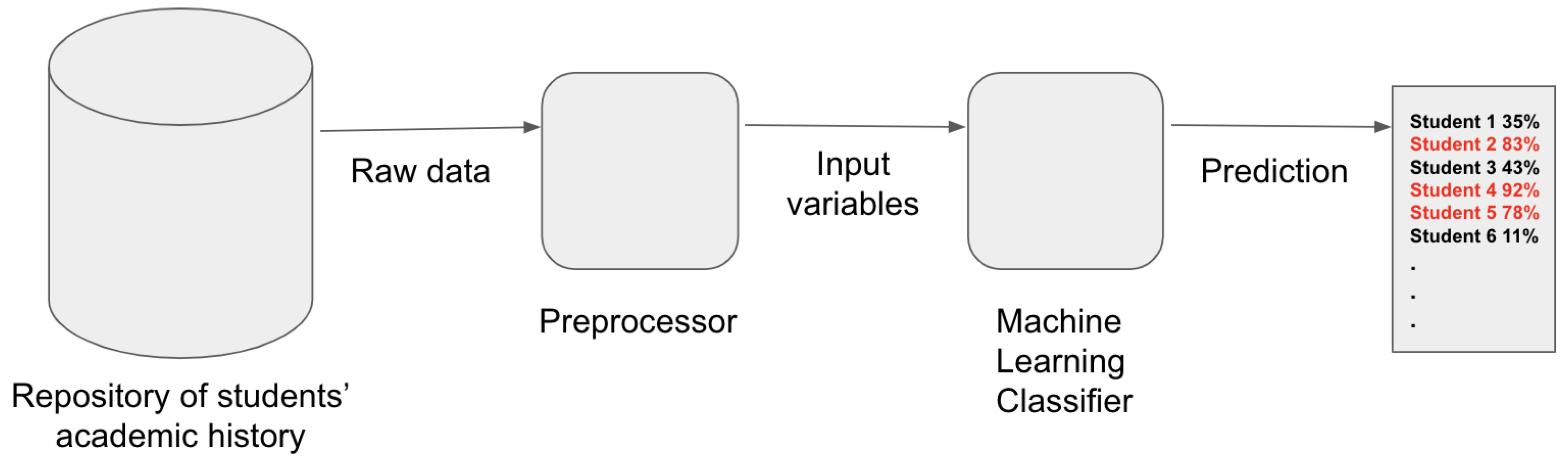
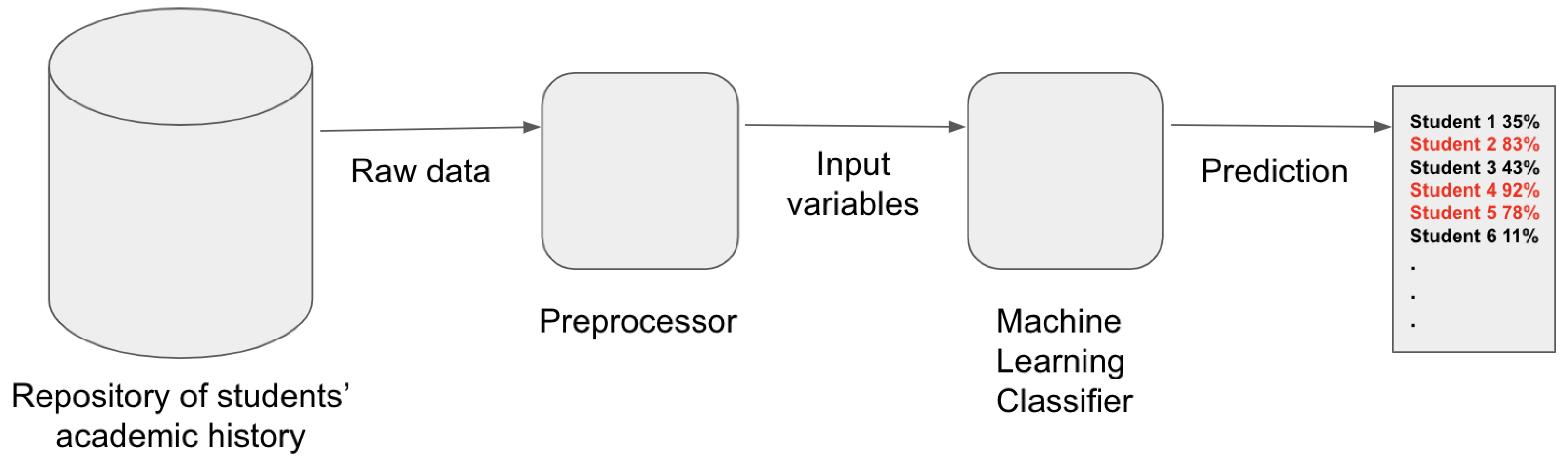
To achieve the goal of this study, which involved conceptualizing an intelligent system for predicting the risk of students failing the numerical methods course, we employed machine learning techniques. In this pursuit, we extended the dataset used in [
6] by conducting a survey among students pursuing a bachelor’s degree in systems engineering at the University of Córdoba in Colombia, a public university. The students’ provided data were anonymized to ensure their privacy, and only their grades were considered, omitting any personal identifiers, such as identification numbers, names, gender, and economic stratum.
The purpose of the evaluation was twofold: to select the most effective machine learning method, and to determine the optimal hyper-parameter settings (e.g., regularization parameter for multilayer perceptrons and logistic regression).
2.1. Representation of the Input Variables
To address our research inquiry, we extended our research beyond [
6] and sustained our investigation into the pivotal numerical methods course, which is an integral element of the curriculum. This course’s theoretical and practical dimensions are intricately intertwined with foundational subjects such as calculus, physics, and computer programming. Our specific focus on this course aimed to unveil the intricate relationships between students’ performance in prerequisite courses and their vulnerability to failure in a subsequent course. The predictive capacity of our intelligent system endeavors to provide indispensable insights, guiding academic interventions and fostering student success.
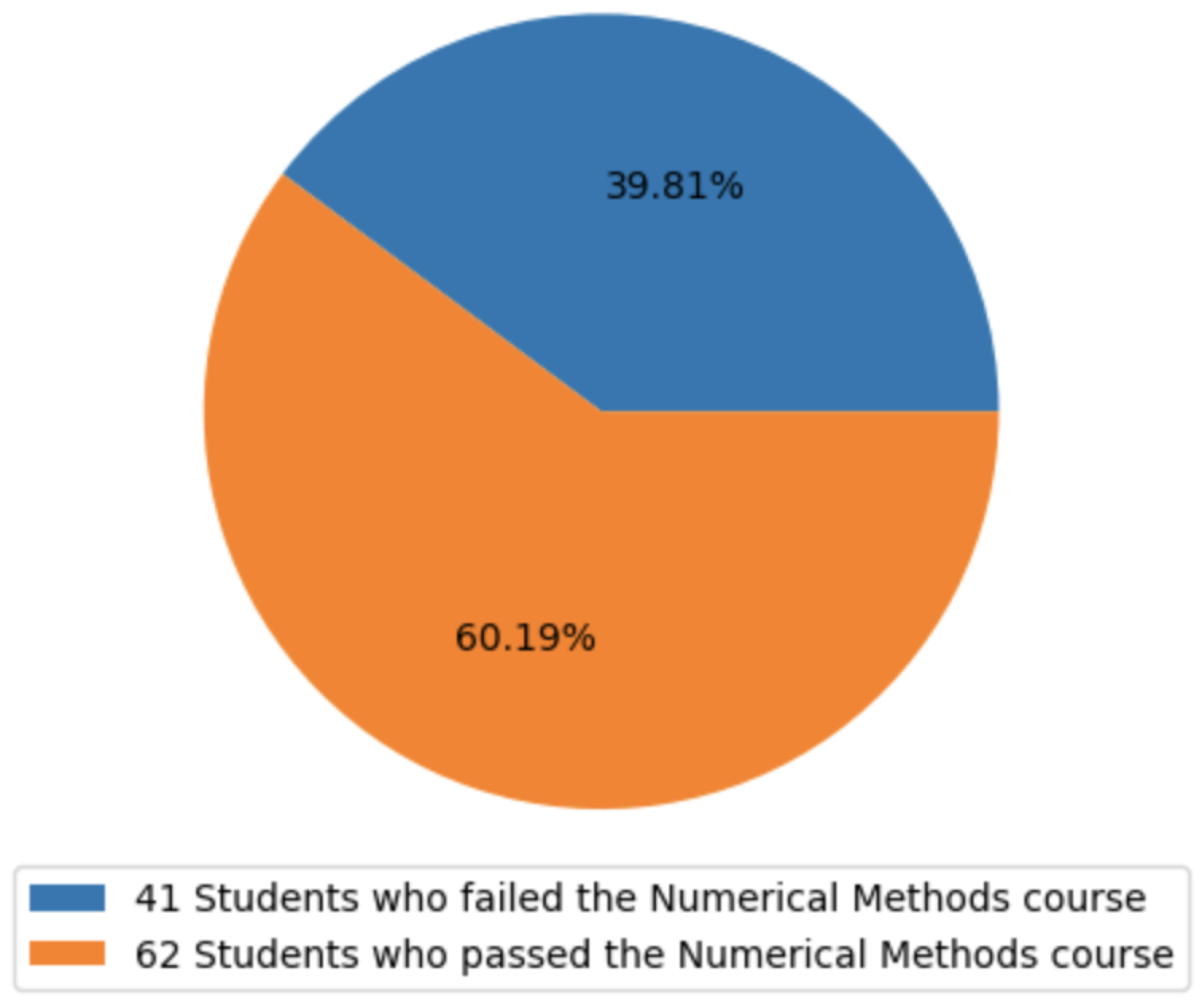
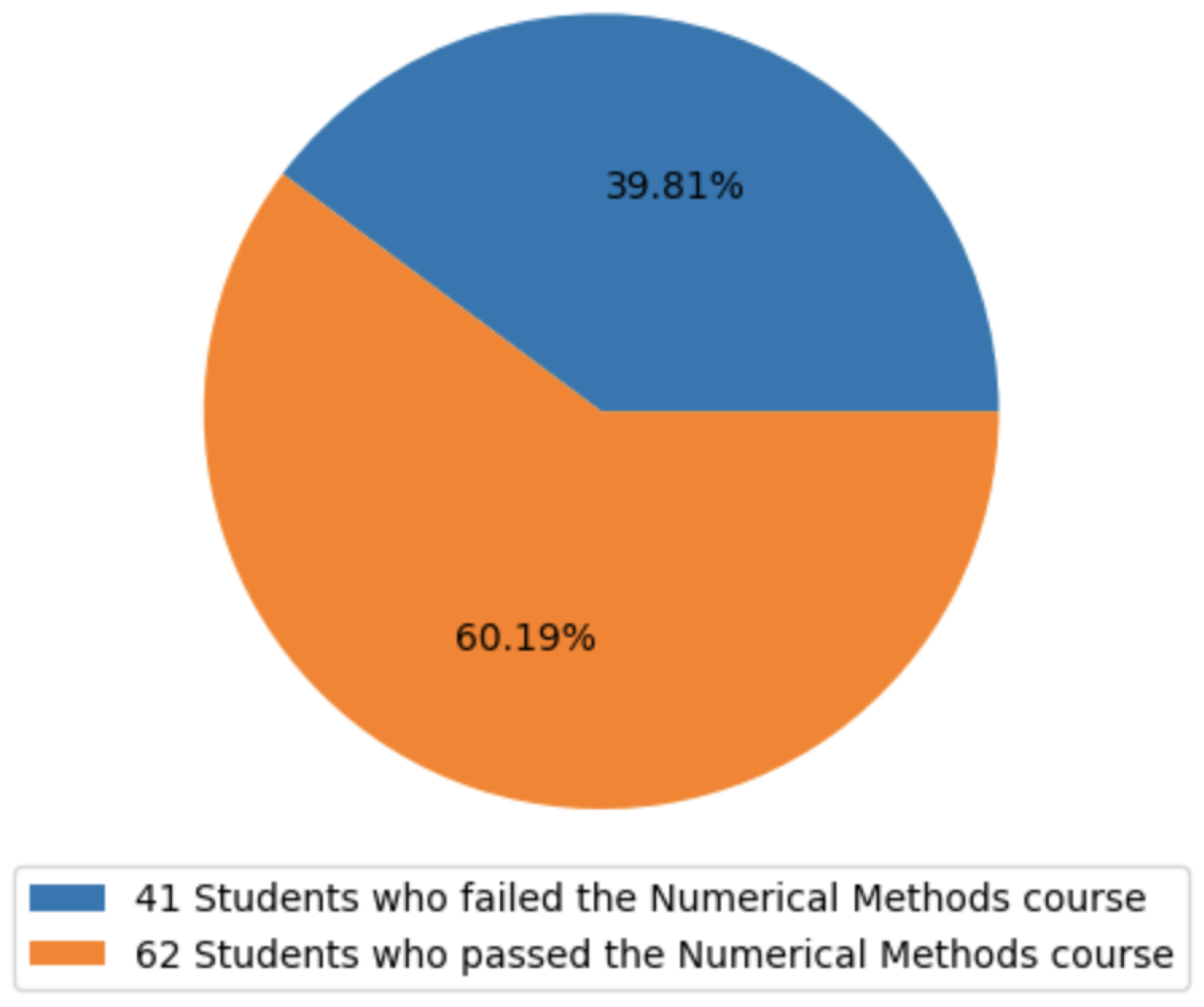
Grades are a pivotal indicator of students’ academic performance, and Colombian universities adhere to a grading system that spans from 0 to 5 for students enrolled in bachelor’s degree programs. Typically, a course is considered passed if a student attains a final grade higher than 3. In our specific research context, the University of Córdoba enforces a minimum global average grade of 3.3, as outlined in Article 16 of the university’s official student code [
11]. Furthermore, the university’s regulations, particularly Article 28, establish additional policies concerning student retention for those whose global average grade falls below the aforementioned 3.3 threshold. These policies serve as essential guidelines for maintaining academic standards and ensuring students’ progress and success.
Therefore, students who attain a global average grade ranging between 3 and 3.3 find themselves in an academic probationary status. To retain their student standing, they must elevate their grade to at least 3.3 in the subsequent semester, as stipulated in Article 16 of the student code [
11]. Failure to meet this requirement could lead to their dismissal from the university. Furthermore, if a student’s global average grade falls below 3, automatic withdrawal from the university ensues. The prospect of losing student status due to academic performance is a pressing concern, commonly referred to as student dropout.
While students’ grades serve as a measure of their performance in each course, the number of semesters a student attends a particular course offers insights into its level of challenge for them. Therefore, for each prerequisite course, our prediction model incorporates three pivotal input variables: (i) the number of semesters the student has been enrolled in the course, (ii) the highest final grade achieved during the semesters the student attended the course, and (iii) the lowest final grade received while the student was enrolled in the course for at least one semester.
We represent these variables for each prerequisite course using a multidimensional real-valued vector. Consequently, the ith student is represented by a D-dimensional vector , with its components corresponding to the above-mentioned variables. Herein, for all . In our context, as we have ten prerequisite courses, and three variables are linked with each course. Each component of the vector represents a specific input variable, as follows:
represents the highest final grade obtained by a student in the calculus I course;
denotes the number of semesters a student has enrolled in the calculus I course;
represents the lowest final grade earned by a student in the calculus I course;
represents the highest final grade obtained by a student in the calculus II course;
denotes the number of semesters a student has enrolled in the calculus II course;
represents the lowest final grade earned by a student in the calculus II course;
represents the highest final grade obtained by a student in the calculus III course;
denotes the number of semesters a student has enrolled in the calculus III course;
represents the lowest final grade earned by a student in the Calculus III course;
represents the highest final grade obtained by a student in the linear algebra course;
denotes the number of semesters a student has enrolled in the linear algebra course;
represents the lowest final grade earned by a student in the linear algebra course;
represents the highest final grade obtained by a student in the physics I course;
denotes the number of semesters a student has enrolled in the physics I course;
represents the lowest final grade earned by a student in the physics I course;
represents the highest final grade obtained by a student in the physics II course;
denotes the number of semesters a student has enrolled in the physics II course;
represents the lowest final grade earned by a student in the physics II course;
represents the highest final grade obtained by a student in the physics III course;
denotes the number of semesters a student has enrolled in the physics III course;
represents the lowest final grade earned by a student in the physics III course;
represents the highest final grade obtained by a student in the introduction to computer programming course;
denotes the number of semesters a student has enrolled in the introduction to computer programming course;
represents the lowest final grade earned by a student in the introduction to computer programming course;
represents the highest final grade obtained by a student in the computer programming I course;
denotes the number of semesters a student has enrolled in the computer programming I course;
represents the lowest final grade earned by a student in the computer programming I course;
represents the highest final grade obtained by a student in the computer programming II course;
denotes the number of semesters a student has enrolled in the computer programming II course;
represents the lowest final grade earned by a student in the computer programming II course;
represents the highest final grade obtained by a student in the computer programming III course;
denotes the number of semesters a student has enrolled in the computer programming III course;
represents the lowest final grade earned by a student in the computer programming III course.
It is noteworthy that, out of the available 38 variables, we opted to use 33 in our study. This decision stemmed from our research’s exclusive emphasis on students’ performance in prerequisite courses, leading us to exclude admission-related variables from our input set.
To formalize the problem, let for all denote the training dataset. Here, n represents the number of instances within the set (i.e., , due to a portion being reserved for evaluation). Each element in is a real-valued vector representing the academic record of the ith student, along with the corresponding target variable . The target variable takes a value of one if the student either failed or dropped out of the numerical methods course (), or zero otherwise ().
In other words, the problem addressed in our study is to determine the function f, where , that maps the input variables from the academic record to the target variable, utilizing the provided training dataset. To tackle this challenge, we have chosen a supervised learning approach, specifically employing classification methods.
2.3. Machine Learning Methods
To solve the previously defined problem of predicting the risk of course failure, we adopted classification methods such as logistic regression, which is well-suited for binary outcome prediction tasks. Logistic regression utilizes the logistic function of the linear combination between input variables and weights, and a classifier is fitted by maximizing the objective function based on the log-likelihood of the training data given the binary outcome [
12]. In our study, we employed the limited-memory Broyden–Fletcher–Goldfarb–Shanno (L-BFGS) algorithm [
13,
14] to efficiently fit the logistic regression classifier.
With the logistic regression method, it is assumed that a hyperplane exists to separate vectors into two classes within a multidimensional real-valued vector space. While this assumption might be reasonable taking into account the high dimensionality (i.e.,
) of the dataset used in this study, we also adopted other classifiers more suited for non-linear classification problems, such as the Gaussian process classifier. The Gaussian process is a probabilistic method based on Bayesian inference, where the probability distribution of the target variable is Gaussian or normal, explaining the name of the method [
15,
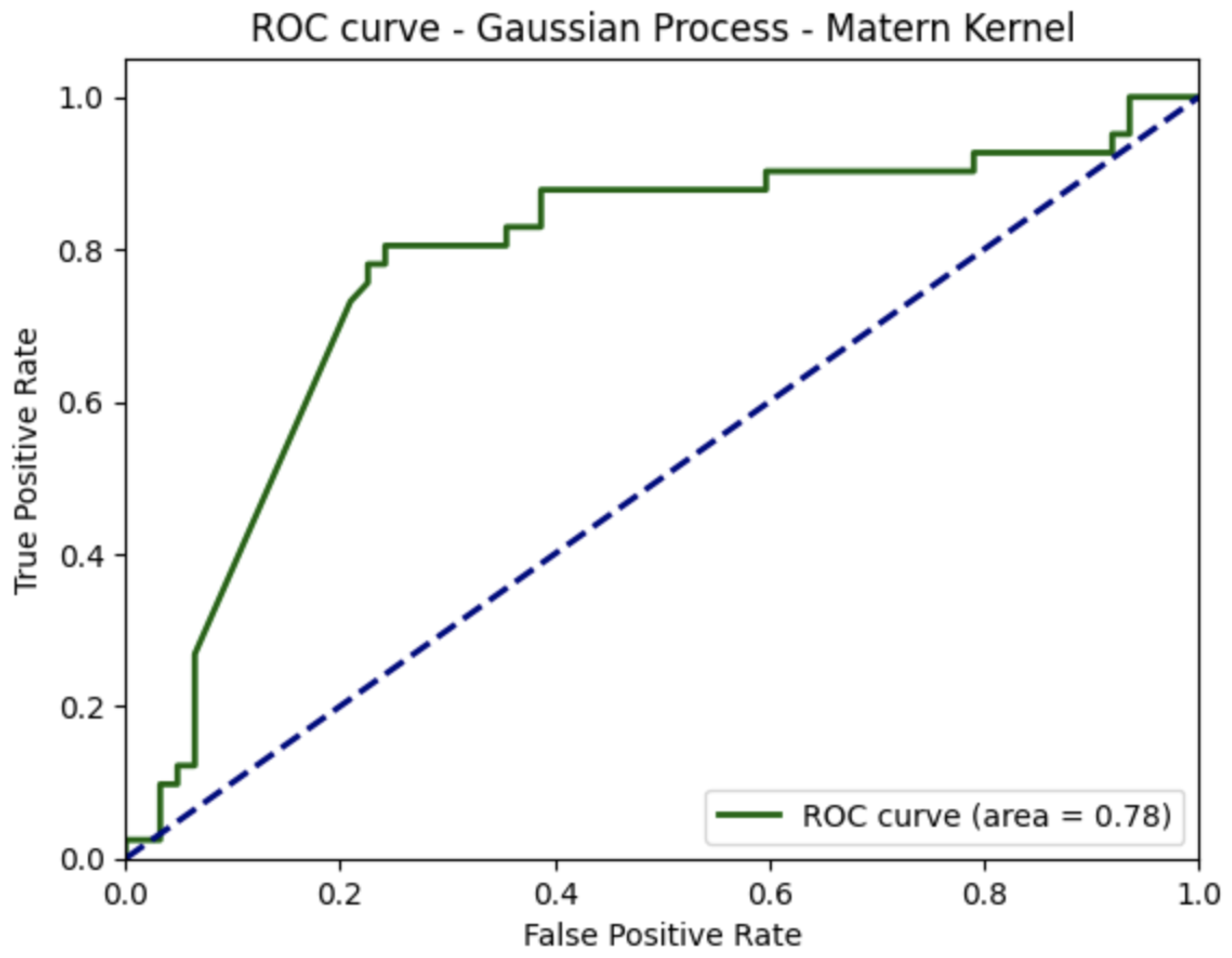
16]. One of the main advantages of the Gaussian process classifier is its ability to incorporate prior knowledge about the problem, thereby improving its forecasting, even with a small training dataset. Furthermore, within the context of this study, where the dataset is rather small, the Gaussian process classifier is a suitable choice.
In this study, we used several kernels (a.k.a., covariant functions) with Gaussian processes. For instance, the radial basis function kernel, which is defined as follows:
where
are two
D-dimensional vectors in real-valued space, and
are scalars corresponding to the weight and length scale of the kernel, respectively.
In addition, we used the Matern kernel, which is defined as follows:
where
and
are the modified Bessel function and the gamma function, respectively. The hyperparameter
controls the smoothness of the kernel function.
Moreover, we employed a rational quadratic kernel, defined as follows:
where
is used for the same purpose as in Equation (
1), while
is the scale mixture parameter, such that
.
Furthermore, we combined Matern and radial basis function kernels by summing both as follows:
where
and
are the weights assigned to the kernels.
On the other hand, the support vector machines (SVM) method is, to date, the best theoretical mehods and one of the most successful methods in the practice of modern machine learning ([
17], p. 79).It is based on convex optimization, allowing for a global maximum solution to be found, which is its main advantage. However, the SVM method is not well suited for interpretation in data mining, and it is better suited for training accurate machine-learning-based systems. A detailed description of this method can be found in [
18].
Both SVM and logistic regression are linear classification methods that assume the input vector space can be separated by a linear decision boundary (or a hyperplane in the case of a multidimensional real-valued space). However, when this assumption is not satisfied, SVM can be used along with kernel methods to handle non-linear decision boundaries (see [
18] for further details). In this study, we used the radial basis function kernel, which is similar to the one presented in Equation (
1), and it is defined as follows:
where
controls the radius of this spherical kernel, whose center is
. Additionally, we used the polynomial and Sigmoid kernels defined in Equations (
6) and (
7), respectively. In Equation (
6),
is the degree of the kernel, and
is the coefficient in Equation (
7).
Although the SVM method is considered one of the most successful methods in the practice of modern machine learning, multilayer perceptrons and their variants, which are artificial neural networks, are the most successful methods in the practice of deep learning and big data, particularly in tasks such as speech recognition, computer vision, natural language processing, and so forth. ([
19], p. 3). In this research, we adopted multilayer perceptrons fitted through back-propagated cross-entropy error [
20], and the optimization algorithm known as Adam [
21]. We used multilayer perceptrons with one and five hidden layers.
The multilayer perceptron method is a universal approximator (i.e., it is able to approximate any function for either classification or regression), which is its main advantage. However, its main disadvantage is that the objective function (a.k.a., loss function) based on the cross-entropy error is not convex. Therefore, the synaptic weights obtained through the fitting process might not converge to the most optimum solution because there are several local minima in the objective function. Thus, finding a solution depends on the random initialization of the synaptic weights. Furthermore, multilayer perceptrons have more hyperparameters to be tuned than other learning algorithms (e.g., support vector machines or naive Bayes), which is an additional shortcoming.
Except for the logistic regression method, all the above-mentioned methods are not easily interpretable. Therefore, we adopted decision trees, which are classification algorithms commonly used in data mining and knowledge discovery. In decision tree training, a tree is created using the dataset as input, where each internal node represents a test on an independent variable, each branch represents the result of the test, and leaves represent forecasted classes. The construction of the tree is carried out in a recursive way, beginning with the whole dataset as the root node, and at each iteration, the fitting algorithm selects the next attribute that best separates the data into different classes. The fitting algorithm can be stopped based on several criteria, such as when all the training data are classified or when the accuracy or performance of the classifier cannot be further improved.
Decision trees are fitted through heuristic algorithms, such as greedy algorithms, which may lead to several local optimal solutions at each node. This is one of the reasons why there is no guarantee that the learning algorithm will converge to the most optimal solution, which is also the case with the multilayer perceptrons algorithm. Therefore, this is the main drawback of decision trees, and it can cause completely different tree shapes due to small variations in the training dataset. Decision trees were proposed in 1984, and in [
22], Breiman et al. delve into the details of this method. We also adopted ensemble methods based on multiple-decision trees such as, Adaboost (stands for adaptive boosting) [
23], random forest [
24], and extreme gradient boosting, a.k.a. XGBoost [
25].








{kind=link}
{kind=link}
{kind=link}
{kind=link}