
Artificial Intelligence and Urban Green Space Facilities Optimization Using the LSTM Model: Evidence from China

 , and
, and
Abstract
1. Introduction
2. Algorithms for Predicting PM 2.5 Concentration Based on Neural Networks
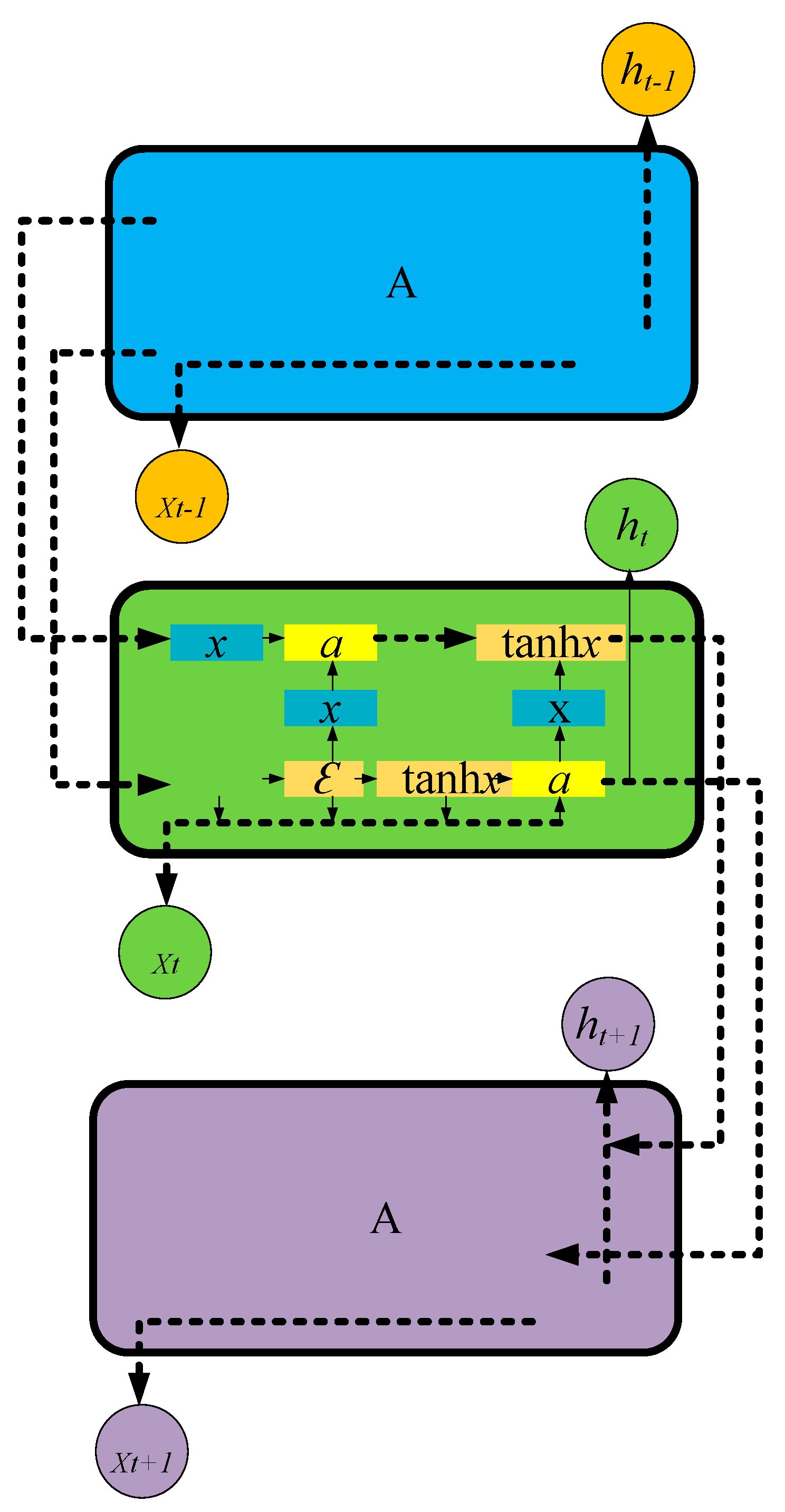
2.1. RNN and LSTM Algorithm
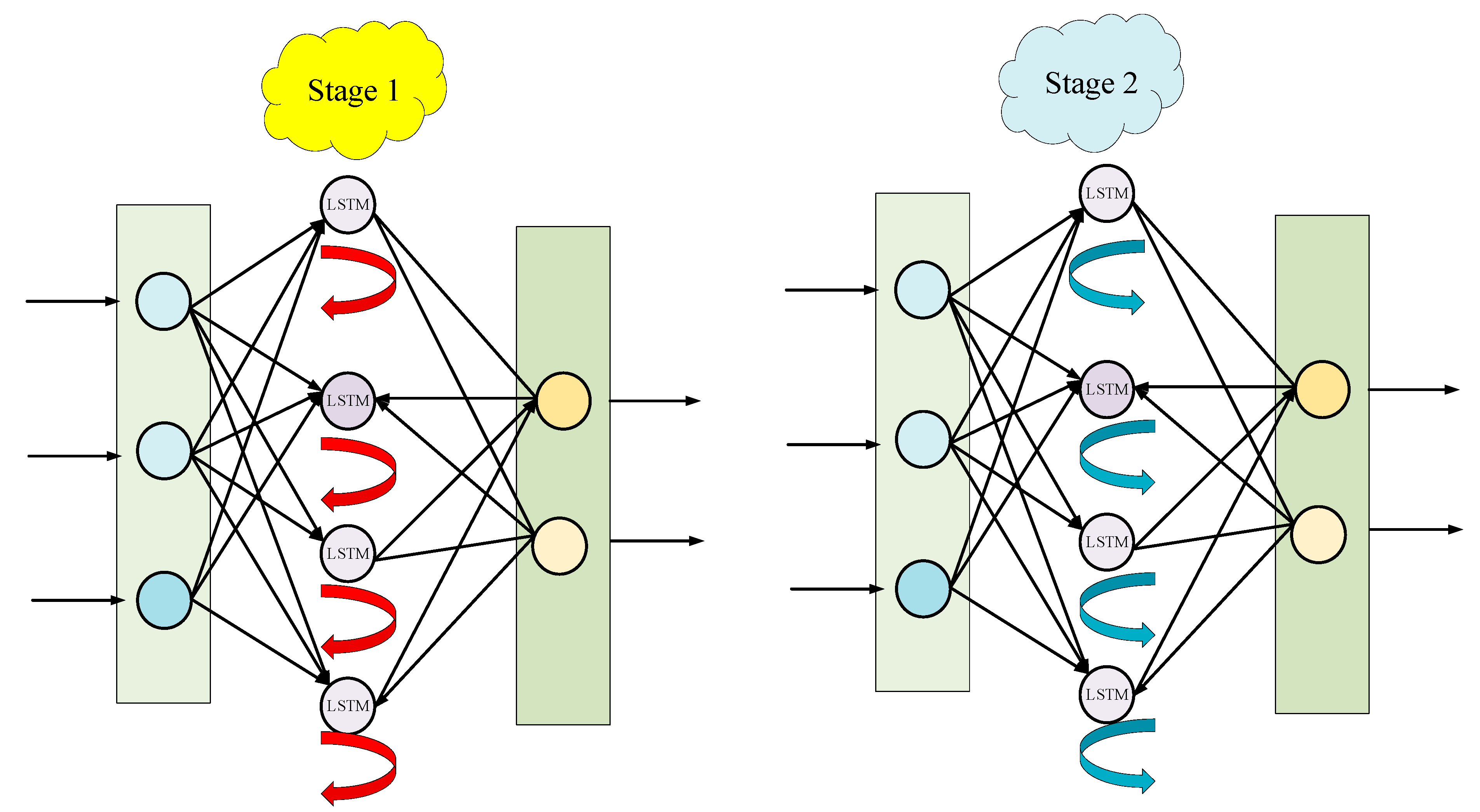
2.2. Prediction Algorithm Based on Self-Organizing LSTM
| Algorithm 1 Self-organizing LSTM algorithm flow |
| Randomly initialize the number and parameters of hidden layer neurons While maximum iteration Calculate the loss function of the network Calculate the indirect sensitivity of hidden layer neurons Calculate the direct sensitivity of hidden layer neurons Calculate the total sensitivity of hidden layer neurons If Insert a new hidden layer neuron Initialize the weight of this neuron If Delete the m-th hidden layer neuron Adjust the weight of this neuron End |
3. Data and Methods
Selection of Test Points and Setup of Experimental Hardware Equipment
4. Analysis of UGS Planning Schemes and Algorithm Results
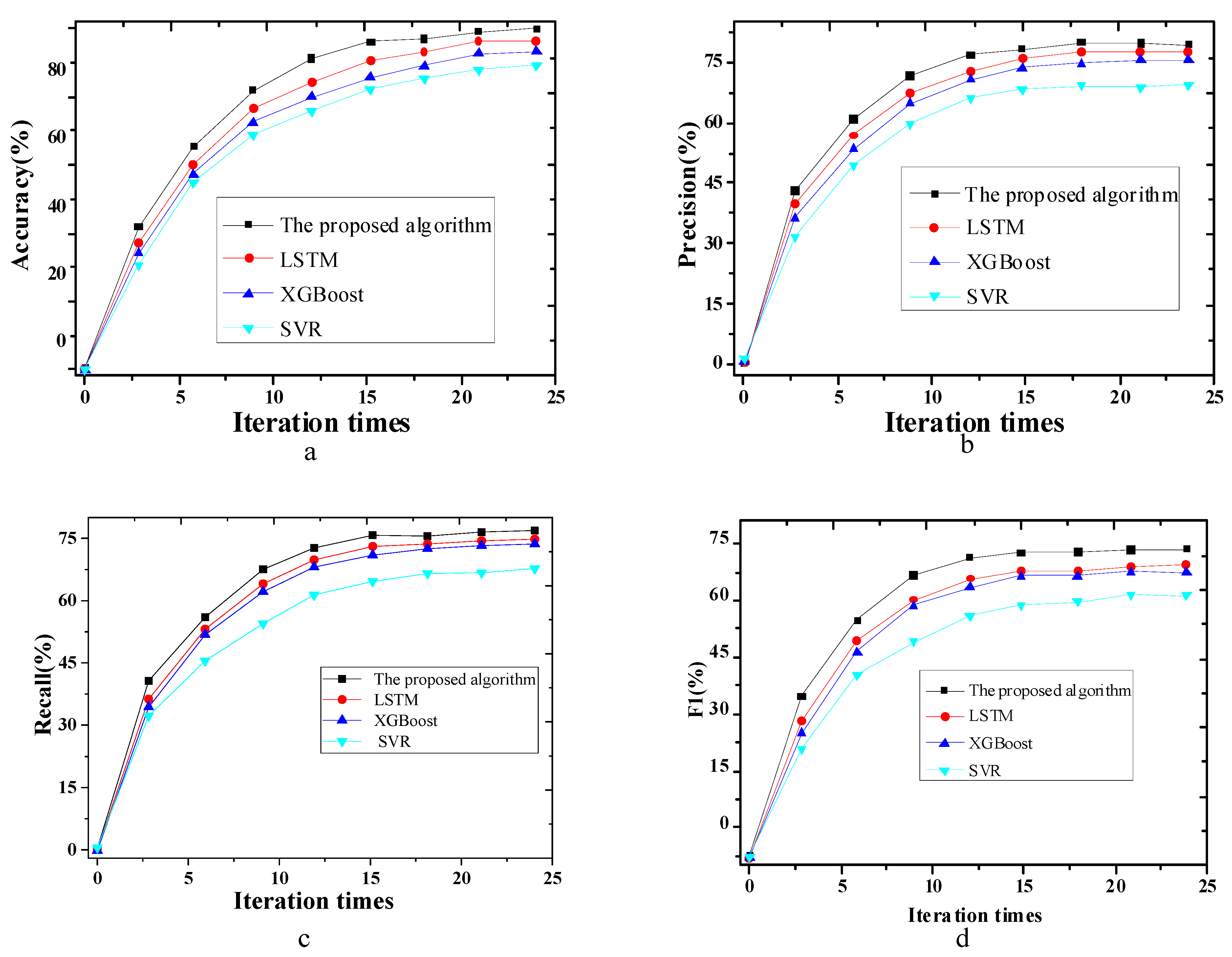
4.1. Comparative Analysis of the Fitting Effects of Self-Organizing LSTM Based on Sensitivity and Other Models
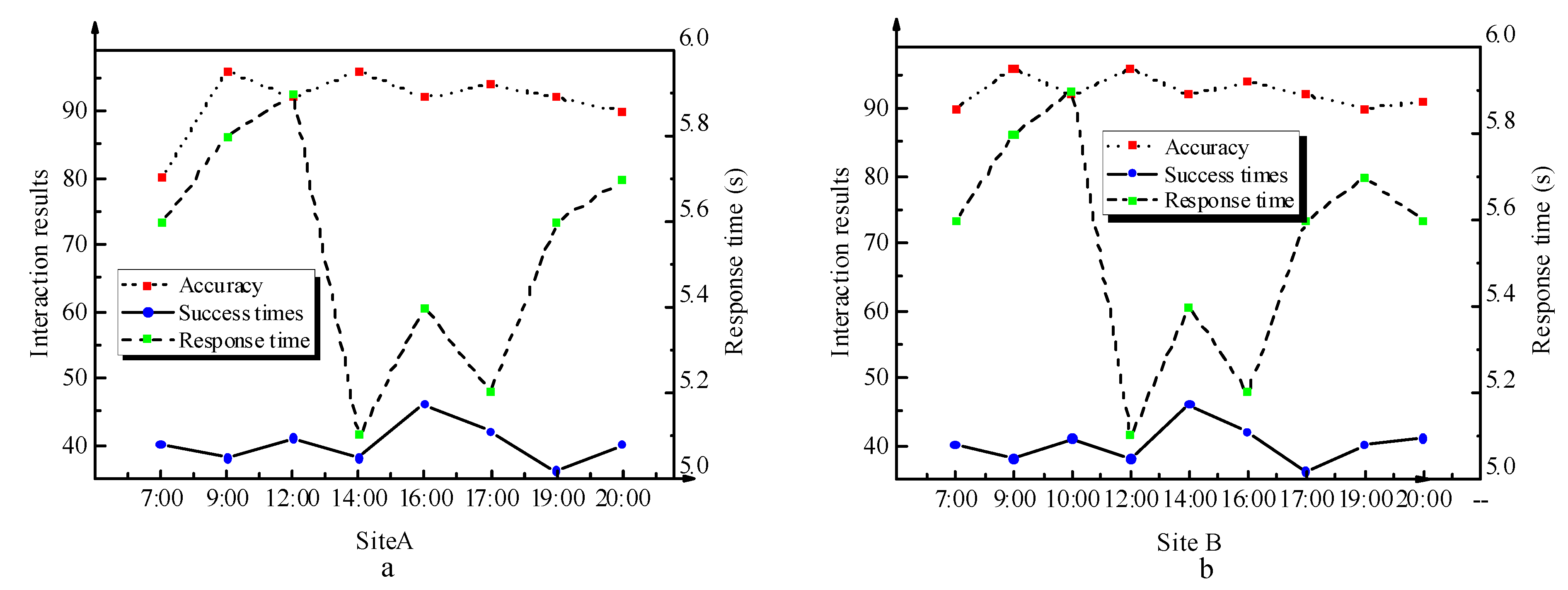
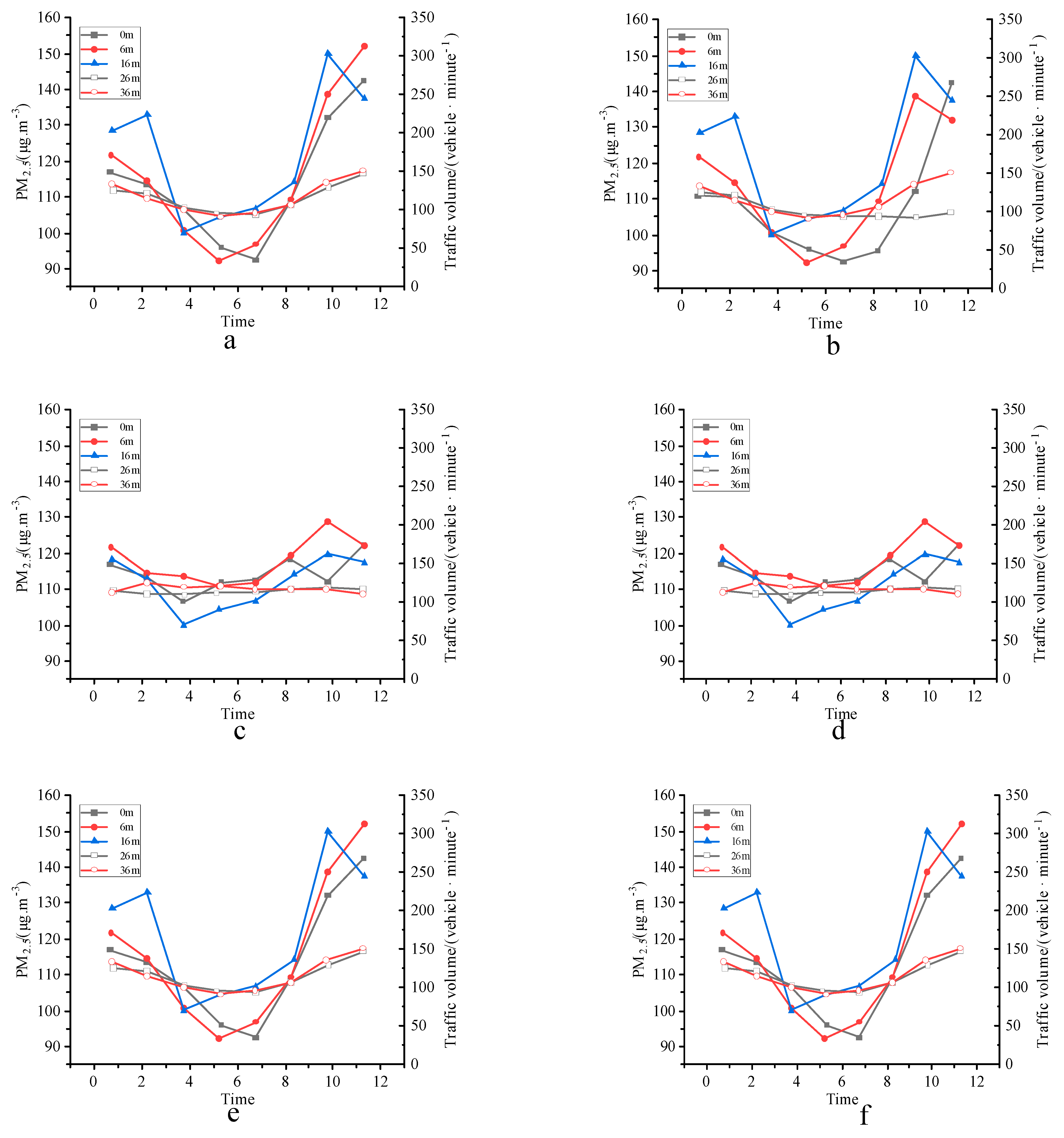
4.2. Comparison of Daily Changes in PM 2.5 Concentration
4.3. Experimental Results of the Reducing Effect of Road Greenbelt on PM 2.5
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sultana, R.; Selim, S.A.; Alam, M.S. Diverse perceptions of supply and demand of cultural ecosystem services offered by urban green spaces in Dhaka, Bangladesh. J. Urban Ecol. 2022, 8, juac003. [Google Scholar] [CrossRef]
- Stessens, P.; Canters, F.; Huysmans, M.; Khan, A.Z. Urban green space qualities: An integrated approach towards GIS-based assessment reflecting user perception. Land Use Policy 2020, 91, 104319. [Google Scholar] [CrossRef]
- Geary, R.S.; Wheeler, B.; Lovell, R.; Jepson, R.; Hunter, R.; Rodgers, S. A call to action: Improving urban green spaces to reduce health inequalities exacerbated by COVID-19. Prev. Med. 2021, 145, 106425. [Google Scholar] [CrossRef]
- Wang, Z.; Deng, Y.; Zhou, S.; Wu, Z. Achieving sustainable development goal 9: A study of enterprise resource optimization based on artificial intelligence algorithms. Resour. Policy 2023, 80, 103212. [Google Scholar] [CrossRef]
- Yin, X. The Planning Strategy of Urban Space Under the Influence of Shared Transportation. Int. J. Soc. Sci. Educ. Res. 2020, 3, 84–87. [Google Scholar]
- Fialová, J.; Bamwesigye, D.; Łukaszkiewicz, J.; Fortuna-Antoszkiewicz, B. Smart Cities Landscape and Urban Planning for Sustainability in Brno City. Land 2021, 10, 870. [Google Scholar] [CrossRef]
- Zhang, J.; Yu, Z.; Zhao, B. Impact Mechanism of Urban Green Spaces in Promoting Public Health: Theoretical Framework and Inspiration for Practical Experiences. Landsc. Archit. Front. 2020, 8, 104–113. [Google Scholar] [CrossRef]
- Fialová, J.; Březina, D.; Žižlavská, N.; Michal, J.; Machar, I. Assessment of Visitor Preferences and Attendance to Singletrails in the Moravian Karst for the Sustainable Development Proposals. Sustainability 2019, 11, 3560. [Google Scholar] [CrossRef]
- Shan, J.; Huang, Z.; Chen, S.; Li, Y.; Ji, W. Green Space Planning and Landscape Sustainable Design in Smart Cities considering Public Green Space Demands of Different Formats. Complexity 2021, 2021, 5086636. [Google Scholar] [CrossRef]
- Lukaszewicz, J.; Fortuna-Antoszkiewicz, B.; Długoński, A.; Wiśniewski, P. From the heap to the park—Reclamation and adaptation of degraded urban areas for recreational functions in Poland. Sci. Rev. Eng. Environ. Sci. (SREES) 2019, 28, 664–681. [Google Scholar] [CrossRef]
- Wang, Z.; Liang, F.; Li, C.; Xiong, W.; Chen, Y.; Xie, F. Does China’s low-carbon city pilot policy promote green development? Evidence from the digital industry. J. Innov. Knowl. 2023, 8, 100339. [Google Scholar] [CrossRef]
- Hu, H.; Qi, S.; Chen, Y. Using green technology for a better tomorrow: How enterprises and government utilize the carbon trading system and incentive policies. China Econ. Rev. 2023, 78, 101933. [Google Scholar] [CrossRef]
- Zou, H.; Wang, X. Progress and Gaps in Research on Urban Green Space Morphology: A Review. Sustainability 2021, 13, 1202. [Google Scholar] [CrossRef]
- Łukaszkiewicz, J.; Fortuna-Antoszkiewicz, B.; Oleszczuk, Ł.; Fialová, J. The Potential of Tram Networks in the Revitalization of the Warsaw Landscape. Land 2021, 10, 375. [Google Scholar] [CrossRef]
- Liu, O.Y.; Russo, A. Assessing the contribution of urban green spaces in green infrastructure strategy planning for urban ecosystem conditions and services. Sustain. Cities Soc. 2021, 68, 102772. [Google Scholar] [CrossRef]
- Wang, A.; Wang, H.; Chan, E.H. The incompatibility in urban green space provision: An agent-based comparative study. J. Clean. Prod. 2020, 253, 120007. [Google Scholar] [CrossRef]
- Hu, H.; Xu, J.; Liu, M.; Lim, M.K. Vaccine supply chain management: An intelligent system utilizing blockchain, IoT and machine learning. J. Bus. Res. 2023, 156, 113480. [Google Scholar] [CrossRef]
- Suligowski, R.; Ciupa, T.; Cudny, W. Quantity assessment of urban green, blue, and grey spaces in Poland. Urban For. Urban Green. 2021, 64, 127276. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, S.; Zhao, Y.; Chen, C.; Dong, X. Risk prediction and credibility detection of network public opinion using blockchain technology. Technol. Forecast. Soc. Chang. 2023, 187, 122177. [Google Scholar] [CrossRef]
- Kim, M.; Rupprecht, C.D.; Furuya, K. Typology and Perception of Informal Green Space in Urban Interstices: A case study of Ichikawa City, Japan. Int. Rev. Spat. Plan. Sustain. Dev. 2020, 8, 4–20. [Google Scholar] [CrossRef]
- Ojeda-Revah, L.; González, Y.O.; Vera, L. Fragmented Urban Greenspace Planning in Major Mexican Municipalities. J. Urban Plan. Dev. 2020, 146, 04020019. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, Y.; Chen, Y.; Peng, Q.; Liao, Z.; Zhu, J. A case study of development and utilization of urban underground space in Shenzhen and the Guangdong-Hong Kong-Macao Greater Bay Area. Tunn. Undergr. Space Technol. 2021, 107, 103651. [Google Scholar] [CrossRef]
- Hanson, H.I.; Eckberg, E.; Widenberg, M.; Olsson, J.A. Gardens’ contribution to people and urban green space. Urban For. Urban Green. 2021, 63, 127198. [Google Scholar] [CrossRef]
- Shekhar, S.; Aryal, J. Monitoring urban green spaces using geospatial technologies—A case study of Hobart, Tasmania, Australia. Trans. Inst. Indian Geogr. 2021, 43, 78–90. [Google Scholar]
- Cobbinah, P.B.; Asibey, M.O.; Zuneidu, M.A.; Erdiaw-Kwasie, M.O. Accommodating green spaces in cities: Perceptions and attitudes in slums. Cities 2021, 111, 103094. [Google Scholar] [CrossRef]
- Kuang, W.; Zhang, S.; Li, X.; Lu, D. A 30 m resolution dataset of China’s urban impervious surface area and green space, 2000–2018. Earth Syst. Sci. Data 2021, 13, 63–82. [Google Scholar] [CrossRef]
- Li, C.; Xu, Y.; Zheng, H.; Wang, Z.; Han, H.; Zeng, L. Artificial intelligence, resource reallocation, and corporate innovation efficiency: Evidence from China’s listed companies. Resour. Policy 2023, 81, 103324. [Google Scholar] [CrossRef]
- Sari, D.A.K.; Widyawati, L.F.; Pramesti, D. The availability and role of urban green space in South Jakarta. IOP Conf. Ser. Earth Environ. Sci. 2020, 447, 012055. [Google Scholar] [CrossRef]
- Cobbinah, P.B.; Nyame, V. A city on the edge: The political ecology of urban green space. Environ. Urban. 2021, 33, 413–435. [Google Scholar] [CrossRef]
- Ghosh, S.; Das Chatterjee, N.; Dinda, S. Urban ecological security assessment and forecasting using integrated DEMATEL-ANP and CA-Markov models: A case study on Kolkata Metropolitan Area, India. Sustain. Cities Soc. 2021, 68, 102773. [Google Scholar] [CrossRef]
- Tamara, M.E.L.; Latty, T.; Threlfall, C.G.; Hochuli, D.F. Major insect groups show distinct responses to local and regional attributes of urban green spaces. Landsc. Urban Plan. 2021, 216, 104238. [Google Scholar] [CrossRef]
- Vaňo, S.; Olafsson, A.S.; Mederly, P. Advancing urban green infrastructure through participatory integrated planning: A case from Slovakia. Urban For. Urban Green. 2021, 58, 126957. [Google Scholar] [CrossRef]
- Guo, J.; Niu, H.; Xiao, D.; Sun, X.; Fan, L. Urban Green-space Water-consumption characteristics and its driving factors in China. Ecol. Indic. 2021, 130, 108076. [Google Scholar] [CrossRef]
- Huera-Lucero, T.; Salas-Ruiz, A.; Changoluisa, D.; Bravo-Medina, C. Towards Sustainable Urban Planning for Puyo (Ecuador): Amazon Forest Landscape as Potential Green Infrastructure. Sustainability 2020, 12, 4768. [Google Scholar] [CrossRef]
- Kim, D.; Ho, C.-H.; Park, I.; Kim, J.; Chang, L.-S.; Choi, M.-H. Untangling the contribution of input parameters to an artificial intelligence PM2.5 forecast model using the layer-wise relevance propagation method. Atmos. Environ. 2022, 276, 119034. [Google Scholar] [CrossRef]
- Cho, S.; Park, H.; Son, J.; Chang, L. Development of the Global to Mesoscale Air Quality Forecast and Analysis System (GMAF) and Its Application to PM2.5 Forecast in Korea. Atmosphere 2021, 12, 411. [Google Scholar] [CrossRef]
- Lu, G.; Yu, E.; Wang, Y.; Li, H.; Cheng, D.; Huang, L.; Liu, Z.; Manomaiphiboon, K.; Li, L. A Novel Hybrid Machine Learning Method (OR-ELM-AR) Used in Forecast of PM2.5 Concentrations and Its Forecast Performance Evaluation. Atmosphere 2021, 12, 78. [Google Scholar] [CrossRef]
- Rybak, A.; Rybak, A. The Impact of the COVID-19 Pandemic on Gaseous and Solid Air Pollutants Concentrations and Emissions in the EU, with Particular Emphasis on Poland. Energies 2021, 14, 3264. [Google Scholar] [CrossRef]
- Hu, H.; Xie, N.; Fang, D.; Zhang, X. The role of renewable energy consumption and commercial services trade in carbon dioxide reduction: Evidence from 25 developing countries. Appl. Energy 2018, 211, 1229–1244. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Point | Species | Distance | Canopy Density |
|---|---|---|---|
| A | Buchoe dactyloides | 1 | 70 |
| Sabina vulgaris | 6 | ||
| Indian white wax | 18 | ||
| Populus tomentosa | 30 | ||
| B | Buchoe dactyloides | 1 | 50 |
| Goldilocks | 6 | ||
| Chinese redbud | 18 | ||
| Juniper | 30 | ||
| C | Ophiopogon japonicus | 1 | 30 |
| Chinese scholartree | 6 | ||
| Ginkgo | 18 | ||
| Catalpa | 30 |
| Different Models | RMSE μg.m−3 | MAE μg.m−3 | MAPE μg.m−3 | R2 | |
|---|---|---|---|---|---|
| A (7:00, 0 m) | Self-organizing LSTM algorithm based on the sensitivity | 120 | 115 | 132 | 0.826 |
| LSTM | 110 | 111 | 110 | 0.833 | |
| XGBoost | 120 | 112 | 134 | 0.617 | |
| SVR | 112 | 145 | 101 | 0.842 | |
| Calculated value | 1.75 | 1.12 | 6.06 | / | |
| B (7:00, 0 m) | Self-organizing LSTM algorithm based on the sensitivity | 110 | 120 | 115 | 0.859 |
| LSTM | 111 | 121 | 123 | 0.86 | |
| XGBoost | 118 | 125 | 131 | 0.843 | |
| SVR | 120 | 125 | 132 | 0.790 | |
| Calculated value | 1.75 | 1.11 | 6.05 | / | |
| C (7:00, 0 m) | Self-organizing LSTM algorithm based on the sensitivity | 118 | 115 | 112 | 0.867 |
| LSTM | 110 | 123 | 145 | 0.777 | |
| XGBoost | 129 | 135 | 132 | 0.735 | |
| SVR | 134 | 132 | 130 | 0.805 | |
| Calculated value | 1.70 | 1.16 | 6.06 | / |
| Under Zero-Pollution or Light Pollution Conditions | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Green Belt Width | |||||||||||
| 6 m | 16 m | 26 m | 36 m | ||||||||
| A | B | C | A | B | C | A | B | C | A | B | C |
| 7.24% | 0.64% | 0.5% | 10.2% | 1.46% | 1.95% | 9.31% | 2.34% | 4.52% | 12.22% | 3.54% | 3.72% |
| Under Moderate Pollution Conditions | |||||||||||
| Green Belt Width | |||||||||||
| 6 m | 16 m | 26 m | 36 m | ||||||||
| A | B | C | A | B | C | A | B | C | A | B | C |
| 0.8% | −7.5% | −0.6% | 3.4% | −4.2% | 0.49% | 0.83% | −2.6% | −2.5% | 0.51% | −7.2% | −6.8% |
| Under Severe Pollution Conditions | |||||||||||
| Green Belt Width | |||||||||||
| 6 m | 16 m | 26 m | 36 m | ||||||||
| A | B | C | A | B | C | A | B | C | A | B | C |
| −0.09% | −1.3% | −2.8% | −0.9% | −1.9% | −3.5% | −3.1% | −2.6% | −5.3% | −4.4% | −3.7% | −2.72% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, S.; Guan, X.; Zhu, J.; Wang, Z.; Jian, Y.; Wang, W.; Yang, Y. Artificial Intelligence and Urban Green Space Facilities Optimization Using the LSTM Model: Evidence from China. Sustainability 2023, 15, 8968. https://doi.org/10.3390/su15118968
Yu S, Guan X, Zhu J, Wang Z, Jian Y, Wang W, Yang Y. Artificial Intelligence and Urban Green Space Facilities Optimization Using the LSTM Model: Evidence from China. Sustainability. 2023; 15(11):8968. https://doi.org/10.3390/su15118968
Chicago/Turabian StyleYu, Shuhui, Xin Guan, Junfan Zhu, Zeyu Wang, Youting Jian, Weijia Wang, and Ya Yang. 2023. "Artificial Intelligence and Urban Green Space Facilities Optimization Using the LSTM Model: Evidence from China" Sustainability 15, no. 11: 8968. https://doi.org/10.3390/su15118968
APA StyleYu, S., Guan, X., Zhu, J., Wang, Z., Jian, Y., Wang, W., & Yang, Y. (2023). Artificial Intelligence and Urban Green Space Facilities Optimization Using the LSTM Model: Evidence from China. Sustainability, 15(11), 8968. https://doi.org/10.3390/su15118968