Sustainable Financial Fraud Detection Using Garra Rufa Fish Optimization Algorithm with Ensemble Deep Learning


Abstract
:1. Introduction
2. Related Works
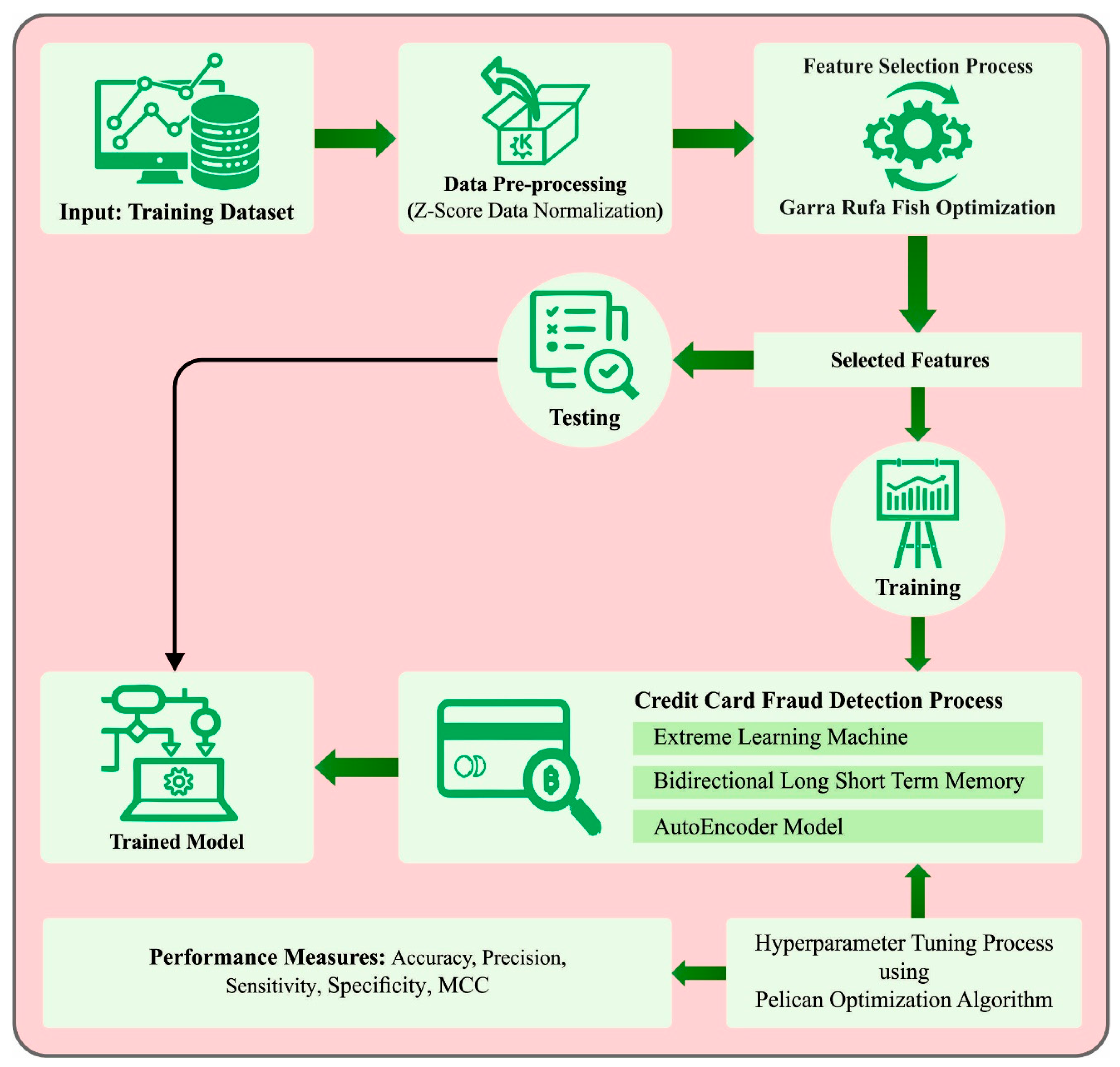
3. The Proposed Model
3.1. Data Normalization
3.2. Feature Selection Using GRFO Algorithm
- Step 1:
- Initialization
- Step 2:
- Random generation
- Step 3:
- Fitness calculation
- Step 4:
- Resort the parameter
- Step 5:
- Check the iteration
- Step 6:
- Upgrade the parameter
- Step 7:
- Find the best and the worst leaders
- Step 8:
- Upgrade the position as well as the speed
3.3. Ensemble-Learning Process
3.3.1. ELM Model
- Random assignment of the input layer weight and HL bias;
- Computation of the resultant matrix of HL, ;
- Computation of the resultant weight,
3.3.2. AE Model
3.3.3. BiLSTM Model
3.4. Parameter Tuning Using POA
- Stage 1:
- moving towards the prey (exploration stage)
- Stage 2:
- winging on the water surface (exploitation stage)
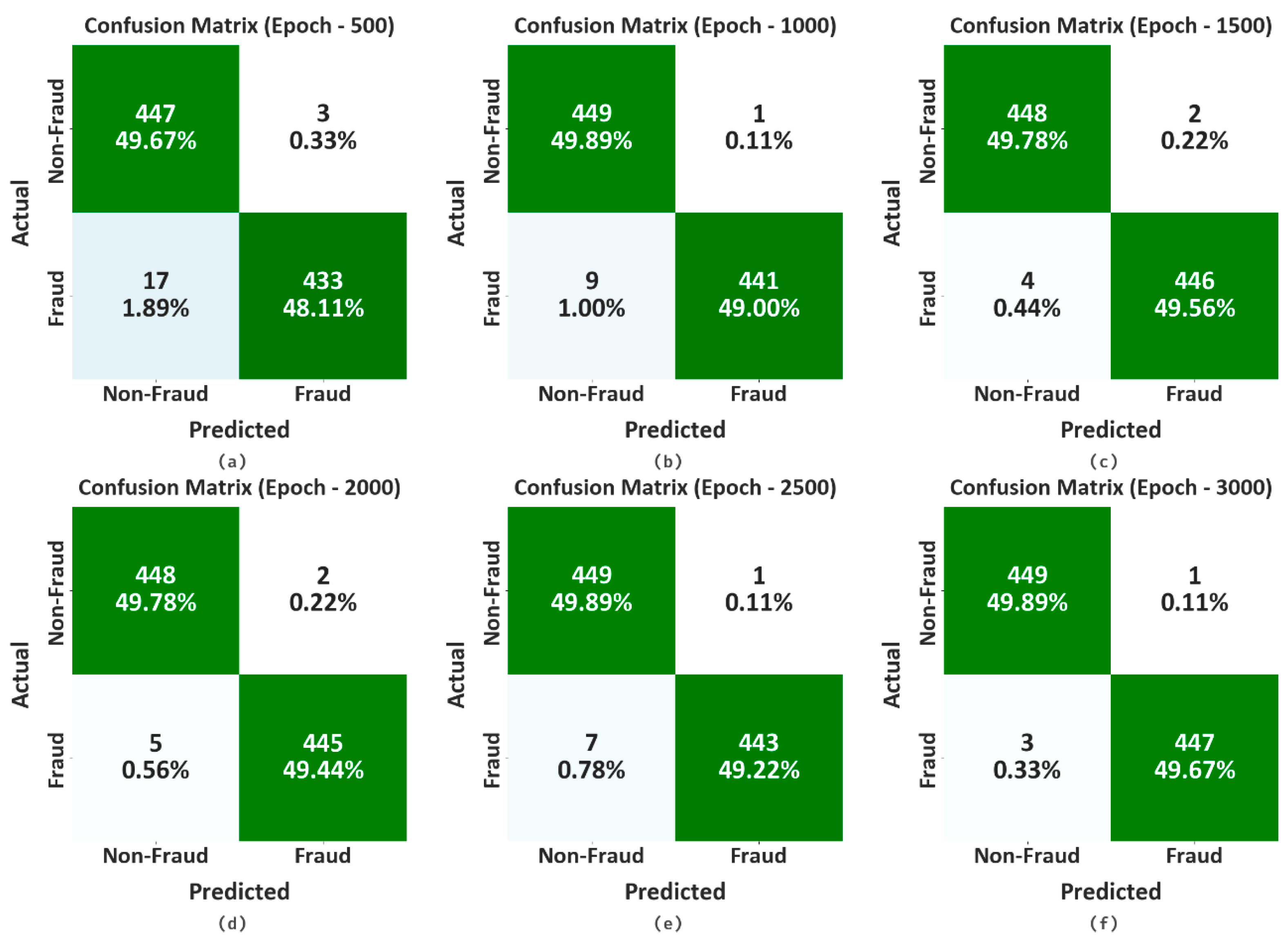
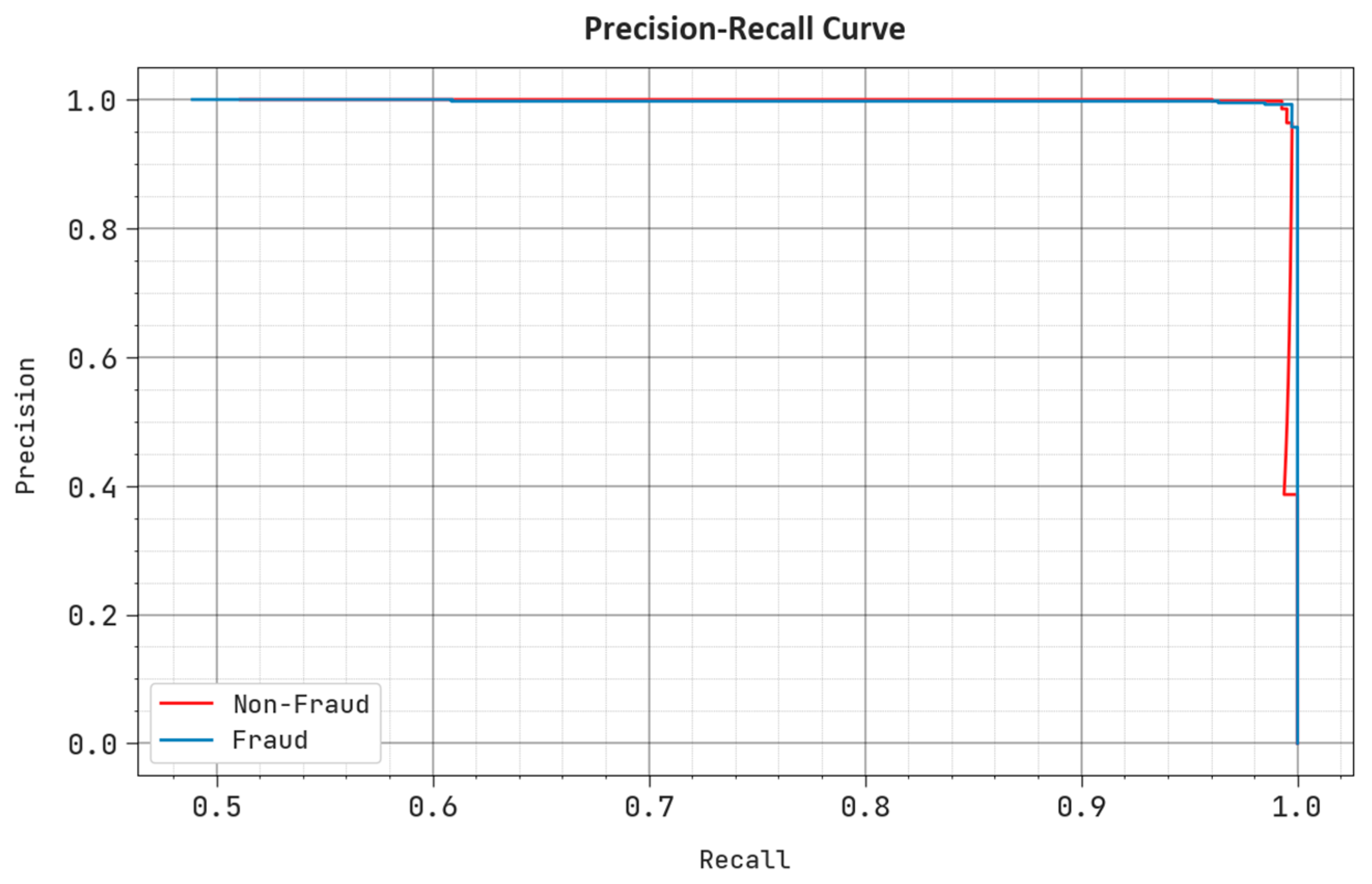
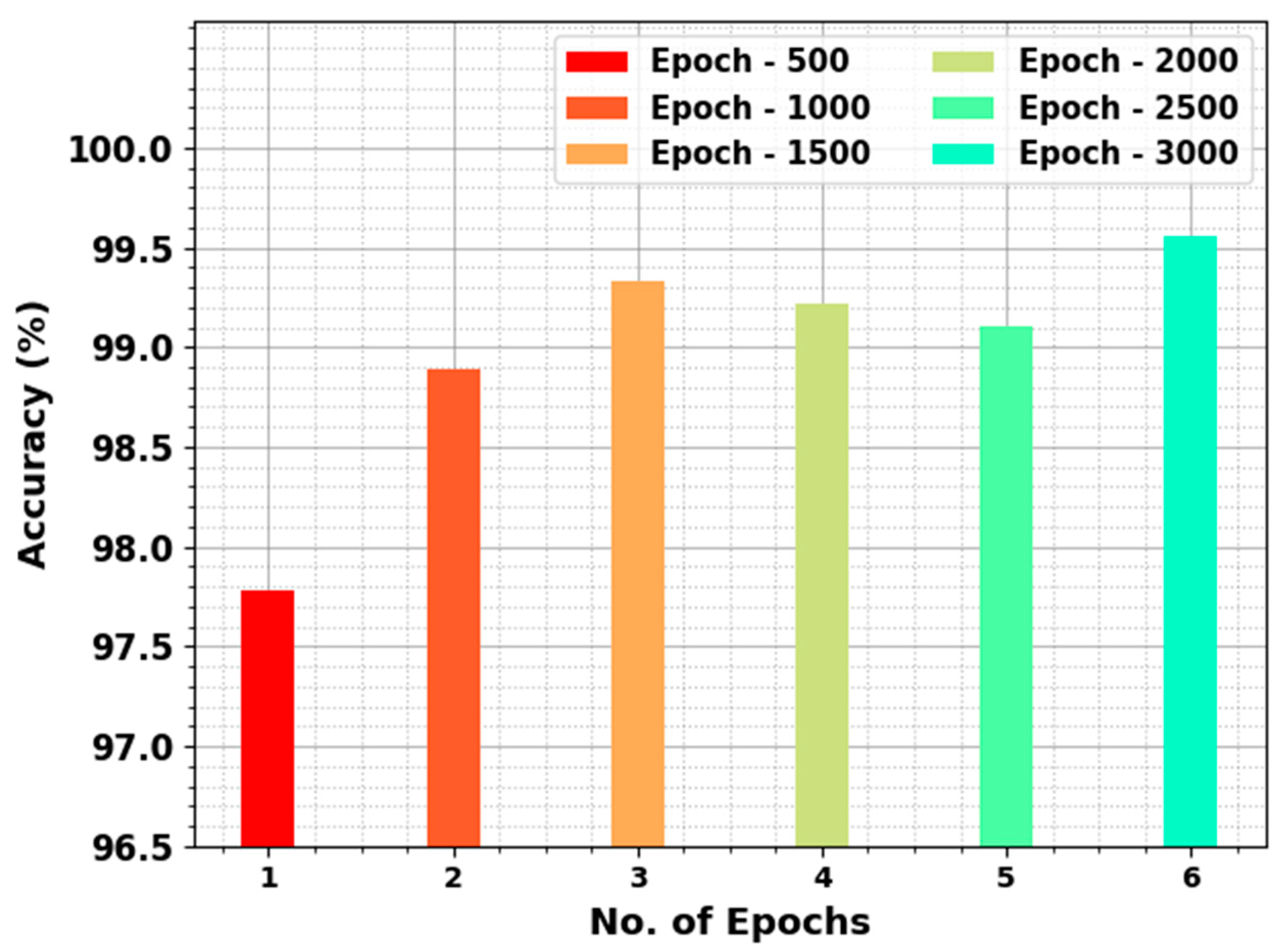
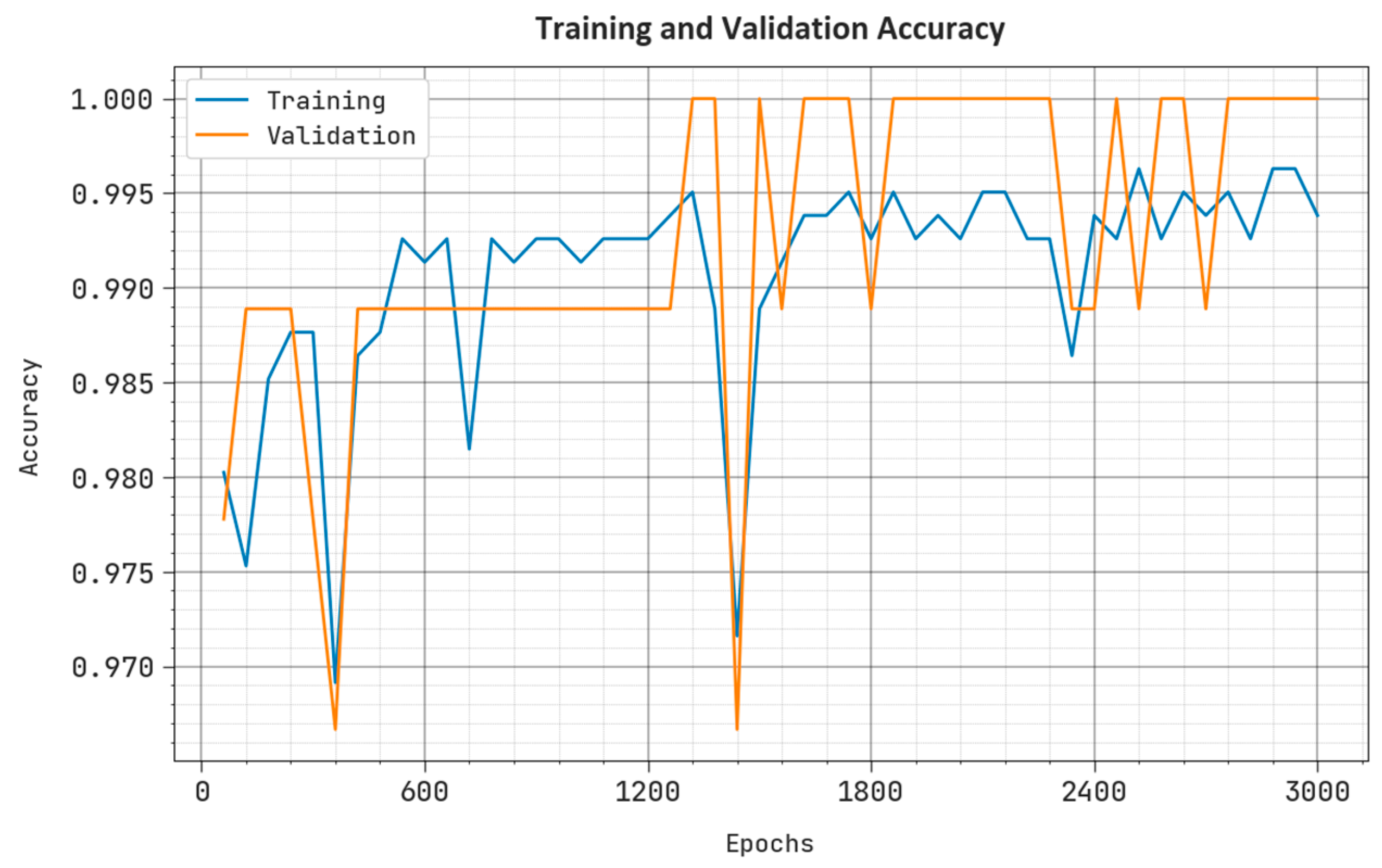
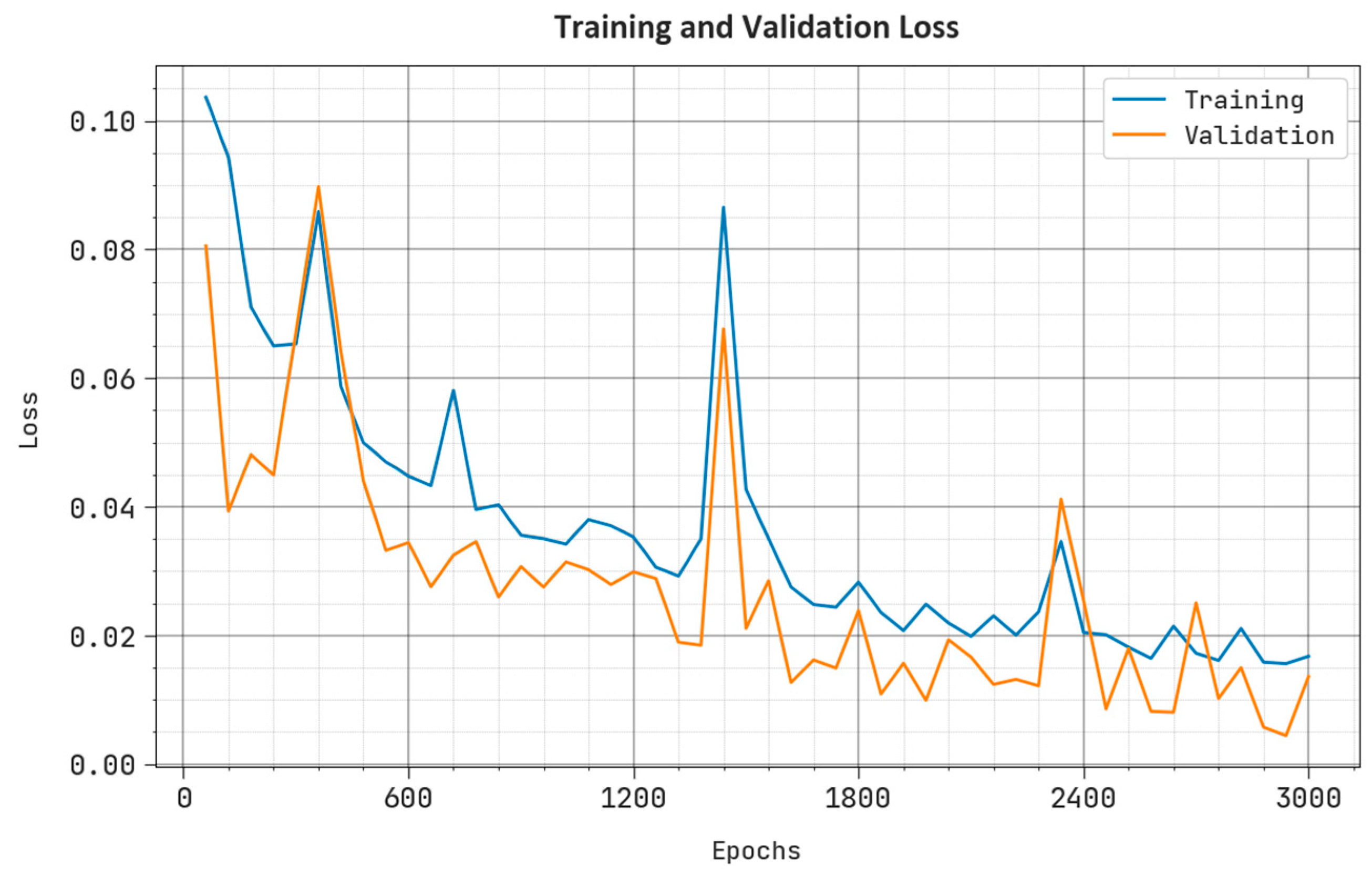
4. Experimental Validation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Strelcenia, E.; Prakoonwit, S. Improving Classification Performance in Credit Card Fraud Detection by Using New Data Augmentation. AI 2023, 4, 172–198. [Google Scholar] [CrossRef]
- Han, S.; Zhu, K.; Zhou, M.; Cai, X. Competition-driven multimodal multiobjective optimization and its application to feature selection for credit card fraud detection. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 7845–7857. [Google Scholar] [CrossRef]
- Zhang, X.; Han, Y.; Xu, W.; Wang, Q. HOBA: A novel feature engineering methodology for credit card fraud detection with a deep learning architecture. Inf. Sci. 2021, 557, 302–316. [Google Scholar] [CrossRef]
- Fanai, H.; Abbasimehr, H. A novel combined approach based on deep Autoencoder and deep classifiers for credit card fraud detection. Expert Syst. Appl. 2023, 217, 119562. [Google Scholar] [CrossRef]
- Alam, M.N.; Podder, P.; Bharati, S.; Mondal, M.R.H. Effective machine learning approaches for credit card fraud detection. In Innovations in Bio-Inspired Computing and Applications: Proceedings of the 11th International Conference on Innovations in Bio-Inspired Computing and Applications (IBICA 2020) Held during December 16–18, 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; Volume 11, pp. 154–163. [Google Scholar]
- Chang, V.; Di Stefano, A.; Sun, Z.; Fortino, G. Digital payment fraud detection methods in digital ages and Industry 4.0. Comput. Electr. Eng. 2022, 100, 107734. [Google Scholar] [CrossRef]
- Mustaqim, A.Z.; Adi, S.; Pristyanto, Y.; Astuti, Y. The effect of recursive feature elimination with cross-validation (RFECV) feature selection algorithm toward classifier performance on credit card fraud detection. In Proceedings of the 2021 International Conference on Artificial Intelligence and Computer Science Technology (ICAICST), Yogyakarta, Indonesia, 29–30 June 2021; pp. 270–275. [Google Scholar]
- Malik, E.F.; Khaw, K.W.; Belaton, B.; Wong, W.P.; Chew, X. Credit card fraud detection using a new hybrid machine learning architecture. Mathematics 2022, 10, 1480. [Google Scholar] [CrossRef]
- Fragkos, G.; Minwalla, C.; Plusquellic, J.; Tsiropoulou, E.E. Age Appropriate Digital Services for Young People: Major Reforms. IEEE Consum. Electron. Mag. 2021, 10, 81–89. [Google Scholar] [CrossRef]
- Sharma, P.; Banerjee, S.; Tiwari, D.; Patni, J.C. Machine learning model for credit card fraud detection-a comparative analysis. Int. Arab J. Inf. Technol. 2021, 18, 789–796. [Google Scholar] [CrossRef]
- Prabhakaran, N.; Nedunchelian, R. Oppositional Cat Swarm Optimization-Based Feature Selection Approach for Credit Card Fraud Detection. Comput. Intell. Neurosci. 2023, 2023, 2693022. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, H.; Kasasbeh, B.; Aldabaybah, B.; Rawashdeh, E. Class balancing framework for credit card fraud detection based on clustering and similarity-based selection (SBS). Int. J. Inf. Technol. 2023, 15, 325–333. [Google Scholar] [CrossRef]
- Gradxs, G.P.B.; Rao, N. Behaviour Based Credit Card Fraud Detection Design And Analysis By Using Deep Stacked Autoencoder Based Harris Grey Wolf (Hgw) Method. Scand. J. Inf. Syst. 2023, 35, 1–8. [Google Scholar]
- Ileberi, E.; Sun, Y.; Wang, Z. A machine learning based credit card fraud detection using the GA algorithm for feature selection. J. Big Data 2022, 9, 1–17. [Google Scholar] [CrossRef]
- Kajal, D.; Kaur, K. Credit card fraud detection using imbalance resampling method with feature selection. Int. J. 2021, 10, 2061–2071. [Google Scholar]
- Poongodi, K.; Kumar, D. Support vector machine with information gain based classification for credit card fraud detection system. Int. Arab J. Inf. Technol. 2021, 18, 199–207. [Google Scholar]
- Benchaji, I.; Douzi, S.; El Ouahidi, B.; Jaafari, J. Enhanced credit card fraud detection based on attention mechanism and LSTM deep model. J. Big Data 2021, 8, 1–21. [Google Scholar] [CrossRef]
- Velicheti, S.S.; Pavan, A.S.H.; Reddy, B.T.; Srikala, N.V.; Pranay, R.; Kannaiah, S.K. The Hustlee Credit Card Fraud Detection using Machine Learning. In Proceedings of the 2023 7th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 21–23 February 2023; pp. 139–144. [Google Scholar]
- Shyamala Devi, M.; Arun Pandian, J.; Ramesh, P.S.; Prem Chand, A.; Raj, A.; Raj, A.; Thakur, R.K. Oversampled Deep Fully Connected Neural Network Towards Improving Classifier Performance for Fraud Detection. In Advances in Data and Information Sciences: Proceedings of ICDIS 2022; Springer Nature: Singapore, 2022; pp. 363–371. [Google Scholar]
- Jiang, S.; Dong, R.; Wang, J.; Xia, M. Credit Card Fraud Detection Based on Unsupervised Attentional Anomaly Detection Network. Systems 2023, 11, 305. [Google Scholar] [CrossRef]
- Makkineni, N.; Ciripuram, A.; Subhani, S.; Kakulapati, V. Fraud Detection of AD Clicks Using Machine Learning Techniques. J. Sci. Res. Rep. 2023, 29, 84–89. [Google Scholar] [CrossRef]
- Nalluri, V.; Chang, J.R.; Chen, L.S.; Chen, J.C. Building prediction models and discovering important factors of health insurance fraud using machine learning methods. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 9607–9619. [Google Scholar] [CrossRef]
- Reddy, C.S.R.; Prasanth, B.V.; Chandra, B.M. Active power management of grid-connected PV-PEV using a Hybrid GRFO-ITSA technique. Sci. Technol. Energy Transit. 2023, 78, 7. [Google Scholar] [CrossRef]
- Zhu, H.; Li, D.; Yang, M.; Ye, D. Prediction of Microstructure and Mechanical Properties of Atmospheric Plasma-Sprayed 8YSZ Thermal Barrier Coatings Using Hybrid Machine Learning Approaches. Coatings 2023, 13, 602. [Google Scholar] [CrossRef]
- Zhu, H.; Shang, Y.; Wan, Q.; Cheng, F.; Hu, H.; Wu, T. A Model Transfer Method among Spectrometers Based on Improved Deep Autoencoder for Concentration Determination of Heavy Metal Ions by UV-Vis Spectra. Sensors 2023, 23, 3076. [Google Scholar] [CrossRef] [PubMed]
- Du, S.; Li, T.; Yang, Y.; Horng, S.J. Deep air quality forecasting using hybrid deep learning framework. IEEE Trans. Knowl. Data Eng. 2019, 33, 2412–2424. [Google Scholar] [CrossRef]
- Rezk, H.; Olabi, A.G.; Abdelkareem, M.A.; Alahmer, A.; Sayed, E.T. Maximizing Green Hydrogen Production from Water Electrocatalysis: Modeling and Optimization. J. Mar. Sci. Eng. 2023, 11, 617. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud (accessed on 21 February 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Mean | 3.046538594859702 |
| Median | 0.0037348229952574 |
| Mode | 0.1653518004028392 |
| Range | (−27.09050638644751, 906.7002687825046) |
| Variance | 2158.3034791158266 |
| Standard Deviation | 46.26638560626861 |
| Skewness | 1.9831378890382467 |
| Kurtosis | 143.9746801155737 |
| Count (Number of Classes) | 2 |
| Class | Accuracy | Precision | Sensitivity | Specificity | MCC |
|---|---|---|---|---|---|
| Epoch—500 | |||||
| Non-Fraud | 99.33 | 96.34 | 99.33 | 96.22 | 95.60 |
| Fraud | 96.22 | 99.31 | 96.22 | 99.33 | 95.60 |
| Average | 97.78 | 97.82 | 97.78 | 97.78 | 95.60 |
| Epoch—1000 | |||||
| Non-Fraud | 99.78 | 98.03 | 99.78 | 98.00 | 97.79 |
| Fraud | 98.00 | 99.77 | 98.00 | 99.78 | 97.79 |
| Average | 98.89 | 98.90 | 98.89 | 98.89 | 97.79 |
| Epoch—1500 | |||||
| Non-Fraud | 99.56 | 99.12 | 99.56 | 99.11 | 98.67 |
| Fraud | 99.11 | 99.55 | 99.11 | 99.56 | 98.67 |
| Average | 99.33 | 99.33 | 99.33 | 99.33 | 98.67 |
| Epoch—2000 | |||||
| Non-Fraud | 99.56 | 98.90 | 99.56 | 98.89 | 98.45 |
| Fraud | 98.89 | 99.55 | 98.89 | 99.56 | 98.45 |
| Average | 99.22 | 99.22 | 99.22 | 99.22 | 98.45 |
| Epoch—2500 | |||||
| Non-Fraud | 99.78 | 98.46 | 99.78 | 98.44 | 98.23 |
| Fraud | 98.44 | 99.77 | 98.44 | 99.78 | 98.23 |
| Average | 99.11 | 99.12 | 99.11 | 99.11 | 98.23 |
| Epoch—3000 | |||||
| Non-Fraud | 99.78 | 99.34 | 99.78 | 99.33 | 99.11 |
| Fraud | 99.33 | 99.78 | 99.33 | 99.78 | 99.11 |
| Average | 99.56 | 99.56 | 99.56 | 99.56 | 99.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maashi, M.; Alabduallah, B.; Kouki, F. Sustainable Financial Fraud Detection Using Garra Rufa Fish Optimization Algorithm with Ensemble Deep Learning. Sustainability 2023, 15, 13301. https://doi.org/10.3390/su151813301
Maashi M, Alabduallah B, Kouki F. Sustainable Financial Fraud Detection Using Garra Rufa Fish Optimization Algorithm with Ensemble Deep Learning. Sustainability. 2023; 15(18):13301. https://doi.org/10.3390/su151813301
Chicago/Turabian StyleMaashi, Mashael, Bayan Alabduallah, and Fadoua Kouki. 2023. "Sustainable Financial Fraud Detection Using Garra Rufa Fish Optimization Algorithm with Ensemble Deep Learning" Sustainability 15, no. 18: 13301. https://doi.org/10.3390/su151813301
APA StyleMaashi, M., Alabduallah, B., & Kouki, F. (2023). Sustainable Financial Fraud Detection Using Garra Rufa Fish Optimization Algorithm with Ensemble Deep Learning. Sustainability, 15(18), 13301. https://doi.org/10.3390/su151813301