
TomTom Data Applications for the Assessment of Tactical Urbanism Interventions: The Case of Bologna

 ,
,
Abstract
:1. Introduction
- To what extent can a punctual intervention affect the surrounding road network?
- What happens in the streets directly affected? And what about the buffer area? How large is such area?
- Can a GPS-based Floating Car Data (FCD) dataset overcome underdetermination problems when estimating OD matrices through recorded link traffic counts and average speeds/travel times? If yes, how?
- Which procedure is suitable for obtaining such a matrix without any ground truth OD data? Will it provide a reliable matrix?
2. Literature Review
2.1. Tactical Urbanism
2.2. Floating Car Data
2.3. OD Matrices Estimation
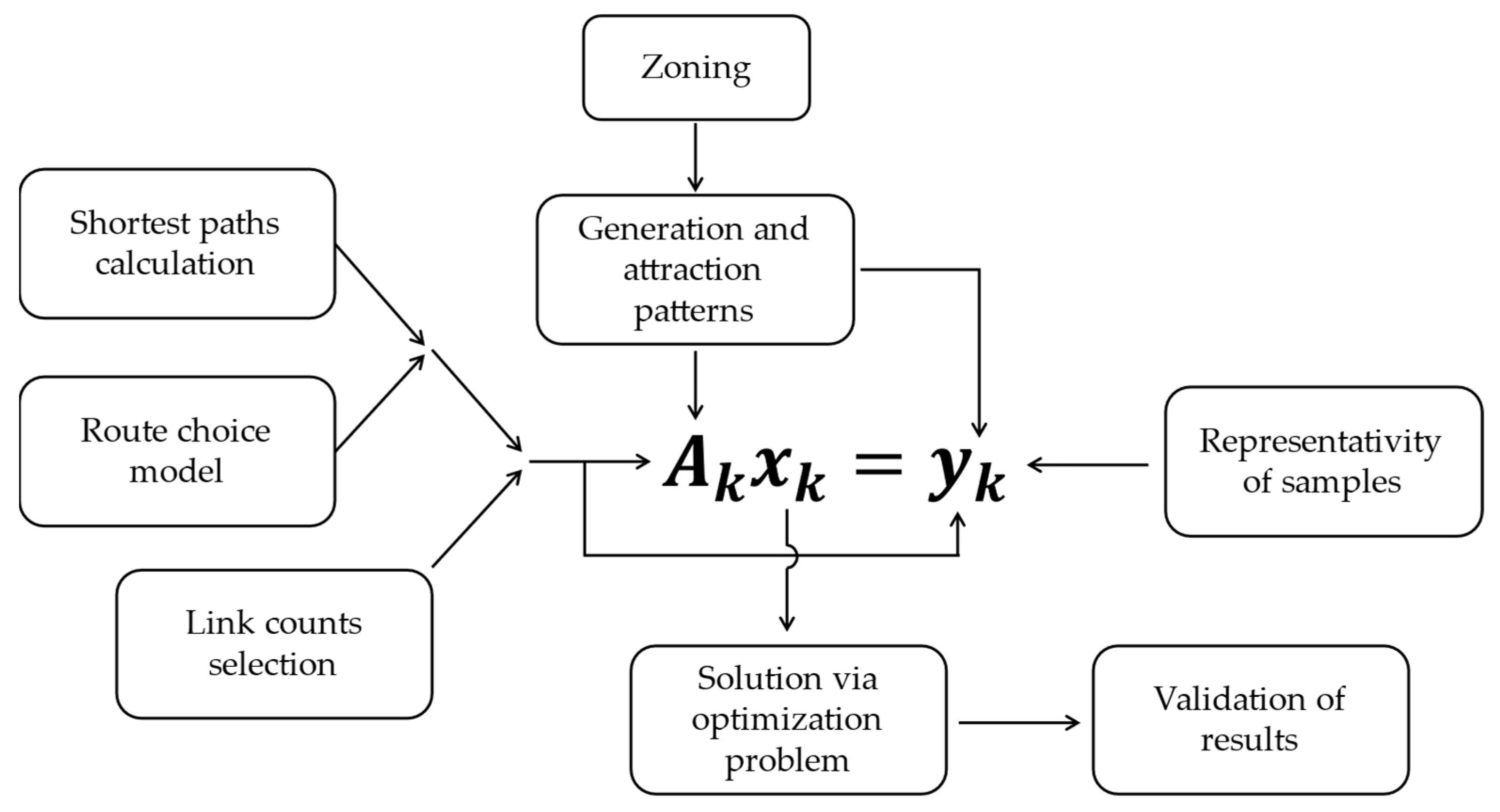
3. Enabling Data and Methodology
3.1. Enabling Data
- periods of time: September and October 2021 (ex-ante)–September and October 2022 (ex-post);
- date ranges: weekdays (Mondays to Fridays)–weekends (Saturdays, Sundays);
- daily time slots: 3 two-hour slots split into 15-min fractions (7:00–9:00 a.m.; 1:00–3:00 p.m.; 5:00–7:00 p.m.);
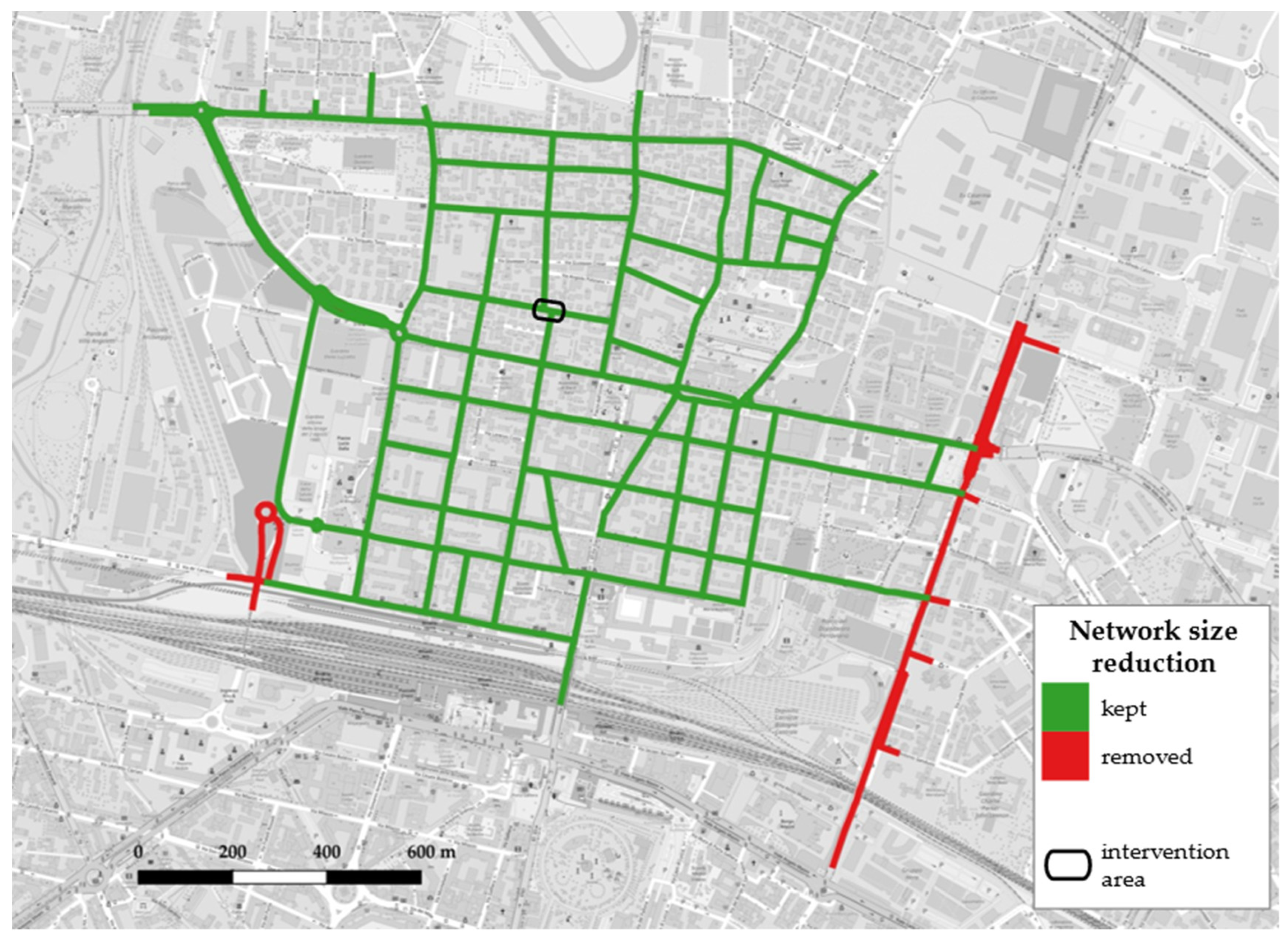
- area: Bolognina district, Bologna (see Figure 1);
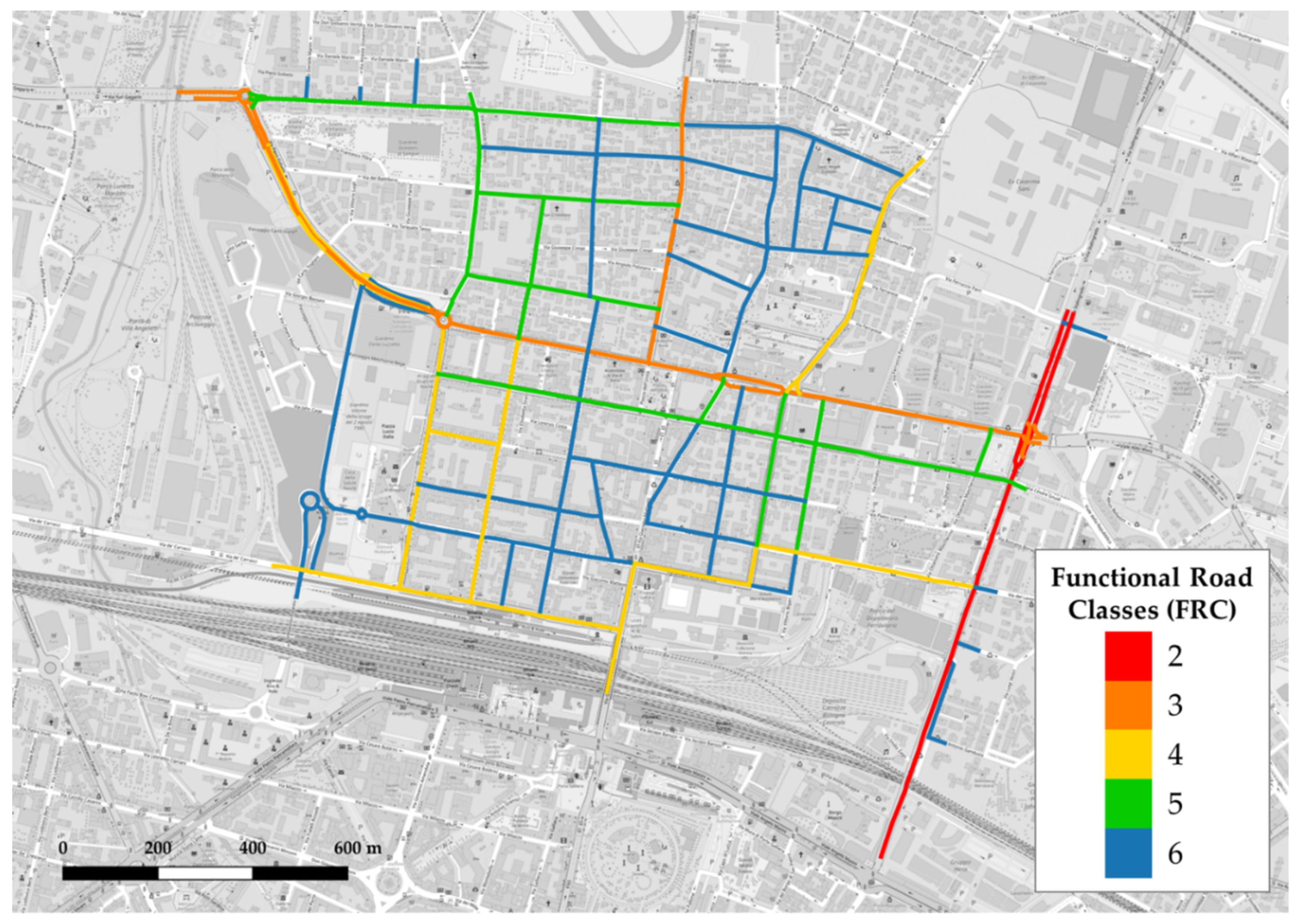
- FRCs: 1 to 6 (see Figure 2).
- in the months of September and October, schools are open, a fundamental requirement given that the intervention is also expected to impact school-related traffic;
- a two-month dataset is enough to use as representative for mean traffic values;
- as the implementation of the temporary square happened in March, ex-post data are collected sufficiently later than the implementation of the temporary square, which is advisable to consider as several pieces of research literature [9,23] encountered unusual congestion in the days straight after the road closure;
- the same months have been selected for both ex-ante and ex-post scenarios, to avoid issues of seasonality when comparing.
3.2. Methodology
3.2.1. Statistical Trend Analysis
- if , empirical evidence is not strong enough to reject the initial hypothesis;
- if , observed data are statistically significant, so the null hypothesis is rejected.
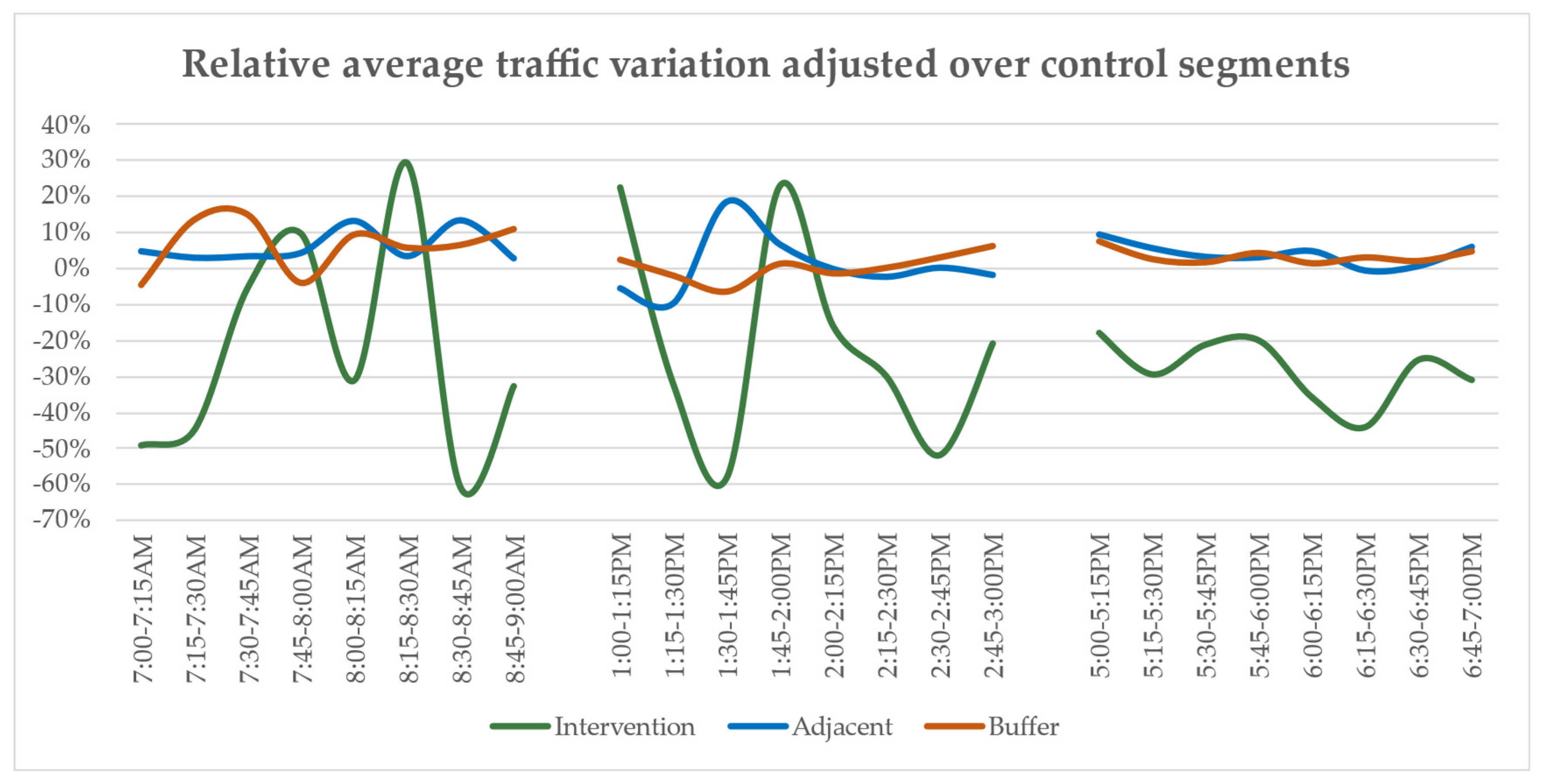
- the intervention streets are segments directly affected by the modification;
- adjacent streets are close to the intervention and represent the best alternatives to avoid the site of intervention;
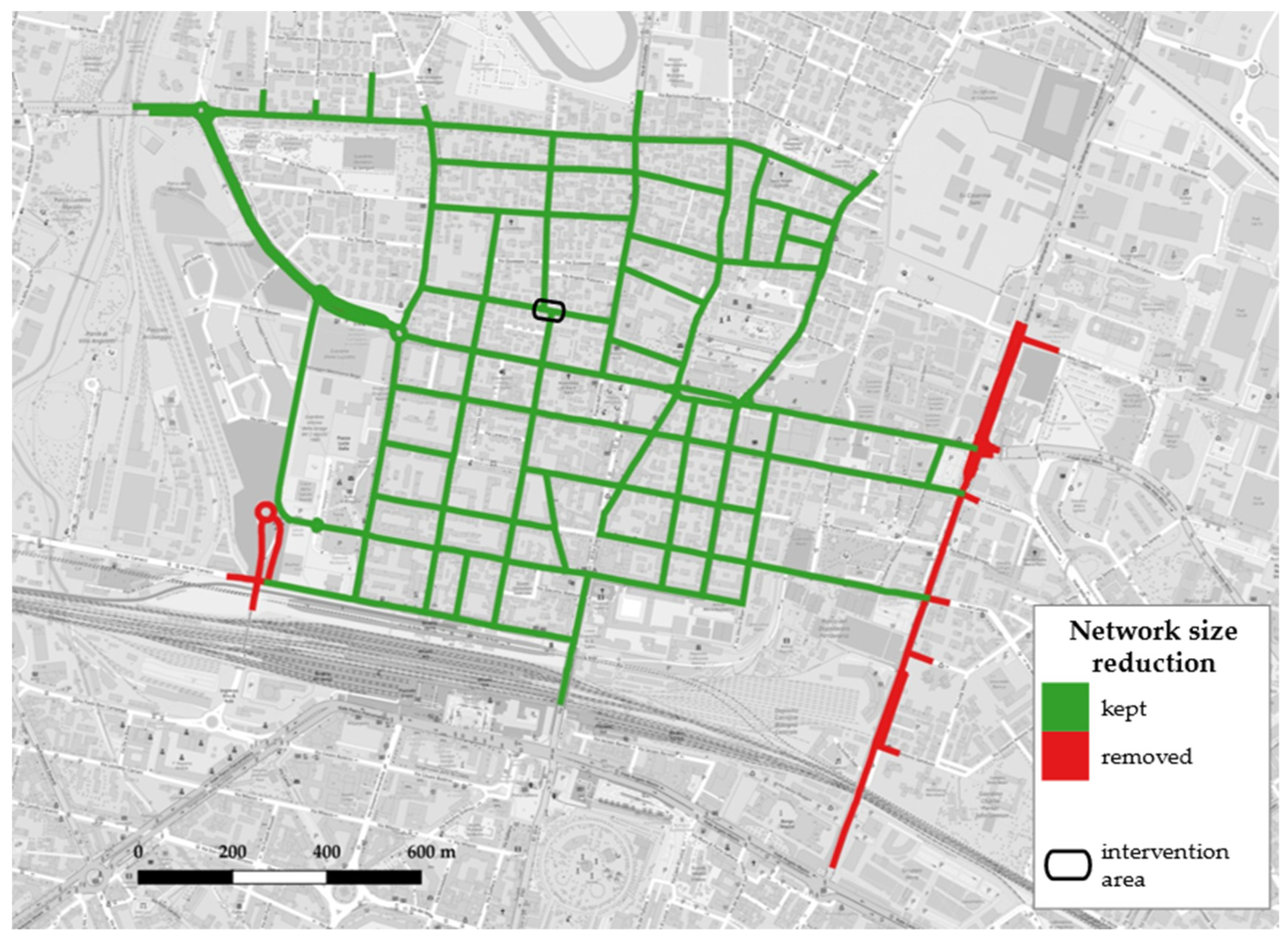
- streets in the buffer area are no farther than 400 m on road graph distance and so are thought to still be impacted from disturbances caused by the implementation of the temporary school square;
- all the other roads in the network are classified as control segments, on which global variations of traffic-related parameters will be computed and assumed for the entire network, in order to adjust fluctuations of the other segment clusters and focus on the effects of the intervention.
3.2.2. OD Matrices Estimation
- the demand for OD pair i → j of trips departing in time fraction k;
- the sum of outbound OD flows from origin node i during time fraction k;
- the sum of inbound OD flows to destination node j during time fraction k.
- route choice proportional factor of path n;
- ;
- path size parameter to be estimated;
- path size factor of path n.
- is the length of link ;
- is the length of path ;
- is an integer variable expressing the link-path incidence, i.e., the number of paths in the set which link a features.
- data inconsistencyTraffic counts are affected from multiple errors caused by intrinsic flaws in the measurement procedure, leading to inconsistent flows attributed to each link; this means that even if the equation system is full rank, there might be no matrix able to satisfy each value of the observed flow vector; it is thus necessary to consider a vector of errors affecting the set of observed flows.
- data dependenceTraffic is modelled over the road network under the hypothesis of flow continuity at nodes, meaning that the difference between inbound and outbound flows must be null; thus, flow on one of the segments related to each node is deductible as a linear combination of the others, leading to linearly dependent equations which would not bring any additional information.
- OD pair coverage: a minimum share of demand flow per OD pair should be observed;
- Maximum flow fraction: for each OD pair, the link with the greatest demand flow fraction between the pair should be observed;
- Maximum coverage: in the case of limitations of the number of available counters, the greatest number possible of OD pairs is to be observed;
- Link independence: traffic counts should not be linearly dependent.
- Equations (2) and (3) are chosen as first equations of the linear system, being “privileged” traffic counts providing information of production and attraction patterns, though it should be noted that one equation must be discarded because it is a linear combination of all the others in the set;
- for each link in the network, excluding access/exit segments, which have already been considered in the previous step, it is computed how many OD pairs have at least one path transiting through the link itself;
- starting from the link with the highest number of transiting ODs, the corresponding matrix row is added, and a rank check is performed; if the rank of the matrix at this step is lower than the rank of the matrix with the added row, the row is declared linearly independent and the corresponding equation is definitely added to the solving equation system.
- n being the number of elements in both the observed and estimated data;
- the estimations;
- the observations.
4. Results
4.1. Statistical Trend Analysis
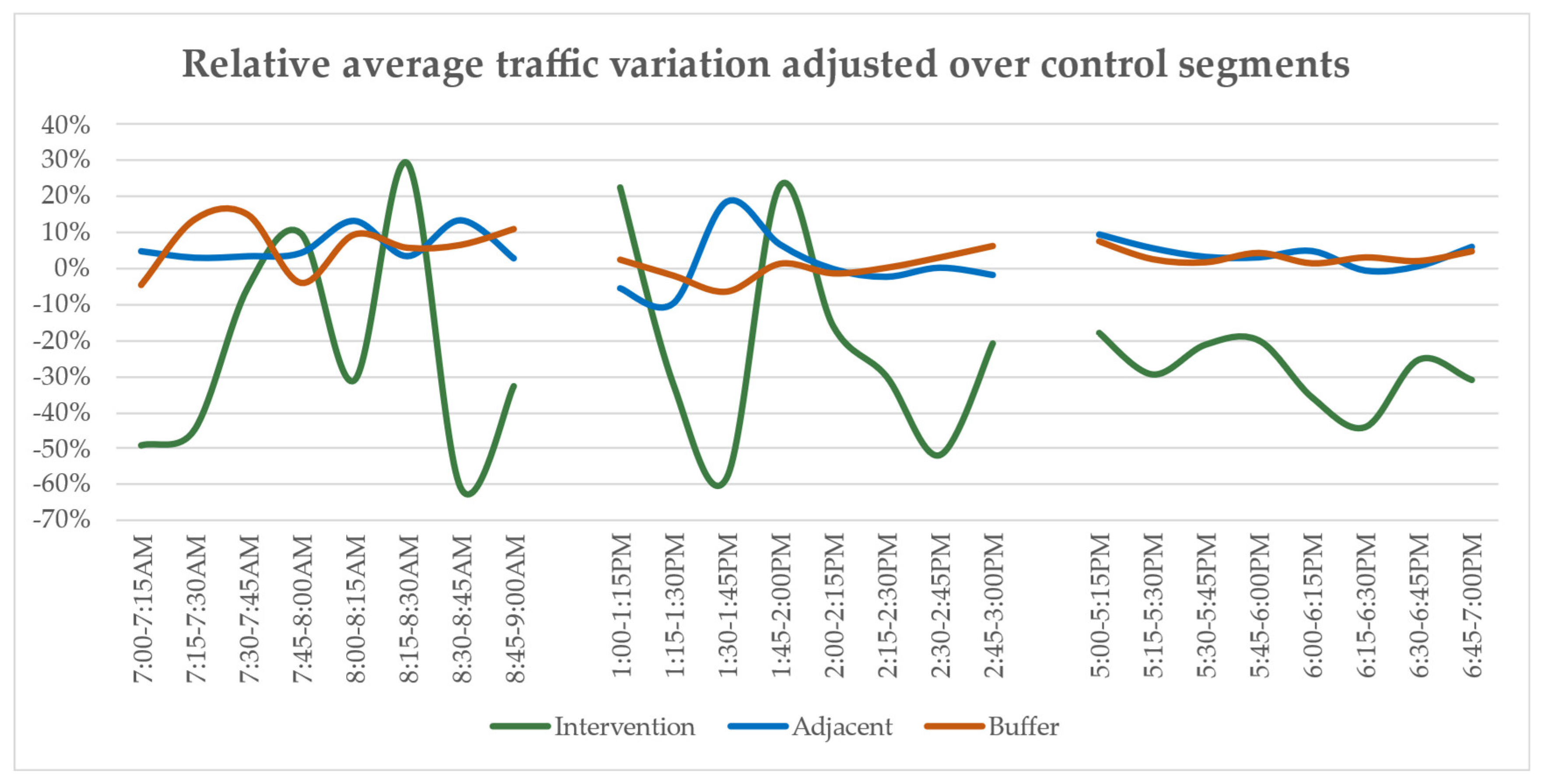
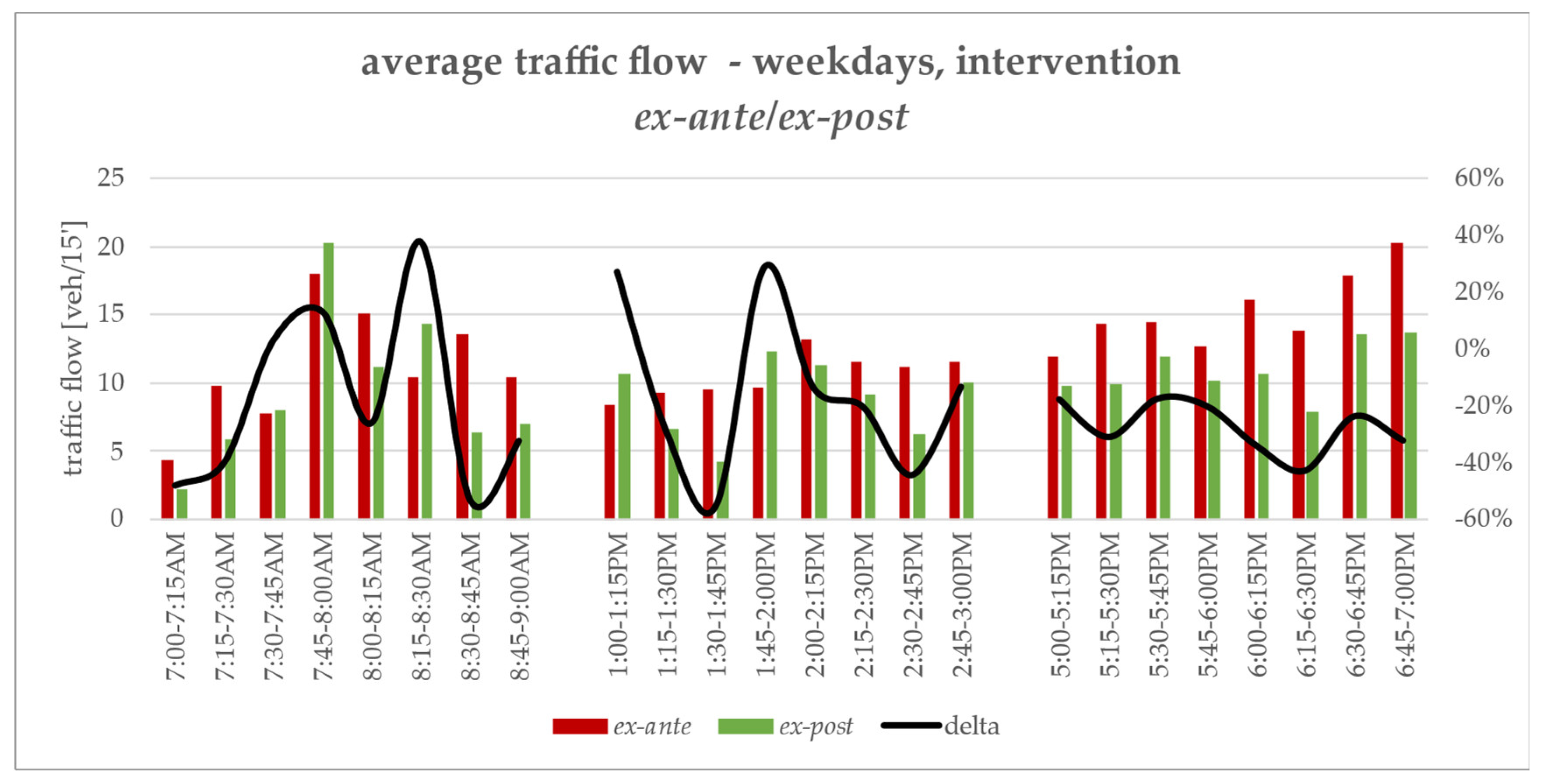
- the intervention streets, despite presenting considerable peaks due to little flow, so more sensitive to variations, on average faced a consistent reduction, consistent with both the nature and the main purpose of a capacity-limiting, pedestrian-friendly road intervention;
- segments in the adjacent and buffer zones have recorded, albeit lower both in relative and in absolute terms with respect to intervention segments, a positive relative variation in the matter of traffic flow with respect to the general fluctuations calculated over control segments.
- intervention segments have recorded a slight negative variation in every addressed time slot;
- adjoining and neighbouring segments such as the major axis which accesses the neighbourhood from its northern side, or core axes for the east–west through-traffic phenomenon, figuring either in the adjacent or buffer class, have been affected by an appreciable increase in traffic flow.
4.2. OD Matrices Estimation
- (a)
- variability in the data;
- (b)
- matching degree for shapes for distributions;
- (c)
- nonlinearity;
- (d)
- outliers;
- (e)
- sample characteristics;
- (f)
- measurements errors.
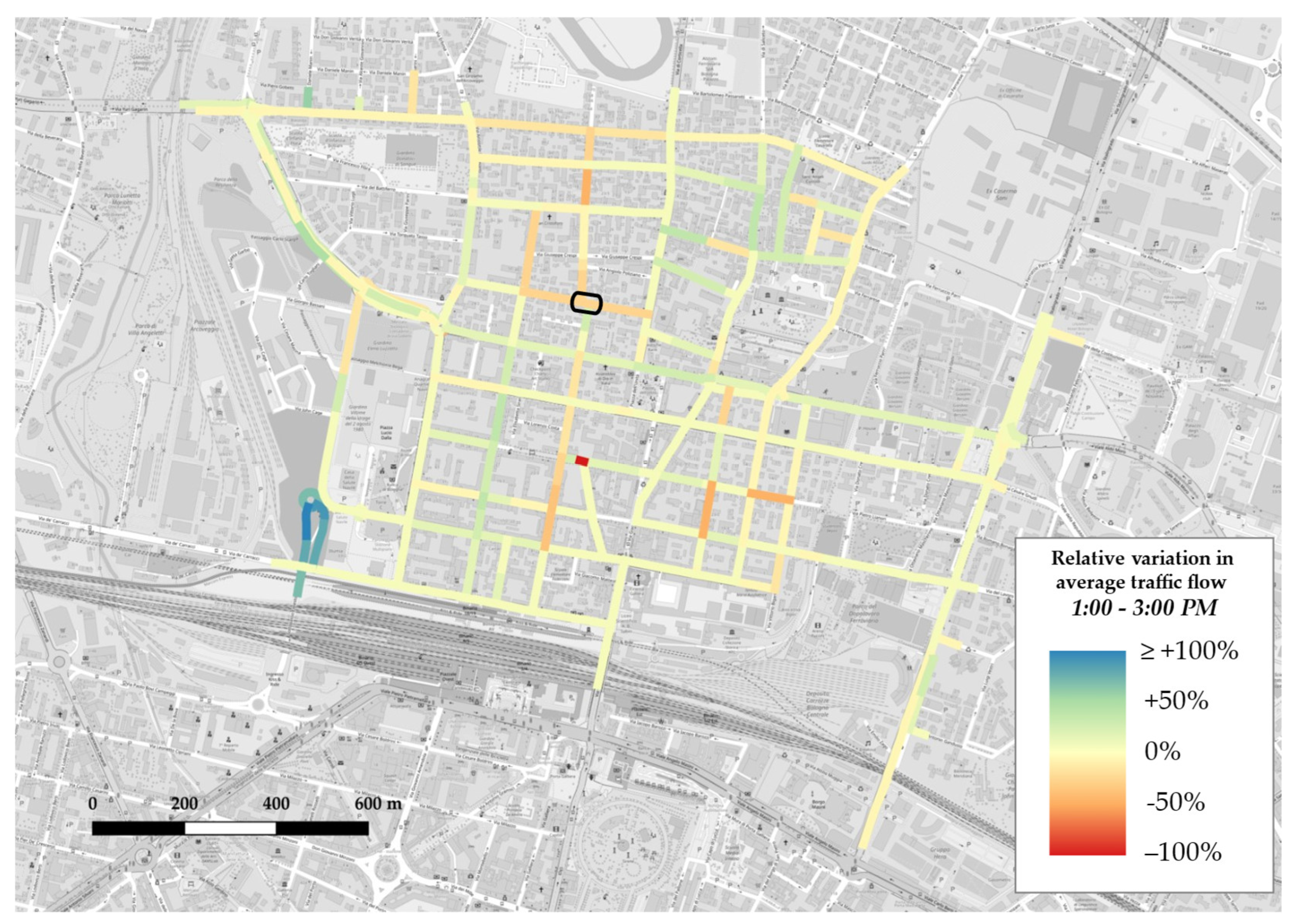
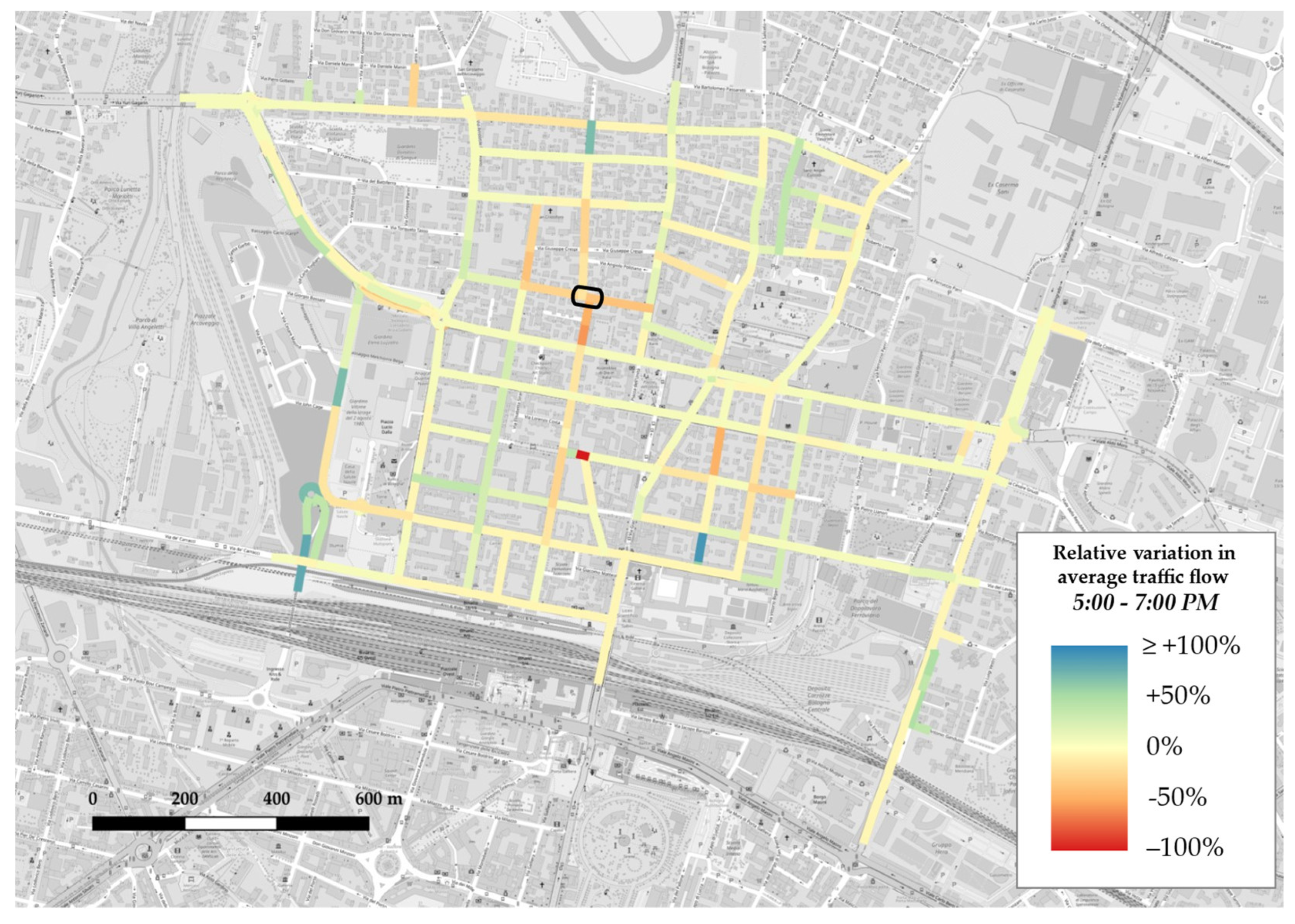
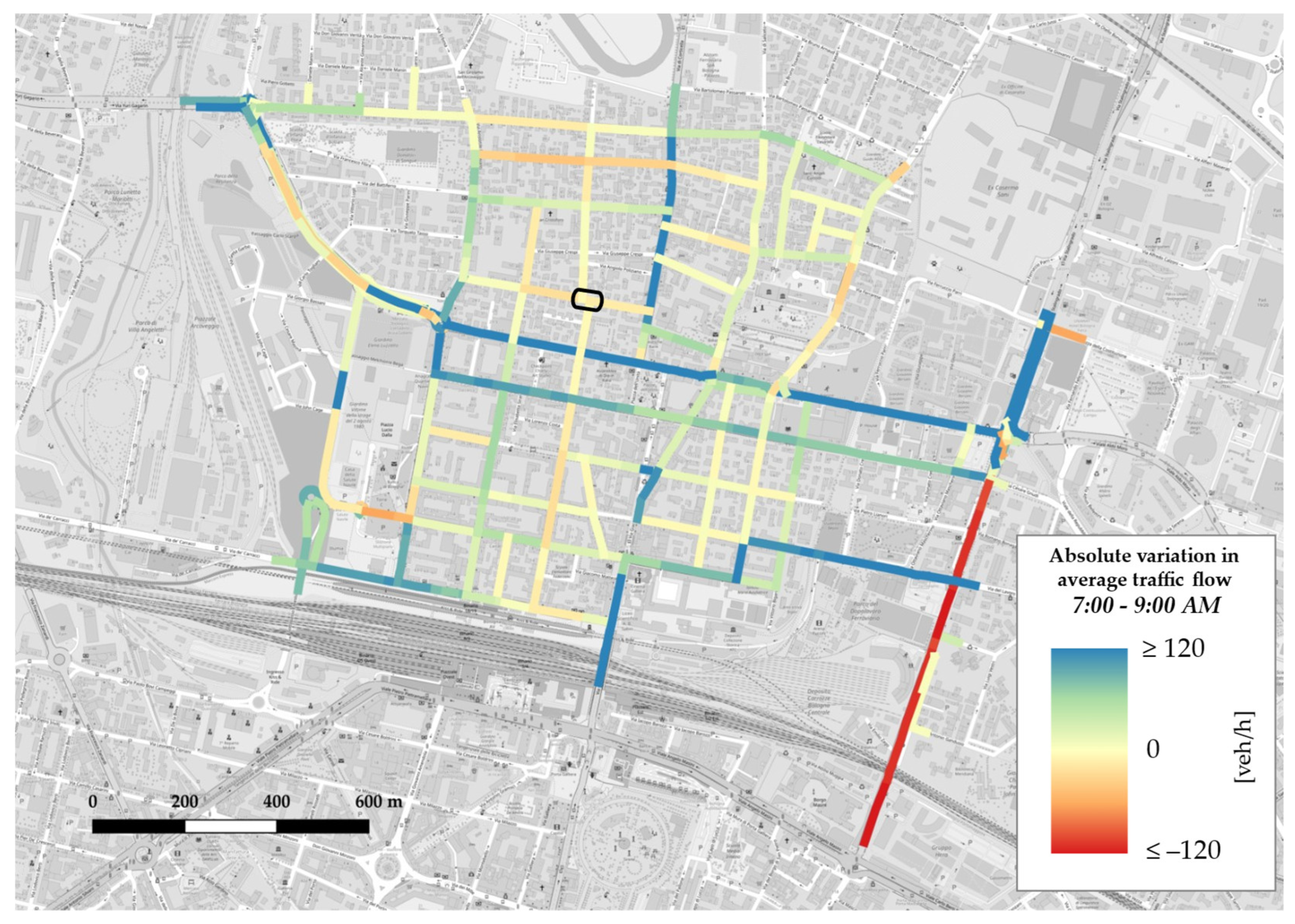
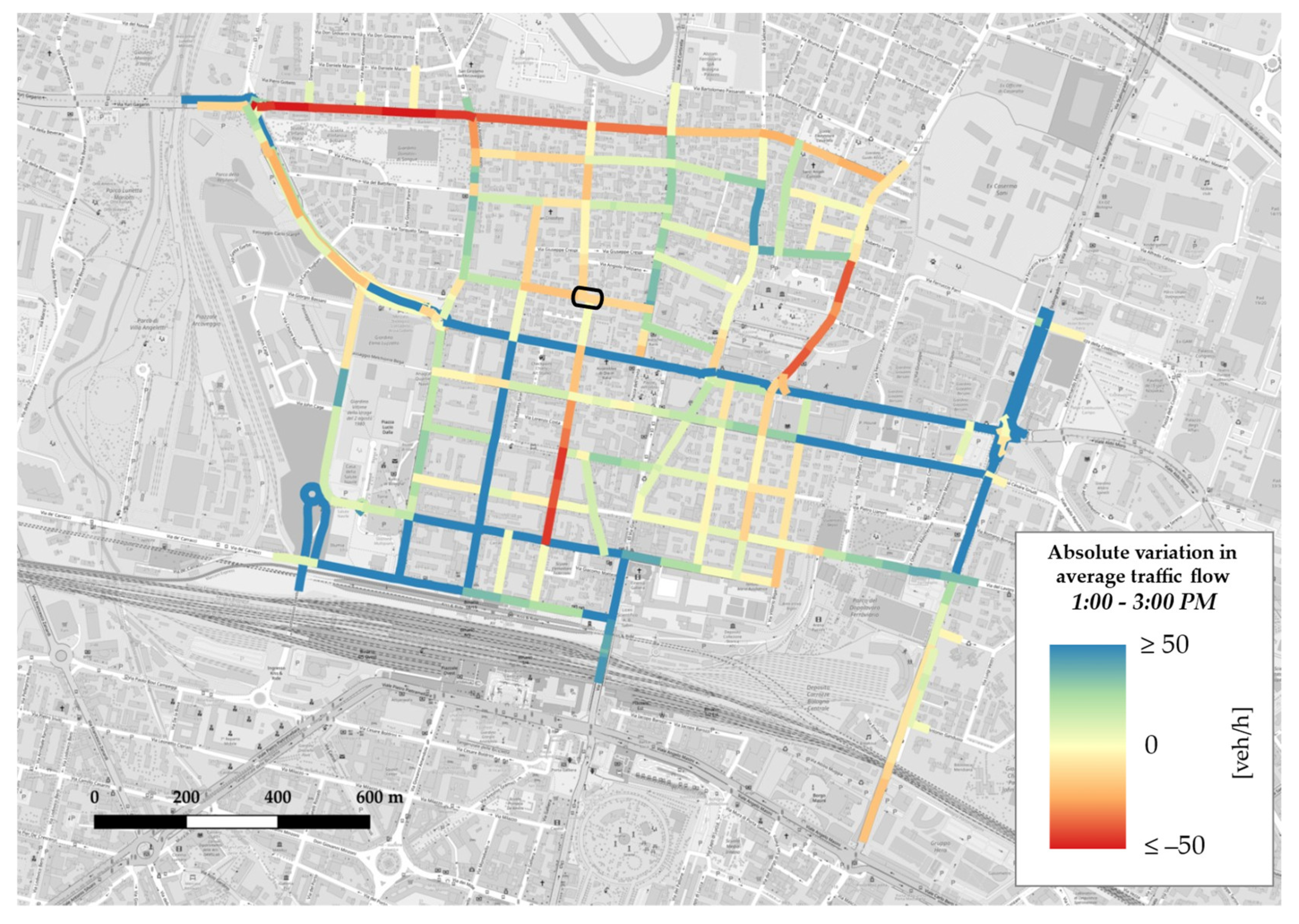
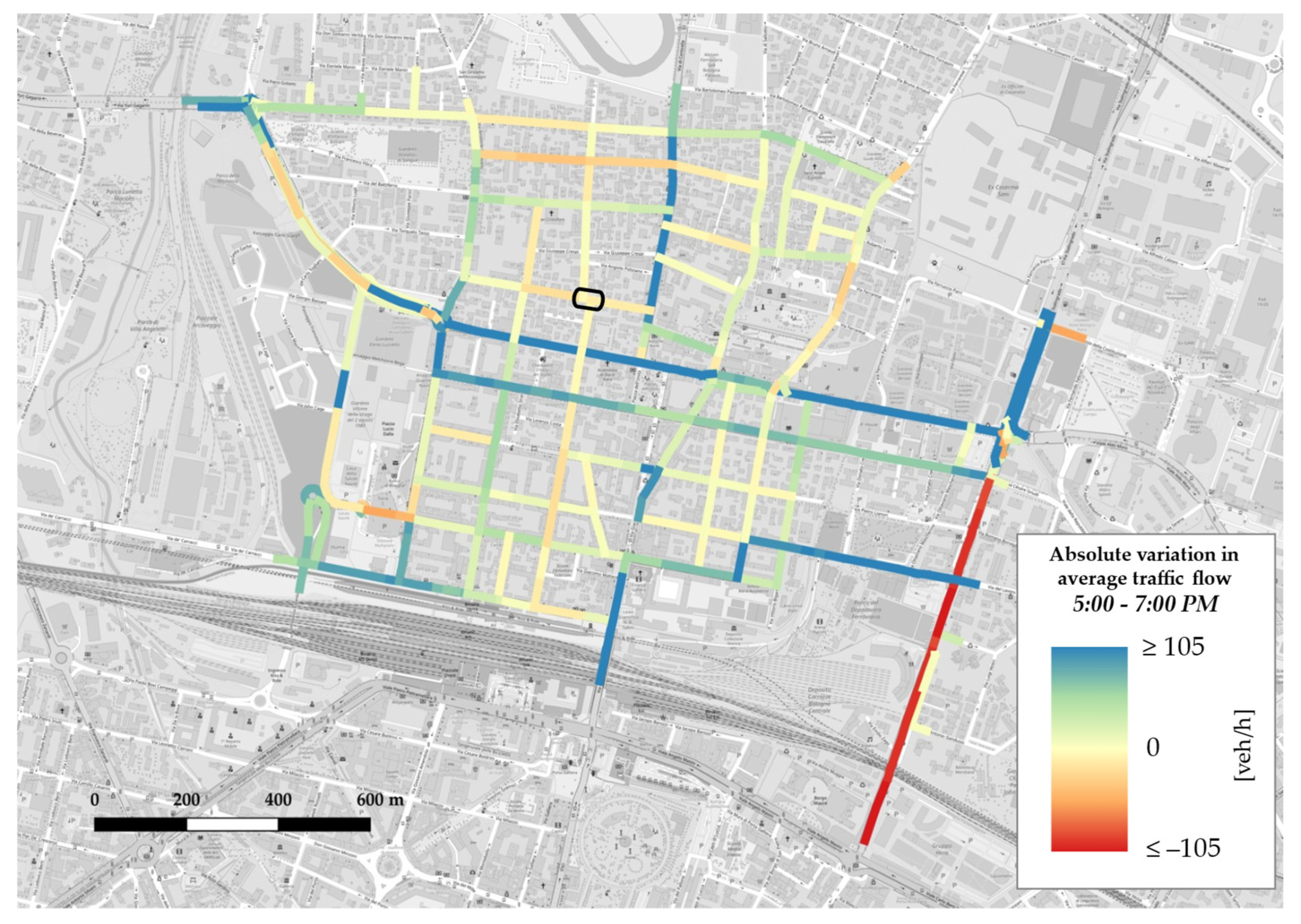
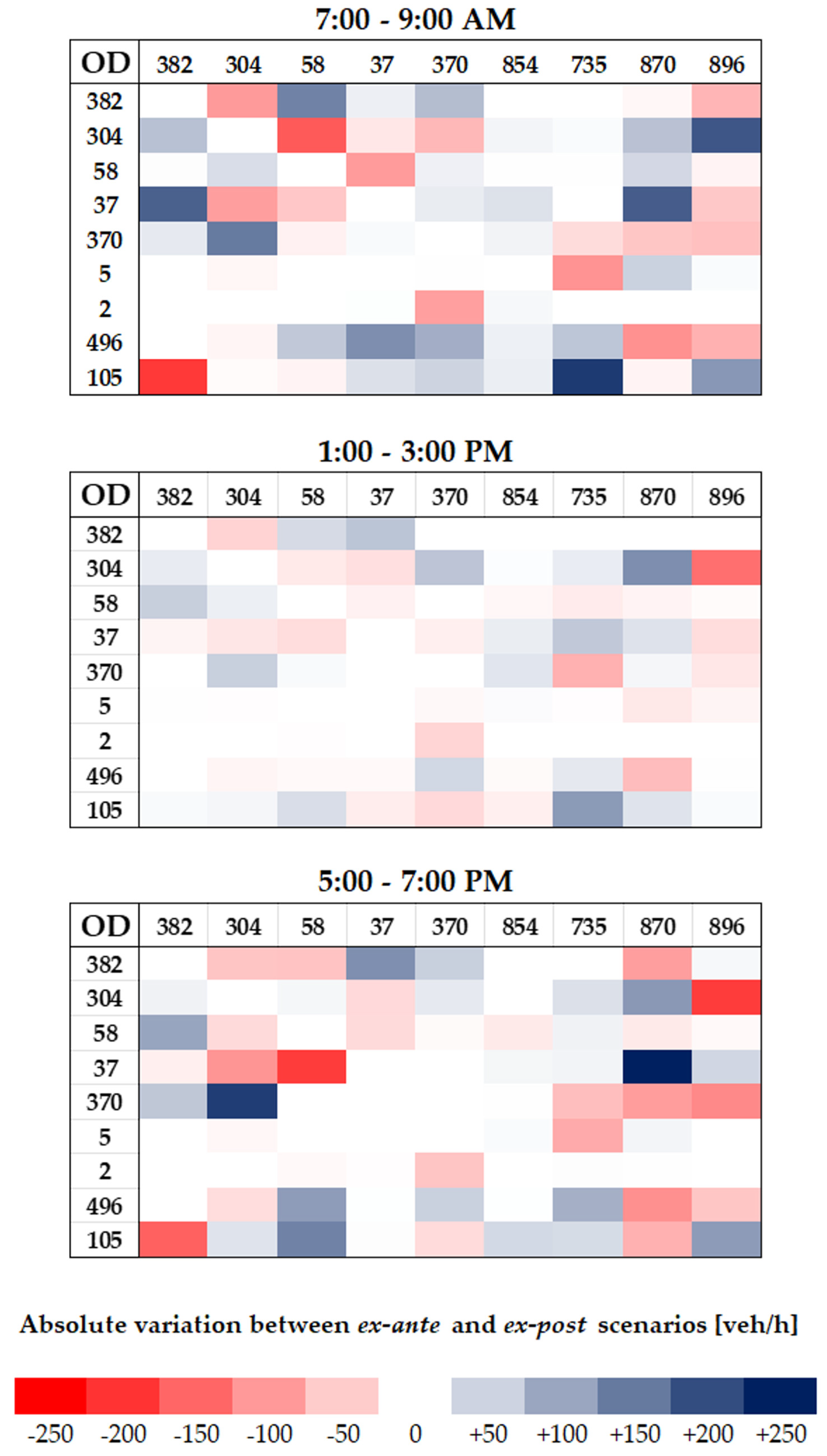
- in all three matrices, from the lightest shade to the darkest one, blue cells depicting increments are more than red cells, which denote decrements; this is consistent with trend analysis for average traffic flow on weekdays (see Figure 10), which displayed a general rise in each time slot;
- the darkest colours appear in correspondence with OD pairs whose source and/or sink nodes represent accesses or exits from the network through major axes, in accordance with network absolute variation maps (see Figure A4, Figure A5 and Figure A6), which reported increases on east–west through-traffic routes and main accesses to the neighbourhood from both north and south;
- time slot 1:00–3:00 p.m. features lighter colours, a sign that absolute variations during lunchtime are lower with respect to the morning and evening slots; this could either suggest a less disrupted pattern behaviour or, more probably, be a consequence of the fact that, as it is not one of the two peak time slots by definition, it reportedly carries less traffic flow, so in absolute terms variations also tend to be less evident.
5. Discussion
6. Conclusions
- microsimulations of the road network exploiting as demand inputs the extracted OD matrices through the implementation of traditional traffic models, both as further validation of the extracting procedure and as a more thorough assessment of the impact the tactical urbanism intervention had on the private mobility patterns via extraction of traffic-related metrics (queue lengths at intersections, level of service);
- vehicular network performance-based evaluation of further developments of the design of the temporary school square with the already retrieved input data;
- a standardization of the trend analyses procedure, aimed at collecting data from other similar road interventions and organizing results based, for instance, on road graph distance or hierarchy of segments on the graph, in order to build a solid reference database designed to advise in the decision-making process;
- an improvement of the adopted procedure for the estimation of OD matrices through harmonization of the road graph and segment attributes in order to overcome issues such as encountered outliers or considerable data inconsistency;
- consequently, a standardization of the process aimed at automatizing the extraction of OD flows independently from network size and layout.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Results of t-Tests

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Speed | ex-ante | ex-post | p-Value | ΔM | |||
|---|---|---|---|---|---|---|---|
| M | SD | M | SD | ||||
| weekdays | 30.82 | 9.77 | 29.74 | 9.29 | 7.06 × 10−29 | −1.08 *** | 7–9 a.m. |
| 31.55 | 9.62 | 30.77 | 9.17 | 2.04 × 10−19 | −0.77 *** | 1–3 p.m. | |
| 28.13 | 9.59 | 27.24 | 9.11 | 2.78 × 10−18 | −0.89 *** | 5–7 p.m. | |
| weekends | 34.40 | 11.49 | 33.31 | 11.15 | 3.07 × 10−12 | −1.09 *** | 7–9 a.m. |
| 32.58 | 10.06 | 31.73 | 9.67 | 6.03 × 10−15 | −0.86 *** | 1–3 p.m. | |
| 30.55 | 9.65 | 29.07 | 9.13 | 6.80 × 10−25 | −1.49 *** | 5–7 p.m. | |
| FRC 2–3 | 37.48 | 10.40 | 36.73 | 9.79 | 2.10 × 10−11 | −0.76 *** | 7–9 a.m. |
| 36.61 | 9.38 | 36.14 | 9.03 | 2.55 × 10−7 | −0.48 *** | 1–3 p.m. | |
| 32.84 | 9.20 | 32.18 | 9.20 | 7.60 × 10−8 | −0.66 *** | 5–7 p.m. | |
| FRC 4–6 | 30.38 | 10.25 | 29.15 | 9.81 | 1.53 × 10−23 | −1.24 *** | 7–9 a.m. |
| 29.98 | 9.35 | 29.01 | 8.75 | 6.09 × 10−26 | −0.97 *** | 1–3 p.m. | |
| 27.74 | 9.27 | 26.31 | 8.54 | 4.50 × 10−35 | −1.43 *** | 5–7 p.m. | |
| weekdays FRC 2–3 | 34.29 | 9.62 | 33.64 | 9.30 | 9.43 × 10−9 | −0.65 *** | 7–9 a.m. |
| 35.75 | 9.38 | 35.18 | 8.90 | 1.11 × 10−5 | −0.57 *** | 1–3 p.m. | |
| 31.01 | 9.63 | 30.51 | 9.35 | 1.06 × 10−3 | −0.50 ** | 5–7 p.m. | |
| weekdays FRC 4–6 | 29.23 | 9.43 | 27.96 | 8.73 | 1.73 × 10−22 | −1.27 *** | 7–9 a.m. |
| 29.62 | 9.10 | 28.75 | 8.58 | 3.57 × 10−15 | −0.87 *** | 1–3 p.m. | |
| 26.81 | 8.60 | 25.74 | 8.60 | 3.59 × 10−16 | −1.07 *** | 5–7 p.m. | |
| weekends FRC 2–3 | 40.68 | 10.20 | 39.82 | 9.29 | 1.03 × 10−5 | −0.86 *** | 7–9 a.m. |
| 37.48 | 9.32 | 37.09 | 9.08 | 3.69 × 10−3 | −0.38 ** | 1–3 p.m. | |
| 34.68 | 9.43 | 33.85 | 8.75 | 2.04 × 10−5 | −0.83 *** | 5–7 p.m. | |
| weekends FRC 4–6 | 31.53 | 10.90 | 30.34 | 10.67 | 1.22 × 10−8 | −1.20 *** | 7–9 a.m. |
| 30.34 | 9.59 | 29.27 | 8.92 | 3.73 × 10−13 | −1.07 *** | 1–3 p.m. | |
| 28.67 | 9.17 | 26.88 | 8.45 | 4.63 × 10−21 | −1.79 *** | 5–7 p.m. | |
| Sample Size | ex-ante | ex-post | p-Value | ΔM | |||
|---|---|---|---|---|---|---|---|
| M | SD | M | SD | ||||
| weekdays | 68.46 | 66.58 | 72.62 | 68.70 | 4.60 × 10−55 | 4.16 *** | 7–9 a.m. |
| 61.52 | 60.89 | 64.88 | 64.01 | 2.85 × 10−51 | 3.36 *** | 1–3 p.m. | |
| 85.05 | 77.51 | 86.12 | 77.18 | 9.73 × 10−10 | 1.07 *** | 5–7 p.m. | |
| weekends | 22.38 | 23.58 | 25.38 | 25.68 | 3.41 × 10−86 | 3.00 *** | 7–9 a.m. |
| 51.78 | 57.68 | 56.07 | 60.01 | 7.13 × 10−83 | 4.28 *** | 1–3 p.m. | |
| 69.95 | 75.79 | 72.39 | 73.65 | 5.35 × 10−21 | 2.44 *** | 5–7 p.m. | |
| FRC 2–3 | 86.03 | 70.39 | 92.47 | 71.29 | 1.29 × 10−62 | 6.44 *** | 7–9 a.m. |
| 108.91 | 70.02 | 116.67 | 71.76 | 1.57 × 10−91 | 7.76 *** | 1–3 p.m. | |
| 148.84 | 80.84 | 149.88 | 80.84 | 3.50 × 10−3 | 1.04 ** | 5–7 p.m. | |
| FRC 4–6 | 26.83 | 32.30 | 29.10 | 33.88 | 4.32 × 10−74 | 2.27 *** | 7–9 a.m. |
| 32.73 | 33.08 | 34.74 | 34.24 | 3.64 × 10−62 | 2.01 *** | 1–3 p.m. | |
| 44.84 | 44.87 | 46.92 | 45.18 | 1.39 × 10−38 | 2.09 *** | 5–7 p.m. | |
| weekdays FRC 2–3 | 129.38 | 73.37 | 137.12 | 73.16 | 1.20 × 10−28 | 7.74 *** | 7–9 a.m. |
| 115.74 | 68.58 | 123.86 | 70.84 | 2.00 × 10−45 | 8.12 *** | 1–3 p.m. | |
| 157.91 | 77.75 | 159.86 | 76.07 | 3.96 × 10−6 | 1.95 *** | 5–7 p.m. | |
| weekdays FRC 4–6 | 40.57 | 39.09 | 43.10 | 40.73 | 3.42 × 10−38 | 2.52 *** | 7–9 a.m. |
| 36.70 | 36.00 | 37.88 | 36.85 | 4.11 × 10−21 | 1.18 *** | 1–3 p.m. | |
| 51.69 | 49.11 | 52.36 | 49.11 | 5.36 × 10−5 | 0.67 *** | 5–7 p.m. | |
| weekends FRC 2–3 | 42.68 | 27.80 | 47.82 | 28.80 | 2.71 × 10−61 | 5.14 *** | 7–9 a.m. |
| 102.08 | 70.95 | 109.49 | 72.12 | 2.57 × 10−48 | 7.40 *** | 1–3 p.m. | |
| 139.78 | 89.24 | 139.90 | 84.35 | 8.24 × 10−1 | 0.13 | 5–7 p.m. | |
| weekends FRC 4–6 | 13.08 | 13.52 | 15.10 | 15.70 | 9.00 × 10−39 | 2.02 *** | 7–9 a.m. |
| 28.76 | 29.39 | 31.61 | 31.13 | 1.04 × 10−44 | 2.85 *** | 1–3 p.m. | |
| 37.98 | 38.51 | 41.48 | 40.21 | 1.29 × 10−39 | 3.50 *** | 5–7 p.m. | |
| Speed 85th Percentile | ex-ante | ex-post | p-Value | ΔM | |||
|---|---|---|---|---|---|---|---|
| M | SD | M | SD | ||||
| weekdays | 41.98 | 11.93 | 40.41 | 10.79 | 1.14 × 10−14 | −1.57 *** | 7–9 a.m. |
| 42.78 | 11.69 | 41.72 | 10.67 | 3.40 × 10−9 | −1.06 *** | 1–3 p.m. | |
| 39.10 | 11.95 | 37.67 | 10.66 | 3.21 × 10−12 | −1.43 *** | 5–7 p.m. | |
| weekends | 45.83 | 14.56 | 44.02 | 13.71 | 1.71 × 10−12 | −1.80 *** | 7–9 a.m. |
| 44.04 | 12.78 | 42.44 | 11.55 | 3.45 × 10−11 | −1.59 *** | 1–3 p.m. | |
| 41.18 | 12.04 | 39.65 | 10.80 | 9.39 × 10−10 | −1.53 *** | 5–7 p.m. | |
| FRC 2–3 | 50.28 | 11.46 | 49.14 | 10.59 | 1.66 × 10−11 | −1.14 *** | 7–9 a.m. |
| 48.92 | 10.43 | 48.22 | 9.75 | 2.52 × 10−6 | −0.70 *** | 1–3 p.m. | |
| 44.54 | 10.19 | 43.94 | 10.19 | 7.06 × 10−5 | −0.60 *** | 5–7 p.m. | |
| FRC 4–6 | 40.99 | 13.28 | 39.05 | 11.97 | 6.94 × 10−18 | −1.94 *** | 7–9 a.m. |
| 40.89 | 12.21 | 39.27 | 10.57 | 7.45 × 10−15 | −1.62 *** | 1–3 p.m. | |
| 38.13 | 12.04 | 36.24 | 10.15 | 5.18 × 10−17 | −1.89 *** | 5–7 p.m. | |
| weekdays FRC 2–3 | 46.39 | 10.55 | 45.61 | 10.23 | 9.51 × 10−11 | −0.78 *** | 7–9 a.m. |
| 47.84 | 10.46 | 47.25 | 9.73 | 5.41 × 10−4 | −0.59 *** | 1–3 p.m. | |
| 42.69 | 10.93 | 42.14 | 10.44 | 1.48 × 10−3 | −0.55 ** | 5–7 p.m. | |
| weekdays FRC 4–6 | 39.97 | 12.00 | 38.03 | 10.19 | 2.82 × 10−11 | −1.94 *** | 7–9 a.m. |
| 40.46 | 11.50 | 39.18 | 10.12 | 3.18 × 10−7 | −1.28 *** | 1–3 p.m. | |
| 37.46 | 10.13 | 35.62 | 10.13 | 1.85 × 10−10 | −1.84 *** | 5–7 p.m. | |
| weekends FRC 2–3 | 54.18 | 11.03 | 52.67 | 9.76 | 1.93 × 10−6 | −1.51 *** | 7–9 a.m. |
| 50.00 | 10.30 | 49.19 | 9.70 | 9.22 × 10−4 | −0.81 *** | 1–3 p.m. | |
| 46.39 | 10.39 | 45.74 | 9.63 | 8.78 × 10−3 | −0.65 ** | 5–7 p.m. | |
| weekends FRC 4–6 | 42.00 | 14.39 | 40.07 | 13.45 | 1.68 × 10−8 | −1.94 *** | 7–9 a.m. |
| 41.31 | 12.88 | 39.35 | 11.01 | 4.01 × 10−9 | −1.95 *** | 1–3 p.m. | |
| 38.79 | 12.01 | 36.86 | 10.15 | 2.27 × 10−8 | −1.93 *** | 5–7 p.m. | |
Appendix B. GIS Maps


References
- Cariello, A.; Ferorelli, R.; Rotondo, F. Tactical Urbanism in Italy: From Grassroots to Institutional Tool—Assessing Value of Public Space Experiments. Sustainability 2021, 13, 11482. [Google Scholar] [CrossRef]
- Global Design Cities Initiative. How to Implement Street Transformations. A Focus on Pop-Up and Interim Road Safety Projects. Available online: https://globaldesigningcities.org/publication/how-to-implement-street-transformations/ (accessed on 29 June 2023).
- United Nations. Transforming Our World: The 2030 Agenda for Sustainable Development; United Nations: New York, NY, USA, 2016. [Google Scholar]
- Yassin, H.H. Livable City: An Approach to Pedestrianization through Tactical Urbanism. Alex. Eng. J. 2019, 58, 251–259. [Google Scholar] [CrossRef]
- Nello-Deakin, S. Exploring traffic evaporation: Findings from tactical urbanism interventions in Barcelona. Case Stud. Transp. Policy 2022, 10, 2430–2442. [Google Scholar] [CrossRef]
- Ceccarelli, G.; Messa, F.; Gorrini, A.; Presicce, D.; Choubassi, R. Deep Learning Analytics for Pre-post Evaluation of Tactical Urbanism Interventions: The Case of Bologna. J. Public Space 2023. submitted. [Google Scholar]
- Bertolini, L. From “streets for traffic” to “streets for people”: Can street experiments transform urban mobility? Transp. Rev. 2020, 40, 734–753. [Google Scholar] [CrossRef]
- Cairns, S.; Atkins, S.; Goodwin, P.; Bayliss, D. Disappearing traffic? The story so far. Proc. Inst. Civ. Eng. Munic. Eng. 2002, 151, 13–22. [Google Scholar] [CrossRef]
- Hunt, J.D.; Brownlee, A.T.; Stefan, K.J. Responses to Centre Street Bridge Closure: Where the “Disappearing” Travelers Went. Transp. Res. Rec. 2002, 1807, 51–58. [Google Scholar] [CrossRef]
- Tennøy, A.; Hagen, O.H. Urban main road capacity reduction: Adaptations, effects and consequences. Transp. Res. Part D Transp. Environ. 2021, 96, 102848. [Google Scholar] [CrossRef]
- Leduc, G. Road Traffic Data: Collection Methods and Applications. Work. Pap. Energy Transp. Clim. Chang. 2008, 1, 1–55. [Google Scholar]
- Necula, E. Analyzing Traffic Patterns on Street Segments Based on GPS Data Using R. Transp. Res. Procedia 2015, 10, 276–285. [Google Scholar] [CrossRef]
- Deng, B.; Denman, S.; Zachariadis, V.; Jin, Y. Estimating traffic delays and network speeds from low-frequency GPS taxis traces for urban transport modelling. Eur. J. Transp. Infrastruct. Res. 2015, 15. [Google Scholar] [CrossRef]
- D’Andrea, E.; Marcelloni, F. Detection of traffic congestion and incidents from GPS trace analysis. Expert Syst. Appl. 2017, 73, 43–56. [Google Scholar] [CrossRef]
- Cascetta, E. Teoria e Metodi Dell’ingegneria dei Sistemi di Trasporto, 2nd ed.; UTET: Torino, Italy, 1998. [Google Scholar]
- Bonnel, P.; Fekih, M.; Smoreda, Z. Origin-Destination estimation using mobile network probe data. Transp. Res. Procedia 2018, 32, 69–81. [Google Scholar] [CrossRef]
- Fekih, M.; Bellemans, T.; Smoreda, Z.; Bonnel, P.; Furno, A.; Galland, S. A data-driven approach for origin–destination matrix construction from cellular network signalling data: A case study of Lyon region (France). Transportation 2021, 48, 1671–1702. [Google Scholar] [CrossRef]
- Croce, A.I.; Musolino, G.; Rindone, C.; Vitetta, A. Estimation of Travel Demand Models with Limited Information: Floating Car Data for Parameters’ Calibration. Sustainability 2021, 13, 8838. [Google Scholar] [CrossRef]
- Demissie, M.G.; Kattan, L. Estimation of truck origin-destination flows using GPS data. Transp. Res. Part E Logist. Transp. Rev. 2022, 159, 102621. [Google Scholar] [CrossRef]
- Ge, Q.; Fukuda, D. Updating origin–destination matrices with aggregated data of GPS traces. Transp. Res. Part C Emerg. Technol. 2016, 69, 291–312. [Google Scholar] [CrossRef]
- Tolouei, R.; Psarras, S.; Prince, R. Origin-destination trip matrix development: Conventional methods versus mobile phone data. Transp. Res. Procedia 2017, 26, 39–52. [Google Scholar] [CrossRef]
- Krishnakumari, P.; van Lint, H.; Djukic, T.; Cats, O. A data driven method for OD matrix estimation. Transp. Res. Procedia 2019, 38, 139–159. [Google Scholar] [CrossRef]
- Goodwin, P.; Hass-Klau, C.; Cairns, S. Evidence on the Effects of Road Capacity Reductions on Traffic Levels. Traffic Eng. Control 1998, 348–354. [Google Scholar]
- Yen, J.Y. Finding the K Shortest Loopless Paths in a Network. Manag. Sci. 1971, 17, 712–716. [Google Scholar] [CrossRef]
- Prato, C.G. Route choice modeling: Past, present and future research directions. J. Choice Model. 2009, 2, 65–100. [Google Scholar] [CrossRef]
- Ben-Akiva, M.; Bierlaire, M. Discrete Choice Methods and Their Applications to Short Term Travel Decisions. In Handbook of Transportation Science; Kluwer Academic Publishers: New York, NY, USA, 1999; pp. 5–33. [Google Scholar]
- Ortúzar, J.; Willumsen, L. Modelling Transport, 4th ed.; Wiley: Bognor Regis, UK, 2011. [Google Scholar]
- Espitia Echeverría, E.A. Analisi Dell’influenza Della Localizzazione di Sensori di Rilevamento di Traffico Nell’aggiornamento di Matrici OD—Caso di Studio: Torino. Master’s Thesis, Politecnico di Milano, Milan, Italy, 2018. [Google Scholar]
- Yang, H.; Zhou, J. Optimal traffic counting locations for origin–destination matrix estimation. Transp. Res. Part B Methodol. 1998, 32, 109–126. [Google Scholar] [CrossRef]
- Toledo, T.; Koutsopoulos, H.N. Statistical Validation of Traffic Simulation Models. Transp. Res. Rec. 2004, 1876, 142–150. [Google Scholar] [CrossRef]
- Barceló, J.; Montero, L.; Marqués, L.; Carmona, C. Travel Time Forecasting and Dynamic Origin-Destination Estimation for Freeways Based on Bluetooth Traffic Monitoring. Transp. Res. Rec. 2010, 2175, 19–27. [Google Scholar] [CrossRef]
- Goodwin, L.D.; Leech, N.L. Understanding Correlation: Factors That Affect the Size of r. J. Exp. Educ. 2006, 74, 249–266. [Google Scholar] [CrossRef]

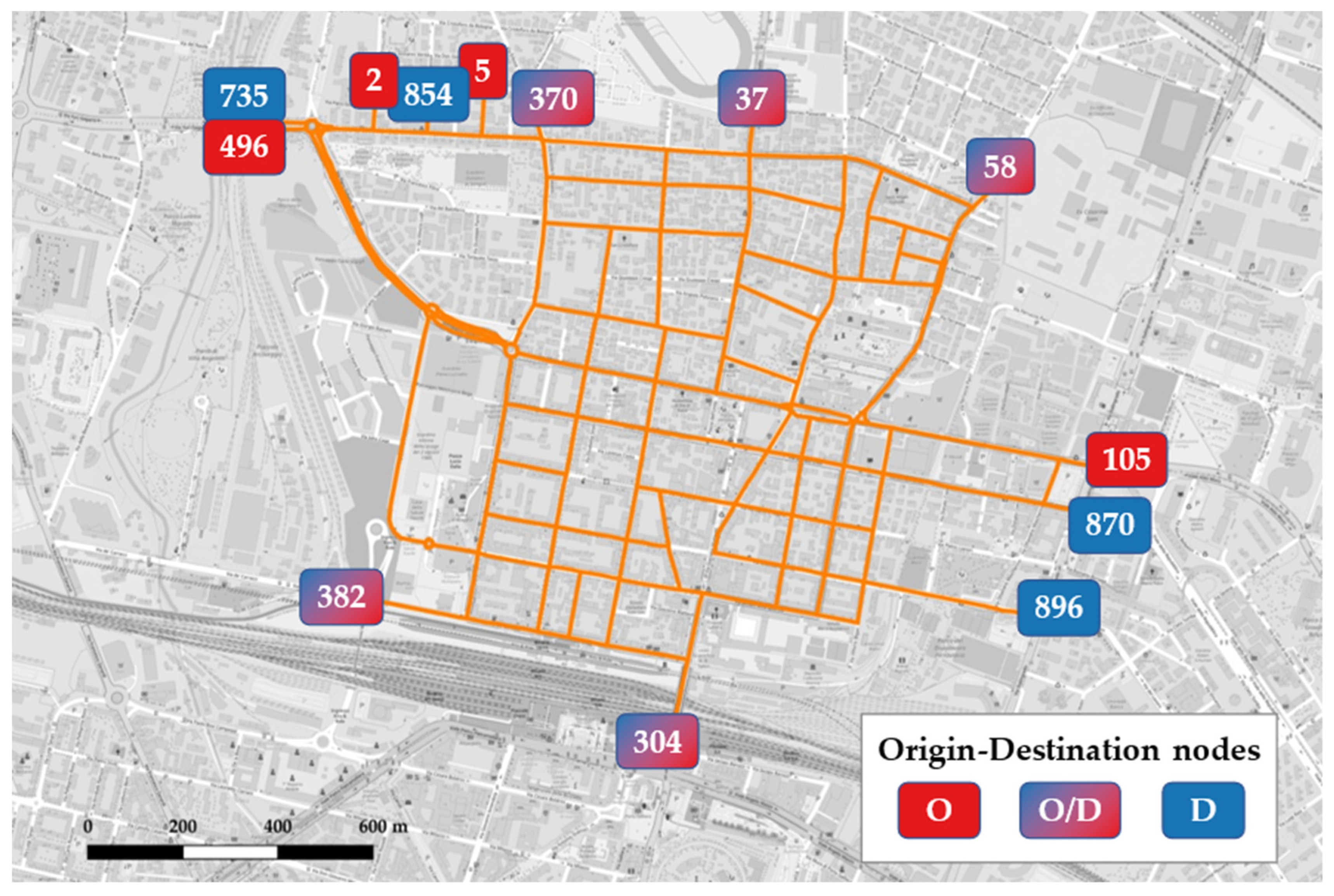




| Node ID | Access/Exit Segment | Origin | Destination |
|---|---|---|---|
| 382 | Via de’ Carracci | • | • |
| 304 | Via Giacomo Matteotti | • | • |
| 58 | Via Ferrarese | • | • |
| 37 | Via di Corticella | • | • |
| 370 | Via Aristotile Fioravanti | • | • |
| 5 | Via Ezio Cesarini | • | - |
| 854 | Via Alceste Giovannini | - | • |
| 2 | Via Daniele Manin | • | - |
| 735 | Via Yuri Gagarin | - | • |
| 496 | Via Yuri Gagarin | • | - |
| 105 | Via della Liberazione | • | - |
| 870 | Via Donato Creti | - | • |
| 896 | Via Sebastiano Serlio | - | • |
| Buffer Segment Class | 7:00–9:00 a.m. | 1:00–3:00 p.m. | 5:00–7:00 p.m. | Average |
|---|---|---|---|---|
| Intervention | −23.11% | −20.42% | −28.08% | −23.87% |
| Adjacent | +5.95% | +0.64% | +3.94% | +3.51% |
| Buffer | +6.57% | +0.48% | +3.46% | +3.50% |
| ex-ante, k | ex-post, k | ||||||
|---|---|---|---|---|---|---|---|
| 2 | 3 | 15 | 20 | 24 | 2 | 3 | |
| U | 0.2110 | 0.2699 | 0.1913 | 0.1843 | 0.1768 | 0.1997 | 0.2091 |
| UM | 0.0008 | 0.0119 | 0.0110 | 0.0090 | 0.0038 | 0.0001 | 0.0004 |
| US | 0.0015 | 0.0549 | 0.0007 | 0.0009 | 0.0070 | 0.0002 | 0.0078 |
| UC | 0.9977 | 0.9332 | 0.9883 | 0.9901 | 0.9892 | 0.9997 | 0.9918 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pozzoni, M.; Ceccarelli, G.; Gorrini, A.; Manenti, L.; Sanfilippo, L. TomTom Data Applications for the Assessment of Tactical Urbanism Interventions: The Case of Bologna. Sustainability 2023, 15, 12716. https://doi.org/10.3390/su151712716
Pozzoni M, Ceccarelli G, Gorrini A, Manenti L, Sanfilippo L. TomTom Data Applications for the Assessment of Tactical Urbanism Interventions: The Case of Bologna. Sustainability. 2023; 15(17):12716. https://doi.org/10.3390/su151712716
Chicago/Turabian StylePozzoni, Marco, Giulia Ceccarelli, Andrea Gorrini, Lorenza Manenti, and Luigi Sanfilippo. 2023. "TomTom Data Applications for the Assessment of Tactical Urbanism Interventions: The Case of Bologna" Sustainability 15, no. 17: 12716. https://doi.org/10.3390/su151712716
APA StylePozzoni, M., Ceccarelli, G., Gorrini, A., Manenti, L., & Sanfilippo, L. (2023). TomTom Data Applications for the Assessment of Tactical Urbanism Interventions: The Case of Bologna. Sustainability, 15(17), 12716. https://doi.org/10.3390/su151712716