
Influence of Traffic Parameters on the Spatial Distribution of Crashes on a Freeway to Increase Safety


Abstract
1. Introduction
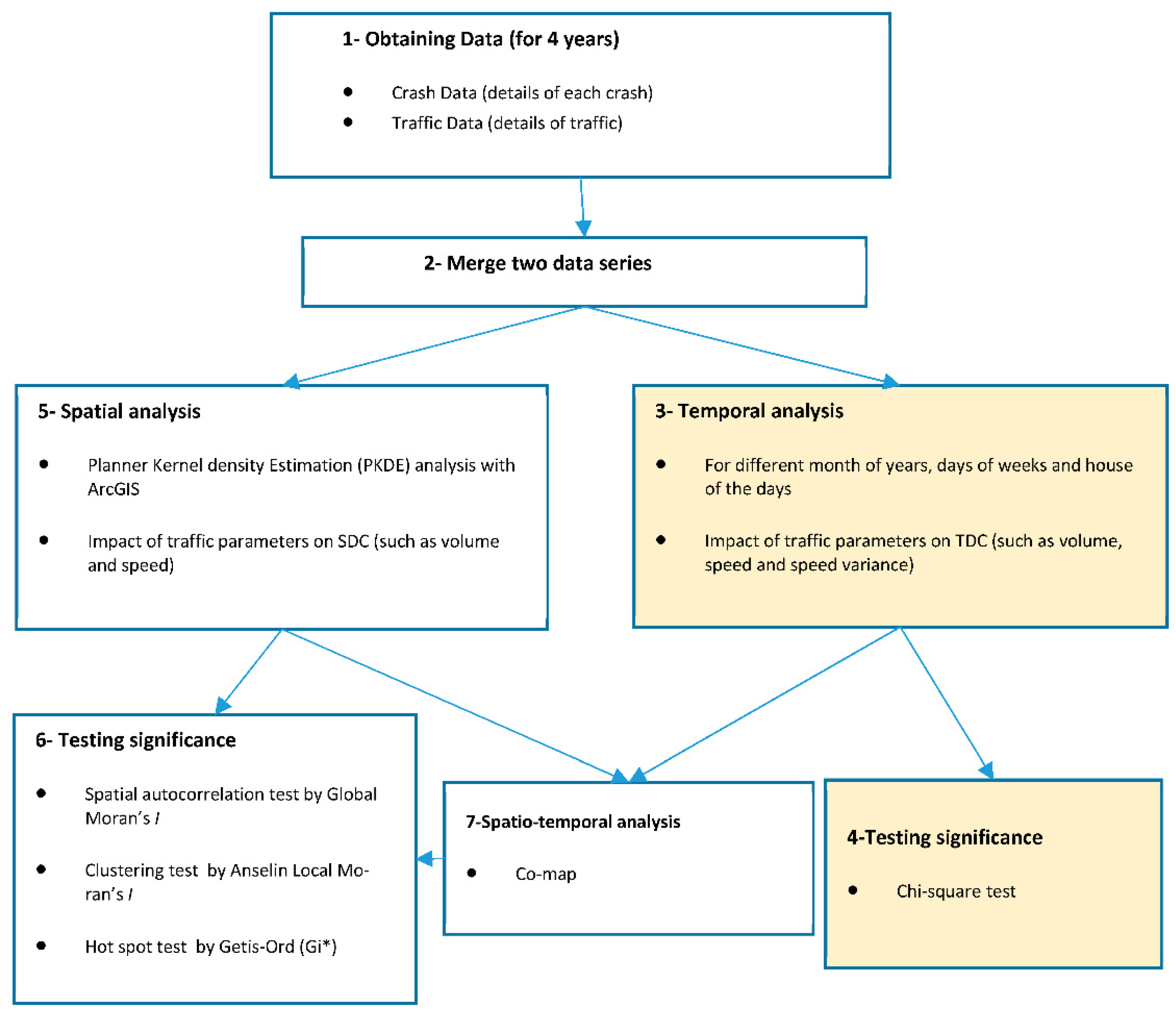
2. Methodology
2.1. Spatial Analysis
2.2. High-Frequency Crash Locations
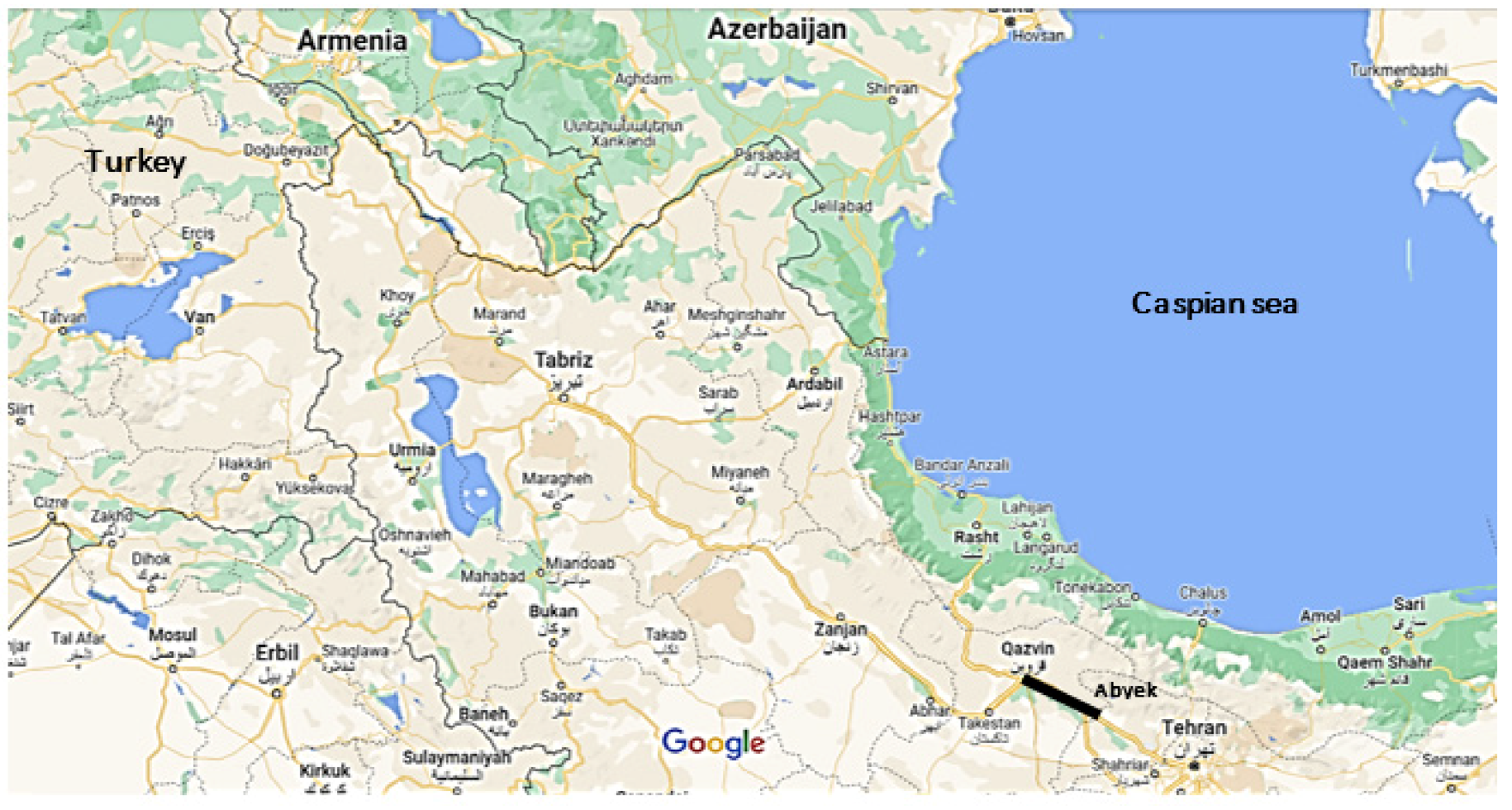
3. Case Study and Data
4. Results and Discussion
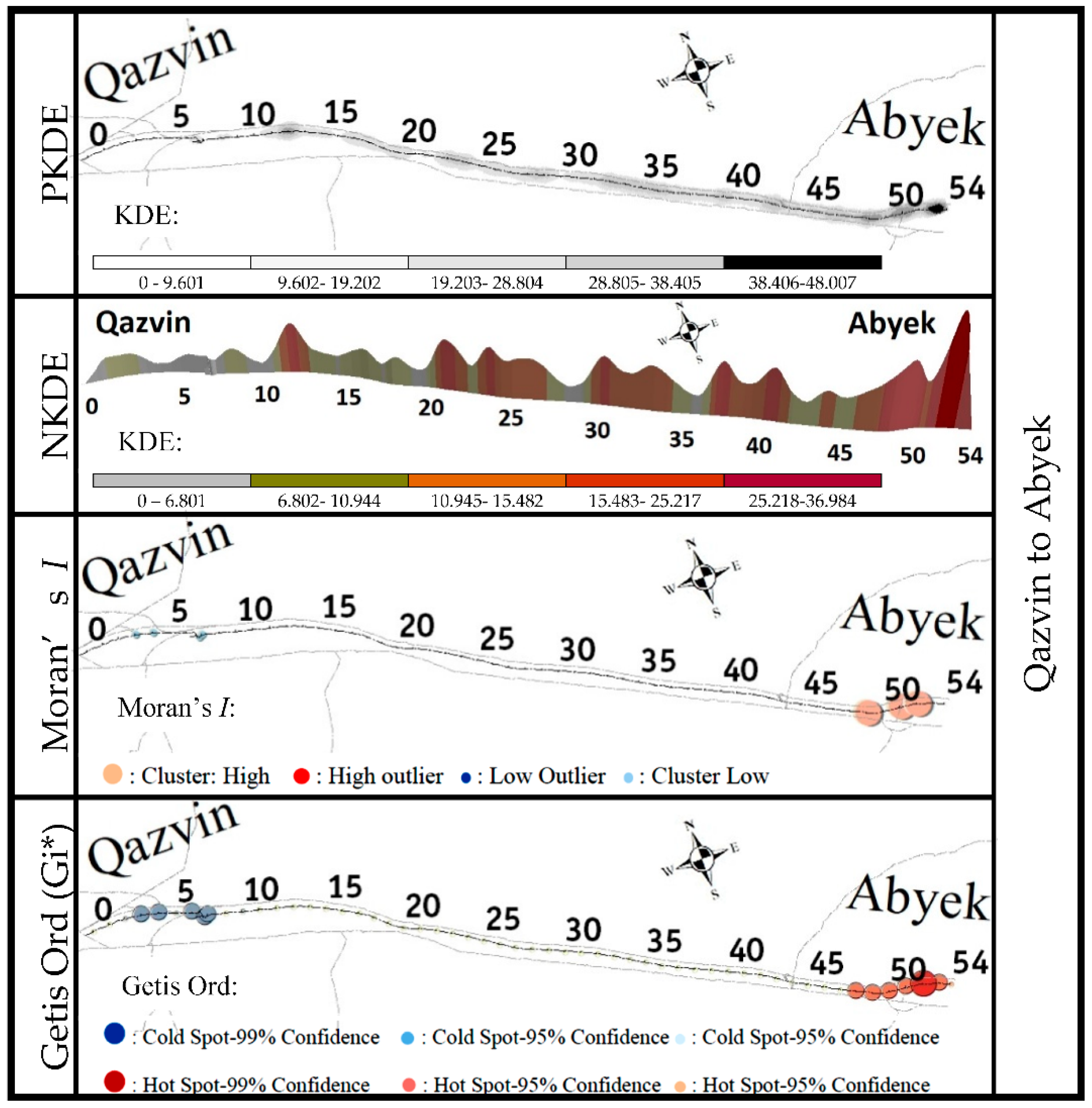
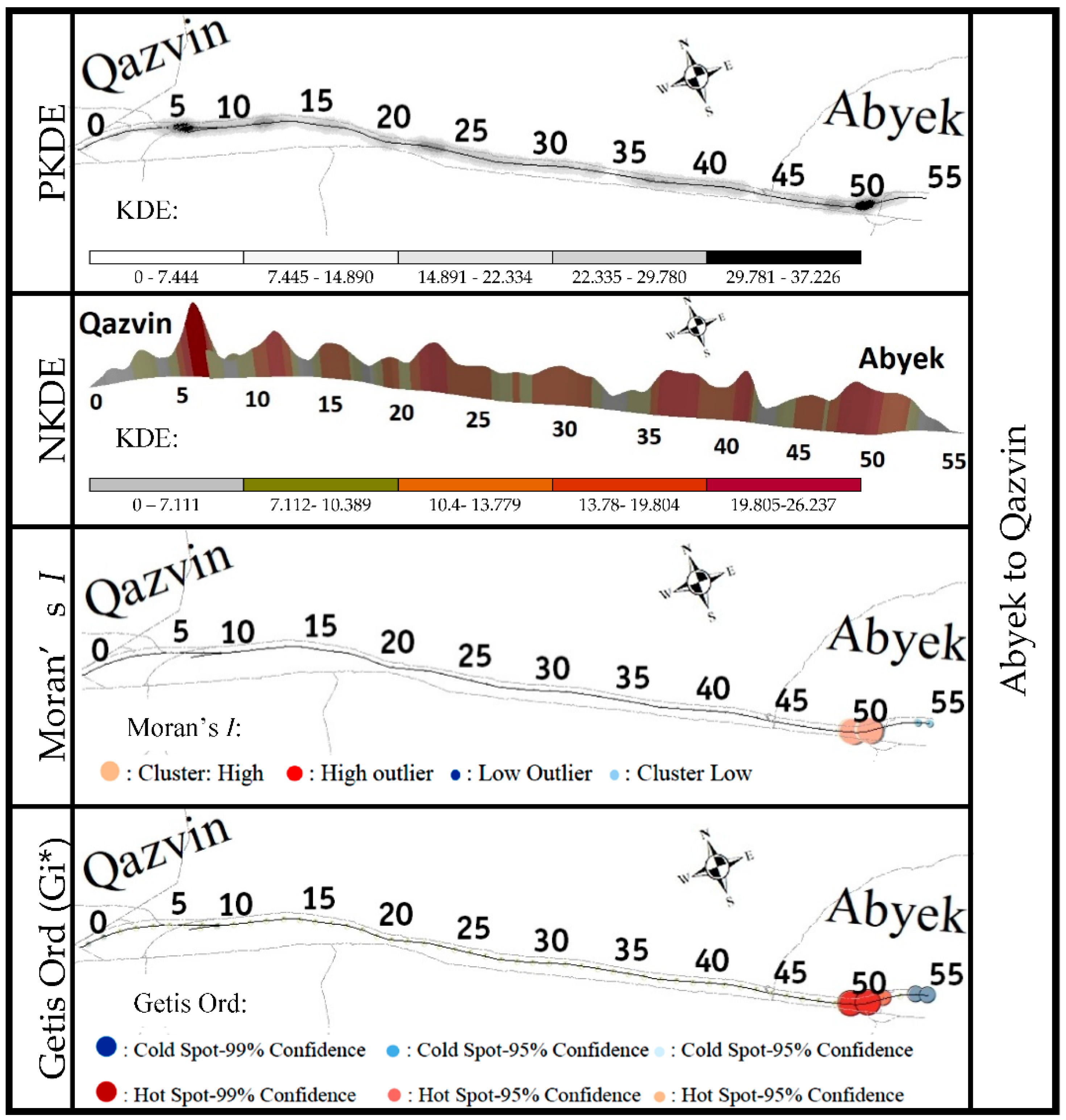
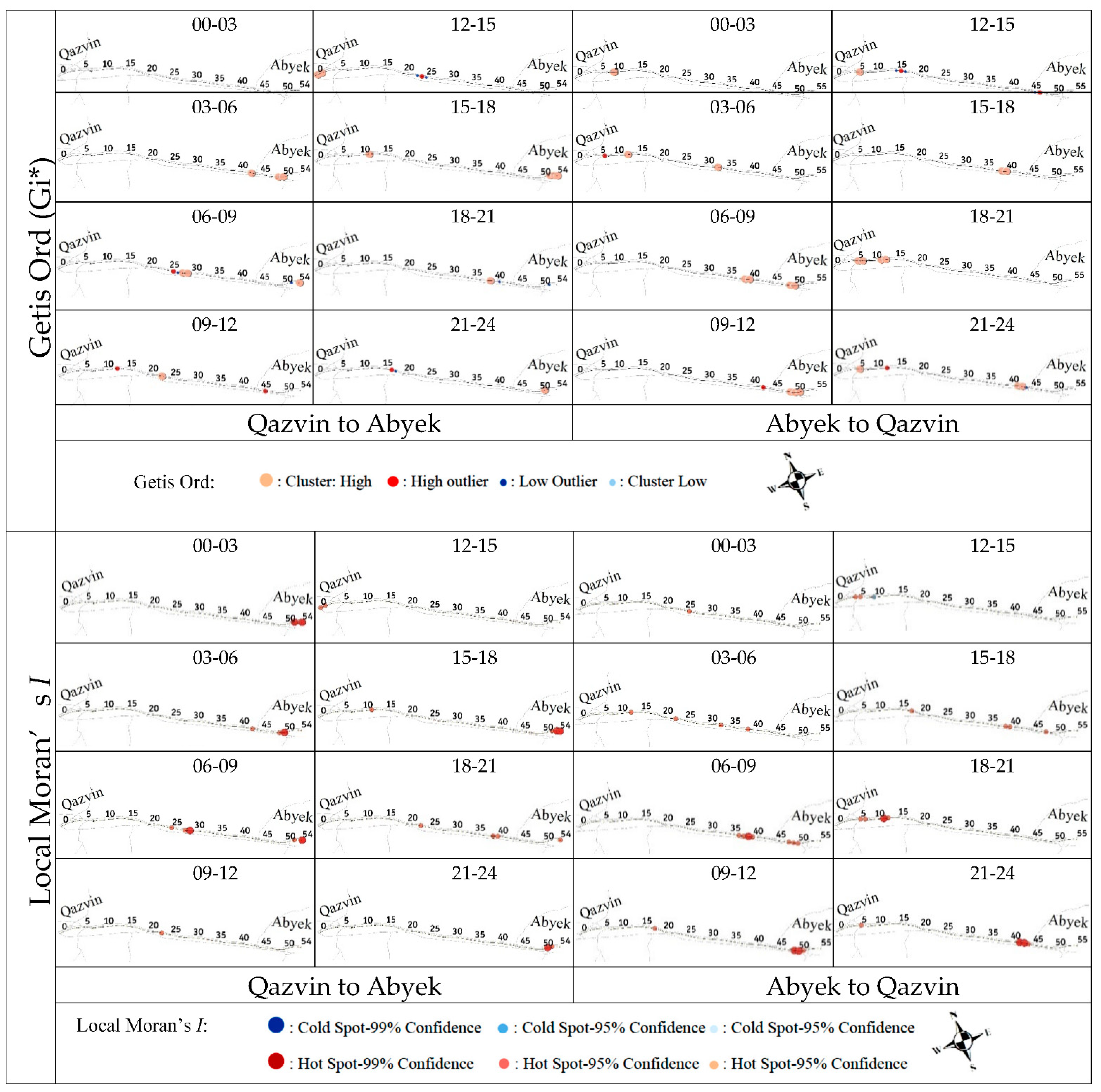
4.1. SDC Analysis
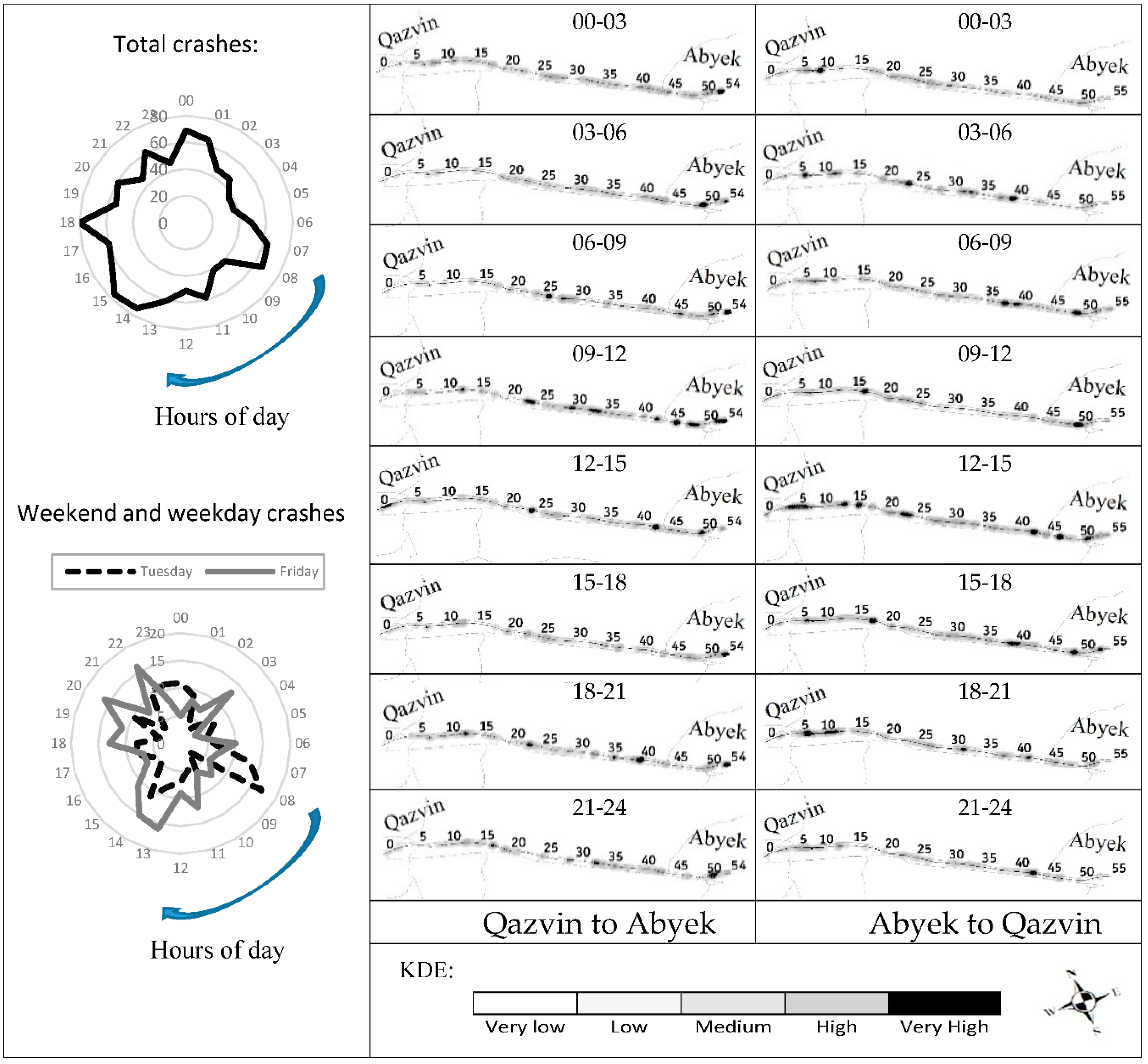
4.2. STDC Analysis
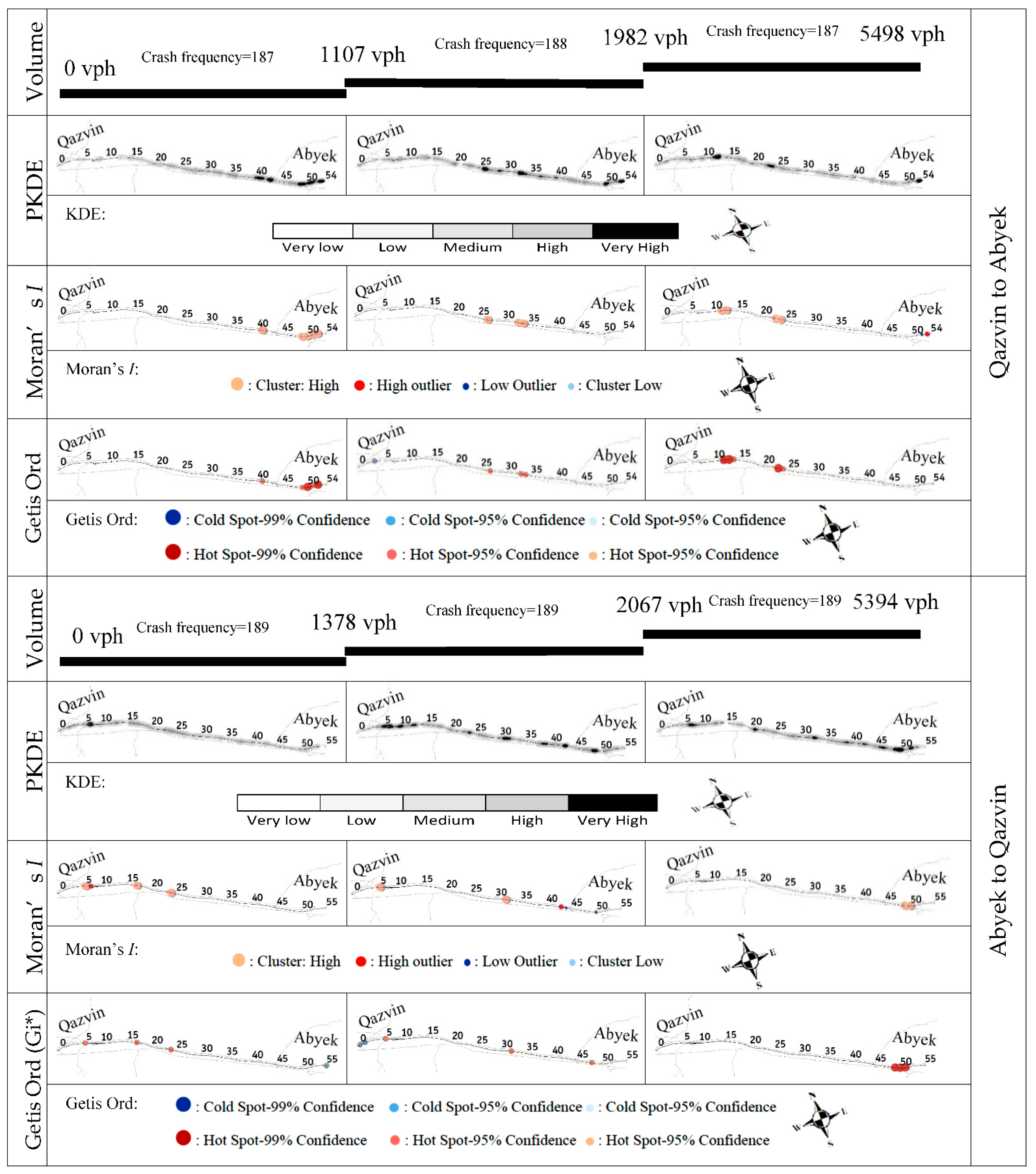
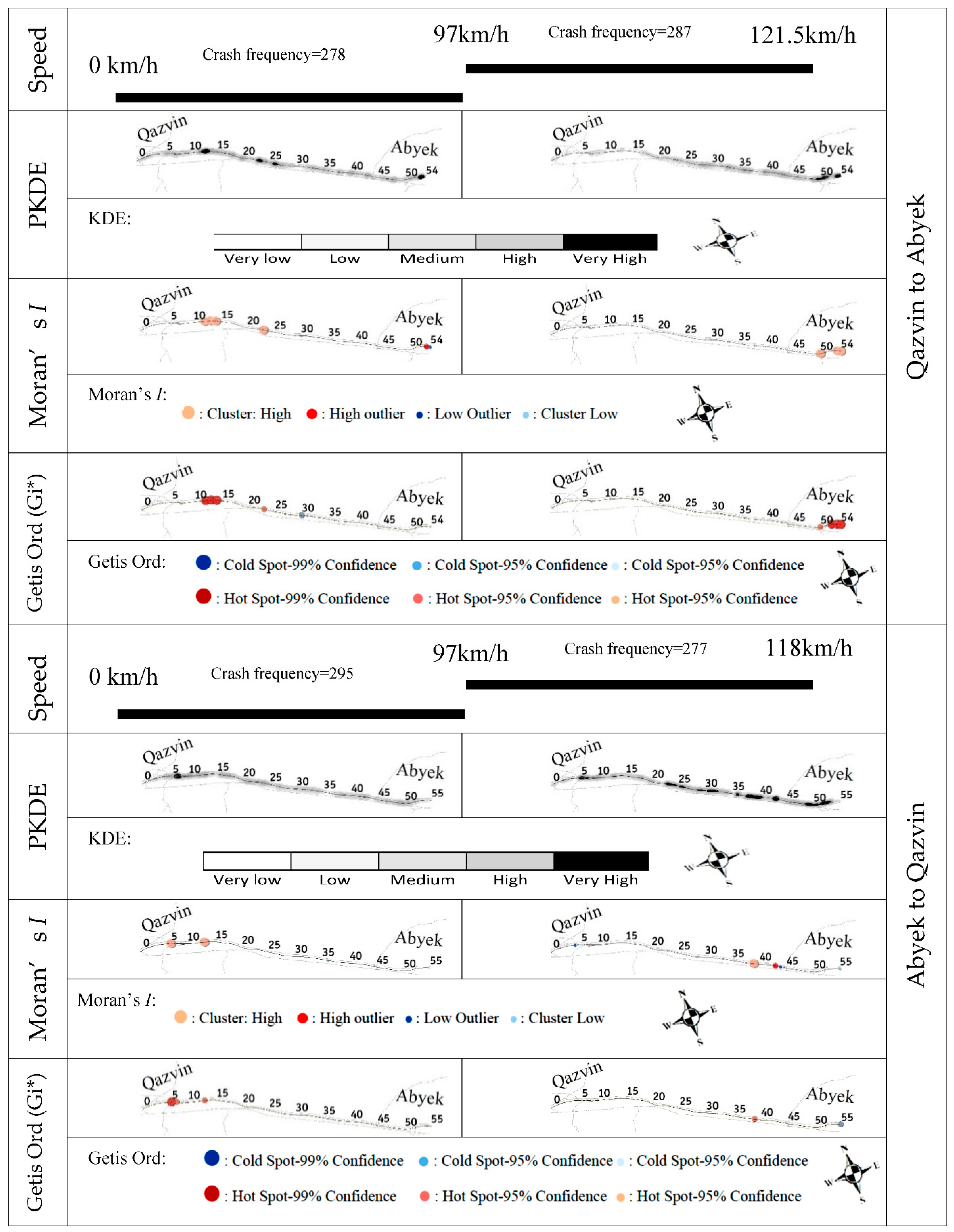
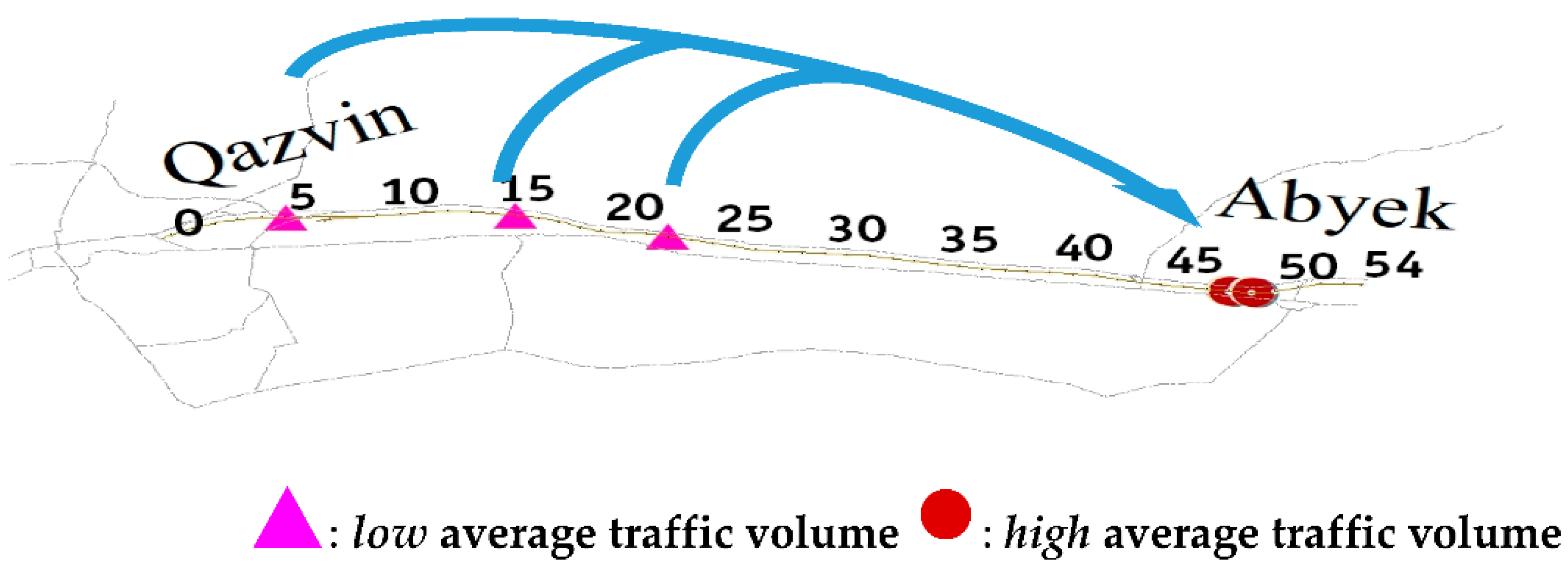
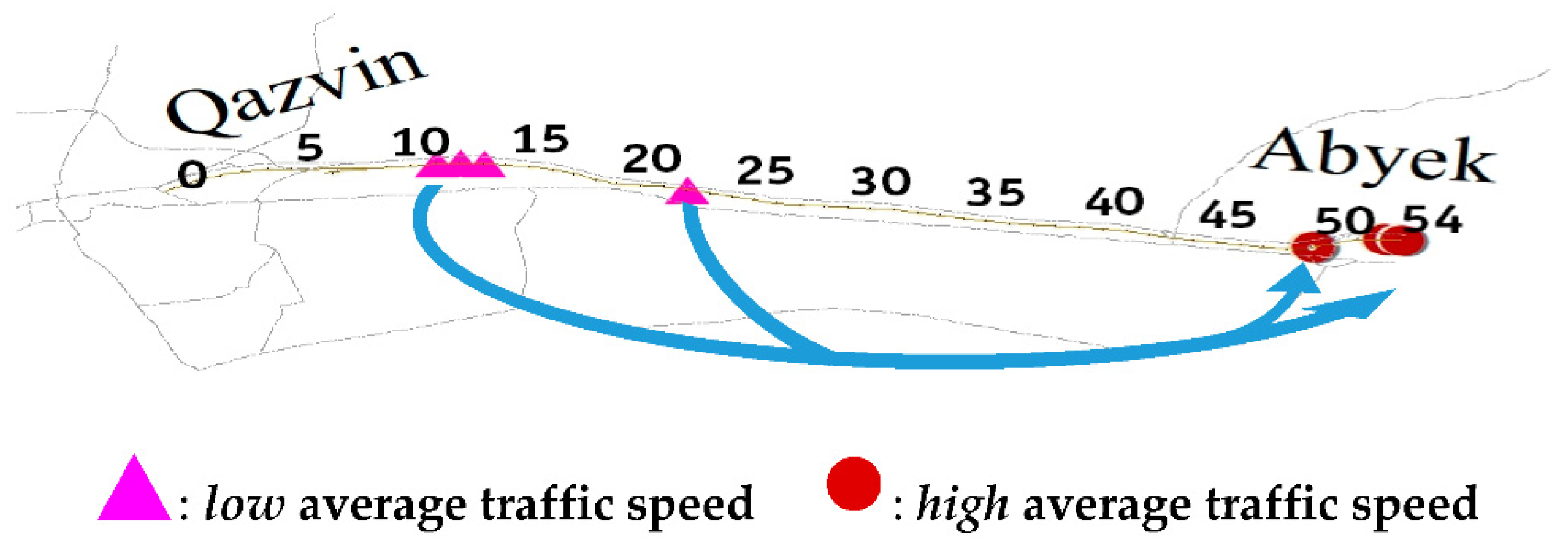
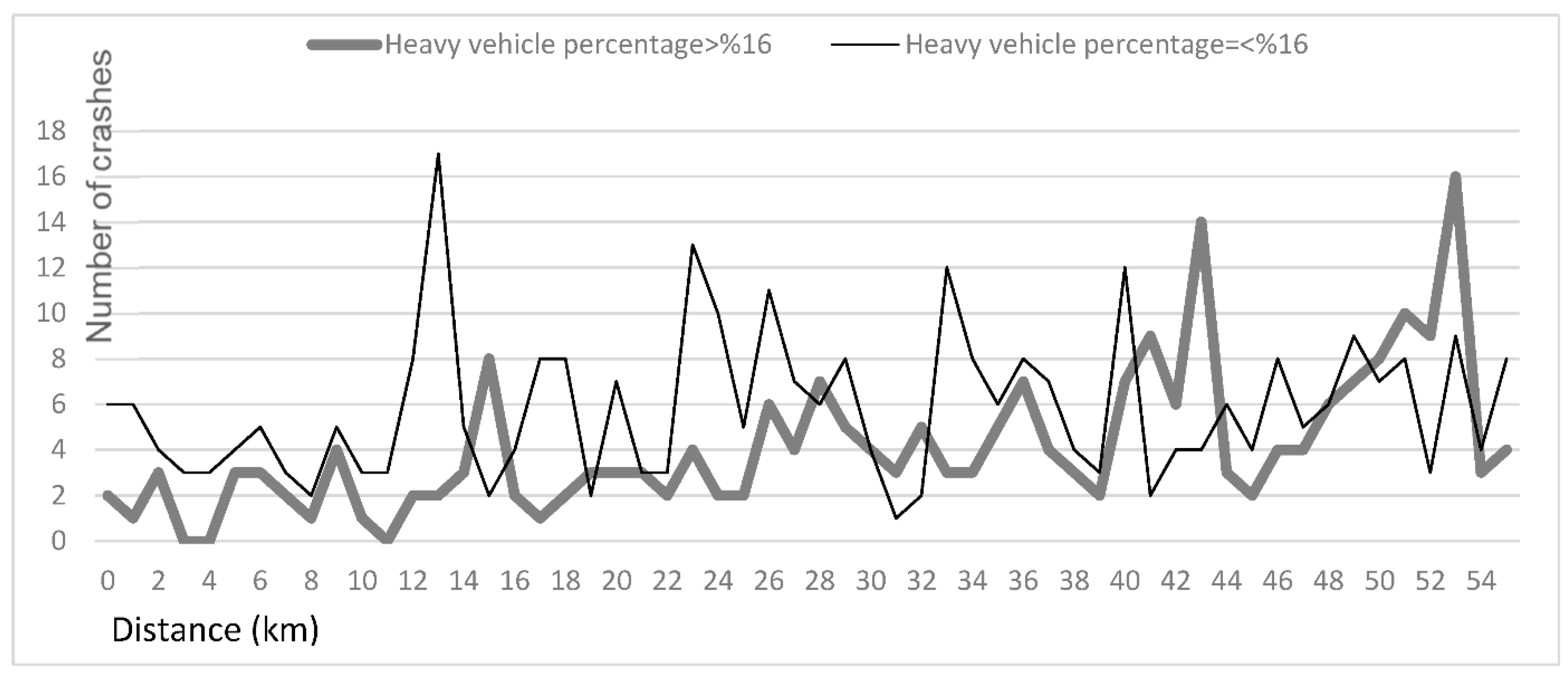
4.3. Influence of Traffic Parameters on the SDC
4.4. Spatial Autocorrelation between Crashes in Different Conditions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SOURCE_ID | Accident | Low Volume | Mid Volume | High Volume | Low Speed | High Speed | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | |
| 7 | 0.0076 | 2.04 | 0.0417 | LL | 0.0039 | 1.07 | 0.2848 | 0.0027 | 0.74 | 0.4610 | 0.0010 | 0.29 | 0.7746 | 0.0014 | 0.40 | 0.6873 | 0.0036 | 0.97 | 0.3324 | |||||
| 8 | 0.0078 | 2.10 | 0.0353 | LL | 0.0042 | 1.15 | 0.2508 | 0.0028 | 0.76 | 0.4467 | 0.0010 | 0.29 | 0.7747 | 0.0014 | 0.41 | 0.6843 | 0.0033 | 0.89 | 0.3739 | |||||
| 12 | −0.0007 | −0.68 | 0.4943 | 0.0005 | 0.49 | 0.6220 | 0.0002 | 0.21 | 0.8352 | 0.0063 | 6.52 | 0.0000 | HH | 0.0031 | 3.17 | 0.0015 | HH | 0.0007 | 0.72 | 0.4725 | ||||
| 13 | −0.0018 | −1.29 | 0.1982 | 0.0008 | 0.60 | 0.5472 | 0.0001 | 0.07 | 0.9453 | 0.0045 | 3.35 | 0.0008 | HH | 0.0061 | 4.52 | 0.0000 | HH | 0.0016 | 1.14 | 0.2525 | ||||
| 14 | −0.0011 | −1.12 | 0.2627 | 0.0003 | 0.35 | 0.7259 | −0.0001 | −0.11 | 0.9108 | −0.0018 | −1.83 | 0.0676 | 0.0031 | 3.17 | 0.0015 | HH | 0.0009 | 0.89 | 0.3761 | |||||
| 23 | 0.0004 | 0.45 | 0.6499 | 0.0000 | 0.00 | 0.9963 | −0.0005 | −0.47 | 0.6368 | 0.0036 | 3.83 | 0.0001 | HH | 0.0019 | 2.02 | 0.0431 | HH | 0.0000 | 0.01 | 0.9916 | ||||
| 24 | 0.0000 | 0.06 | 0.9558 | 0.0001 | 0.07 | 0.9451 | −0.0004 | −0.24 | 0.8072 | 0.0034 | 2.55 | 0.0108 | HH | 0.0017 | 1.24 | 0.2141 | −0.0001 | −0.04 | 0.9644 | |||||
| 27 | −0.0001 | −0.08 | 0.9372 | 0.0000 | 0.03 | 0.9757 | 0.0020 | 2.05 | 0.0405 | HH | −0.0001 | −0.06 | 0.9527 | 0.0011 | 1.16 | 0.2461 | 0.0000 | −0.03 | 0.9752 | |||||
| 30 | −0.0001 | −0.01 | 0.9915 | −0.0001 | −0.06 | 0.9536 | 0.0000 | 0.01 | 0.9909 | 0.0005 | 0.42 | 0.6724 | 0.0026 | 1.97 | 0.0491 | LL | 0.0003 | 0.27 | 0.7890 | |||||
| 33 | 0.0005 | 0.40 | 0.6881 | −0.0003 | −0.19 | 0.8524 | 0.0028 | 2.05 | 0.0406 | HH | 0.0001 | 0.12 | 0.9073 | −0.0002 | −0.11 | 0.9126 | −0.0001 | −0.06 | 0.9549 | |||||
| 34 | 0.0013 | 1.01 | 0.3143 | −0.0008 | −0.57 | 0.5693 | 0.0036 | 2.61 | 0.0089 | HH | −0.0002 | −0.09 | 0.9308 | −0.0001 | −0.04 | 0.9684 | 0.0006 | 0.47 | 0.6407 | |||||
| 41 | −0.0002 | −0.14 | 0.8900 | 0.0044 | 3.22 | 0.0013 | HH | −0.0007 | −0.46 | 0.6471 | 0.0003 | 0.26 | 0.7986 | 0.0000 | 0.03 | 0.9751 | 0.0008 | 0.60 | 0.5476 | |||||
| 49 | 0.0027 | 1.99 | 0.0462 | HH | 0.0045 | 3.29 | 0.0010 | HH | −0.0010 | −0.69 | 0.4907 | 0.0001 | 0.12 | 0.9044 | −0.0008 | −0.57 | 0.5659 | 0.0020 | 1.48 | 0.1395 | ||||
| 50 | 0.0019 | 1.94 | 0.0529 | 0.0033 | 3.37 | 0.0008 | HH | −0.0014 | −1.37 | 0.1699 | 0.0002 | 0.27 | 0.7849 | 0.0003 | 0.31 | 0.7528 | 0.0031 | 3.13 | 0.0017 | HH | ||||
| 51 | 0.0022 | 2.22 | 0.0262 | HH | 0.0022 | 2.22 | 0.0264 | HH | 0.0001 | 0.11 | 0.9140 | −0.0005 | −0.54 | 0.5887 | −0.0001 | −0.08 | 0.9387 | −0.0001 | −0.09 | 0.9255 | ||||
| 52 | 0.0050 | 3.67 | 0.0002 | HH | 0.0043 | 3.17 | 0.0015 | HH | 0.0007 | 0.55 | 0.5823 | −0.0033 | −2.43 | 0.0152 | LH | 0.0008 | 0.62 | 0.5325 | −0.0002 | −0.13 | 0.8938 | |||
| 53 | 0.0000 | 0.04 | 0.9702 | 0.0006 | 0.35 | 0.7228 | −0.0014 | −0.77 | 0.4412 | −0.0051 | −2.99 | 0.0028 | HL | −0.0046 | −2.67 | 0.0077 | HL | 0.0087 | 5.04 | 0.0000 | HH | |||
| 54 | −0.0028 | −1.93 | 0.0530 | −0.0016 | −1.07 | 0.2828 | −0.0020 | −1.37 | 0.1699 | −0.0023 | −1.64 | 0.1016 | −0.0055 | −3.84 | 0.0001 | LH | 0.0088 | 6.09 | 0.0000 | HH | ||||
| SOURCE_ID | Accident | Low Volume | Mid Volume | High Volume | Low Speed | High Speed | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | LMiIndex | LMiZScore | LMiPValue | COType | |
| 4 | −0.0010 | −1.03 | 0.3026 | −0.0010 | −1.04 | 0.2975 | 0.0005 | 0.56 | 0.5784 | 0.0001 | 0.13 | 0.8990 | 0.0004 | 0.49 | 0.6240 | −0.0022 | −2.20 | 0.0275 | LH | |||||
| 5 | 0.0016 | 1.19 | 0.2335 | 0.0031 | 2.33 | 0.0196 | HH | 0.0045 | 3.25 | 0.0012 | HH | −0.0002 | −0.10 | 0.9205 | 0.0043 | 3.38 | 0.0007 | HH | −0.0013 | −0.89 | 0.3711 | |||
| 6 | −0.0014 | −0.80 | 0.4258 | −0.0036 | −2.10 | 0.0357 | HL | 0.0009 | 0.53 | 0.5927 | −0.0009 | −0.47 | 0.6380 | 0.0004 | 0.28 | 0.7780 | −0.0009 | −0.50 | 0.6145 | |||||
| 13 | 0.0003 | 0.35 | 0.7298 | 0.0003 | 0.30 | 0.7656 | 0.0010 | 1.03 | 0.3029 | −0.0005 | −0.45 | 0.6521 | 0.0023 | 2.49 | 0.0126 | HH | −0.0005 | −0.44 | 0.6583 | |||||
| 17 | −0.0003 | −0.16 | 0.8729 | 0.0031 | 2.33 | 0.0197 | HH | 0.0000 | 0.01 | 0.9918 | 0.0008 | 0.59 | 0.5538 | 0.0011 | 0.89 | 0.3743 | 0.0003 | 0.21 | 0.8365 | |||||
| 24 | 0.0016 | 1.21 | 0.2269 | 0.0039 | 2.97 | 0.0030 | HH | −0.0011 | −0.76 | 0.4489 | −0.0001 | −0.04 | 0.9651 | 0.0002 | 0.19 | 0.8500 | 0.0012 | 0.92 | 0.3558 | |||||
| 32 | 0.0000 | 0.01 | 0.9887 | 0.0003 | 0.34 | 0.7333 | 0.0022 | 2.28 | 0.0229 | HH | −0.0001 | −0.11 | 0.9128 | 0.0000 | 0.00 | 0.9988 | 0.0009 | 0.95 | 0.3408 | |||||
| 36 | 0.0005 | 0.41 | 0.6801 | 0.0008 | 0.65 | 0.5131 | 0.0015 | 1.13 | 0.2578 | −0.0004 | −0.23 | 0.8162 | 0.0026 | 2.04 | 0.0412 | LL | −0.0026 | −1.86 | 0.0625 | |||||
| 39 | 0.0000 | −0.03 | 0.9762 | −0.0004 | −0.36 | 0.7179 | 0.0004 | 0.41 | 0.6836 | 0.0009 | 0.91 | 0.3603 | 0.0000 | 0.03 | 0.9793 | 0.0024 | 2.45 | 0.0142 | HH | |||||
| 43 | −0.0006 | −0.42 | 0.6779 | −0.0010 | −0.71 | 0.4767 | −0.0030 | −2.12 | 0.0340 | HL | 0.0001 | 0.13 | 0.8969 | −0.0004 | −0.27 | 0.7845 | −0.0040 | −2.83 | 0.0046 | HL | ||||
| 44 | −0.0008 | −0.85 | 0.3961 | −0.0006 | −0.64 | 0.5236 | −0.0026 | −2.59 | 0.0097 | LH | −0.0007 | −0.74 | 0.4594 | −0.0007 | −0.71 | 0.4795 | −0.0020 | −1.98 | 0.0473 | LH | ||||
| 49 | 0.0008 | 0.61 | 0.5402 | 0.0011 | 0.82 | 0.4141 | −0.0008 | −0.58 | 0.5641 | 0.0060 | 4.38 | 0.0000 | HH | 0.0002 | 0.16 | 0.8706 | 0.0010 | 0.72 | 0.4721 | |||||
| 50 | 0.0033 | 2.46 | 0.0140 | HH | 0.0000 | 0.06 | 0.9501 | −0.0035 | −2.49 | 0.0126 | LH | 0.0059 | 4.28 | 0.0000 | HH | 0.0007 | 0.58 | 0.5623 | 0.0016 | 1.14 | 0.2527 | |||
| 51 | 0.0048 | 3.55 | 0.0004 | HH | −0.0005 | −0.32 | 0.7502 | −0.0010 | −0.73 | 0.4660 | −0.0008 | −0.55 | 0.5827 | 0.0000 | 0.00 | 0.9985 | 0.0018 | 1.36 | 0.1738 | |||||
| 54 | 0.0042 | 2.65 | 0.0081 | LL | 0.0027 | 1.72 | 0.0855 | 0.0007 | 0.46 | 0.6442 | 0.0024 | 1.50 | 0.1342 | 0.0026 | 1.74 | 0.0819 | 0.0018 | 1.13 | 0.2585 | |||||
| 55 | 0.0041 | 3.17 | 0.0015 | LL | 0.0025 | 1.96 | 0.0503 | 0.0006 | 0.47 | 0.6406 | 0.0022 | 1.70 | 0.0886 | 0.0017 | 1.37 | 0.1707 | 0.0030 | 2.28 | 0.0224 | LL | ||||
References
- Prasannakumar, V.; Vijith, H.; Charutha, R.; Geetha, N. Spatio-temporal clustering of road accidents: GIS based analysis and assessment. J. Transp. Geogr. 2011, 21, 317–325. [Google Scholar] [CrossRef]
- Li, L.; Zhu, L.; Sui, D.Z. A GIS-based Bayesian approach for analyzing spatial–temporal patterns of intra-city motor vehicle crashes. J. Transp. Geogr. 2007, 15, 274–285. [Google Scholar] [CrossRef]
- Plug, C.; Xia, J.; Caulfield, C. Spatial and temporal visualisation techniques for crash analysis. Accid. Anal. Prev. 2011, 43, 1937–1946. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.C. Data mining of driver characteristics to spatial and temporal hotspots of single vehicle crashes in Western Australia. In Proceedings of 19th International Congress on Modelling and Simulation; Modelling and Simulation Society of Australia and New Zealand: Perth, Australia, 2011. [Google Scholar]
- Eckley, D.C.; Curtin, K.M. Evaluating the spatiotemporal clustering of traffic incidents. Comput. Environ. Urban Syst. 2013, 37, 70–81. [Google Scholar] [CrossRef]
- Kulldorff, M.; Hjalmars, U. The Knox Method and Other Tests for Space-Time Interaction. Biometrics 1999, 55, 544–552. [Google Scholar] [CrossRef]
- Matkan, A.A.; Mohaymany, A.S.; Shahri, M.; Mirbagheri, B. Detecting the spatial–temporal autocorrelation among crash frequencies in urban areas. Can. J. Civ. Eng. 2013, 40, 195–203. [Google Scholar] [CrossRef]
- Li, X.; Liu, J.; Zhang, Z.; Parrish, A.; Jones, S. A spatiotemporal analysis of motorcyclist injury severity: Findings from 20 years of crash data from Pennsylvania. Accid. Anal. Prev. 2021, 151, 105952. [Google Scholar] [CrossRef]
- Bíl, M.; Andrášik, R.; Sedoník, J. A detailed spatiotemporal analysis of traffic crash hotspots. Appl. Geogr. 2019, 107, 82–90. [Google Scholar] [CrossRef]
- Abdulhafedh, A. Road crash prediction models: Different statistical modeling approaches. J. Transp. Technol. 2017, 7, 190. [Google Scholar] [CrossRef]
- Zhao, X.; Xu, W.; Ma, J.; Li, H.; Chen, Y. An analysis of the relationship between driver characteristics and driving safety using structural equation models. Transp. Res. Part F Traffic Psychol. Behav. 2019, 62, 529–545. [Google Scholar] [CrossRef]
- Shirmohammadi, H.; Hadadi, F.; Saeedian, M. Clustering Analysis of Drivers Based on Behavioral Characteristics Regarding Road Safety. Int. J. Civ. Eng. 2019, 62, 529–545. [Google Scholar] [CrossRef]
- Besharati, M.M.; Kashani, A.T. Factors contributing to intercity commercial bus drivers’ crash involvement risk. Arch. Environ. Occup. Health 2018, 73, 243–250. [Google Scholar] [CrossRef] [PubMed]
- Kaygisiz, Ö.; Düzgün, Ş.; Yildiz, A.; Senbil, M. Spatio-temporal accident analysis for accident prevention in relation to behavioral factors in driving: The case of South Anatolian Motorway. Transp. Res. Part F Traffic Psychol. Behav. 2015, 33, 128–140. [Google Scholar] [CrossRef]
- Ulak, M.B.; Ozguven, E.E.; Spainhour, L. Age-Based Stratification of Drivers to Evaluate the Effects of Age on Crash Involvement. Transp. Res. Procedia 2017, 22, 551–560. [Google Scholar] [CrossRef]
- Toran Pour, A.; Moridpour, S.; Tay, R.; Rajabifard, A. Influence of pedestrian age and gender on spatial and temporal distribution of pedestrian crashes. Traffic Inj. Prev. 2018, 19, 81–87. [Google Scholar] [CrossRef]
- Anvari, M.B.; Kashani, A.T.; Rabieyan, R. Identifying the most important factors in the at-fault probability of motorcyclists by data mining, based on classification tree models. Int. J. Civ. Eng. 2017, 15, 653–662. [Google Scholar] [CrossRef]
- Deluka-Tibljaš, A.; Otković, I.I.; Campisi, T.; Šurdonja, S. Comparative analyses of parameters influencing children pedestrian behavior in conflict zones of urban intersections. Safety 2021, 7, 5. [Google Scholar] [CrossRef]
- Khan, G.; Qin, X.; Noyce, D.A. Spatial analysis of weather crash patterns. J. Transp. Eng. 2008, 134, 191–202. [Google Scholar] [CrossRef]
- Qu, X.; Kuang, Y.; Oh, E.; Jin, S. Safety evaluation for expressways: A comparative study for macroscopic and microscopic indicators. Traffic Inj. Prev. 2014, 15, 89–93. [Google Scholar] [CrossRef]
- Choi, S.; Oh, C.; Kim, M. Risk factors related to fatal truck crashes on Korean freeways. Traffic Inj. Prev. 2014, 15, 73–80. [Google Scholar] [CrossRef]
- Gargoum, S.A.; El-Basyouny, K. Exploring the association between speed and safety: A path analysis approach. Accid. Anal. Prev. 2016, 93, 32–40. [Google Scholar] [CrossRef] [PubMed]
- Quddus, M. Exploring the relationship between average speed, speed variation, and accident rates using spatial statistical models and GIS. J. Transp. Saf. Secur. 2013, 5, 27–45. [Google Scholar] [CrossRef]
- Theofilatos, A.; Yannis, G. A review of the effect of traffic and weather characteristics on road safety. Accid. Anal. Prev. 2014, 72, 244–256. [Google Scholar] [CrossRef] [PubMed]
- Kashani, A.T.; Zandi, K. Influence of Traffic Parameters on the Temporal Distribution of Crashes. KSCE J. Civ. Eng. 2020, 24, 954–961. [Google Scholar] [CrossRef]
- Salem, O.; Genaidy, A.; Wei, H.; Deshpande, N. Spatial distribution and characteristics of accident crashes at work zones of interstate freeways in Ohio. In Proceedings of the 2006 IEEE Intelligent Transportation Systems Conference, Toronto, ON, Canada, 17–20 September 2006. [Google Scholar]
- Vemulapalli, S.S.; Ulak, M.B.; Ozguven, E.E.; Sando, T.; Horner, M.W.; Abdelrazig, Y.; Moses, R. GIS-based spatial and temporal analysis of aging-Involved accidents: A case study of three counties in florida. Appl. Spat. Anal. Policy 2016, 10, 537–563. [Google Scholar] [CrossRef]
- Kuo, P.F.; Zeng, X.; Lord, D. Guidelines for choosing hot-spot analysis tools based on data characteristics, network restrictions, and time distributions. In Proceedings of the 91 Annual Meeting of the Transportation Research Board, College Station, TX, USA, 14 November 2011. [Google Scholar]
- Mohaymany, A.S.; Shahri, M.; Mirbagheri, B. GIS-based method for detecting high-crash-risk road segments using network kernel density estimation. Geo-Spat. Inf. Sci. 2013, 16, 113–119. [Google Scholar] [CrossRef]
- Erdogan, S. Explorative spatial analysis of traffic accident statistics and road mortality among the provinces of Turkey. J. Saf. Res. 2009, 40, 341–351. [Google Scholar] [CrossRef]
- Soltani, A.; Askari, S. Exploring spatial autocorrelation of traffic crashes based on severity. Injury 2017, 48, 637–647. [Google Scholar] [CrossRef]
- Hashimoto, S.; Yoshiki, S.; Saeki, R.; Mimura, Y.; Ando, R.; Nanba, S. Development and application of traffic accident density estimation models using kernel density estimation. J. Traffic Transp. Eng. 2016, 3, 262–270. [Google Scholar] [CrossRef]
- Boroujerdian, A.M.; Karimi, A.; Seyedabrishami, S. Identification of hazardous situations using Kernel density estimation method based on time to collision, case study: Left-turn on unsignalized intersection. Int. J. Transp. Eng. 2014, 1, 223–240. [Google Scholar]
- Benedek, J.; Ciobanu, S.M.; Man, T.C. Hotspots and social background of urban traffic crashes: A case study in Cluj-Napoca (Romania). Accid. Anal. Prev. 2016, 87, 117–126. [Google Scholar] [CrossRef] [PubMed]
- Okabe, A.; Sugihara, K. Spatial Analysis along Networks: Statistical and Computational Methods; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Okabe, A.; Okunuki, K.-I.; Shiode, S. The SANET toolbox: New methods for network spatial analysis. Trans. GIS 2006, 10, 535–550. [Google Scholar] [CrossRef]
- Loo, B.P.Y.; Anderson, T.K. Spatial Analysis Methods of Road Traffic Collisions; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Anselin, L. Local indicators of spatial association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Shariat-Mohaymany, A.; Shahri, M. Crash prediction modeling using a spatial semi-local model: A case study of Mashhad, Iran. Appl. Spat. Anal. Policy 2017, 10, 565–584. [Google Scholar] [CrossRef]
- Bíl, M.; Andrášik, R.; Svoboda, T.; Sedoník, J. The KDE+ software: A tool for effective identification and ranking of animal-vehicle collision hotspots along networks. Landsc. Ecol. 2016, 31, 231–237. [Google Scholar] [CrossRef]
- Okabe, A.; Satoh, T.; Sugihara, K. A kernel density estimation method for networks, its computational method and a GIS-based tool. Int. J. Geogr. Inf. Sci. 2009, 23, 7–32. [Google Scholar] [CrossRef]
- Siamidoudaran, M.; Iscioglu, E.; Siamidodaran, M. Traffic injury severity prediction along with identification of contributory factors using learning vector quantization: A case study of the city of London. SN Appl. Sci. 2019, 1, 1–13. [Google Scholar] [CrossRef]
- Zhao, L.; Zhang, X.; Zhang, Y.; Xu, T. Length of Slope Determination with Heavy Duty Vehicles. In CICTP 2020; ASCE Library: Reston, VA, USA, 2020; pp. 4255–4267. [Google Scholar]
- Hossain, M.; Muromachi, Y. A Bayesian network based framework for real-time crash prediction on the basic freeway segments of urban expressways. Accid. Anal. Prev. 2012, 45, 373–381. [Google Scholar] [CrossRef]
- Shi, Q.; Abdel-Aty, M. Big data applications in real-time traffic operation and safety monitoring and improvement on urban expressways. Transp. Res. Part C Emerg. Technol. 2015, 58, 380–394. [Google Scholar] [CrossRef]











| Direction | Crashes | No. of Deaths | No. of Injuries |
|---|---|---|---|
| Qazvin to Abyek | 1550 | 204 | 2165 |
| Abyek to Qazvin | 1708 | 193 | 1993 |
| Total | 3258 | 397 | 4158 |
| Direction | Direction | |||||
|---|---|---|---|---|---|---|
| Qazvin to Abyek | Abyek to Qazvin | |||||
| Distance (m) | Moran’s Index | z-Score | p-Value | Moran’s Index | z-Score | p-Value |
| 500 | 0.280477 | 14.45204 | 0.00 | 0.262819 | 13.56918 | 0.00 |
| 600 | 0.253837 | 14.58366 | 0.00 | 0.235518 | 13.48739 | 0.00 |
| 700 | 0.230517 | 14.72402 | 0.00 | 0.204491 | 13.1025 | 0.00 |
| 800 | 0.194255 | 13.36734 | 0.00 | 0.197075 | 13.54769 | 0.00 |
| 900 | 0.167901 | 12.22441 | 0.00 | 0.168325 | 12.33501 | 0.00 |
| 1000 | 0.152191 | 11.81901 | 0.00 | 0.145903 | 11.38119 | 0.00 |
| 1100 | 0.163536 | 13.45219 | 0.00 | 0.12565 | 10.28813 | 0.00 |
| 1200 | 0.147651 | 12.63698 | 0.00 | 0.105662 | 9.085491 | 0.00 |
| Direction | Moran’s I | Z | p-Value | Spatial Distribution (95% Confidence) |
|---|---|---|---|---|
| Qazvin to Abyek | 0.436746 | 2.553551 | 0.010663 | Clustered |
| Abyek to Qazvin | 0.155543 | 0.991892 | 0.32125 | Random |
| Condition | Moran’s I | Z | p-Value | Spatial Distribution (95% Confidence) | |||
|---|---|---|---|---|---|---|---|
| Direction | Qazvin to Abyek | Volume (V) (veh/h) | V < 1107 | 0.489669 | 2.846972 | 0.004414 | Clustered |
| 1107 < V < 1982 | 0.153117 | 0.912806 | 0.361345 | Random | |||
| V > 1982 | 0.124857 | 0.823357 | 0.410305 | Random | |||
| Speed (S) (km/h) | S < 97 | 0.074382 | 0.527389 | 0.597924 | Random | ||
| S > 97 | 0.698778 | 3.989106 | 0.000066 | Clustered | |||
| Time (hours) | 00–03 | 0.066896 | 0.492272 | 0.622527 | Random | ||
| 03–06 | 0.524641 | 3.042979 | 0.002342 | Clustered | |||
| 06–09 | 0.177791 | 1.094382 | 0.273788 | Random | |||
| 09–12 | 0.045235 | 0.352046 | 0.724804 | Random | |||
| 12–15 | −0.203112 | −1.036415 | 0.300009 | Random | |||
| 15–18 | 0.181377 | 1.109924 | 0.267032 | Random | |||
| 18–21 | 0.089734 | 0.621703 | 0.534137 | Random | |||
| 21–24 | 0.003544 | 0.12394 | 0.901363 | Random | |||
| Abyek to Qazvin | Volume (V) (veh/h) | V < 1378 | 0.102881 | 0.703368 | 0.481827 | Random | |
| 1378 < V < 1982 | 0.055929 | 0.417969 | 0.67597 | Random | |||
| V > 2067 | 0.393178 | 2.33552 | 0.019516 | Clustered | |||
| Speed (S) (km/h) | S < 97 | 0.202809 | 1.347552 | 0.177802 | Random | ||
| S > 97 | −0.114638 | −0.5438 | 0.586579 | Random | |||
| Time (hours) | 00–03 | 0.153025 | 0.985104 | 0.324573 | Random | ||
| 03–06 | −0.141334 | −0.700012 | 0.48392 | Random | |||
| 06–09 | −0.010544 | 0.044112 | 0.964815 | Random | |||
| 09–12 | −0.045932 | −0.159563 | 0.873225 | Random | |||
| 12–15 | −0.151469 | −0.75118 | 0.452544 | Random | |||
| 15–18 | 0.063173 | 0.464509 | 0.642283 | Random | |||
| 18–21 | 0.160602 | 0.778682 | 0.436167 | Random | |||
| 21–24 | 0.057169 | 0.443945 | 0.657082 | Random | |||
| Crash Percentage for Heavy Vehicle Non-Culpable | Crash Number for Heavy Vehicle Non-Culpable | Crash Percentage for Heavy Vehicle Responsible | Crash Number for Heavy Vehicle Responsible | Crash Frequency | Time |
|---|---|---|---|---|---|
| 0.185507246 | 128 | 0.137681159 | 95 | 690 | 0–24 |
| 0.25 | 19 | 0.184210526 | 14 | 76 | 03–06 |
| LV | HS | T0306 | HVP | |
|---|---|---|---|---|
| LV | 1 | 0.801 ** | 0.568 ** | 0.891 ** |
| HS | 0.801 ** | 1 | 0.487 ** | 0.701 ** |
| T0306 | 0.568 ** | 0.487 ** | 1 | 0.565 ** |
| HVP | 0.891 ** | 0.701 ** | 0.565 ** | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zandi, K.; Tavakoli Kashani, A.; Okabe, A. Influence of Traffic Parameters on the Spatial Distribution of Crashes on a Freeway to Increase Safety. Sustainability 2023, 15, 493. https://doi.org/10.3390/su15010493
Zandi K, Tavakoli Kashani A, Okabe A. Influence of Traffic Parameters on the Spatial Distribution of Crashes on a Freeway to Increase Safety. Sustainability. 2023; 15(1):493. https://doi.org/10.3390/su15010493
Chicago/Turabian StyleZandi, Kamran, Ali Tavakoli Kashani, and Atsuyuki Okabe. 2023. "Influence of Traffic Parameters on the Spatial Distribution of Crashes on a Freeway to Increase Safety" Sustainability 15, no. 1: 493. https://doi.org/10.3390/su15010493
APA StyleZandi, K., Tavakoli Kashani, A., & Okabe, A. (2023). Influence of Traffic Parameters on the Spatial Distribution of Crashes on a Freeway to Increase Safety. Sustainability, 15(1), 493. https://doi.org/10.3390/su15010493