
ILS Validity Analysis for Secondary Grade through Factor Analysis and Internal Consistency Reliability


 , , and
, , and
Abstract
1. Introduction
- To carry out a comprehensive study on the ILS validity and reliability using the data collected from different secondary schools.
- A comprehensive evaluation of psychometric analysis of ILS to investigate the learning styles of secondary-grade students.
- To explore the internal consistency reliability and construct validity using exploratory and confirmatory factor analysis of the Felder–Silverman’s ILS for the secondary grade students.
- The use of various fitting models to designate the best fit for the collected data.
- To inspect the average item correlation and exploratory and confirmatory factor analysis for the statistical evidence of validity and reliability of ILS for secondary-grade students.
2. Background
2.1. Felder–Silverman Learning Style Model
2.2. Index of Learning Styles (ILS)
2.3. Assessment Tools
3. Literature Review
4. Methodology
4.1. Participants
4.2. Research Design
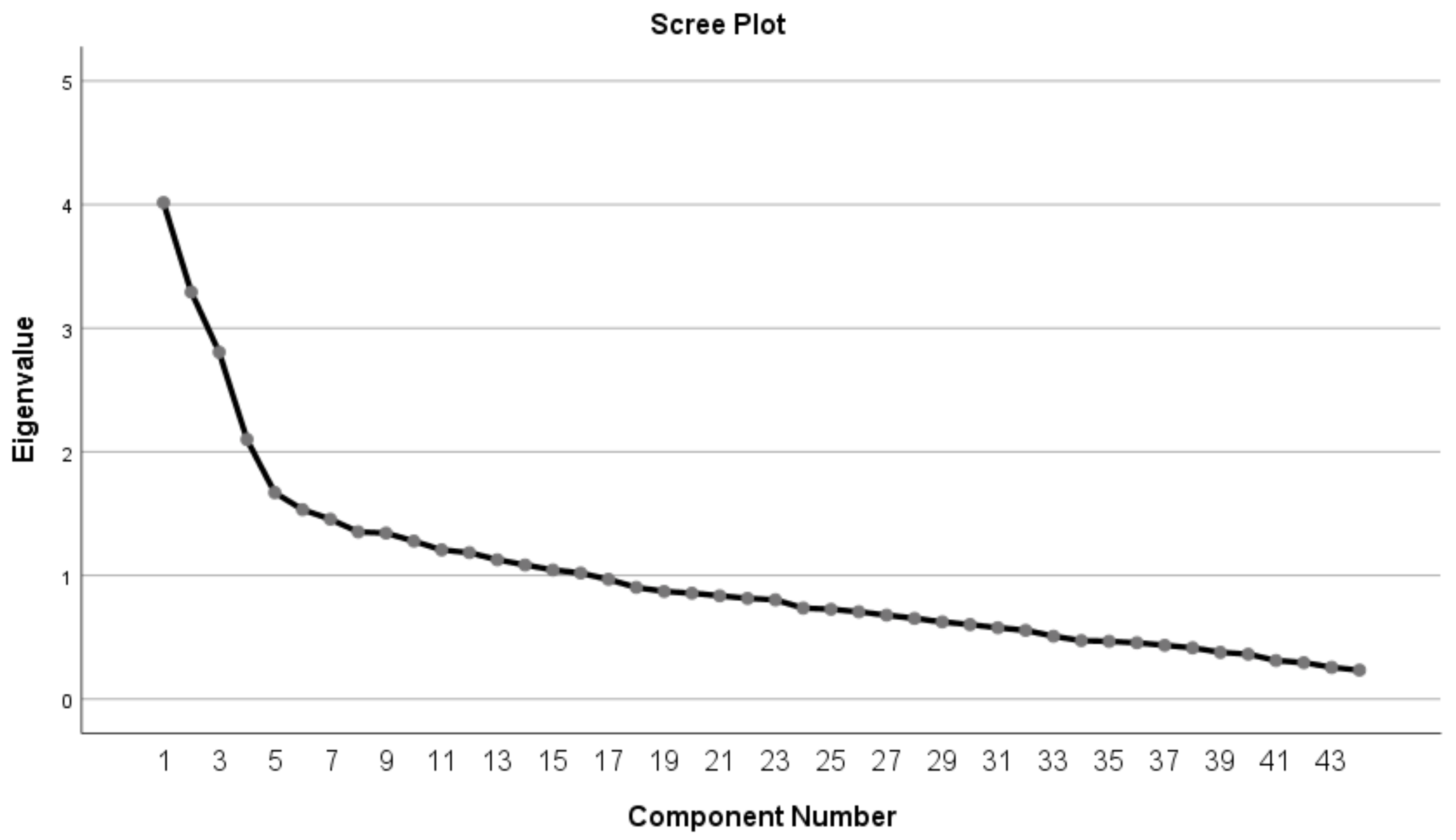
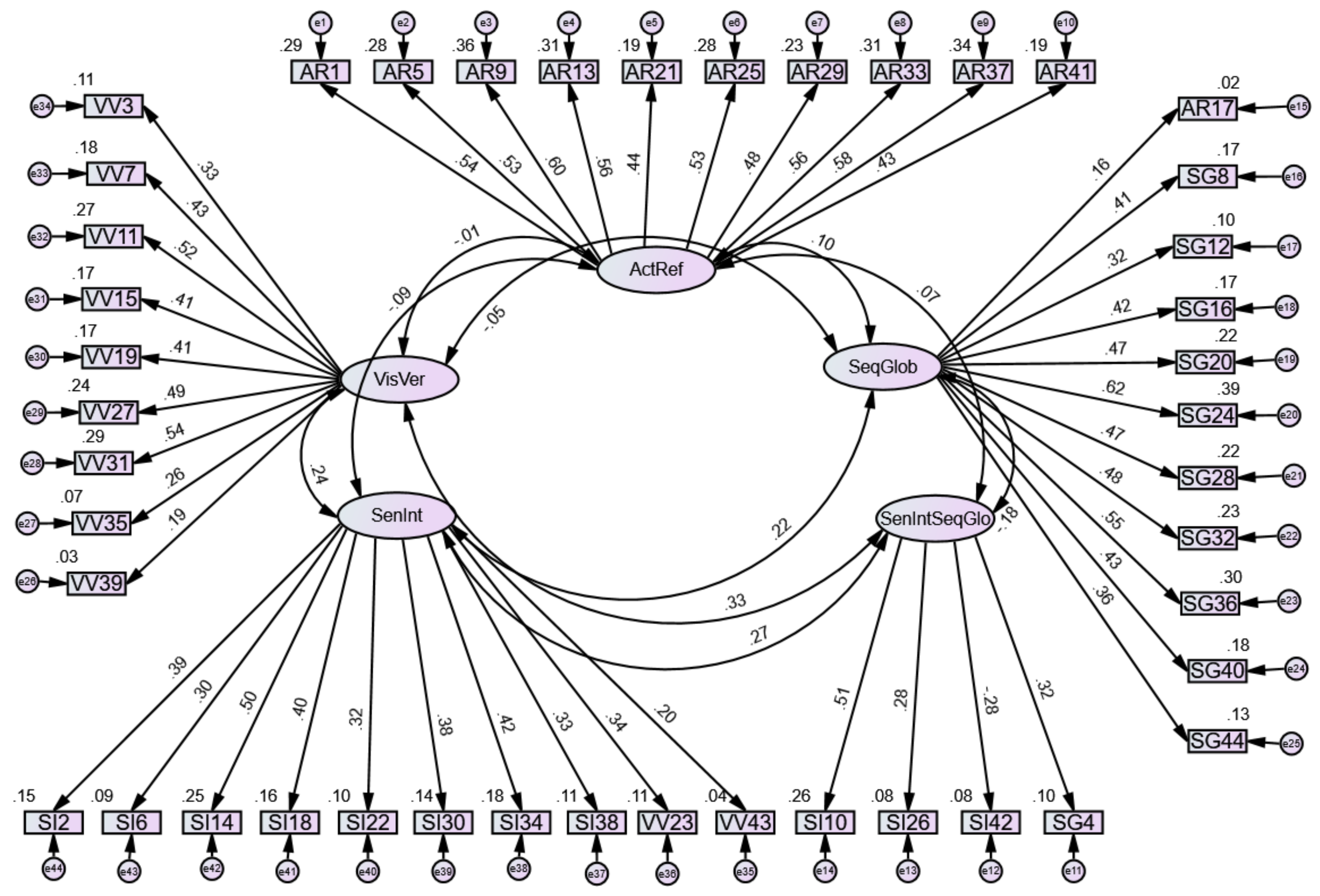
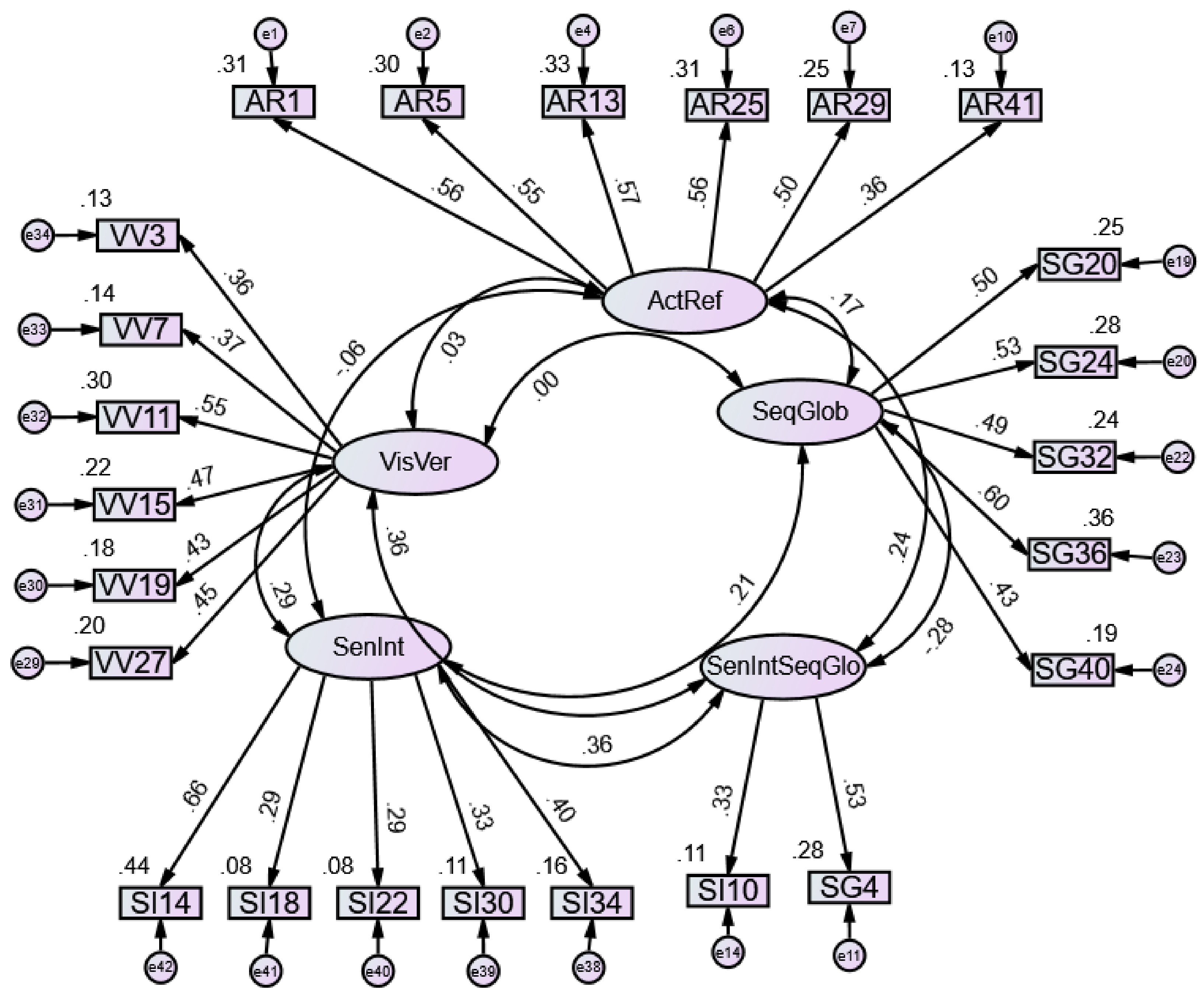
5. Findings
Internal Consistency Reliability
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Buble, M.; Zelic, M. The Modern Model of Education as a Driver of the Development of Entrepreneurial Thinking and Learning. Econ. Soc. Dev. 2020, 70–76. [Google Scholar]
- Stropnik Kunič, N. Individualization and differentation as a model of new communication in the learning process. Informatologia 2012, 45, 44–52. [Google Scholar]
- Roy, A.; Guay, F.; Valois, P. The big-fish–little-pond effect on academic self-concept: The moderating role of differentiated instruction and individual achievement. Learn. Individ. Differ. 2015, 42, 110–116. [Google Scholar] [CrossRef]
- Roy, A.; Guay, F.; Valois, P. Teaching to address diverse learning needs: Development and validation of a differentiated instruction scale. Int. J. Incl. Educ. 2013, 17, 1186–1204. [Google Scholar] [CrossRef]
- Hall, T. Differentiated Instruction. 2002. Available online: http://www.dr-hatfield.com/educ342/Differentiated_Instruction.pdf (accessed on 12 May 2022).
- Roiha, A.; Polso, J. The 5-dimensional model: A tangible framework for differentiation. Pract. Assess. Res. Eval. 2021, 26, 20. [Google Scholar]
- Marjanovič Umek, L. Diferenciacija v šoli: Enako ali različno za različne otroke. Sodob. Pedagog. 2007, 58, 108–127. [Google Scholar]
- Available online: https://edulastic.com/blog/personalized-learning-differentiated-instruction/ (accessed on 12 May 2022).
- Available online: https://edulastic.com/blog/personalized-learning/ (accessed on 12 May 2022).
- Available online: https://www.prodigygame.com/main-en/blog/differentiated-instruction-strategies-examples-download/ (accessed on 12 May 2022).
- Felder, R.M.; Silverman, L.K. Learning and teaching styles in engineering education. Eng. Educ. 1988, 78, 674–681. [Google Scholar]
- Soloman, B.A.; Felder, R.M. Index of Learning Styles Questionnaire; NC State University: Raleigh, NC, USA, 2005; Volume 70, Available online: https://www.webtools.ncsu.edu/learningstyles/ (accessed on 12 May 2022).
- Bajraktarevic, N.; Hall, W.; Fullick, P. Incorporating learning styles in hypermedia environment: Empirical evaluation. In Proceedings of the Workshop on Adaptive Hypermedia and Adaptive Web-Based Systems, Phoenix, AZ, USA, 26 August 2003; pp. 41–52. [Google Scholar]
- Feldman, J.; Monteserin, A.; Amandi, A. Automatic detection of learning styles: State of the art. Artif. Intell. Rev. 2015, 44, 157–186. [Google Scholar] [CrossRef]
- Ovariyanti, A.S.; Santoso, H.B. An adaptation of the Index of Learning Style (ILS) to Indonesian version: A contribution to Index of Learning Style (ILS), validity and reliability score. In Proceedings of the 2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Malang, Indonesia, 15–16 October 2016; pp. 129–134. [Google Scholar]
- Švarcová, E.; Jelínková, K. Detection of learning styles in the focus group. Procedia-Soc. Behav. Sci. 2016, 217, 177–182. [Google Scholar] [CrossRef][Green Version]
- Wang, J.; Mendori, T. The reliability and validity of felder-silverman index of learning styles in mandarin version. Inf. Eng. Express 2015, 1, 1–8. [Google Scholar] [CrossRef]
- Raleiras, M.; Nabizadeh, A.H.; Costa, F.A. Automatic learning styles prediction: A survey of the State-of-the-Art (2006–2021). J. Comput. Educ. 2022, 9, 1–93. [Google Scholar] [CrossRef]
- Ngatirin, N.R.; Zainol, Z. Automatic Detection of Learning Styles: A Decade Review on Data-driven Approaches. J. Phys. 2021, 1997, 012001. [Google Scholar] [CrossRef]
- Ndognkon Manga, M.; Fouda Ndjodo, M. An Approach for Non-deterministic and Automatic Detection of Learning Styles with Deep Belief Net. In Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 427–452. [Google Scholar]
- Amir, E.S.; Sumadyo, M.; Sensuse, D.I.; Sucahyo, Y.G.; Santoso, H.B. Automatic detection of learning styles in learning management system by using literature-based method and support vector machine. In Proceedings of the 2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Malang, Indonesia, 15–16 October 2016; pp. 141–144. [Google Scholar]
- Bernard, J.; Chang, T.W.; Popescu, E.; Graf, S. Learning style Identifier: Improving the precision of learning style identification through computational intelligence algorithms. Expert Syst. Appl. 2017, 75, 94–108. [Google Scholar]
- El Aissaoui, O.; El Alami, Y.E.M.; Oughdir, L.; El Allioui, Y. Integrating web usage mining for an automatic learner profile detection: A learning styles-based approach. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; pp. 1–6. [Google Scholar]
- Sheeba, T.; Krishnan, R. Prediction of student learning style using modified decision tree algorithm in e-learning system. In Proceedings of the 2018 International Conference on Data Science and Information Technology, Singapore, 20–22 July 2018; pp. 85–90. [Google Scholar]
- Karagiannis, I.; Satratzemi, M. An adaptive mechanism for Moodle based on automatic detection of learning styles. Educ. Inf. Technol. 2018, 23, 1331–1357. [Google Scholar] [CrossRef]
- Maaliw, R.R., III; Ballera, M.A.; Ambat, S.C.; Dumlao, M.F. Comparative analysis of data mining techniques for classification of student’s learning styles. In Proceedings of the International Conference on Advances in Science, Engineering and Technology (ICASET-17), Qingdao, China, 20–22 May 2017; pp. 18–19. [Google Scholar]
- Xing, W.; Li, C.; Chen, G.; Huang, X.; Chao, J.; Massicotte, J.; Xie, C. Automatic assessment of students’ engineering design performance using a Bayesian network model. J. Educ. Comput. Res. 2021, 59, 230–256. [Google Scholar] [CrossRef]
- El Aissaoui, O.; El Madani, Y.E.A.; Oughdir, L.; El Allioui, Y. Combining supervised and unsupervised machine learning algorithms to predict the learners’ learning styles. Procedia Comput. Sci. 2019, 148, 87–96. [Google Scholar] [CrossRef]
- El Mezouary, A.; Hmedna, B.; Omar, B. An evaluation of learner clustering based on learning styles in mooc course. In Proceedings of the 2019 International Conference of Computer Science and Renewable Energies (ICCSRE), Agadir, Morocco, 22–24 July 2019; pp. 1–5. [Google Scholar]
- Kika, A.; Leka, L.; Maxhelaku, S.; Ktona, A. Using data mining techniques on Moodle data for classification of student? S learning styles. In Proceedings of the International Academic Conferences, Rome, Italy, 19–21 November 2019; p. 9211567. [Google Scholar]
- Felder, R.M.; Spurlin, J. Applications, reliability and validity of the index of learning styles. Int. J. Eng. Educ. 2005, 21, 103–112. [Google Scholar]
- Viola, S.R.; Graf, S.; Leo, T. Investigating relationships within the index of learning styles: A data driven approach. Interact. Technol. Smart Educ. 2007, 4, 7–18. [Google Scholar] [CrossRef]
- Khine, M.S. Application of Structural Equation Modeling in Educational Research and Practice; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7. [Google Scholar]
- Pallant, J. SPSS Survival Manual; McGraw-Hill Education: London, UK, 2013. [Google Scholar]
- Zywno, M. A contribution to validation of score meaning for Felder Soloman’s Index of Learning Styles. In Proceedings of the 2003 Annual Conference, Boston, MA, USA, 24–28 July 2003; pp. 8–31. [Google Scholar]
- Felder, R.M. Matters of style. ASEE Prism 1996, 6, 18–23. [Google Scholar]
- Kolb, D.A. Experiential Learning: Experience as the Source of Learning and Development; FT Press: Upper Saddle River, NJ, USA, 2014. [Google Scholar]
- Jung, C.G. Collected Works of CG Jung, Volume 8: Structure & Dynamics of the Psyche; Princeton University Press: Princeton, NJ, USA, 2014; Volume 47. [Google Scholar]
- Solomon, B.; Felder, R. Index of Learning Styles. 1999. Available online: https://www.researchgate.net/publication/228403640_Index_of_Learning_Styles_Questionnaire (accessed on 12 May 2022).
- Rahadian, R.B.; Budiningsih, C.A. What are the suitable instructional strategy and media for student learning styles in middle schools? arXiv 2018, arXiv:1801.05024. [Google Scholar] [CrossRef]
- Esfandabad, H.S. A comparative study of learning styles among monolingual (Persian) and bilingual (Turkish-Persian) secondary school students. Procedia-Soc. Behav. Sci. 2010, 5, 2419–2422. [Google Scholar]
- Hosford, C.C.; Siders, W.A. Felder-Soloman’s index of learning styles: Internal consistency, temporal stability, and factor structure. Teach. Learn. Med. 2010, 22, 298–303. [Google Scholar] [CrossRef]
- Felder, R.; Litzinger, T.; Lee, S.H.; Wise, J. A study of the reliability and validity of the felder soloman index of learning styles. In Proceedings of the 2005 Annual Conference, Chania, Greece, 24–26 September 2005; pp. 10–95. [Google Scholar]
- Litzinger, T.A.; Lee, S.H.; Wise, J.C.; Felder, R.M. A psychometric study of the index of learning styles©. J. Eng. Educ. 2007, 96, 309–319. [Google Scholar] [CrossRef]
- Kaliská, L. Felder’s learning style concept and its index of learning style questionnaire in the Slovak conditions. GRANT J. 2012, 1, 52–56. [Google Scholar]
- Graf, S.; Viola, S.R.; Kinshuk, T.L. Representative characteristics of felder-silverman learning styles: An empirical model. In Proceedings of the IADIS International Conference on Cognition and Exploratory Learning in Digital Age (CELDA 2006), Barcelona, Spain, 8–10 December 2006; pp. 235–242. [Google Scholar]
- Graf, S.; Viola, S.R.; Leo, T.; Kinshuk. In-depth analysis of the Felder-Silverman learning style dimensions. J. Res. Technol. Educ. 2007, 40, 79–93. [Google Scholar] [CrossRef]
- Flake, J.K.; Pek, J.; Hehman, E. Construct validation in social and personality research: Current practice and recommendations. Soc. Psychol. Personal. Sci. 2017, 8, 370–378. [Google Scholar] [CrossRef]
- De Souza, A.C.; Alexandre, N.M.C.; de Guirardello, E.B. Psychometric properties in instruments evaluation of reliability and validity. Epidemiol. E Serv. Saude 2017, 26, 649–659. [Google Scholar]
- Cronbach, L.J.; Meehl, P.E. Construct validity in psychological tests. Psychol. Bull. 1955, 52, 281. [Google Scholar] [CrossRef]
- Leech, N.; Barrett, K.; Morgan, G.A. SPSS for Intermediate Statistics: Use and Interpretation; Routledge: London, UK, 2013. [Google Scholar]
- Beavers, A.S.; Lounsbury, J.W.; Richards, J.K.; Huck, S.W.; Skolits, G.J.; Esquivel, S.L. Practical considerations for using exploratory factor analysis in educational research. Pract. Assessment, Res. Eval. 2013, 18, 6. [Google Scholar]
- Tabachnick, B.G.; Fidell, L.S.; Ullman, J.B. Using Multivariate Statistics; Pearson: Boston, MA, USA, 2007; Volume 5. [Google Scholar]
- Rinehart, A.; Sharkey, J.; Kahl, C. Learning style dimensions and professional characteristics of academic librarians. Coll. Res. Libr. 2015, 76, 450–468. [Google Scholar] [CrossRef][Green Version]
- Middleton, K.; Ricks, E.; Wright, P.; Grant, S.; Middleton, K.; Ricks, E.; Wright, P.; Grant, S. Examining the relationship between learning style preferences and attitudes toward Mathematics among students in higher education. Inst. Learn. Styles J. 2013, 1, 1–15. [Google Scholar]
- Van Zwanenberg, N.; Wilkinson, L.; Anderson, A. Felder and Silverman’s Index of Learning Styles and Honey and Mumford’s Learning Styles Questionnaire: How do they compare and do they predict academic performance? Educ. Psychol. 2000, 20, 365–380. [Google Scholar] [CrossRef]
- Livesay, G.; Dee, K.; Nauman, E.; Hites, L., Jr. Engineering student learning styles: A statistical analysis using Felder’s Index of Learning Styles. In Proceedings of the Annual Conference of the American Society for Engineering Education, Montreal, QC, Canada, 5–8 June 2002. [Google Scholar]
- Franzoni, A.L.; Assar, S.; Defude, B.; Rojas, J. Student learning styles adaptation method based on teaching strategies and electronic media. In Proceedings of the 2008 Eighth IEEE International Conference on Advanced Learning Technologies, Tartu, Estonia, 1–5 July 2008; pp. 778–782. [Google Scholar]
- Psycharis, S.; Botsari, E.; Chatzarakis, G. Examining the effects of learning styles, epistemic beliefs and the computational experiment methodology on learners’ performance using the easy java simulator tool in stem disciplines. J. Educ. Comput. Res. 2014, 51, 91–118. [Google Scholar] [CrossRef]
- Kyriazos, T.A. Applied psychometrics: Sample size and sample power considerations in factor analysis (EFA, CFA) and SEM in general. Psychology 2018, 9, 2207. [Google Scholar] [CrossRef]
- Hooper, D.C.J.; Mullen, M. Structural equation modelling: Guidelines for determining model fit. Electron. J. Bus. Res. Methods 2008, 6, 53–60. [Google Scholar]
- Hatcher, L.; O’Rourke, N. A Step-by-Step Approach to USING SAS for Factor Analysis and Structural Equation Modeling; Sas Institute: Cary, NC, USA, 2013. [Google Scholar]
- Kaiser, H.F. A second generation little jiffy. Psychometrika 1970, 35, 401–415. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Study | N | AR | SI | VV | SG |
|---|---|---|---|---|---|
| [35] | 56 | 0.59 | 0.70 | 0.63 | 0.53 |
| [17] | 198 | 0.51 | 0.63 | 0.64 | 0.51 |
| [56] | 572 | 0.51 | 0.65 | 0.56 | 0.41 |
| [31] | 584 | 0.70 | 0.76 | 0.69 | 0.55 |
| [57] | 242 | 0.56 | 0.72 | 0.62 | 0.54 |
| [21] | 500 | 0.87 | 0.77 | 0.77 | 0.61 |
| [42] | 358 | 0.63 | 0.76 | 0.64 | 0.62 |
| Present | 421 | 0.61 | 0.52 | 0.55 | 0.62 |
| Learning Style | Valid Cases | Items | Mean | Variance | Cronbach Alpha () |
|---|---|---|---|---|---|
| AR | 421 | 11 | 7.34 | 6.45 | 0.61 |
| SI | 421 | 11 | 5.50 | 4.92 | 0.52 |
| VV | 421 | 11 | 6.95 | 4.84 | 0.55 |
| SG | 421 | 11 | 6.90 | 5.70 | 0.62 |
| Learning Styles | Factors | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |
| AR | 10 | 1 | 1 | 1 | ||||||||||||
| SG | 10 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||
| VV | 10 | 4 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 2 | ||||||
| SI | 3 | 5 | 3 | 3 | 2 | 1 | 2 | 1 | 1 | |||||||
| Components | Components | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | ||
| AR1 | 0.636 | 0.137 | −0.009 | 0.076 | 0.054 | SG8 | 0.117 | 0.503 | 0.109 | −0.119 | 0.129 |
| AR5 | 0.595 | −0.019 | 0.115 | −0.016 | 0.163 | SG12 | −0.014 | 0.407 | −0.167 | 0.027 | 0.186 |
| AR9 | 0.684 | 0.104 | −0.117 | −0.127 | −0.079 | SG16 | 0.101 | 0.560 | 0.064 | −0.018 | −0.124 |
| AR13 | 0.633 | 0.111 | 0.096 | −0.026 | 0.072 | SG20 | 0.155 | 0.562 | −0.046 | 0.049 | 0.006 |
| AR21 | 0.479 | −0.066 | −0.061 | 0.061 | −0.298 | SG24 | 0.022 | 0.726 | 0.039 | 0.029 | 0.007 |
| AR25 | 0.551 | 0.151 | −0.084 | −0.069 | 0.109 | SG28 | −0.084 | 0.512 | −0.193 | 0.223 | 0.115 |
| AR29 | 0.534 | −0.004 | −0.068 | −0.076 | −0.099 | SG32 | −0.080 | 0.557 | −0.001 | 0.029 | −0.112 |
| AR33 | 0.610 | −0.080 | −0.022 | −0.057 | 0.069 | SG36 | 0.100 | 0.600 | −0.063 | 0.182 | −0.170 |
| AR37 | 0.666 | −0.003 | 0.169 | −0.038 | −0.195 | SG40 | −0.112 | 0.513 | 0.024 | −0.018 | −0.155 |
| AR41 | 0.474 | −0.004 | 0.142 | 0.039 | −0.108 | SG44 | 0.148 | 0.411 | −0.036 | 0.128 | −0.279 |
| AR17 | 0.09 | 0.218 | −0.079 | 0.197 | 0.155 | SG4 | 0.104 | −0.129 | 0.170 | 0.052 | 0.357 |
| VV3 | −0.055 | 0.061 | 0.407 | −0.057 | 0.274 | SI2 | −0.151 | −0.043 | −0.002 | 0.442 | 0.094 |
| VV7 | 0.069 | −0.110 | 0.480 | 0.240 | 0.077 | SI6 | 0.039 | 0.179 | 0.157 | 0.310 | −0.213 |
| VV11 | −0.142 | −0.133 | 0.560 | 0.058 | −0.200 | SI14 | −0.150 | 0.054 | 0.218 | 0.450 | 0.178 |
| VV15 | −0.177 | −0.047 | 0.477 | 0.142 | 0.040 | SI18 | 0.145 | −0.030 | 0.025 | 0.480 | −0.173 |
| VV19 | 0.085 | 0.120 | 0.483 | −0.014 | 0.084 | SI22 | −0.071 | 0.208 | 0.171 | 0.337 | 0.003 |
| VV27 | 0.052 | 0.017 | 0.600 | −0.088 | 0.130 | SI30 | −0.180 | 0.046 | −0.024 | 0.462 | 0.269 |
| VV31 | 0.082 | −0.130 | 0.629 | 0.079 | −0.157 | SI34 | −0.070 | 0.098 | −0.144 | 0.550 | −0.084 |
| VV35 | 0.053 | 0.070 | 0.319 | 0.125 | 0.126 | SI38 | −0.064 | −0.038 | 0.141 | 0.364 | 0.120 |
| VV39 | 0.240 | −0.023 | 0.321 | 0.262 | −0.257 | SI10 | 0.054 | −0.115 | 0.145 | 0.141 | 0.559 |
| VV23 | 0.113 | 0.062 | 0.126 | 0.504 | 0.128 | SI26 | −0.122 | −0.031 | 0.021 | 0.297 | 0.425 |
| VV43 | 0.153 | 0.073 | 0.044 | 0.367 | −0.248 | SI42 | −0.112 | 0.072 | −0.299 | 0.245 | −0.345 |
| Learning Styles | Factors | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| AR | 10 | ||||
| SG | 10 | 1 | |||
| VV | 9 | 2 | |||
| SI | 8 | 3 | |||
| Factors | Items | Label | Factors Explained |
|---|---|---|---|
| 1 | 1, 5, 9, 13, 21, 25, 29, 33, 37, 41, 17 | AR | Action first or reflection first |
| 2 | 17, 8, 12, 16, 20, 24, 28, 32, 36, 40, 44 | SG | Linear VS sequential or random VS holistic thinking |
| 3 | 3, 8, 11, 15, 19, 27, 31, 35, 39 | VV | Information format preferred as input or memory |
| 4 | 23, 43, 2, 6, 14, 18, 22, 30, 34, 37 | SI | Information format preferred and preference of concrete or abstract information |
| 5 | 4, 10, 26, 42 | SI-SG | Conceptual VS factual and detail VS theme |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mirza, M.A.; Khurshid, K.; Shah, Z.; Ullah, I.; Binbusayyis, A.; Mahdavi, M. ILS Validity Analysis for Secondary Grade through Factor Analysis and Internal Consistency Reliability. Sustainability 2022, 14, 7950. https://doi.org/10.3390/su14137950
Mirza MA, Khurshid K, Shah Z, Ullah I, Binbusayyis A, Mahdavi M. ILS Validity Analysis for Secondary Grade through Factor Analysis and Internal Consistency Reliability. Sustainability. 2022; 14(13):7950. https://doi.org/10.3390/su14137950
Chicago/Turabian StyleMirza, Munazza A., Khawar Khurshid, Zawar Shah, Imdad Ullah, Adel Binbusayyis, and Mehregan Mahdavi. 2022. "ILS Validity Analysis for Secondary Grade through Factor Analysis and Internal Consistency Reliability" Sustainability 14, no. 13: 7950. https://doi.org/10.3390/su14137950
APA StyleMirza, M. A., Khurshid, K., Shah, Z., Ullah, I., Binbusayyis, A., & Mahdavi, M. (2022). ILS Validity Analysis for Secondary Grade through Factor Analysis and Internal Consistency Reliability. Sustainability, 14(13), 7950. https://doi.org/10.3390/su14137950