
Analysis of Machine Learning Models for Wastewater Treatment Plant Sludge Output Prediction

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection and Preprocessing
2.2. Model Building
2.2.1. Machine Learning Algorithms
Lasso and Kernel Ridge Regression
DT
Support Vector Regression
KNN Regression
FCNN
RF
XGBoost
2.2.2. Standardization of Original Data
2.2.3. Feature Enhancement Based on Sludge Generation Mechanism
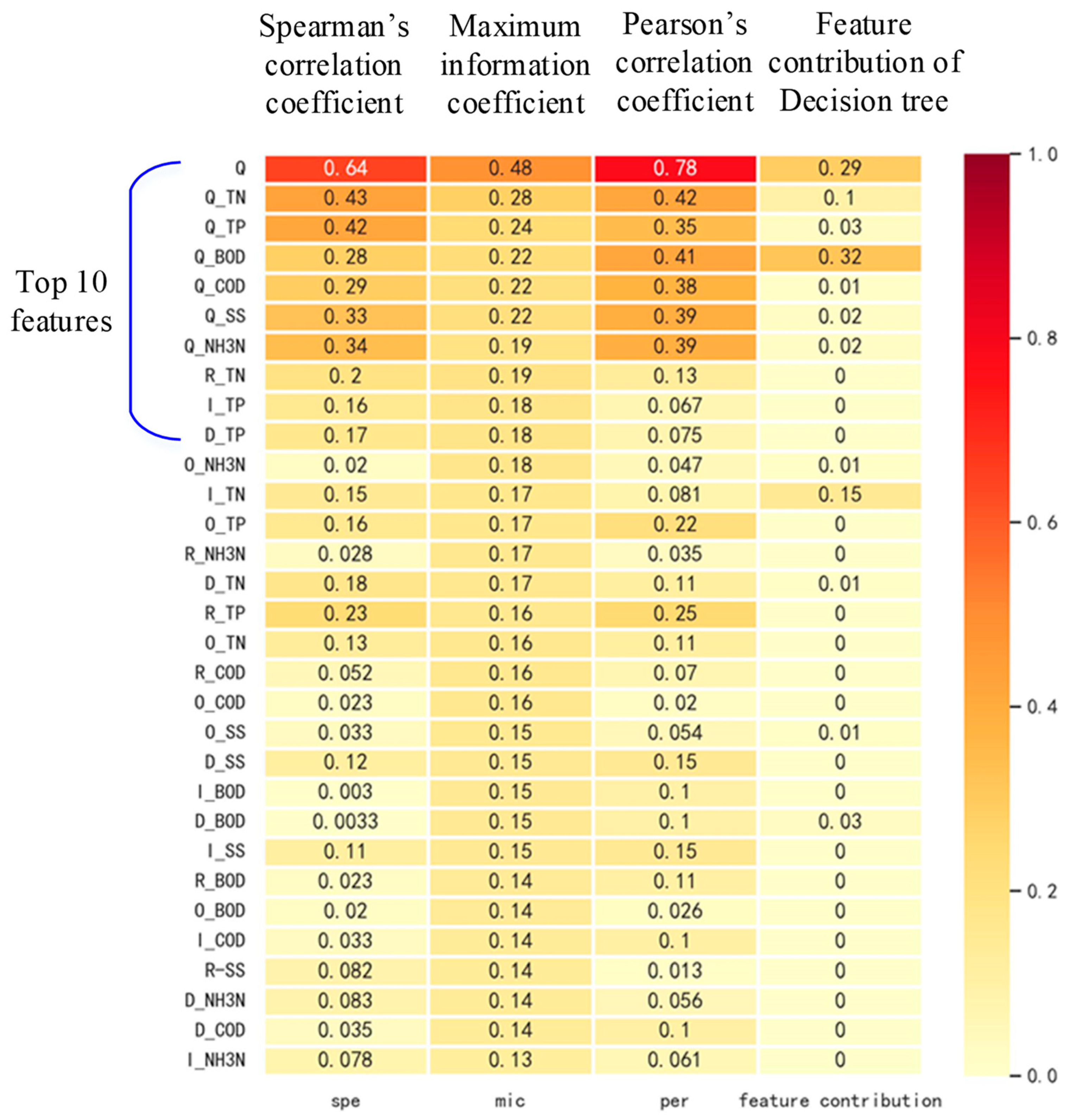
2.2.4. Feature Filtering
2.2.5. Model Hyperparameter Optimization
2.2.6. Model Metrics
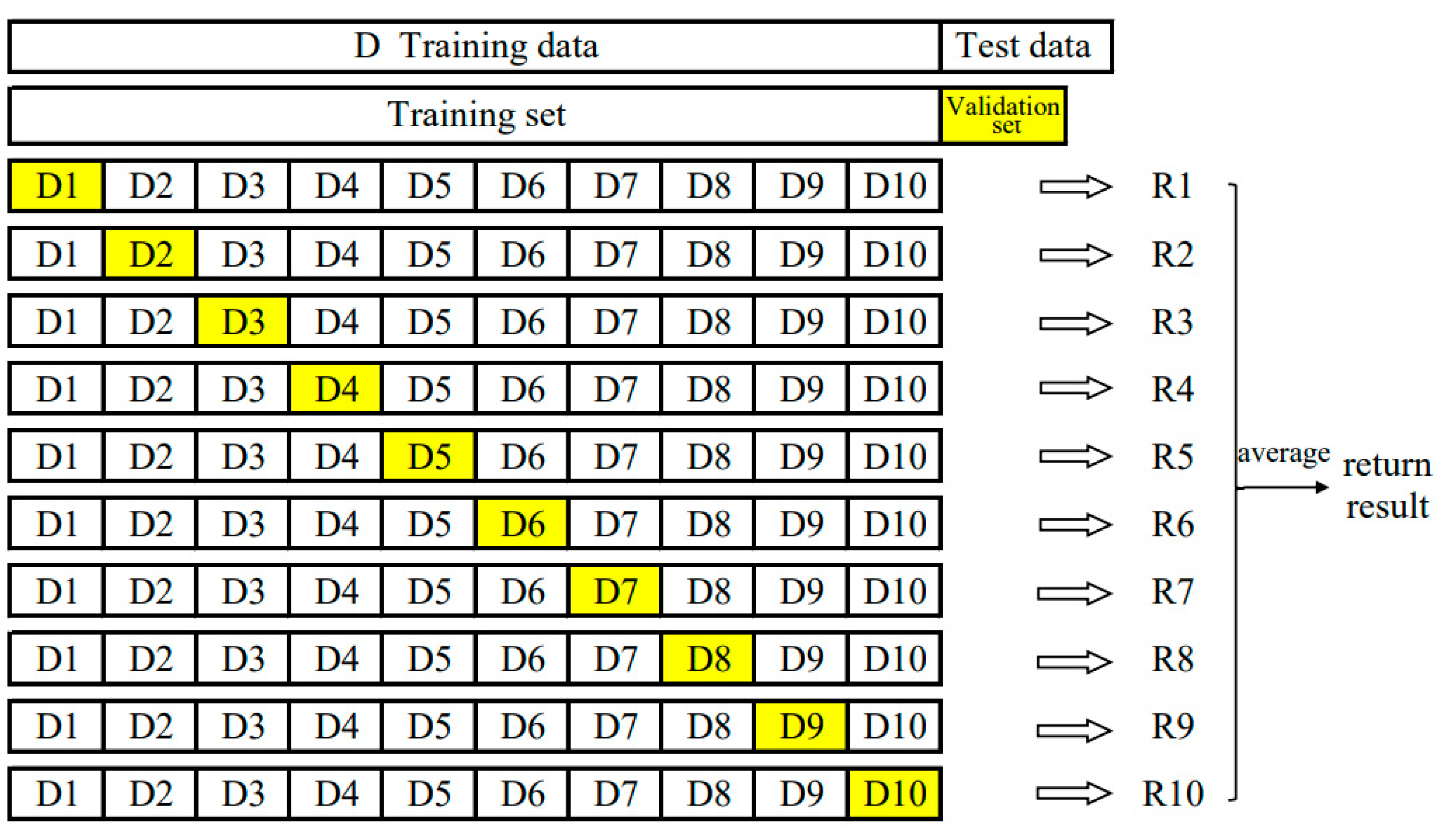
2.2.7. Modeling Process
- Data fusion and preprocessing: Fusion and preprocessing of multi-source data included time scale matching, deduplication, and filling/deleting missing values to form a sample set containing features and system response.
- Sample feature enhancement: The data set was normalized using Z-score normalization. Simultaneously, based on the sewage treatment process, we calculated the water quality concentration difference, reduction percentage, and indicator reduction amount before and after sewage treatment and added temperature and rainfall data under the corresponding time scale to achieve feature enhancement.
- Feature filtering: Multiple linear and nonlinear correlation analyses and feature contribution analyses were utilized to jointly filter out factors with lower sensitivity to the system response.
- ML model construction: All ML algorithms mentioned in Section 2.2.1 were combined with K-fold, grid search, and random search hyperparameter optimization to confirm the optimal structure for each type of model.
- Model evaluation and selection: MAP, RMSE, MAPE, and R2 were used to evaluate the prediction performance of each model.
3. Results and Discussion
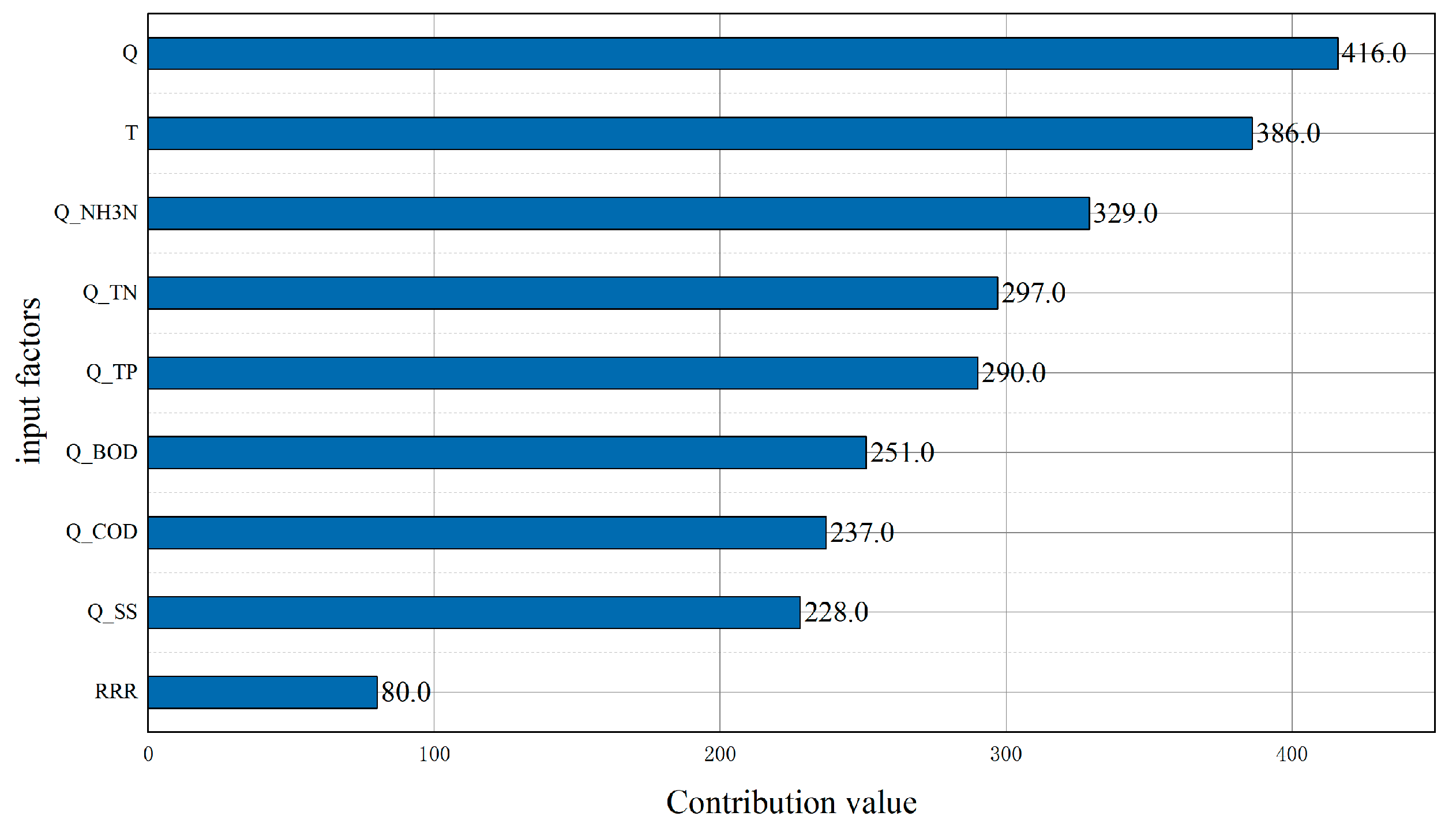
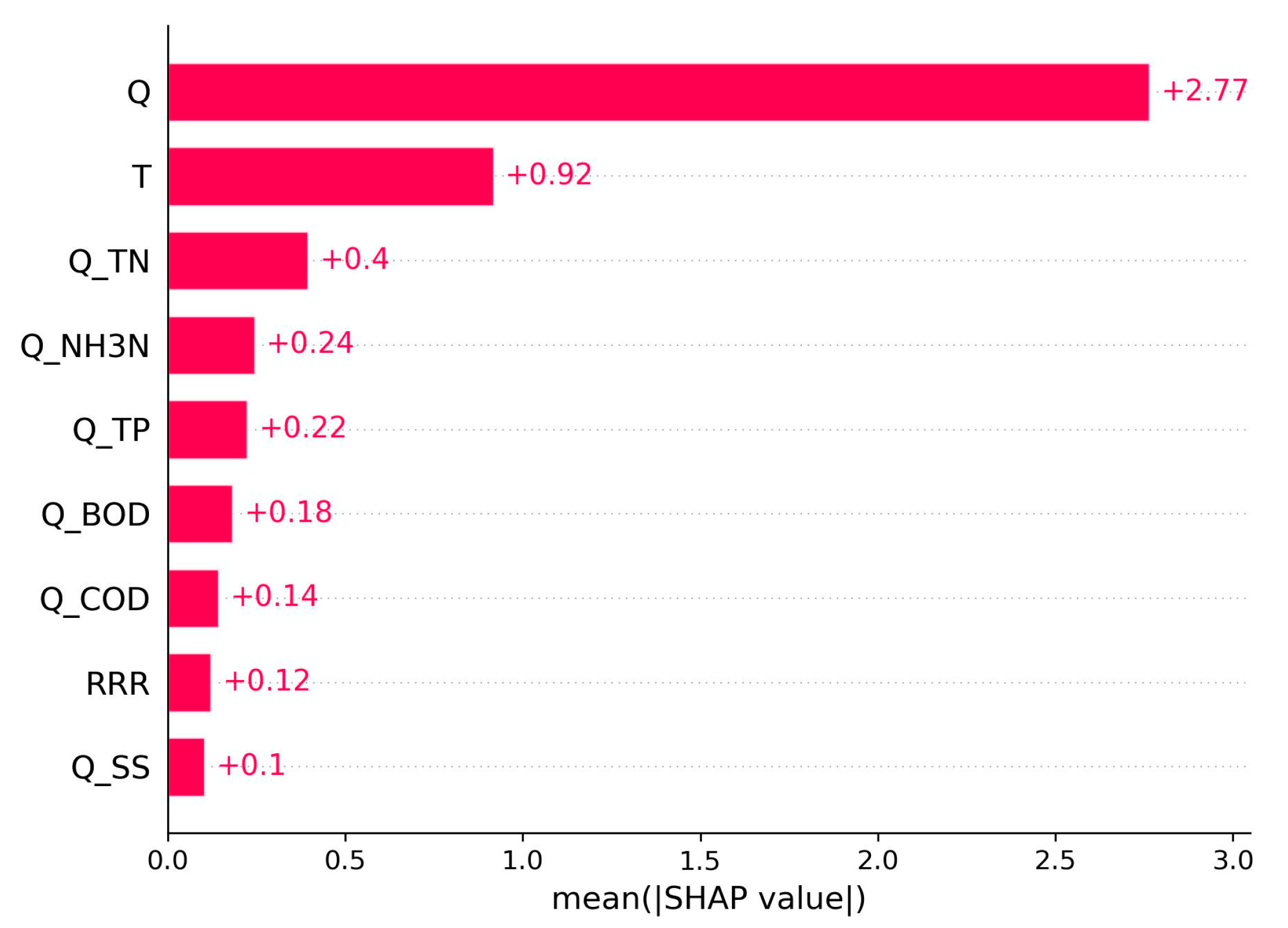
3.1. Feature Engineering Analysis
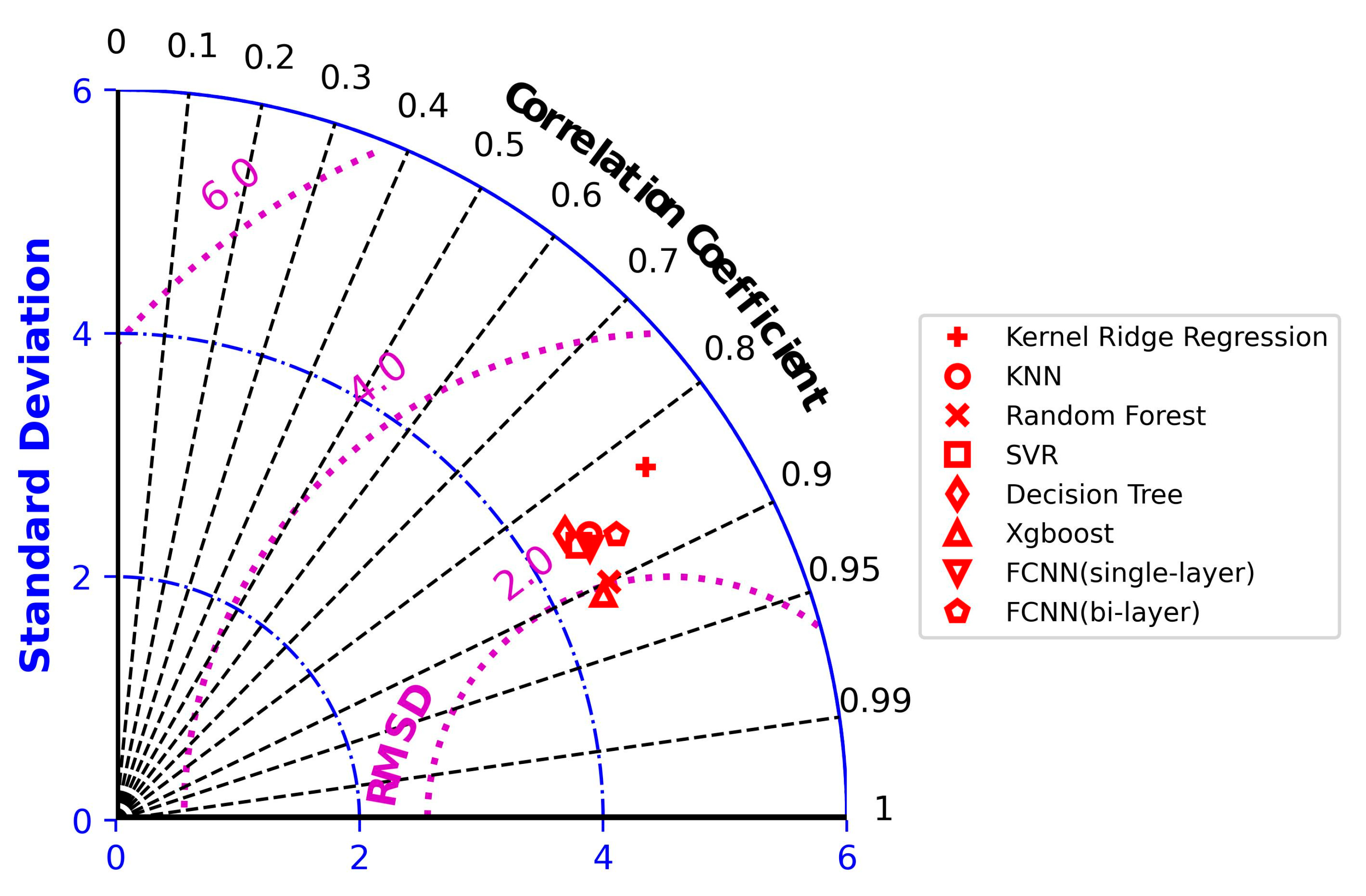
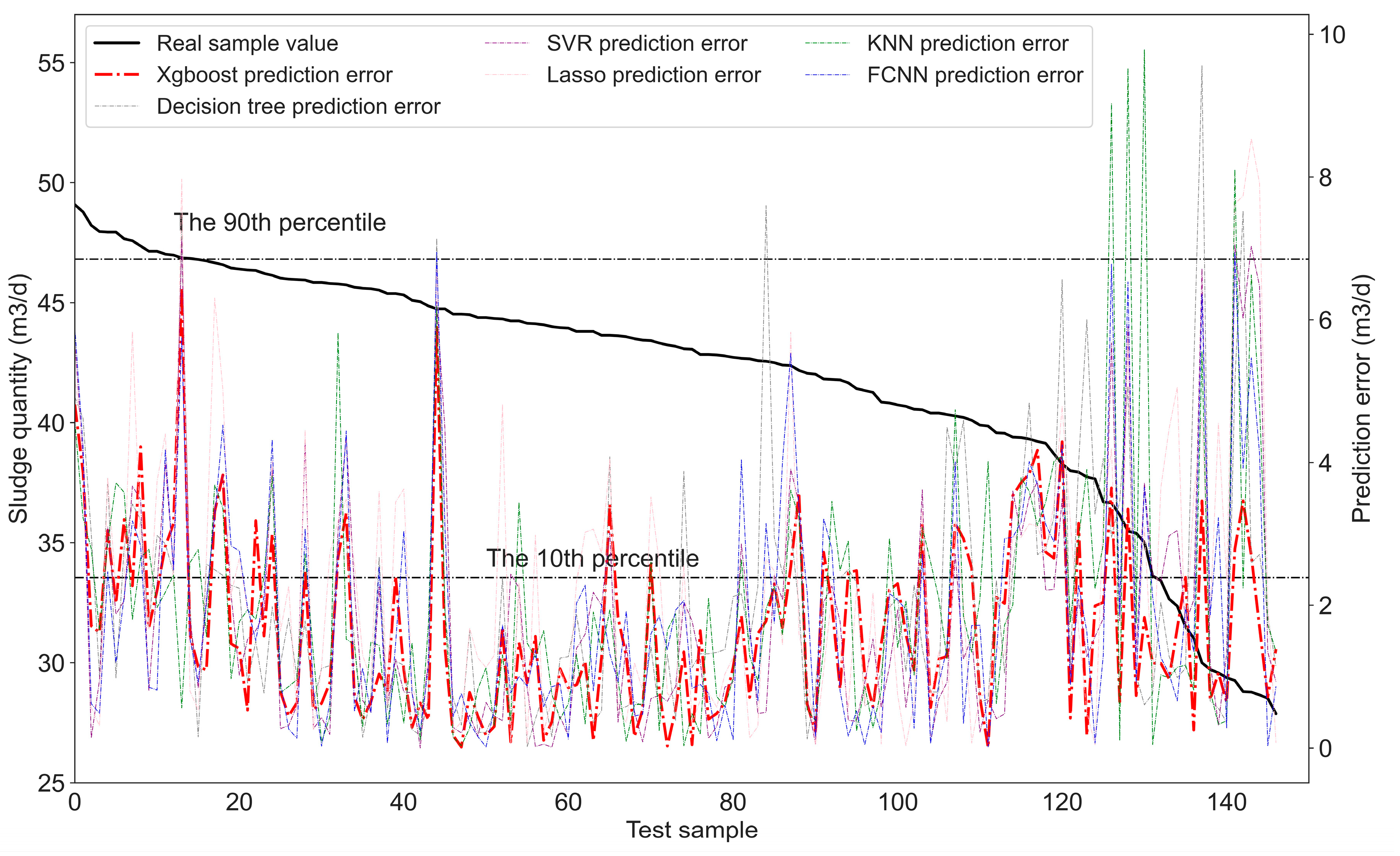
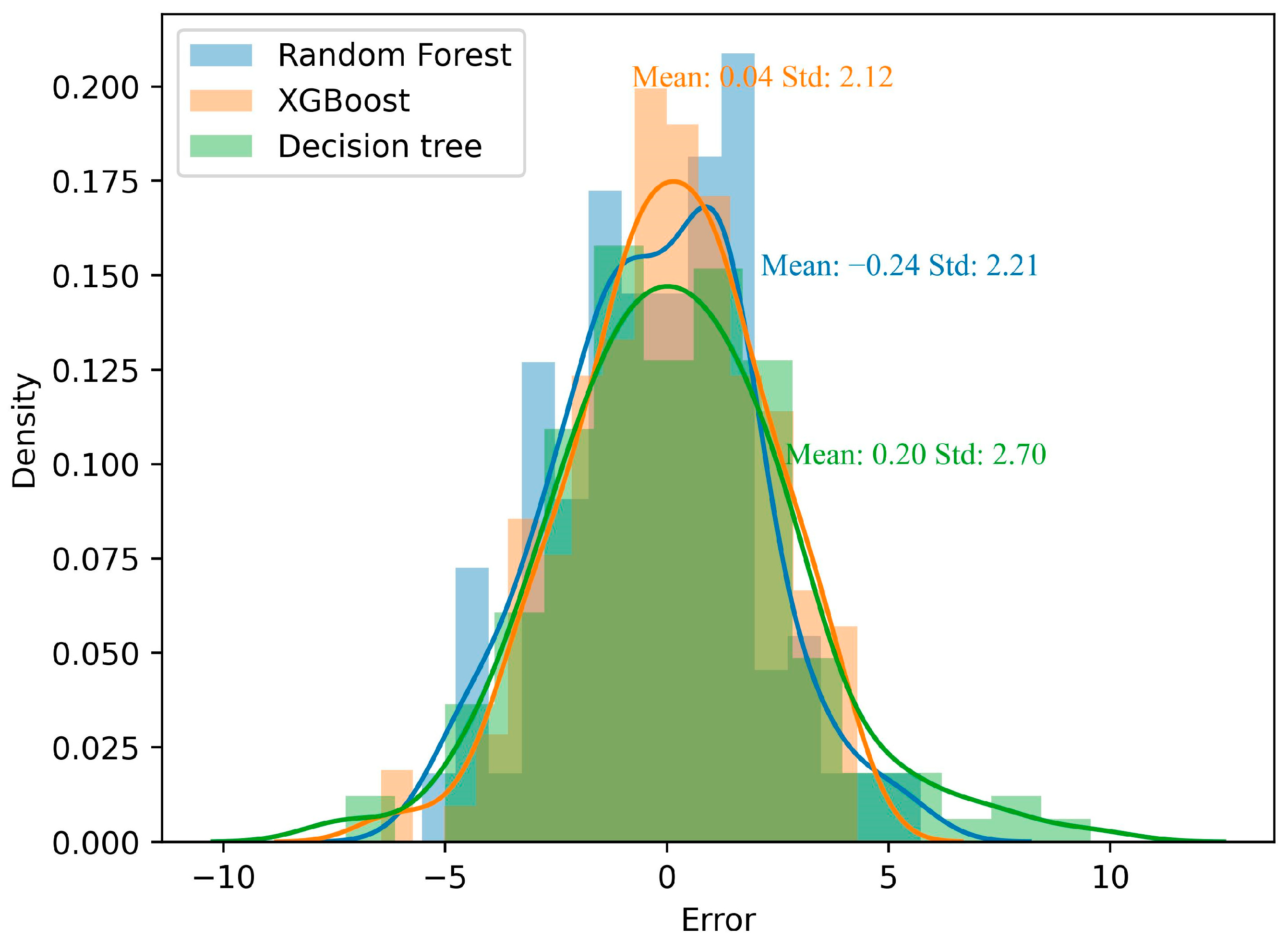
3.2. Optimal Result Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ministry of Housing and Urban-Rural Development of the People’s Republic of China. 2021 China Urban-Rural Construction Statistical Yearbook. Available online: https://www.mohurd.gov.cn/gongkai/fdzdgknr/sjfb/index.html (accessed on 30 May 2023).
- Wang, L. Analysis of seasonal variation and influencing factors of sludge yield in municipal sewage plant. Water Purif. Technol. 2018, 37, 36–40. [Google Scholar]
- Ministry of Ecology and Environment of the People’s Republic of China. Technical Specification for Application and Issuance of Pollutant Permit-Wastewater Treatment (on Trial). [EB/OL]. Available online: https://www.mee.gov.cn/ywgz/fgbz/bz/bzwb/pwxk/201811/t20181115_673874.shtml (accessed on 31 May 2023).
- Henze, M.; Grady, C., Jr.; Gujer, W.; Matsuo, T. Activated Sludge Model No.1: IWA Scientific and Technical Report No.1; IAWPRC: London, UK, 1987. [Google Scholar]
- Zhou, B.; Zhou, D.; Zhang, L.W.; Yu, F.H. Discussion on the design calculation method of activated sludge process. China Water Wastewater 2001, 17, 45–49. [Google Scholar]
- GB50014-2021; Standard for Design of Outdoor Wastewater Engineering. China Planning Press: Beijing, China, 2021.
- Jian, P.; Han, H.S.; Yi, Y.; Huang, H.; Xie, L. Machine learning and deep learning modeling and simulation for predicting PM2.5 concentrations. Chemosphere 2022, 308, 136353. [Google Scholar]
- Quintelas, C.; Melo, A.; Costa, M.; Mesquita, D.; Ferreira, E.; Amaral, A. Environmentally-friendly technology for rapid identification and quantification of emerging pollutants from wastewater using infrared spectroscopy. Environ. Toxicol. Phar. 2020, 80, 103458. [Google Scholar] [CrossRef] [PubMed]
- Torregrossa, D.; Leopold, U.; Hernández-Sancho, F.; Hansen, J. Machine learning for energy cost modelling in wastewater treatment plants. J. Environ. Manag. 2018, 223, 1061–1067. [Google Scholar] [CrossRef]
- Vyas, M.; Kulshrestha, M. Artificial neural networks for forecasting wastewater parameters of a common effluent treatment plant. Int. J. Environ. Waste Manag. 2019, 24, 313–336. [Google Scholar] [CrossRef]
- Ozkan, O.; Ozdemir, O.; Azgin, T.S. Prediction of Biochemical Oxygen Demand in a Wastewater Treatment Plant by Artificial Neural Networks. Chem. Asian. J. 2009, 21, 4821–4830. [Google Scholar]
- Dong, W.; Sven, T.; Ulrika, L.; Jiang, L.; Trygg, J.; Tysklind, M.; Souihi, N. A machine learning framework to improve effluent quality control in wastewater treatment plants. Sci. Total. Environ. 2021, 784, 147138. [Google Scholar]
- Zhou, P.; Li, Z.; Snowling, S.; Baetz, B.W.; Na, D.; Boyd, G. A random forest model for inflow prediction at wastewater treatment plants. Stoch Environ. Res. Risk Assess. 2019, 33, 1781–1792. [Google Scholar] [CrossRef]
- Liu, Z.-J.; Wan, J.-Q.; Ma, Y.-W.; Wang, Y. Online prediction of effluent COD in the anaerobic wastewater treatment system based on PCA-LSSVM algorithm. Evnviron. Sci. Pollution Res. 2019, 26, 12828–12841. [Google Scholar] [CrossRef]
- Wang, R.; Yu, Y.; Chen, Y.; Pan, Z.; Li, X.; Tan, Z.; Zhang, J. Model construction and application for effluent prediction in wastewater treatment plant: Data processing method optimization and process parameters integration. J. Environ. Manag. 2022, 302, 114020. [Google Scholar] [CrossRef] [PubMed]
- Bagherzadeh, F.; Mehrani, M.-J.; Basirifard, M.; Roostaei, J. Comparative study on total nitrogen prediction in wastewater treatment plant and effect of various feature selection methods on machine learning algorithms performance. J. Water Process Eng. 2021, 41, 102033. [Google Scholar] [CrossRef]
- Miao, S.; Zhou, C.; AlQahtani, S.A.; Alrashoud, M.; Ghoneim, A.; Lv, Z. Applying machine learning in intelligent sewage treatment: A case study of chemical plant in sustainable cities. Sustain. Cities Soc. 2021, 702, 103009. [Google Scholar] [CrossRef]
- Mehrani, M.-J.; Bagherzadeh, F.; Zheng, M.; Kowal, P.; Sobotka, D.; Mąkinia, J. Application of a hybrid mechanistic/machine learning model for prediction of nitrous oxide (N2O) production in a nitrifying sequencing batch reactor. Process Saf. Environ. 2022, 162, 1015–1024. [Google Scholar] [CrossRef]
- Wu, X.; Zheng, Z.; Wang, L.; Li, X.; Yang, X.; He, J. Coupling process-based modeling with machine learning for long-term simulation of wastewater treatment plant operations. J. Environ. Manag. 2023, 341, 118116. [Google Scholar] [CrossRef] [PubMed]
- Arslan, K.; Imtiaz, A.; Wasif, F.; Naqvi, S.R.; Mehran, M.T.; Shahid, A.; Liaquat, R.; Anjum, M.W.; Naqvi, M. Investigation of combustion performance of tannery sewage sludge using thermokinetic analysis and prediction by artificial neural network. Case Stud. Therm. Eng. 2022, 40, 102586. [Google Scholar]
- Usman, S.; Jorge, L.; Hai-Tra, N.; Yoo, C. A hybrid extreme learning machine and deep belief network framework for sludge bulking monitoring in a dynamic wastewater treatment process. J. Water Process Eng. 2022, 46, 102580. [Google Scholar]
- Bi, H.; Wang, C.; Jiang, X.; Jiang, C.; Bao, L.; Lin, Q. Thermodynamics, kinetics, gas emissions and artificial neural network modeling of co-pyrolysis of sewage sludge and peanut shell. Fuel 2021, 284, 118988. [Google Scholar] [CrossRef]
- Flores-Alsina, X.; Ramin, E.; Ikumi, D.; Harding, T.; Batstone, D.; Brouckaert, C.; Sotemann, S.; Gernaey, K.V. Assessment of sludge management strategies in wastewater treatment systems using a plant-wide approach. Water Res. 2021, 190, 116714. [Google Scholar] [CrossRef]
- Xu, Z. Study on influencing factors of initial sludge yield in municipal sewage treatment. Urban Roads Bridges Flood Control. 2014, 3, 80–82. [Google Scholar]
- Wu, H.M. A Study on Sludge Production in City Sewage Treatment Works. China Munic. Eng. 1998, 83, 40–42. [Google Scholar]
- Ministry of Ecology and Environment of the People’s Republic of China. Discharge Standard of Pollutants for Municipal Wastewater Treatment Plant (GB 18918-2002). [EB/OL]. Available online: https://www.mee.gov.cn/ywgz/fgbz/bz/bzwb/shjbh/swrwpfbz/200307/t20030701_66529.shtml (accessed on 1 June 2023).
- China Urban Water Association. Annual Report of Chinese Uran Water Utilities (2019); China Architecture & Building Press: Beijing, China, 2020; pp. 130–140. [Google Scholar]
- State Environmental Protection Administration of China. Water and Wastewater Monitoring and Analysis Methods, 4th ed.; China Environmental Science Press: Beijing, China, 2002; pp. 210–213. [Google Scholar]
- Robert, T. Regression shrinkage and selection via the lasso. J. R. Statist. Soc. 1996, 58, 267–288. [Google Scholar]
- Miller, A. Subset Selection in Regression, 2nd ed.; Chapman & Hall/CRC: New York, NJ, USA, 2002. [Google Scholar]
- Draper, N.R.; Smith, H. Applied Regression Analysis, 3rd ed.; Wiley: Hoboken, NJ, USA, 1998. [Google Scholar]
- Hunt, E.B.; Marin, J.; Stone, P.J. Experiments in induction. Acad. Press 1966, 80. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1999. [Google Scholar]
- Denoeux, T. A k-nearest neighbor classification rule-based on dempster-shafer theory. IEEE Trans. Syst. Man Cybern. 1995, 25, 804–813. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.Q.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Pearson, K. Notes on regression and inheritance in the case of two parents. Proc. R. Soc. Lond. 1895, 58, 240–242. [Google Scholar]
- Fieller, E.C.; Hartley, H.O.; Pearson, E.S. Tests for rank correlation coefficients I. Biometrika 1957, 44, 470–481. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; McVean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Monitoring Indicator | Mean Value | Minimum Value | Maximum Value | Median Value | Standard Deviation |
|---|---|---|---|---|---|
| Sludge quantity, (m3/d) | 42.04 | 23.46 | 51.42 | 43.38 | 5.00 |
| Water Quantity of influent water, (m3/d) | 80497.48 | 38139 | 95472 | 81948 | 9711.95 |
| COD of influent water (mg/L) | 225.18 | 88 | 604 | 217 | 58.54 |
| BOD of influent water (mg/L) | 118.71 | 47.94 | 265.76 | 115.65 | 27.81 |
| Ammonia Nitrogen of influent water (mg/L) | 17.47 | 4.35 | 37.22 | 17.41 | 4.01 |
| TP of influent water (mg/L) | 4.03 | 1.58 | 17.26 | 3.84 | 1.21 |
| TN of influent water (mg/L) | 32.19 | 13.65 | 60.07 | 32.16 | 6.00 |
| SS of influent water (mg/L) | 177.27 | 48 | 476 | 180 | 54.04 |
| COD of effluent water (mg/L) | 14.42 | 6.5 | 26.4 | 14.6 | 2.29 |
| BOD of effluent water (mg/L) | 1.52 | 0.98 | 2.56 | 1.53 | 0.21 |
| Ammonia Nitrogen of effluent water (mg/L) | 0.26 | 0.01 | 3.02 | 0.09 | 0.39 |
| TP of effluent water (mg/L) | 0.12 | 0.03 | 0.27 | 0.11 | 0.05 |
| TN of effluent water (mg/L) | 10.38 | 4.46 | 13.7 | 10.47 | 1.56 |
| SS of effluent water (mg/L) | 2.01 | 0.2 | 5.2 | 2 | 0.93 |
| Temperature (°C) | 12.18 | −14.8 | 28.72 | 13.24 | 9.73 |
| Rainfall (mm) | 8.09 | 0 | 247 | 0 | 28.19 |
| Model | Factors Selected for Hyperparameter Optimization | RMSE (m3/d) | MAE (m3/d) | MAPE (p.u.) | R2 (p.u.) |
|---|---|---|---|---|---|
| Lasso Regression | alpha = 0.01 | 2.9891 | 2.1147 | 0.05149 | 0.6470 |
| Kernel Ridge Regression | kernel = ‘polynomial’ alpha = 0.7333333 degree = 3 | 2.0723 | 2.7216 | 0.05112 | 0.7074 |
| DT | max_features = 6 max_depth = 5 | 2.7085 | 2.0878 | 0.05201 | 0.7083 |
| SVR | C = 1 gamma = 0.1 epsilon = 0.01 | 2.5850 | 1.9793 | 0.04809 | 0.7360 |
| KNN Regression | n_neighbors = 9 | 2.6187 | 2.0260 | 0.04949 | 0.7291 |
| FCNN (single-layer) | weight_decay = 0.005 momentum = 0.9 learning_rate = 0.01 epoch = 10,000 network structure = 1024 | 2.5198 | 1.9546 | 0.04743 | 0.7492 |
| FCNN (bi-layer) | weight_decay = 0.005 momentum = 0.9 learning_rate = 0.01 epoch = 10,000 network structure = 1024 × 1024 | 2.2464 | 1.7707 | 0.04319 | 0.8006 |
| RF | max_features = 7 max_depth = 7 n_estimators = 365 | 2.2090 | 1.7710 | 0.04297 | 0.8072 |
| XGBoost | learning_rate = 0.1147 n_estimators = 90 max_depth = 5 | 2.1169 | 1.7032 | 0.0415 | 0.8218 |
| Model | Factors Selected for Hyperparameter Optimization | RMSE (m3/d) | MAE (m3/d) | MAPE (p.u.) | R2 (p.u.) |
|---|---|---|---|---|---|
| Lasso Regression | alpha = 0.01 | 2.7901 | 2.1218 | 0.05324 | 0.6875 |
| Kernel Ridge Regression | kernel = ‘polynomial’ alpha = 0.7333333 degree = 3 | 2.5106 | 1.9268 | 0.04780 | 0.7470 |
| DT | max_features = 6 max_depth = 5 | 2.0847 | 1.6389 | 0.0393 | 0.8255 |
| SVR | C = 1 gamma = 0.1 epsilon = 0.01 | 2.3173 | 1.6148 | 0.04026 | 0.7841 |
| KNN Regression | n_neighbors = 9 | 2.4501 | 1.8520 | 0.04572 | 0.7590 |
| FCNN (single-layer) | weight_decay = 0.005 momentum = 0.9 learning_rate = 0.01 epoch = 10,000 network structure = 1024 | 1.9060 | 1.4605 | 0.03602 | 0.8539 |
| FCNN (bi-layer) | weight_decay = 0.005 momentum = 0.9 learning_rate = 0.01 epoch = 10,000 network structure = 1024 × 1024 | 1.7695 | 1.3694 | 0.03342 | 0.8743 |
| RF | max_features = 7 max_depth = 7 n_estimators = 365 | 1.2015 | 1.4862 | 0.02905 | 0.9112 |
| XGBoost | learning_rate = 0.1147 n_estimators = 90 max_depth = 5 | 1.1723 | 1.4925 | 0.02852 | 0.9106 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, S.; Fu, D.; Yang, T.; Mu, H.; Gao, Q.; Zhang, Y. Analysis of Machine Learning Models for Wastewater Treatment Plant Sludge Output Prediction. Sustainability 2023, 15, 13380. https://doi.org/10.3390/su151813380
Shao S, Fu D, Yang T, Mu H, Gao Q, Zhang Y. Analysis of Machine Learning Models for Wastewater Treatment Plant Sludge Output Prediction. Sustainability. 2023; 15(18):13380. https://doi.org/10.3390/su151813380
Chicago/Turabian StyleShao, Shuai, Dianzheng Fu, Tianji Yang, Hailin Mu, Qiufeng Gao, and Yun Zhang. 2023. "Analysis of Machine Learning Models for Wastewater Treatment Plant Sludge Output Prediction" Sustainability 15, no. 18: 13380. https://doi.org/10.3390/su151813380
APA StyleShao, S., Fu, D., Yang, T., Mu, H., Gao, Q., & Zhang, Y. (2023). Analysis of Machine Learning Models for Wastewater Treatment Plant Sludge Output Prediction. Sustainability, 15(18), 13380. https://doi.org/10.3390/su151813380