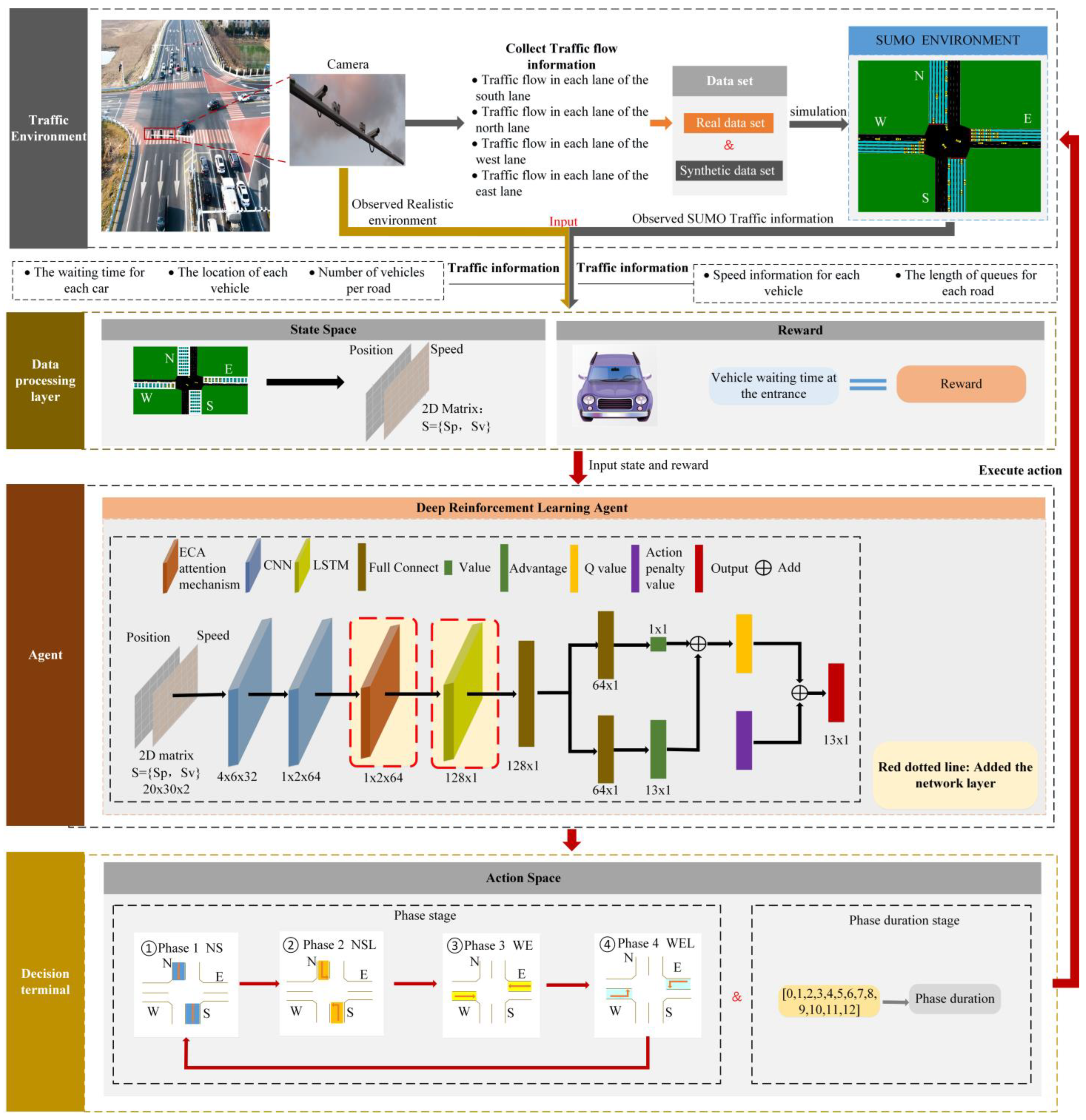
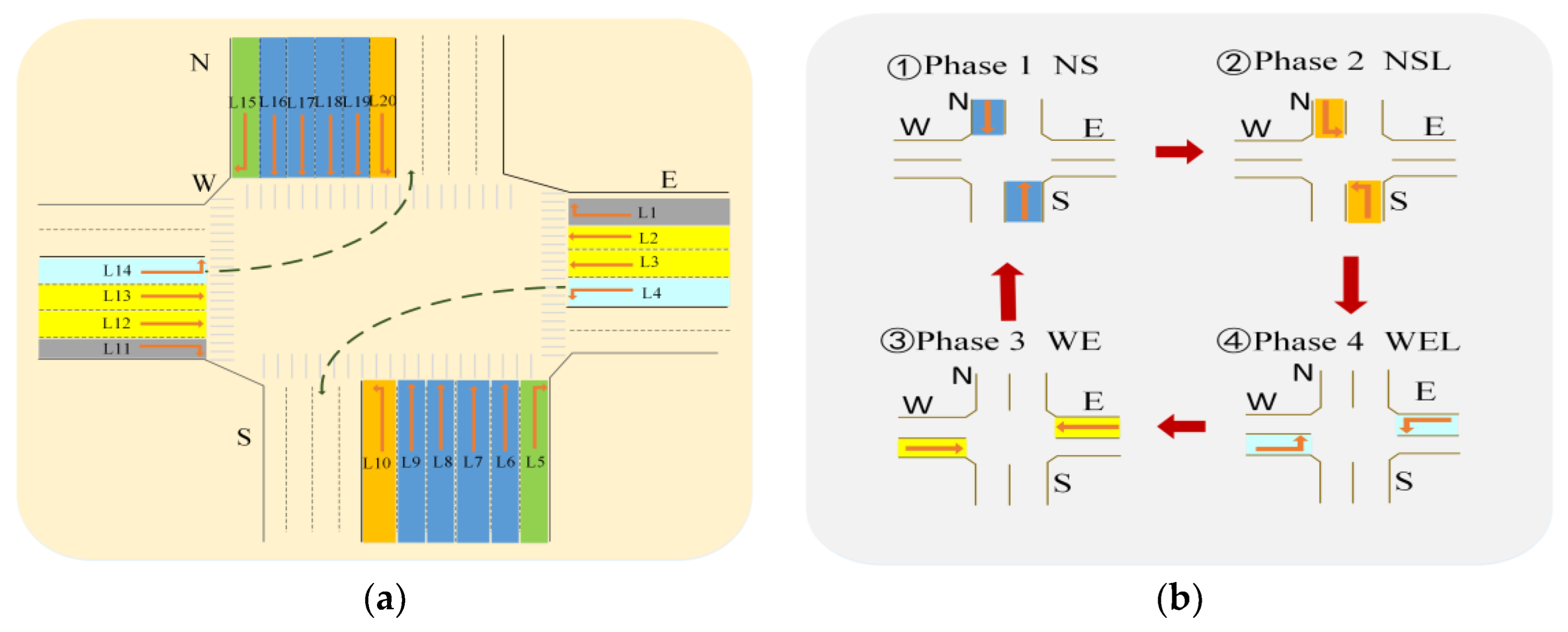
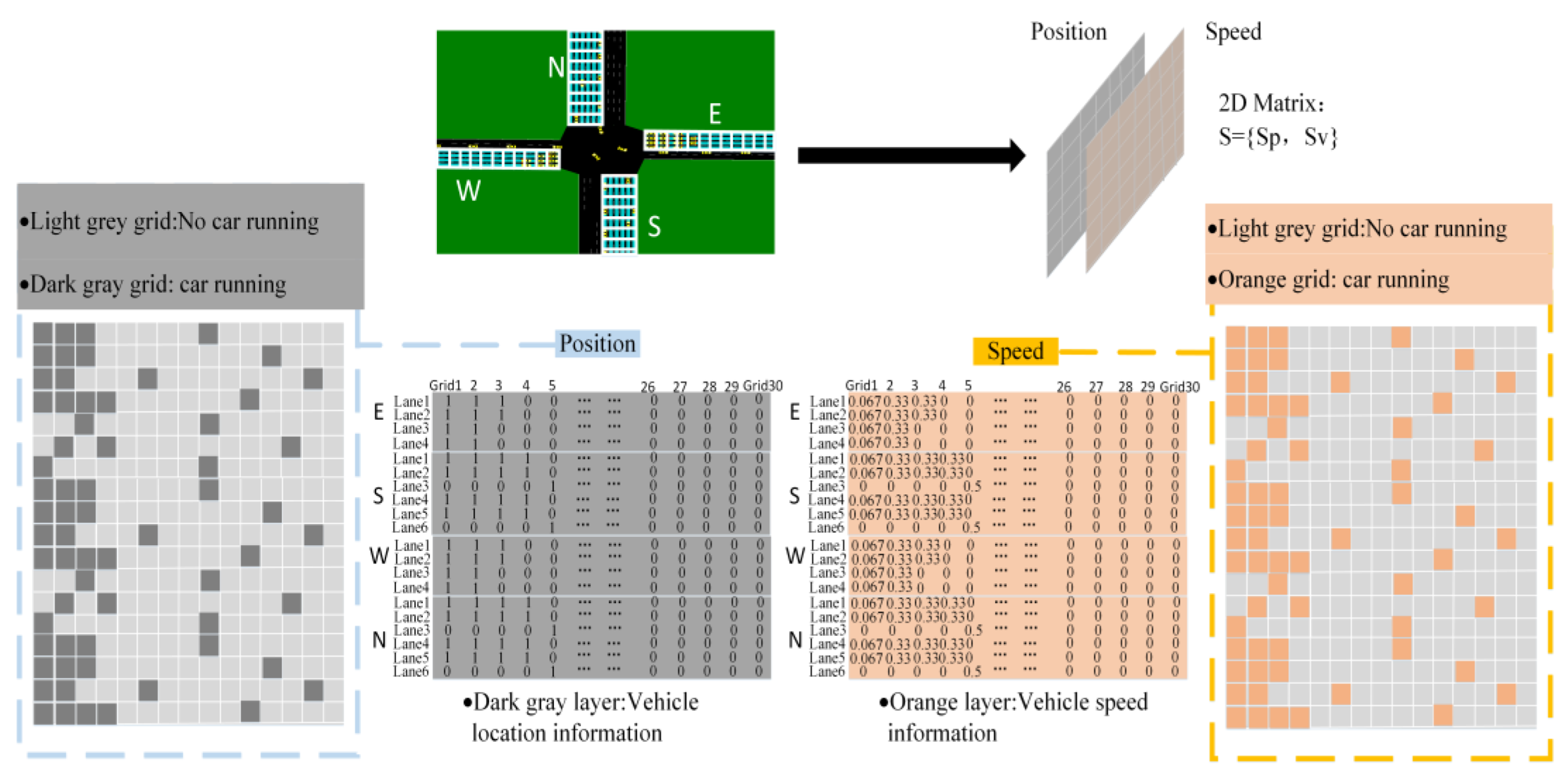
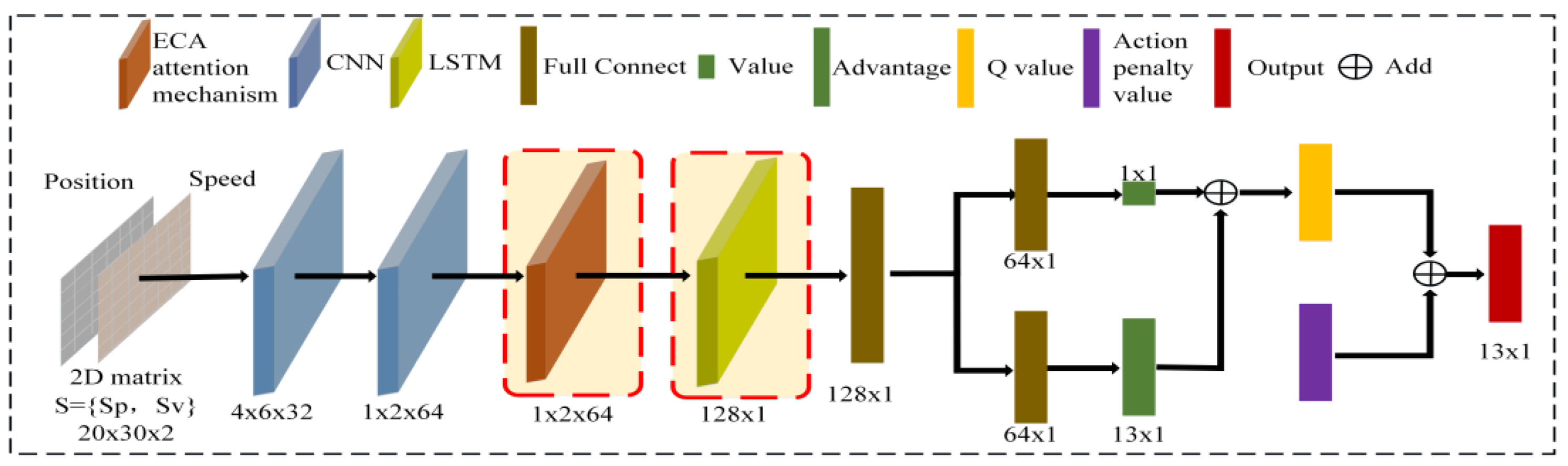
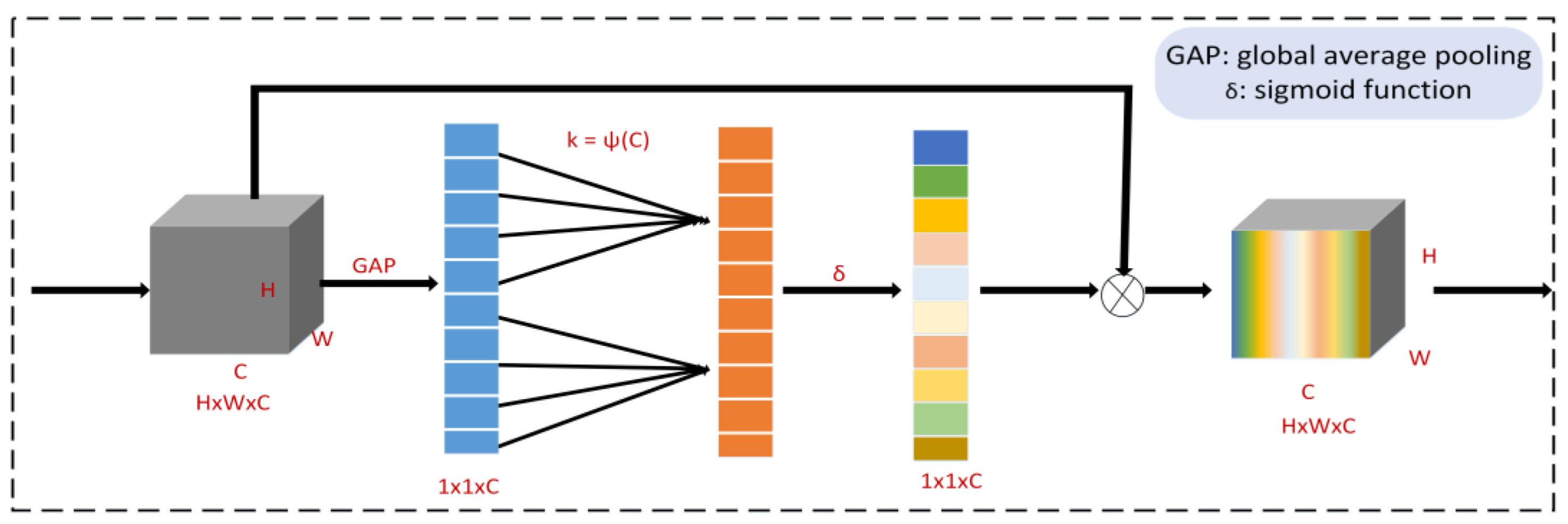
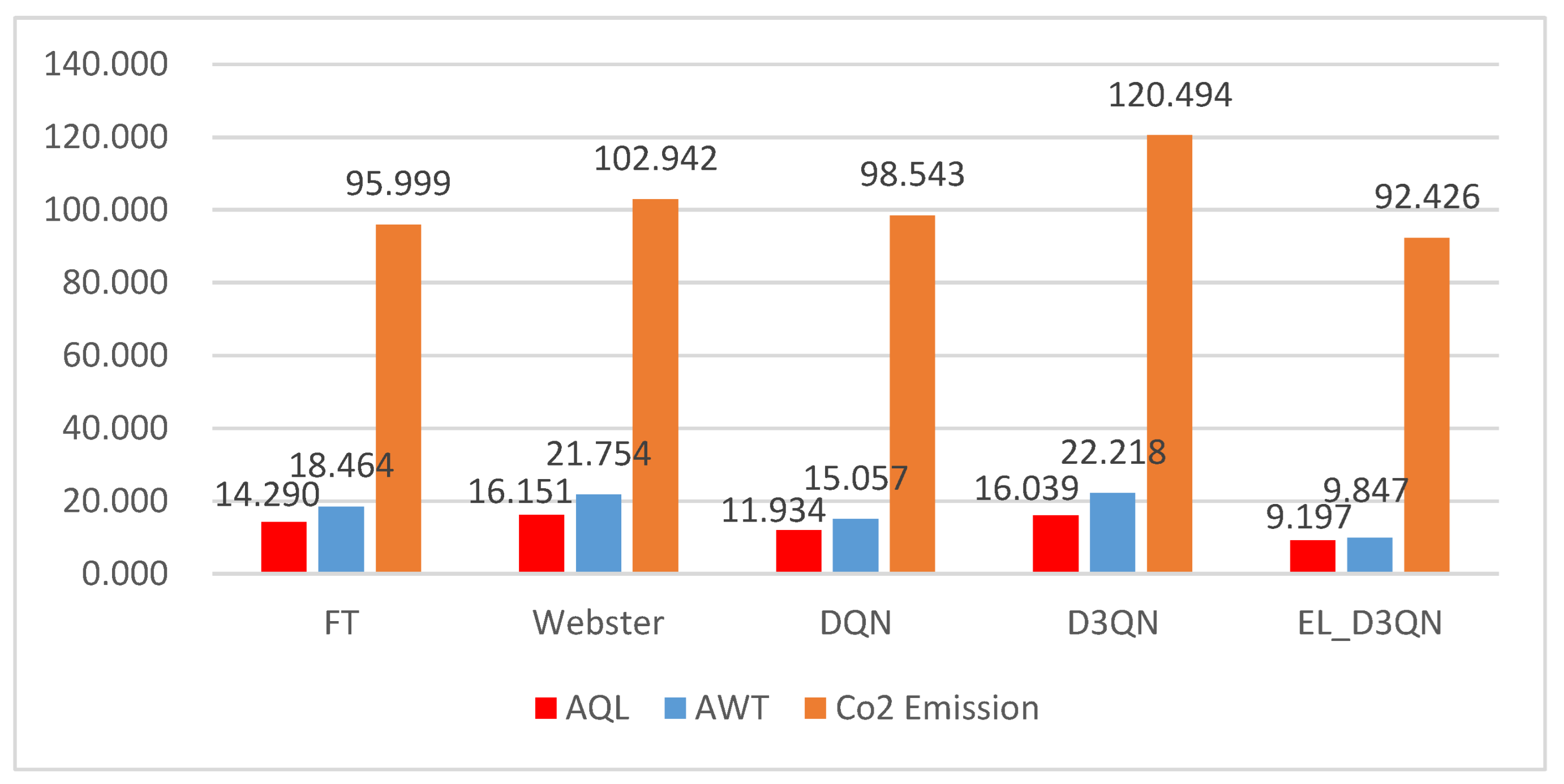
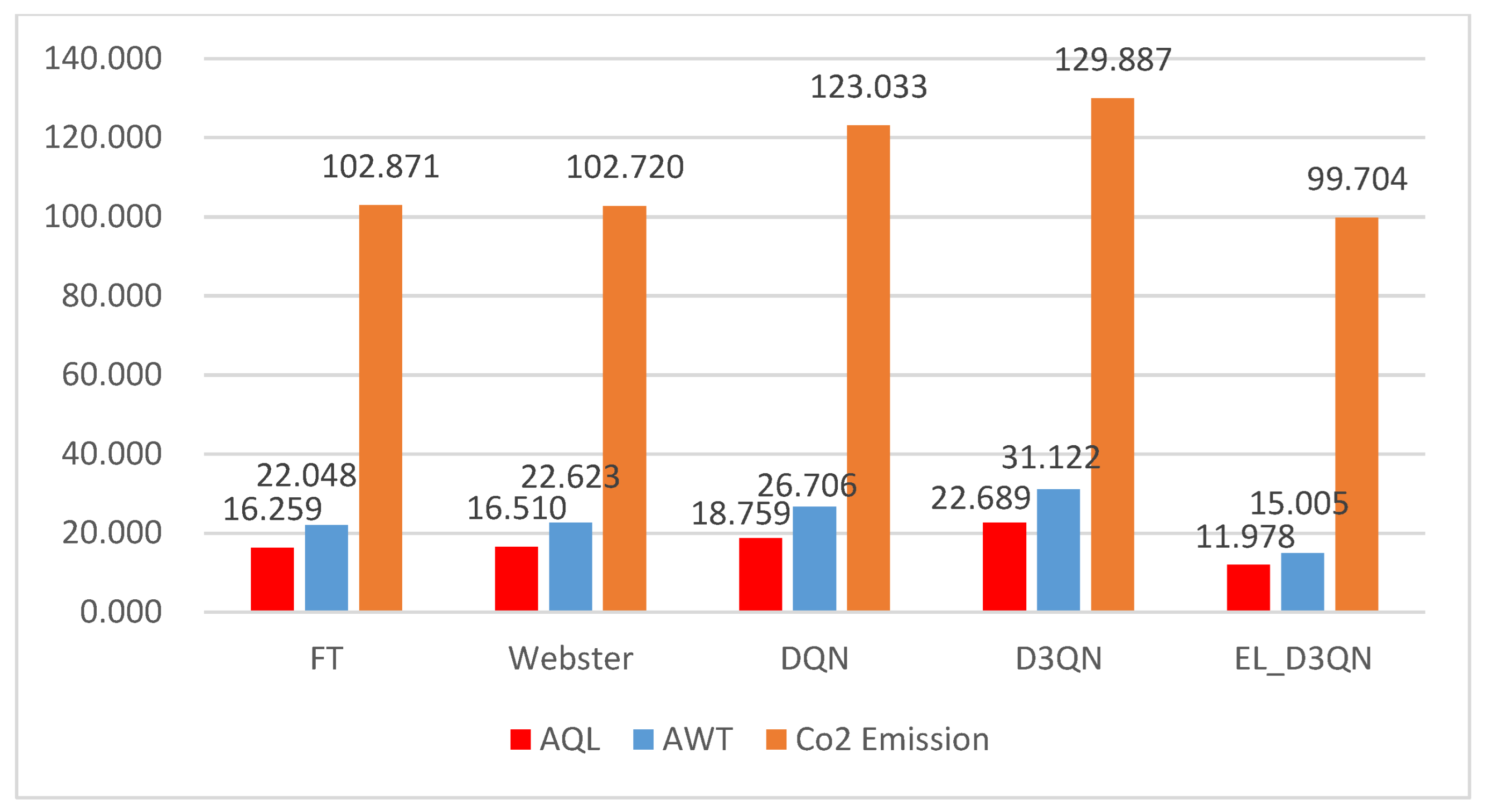
The experiments presented in this study are split into three categories: ablation experiments, experimental investigation of various vehicle circumstances, and special scenario test studies. The initial part is to ascertain whether the modules added to EL_D3QN improve the signal control performance. Verifying the control effectiveness and generalizability of EL_D3QN is the second part. Verifying the robustness of EL_D3QN is the third component. In addition, the table values obtained during training were averaged over the last 20 epochs. The table values obtained during the testing period were averaged over 19 epochs.
5.3.2. Experimental Investigation of Various Vehicle Circumstances
This section compares the control performance of EL_D3QN used in this paper to models with various parameters and architectural settings using a variety of traffic scenarios (synthetic vs. actual datasets). The yellow line in
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13 depicts FT, the orange line Webster, the green line DQN, the blue line D3QN, and the red line EL_D3QN presented in this study.
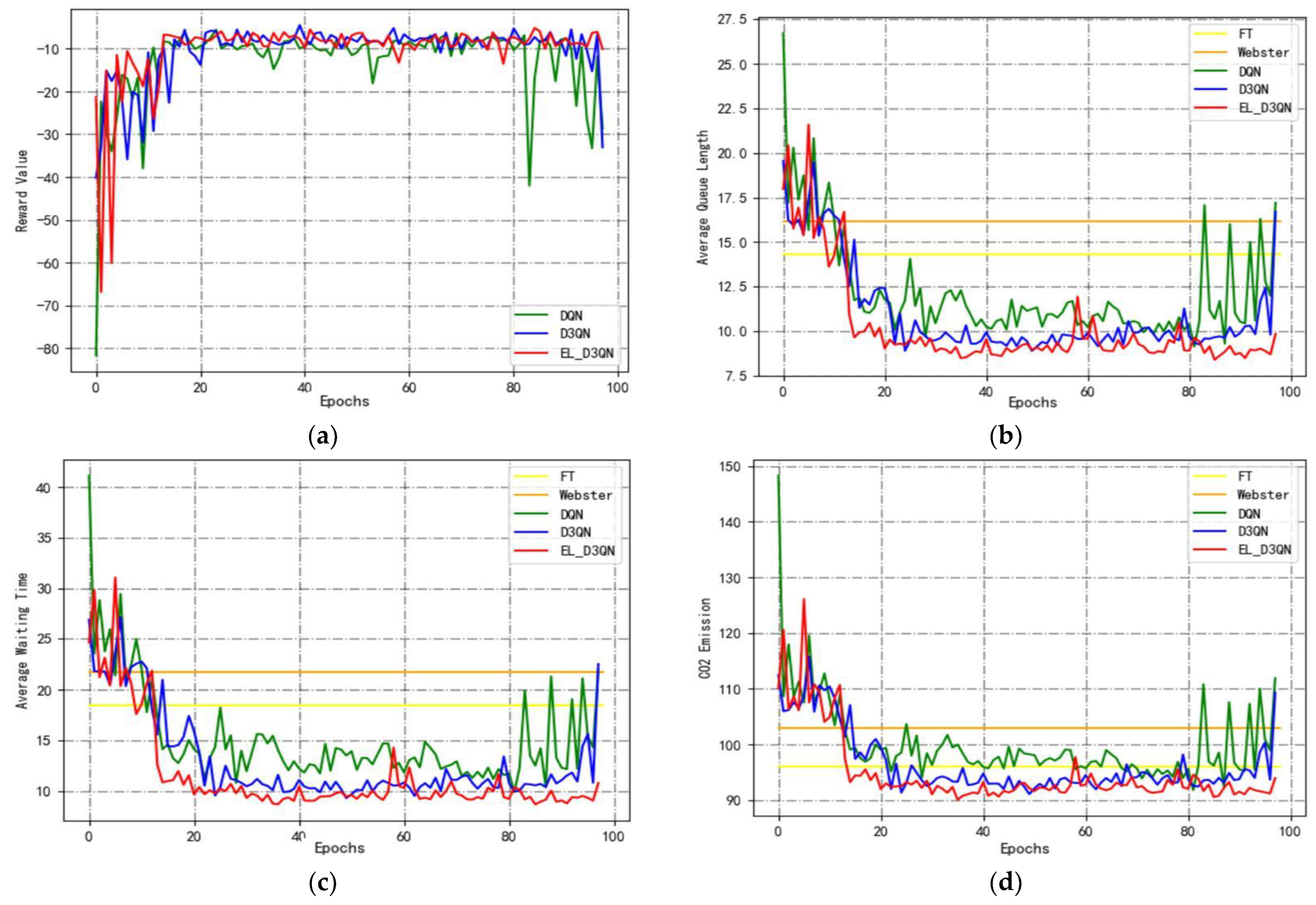
Experiment 1 was conducted based on Configuration 1, and
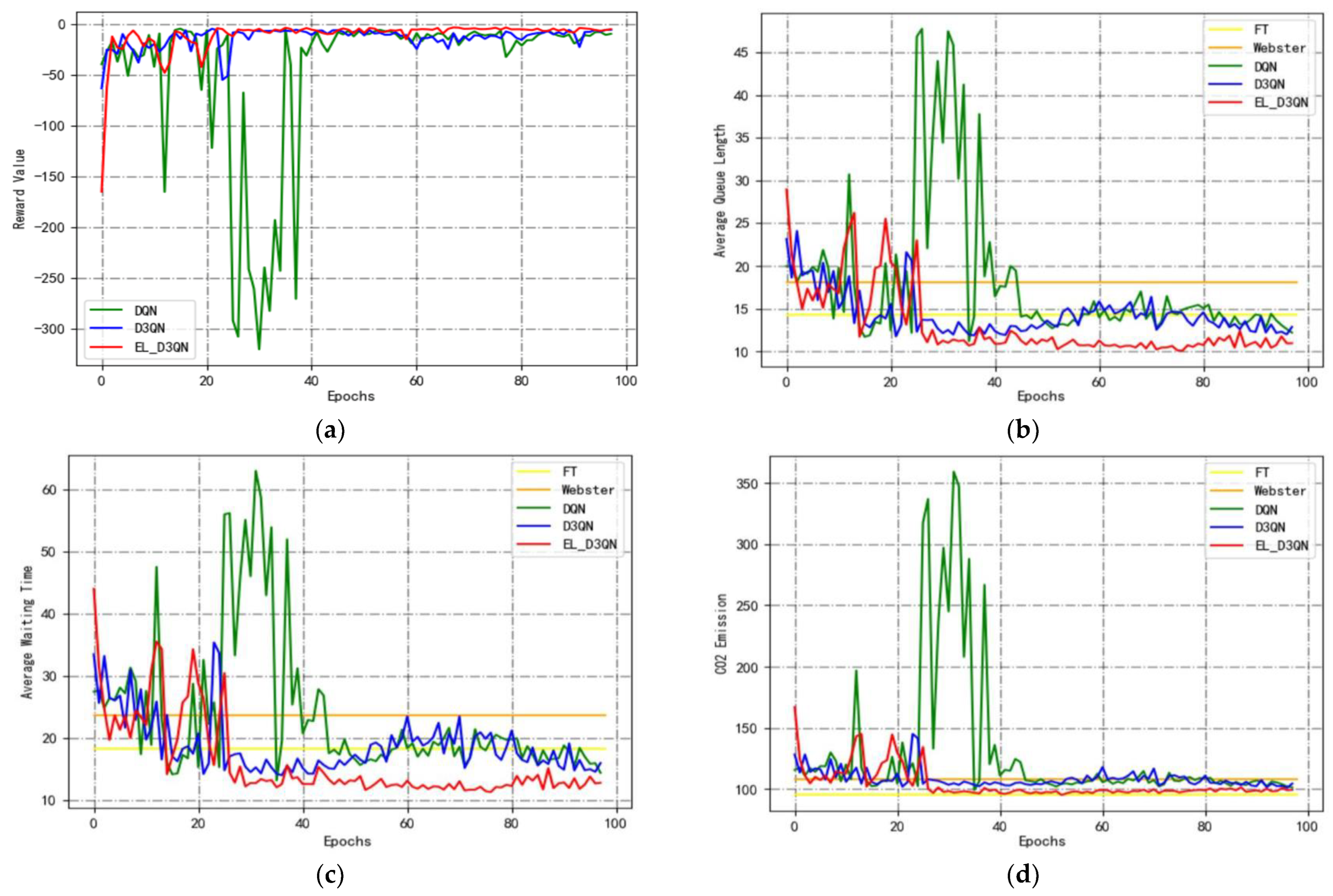
Figure 9 shows a graph comparing the performance of different models in Configuration 1 during training.
Figure 9a displays the cumulative reward trend for several models. In the early phase, it continuously increases, and in the later time, it maintains a specific level line. DQN begins to converge at 30 epochs, as can be observed, but the subsequent leaps are substantial because the ideal timing approach has not been identified. D3QN starts to converge at 25 epochs, and its jumps are smaller than that of DQN, but the jumps suddenly become larger after 90 epochs. The EL_D3QN presented in this study begins to converge at 18 epochs and becomes more stable and converge to a particular level. It can also be seen from the result plots of the three evaluation metrics in
Figure 9b–d that all three metrics of EL_D3QN are smaller than the other four models, indicating that the performance is better than that of FT, Webster, DQN, and D3QN.
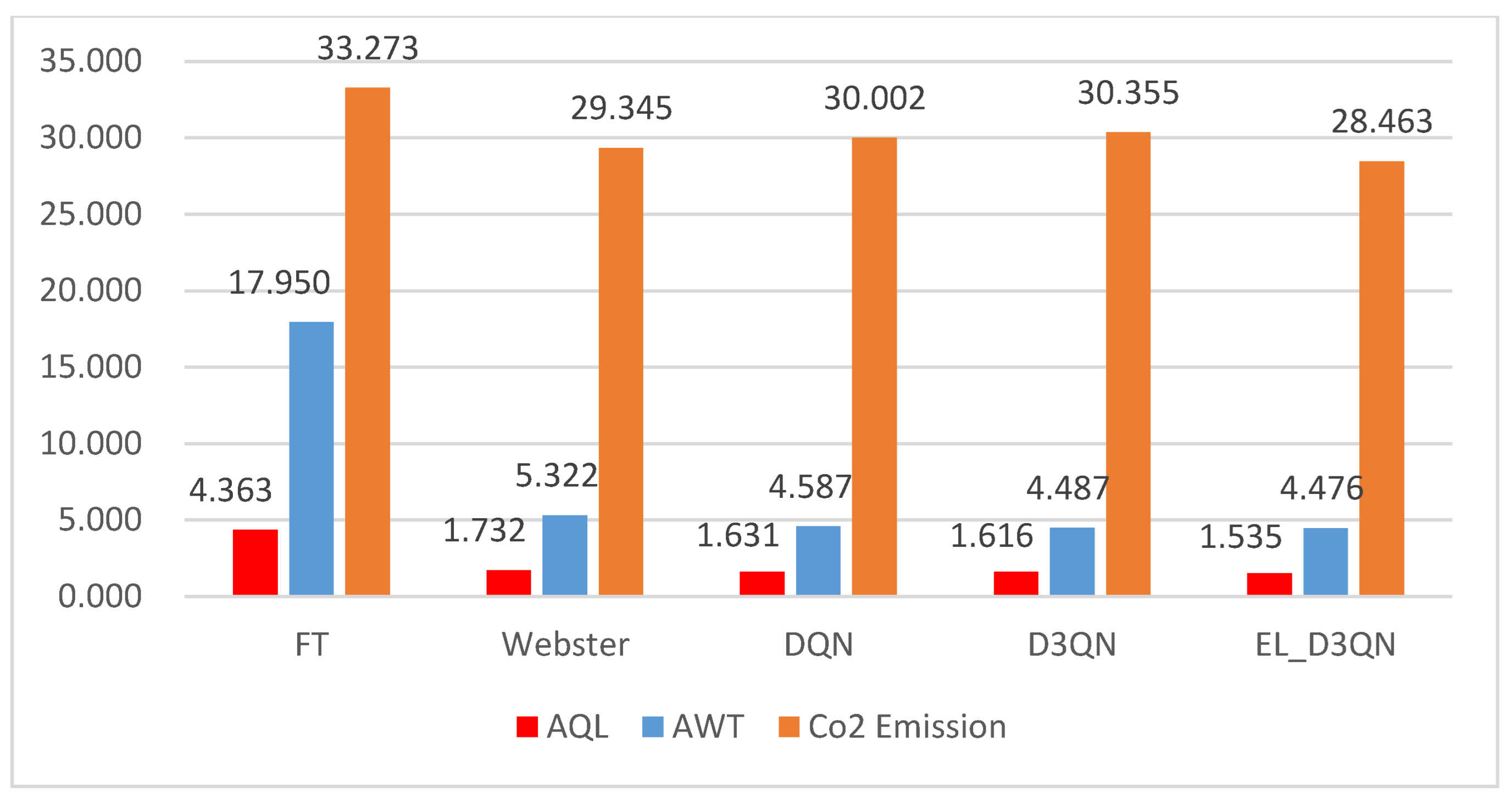
Table 4 displays the performance outcomes of different models during Configuration 1 training. The table also shows that the AQL, AWT, and
emissions of EL_D3QN all decrease when compared to FT by 36.8%, 48.3%, and 3.9%, respectively. The three metrics of EL_D3QN are each decreased by 44.1%, 56.1%, and 10.4% when compared to Webster. This demonstrates how the deep reinforcement learning method can increase the effectiveness of signal control. The cumulative reward of EL_D3QN is 45.7% higher than DQN, and the other three assessment metrics are decreased by 25.6%, 34.6%, and 7.2%, respectively. The AQL, AWT, and
emissions from this paper are all decreased by 13.2%, 20.2%, and 3.2%, respectively, when compared to D3QN, while the cumulative reward is increased by 15.7%. The data findings and trend graphs from Experiment 1 demonstrate that the control performance of EL_D3QN is more efficient and can lessen the phenomena of traffic congestion.
Figure 9.
Performance comparison of different models for Configuration 1 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
Figure 9.
Performance comparison of different models for Configuration 1 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
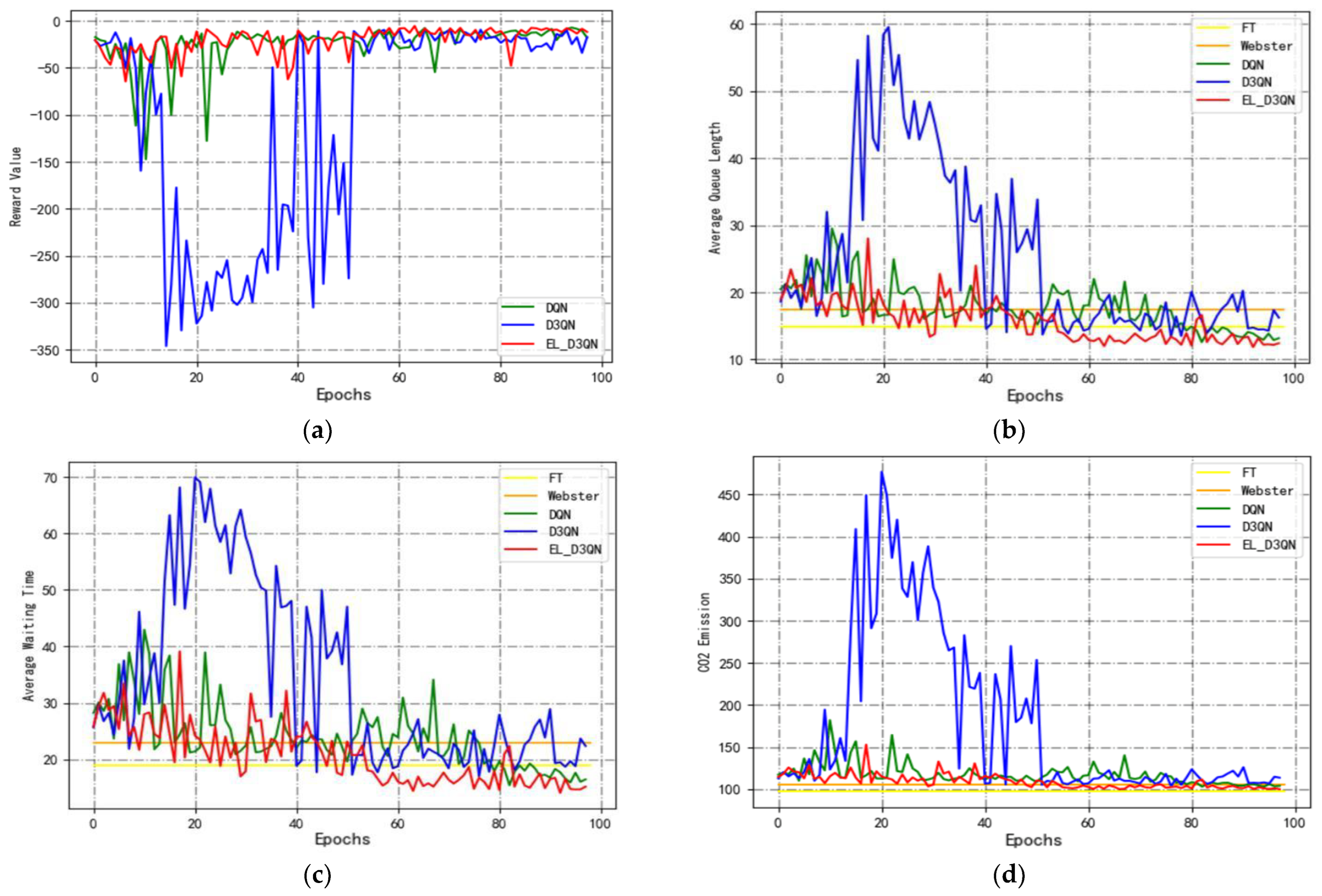
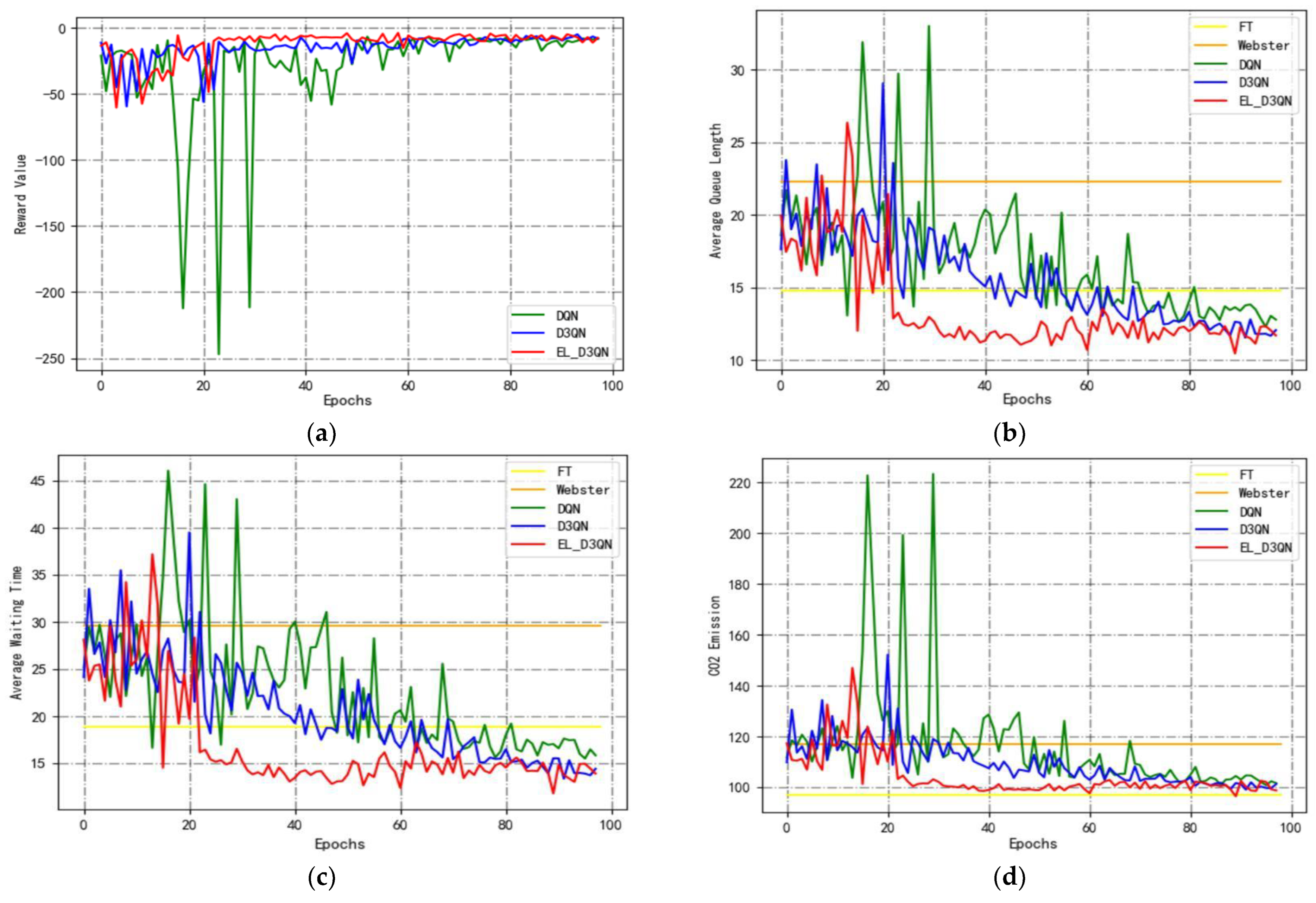
Based on Configuration 2, Experiment 2 is carried out, and the experimental outcomes from the training period are displayed in
Figure 10 and
Table 5. It is evident from
Figure 10a that EL_D3QN has superior convergence and stability than DQN and D3QN. Additionally, EL_D3QN has greater control performance and is more suited to the current setup environment, as shown in
Figure 10b–d.
Table 5 shows that, specifically, the AQL and AWT of EL_D3QN decreased by 19.1% and 23.9%, respectively, while the
emissions increased by 3.4% compared to FT. This was likely due to the smoother vehicle operation in the static condition and the high volatility of the vehicle operation in the dynamic condition, which would result in more serious pollution. For the three metrics, EL_D3QN demonstrated a reduction of 46.4%, 51.5%, and 14.2% in comparison to Webster. The cumulative rewards were increased by 27.7% over DQN, whereas the other three assessment measures were decreased by 10.5%, 14.8%, and 2.6%, respectively. Comparing EL_D3QN to D3QN, the cumulative reward increases by 8.4%, and the AQL, AWT, and
emissions decrease by 3.0%, 3.2%, and 0.6%, respectively. The data from Experiment 2’s trend graphs and data findings show that EL_D3QN’s control performance is quite successful in this flow scenario.
Figure 10.
Performance comparison of different models for Configuration 2 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
Figure 10.
Performance comparison of different models for Configuration 2 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
Table 5.
Different model performance results for Configuration 2 (train).
Table 5.
Different model performance results for Configuration 2 (train).
| Method | Reward | AQL (m) | AWT (s) | CO2 Emissions (g) |
|---|
| FT (30 s) | / | 14.757 ↓19.1% | 18.888 ↓23.9% | 97.098 ↑3.4% |
| Webster | / | 22.283 ↓46.4% | 29.598 ↓51.5% | 117.088 ↓14.2% |
| DQN | −10.458 ↑27.7% | 13.343 ↓10.5% | 16.855 ↓14.8% | 103.088 ↓2.6% |
| D3QN | −8.255 ↑8.4% | 12.308 ↓3.0% | 14.842 ↓3.2% | 101.040 ↓0.6% |
| EL_D3QN | −7.560 | 11.945 | 14.369 | 100.443 |
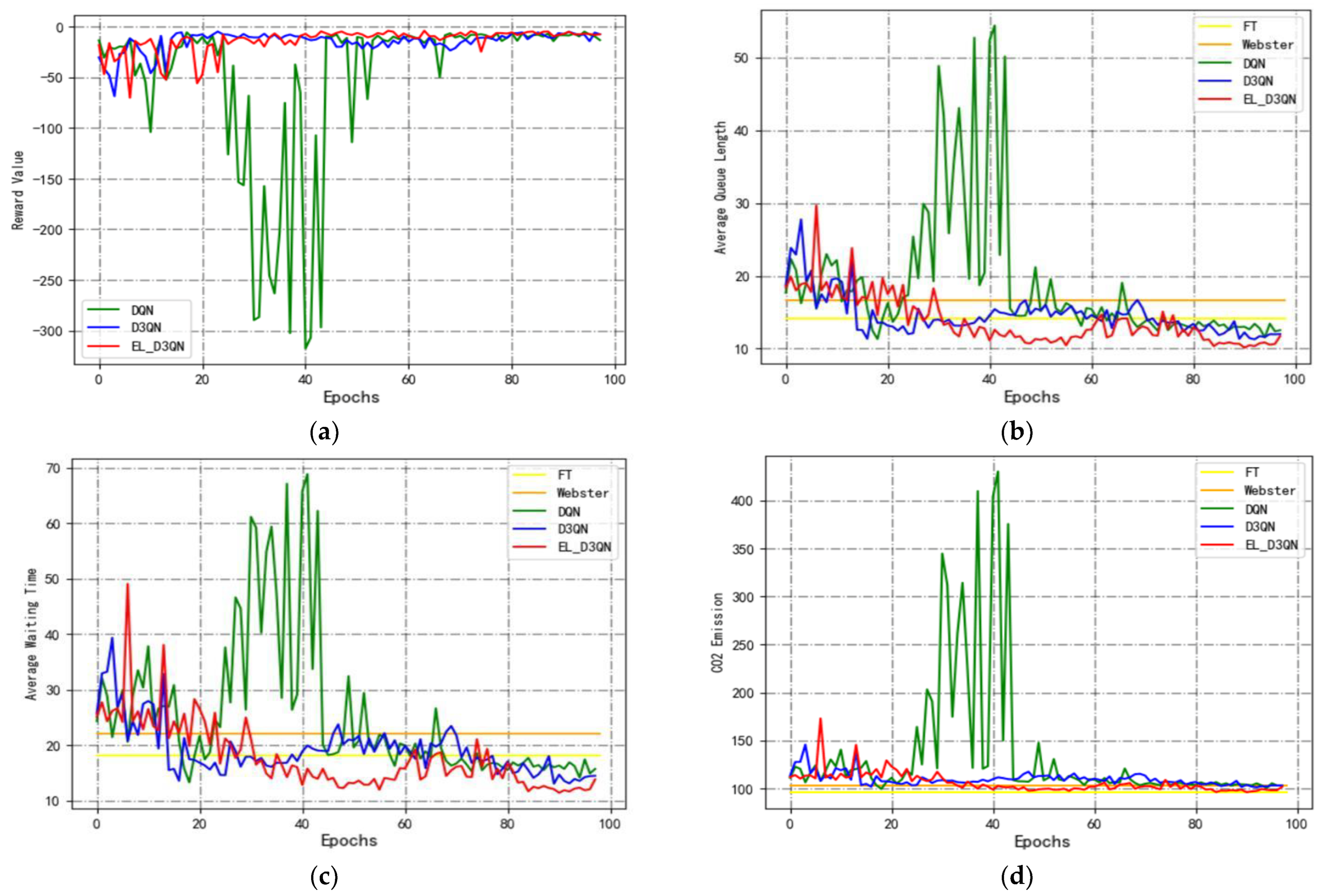
Experiment 3 is carried out in Configuration 3’s traffic environment, and the training period’s experimental outcomes are displayed in
Figure 11 and
Table 6. Its analytic procedure is identical to Experiment 2’s. From
Figure 11, it is clear that EL_D3QN has better stability and convergence than DQN and D3QN, as well as better stability and smoothness than EL_D3QN in Experiment 2. This further suggests that the model in this paper can produce better control results during equal steady peak periods. The control performance of EL_D3QN outperforms the other four approaches, as demonstrated in
Table 6.
Figure 11.
Performance comparison of different models for Configuration 3 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
Figure 11.
Performance comparison of different models for Configuration 3 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
Experiment 4 was carried out in Configuration 4’s traffic environment, and the training period’s experimental outcomes are displayed in
Figure 12 and
Table 7. The early era of D3QN is evidently quite jumpy from
Figure 12a. It takes a long time for the timing scheme to attain convergence since the traffic has a low peak and is unstable. It is stable but has a big jump in the late period. In comparison to D3QN, DQN is more suited to unstable low peak circumstances. Although it also tends to a specific degree of state in the late period, the EL_D3QN jumps are a little bit greater than the jumps from Configuration 1 to Configuration 3, and the control effect is not as strong as that in the first three datasets.
Table 7 depicts the overall performance effect and demonstrates that, when compared to other approaches, EL_D3QN has the biggest cumulative reward and the least AQL, AWT, and
emissions. The outcomes demonstrate that EL_D3QN can significantly enhance control performance.
Figure 12.
Performance comparison of different models for Configuration 4 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
Figure 12.
Performance comparison of different models for Configuration 4 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
The outcomes of Experiment 5 are displayed in
Figure 13 and
Table 8 and were carried out in the Configuration 5 traffic scenario. In contrast to the outcomes of Experiment 4, it is evident from
Figure 13a that DQN is extremely jumpy upfront. While DQN is more appropriate for instances with unstable low-peak periods, D3QN is more appropriate for those with unstable peak periods. Both cases show that neither of the models performs controls as well as EL_D3QN.
Table 8 demonstrates that, in comparison to FT, EL_D3QN decreases the AQL and AWT by 21.9% and 28.9%, respectively, while improving the
emissions by 3.4%, resulting in an increase in the release that is consistent with Experiments 2, 3, and 4. All three EL_D3QN indices reduced when compared to Webster, DQN, and D3QN. The control performance and stability of EL_D3QN are less stable and perform poorly during the peak time than during the low-peak period, according to a comparison between Experiments 4 and 5.
Figure 13.
Performance comparison of different models for Configuration 5 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
Figure 13.
Performance comparison of different models for Configuration 5 (train). (a) Cumulative reward; (b) average queue length; (c) average waiting time; (d) emissions.
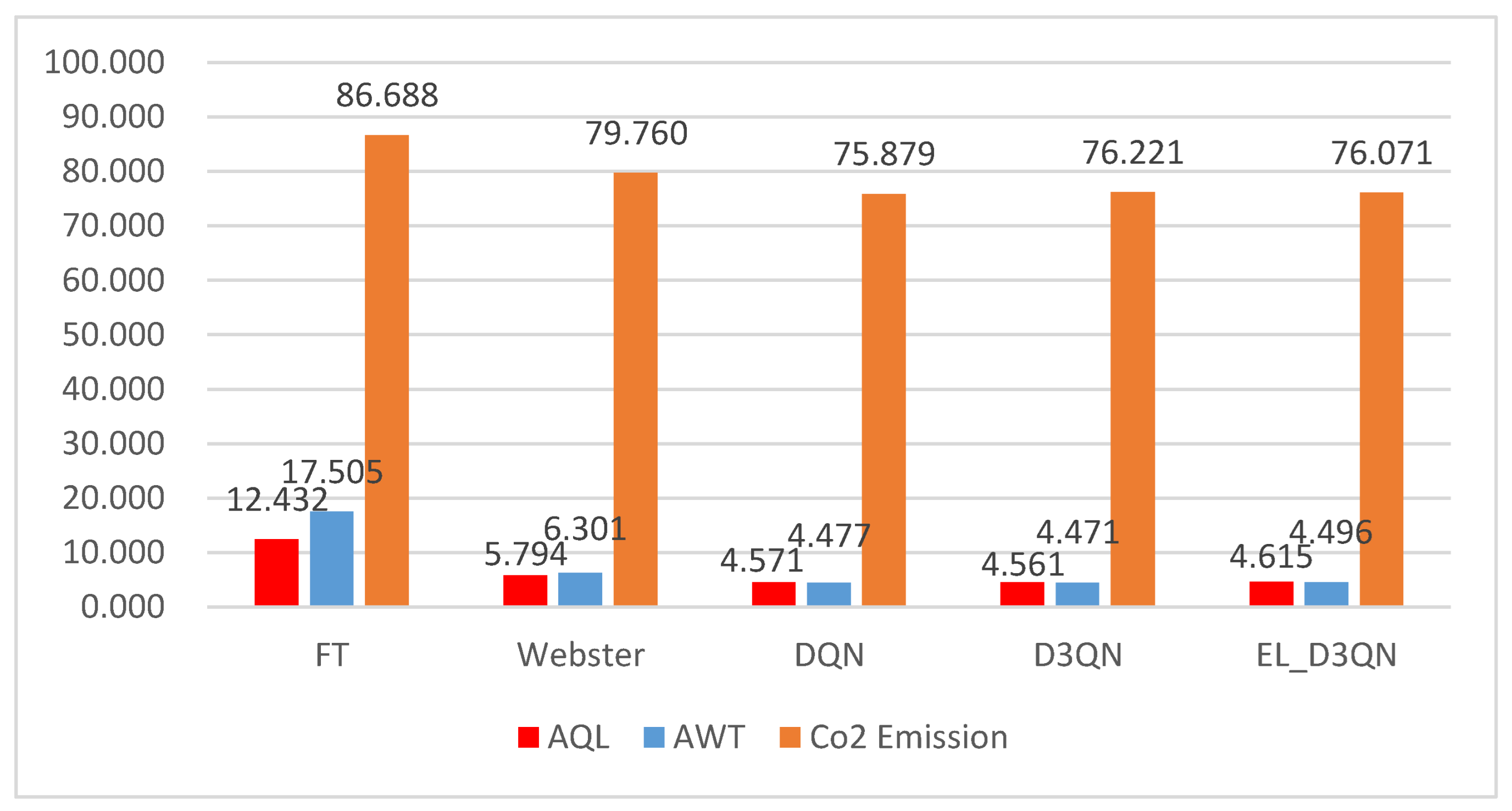
Experiment 6 was tested on a real dataset during a low-peak period, with data for a particular hour on a particular day in Hangzhou, and 19 epochs were tested. It is evident from
Figure 14 and
Table 9 that EL_D3QN has lower AQL, AWT, and
emissions when compared to FT by 64.8%, 75.1%, and 14.5%, respectively. The three measures decreased by 11.4%, 15.9%, and 3.0%, respectively, when compared to Webster. EL_D3QN has the least AQL, AWT, and
emissions when compared to DQN and D3QN. EL_D3QN performs better under control overall.
A real dataset from the peak time was used to evaluate Experiment 7, with all other variables being the same. The adaptive traffic signal control model outperforms FT and Webster, as demonstrated in
Figure 15 and
Table 10. All three adaptive approaches can reduce traffic congestion during peak hours; however, EL_D3QN performs somewhat worse in terms of control than the other two.
The results of several sets of experiments using the simulation experiments with various traffic configurations demonstrated that EL_D3QN has good control performance and its ability to generalize, with the exception of Experiment 7, where its performance is marginally inferior to that of the other two control methods, but the control effect is still good.
5.3.3. Special Scenario Test Research
This section of the article opts to build on Configuration 1’s synthetic dataset and sets up two unique situations to test. Each scenario is tested for a total of 19 epochs.
Experiment 1 involves a traffic surge scenario in which there is a significant sporting event in the west. As a result, the arrival rates of vehicles in the east–west straight direction, north–west right turn, and south–west left turn directions, which are 0.5, 0.3, and 0.3, respectively, all suddenly increase in the second half of the hour. As can be shown from
Figure 16 and
Table 11, the EL_D3QN’s AQL and AWT decrease by 35.6% and 46.7%, respectively, in comparison to the FT, and the
emissions increase by 3.7%. Compared to Webster, DQN, and D3QN, it emits the least AQL, AWT, and
emissions.
In Experiment 2, a road capacity limitation situation is simulated, wherein some road sections have traffic accidents or are unable to undergo construction. The south entrance left turn lane serves as the construction road in this article.
Figure 17 and
Table 12 illustrate how EL_D3QN improves
emissions by 3.1% while reducing AQL and AWT by 26.3% and 31.9%, respectively, when compared to FT. In comparison to the other three approaches, EL_D3QN has the lowest three metrics.
Overall, the other four models are weakly resilient and unable to handle unique scenarios. Good control performance and robustness allow EL_D3QN to perform normally in unusual circumstances.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}