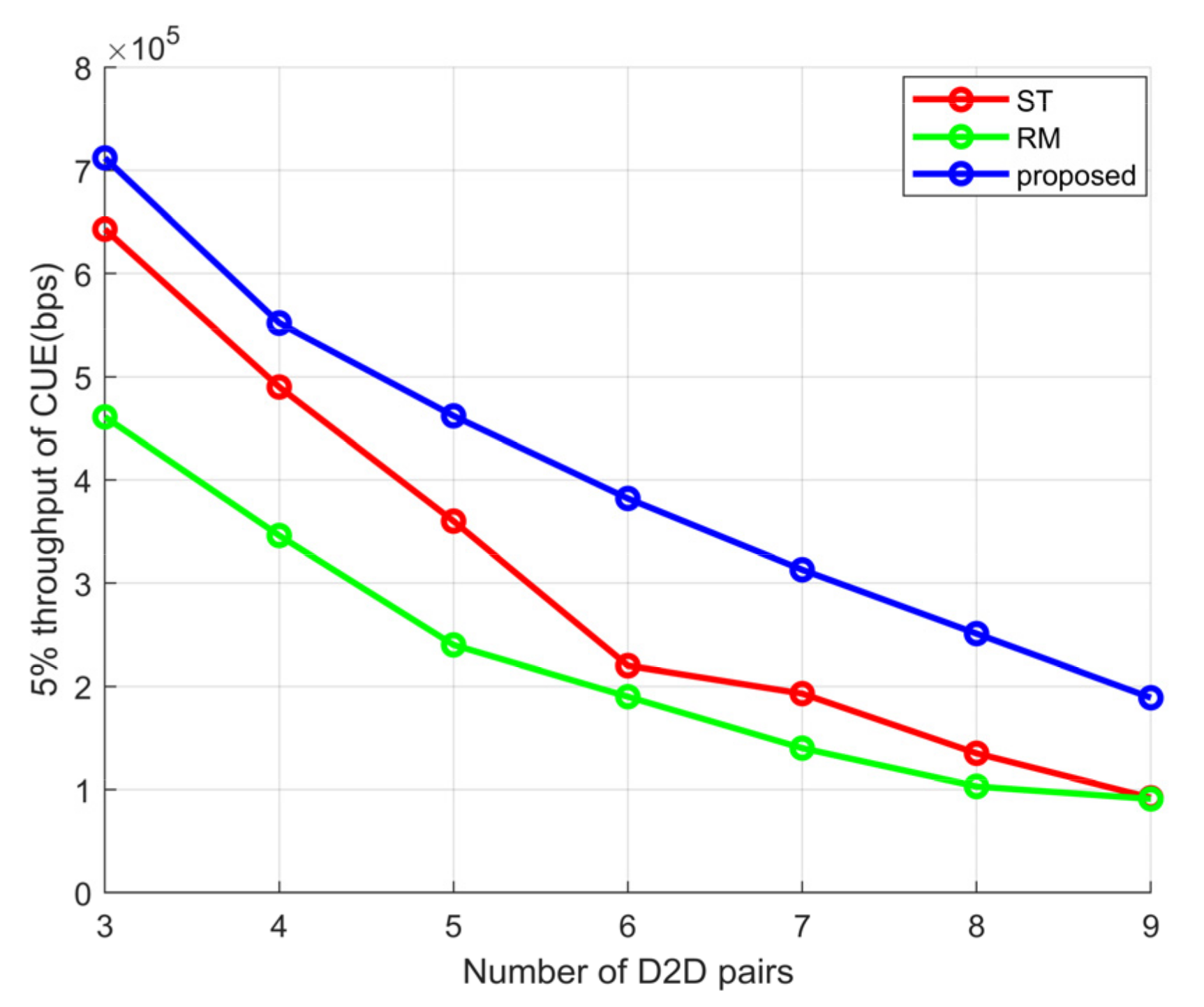
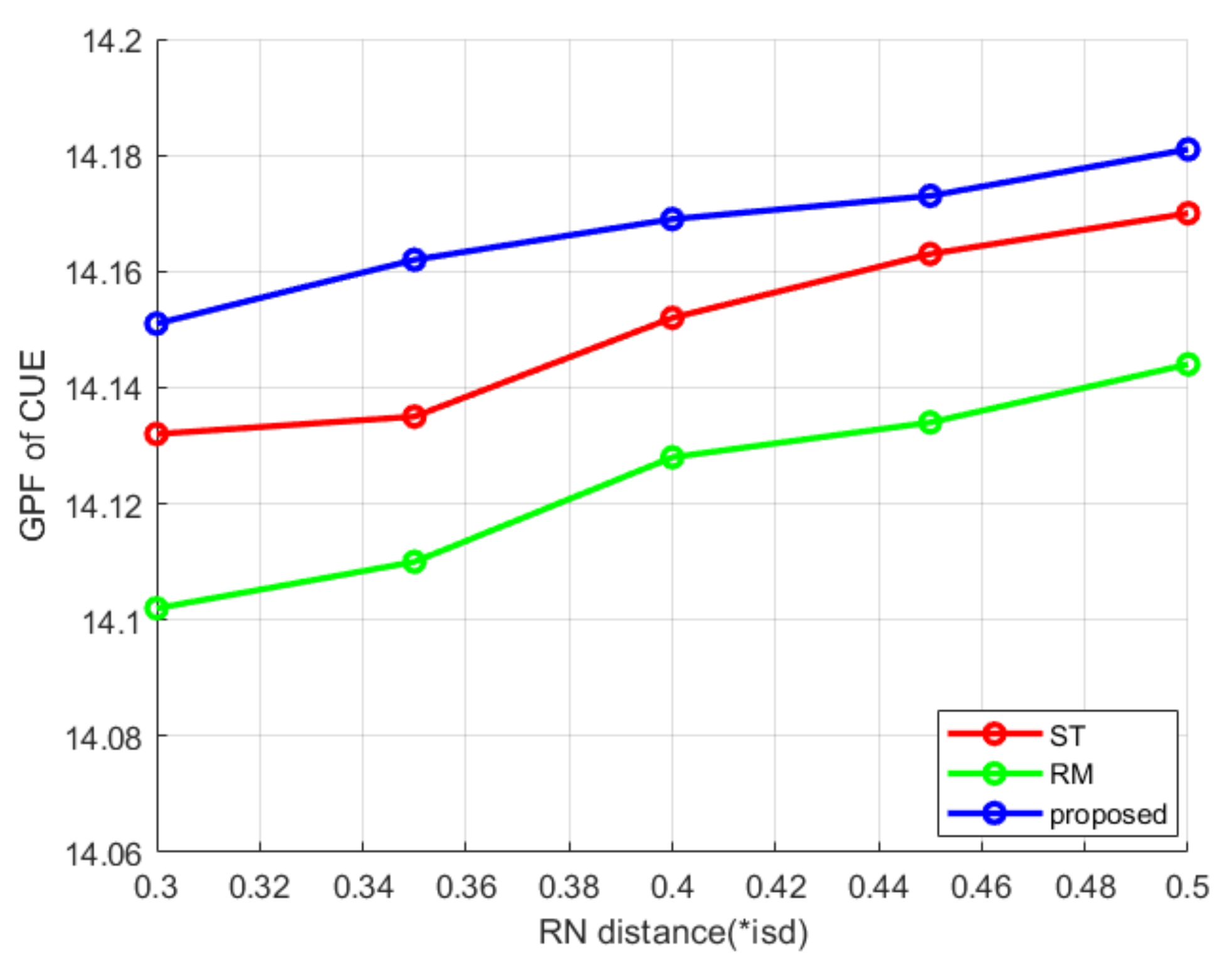
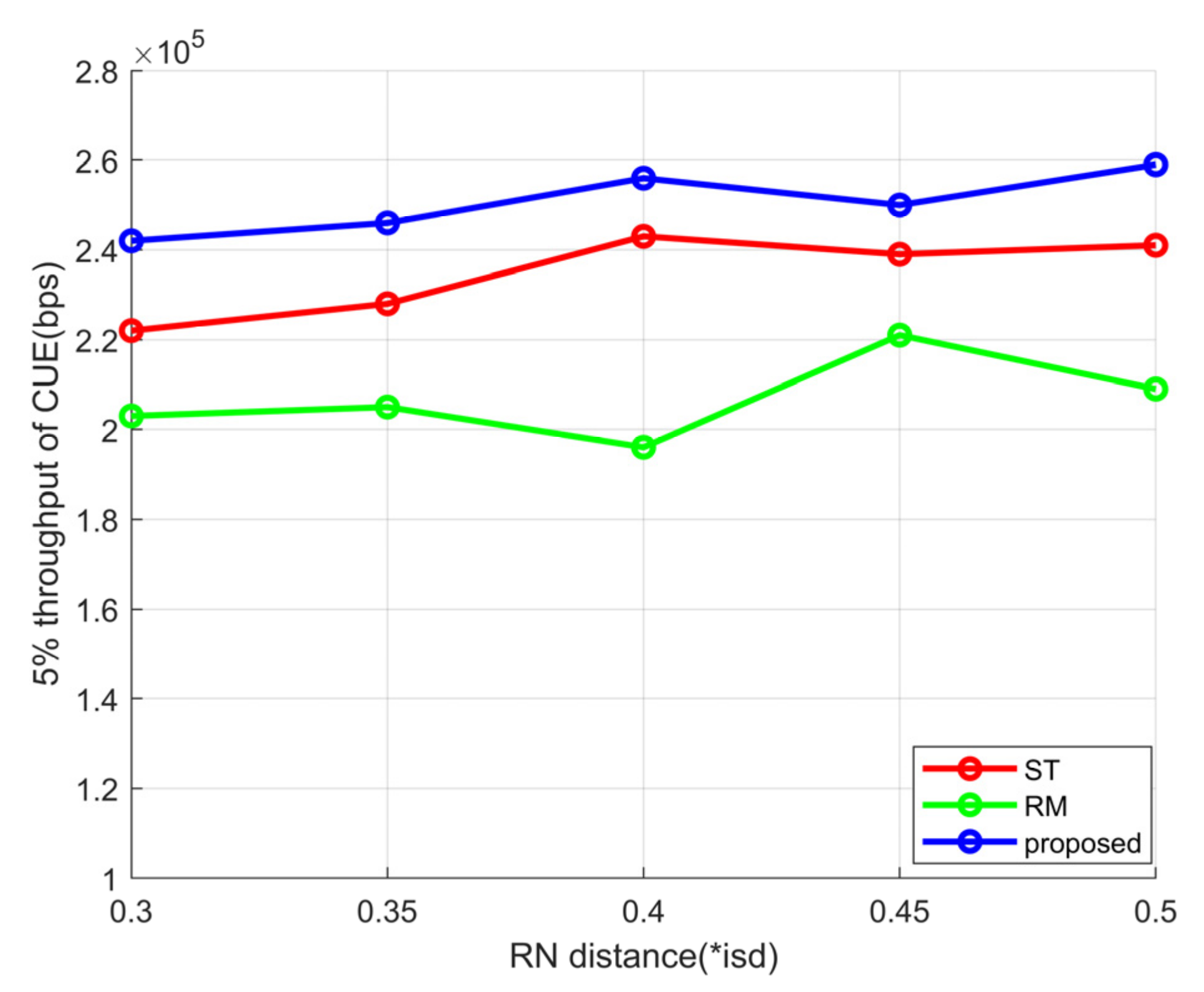
4. Simulation Experiment Results and Analysis
5. Conclusions
6. Patents
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, D.; Ouamri, M.A.; Muthanna, M.S.A.; Adam, A.B.M.; Muthanna, A.; Koucheryavy, A.; El-Latif, A.A.A. A Generalized Approach on Outage Performance Analysis of Dual-Hop Decode and Forward Relaying for 5G and beyond Scenarios. Sustainability 2022, 14, 12870. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, Y.; Iftikhar, H.; Ullah, A.; Mao, J.; Wang, T. Dynamic Influence of Digital and Technological Advancement on Sustainable Economic Growth in Belt and Road Initiative (BRI) Countries. Sustainability 2022, 14, 15782. [Google Scholar] [CrossRef]
- Taghizad-Tavana, K.; Ghanbari-Ghalehjoughi, M.; Razzaghi-Asl, N.; Nojavan, S.; Alizadeh, A. An Overview of the Architecture of Home Energy Management System as Microgrids, Automation Systems, Communication Protocols, Security, and Cyber Challenges. Sustainability 2022, 14, 15938. [Google Scholar] [CrossRef]
- Balfaqih, M.; Alharbi, S.A. Associated Information and Communication Technologies Challenges of Smart City Development. Sustainability 2022, 14, 16240. [Google Scholar] [CrossRef]
- Baek, Y.; Joo, H. A Study on the Spatial Structure of the Bu-Ul-Gyeong Megacity Using the City Network Paradigm. Sustainability 2022, 14, 15845. [Google Scholar] [CrossRef]
- Okey, O.D.; Maidin, S.S.; Lopes Rosa, R.; Toor, W.T.; Carrillo Melgarejo, D.; Wuttisittikulkij, L.; Saadi, M.; Zegarra Rodríguez, D. Quantum Key Distribution Protocol Selector Based on Machine Learning for Next-Generation Networks. Sustainability 2022, 14, 15901. [Google Scholar] [CrossRef]
- Chen, G.; Chen, G. A Method of Relay Node Selection for UAV Cluster Networks Based on Distance and Energy Constraints. Sustainability 2022, 14, 16089. [Google Scholar] [CrossRef]
- Adanvo, V.F.; Mafra, S.; Montejo-Sánchez, S.; Fernández, E.M.G.; Souza, R.D. Buffer-Aided Relaying Strategies for Two-Way Wireless Networks. Sustainability 2022, 14, 13829. [Google Scholar] [CrossRef]
- Aditya, M.V.S.; Pancholi, H.; Priyanka, P.; Kasbekar, G.S. Beyond the VCG mechanism: Truthful reverse auctions for relay selection with high data rates, high base station utility and low interference in D2D networks. Wirel. Netw. 2020, 26, 3861–3882. [Google Scholar] [CrossRef]
- Seoyoung, Y.; Lee, J.W. Deep Reinforcement Learning Based Resource Allocation for D2D Communications Underlay Cellular Networks. Sensors 2022, 22, 9459. [Google Scholar]
- Sun, M.; Jin, Y.; Wang, S.; Mei, E. Joint Deep Reinforcement Learning and Unsupervised Learning for Channel Selection and Power Control in D2D Networks. Entropy 2022, 24, 1722. [Google Scholar] [CrossRef]
- Ahmad, N.; Sidhu, G.A.S.; Khan, W.U. A Learning Based Framework for Enhancing Physical Layer Security in Cooperative D2D Network. Electronics 2022, 11, 3981. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Y.; Tang, L.; Xia, Y. D2D Social Selection Relay Algorithm Combined with Auction Principle. Sensors 2022, 22, 9265. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, A.; Rahim, M.; Hussain, R.; Noorwali, A.; Khan, M.Z.; Shakeel, A.; Khan, I.L.; Javed, M.A.; Hasan, Q.U.; Malik, S.A. cDERSA: Cognitive D2D enabled relay selection algorithm to mitigate blind-spots in 5G cellular networks. IEEE Access 2021, 9, 89972–89988. [Google Scholar] [CrossRef]
- Alsharoa, A.; Yuksel, M. Energy efficient D2D communications using multiple UAV relays. IEEE Transactions on Communications 2021, 69, 5337–5351. [Google Scholar] [CrossRef]
- Syed, W.H.S.; Li, R.; Rahman, M.M.U.; Mian, A.N.; Aman, W.; Crowcroft, J. Statistical QoS guarantees of a device-to-device link assisted by a full-duplex relay. Trans. Emerg. Telecommun. Technol. 2021, 32, e4339. [Google Scholar]
- Qiang, L.; Ren, P. Collaborative D2D communication in relay networks with energy harvesting. China Commun. 2022, 19, 162–170. [Google Scholar]
- Omnia M, E.-N.; Obayya, M.I.; Kishk, S.E. Stable Matching Relay Selection (SMRS) for TWR D2D Network With RF/RE EH Capabilities. IEEE Access 2022, 10, 22381–22391. [Google Scholar]
- The, A.T.; Luong, N.C.; Niyato, D. A deep reinforcement learning approach for backscatter-assisted relay communications. IEEE Wirel. Commun. Letters 2020, 10, 166–169. [Google Scholar]
- Pavel, M.; Spyropoulos, T.; Becvar, Z. Incentive-based D2D relaying in cellular networks. IEEE Trans. Commun. 2020, 69, 1775–1788. [Google Scholar]
- Han, L.; Zhou, R.; Li, Y.; Zhang, B.; Zhang, X. Power control for two-way AF relay assisted D2D communications underlaying cellular networks. IEEE Access 2020, 8, 151968–151975. [Google Scholar] [CrossRef]
- Ali, Z.; Sidhu, G.A.S.; Gao, F.; Jiang, J.; Wang, X. Deep learning based power optimizing for NOMA based relay aided D2D transmissions. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 917–928. [Google Scholar] [CrossRef]
- Liu, Z.; Li, X.; Yuan, Y.; Yang, Y.; Guan, X. Game based robust power allocation strategy with QoS guarantee in D2D communication network. Comput. Netw. 2021, 193, 108130. [Google Scholar] [CrossRef]
- Sankha, S.S.; Hazra, R. Interference management for D2D communication in mmWave 5G network: An Alternate Offer Bargaining Game theory approach. In Proceedings of the 2020 7th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 27–28 February 2020. [Google Scholar]
- Chen, Y.; Ai, B.; Niu, Y.; Han, Z.; He, R.; Zhong, Z.; Shi, G. Sub-channel allocation for full-duplex access and device-to-device links underlaying heterogeneous cellular networks using coalition formation games. IEEE Trans. Veh. Technol. 2020, 69, 9736–9749. [Google Scholar] [CrossRef]
- Zhang, H.; Chong, S.; Zhang, X.; Lin, N. A deep reinforcement learning based D2D relay selection and power level allocation in mmWave vehicular networks. IEEE Wirel. Commun. Lett. 2019, 9, 416–419. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, Y.; Chu, X.; Zhang, J. Energy-Efficient Transmission Rate Selection andPower Control for Relay-Assisted Device-to-DeviceCommunications Underlaying Cellular Networks. IEEE Wirel. Commun. Lett. 2020, 9, 1133–1136. [Google Scholar] [CrossRef]
- Miaomiao, L.; Zhang, L. Graph colour-based resource allocation for relay-assisted D2D underlay communications. IET Commun. 2020, 14, 2701–2708. [Google Scholar]
- Mingjie, F.; Mao, S.; Jiang, T. Dealing with Link Blockage in mmWave Networks: A Combination of D2D Relaying, Multi-beam Reflection, and Handover. IEEE Trans. Wirel. Commun. 2022, 21. [Google Scholar] [CrossRef]
- Wang, X.; Jin, T.; Hu, L.; Qian, Z. Energy-efficient power allocation and Q-learning-based relay selection for relay-aided D2D communication. IEEE Trans. Veh. Technol. 2020, 69, 6452–6462. [Google Scholar] [CrossRef]
- Tariq, I.; Kwon, C.; Noh, Y. Transmission Power Control and Relay Strategy for Increasing Access Rate in Device to Device Communication. IEEE Access 2022, 10, 49975–49990. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Considered Angles | Optimization Idea | Optimization Direction |
|---|---|---|---|
| [14,17,20] | Relay | Relay sensing | System throughput; energy efficiency |
| [15,18] | Relay | Auction idea | Data rate; energy efficiency |
| [16,19] | Relay | Iteration idea | Outage probability; energy efficiency |
| [21,22] | D2D | Power control | System throughput; data rate |
| [23,24,25] | D2D | Game theory | Data rate; energy efficiency |
| [26,30] | Relay + D2D | Auction idea | Astringency; time delay; QoS |
| [27,29,31] | Relay + D2D | Joint optimization | System throughput; access rate |
| [28] | Relay + D2D | Graph theory | System throughput; data rate |
| Simulation Parameters | Parameter Value (Unit) |
|---|---|
| Frequency | 28 GHz |
| System bandwidth | 1 GHz |
| Cell radius | 500 m |
| Number of cellular users (CUE, RUE) | 30 |
| Coverage of relay nodes | 0.35 × 500 m |
| Road loss model of Cellular link | 3GPP TR36.814 V9 A.2.1.1.2 |
| Road loss model relay link | 3GPP TS 36.814 V9.0.0 |
| Road loss model of D2D link | 3GPP TR36.814 V12 A.2.1.2 |
| Noise power spectral density | −174 dBm/Hz |
| Maximum transmit power of D2D link | 24 dBm |
| D2D communication link interference threshold | −105 dBm |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Chen, G.; Wu, G.; Sun, Z.; Chen, G. D2D Communication Network Interference Coordination Scheme Based on Improved Stackelberg. Sustainability 2023, 15, 961. https://doi.org/10.3390/su15020961
Li X, Chen G, Wu G, Sun Z, Chen G. D2D Communication Network Interference Coordination Scheme Based on Improved Stackelberg. Sustainability. 2023; 15(2):961. https://doi.org/10.3390/su15020961
Chicago/Turabian StyleLi, Xinzhou, Guifen Chen, Guowei Wu, Zhiyao Sun, and Guangjiao Chen. 2023. "D2D Communication Network Interference Coordination Scheme Based on Improved Stackelberg" Sustainability 15, no. 2: 961. https://doi.org/10.3390/su15020961
APA StyleLi, X., Chen, G., Wu, G., Sun, Z., & Chen, G. (2023). D2D Communication Network Interference Coordination Scheme Based on Improved Stackelberg. Sustainability, 15(2), 961. https://doi.org/10.3390/su15020961