
Implementing Artificial Intelligence Techniques to Predict Environmental Impacts: Case of Construction Products

 , ,
, , 
Abstract
1. Introduction
2. Materials and Methods
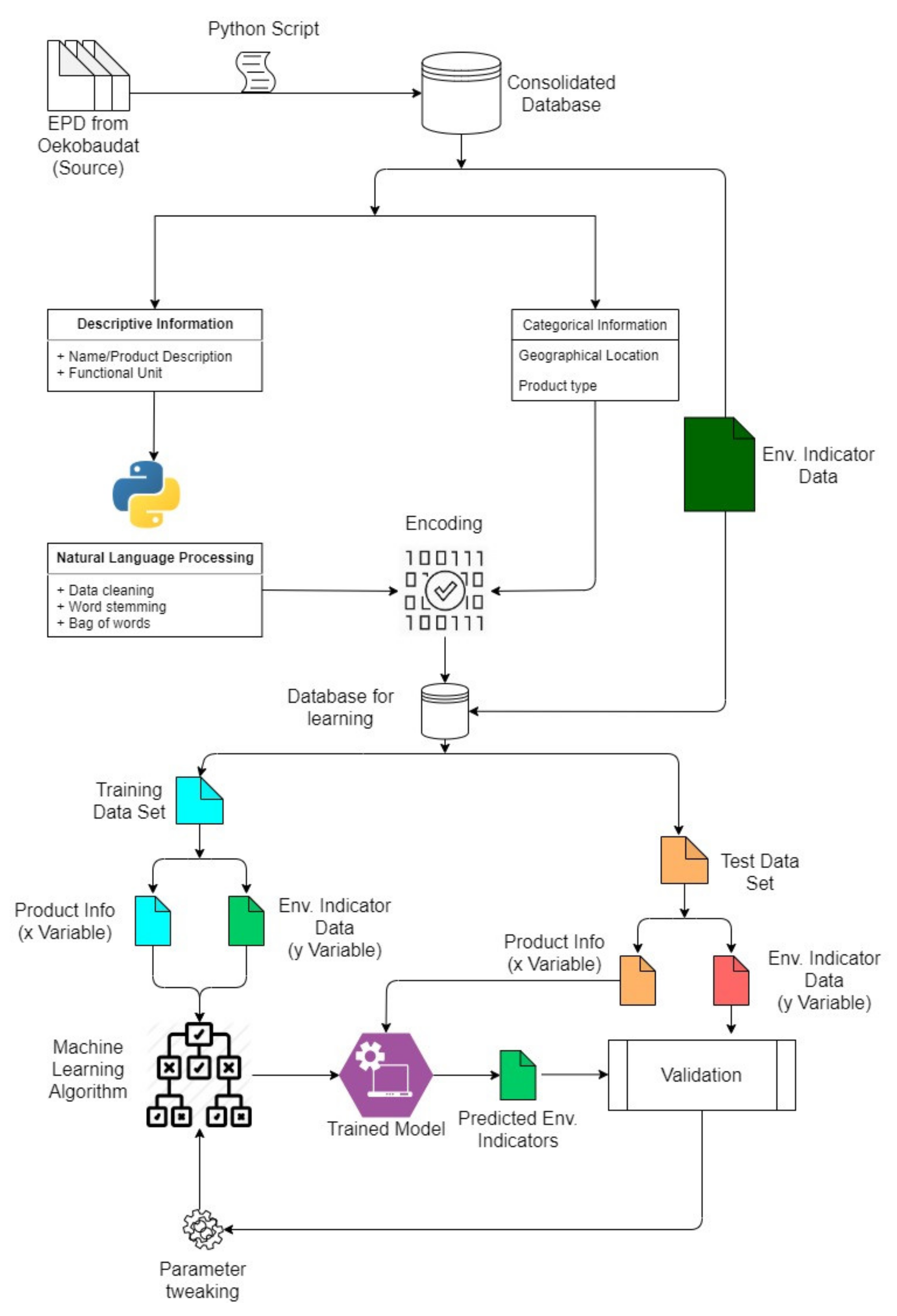
2.1. Data Source: EPD
2.2. Data Collection and Pre-Processing
2.3. Natural Language Processing (NLP)
2.4. Tree-Based Algorithm
2.5. Random Forest Regression
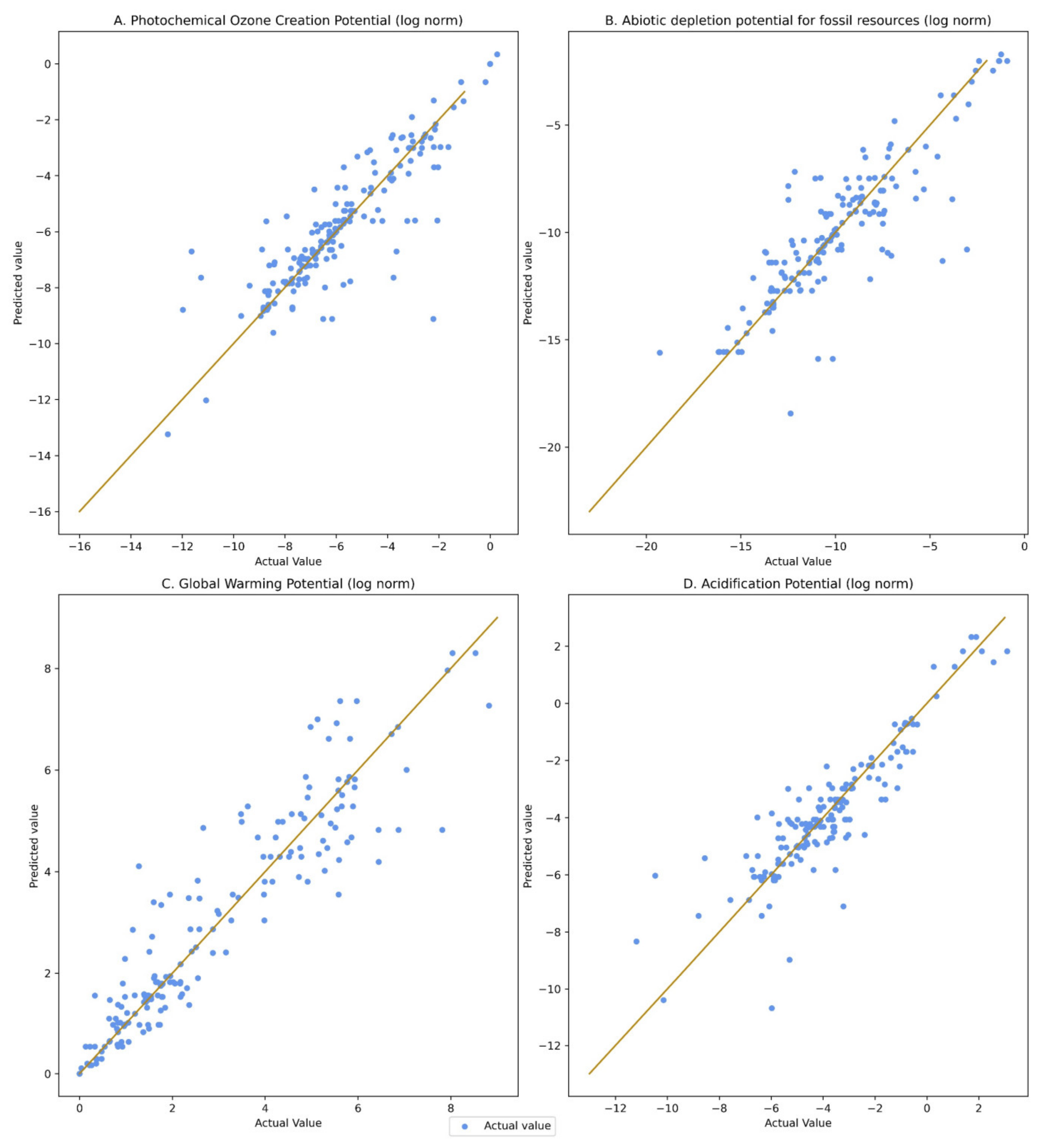
3. Results and Discussion
Results and Performance of the Model
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Glossary
| LCA | Life Cycle Assessment |
| ISO | International Standard Organization |
| EPD | Environmental Product Development |
| EU | European Union |
| PCR | Product Category Rules |
| PEF | Product Environmental Footprint |
| NGO | Non-Government Organizations |
| AI | Artificial Intelligence |
| GT | Game Theory |
| ABM | Agent-Based Model |
| ANN | Artificial Neural Network |
| ML | Machine Learning |
| SVM | Support Vector Machine |
| BN | Bayesian Network |
| GA | Genetic Algorithm |
| KNN | K-Nearest Neighbor |
| Adaboost | Adaptive Boosting |
| GBM | Gradient Boosting Machine |
| NN | Neural Network |
| XML | Extensible Markup Language |
| HTML | Hypertext Markup Language |
| ILCD | International Reference Life Cycle Data System |
| NLP | Natural Language Processing |
| DT | Decision Tree |
| RF | Random Forest |
| IBU | The Institut Bauen und Umwelt e.V. |
| GWP | Global Warming Potential |
| POCP | Photochemical Ozone Creation Potential |
| AP | Acidification Potential |
| ADPF | Abiotic Depletion Potential for Fossil Resources |
| MSE | Mean Squared Error |
| RMSE | Root Mean Squared Error |
| R2 | R Squared |
References
- Clift, R.; Doig, A.; Finnveden, G. The application of Life Cycle Assessment to Integrated Solid Waste Management. Part 1—Methodology. Process Saf. Environ. Prot. 2000, 78, 279–287. [Google Scholar] [CrossRef]
- ISO 14025; Environmental Labels and Declarations—Type III Environmental Declarations—Principles and Procedures. International Organization for Standardization: Geneva, Switzerland, 2010. Available online: http://www.cscses.com/uploads/2016328/20160328110527052705.pdf (accessed on 7 March 2022).
- Jose, F.; Benjamin, E.; Shelie, A. Developing LCA Techniques for Emerging Systems: Game Theory, Agent Modeling as Prediction Tools. In Proceedings of the 2010 IEEE International Symposium on Sustainable Systems and Technology, Arlington, VA, USA, 17–19 May 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Halog, A.; Manik, Y. Advancing integrated systems modelling framework for life cycle sustainability assessment. Sustainability 2011, 3, 469–499. [Google Scholar] [CrossRef]
- Bonabeau, E. Agent-based modeling: Methods and techniques for simulating human systems. Proc. Natl. Acad. Sci. USA 2002, 99 (Suppl. S3), 7280–7287. [Google Scholar] [CrossRef]
- Miller, S.A.; Moysey, S.; Sharp, B.; Alfaro, J. A Stochastic Approach to Model Dynamic Systems in Life Cycle Assessment. J. Ind. Ecol. 2012, 17, 352–362. [Google Scholar] [CrossRef]
- Micolier, A.; Loubet, P.; Taillandier, F.; Sonnemann, G. To what extent can agent-based modelling enhance a life cycle assessment? Answers based on a literature review. J. Clean. Prod. 2019, 239, 118123. [Google Scholar] [CrossRef]
- Das, K.; Behera, R.N. A Survey on Machine Learning: Concept, Algorithms and Applications. Int. J. Innov. Res. Comput. Commun. Eng. 2017, 5, 1301–1309. [Google Scholar]
- Barros, N.N.; Ruschel, R.C. Machine Learning for Whole-Building Life Cycle Assessment: A Systematic Literature Review. In Proceedings of the 18th International Conference on Computing in Civil and Building Engineering, São Paulo, Brazil, 18–20 August 2020; Springer: Cham, Switzerland, 2021; pp. 109–122. [Google Scholar]
- Nabavi-Pelesaraei, A.; Rafiee, S.; Mohtasebi, S.S.; Hosseinzadeh-Bandbafha, H.; Chau, K.w. Integration of artificial intelligence methods and life cycle assessment to predict energy output and environmental impacts of paddy production. Sci. Total Environ. 2018, 631–632, 1279–1294. [Google Scholar] [CrossRef]
- Kaab, A.; Sharifi, M.; Mobli, H.; Nabavi-Pelesaraei, A.; Chau, K.w. Combined life cycle assessment and artificial intelligence for prediction of output energy and environmental impacts of sugarcane production. Sci. Total Environ. 2019, 664, 1005–1019. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Trees vs. Neurons: Comparison between random forest and ANN for high-resolution prediction of building energy consumption. Energy Build. 2017, 147, 77–89. [Google Scholar] [CrossRef]
- Stangierski, J.; Weiss, D.; Kaczmarek, A. Multiple regression models and Artificial Neural Network (ANN) as prediction tools of changes in overall quality during the storage of spreadable processed Gouda cheese. Eur. Food Res. Technol. 2019, 245, 2539–2547. [Google Scholar] [CrossRef]
- Hou, P.; Jolliet, O.; Zhu, J.; Xu, M. Estimate ecotoxicity characterization factors for chemicals in life cycle assessment using machine learning models. Environ. Int. 2020, 135, 105393. [Google Scholar] [CrossRef]
- European Commission. Environmental Footprint. European Platform on Life Cycle Assessment. Available online: https://eplca.jrc.ec.europa.eu/EnvironmentalFootprint.html (accessed on 7 March 2022).
- Passer, A.; Lasvaux, S.; Allacker, K.; De Lathauwer, D.; Spirinckx, C.; Wittstock, B.; Kellenberger, D.; Gschösser, F.; Wall, J.; Wallbaum, H. Environmental product declarations entering the building sector: Critical reflections based on 5 to 10 years experience in different European countries. Int. J. Life Cycle Assess. 2015, 20, 1199–1212. [Google Scholar] [CrossRef]
- Allander, A. Successful certification of an environmental product declaration for an ABB product. Corp. Environ. Strateg. 2001, 8, 133–141. [Google Scholar] [CrossRef]
- Bovea, M.D.; Ibáñez-Forés, V.; Agustí-Juan, I. Environmental product declaration (EPD) labelling of construction and building materials. In Eco-Efficient Construction and Building Materials. Life Cycle Assessment (LCA), Eco-Labelling and Case Studies; Woodhead Publishing: Cambridge, UK, 2013; pp. 125–150. [Google Scholar] [CrossRef]
- Del Borghi, A. LCA and communication: Environmental Product Declaration. Int. J. Life Cycle Assess. 2013, 18, 293–295. [Google Scholar] [CrossRef]
- Minkov, N.; Schneider, L.; Lehmann, A.; Finkbeiner, M. Type III Environmental Declaration Programmes and harmonization of product category rules: Status quo and practical challenges. J. Clean. Prod. 2015, 94, 235–246. [Google Scholar] [CrossRef]
- Durão, V.; Silvestre, J.D.; Mateus, R.; de Brito, J. Assessment and communication of the environmental performance of construction products in Europe: Comparison between PEF and EN 15804 compliant EPD schemes. Resour. Conserv. Recycl. 2020, 156, 104703. [Google Scholar] [CrossRef]
- Adibi, N.; Mousavi, M.; Escobar, M.M.; Glachant, R.; Adibi, A. Mainstream Use of EPDs in Buildings: Lessons Learned from Europe. In ISBS 2019; IntechOpen: London, UK, 2019; p. 890. [Google Scholar]
- Institut Bauen und Umwelt e.V. Available online: https://ibu-epd.com/ibu/ (accessed on 7 March 2022).
- Lasvaux, S.; Habert, G.; Peuportier, B.; Chevalier, J. Comparison of generic and product-specific Life Cycle Assessment databases: Application to construction materials used in building LCA studies. Int. J. Life Cycle Assess. 2015, 20, 1473–1490. [Google Scholar] [CrossRef]
- Pardede, E.; Rahayu, J.W.; Taniar, D. XML data update management in XML-enabled database. J. Comput. Syst. Sci. 2008, 74, 170–195. [Google Scholar] [CrossRef][Green Version]
- Recchioni, M.; Mathieux, F.; Goralczyk, M.; Schau, E.M. ILCD Data Network and ELCD Database—Current Use and Further Needs for Supporting Environmental Footprint and Life Cycle Indicator Projects; Report EUR 25744 EN; European Commission: Luxembourg, 2013. [Google Scholar]
- Baitz, M.; Makishi Colodel, C.; Kupfer, K.; Florin, J.; Schuller, O.; Kokborg, M.; Köhler, A.; Thylmann, D.; Stoffregen, A.; Schöll, S.; et al. GaBi Database & Modelling Principles 2014; PE International AG: Stuttgart, Germany, 2014. [Google Scholar]
- Oekobaudat. Available online: https://www.oekobaudat.de/datenbank/browser-oekobaudat.html (accessed on 7 March 2022).
- Selenium Selenium Client Driver Documentation. Available online: https://www.selenium.dev/selenium/docs/api/py/ (accessed on 7 March 2022).
- Sqlite3 sqlite3—DB-API 2.0 interface for SQLite databases. Available online: https://docs.python.org/3/library/sqlite3.html (accessed on 7 March 2022).
- Probst, P.; Wright, M.N.; Boulesteix, A.L. Hyperparameters and tuning strategies for random forest. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef]
- Zeroual, I.; Lakhouaja, A. Data science in light of natural language processing: An overview. Procedia Comput. Sci. 2018, 127, 82–91. [Google Scholar] [CrossRef]
- Joseph, S.R.; Hloman, H.; Letsholo, K.; Sedimo, K. Natural Language Processing: A Review. Int. J. Res. Eng. Appl. Sci. 2016, 6, 1–8. [Google Scholar]
- Vallbé, J.-J.; Martí, M.A.; Blaž, F.; Jakulin, A.; Mladenič, D.; Casanovas, P. Stemming and lemmatisation: Improving knowledge management through language processing techniques. In Trends in Legal Knowledge: The Semantic Web and the Regulation of Electronic Social Systems; European Press Academic Publishing: Florence, Italy, 2007; pp. 1–16. Available online: https://www.researchgate.net/publication/228704765 (accessed on 7 March 2022).
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- SoleimanianGharehchopogh, F.; Mohammadi, P.; Hakimi, P. Application of Decision Tree Algorithm for Data Mining in Healthcare Operations: A Case Study. Int. J. Comput. Appl. 2012, 52, 21–26. [Google Scholar] [CrossRef]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control Eng. 2014, 2, 602–609. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar] [CrossRef]
- Umarani, V.; Rathika, C. Predicting Safety Information of Drugs Using Data Mining Technique. Int. J. Comput. Eng. Technol. 2019, 10, 83–90. [Google Scholar] [CrossRef]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Cameron, A.C.; Windmeijer, F.A.G. An R-squared measure of goodness of fit for some common nonlinear regression models. J. Econom. 1997, 77, 329–342. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Product | Seal | Component | Treat | Cool | Steel | Metal | Work | Hot | |
|---|---|---|---|---|---|---|---|---|---|
| Name 1 | 1 | 1 | 2 | 1 | 0 | 0 | 0 | 1 | 0 |
| Name 2 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 |
| Name 3 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
| Impact Category | Number of Data Points | Mean Squared Error | R-Squared Results |
|---|---|---|---|
| Photochemical Ozone Creation Potential | 196 | 0.07 | 70% |
| Abiotic depletion potential for fossil resources | 196 | 0.01 | 77% |
| Global warming potential | 196 | 0.28 | 81% |
| Acidification potential | 196 | 1.12 | 68% |
| Environmental Impact Indicators | Original Values | Units | Predicted Values |
|---|---|---|---|
| Photochemical Ozone Creation Potential (POCP) | 0.000266 | kg Ethene eq. | 0.00019152 |
| Abiotic depletion potential for fossil resources (ADPF) | 7.627 | MJ | 6.102 |
| Global warming potential (GWP) | 0.6834 | kg CO2 eq. | 0.564 |
| Acidification potential (AP) | 0.001282 | kg SO2 eq. | 0.00071792 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koyamparambath, A.; Adibi, N.; Szablewski, C.; Adibi, S.A.; Sonnemann, G. Implementing Artificial Intelligence Techniques to Predict Environmental Impacts: Case of Construction Products. Sustainability 2022, 14, 3699. https://doi.org/10.3390/su14063699
Koyamparambath A, Adibi N, Szablewski C, Adibi SA, Sonnemann G. Implementing Artificial Intelligence Techniques to Predict Environmental Impacts: Case of Construction Products. Sustainability. 2022; 14(6):3699. https://doi.org/10.3390/su14063699
Chicago/Turabian StyleKoyamparambath, Anish, Naeem Adibi, Carolina Szablewski, Sierra A. Adibi, and Guido Sonnemann. 2022. "Implementing Artificial Intelligence Techniques to Predict Environmental Impacts: Case of Construction Products" Sustainability 14, no. 6: 3699. https://doi.org/10.3390/su14063699
APA StyleKoyamparambath, A., Adibi, N., Szablewski, C., Adibi, S. A., & Sonnemann, G. (2022). Implementing Artificial Intelligence Techniques to Predict Environmental Impacts: Case of Construction Products. Sustainability, 14(6), 3699. https://doi.org/10.3390/su14063699