
Empirical Study of ESG Score Prediction through Machine Learning—A Case of Non-Financial Companies in Taiwan

Abstract
:1. Introduction
2. Materials and Methods
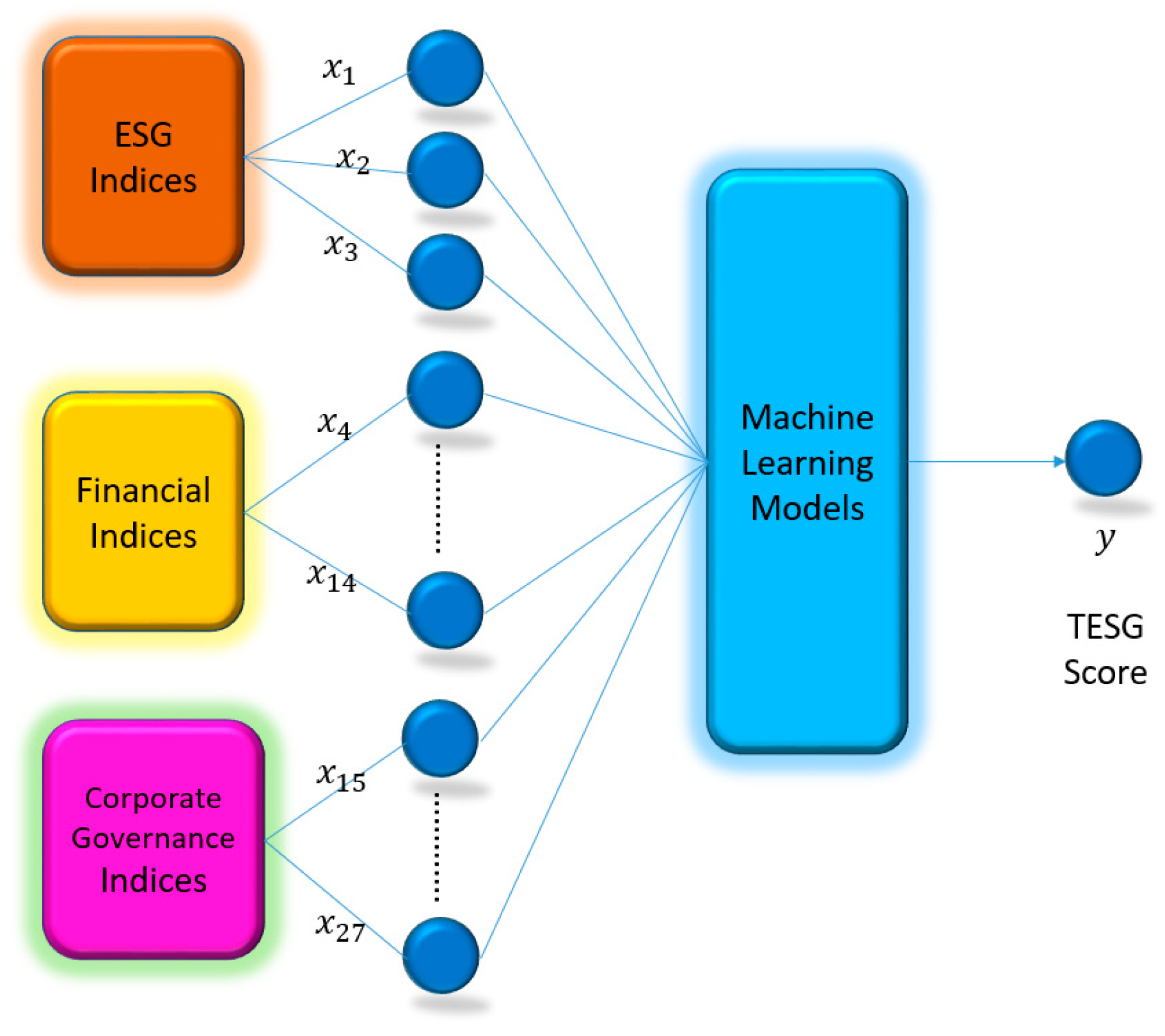
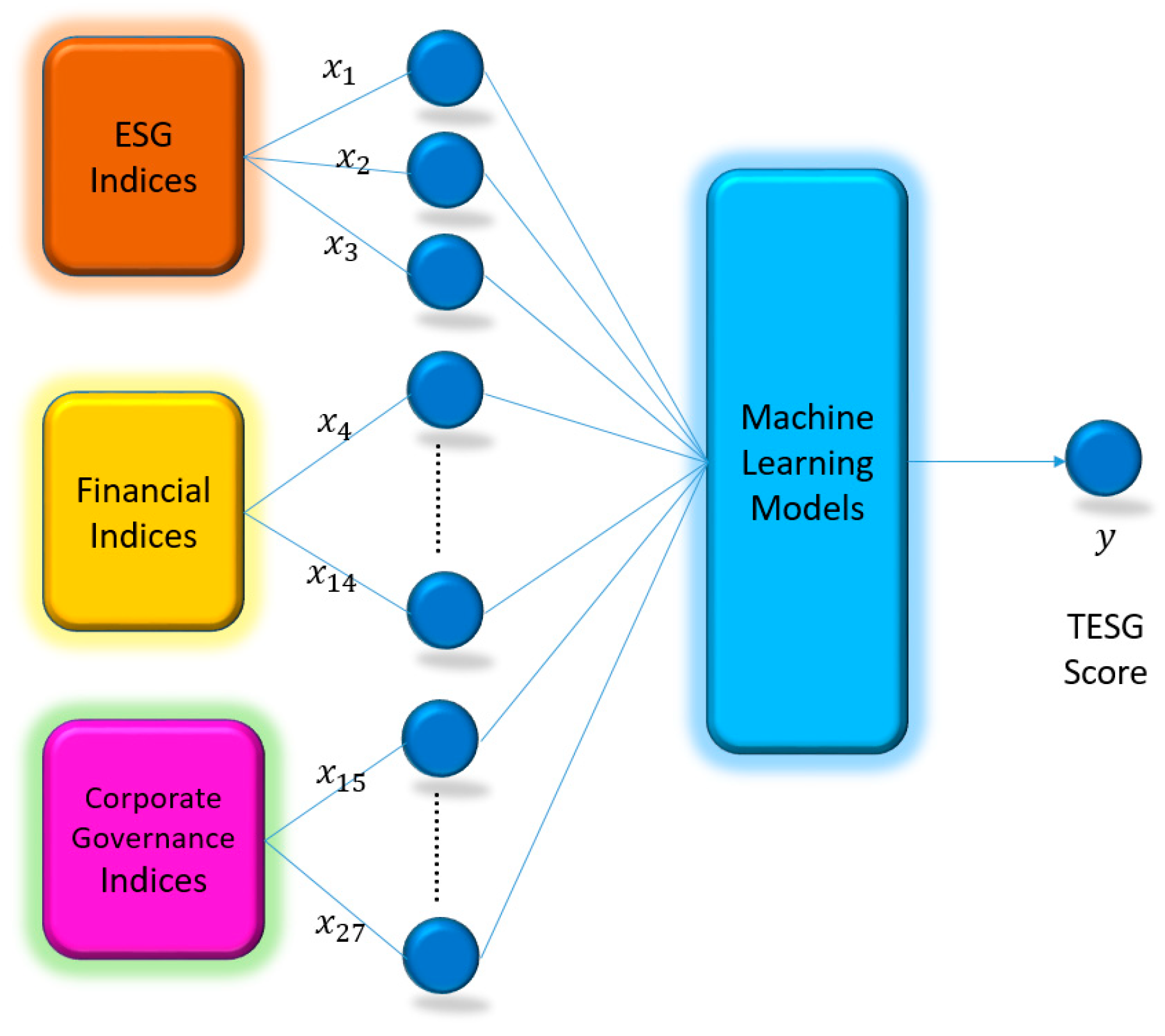
2.1. Variables
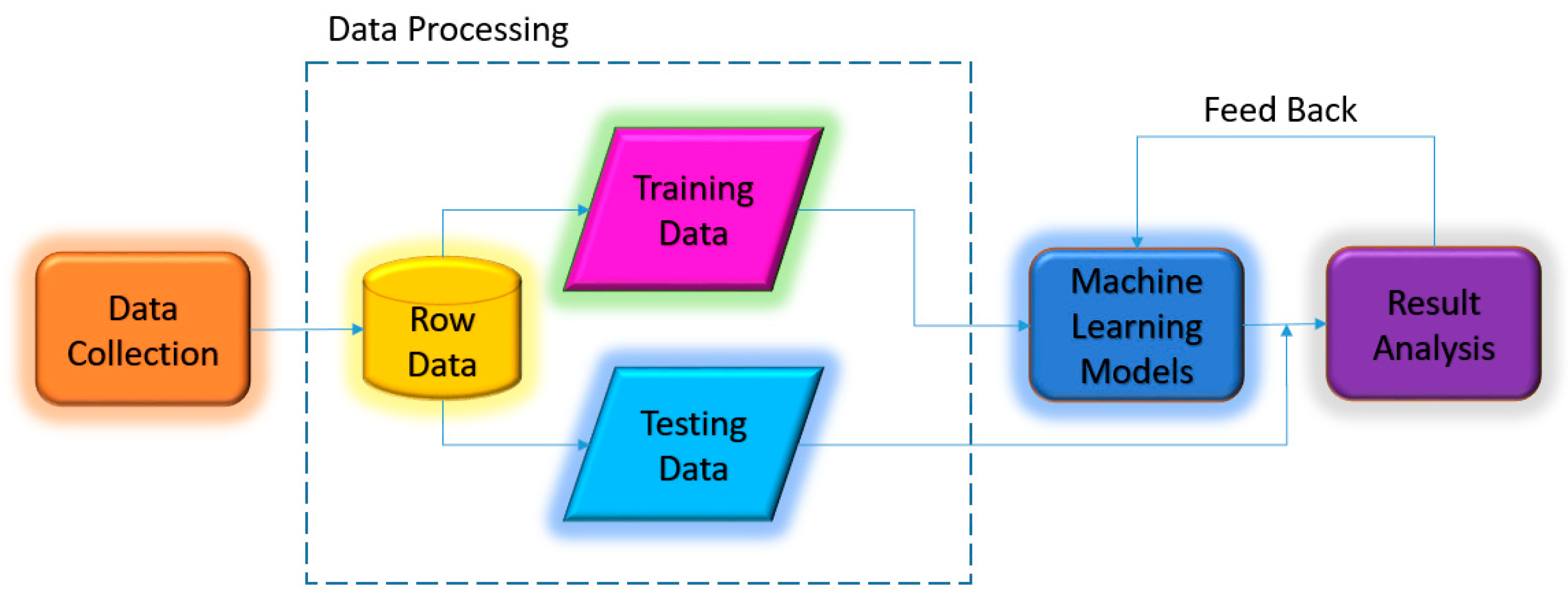
- Data Preprocessing: If there are any missing data or other reasons that make it impossible to obtain trading information in the TEJ database, the entire dataset is excluded. After removing the missing values, a total of 5829 data points were used in this study (see Table 2).
- Model Building: This study utilizes the ESG scores of listed and over-the-counter non-financial companies in Taiwan that comply with ESG standards from 2018 to 2021 to establish four commonly used machine learning models for predicting TESG scores. The models include random forest (RF), Elaboration Likelihood Model (ELM), support vector machine (SVM), and eXtreme Gradient Boosting (XGBoost).
- Setting Training and Testing Parameters: These data are split into a 70–30 ratio, where 70% is used for the training phase and 30% for the testing phase.
- Normalization of Data: The variables are normalized to a range between 0 and 1. The normalization process is performed using the maximum () and minimum () values of these sampled data within a specific range. Depending on whether the variable’s initial value is greater than or equal to 0 or has negative values, two different formulas, (1) and (2), are utilized to obtain the normalized value (). These normalized values are input variable data for the deep learning models in this study.
- 5.
- Train the Model.
- 6.
- Validate the Predictions.
- 7.
- Model Comparison: Compare RMSE, MAE, MAPE, and r2 of the different models from step 6).
2.2. Machine Learning Models
2.2.1. SVM
2.2.2. ELM
2.2.3. RF
2.2.4. XGBoost
2.3. Evaluation Index
3. Results
3.1. Model Parameters
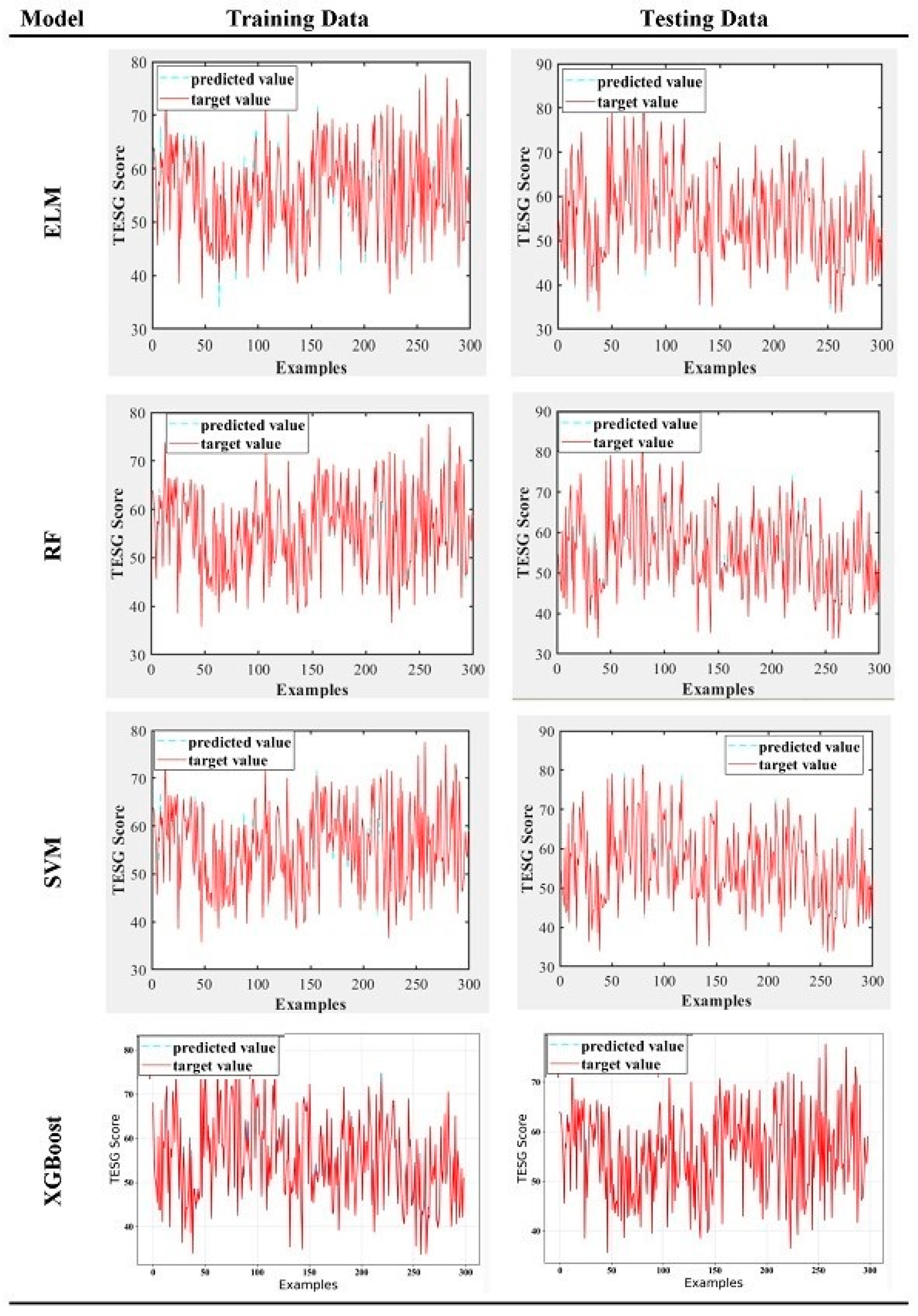
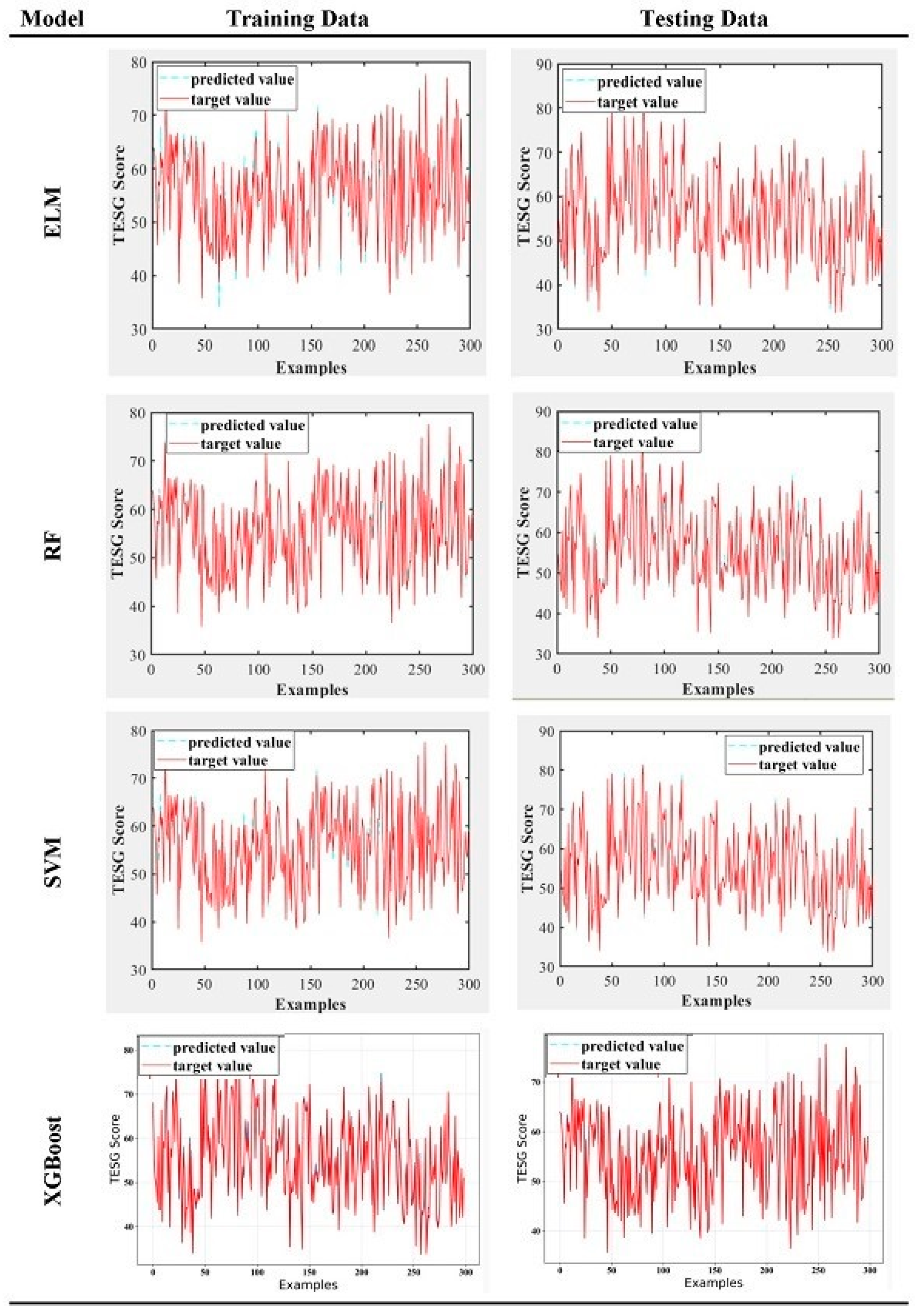
3.2. Empirical Prediction Results
4. Discussion
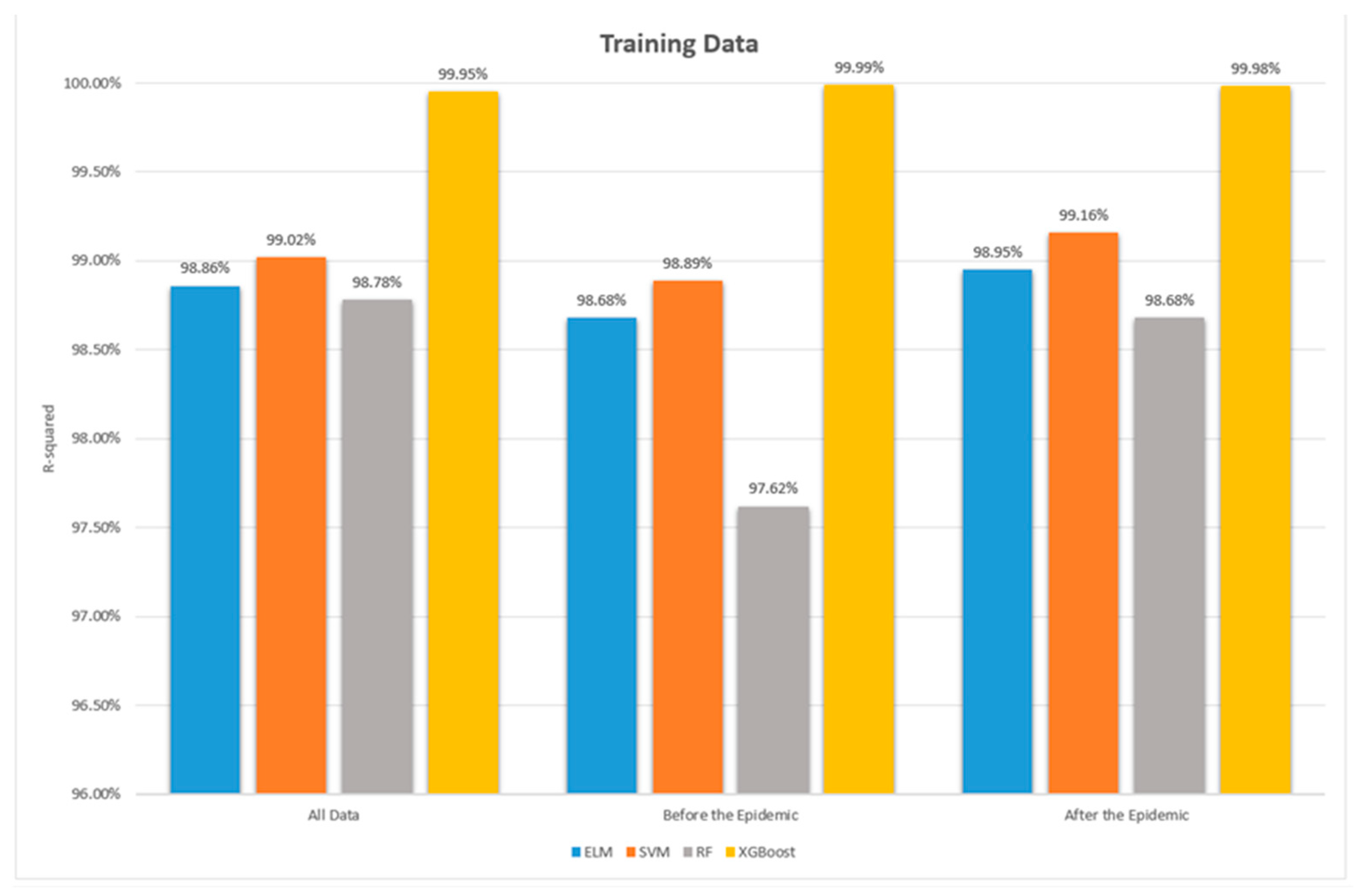
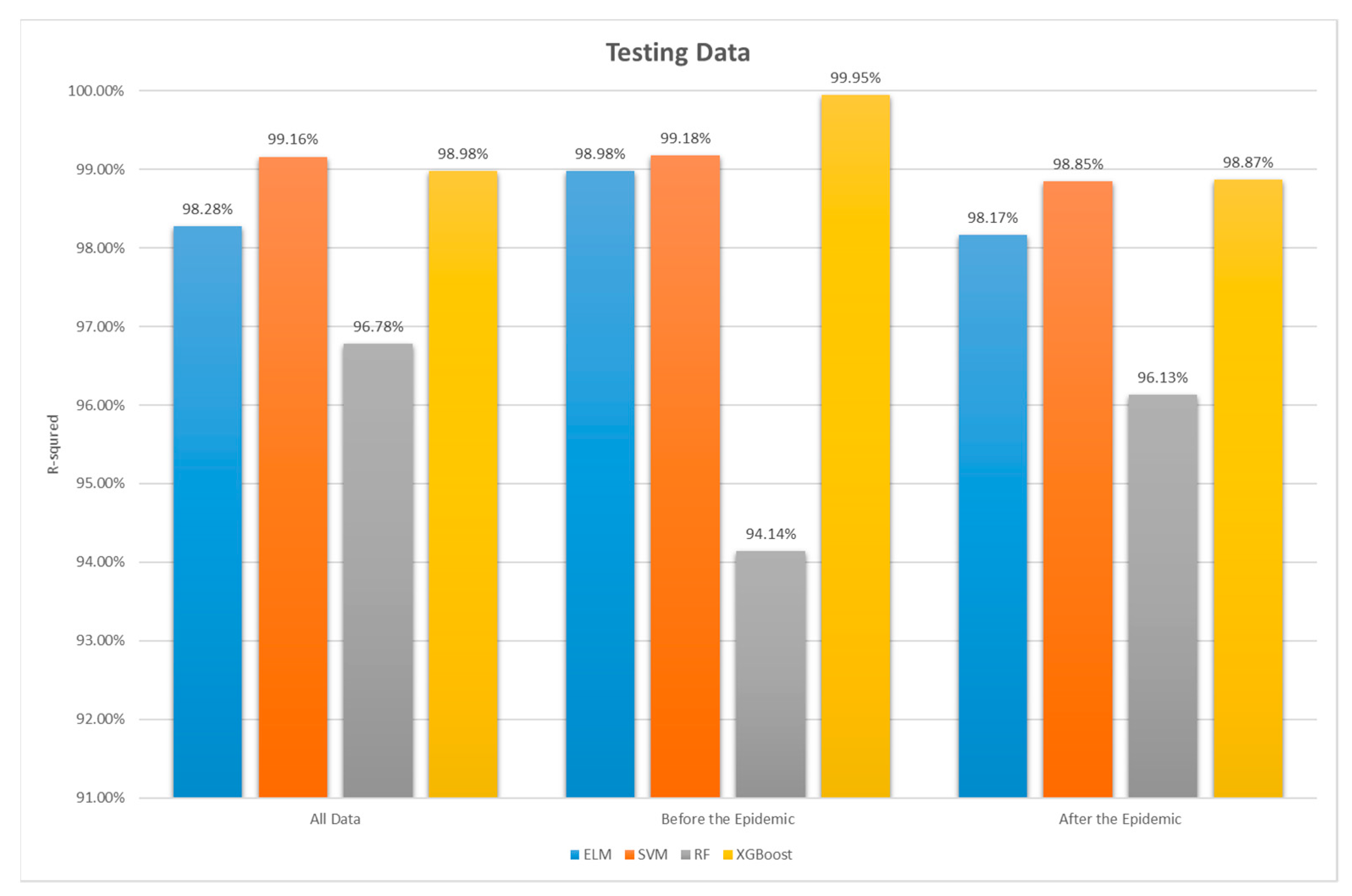
- Overall, all four machine learning models, whether during the pandemic or non-pandemic periods or for the entire period from 2018 to 2021, have an r2 value greater than 0.975 in the training stage and greater than 0.94 in the testing stage. Generally, an r2 value ranges from 0 to 1, where an r2 value greater than 0.75 indicates a well-fitted model with high interpretability, while an r2 value less than 0.5 indicates poor model fitting. The results of this study show that all four models have good predictive capabilities for ESG scores in both the training and testing stages. Especially for ELM, XGBoost, and SVM models, their testing stage r2 values are all above 0.98, indicating excellent performance. Therefore, it can be inferred that, in terms of supervised learning models, machine learning is faster and more suitable for predicting complex problems than traditional mathematical models. For predicting ESG scores, machine learning is highly suitable and effective.
- Regarding ESG prediction, the accuracy is consistently high, regardless of whether during the pandemic or non-pandemic periods, with no significant differences. In the testing stage, ELM and SVM show better predictive performance during non-pandemic periods, while RF performs better during pandemic periods. As for XGBoost, although its r2 value during non-pandemic periods is better, the RMSE, MAPE, and MAE metrics show the opposite result. Although the differences are not significant, the inconsistent performance among different metrics still warrants further research and investigation. Therefore, this study concludes that the predictive performance of RF and XGBoost models is inferior to that of ELM and SVM models.
- While the extensive and widespread use of artificial intelligence and machine learning has become a trend in recent years, challenges such as overfitting and the “black box” nature of learning algorithms still exist. Specifically, the ELM model’s limitation lies in its random initialization of input weights and biases, making it effective only for simple functions and small labeled datasets. The SVM model also encounters similar issues, including a tendency to overfit, limitations in handling large samples, and complex clustering problems. Future research could explore the integration of genetic algorithms in the preliminary training phase to enhance and refine the parameter optimization processes for ELMs and SVMs.
- Since the outbreak of COVID-19 in 2020, global attention to sustainability issues has become more intense than ever. The rise in ESG awareness poses challenges to traditional business models, impacting various aspects such as economic factors (investment trends in financial markets), social considerations (expectations from stakeholders such as investors and the general public for increased focus on sustainability), technological advancements (sustainable innovation in fields such as environmental protection and carbon reduction), environmental considerations (incorporating environmental factors into supply chain planning), as well as legal and political aspects. While this study mainly examines the correlation between ESG scores and financial performance and corporate governance, future research could consider incorporating technical, social, and policy-related dimensions to strengthen the overall ESG rating criteria, thereby improving the comprehensiveness of ESG evaluation mechanisms.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alipour, P.; Bastani, A.F. Value-at-Risk-Based Portfolio Insurance: Performance Evaluation and Benchmarking Against CPPI in a Markov-Modulated Regime-Switching Market. arXiv 2023, arXiv:2305.12539. [Google Scholar]
- Zheng, W.; Yin, L.; Chen, X.; Ma, Z.; Liu, S.; Yang, B. Knowledge base graph embedding module design for Visual question answering model. Pattern Recognit. 2021, 120, 108153. [Google Scholar] [CrossRef]
- PwC. Global Investor Survey: The Economic Realities of ESG. December 2021. Available online: https://www.pwc.com/gx/en/services/audit-assurance/corporate-reporting/2021-esg-investor-survey.html (accessed on 1 June 2023).
- Kao, L.L. ESG-Based Performance Assessment of the Operation and Management of Industrial Parks in Taiwan. Sustainability 2023, 15, 1424. [Google Scholar] [CrossRef]
- Choi, Y.; Wang, J.; Zhu, Y.; Lai, W. Students’ perception and expectation towards pharmacy education: A qualitative study of pharmacy students in a developing country. Indian J. Pharm. Educ. Res. 2021, 55, 63–69. [Google Scholar] [CrossRef]
- Shen, L.; Wu, Y.; Zhang, X. Key Assessment Indicators for the Sustainability of Infrastructure Projects. J. Constr. Eng. Manag. 2011, 137, 441–451. [Google Scholar] [CrossRef]
- Dong, X.; Du, X.; Li, K.; Zeng, S.; Bledsoe, B.P. Benchmarking Sustainability of Urban Water Infrastructure Systems in China. J. Clean. Prod. 2018, 170, 330–338. [Google Scholar] [CrossRef]
- Koop, S.H.A.; van Leeuwen, C.J. Assessment of the Sustainability of Water Resources Management: A Critical Review of the City Blueprint Approach. Water Resour. Manag. 2015, 29, 5649–5670. [Google Scholar] [CrossRef]
- Gore, R.; Lynch, C.J.; Jordan, C.A.; Collins, A.; Robinson, R.M.; Fuller, G.; Ames, P.; Keerthi, P.; Kandukuri, Y. Estimating the Health Effects of Adding Bicycle and Pedestrian Paths at the Census Tract Level: Multiple Model Comparison. JMIR Public Health Surveill. 2022, 8, e37379. [Google Scholar] [CrossRef]
- Zamponi, V.; O’Brien, K.; Jensen, E.; Feldhaus, B.; Moore, R.; Lynch, C.J.; Gore, R. Understanding and Assessing Demographic (In)Equity Resulting from Extreme Heat and Direct Sunlight Exposure Due to Lack of Tree Canopies in Norfolk, VA Using Agent-Based Modeling. Ecol. Model. 2023, 483, 110445. [Google Scholar] [CrossRef]
- Christensen, D.M.; Serafeim, G.; Sikochi, A. Why is corporate virtue in the eye of the beholder? The case of ESG ratings. Account. Rev. 2022, 97, 147–175. [Google Scholar] [CrossRef]
- D’Amato, V.; D’Ecclesia, R.; Levantesi, S. ESG score prediction through Random Forest algorithm. Comput. Manag. Sci. 2021, 19, 347–373. [Google Scholar] [CrossRef]
- Abhayawansa, S.; Tyagi, S. Sustainable investing: The black box of environmental, social, and governance (ESG) ratings. J. Wealth Manag. 2021, 24, 49–54. [Google Scholar] [CrossRef]
- Liu, M. Quantitative ESG disclosure and divergence of ESG ratings. Front. Psychol. 2022, 13, 936798. [Google Scholar] [CrossRef]
- Chatterji, A.K.; Durand, R.; Levine, D.I.; Touboul, S. Do ratings of firms converge? Implications for managers, investors, and strategy researchers. Strateg. Manag. J. 2016, 37, 1597–1614. [Google Scholar] [CrossRef]
- Gibson, B.R.; Krueger, P.; Schmidt, P.S. ESG rating disagreement and stock returns. Financ. Anal. J. 2021, 77, 104–127. [Google Scholar] [CrossRef]
- Berg, F.; Koelbel, J.F.; Rigobon, R. Aggregate confusion: The divergence of ESG rating. Rev. Financ. 2022, 26, 1–30. [Google Scholar] [CrossRef]
- Avramov, D.; Cheng, S.; Lioui, A.; Tarelli, A. Sustainable investing with ESG rating uncertainty. J. Finan. Econ. 2022, 145, 642–664. [Google Scholar] [CrossRef]
- Kotsantonis, S.; Serafeim, G. Four Things No One Will Tell You About ESG Data. J. Appl. Corp. Financ. 2019, 31, 50–58. [Google Scholar] [CrossRef]
- Li, C.; Zhang, L.; Huang, J.; Xiao, H.; Zhou, Z. Social responsibility portfolio optimization incorporating ESG criteria. J. Manag. Sci. Eng. 2021, 6, 75–85. [Google Scholar]
- Galagedera, D.U.A. Modelling social responsibility in mutual fund performance appraisal: A two-stage data envelopment analysis model with non-discretionary first stage output. Qual. Quant. 2019, 273, 376–389. [Google Scholar] [CrossRef]
- Licari, J.; Loiseau-Aslanidi, O.; Piscaglia, S.; Solis Gonzalez, B. ESG Score Predictor: Applying a Quantitative Approach for Expanding Company Coverage. Moody’s Anal. Available online: https://www.moodysanalytics.com/-/media/article/2021/esg-score-predictor.pdf (accessed on 23 July 2023).
- Del Vitto, A.; Marazzina, D.; Stocco, D. ESG Ratings Explainability through Machine Learning Techniques. Ann. Oper. Res. 2023, 1–30. [Google Scholar] [CrossRef]
- Wang, H.; Lengerich, B.J.; Aragam, B.; Xing, E.P. Precision Lasso: Accounting for Correlations and Linear Dependencies in High-Dimensional Genomic Data. Bioinformatics 2019, 35, 1181–1187. [Google Scholar] [CrossRef] [PubMed]
- Tehranian, K. Can Machine Learning Catch Economic Recessions Using Economic and Market Sentiments? arXiv 2023, arXiv:2308.16200. [Google Scholar] [CrossRef]
- Maydanchi, M.; Ziaei, A.; Basiri, M.; Azad, A.N.; Pouya, S.; Ziaei, M.; Haji, F.; Sargolzaei, S. Comparative Study of Decision Tree, AdaBoost, Random Forest, Naïve Bayes, KNN, and Perceptron for Heart Disease Prediction. In Proceedings of the SoutheastCon 2023, Orlando, FL, USA, 1–16 April 2023; pp. 204–208. [Google Scholar] [CrossRef]
- Ghasemi, A.; Naser, M.Z. Tailoring 3D Printed Concrete through Explainable Artificial Intelligence. Structures 2023, 56, 104850. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, X.; Ariffin, M.M.; Abolfathi, M.; Alqhatani, A.; Almutairi, L. Attack Detection Analysis in Software-Defined Networks Using Various Machine Learning Methods. Comput. Electr. Eng. 2023, 108, 108655. [Google Scholar] [CrossRef]
- Ang, G.; Guo, Z.; Lim, E.P. On Predicting ESG Ratings Using Dynamic Company Networks. ACM Trans. Manag. Inf. Syst. 2023, 14, 1–34. [Google Scholar] [CrossRef]
- Biju, A.K.V.N.; Thomas, A.S.; Thasneem, J. Examining the Research Taxonomy of Artificial Intelligence, Deep Learning & Machine Learning in the Financial Sphere—A Bibliometric Analysis. Qual. Quant. 2023, 2, 1–30. [Google Scholar]
- Sokolov, A.; Mostovoy, J.; Ding, J.; Seco, L. Building Machine Learning Systems for Automated ESG Scoring. J. Impact ESG Investig. 2021, 1, 39–50. [Google Scholar] [CrossRef]
- Svanberg, J.; Ardeshiri, T.; Samsten, I.; Öhman, P.; Neidermeyer, P. Prediction of Controversies and Estimation of ESG Performance: An Experimental Investigation Using Machine Learning. In Handbook of Big Data and Analytics in Accounting and Auditing; Rana, T., Svanberg, J., Öhman, P., Lowe, A., Eds.; Springer: Singapore, 2023; pp. 65–87. [Google Scholar]
- Dwivedi, D.; Batra, S.; Pathak, Y.K. A Machine Learning Based Approach to Identify Key Drivers for Improving Corporate’s ESG Ratings. J. Law Sustain. Dev. 2023, 11, 1–15. [Google Scholar] [CrossRef]
- D’Amato, V.; D’Ecclesia, R.; Levantesi, S. Fundamental Ratios as Predictors of ESG Scores: A Machine Learning Approach. Decis. Econ. Financ. 2021, 44, 1087–1110. [Google Scholar] [CrossRef]
- García, F.; González-Bueno, J.; Guijarro, F.; Oliver, J. Forecasting the Environmental, Social, and Governance Rating of Firms by Using Corporate Financial Performance Variables: A Rough Set Approach. Sustainability 2020, 12, 3324. [Google Scholar] [CrossRef]
- Krappel, T.; Bogun, A.; Borth, D. Heterogeneous Ensemble for ESG Ratings Prediction. arXiv 2021, arXiv:2109.10085. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with Categorical Features Support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Jabeur, S.B.; Sadaaoui, A.; Sghaier, A.; Aloui, R. Machine Learning Models and Cost-Sensitive Decision Trees for Bond Rating Prediction. J. Oper. Res. Soc. 2020, 71, 1161–1179. [Google Scholar] [CrossRef]
- Jones, S.; Johnstone, D.; Wilson, R. An Empirical Evaluation of the Performance of Binary Classifiers in the Prediction of Credit Ratings Changes. J. Bank. Financ. 2015, 56, 72–85. [Google Scholar] [CrossRef]
- Ozturk, H.; Namli, E.; Erdal, H.I. Modelling Sovereign Credit Ratings: The Accuracy of Models in a Heterogeneous Sample. Econ. Model. 2016, 54, 469–478. [Google Scholar] [CrossRef]
- Teoh, T.T.; Heng, Q.K.; Chia, J.J.; Shie, J.M.; Liaw, S.W.; Yang, M.; Nguwi, Y.Y. Machine Learning-Based Corporate Social Responsibility Prediction. In Proceedings of the 2019 IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Bangkok, Thailand, 18–20 November 2019; pp. 501–505. [Google Scholar]
- Michalski, L.; Lachlan; Low, R.K.Y. Corporate Credit Rating Feature Importance: Does ESG Matter? SSRN Paper 2021, 53–54. [Google Scholar] [CrossRef]
- Raza, H.; Khan, M.A.; Mazliham, M.S.; Alam, M.M.; Aman, N.; Abbas, K. Applying Artificial Intelligence Techniques for Predicting the Environment, Social, and Governance (ESG) Pillar Score Based on Balance Sheet and Income Statement Data: A Case of Non-Financial Companies of USA, UK, and Germany. Front. Environ. Sci. 2022, 10, 975487. [Google Scholar] [CrossRef]
- Agosto, A.; Cerchiello, P.; Giudici, P. Bayesian Learning Models to Measure the Relative Impact of ESG Factors on Credit Ratings. Int. J. Data Sci. Anal. 2023. [Google Scholar] [CrossRef]
- Shaik, A.B.; Srinivasan, S. A Brief Survey on Random Forest Ensembles in Classification Model. In International Conference on Innovative Computing and Communications; Bhattacharyya, S., Hassanien, A., Gupta, D., Khanna, A., Pan, I., Eds.; Springer: Singapore, 2019; pp. 1–5. [Google Scholar]
- Anguita, D.; Ghio, A.; Greco, N.; Oneto, L.; Ridella, S. Model Selection for Support Vector Machines: Advantages and Disadvantages of the Machine Learning Theory. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Ding, X.; Jiang, T.; Xue, W.; Li, Z.; Zhong, Y. A New Method of Human Gesture Recognition Using Wi-Fi Signals Based on XGBoost. In Proceedings of the 2020 IEEE/CIC International Conference on Communications in China (ICCC Workshops), Chongqing, China, 9–11 August 2020; pp. 237–241. [Google Scholar]
- Cao, J.W.; Zhang, K.; Luo, M.X.; Yin, C.; Lai, X.P. Extreme Learning Machine and Adaptive Sparse Representation for Image Classification. Neural Netw. 2016, 81, 91–102. [Google Scholar] [CrossRef]
- Burdekin, R.C.; Harrison, S. Relative Stock Market Performance during the Coronavirus Pandemic: Virus vs. Policy Effects in 80 Countries. J. Risk Financ. Manag. 2021, 14, 177. [Google Scholar] [CrossRef]
- Rubbaniy, G.; Khalid, A.A.; Rizwan, F.; Ali, S. Are ESG Stocks Safe-Haven during COVID-19? Studies in Economics and Finance 2021. Available online: https://ssrn.com/abstract=3779430 (accessed on 15 August 2023).
- Lee, M.T.; Suh, I. Understanding the Effects of Environment, Social, and Governance Conduct on Financial Performance: Arguments for a Process and Integrated Modelling Approach. Sustain. Technol. Entrep. 2022, 1, 100004. [Google Scholar] [CrossRef]
- Citterio, A.; King, T. The Role of Environmental, Social, and Governance (ESG) in Predicting Bank Financial Distress. Financ. Res. Lett. 2023, 51, 103411. [Google Scholar] [CrossRef]
- Aydoğmuş, M.; Gülay, G.; Ergun, K. Impact of ESG Performance on Firm Value and Profitability. Borsa Istanb. Rev. 2022, 22, S119–S127. [Google Scholar] [CrossRef]
- Gupta, A.; Sharma, U.; Gupta, S.K. The Role of ESG in Sustainable Development: An Analysis Through the Lens of Machine Learning. In Proceedings of the 2021 IEEE International Humanitarian Technology Conference (IHTC), Virtual, 2–4 December 2021; pp. 1–5. [Google Scholar]
- Kaiser, H.F. The Application of Electronic Computers to Factor Analysis. Educ. Psychol. Meas. 1960, 20, 141–151. [Google Scholar] [CrossRef]
- Kaiser, H.F. An Index of Factorial Simplicity. Psychometrika 1974, 39, 31–36. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lewis, E.B. Control of Body Segment Differentiation in Drosophila by the Bithorax Gene Complex. Embryonic Dev. 1982, 1, 383–417. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Variables |
|---|---|
| ESG Indicators | Environmental Aspect Score |
| Social Aspect Score | |
| Corporate Governance Aspect Score | |
| Financial Indicators | Long-term capital adequacy ratio (%) |
| Current ratio (%) | |
| Quick ratio (%) | |
| Fixed assets turnover ratio | |
| Return on Operating Assets (%) | |
| ROA(A) before tax and interest | |
| ROE(A) after tax | |
| Operating profit to paid-up capital ratio (%) | |
| Pre-tax net income to paid-up capital ratio (%) | |
| Net profit margin after tax (%) | |
| Sustainable EPS | |
| Corporate Governance Indicators | Stock Earnings Deviation (%) |
| Stock Seats Deviation Ratio (%) | |
| Earnings Seats Deviation Ratio (%) | |
| Seats Earnings Deviation Multiplier | |
| Total Shares Held by Directors | |
| Shares Held by Directors’ Relatives | |
| Shares Held by Supervisors | |
| Supervisor Ownership Ratio (%) | |
| Shares Held by Managers | |
| Shares Held by Managers’ Relatives | |
| Manager Pledged Shares | |
| Number of Regular Directors | |
| Number of Independent Supervisors |
| TESG Category | Pre-Pandemic | Pandemic | Entire Period |
|---|---|---|---|
| Chemical Industry | 64 | 95 | 159 |
| Cultural and Creative Industry | 17 | 86 | 103 |
| Cement Industry | 14 | 14 | 28 |
| Semiconductor | 148 | 381 | 529 |
| Biotechnology and Medical Care | 100 | 390 | 490 |
| Optoelectronics Industry | 103 | 301 | 404 |
| Automobile Industry | 32 | 69 | 101 |
| Other Electronic Industry | 89 | 194 | 283 |
| Oil, Electricity, and Gas Industry | 8 | 28 | 36 |
| Building Materials and Construction | 108 | 164 | 272 |
| Glass and Ceramics | 8 | 10 | 18 |
| Food Industry | 49 | 61 | 110 |
| Textile and Fiber Industry | 94 | 110 | 204 |
| Shipping Industry | 37 | 62 | 99 |
| Communication and Networking Industry | 87 | 198 | 285 |
| Paper Industry | 12 | 13 | 25 |
| Trade and Department Stores | 35 | 83 | 118 |
| Plastic Industry | 42 | 52 | 94 |
| Information Services Industry | 38 | 103 | 141 |
| Agricultural Technology | 3 | 16 | 19 |
| E-commerce | 3 | 22 | 25 |
| Electronic Retailing | 43 | 74 | 117 |
| Electronic Components | 230 | 449 | 679 |
| Computers and Peripherals | 122 | 235 | 357 |
| Electrical Equipment and Cables | 30 | 38 | 68 |
| Electrical Machinery | 110 | 227 | 337 |
| Rubber Industry | 21 | 25 | 46 |
| Steel Industry | 68 | 101 | 169 |
| Tourism Industry | 26 | 109 | 135 |
| Electronic Industry | 0 | 4 | 4 |
| Others | 62 | 312 | 374 |
| ELM | |
|---|---|
| Hidden Layer | 1 layer |
| Hidden Layer Nodes | 30 |
| Feature Mapping Function | Sigmoid Function |
| Other Parameters | Default settings for the program |
| RF | |
| Number of decision trees | 20 |
| Decision Tree Function | TreeBagger Function |
| Feature Splitting Method | Curvature |
| Other Parameters | Default settings for the program |
| SVM | |
| Feature Function | Linear Kernel Function |
| Other parameters | Default settings for the program |
| XGBoost | |
| Booster Type | gbtree |
| Learning Rate | 0.1 |
| Max_delta_step | 5 |
| Number of Iterations | 500 |
| Parallel Tree Construction | 1 |
| Period | Training Sample | Testing Sample |
|---|---|---|
| Entire Period (2018–2021) | 4080 | 1749 |
| Pre-Pandemic (2018–2019) | 1262 | 541 |
| Pandemic (2020–2021) | 2818 | 1208 |
| Predicted Values | Mean | SD | t | p-Value /Significance (Two-Tailed) | |
|---|---|---|---|---|---|
| ELM | Training | 54.2511 | 8.4078 | 0.007 | 0.995 |
| Testing | 52.8998 | 8.7541 | −0.468 | 0.640 | |
| SVM | Training | 54.2305 | 8.4123 | −0.149 | 0.881 |
| Testing | 52.9746 | 8.6652 | −0.102 | 0.919 | |
| RF | Training | 54.2468 | 8.0846 | −0.027 | 0.978 |
| Testing | 53.2124 | 7.9197 | 1.145 | 0.252 | |
| XGBoost | Training | 54.2502 | 8.4551 | 0.000 | 1.000 |
| Testing | 53.0388 | 8.5801 | 0.210 | 0.833 | |
| Period | Index | Stage | ELM | SVM | RF | XGBoost |
|---|---|---|---|---|---|---|
| Entire Period (2018–2021) | RMSE | Training | 0.9022 | 0.8364 | 0.9344 | 0.1854 |
| Testing | 1.1411 | 0.7985 | 1.5602 | 0.8802 | ||
| MAE | Training | 0.6085 | 0.5505 | 0.6269 | 0.1365 | |
| Testing | 0.6100 | 0.5309 | 1.1178 | 0.6359 | ||
| MAPE | Training | 1.1183 | 1.0110 | 1.1783 | 0.2542 | |
| Testing | 1.1591 | 1.0053 | 2.1923 | 1.2156 | ||
| r2 | Training | 0.9886 | 0.9902 | 0.9878 | 0.9995 | |
| Testing | 0.9828 | 0.9916 | 0.9678 | 0.9898 | ||
| Pre-Pandemic (2018–2019) | RMSE | Training | 0.8995 | 0.8250 | 1.2095 | 0.0517 |
| Testing | 0.9003 | 0.8104 | 2.1609 | 0.9995 | ||
| MAE | Training | 0.5914 | 0.5354 | 0.8391 | 0.0364 | |
| Testing | 0.5967 | 0.5193 | 1.5345 | 0.7035 | ||
| MAPE | Training | 1.0821 | 0.9802 | 1.5655 | 0.0679 | |
| Testing | 1.0622 | 0.9333 | 2.7273 | 1.2584 | ||
| r2 | Training | 0.9868 | 0.9889 | 0.9762 | 0.9999 | |
| Testing | 0.9898 | 0.9918 | 0.9414 | 0.9995 | ||
| Pandemic (2020–2021) | RMSE | Training | 0.9036 | 0.8089 | 1.0106 | 0.1258 |
| Testing | 1.1151 | 0.8827 | 1.6205 | 0.8745 | ||
| MAE | Training | 0.6120 | 0.5400 | 0.6868 | 0.0914 | |
| Testing | 0.6722 | 0.5702 | 1.1655 | 0.6331 | ||
| MAPE | Training | 1.1380 | 1.0033 | 1.2979 | 0.1716 | |
| Testing | 1.2721 | 1.0794 | 2.2705 | 1.2166 | ||
| r2 | Training | 0.9895 | 0.9916 | 0.9868 | 0.9998 | |
| Testing | 0.9817 | 0.9885 | 0.9613 | 0.9887 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, H.-Y.; Hsu, B.-W. Empirical Study of ESG Score Prediction through Machine Learning—A Case of Non-Financial Companies in Taiwan. Sustainability 2023, 15, 14106. https://doi.org/10.3390/su151914106
Lin H-Y, Hsu B-W. Empirical Study of ESG Score Prediction through Machine Learning—A Case of Non-Financial Companies in Taiwan. Sustainability. 2023; 15(19):14106. https://doi.org/10.3390/su151914106
Chicago/Turabian StyleLin, Hsio-Yi, and Bin-Wei Hsu. 2023. "Empirical Study of ESG Score Prediction through Machine Learning—A Case of Non-Financial Companies in Taiwan" Sustainability 15, no. 19: 14106. https://doi.org/10.3390/su151914106
APA StyleLin, H.-Y., & Hsu, B.-W. (2023). Empirical Study of ESG Score Prediction through Machine Learning—A Case of Non-Financial Companies in Taiwan. Sustainability, 15(19), 14106. https://doi.org/10.3390/su151914106