
Machine Learning for Pan Evaporation Modeling in Different Agroclimatic Zones of the Slovak Republic (Macro-Regions)

 , ,
, ,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
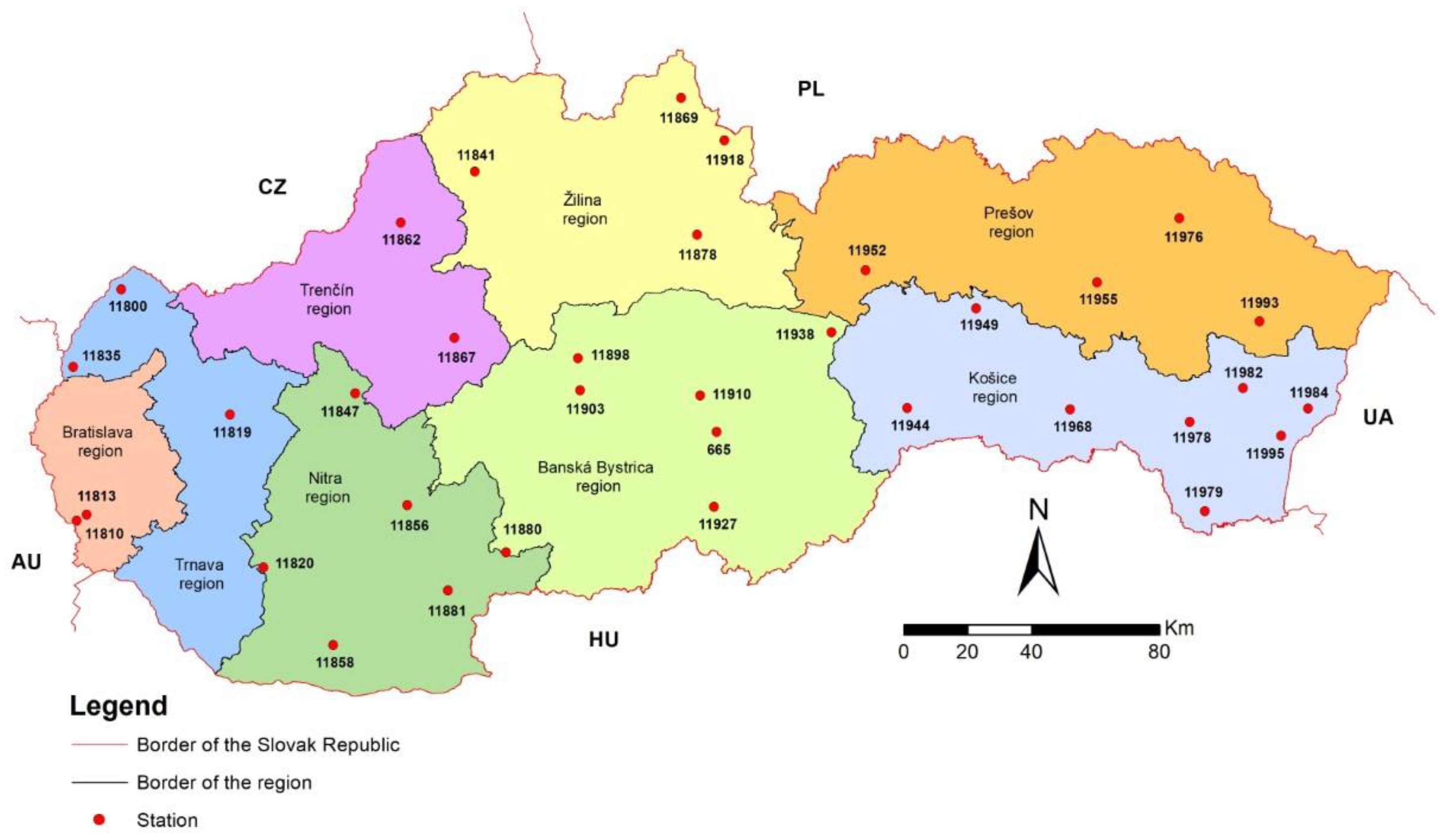
2.1. Study Location and Climatic Data Collection
Slovak Republic Zoning Criteria
- Warm agroclimatic macro-area with TS10 from 3100 to 2400 °C;
- Slightly warm agroclimatic macro-region with TS10 from 2400 to 2000 °C; and
- Cold agroclimatic macro-region with TS10 from 2000 to 1600 °C.
- Subarea with KVI–VIII ≥ 150 mm—very dry
- Subarea with KVI–VIII 150 to 100 mm—mostly dry
- Subarea with KVI–VIII 100 to 50 mm—slightly dry
- Subarea with KVI–VIII 50 to 0 mm—slightly humid
- Subarea with KVI–VIII 0 to −50 mm—mostly humid
- Subarea with KVI–VIII −50 to −100 mm—humid
- Subarea with KVI–VIII −100 mm—very humid
- Agroclimatic district of mostly mild winter with Tmin ≥ −18 °C;
- Agroclimatic district of relatively mild winters with Tmin from −18.0 °C to −20.0 °C;
- Agroclimatic district of mildly cold winter with Tmin from −20.0 °C to −22.0 °C;
- Agroclimatic district of mostly cold winter with Tmin from −22.0 to −24.0 °C;
- Agroclimatic district of cold winter with Tmin ≤ −24.0 °C.
- Northwest (NW): Trenčín region;
- Southwest (SW): Trnava region, Bratislava region, and Nitra region;
- North-central (NC): Žilina region;
- South-central (SC): Banská Bystrica region;
- Northeast (NE): Prešov region;
- Southeastern (SE): Košice region.
- (1)
- Northwestern Slovakia (NW): Trenčín region—From an agroclimatic point of view, the NW area is assigned to the macro-area of a mildly warm, agroclimatic area of a lightly warm subarea that is moderately humid to mostly humid. Moreover, this area is assigned to agroclimatic precincts with a mild/cold winter to a mostly cold winter. This area also transitions north to the macro-area with a cold, agroclimatic area with a moderately cold sub-area that is mostly humid to humid, and a precinct with mostly cold winters.
- (2)
- Southwestern Slovakia (SW): Bratislava region, Trnava region, and Nitra region—From an agroclimatic point of view, the SW area is assigned to the macro-area of a warm and agroclimatic area that is very warm, a sub-area that is very dry, and a predominantly dry and agroclimatic precinct that has mainly mild winters.
- (3)
- North-central Slovakia (NC): Žilina region—From an agroclimatic point of view, the NC area is assigned to the macro-area of a slightly warm to cold agroclimatic area from a slightly to moderate/mildly warm sub-area up to a slightly cold sub-area. This area is also assigned to slightly dry, moderately humid, mostly humid, and agroclimatic precincts that are mildly cold to mostly cold in the winter. This area transitions north to a macro-area of a cold, agroclimatic area that is mostly cold, a sub-area that is mostly humid to humid, and a precinct that is mostly cold/cold in the winter.
- (4)
- South-central Slovakia (SC): Banská Bystrica region—From an agroclimatic point of view, the SC area at the southernmost part of the state border is assigned to a warm macro-area, a very warm agroclimatic area, a very dry and predominantly dry sub-area, and an agroclimatic precinct with a predominantly mild winter. This area transitions to a macro-area with a moderately warm, an agroclimatic area that is relatively mild/warm, a sub-area that is slightly humid to mostly humid, and a precinct that is slightly cold in the winter.
- (5)
- Northeastern Slovakia (NE): Prešov region—From an agroclimatic point of view, this area is the most diverse. In the southern part, it is considered a warm macro-area, with an agroclimatic area that is sufficiently warm to relatively/moderately warm, sub-areas that are predominantly dry to moderately dry, and agroclimatic precincts that have relatively mild winters to mild cold winters. This area transitions north to a macro-area that is warm or moderately warm to cold, an agroclimatic area that is relatively mild/warm to slightly cold, sub-areas that are moderately dry or slightly humid, and a precinct that is slightly cold in the winter to mostly cold in the winter.
- (6)
- Southeastern Slovakia (SE): Košice region—From an agroclimatic point of view, the SE area is assigned as the macro-area of a warm and agroclimatic area that is very warm, a sub-area that is very dry and a predominantly dry, and a agroclimatic precinct with a predominantly mild winter. This area transitions to an agroclimatic area that is mostly warm, a sub-area that is very dry, and a precinct that has a relatively mild winter.
2.2. Case Study and Data Description
2.3. ML Models and Evaluation Criteria
2.3.1. Neural Network (NN)
2.3.2. AutoNeural Network (AN)
2.3.3. Decision Tree (DT)
2.3.4. Dmine Regression (DR)
2.3.5. DM Neural Network (DM NN)
2.3.6. Gradient Boosting (GB)
2.3.7. Least Angle Regression (LARS)
2.3.8. Least Ensemble Model (EM)
3. Results
3.1. PE Changes at the Macro-Regional Level
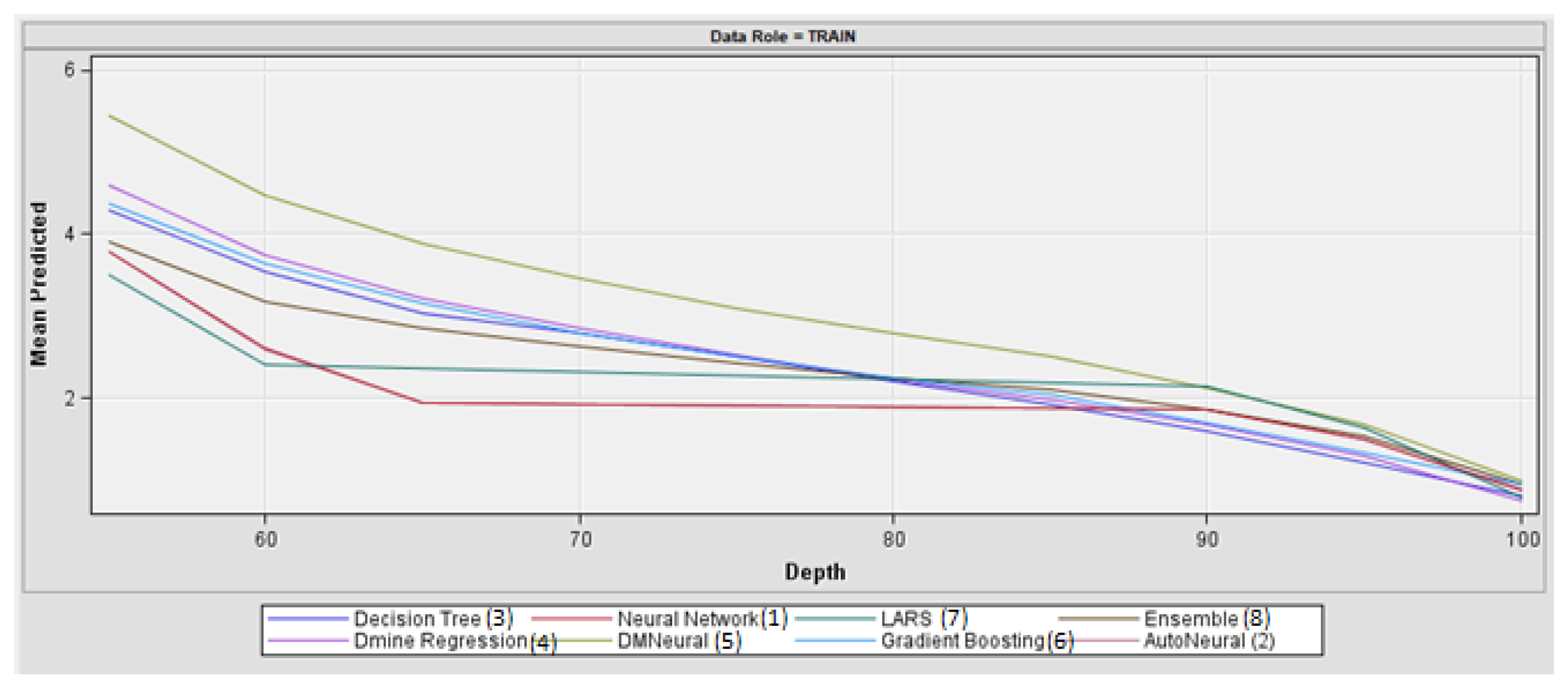
3.2. ML Models’ Accuracy Evaluation
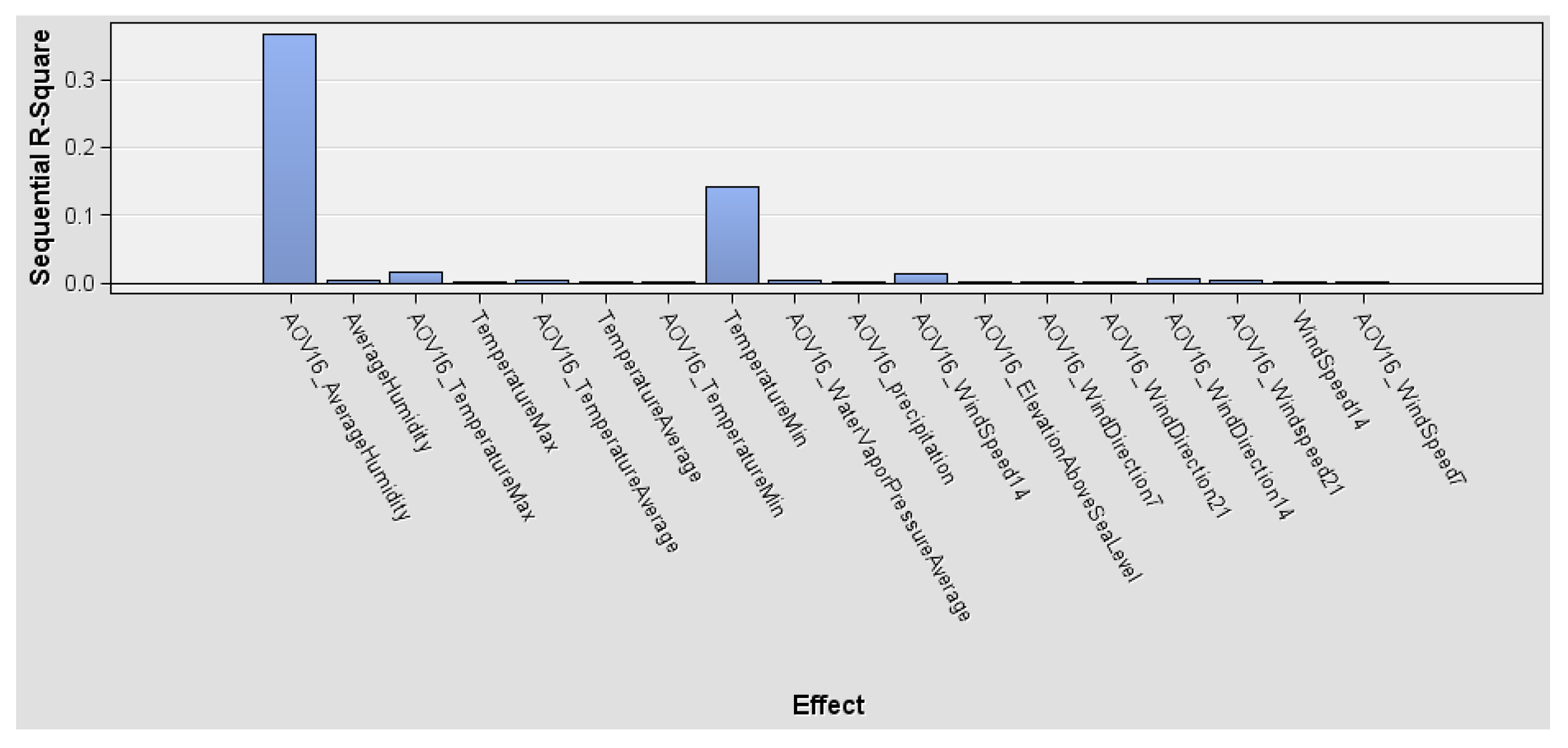
3.3. Relationship between PE and Variables
4. Discussion
5. Conclusions
- (a)
- The lowest PE values were recorded in the NC area, and the highest were recorded in the SE and SW regions. The largest PE change over the observed period (expressed by using the variation range) occurred in the SE region, followed by SC and SW. The smallest PE change was in the NC and NW regions.
- (b)
- The best accuracy of the ML models was obtained by DR (TASE = 0.78819), followed by GB (TASE = 0.77826) and DT (TASE = 0.78094), though it is possible to see very similar results of the predicted values. Both neural network models, AN and NN, were evaluated as the least suitable models for the prediction of PE.
- (c)
- There is a significant but weak relationship between PE and elevation above sea level. However, there is a moderately strong relationship between PE and Taver. A comparison between Tmin and Tmax shows that Tmax is a slightly more important factor.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Mukhtar, M. Modeling of pan evaporation based on the development of machine learning methods. Arch. Meteorol. Geophys. Bioclimatol. Ser. B 2021, 146, 961–979. [Google Scholar] [CrossRef]
- Ghorbani, M.A.; Kazempour, R.; Ahmadi, M.; Shamshirband, S.; Ghazvinei, P.T. Forecasting pan evaporation with an integrated artificial neural network quantum-behaved particle swarm optimization model: A case study in Talesh, Northern Iran. Eng. Appl. Comput. Fluid Mech. 2018, 12, 724–737. [Google Scholar] [CrossRef]
- Moazenzadeh, R.; Mohammadi, B.; Shamshirband, S.; Ahmadi, M. Coupling a firefly algorithm with support vector regression to predict evaporation in northern Iran. Eng. Appl. Comput. Fluid Mech. 2018, 12, 584–597. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Peng, Y.; Fan, J.; Wang, Y. Machine learning models for the estimation of monthly mean daily reference evapotranspiration based on cross-station and synthetic data. Water Policy 2019, 50, 1730–1750. [Google Scholar] [CrossRef]
- Azorin-Molina, C.; Vicente-Serrano, S.M.; Sanchez-Lorenzo, A.; McVicar, T.R.; Morán-Tejeda, E.; Revuelto, J.; El Kenawy, A.; Martín-Hernández, N.; Tomas-Burguera, M. Atmospheric evaporative demand observations, estimates and driving factors in Spain (1961–2011). J. Hydrol. 2015, 523, 262–277. [Google Scholar] [CrossRef] [Green Version]
- Burn, D.H.; Hesch, N.M. Trends in evaporation for the Canadian Prairies. J. Hydrol. 2007, 336, 61–73. [Google Scholar] [CrossRef]
- Majidi, M.; Alizadeh, A.; Farid, A.; Vazifedoust, M. Estimating Evaporation from Lakes and Reservoirs under Limited Data Condition in a Semi-Arid Region. Water Resour. Manag. 2015, 29, 3711–3733. [Google Scholar] [CrossRef]
- Malik, A.; Rai, P.; Heddam, S.; Kisi, O.; Sharafati, A.; Salih, S.; Al-Ansari, N.; Yaseen, Z. Pan Evaporation Estimation in Uttarakhand and Uttar Pradesh States, India: Validity of an Integrative Data Intelligence Model. Atmosphere 2020, 11, 553. [Google Scholar] [CrossRef]
- Malik, A.; Tikhamarine, Y.; Al-Ansari, N.; Shahid, S.; Sekhon, H.S.; Pal, R.K.; Rai, P.; Pandey, K.; Singh, P.; Elbeltagi, A.; et al. Daily pan-evaporation estimation in different agro-climatic zones using novel hybrid support vector regression optimized by Salp swarm algorithm in conjunction with gamma test. Eng. Appl. Comput. Fluid Mech. 2021, 15, 1075–1094. [Google Scholar] [CrossRef]
- Shiri, J.; Martí, P.; Singh, V.P. Evaluation of gene expression programming approaches for estimating daily evaporation through spatial and temporal data scanning. Hydrol. Process. 2012, 28, 1215–1225. [Google Scholar] [CrossRef]
- Wang, L.; Kisi, O.; Zounemat-Kermani, M.; Li, H. Pan evaporation modeling using six different heuristic computing methods in different climates of China. J. Hydrol. 2017, 544, 407–427. [Google Scholar] [CrossRef]
- Ghaemi, A.; Rezaie-Balf, M.; Adamowski, J.; Kisi, O.; Quilty, J. On the applicability of maximum overlap discrete wavelet transform integrated with MARS and M5 model tree for monthly pan evaporation prediction. Agric. For. Meteorol. 2019, 278, 107647. [Google Scholar] [CrossRef]
- Majhi, B.; Naidu, D. Pan evaporation modeling in different agroclimatic zones using functional link artificial neural network. Inf. Process. Agric. 2021, 8, 134–147. [Google Scholar] [CrossRef]
- Dou, X.; Yang, Y. Evapotranspiration estimation using four different machine learning approaches in different terrestrial ecosystems. Comput. Electron. Agric. 2018, 148, 95–106. [Google Scholar] [CrossRef]
- Ghumman, A.; Jamaan, M.; Ahmad, A.; Shafiquzzaman, M.; Haider, H.; Al Salamah, I.; Ghazaw, Y. Simulation of Pan-Evaporation Using Penman and Hamon Equations and Artificial Intelligence Techniques. Water 2021, 13, 793. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Keshtegar, B.; Kisi, O.; Scholz, M. Towards a Comprehensive Assessment of Statistical versus Soft Computing Models in Hydrology: Application to Monthly Pan Evaporation Prediction. Water 2021, 13, 2451. [Google Scholar] [CrossRef]
- Bellido-Jiménez, J.A.; Estévez, J.; García-Marín, A.P. New machine learning approaches to improve reference evapotranspiration estimates using intra-daily temperature-based variables in a semi-arid region of Spain. Agric. Water Manag. 2021, 245, 106558. [Google Scholar] [CrossRef]
- Abrahart, R.J.; Anctil, F.; Coulibaly, P.; Dawson, C.; Mount, N.J.; See, L.M.; Shamseldin, A.; Solomatine, D.P.; Toth, E.; Wilby, R.L. Two decades of anarchy? Emerging themes and outstanding challenges for neural network river forecasting. Prog. Phys. Geogr. Earth Environ. 2012, 36, 480–513. [Google Scholar] [CrossRef]
- Keshtegar, B.; Piri, J.; Kisi, O. A nonlinear mathematical modeling of daily pan evaporation based on conjugate gradient method. Comput. Electron. Agric. 2016, 127, 120–130. [Google Scholar] [CrossRef]
- Kousari, M.R.; Hosseini, M.E.; Ahani, H.; Hakimelahi, H. Introducing an operational method to forecast long-term regional drought based on the application of artificial intelligence capabilities. Arch. Meteorol. Geophys. Bioclimatol. Ser. B 2017, 127, 361–380. [Google Scholar] [CrossRef]
- Moghaddamnia, A.; Gousheh, M.G.; Piri, J.; Amin, S.; Han, D. Evaporation estimation using artificial neural networks and adaptive neuro-fuzzy inference system techniques. Adv. Water Resour. 2009, 32, 88–97. [Google Scholar] [CrossRef]
- Park, S.; Im, J.; Jang, E.; Rhee, J. Drought assessment and monitoring through blending of multi-sensor indices using machine learning approaches for different climate regions. Agric. For. Meteorol. 2016, 216, 157–169. [Google Scholar] [CrossRef]
- Crisci, C.; Ghattas, B.; Perera, G. A review of supervised machine learning algorithms and their applications to ecological data. Ecol. Model. 2012, 240, 113–122. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.-L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- Wilby, R.L.; Yu, D. Rainfall and temperature estimation for a data sparse region. Hydrol. Earth Syst. Sci. 2013, 17, 3937–3955. [Google Scholar] [CrossRef] [Green Version]
- Courault, D.; Seguin, B.; Olioso, A. Review on estimation of evapotranspiration from remote sensing data: From empirical to numerical modeling approaches. Irrig. Drain. Syst. 2005, 19, 223–249. [Google Scholar] [CrossRef]
- Mu, Q.; Heinsch, F.A.; Zhao, M.; Running, S.W. Development of a global evapotranspiration algorithm based on MODIS and global meteorology data. Remote Sens. Environ. 2007, 111, 519–536. [Google Scholar] [CrossRef]
- McCabe, M.F.; Wood, E.F. Scale influences on the remote estimation of evapotranspiration using multiple satellite sensors. Remote Sens. Environ. 2006, 105, 271–285. [Google Scholar] [CrossRef]
- Long, D.; Longuevergne, L.; Scanlon, B.R. Uncertainty in evapotranspiration from land surface modeling, remote sensing, and GRACE satellites. Water Resour. Res. 2014, 50, 1131–1151. [Google Scholar] [CrossRef] [Green Version]
- Gomis-Cebolla, J.; Jimenez, J.C.; Sobrino, J.A.; Corbari, C.; Mancini, M. Intercomparison of remote-sensing based evapotranspiration algorithms over amazonian forests. Int. J. Appl. Earth Obs. Geoinf. 2019, 80, 280–294. [Google Scholar] [CrossRef]
- Chia, M.Y.; Huang, Y.F.; Koo, C.H.; Fung, K.F. Recent Advances in Evapotranspiration Estimation Using Artificial Intelligence Approaches with a Focus on Hybridization Techniques—A Review. Agronomy 2020, 10, 101. [Google Scholar] [CrossRef] [Green Version]
- Jang, J.-C.; Sohn, E.-H.; Park, K.-H.; Lee, S. Estimation of Daily Potential Evapotranspiration in Real-Time from GK2A/AMI Data Using Artificial Neural Network for the Korean Peninsula. Hydrology 2021, 8, 129. [Google Scholar] [CrossRef]
- Zhang, L.; Lemeur, R. Evaluation of daily evapotranspiration estimates from instantaneous measurements. Agric. For. Meteorol. 1995, 74, 139–154. [Google Scholar] [CrossRef]
- Bae, H.; Ji, H.; Lim, Y.-J.; Ryu, Y.; Kim, M.-H.; Kim, B.-J. Characteristics of drought propagation in South Korea: Relationship between meteorological, agricultural, and hydrological droughts. Nat. Hazards 2019, 99, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Kaya, Y.Z.; Zelenakova, M.; Üneş, F.; Demirci, M.; Hlavata, H.; Mesaros, P. Estimation of daily evapotranspiration in Košice City (Slovakia) using several soft computing techniques. Theor. Appl. Clim. 2021, 144, 287–298. [Google Scholar] [CrossRef]
- Hlaváčiková, H.; Novák, V. Comparison of daily potential evapotranspiration calculated by two procedures based on Penman-Monteith type equation. J. Hydrol. Hydromech. 2013, 61, 173–176. [Google Scholar] [CrossRef]
- Fendeková, M.; Gauster, T.; Labudová, L.; Vrablíková, D.; Danáčová, Z.; Fendek, M.; Pekarova, P. Analysing 21st century meteorological and hydrological drought events in Slovakia. J. Hydrol. Hydromech. 2018, 66, 393–403. [Google Scholar] [CrossRef] [Green Version]
- Parajka, J.; Szolgay, J.; Meszaros, I.; Kostka, Z. Grid-based mapping of the long-term mean annual potential and actual evapotranspiration in upper Hron River basin. J. Hydrol. Hydromech. ÚH SAV 2004, 4, 239–254. [Google Scholar]
- Kubiak-Wójcicka, K.; Nagy, P.; Zeleňáková, M.; Hlavatá, H.; Abd-Elhamid, H. Identification of Extreme Weather Events Using Meteorological and Hydrological Indicators in the Laborec River Catchment, Slovakia. Water 2021, 13, 1413. [Google Scholar] [CrossRef]
- Kisi, O. Pan evaporation modeling using least square support vector machine, multivariate adaptive regression splines and M5 model tree. J. Hydrol. 2015, 528, 312–320. [Google Scholar] [CrossRef]
- Abed, M.; Alam Imteaz, M.; Ahmed, A.N.; Huang, Y.F. Application of long short-term memory neural network technique for predicting monthly pan evaporation. Sci. Rep. 2021, 11, 20742. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, L.B.; Duarte, A.B.; Da Cunha, F.F.; Filho, E.I.F. Multivariate adaptive regression splines (MARS) applied to daily reference evapotranspiration modeling with limited weather data. Acta Sci. Agron. 2018, 41, 39880. [Google Scholar] [CrossRef]
- Sattari, M.T.; Ahamadifar, V.; Delirhasannia, R.; Apaydin, H. Estimation of pan evaporation coefficient in cold and dry climate conditions with a decision-tree model. Atmósfera 2020, 34, 289–300. [Google Scholar] [CrossRef]
- Adnan, M.; Latif, M.A.; Rehman, A.-U.; Nazir, M. Estimating Evapotranspiration using Machine Learning Techniques. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 108–113. [Google Scholar] [CrossRef] [Green Version]
- Simon-Gáspár, B.; Soós, G.; Anda, A. Estimation Standard and Seeded Pan Evaporation Using Modelling Approach. Hydrol. Earth Syst. Sci. Discuss. 2021, in review, preprint. [Google Scholar] [CrossRef]
- Pecho, J. The Gulf Stream Is not Weakening Due to Climate Change. 2010. Available online: https://www.shmu.sk/sk/?page=2049&id=159 (accessed on 6 December 2021).
- Kopcsay, M. Weather Weather Forecast: Three Weather Scenarios for Christmas. 2021. Available online: https://www.teraz.sk/pocasie/velka-predpoved-pocasia-tri-scenar/598631-clanok.html (accessed on 10 December 2021).
- Morris, R.D.O. Hebb: The Organization of Behavior, Wiley: New York; 1949. Brain Res. Bull. 1999, 50, 437. [Google Scholar] [CrossRef]
- Keith, D. A Brief History of Machine Learning. 2021. Available online: https://www.dataversity.net/a-brief-history-of-machine-learning/# (accessed on 11 December 2021).
- Granata, F. Evapotranspiration evaluation models based on machine learning algorithms—A comparative study. Agric. Water Manag. 2019, 217, 303–315. [Google Scholar] [CrossRef]
- World Meteorological Organization Guide to Hydrological Practice. Hydrology—From Measurement to Hydrological Information; World Meteorological Organization: Geneva, Switzerland, 2008; Volume I, ISBN 9789263101686. [Google Scholar]
- Kurpelová, M.; Coufal, L.; Čulík, J. Agroklimatické podmienky ČSSR; Hydrometeorologický Ústav: Bratislava, Slovakia, 1975. [Google Scholar]
- Tomlain, J. Climate change impacts on evapotranspiration from the forest on the territory of Slovakia. Acta Meteorol. Univ. Comen. 2000, 29, 1–8. [Google Scholar]
- Rojas, R. Neural Networks: A Systematic Introduction; Springer Science and Business Media: Berlin, Germany, 2013; Volume 46. [Google Scholar]
- Assi, K.J.; Nahiduzzaman, K.M.; Ratrout, N.T.; Aldosary, A.S. Mode choice behavior of high school goers: Evaluating logistic regression and MLP neural networks. Case Stud. Transp. Policy 2018, 6, 225–230. [Google Scholar] [CrossRef]
- Desai, M.; Shah, M. An anatomization on breast cancer detection and diagnosis employing multi-layer perceptron neural network (MLP) and Convolutional neural network (CNN). Clin. eHealth 2021, 4, 1–11. [Google Scholar] [CrossRef]
- Tu, J. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 1996, 49, 1225–1231. [Google Scholar] [CrossRef]
- deVille, B.; Padraic, N. Decision Trees for Analytics Using SAS® Enterprise Miner™; SAS Institute Inc.: Cary, NC, USA, 2013. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 45, 1189–1232. [Google Scholar] [CrossRef]
- Avila, J.; Hauck, T. Least angle regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar] [CrossRef] [Green Version]
- Czika, W.; Maldonado, M.; Liu, Y. Ensemble Modeling: Recent Advances and Applications, SAS3120-2016; Proceedings of the SAS® Global Forum 2016 Conference; SAS Institute Inc.: Cary, NC, USA, 2016; Available online: https://support.sas.com/resources/papers/proceedings16/SAS3120-2016.pdf (accessed on 11 December 2021).
- Ravindran, S.M.; Bhaskaran, S.K.M.; Ambat, S.K.N. A Deep Neural Network Architecture to Model Reference Evapotranspiration Using a Single Input Meteorological Parameter. Environ. Process. 2021, 8, 1567–1599. [Google Scholar] [CrossRef]
- Čimo, J.; Aydın, E.; Šinka, K.; Tárník, A.; Kišš, V.; Halaj, P.; Toková, L.; Kotuš, T. Change in the Length of the Vegetation Period of Tomato (Solanum lycopersicum L.), White Cabbage (Brassica oleracea L. var. capitata) and Carrot (Daucus carota L.) Due to Climate Change in Slovakia. Agronomy 2020, 10, 1110. [Google Scholar] [CrossRef]
- Sudheer, K.P.; Gosain, A.K.; Rangan, D.M.; Saheb, S.M. Modelling evaporation using an artificial neural network algorithm. Hydrol. Process. 2002, 16, 3189–3202. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Country | Recommended Model for PE Estimation | Input Climatic Data Variables * | Statistical Indices ** | Number of the Meteorological Stations |
|---|---|---|---|---|---|
| Majhi and Naidu (2021) [13] | India | functional link artificial neural network (FLANN) | PE, Tmax, Tmin, RH1, RH11 | RMSE = 0.85; MAE = 0.63; EF = 0.70 | 3 |
| Kisi, O. (2015) [40] | Mediterranean Region of Turkey | multivariate adaptive regression splines (MARS), M5 Model Tree (M5Tree) | PE, Taver SR, RH, Us | RMSE = 0.189 | 2 |
| Zounemat-Kermani et al. (2021) [16] | Turkey | Levenberg–Marquardt (MLP-LM) | PE, Tmax, Tmin, SR, S, RH, Us | MAE = 0.492; d = 0.981 | 2 |
| Malik et al. (2021) [9] | Northern India | Slap Swarm Algorithm (SVR-SSA) | PE, Tmax, Tmin, RHmax, Rhmin, SR, Us | MAE = 0.697; RMSE = 1.1; IOS = 0.250; NSE = 0.861; PCC = 0.929; IOA = 0.960 | 3 |
| Abed et al. (2021) [41] | Malaysia | Long Short-Term Memory Neural Network (LSTM) | PE, Taver, Tmax, Tmin, RH, SR, Us | R2 = 0.970; MAE = 0.135; MSE = 0.027; RMSE = 0.166; RAE = 0.173; RSE = 0.029 | 2 |
| Ferreira et al. (2019) [42] | Brazil | multivariate adaptive regression splines (MARS) | Etr, Taver, SR, Us, G, es, ea, ∆, y | R2 (0.79–0.85); RMSE (0.41–0.54); MAE (0.34–0.46) | 8 |
| Al-Mukhtar (2021) [1] | middle, south, and north of Iraq | weighted K-nearest neighbor (KKNN) | PE, Tmax, Tmin, T, RH, Us | R2 = 0.98; RMSE = 26.39; MAE = 18.62; NSE = 0.97; PBIAS = 3.8 | 3 |
| Wang et al. (2017) [11] | China | multiple linear regression (MLR), Stephens and Stewart model (SS) | PE,Taver, SR, S, RH, Us | R2 = 0.988; RSME (0.314–0.405) | 8 |
| Sattari et al. (2021) [43] | Northwest Iran | M5 tree model (M5Tree) | PE, Taver, RH, Us, P | RMSE (0.0042–0.0058); R2(0.9916–0.9952); t-test (0.722–0.96); NSE (0.989 to 0.994) | 4 |
| Adnan et al. (2017) [44] | Pakistan | principal component analysis (PCA) | PE, Tmax, Tmin, Taver RH, SR, Us, P | R = 0.83426 | 1 |
| Simon-Gáspár et al. (2021) [45] | Hungary | multiple stepwise regression (MLR) | PE, Taver, Tmax, Tmin, RH, Us, Rs | RMSE = 0.834; MAE = 0.660; S = 0.217 | 1 |
| Number | Identification | Station Name | Pan Evaporation Measurement | Classification | Region Identification | Classification | Region Identification | Macro-Region Classification | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Setting date | Ending date | ||||||||||
| 1 | 665 | ĎUBÁKOVO | 1 May 2011 | 30 June 2016 | BB (Banskobystrický) | SC (south of central Slovakia) | NW (north of western Slovakia) | TN (Trenčiansky) | NW | NC | NE |
| 2 | 11800 | HOLÍČ | 1 April 2011 | 30 June 2015 | TT (Trnavský) | SW (south of western Slovakia) | SW (south of western Slovakia) | TT (Trnavský) | SW | SC | SE |
| 3 | 11810 | BRATISLAVA–M. DOLINA | 1 April 2011 | 31 October 2020 | BA (Bratislavský) | SW (south of western Slovakia) | BA (Bratislavský) | ||||
| 4 | 11813 | BRATISLAVA-KOLIBA | 1 April 2011 | 31 October 2011 | BA (Bratislavský) | SW (south of western Slovakia) | NR (Nitriansky) | ||||
| 5 | 11819 | JASLOVSKÉ BOHUNICE | 1 April 2011 | 31 July 2011 | TT (Trnavský) | SW (south of western Slovakia) | NC (north of central Slovakia) | ZA (Žilinský) | |||
| 6 | 11820 | ŽIHÁREC | 1 April 2011 | 31 October 2020 | NR (Nitriansky) | SW (south of western Slovakia) | SC (south of central Slovakia) | BB (Banskobystrický) | |||
| 7 | 11835 | MORAVSKÝ SVÄTÝ JÁN | 1 April 2011 | 31 May 2016 | TT (Trnavský) | SW (south of western Slovakia) | NE (north of eastern Slovakia) | PO (Prešovský) | |||
| 8 | 11841 | DOLNÝ HRIČOV | 1 April 2011 | 30 September 2011 | ZA (Žilinský) | NC (north of central Slovakia) | SE (south of eastern Slovakia) | KE (Košický) | |||
| 9 | 11847 | TOPOĽČANY | 1 April 2011 | 31 October 2020 | NR (Nitriansky) | SW (south of western Slovakia) | |||||
| 10 | 11856 | MOCHOVCE | 1 April 2011 | 31 July 2011 | NR (Nitriansky) | SW (south of western Slovakia) | |||||
| 11 | 11858 | HURBANOVO | 1 April 2011 | 31 October 2020 | NR (Nitriansky) | SW (south of western Slovakia) | |||||
| 12 | 11862 | BELUŠA | 1 April 2011 | 31 August 2015 | TN (Trenčiansky) | NW (north of western Slovakia) | |||||
| 13 | 11867 | PRIEVIDZA | 1 April 2011 | 31 October 2020 | TN (Trenčiansky) | NW (north of western Slovakia) | |||||
| 14 | 11869 | RABČA | 1 May 2011 | 31 October 2020 | ZA (Žilinský) | NC (north of central Slovakia) | |||||
| 15 | 11878 | LIPTOVSKÝ MIKULÁŠ | 1 May 2011 | 31 October 2020 | ZA (Žilinský) | NC (north of central Slovakia) | |||||
| 16 | 11880 | DUDINCE | 1 April 2011 | 31 October 2020 | BB (Banskobystrický) | SC (south of central Slovakia) | |||||
| 17 | 11881 | ŽELIEZOVCE | 1 June 2011 | 31 October 2014 | NR (Nitriansky) | SW (south of western Slovakia) | |||||
| 18 | 11898 | BANSKÁ BYSTRICA | 1 May 2011 | 31 October 2020 | BB (Banskobystrický) | SC (south of central Slovakia) | |||||
| 19 | 11903 | SLIAČ | 1 April 2011 | 31 October 2020 | BB (Banskobystrický) | SC (south of central Slovakia) | |||||
| 20 | 11910 | LOM NAD RIMAVICOU | 1 May 2011 | 31 October 2020 | BB (Banskobystrický) | SC (south of central Slovakia) | |||||
| 21 | 11918 | LIESEK | 1 April 2011 | 31 October 2020 | ZA (Žilinský) | NC (north of central Slovakia) | |||||
| 22 | 11927 | BOĽKOVCE | 1 April 2011 | 31 October 2020 | BB (Banskobystrický) | SC (south of central Slovakia) | |||||
| 23 | 11938 | TELGÁRT | 1 May 2011 | 12 October 2020 | BB (Banskobystrický) | SC (south of central Slovakia) | |||||
| 24 | 11944 | ROŽŇAVA | 1 April 2011 | 30 October 2017 | KE (Košický) | SE (south of eastern Slovakia) | |||||
| 25 | 11949 | SPIŠSKÉ VLACHY | 1 May 2011 | 31 October 2020 | KE (Košický) | SE (south of eastern Slovakia) | |||||
| 26 | 11952 | GÁNOVCE | 20 April 2011 | 30 October 2020 | PO (Prešovský) | NE (north of eastern Slovakia) | |||||
| 27 | 11955 | PREŠOV-VOJSKO | 1 May 2011 | 31 October 2020 | PO (Prešovský) | NE (north of eastern Slovakia) | |||||
| 28 | 11968 | KOŠICE, LETISKO | 1 April 2011 | 31 October 2020 | KE (Košický) | SE (south of eastern Slovakia) | |||||
| 29 | 11976 | TISINEC | 1 April 2011 | 31 October 2020 | PO (Prešovský) | NE (north of eastern Slovakia) | |||||
| 30 | 11978 | TREBIŠOV, MILHOSTOV | 1 April 2011 | 30 October 2020 | KE (Košický) | SE (south of eastern Slovakia) | |||||
| 31 | 11979 | SOMOTOR | 1 April 2011 | 31 October 2014 | KE (Košický) | SE (south of eastern Slovakia) | |||||
| 32 | 11982 | MICHALOVCE | 1 April 2011 | 31 October 2020 | KE (Košický) | SE (south of eastern Slovakia) | |||||
| 33 | 11984 | ORECHOVÁ | 1 April 2011 | 31 October 2020 | KE (Košický) | SE (south of eastern Slovakia) | |||||
| 34 | 11993 | KAMENICA N. CIROCHOU | 1 April 2011 | 31 October 2020 | PO (Prešovský) | NE (north of eastern Slovakia) | |||||
| 35 | 11995 | VYSOKÁ NAD UHOM | 1 April 2011 | 31 October 2012 | KE (Košický) | SE (south of eastern Slovakia) | |||||
| Analysis Variable: Pan Evaporation (PE) (mm) | ||||||
|---|---|---|---|---|---|---|
| Region Orientation | Observation Numbers | Mean | Median | Standard Deviation | Coefficient of Variation | Range |
| SW | 23,723 | 2.55 | 2.40 | 1.43 | 56.27 | 14.00 |
| SC | 18,557 | 2.28 | 2.20 | 1.20 | 52.76 | 15.20 |
| NC | 11,128 | 1.96 | 1.90 | 1.10 | 56.18 | 7.00 |
| SE | 22,256 | 2.55 | 2.40 | 1.51 | 59.35 | 18.50 |
| NE | 11,128 | 2.32 | 2.20 | 1.23 | 53.02 | 12.60 |
| NW | 5381 | 2.30 | 2.20 | 1.37 | 59.60 | 8.50 |
| Region Comparison | Difference between Means | Simultaneous 95% Confidence Limits | ||
|---|---|---|---|---|
| SE—SW | 0.00009 | −0.04029 | 0.04047 | |
| SE—NE | 0.22104 | 0.17463 | 0.26744 | *** |
| SE—NW | 0.24533 | 0.18232 | 0.30834 | *** |
| SE—SC | 0.26869 | 0.22804 | 0.30933 | *** |
| SE—NC | 0.58997 | 0.54258 | 0.63735 | *** |
| SW—SE | −0.00009 | −0.04047 | 0.04029 | |
| SW—NE | 0.22094 | 0.17405 | 0.26783 | *** |
| SW—NW | 0.24523 | 0.18186 | 0.30860 | *** |
| SW—SC | 0.26859 | 0.22739 | 0.30980 | *** |
| SW—NC | 0.58987 | 0.54201 | 0.63773 | *** |
| NE—SE | −0.22104 | −0.26744 | −0.17463 | *** |
| NE—SW | −0.22094 | −0.26783 | −0.17405 | *** |
| NE—NW | 0.02429 | −0.04308 | 0.09166 | |
| NE—SC | 0.04765 | 0.00053 | 0.09477 | *** |
| NE—NC | 0.36893 | 0.31589 | 0.42197 | *** |
| NW—SE | −0.24533 | −0.30834 | −0.18232 | *** |
| NW—SW | −0.24523 | −0.30860 | −0.18186 | *** |
| NW—NE | −0.02429 | −0.09166 | 0.04308 | |
| NW—SC | 0.02336 | −0.04018 | 0.08690 | |
| NW—NC | 0.34464 | 0.27659 | 0.41269 | *** |
| SC—SE | −0.26869 | −0.30933 | −0.22804 | *** |
| SC—SW | −0.26859 | −0.30980 | −0.22739 | *** |
| SC—NE | −0.04765 | −0.09477 | −0.00053 | *** |
| SC—NW | −0.02336 | −0.08690 | 0.04018 | |
| SC—NC | 0.32128 | 0.27319 | 0.36936 | *** |
| NC—SE | −0.58997 | −0.63735 | −0.54258 | *** |
| NC—SW | −0.58987 | −0.63773 | −0.54201 | *** |
| NC—NE | −0.36893 | −0.42197 | −0.31589 | *** |
| NC—NW | −0.34464 | −0.41269 | −0.27659 | *** |
| NC—NC | −0.32128 | −0.36936 | −0.27319 | *** |
| ML Model | Valid Average Squared Error | Train Average Squared Error | Test Average Squared Error |
|---|---|---|---|
| Dmine Regression | 0.78819 | 0.77826 | 0.78094 |
| Gradient Boosting | 0.79695 | 0.78867 | 0.79537 |
| Decision Tree | 0.84862 | 0.81904 | 0.84500 |
| Ensemble model | 0.93492 | 0.93011 | 0.93512 |
| DM Neural | 1.13691 | 1.14073 | 1.14558 |
| LARS | 1.38220 | 1.37880 | 1.38476 |
| AutoNeural | 1.62204 | 1.61178 | 1.63309 |
| Neural Network | 1.62526 | 1.61762 | 1.63568 |
| Effect | DF | R-Square | F Value | p-Value | Sum of Squares |
|---|---|---|---|---|---|
| AOV16: Average Humidity | 15 | 0.367893 | 1290.510136 | <0.0001 | 22095 |
| Var: Temperature Min | 1 | 0.142492 | 9679.358776 | <0.0001 | 8557.782572 |
| AOV16: Temperature Max | 10 | 0.015878 | 111.436181 | <0.0001 | 953.574047 |
| AOV16: WindSpeed14 | 15 | 0.012232 | 58.721617 | <0.0001 | 734.603369 |
| AOV16: WindDirection14 | 15 | 0.006584 | 32.049942 | <0.0001 | 395.401311 |
| AOV16: Windspeed21 | 14 | 0.003448 | 18.115361 | <0.0001 | 207.096720 |
| AOV16: Temperature Average | 9 | 0.002904 | 23.875931 | <0.0001 | 174.387981 |
| AOV16: Water Vapor Pressure—Average | 14 | 0.002906 | 15.453458 | <0.0001 | 174.513166 |
| Var: Average Humidity | 1 | 0.002524 | 189.014114 | <0.0001 | 151.605476 |
| AOV16: WindDirection21 | 15 | 0.002285 | 11.461461 | <0.0001 | 137.246991 |
| AOV16: Elevation Above Sea Level | 10 | 0.001970 | 14.880498 | <0.0001 | 118.297418 |
| Var: Temperature Max | 1 | 0.001751 | 132.805014 | <0.0001 | 105.159677 |
| AOV16: Wind Direction7 | 15 | 0.001362 | 6.905653 | <0.0001 | 81.803511 |
| AOV16: Temperature Min | 9 | 0.001215 | 10.295476 | <0.0001 | 72.991107 |
| AOV16: Wind Speed7 | 15 | 0.000957 | 4.873271 | <0.0001 | 57.482001 |
| AOV16: Precipitation | 15 | 0.000854 | 4.355927 | <0.0001 | 51.301760 |
| Var: Wind Speed14 | 1 | 0.000800 | 61.284456 | <0.0001 | 48.030878 |
| Var: Temperature—Average | 1 | 0.000740 | 56.825843 | <0.0001 | 44.461511 |
| Pearson Correlation Coefficients | |
|---|---|
| Prob > |r| under H0: Rho = 0 | |
| Number of Observations | |
| PE | |
| Tmax (°C) | 0.60209 |
| T_max (°C) | <0.0001 |
| 77,531 | |
| Tmin (°C) | 0.43345 |
| T_min (°C) | <0.0001 |
| 77,531 | |
| Taver | 0.58680 |
| Taver (°C) | <0.0001 |
| 77,525 | |
| Elevation | −0.11332 |
| above | <0.0001 |
| sea level (m) | 77,534 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Novotná, B.; Jurík, Ľ.; Čimo, J.; Palkovič, J.; Chvíla, B.; Kišš, V. Machine Learning for Pan Evaporation Modeling in Different Agroclimatic Zones of the Slovak Republic (Macro-Regions). Sustainability 2022, 14, 3475. https://doi.org/10.3390/su14063475
Novotná B, Jurík Ľ, Čimo J, Palkovič J, Chvíla B, Kišš V. Machine Learning for Pan Evaporation Modeling in Different Agroclimatic Zones of the Slovak Republic (Macro-Regions). Sustainability. 2022; 14(6):3475. https://doi.org/10.3390/su14063475
Chicago/Turabian StyleNovotná, Beáta, Ľuboš Jurík, Ján Čimo, Jozef Palkovič, Branislav Chvíla, and Vladimír Kišš. 2022. "Machine Learning for Pan Evaporation Modeling in Different Agroclimatic Zones of the Slovak Republic (Macro-Regions)" Sustainability 14, no. 6: 3475. https://doi.org/10.3390/su14063475
APA StyleNovotná, B., Jurík, Ľ., Čimo, J., Palkovič, J., Chvíla, B., & Kišš, V. (2022). Machine Learning for Pan Evaporation Modeling in Different Agroclimatic Zones of the Slovak Republic (Macro-Regions). Sustainability, 14(6), 3475. https://doi.org/10.3390/su14063475