
Bibliometric Literature Review of Adaptive Learning Systems

 , , ,
, , ,  , and
, and 
Abstract
1. Introduction
2. Multidimensional Scaling for Bibliometric Mapping
- Each object (e.g., Keyword, Author, or Reference) is represented as a point on the 2D map, with its coordinates on the Cartesian plane;
- The objects with co-occurrences are connected with a line;
- The thickness of the line represents the link strength, which is proportional to the similarity (or co-occurrence) between the objects;
- The distances between the objects are indicators of their dissimilarity.
2.1. Baseline Formulation
2.2. Objective Functions
2.3. Optimization Algorithms
| Algorithm 1: Bibliometric map generation |
| Data: Vector of Strings of the Bibliometric Objects Result: optimal positions on the Bibliometric Map Compute co-occurrences of the studied BO and maximum iterations ; Compute from (Equations (1) and (2)); Initialize randomly Assign ;  |
3. The Studied Databases of Papers
3.1. The Scopus Query
3.2. Keywords’ Grouping
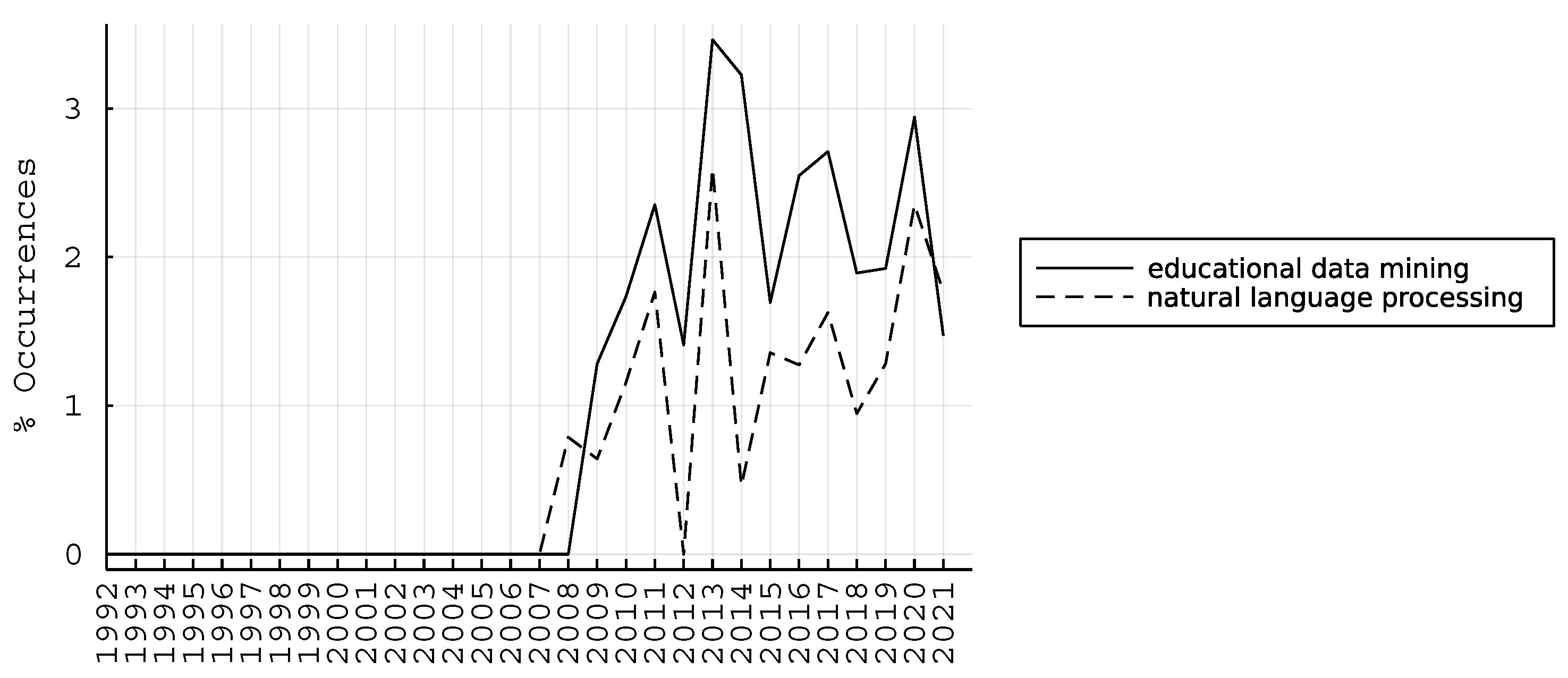
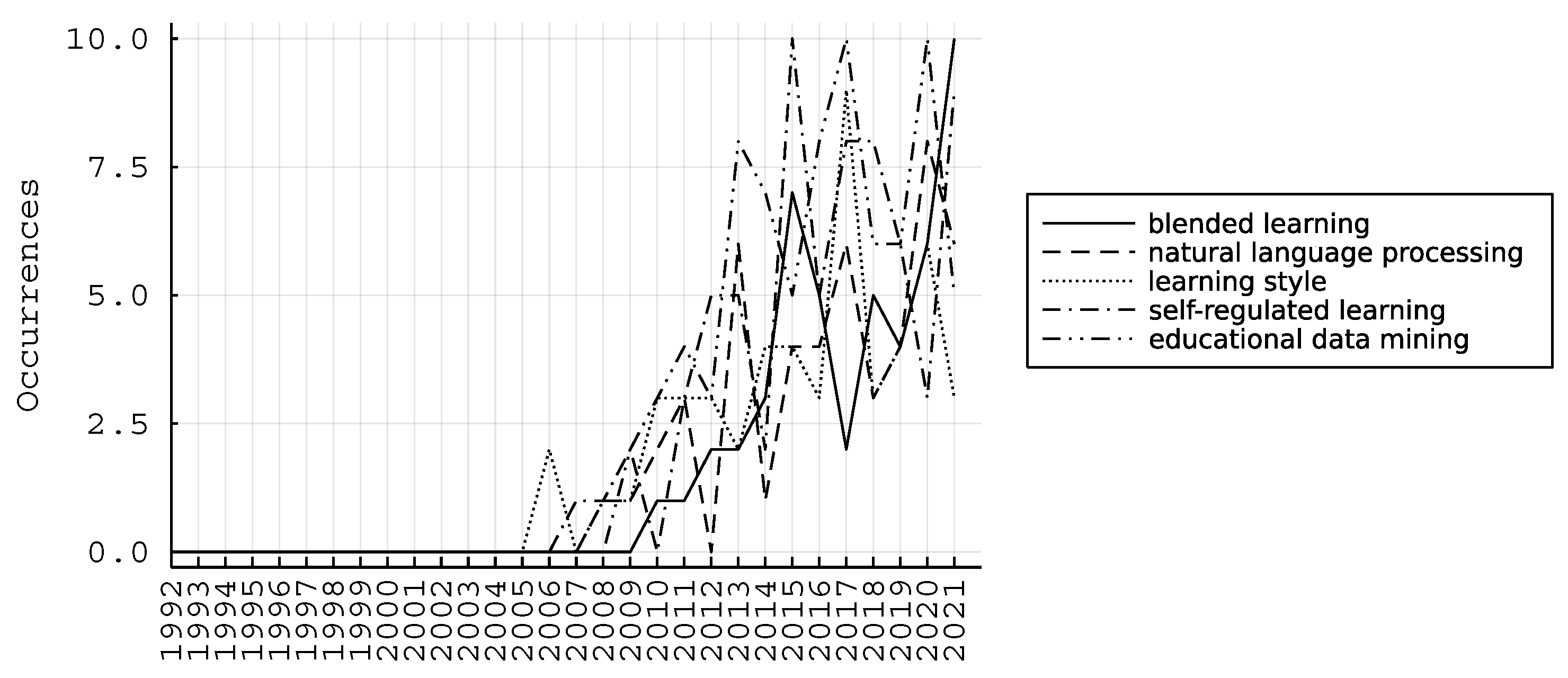
4. Results
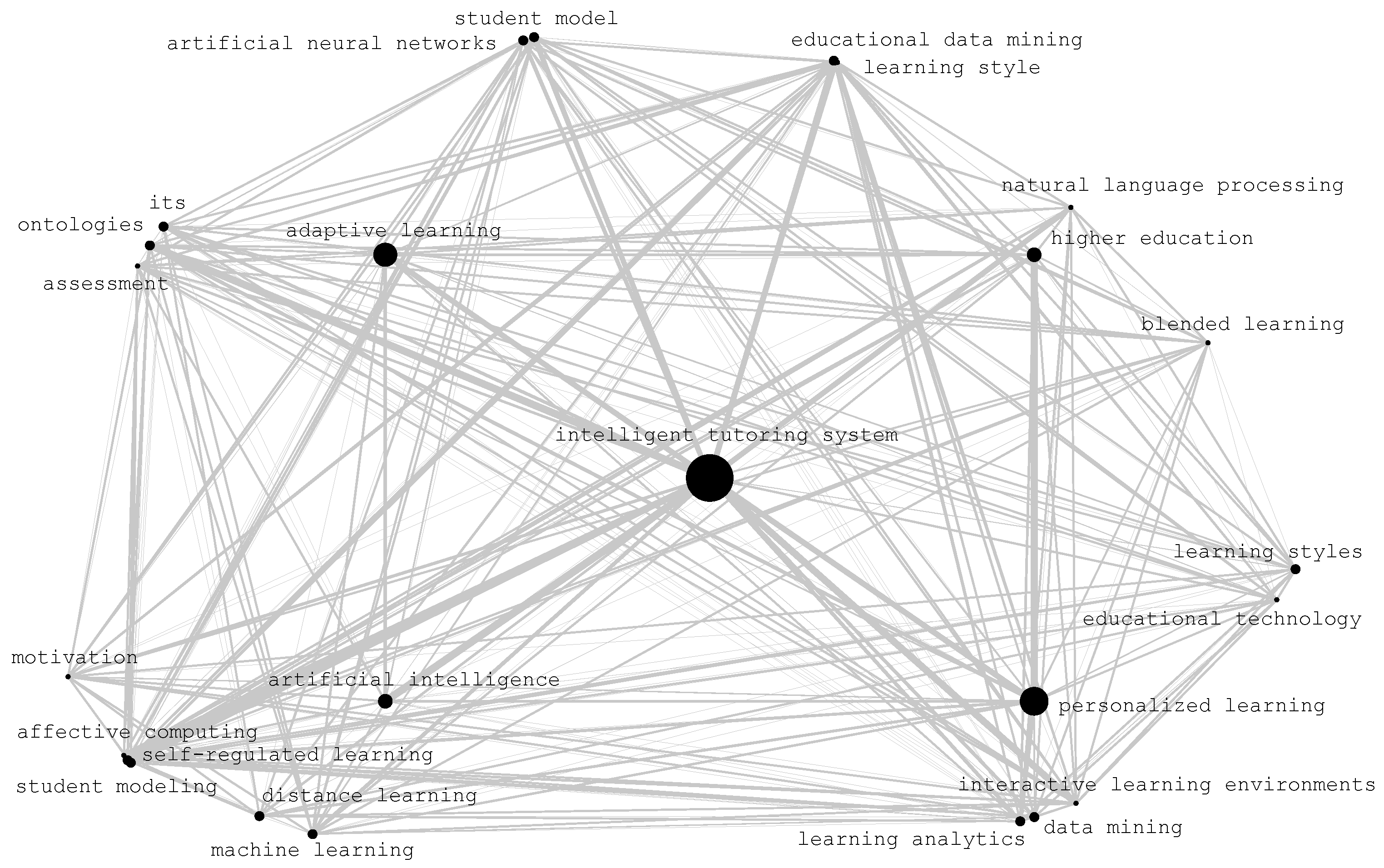
4.1. Bibliometric Map of Keywords
- Adaptive learning;
- Personalized learning;
- Artificial intelligence;
- Higher education.
- Self-regulated learning;
- Affective computing;
- Machine learning;
- Distance learning;
- Student modeling,
- Motivation.
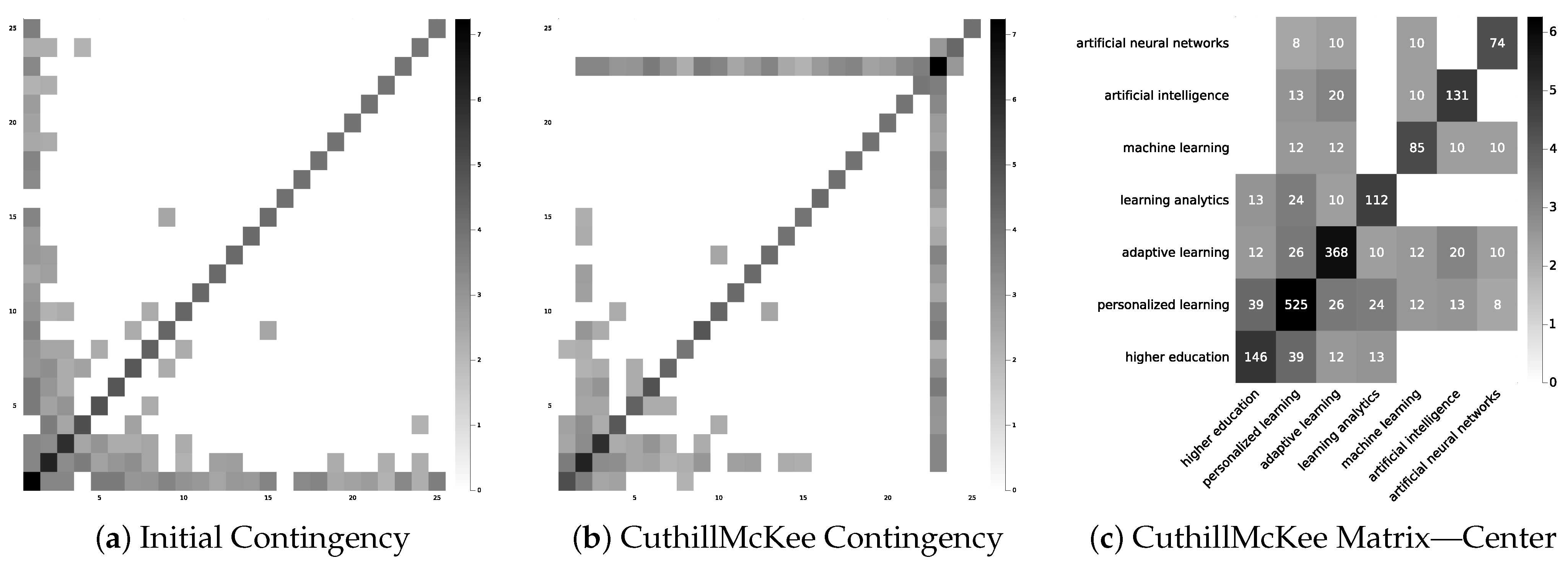
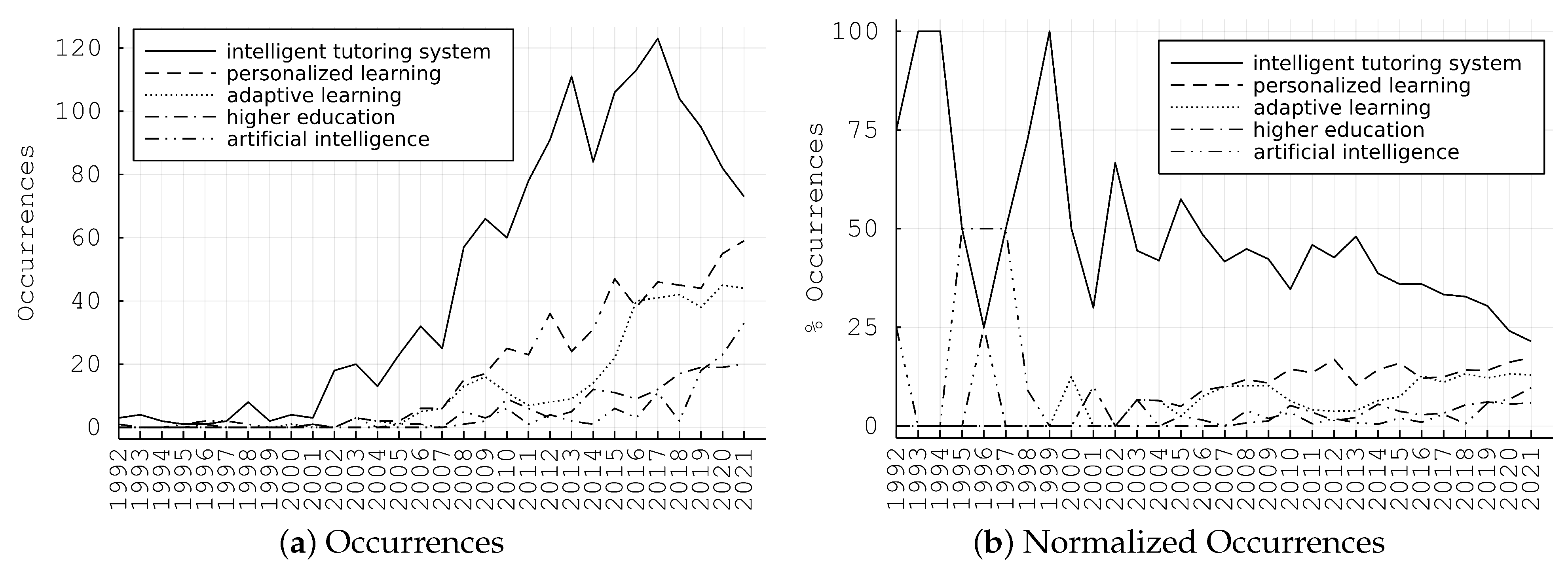
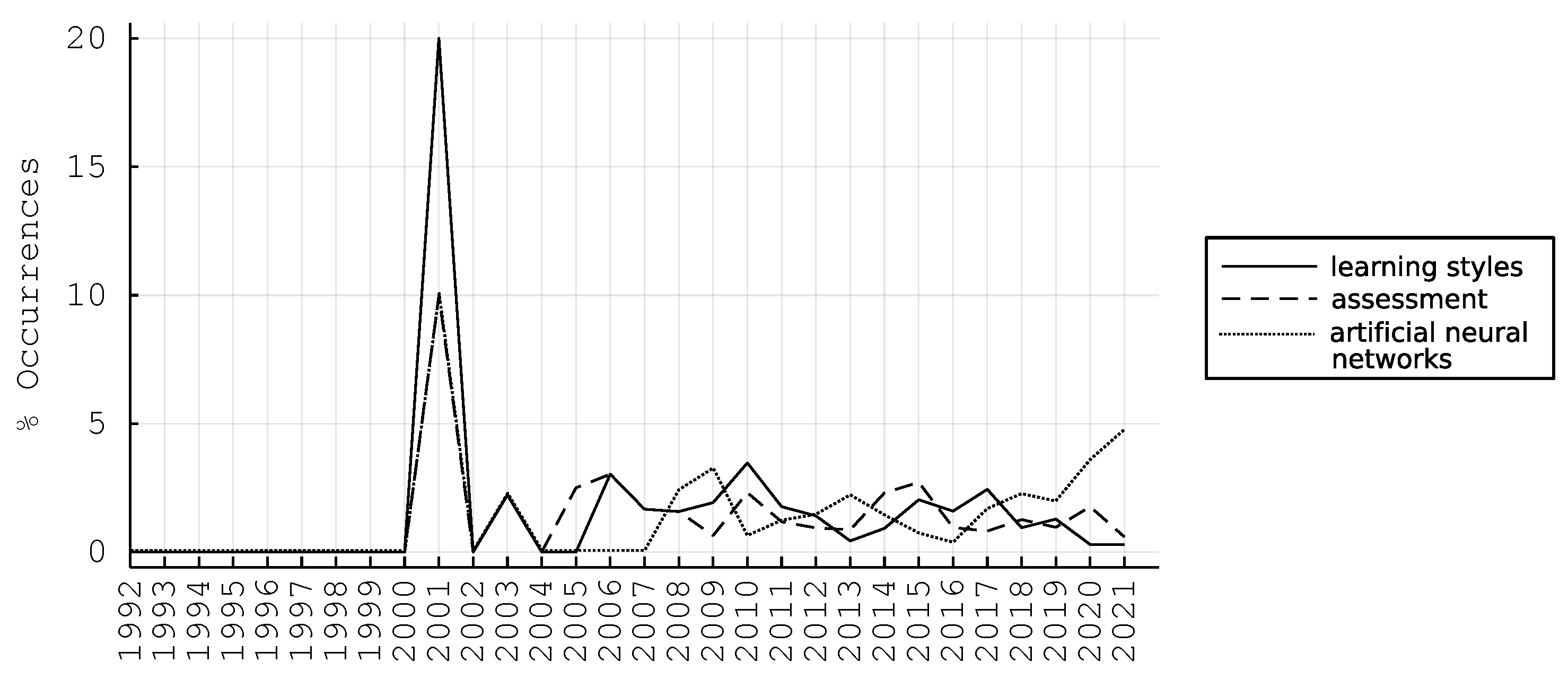
4.2. Current State and Emerging Insights
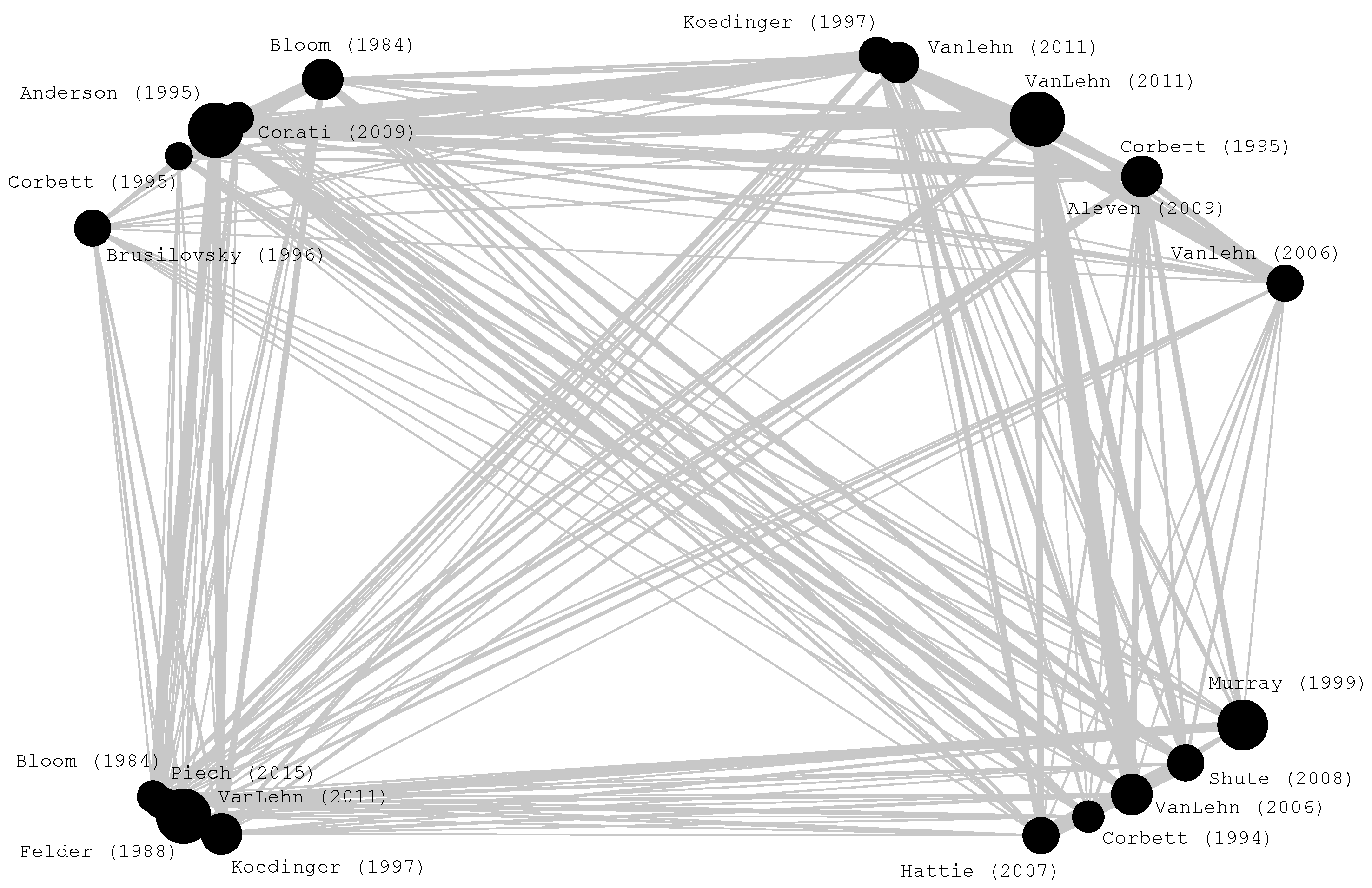
4.3. Map of References
5. Analysis of Top Cited Papers
5.1. Highly Cited Original Research Articles
5.2. Highly Cited Original Research Articles Published in the Last 5 Years
- Digital badges;
- A learner dashboard as the main feature and adaptive learning technology;
- Competency-based technology that adopts algorithm-based tutoring systems.
- What affordances make a learning environment smart?
- Which technologies are used in SLEs?
- In what pedagogical contexts are SLEs used?
- Different contexts (school vs. home) and circumstances (in-person vs. remote learning);
- Demographics;
- Confidence in using technology;
- Perspective on technical usefulness;
- Platform evaluation.
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. The Most Frequent Keywords

| Initial String | Corrected String | Frequency | Initial String | Corrected String | Frequency |
|---|---|---|---|---|---|
| adaptive learning | adaptive learning | 1697 | feedback | NULL | 83 |
| intelligent tutoring systems | intelligent tutoring system | 1518 | web 2.0 | NULL | 83 |
| intelligent tutoring system | intelligent tutoring system | 865 | adaptivity | adaptive learning | 81 |
| personalized learning | personalized learning | 673 | distance learning | NULL | 81 |
| e-learning | NULL | 665 | knowledge tracing | knowledge management | 81 |
| machine learning | machine learning | 282 | learner model | learner model | 80 |
| learning | NULL | 279 | genetic algorithm | genetic algorithm | 78 |
| learning analytics | learning analytics | 241 | intelligent tutoring | intelligent tutoring system | 78 |
| neural network | artificial neural networks | 240 | adaptive learning systems | adaptive learning | 75 |
| artificial intelligence | artificial intelligence | 236 | learning management system | learning management system | 71 |
| personalization | personalized learning | 232 | learning objects | learning objects | 71 |
| neural networks | artificial neural networks | 217 | lifelong learning | NULL | 71 |
| ontology | ontologies | 208 | smart learning | intelligent tutoring system | 70 |
| personal learning environment | personalized learning | 206 | smart learning environments | intelligent tutoring system | 70 |
| mobile learning | NULL | 193 | affect | NULL | 69 |
| personal learning environments | personalized learning | 171 | artificial neural networks | artificial neural networks | 69 |
| online learning | NULL | 169 | problem solving | NULL | 68 |
| adaptive learning rate | adaptive learning | 167 | serious games | NULL | 68 |
| deep learning | artificial neural networks | 167 | adaptive | adaptive learning | 67 |
| education | NULL | 163 | e-learning | NULL | 67 |
| self-regulated learning | self-regulated learning | 163 | instructional design | NULL | 66 |
| reinforcement learning | reinforcement learning | 158 | ontologies | ontologies | 65 |
| collaborative learning | NULL | 155 | recommender systems | recommender systems | 65 |
| learning style | learning style | 148 | virtual reality | NULL | 65 |
| data mining | data mining | 145 | game-based learning | NULL | 64 |
| higher education | NULL | 145 | metacognition | metacognition | 64 |
| educational data mining | data mining | 141 | mooc | NULL | 64 |
| learning styles | learning style | 141 | Bayesian networks | Bayesian networks | 61 |
| student modeling | student modeling | 132 | adaptive hypermedia | adaptive learning | 60 |
| adaptation | adaptive learning | 130 | item response theory | item response theory | 59 |
| its | intelligent tutoring system | 117 | knowledge representation | knowledge management | 59 |
| artificial neural network | artificial neural networks | 108 | clustering | clustering | 58 |
| interactive learning environments | intelligent tutoring system | 106 | user modeling | user modeling | 58 |
| semantic web | NULL | 106 | cloud computing | NULL | 57 |
| adaptive control | adaptive learning | 105 | knowledge management | knowledge management | 57 |
| motivation | motivation | 102 | personalised learning | personalized learning | 57 |
| adaptive learning system | adaptive learning | 100 | bp neural network | artificial neural networks | 55 |
| student model | student modeling | 100 | simulation | NULL | 55 |
| affective computing | NULL | 99 | lms | learning management system | 54 |
| natural language processing | natural language processing | 96 | ubiquitous learning | NULL | 54 |
| evaluation | NULL | 95 | collaboration | NULL | 53 |
| assessment | NULL | 94 | moocs | NULL | 53 |
| blended learning | NULL | 93 | concept drift | concept drift | 52 |
| big data | data mining | 89 | intelligent tutoring system (its) | intelligent tutoring system | 52 |
| ple | personalized learning | 89 | m-learning | NULL | 52 |
| gamification | NULL | 86 | prediction | NULL | 52 |
| smart learning environment | intelligent tutoring system | 85 | augmented reality | NULL | 51 |
| classification | classification | 84 | adaptive e-learning | adaptive learning | 50 |
| fuzzy logic | NULL | 84 | collaborative filtering | recommender systems | 50 |
| educational technology | NULL | 83 | engagement | NULL | 50 |
References
- Koutsantonis, D.; Panayiotopoulos, J.C. Expert system personalized knowledge retrieval. Oper. Res. 2011, 11, 215–227. [Google Scholar] [CrossRef]
- Mastorodimos, D.; Chatzichristofis, S.A. Studying Affective Tutoring Systems for Mathematical Concepts. J. Educ. Technol. Syst. 2019, 48, 14–50. [Google Scholar] [CrossRef]
- Dima, A.; Bugheanu, A.M.; Dinulescu, R.; Potcovaru, A.M.; Stefanescu, C.A.; Marin, I. Exploring the Research Regarding Frugal Innovation and Business Sustainability through Bibliometric Analysis. Sustainability 2022, 14, 1326. [Google Scholar] [CrossRef]
- Popescu, D.V.; Dima, A.; Radu, E.; Dobrotă, E.M.; Dumitrache, V.M. Bibliometric Analysis of the Green Deal Policies in the Food Chain. Amfiteatru Econ. 2022, 24, 410–428. [Google Scholar] [CrossRef]
- Plevris, V.; Solorzano, G.; Bakas, N. Literature review of historical masonry structures with machine learning. In Proceedings of the 7th ECCOMAS Thematic Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, Crete, Greece, 24–26 June 2019; ECCOMAS: Crete, Greece, 2019; pp. 1547–1562. [Google Scholar]
- Plevris, V.; Bakas, N.; Markeset, G.; Bellos, J. Literature review of masonry structures under earthquake excitation utilizing machine learning algorithms. In Proceedings of the 6th ECCOMAS Thematic Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, Rhodes Island, Greece, 15–17 June 2017; ECCOMAS: Rhodes Island, Greece, 2017; pp. 2685–2694. [Google Scholar]
- Papadaki, M.; Bakas, N.; Ochieng, E.; Karamitsos, I.; Kirkham, R. Big data from social media and scientific literature databases reveals relationships among risk management, project management and project success. PM World J. 2019, 8. [Google Scholar] [CrossRef]
- Dimopoulos, T.; Bakas, N. An artificial intelligence algorithm analyzing 30 years of research in mass appraisals. RELAND Int. J. Real Estate Land Plan. 2019, 2, 10–27. [Google Scholar]
- Kruskal, J.B. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 1964, 29, 1–27. [Google Scholar] [CrossRef]
- Moré, J.J. The Levenberg-Marquardt algorithm: Implementation and theory. In Numerical Analysis; Springer: Berlin, Germany, 1978; pp. 105–116. [Google Scholar]
- Shepard, R.N. The analysis of proximities: Multidimensional scaling with an unknown distance function. I. Psychometrika 1962, 27, 125–140. [Google Scholar] [CrossRef]
- van Eck, N.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2009, 84, 523–538. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Conn, A.R.; Gould, N.I.; Toint, P. A globally convergent augmented Lagrangian algorithm for optimization with general constraints and simple bounds. SIAM J. Numer. Anal. 1991, 28, 545–572. [Google Scholar] [CrossRef]
- Audet, C.; Dennis, J.E., Jr. Analysis of generalized pattern searches. SIAM J. Optim. 2002, 13, 889–903. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence, Anchorage, AK, USA, 4–9 May 1998; IEEE: Piscataway, NJ, USA, 1998; pp. 69–73. [Google Scholar]
- Plevris, V. Innovative Computational Techniques for the Optimum Structural Design Considering Uncertainties. Ph.D. Thesis, National Technical University of Athens, Athens, Greece, 2009. [Google Scholar]
- Moayyeri, N.; Gharehbaghi, S.; Plevris, V. Cost-Based Optimum Design of Reinforced Concrete Retaining Walls Considering Different Methods of Bearing Capacity Computation. Mathematics 2019, 7, 1232. [Google Scholar] [CrossRef]
- Byrd, R.H.; Gilbert, J.C.; Nocedal, J. A trust region method based on interior point techniques for nonlinear programming. Math. Program. 2000, 89, 149–185. [Google Scholar] [CrossRef]
- Ugray, Z.; Lasdon, L.; Plummer, J.; Glover, F.; Kelly, J.; Martí, R. Scatter search and local NLP solvers: A multistart framework for global optimization. INFORMS J. Comput. 2007, 19, 328–340. [Google Scholar] [CrossRef]
- Levenberg, K. A method for the solution of certain non-linear problems in least squares. Q. Appl. Math. 1944, 2, 164–168. [Google Scholar] [CrossRef]
- Marquardt, D.W. An algorithm for least-squares estimation of nonlinear parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Bakas, N.P.; Plevris, V.; Langousis, A.; Chatzichristofis, S.A. ITSO: A novel inverse transform sampling-based optimization algorithm for stochastic search. Stoch. Environ. Res. Risk Assess. 2022, 36, 67–76. [Google Scholar] [CrossRef]
- Plevris, V.; Bakas, N.P.; Solorzano, G. Pure Random Orthogonal Search (PROS): A Plain and Elegant Parameterless Algorithm for Global Optimization. Appl. Sci. 2021, 11, 5053. [Google Scholar] [CrossRef]
- Pranckutė, R. Web of Science (WoS) and Scopus: The titans of bibliographic information in today’s academic world. Publications 2021, 9, 12. [Google Scholar] [CrossRef]
- Scopus Database. Available online: https://www.scopus.com/search/ (accessed on 17 March 2022).
- Liu, W.H.; Sherman, A.H. Comparative analysis of the Cuthill–McKee and the reverse Cuthill–McKee ordering algorithms for sparse matrices. SIAM J. Numer. Anal. 1976, 13, 198–213. [Google Scholar] [CrossRef]
- Gates, R.L. CuthillMcKee.jl. Available online: https://github.com/rleegates/CuthillMcKee.jl (accessed on 17 March 2022).
- Anderson, J.R.; Corbett, A.T.; Koedinger, K.R.; Pelletier, R. Cognitive tutors: Lessons learned. J. Learn. Sci. 1995, 4, 167–207. [Google Scholar] [CrossRef]
- VanLehn, K. The relative effectiveness of human tutoring, intelligent tutoring systems, and other tutoring systems. Educ. Psychol. 2011, 46, 197–221. [Google Scholar] [CrossRef]
- Felder, R.M.; Silverman, L.K. Learning and teaching styles in engineering education. Eng. Educ. 1988, 78, 674–681. [Google Scholar]
- Murray, T. Authoring intelligent tutoring systems: An analysis of the state of the art. Int. J. Artif. Intell. Educ. (IJAIED) 1999, 10, 98–129. [Google Scholar]
- Koedinger, K.R.; Anderson, J.R.; Hadley, W.H.; Mark, M.A. Intelligent tutoring goes to school in the big city. Int. J. Artif. Intell. Educ. 1997, 8, 30–43. [Google Scholar]
- Bloom, B.S. The 2 sigma problem: The search for methods of group instruction as effective as one-to-one tutoring. Educ. Res. 1984, 13, 4–16. [Google Scholar] [CrossRef]
- VanLehn, K. The behavior of tutoring systems. Int. J. Artif. Intell. Educ. 2006, 16, 227–265. [Google Scholar]
- Corbett, A.T.; Anderson, J.R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model. -User-Adapt. Interact. 1994, 4, 253–278. [Google Scholar] [CrossRef]
- Brusilovsky, P. Methods and Techniques of Adaptive Hypermedia. In Learner Modeling and Learner-Adapted Interaction; Springer: Dordrecht, The Netherlands, 1996; Volume 6. [Google Scholar]
- Hattie, J.; Timperley, H. The power of feedback. Rev. Educ. Res. 2007, 77, 81–112. [Google Scholar] [CrossRef]
- Shute, V.J. Focus on formative feedback. Rev. Educ. Res. 2008, 78, 153–189. [Google Scholar] [CrossRef]
- Aleven, V.; Mclaren, B.M.; Sewall, J.; Koedinger, K.R. A new paradigm for intelligent tutoring systems: Example-tracing tutors. Int. J. Artif. Intell. Educ. 2009, 19, 105–154. [Google Scholar]
- Conati, C.; Maclaren, H. Empirically building and evaluating a probabilistic model of user affect. User Model. -User-Adapt. Interact. 2009, 19, 267–303. [Google Scholar] [CrossRef]
- Piech, C.; Bassen, J.; Huang, J.; Ganguli, S.; Sahami, M.; Guibas, L.J.; Sohl-Dickstein, J. Deep knowledge tracing. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canads, 7–12 December 2015; Volume 28. [Google Scholar]
- Strayer, J.F. How learning in an inverted classroom influences cooperation, innovation and task orientation. Learn. Environ. Res. 2012, 15, 171–193. [Google Scholar] [CrossRef]
- Baker, R.S.; D’Mello, S.K.; Rodrigo, M.M.T.; Graesser, A.C. Better to be frustrated than bored: The incidence, persistence, and impact of learners’ cognitive–affective states during interactions with three different computer-based learning environments. Int. J. Hum.-Comput. Stud. 2010, 68, 223–241. [Google Scholar] [CrossRef]
- VanLehn, K.; Lynch, C.; Schulze, K.; Shapiro, J.A.; Shelby, R.; Taylor, L.; Treacy, D.; Weinstein, A.; Wintersgill, M. The Andes physics tutoring system: Lessons learned. Int. J. Artif. Intell. Educ. 2005, 15, 147–204. [Google Scholar]
- Schulze, K.G.; Shelby, R.N.; Treacy, D.J.; Wintersgill, M.C.; Vanlehn, K.; Gertner, A. Andes: An intelligent tutor for classical physics. J. Electron. Publ. 2000, 6. [Google Scholar] [CrossRef]
- Conati, C.; Gertner, A.; Vanlehn, K. Using Bayesian networks to manage uncertainty in student modeling. User Model. User-Adapt. Interact. 2002, 12, 371–417. [Google Scholar] [CrossRef]
- Chen, C.M.; Lee, H.M.; Chen, Y.H. Personalized e-learning system using item response theory. Comput. Educ. 2005, 44, 237–255. [Google Scholar] [CrossRef]
- Papanikolaou, K.A.; Grigoriadou, M.; Kornilakis, H.; Magoulas, G.D. Personalizing the Interaction in a Web-based Educational Hypermedia System: The case of INSPIRE. User Model. User-Adapt. Interact. 2003, 13, 213–267. [Google Scholar] [CrossRef]
- Brusilovsky, P.; Schwarz, E.; Weber, G. ELM-ART: An intelligent tutoring system on World Wide Web. In Proceedings of the International Conference on Intelligent Tutoring Systems, Montréal, Canada, 12–14 June 1996; Springer: Berlin, Germany, 1996; pp. 261–269. [Google Scholar]
- Chen, C.M.; Chung, C.J. Personalized mobile English vocabulary learning system based on item response theory and learning memory cycle. Comput. Educ. 2008, 51, 624–645. [Google Scholar] [CrossRef]
- Vrugt, J.A.; Robinson, B.A.; Hyman, J.M. Self-adaptive multimethod search for global optimization in real-parameter spaces. IEEE Trans. Evol. Comput. 2008, 13, 243–259. [Google Scholar] [CrossRef]
- Castro, J.R.; Castillo, O.; Melin, P.; Rodríguez-Díaz, A. A hybrid learning algorithm for a class of interval type-2 fuzzy neural networks. Inf. Sci. 2009, 179, 2175–2193. [Google Scholar] [CrossRef]
- Morze, N.; Varchenko-Trotsenko, L.; Terletska, T.; Smyrnova-Trybulska, E. Implementation of adaptive learning at higher education institutions by means of Moodle LMS. J. Physics Conf. Ser. 2021, 1840-1, 012062. [Google Scholar] [CrossRef]
- Ullah, N.; Mugahed Al-Rahmi, W.; Alzahrani, A.I.; Alfarraj, O.; Alblehai, F.M. Blockchain technology adoption in smart learning environments. Sustainability 2021, 13, 1801. [Google Scholar] [CrossRef]
- Molenaar, I.; Horvers, A.; Baker, R.S. What can moment-by-moment learning curves tell about students’ self-regulated learning? Learn. Instr. 2021, 72, 101206. [Google Scholar] [CrossRef]
- Han, J.; Kim, K.H.; Rhee, W.; Cho, Y.H. Learning analytics dashboards for adaptive support in face-to-face collaborative argumentation. Comput. Educ. 2021, 163, 104041. [Google Scholar] [CrossRef]
- Alamri, H.A.; Watson, S.; Watson, W. Learning technology models that support personalization within blended learning environments in higher education. TechTrends 2021, 65, 62–78. [Google Scholar] [CrossRef]
- Schiff, D. Out of the laboratory and into the classroom: The future of artificial intelligence in education. AI Soc. 2021, 36, 331–348. [Google Scholar] [CrossRef]
- Hutt, S.; Krasich, K.R.; Brockmole, J.; D’Mello, S.K. Breaking out of the lab: Mitigating mind wandering with gaze-based attention-aware technology in classrooms. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–14. [Google Scholar]
- Tabuenca, B.; Serrano-Iglesias, S.; Carruana-Martin, A.; Villa-Torrano, C.; Dimitriadis, Y.A.; Asensio-Perez, J.I.; Alario-Hoyos, C.; Gomez-Sanchez, E.; Bote-Lorenzo, M.L.; Martinez-Mones, A.; et al. Affordances and core functions of smart learning environments: A systematic literature review. IEEE Trans. Learn. Technol. 2021, 14, 129–145. [Google Scholar] [CrossRef]
- Christopoulos, A.; Sprangers, P. Integration of educational technology during the Covid-19 pandemic: An analysis of teacher and student receptions. Cogent Educ. 2021, 8, 1964690. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Adaptive Educational Hypermedia System | OR | Adaptive Educational System | OR |
| adaptive learning | OR | advanced learning technologies | OR |
| intelligent learning platforms | OR | intelligent tutoring systems | OR |
| AI-based learning systems | OR | personal learning environments | OR |
| personalized learning | OR | smart learning environments | OR |
| tutor-based expert systems | OR | web-based adaptive educational applications | |
| AND | |||
| education OR lesson | in | Title OR Keywords |
| Artificial Intelligence | Adaptive Learning | Personalized Learning | Higher Education |
|---|---|---|---|
| self-regulated learning | ontologies | interactive learning environments | natural language processing |
| affective computing | assessment | data mining | blended learning |
| machine learning | learning analytics | ||
| distance learning | educational technology | ||
| student modeling | learning styles | ||
| motivation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koutsantonis, D.; Koutsantonis, K.; Bakas, N.P.; Plevris, V.; Langousis, A.; Chatzichristofis, S.A. Bibliometric Literature Review of Adaptive Learning Systems. Sustainability 2022, 14, 12684. https://doi.org/10.3390/su141912684
Koutsantonis D, Koutsantonis K, Bakas NP, Plevris V, Langousis A, Chatzichristofis SA. Bibliometric Literature Review of Adaptive Learning Systems. Sustainability. 2022; 14(19):12684. https://doi.org/10.3390/su141912684
Chicago/Turabian StyleKoutsantonis, Dionisios, Konstantinos Koutsantonis, Nikolaos P. Bakas, Vagelis Plevris, Andreas Langousis, and Savvas A. Chatzichristofis. 2022. "Bibliometric Literature Review of Adaptive Learning Systems" Sustainability 14, no. 19: 12684. https://doi.org/10.3390/su141912684
APA StyleKoutsantonis, D., Koutsantonis, K., Bakas, N. P., Plevris, V., Langousis, A., & Chatzichristofis, S. A. (2022). Bibliometric Literature Review of Adaptive Learning Systems. Sustainability, 14(19), 12684. https://doi.org/10.3390/su141912684