
A New Container Throughput Forecasting Paradigm under COVID-19


Abstract
:1. Introduction
2. Literature Review
2.1. Forecasting Model
2.2. Decomposition Methods in Forecasting
2.3. Forecasting Considering COVID-19
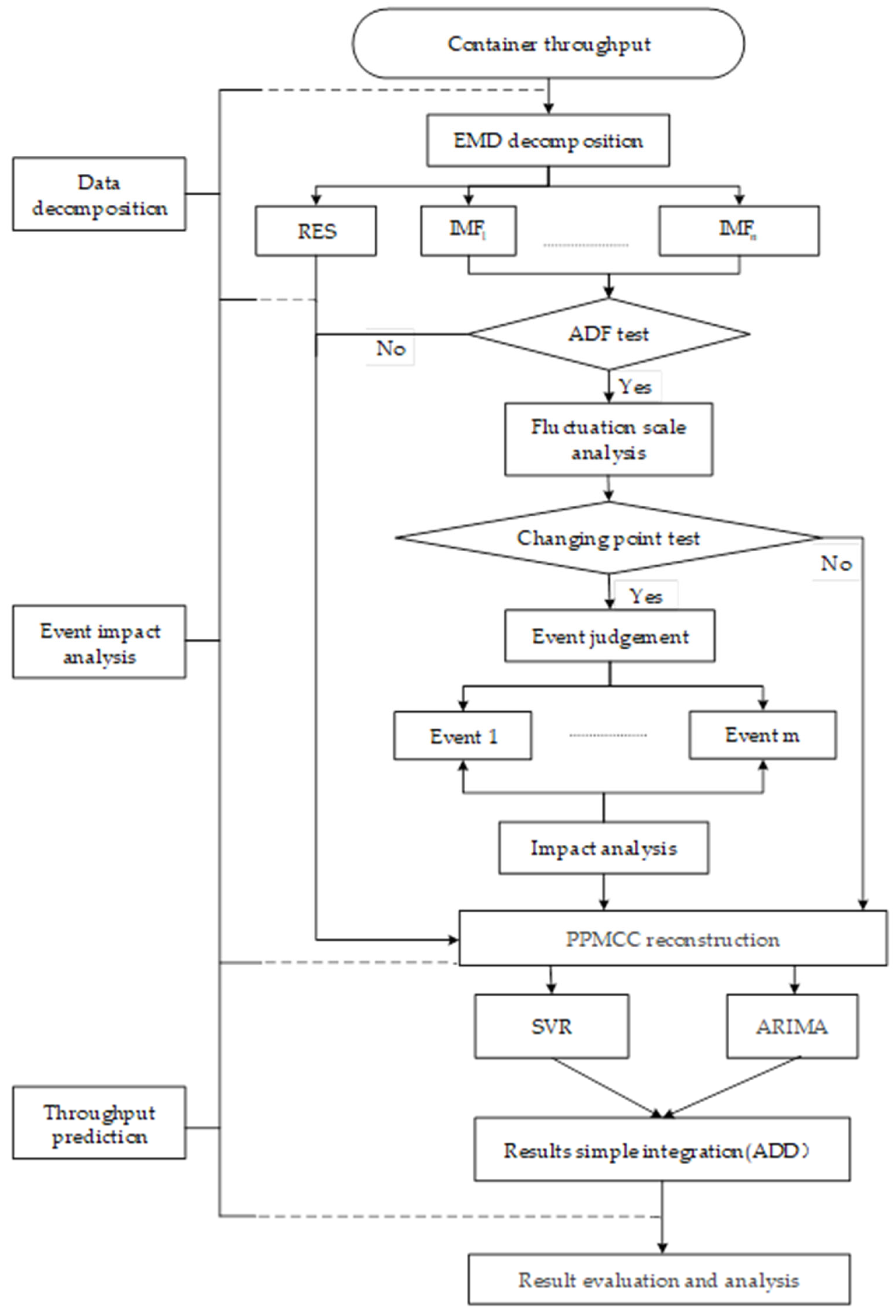
3. Methodology Formulation
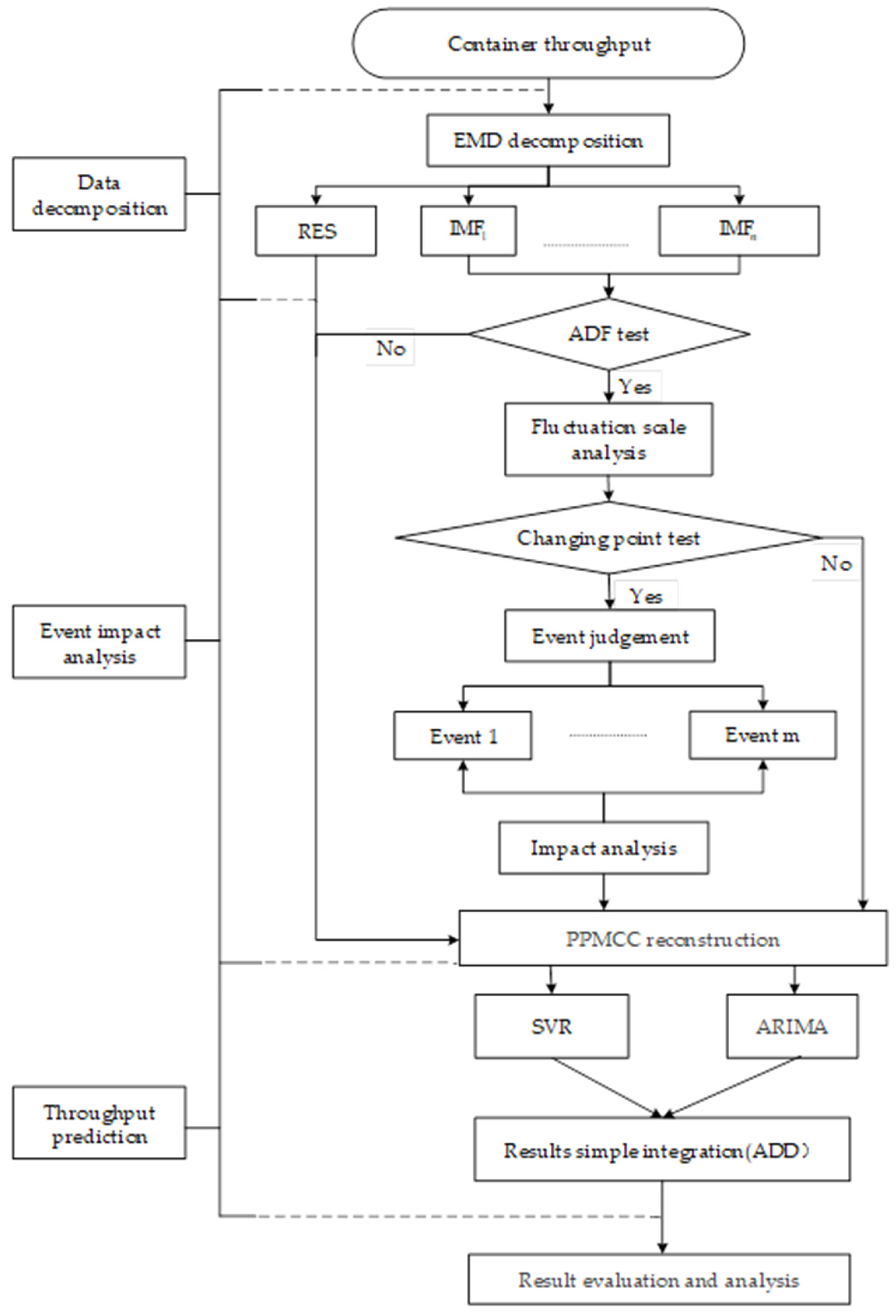
3.1. Framework of the Proposed Methodology
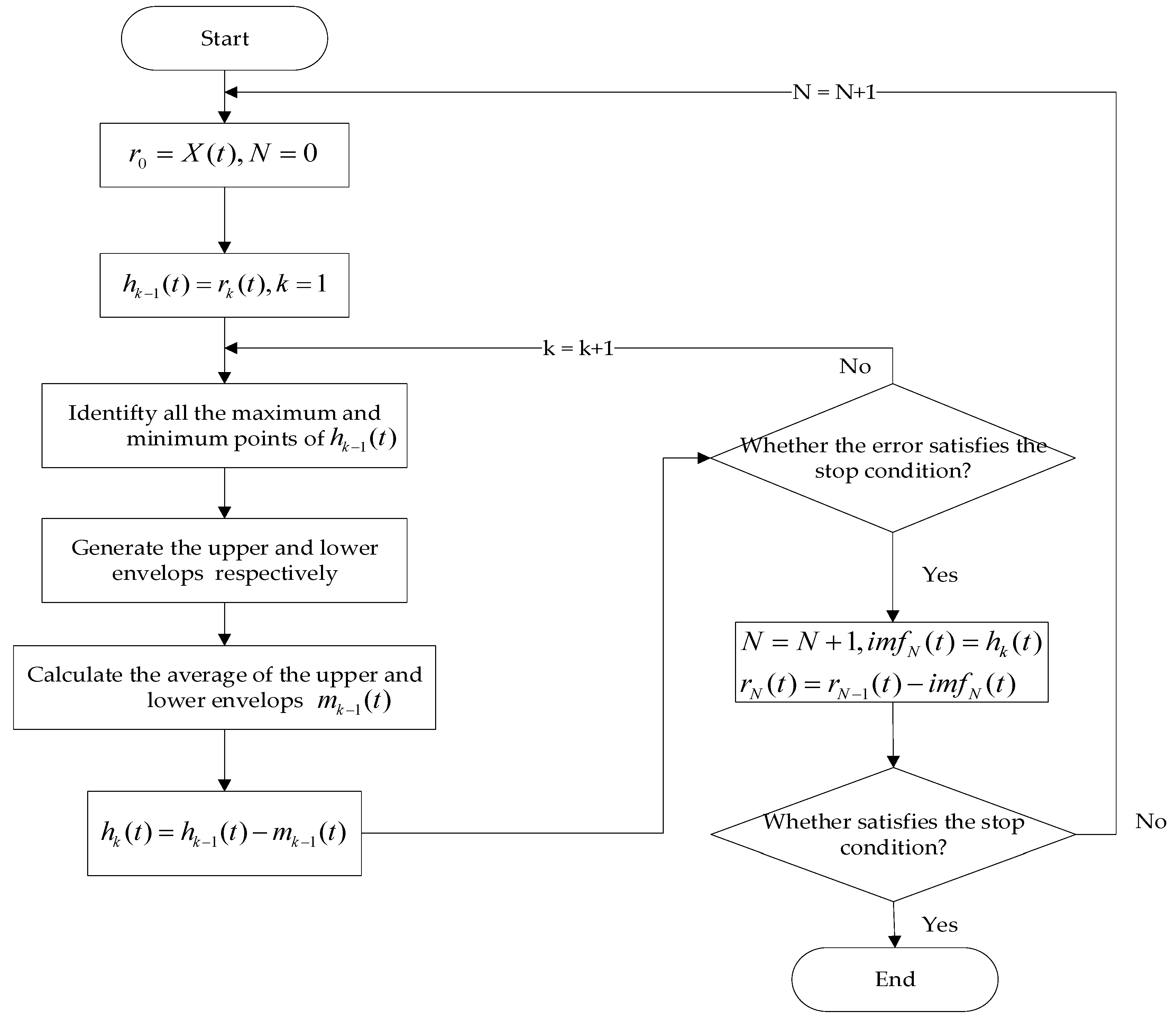
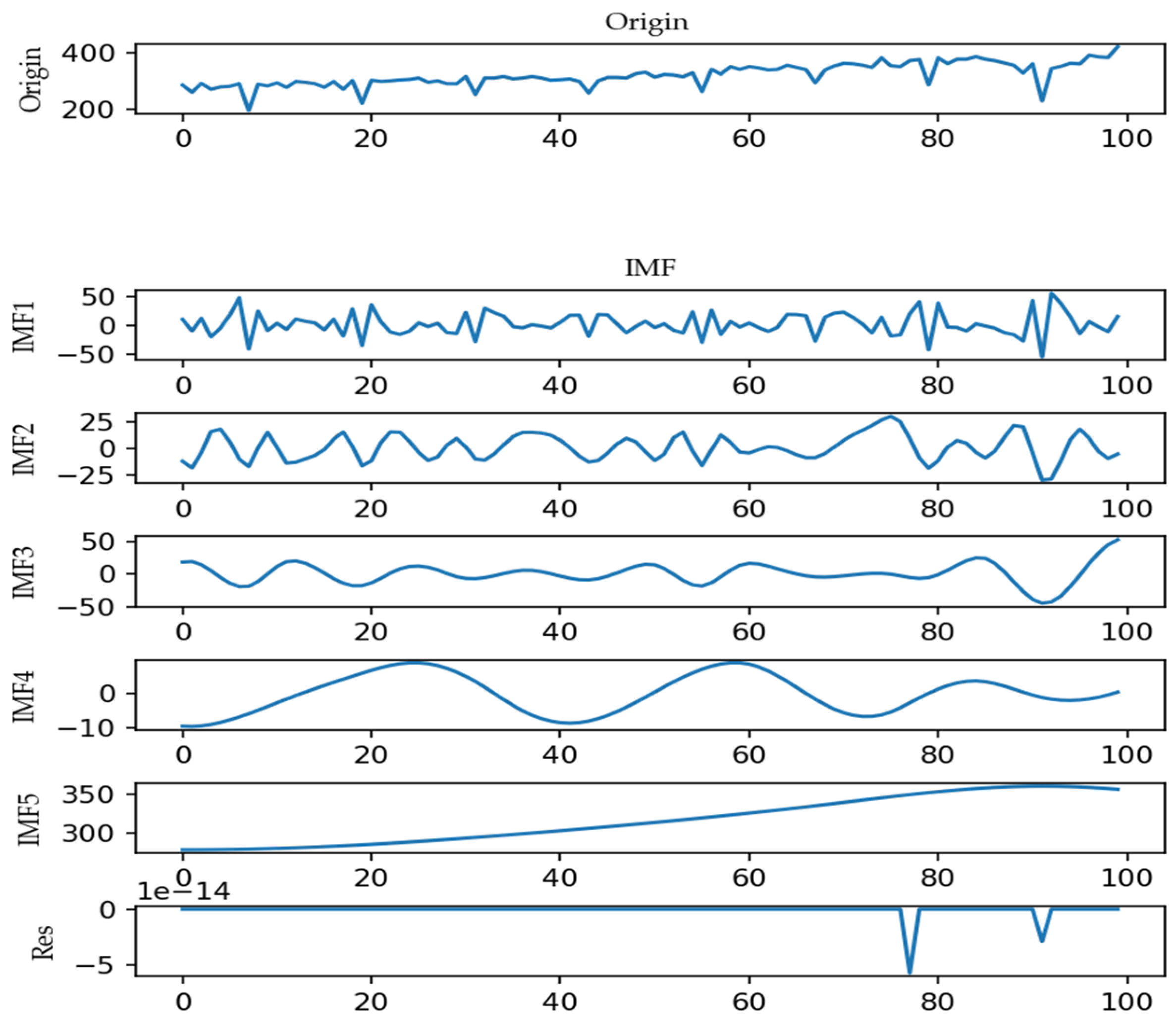
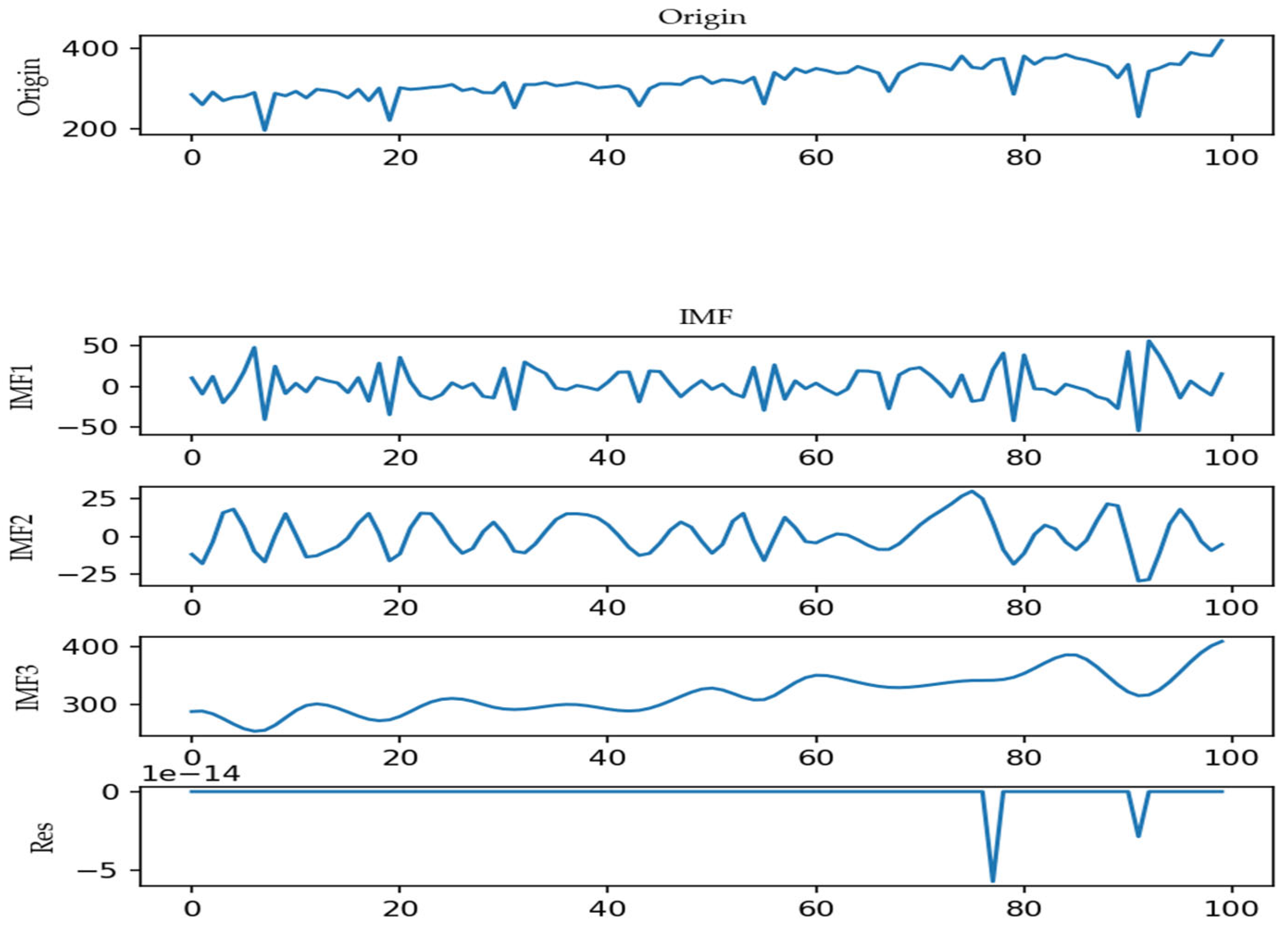
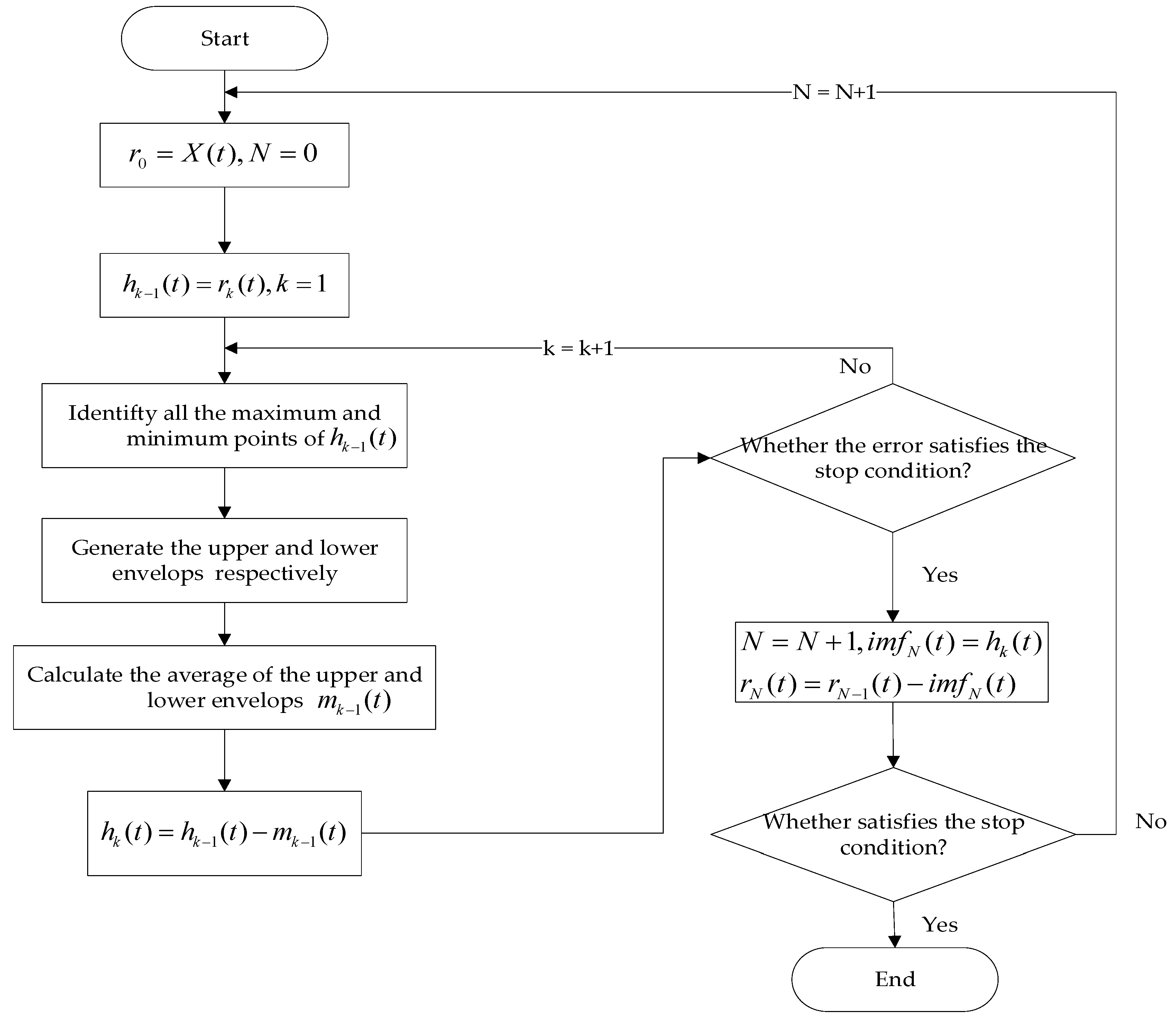
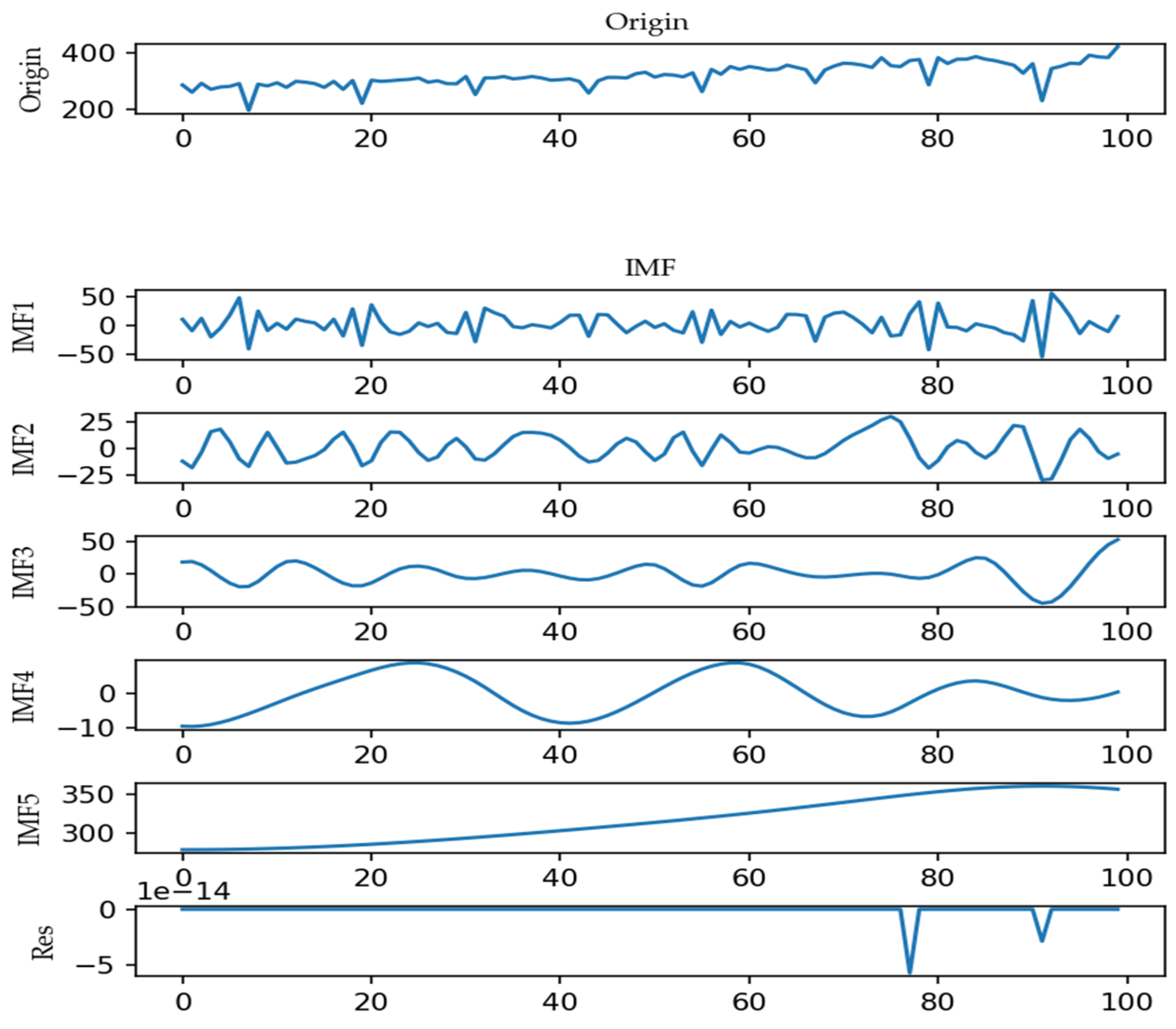
3.2. Data Decomposition
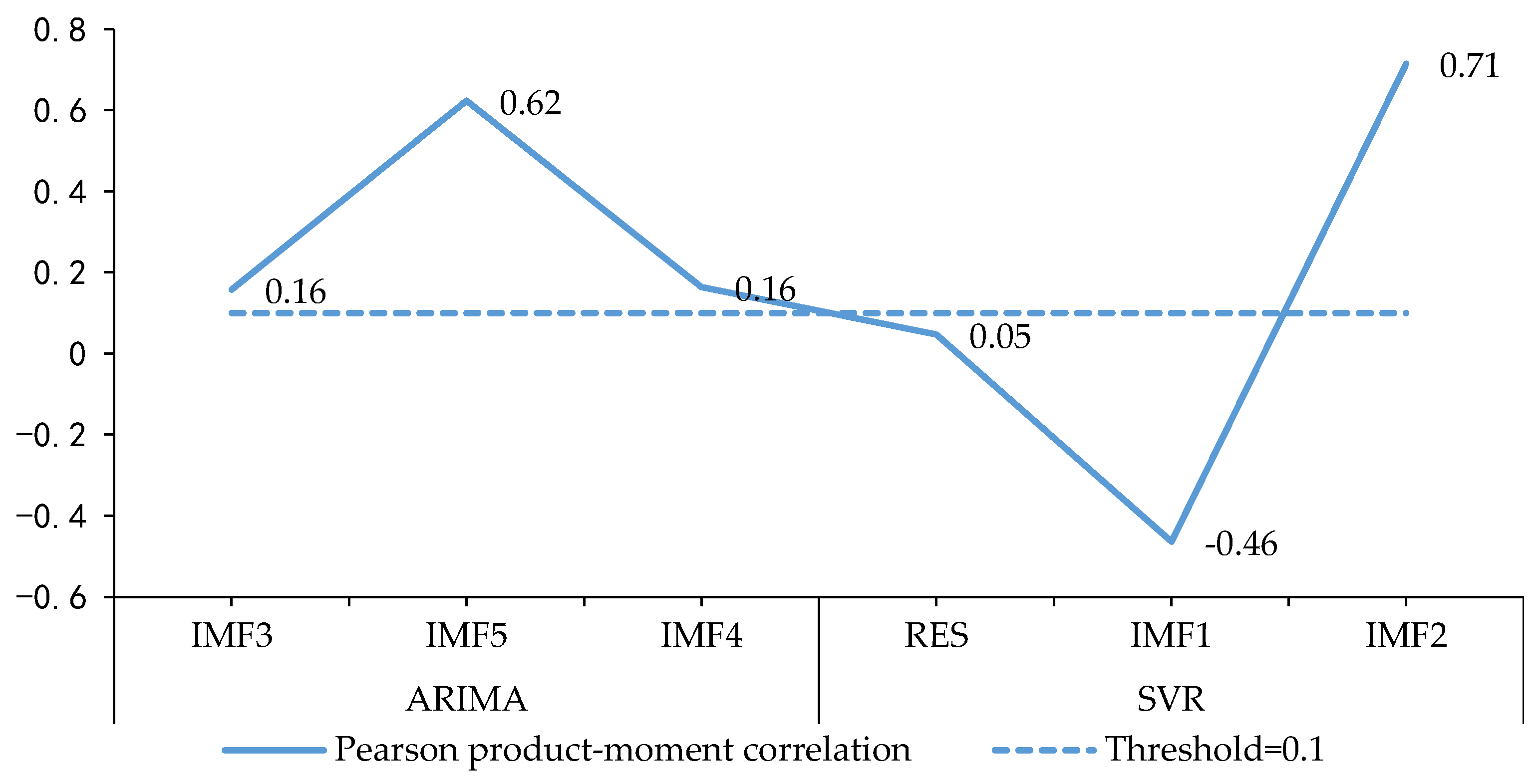
3.3. Mode Feature Analysis
3.3.1. Stationarity Test
3.3.2. Fluctuation Scale Analysis
3.3.3. Fluctuation Scale Analysis
3.4. Throughput Forecasting
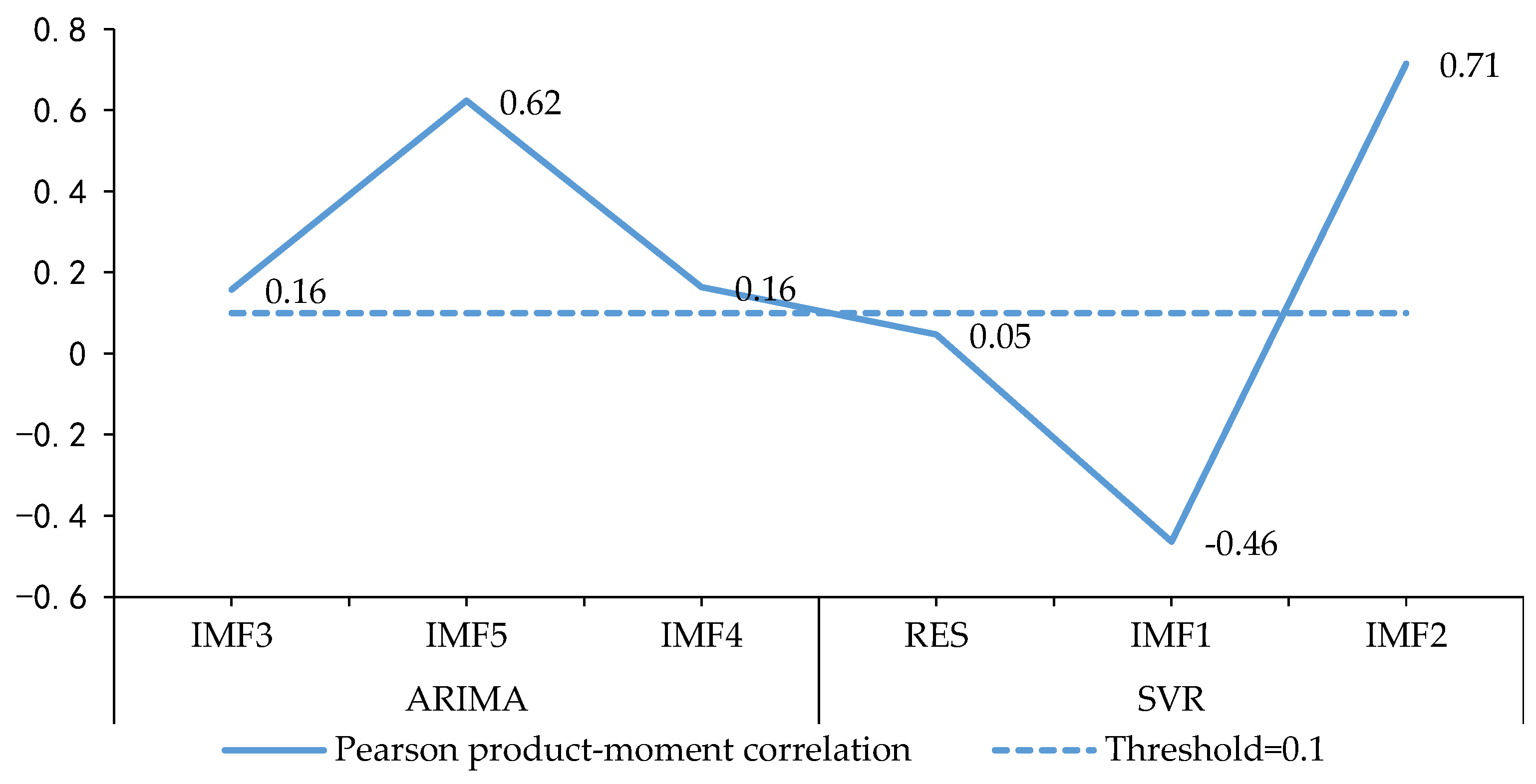
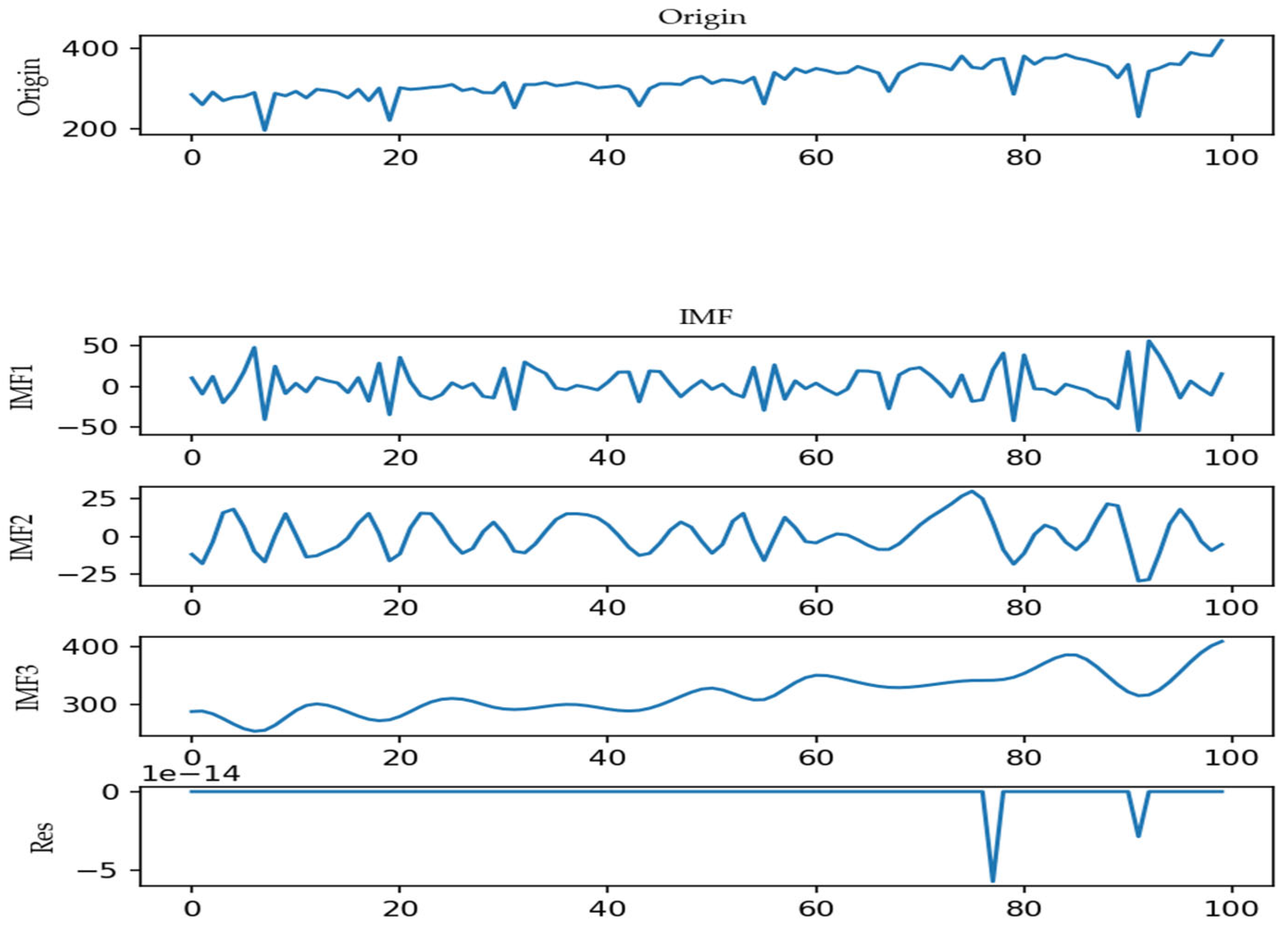
3.4.1. Reconstruction Clustering
3.4.2. Forecasting Model
- (1)
- ARIMA model
- (2)
- SVR model forecasting
3.4.3. Ensemble Forecasting
4. Empirical Analysis
4.1. Empirical Design
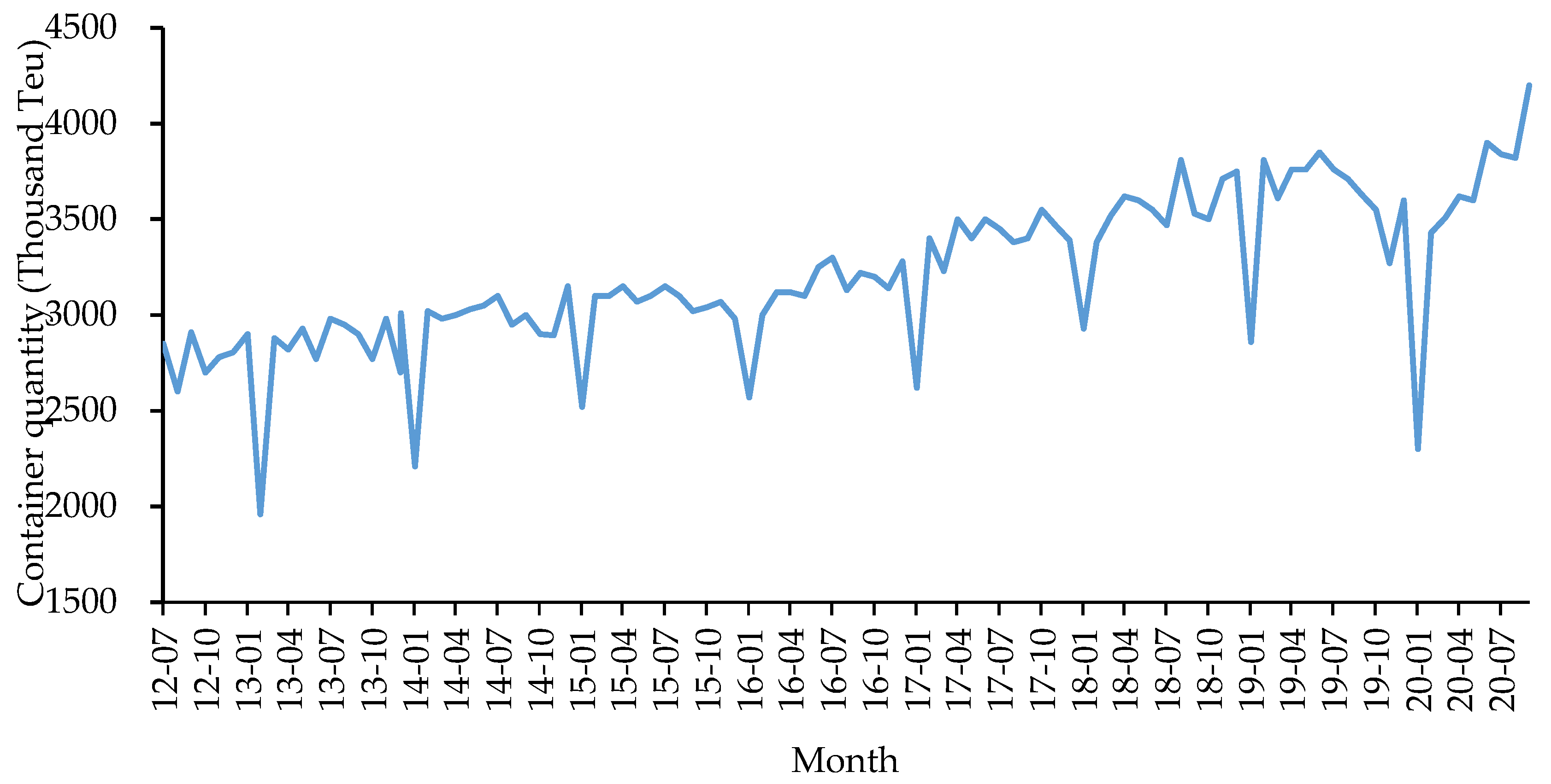
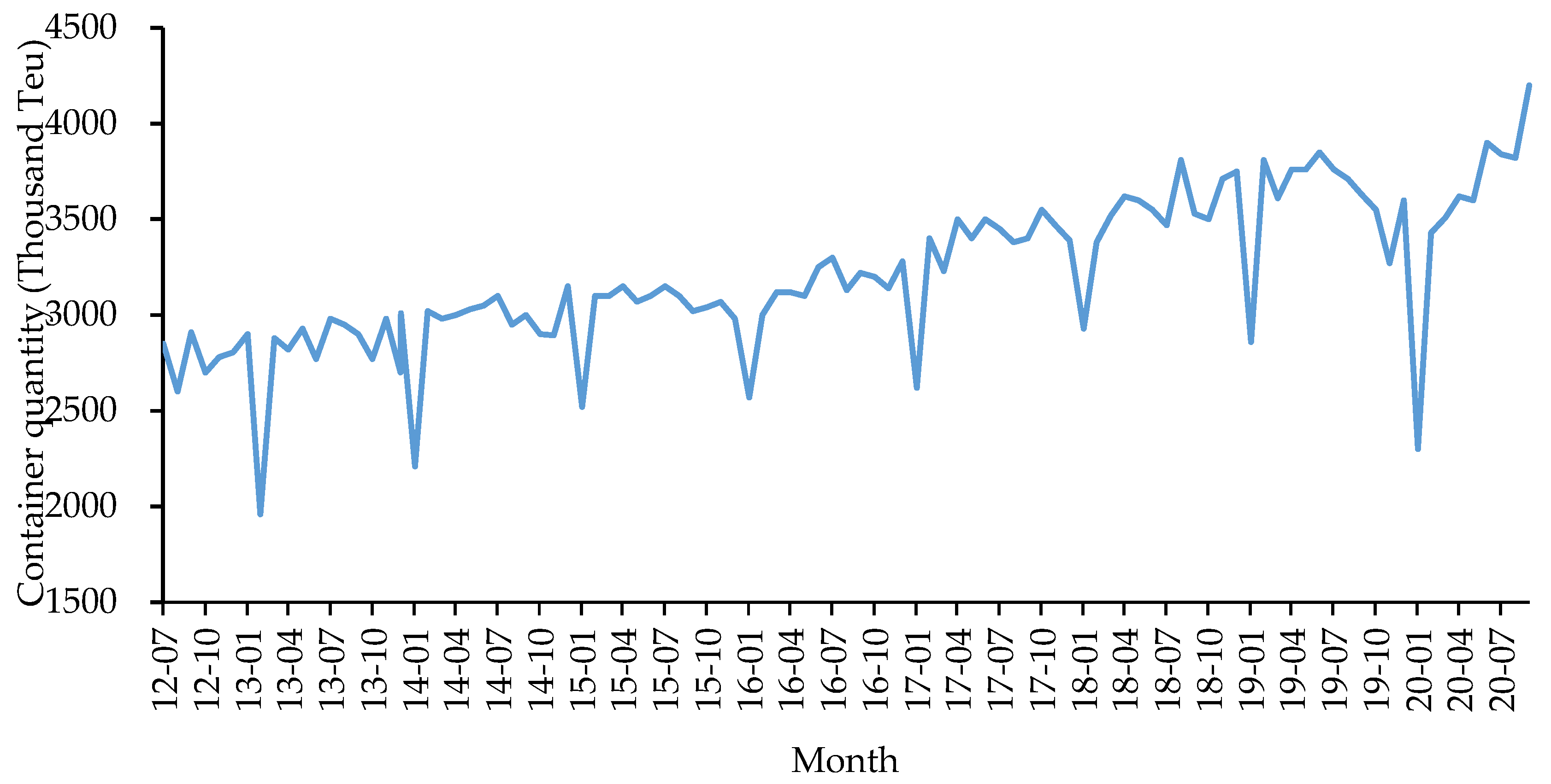
4.1.1. Data Description
4.1.2. Evaluation Criteria and Indicators
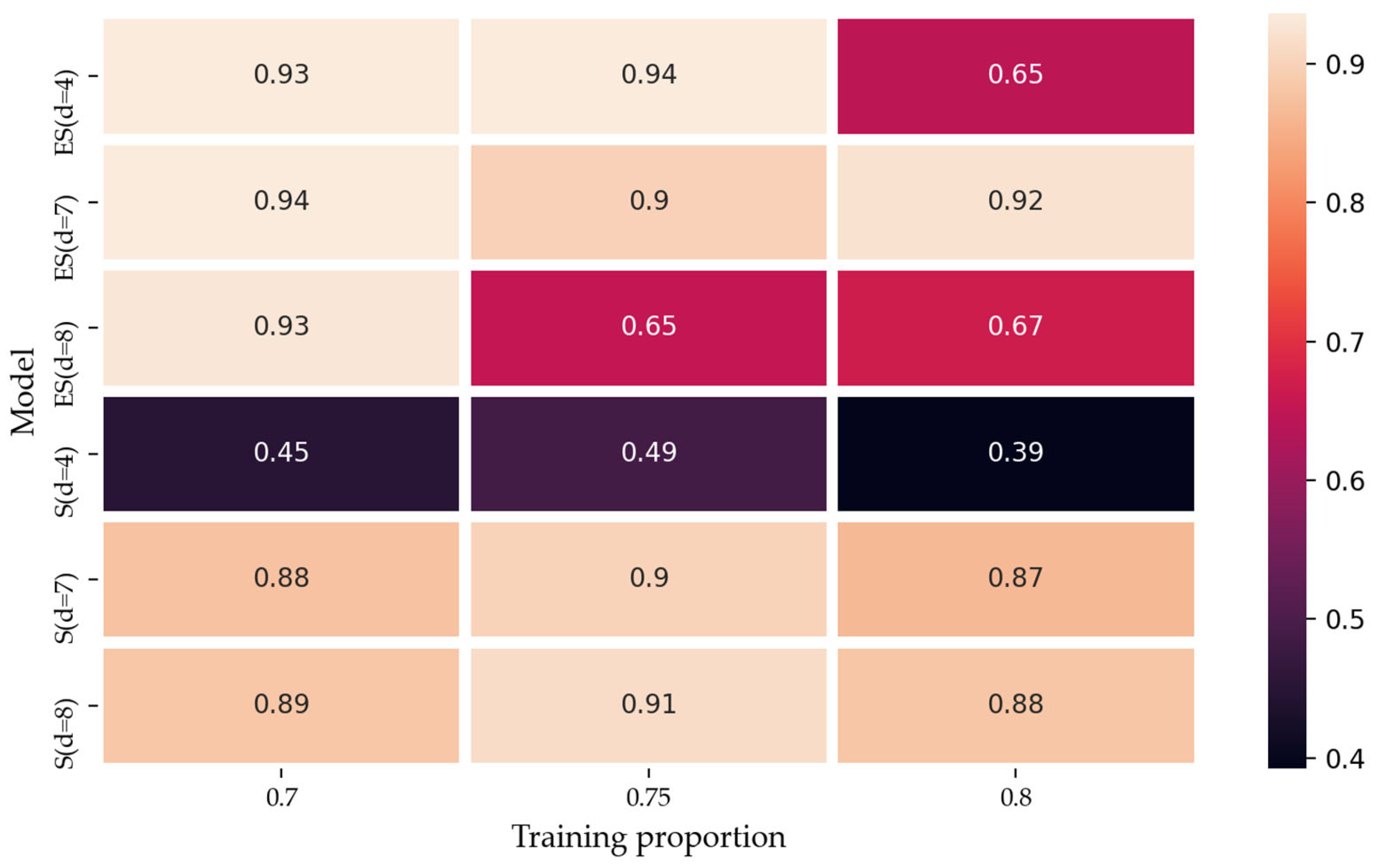
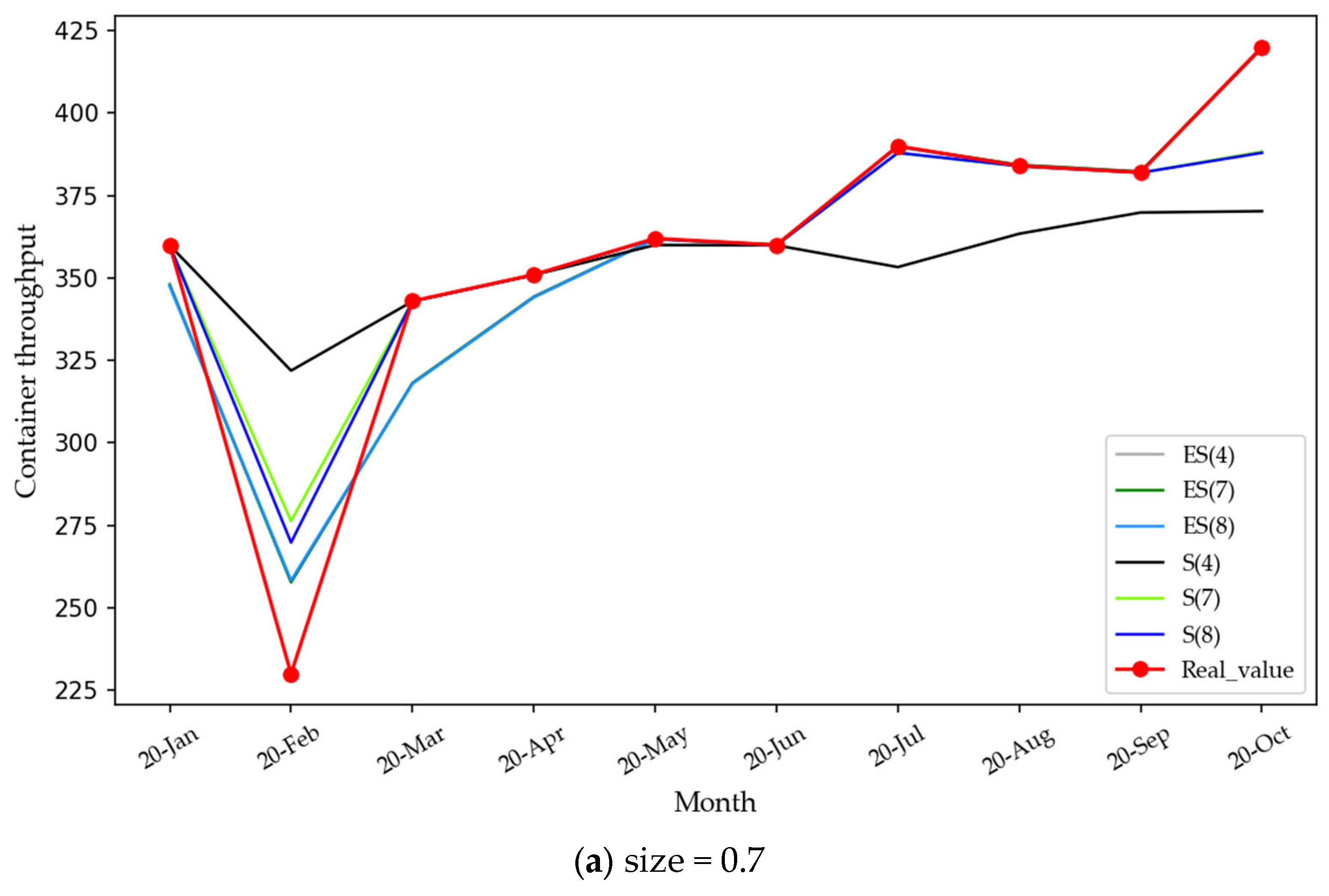
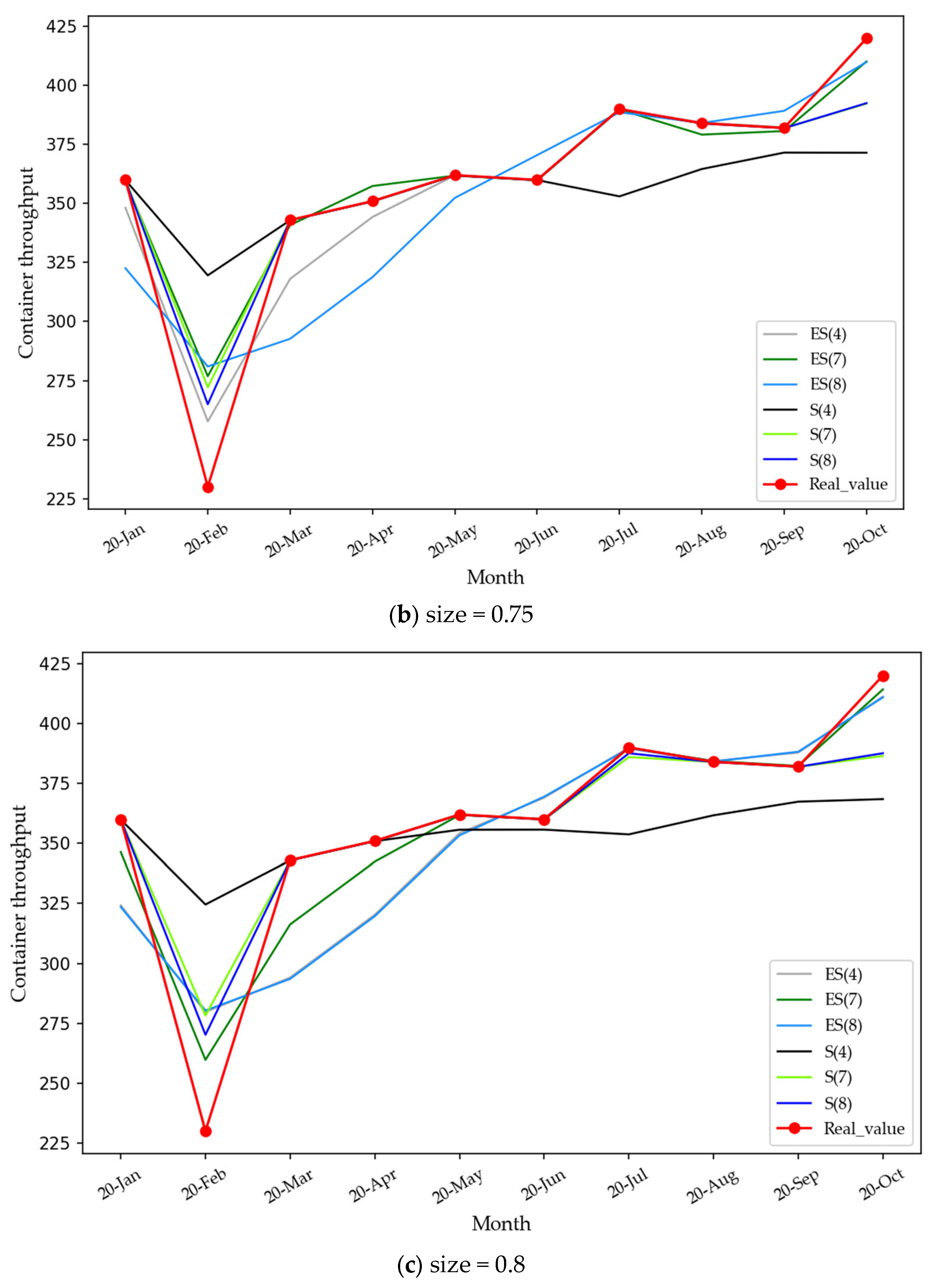
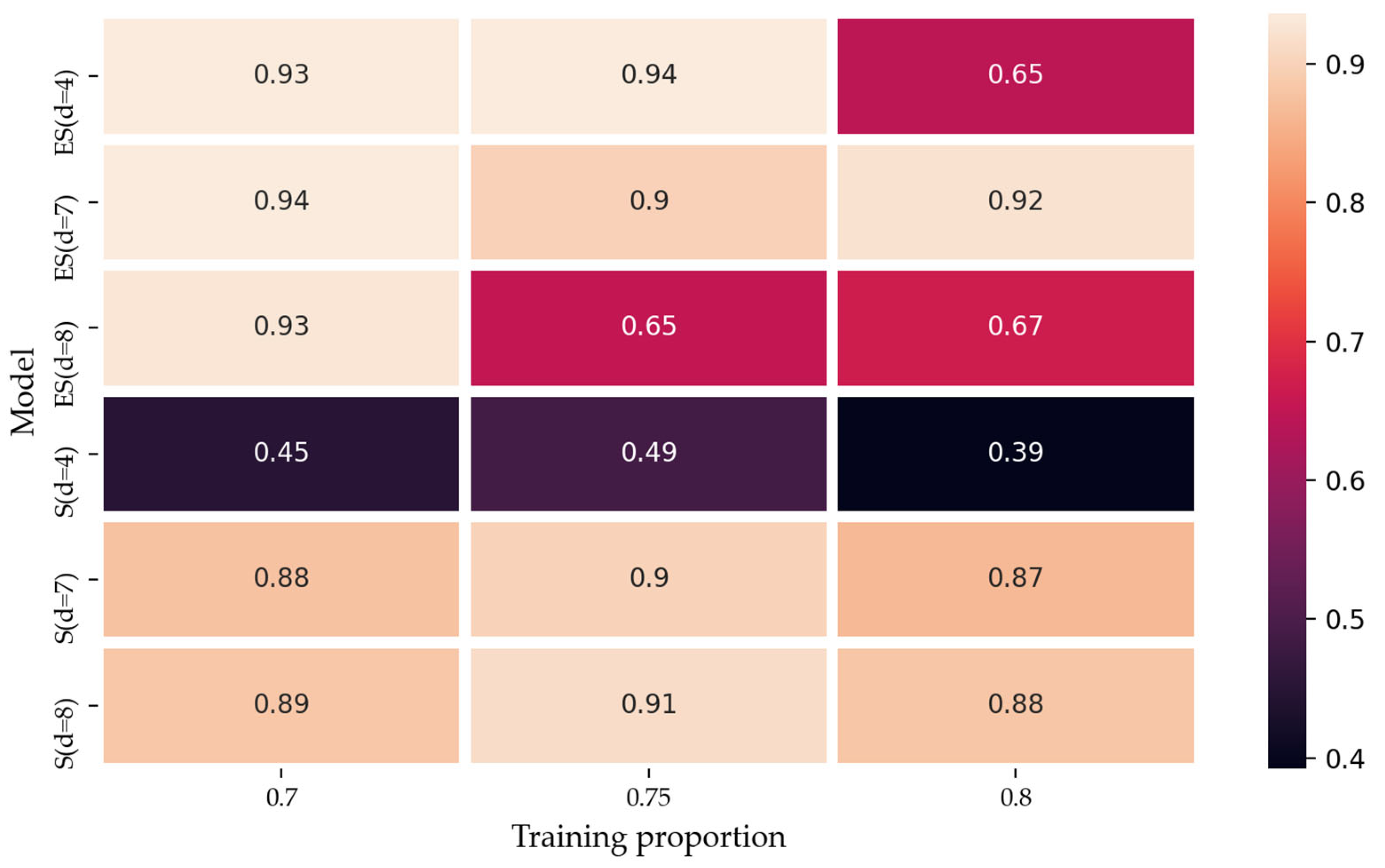
4.2. Empirical Results
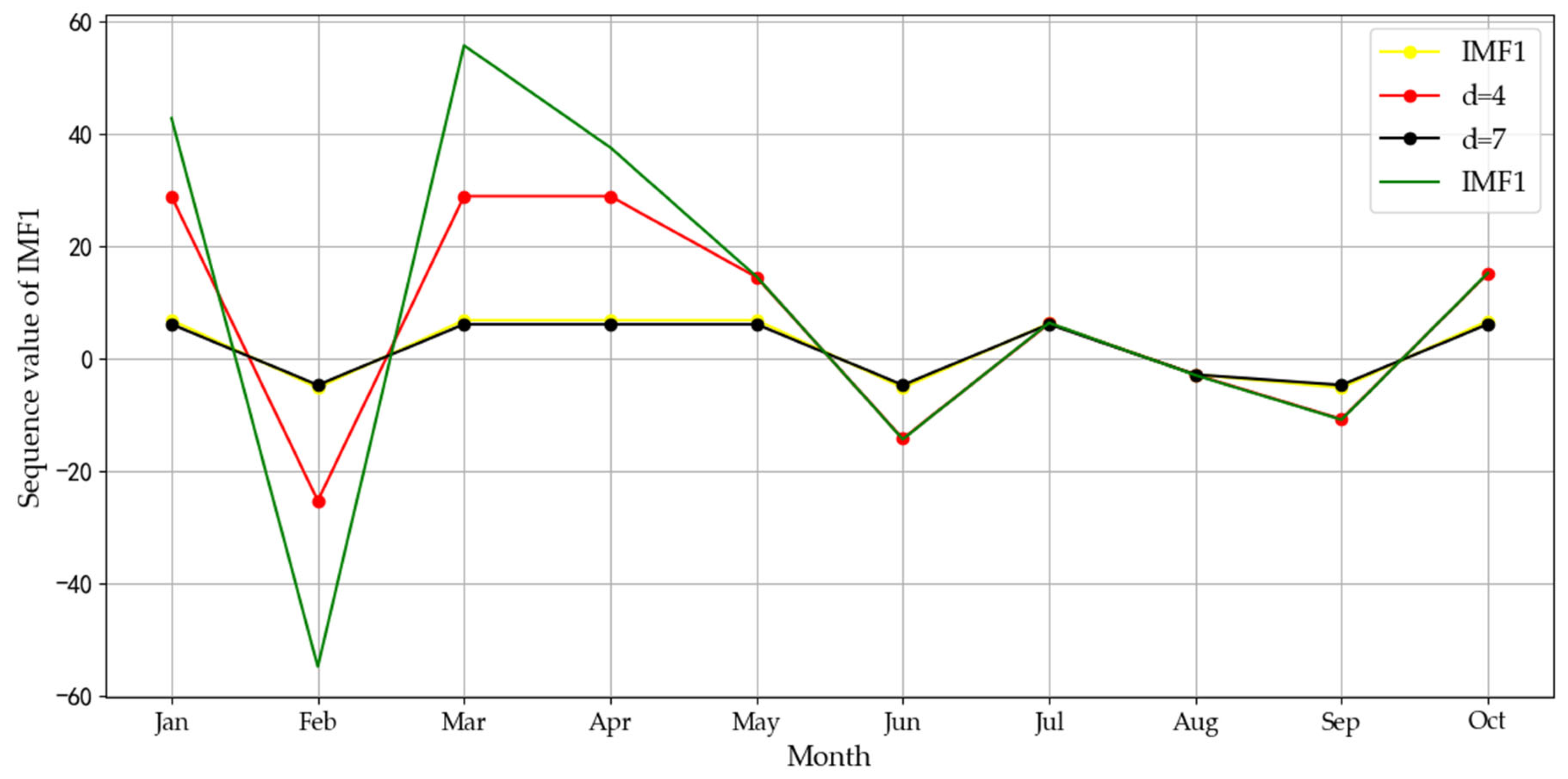
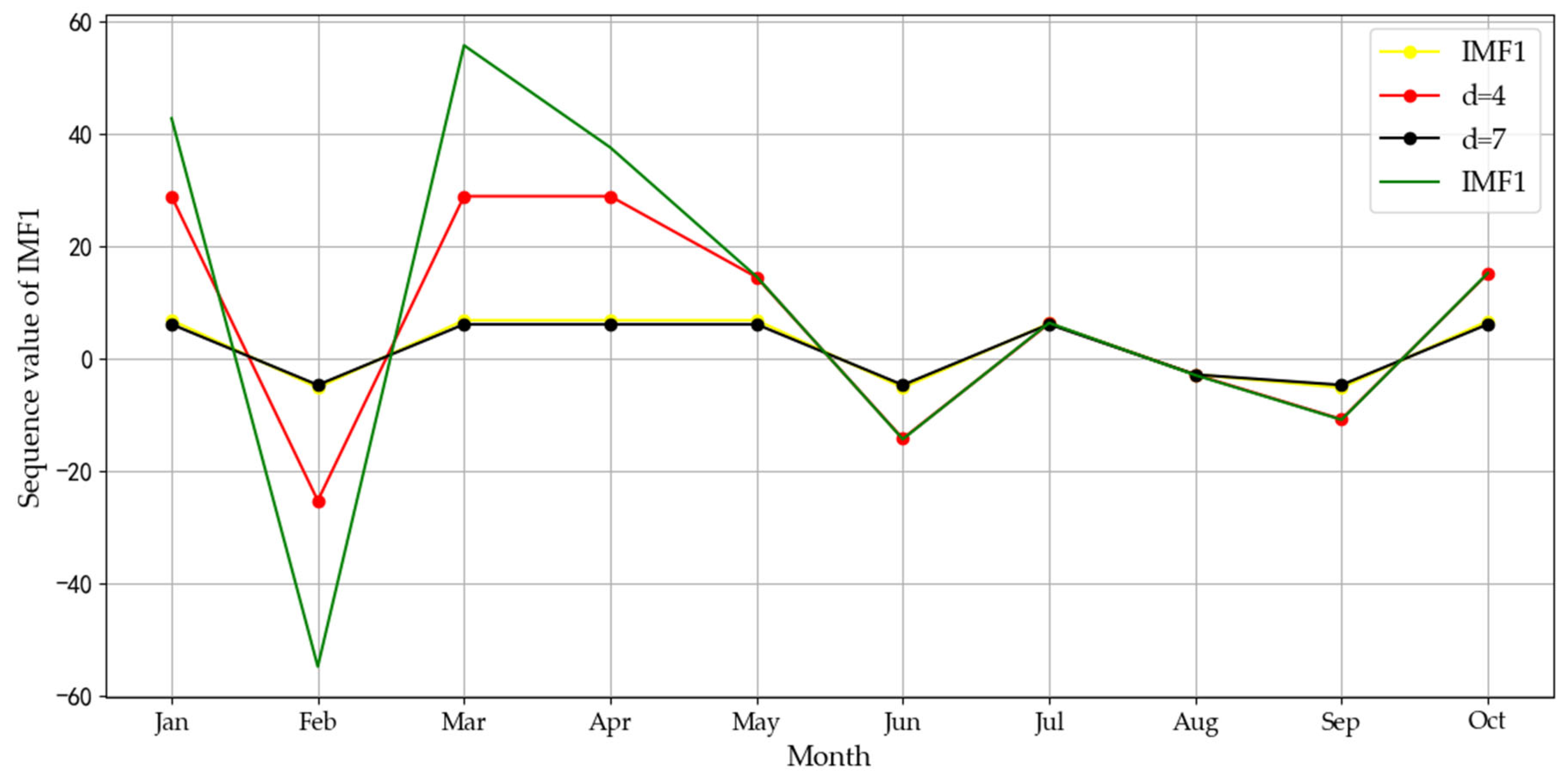
4.2.1. Data Decomposition and Event Analysis
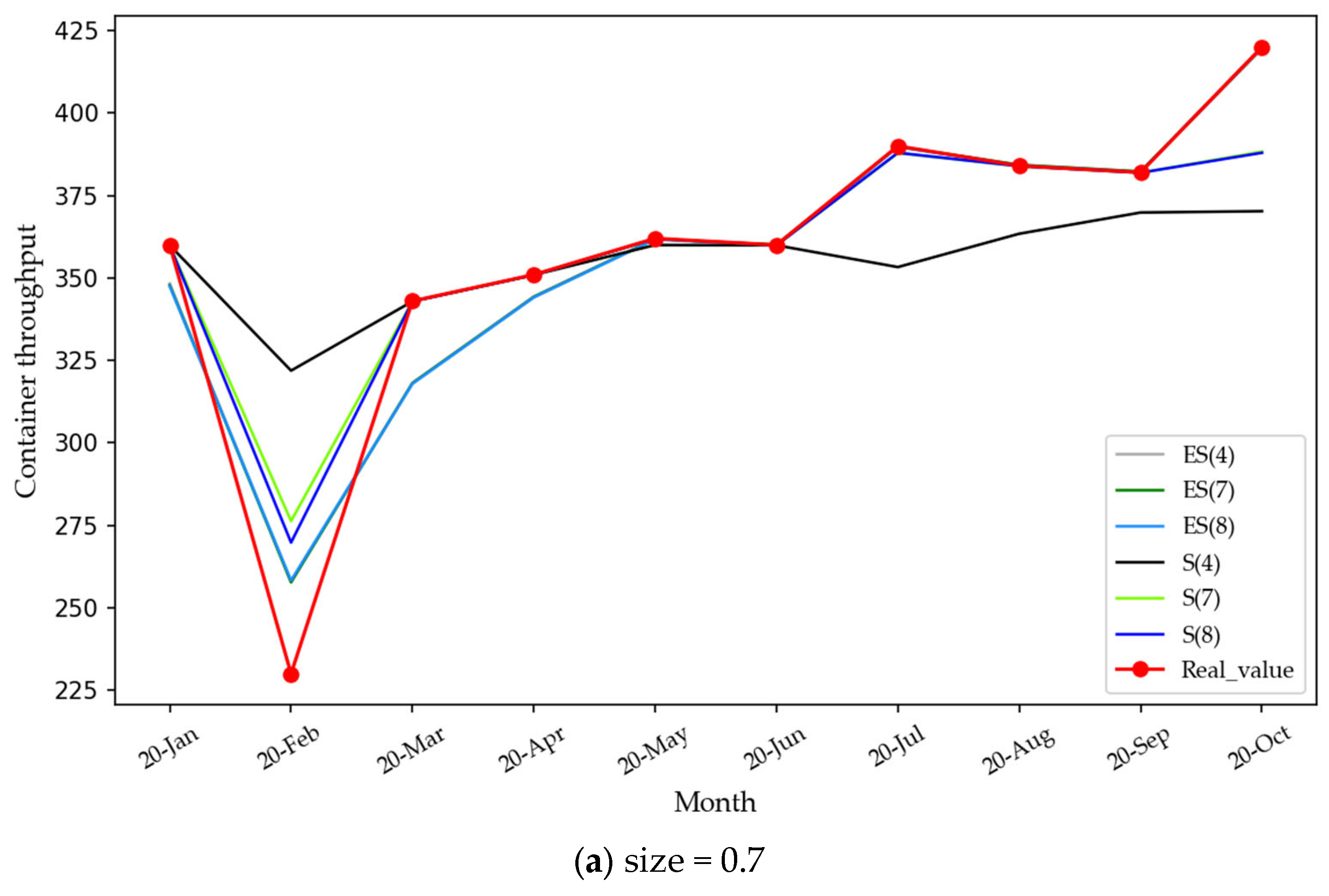
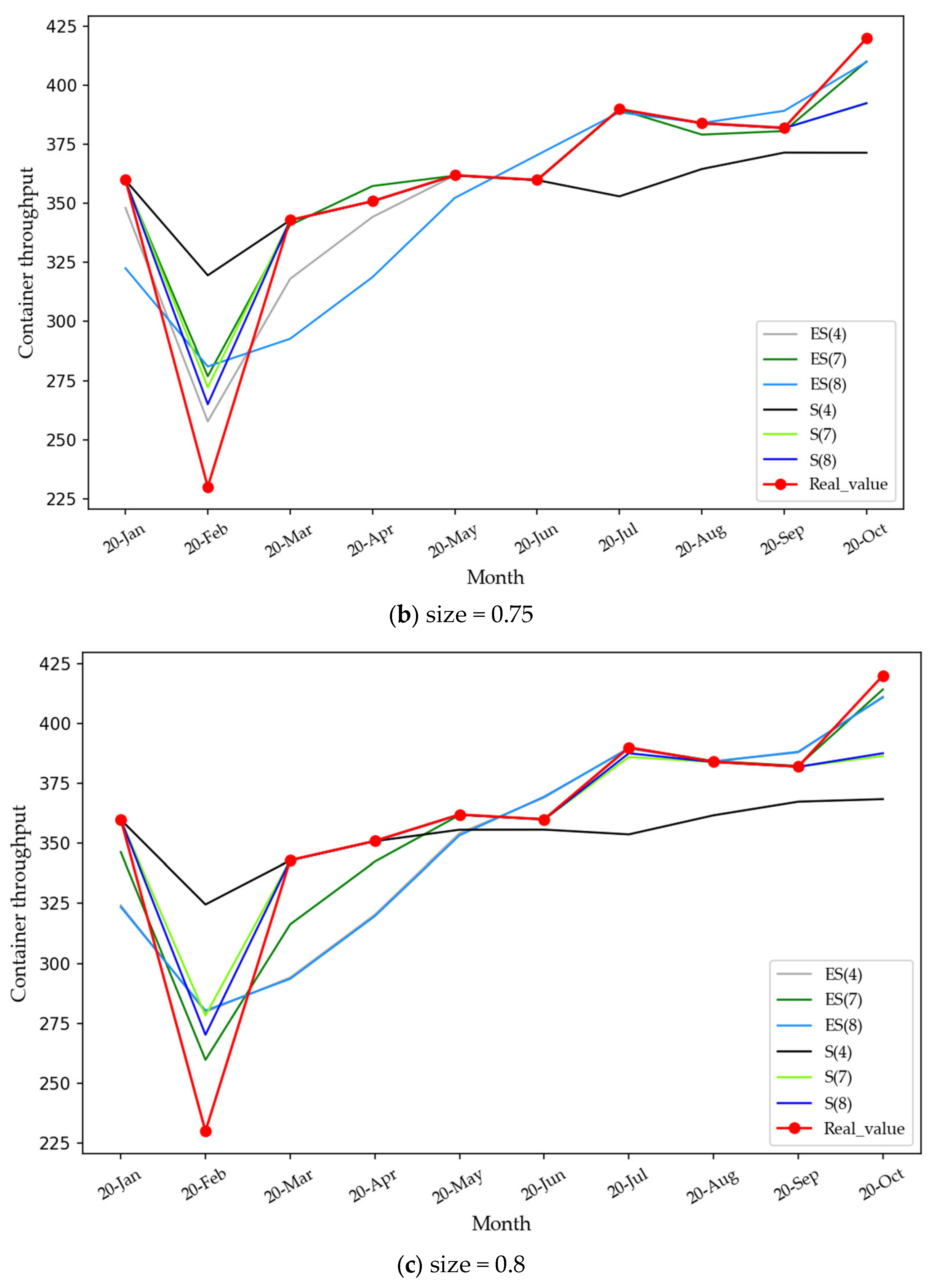
4.2.2. Mode Reconstruction and Integrated Forecasting
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Notteboom, T. The adaptive capacity of container ports in an era of mega vessels: The case of upstream seaports Antwerp and Hamburg. J. Transp. Geogr. 2016, 54, 295–309. [Google Scholar] [CrossRef]
- Notteboom, T.; Pallis, T.; Rodrigue, J.P. Disruptions and resilience in global container shipping and ports: The COVID-19 pandemic versus the 2008–2009 financial crisis. Marit. Econ. Logist. 2021, 23, 179–210. [Google Scholar] [CrossRef]
- World Health Organization (WHO). Available online: https://www.who.int/zh/news/item/29-06-2020-covidtimeline (accessed on 10 February 2022).
- McKibbin, W.; Fernando, R. The Global Macroeconomic Impacts of COVID-19: Seven Scenarios. Asian Econ. Pap. 2021, 20, 1–30. [Google Scholar] [CrossRef]
- Depellegrin, D.; Bastianini, M.; Fadini, A.; Menegon, S. The effects of COVID-19 induced lockdown measures on maritime settings of a coastal region. Sci. Total Environ. 2020, 740, 140123. [Google Scholar] [CrossRef] [PubMed]
- Chou, C.C.; Chu, C.W.; Liang, G.S. A modified regression model for forecasting the volumes of Taiwan’s import containers. Math. Comput. Model. 2008, 47, 797–807. [Google Scholar] [CrossRef]
- Rashed, Y.; Meersman, H.; De Voorde, E.V.; Vanelslander, T. Short-term forecast of container throughout: An ARIMA-intervention model for the port of Antwerp. Marit. Econ. Logist. 2017, 19, 749–764. [Google Scholar] [CrossRef]
- Farhan, J.; Ong, G.P. Forecasting seasonal container throughput at international ports using SARIMA models. Marit. Econ. Logist. 2018, 20, 131–148. [Google Scholar] [CrossRef]
- Ruiz-Aguilar, J.J.; Turias, I.J.; Jimenez-Come, M.J. Hybrid approaches based on SARIMA and artificial neural networks for inspection time series forecasting. Transp. Res. Part E Logist. Transp. Rev. 2014, 67, 1–13. [Google Scholar] [CrossRef]
- Schulze, P.M.; Prinz, A. Forecasting container transshipment in Germany. Appl. Econ. 2009, 41, 2809–2815. [Google Scholar] [CrossRef] [Green Version]
- Fung, M.K. Forecasting in Hong Kong’s container throughput: An error-correction model. J. Forecast. 2002, 21, 69–80. [Google Scholar] [CrossRef]
- Munim, Z.H.; Schramm, H.J. Forecasting container shipping freight rates for the Far East-Northern Europe trade lane. Marit. Econ. Logist. 2016, 19, 106–125. [Google Scholar] [CrossRef]
- Veenstra, A.W.; Haralambides, H.E. Multivariate autoregressive models for forecasting seaborne trade flows. Transp. Res. Part E Logist. Transp. Rev. 2001, 37, 311–319. [Google Scholar] [CrossRef]
- Gao, Y.; Luo, M.F.; Zou, G.H. Forecasting with model selection or model averaging: A case study for monthly container port throughput. Transp. A 2016, 12, 366–384. [Google Scholar] [CrossRef]
- Peng, W.Y.; Chu, C.W. A comparison of univariate methods for forecasting container throughput volumes. Math. Comput. Model. 2009, 50, 1045–1057. [Google Scholar] [CrossRef]
- Guo, Z.X.; Le, W.W.; Wu, Y.K.; Wang, W. A multi-step approach framework for freight forecasting of river-sea direct transport without direct historical data. Sustainability 2019, 11, 4252. [Google Scholar] [CrossRef] [Green Version]
- Ding, M.J.; Zhang, S.Z.; Zhong, H.D.; Wu, Y.H.; Zhang, L.B. A prediction model of the sum of container based on combined BP neural network and SVM. J. Inf. Processing Syst. 2019, 15, 305–319. [Google Scholar]
- He, C.; Wang, H.P. Container Throughput Forecasting of Tianjin-Hebei Port Group Based on Grey Combination Model. J. Math. 2021, 2021, 8877865. [Google Scholar] [CrossRef]
- Jing, G.; Li, M.W.; Dong, Z.H.; Liao, Y.S. Port throughput forecasting by MARS-RSVR with chaotic simulated annealing particle swarm optimization algorithm. Neurocomputing 2015, 147, 239–250. [Google Scholar]
- Xiao, J.; Xiao, Y.; Fu, J.L.; Lai, K.K. A transfer forecasting model for container throughput guided by discrete PSO. J. Syst. Sci. Complex. 2014, 27, 181–192. [Google Scholar] [CrossRef]
- Liu, S.; Tian, L.X.; Huang, Y.S. A comparative study on prediction of throughput in coal ports among three models. Int. J. Mach. Learn. Cybern. 2014, 5, 125–133. [Google Scholar] [CrossRef]
- Milenkovic, M.; Milosavljevic, N.; Bojovic, N.; Val, S. Container flow forecasting through neural networks based on metaheuristics. Oper. Res. 2021, 21, 965–997. [Google Scholar] [CrossRef]
- Yu, L.A.; Wang, Z.S.; Tang, L. A decomposition–ensemble model with data-characteristic-driven reconstruction for crude oil price forecasting. Appl. Energy 2015, 156, 251–267. [Google Scholar] [CrossRef]
- Tang, L.; Yu, L.; Wang, S.; Li, J.P.; Wang, S.Y. A novel hybrid ensemble learning paradigm for nuclear energy consumption forecasting. Appl. Energy 2012, 93, 432–443. [Google Scholar] [CrossRef]
- Hang, A.Q.; Lai, K.; Li, Y.H.; Wang, S.Y. Forecasting Container Throughput of Qingdao Port with a Hybrid Model. J. Syst. Sci. Complex. 2015, 28, 105–121. [Google Scholar] [CrossRef]
- Yu, L.; Liang, S.; Chen, R. Predicting monthly bio fuel production using a hybrid ensemble forecasting methodology. Int. J. Forecast. 2019, 38, 3–20. [Google Scholar] [CrossRef]
- Xie, G.; Wang, S.Y.; Zhao, Y.X.; Lai, K.K. Hybrid approaches based on LSSVR model for container throughput forecasting: A comparative study. Appl. Soft Comput. 2013, 13, 2232–2241. [Google Scholar] [CrossRef]
- Yu, L.A.; Zhao, Y.; Tang, L. Ensemble Forecasting for Complex Time Series Using Sparse Representation and Neural Networks. J. Forecast. 2016, 36, 122–138. [Google Scholar] [CrossRef]
- Jianwei, E.; Bao, Y.L.; Ye, J.M. Crude oil price analysis and forecasting based on variational mode decomposition and independent component analysis. Physical A 2017, 484, 412–427. [Google Scholar]
- Yu, L.; Wang, S.Y.; Lai, K.K. Forecasting crude oil price with an EMD-based neural network ensemble learning paradigm. Energy Econ. 2008, 30, 2623–2635. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. A-Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, L.; Wang, S.Y.; Lai, K.K. Estimating the impact of extreme events on crude oil price: An EMD-based event analysis method. Energy Econ. 2009, 31, 768–778. [Google Scholar] [CrossRef]
- Zhang, X.; Lai, K.K.; Wang, S.Y. A new approach for crude oil price analysis based on Empirical Mode Decomposition. Energy Econ. 2008, 30, 905–918. [Google Scholar] [CrossRef]
- Inclán, C.; Tiao, G.C. Use of Cumulative Sums of Squares for Retrospective Detection of Changes of Variance. J. Am. Stat. Assoc. 1994, 89, 913–923. [Google Scholar]
- Wu, B.R.; Wang, L.; Lv, S.X.; Zeng, Y.R. Effective crude oil price forecasting using new text-based and big-data-driven model. Measurement 2021, 168, 108468. [Google Scholar] [CrossRef]
- Wu, B.R.; Wang, L.; Wang, S.R.; Zeng, Y.R. Forecasting the US oil markets based on social media information during the COVID-19 pandemic. Energy 2021, 226, 120403. [Google Scholar] [CrossRef]
- Weng, F.T.; Zhang, H.W.; Yang, C. Volatility forecasting of crude oil futures based on a genetic algorithm regularization online extreme learning machine with a forgetting factor: The role of news during the COVID-19 pandemic. Resour. Policy 2021, 73, 102148. [Google Scholar] [CrossRef]
- Stifanic, D.; Musulin, J.; Miocevic, A.; Segota, S.B.; Subic, R.; Car, Z. Impact of COVID-19 on Forecasting Stock Prices: An Integration of Stationary Wavelet Transform and Bidirectional Long Short-Term Memory. Complexity 2020, 2020, 1846926. [Google Scholar] [CrossRef]
- Koyuncu, K.; Tavacioglu, L.; Gokmen, N.; Arican, U.C. Forecasting COVID-19 impact on RWI/ISL container throughput index by using SARIMA models. Marit. Policy Manag. 2021, 48, 1096–1108. [Google Scholar] [CrossRef]
- Tang, L.; Dai, W.; Yu, L.A. A Novel CEEMD-Based EELM Ensemble Learning Paradigm for Crude Oil Price Forecasting. Int. J. Inf. Technol. Decis. Mak. 2015, 14, 141–169. [Google Scholar] [CrossRef]
- Rodgers, L.; Nicewander, W.A. Thirteen ways to look at the correlation coefficient. J. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Box, G.; Pierce, D.A. Distribution of Residual Autocorrelations in ARIMA Time Series Models. J. Am. Stat. Assoc. 1970, 72, 397–402. [Google Scholar]
- Bousquet, O. New approaches to statistical learning theory. Ann. Inst. Stat. Math. 2003, 55, 371–389. [Google Scholar] [CrossRef]
- Xie, G.; Yue, W.; Wang, S. Energy efficiency decision and selection of main engines in a sustainable shipbuilding supply chain. Transp. Res. Part D Transp. Environ. 2017, 53, 290–305. [Google Scholar] [CrossRef]
- Twrdy, E.; Batista, M. Modeling of container throughput in Northern Adriatic ports over the period 1990-2013. J. Transp. Geogr. 2016, 52, 131–142. [Google Scholar] [CrossRef]
- D’Agostino, R.B. An omnibus test of normality for moderate and large size samples. Biometrika 1971, 2, 341–348. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Model | Mixed Model | AI Model | The Impact of Major Events | Decomposition–Ensemble Model |
|---|---|---|---|---|---|
| Rashed et al. [7] | ARIMA | × | × | × | × |
| Farhan et al. [8] | SARIMA | × | × | × | × |
| Ruiz et al. [9] | SARIMA-ANN | √ | √ | × | × |
| Schulze et al. [10] | SARIMA and Holt–Winters | × | × | × | × |
| Fung et al. [11] | Error-correction model | × | × | × | × |
| Munim et al. [12] | ARIMA-ARCH | √ | × | × | × |
| Veenstra et al. [13] | Vector autoregressive model | × | × | × | × |
| Gao et al. [14] | Structural change VAR model | × | × | × | × |
| Peng et al. [15] | Grey model | × | × | × | × |
| Guo et al. [16] | Grey model | × | × | × | × |
| Ding et al. [17] | BP Neural Network | × | √ | × | × |
| He et al. [18] | GM(1,1)-BPNN | √ | √ | × | × |
| Jing et al. [19] | MARS-RSVR | √ | √ | × | × |
| Xiao et al. [20] | TF-DPSO | √ | √ | × | × |
| Liu et al. [21] | BPNN | × | √ | × | × |
| Milenkovic et al. [22] | FNN | × | √ | × | × |
| Yu et al. [23] | EEMD-DCD-ANN, EEMD-DCD-LSSVR | √ | √ | × | √ |
| Tang et al. [24] | EEMD-LSSVR | √ | √ | × | √ |
| Hang et al. [25] | PPR-GP | √ | √ | × | × |
| Yu et al. [26] | EMD-LSTM-ELM | √ | √ | × | √ |
| Xie et al. [27] | SARIMA-LSSVR, SD-LSSVR, and CD–LSSVR | √ | √ | × | √ |
| Yu et al. [28] | SR-FNN-ADD | √ | √ | × | √ |
| Jianwei et al. [29] | VMD-ICA-ARIMA | √ | √ | × | √ |
| Yu et al. [30] | EMD-FNN-ALNN | √ | √ | × | √ |
| Wu et al. [35] | CNN-BPNN/MLR/SVM/LSTM/RNN | √ | √ | √ | × |
| Wu et al. [36] | CNN-VMD | √ | √ | √ | × |
| Weng et al. [37] | GA-RFOS-ELM | √ | √ | √ | × |
| Stifanic et al. [38] | BDLSTM + WT-ADA | √ | √ | √ | √ |
| Koyuncu et al. [39] | SARIMA and ETS | × | × | × | × |
| This paper | EMD-Event Analysis-ARIMA-SVR | √ | √ | √ | √ |
| Mode Test | IMF1 | IMF2 | IMF3 | IMF4 | IMF5 |
|---|---|---|---|---|---|
| ADF test | × | √ | √ | √ | √ |
| fluctuation scale analysis | - | √ | × | √ | √ |
| Number | Time | Events |
|---|---|---|
| 1 | 2017.4–2017.5 | Big congestion event |
| 2 | 2019.12–2020.5 | COVID-19 incident |
| Index | IMF2 | IMF3 | IMF4 | IMF5 |
|---|---|---|---|---|
| variance contribution rate | 11.16% | 19.00% | 2.33% | 67.50% |
| correlation coefficient r | 28.00% | 35.00% | 11.00% | 77.00% |
| fluctuation cycle | 3.45 | 6.25 | 14.29 | long-term trend |
| Number | Meaning of Mode | Impact Points Determined by ICSS | Adjusted Influence Point | Corresponding Event |
|---|---|---|---|---|
| IMF2 | short-term self-adjusting cycle | point 94 | point 92 | COVID-19 |
| IMF3 | seasonal periodic fluctuation | null | null | null |
| IMF5 | long-term trend | null | null | null |
| Mode | IMF2 | IMF3 | |||
|---|---|---|---|---|---|
| Data segment | First segment | Second segment | First segment | Second segment | |
| general statistics | maximum | 92.70 | 170.30 | 25.32 | −24.22 |
| minimum | −89.88 | −153.33 | −20.55 | −28.82 | |
| median | 0.22 | 100.78 | 0.34 | −1.43 | |
| average value | 4.19 | 38.29 | 0.99 | −27.33 | |
| standard deviation | 24.49 | 136.72 | 11.76 | 1.43 | |
| amplitude | maximum | 84.00 | 5.00 | 74.00 | 0.00 |
| minimum | 2.00 | 5.00 | 5.00 | 0.00 | |
| median | 43.00 | 5.00 | 39.50 | 0.00 | |
| normal distribution | skewness | 0.87 | −0.44 | 0.06 | 1.09 |
| kurtosis | 5.47 | −1.54 | −0.82 | 0.54 | |
| statistical value | 30.70 | 2.56 | 0.67 | 1.47 | |
| probability | 0.00 | 0.19 | 0.06 | 0.06 | |
| Size = 0.75 | Tested Index | RMSE | APE | MAPE | Coefficient of Determination | Running Time (/s) |
|---|---|---|---|---|---|---|
| tested model | EPSA (d = 7) | 11.62 | 0.23 | 0.02 | 0.94 | 2028.07 |
| ES (d = 7) | 19.78 | 0.40 | 0.04 | 0.83 | 4147.40 | |
| SVR (d = 7) | 15.95 | 0.25 | 0.03 | 0.89 | 369.04 | |
| ARIMA | 24.09 | 0.56 | 0.06 | 0.75 | 218.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, A.; Liu, X.; Rao, C.; Zhang, Y.; He, Y. A New Container Throughput Forecasting Paradigm under COVID-19. Sustainability 2022, 14, 2990. https://doi.org/10.3390/su14052990
Huang A, Liu X, Rao C, Zhang Y, He Y. A New Container Throughput Forecasting Paradigm under COVID-19. Sustainability. 2022; 14(5):2990. https://doi.org/10.3390/su14052990
Chicago/Turabian StyleHuang, Anqiang, Xinjun Liu, Changrui Rao, Yi Zhang, and Yifan He. 2022. "A New Container Throughput Forecasting Paradigm under COVID-19" Sustainability 14, no. 5: 2990. https://doi.org/10.3390/su14052990
APA StyleHuang, A., Liu, X., Rao, C., Zhang, Y., & He, Y. (2022). A New Container Throughput Forecasting Paradigm under COVID-19. Sustainability, 14(5), 2990. https://doi.org/10.3390/su14052990