

Analysis of Factors Influencing the Severity of Vehicle-to-Vehicle Accidents Considering the Built Environment: An Interpretable Machine Learning Model


Abstract
:1. Introduction
2. Literature Review
3. Data
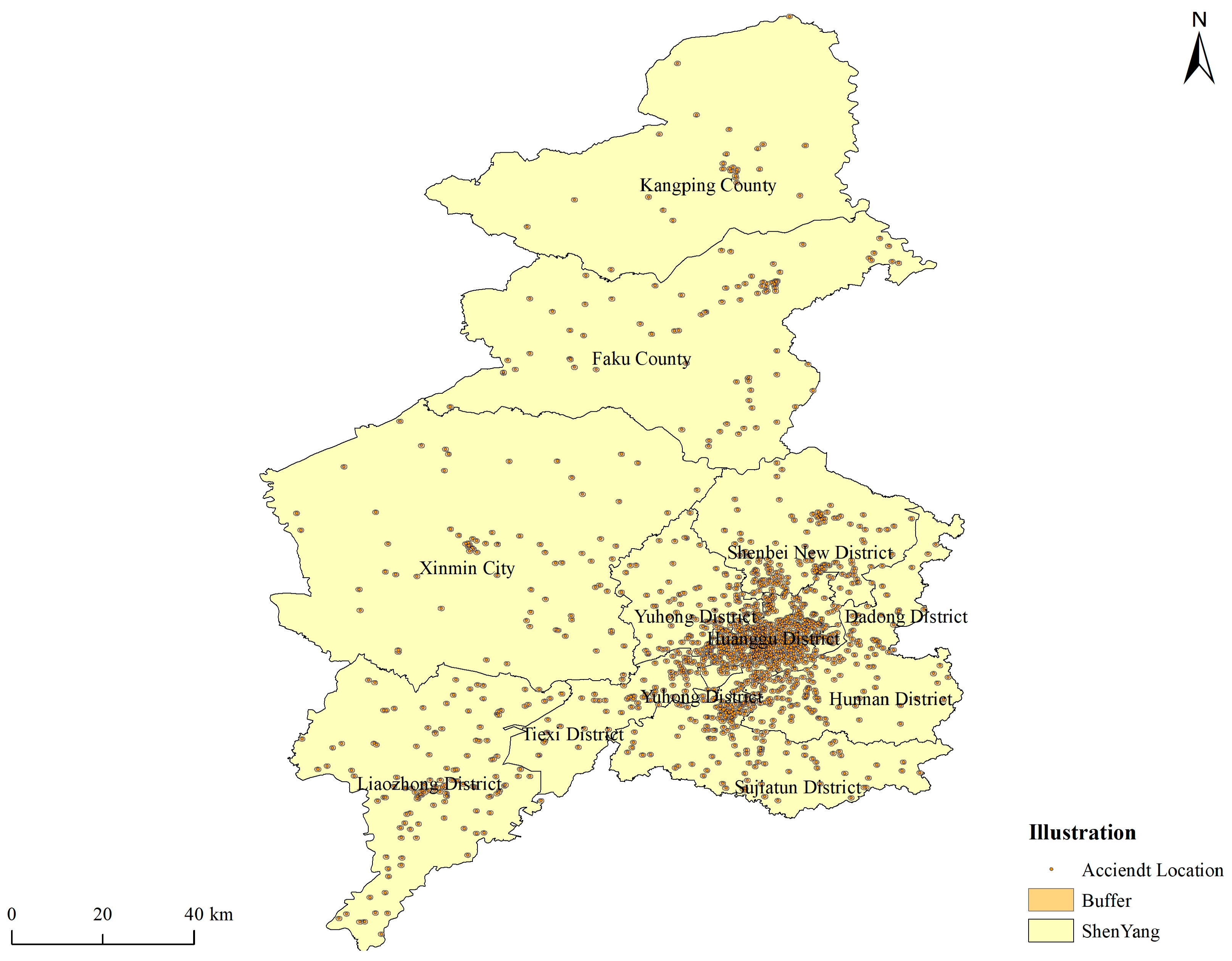
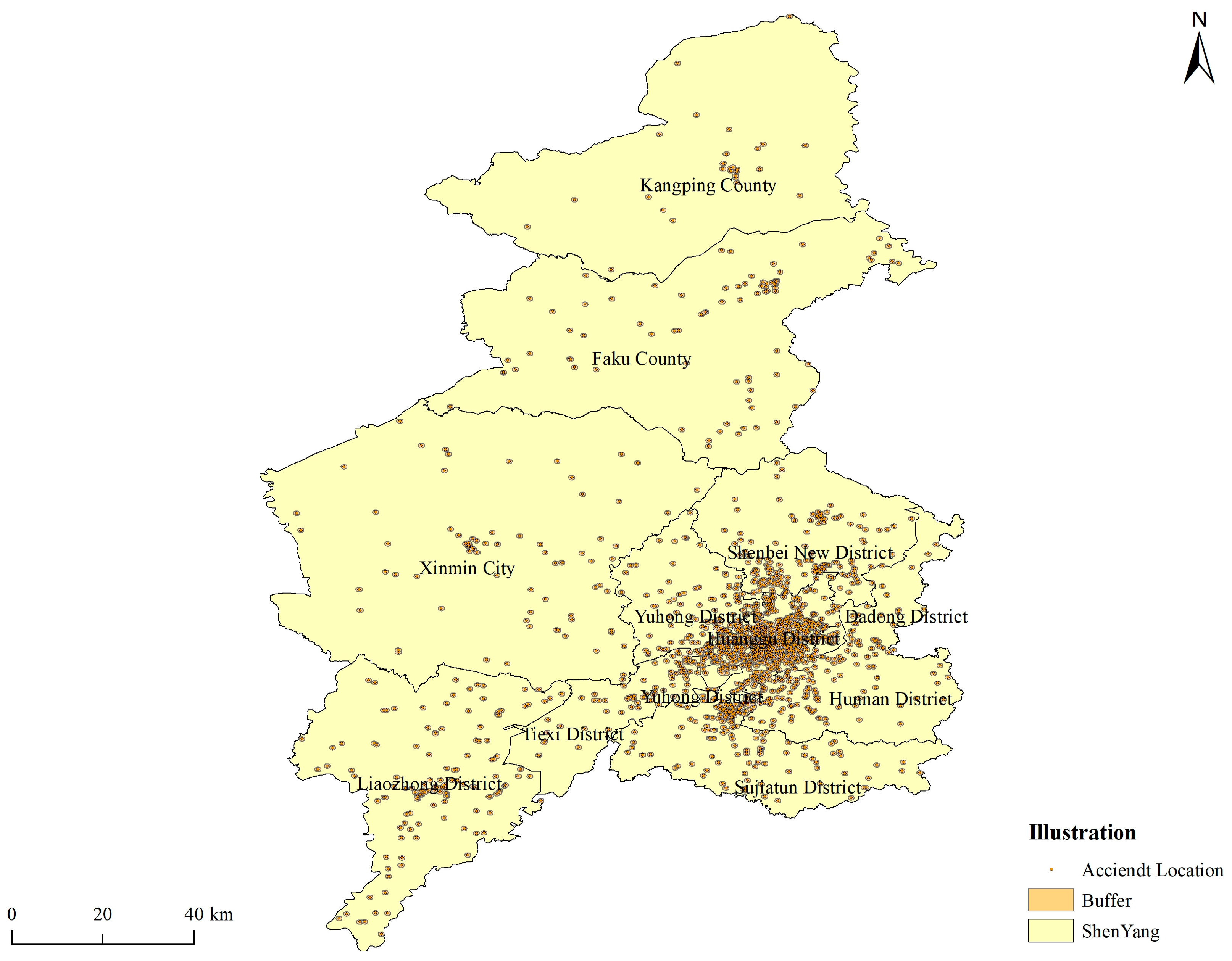
3.1. Data Resource and Processing
- (1)
- Data containing pedestrians and collision data of single vehicles were excluded; data on crash between motor vehicles and motor vehicles, non-motor vehicles and motor vehicles, and non-motor vehicles and non-motor vehicles were selected;
- (2)
- Extracted data on driver accidents with equal, primary, and total responsibility in the liability determination;
- (3)
- Data on exceptional cases, such as tire blowouts and driver’s sudden illness, were removed;
- (4)
- During the coordinate matching process, data with latitude and longitude accuracies below 30% were excluded.
3.2. Variable Selection
4. Methodology
4.1. Random Forest
- (1)
- Construct sample subset. Randomly select N samples from the original training sample set C to generate a new training set, and repeat this process K times to generate K sample sets.
- (2)
- Construct the genus subspace. For each subsample set, m features are randomly selected from all M random feature variables, m < M.
- (3)
- Build a decision tree. In the process of generating the Random Forest, K decision trees are generated based on the above constructed subsample sets and generic subspaces, each corresponding to each training subset.
- (4)
- Construct the Random Forest model. The K decision trees generated in step (2) are combined into a Random Forest, and the model is trained with training data.
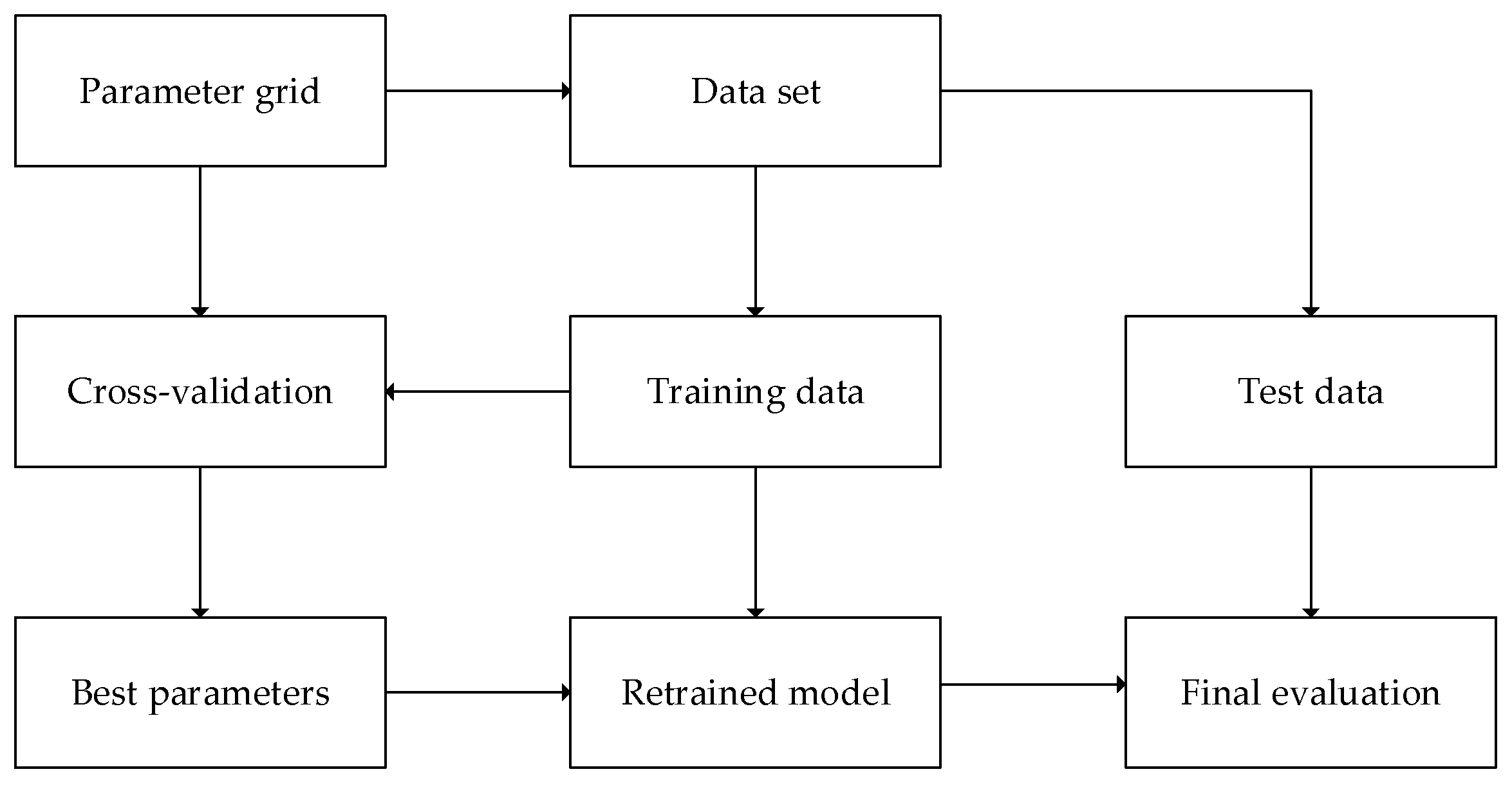
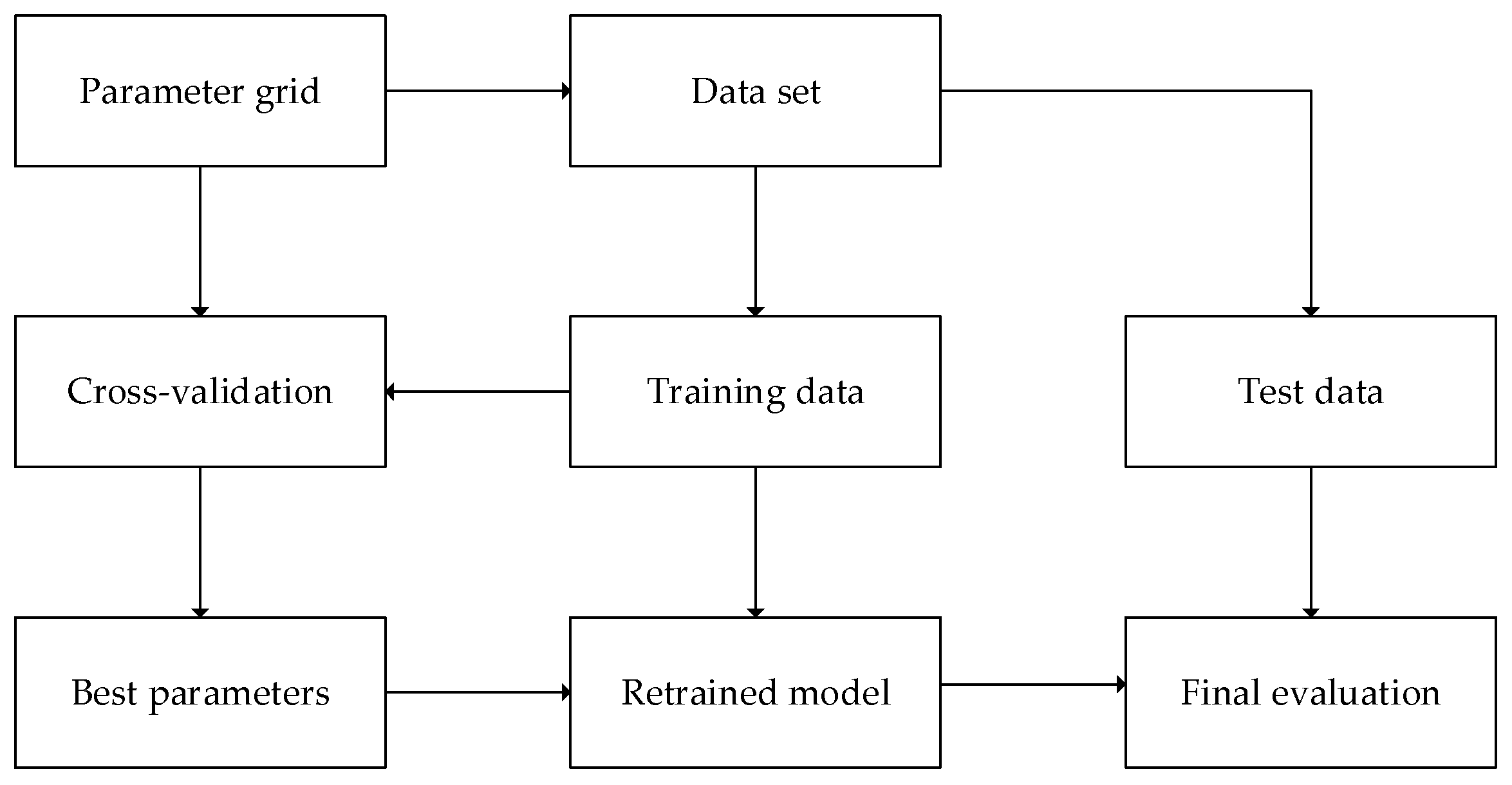
4.2. Hyperparameter Adjustment
4.3. Shapley Value and SHAP
5. Result and Discussion
5.1. Analysis and Discussion of Results
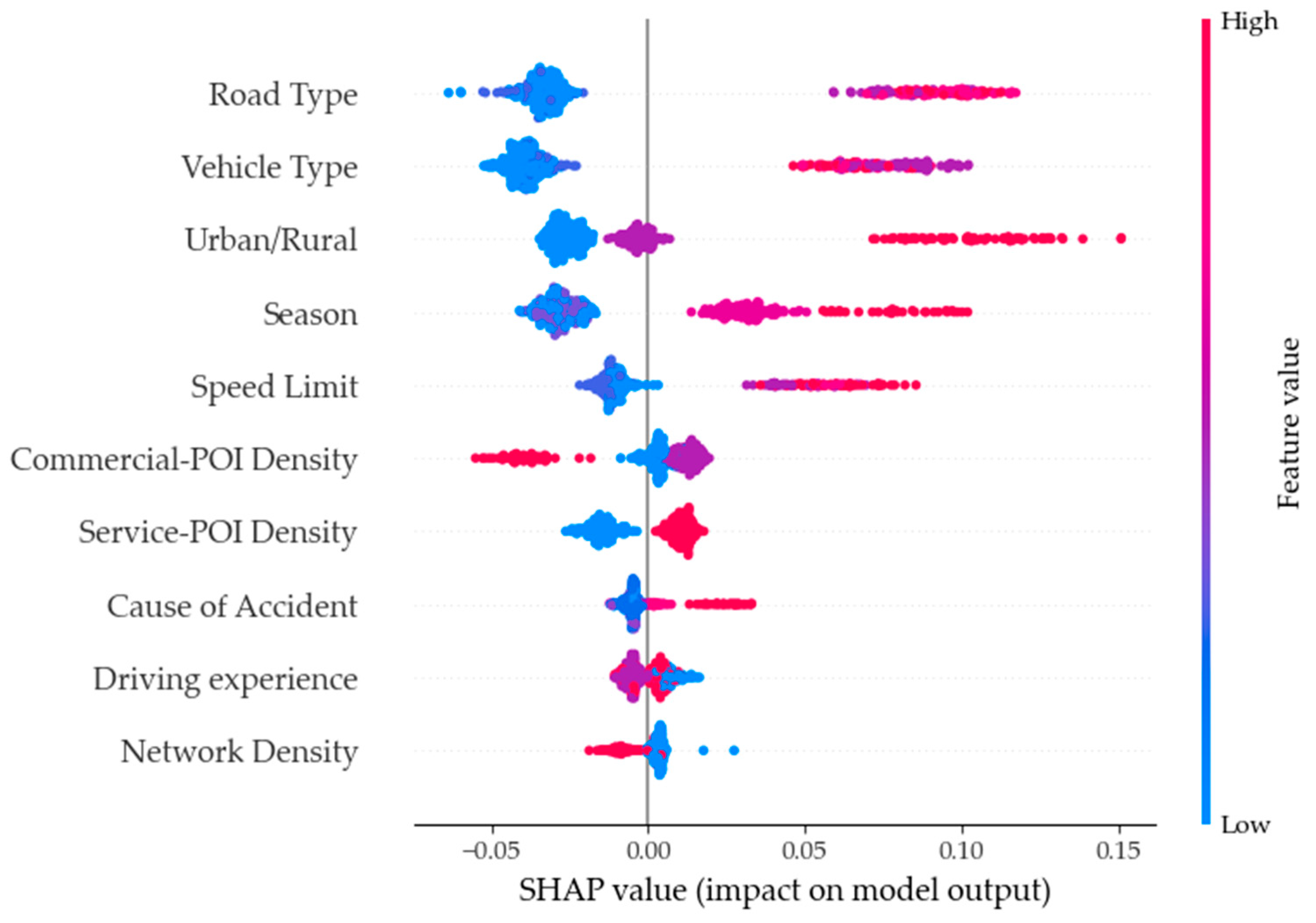
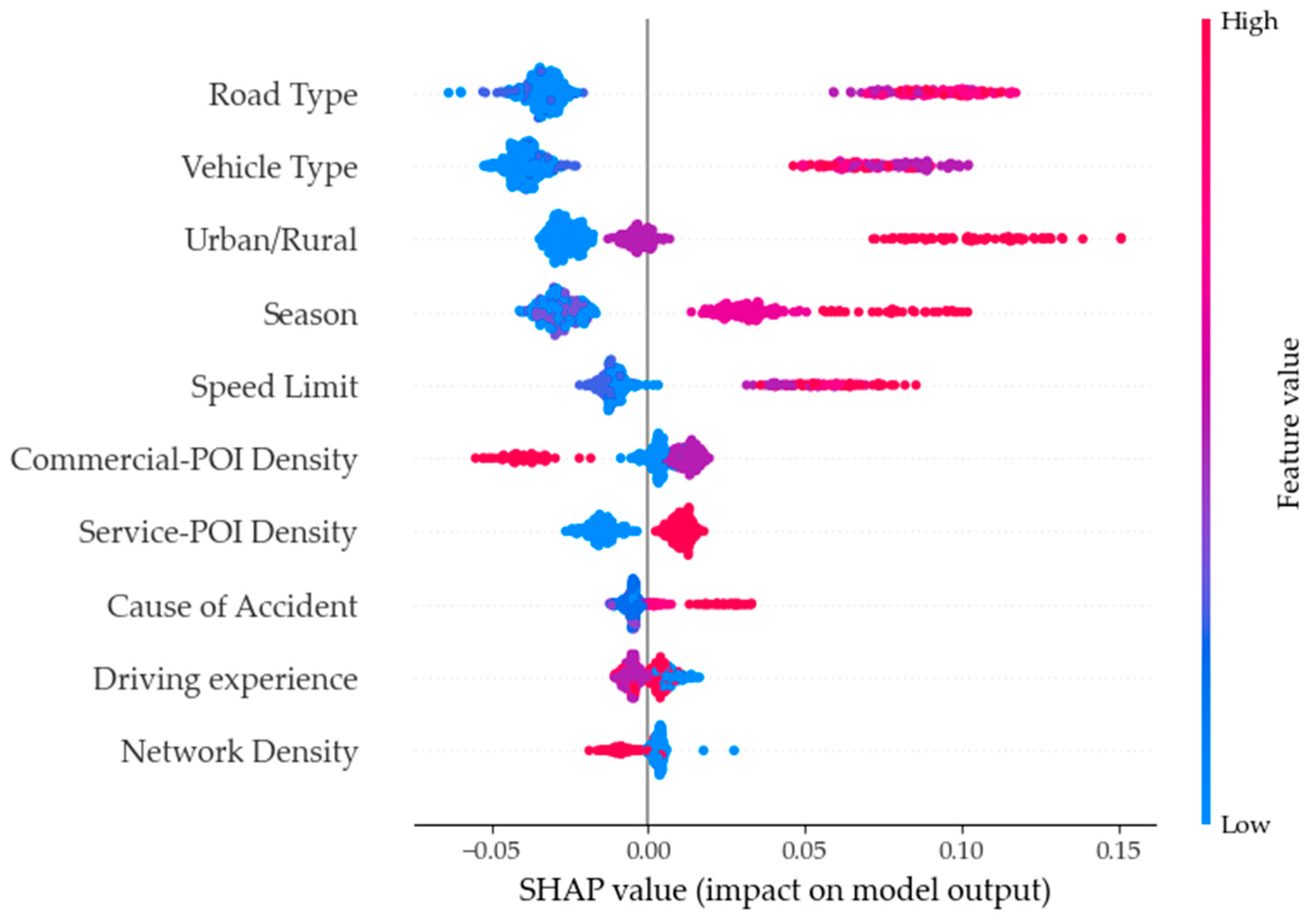
- (1)
- For road type, as its feature value increases, it positively affects the severity of high-level accidents, such as accidents on urban expressways, which are usually more severe. As its feature value decreases, it harms the severity of high-level accidents, such as accidents on trunk roads or lower-level roads, which are usually less severe. This result was consistent with previous studies’ results [43]. This is consistent with previous studies, and contrary to previous perceptions, low-grade roads may instead have a more negative impact on fatal accidents due to the mandatory restrictions of overly narrow roads or one-way streets, and it is not difficult to find that high-grade roads tend to have higher speed limits in China, so high-speed limits are one of the reasons for the positive impact on fatal accidents.
- (2)
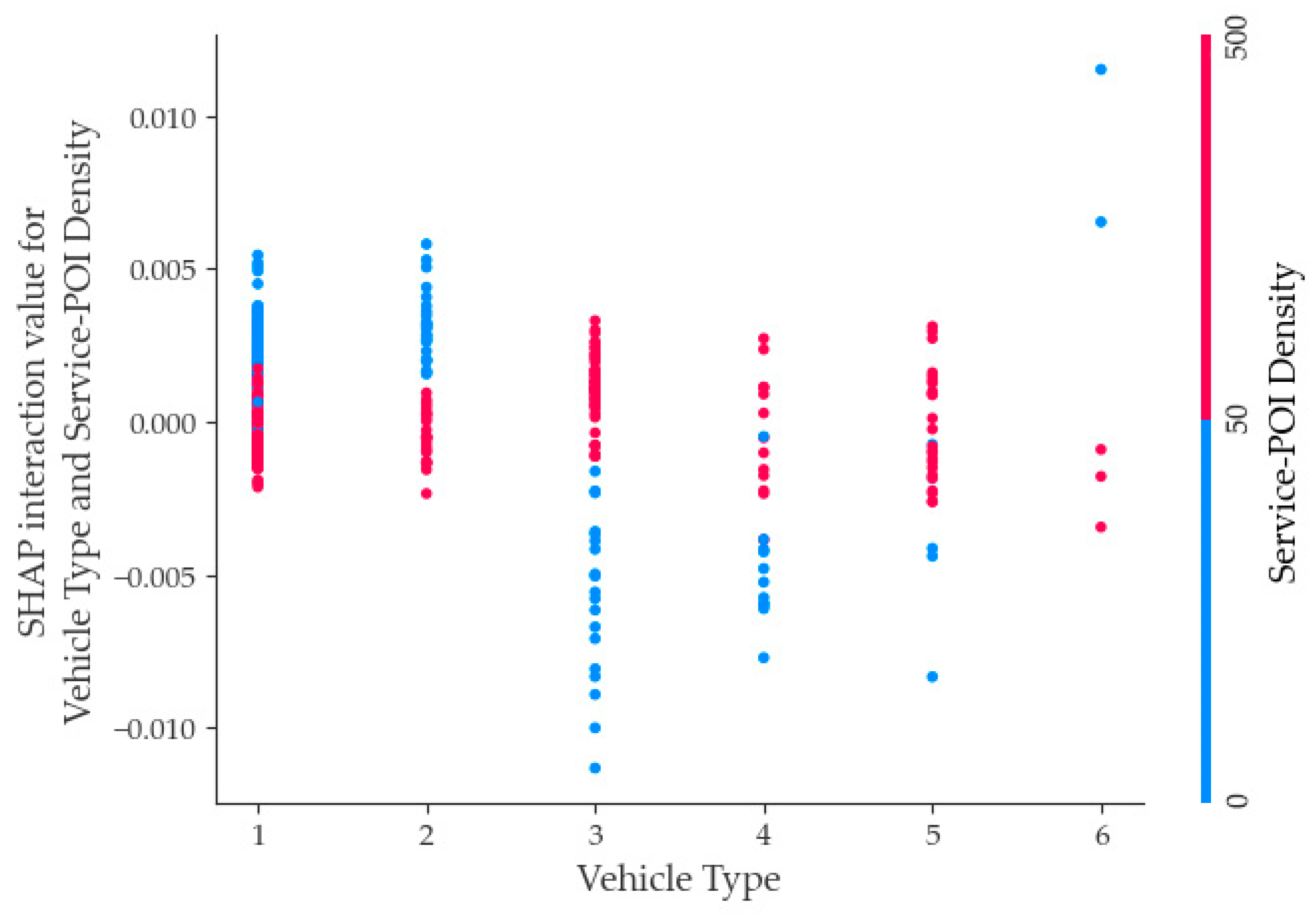
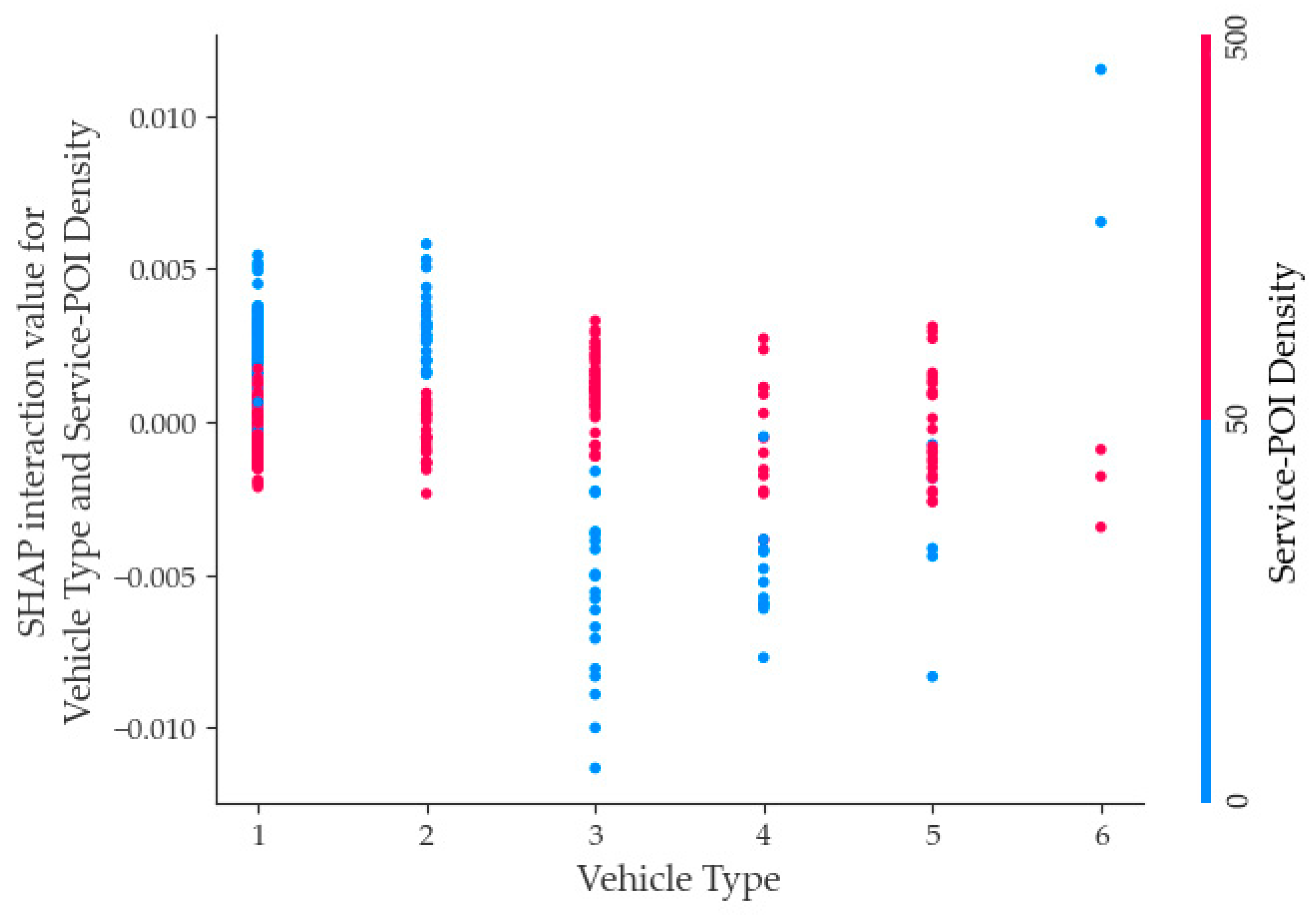
- Regarding vehicle type, a decrease in its feature value is associated with a negative impact on fatal accidents. Specifically, if the driver at fault is driving a non-motorized vehicle, the effects of vehicle type on fatal accidents are relatively small. However, when the feature value of vehicle type is at an intermediate level, it has a more significant positive effect on fatal accidents than when its feature value is high. In other words, if the driver at fault is driving a minivan or motorcar, the impact of vehicle type on fatal accidents is more considerable than if the driver at fault is driving a non-motorized vehicle. The dataset’s sample size of drivers driving minivans and small trucks is lower; a common phenomenon in general developed cities in China today, where passenger car travel is prevalent. However, the construction of road infrastructure still leaves much to be desired and can create traffic congestion in most areas, leading to higher accident rates and high severity of accidents.
- (3)
- For urban/rural areas, the two colors of its feature values correspond to urban (blue) and rural (red). The areas where the SHAP values are less than zero are mainly blue points, indicating a negative effect on the severity of accidents, i.e., the possibility of minor accidents is greater when accidents occur in urban districts. The areas where the SHAP values are greater than zero are mainly red points, indicating a positive effect on the severity of accidents, i.e., accidents in rural districts are usually more severe [43]. The positive effect of suburban areas on fatal accidents is much more significant than that of urban areas, which is similar to the principle mentioned above, precisely because of the developed road network in cities and towns. Meanwhile, suburban areas are primarily national or provincial roads, so drivers are less alert, thus having a positive effect on fatal accidents, which is corroborated by the result that lower road network density has a more positive impact.
- (4)
- For speed limit, as its feature value increases, it positively affects the severity of accidents, i.e., the higher the speed limit, the more severe the accident. Similar findings have been generated in previous studies [44]. As its feature value decreases, it has a negative effect on the severity of accidents, i.e., the lower the speed limit, the less severe the accident.
- (5)
- For the age of the driver, as its feature value increases or decreases, it has a positive effect on the severity of accidents, i.e., the higher or lower the age range of the driver, the more severe the accident. This is related to driver behavior psychology, as research shows that middle-aged drivers have safer driving styles, while young people may have more impulsive or less experienced driving skills. In traffic behavior psychology studies, drivers who are too young lack driving experience and are prone to rashness and recklessness, while drivers who are too old have a low reaction time and lose their ability to handle emergencies or lag in their reactions [36], so these people have higher accident severity than middle-aged people.
- (6)
- For season, the severity of accidents corresponds to multiple feature values, but the positive SHAP values mainly consist of red dots, indicating that accidents occurring in winter tend to be more severe. This is due to the distinct feature of long winters in Shenyang, China, where most days between November and March have low temperatures and snowy weather, resulting in worse road conditions and more severe accidents [17]. This result also indirectly demonstrates that weather may have an impact on the severity of accidents. Shenyang is one of the cities in northeastern China, and the most crucial feature of this region is the long winter season, up to six months, half of the year in a low-temperature environment, where road conditions are complicated by low temperatures or snowfall, requiring a high level of driving operation and vehicle performance. Therefore, the long winter season has had a positive impact on fatal accidents.
- (7)
- For Service-POI density, as its feature value increases, it has a positive effect on the severity of accidents, indicating that when the density of the POI is high, the severity of accidents tends to be higher. This result was consistent with previous studies’ results [38]. As its feature value decreases, it has a negative effect on the severity of accidents, indicating that when the density of the Service-POI density is low, the severity of accidents tends to be lower.
- (8)
- For the cause of the accident, as its feature value increases, it has a positive effect on the severity of accidents, indicating that when the cause of accidents is failure to follow signal instructions, the severity of accidents tends to be higher [40]. As its feature value decreases, it has a negative effect on the severity of accidents, indicating that when the cause of accidents is the improper operation of the driver, the severity of accidents tends to be lower. In Shenyang, motor vehicles’ disobedience of signals can be very costly, while non-motorized vehicles and pedestrians do not have better enforcement, especially with the development of the take-out industry, which is more prominent. Often disobeying signals is more likely to produce fatal accidents and is also a more oriented result. After all, extreme penalties for drivers who violate signal rules have been incorporated into Chinese traffic laws.
- (9)
- For network density, as its feature value decreases, it positively affects the severity of accidents, indicating that when the road network density is low, the severity of accidents tends to be higher. As its feature value increases, it has a negative effect on the severity of accidents, indicating that when the road network density is high, the severity of accidents tends to be lower. Meanwhile, in a study by Zafri et al. [45], they found that higher road network density has a positive effect on fatalities in pedestrian accidents.
- (10)
- For Commercial-POI density, as its feature value decreases, it positively affects the severity of accidents, indicating that when the density of the Commercial-POI is low, the severity of accidents tends to be higher [46]. As its feature value increases, it has a negative effect on the severity of accidents, indicating that when the density of the Commercial-POI is high, the severity of accidents tends to be lower.
5.2. Selected Sources of Research Methodology
6. Conclusions
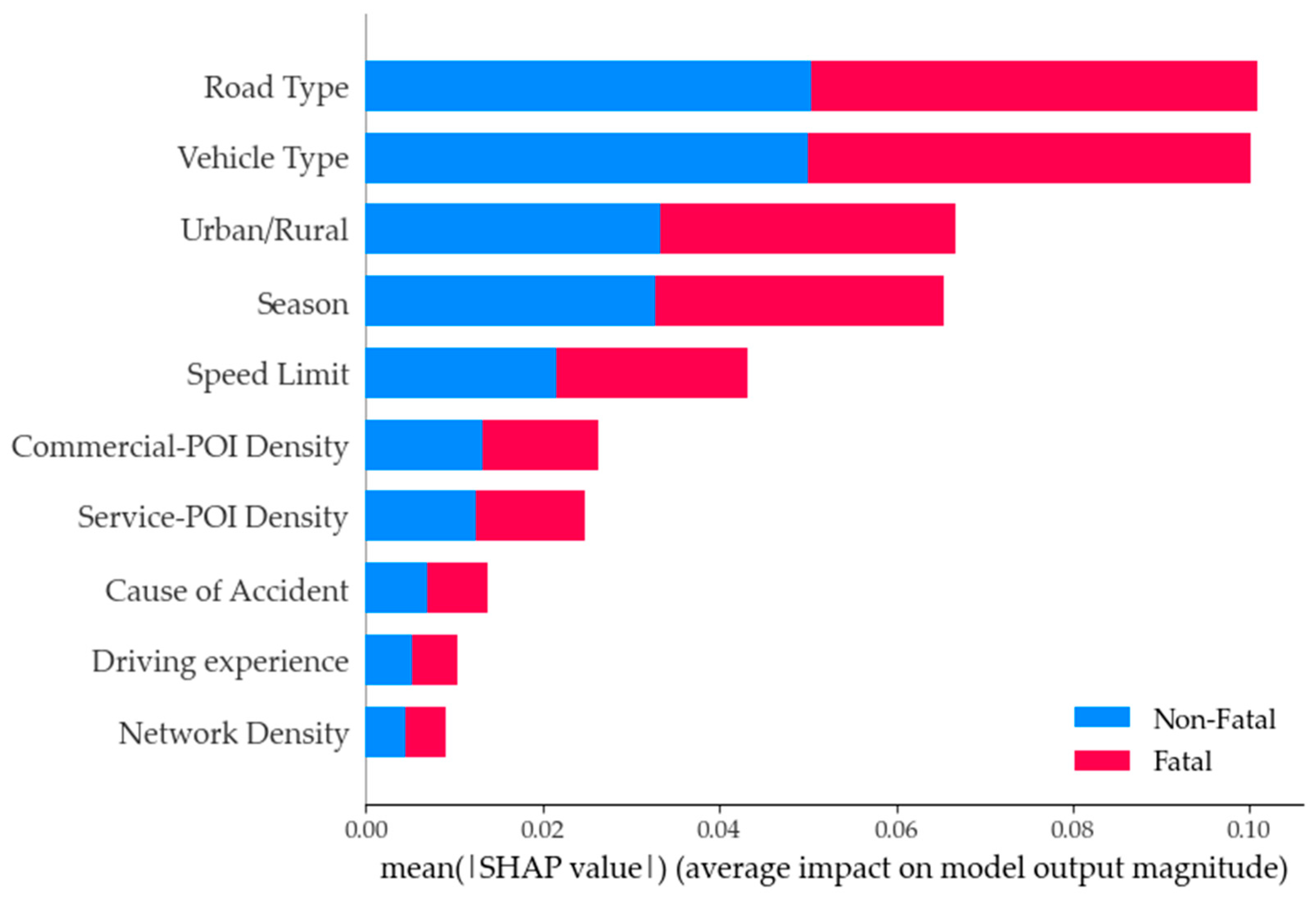
- The Shenyang data underwent descriptive statistical analysis and variable classification processing. To assess the importance and influence of 23 accident-related factors, the Random Forest and SHAP methods were employed. The results demonstrate that the most significant feature impacting accident severity is road type, followed by vehicle type, urban/rural, season, speed limit, Commercial-POI, Service-POI, cause of accident, age of driver, and network. Fatal accidents are more likely to occur on high-grade roads, particularly when involving small passenger and cargo vehicles in rural areas and during winter. Additional contributing factors included high speed limits, failure to adhere to signal instructions, varying driver experience levels, and the moderately low density of Commercial-POIs and road networks.
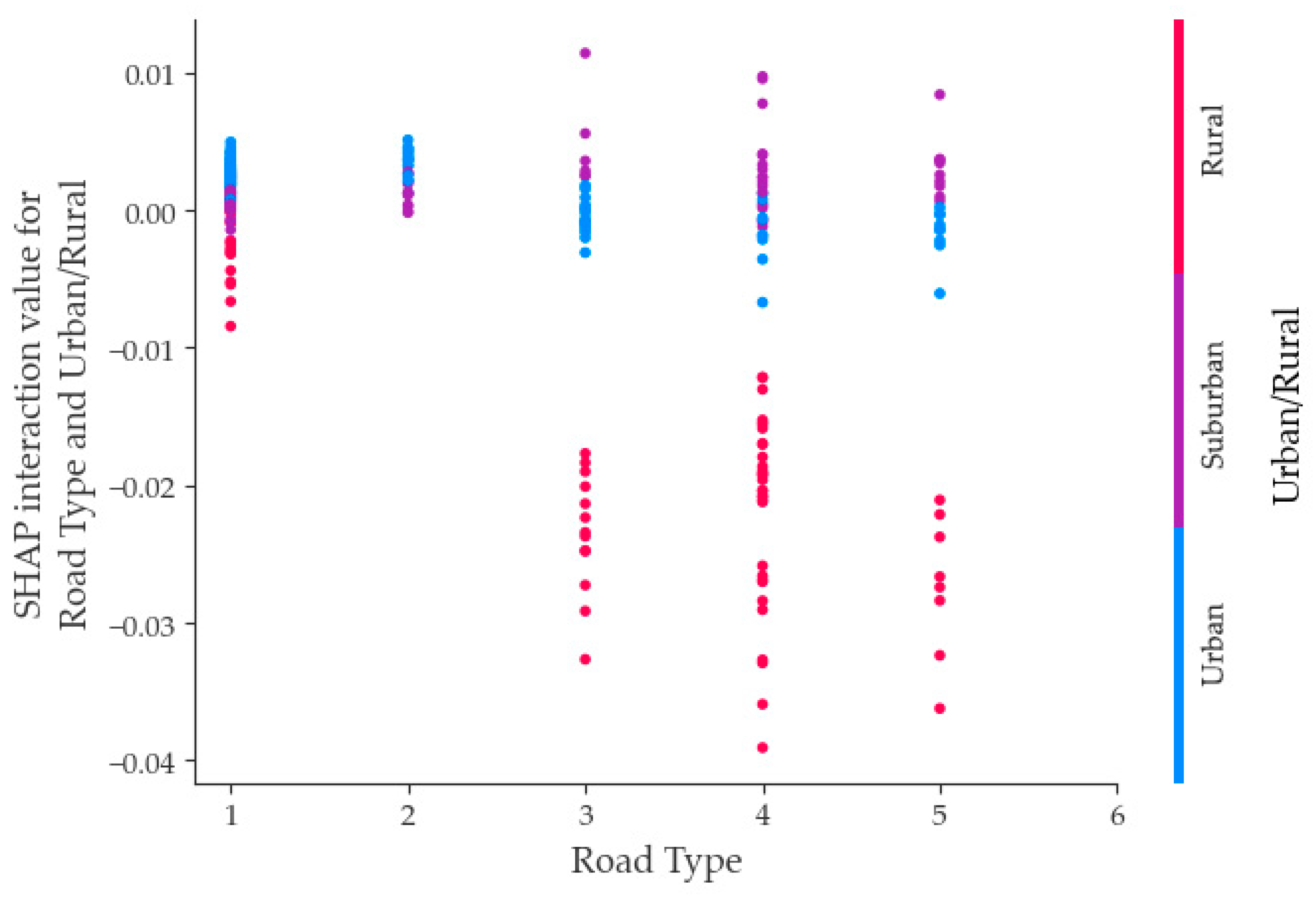
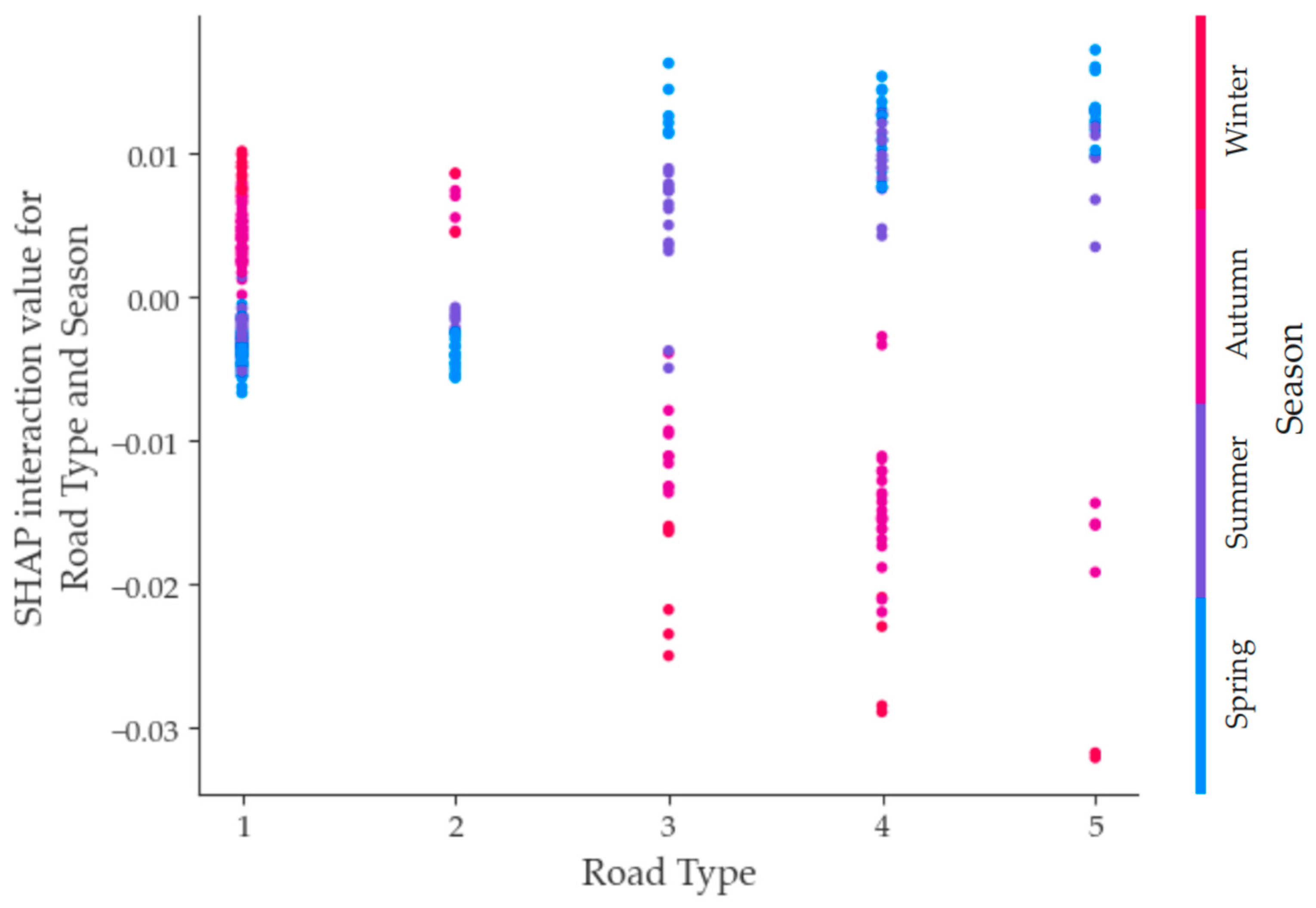
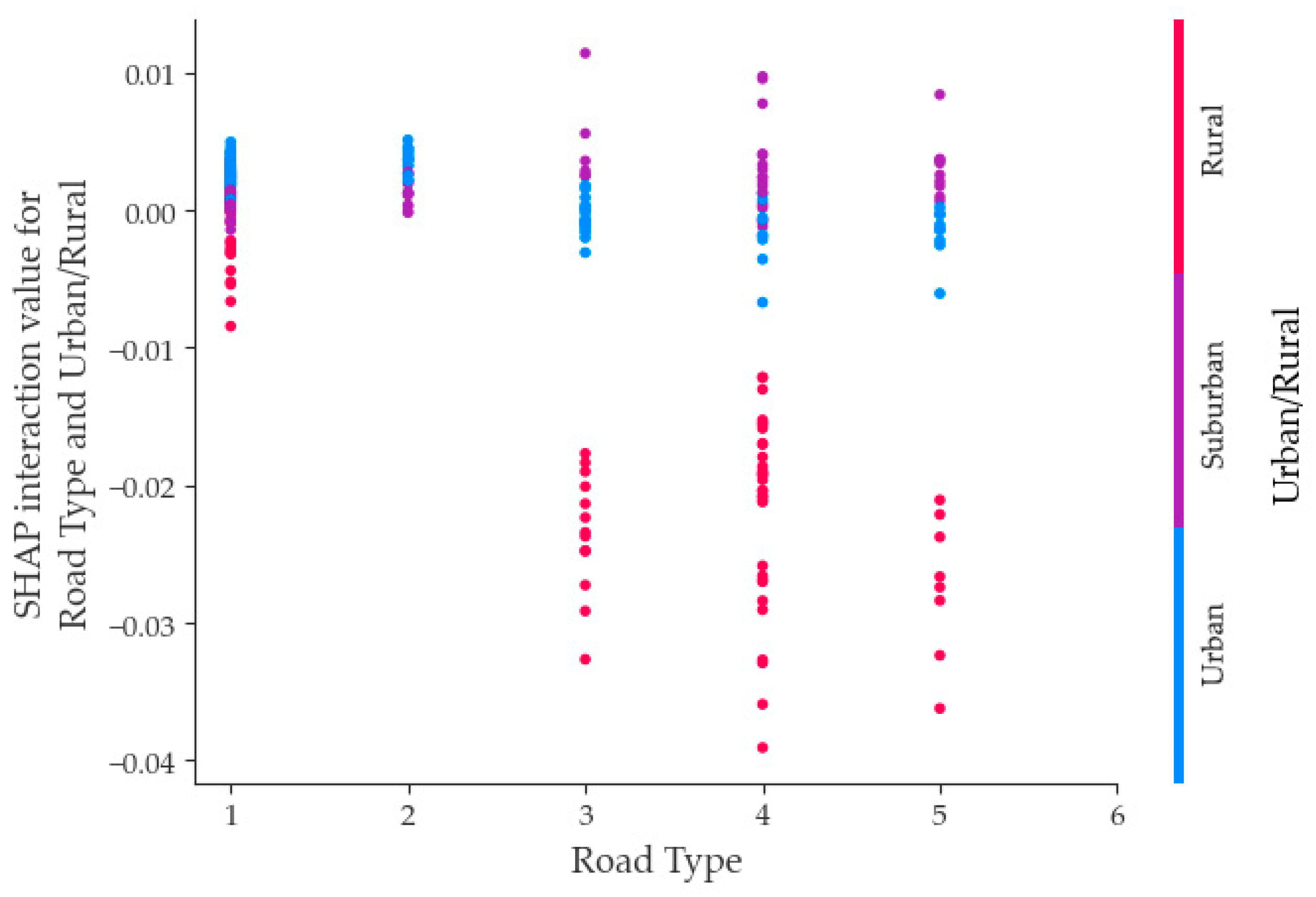
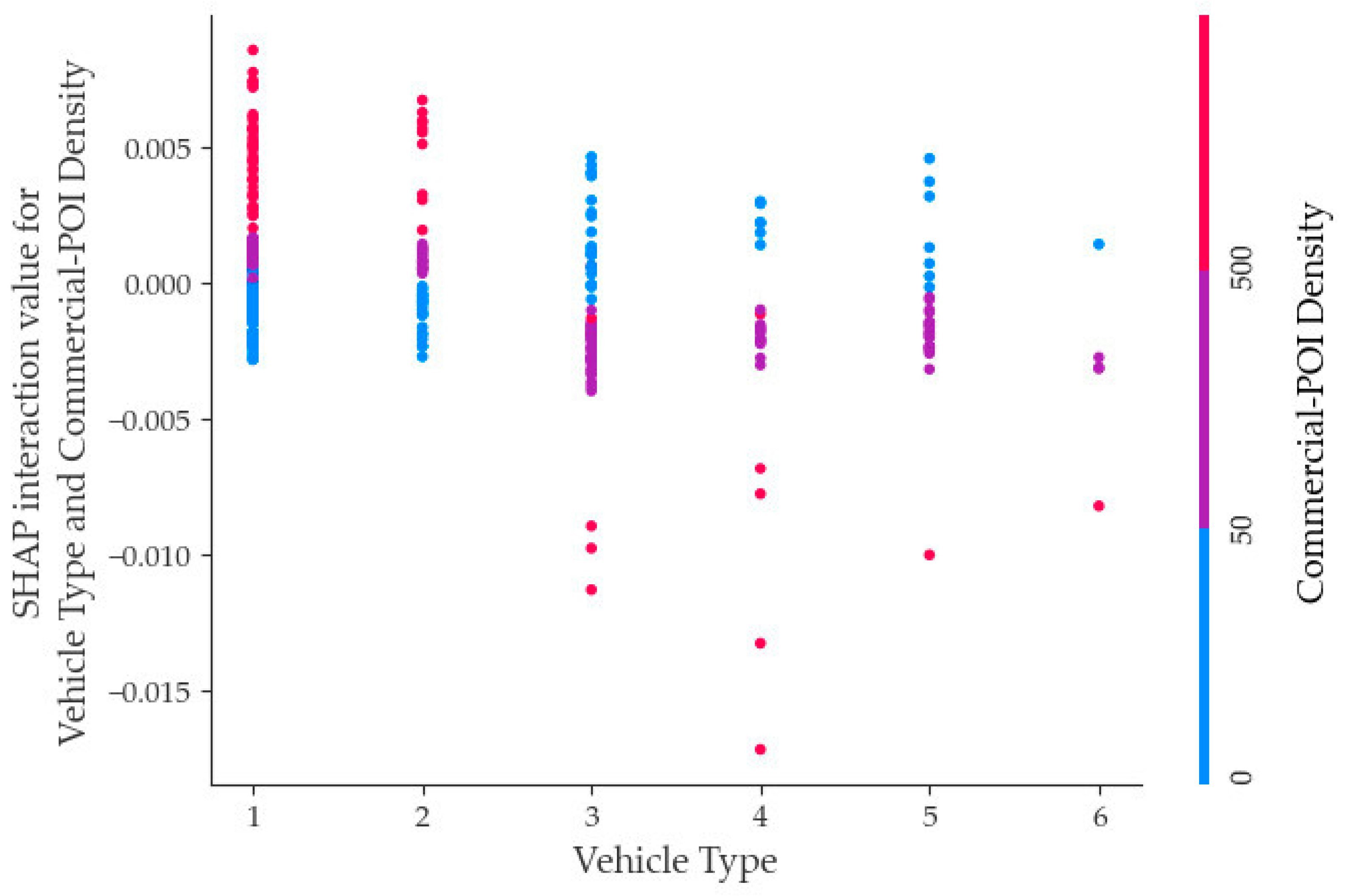
- Focusing on the top 10 selected variables, this study delved into the mechanism of influence regarding fatal accidents within the context of two-factor interactions. The findings indicate that the interaction between road type and season, vehicle type and Commercial-POI, as well as road type and urban/rural displayed noteworthy characteristics concerning fatal accidents. Consequently, this investigation contributes theoretical support to traffic management.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2020; World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Liu, P.; Fan, W. Exploring injury severity in head-on crashes using latent class clustering analysis and mixed logit model: A case study of North Carolina. Accid. Anal. Prev. 2020, 135, 105388. [Google Scholar] [CrossRef]
- Liu, J.; Hainen, A.; Li, X.; Nie, Q.; Nambisan, S. Pedestrian injury severity in motor vehicle crashes: An integrated spatio-temporal modeling approach. Accid. Anal. Prev. 2019, 132, 105272. [Google Scholar] [CrossRef]
- Li, Y.; Song, L.; Fan, W.D. Day-of-the-week variations and temporal instability of factors influencing pedestrian injury severity in pedestrian-vehicle crashes: A random parameters logit approach with heterogeneity in means and variances. Anal. Methods Accid. Res. 2021, 29, 100152. [Google Scholar] [CrossRef]
- Song, D.; Yang, X.; Zu, X.; Si, B. Examination of Driver Injury Severity in Urban Crashes: A Random Parameters Logit Model with Heterogeneity in Means Approach. J. Transp. Syst. Eng. Inf. Technol. 2021, 21, 214–220. [Google Scholar]
- Shen, X.; Shen, J.; Zheng, C.; Yu, M. Severity Analysis of Slow Traffic Accidents in North Carolina Based on Multinomial Logit Model. Traffic Transp. 2021, 37, 24–28. [Google Scholar]
- Clifton, K.J.; Burnier, C.V.; Akar, G. Severity of injury resulting from pedestrian–vehicle crashes: What can we learn from examining the built environment? Transp. Res. Part D Transp. Environ. 2009, 14, 425–436. [Google Scholar] [CrossRef]
- Hosseinzadeh, A.; Moeinaddini, A.; Ghasemzadeh, A. Investigating factors affecting severity of large truck-involved crashes: Comparison of the SVM and random parameter logit model. J. Saf. Res. 2021, 77, 151–160. [Google Scholar] [CrossRef]
- Ahmed, S.; Hossain, M.A.; Ray, S.K.; Bhuiyan, M.M.I.; Sabuj, S.R. A study on road accident prediction and contributing factors using explainable machine learning models: Analysis and performance. Transp. Res. Interdiscip. Perspect. 2023, 19, 100814. [Google Scholar] [CrossRef]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A.K. Toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef]
- Yang, Y.; Yuan, Z.; Meng, R. Exploring Traffic Crash Occurrence Mechanism toward Cross-Area Freeways via an Improved Data Mining Approach. J. Transp. Eng. Part A Syst. 2022, 148, 04022052. [Google Scholar] [CrossRef]
- Ahmad, N.; Ahmad, A.; Wali, B.; Saeed, T.U. Exploring factors associated with crash severity on motorways in Pakistan. Proc. Inst. Civ. Eng.-Transp. 2022, 175, 189–198. [Google Scholar] [CrossRef]
- Se, C.; Champahom, T.; Jomnonkwao, S.; Karoonsoontawong, A.; Ratanavaraha, V. Temporal stability of factors influencing driver-injury severities in single-vehicle crashes: A correlated random parameters with heterogeneity in means and variances approach. Anal. Methods Accid. Res. 2021, 32, 100179. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Wang, W.; Ju, X. Factors Affecting Electric Bicycle Rider Injury in Accident Based on Random Forest Model. J. Transp. Syst. Eng. Inf. Technol. 2021, 01, 196–200. [Google Scholar]
- Zhu, X.; Srinivasan, S. A comprehensive analysis of factors influencing the injury severity of large-truck crashes. Accid. Anal. Prev. 2011, 43, 49–57. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, K.; Yuan, Z.; Liu, D. Predicting Freeway Traffic Crash Severity Using XGBoost-Bayesian Network Model with Consideration of Features Interaction. J. Adv. Transp. 2022, 2022, 4257865. [Google Scholar] [CrossRef]
- Adanu, E.K.; Agyemang, W.; Islam, R.; Jones, S. A comprehensive analysis of factors that influence interstate highway crash severity in Alabama. J. Transp. Saf. Secur. 2022, 14, 1552–1576. [Google Scholar] [CrossRef]
- Jiao, P.; Li, R.; Wang, J.; Ge, H.; Chen, Y. Causes Analysis on Severity of Elderly Pedestrian Crashes Considering Latent Classes. J. Transp. Syst. Eng. Inf. Technol. 2022, 05, 328–336. [Google Scholar]
- Kullgren, A.; Stigson, H.; Ydenius, A.; Axelsson, A.; Engström, E.; Rizzi, M. The potential of vehicle and road infrastructure interventions in fatal bicyclist accidents on Swedish roads—What can in-depth studies tell us? Traffic Inj. Prev. 2019, 20, S7–S12. [Google Scholar] [CrossRef]
- Tay, R.; Rifaat, S.M. Factors contributing to the severity of intersection crashes. J. Adv. Transp. 2007, 41, 245–265. [Google Scholar] [CrossRef]
- Jiang, C.; He, J.; Zhu, S.; Zhang, W.; Li, G.; Xu, W. Injury-Based Surrogate Resilience Measure: Assessing the Post-Crash Traffic Resilience of the Urban Roadway Tunnels. Sustainability 2023, 15, 6615. [Google Scholar] [CrossRef]
- Yang, Y.; Tian, N.; Wang, Y.; Yuan, Z. A Parallel FP-Growth Mining Algorithm with Load Balancing Constraints for Traffic Crash Data. Int. J. Comput. Commun. Control 2022, 17, 4806. [Google Scholar] [CrossRef]
- Zeng, Q.; Wang, X.; Zhang, X.; Wen, H. Seasonal Analysis of Contributing Factors to Freeway Crash Frequency Using a Spatio-temporal lnteraction Model. China J. Highw. Transp. 2020, 33, 255–263. [Google Scholar]
- Ding, C.; Chen, P.; Jiao, J. Non-linear effects of the built environment on automobile-involved pedestrian crash frequency: A machine learning approach. Accid. Anal. Prev. 2018, 112, 116–126. [Google Scholar] [CrossRef]
- Ewing, R.; Dumbaugh, E. The Built Environment and Traffic Safety: A Review of Empirical Evidence. J. Plan. Lit. 2009, 23, 347–367. [Google Scholar] [CrossRef]
- Ahmad, N.; Wali, B.; Khattak, A.J.; Dumbaugh, E. Built environment, driving errors and violations, and crashes in naturalistic driving environment. Accid. Anal. Prev. 2021, 157, 106158. [Google Scholar] [CrossRef]
- Muhammad, U.; Irfan, A.R.; Rida, H.L. The impact of urban design and the built environment on road traffic crashes: A case study of Rawalpindi, Pakistan. Case Stud. Transp. Policy 2022, 10, 417–426. [Google Scholar]
- Lee, S.; Yoon, J.; Woo, A. Does elderly safety matter? Associations between built environments and pedestrian crashes in Seoul, Korea. Accid. Anal. Prev. 2020, 144, 105621. [Google Scholar] [CrossRef] [PubMed]
- Merlin, L.A.; Guerra, E.; Dumbaugh, E. Crash risk, crash exposure, and the built environment: A conceptual review. Accid. Anal. Prev. 2019, 134, 105244. [Google Scholar] [CrossRef]
- Nam, D.; Mannering, F. An exploratory hazard-based analysis of highway incident duration. Transp. Res. Part A Policy Pract. 2000, 34, 85–102. [Google Scholar] [CrossRef]
- Huang, H.; Chin, H.C.; Haque, M.M. Severity of driver injury and vehicle damage in traffic crashes at intersections: A Bayesian hierarchical analysis. Accid. Anal. Prev. 2008, 40, 45–54. [Google Scholar] [CrossRef]
- Haleem, K.; Gan, A. Contributing factors of crash injury severity at public highway-railroad grade crossings in the U.S. J. Saf. Res. 2015, 53, 23–29. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Lu, H.; Sun, Z.; Wang, T. Identification method of factors influencing the severity of vehicle collision crashes based on MNL model. Highw. Traffic Sci. Technol. 2021, 38, 107–113. [Google Scholar]
- Xu, R.; Luo, F. Risk prediction and early warning for air traffic controllers’ unsafe acts using association rule mining and random forest. Saf. Sci. 2021, 135, 105125. [Google Scholar] [CrossRef]
- Yang, Y.; He, K.; Wang, Y.P.; Yuan, Z.; Yin, Y.H.; Guo, M. Identification of dynamic traffic crash risk for cross-area freeways based on statistical and machine learning methods. Phys. A Stat. Mech. Its Appl. 2022, 595, 127083. [Google Scholar] [CrossRef]
- Das, A.; Abdel-Aty, M.; Pande, A. Using conditional inference forests to identify the factors affecting crash severity on arterial corridors. J. Saf. Res. 2009, 40, 317–327. [Google Scholar] [CrossRef]
- Wen, X.; Xie, Y.; Wu, L.; Jiang, L. Quantifying and comparing the effects of key risk factors on various types of roadway segment crashes with LightGBM and SHAP. Accid. Anal. Prev. 2021, 159, 106261. [Google Scholar] [CrossRef]
- Chang, I.; Park, H.; Hong, E.; Lee, J.; Kwon, N. Predicting effects of built environment on fatal pedestrian accidents at location-specific level: Application of XGBoost and SHAP. Accid. Anal. Prev. 2022, 166, 106545. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Chen, M.; Yuan, Q. The application of XGBoost and SHAP to examining the factors in freight truck-related crashes: An exploratory analysis. Accid. Anal. Prev. 2021, 158, 106153. [Google Scholar] [CrossRef]
- Wang, Z.; Jiao, P.; Wang, J.; Huang, Q.; Li, R.; Lu, H. The level of delay caused by crashes (LDC) in metropolitan and non-metropolitan areas: A comparative analysis of improved Random Forests and LightGBM. Int. J. Crashworthiness 2022. [Google Scholar] [CrossRef]
- Choi, D.; Ewing, R. Effect of street network design on traffic congestion and traffic safety. J. Transp. Geogr. 2021, 96, 103200. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Goswamy, A.; Abdel-Aty, M.; Islam, Z. Factors affecting injury severity at pedestrian crossing locations with Rectangular RAPID Flashing Beacons (RRFB) using XGBoost and random parameters discrete outcome models. Accid. Anal. Prev. 2023, 181, 106937. [Google Scholar] [CrossRef]
- Dash, I.; Abkowitz, M.; Philip, C. Factors impacting bike crash severity in urban areas. J. Saf. Res. 2022, 83, 128–138. [Google Scholar] [CrossRef] [PubMed]
- Zafri, N.M.; Khan, A. A spatial regression modeling framework for examining relationships between the built environment and pedestrian crash occurrences at macroscopic level: A study in a developing country context. Geogr. Sustain. 2022, 3, 312–324. [Google Scholar] [CrossRef]
- Cai, Q.; Abdel-Aty, M.; Zheng, O.; Wu, Y. Applying machine learning and google street view to explore effects of drivers’ visual environment on traffic safety. Transp. Res. Part C Emerg. Technol. 2022, 135, 103541. [Google Scholar] [CrossRef]
- Wang, X.; Chen, J.; Quddus, M.; Zhou, W.; Shen, M. Influence of familiarity with traffic regulations on delivery riders’ e-bike crashes and helmet use: Two mediator ordered logit models. Accid. Anal. Prev. 2021, 159, 106277. [Google Scholar] [CrossRef] [PubMed]
- Outay, F.; Adnan, M.; Gazder, U.; Baqueri, S.F.A.; Awan, H.H. Random forest models for motorcycle accident prediction using naturalistic driving based big data. Int. J. Inj. Control Saf. Promot. 2023, 30, 282–293. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.; Brown, C.T.; Dadashova, B.; Ye, X.; Sohrabi, S.; Potts, I. Investigation on the driver-victim pairs in pedestrian and bicyclist crashes by latent class clustering and random forest algorithm. Accid. Anal. A Prev. 2023, 182, 106964. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Type | Variable | Description | Description | Counting | Proportion (%) | |
|---|---|---|---|---|---|---|
| Dependent Variables | y | Crash injury levels | The severity of a crash based on the most severe injury to any person involved in the crash. | 0 = Non-fatal | 890 | 0.645 |
| 1 = Fatal | 488 | 0.354 | ||||
| Human and Vehicle Attributes at Fault | x1 | Gender of driver | The sex of person involved in a crash. | 1 = Male | 1236 | 0.896 |
| 2 = Female | 142 | 0.103 | ||||
| x2 | Age of driver | The age of driver involved in a crash. If it not available, the approximate age. | 1 ≤ 25 years | 107 | 0.077 | |
| 2 = 26–45 years | 767 | 0.556 | ||||
| 3 = 46–60 years | 382 | 0.277 | ||||
| 4 > 60 years | 122 | 0.088 | ||||
| x3 | Driving experience | The number of years a driver has been licensed to drive. | 1 = 0–6 years | 625 | 0.453 | |
| 2 = 7–16 years | 497 | 0.36 | ||||
| 3 > 16 years | 256 | 0.185 | ||||
| x4 | Liability | The liability of driver in the accident is determined. | 1 = Full Liability | 536 | 0.388 | |
| 2 = Primary Liability | 480 | 0.348 | ||||
| 3 = Equal Liability | 362 | 0.262 | ||||
| x5 | Vehicle type | The type of vehicle by the driver. | 1 = Non-Motorized Vehicle | 192 | 0.139 | |
| 2 = Motorcycle | 103 | 0.075 | ||||
| 3 = Motorcar | 730 | 0.530 | ||||
| 4 = Minivan | 91 | 0.066 | ||||
| 5 = Large Passenger Truck. | 245 | 0.178 | ||||
| 6 = Other | 17 | 0.012 | ||||
| x6 | Cause of accident | The cause of the accident (this information is generally determined by the police at the time of the accident determination). | 1 = Improper operation of the driver | 153 | 0.111 | |
| 2 = Overspeed or overloading | 80 | 0.058 | ||||
| 3 = Drunk or fatigued driving | 126 | 0.091 | ||||
| 4 = Failure to give way as required | 129 | 0.093 | ||||
| 5 = Hit-run | 22 | 0.015 | ||||
| 6 = Failure to follow signal instructions | 56 | 0.04 | ||||
| 7 = Other violations | 812 | 0.589 | ||||
| Infrastructure | x7 | Position | The location of the road cross-section of the accident. | 1 = Non-motor vehicle lane | 70 | 0.05 |
| 2 = Motor vehicle lane | 1055 | 0.765 | ||||
| 3 = Mixed lane of motor vehicles and non-motor vehicles | 182 | 0.132 | ||||
| 4 = Other | 71 | 0.051 | ||||
| x8 | Intersections | Whether the accident occurred at an intersection. | 1 = No | 837 | 0.607 | |
| 2 = Yes | 541 | 0.392 | ||||
| x9 | Road type | Route class of the On Road. | 1 = Other | 66 | 0.047 | |
| 2 = Trunk Road | 929 | 0.674 | ||||
| 3 = Secondary and Tertiary Roads | 190 | 0.137 | ||||
| 4 = Primary Roads and Highways. | 103 | 0.074 | ||||
| 5 = Urban Expressways | 90 | 0.065 | ||||
| x10 | Speed limit | Authorized speed limit for the vehicle at the time of the crash (km/h). | 1 ≤ 20 | 580 | 0.42 | |
| 2 = 20–40 | 532 | 0.386 | ||||
| 3 = 40–60 | 127 | 0.092 | ||||
| 4 = 60–80 | 115 | 0.083 | ||||
| 5 ≥ 80 | 24 | 0.017 | ||||
| x11 | Physical isolation | The type of physical isolation facilities set up at the point of accident. | 1 = No Isolation | 944 | 0.685 | |
| 2 = Isolation Only Between Motor and Non-motor Vehicle | 33 | 0.023 | ||||
| 3 = Only Central Isolation | 320 | 0.232 | ||||
| 4= Full Isolation | 81 | 0.058 | ||||
| Time | x12 | Weekday | Whether the accident occurred on a weekday. | 1 = No | 556 | 0.563 |
| 2 = Yes | 822 | 0.271 | ||||
| x13 | Rush hour | Whether the accident occurred during rush hour. (peak hours are set from 7:00 to 9:00; 17:00 to 19:00). | 1 = No | 928 | 0.165 | |
| 2 = Yes | 450 | 0.403 | ||||
| x14 | Nighttime crash | Whether the accident occurred at night. | 1 = No | 1107 | 0.596 | |
| 2 = Yes | 271 | 0.673 | ||||
| Climate | x15 | Season | The season in which the accident occurred (due to the special geographical location of Shenyang, spring and autumn are shorter, while winter is longer). | 1 = Spring (4–5) | 392 | 0.326 |
| 2 = Summer (6–8) | 439 | 0.803 | ||||
| 3 = Autumn (9–10) | 117 | 0.196 | ||||
| 4 = Winter (1–3;11–12) | 40 | 0.284 | ||||
| x16 | Weather | The general atmospheric conditions that existed at the time of the crash. | 1 = Sunny | 1258 | 0.912 | |
| 2 = Cloudy | 59 | 0.042 | ||||
| 3 = Rain | 53 | 0.038 | ||||
| 4 = Fog | 2 | 0.001 | ||||
| 5 = Snow | 6 | 0.004 | ||||
| x17 | Extreme temperatures | Whether the temperature was higher than 30 °C or lower than 0 °C on the day of the accident. | 1 = No | 1051 | 0.762 | |
| 2 = Yes | 327 | 0.237 | ||||
| x18 | Network density | The density of road network in the buffer zone (km/km2). | 1 ≤ 10 | 1049 | 0.761 | |
| 2 = 10–20 | 310 | 0.224 | ||||
| 3 > 20 | 19 | 0.013 | ||||
| Land Use | X19 | Rural or urban | Indicates if the crash occurred within a municipality (urban) or in a rural location. | 1 = Urban District | 776 | |
| 2 = Suburban District | 374 | |||||
| 3 = Rural District | 228 | |||||
| x20 | Commercial | The density of restaurant and commercial centers in the buffer zone (pcs/km2). | 1 ≤ 50 | 603 | 0.437 | |
| 2 = 50–500 | 573 | 0.415 | ||||
| 3 > 500 | 202 | 0.146 | ||||
| x21 | Education | The density of scientific, educational, and cultural facilities in the buffer zone (pcs/km2). | 1 ≤ 50 | 1126 | 0.817 | |
| 2 = 50–500 | 252 | 0.182 | ||||
| 3 > 500 | 0 | 0 | ||||
| x22 | Residential | The density of commercial and residential facilities in the buffer zone (pcs/km2). | 1 ≤ 50 | 1344 | 0.975 | |
| 2 = 50–500 | 34 | 0.024 | ||||
| 3 > 500 | 0 | 0 | ||||
| x23 | Service | The density of living service in the buffer zone (pcs/km2). | 1 ≤ 50 | 805 | 0.584 | |
| 2 = 50–500 | 572 | 0.415 | ||||
| 3 > 500 | 1 | 0.0001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Ji, L.; Ma, S.; Sun, X.; Wang, M. Analysis of Factors Influencing the Severity of Vehicle-to-Vehicle Accidents Considering the Built Environment: An Interpretable Machine Learning Model. Sustainability 2023, 15, 12904. https://doi.org/10.3390/su151712904
Wang J, Ji L, Ma S, Sun X, Wang M. Analysis of Factors Influencing the Severity of Vehicle-to-Vehicle Accidents Considering the Built Environment: An Interpretable Machine Learning Model. Sustainability. 2023; 15(17):12904. https://doi.org/10.3390/su151712904
Chicago/Turabian StyleWang, Jianyu, Lanxin Ji, Shuo Ma, Xu Sun, and Mingxin Wang. 2023. "Analysis of Factors Influencing the Severity of Vehicle-to-Vehicle Accidents Considering the Built Environment: An Interpretable Machine Learning Model" Sustainability 15, no. 17: 12904. https://doi.org/10.3390/su151712904
APA StyleWang, J., Ji, L., Ma, S., Sun, X., & Wang, M. (2023). Analysis of Factors Influencing the Severity of Vehicle-to-Vehicle Accidents Considering the Built Environment: An Interpretable Machine Learning Model. Sustainability, 15(17), 12904. https://doi.org/10.3390/su151712904