
“The Big One” Earthquake Preparedness Assessment among Younger Filipinos Using a Random Forest Classifier and an Artificial Neural Network


Abstract
1. Introduction
- Will the random forest classifier surpass the accuracy rate of the basic decision tree as claimed by related studies in line with earthquake preparedness?
- Will the results of the different MLAs be similar for factors affecting earthquake preparedness?
- Can nonlinear relationship frameworks be effectively assessed by MLAs?
- Are the results different from SEMs and MLAs?
- How can the results be practically applied by the Philippines for disaster preparedness?
2. Theoretical Framework
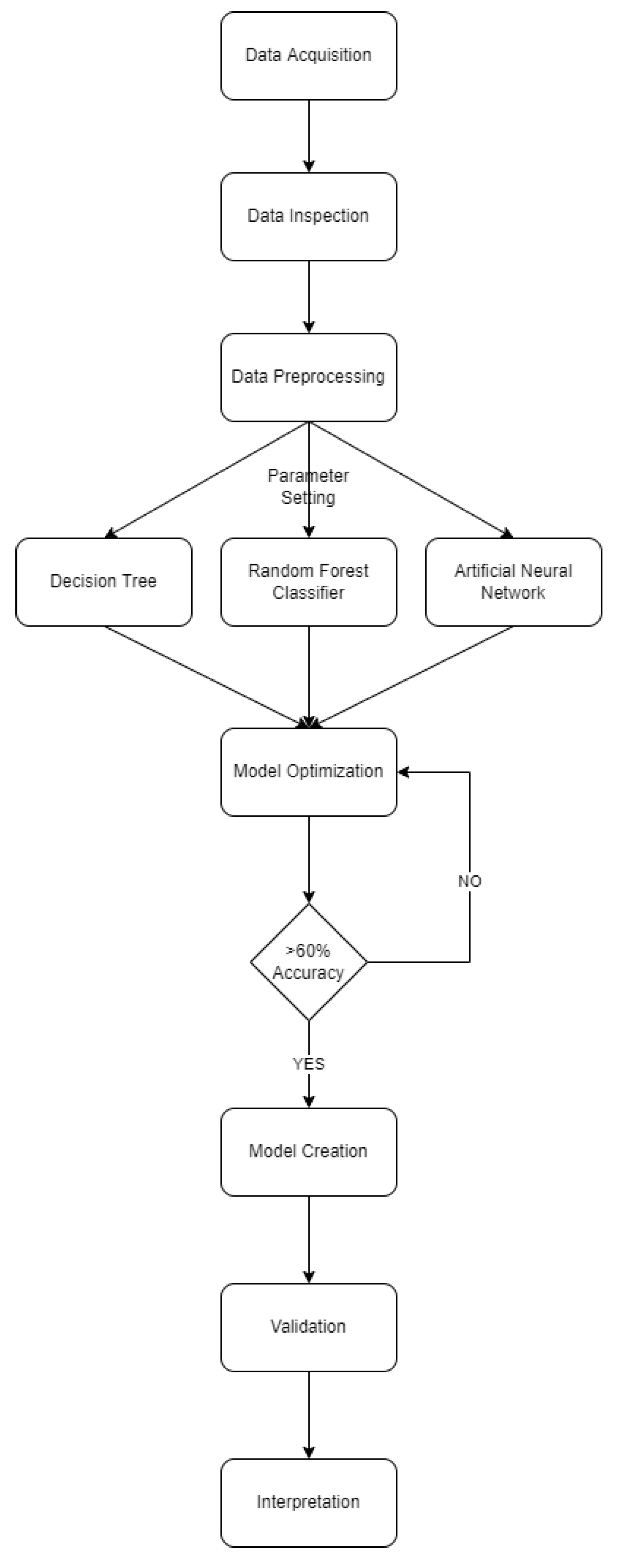
3. Methodology
3.1. Data Collection
3.2. Data Cleaning and Aggregation
3.3. Prediction Using Machine Learning Algorithms
3.3.1. Decision Tree
3.3.2. Random Forest Classifier
3.3.3. Artificial Neural Network
3.3.4. Swish Activation Function (SWAF)
3.3.5. SoftMax Activation Function (SAF)
3.3.6. RMSProp Optimizer
4. Results
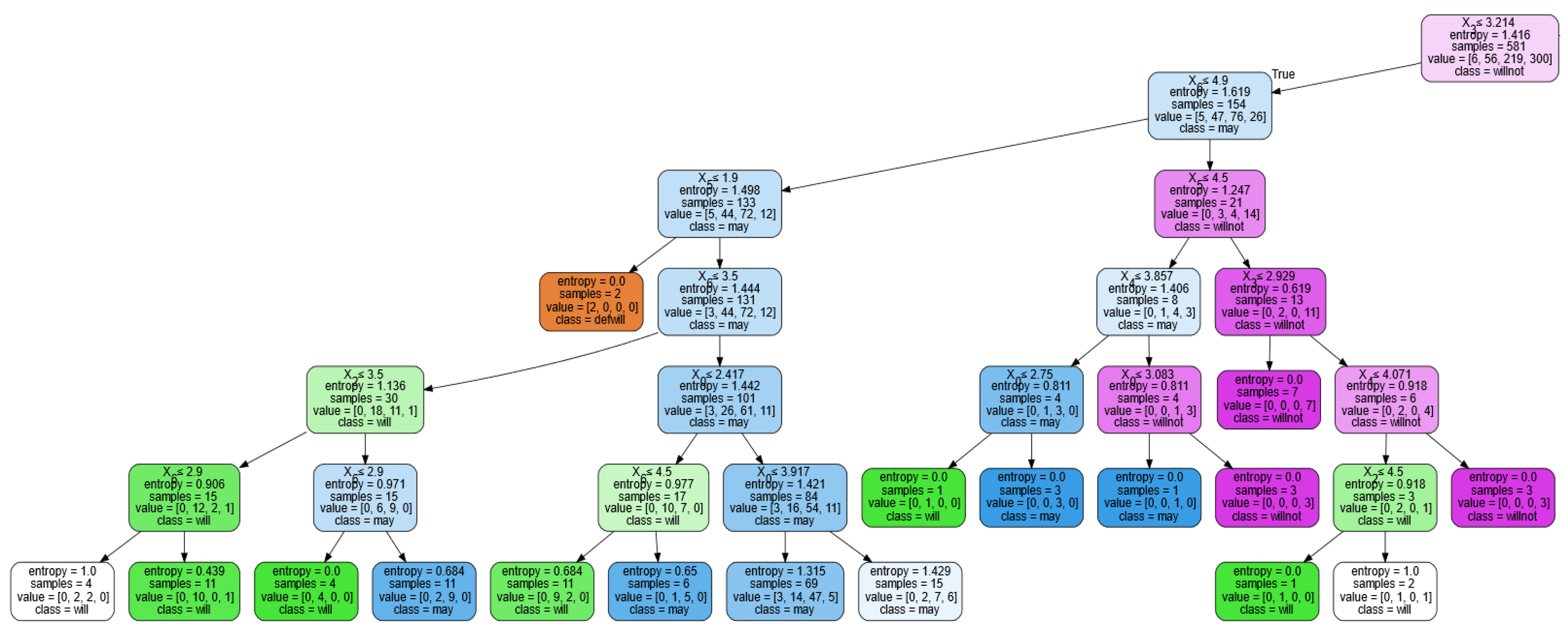
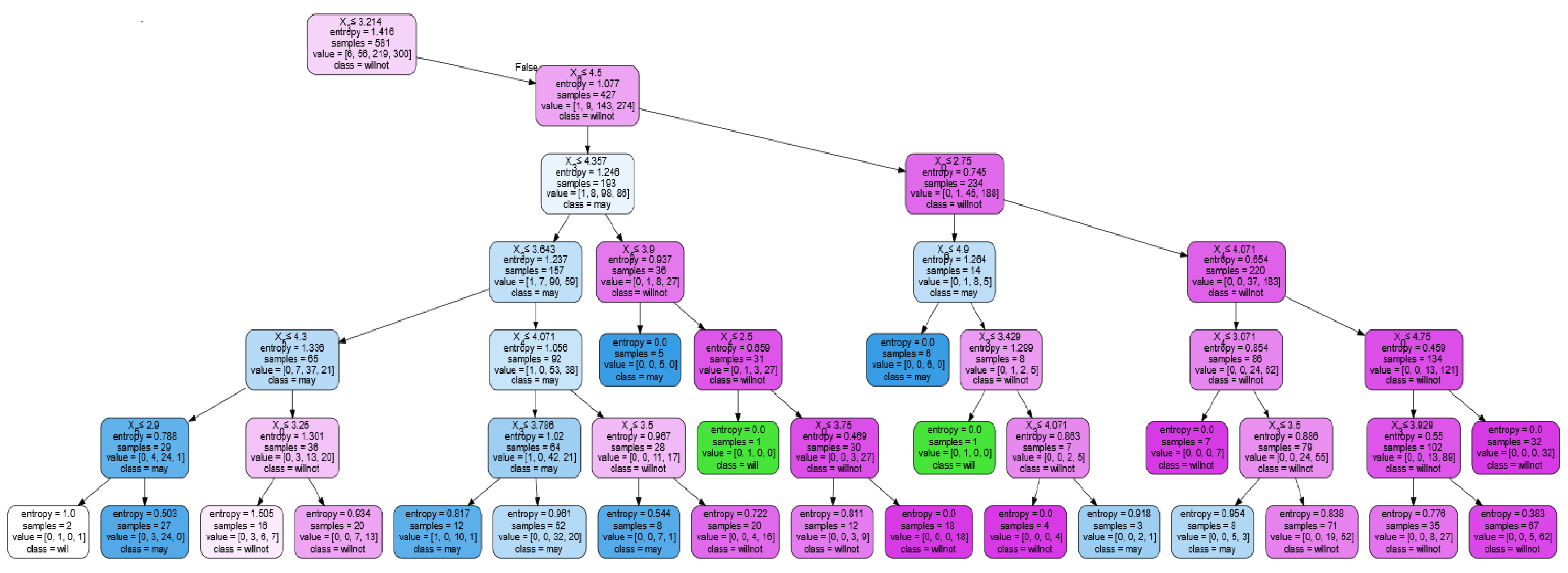
4.1. Decision Tree
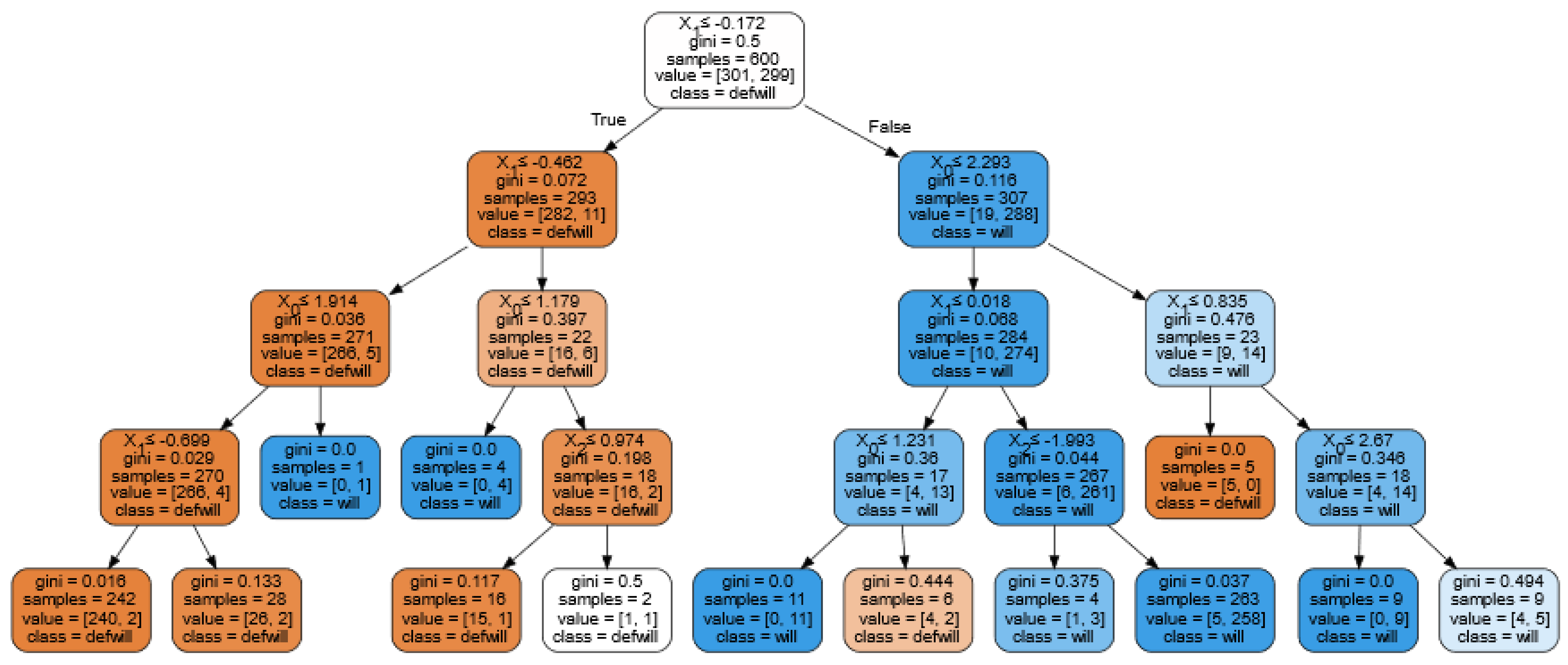
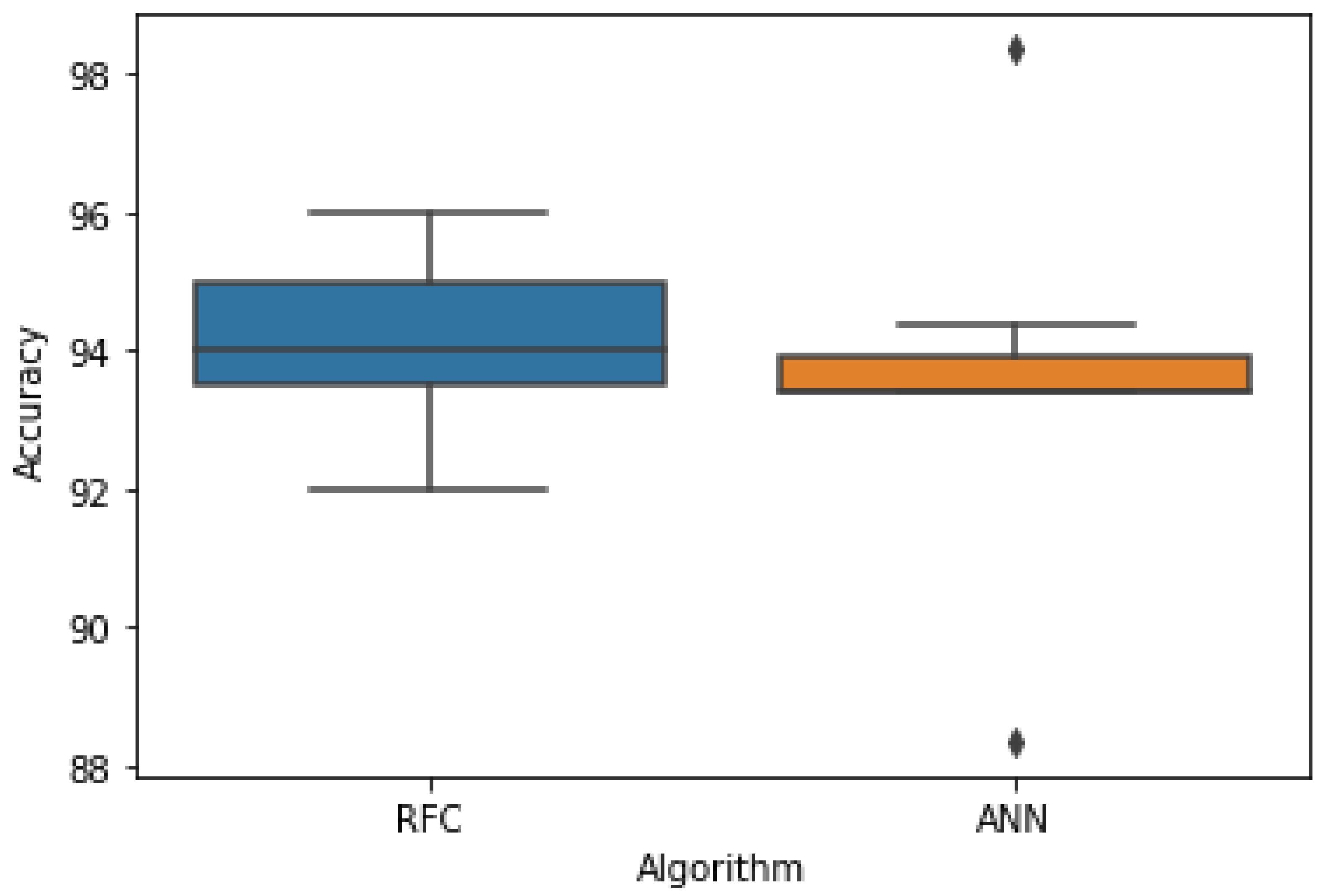
4.2. Random Forest Classifier
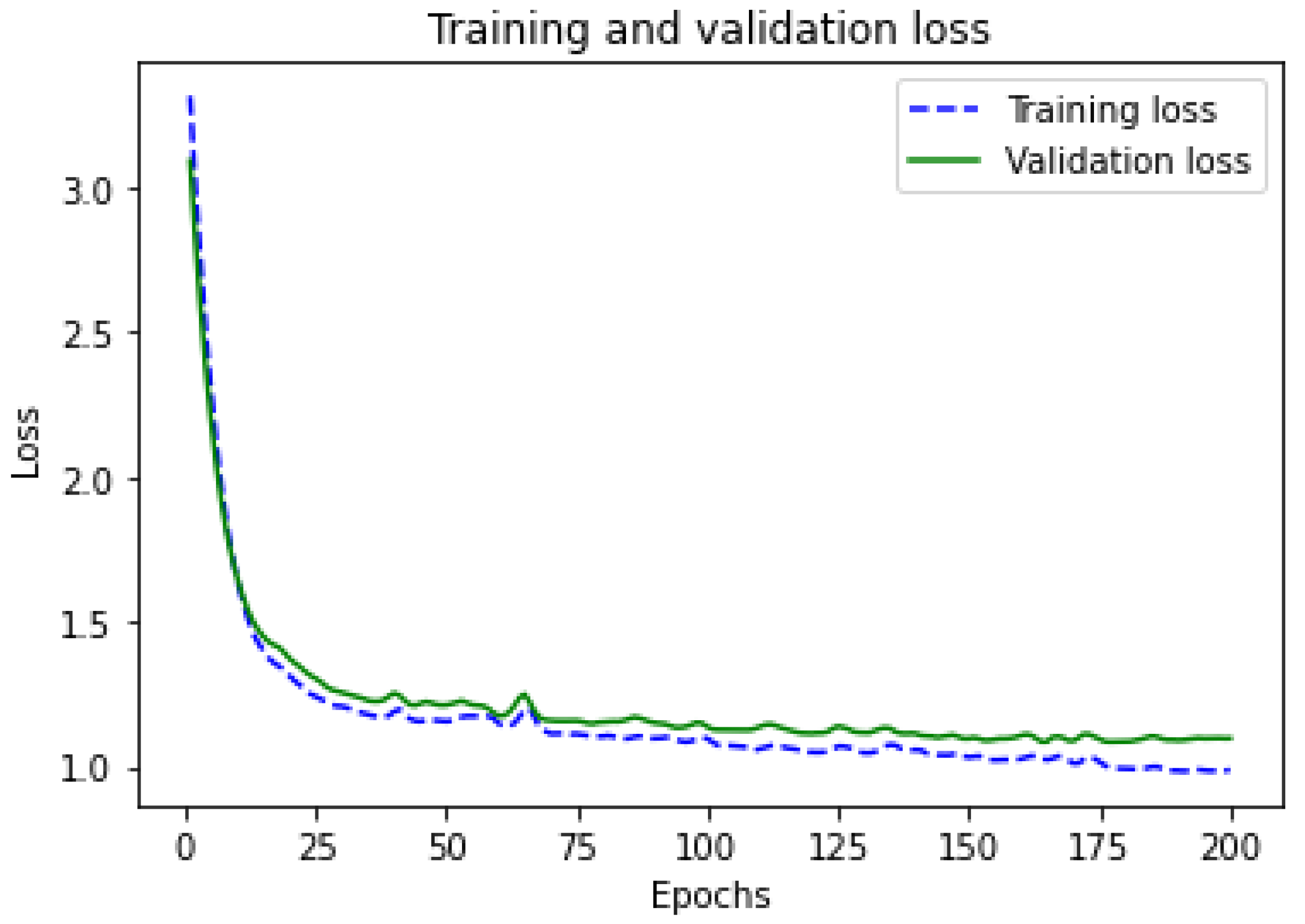
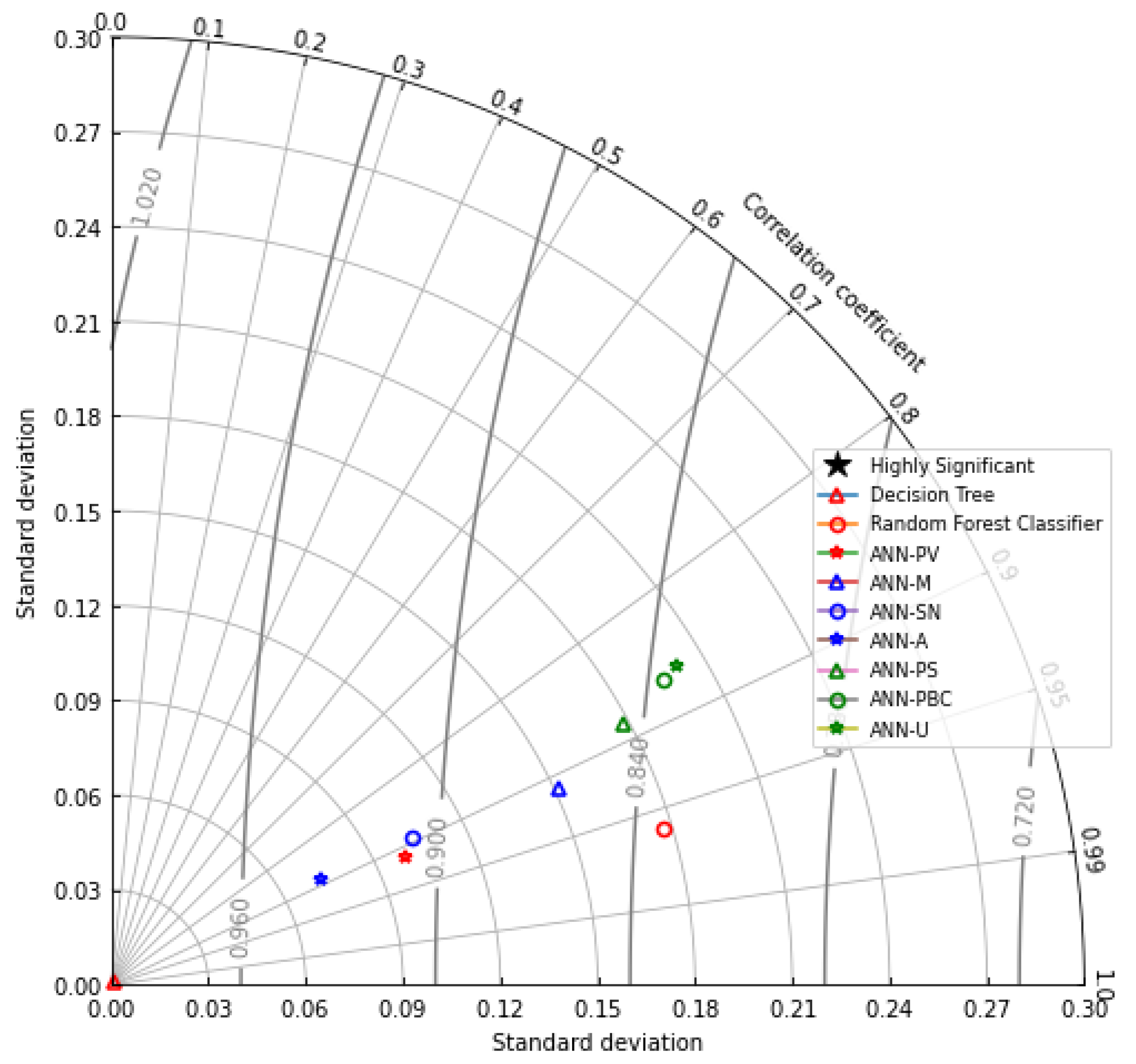
4.3. Artificial Neural Network
5. Discussion
5.1. Practical Implications
5.2. Contribution and Application
5.3. Limitations and Recommendations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Morales, N.J. Magnitude 6.7 Quake Hits South of the Philippine Capital. Available online: https://www.reuters.com/world/asia-pacific/magnitude-67-quake-hits-south-philippine-capital-2021-07-23/ (accessed on 30 December 2021).
- Badillo, V. The Moro Gulf tidal wave of 17 August 1976. Philipp. Stud. 1978, 26, 426–436. [Google Scholar]
- World, B. Natural Disaster Risk Management in the Philippines Reducing Vulnerability; Pacific Consultants International: Tama, Japan, 2005. [Google Scholar]
- Philippine Institute of Volcanology. 1990 July 16 Ms7.8 Luzon Earthquake; Philippine Institute of Volcanology: Manila, The Philippines, 2018.
- Yariyan, P.; Zabihi, H.; Wolf, I.D.; Karami, M.; Amiriyan, S. Earthquake risk assessment using an integrated Fuzzy Analytic Hierarchy Process with Artificial Neural Networks based on GIS: A case study of Sanandaj in Iran. Int. J. Disaster Risk Reduct. 2020, 50, 101705. [Google Scholar] [CrossRef]
- National Centers for Environmental. Philippines Earthquakes; National Centers for Environmental: Manila, The Philippines, 2021.
- Smoczyk, G.M.; Hayes, G.P.; Hamburger, M.W.; Benz, H.M.; Villaseñor, A.; Furlong, K.P. Seismicity of the Earth 1900–2012 Philippine Sea Plate and Vicinity: US. Geological Survey Open-File Report 2010–1083-M 2013, 1 Sheet, Scale 1 10,000,000; USGS: Washington, DC, USA, 2013.
- Carteciano, J.A. The Big One Part 2; National Research Council of the Philippines: Manila, The Philippines, 2017.
- Carteciano, J.A. The Big One: Facts and Impacts; National Research Council of the Philippines: Manila, The Philippines, 2017.
- Williams, L.; Arguillas, F.; Arguillas, M. Major storms, rising tides, and wet feet: Adapting to flood risk in the Philippines. Int. J. Disaster Risk Reduct. 2020, 50, 101810. [Google Scholar] [CrossRef]
- Ong, A.K.S.; Prasetyo, Y.T.; Lagura, F.C.; Ramos, R.N.; Sigua, K.M.; Villas, J.A.; Young, M.N.; Diaz, J.F.T.; Persada, S.F.; Redi, A.A.N.P. Factors affecting intention to prepare for mitigation of “the big one” earthquake in the Philippines: Integrating protection motivation theory and extended theory of planned behavior. Int. J. Disaster Risk Reduct. 2021, 63, 102467. [Google Scholar] [CrossRef]
- Prasetyo, Y.T.; Castillo, A.M.; Salonga, L.J.; Sia, J.A.; Seneta, J.A. Factors affecting perceived effectiveness of COVID-19 prevention measures among Filipinos during Enhanced Community Quarantine in Luzon, Philippines: Integrating Protection Motivation Theory and extended Theory of Planned Behavior. Int. J. Infect. Dis. 2020, 99, 312–323. [Google Scholar] [CrossRef]
- Kurata, Y.B.; Prasetyo, Y.T.; Ong, A.K.; Nadlifatin, R.; Persada, S.F.; Chuenyindee, T.; Cahigas, M.M. Determining factors affecting preparedness beliefs among Filipinos on Taal Volcano eruption in Luzon, Philippines. Int. J. Disaster Risk Reduct. 2022, 76, 103035. [Google Scholar] [CrossRef]
- Fan, Y.; Chen, J.; Shirkey, G.; John, R.; Wu, S.R.; Park, H.; Shao, C. Applications of structural equation modeling (SEM) in Ecological Studies: An updated review. Ecol. Process. 2016, 5, 19. [Google Scholar] [CrossRef]
- Woody, E. An SEM perspective on evaluating mediation: What every clinical researcher needs to know. J. Exp. Psychopathol. 2011, 2, 210–251. [Google Scholar] [CrossRef]
- German, J.D.; Redi, A.A.; Ong, A.K.; Prasetyo, Y.T.; Sumera, V.L. Predicting factors affecting preparedness of volcanic eruption for a sustainable community: A case study in the Philippines. Sustainability 2022, 14, 11329. [Google Scholar] [CrossRef]
- Gaillard, J. Alternative paradigms of volcanic risk perception: The case of Mt. Pinatubo in the Philippines. J. Volcanol. Geotherm. Res. 2008, 172, 315–328. [Google Scholar] [CrossRef]
- Bolletino, V.; Stevens, A.; Sharma, M.; Dy, P.; Pham, P.; Vinck, P. Public perception of climate change and disaster preparedness: Evidence from the Philippines. Clim. Risk Manag. 2020, 30, 250. [Google Scholar] [CrossRef]
- Venable, C.; Javernick-Will, A.; Liel, A.; Koschmann, M. Revealing (mis)alignments between household perceptions and engineering assessments of post-disaster housingsafety in typhoons. Int. J. Disaster Risk Reduct. 2021, 53, 101976. [Google Scholar] [CrossRef]
- Yang, W.; Zhou, S. Using decision tree analysis to identify the determinants of residents’ CO2 emissions from different types of trips: A case study of guangzhou, China. J. Clean. Prod. 2020, 277, 124071. [Google Scholar] [CrossRef]
- Milani, L.; Grumi, S.; Camisasca, E.; Miragoli, S.; Traficante, D.; Di Blasio, P. Familial risk and protective factors affecting CPS professionals’ child removal decision: A decision tree analysis study. Child. Youth Serv. Rev. 2020, 109, 104687. [Google Scholar] [CrossRef]
- Kim, Y.; Hardisty, R.; Torres, E.; Marfurt, K.J. Seismic facies classification using random forest algorithm. SEG Tech. Program Expand. Abstr. 2018, 2161–2165. [Google Scholar] [CrossRef]
- Snehil; Goel, R. Flood Damage Analysis Using Machine Learning Techniques. Procedia Comput. Sci. 2020, 173, 78–85. [Google Scholar] [CrossRef]
- Chen, J.; Li, Q.; Wang, H.; Deng, M. A Machine Learning Ensemble Approach Based on Random Forest and Radial Basis Function Neural Network for Risk Evaluation of Regional Flood Disaster: A Case Study of the Yangtze River Delta, China. Int. J. Environ. Res. Public Health 2019, 17, 49. [Google Scholar] [CrossRef]
- Zagajewski, B.; Kluczek, M.; Raczko, E.; Njegovec, A.; Dabija, A.; Kycko, M. Comparison of random forest, support vector machines, and neural networks for post-disaster forest species mapping of the Krkonoše/Karkonosze Transboundary Biosphere Reserve. Remote Sens. 2021, 13, 2581. [Google Scholar] [CrossRef]
- Benemaran, R.S.; Esmaeili-Falak, M.; Javadi, A. Predicting resilient modulus of flexible pavement foundation using extreme gradient boosting based optimised models. Int. J. Pavement Eng. 2022, 1–20. [Google Scholar] [CrossRef]
- Moustra, M.; Avraamides, M.; Christodoulo, C. Artificial neural networks for earthquake prediction using time series magnitude data or Seismic Electric Signal. Expert Syst. Appl. 2011, 38, 15032–15039. [Google Scholar] [CrossRef]
- Kimes, D.S.; Nelson, R.F.; Manry, M.T.; Fung, A.K. Review article: Attributes of neural networks for extracting continuous vegetation variables from optical and radar measurements. Int. J. Remote Sens. 2010, 19, 2639–2663. [Google Scholar] [CrossRef]
- Oktarina, R.; Bahagia, S.N.; Diawati, L.; Pribadi, K.S. Artificial neural network for predicting earthquake casualties and damages in Indonesia. IOP Sci. Earth Environ. Sci. 2020, 426, 012156. [Google Scholar] [CrossRef]
- Heidenrich, A.; Masson, T.; Bamberg, S. Let’s talk about flood risk—Evaluating a series of workshops on private flood protection. Int. J. Disaster Risk Reduct. 2020, 50, 101880. [Google Scholar] [CrossRef]
- Prasetyo, Y.T.; Senoro, D.B.; German, J.D.; Robielos, R.A.; Ney, F.P. Confirmatory factor analysis of vulnerability to natural hazards: A household Vulnerability Assessment in Marinduque Island, Philippines. Int. J. Disaster Risk Reduct. 2020, 50, 101831. [Google Scholar] [CrossRef]
- Vinnell, L.J.; Wallis, A.; Becker, J.S.; Johnston, D.M. Evaluating the ShakeOut drill in Aotearoa/New Zealand: Effects on knowledge, attitudes, and behaviour. Int. J. Disaster Risk Reduct. 2020, 48, 101721. [Google Scholar] [CrossRef]
- Becker, J.S.; Paton, D.; Johnston, D.M.; Ronan, K.R.; McClure, J. The role of prior experience in informing and motivating earthquake preparedness. Int. J. Disaster Risk Reduct. 2017, 22, 179–193. [Google Scholar] [CrossRef]
- Budhathoki, N.K.; Paton, D.; Lassa, J.A.; Zander, K.K. Assessing farmers’ preparedness to cope with the impacts of multiple climate change-related hazards in the Terai lowlands of Nepal. Int. J. Disaster Risk Reduct. 2020, 49, 101656. [Google Scholar] [CrossRef]
- Ataei, P.; Gholamrezai, S.; Movahedi, R.; Aliabadi, V. An analysis of farmers’ intention to use green pesticides: The application of the extended theory of planned behavior and health belief model. J. Rural Stud. 2021, 81, 378–384. [Google Scholar] [CrossRef]
- Song, Z.; Shi, X. Cherry growers’ perceived adaption efficacy to climate change and meteorological hazards in Northwest China. Int. J. Disaster Risk Reduct. 2020, 46, 101620. [Google Scholar] [CrossRef]
- Aboelmaged, M. E-waste recycling behaviour: An integration of recycling habits into the theory of planned behaviour. J. Clean. Prod. 2021, 278, 124182. [Google Scholar] [CrossRef]
- LaMorte, W. The Theory of Planned Behavior; Boston University School of Public Health: Boston, PA, USA, 2019. [Google Scholar]
- Memon, M.A.; Ting, H.; Ramayah, T.; Chuah, F.; Cheah, J. A review of the methodological misconceptions and guidelines related to the application of structural equation modeling: A Malaysian scenario. J. Appl. Struct. Equ. Model. 2017, 1, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Hair, J.F. Multivariate Data Analysis: A Global Perspective; Pearson: London, UK, 2010. [Google Scholar]
- Vogels, E. Millenials Stand Out for Their Technology Use, But Older Generations Also Embrace Digitals Life; Pew Research Center: Washington, DC, USA, 2019. [Google Scholar]
- Mallouhy, R.; Jaoude, C.A.; Guyeux, C.; Makhoul, A. Major earthquake event prediction using various machine learning algorithm. In Proceedings of the 2019 International Conference on Information and Communication Technologies for Disaster Management (ICT-DM), Paris, France, 18–20 December 2019. [Google Scholar]
- Jahangir, M.H.; Reineh, S.M.M.; Abolghasemi, M. Spatial prediction of flood zonation mapping in Kan River Basin, Iran, using artificial neural network algorithm. Weather Clim. Extrem. 2019, 25, 100215. [Google Scholar] [CrossRef]
- Reese, K. Deep learning artificial neural networks for non-destructive archeological site dating. J. Archaeol. Sci. 2021, 132, 105413. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation Functions in Neural Network. Int. J. Eng. Appl. Sci. Technol. 2020, 4, 310–316. [Google Scholar] [CrossRef]
- Feng, J.; Lu, S. Performance Analysis of Various Activation Function in Artificial Neural Networks. IOP Conf. Ser. J. Phys. Conf. Ser. 2019, 1237, 022030. [Google Scholar] [CrossRef]
- Eckle, K.; Schmidt-Heiber, J. A comparison of deep networks with RELU activation function and linear spline-type methods. Neural Netw. 2019, 110, 232–242. [Google Scholar] [CrossRef]
- Pi, Y.; Nath, N.D.; Behzadan, A.H. Convultional neural networks for object detection in aerial imagery for disaster response and recovery. Adv. Eng. Inform. 2020, 43, 101009. [Google Scholar] [CrossRef]
- Anbarasan, M.; Muthu, B.; Sivaparthipan, C.B.; Sundarasekar, R.; Kadry, S.; Krishnamoorthy, S.; Samuel, D.J.; Dasel, A.A. Detection of flood disaster system based on IoT, big data, and convolutional neural network. Comput. Commun. 2010, 150, 150–157. [Google Scholar] [CrossRef]
- Satwik, P.M.; Sundram, M. An integrated approach for weather forecasting and disaster prediction using deep learning architecture based on memory Augmented Neural Network’s (MANN’s). Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Jena, R.; Pradhan, B.; Beydoun, G.; Nizamuddin, A.; Sofyan, H.; Affan, H. Integrated model for earthquake risk assessment using neural network and analytical heirarchy process: Aceh provincce, Indonesia. Geosci. Front. 2020, 11, 613–634. [Google Scholar] [CrossRef]
- Jena, R.; Pradhan, B. Integrated ANN-cross-validation and AHP-TOPSIS model to improve earthquake risk assessment. Int. J. Disaster Risk Reduct. 2020, 50, 101723. [Google Scholar] [CrossRef]
- Yousefzadeh, M.; Hosseini, S.A.; Farnaghi, M. Spatiotemporally explicit earthquake prediction using deep neural network. Soil Dyn. Earthq. Eng. 2021, 144, 106663. [Google Scholar] [CrossRef]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Pradhan, B.; Lee, S. Landslide susceptibility assessment and factor effect analysis: Backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ. Model. Softw. 2010, 25, 747–759. [Google Scholar] [CrossRef]
- Brownlee, J. Difference Between A Batch and An Epoch in A Neural Network; Machine Learning Mastery: San Juan, PR, USA, 2019. [Google Scholar]
- Bushaev, V. Understanding RMSProp—Faster Neural Network Learning; Towards Data Science: Toronto, ON, USA, 2018. [Google Scholar]
- Xu, D.; Zhang, S.; Zhang, H.; Mandic, D.P. Convergence of the RMSProp deep learning method with penalty for nonconvex optimization. Neural Netw. 2021, 139, 17–23. [Google Scholar] [CrossRef]
- Kolose, S.; Stewart, T.; Hume, P.; Tomkinson, G.R. Prediction of Military combat clothing size using Decision Trees and 3D body scan data. Appl. Ergon. 2021, 95, 103435. [Google Scholar] [CrossRef]
- Aznar, P. Decision Trees: Gini vs Entropy. Quantdare, 2 December 2020. Available online: https://quantdare.com/decision-trees-gini-vs-entropy/#:~:text=The%20Gini%20Index%20and%20the,both%20of%20them%20are%20represented (accessed on 13 December 2022).
- Lara, F.; Lara-Cueva, R.; Larco, J.C.; Carrera, E.V.; Leon, R. A deep learning approach for automation recognition of Seismo-volcanic events at the Cotopaxi volcano. J. Volcanol. Geotherm. Res. 2021, 409, 107142. [Google Scholar] [CrossRef]
- Kizrak, A. Comparison of Activation Functions for Deep Neural Network; Towards Data Science: Toronto, ON, USA, 2019. [Google Scholar]
- Gao, F.; Li, B.; Chen, L.; Shang, Z.; Wei, X.; He, C. A softmax classifier for high-precision classification of ultrasonic similar signal. Ultrasonic 2021, 112, 106344. [Google Scholar] [CrossRef]
- Nhu, V.; Hoang, N.; Nguyen, H.; Ngo, P.T.T.; Buo, T.T.; Hao, P.V.; Samui, P.; Bui, D.T. Effective assessment of Keras based deep learning with different robust optimization algorithm for shallow landslide susceptibility mapping at tropical area. Catena 2020, 188, 104458. [Google Scholar] [CrossRef]
- Walczak, S.; Cerpa, N. Artificial Neural Network. In Encyclopedia of Physical Science and Technology; Academic Press: Cambridge, MA, USA, 2003; pp. 631–645. [Google Scholar] [CrossRef]
- Lam, S. Predicting intention to save water: Theory ofplanned behavior, response efficacy, vulnerability, and perceived efficiency of alternative solutions. J. Appl. Soc. Psychol. 2006, 36, 2803–2824. [Google Scholar] [CrossRef]
- Garcia, T.A.; Fairlie, A.M.; Litt, D.M.; Waldron, K.A.; Lewis, M.A. Perceived vulnerability moderates the relations between the use of protective behavioral strategies and alcohol use and consequences among high-risk young adults. Addict. Behav. 2018, 81, 150–156. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Ni, Q.; Zhou, R. What factors influence the mobile health service adoption? A meta-analysis and the moderating role of age. Int. J. Inf. Manag. 2018, 43, 342–350. [Google Scholar] [CrossRef]
- Yau, S.; Wongsawat, P.; Songthap, A. Knowledge, Attitude and Perception of Risk and Preventive Behaviors toward Premarital Sexual Practice among In-School Adolescents. Eur. J. Investig. Health Psychol. Educ. 2020, 10, 497–510. [Google Scholar] [CrossRef]
- Laato, S.; Islam, A.N.; Laine, T.H. Did location-based games motivate players to socialize during COVID-19? Telemat. Inform. 2020, 54, 101458. [Google Scholar] [CrossRef] [PubMed]
- Wu, D. Empirical study of knowledge withholding in cyberspace: Integrating protection motivation theory and theory of reasoned behavior. Comput. Hum. Behav. 2020, 105, 106229. [Google Scholar] [CrossRef]
- Guo, C.; Sim, T.; Ho, H.C. Impact of information seeking, disaster preparedness and typhoon emergency response on perceived community resilience in Hong Kong. Int. J. Disaster Risk Reduct. 2020, 50, 101744. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | References |
|---|---|
| Hidden Layer Activation Function | |
| Swish | Sharma et al. [45] |
| Elu | Feng and Lu [46]; Eckle and Schmidt-Hieber [47] |
| Tanh | Sharma et al. [45]; Feng and Lu [46]; Eckle and Schmidt-Hieber [47] |
| Output Layer Activation Function | |
| SoftMax | Pi et al. [48]; Anbarasan et al. [49]; Satwik and Sundram [50]; Sharma et al. [45] |
| ReLu | Jena et al. [51]; Jena and Pradhan [52]; Yousefzadeh et al. [53] |
| Sigmoid | Elfwing et al. [54] |
| Optimizer | |
| Adam | Eckle and Schmidt-Hieber [47] |
| RMSProp | Yousefzadeh et al., [53] |
| SGD | Jena et al. [51]; Jena and Pradhan [52] |
| Category | 40:60 | 50:50 | 60:40 | 70:30 | 80:20 | 90:10 |
|---|---|---|---|---|---|---|
| Random | ||||||
| Gini | 59.21 | 60.01 | 60.89 | 58.77 | 58.77 | 56.80 |
| Std. Dev | 2.378 | 3.539 | 2.813 | 2.477 | 2.477 | 4.624 |
| Entropy | 57.92 | 60.12 | 60.17 | 60.63 | 58.52 | 56.04 |
| Std. Dev | 2.667 | 2.665 | 2.694 | 3.172 | 2.796 | 4.373 |
| Best | ||||||
| Gini | 57.64 | 60.00 | 60.32 | 63.74 | 60.57 | 56.00 |
| Std. Dev | 0.632 | 0.000 | 0.533 | 0.761 | 0.884 | 0.000 |
| Entropy | 60.50 | 62.22 | 61.18 | 62.98 | 64.00 | 60.31 |
| Std. Dev | 0.997 | 0.646 | 0.531 | 0.379 | 0.000 | 1.525 |
| Category | 40:60 | 50:50 | 60:40 | 70:30 | 80:20 | 90:10 |
|---|---|---|---|---|---|---|
| Random | ||||||
| Gini | 90.59 | 89.38 | 89.18 | 89.98 | 88.62 | 86.74 |
| Std. Dev | 5.973 | 7.749 | 8.765 | 6.650 | 10.80 | 9.208 |
| Entropy | 88.91 | 90.02 | 88.71 | 88.43 | 89.52 | 87.93 |
| Std. Dev | 9.770 | 7.624 | 9.502 | 8.958 | 9.687 | 9.542 |
| Best | ||||||
| Gini | 94.00 | 94.00 | 96.00 | 96.00 | 96.00 | 95.00 |
| Std. Dev | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Entropy | 94.00 | 93.00 | 95.00 | 92.00 | 94.00 | 93.00 |
| Std. Dev | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Latent | Activation (H-layer) | Activation (O-layer) | Optimizer | Average Training | STDEV | Average Testing | STDEV |
|---|---|---|---|---|---|---|---|
| U | Swish | Sigmoid | Adam | 73.982 | 3.687 | 67.361 | 2.508 |
| PV | Swish | SoftMax | RMSProp | 75.057 | 2.321 | 68.350 | 1.703 |
| PS | Swish | Sigmoid | Adam | 72.091 | 2.978 | 67.386 | 3.109 |
| SN | Tanh | SoftMax | Adam | 73.574 | 2.871 | 67.526 | 1.870 |
| PBC | Swish | Sigmoid | Adam | 73.787 | 2.557 | 67.385 | 2.501 |
| A | Swish | Sigmoid | Adam | 73.209 | 4.083 | 67.422 | 3.598 |
| M | Swish | SoftMax | Adam | 72.413 | 3.303 | 68.350 | 2.121 |
| U | PV | PS | SN | PBC | A | M | |
|---|---|---|---|---|---|---|---|
| PV | 0.298 | ||||||
| PS | 0.194 | 0.368 | |||||
| SN | 0.412 | 0.258 | 0.272 | ||||
| PBC | 0.477 | 0.307 | 0.235 | 0.434 | |||
| A | 0.144 | 0.297 | 0.364 | 0.425 | 0.182 | ||
| M | 0.295 | 0.259 | 0.372 | 0.421 | 0.429 | 0.363 | |
| IP | 0.446 | 0.687 | 0.468 | 0.612 | 0.448 | 0.457 | 0.596 |
| Ranking | SEM | MLA |
|---|---|---|
| 1 | M | PV |
| 2 | A | M |
| 3 | PS | SN |
| 4 | SN | A |
| 5 | U | PS |
| 6 | PV | PBC |
| 7 | PBC | U |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ong, A.K.S.; Zulvia, F.E.; Prasetyo, Y.T. “The Big One” Earthquake Preparedness Assessment among Younger Filipinos Using a Random Forest Classifier and an Artificial Neural Network. Sustainability 2023, 15, 679. https://doi.org/10.3390/su15010679
Ong AKS, Zulvia FE, Prasetyo YT. “The Big One” Earthquake Preparedness Assessment among Younger Filipinos Using a Random Forest Classifier and an Artificial Neural Network. Sustainability. 2023; 15(1):679. https://doi.org/10.3390/su15010679
Chicago/Turabian StyleOng, Ardvin Kester S., Ferani Eva Zulvia, and Yogi Tri Prasetyo. 2023. "“The Big One” Earthquake Preparedness Assessment among Younger Filipinos Using a Random Forest Classifier and an Artificial Neural Network" Sustainability 15, no. 1: 679. https://doi.org/10.3390/su15010679
APA StyleOng, A. K. S., Zulvia, F. E., & Prasetyo, Y. T. (2023). “The Big One” Earthquake Preparedness Assessment among Younger Filipinos Using a Random Forest Classifier and an Artificial Neural Network. Sustainability, 15(1), 679. https://doi.org/10.3390/su15010679