

Prediction of Daily Temperature Based on the Robust Machine Learning Algorithms


Abstract
1. Introduction
2. Materials and Methods
2.1. Proposed Models Using a Deep Learning Approach
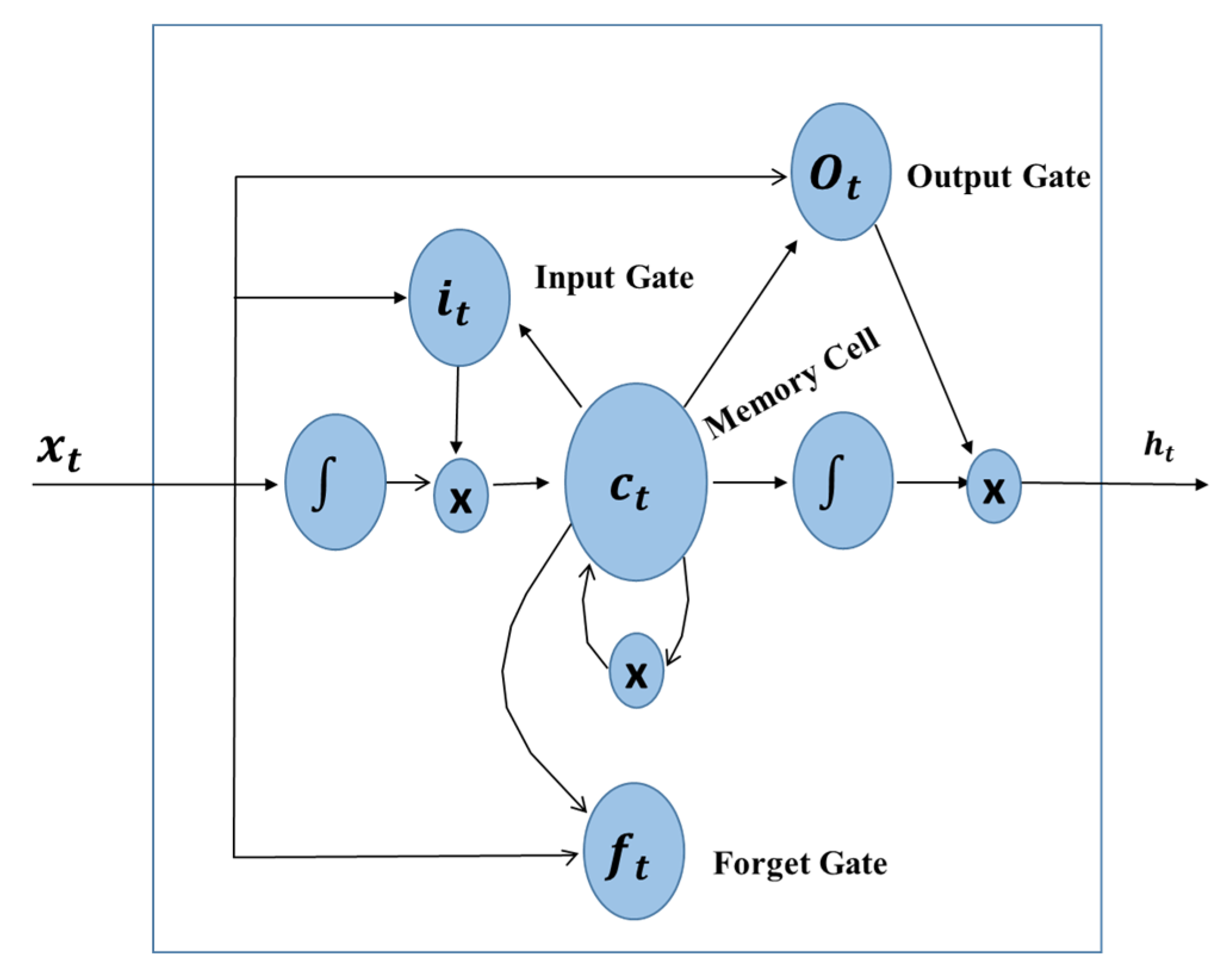
2.2. LSTM Neural Network
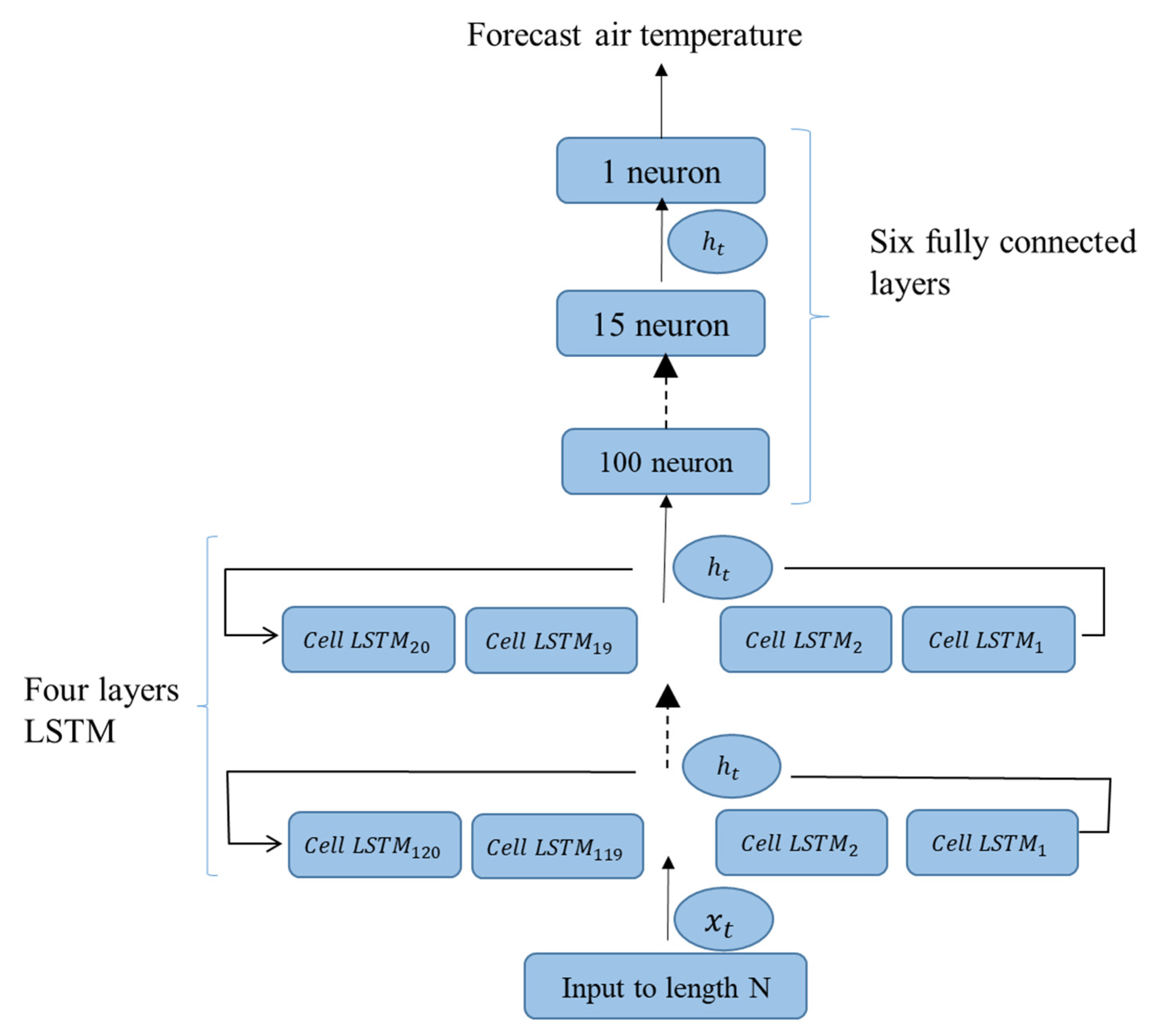
2.3. The Structure of the Neural Network of the First Model
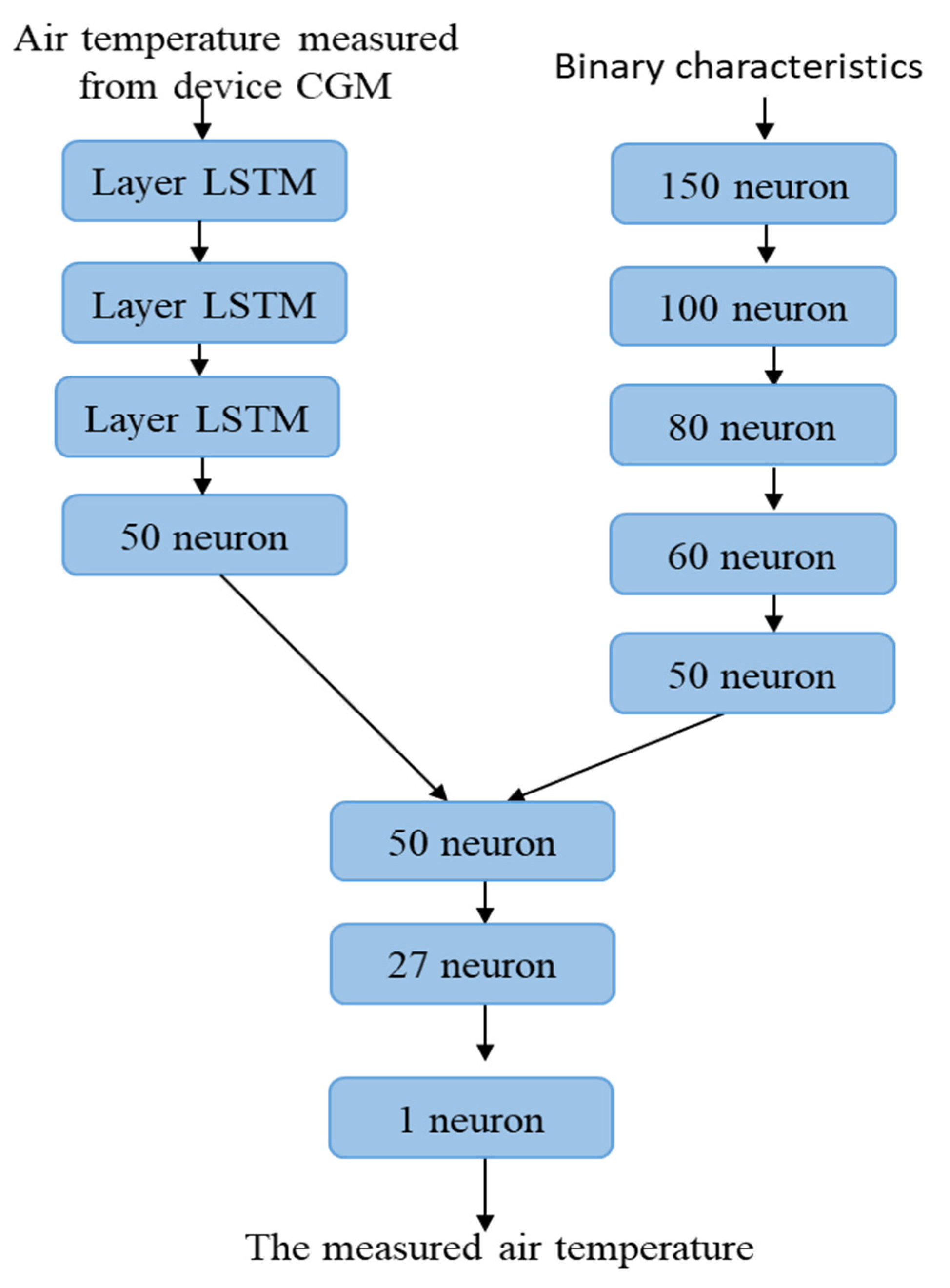
2.4. Examining the Structure of the Neural Network of the Second Model
2.5. Neural Network Training of Proposed Models
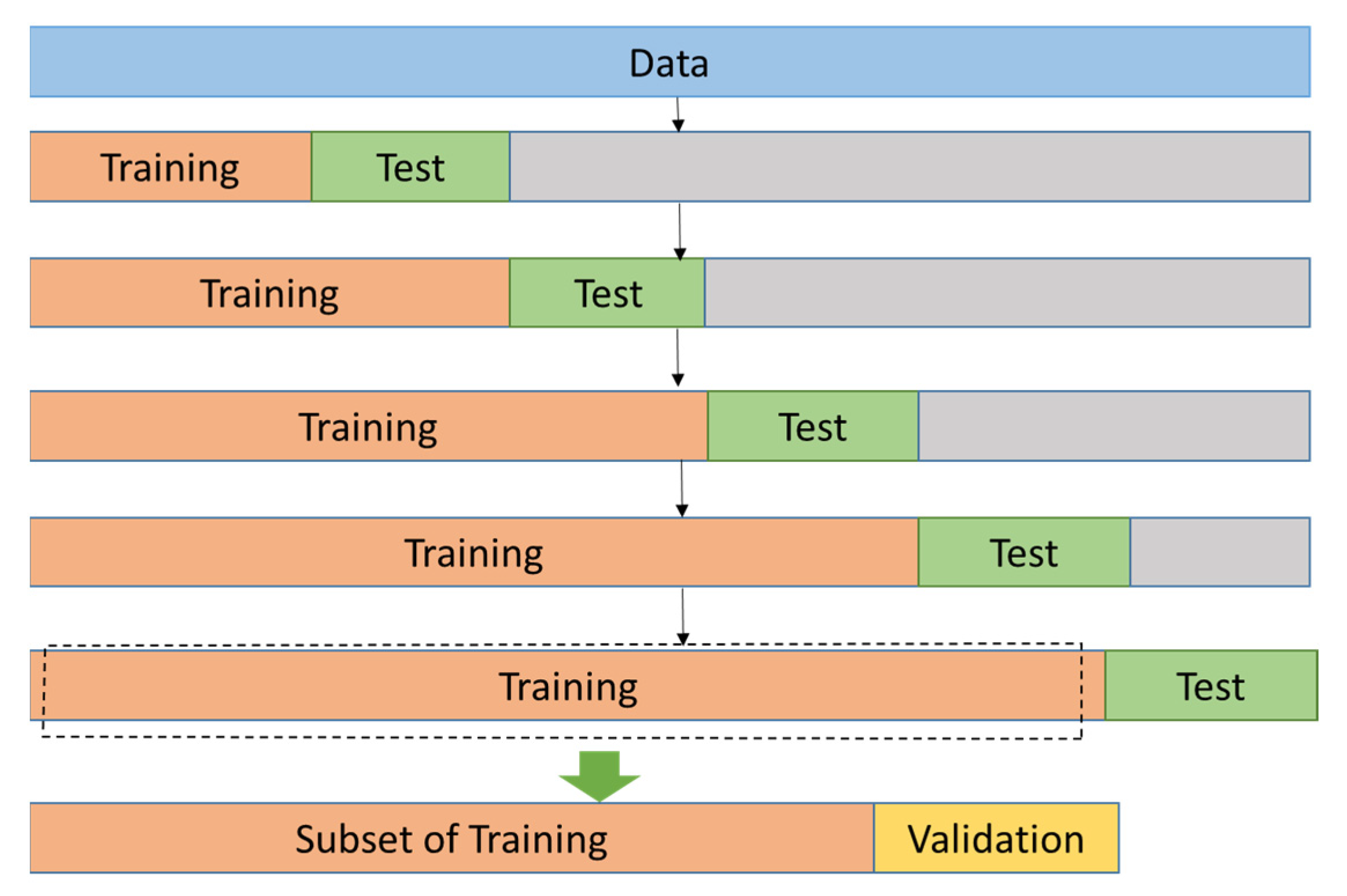
2.6. Meta Parameters
2.7. Error Parameters
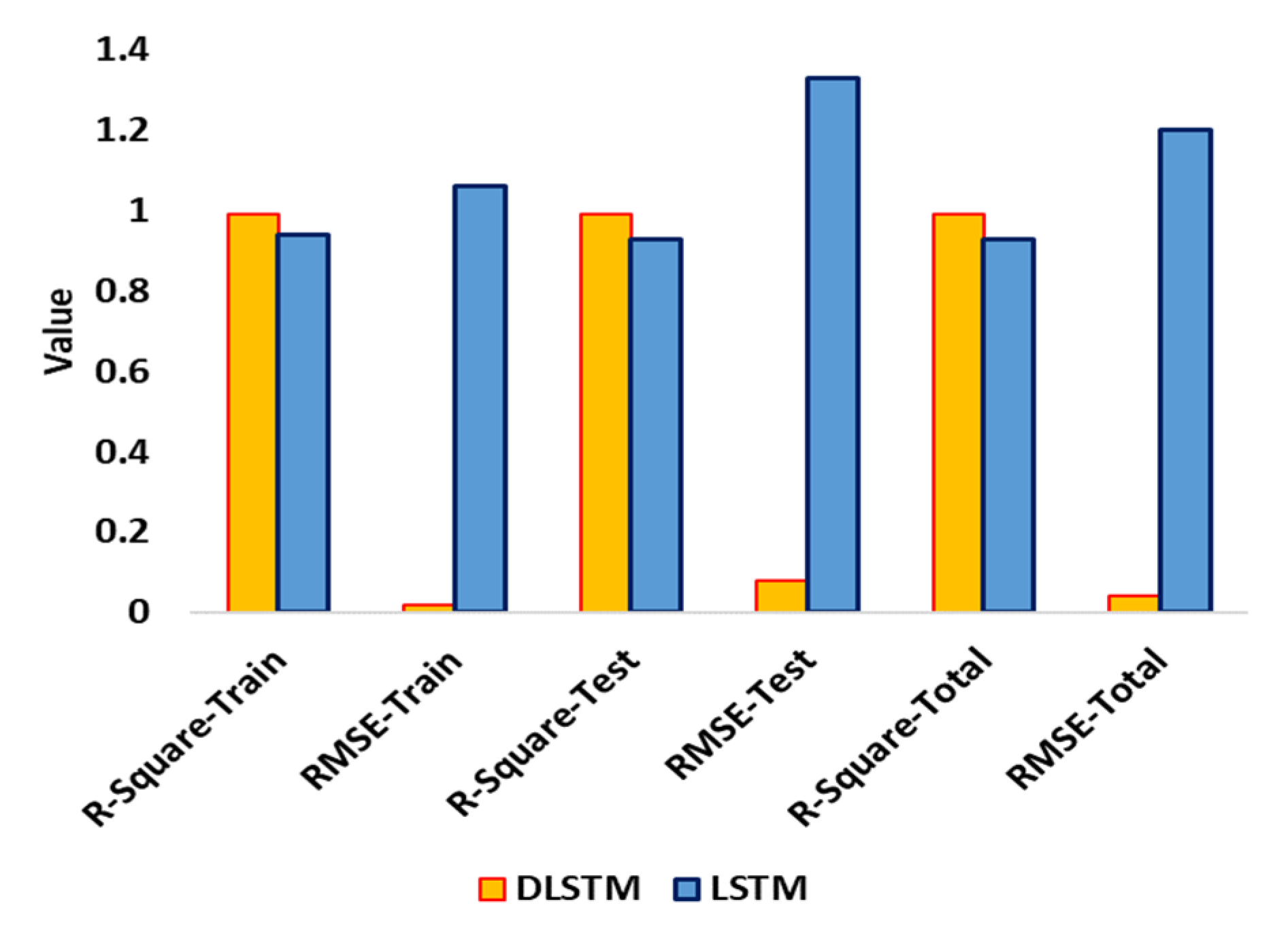
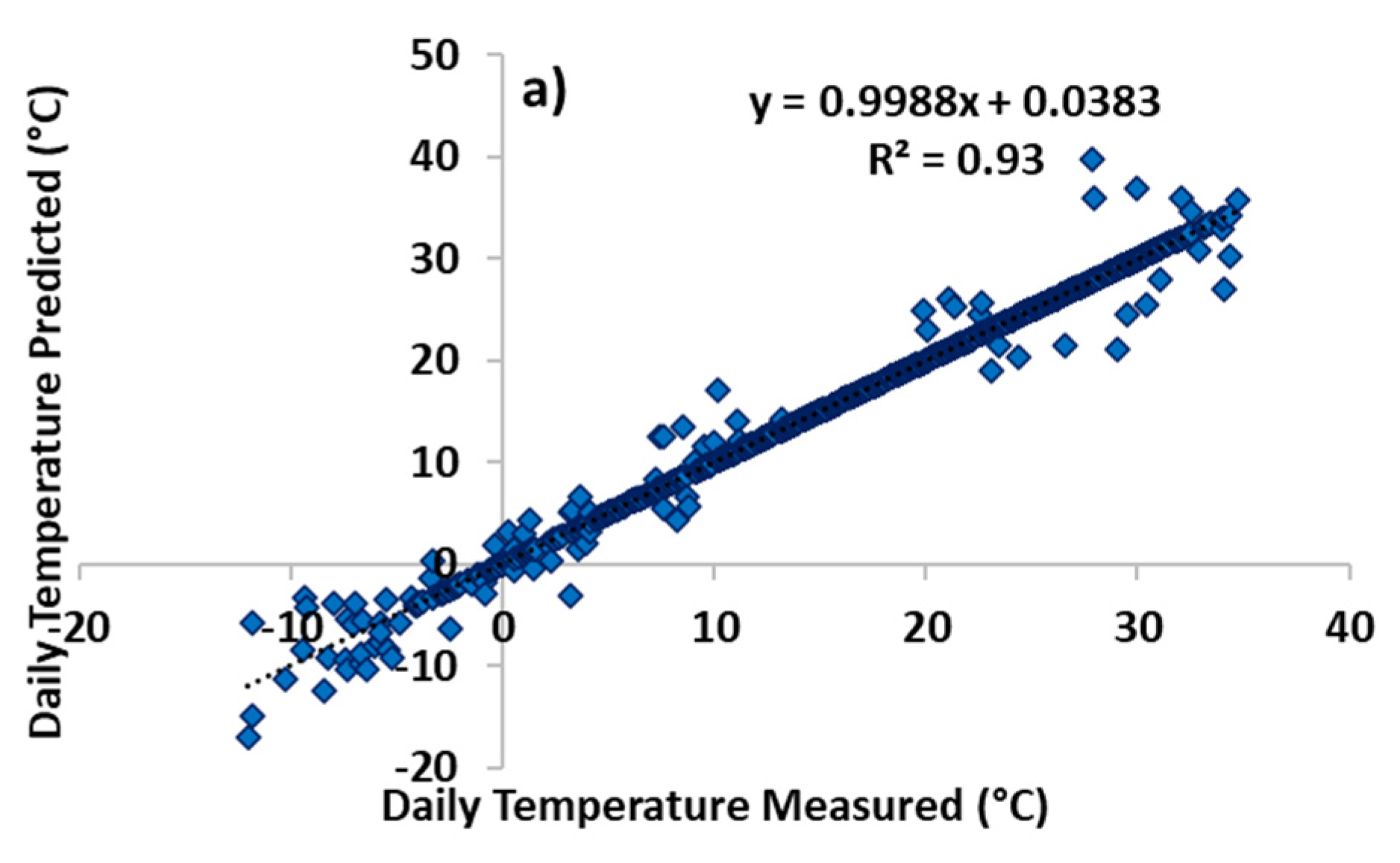
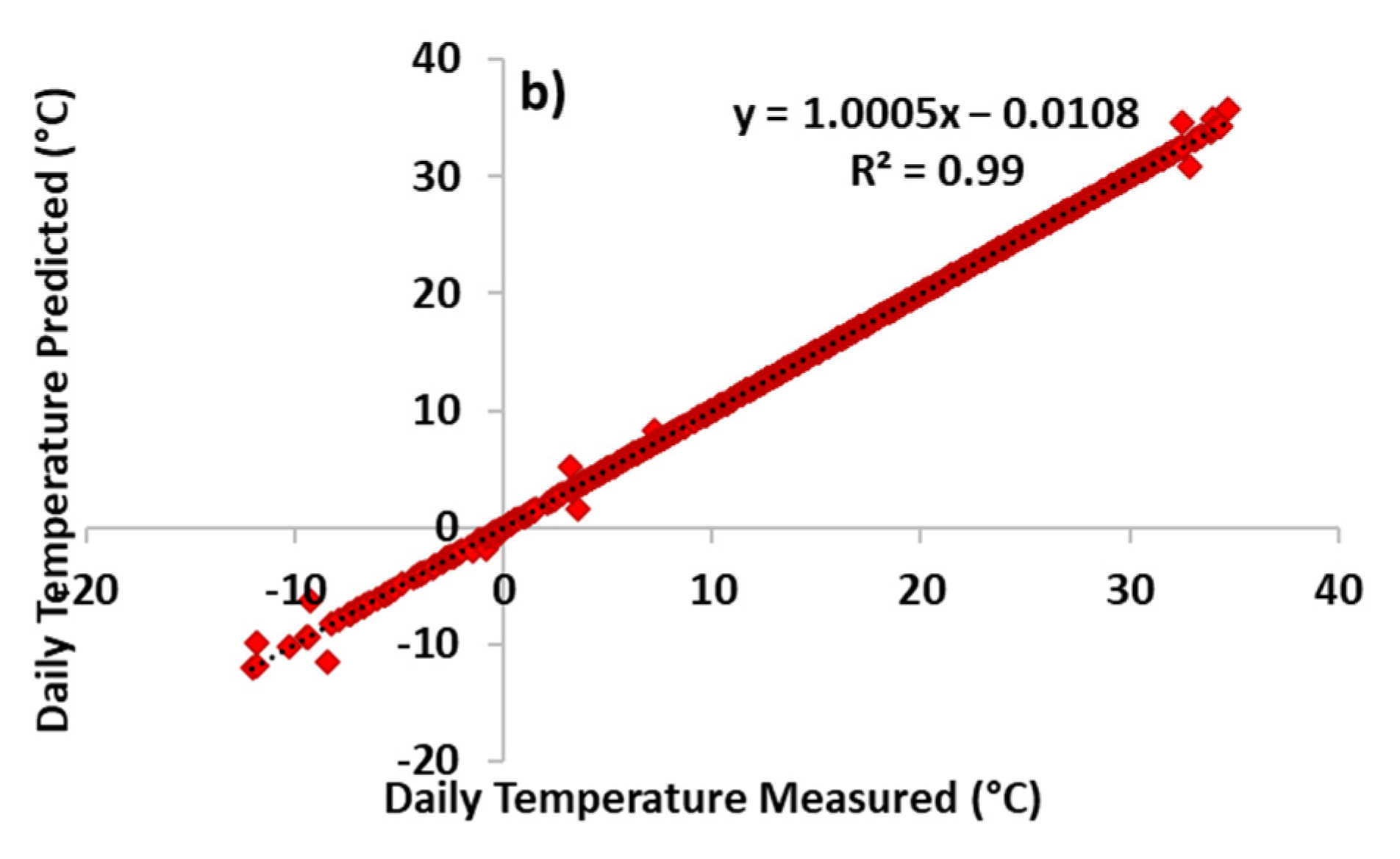
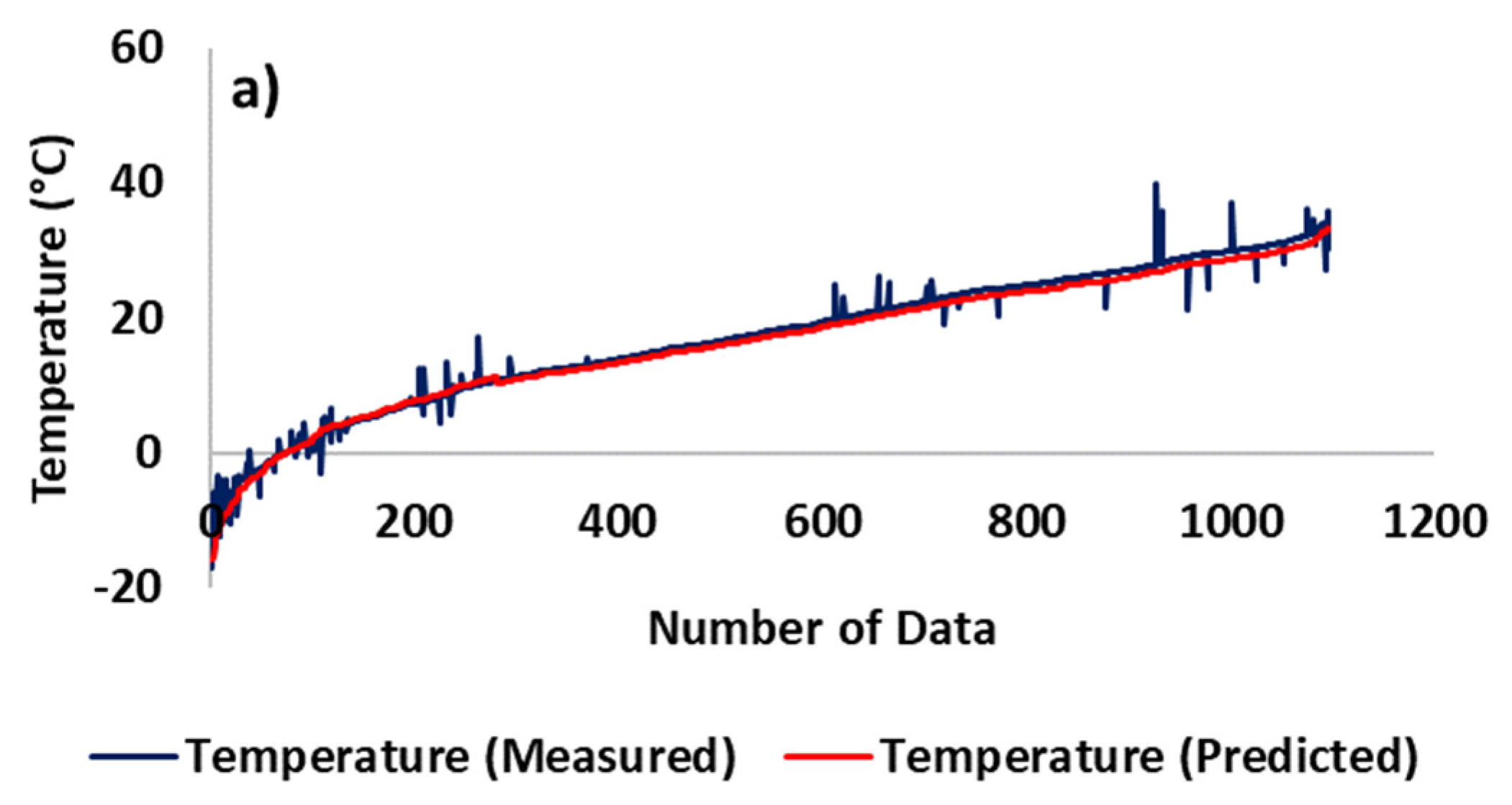
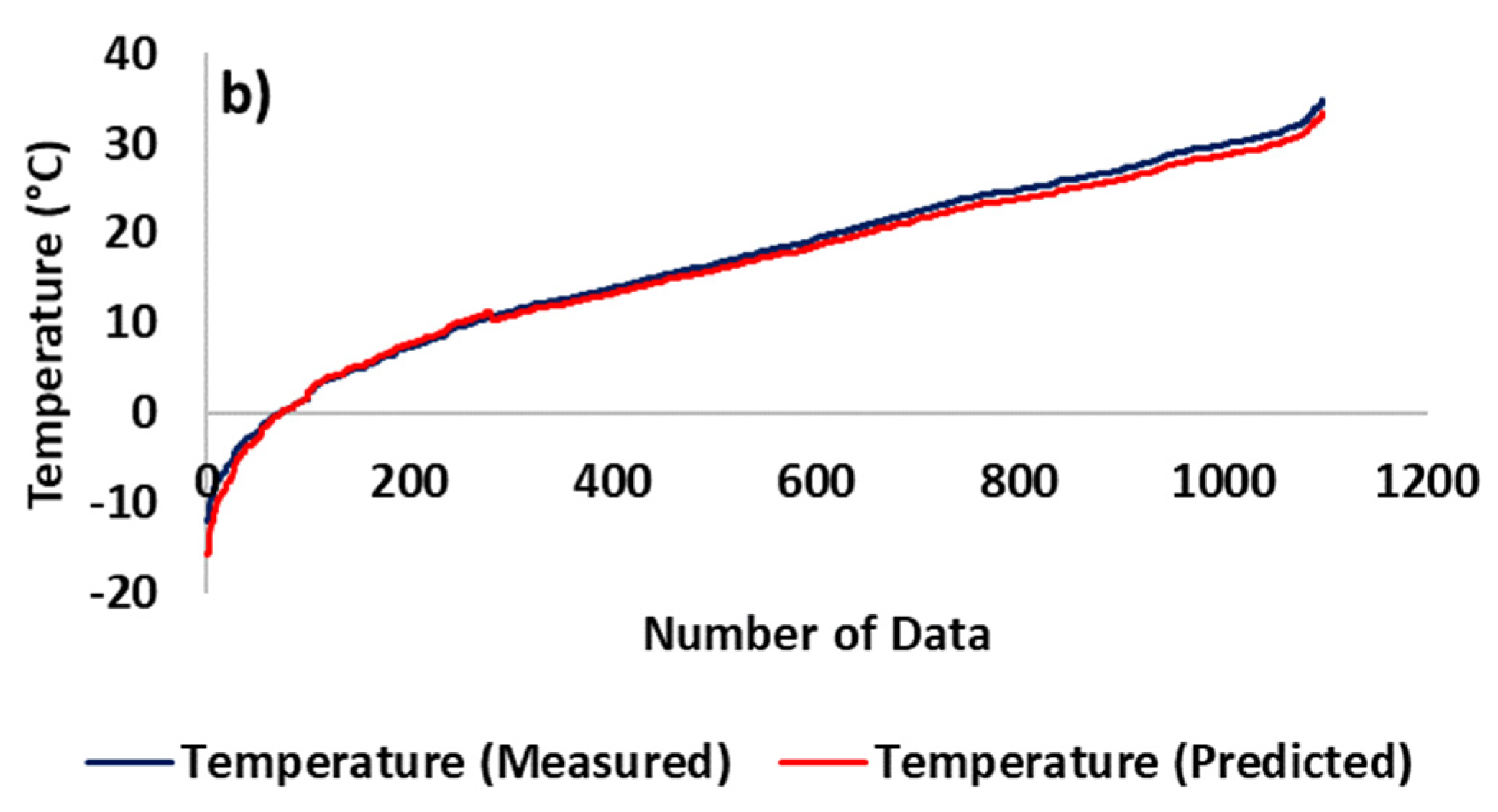
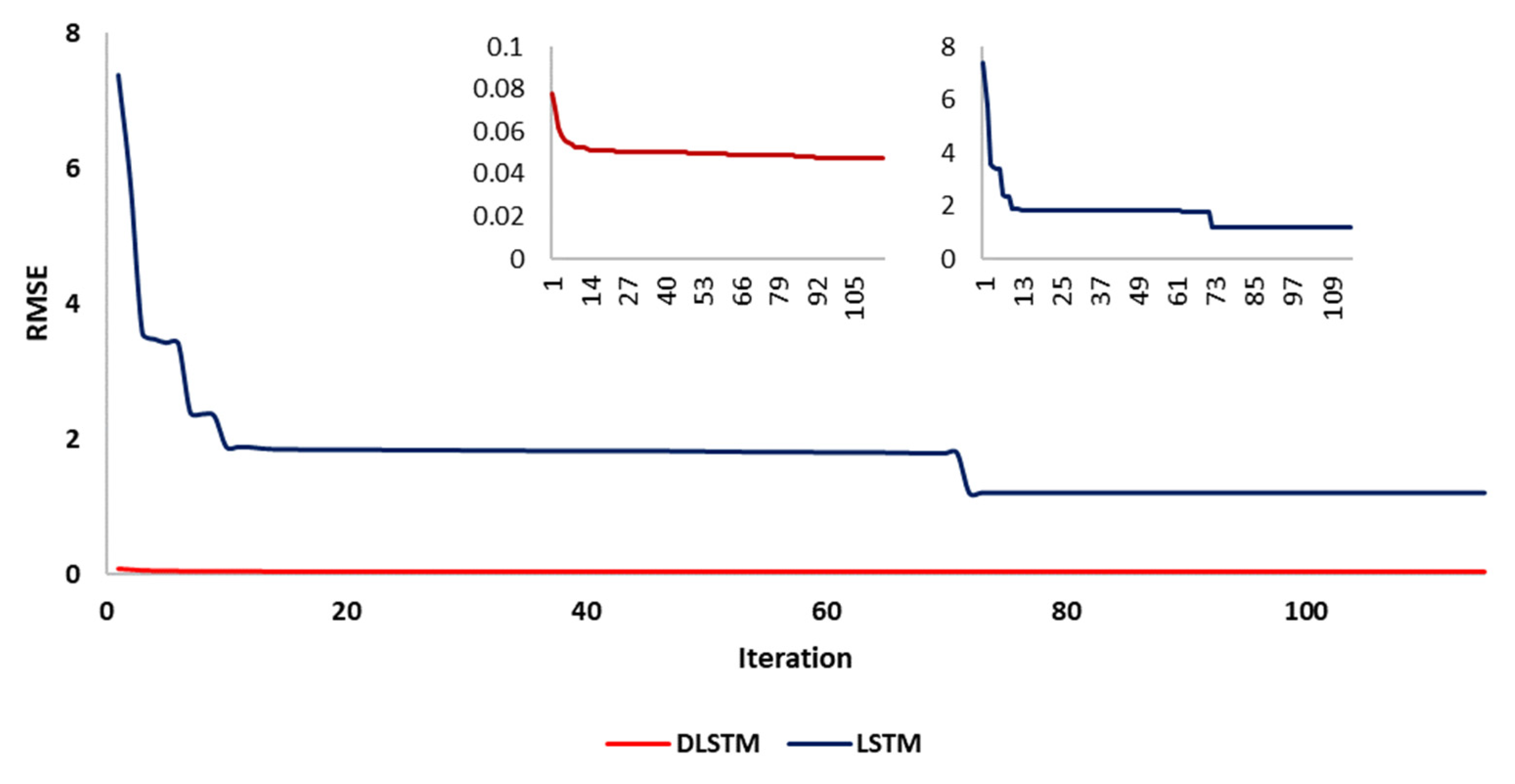
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tol, R.S.J. Estimates of the damage costs of climate change, Part II. Dynamic estimates. Environ. Resour. Econ. 2002, 21, 135–160. [Google Scholar] [CrossRef]
- Thober, S.; Kumar, R.; Wanders, N.; Marx, A.; Pan, M.; Rakovec, O.; Samaniego, L.; Sheffield, J.; Wood, E.F.; Zink, M. Multi-model ensemble projections of European river floods and high flows at 1.5, 2, and 3 degrees global warming. Environ. Res. Lett. 2018, 13, 014003. [Google Scholar] [CrossRef]
- Van Vliet, M.T.H.; Franssen, W.H.P.; Yearsley, J.R.; Ludwig, F.; Haddeland, I.; Lettenmaier, D.P.; Kabat, P. Global river discharge and water temperature under climate change. Glob. Environ. Chang. 2013, 23, 450–464. [Google Scholar] [CrossRef]
- Pearson, R.G.; Dawson, T.P. Predicting the impacts of climate change on the distribution of species: Are bioclimate envelope models useful? Glob. Ecol. Biogeogr. 2003, 12, 361–371. [Google Scholar] [CrossRef]
- Bale, J.S.; Masters, G.J.; Hodkinson, I.D.; Awmack, C.; Bezemer, T.M.; Brown, V.K.; Butterfield, J.; Buse, A.; Coulson, J.C.; Farrar, J. Herbivory in global climate change research: Direct effects of rising temperature on insect herbivores. Glob. Chang. Biol. 2002, 8, 1–16. [Google Scholar] [CrossRef]
- Canton, H. World Meteorological Organization—WMO. In The Europa Directory of International Organizations 2021; Routledge: London, UK, 2021; pp. 388–393. [Google Scholar]
- World Meteorological Organization; World Health Organization (WHO). Heatwaves and Health: Guidance on Warning-System Development; WHO: Geneva, Switzerland, 2015. [Google Scholar]
- Bate-Sproston, C. Sustainable Development Commission 2 (SDC2) Issue: Developing Heat Health Warning Systems in Countries Facing Heat Waves. In Proceedings of the Hague International Model United Nations (THIMUN The Hague), Hague, The Netherlands, 23–26 January 2023. [Google Scholar]
- Williams, S.; Nitschke, M.; Weinstein, P.; Pisaniello, D.L.; Parton, K.A.; Bi, P. The impact of summer temperatures and heatwaves on mortality and morbidity in Perth, Australia 1994–2008. Environ. Int. 2012, 40, 33–38. [Google Scholar] [CrossRef]
- Ebi, K.L.; Lewis, N.D.; Corvalan, C. Climate variability and change and their potential health effects in small island states: Information for adaptation planning in the health sector. Environ. Health Perspect. 2006, 114, 1957–1963. [Google Scholar] [CrossRef]
- Xie, Y.; Fan, S.; Chen, M.; Shi, J.; Zhong, J.; Zhang, X. An assessment of satellite radiance data assimilation in RMAPS. Remote Sens. 2018, 11, 54. [Google Scholar] [CrossRef]
- Shahzaman, M.; Zhu, W.; Ullah, I.; Mustafa, F.; Bilal, M.; Ishfaq, S.; Nisar, S.; Arshad, M.; Iqbal, R.; Aslam, R.W. Comparison of multi-year reanalysis, models, and satellite remote sensing products for agricultural drought monitoring over south asian countries. Remote Sens. 2021, 13, 3294. [Google Scholar] [CrossRef]
- Gauer, R.L.; Meyers, B.K. Heat-related illnesses. Am. Fam. Physician 2019, 99, 482–489. [Google Scholar]
- Iyakaremye, V.; Zeng, G.; Yang, X.; Zhang, G.; Ullah, I.; Gahigi, A.; Vuguziga, F.; Asfaw, T.G.; Ayugi, B. Increased high-temperature extremes and associated population exposure in Africa by the Mid-21st Century. Sci. Total Environ. 2021, 790, 148162. [Google Scholar] [CrossRef] [PubMed]
- Ullah, I.; Saleem, F.; Iyakaremye, V.; Yin, J.; Ma, X.; Syed, S.; Hina, S.; Asfaw, T.G.; Omer, A. Projected changes in socioeconomic exposure to heatwaves in South Asia under changing climate. Earth’s Future 2022, 10, e2021EF002240. [Google Scholar] [CrossRef]
- Tabasi, S.; Tehrani, P.S.; Rajabi, M.; Wood, D.A.; Davoodi, S.; Ghorbani, H.; Mohamadian, N.; Alvar, M.A. Optimized machine learning models for natural fractures prediction using conventional well logs. Fuel 2022, 326, 124952. [Google Scholar] [CrossRef]
- Beheshtian, S.; Rajabi, M.; Davoodi, S.; Wood, D.A.; Ghorbani, H.; Mohamadian, N.; Alvar, M.A.; Band, S.S. Robust computational approach to determine the safe mud weight window using well-log data from a large gas reservoir. Mar. Pet. Geol. 2022, 142, 105772. [Google Scholar] [CrossRef]
- Rajabi, M.; Hazbeh, O.; Davoodi, S.; Wood, D.A.; Tehrani, P.S.; Ghorbani, H.; Mehrad, M.; Mohamadian, N.; Rukavishnikov, V.S.; Radwan, A.E. Predicting shear wave velocity from conventional well logs with deep and hybrid machine learning algorithms. J. Pet. Explor. Prod. Technol. 2022, 13, 19–42. [Google Scholar] [CrossRef]
- Kamali, M.Z.; Davoodi, S.; Ghorbani, H.; Wood, D.A.; Mohamadian, N.; Lajmorak, S.; Rukavishnikov, V.S.; Taherizade, F.; Band, S.S. Permeability prediction of heterogeneous carbonate gas condensate reservoirs applying group method of data handling. Mar. Pet. Geol. 2022, 139, 105597. [Google Scholar] [CrossRef]
- Qian, Q.F.; Jia, X.J.; Lin, H. Machine learning models for the seasonal forecast of winter surface air temperature in North America. Earth Space Sci. 2020, 7, e2020EA001140. [Google Scholar] [CrossRef]
- Novitasari, D.C.R.; Rohayani, H.; Junaidi, R.; Setyowati, R.D.N.; Pramulya, R.; Setiawan, F. Weather parameters forecasting as variables for rainfall prediction using adaptive neuro fuzzy inference system (ANFIS) and support vector regression (SVR). J. Phys. Conf. Ser. 2020, 1501, 012012. [Google Scholar] [CrossRef]
- Hanoon, M.S.; Ahmed, A.N.; Zaini, N.a.; Razzaq, A.; Kumar, P.; Sherif, M.; Sefelnasr, A.; El-Shafie, A. Developing machine learning algorithms for meteorological temperature and humidity forecasting at Terengganu state in Malaysia. Sci. Rep. 2021, 11, 18935. [Google Scholar] [CrossRef]
- Gad, I.; Hosahalli, D. A comparative study of prediction and classification models on NCDC weather data. Int. J. Comput. Appl. 2022, 44, 414–425. [Google Scholar] [CrossRef]
- Katušić, D.; Pripužić, K.; Maradin, M.; Pripužić, M. A comparison of data-driven methods in prediction of weather patterns in central Croatia. Earth Sci. Inform. 2022, 15, 1249–1265. [Google Scholar] [CrossRef]
- Essien, A.; Giannetti, C. A deep learning framework for univariate time series prediction using convolutional LSTM stacked autoencoders. In Proceedings of the 2019 IEEE International Symposium on Innovations in Intelligent Systems and Applications (INISTA), Sofia, Bulgaria, 3–5 July 2019; pp. 1–6. [Google Scholar]
- Tsochantaridis, I.; Joachims, T.; Hofmann, T.; Altun, Y.; Singer, Y. Large margin methods for structured and interdependent output variables. J. Mach. Learn. Res. 2005, 6, 1453–1484. [Google Scholar]
- Muralitharan, K.; Sakthivel, R.; Vishnuvarthan, R. Neural network based optimization approach for energy demand prediction in smart grid. Neurocomputing 2018, 273, 199–208. [Google Scholar] [CrossRef]
- Brownlee, J. Deep Learning for Time Series Forecasting: Predict the Future with MLPs, CNNs and LSTMs in Python; Machine Learning Mastery: Victoria, Australia, 2018. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Dennis, J.B.; Misunas, D.P. A preliminary architecture for a basic data-flow processor. In Proceedings of the 2nd Annual Symposium on Computer Architecture, Houston, TX, USA, 1 December 1974; pp. 126–132. [Google Scholar]
- Adam, K.; Smagulova, K.; James, A.P. Memristive LSTM network hardware architecture for time-series predictive modeling problems. In Proceedings of the 2018 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Chengdu, China, 26–30 October 2018; pp. 459–462. [Google Scholar]
- Liu, P.; Sun, X.; Han, Y.; He, Z.; Zhang, W.; Wu, C. Arrhythmia classification of LSTM autoencoder based on time series anomaly detection. Biomed. Signal Process. Control 2022, 71, 103228. [Google Scholar] [CrossRef]
- Ji, Y.; Yamashita, A.; Asama, H. RGB-D SLAM using vanishing point and door plate information in corridor environment. Intell. Serv. Robot. 2015, 8, 105–114. [Google Scholar] [CrossRef]
- Faghihi Nezhad, M.T.; Minaei Bidgoli, B. Development of an ensemble learning-based intelligent model for stock market forecasting. Sci. Iran 2021, 28, 395–411. [Google Scholar]
- Sen, S.; Raghunathan, A. Approximate computing for long short term memory (LSTM) neural networks. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2266–2276. [Google Scholar] [CrossRef]
- Kim, T.; Kim, H.Y. Forecasting stock prices with a feature fusion LSTM-CNN model using different representations of the same data. PLoS ONE 2019, 14, e0212320. [Google Scholar] [CrossRef]
- Mustafaraj, G.; Lowry, G.; Chen, J. Prediction of room temperature and relative humidity by autoregressive linear and nonlinear neural network models for an open office. Energy Build. 2011, 43, 1452–1460. [Google Scholar] [CrossRef]
- Xie, J.; Wang, Q. Benchmark machine learning approaches with classical time series approaches on the blood glucose level prediction challenge. CEUR Workshop Proc. 2018, 2148, 97–102. [Google Scholar]
- Tsangaratos, P.; Ilia, I. Comparison of a logistic regression and Naïve Bayes classifier in landslide susceptibility assessments: The influence of models complexity and training dataset size. Catena 2016, 145, 164–179. [Google Scholar] [CrossRef]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Z.; Cui, Y.; Liu, Z.; Zhao, Y.; Hu, M.; Hu, J. Evaluating explorative prediction power of machine learning algorithms for materials discovery using k-fold forward cross-validation. Comput. Mater. Sci. 2020, 171, 109203. [Google Scholar] [CrossRef]
- Barrow, D.K.; Crone, S.F. Crogging (cross-validation aggregation) for forecasting—A novel algorithm of neural network ensembles on time series subsamples. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar]
- Rossi, F.; Lendasse, A.; François, D.; Wertz, V.; Verleysen, M. Mutual information for the selection of relevant variables in spectrometric nonlinear modelling. Chemom. Intell. Lab. Syst. 2006, 80, 215–226. [Google Scholar] [CrossRef]
- Lahiri, S.K.; Ghanta, K.C. Regime identification of slurry transport in pipelines: A novel modelling approach using ANN & differential evolution. Chem. Ind. Chem. Eng. Q. 2010, 16, 329–343. [Google Scholar]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends® Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Breuel, T.M. The effects of hyperparameters on SGD training of neural networks. arXiv 2015, arXiv:1508.02788. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Meta Parameter | Settings |
|---|---|
| Activation function | SELU, ReLU |
| Cost dependent | MSE |
| Batch size | 72 |
| Learning rate | 0/001 |
| Optimizer | Adam |
| Maximum number of iterations | 100 |
| The number of network layers | The first model:10 The second model:12 |
| Models | Dataset | ARE (%) | AARE (%) | SD (°C) | RMSE SD (°C) | R-Square |
|---|---|---|---|---|---|---|
| LSTM | Train | 0.12 | 0.06 | 1.05 | 1.06 | 0.94 |
| Test | −0.24 | 0.09 | 1.30 | 1.33 | 0.93 | |
| Total | 0.13 | 0.07 | 1.22 | 1.20 | 0.93 | |
| DLSTM | Train | −0.01 | 0.01 | 0.02 | 0.02 | 0.99 |
| Test | −0.04 | 0.04 | 0.08 | 0.08 | 0.99 | |
| Total | −0.03 | 0.02 | 0.04 | 0.04 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, T.; Lv, W.; Liang, Z.; Wang, J. Prediction of Daily Temperature Based on the Robust Machine Learning Algorithms. Sustainability 2023, 15, 9289. https://doi.org/10.3390/su15129289
Li Y, Li T, Lv W, Liang Z, Wang J. Prediction of Daily Temperature Based on the Robust Machine Learning Algorithms. Sustainability. 2023; 15(12):9289. https://doi.org/10.3390/su15129289
Chicago/Turabian StyleLi, Yu, Tongfei Li, Wei Lv, Zhiyao Liang, and Junxian Wang. 2023. "Prediction of Daily Temperature Based on the Robust Machine Learning Algorithms" Sustainability 15, no. 12: 9289. https://doi.org/10.3390/su15129289
APA StyleLi, Y., Li, T., Lv, W., Liang, Z., & Wang, J. (2023). Prediction of Daily Temperature Based on the Robust Machine Learning Algorithms. Sustainability, 15(12), 9289. https://doi.org/10.3390/su15129289