
Research on the Prediction Model of the Used Car Price in View of the PSO-GRA-BP Neural Network


Abstract
:1. Introduction
- (1)
- In view of the shortcomings of the traditional BP neural network, use grey relation analysis to screen feature variables, combine with particle swarm optimization algorithm to further optimize, and apply the improved model to the evaluation of used car prices.
- (2)
- The PSO-GRA-BPNN established in this paper is compared with the traditional BP neural network, multiple linear regression, random forest [12], and support vector machine regression models [30], and the advantages of the prediction accuracy of this model are verified by actual cases, which provides a new idea and method for used car evaluation.
2. Data and Model Assumptions
2.1. Analysis of Elements Making the Price of Used Cars Different
2.2. Data Selection and Processing
- (1)
- For data columns that can be calculated quantitatively, such as displacement and new car price, use Lagrange interpolation to calculate their missing values, and delete missing values that are difficult to quantify such as brand and region.
- (2)
- According to the ranking of “100 Most Valuable Auto Brands in the World in 2021” released by Brand Finance, different brands are coded and digitized.
- (3)
- There are three driving modes: front-wheel drive, rear-wheel drive, and four-wheel drive, which are denoted by the numbers 0, 1, and 2.
- (4)
- The gearbox is divided into two types: automatic and manual, and it is converted into a Boolean type, that is, the number of automatic is 0, and the number of manual is 1.
- (5)
- The body structure is divided into the single box, hatchback, and sedan, delete a few single boxes, convert the hatchback to number 0, and the sedan to number 1.
- (6)
- The usage time is converted to the number of days since the data were acquired.
- (7)
- Since the National III cars are gradually being phased out, a small number of National III cars are deleted, and National IV is converted to the number 4, National V is converted to the number 5, and National VI is converted to the number 6.
- (8)
- The value is assigned according to the number of prefecture level cities in different provinces. Anhui Province is assigned 1–17, Zhejiang Province is assigned 18–28, Fujian Province is assigned 29–38, Jiangxi Province is assigned 39–51, Jiangsu Province is assigned 52–65, Shandong Province is assigned 66–81, and Shanghai is assigned 82.
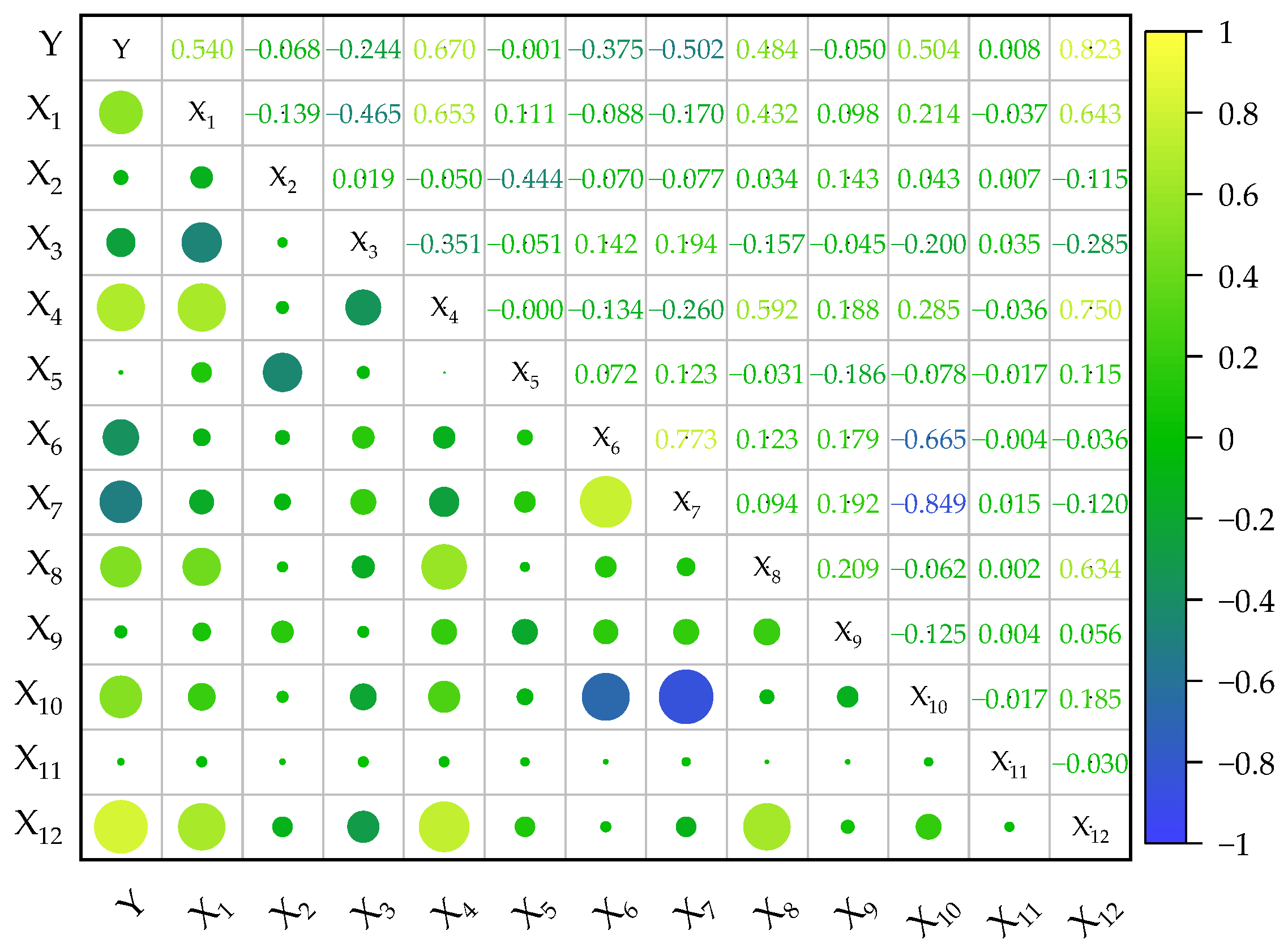
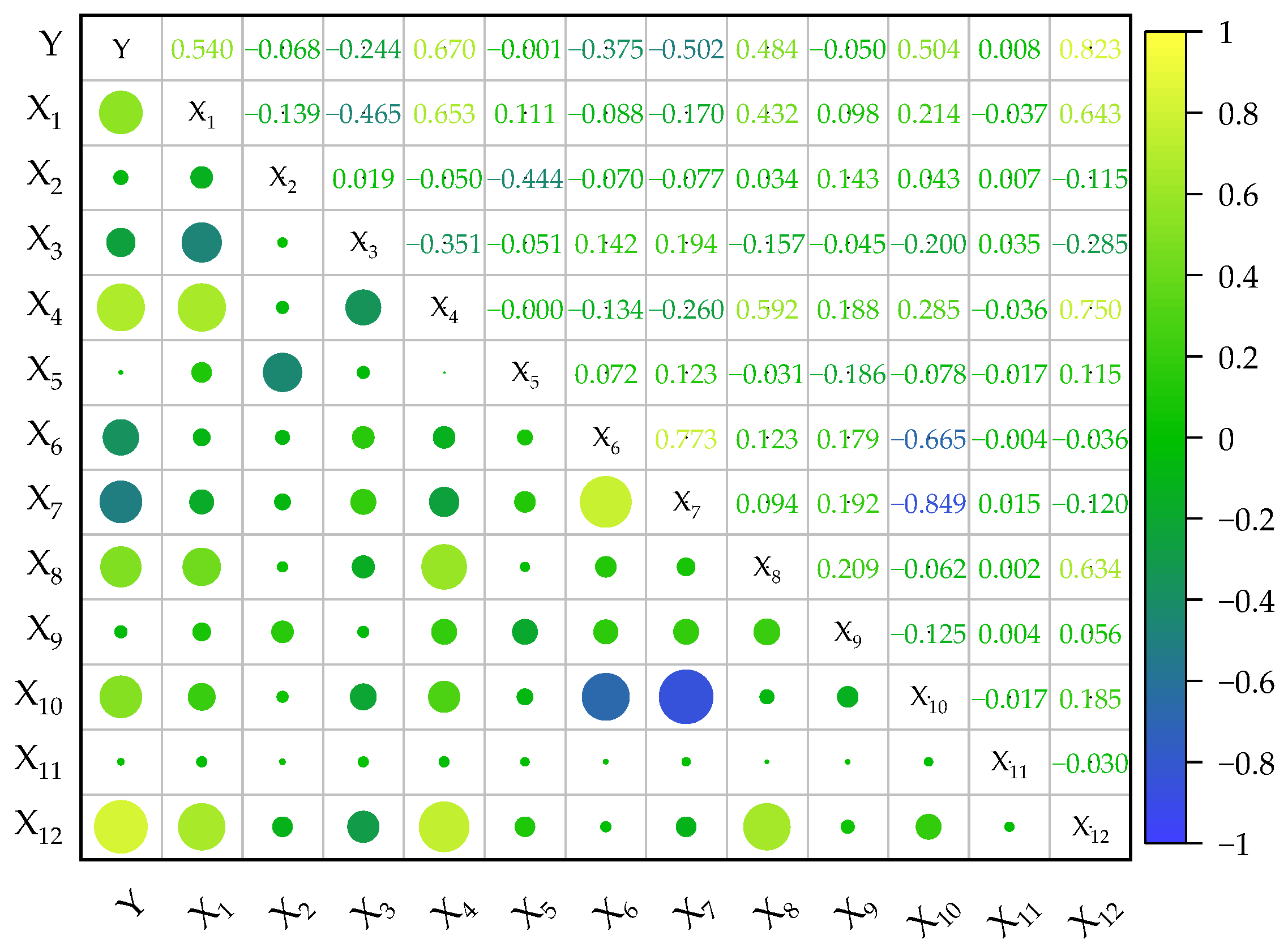
2.3. Analysis of Pearson Correlation
2.4. Assumptions
- (1)
- Since the collected data are not the data after the actual transaction on the platform, we assume that every used car on the platform can be successfully traded at the page price.
- (2)
- The price of used cars is not only affected by their internal configuration but also by the external environment. We assume that the price of used car pages provided by the platform will not be affected by the external environment.
3. Methodology
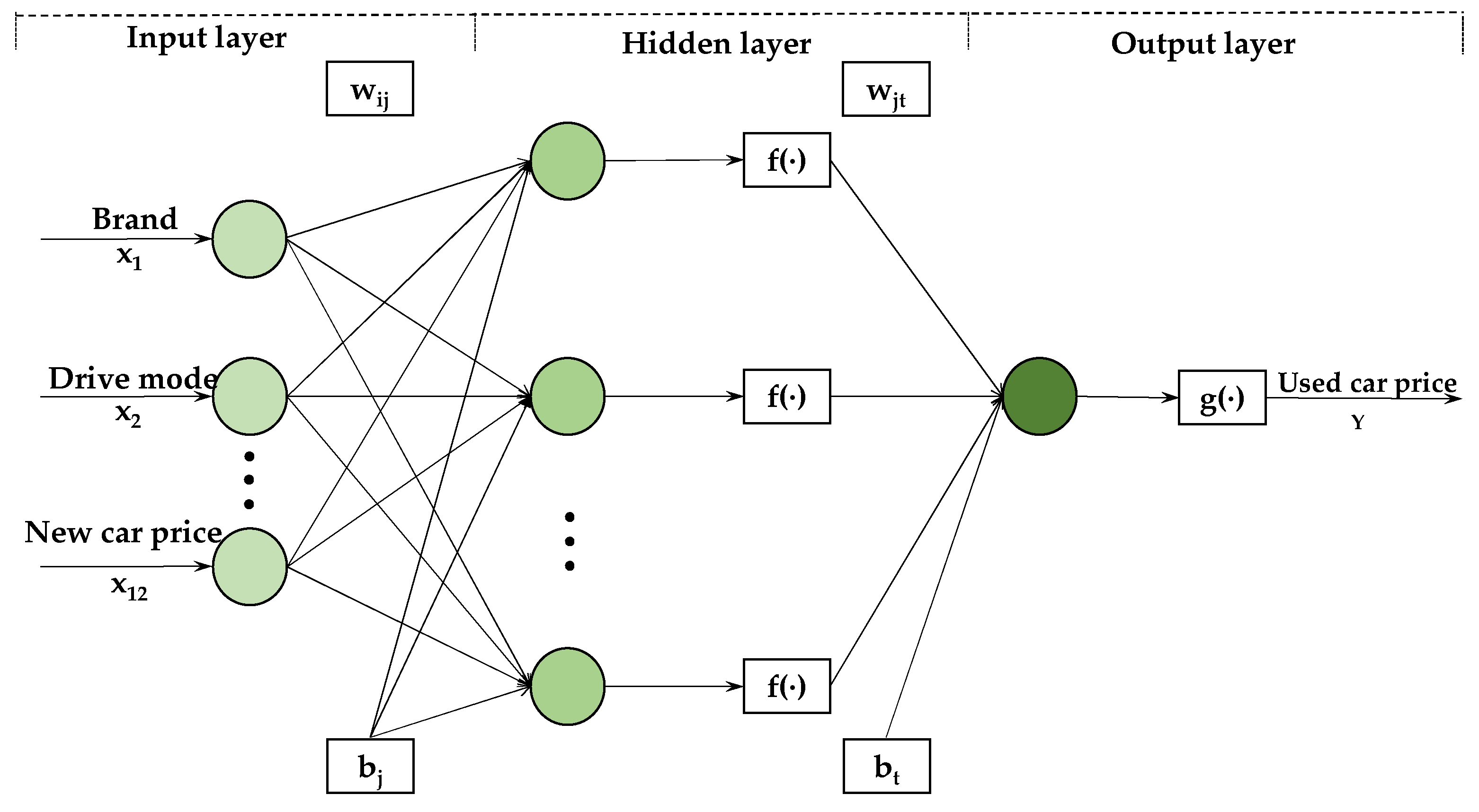
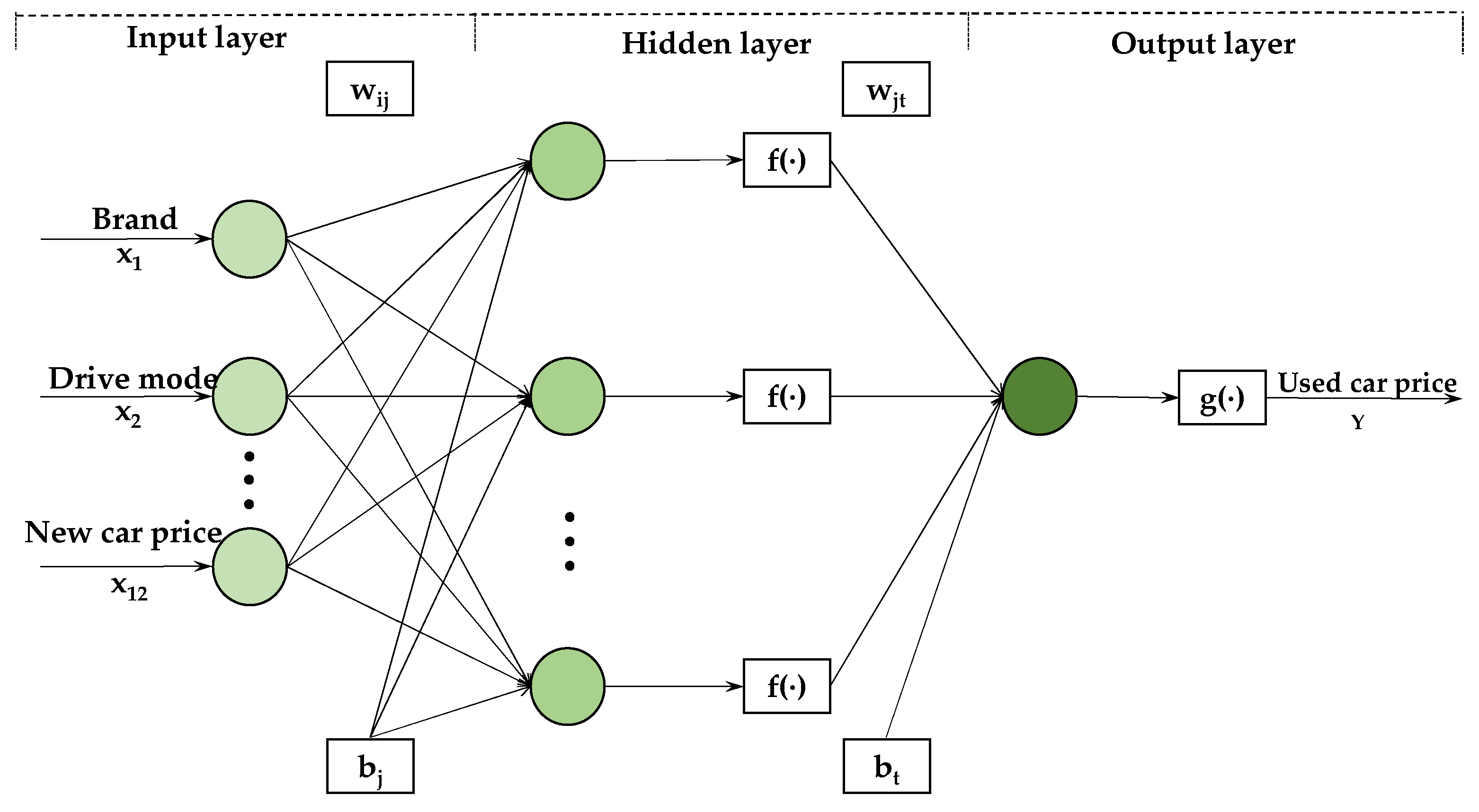
3.1. BP Neural Network
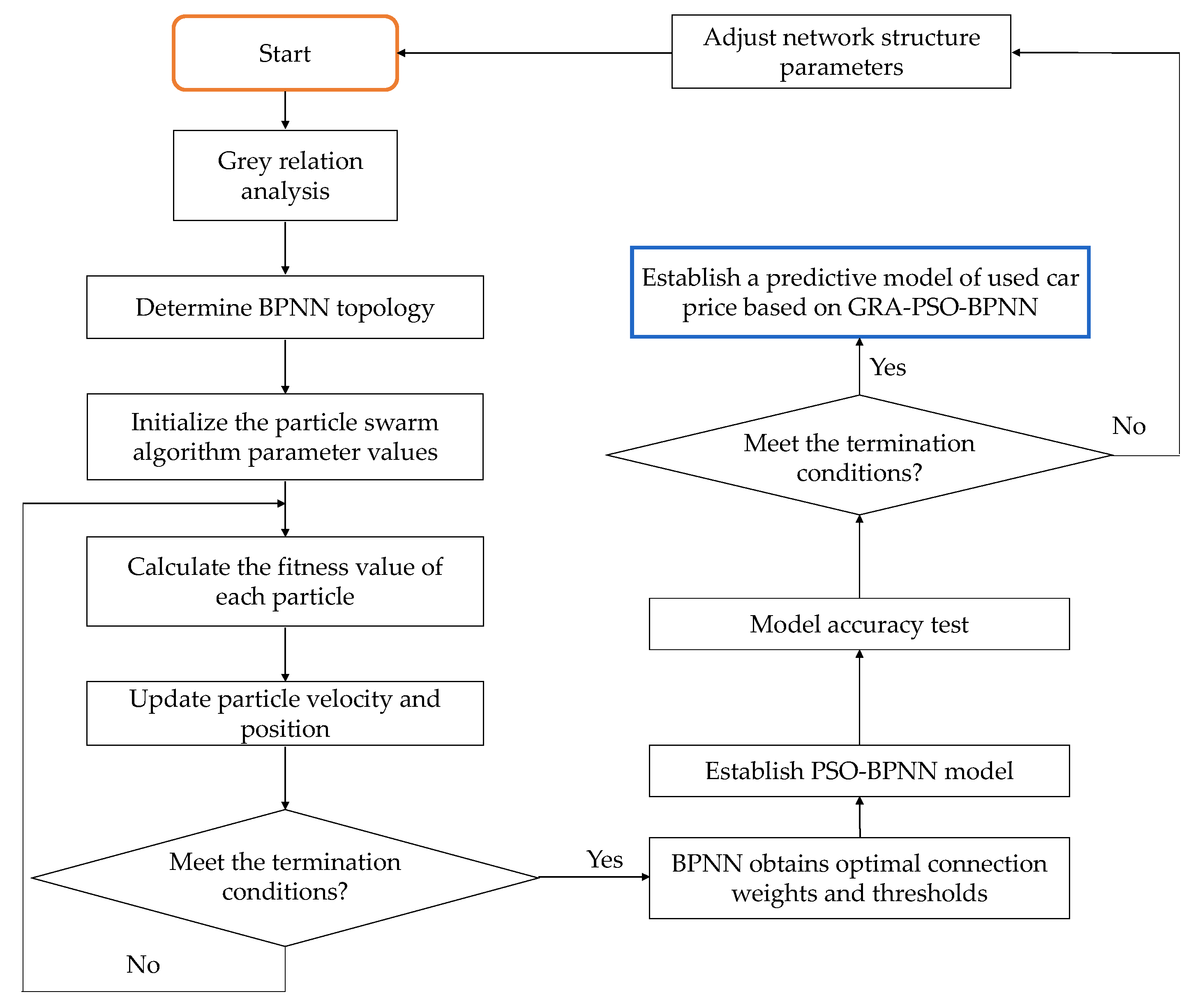
3.2. BPNN Prediction Model Based on GRA Variable Screening
- Step 1: Determine the analysis index system and collect analysis data. Let m data sequences form the following matrix:
- Step 2: Determine the reference and comparison sequences in the system.
- Step 3: Apply dimensionless processing to the dependent and independent variable sequences, using the mean value processing approach described below.
- Step 4: Calculate the absolute difference between each compared sequence and the corresponding element of the reference sequence in turn.
- Step 5: Calculate the correlation coefficient between the compared sequence and the corresponding factor in the reference sequence.
- Step 6: Calculate the degree of association and sort the degree of association to obtain the relative closeness of each comparison sequence and the reference sequence.
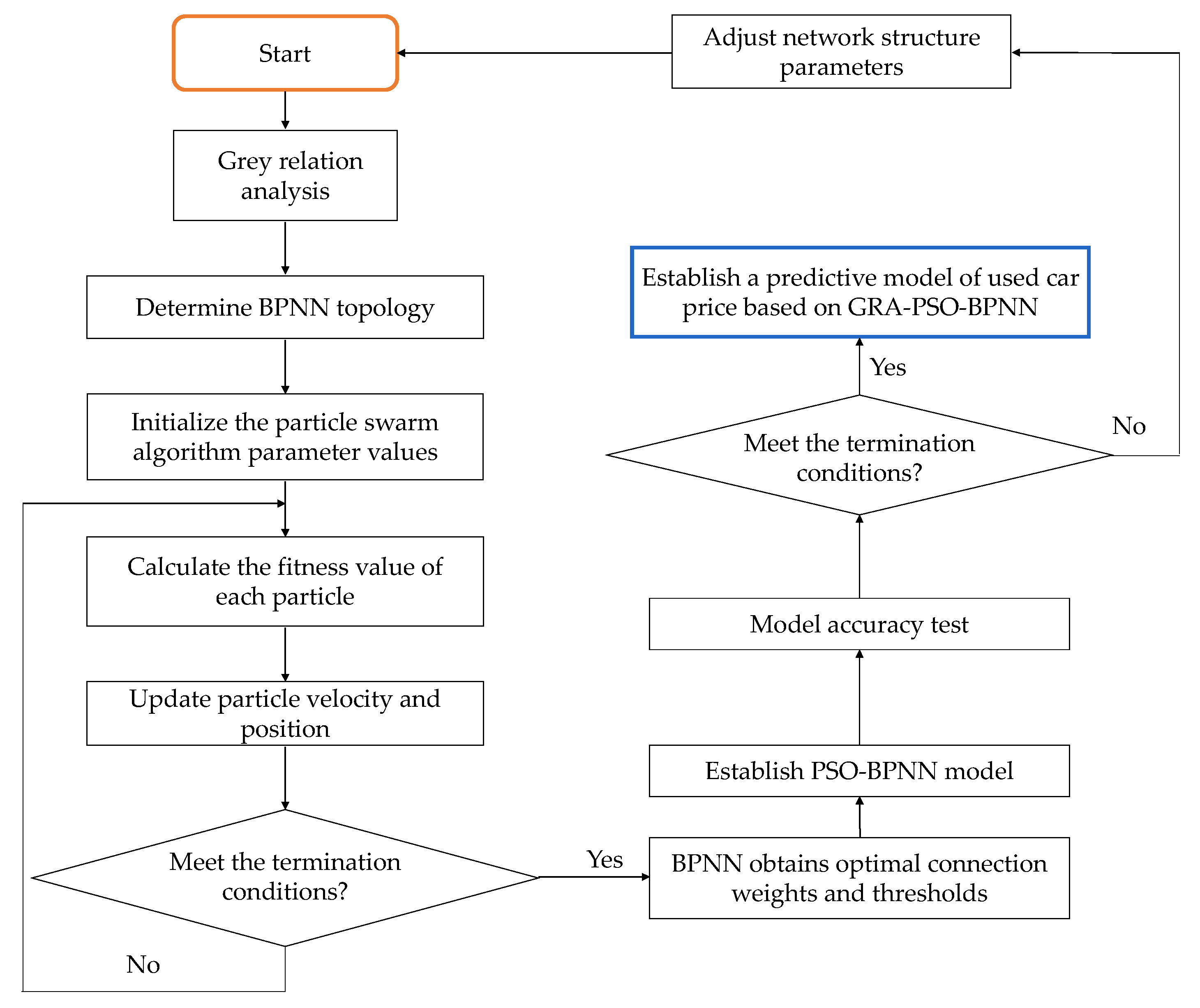
3.3. Construction of GRA-BPNN Prediction Model Based on PSO Optimization Algorithm
- Step 1: Define the PSO-GRA-BPNN model’s inputs and outputs.
- Step 2: Particle swarm initialization.
- Step 3: Calculate a single particle’s fitness value.
- Step 4: Update particle velocity and position.
- Step 5: Optimal particle count.
- Step 6: PSO-GRA-BPNN model training.
4. Results
4.1. Model Evaluation Metrics
4.2. Model Building Process
4.2.1. BPNN Prediction Model
4.2.2. GRA-BPNN Prediction Model
4.2.3. PSO-GRA-BPNN Prediction Model
- (1)
- The learning factors c1 and c2: c1 and c2 are mainly the adjustment weights of particles that affect their own and group experience. If the value of c1 is zero, the particles only have group experience, and local convergence may occur; if the value of c2 is zero, information sharing cannot be carried out in the group, and you only have your own experience. If both are zero, particles cannot effectively obtain empirical information, and the motion of particle swarm will show a chaotic state. Therefore, the values of c1 and c2 can have a great impact on the whole model. In this paper, the values of c1 and c2 are taken as 1.49445.
- (2)
- The maximum speed Vmax: During the effective search process of particles, the velocity of particle motion is usually described by Vmax, and the search step size of particles is adjusted. When the value of Vmax is too large, the position of the particle may exceed the optimal position; when the value of Vmax is too small, the particle may have a problem of slow convergence. In this paper, Vmax is chosen to be one.
- (3)
- The inertia weight ω: The inertia weight ω will have a significant impact on the convergence of the particle swarm optimization algorithm. If ω is relatively small, the local search ability of the particle swarm optimization algorithm is strong, but the global search ability is low; if ω is large, the opposite characteristics are exhibited. Therefore, this paper selects the inertia weight as 0.9.
- (4)
- Population size N: Too small of a population size will lead to insufficient accuracy and will be extremely unstable, and too large of a population size will lead to performance degradation. For higher accuracy and stability, this paper takes n as 200.
- (5)
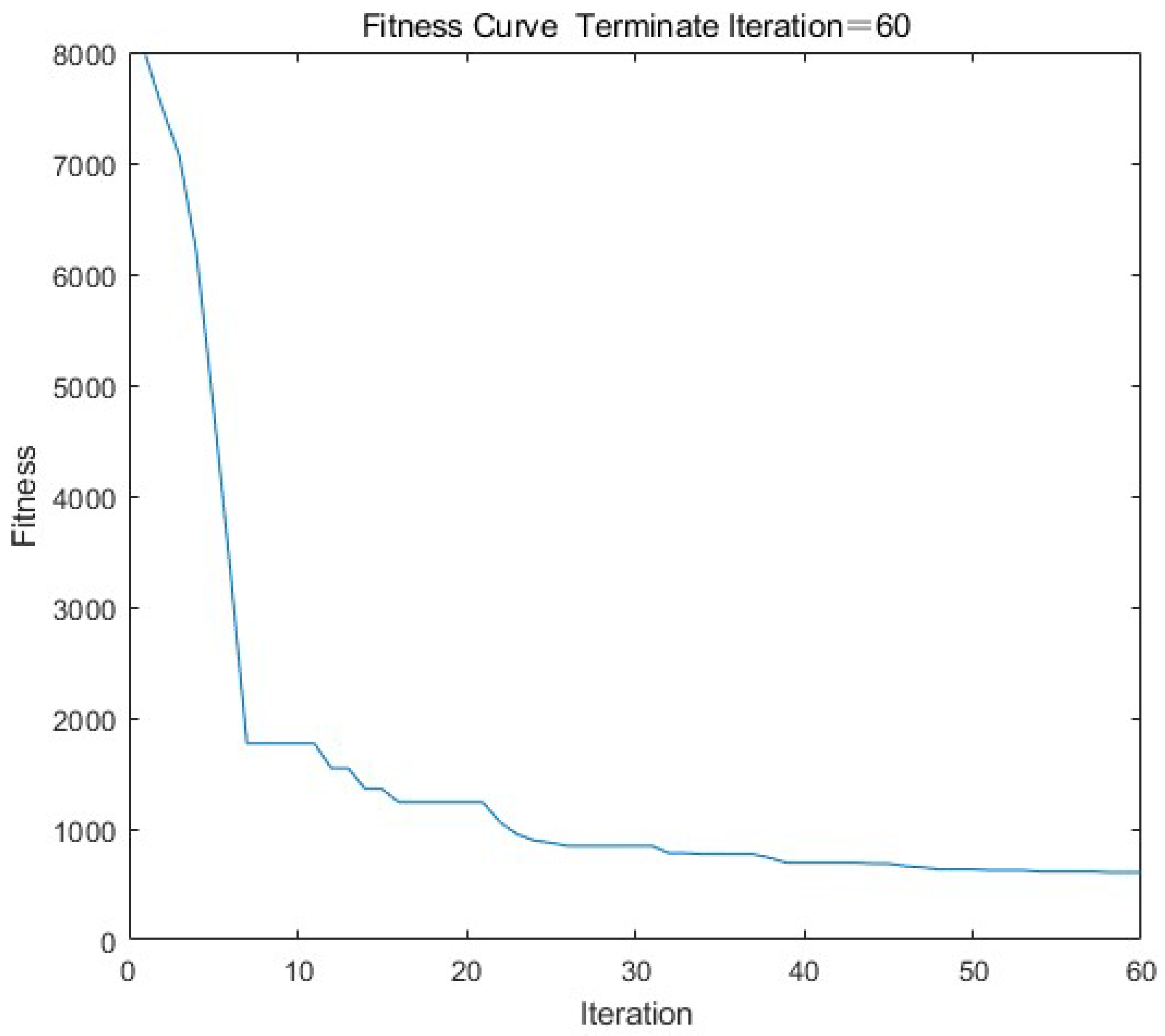
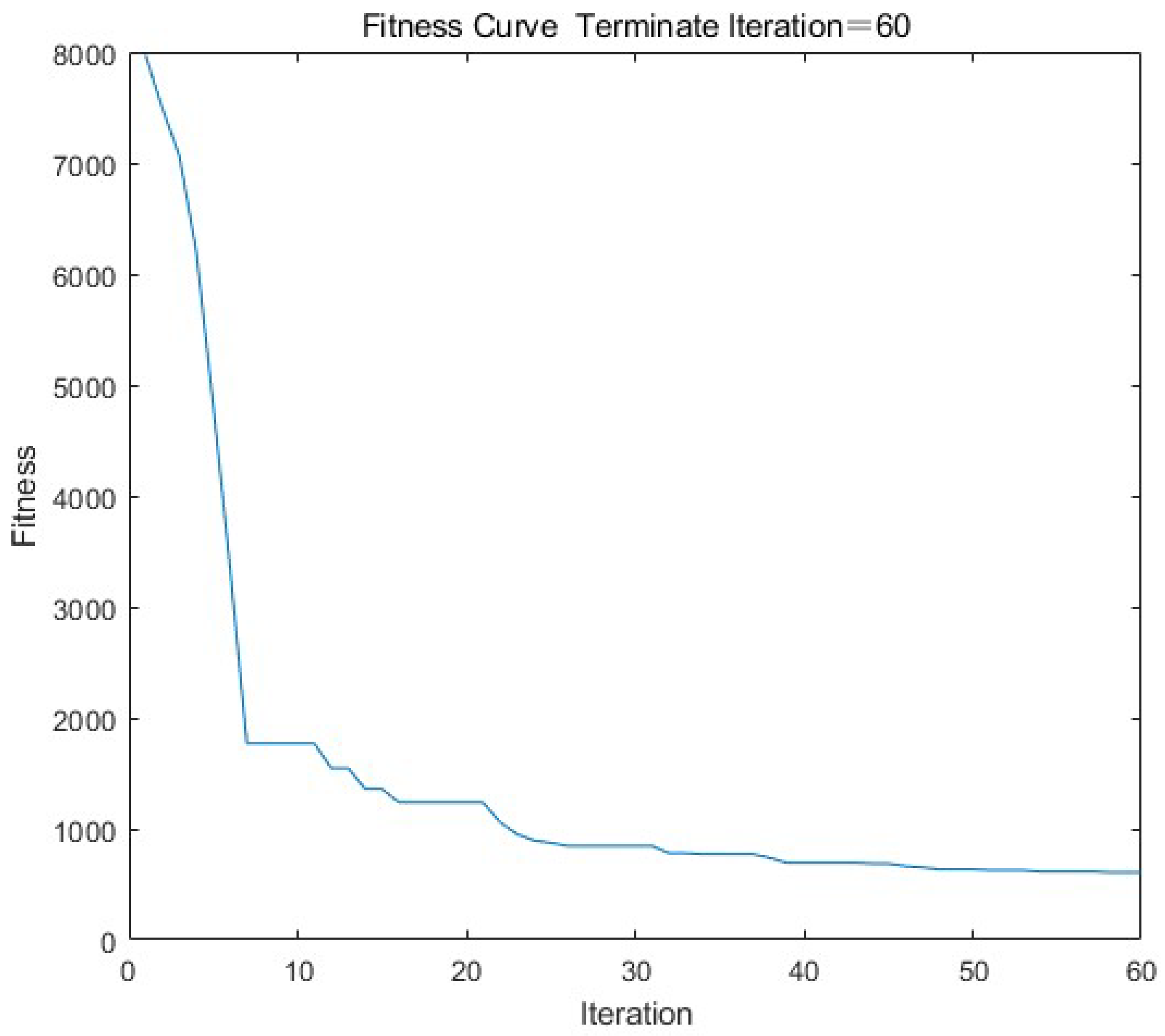
- Number of iterations: As can be seen from the Figure 4 below, the change trend of the error between the expected value and the absolute value of the actual output is that with the number of iterations from 0 to 20, and the overall error of the model decreases significantly. When the number of iterations is from 20 to 60, the slope of the curve tends to be zero, and the error of the model no longer decreases. If you continue to increase the number of iterations of the model, it will consume a lot of time resources, and the performance of the model will not be well-improved. Therefore, set the number of iterations to 60.
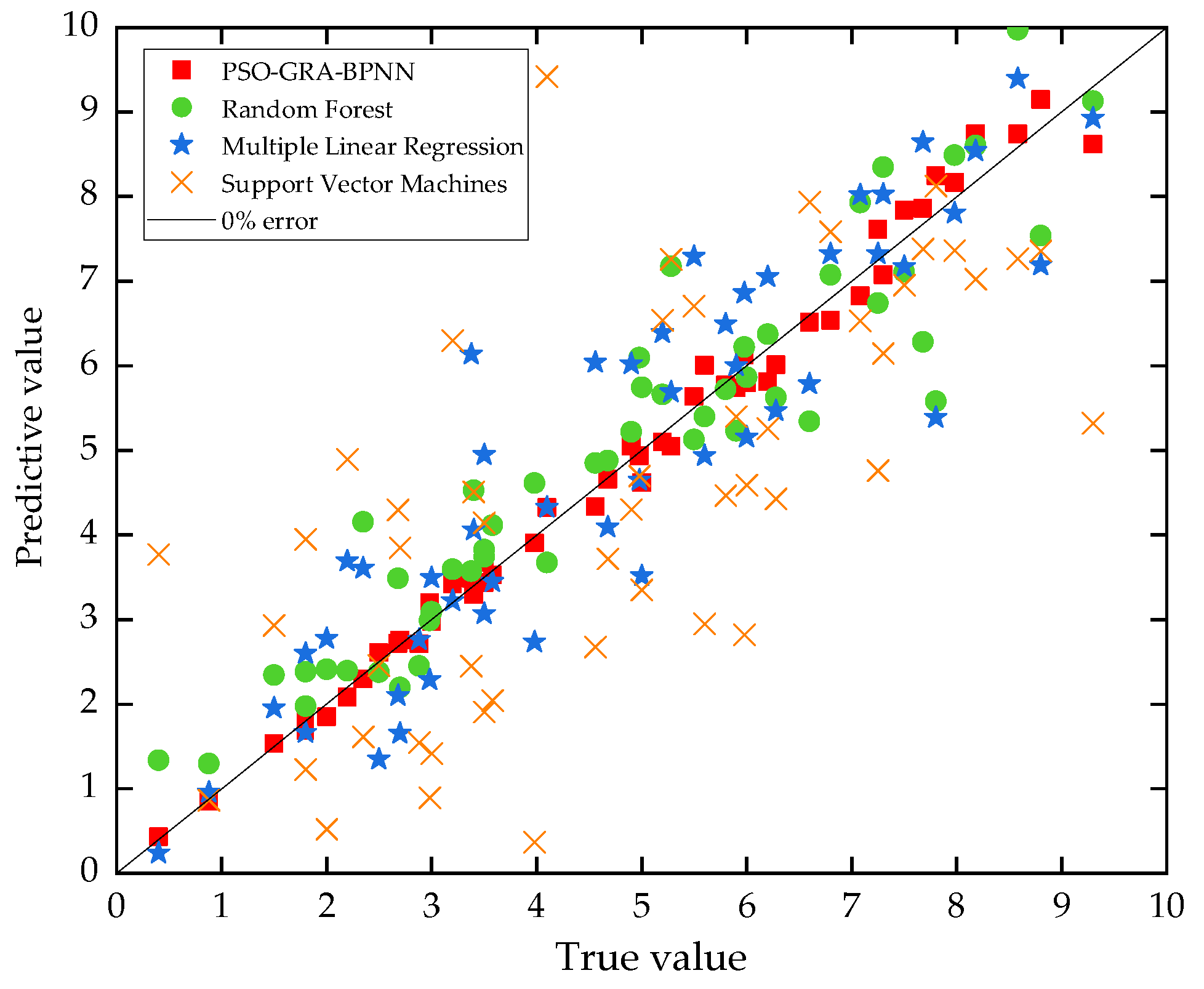
4.3. Models Comparison
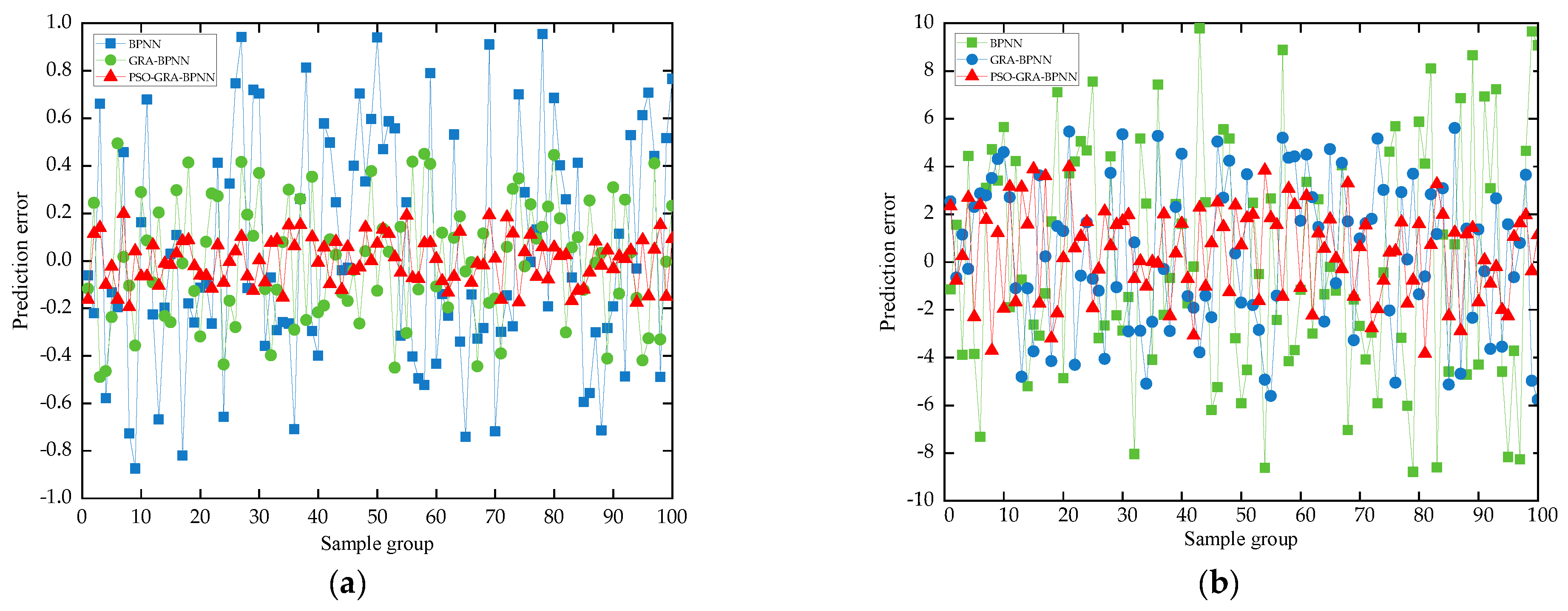
4.3.1. Comparison of Results of Different BPNN Prediction Models
- (1)
- MAPE can more correctly depict the percentage difference between anticipated and true values, and the lower its value, the better the fitting effect. From the above table, we can see that the MAPE of PSO-GRA-BPNN is the smallest, GRA-BPNN is the second, and BPNN is the largest. This indicates that PSO-GRA-BPNN has high prediction accuracy.
- (2)
- MAE is the sum of the absolute values of the difference between the predicted value and the actual value. It measures the closeness of the predicted result to the actual dataset. The smaller the value and the closer to zero, the better the fitting effect. The MAE of PSO-GRA-BPNN is the smallest, and its value is 0.475, which indicates that the deviation of the predicted value of PSO-GRA-BPNN from the actual value is the smallest, and the actual prediction error value is the smallest.
- (3)
- R is between zero and one. The closer it is to one, the better the model’s prediction, and the closer it is to zero, the worse the model’s prediction. R is the smallest for BPNN with a value of 0.991, followed by GRA-BPNN with a value of 0.995, and the largest for PSO-GRA-BPNN with a value of 0.998. This indicates that the predicted value of PSO-GRA-BPNN has the strongest correlation with the true value.
- (4)
- R2 is the goodness of fit, and the closer the value of the coefficient of determination is to one, the better the regression is. From the table, we can see that PSO-GRA-BPNN has the largest R2 value, 0.984, which is the best goodness of fit among these three models.
- (5)
- From the training speed, it can be seen that PSO-GRA-BPNN has the slowest training speed with a time of 94.153 s, and GRA-BPNN has the fastest training speed with a time of 6.506 s. Using the GRA method can effectively shorten the running time of the model, but adding the PSO method increases the running time, although the prediction accuracy of PSO-GRA-BPNN is higher than that of BPNN and GRA-BPNN, and the time is lost.
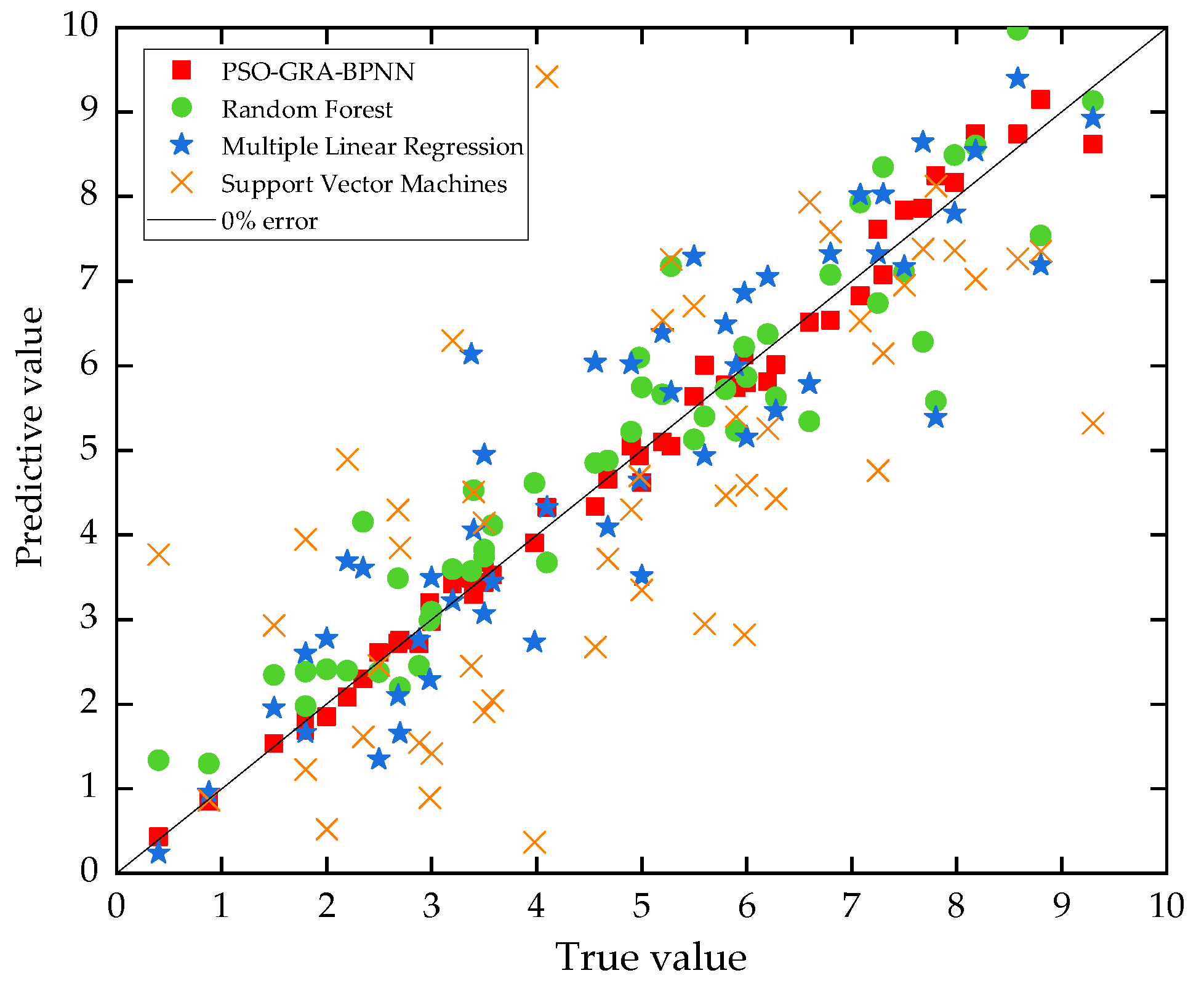
4.3.2. Comparison with Other Used Car Price Prediction Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ticknor, J.L. A Bayesian regularized artificial neural network for stock market forecasting. Expert Syst. Appl. 2013, 40, 5501–5506. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pinteals, E.; Pintelas, P. A CNN-LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Dou, Z.-W.; Ji, M.-X.; Wang, M.; Shao, Y.-N. Price prediction of Pu’er tea based on ARIMA and BP models. Neural Comput. Appl. 2021, 34, 3495–3511. [Google Scholar] [CrossRef]
- Mehmet, Ö. Predicting second-hand car sales price using decision trees and genetic algorithms. Alphanumeric J. 2017, 5, 103–114. [Google Scholar]
- Dimoka, A.; Hong, Y.-L.; Pavlou, P.A. On product uncertainty in online markets: Theory and evidence. Mis Quart. 2012, 36, 395–426. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Tang, W.-S.; Zhou, C. Operation strategy under additional service and refurbishing effort in online second-hand market. J. Clean. Prob. 2021, 290, 125608. [Google Scholar] [CrossRef]
- Shafiee, M.; Chukova, S. Optimal upgrade strategy, warranty policy and sale price for second-hand products. Appl. Stoch. Models Bus. Ind. 2013, 29, 157–169. [Google Scholar] [CrossRef]
- Kwak, M.; Kim, H.; Thurston, D. Formulating second-hand market value as a function of product specifications, age, and conditions. J. Mech Design. 2012, 134, 032001. [Google Scholar] [CrossRef]
- Fathalla, A.; Salah, A.; Li, K.-L.; Li, K.-Q.; Francesco, P. Deep end-to-end learning for price prediction of second-hand items. Knowl. Inf. Syst. 2020, 62, 4541–4568. [Google Scholar] [CrossRef]
- Stefan, L.; Stefan, V. Car resale price forecasting: The impact of regression method, private information, and heterogeneity on forecast accuracy. Int. J. Forecasting 2017, 33, 864–877. [Google Scholar]
- Tan, Z.-P.; Cai, Y.; Wang, Y.-D.; Mao, P. Research on the Value Evaluation of Used Pure Electric Car Based on the Replacement Cost Method. In Proceedings of the 5th International Conference on Mechanical Engineering, Materials Science and Civil Engineering (ICMEMSCE), Kuala Lumpur, Malaysia, 15–16 December 2017; Volume 324. [Google Scholar]
- Chen, C.-C.; Hao, L.-L.; Xu, C. Comparative analysis of used car price evaluation models. In Proceedings of the International Conference on Materials Science, Energy Technology, Power Engineering (MEP), Hangzhou, China, 15–16 April 2017; Volume 1839. [Google Scholar]
- Moayedi, H.; Mehrabi, M.; Mosallanezhad, M.; Rashid, A.S.A.; Pradhan, B. Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng. Comput. 2019, 35, 967–984. [Google Scholar] [CrossRef]
- Nilashi, M.; Cavallaro, F.; Mardani, A.; Zavadskas, E.K.; Samad, S.; Ibrahim, O. Measuring Country Sustainability-Basel Performance Using Ensembles of Neuro-Fuzzy Technique. Sustainability 2018, 10, 2707. [Google Scholar] [CrossRef] [Green Version]
- Drezewski, R.; Dziuban, G.; Pajak, K. The Bio-Inspired Optimization of Trading Strategies and Its Impact on the Efficient Market Hypothesis and Sustainable Development Strategies. Sustainability 2018, 10, 1460. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.-D.; Hsu, C.-C.; Chen, H.-C. An expert system of price forecasting for used cars using adaptive neuro-fuzzy inference. Expert Syst. Appl. 2009, 36, 7809–7817. [Google Scholar] [CrossRef]
- Zhou, X. The usage of artificial intelligence in the commodity house price evaluation model. J. Amb Intel. Hum Comp. 2020, 1–8. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, F.-L.; Sun, T.; Xu, B. A constrained optimization method based on BP neural network. Neural Comput. Appl. 2018, 29, 413–421. [Google Scholar] [CrossRef]
- Sun, N.; Bai, H.-X.; Geng, Y.-X.; Shi, H.-Z. R Price Evaluation Model in Second-hand Car System based on BP Neural Network Theory. In Proceedings of the 18th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Kanazawa, Japan, 26–28 January 2018; pp. 431–436. [Google Scholar]
- Han, J.-X.; Ma, M.-Y.; Wang, K. Product modeling design based on genetic algorithm and BP neural network. Neural Comput. Appl. 2021, 33, 4111–4117. [Google Scholar] [CrossRef]
- Ding, F.-J.; Jia, X.-D.; Hong, T.-J.; Xu, Y.-L. Flow Stress Prediction Model of 6061 Aluminum Alloy Sheet Based on GA-BP and PSO-BP Neural Networks. Rare Met. Mater. Eng. 2020, 49, 1840–1853. [Google Scholar]
- Ren, C.; An, N.; Wang, J.-Z.; Li, L.; Hu, B.; Shang, D. Optimal parameters selection for BP neural network based on particle swarm optimization: A case study of wind speed forecasting. Knowl.-Based Syst. 2014, 56, 226–239. [Google Scholar] [CrossRef]
- Mohamad, E.T.; Armaghani, D.J.; Momeni, E.; Yazdavar, A.H.; Ebrahimi, M. Rock strength estimation: A PSO-based BP approach. Neural Comput. Appl. 2018, 30, 1635–1646. [Google Scholar] [CrossRef]
- Luejai, W.; Suwanasri, T.; Suwanasri, C. D-distance Risk Factor for Transmission Line Maintenance Management and Cost Analysis. Sustainability 2021, 13, 8208. [Google Scholar] [CrossRef]
- Cao, J.-S.; Wang, J.-H. Exploration of stock index change prediction model based on the combination of principal component analysis and artificial neural network. Soft Comput. 2020, 24, 7851–7860. [Google Scholar] [CrossRef]
- Niu, D.X.; Li, S.; Dai, S.Y. Comprehensive Evaluation for Operating Efficiency of Electricity Retail Companies Based on the Improved TOPSIS Method and LSSVM Optimized by Modified Ant Colony Algorithm from the View of Sustainable Development. Sustainability 2018, 10, 860. [Google Scholar] [CrossRef] [Green Version]
- Yao, Z.-X.; Zhang, T.; Wang, J.-B.; Zhu, L.-C. A Feature Selection Approach based on Grey Relational Analysis for Within-project Software Defect Prediction. J. Grey Syst. 2019, 31, 105–116. [Google Scholar]
- Javanmardi, E.; Liu, S.-F.; Xie, N.-M. Exploring grey systems theory-based methods and applications in Sustainability-Basel studies: A systematic review approach. Sustainability 2020, 12, 4437. [Google Scholar] [CrossRef]
- Wei, G.-W. Gray relational analysis method for intuitionistic fuzzy multiple attribute decision making. Expert Syst. Appl. 2011, 38, 11671–11677. [Google Scholar] [CrossRef]
- Zhang, W.-S.; Ma, L.-P. Research and application of second-hand commodity price evaluation methods on B2C platform: Take the used car platform as an example. Ann. Oper. Res. 2021, 11, 1–13. [Google Scholar] [CrossRef]
- Li, D.-M.; Li, M.-G.; Han, G.; Li, T. A combined deep learning method for internet car evaluation. Neural Comput. Appl. 2020, 33, 4623–4637. [Google Scholar] [CrossRef]
- Arawomo, D.F.; Osigwe, A.C. Nexus of fuel consumption, car features and car prices: Evidence from major institutions in Ibadan. Renew. Sustain. Energ. Rev. 2016, 59, 1220–1228. [Google Scholar] [CrossRef]
- Kihm, A.; Vance, C. The determinants of equity transmission between the new and used car markets: A hedonic analysis. J. Oper Res Soc. 2016, 67, 1250–1258. [Google Scholar] [CrossRef] [Green Version]
- Min, Y.; Wei, X.; Li, M. Short-Term Electricity Price Forecasting Based on BP Neural Network Optimized by SAPSO. Energies 2021, 14, 6514. [Google Scholar]
- Wu, D.-Q.; Zhang, D.-W.; Liu, S.-P.; Jin, Z.-H.; Chowwanonthapunya, T.; Gao, J.; Li, X.-G. Prediction of polycarbonate degradation in natural atmospheric environment of China based on BP-ANN model with screened environmental factors. Chem Eng. J. 2020, 399, 125878. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural. Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, F.-L.; Xu, B.; Chi, W.-Y.; Wang, Q.-Y.; Sun, T. Prediction of stock prices based on LM-BP neural network and the estimation of overfitting point by RDCI. Neural. Comput. Appl. 2018, 30, 1425–1444. [Google Scholar] [CrossRef]
- Xu, B.; Yuan, X. A novel method of BP neural network based green building design-the case of hotel buildings in hot summer and cold winter region of China. Sustainability 2022, 14, 2444. [Google Scholar] [CrossRef]
- Deng, Y.; Xiao, H.-J.; Xu, J.-X.; Wang, H. Prediction model of PSO-BP neural network on coliform amount in special food. Saudi J. Biol. Sci. 2019, 26, 1154–1160. [Google Scholar] [CrossRef]
- Liu, D.W.; Liu, C.; Tang, Y.; Gong, C. A GA-BP Neural Network Regression Model for Predicting Soil Moisture in Slope Ecological Protection. Sustainability 2022, 14, 1386. [Google Scholar] [CrossRef]
- Li, Z.-J. Application of the BP neural network model of gray relational analysis in economic management. J. Math. 2022, 2022, 4359383. [Google Scholar] [CrossRef]
- Arce, M.E.; Saavedra, A.; Miguez, J.L. The use of grey-based methods in multi-criteria decision analysis for the evaluation of sustainable energy systems: A review. Renew. Sustain. Energ. Rev. 2015, 47, 924–932. [Google Scholar] [CrossRef]
- Ma, D.; Duan, H.-Y.; Li, W.-X.; Zhang, J.-X.; Liu, W.-T.; Zhou, Z.-L. Prediction of water inflow from fault by particle swarm optimization-based modified grey models. Environ. Sci. Pollut. Res. 2020, 27, 42051–42063. [Google Scholar] [CrossRef]
- Altintas, K.O.; Vayvay, S.; Apak, S.; Cobanoglu, E. An extended GRA method integrated with fuzzy AHP to construct a multidimensional index for ranking overall energy Sustainability-Basel performances. Sustainability 2020, 12, 1602. [Google Scholar] [CrossRef] [Green Version]
- Wei, G.-W. GRA method for multiple attribute decision making with incomplete weight information in intuitionistic fuzzy setting. Knowl.-Based Syst. 2010, 23, 243–247. [Google Scholar] [CrossRef]
- Eltamaly, A.M.; Farh, H.M.H.; Al Saud, M.S. Impact of PSO Reinitialization on the Accuracy of Dynamic Global Maximum Power Detection of Variant Partially Shaded PV Systems. Sustainability 2019, 11, 2091. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.-S.; Tan, D.-P.; Liu, L. Particle swarm optimization algorithm: An overview. Soft Comput. 2019, 22, 387–408. [Google Scholar] [CrossRef]
- Shen, M.L.; Lee, C.F.; Liu, H.H.; Chang, P.Y.; Yang, C.H. An Effective Hybrid Approach for Forecasting Currency Exchange Rates. Sustainability 2021, 13, 2761. [Google Scholar] [CrossRef]
- Olayode, I.O.; Tartibu, L.K.; Okwu, M.O.; Severino, A. Comparative Traffic Flow Prediction of a Heuristic ANN Model and a Hybrid ANN-PSO Model in the Traffic Flow Modelling of Vehicles at a Four-Way Signalized Road Intersection. Sustainability 2021, 13, 10704. [Google Scholar] [CrossRef]
- Zhou, J.G.; Yu, X.C.; Jin, B.L. Short-Term Wind Power Forecasting: A New Hybrid Model Combined Extreme-Point Symmetric Mode Decomposition, Extreme Learning Machine and Particle Swarm Optimization. Sustainability 2018, 10, 3202. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.Q.; Hasanipanah, M.; Tahir, M.M.; Bui, D.T. Intelligent Prediction of Blasting-Induced Ground Vibration Using ANFIS Optimized by GA and PSO. Nat. Resour. Res. 2020, 29, 739–750. [Google Scholar] [CrossRef]
- Nguyen, H.; Moayedi, H.; Foong, L.K.; Al Najjars, H.A.H.; Jusoh, W.A.W.; Rashid, A.S.A.; Jamali, J. Optimizing ANN models with PSO for predicting short building seismic response. Eng. Comput. 2020, 36, 823–837. [Google Scholar] [CrossRef]
- Zhang, X.-L.; Nguyen, H.; Bui, X.N.; Tran, Q.H.; Nguyen, D.A.; Bui, D.T.; Moayedi, H. Novel Soft Computing Model for Predicting Blast-Induced Ground Vibration in Open-Pit Mines Based on Particle Swarm Optimization and XGBoost. Nat. Resour. Res. 2020, 29, 711–721. [Google Scholar] [CrossRef]
- Hussain, A.; Surendar, A.; Clementking, A.; Kanagarajan, S.; Ilyashenko, L.K. Rock brittleness prediction through two optimization algorithms namely particle swarm optimization and imperialism competitive algorithm. Eng. Comput. 2019, 35, 1027–1035. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition | Variable | Definition |
|---|---|---|---|
| x1 | Brand | x7 | Usage time |
| x2 | Drive mode | x8 | Displacement |
| x3 | Gearbox | x9 | Fuel consumption |
| x4 | Engine power | x10 | Emission standard |
| x5 | Body structure | x11 | Region |
| x6 | Mileage | x12 | New car price |
| Neurons in the Hidden Layer | MAPE | MAE | Training Speed | Number of Network Iterations |
|---|---|---|---|---|
| = 4 | 30.914% | 0.671 | 0.419 s | 13 |
| = 5 | 32.873% | 1.256 | 1.103 s | 48 |
| = 6 | 28.245% | 0.753 | 0.714 s | 24 |
| = 7 | 51.237% | 1.493 | 0.542 s | 16 |
| = 8 | 38.634% | 0.957 | 1.906 s | 62 |
| = 9 | 43.670% | 1.374 | 1.788 s | 57 |
| = 10 | 9.891% | 0.585 | 1.868 s | 54 |
| = 11 | 13.934% | 0.816 | 2.261 s | 55 |
| = 12 | 27.836% | 1.073 | 0.751 s | 14 |
| = 13 | 20.897% | 1.016 | 1.714 s | 40 |
| = 14 | 45.383% | 0.924 | 1.324 s | 17 |
| Variable | Correlation | Ranking | Variable | Correlation | Ranking |
|---|---|---|---|---|---|
| x12 | 0.913 | 1 | x2 | 0.595 | 7 |
| x8 | 0.861 | 2 | x11 | 0.591 | 8 |
| x6 | 0.819 | 3 | x4 | 0.589 | 9 |
| x3 | 0.775 | 4 | x10 | 0.578 | 10 |
| x9 | 0.733 | 5 | x5 | 0.497 | 11 |
| x7 | 0.720 | 6 | x1 | 0.472 | 12 |
| Model | MAPE | MAE | R | R2 | Training Speed |
|---|---|---|---|---|---|
| BPNN | 9.891% | 0.585 | 0.991 | 0.912 | 12.549 s |
| GRA-BPNN | 7.118% | 0.529 | 0.995 | 0.969 | 6.506 s |
| PSO-GRA-BPNN | 3.936% | 0.475 | 0.998 | 0.984 | 94.153 s |
| Model | MAPE | MAE | R | R2 | Training Speed |
|---|---|---|---|---|---|
| PSO-GRA-BPNN | 3.936% | 0.475 | 0.998 | 0.984 | 94.153 s |
| Random Forest | 19.933% | 0.842 | 0.664 | 0.553 | 20.810 s |
| Multiple Linear Regression | 33.977% | 1.097 | 0.949 | 0.917 | 1.914 s |
| Support Vector Machines | 153.958% | 0.028 | 0.943 | 0.863 | 0.057 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, E.; Li, J.; Zheng, A.; Liu, H.; Jiang, T. Research on the Prediction Model of the Used Car Price in View of the PSO-GRA-BP Neural Network. Sustainability 2022, 14, 8993. https://doi.org/10.3390/su14158993
Liu E, Li J, Zheng A, Liu H, Jiang T. Research on the Prediction Model of the Used Car Price in View of the PSO-GRA-BP Neural Network. Sustainability. 2022; 14(15):8993. https://doi.org/10.3390/su14158993
Chicago/Turabian StyleLiu, Enci, Jie Li, Anni Zheng, Haoran Liu, and Tao Jiang. 2022. "Research on the Prediction Model of the Used Car Price in View of the PSO-GRA-BP Neural Network" Sustainability 14, no. 15: 8993. https://doi.org/10.3390/su14158993
APA StyleLiu, E., Li, J., Zheng, A., Liu, H., & Jiang, T. (2022). Research on the Prediction Model of the Used Car Price in View of the PSO-GRA-BP Neural Network. Sustainability, 14(15), 8993. https://doi.org/10.3390/su14158993