1. Introduction
Air contamination can be one of the most severe worldwide issues causing ecological and environmental damage [
1,
2,
3] as well as damage to human fitness [
4,
5,
6], especially under long-term high-PM
2.5 (diameter less than or equal 2.5 μg/m
3) concentration conditions, which would pose serious threats to public health and respiratory filtration systems. PM
2.5 is known as “pulmonary particulate matter” and is a key index for assessing fitness harm [
7,
8]. Therefore, an accurate understanding of PM
2.5 concentration is of great significance for early warning of atmospheric quality, which helps to reduce health damage and economic loss.
It is indeed challenging to use a single linear model to consider the complex, multi-parameter, nonlinear PM
2.5 concentration prediction process [
3,
9,
10]. For example, Lu et al. [
11] showed that the coupled model of back-propagation artificial neural network (BPANN) as well as support vector regression (SVR) have a significant advantage in solving the nonlinear relationship between the input parameters and dependent variable than those of partial least squares regression (PLSR) under the same input parameters. Thus, more and more research has employed the machine learning methods to manage the nonlinear problems. By using the artificial neural network (ANN), support vector machine (SVM), and other machine study algorithms, Zhu and Lu [
12] obtained a higher correlation with R
2 value at 0.8 than the linear methods performed during the PM
2.5 and PM
10 (diameter less than or equal 10 μg/m
3) concentration forecasts. Moreover, in order to catch the hourly variation of the PM
2.5 concentration, Shang et al. [
13] employed the extreme learning machine (ELM) and classification regression tree (CART) mixed models.
Gradually, with the deepening of research, a series of deep networks, such as deep belief network (DBN) and long- and short-memory neural network (LSTM), were introduced to verify its performance. Each model showed better results than traditional machine learning ways [
2,
14,
15,
16,
17]. Therefore, the in-depth neural nets were treated as advanced methods with systematic and scientific neuron and network structures and performed well in capturing input–output parameter characteristics. In addition to the abovementioned, BiLSTM has much more strength for forecasting PM
2.5 concentration. Without considering the input parameters of forward and backward information, the normal time series features are extracted from the forward LSTM layer, and the future change information is obtained from the reverse LSTM layer to further improve the prediction results.
However, with a single deep neural net, it is hard to achieve a precise forecast of the PM
2.5 concentration. For example, Dai et al. [
18] showed that the RNN (recurrent neural network) model could calculate obvious deviation with gradient explosion and gradient disappearance, which is the same as the LSTM model [
19], and could hardly reflect spatial information. Therefore, more and more studies introduced mixed models for prediction, which are beneficial to a singular model [
9,
20,
21]. Using this method, each step would perform better with the advantage utilized, such as maximizing input parameter information [
22], spatiotemporal data [
23], deviation correction data [
24], etc., to calculate more precise estimate consequences. As Zhang et al. [
25] demonstrated, the PM
2.5 concentration prediction could be treated as a statistical method by capturing the historical trend and assessing the future periods. Additionally, the univariate and multivariate parameters constitute forecasting input elements. Taking the autoregressive integrated moving average (ARIMA) mode as an example [
26], we could acquire accuracy results just by using the PM
2.5 series data information in the short term. A much better prediction could be obtained if studies apply plenty of variables as input parameters to acquire the variation of influencing factors and forecast targets [
27,
28]. An adaptive method for decomposing was widely used based on the RF algorithm, and the prediction of PM
2.5 concentration can serve as a statistical method by capturing historical trends and assessing future periods. Univariate and multivariate parameters constitute the predictive inputs. Taking ARIMA as an example [
26], accurate results can be obtained in a short period using only PM
2.5 series data information.
However, the accuracy of prediction results is greatly reduced due to the increasing uncertainty of disturbance factors when dealing with a long-term forecast. Chen [
29] and Sawlani et al. [
30] reported that meteorological conditions and other air pollution are the main influencing factors (such as PM
10, SO
2, VOCs, and NOx, etc.) for changes in PM
2.5 concentrations. If many variables are used as input parameters to obtain the change in influencing factors and forecast targets, better prediction results can be obtained [
27,
28]. An adaptive decomposition method based on the RF (random forest) algorithm was widely used, and it had advantages in managing complicated nonlinear relations between variables. Bai et al. [
4] used a radio-frequency model that incorporated different spatial–temporal variable sources for PM
2.5 predictions in New York state and achieved good consequences. Based on this function, the RF model has the advantage of using time series data and reflecting changing features, while the Fourier transforms method and other methods could not achieve those functions as well as the wavelet decomposition method.
In fact, the PM
2.5 concentration prediction methods are in depth but still present challenges. Most of the existing time series prediction focuses on the increasing forecast performance of the original sequence without making full use of the effective information implicit in the predictive error sequence. For instance, both precision of peak forecast [
31] and the long-term forecast error reduction [
29] need improvement. Considering the aforementioned issues, a novel mixed model was proposed with the (RF-BiLSTM) bonding RF approach as well as BiLSTM model to forecast the concentration of PM
2.5 in the short term (
T + 1,
T + 3 moments) as well as the long term (
T + 12 moments).
Herein, we present the following innovations: (1) A novel PM2.5 concentration forecast mixed model was recommended to significantly ameliorate forecast precision for the short term as well as the long term. (2) The results showed that the RF model is introduced to decompose the test set independently while the BiLSTM model is coupled. (3) The model was compared with LSTM, SVM, RF, and Tree algorithms. (4) The model was compared with other algorithms, such as LSTM, SVM, RF, and tree. The parameters of different models were adjusted according to the model performance, and the data of different lead times were selected to observe the experimental results. (5) The new mixed-mixing model performs well in spatiotemporal generalization and in reflecting the context relationship of the time point.
2. Methods and Materials
2.1. Study Area and Materials
Beijing, Guangzhou, Xi’an, and Shenyang are the typical representatives of China’s capital, south, central, and northeast regions with high population density and economic prosperity. Beijing is bordered by Tianjin in the east and Hebei in the west, with high terrain in the northwest. Guangzhou presents the characteristics of high terrain in the northeast, high terrain in the southwest, and mountains next to the sea. Xi’an is the highest of all the Chinese cities, and its meteorological characteristics vary greatly from season to season. Shenyang has obvious location advantages and dense transportation networks. It is a famous industrial city that focuses on equipment manufacturing. Under such circumstances, more scientific and precise prediction consequences of PM2.5 concentration is needed to reduce risk exposure.
In the research, the surface meteorological and air quality data from January 2013 to December 2015 were applied as input parameters for the model. Therein, meteorological data including dew point temperature (DT), hourly temperature (T), wind direction at 2 m (U), and wind speed at 2 m (V) were downloaded from the national oceanic and atmospheric administration (
https://www.ncdc.noaa.gov/, accessed on 6 July 2022). Hourly data of six pollutants (e.g., PM
2.5, PM
10 (particulate matter 10), SO
2 (sulfur dioxide), NO
2 (nitrogen dioxide), O
3 (ozone), and CO
2 (carbon dioxide)) were acquired from the Chinese ministry of environment (
http://www.cnemc.cn/, accessed on 6 June 2022). The position of the research area is illustrated in
Figure 1. Since there are transmission errors and sensor failures at the observation points [
32], abnormal issues and irregular disappearance in the monitor information need verification as well as testing. Meanwhile, an unmodified, objective, and relatively complete basic data set of time series is the cornerstone of prediction. From previous studies, we chose the mean completion to recension pollutants concentration data, while the missing rate between 0% and 3%, and missing rate between 3.01% and 10% was applied using linear interpolation.
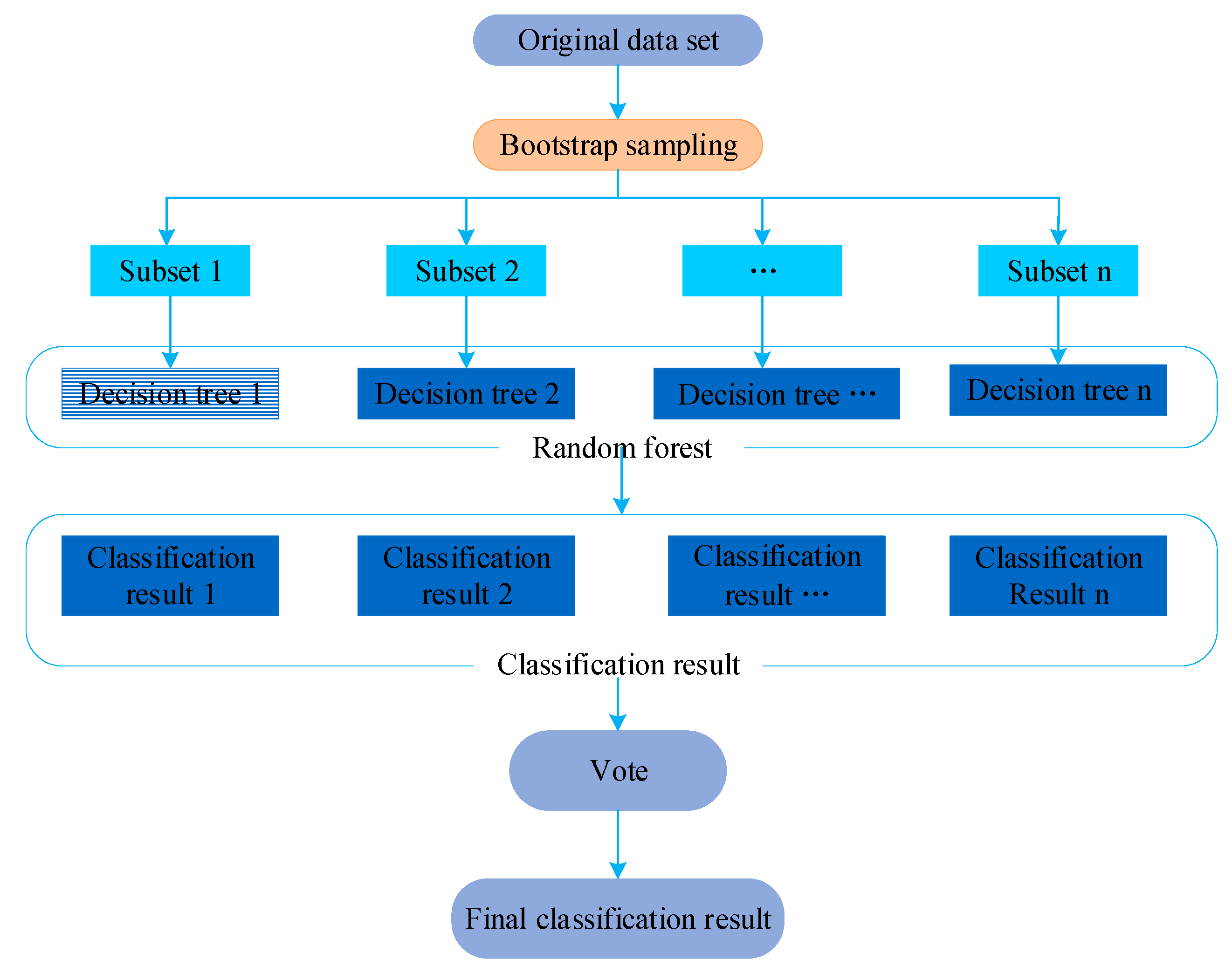
2.2. Random Forest
Random forest is a supervisory machine study algorithm. It extracts multiple subsets from the original data, trains each subset, and summarizes the classification results of different subsets to get the final result (
Figure 2). In addition, random forest has an important feature which can calculate the importance of individual feature variables. Therefore, this study calculated the importance of each feature’s influence on PM
2.5 concentration, sorted these features, and screened out the most important feature.
2.3. Bi-Directional Long Short-Term Memory
Before introducing BiLSTM, we need to know about the LSTM. Hochreiter and Schmidhuber [
33] were the first researchers to propose the model of LSTM, which has achieved great success in solving many problems and has been used in many subjects [
34,
35]. Compared to other models, the scale of data required for LSTM studies is not as long.
LSTM consists of the import word , cell status , temporary cell status , concealed layer status , forgetting gate , memory gate , as well as output gate at time t. The calculation procedure is below:
(1) Count the forgetting gate and choose the data to be forgotten.
Import: concealed layer status of former time, import word of present time.
Export: forgetting gate score .
(2) Calculate the memory gate and select the information to be memorized.
Input: hidden layer state of the previous time, input word of the current time.
Output: memory gate value , temporary cell state .
(3) Calculate the cell state at the current time.
Input: memory gate value , forgetting gate value , temporary cell state , last moment cell status .
Output: cell state C at the current time.
(4) Calculate the output gate and current hidden layer state.
Import: hidden layer state of the previous time, the input word of the current time, cell status of the present time.
Export: output gate value o, hidden layer state .
In a word, the calculation process of LSTM is to take the operation of forgetting data and remembering novel data to the cell status, move the helpful data for succeeding time, and output concealed layer status at every time point. BiLSTM is the integration of forwarding LSTM as well as backward LSTM. The hidden layer needs to store two values, one for forwarding calculation and the other for reverse calculation. The final output value depends on these two values.
2.4. Modeling Process
Figure 3 describes the research framework of this paper. It consists of three parts:
(1) Selection of variables.
Wind direction, humidity, air pressure, air temperature, and other features were selected as the more important features of the input variables [
36]. Additionally, to ensure the complete integrity of the PM
2.5 sample in the time series, linear interpolation was employed to fill the missing value.
(2) Model parameter adjustment and training.
Then, the time series of training, test, and validation sets were different, and the data set ratio was shown in the following in detail. Additionally, the number of components was also different. After a comparison of different components, the fitter component could be chosen as fixed input variables. Next, the input parameters of LSTM, SVM, RF, and Tree models were adjusted to predict PM2.5 concentration.
(3) Effect evaluation.
Mean absolute error (MAE) and root mean square error (RMSE) are applied to assess the prediction results of the model and contrast them with other models to discuss the effect of the model in different regions and different lead times.
Each city’s time series data is separated into three data sets in the ratio of 7:1:2, which are the training set, the validation set, and the test set. The training set data is hourly data from April 1, 2013, to March 5, 2015, and the subsequent hourly data is the verification set from June 13. The validation set serves as a reference for fine-tuning model parameters, whereas the training set is utilized for initial model training. The split-out test set is primarily utilized to validate the model’s validity since the trained model has never encountered it before. The hourly environmental data from 14 June 2015 to 31 December 2015 was used as the test set. By comparing with the LSTM, SVM, RF, and tree models, the advantages of the RF-BiLSTM model are shown in
Section 3.2.
2.5. Evaluation Indicators
To evaluate the performance, we adopted 3 statistical indexes: coefficient of determination (R
2), MAE, and RMSE, which have been widely used in the assessment of precise indictors in former research scholar’s work [
32,
37]. The definitions of those indicators are as follows:
where
i represents the time a serial number of prediction and observation specimens,
T represents the amount time serial number of prediction and observation samples,
denotes the PM
2.5 concentration in time
I,
represents concentration of PM
2.5 forecasting consequence of sample in time
i, and
represents the mean value the observation concentration of sample in time
i. R
2 denotes the degree of fitting value among the prediction concentration as well as actual concentration at the corresponding time, which when closer to the value of 1, the precise result performed much better. Additionally, the rest of the indictors of RMSE and MAPE are error assessment indicators that analyze deviation among prediction as well as actual value simultaneously.
4. Conclusions
The environmental damage caused by frantic industrial development will eventually have an impact on human health, and PM2.5 is not the only product, but it is a crucial one. Accurately predicting PM2.5 concentrations can help to issue air quality alerts, allow people to avoid long-term exposure to high pollution levels, and ease the pain of respiratory diseases. The PM2.5 concentration curves of four typical cities with regional characteristics, Shenyang, Beijing, Xi’an, and Guangzhou, were illustrated by using the random forest model. The conclusion is as follows:
(1) The variation of the concentration of PM2.5 in China is related to lifestyle and meteorological factors. Xi’an is located in the mainland, so the accumulation of pollutants is mainly due to the more stationary wind. Meanwhile, Guangzhou is located in the south, adjacent to the Pearl River, and the air humidity is higher than in other areas, so the pollutant accumulation level is low. By comparing weekend and weekday PM2.5 concentrations, it was found that human activities also have an impact on pollutant levels in the area.
(2) Feature selection can effectively reduce the model complexity by compressing the input variable dimensions. In this paper, the DEWP, TEMP, HUMI, PRES, and Iws of different lead times are selected as input variables according to the correlations assessed using RF. The selected variables contain most of the previous environmental attributes to ensure the accuracy of the model. Since the input dimension was reduced by 80%, the memory required for model operation was doubled, making it possible to deploy edge computing on low-performance computers.
(3) The proposed RF-BiLSTM mixed model shows superior performance on different statistical indicators compared to others. The model can identify and fit the variation rule of concentration, and it can also identify the key variables to some extent. At the same time, it is highly portable and can be used to predict pollutants in different geographical areas at a low cost. In future work, the model will be improved in the following aspects: for regions with the same geographical characteristics, input variables are selected to verify the universality of the model, and the random forest feature selection method is selected. Other feature selection methods will also be tested for better performance.
(4) In recent years, the majority of cities in China have witnessed the high frequency of haze pollution. With the help of the forecasting model, especially in short- and long-term prediction, PM2.5 concentration variation characteristics have been significantly captured based on the RF-BiLSTM model. Under this circumstance, joint prevention and control and targeted policies to reduce emissions could be established and implemented, and human health can be significantly improved.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}