
Research on Accurate Estimation Method of Eucalyptus Biomass Based on Airborne LiDAR Data and Aerial Images


Abstract
:1. Introduction
2. Study Area and Data Sources
2.1. Study Area
2.2. Data Sources
2.2.1. Image Data
2.2.2. Sample Data
3. Research Methods
3.1. Single Wood Extraction
3.2. Biomass Estimation
3.2.1. Variable Filtering
3.2.2. Multiple Stepwise Regression Method
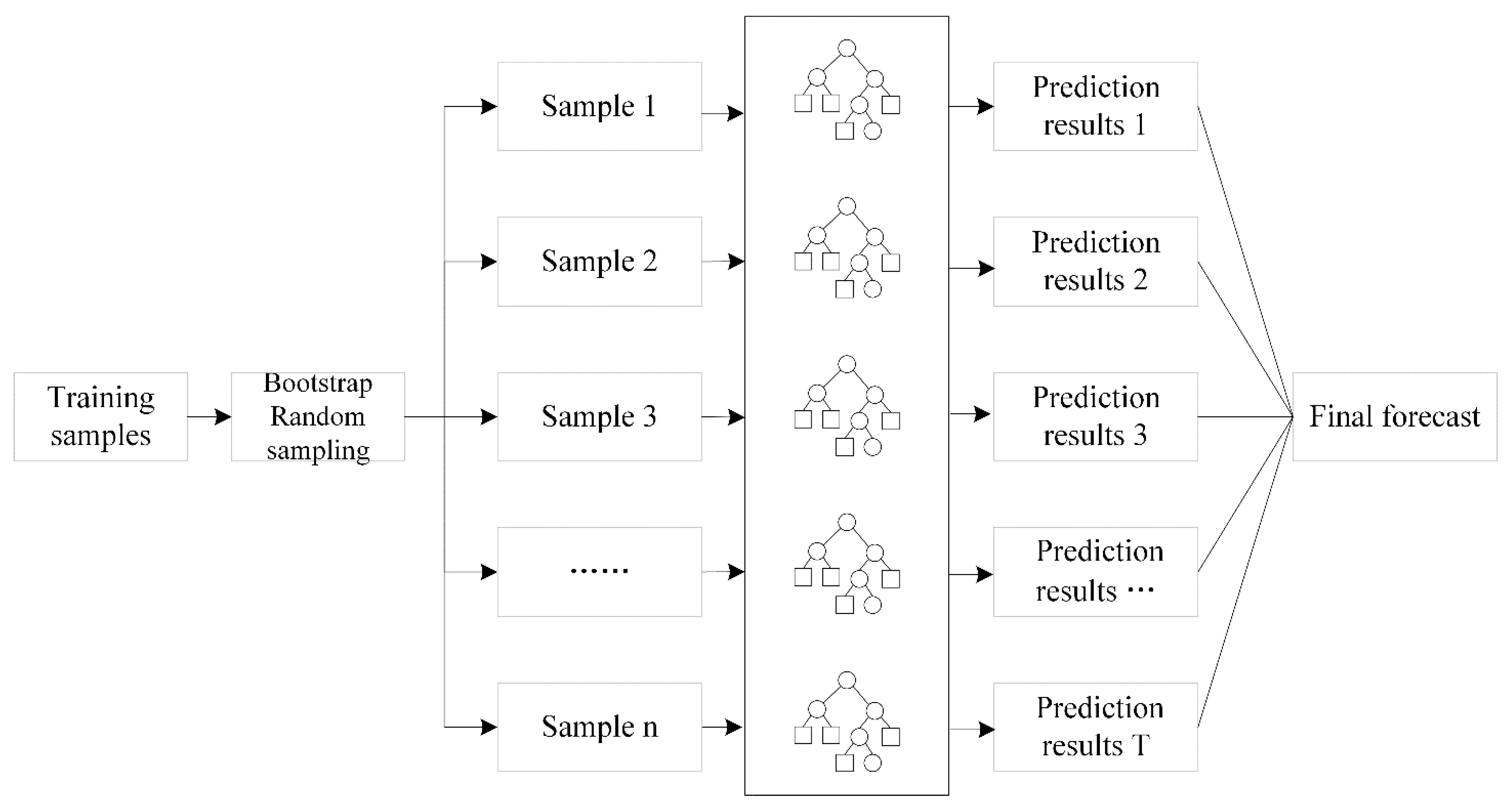
3.2.3. Random Forest Algorithm
3.2.4. Support Vector Machines
3.2.5. Decision Trees
3.3. Accuracy Evaluation
4. Results and Analysis
4.1. Single Wood Extraction Results
4.2. Biomass Estimation Results
5. Discussions
- (1)
- In terms of single wood segmentation in dense vegetation cover areas, how to determine whether there are small trees below the dense canopy and how to identify and segment these small trees are issues that need to be studied in depth in the next step. The further inclusion of data sources, such as ground-based radar data, on top of fused data can be considered in order to obtain more information on tree structure and location, and thus improve the accuracy of the Eucalyptus biomass estimation model.
- (2)
- Data such as tree age and storage volume were not used in this study, and further consideration can be given to adding data such as the age of Eucalyptus trees and the storage volume of the area in which they are located in subsequent studies to further improve the accuracy of biomass modelling.
- (3)
- The combination of multi-source data and machine learning algorithms can provide accurate and rapid biomass measurements at the single-wood scale, which can provide more accurate information for the management of regional biomass resources statistics. Deep learning algorithms may also be considered in the future to explore the performance of different algorithms for biomass estimation of eucalypts over large areas.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hyypp, J.; Kelle, O.; Lehikoinen, M.; Inkinen, M. A segmentation-based method to retrieve stem volume estimates from 3-D tree height models produced by laser scanners. IEEE Trans. Geosci. Remote Sens. 2001, 39, 969–975. [Google Scholar] [CrossRef]
- Fang, J.; Chen, A.; Peng, C.; Zhao, S.; Ci, L. Changes in Forest Biomass Carbon Storage in China Between 1949 and 1998. Science 2001, 292, 2320–2322. [Google Scholar] [CrossRef]
- Yu, X.X.; Lu, S.W.; Jin, F.; Chen, L.H.; Rao, L.Y.; Lu, G.Q. The assessment of the forest ecosystem services evaluation in China. Acta Ecol. Sin. 2005, 25, 2096–2102. [Google Scholar]
- Li, H.K.; Lei, Y.C.; Zeng, W.S. Forest carbon storage in China estimated using forestry inventory data. Sci. Silvae Sin. 2011, 47, 7–12. [Google Scholar]
- Li, D.R.; Wang, C.W.; Hu, M.Y.; Liu, S.G. Research progress in estimating forest biomass by remote sensing technology. Geomat. Inf. Sci. Wuhan Univ. 2012, 37, 631–635. [Google Scholar]
- Jiao, Y.; Hu, H.Q. Carbon storage and its dynamics of forest vegetations in Heilongjiang Province. Chin. J. Appl. Ecol. 2005, 16, 2248–2252. [Google Scholar]
- Zhang, L.Q. Research on Remote Sensing Biomass Estimate of Eucalyptus Plantation; Guangxi University: Nanning, China, 2012. [Google Scholar]
- Thomas, V.; Treitz, P.; Mccaughey, J.H.; Morrison, I. Mapping stand-level forest biophysical variables for a mixedwood boreal forest using lidar: An examination of scanning density. Can. J. For. Res. 2006, 36, 34–47. [Google Scholar] [CrossRef]
- Zheng, H.M. Compatible Models of Individual Tree Biomass Factors for Simao Pine Natural Forest; Southwest Forestry University: Kunming, China, 2015. [Google Scholar]
- Ou, J.D.; Ou, J.L.; Kang, Y.W. Single tree biomass simulation of taxus yunnanensis plantation based on crown morphological index. J. Southwest For. Univ. Nat. Sci. 2022, 42, 1–9. [Google Scholar]
- Gleason, C.J.; Im, J. Forest biomass estimation from airborne LiDAR data using machine learning approaches. Remote Sens. Environ. 2012, 125, 80–91. [Google Scholar] [CrossRef]
- Li, D. Retrieval and Estimation Research of Forest Parameters Based on Digital Aerial Photograph Data; Institute of Remote Sensing and Digital Earth Chinese Academy of Sciences: Beijing, China, 2018. [Google Scholar]
- Zhang, P.; Ma, Q.X.; Lv, J.; Ji, J.L.; Li, Z.W. Application of machine learning algorithms in estimation of aboveground biomass of forest. Bull. Surv. Mapp. 2021, 28–32. [Google Scholar] [CrossRef]
- Wang, Y.F.; Yue, T.X.; Zhao, M.W.; Du, Z.P.; Liu, X.F.; Liu, S.; Song, E.F.; Sun, W.Z.; Zhang, Y.L. Study of factors impacting the tree height extraction based on airborne LIDAR data. J. Geo-Inf. Sci. 2014, 16, 958–964. [Google Scholar]
- Zhang, H.Q. Research on Single Wood Segmentation and Tree Height Estimation Method Based on UAV LiDAR; Kunming University of Science and Technology: Kunming, China, 2021. [Google Scholar]
- Jin, Z.M.; Cao, S.S.; Wang, L.; Sun, W. A method for individual tree-crown extraction from USA remote sensing image based on U-Net and watershed algorithm. J. Northwest For. Univ. 2020, 35, 194–204. [Google Scholar]
- Ding, J.Q.; Huang, W.L.; Liu, Y.C.; Hu, Y. Estimation of forest aboveground biomass in northwest hunan province based on machine learning and multi-source data. Sci. Silvae Sin. 2021, 57, 36–48. [Google Scholar]
- Cho, A. High density biomass estimation for wetland vegetation using WorldView-2 imagery and random forest regression algorithm. Int. J. Appl. Earth Obs. 2012, 18, 399–406. [Google Scholar]
- Wang, Y.F.; Pang, Y.; Shu, Q.T.; University, S.F. Counter-estimation on aboveground biomass of hevea brasiliensis plantation by remote sensing with random forest algorithm-a case study of Jinghong. J. Southwest For. Univ. 2013, 33, 38–45. [Google Scholar]
- You, S.B.; Yan, Y. Stepwise regression analysis and its application. Stat. Decis. 2017, 14, 31–35. [Google Scholar]
- Vapnik, V.; Chapelle, O. Bounds on error expectation for support vector machines. Neural Comput. 2000, 12, 2013–2036. [Google Scholar] [CrossRef]
- Ara, A.; Maia, M.; Louzada, F.; Macêdo, S. Regression random machines: An ensemble support vector regression model with free kernel choice. Expert Syst. Appl. 2022, 202, 117107. [Google Scholar] [CrossRef]
- Gao, Y.K. Aboveground Forest Biomass Estimation Based on Machine Learning Algorithms and Multi-Source Data in a Typical Subtropical Region; Zhejiang A&F University: Hangzhou, China, 2018. [Google Scholar]
- Karka, P.; Papadokonstantakis, S.; Kokossis, A. Environmental impact assessment of biomass process chains at early design stages using decision trees. Int. J. Life Cycle Assess. 2019, 24, 1675–1700. [Google Scholar] [CrossRef]
- Dong, H.Z.; Xu, H.P.; Lu, B.; Yang, Q. A cart-based approach to predict nitrogen oxide concentration along urban traffic roads. Acta Sci. Circumstantiae 2019, 39, 1086–1094. [Google Scholar]
- Li, C.; Li, Y.; Li, M. Improving forest aboveground biomass (AGB) estimation by incorporating crown density and using Landsat 8 OLI iImages of a subtropical forest in western hunan in central China. Forests 2019, 10, 104. [Google Scholar] [CrossRef] [Green Version]
- Xu, G.C. Forest LAI and individual trees biomass estimation using small-footprint fyll-waveform LiDAR data. Chin. Acad. For. Sci. 2013. Available online: https://kns.cnki.net/KCMS/detail/detail.aspx?dbname=CDFD1214&filename=1013378640.nh (accessed on 14 June 2022).
- Liu, F.; Tan, C.; Zhang, G.; Liu, J.X. Estimation of forest parameter and biomass for individual pine trees using airborne LiDAR. Trans. Chin. Soc. Agric. Mach. 2013, 44, 219–224. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Specification |
|---|---|
| Flight height/m | 500 |
| Ground speed/kn | 60 |
| Mapping bandwidth/m | 175 |
| Laser wavelength/nm | 1064 |
| Pulse repetition rate/kHz | 50~1000 |
| Scanning view/(°) | 10~60 |
| Average point cloud density/(pts/m2) | 180 |
| Positioning and orientation systems | POS AV™ AP60 (OEM); 220-channel dual-frequency GNSS receiver; GNSS airborne antenna with iridium filter; Highly accurate AIMU (Type 57); |
| Tree Number | Longitude | Latitude | DBH/cm | Height/m |
|---|---|---|---|---|
| 1 | 113°47′22″ E | 23°19′53″ N | 35.00 | 23.80 |
| 2 | 113°47′28″ E | 23°19′42″ N | 20.30 | 17.00 |
| 3 | 113°47′29″ E | 23°19′43″ N | 7.50 | 7.80 |
| 4 | 113°47′29″ E | 23°19′53″ N | 18.40 | 14.80 |
| 5 | 113°47′25″ E | 23°19′51″ N | 4.00 | 3.10 |
| … | … | … | … | … |
| 98 | 113°47′24″ E | 23°19′51″ N | 19.00 | 16.20 |
| 99 | 113°47′28″ E | 23°19′50″ N | 13.60 | 14.20 |
| 100 | 113°47′22″ E | 23°19′49″ N | 23.50 | 19.00 |
| Methods | Training Set | Test Set | ||
|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | |
| MLR | 0.4132 | 19.4161 | 0.3490 | 20.2352 |
| RF | 0.9375 | 9.8024 | 0.7855 | 13.0377 |
| SVR | 0.7173 | 14.1331 | 0.4822 | 17.1953 |
| CART | 0.5722 | 16.7032 | 0.2856 | 22.3906 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, R.; Shi, W.; Yu, Q.; Li, X.; Chen, X. Research on Accurate Estimation Method of Eucalyptus Biomass Based on Airborne LiDAR Data and Aerial Images. Sustainability 2022, 14, 10576. https://doi.org/10.3390/su141710576
Li Y, Wang R, Shi W, Yu Q, Li X, Chen X. Research on Accurate Estimation Method of Eucalyptus Biomass Based on Airborne LiDAR Data and Aerial Images. Sustainability. 2022; 14(17):10576. https://doi.org/10.3390/su141710576
Chicago/Turabian StyleLi, Yiran, Ruirui Wang, Wei Shi, Qiang Yu, Xiuting Li, and Xingwang Chen. 2022. "Research on Accurate Estimation Method of Eucalyptus Biomass Based on Airborne LiDAR Data and Aerial Images" Sustainability 14, no. 17: 10576. https://doi.org/10.3390/su141710576
APA StyleLi, Y., Wang, R., Shi, W., Yu, Q., Li, X., & Chen, X. (2022). Research on Accurate Estimation Method of Eucalyptus Biomass Based on Airborne LiDAR Data and Aerial Images. Sustainability, 14(17), 10576. https://doi.org/10.3390/su141710576