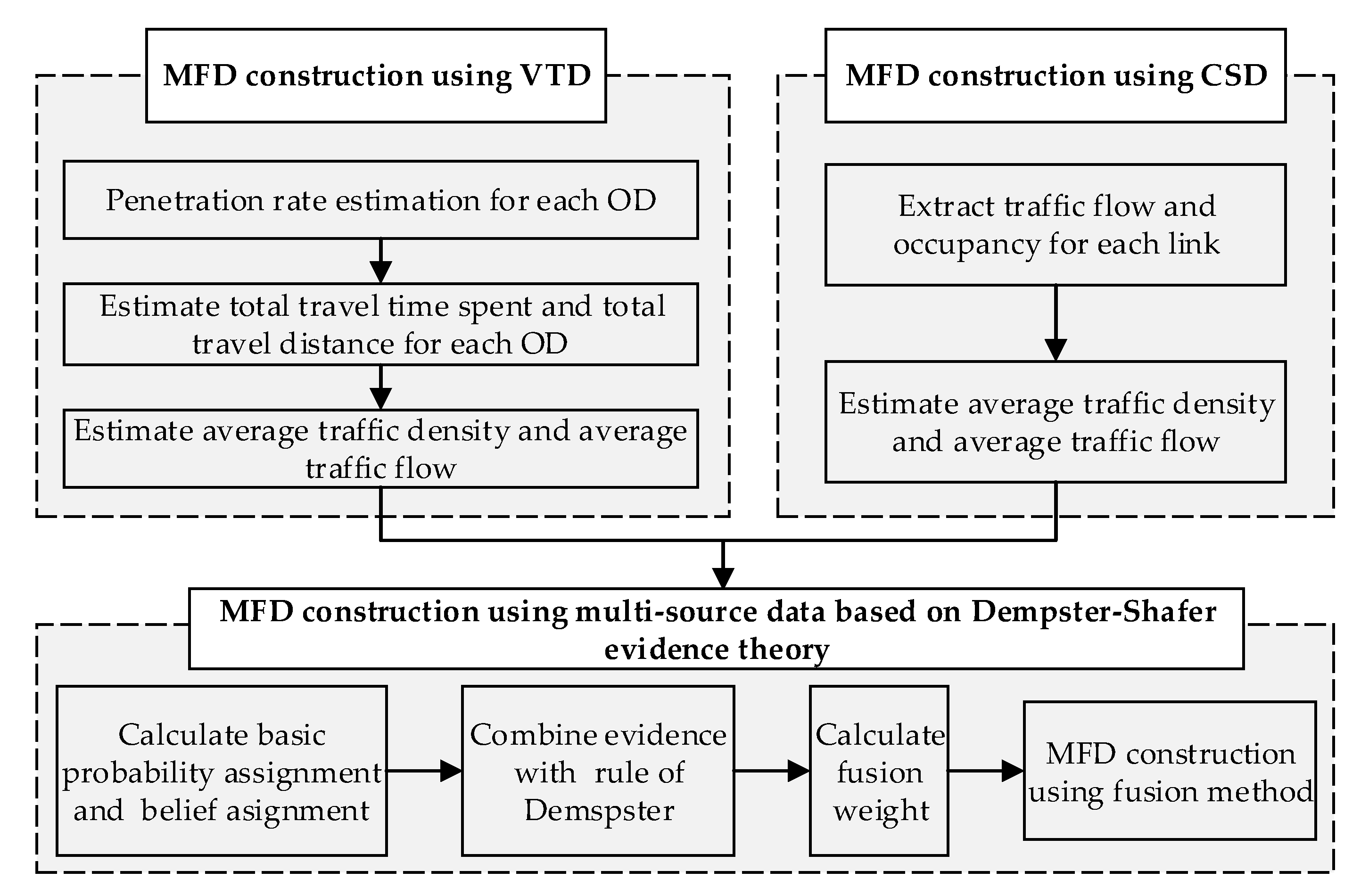
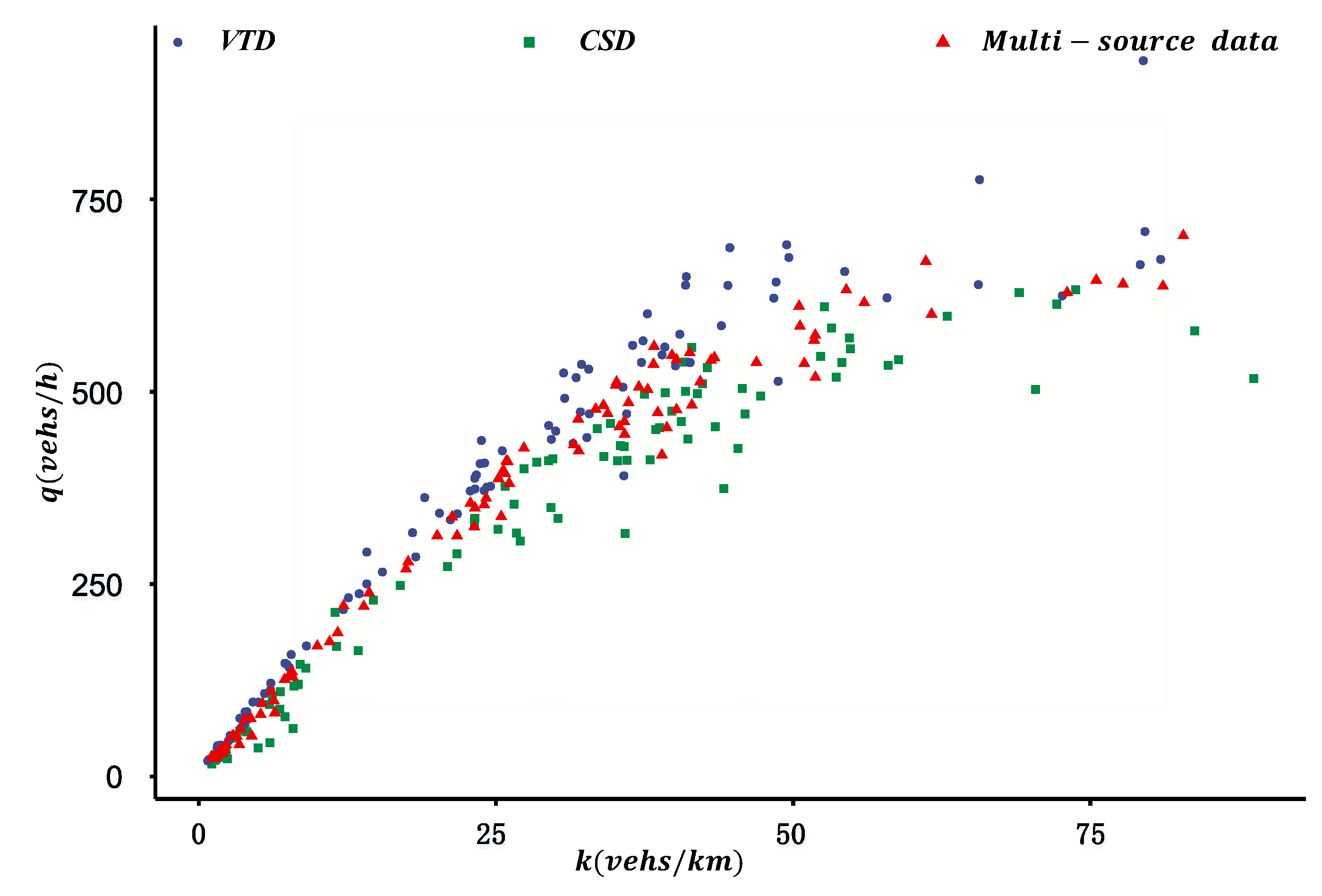
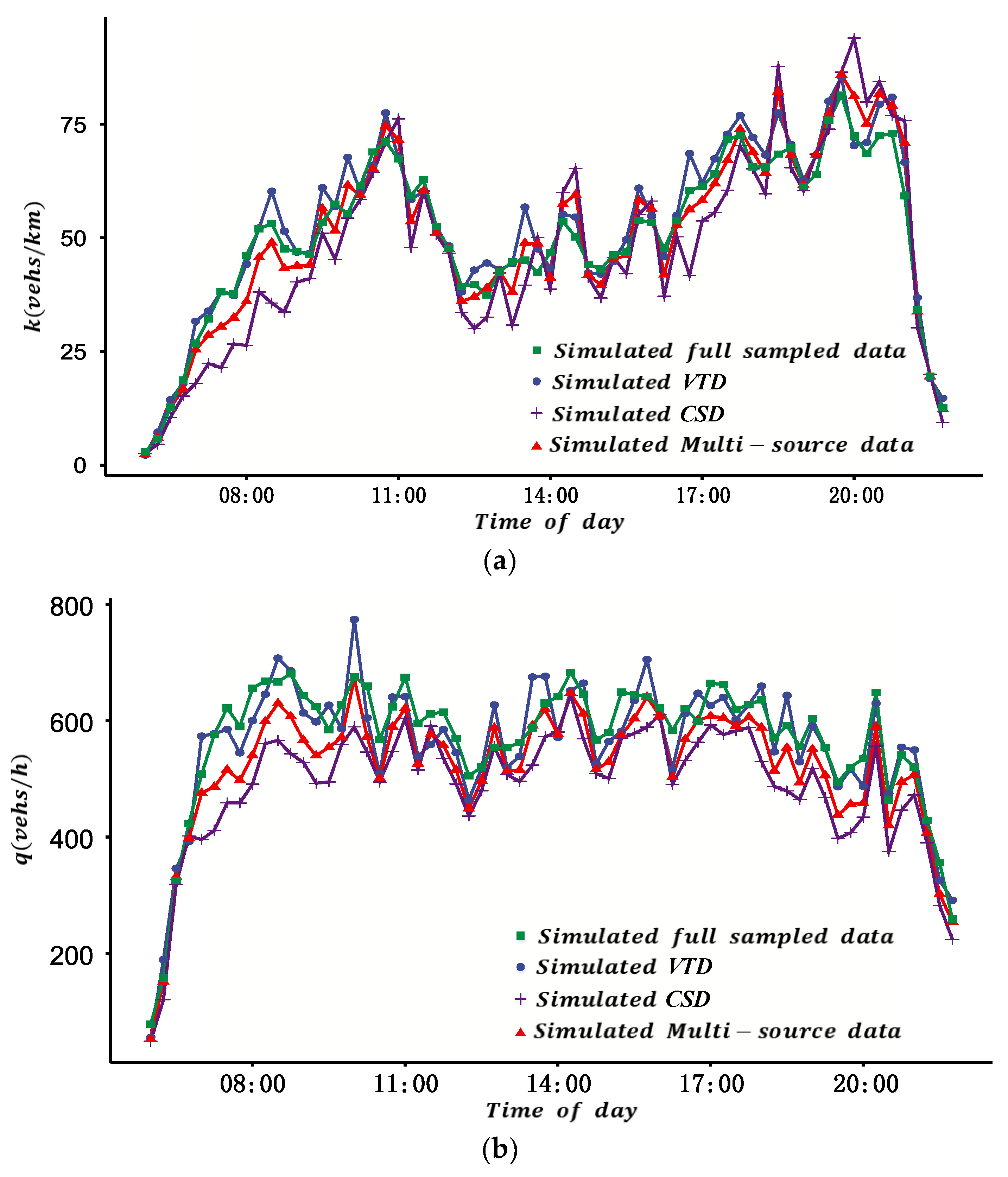
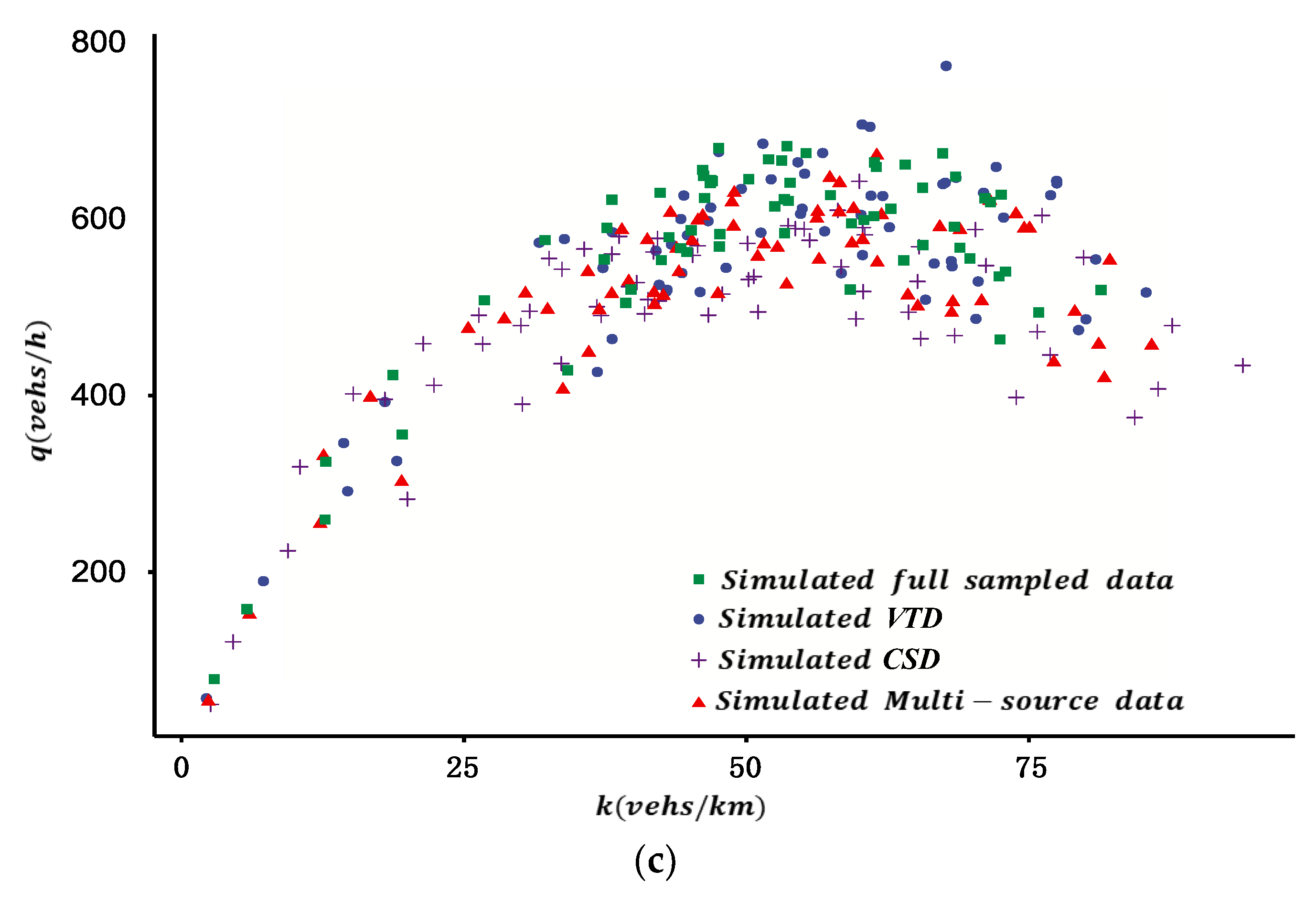
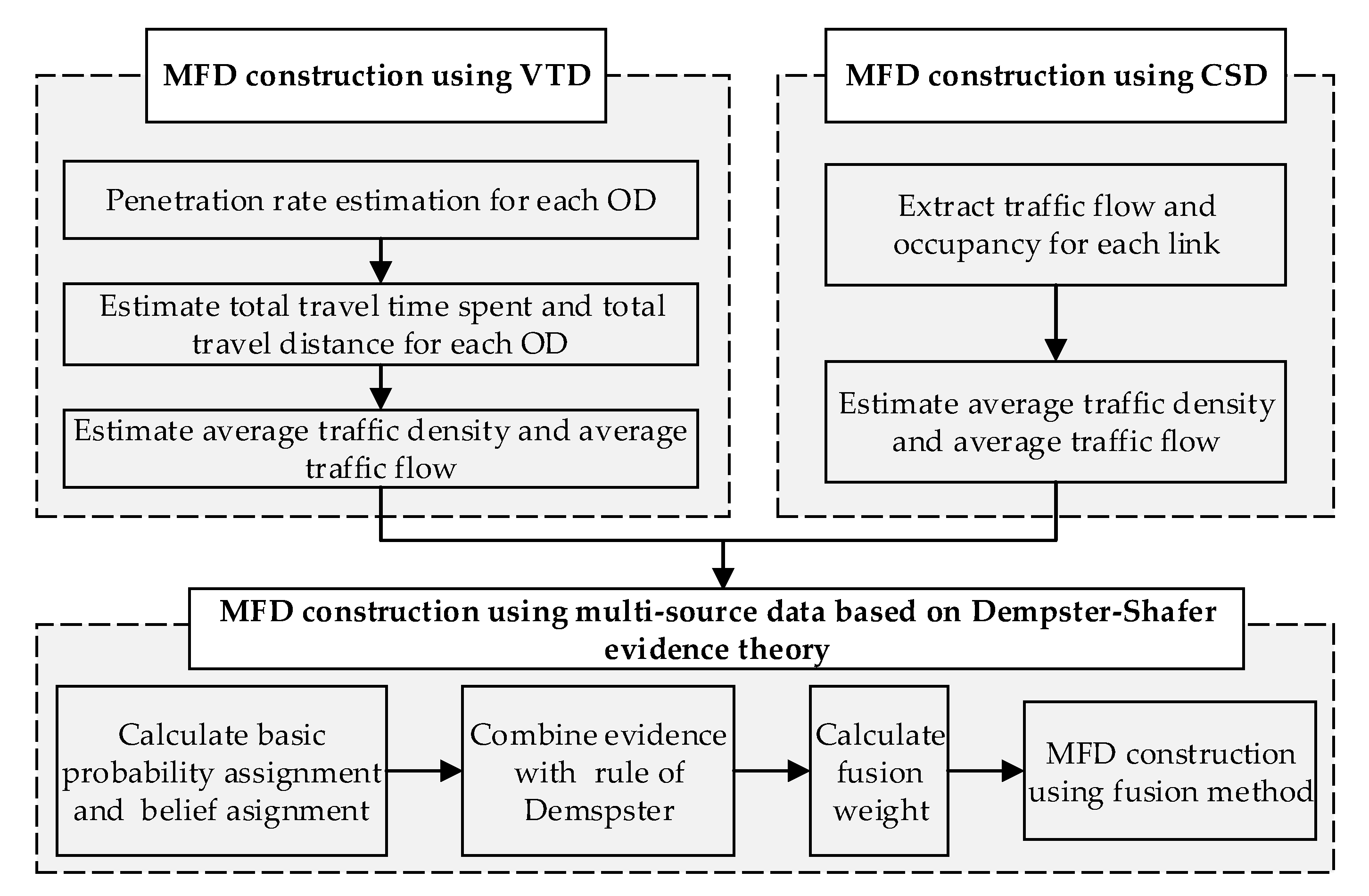
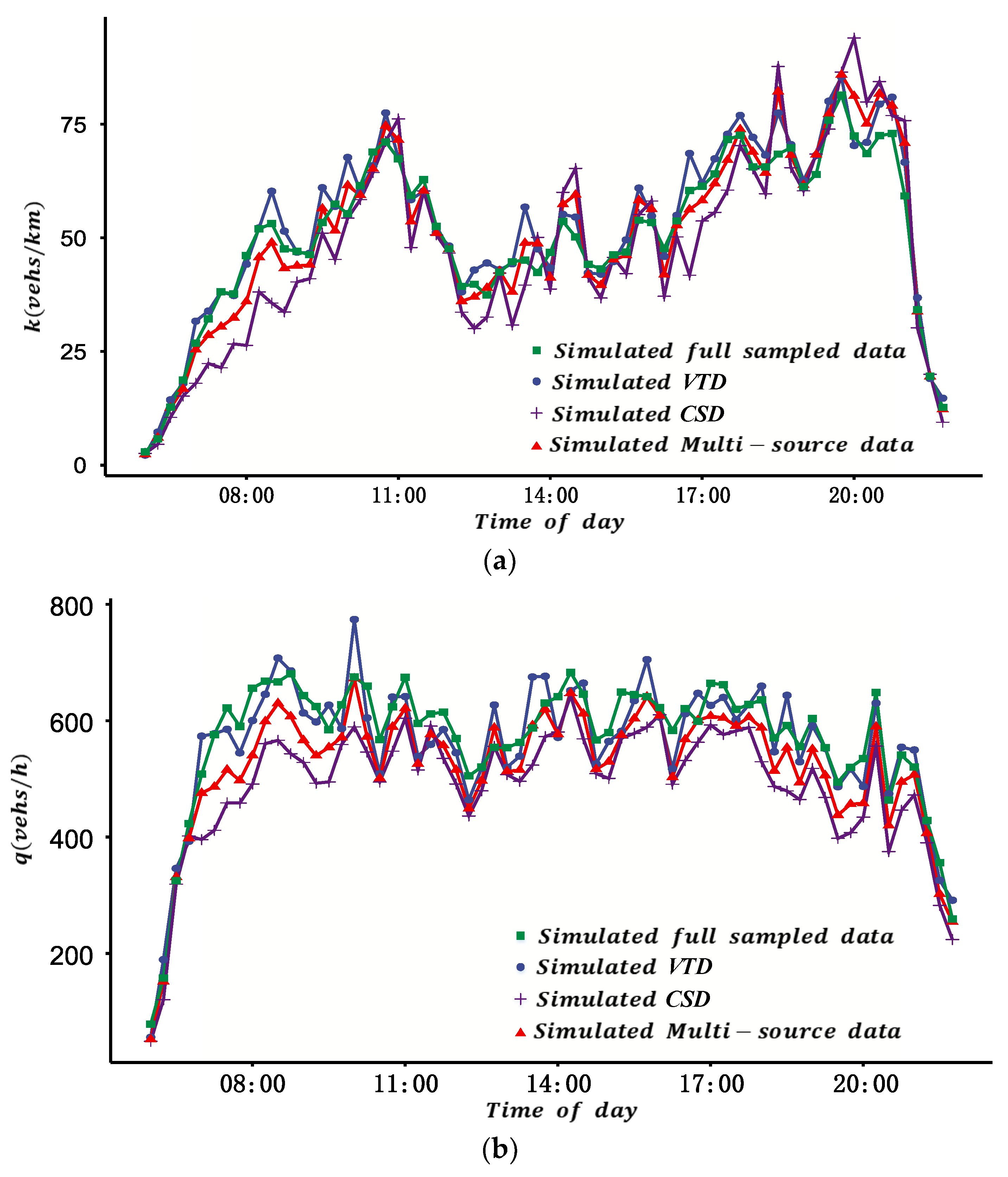
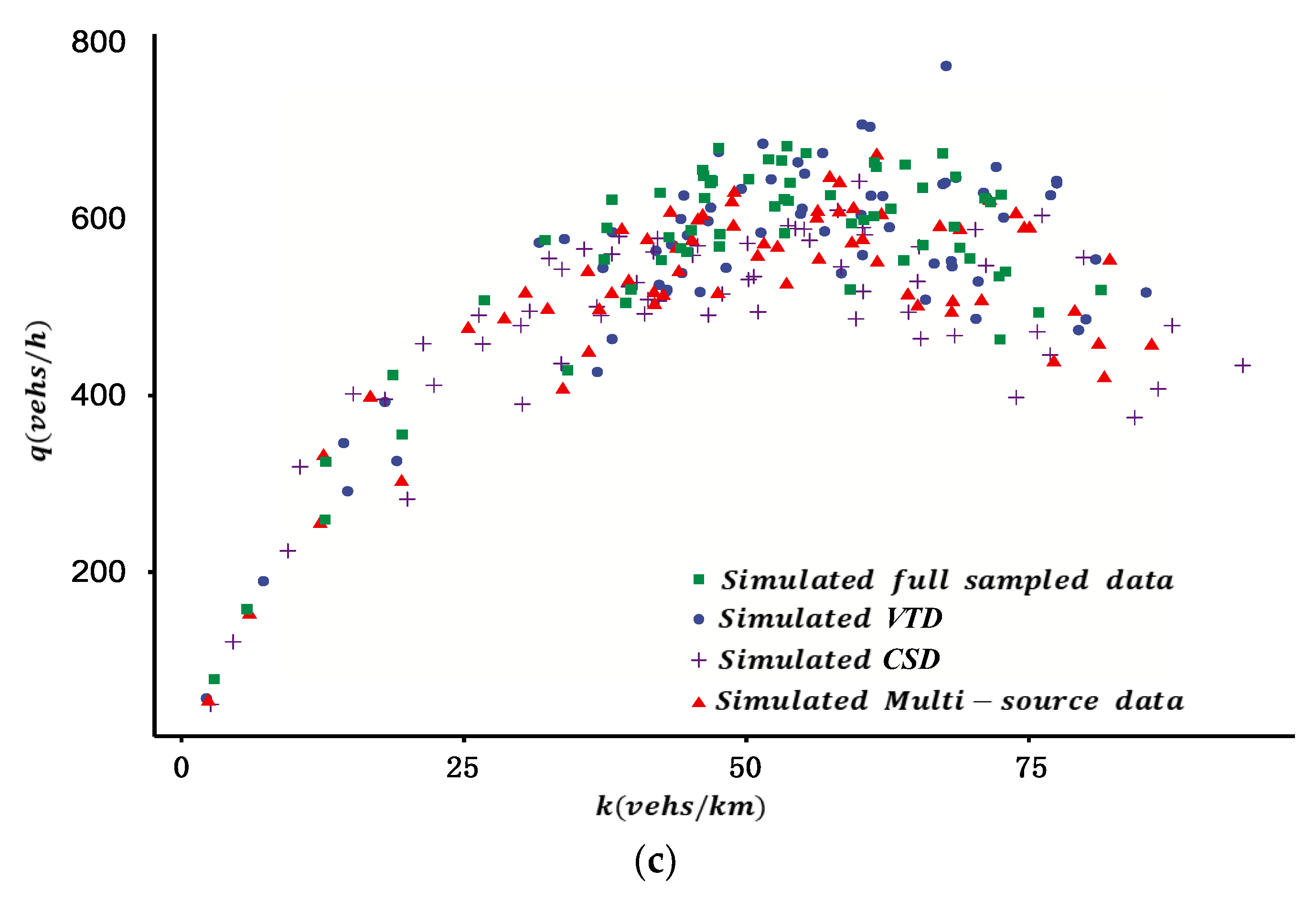
Considering the reliability of different data sources, an MFD construction method is proposed using multi-source data. The framework of the study is shown in
Figure 1. The abbreviations in
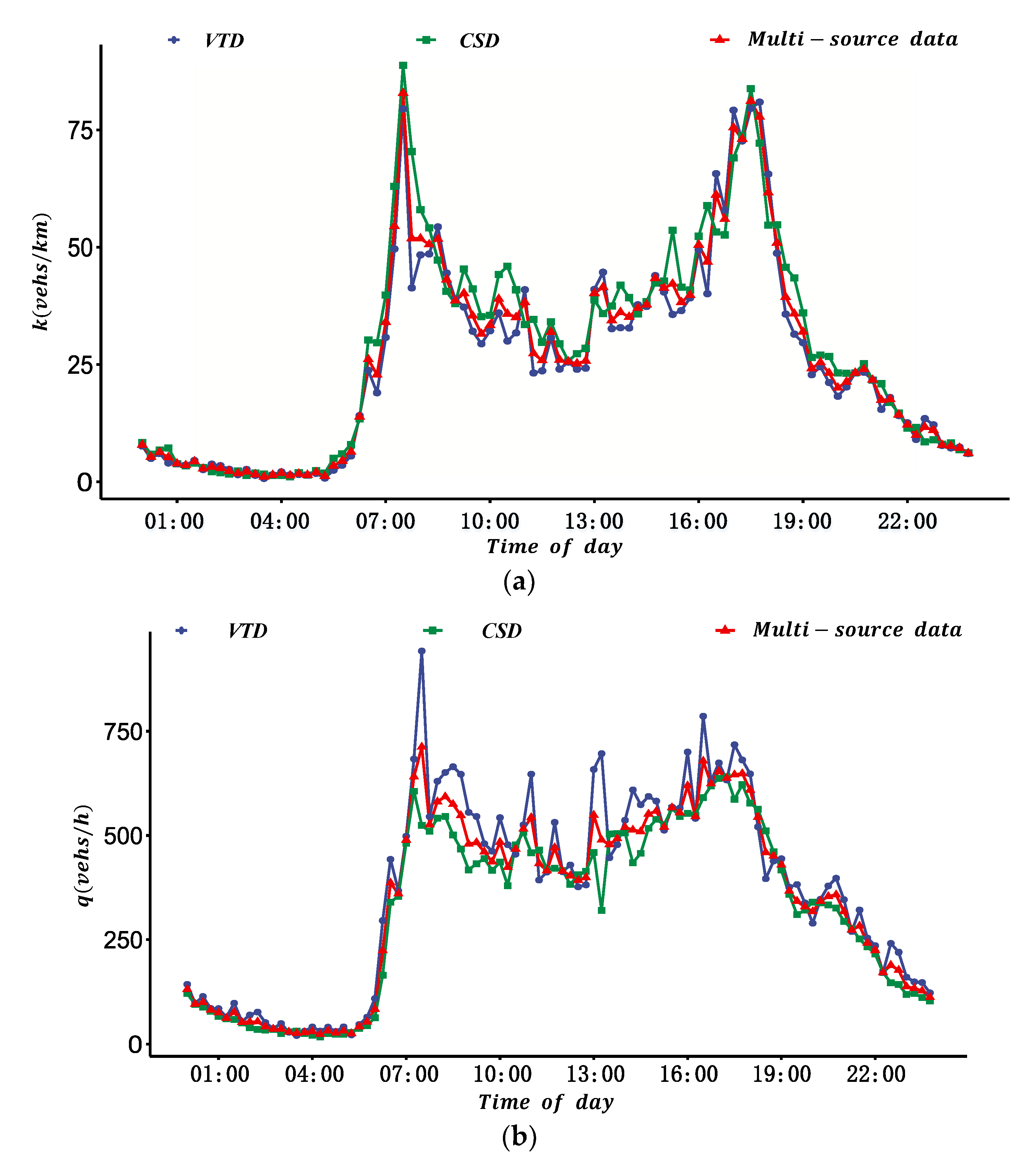
Figure 1 are listed in Appendix (Abbreviations). Firstly, the MFD was constructed based on VTD by estimating the total travel distance (TTD) and total travel time spent (TTS) of all vehicles considering the different penetration rates of probe vehicles in different ODs. Secondly, drawing on existing research, the MFD was constructed based on CSD. Finally, considering the different reliability of different sources of data, the two types of data were fused, and the MFD was constructed based on the DS evidence theory. The contents of each part are described as follows.
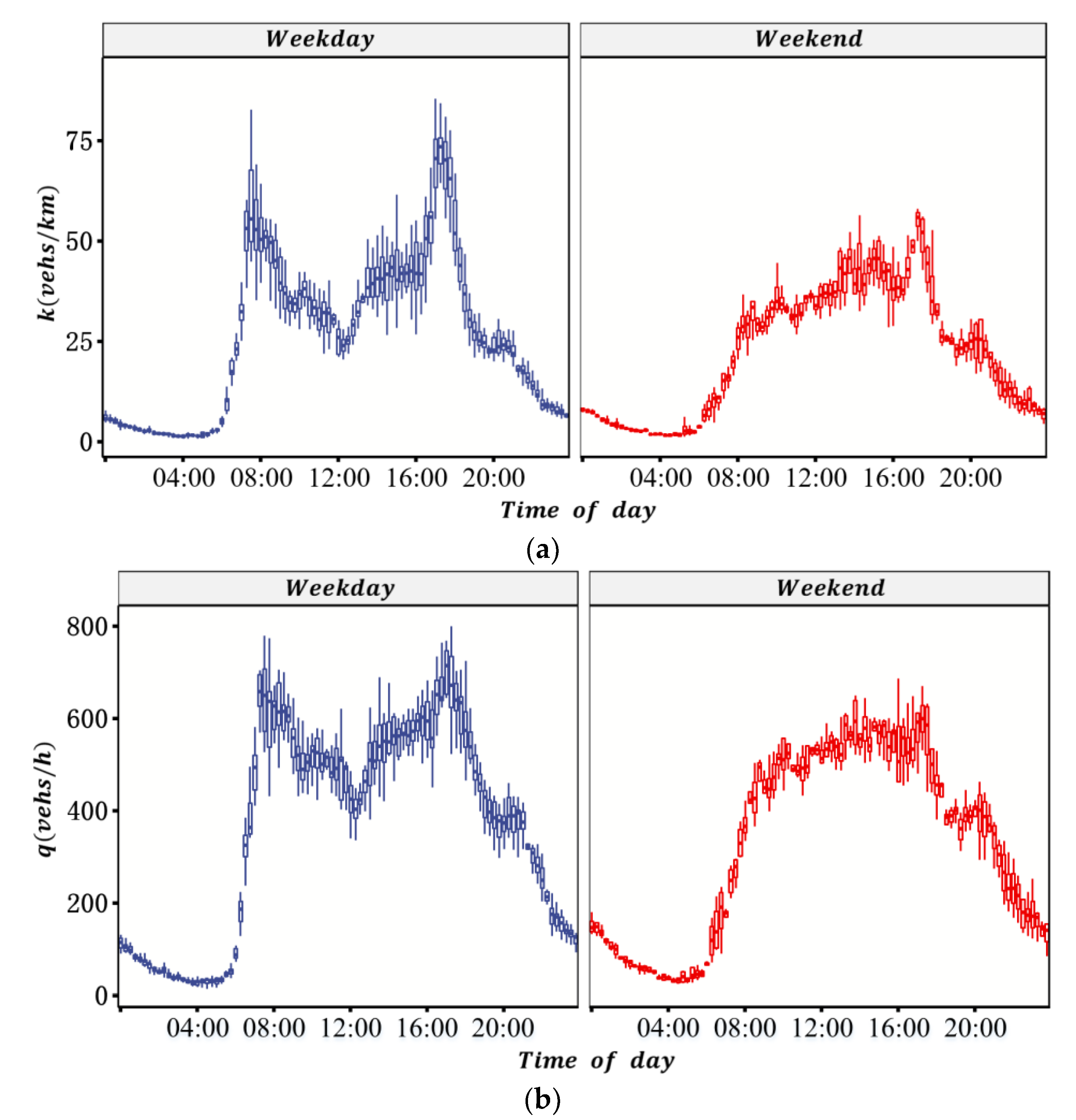
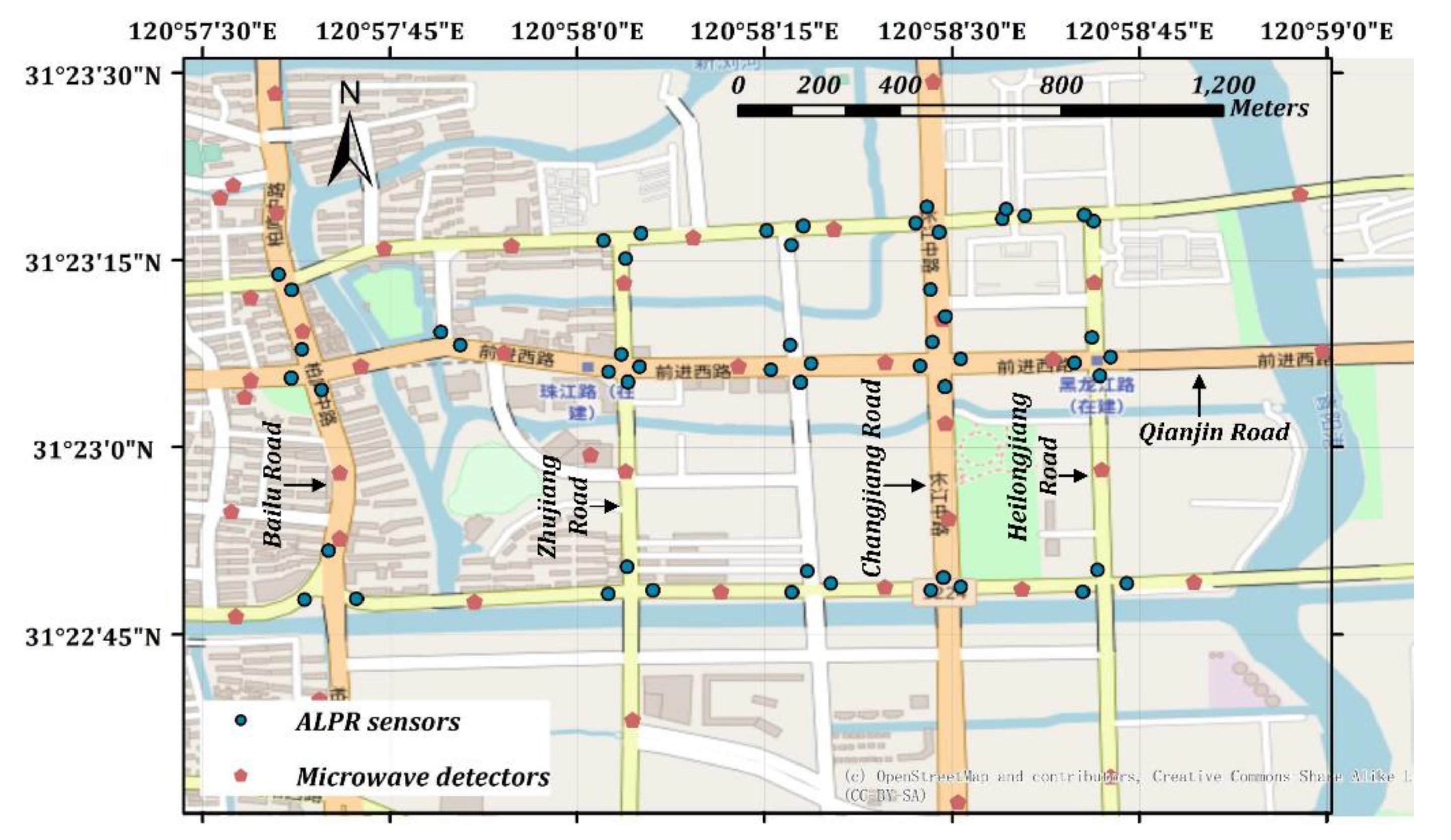
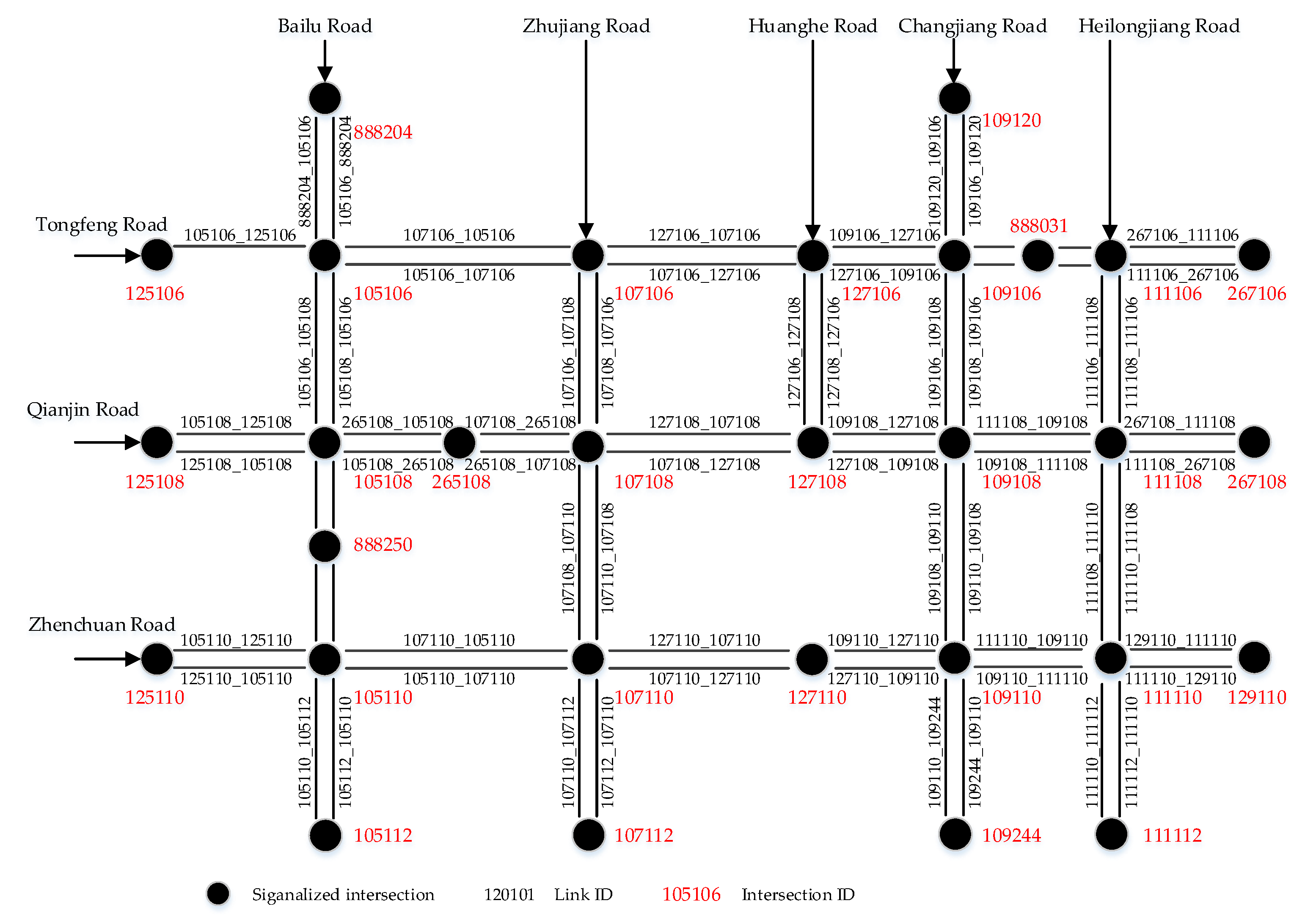
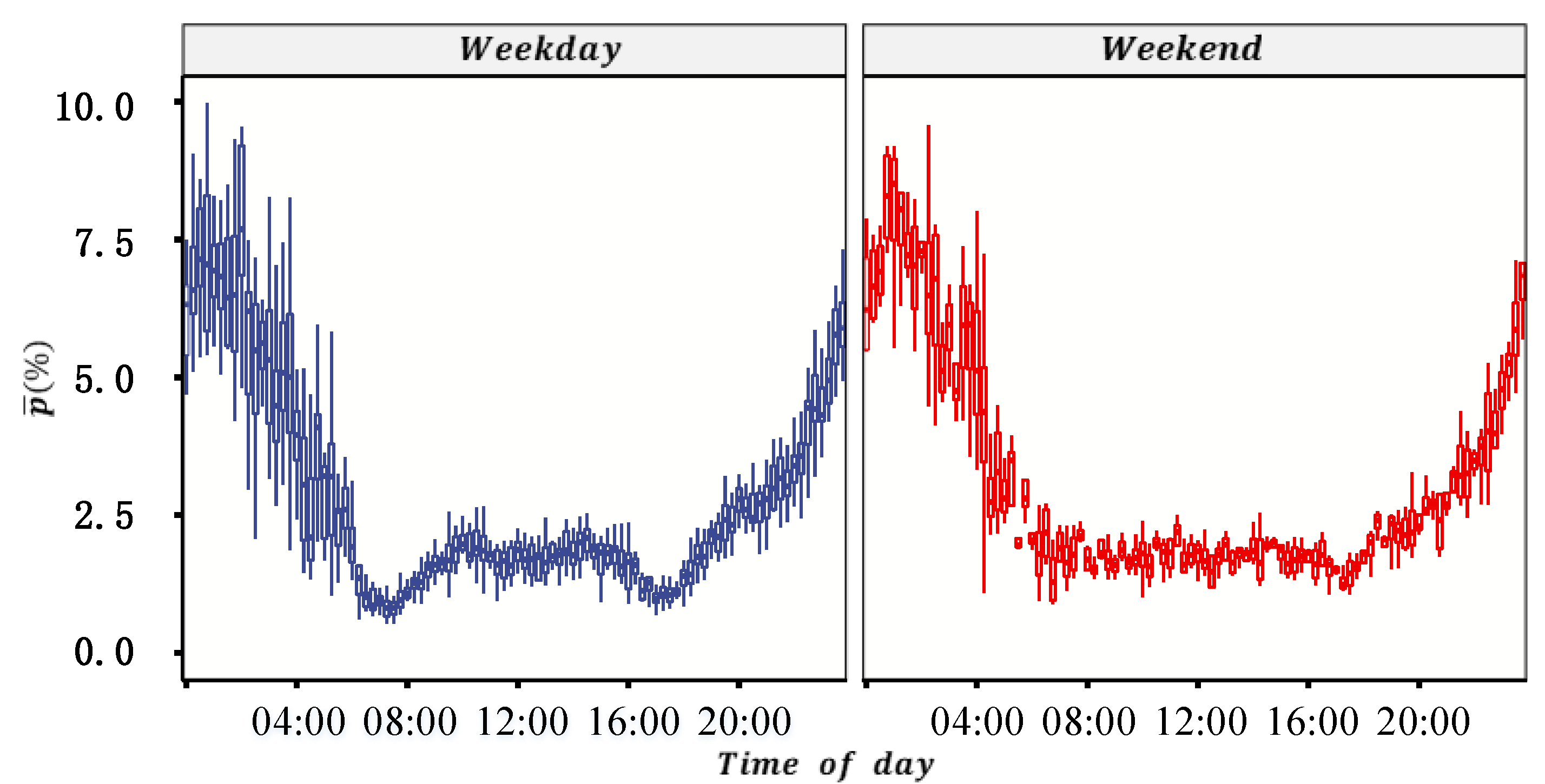
VTD has the advantages of wide spatial coverage and high estimation accuracy of the ATD of the road network, but it also has disadvantages such as a low penetration rate and uneven spatial distribution of probe vehicles. Because of this, firstly, the probe vehicle’s penetration rate of each OD in each period was estimated by the proportion of probe vehicles detected by automatic license plate recognition (ALPR) equipment between each OD. Secondly, the travel time and travel distance of all probe vehicles in each period of each OD in the road network were calculated. Thirdly, the total travel time and total travel distance of all vehicles in each period for the road network were derived from the estimated penetration rate. Finally, the ATD and the ATF of the test site were calculated.
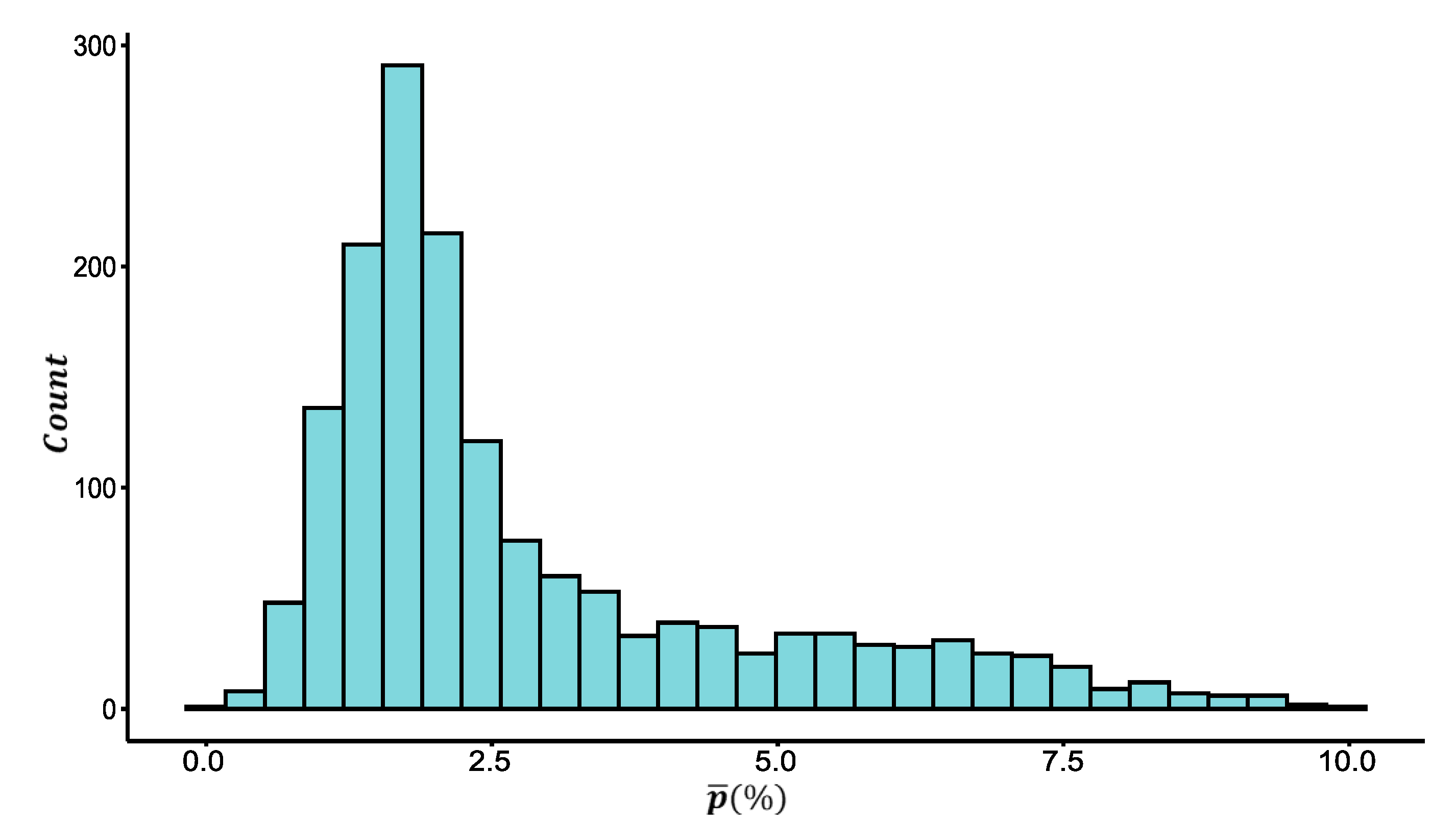
The traffic flow data for a location of a link are collected by fixed vehicle detectors (such as microwave, video, etc.). The ATF derived from the CSD can accurately reflect the traffic flow of a road networks when the spatial coverage of fixed vehicle detectors is sufficient (such as more than 25% in reference [
7]). In view of this, referring to the research of Ortigosa et al. [
7], the basic idea of our study is to use link length as weight, and aggregate the links’ traffic density and traffic flow using the CSD to construct an MFD.
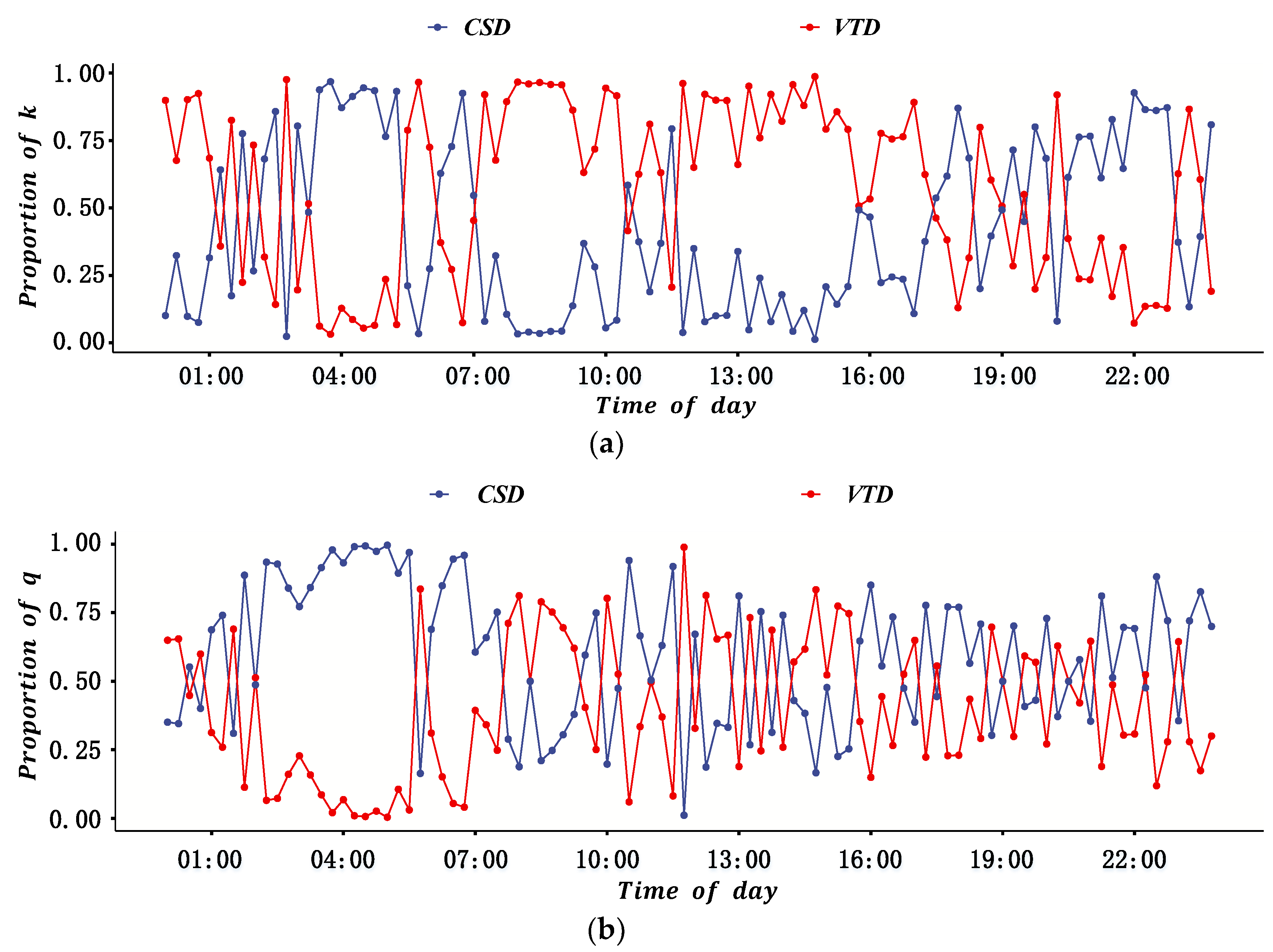
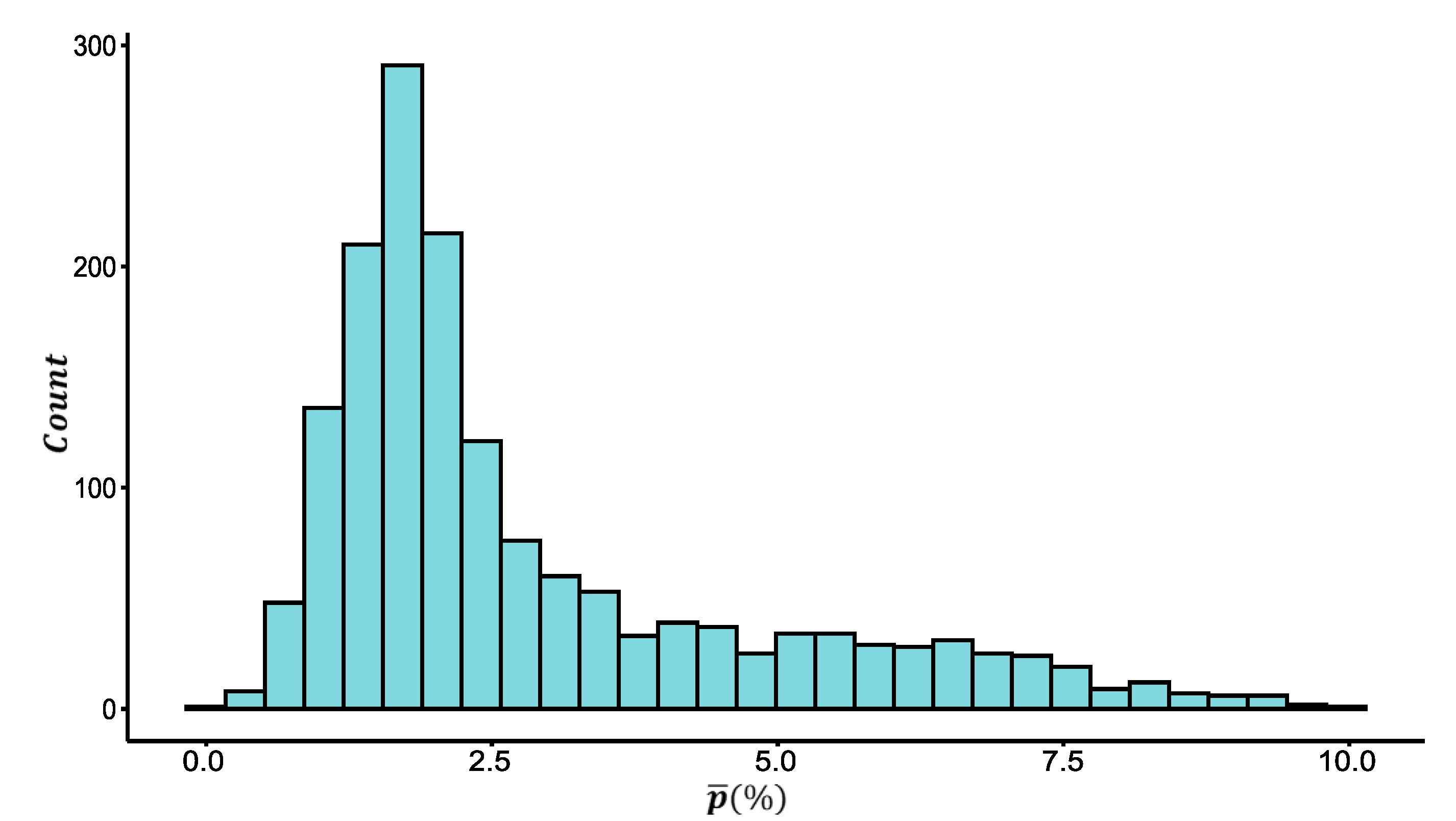
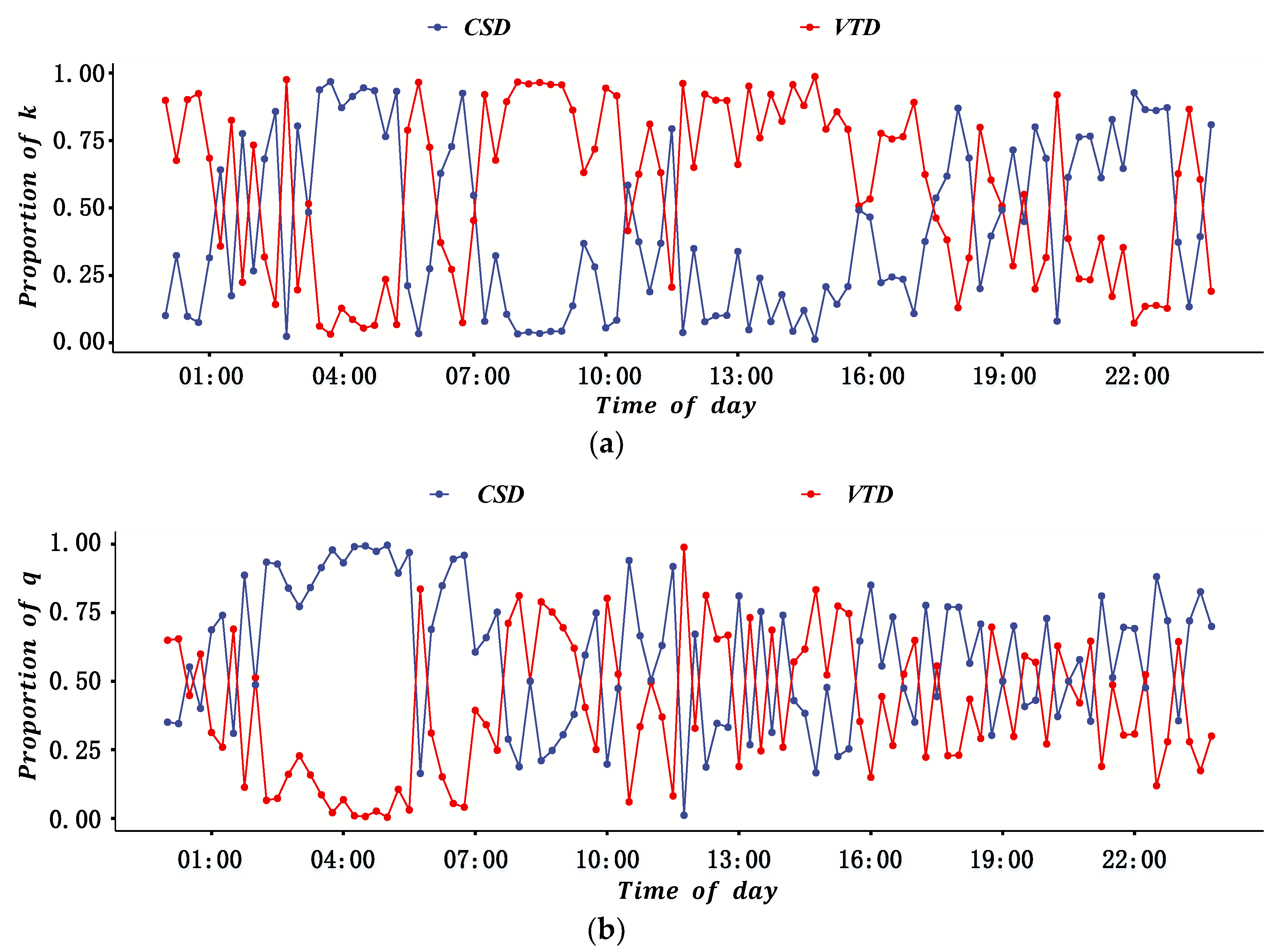
Because of the low penetration rate and disequilibrium spatial distribution of probe vehicles, and the insufficient coverage of fixed vehicle detectors in real road networks, the reliability of the two sources of data in the estimation of ATD and ATF is different. Furthermore, there may be inconsistencies if estimating ATD and ATF with different sources of data. Because of this, it is proposed to quantify the fusion weight of different sources of data by their reliability based on the DS evidence theory, and then construct an MFD with the fusion method. The basic idea to determine the fusion weight is introduced as follows: (1) Establish the recognition framework of the DS evidence model based on estimated ATF and ATD for the two sources of data. (2) Quantify the reliability of each source of data for ATF and ATD based on the means and variances of historical data for multiple days; on this basis, calculate the basic probability distribution and basic trust distribution. (3) Synthesize the evidence and calculate the fusion weight of different sources of data based on the Dempster synthesis rule.
3.1. MFD Construction Using VTD
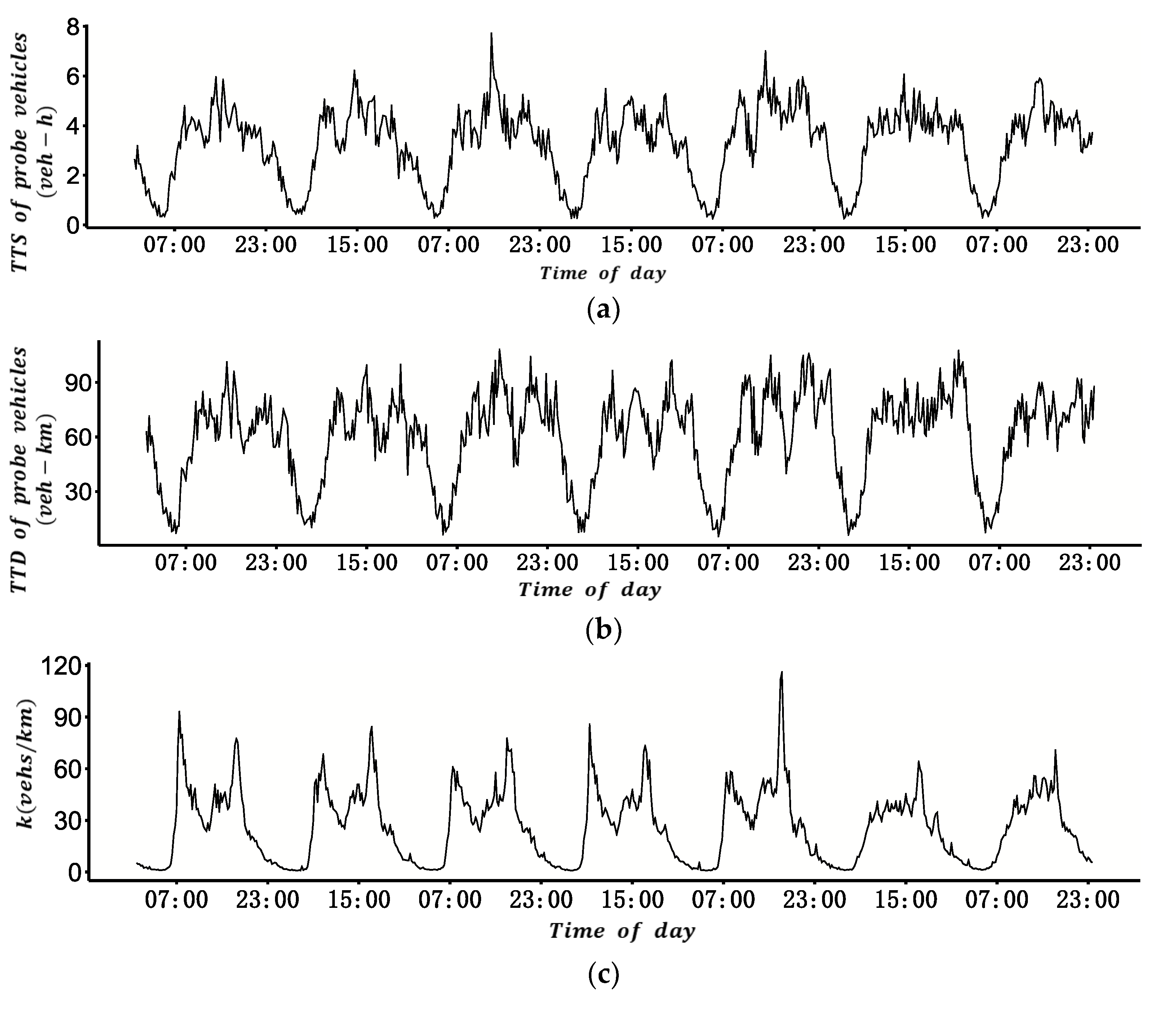
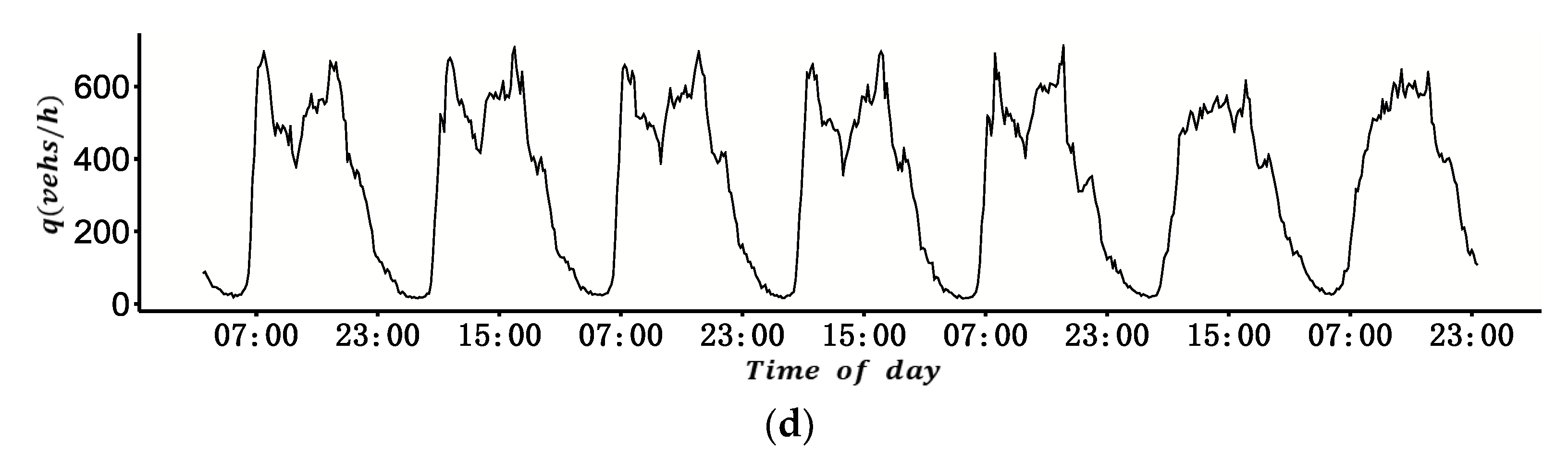
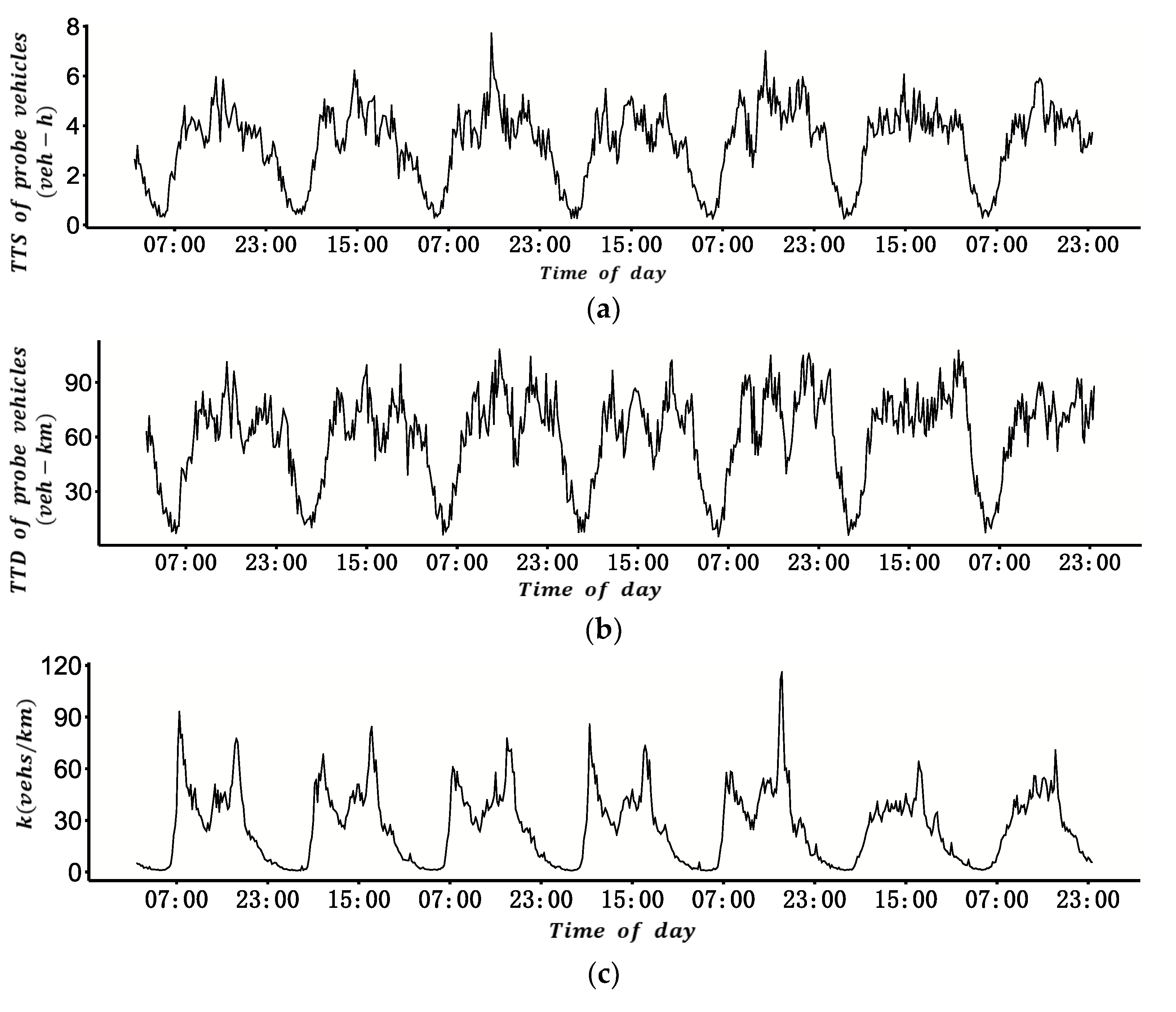
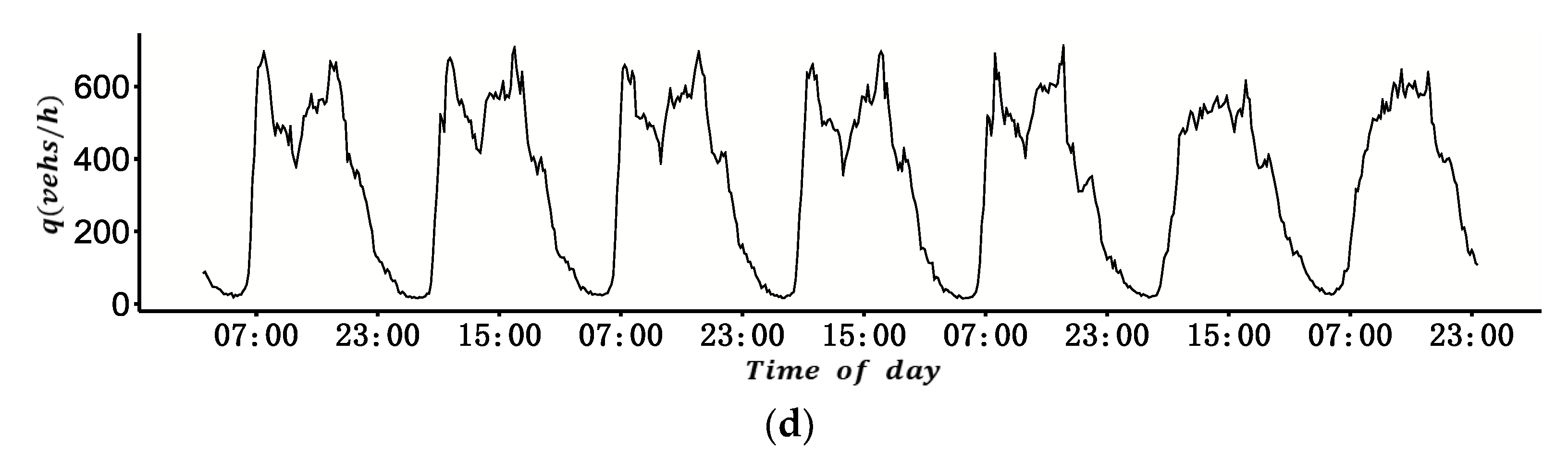
According to Edie’s [
21] definition, the parameters of MFD are ATF and ATD, which are linearly related to total travel distance (TTD) and total travel time spent (TTS) of all vehicles, respectively. The specific definitions are shown as Equations (1) and (2),
where
q (vehs/h) and
k (vehs/km) are ATF and ATD of network traffic, respectively.
(veh-km) and
(veh-h) are total travel distance and total travel time spent of all vehicles during the research period in the test site, respectively; and
(km) is the length of the test site.
is the research period, considering the time-varying characteristics of road network traffic; the research period in this paper is 0.25 h.
To estimate the total vehicle travel time and total vehicle travel distance, MFD construction using VTD assumed that the number of probe vehicles is sufficiently large and the penetration rate was homogeneous in all areas of a road network. However, these assumptions are inconsistent with the actual situation. Taking taxis as an example, their distribution often varies greatly in different ODs, and their trips are usually more frequent in the central business district of a city. Given this, we intend to construct an MFD using VTD considering the difference in the penetration rate of probe vehicles between different ODs. The method involves two key issues: first, estimating different OD penetration rates of probe vehicles, and second, estimating the total travel time and total travel distance of all vehicles with the penetration rate.
For the first issue, the penetration rate was estimated based on the vehicle identity and location information collected by probe vehicles, supplemented by traffic flow data collected by ALPR. Then, the penetration rate was estimated as the proportion of probe vehicles detected by ALPR detectors between different ODs. The estimation method [
14] is shown in Equation (3):
where
and
are the first link (link
) and last link (link
) installed with ALPR detectors that the probe vehicles passed by, respectively;
is the penetration rate of
during period
; and
(vehs) and
(vehs) denote the count of detected probe vehicles and the count of all detected vehicles from ALPR detectors for
during period
.
For ODs without ALPR detectors or probe vehicles, the penetration rate was calculated as the proportion of probe vehicles detected by all ALPR detectors in a road network during period
. The specific method is shown in Equation (4).
where
is the averaged penetration rate for the road network during period
, and
(vehs) and
(vehs) are the counts of probe vehicles and all vehicles detected by ALPR detectors during period
, respectively.
With the estimated penetration rate, the total travel time and total travel distance were derived by the sum of the expanded travel time and travel distance of each OD. According to Edie’s definition 20, the travel time and travel distance were converted into the ATD and ATF, respectively. For example, the network traffic flow during period
is equal to the number of times of all vehicles running on the road network during period
. The specific method is shown in Equations (5) and (6).
where
(vehs/h) and
(vehs/km) represent the ATF and ATD, respectively, based on VTD during period
;
(km) and
(h) denote all probe vehicles’ travel distance and travel time, respectively, of
in the road network during period
; and
and
are the count of the first and last links, respectively, installed with ALPR detectors that the probe vehicles passed by during period
.
3.3. A Fusion Method for MFD Construction Using Multi-Source Data
It is theoretically possible to estimate ATF and ATD of road networks based on VTD or CSD. To accurately estimate MFD, some studies [
10] used different sources of data to estimate different parameters. However, the assumptions for estimating ATF and ATD with different data sources are different. For ATD estimation, it is generally assumed that the probe vehicles’ amount is sufficient and spatial distribution is uniform. For ATF estimation, it is usually assumed that the traffic flow achieved from detectors is representative. Therefore, there may be inconsistencies in the parameters of MFD using different sources of data to estimate different parameters. Considering the different reliability of different data sources, the basic framework of the fusion method for MFD construction under multi-source data is shown in Equations (9) and (10):
where
(vehs/h) and
(vehs/km) denote the ATF and ATD with fusion method in
, respectively. The meanings of
,
, and
are the same as in Equations (5)–(8).
and
are the weight of VTD and CSD for traffic flow estimation in
, respectively.
and
are the weight of VTD and CSD for traffic density estimation in
, respectively.
The core of the fusion method is to determine the weight of the two types of data. The weights were achieved using the ATF, ATD, and their variance distribution (reliability) for different periods during multiple days based on the DS evidence theory [
22]. Taking the estimation of
for ATF in
as an example, the specific process is described as follows.
First, we establish the recognition framework
of the DS evidence inference model based on the two types of data; the specific description is shown as Equation (11):
where
and
denote the estimated weight of CSD and VTD for ATF in
, respectively.
Since
and
come from different sources of data, they can be considered mutually exclusive. Thus, the power set
composed of all elements in
is shown in Equation (12):
where
is the empty set;
is
norm
of , namely, the non-zero element of
; and
are non-empty sub-collections of
,
(vehs/h), and
(vehs/h), respectively. The first two denote the decision of ATF based on CSD and VTD, while
is an uncertain decision, which means it cannot determine the decision between
and
.
Secondly, DS evidence theory involves two important concepts: basic trust distribution (also known as evidence function) and the Dempster evidence synthesis rule. The basic trust distribution is an indicator to quantify the support degree for a certain decision (namely, the evidence of each decision). The evidence synthesis rule is a comprehensive analysis rule of pieces of evidence corresponding to each decision. Let
:
, meaning that the basic trust distribution
is a mapping
, which needs to satisfy the requirements described in Equation (13):
where
is the
-th evidence provided by the
-th type of data, and
is the
-th decision. The meanings of
and
are the same as in Equation (12).
represents the degree of support for the decision
provided by the
-th type of data evidence, which is equal to the basic trust distribution of decision
. The basic trust value of the empty set is 0, and the sum of the trust of the other subset is equal to 1.
The basic trust distribution is determined by the basic probability distribution function
of the decision
under each type of data; the specific method is shown in Equation (14).
where the meaning of
is the same as in Equation (13), and
is the basic probability distribution function of decision
under different types of data.
Assuming that
satisfies
, where
and
represent the mean and variance (
i = 1, 2) of ATF
during period
for the historical data of the
-th type of data,
can be calculated according to Equation (15) [
22]:
where
are the integral intervals to calculate
with given
. Moreover,
,
, and
represent the occurrence probability of decisions
,
, and
, respectively, under the evidence provided by different types of data.
Based on the basic trust assignment
of the decision
, the evidence synthesis is conducted with the basic probability assignments of multiple types of evidence using the Dempster evidence synthesis rule [
22]. The specific method is shown in Equation (16):
where
,
is synthetic trust distribution, and
is the decision provided by the evidence of the
-th type of data.
is the conflict coefficient between evidence provided by different types of data, calculated as
; the closer
is to 0, the greater the degree of conflict between the evidence provided by different data sources is, and when
, the sum under the Dempster evidence synthesis rule does not exist.
Finally, the fusion weight is determined by the synthetic trust distribution; the method to calculate the weight for
is shown in Equation (17):
where, the meaning of
is the same as in Equation (9), and
,
and
represent the synthetic trust distribution of each decision under the evidence provided by each type of data. The abbreviations and variables used in the paper are listed in the Abbreviations.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}