1. Introduction
Estimating the diameter increment of forests is one of the most important relationships in forest management and planning [
1,
2]. Therefore, choosing an accurate method to determine this relationship in the forests has great importance. A great variety of growth model systems exist, and they are usually grouped in different levels of resolution such as stand, diameter class, and individual tree [
3].
Growth and yield models predict the dynamics of forests, including future forest growth and products that enable the study of alternative management options [
4,
5]. The diameter increment of trees is affected by internal factors such as physiology, species, age, and genetic characteristics and external factors such as climatic conditions, ground slope, soil type, and competition from nearby trees [
6].
The revolution in computing technology has affected growth and yield modeling as it has all fields of science [
7]. Computationally intensive methods have been applied in various studies, showing that the use of machine learning methods has many advantages [
8,
9,
10,
11]. Machine learning methods have been used to detect complex nonlinear relationships and work with qualitative data. The utility of these methods has been well demonstrated in many studies [
12,
13,
14,
15,
16,
17]. ANNs form a subset of machine learning that is used for a wide range of problem-solving tasks, including in optimization, prediction, diagnosis, and control [
18]. Another method of machine learning that has many applications in various fields, including forestry, is the ANFIS method, and the results of various studies in this field are satisfactory [
15,
19]. This method has been widely used in recent years because it is not limited to the assumptions of experimental models and has the ability to solve problems related to nonlinear relationships [
13]. The ANFIS is a fuzzy system with a parallel structure, and neural network learning algorithms are used to adjust the parameters of the fuzzy system [
20].
Among the available methods in machine learning, ANNs are the most common method for modeling at the individual-tree level [
21], while usage of other techniques such as the adaptive neuro-fuzzy inference system (ANFIS) and fuzzy logic are in their early stages [
18]. The ANFIS as a nonlinear model was proposed by Jang [
22] for the first time. In its structure, there are two different parametric groups that include premise and consequence. The training of the ANFIS involves determining these parameters using an optimization algorithm [
23]. The ANFIS is a two-in-one package, as if you are utilizing a neural network and fuzzy logic advantages at the same time [
22].
Different studies have been conducted in various fields of forest science using ANNs and ANFIS methods. Reis et al. [
24] investigated the mortality and survival of individual-trees in selectively harvested forests using ANNs in Amazon rainforests. Training and testing of ANNs were performed for modeling, classification, mortality, and survival, using different input variables. Reis et al. [
24] argued that the overall efficiencies of the classification in the training and testing phases were above 89% and 90%, respectively. In another study conducted by Vieira et al. [
18], the predicted growth of diameter at breast height (DBH) and height of eucalyptus trees were determined using both techniques (ANN and ANFIS). These two methods have high predictive accuracy for DBH growth and tree height. Reis et al. [
25], in their research, predicted a diameter growth model using an ANN with a correlation above 99% and root mean square error (RMSE) below 11%. They argued that the ANN could be used effectively to help in the management of rainforests and ensure the environmental and economic sustainability of the forest. Ashraf et al. [
26], using machine learning, developed growth and yield models (basal area and volume increment) in forests. The coefficients of determination (
R2) of the model using field data were 0.38 and 0.60 for the increments of the basal area and volume, respectively. Other studies have also highlighted the successful use of ANNs in forest model development, including predicting the growth and mortality of trees (e.g., [
27,
28,
29]). In the Hyrcanian uneven-aged and mixed forests, Bayat et al. [
15] estimated forest tree height using an ANN and ANFIS and concluded that these methods have good ability for tree height estimation.
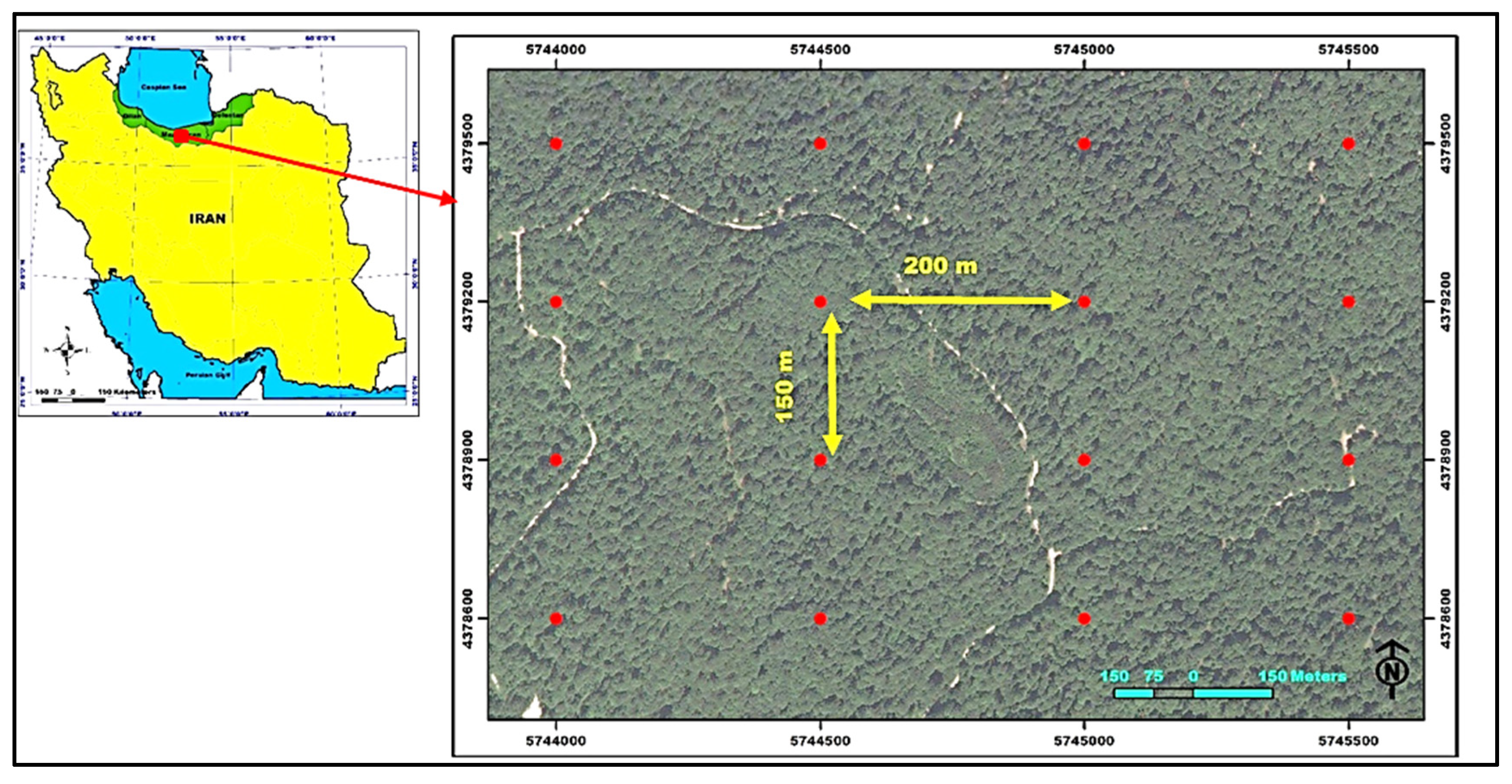
Hyrcanian forests are of great importance as the only commercial forests in Iran that have temperate broad-leaved species. Their approximate area is 1.85 million hectares and about 15% of Iran’s forests. This region is of special importance with about 44% of the vascular plants in Iran. There are about 500 species of plants native to Iran in these forests. Therefore, sustainable and effective planning and management in this region have always been a major concern. Accurate estimation of the characteristics of these forests, including diameter increment, has great importance for planners [
30].
However, the application of ANNs and the ANFIS to predict the diameter increment in uneven-aged forests has not been previously conducted in the world. Therefore, by providing diameter increment models in mixed and uneven-aged Caspian forests using these two techniques, we are presenting here an account of novel approaches to build a foundation for future studies.
Therefore, in this study, some specific issues were investigated: (1) estimation of the diameter increment in mixed and uneven-aged forests using machine learning (the main objective), (2) the potential use of nonparametric models including ANNs and the ANFIS for the estimation of the diameter increment, (3) a comparison between the ANFIS and ANN in estimating tree increment, and finally (4) optimization of ANN and ANFIS methods when used in predicting tree diameter increment.
4. Discussion
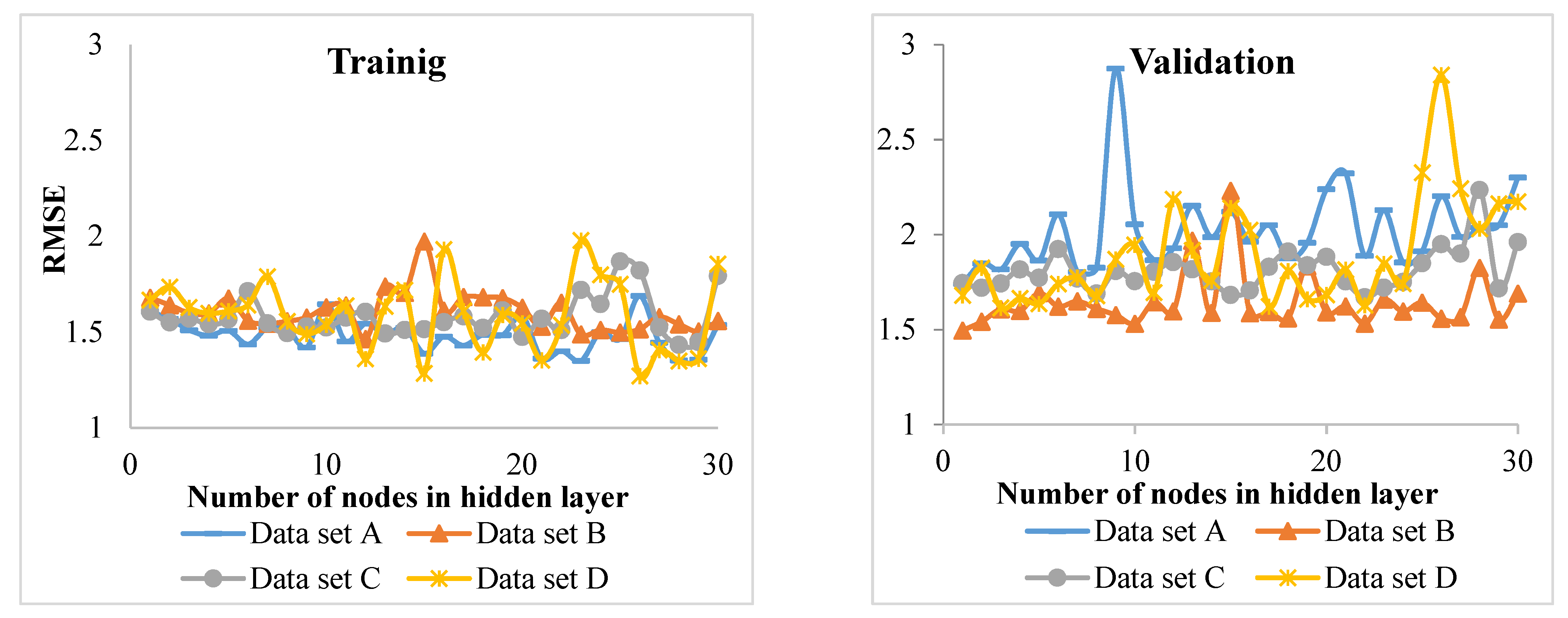
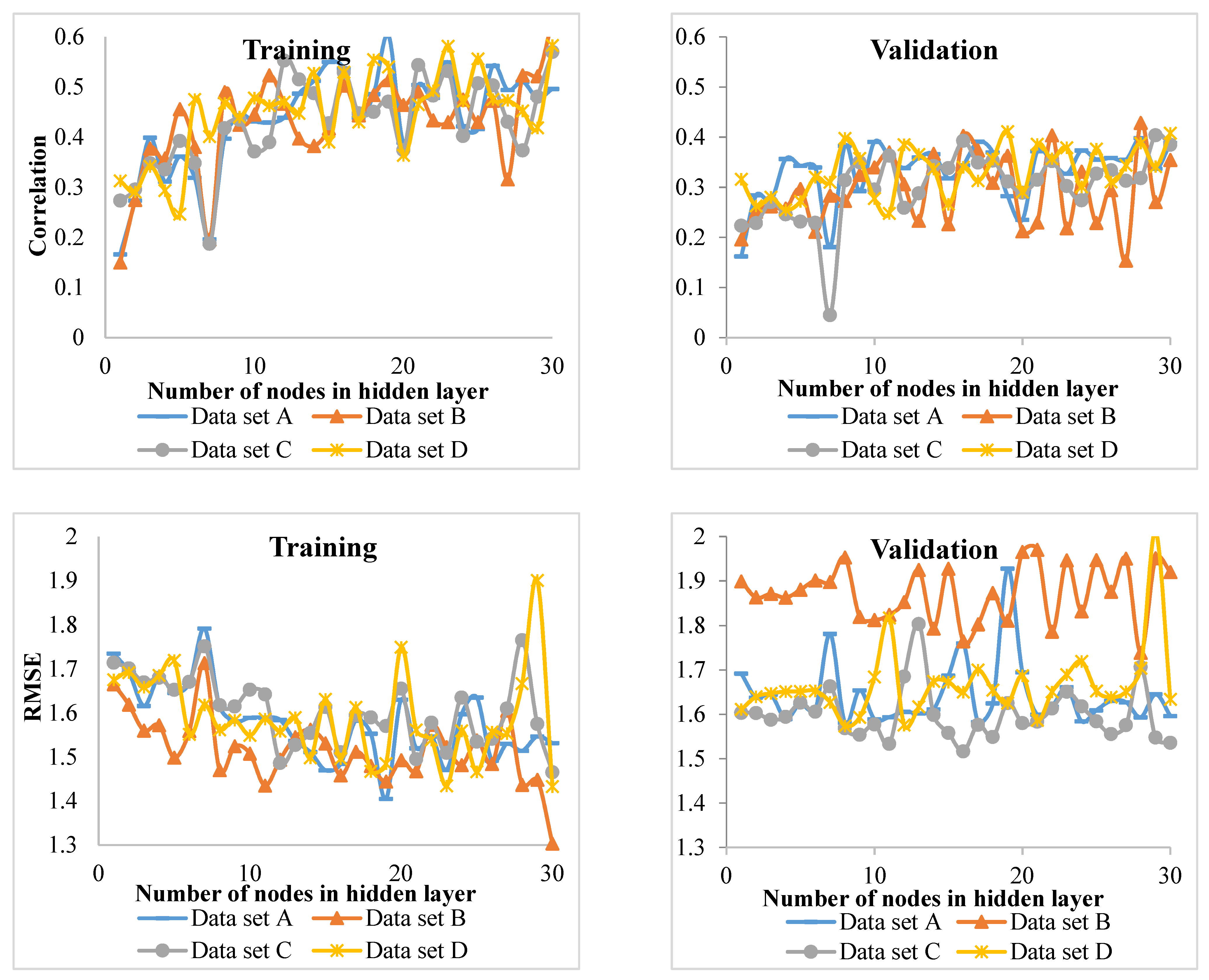
Since the habitat conditions of the Hyrcanian forests change from west to east and in elevation, it is very difficult to develop increment models. Therefore, identifying the appropriate predictors (inputs of the model) on increment and incorporating them into increment models is key to making predictions. For this purpose, the best input variables in the diameter increment models of four groups of beech, hornbeam, chestnut-leaved oak, and other species were identified using MLP (a class of feedforward ANN) and ANFIS techniques. The results were then compared.
Our results indicated that in relation to each group of species, different parameters could be significant, such as a previous study concluded [
55,
56]. For example, in relation to beech species, factors such as DBH and natural logarithm of DBH, BAL,
Hd, and average of BA were significant. These variables are associated with hornbeam (DBH, natural logarithm of DBH, and BAL) and chestnut-leaved oak, and other species (DBH and natural logarithm of DBH, BAL, and H
s) showed a different pattern. The effectiveness of the two indices, size diversity and species diversity of Shannon–Wiener, on the increment rate were consistent with the results of Liang [
57]. In the research for oak forests, an individual-tree model was presented, and it was concluded that the indices affecting the diameter increment include tree size, basal area, tree diameter, volume inventory, and site index [
58]. The results of Lhotka and Loewenstein [
59] on the development of individual-tree diameter growth models for the Missouri forest stands in the United States showed that the BAL parameter was effective for all species, while the patterns of remaining predictors were different for other species. The results of Lhotka and Loewenstein [
59] were in line with the findings of the present study, except in one case. Unlike their findings, in our study the species composition (species diversity index) was not effective for all species groups. In general, the BAL variable has been used as the most important competition variable in previous growth and increment modeling studies (e.g., [
60,
61,
62,
63,
64]). In this study, we incorporated all the measured independent variables, i.e., DBH, BAL,
HS, Hd, BA, number of trees per hectare, slope, aspect, and altitude into the modeling process. However, only DBH, BAL, BA,
HS, and
Hd were significant and considered in the final model. Other variables were removed from the final model because they were insignificant in terms of correlation because the study area was relatively consistent in some respects (e.g., slope). If a larger area is selected for study, these variables may become meaningful [
30,
40]. However, variables of size diversity and species diversity have not been closely evaluated, except for few studies (e.g., [
1,
57]). Given the fact that the Hyrcanian forests have high biodiversity (species diversity) and high size diversity [
30], consideration of these two indices in new studies is most important.
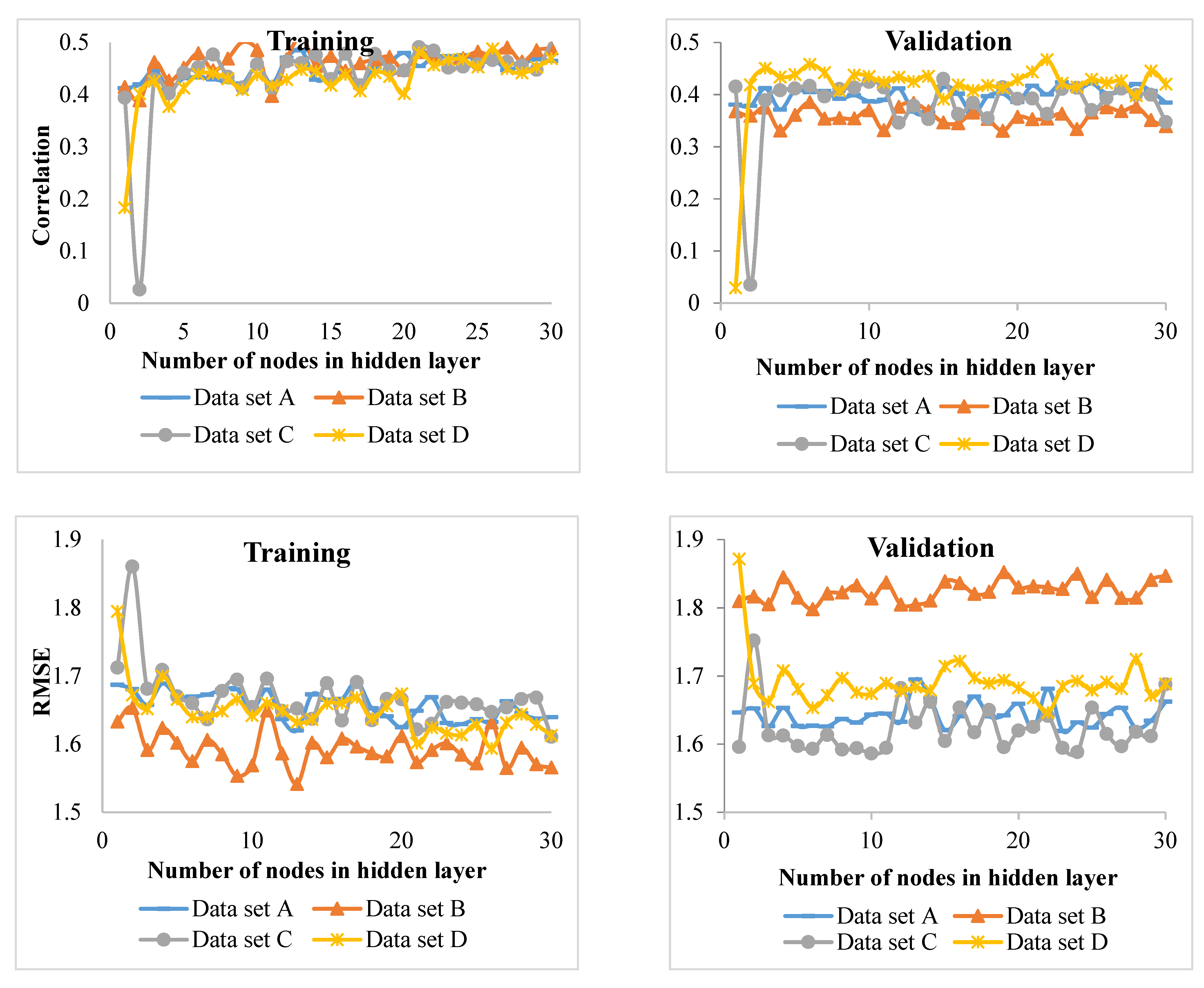
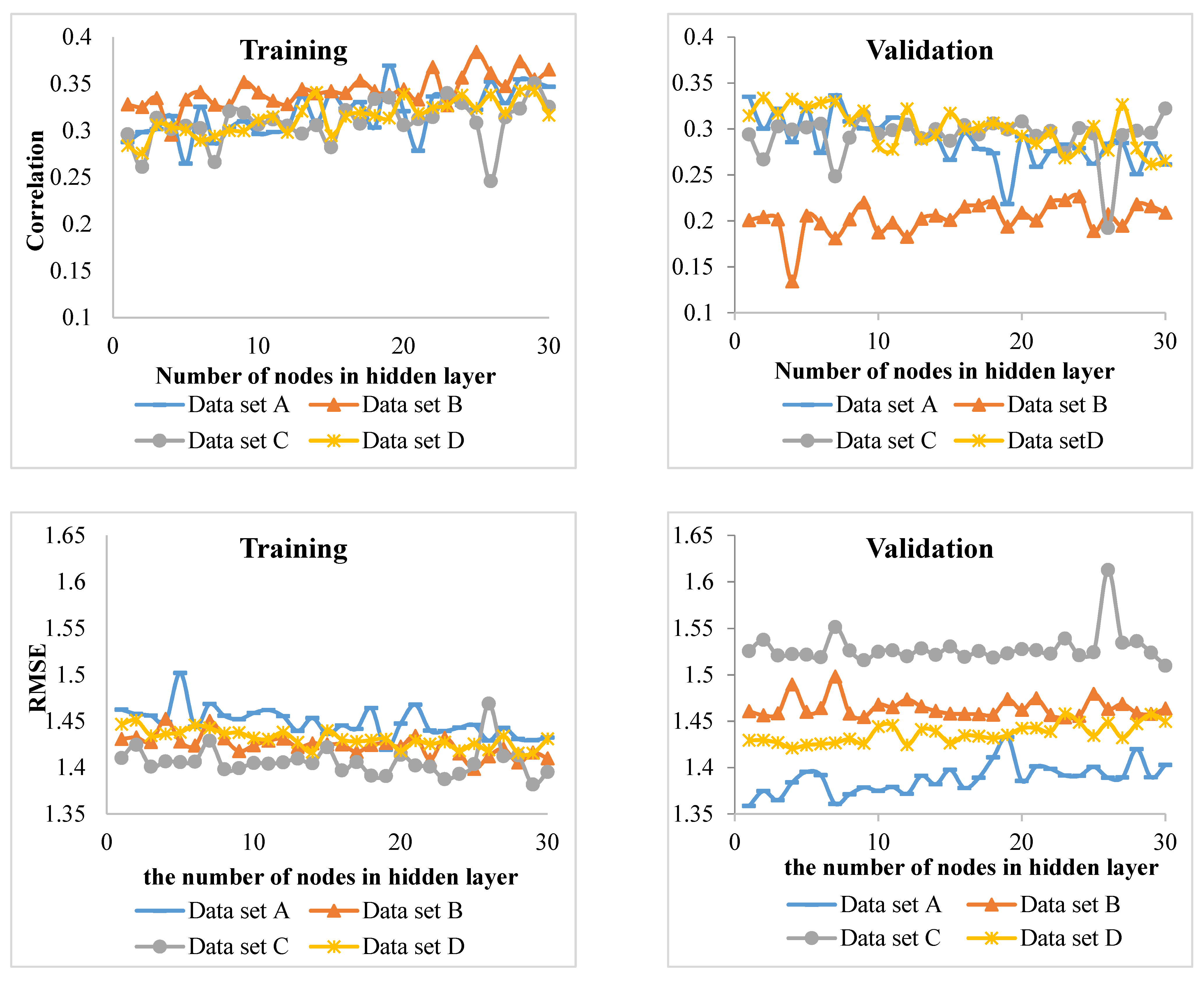
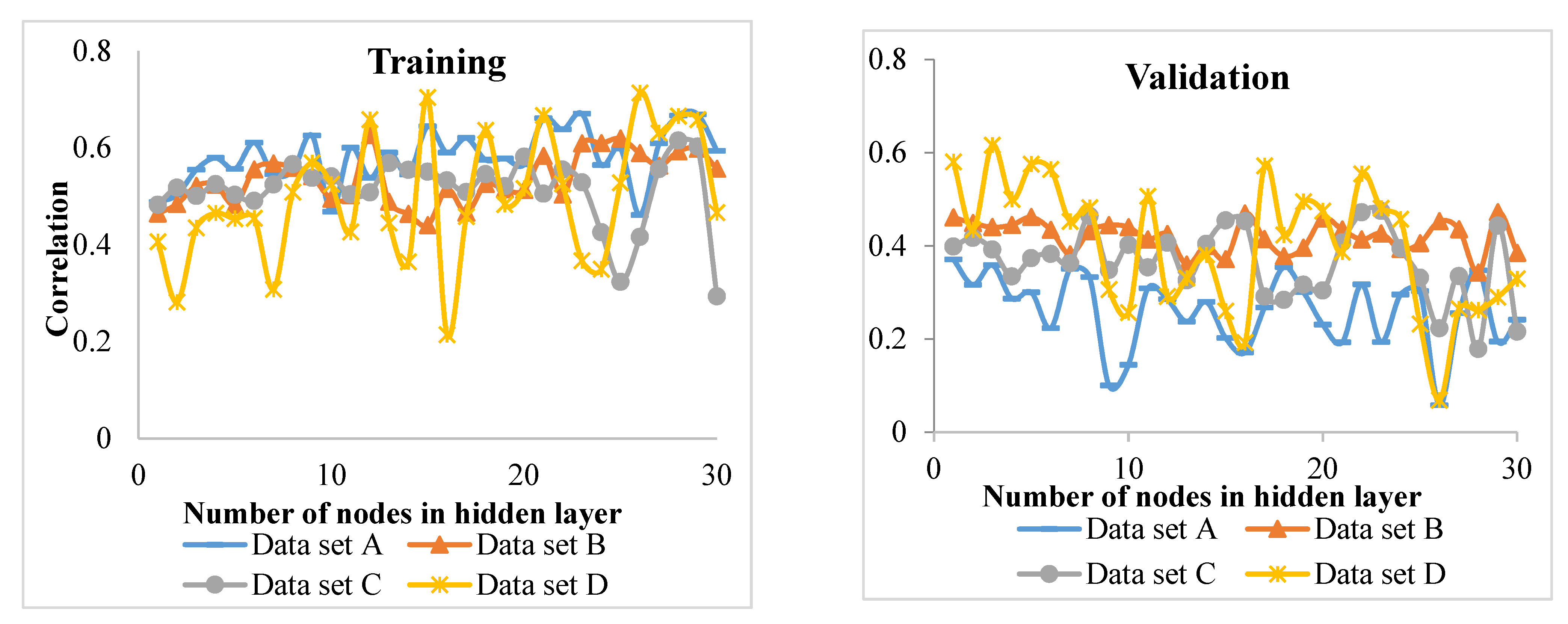
Comparison of the MLP and ANFIS techniques showed that the latter performed better for of the beech and chestnut-leaved oak groups. On the other hand, MLP showed promising results for the hornbeam and other species groups. However, in the study of Vieira et al. [
18], no significant difference was observed for diameter growth estimation between the ANFIS and ANN techniques. It seems that with increasing complexity of the relationship, the ANN technique brings better results [
65]. Beech and chestnut-leaved oak clusters occupy more distinctive site conditions than the other two groups in the Hyrcanian forests. For instance, the beech class is mainly situated in the northern side [
6], while the chestnut-leaved oak group is situated in the southern and southwestern directions. The hornbeam group appeared in almost all sample plots (high distribution). Therefore, the determination of its diameter increment was more challenging and complicated, and the coefficient of determination (
R2) of the model showed the lowest value compared to the other tree groups. This means that the inputs of the model did not properly account for the variation in the diameter increment. It is recommended that hybrid models be fitted for this group. The low
R2 values can be attributed to a large number of heterogeneous data used in this study. However, the values were statistically significant and allowed for identifying major growth driving factors. For future works, other factors (e.g., soil properties) from a large-scale area might be incorporated into the models for measuring, and perhaps improving, their performance.
Using the k-fold strategy in evaluation showed that different combinations of data give different results. Therefore, the use of this strategy and the acquisition of the final model of the four-folds (where, k = 4) average provides the most realistic result. We found this strategy useful, as it has been considered promising in other recent studies (e.g., [
26,
61,
63]). The correlation coefficient of models, despite not having high values, were significant at a 0.01 level. There could be several reasons for such a pattern of correlation coefficients. One possibility could be the existence of trees with the same diameter and significant differences in diameter increment values [
66], which resulted from forest competition and succession [
67]. The second reason might be the autocorrelation of data used in increment models due to both time and spatial components [
26]. Although permanent sample plots are the most popular method for estimating forest growth and yield and have been used in numerous studies (e.g., [
60,
61,
62,
63]), they are not immune from the autocorrelation. The autocorrelation created within the sample plots was greater than the autocorrelation between the sample plots, because the sample plots are separated by more distance than the trees within a sample plot [
26].
Since previous studies carried out using ANNs and the ANFIS are different from our study in terms of diverse aspects such as forest type (even-aged or uneven-aged) and research goal (diameter increment, diameter growth, basal area growth survival, etc.), comparisons between our results and those of most prior studies are not possible.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





