
Variable Speed Limit Control for the Motorway–Urban Merging Bottlenecks Using Multi-Agent Reinforcement Learning



Abstract
1. Introduction
2. Methodology
2.1. Reinforcement Learning
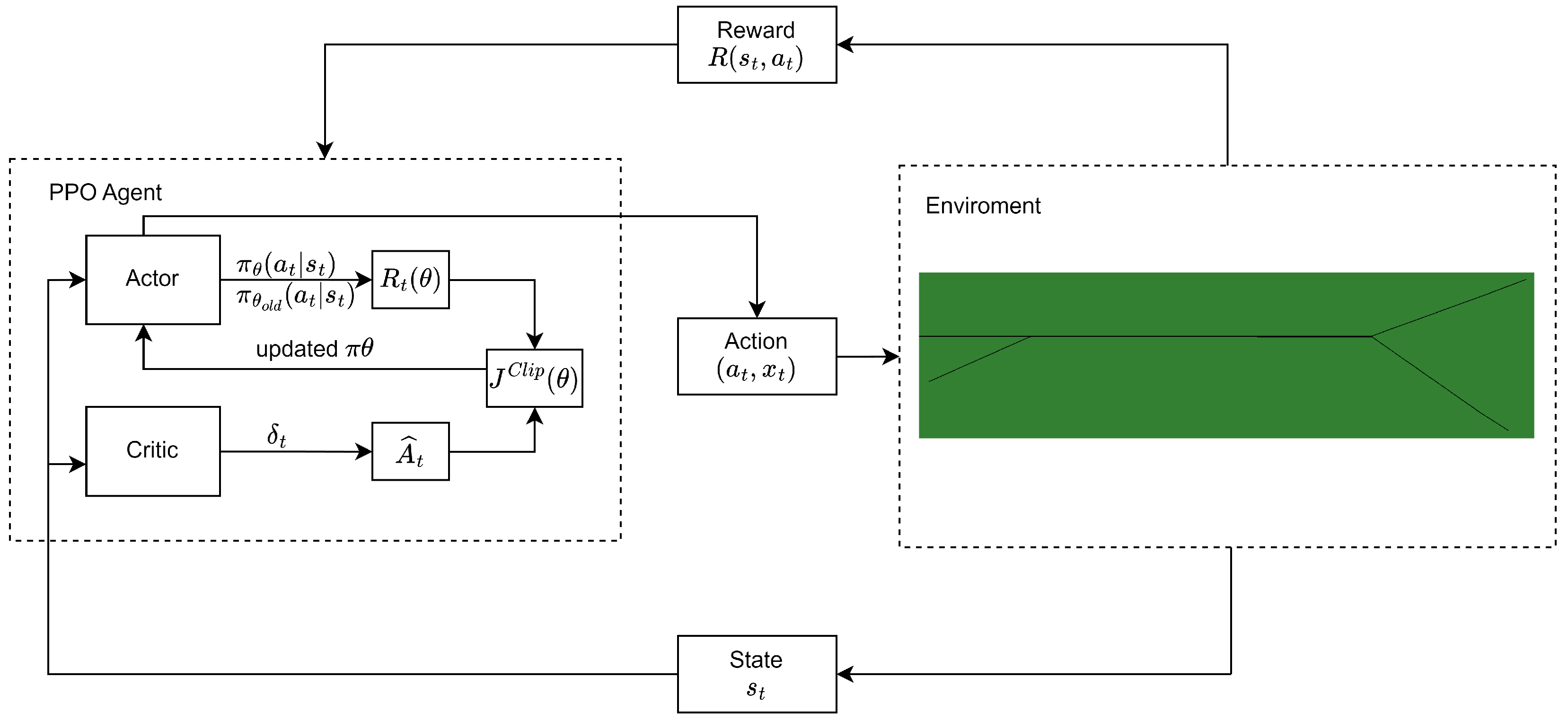
2.2. Proximal Policy Optimization
2.3. Multi-Agent Proximal Policy Optimization
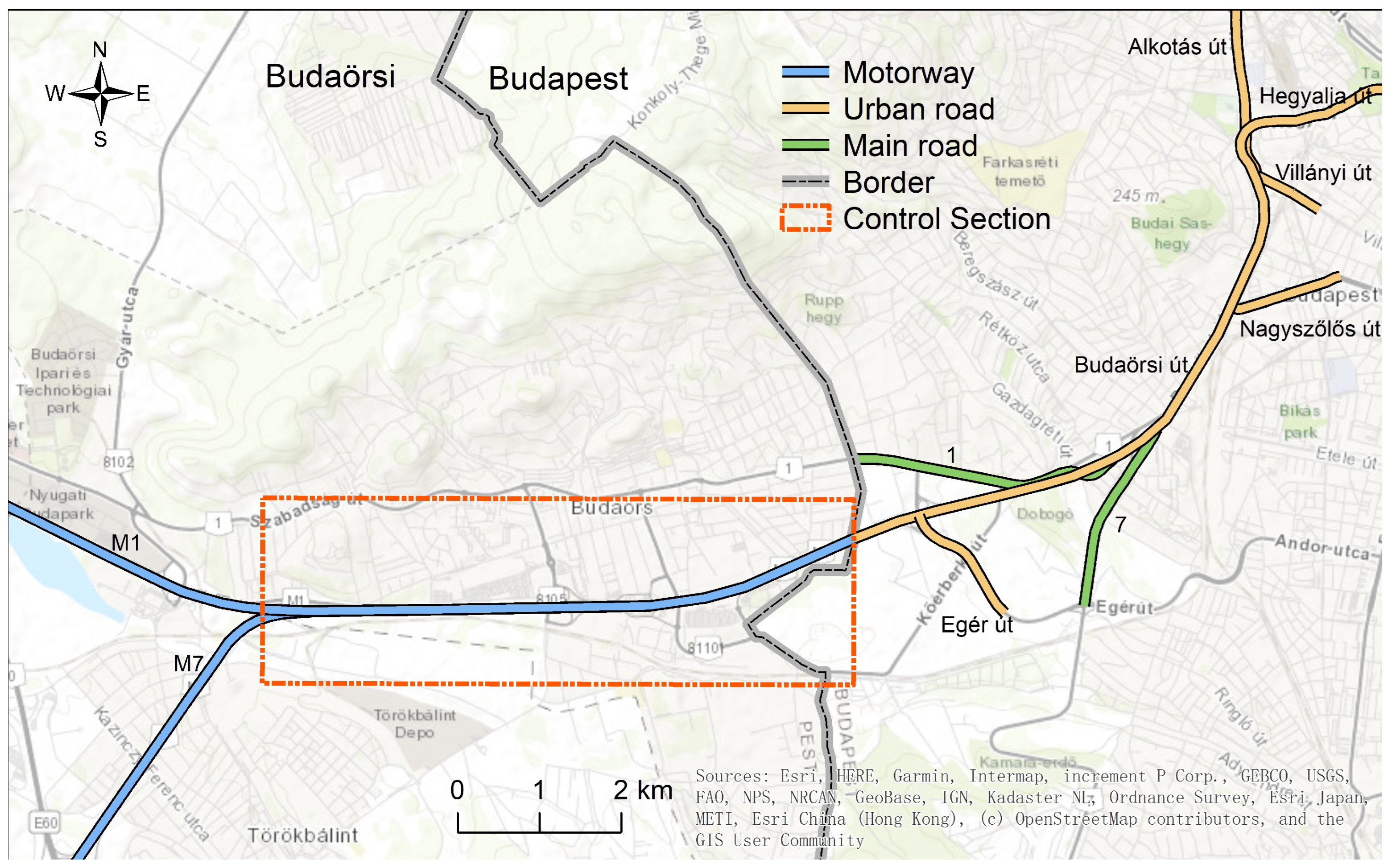
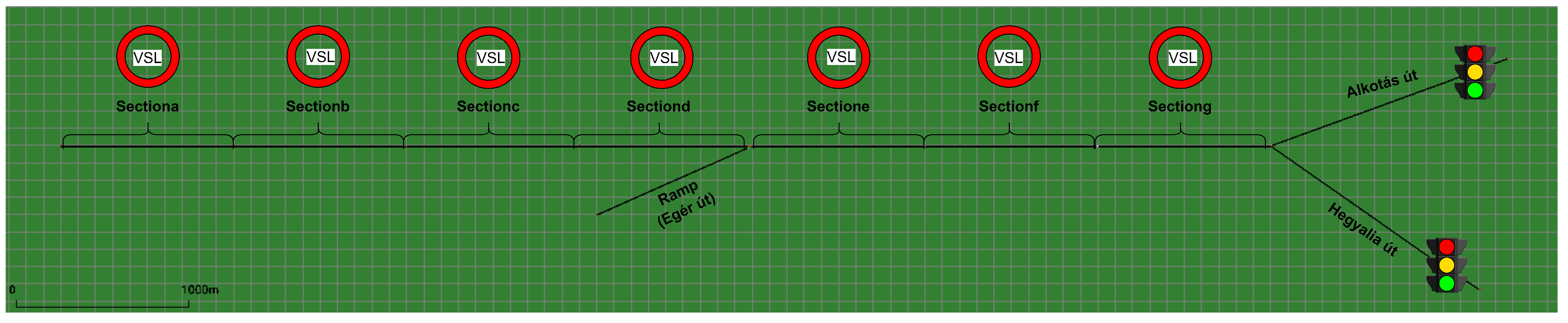
3. Simulation Environment
4. Results and Discussion
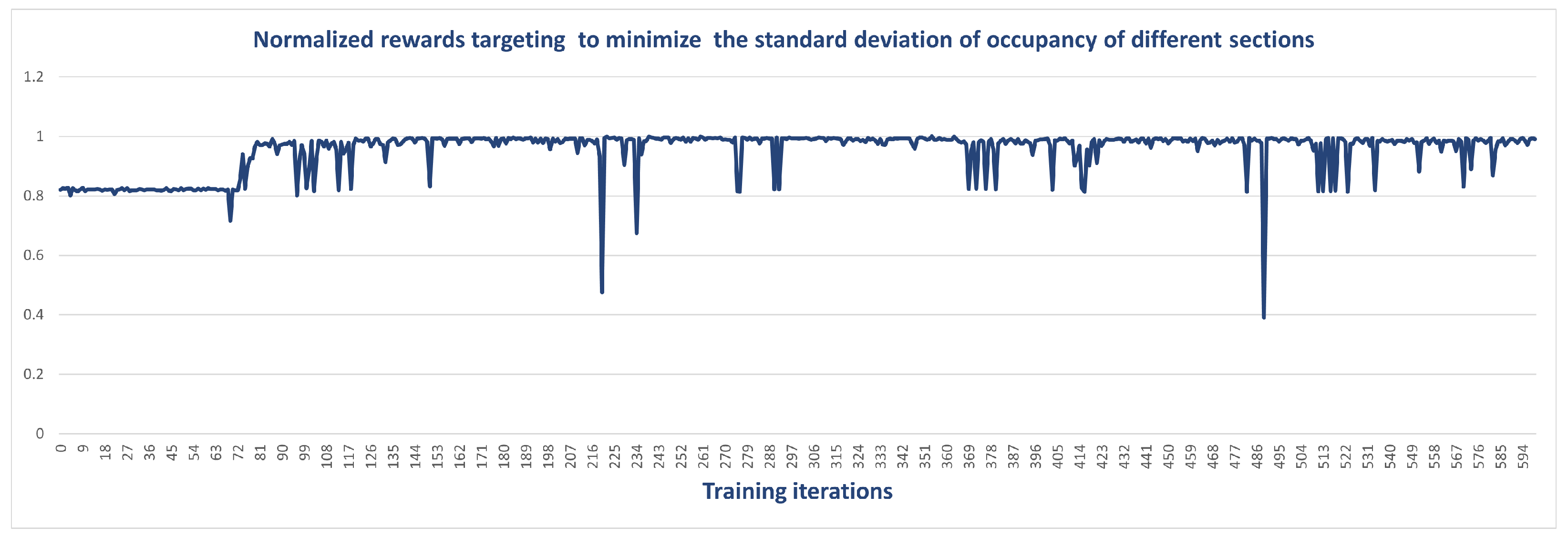
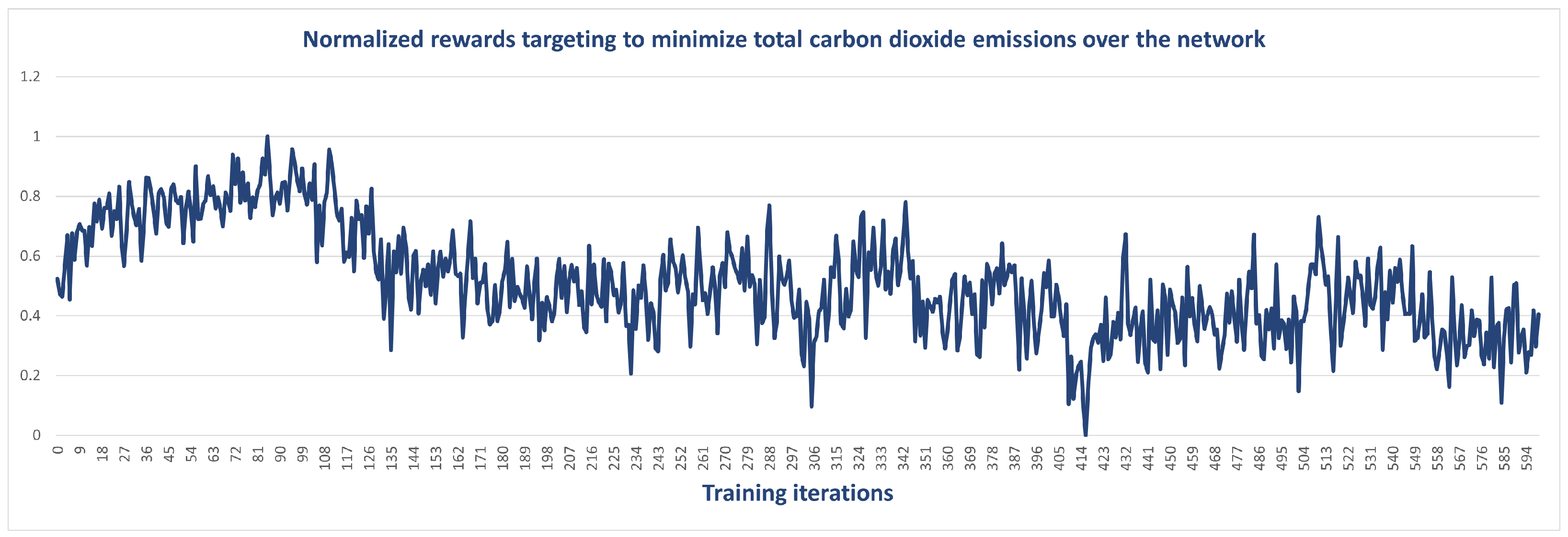
4.1. Training Setting of MAPPO Algorithm
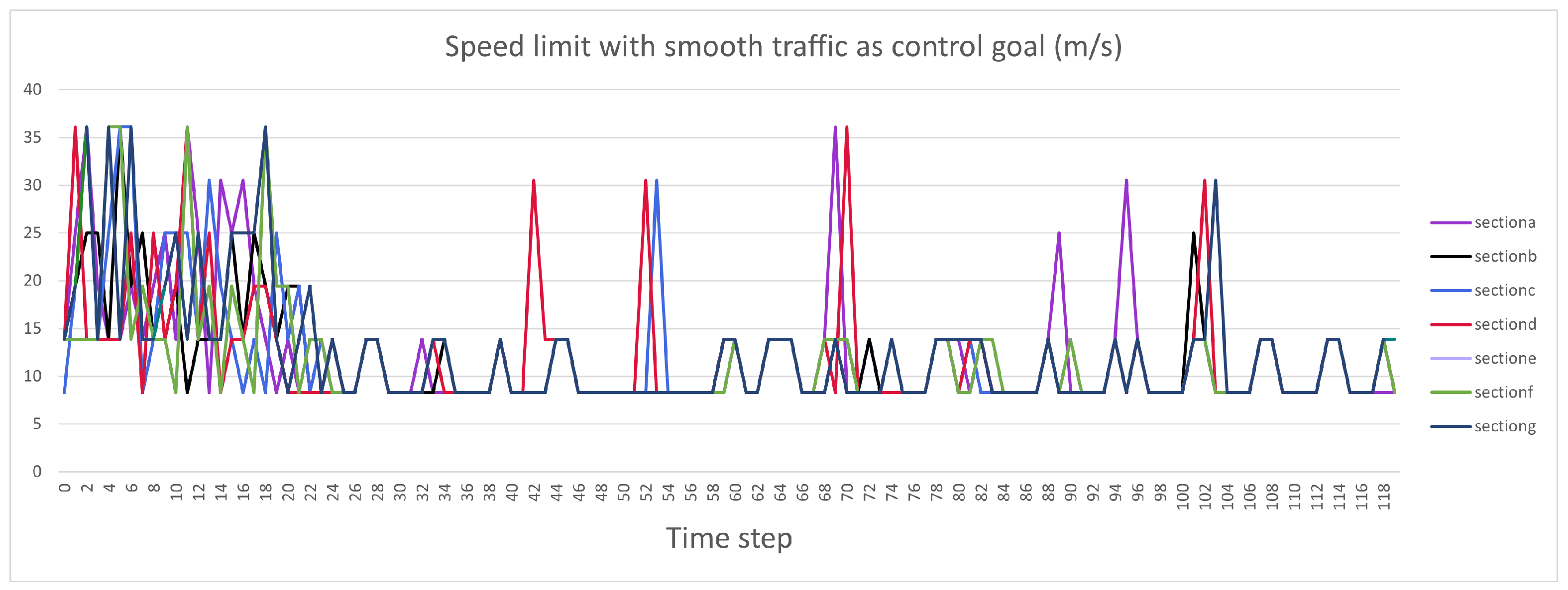
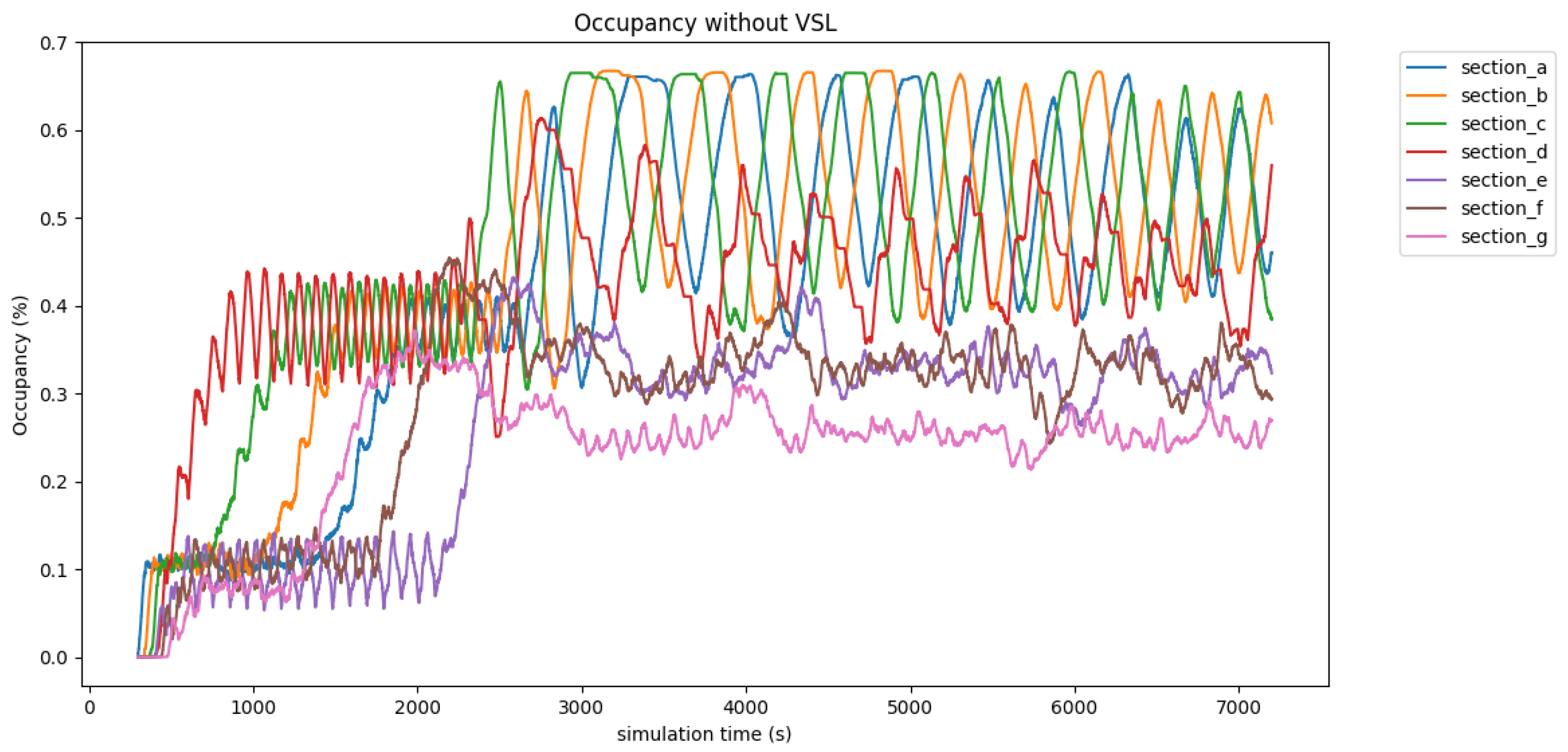
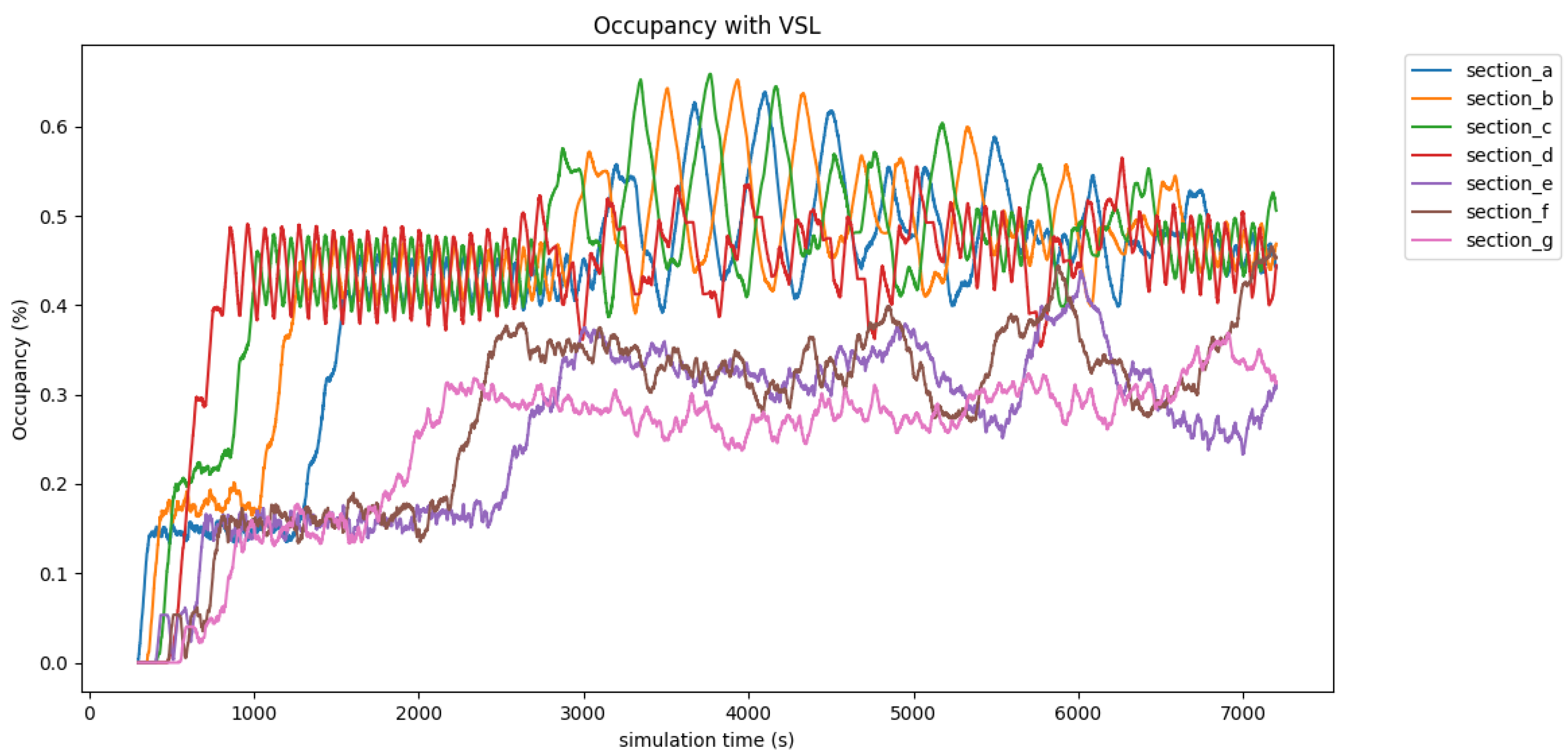
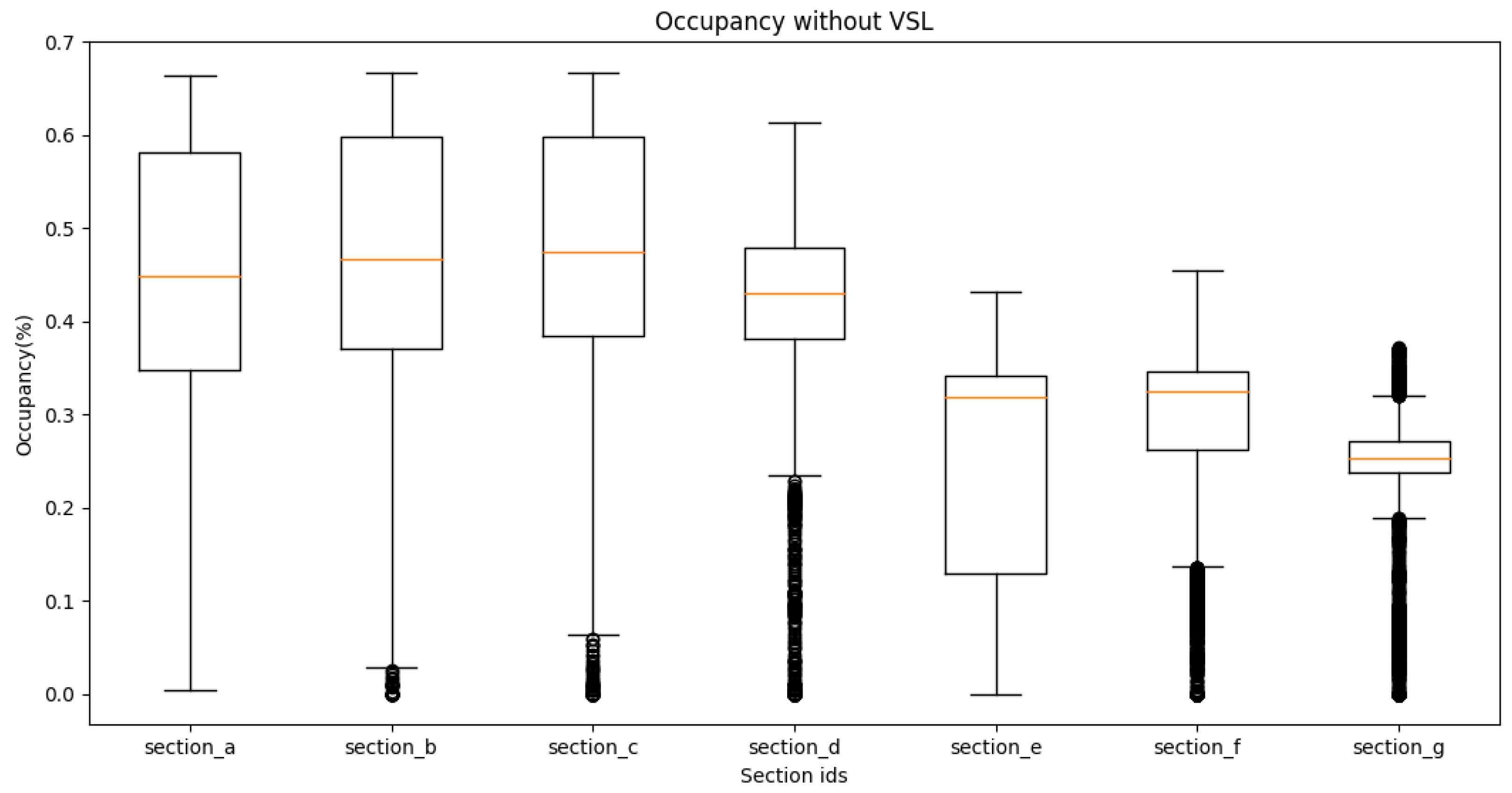
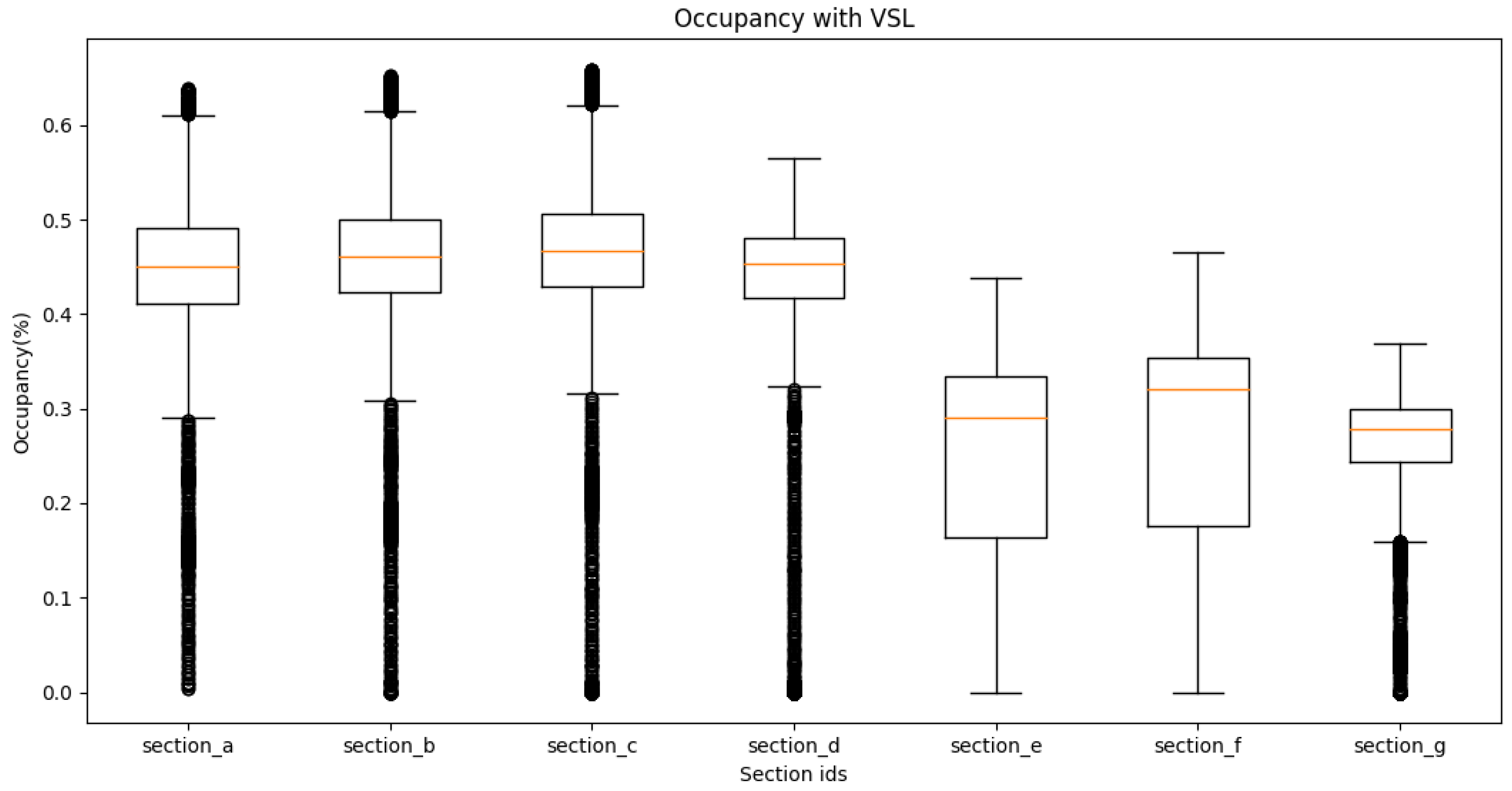
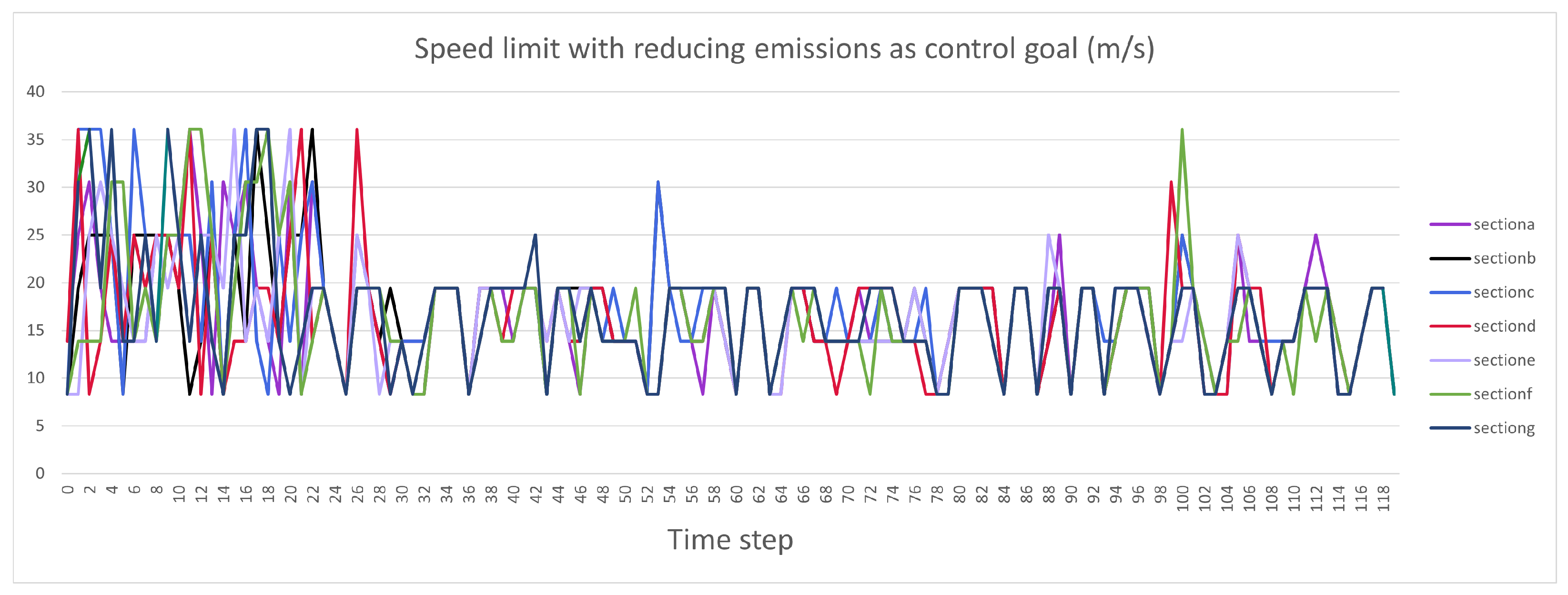
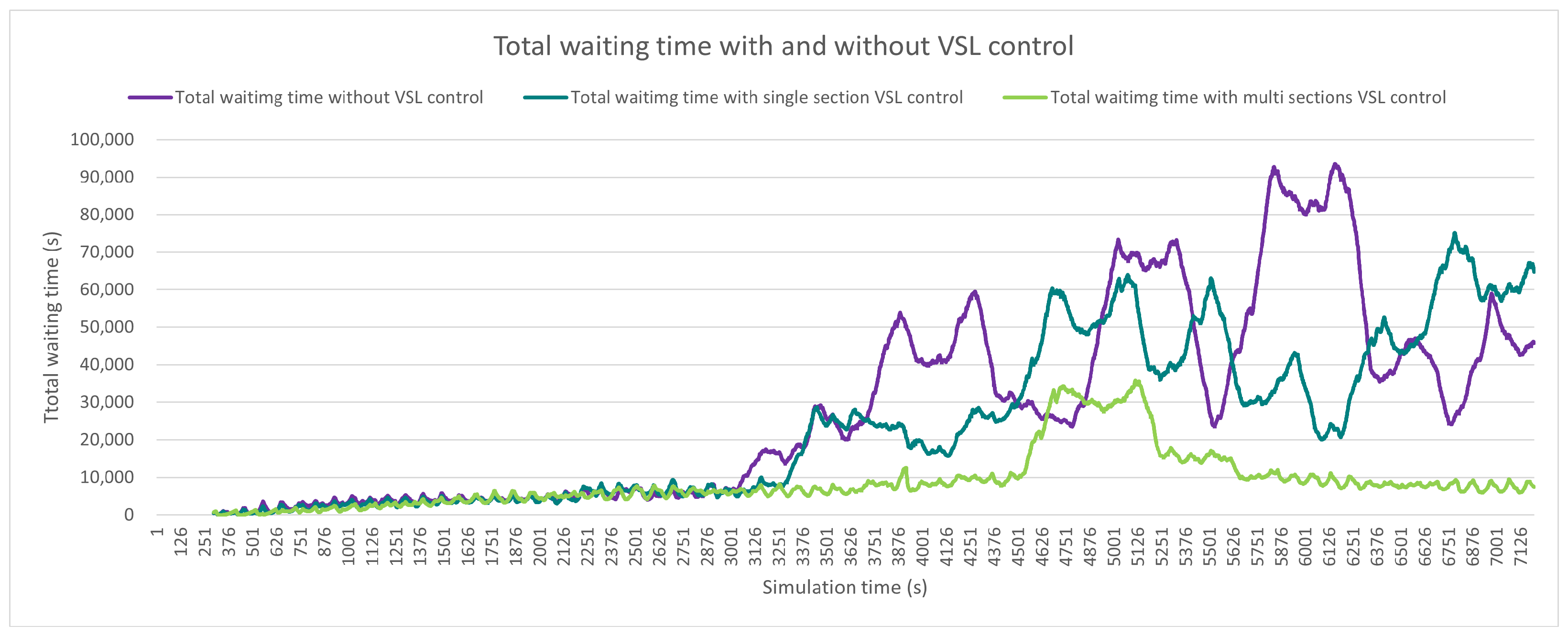
4.2. Traffic Performance Measurements
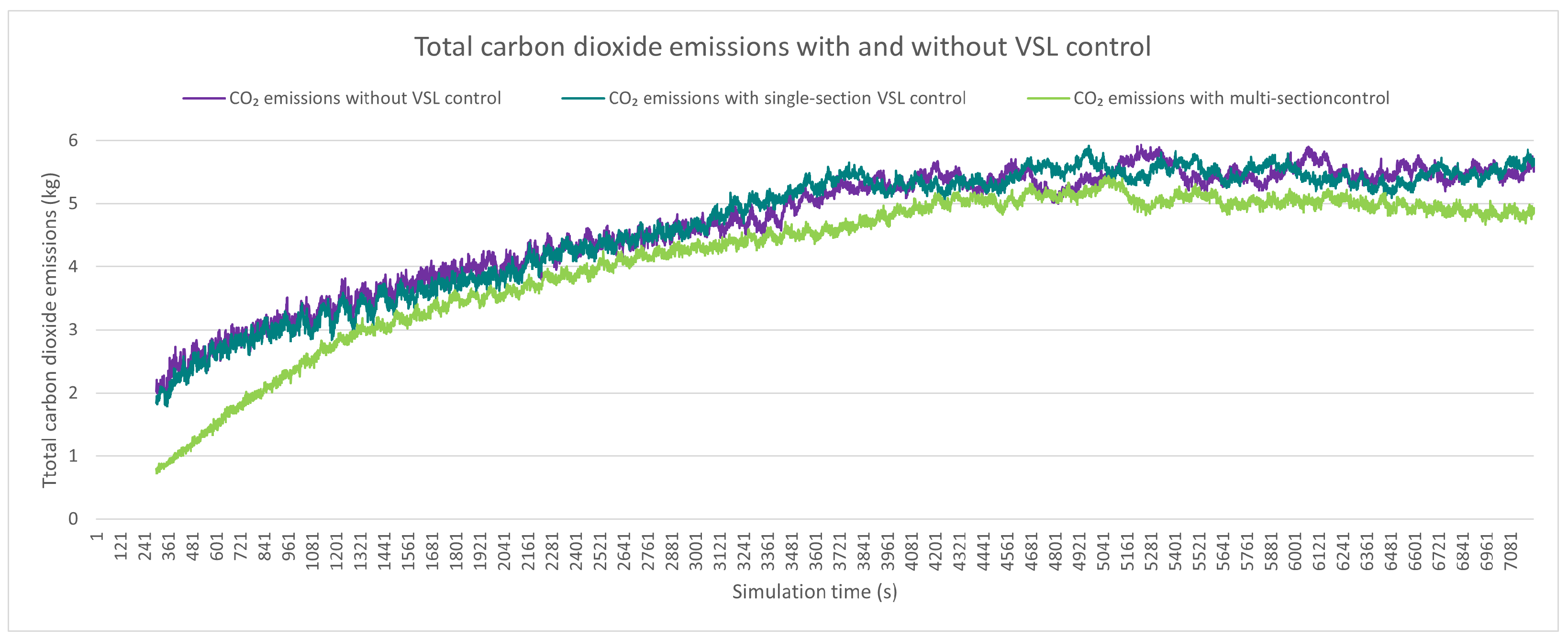
4.3. Sustainability Measurements
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ITS | Intelligent Transportation System |
| VSL | Variable Speed Limit |
| DRL | Deep Reinforcement Learning |
| DQN | Deep Q-Network |
| MAPPO | Multi-Agent Proximal Policy Optimization |
| SUMO | Simulation of Urban Mobility |
| RL | Reinforcement Learning |
| ML | Machine Learning |
| DL | Deep Learning |
| DNN | Deep Neural Networks |
| NN | Neural Networks |
| PG | Policy Gradient |
| AC | Actor–Critic |
| A3C | Advantage Actor–Critic |
| TRPO | Trust Region Policy Optimization |
| PPO | Proximal Policy Optimization |
| MARL | Multi-Agent Reinforcement Learning |
| CTDE | Centralized Training with Decentralized Execution |
| GAE | Generalized Advantage Estimation |
| TraCI | Traffic Control Interface |
| OSM | OpenStreetMap |
| TTT | Total Time Spent |
| CAV | Connected and Automated Vehicles |
| V2V | Vehicle to Vehicle |
| HBEFA 3 | Third Version of Handbook Emission Factors for Road Transport |
References
- Wang, C.; Zhang, J.; Xu, L.; Li, L.; Ran, B. A new solution for freeway congestion: Cooperative speed limit control using distributed reinforcement learning. IEEE Access 2019, 7, 41947–41957. [Google Scholar] [CrossRef]
- Szele, A.; Kisgyörgy, L. Traffic operation on a road network with recurrent congestion. In Proceedings of the WIT Transactions on The Built Environment, Rome, Italy, 10–12 October 2022; WIT Press: Southampton, UK, 2018. [Google Scholar] [CrossRef]
- Tang, L.; Wang, Y.; Zhang, X. Identifying recurring bottlenecks on urban expressway using a fusion method based on loop detector data. Math. Probl. Eng. 2019, 2019, 5861414. [Google Scholar] [CrossRef]
- Den Hertog, D.; Van Zante-De Fokkert, J.; Sjamaar, S.; Beusmans, R. Optimal working zone division for safe track maintenance in The Netherlands. Accid. Anal. Prev. 2005, 37, 890–893. [Google Scholar] [CrossRef] [PubMed]
- Kerner, B.S. Features of Traffic Congestion caused by bad Weather Conditions or Accident. arXiv 2007, arXiv:0712.1728. [Google Scholar]
- Zeng, J.; Qian, Y.; Lv, Z.; Yin, F.; Zhu, L.; Zhang, Y.; Xu, D. Expressway traffic flow under the combined bottleneck of accident and on-ramp in framework of Kerner’s three-phase traffic theory. Phys. Stat. Mech. Its Appl. 2021, 574, 125918. [Google Scholar] [CrossRef]
- Li, H.; Zhang, J.; Zhang, Z.; Huang, Z. Active lane management for intelligent connected vehicles in weaving areas of urban expressway. J. Intell. Connect. Veh. 2021, 4, 52–67. [Google Scholar] [CrossRef]
- Jithender, J.; Mehar, A. Estimation of Queue Length at Signalized Intersection Under Non-Lane Based Traffic Conditions. Periodica Polytechnica Transp. Eng. 2023, 51, 31–39. [Google Scholar] [CrossRef]
- Péter, T.; Lakatos, I.; Pup, D.; Szauter, F.; Szabó, K. An integrated analysis of processes concerning traffic and vehicle dynamics, development of laboratory applying real traffic scenarios. In Proceedings of the 2017 ASME/IEEE International Conference on Mechatronic and Embedded Systems and Applications (MESA2017), Cleveland, OH, USA, 6–9 August 2017. [Google Scholar]
- Lakatos, I. Diagnostic measurement for the effective performance of motor vehicles. Acta Polytech. Hung. 2013, 10, 239–249. [Google Scholar] [CrossRef]
- Coppola, A.; Di Costanzo, L.; Pariota, L.; Bifulco, G.N. Fuzzy-based Variable Speed Limits System under Connected Vehicle environment: A Simulation-Based Case Study in the city of Naples. IEEE Open J. Intell. Transp. Syst. 2023, 4, 267–278. [Google Scholar] [CrossRef]
- Li, Z.; Liu, P.; Xu, C.; Duan, H.; Wang, W. Reinforcement learning-based variable speed limit control strategy to reduce traffic congestion at freeway recurrent bottlenecks. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3204–3217. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Gou, Y.; Liu, J.; Zhao, L.; Li, Y. Variable speed limit control method of freeway mainline in intelligent connected environment. J. Adv. Transp. 2021, 2021, 8863487. [Google Scholar] [CrossRef]
- Zegeye, S.K.; De Schutter, B.; Hellendoorn, J.; Breunesse, E.A. Variable speed limits for area-wide reduction of emissions. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Madeira, Portugal, 19–22 September 2010; pp. 507–512. [Google Scholar]
- Chen, R.; Zhang, T.; Levin, M.W. Effects of variable speed limit on energy consumption with autonomous vehicles on urban roads using modified cell-transmission model. J. Transp. Eng. Part A Syst. 2020, 146, 04020049. [Google Scholar] [CrossRef]
- Li, Z.; Xu, C.; Guo, Y.; Liu, P.; Pu, Z. Reinforcement learning-based variable speed limits control to reduce crash risks near traffic oscillations on freeways. IEEE Intell. Transp. Syst. Mag. 2020, 13, 64–70. [Google Scholar] [CrossRef]
- Allaby, P.; Hellinga, B.; Bullock, M. Variable speed limits: Safety and operational impacts of a candidate control strategy for freeway applications. IEEE Trans. Intell. Transp. Syst. 2007, 8, 671–680. [Google Scholar] [CrossRef]
- Li, D.; Ranjitkar, P. A fuzzy logic-based variable speed limit controller. J. Adv. Transp. 2015, 49, 913–927. [Google Scholar] [CrossRef]
- Vrbanić, F.; Ivanjko, E.; Kušić, K.; Čakija, D. Variable speed limit and ramp metering for mixed traffic flows: A review and open questions. Appl. Sci. 2021, 11, 2574. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, L.; Sun, D.; Wang, D. Optimize the settings of variable speed limit system to improve the performance of freeway traffic. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3249–3257. [Google Scholar] [CrossRef]
- Li, Y.; Chow, A.H.; Cassel, D.L. Optimal control of motorways by ramp metering, variable speed limits, and hard-shoulder running. Transp. Res. Rec. 2014, 2470, 122–130. [Google Scholar] [CrossRef]
- Yuan, N.; Ma, M.; Liang, S.; Wang, W.; Zhang, H. Optimal control method of freeway based on tollbooths lane configuration and variable speed limit control. Phys. Stat. Mech. Its Appl. 2022, 603, 127801. [Google Scholar] [CrossRef]
- Carlson, R.C.; Papamichail, I.; Papageorgiou, M.; Messmer, A. Optimal mainstream traffic flow control of large-scale motorway networks. Transp. Res. Part Emerg. Technol. 2010, 18, 193–212. [Google Scholar] [CrossRef]
- Yang, X.; Lu, Y.; Chang, G. Proactive optimal variable speed limit control for recurrently congested freeway bottlenecks. In Proceedings of the Transportation Research Board Meeting, Washington, DC, USA, 13–17 January 2013. [Google Scholar]
- Wang, S.; Stern, R.; Levin, M.W. Optimal control of autonomous vehicles for traffic smoothing. IEEE Trans. Intell. Transp. Syst. 2021, 23, 3842–3852. [Google Scholar] [CrossRef]
- Frejo, J.R.D.; Núnez, A.; De Schutter, B.; Camacho, E.F. Hybrid model predictive control for freeway traffic using discrete speed limit signals. Transp. Res. Part Emerg. Technol. 2014, 46, 309–325. [Google Scholar] [CrossRef]
- Carlson, R.C.; Papamichail, I.; Papageorgiou, M. Local feedback-based mainstream traffic flow control on motorways using variable speed limits. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1261–1276. [Google Scholar] [CrossRef]
- Lu, X.Y.; Shladover, S. MPC-based variable speed limit and its impact on traffic with V2I type ACC. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3923–3928. [Google Scholar]
- Kušić, K.; Dusparic, I.; Guériau, M.; Gregurić, M.; Ivanjko, E. Extended variable speed limit control using multi-agent reinforcement learning. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–8. [Google Scholar]
- Zhu, F.; Ukkusuri, S.V. Accounting for dynamic speed limit control in a stochastic traffic environment: A reinforcement learning approach. Transp. Res. Part C Emerg. Technol. 2014, 41, 30–47. [Google Scholar] [CrossRef]
- Cheng, M.; Zhang, C.; Jin, H.; Wang, Z.; Yang, X. Adaptive Coordinated Variable Speed Limit between Highway Mainline and On-Ramp with Deep Reinforcement Learning. J. Adv. Transp. 2022. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Yu, C.; Velu, A.; Vinitsky, E.; Wang, Y.; Bayen, A.; Wu, Y. The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games. arXiv 2021, arXiv:2103.01955. [Google Scholar]
- Alagha, A.; Singh, S.; Mizouni, R.; Bentahar, J.; Otrok, H. Target localization using multi-agent deep reinforcement learning with proximal policy optimization. Future Gener. Comput. Syst. 2022, 136, 342–357. [Google Scholar] [CrossRef]
- Lohse, O.; Pütz, N.; Hörmann, K. Implementing an Online Scheduling Approach for Production with Multi Agent Proximal Policy Optimization (MAPPO). In Proceedings of the Advances in Production Management Systems, Artificial Intelligence for Sustainable and Resilient Production Systems: IFIP WG 5.7 International Conference, APMS 2021, Nantes, France, 5–9 September 2021; Proceedings Part V.. Springer: Berlin/Heidelberg, Germany, 2021; pp. 586–595. [Google Scholar]
- Park, Y.M.; Hassan, S.S.; Tun, Y.K.; Han, Z.; Hong, C.S. Joint Trajectory and Resource Optimization of MEC-Assisted UAVs in Sub-THz Networks: A Resources-based Multi-Agent Proximal Policy Optimization DRL with Attention Mechanism. arXiv 2022, arXiv:2209.07228. [Google Scholar]
- Lopez, P.A.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flötteröd, Y.P.; Hilbrich, R.; Lücken, L.; Rummel, J.; Wagner, P.; Wießner, E. Microscopic Traffic Simulation using SUMO. In Proceedings of the 21st IEEE International Conference on Intelligent Transportation Systems, Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Wiering, M.A.; Van Otterlo, M. Reinforcement learning. Adapt. Learn. Optim. 2012, 12, 729. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]
- Konda, V.; Tsitsiklis, J. Actor-critic algorithms. Adv. Neural Inf. Process. Syst. 1999, 12, 1008–1014. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- De Witt, C.S.; Peng, B.; Kamienny, P.A.; Torr, P.; Böhmer, W.; Whiteson, S. Deep multi-agent reinforcement learning for decentralized continuous cooperative control. arXiv 2020, arXiv:2003.06709. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Li, Y.; Ni, P.; Chang, V. Application of deep reinforcement learning in stock trading strategies and stock forecasting. Computing 2020, 102, 1305–1322. [Google Scholar] [CrossRef]
- Kušić, K.; Ivanjko, E.; Gregurić, M. A comparison of different state representations for reinforcement learning based variable speed limit control. In Proceedings of the 26th Mediterranean Conference on Control and Automation (MED), Zadar, Croatia, 19–22 June 2018; pp. 1–6. [Google Scholar]
- Wu, Y.; Tan, H.; Jiang, Z.; Ran, B. ES-CTC: A deep neuroevolution model for cooperative intelligent freeway traffic control. arXiv 2019, arXiv:1905.04083. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Xu, Z.; Cao, Y.; Kang, Y.; Zhao, Z. Vehicle emission control on road with temporal traffic information using deep reinforcement learning. IFAC-PapersOnLine 2020, 53, 14960–14965. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Qin, L.; Ran, B. Differential variable speed limits control for freeway recurrent bottlenecks via deep actor-critic algorithm. Transp. Res. Part Emerg. Technol. 2020, 117, 102649. [Google Scholar] [CrossRef]
- Keller, M.; Hausberger, S.; Matzer, C.; Wüthrich, P.; Notter, B. HBEFA Version 3.3. Backgr. Doc. Berne 2017, 12. Available online: https://www.google.com.hk/search?q=Keller%2C+M.%3B+Hausberger%2C+S.%3B+Matzer%2C+C.%3B+Wuthrich%2C+P.%3B+Notter%2C+B.+HBEFA+Version+3.3&ei=YzC6ZI30DOfM2roP3f6piAs&ved=0ahUKEwjNsdemoJ-AAxVnplYBHV1_CrEQ4dUDCA4&uact=5&oq=Keller%2C+M.%3B+Hausberger%2C+S.%3B+Matzer%2C+C.%3B+Wuthrich%2C+P.%3B+Notter%2C+B.+HBEFA+Version+3.3&gs_lp=Egxnd3Mtd2l6LXNlcnAiUktlbGxlciwgTS47IEhhdXNiZXJnZXIsIFMuOyBNYXR6ZXIsIEMuOyBXdXRocmljaCwgUC47IE5vdHRlciwgQi4gSEJFRkEgVmVyc2lvbiAzLjMyBxAAGB4YsANIv0VQkQJYxztwAXgAkAEAmAEAoAEAqgEAuAEDyAEA-AEC-AEB4gMEGAEgQYgGAZAGAQ&sclient=gws-wiz-serp (accessed on 30 May 2023).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| Number of training iterations | 600 |
| Learning rate | 0.0005 |
| Number of agent | 7 |
| PPO clip parameter | 0.2 |
| Discount factor | 0.99 |
| GAE parameter | 0.95 |
| Time step per update | 120 |
| Number of PPO epochs per update | 15 |
| Hidden layers | 64 × 64 × 64 |
| Hidden layers activation function | RELU |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, X.; Péter, T.; Tettamanti, T. Variable Speed Limit Control for the Motorway–Urban Merging Bottlenecks Using Multi-Agent Reinforcement Learning. Sustainability 2023, 15, 11464. https://doi.org/10.3390/su151411464
Fang X, Péter T, Tettamanti T. Variable Speed Limit Control for the Motorway–Urban Merging Bottlenecks Using Multi-Agent Reinforcement Learning. Sustainability. 2023; 15(14):11464. https://doi.org/10.3390/su151411464
Chicago/Turabian StyleFang, Xuan, Tamás Péter, and Tamás Tettamanti. 2023. "Variable Speed Limit Control for the Motorway–Urban Merging Bottlenecks Using Multi-Agent Reinforcement Learning" Sustainability 15, no. 14: 11464. https://doi.org/10.3390/su151411464
APA StyleFang, X., Péter, T., & Tettamanti, T. (2023). Variable Speed Limit Control for the Motorway–Urban Merging Bottlenecks Using Multi-Agent Reinforcement Learning. Sustainability, 15(14), 11464. https://doi.org/10.3390/su151411464