
Human–System Interaction Based on Eye Tracking for a Virtual Workshop


Abstract
1. Introduction
2. Related Research
2.1. Related Research on Recognition of Eye Movement Behavior
2.2. Related Research on Intention Understanding
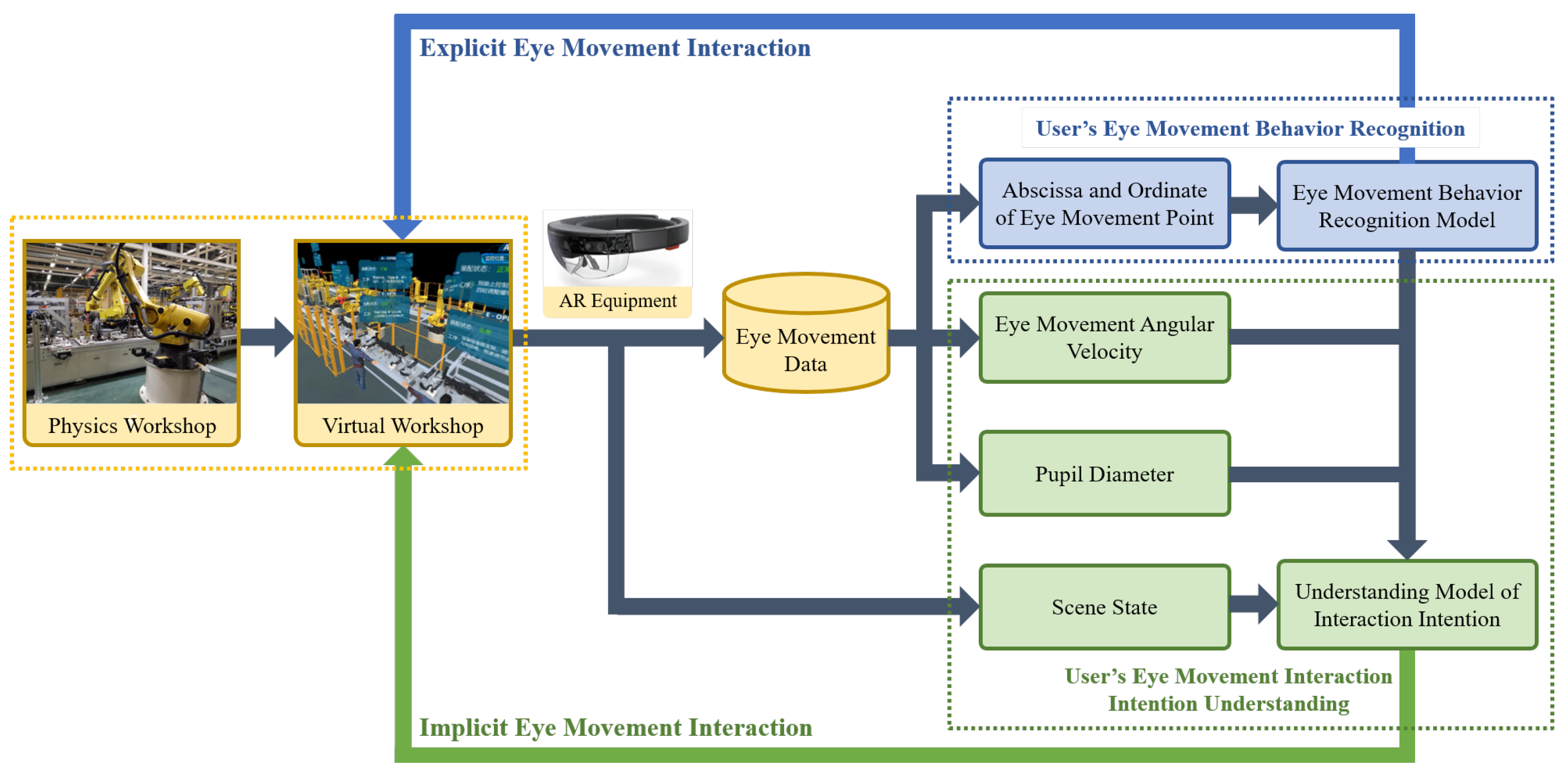
3. Technical Framework of 3D Eye Movement Interaction
3.1. Eye Movement Behavior Recognition
- 1.
- The eye movement behavior of the user is acquired by the eye tracking module of the AR glasses in real-time;
- 2.
- The AR program is developed by Unity 3D. The connection with the AR program is created through the API of AR glasses, so that the collected eye movement data can be acquired in real-time in the AR program;
- 3.
- The eye movement behavior is recognized by the CNN and Bi-LSTM hybrid neural network based on the eye movement data.

3.2. Intention Understanding of Eye Movement Interaction
- eye movement characteristics + eye movement state;
- eye movement characteristics + psychological state;
- eye movement characteristics + eye movement state + psychological state;
- eye movement characteristics + eye movement state + scene state;
- eye movement characteristics + psychological state + scene state;
- eye movement characteristics + eye movement state + psychological state + scene state.
4. Materials and Methods
4.1. Participants and Data Set
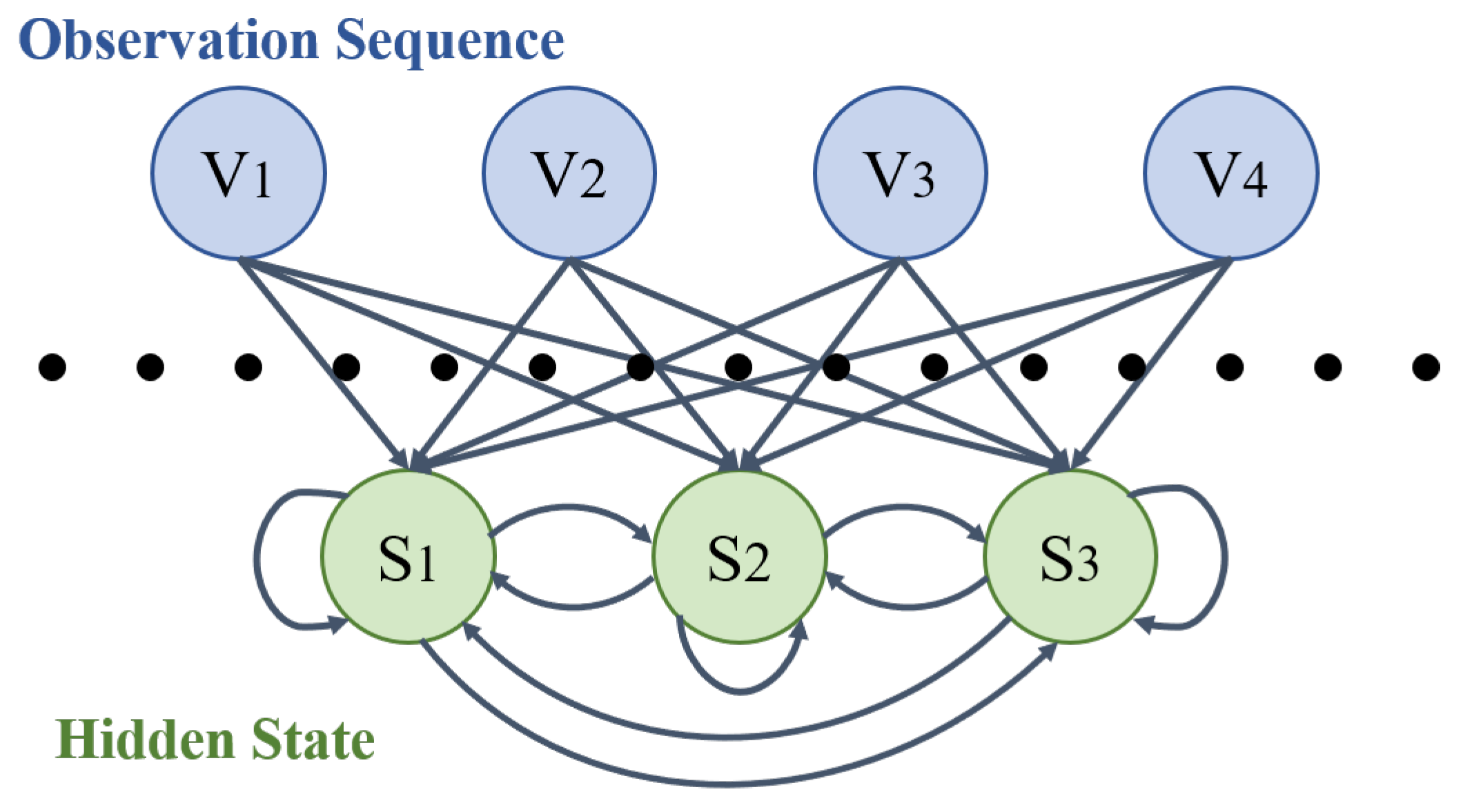
4.2. Verification Experiment of Eye-Movement Behavior Recognition Model
4.3. Verification Experiment of Eye-Movement Interaction Intention Understanding Model
4.4. Application
5. Results and Discussion
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AR | Augmented reality |
| CNN | Convolutional Neural Network |
| Bi-LSTM | Bi-directional Long Short-term Memory Network |
| HMM | Hidden Markov Model |
| SVM | Support Vector Machine |
| CDT | Fixation dispersion algorithm based on covariance |
| EM | Engbert and Mergenthaler |
| IDT | Identification by dispersion threshold |
| IKT | Identification by Kalman filter |
| IMST | Identification by minimal spanning tree |
| IHMM | Identification by hidden Markov model |
| IVT | Identification by velocity threshold |
| NH | Nyström and Holmqvist |
| BIT | Binocular-individual threshold |
| LNS | Larsson, Nystrom and Stridh |
| GMM | Gaussian Mixture Model |
| EOG | Electro-Oculogram |
| ANFIS | Adaptive Neural Fuzzy Inference System |
| EEG | Electroencephalogram |
| ECG | Electrocardiograph |
| RF | Random Forest |
References
- Nahavandi, S. Industry 5.0—A Human-Centric Solution. Sustainability 2019, 11, 4371. [Google Scholar] [CrossRef]
- Hyrskykari, A.; Majaranta, P.; Räihä, K.J. From gaze control to attentive interfaces. Proc. HCII 2005, 2, 17754474. [Google Scholar]
- Ponce, H.R.; Mayer, R.E. An eye movement analysis of highlighting and graphic organizer study aids for learning from expository text. Comput. Hum. Behav. 2014, 41, 21–32. [Google Scholar] [CrossRef]
- Wang, S.; Wang, Q.; Chen, H. Research and Application of Eye Movement Interaction based on Eye Movement Recognition. MATEC Web Conf. 2018, 246, 03038. [Google Scholar] [CrossRef][Green Version]
- Katona, J. Analyse the Readability of LINQ Code using an Eye-Tracking-based Evaluation. Acta Polytech. Hung. 2021, 18, 193–215. [Google Scholar] [CrossRef]
- Katona, J. Clean and dirty code comprehension by eye-tracking based evaluation using GP3 eye tracker. Acta Polytech. Hung. 2021, 18, 79–99. [Google Scholar] [CrossRef]
- Katona, J. Measuring Cognition Load Using Eye-Tracking Parameters Based on Algorithm Description Tools. Sensors 2022, 22, 912. [Google Scholar] [CrossRef]
- Andersson, R.; Larsson, L.; Holmqvist, K.; Stridh, M.; Nyström, M. One algorithm to rule them all? An evaluation and discussion of ten eye movement event-detection algorithms. Behav. Res. Methods 2017, 49, 616–637. [Google Scholar] [CrossRef]
- Wang, X.; Xiao, Y.; Deng, F.; Chen, Y.; Zhang, H. Eye-Movement-Controlled Wheelchair Based on Flexible Hydrogel Biosensor and WT-SVM. Biosensors 2021, 11, 198. [Google Scholar] [CrossRef]
- Dong, W.; Yang, L.; Gravina, R.; Fortino, G. ANFIS fusion algorithm for eye movement recognition via soft multi-functional electronic skin. Inf. Fusion 2021, 71, 99–108. [Google Scholar] [CrossRef]
- Cheng, B.; Zhang, C.; Ding, X.; Wu, X. Convolutional neural network implementation for eye movement recognition based on video. In Proceedings of the 2018 33rd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Nanjing, China, 18–20 May 2018. [Google Scholar] [CrossRef]
- Umemoto, K.; Yamamoto, T.; Nakamura, S.; Tanaka, K. Search intent estimation from user’s eye movements for supporting information seeking. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Naples, Italy, 21–25 May 2012; pp. 349–356. [Google Scholar] [CrossRef]
- Chen, Y.N.; Hakkani-Tur, D.; Tur, G.; Gao, J.F.; Deng, L. End-to-End Memory Networks with Knowledge Carryover for Multi-Turn Spoken Language Understanding. In Proceedings of the Annual Conference of International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 3245–3249. [Google Scholar] [CrossRef]
- Yang, M.H.; Tao, J.H.; Li, H.; Chao, L. Nature Multimodal Human-Computer-Interaction Dialog System. Comput. Sci. 2014, 41, 12–18. [Google Scholar] [CrossRef]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. Unsupervised Event-Based Learning of Optical Flow, Depth, and Egomotion. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Schutz, A.C.; Braun, D.I.; Gegenfurtner, K.R. Eye movements and perception: A selective review. J. Vis. 2011, 11, 89–91. [Google Scholar] [CrossRef] [PubMed]
- Jang, Y.M.; Mallipeddi, R.; Lee, S.; Kwak, H.W.; Lee, M. Human intention recognition based on eyeball movement pattern and pupil size variation. Neurocomputing 2014, 128, 421–432. [Google Scholar] [CrossRef]
- Li, S.; Zhang, X. Implicit Intention Communication in Human–Robot Interaction Through Visual Behavior Studies. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 437–448. [Google Scholar] [CrossRef]
- Koochaki, F.; Najafizadeh, L. A Data-Driven Framework for Intention Prediction via Eye Movement with Applications to Assistive Systems. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 974–984. [Google Scholar] [CrossRef] [PubMed]
- Shi, L.; Copot, C.; Vanlanduit, S. Gazeemd: Detecting visual intention in gaze-based human-robot interaction. Robotics 2021, 10, 68. [Google Scholar] [CrossRef]
- Antoniou, E.; Bozios, P.; Christou, V.; Tzimourta, K.D.; Kalafatakis, K.; Tsipouras, M.G.; Giannakeas, N. Tzallas A.T. EEG-Based Eye Movement Recognition Using Brain–Computer Interface and Random Forests. Sensors 2021, 21, 2339. [Google Scholar] [CrossRef]
- Park, H.; Lee, S.; Lee, M.; Chang, M.S.; Kwak, H.W. Using eye movement data to infer human behavioral intentions. Comput. Hum. Behav. 2016, 63, 796–804. [Google Scholar] [CrossRef]
- Bellet, M.E.; Bellet, J.; Nienborg, H.; Hafed, Z.M.; Berens, P. Human-level saccade detection performance using deep neural networks. J. Neurophysiol. 2019, 121, 646–661. [Google Scholar] [CrossRef]
- Liu, S.; Zheng, K.; Zhao, L.; Fan, P. A driving intention prediction method based on hidden Markov model for autonomous driving. Comput. Commun. 2020, 157, 143–149. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, J.; Su, P. Survey of Monosyllable Recognition in Speech Recognition. Comput. Sci. 2020, 47, 4. [Google Scholar]
- An, X.N.; Wang, Z.W.; Zhang, C.L. Face feature labeling and recognition based on hidden Markov model. J. Guangxi Univ. Sci. Technol. 2020, 31, 118–125. [Google Scholar]
- Newman-Toker, D.E.; Curthoys, I.S.; Halmagyi, G.M. Diagnosing stroke in acute vertigo: The HINTS family of eye movement tests and the future of the “Eye ECG”. In Seminars in Neurology; Thieme Medical Publishers: New York, NY, USA, 2015; Volume 35, pp. 506–521. [Google Scholar] [CrossRef]
- Katona, J.; Ujbanyi, T.; Sziladi, G.; Kovari, A. Examine the effect of different web-based media on human brain waves. In Proceedings of the 2017 8th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Debrecen, Hungary, 11–14 September 2017; pp. 000407–000412. [Google Scholar] [CrossRef]
- Katona, J. Examination and comparison of the EEG based Attention Test with CPT and TOVA. In Proceedings of the 2014 IEEE 15th International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, 19–21 November 2014; pp. 117–120. [Google Scholar] [CrossRef]
- Mathur, P.; Mittal, T.; Manocha, D. Dynamic graph modeling of simultaneous eeg and eye-tracking data for reading task identification. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 6–12 June 2021; pp. 1250–1254. [Google Scholar] [CrossRef]
- Souchet, A.D.; Philippe, S.; Lourdeaux, D.; Leroy, L. Measuring visual fatigue and cognitive load via eye tracking while learning with virtual reality head-mounted displays: A review. Int. J. Hum.-Comput. Interact. 2022, 38, 801–824. [Google Scholar] [CrossRef]
- Cheng, B.; Luo, X.; Mei, X.; Chen, H.; Huang, J. A Systematic Review of Eye-Tracking Studies of Construction Safety. Front. Neurosci. 2022, 16, 891725. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 (Fixation) | 1 (Saccade) | |
|---|---|---|
| Number of tags in dataset A | 62,374 | 7399 |
| Number of tags in dataset B | 59,539 | 18,409 |
| Number of tags in dataset C | 10,393 | 7921 |
| Number of tags in dataset D | 55,372 | 8687 |
| Number of tags in dataset E | 48,805 | 9870 |
| Number of tags in dataset F | 56,493 | 11,453 |
| Number of tags in dataset G | 20,548 | 9056 |
| Number of tags in dataset H | 48,540 | 11,098 |
| Number of tags in dataset I | 53,360 | 16,263 |
| Number of tags in dataset J | 32,225 | 5399 |
| Number of tags in dataset K | 45,458 | 6076 |
| Number of tags in dataset L | 66,460 | 9513 |
| Number of tags in dataset M | 39,157 | 5126 |
| Number of tags in dataset N | 48,943 | 8175 |
| Dataset | Evaluation Index | Models | |||
|---|---|---|---|---|---|
| CNN+Bi-LSTM | CNN | I-HMM | EM | ||
| Kappa coefficient | 0.890 | 0.873 | 0.175 | 0 | |
| A | F1 score | 0.909 | 0.868 | 0.574 | 0.473 |
| Time-consuming operation/s | 0.088 | 0.086 | 1.504 | 1.283 | |
| Kappa coefficient | 0.864 | 0.847 | 0.684 | 0.681 | |
| B | F1 score | 0.886 | 0.834 | 0.842 | 0.840 |
| Time-consuming operation/s | 0.101 | 0.064 | 1.518 | 1.243 | |
| Kappa coefficient | 0.828 | 0.783 | 0.683 | 0.714 | |
| C | F1 score | 0.880 | 0.798 | 0.842 | 0.857 |
| Time-consuming operation/s | 0.061 | 0.069 | 0.360 | 0.295 | |
| Kappa coefficient | 0.856 | 0.839 | 0.638 | 0.629 | |
| D | F1 score | 0.881 | 0.830 | 0.817 | 0.812 |
| Time-consuming operation/s | 0.078 | 0.054 | 1.618 | 1.002 | |
| Kappa coefficient | 0.890 | 0.858 | 0.116 | 0 | |
| E | F1 score | 0.885 | 0.848 | 0.531 | 0.456 |
| Time-consuming operation/s | 0.148 | 0.052 | 1.543 | 1.359 | |
| Kappa coefficient | 0.900 | 0.889 | 0.693 | 0.686 | |
| F | F1 score | 0.888 | 0.835 | 0.845 | 0.842 |
| Time-consuming operation/s | 0.083 | 0.052 | 1.436 | 1.072 | |
| Kappa coefficient | 0.845 | 0.844 | 0.712 | 0.705 | |
| G | F1 score | 0.915 | 0.882 | 0.856 | 0.853 |
| Time-consuming operation/s | 0.072 | 0.041 | 0.628 | 0.464 | |
| Kappa coefficient | 0.850 | 0.842 | 0.089 | 0 | |
| H | F1 score | 0.869 | 0.817 | 0.506 | 0.448 |
| Time-consuming operation/s | 0.083 | 0.066 | 1.426 | 1.197 | |
| Kappa coefficient | 0.861 | 0.858 | 0.065 | 0 | |
| I | F1 score | 0.885 | 0.867 | 0.482 | 0.437 |
| Time-consuming operation/s | 0.105 | 0.072 | 1.374 | 1.221 | |
| Kappa coefficient | 0.913 | 0.902 | 0.679 | 0 | |
| J | F1 score | 0.915 | 0.816 | 0.837 | 0.462 |
| Time-consuming operation/s | 0.056 | 0.042 | 0.752 | 0.678 | |
| Kappa coefficient | 0.914 | 0.900 | 0.656 | 0.656 | |
| K | F1 score | 0.946 | 0.907 | 0.826 | 0.827 |
| Time-consuming operation/s | 0.074 | 0.051 | 1.046 | 0.833 | |
| Kappa coefficient | 0.856 | 0.849 | 0.037 | 0 | |
| L | F1 score | 0.872 | 0.826 | 0.490 | 0.468 |
| Time-consuming operation/s | 0.079 | 0.051 | 1.510 | 1.416 | |
| Kappa coefficient | 0.887 | 0.877 | 0.621 | 0.618 | |
| M | F1 score | 0.913 | 0.865 | 0.808 | 0.807 |
| Time-consuming operation/s | 0.075 | 0.043 | 0.857 | 0.710 | |
| Kappa coefficient | 0.871 | 0.864 | 0.284 | 0 | |
| N | F1 score | 0.913 | 0.862 | 0.630 | 0.463 |
| Time-consuming operation/s | 0.086 | 0.059 | 1.121 | 1.036 | |
| Feature Variable Combination | Accuracy |
|---|---|
| Eye movement characteristics + Eye movement status | 74.47% |
| Eye movement characteristics + Mental state | 82.22% |
| Eye movement characteristics + Eye movement state + Mental state | 77.52% |
| Eye movement characteristics + Eye movement state + Scene state | 76.34% |
| Eye movement characteristics + Mental state + Scene state | 82.24% |
| Eye movement characteristics + Eye movement state + Mental state + Scene state | 88.33% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Z.; Li, J.; Dong, M.; Yang, R.; Liu, L. Human–System Interaction Based on Eye Tracking for a Virtual Workshop. Sustainability 2022, 14, 6841. https://doi.org/10.3390/su14116841
Gao Z, Li J, Dong M, Yang R, Liu L. Human–System Interaction Based on Eye Tracking for a Virtual Workshop. Sustainability. 2022; 14(11):6841. https://doi.org/10.3390/su14116841
Chicago/Turabian StyleGao, Zenggui, Jiaying Li, Mengyao Dong, Ruining Yang, and Lilan Liu. 2022. "Human–System Interaction Based on Eye Tracking for a Virtual Workshop" Sustainability 14, no. 11: 6841. https://doi.org/10.3390/su14116841
APA StyleGao, Z., Li, J., Dong, M., Yang, R., & Liu, L. (2022). Human–System Interaction Based on Eye Tracking for a Virtual Workshop. Sustainability, 14(11), 6841. https://doi.org/10.3390/su14116841