
Research on Real-Time Detection of Safety Harness Wearing of Workshop Personnel Based on YOLOv5 and OpenPose


Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Image Collection of Safety Harness
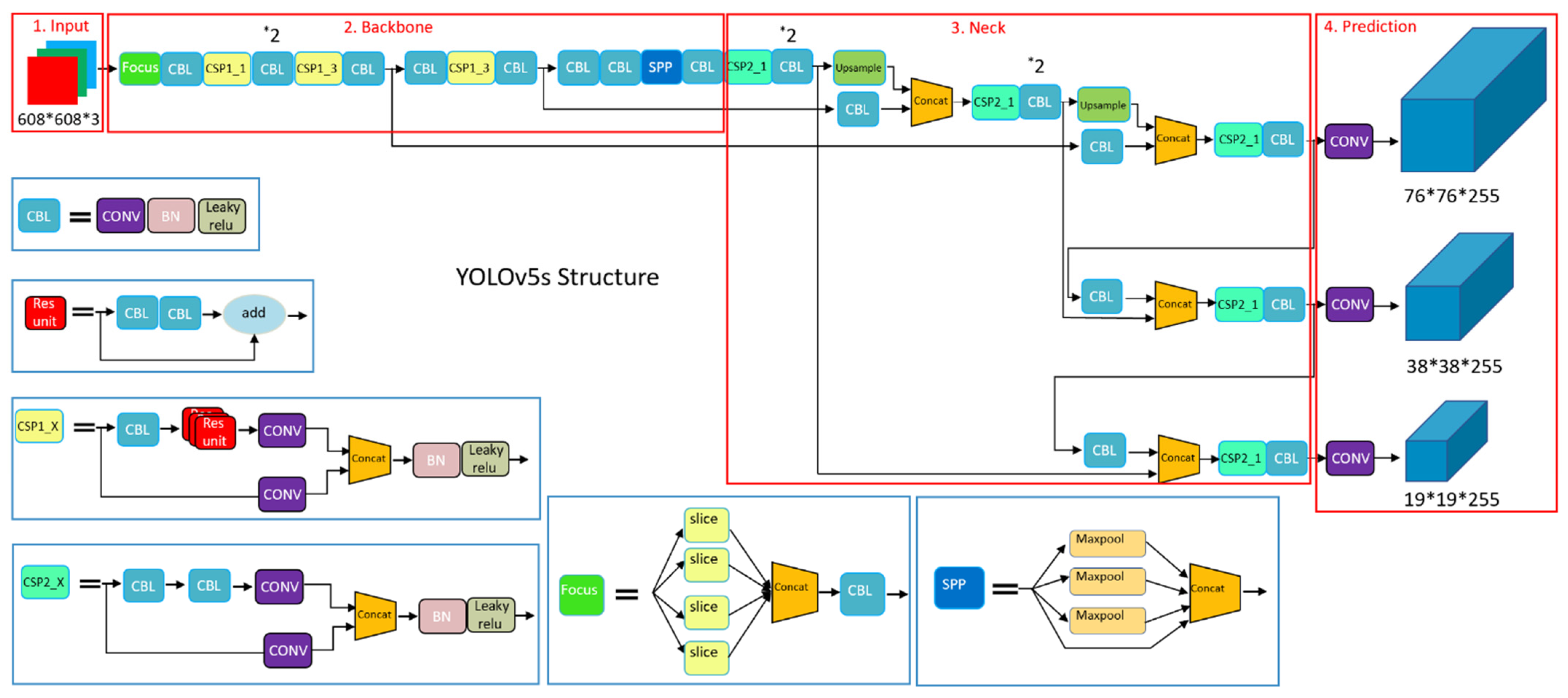
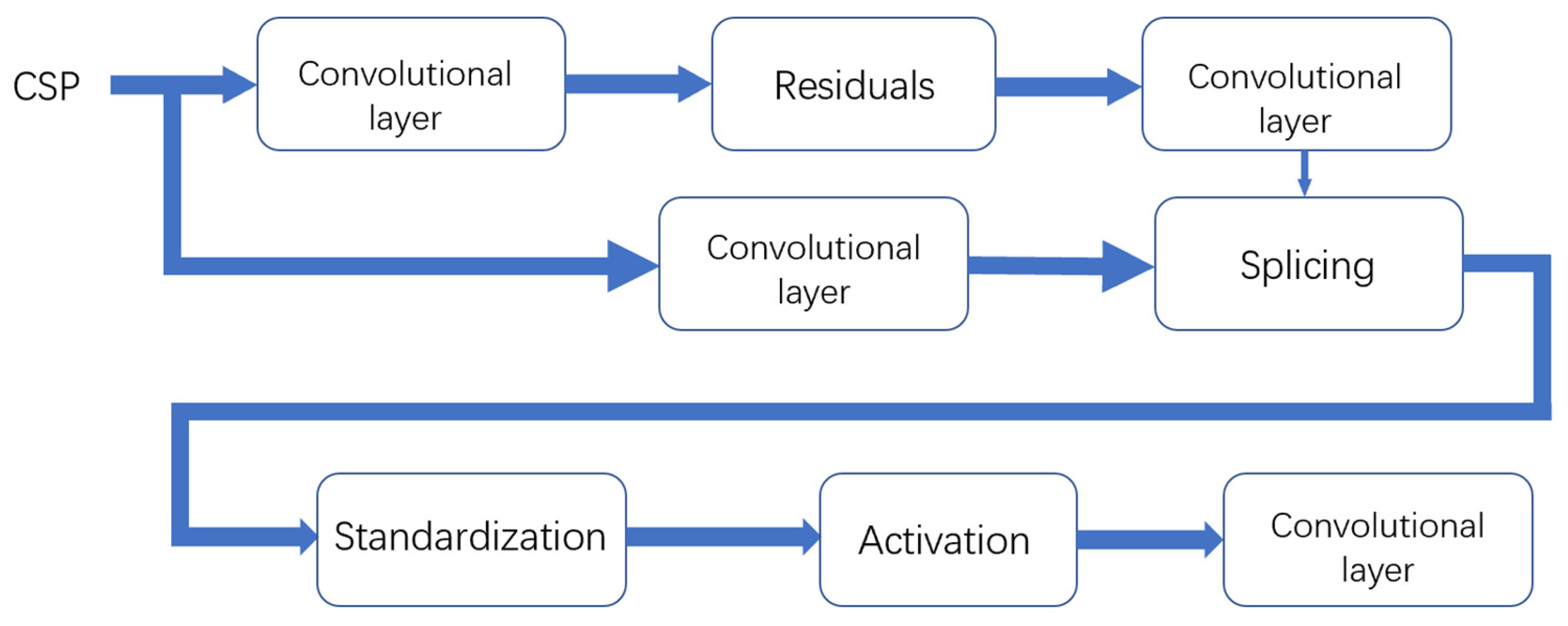
3.2. The Network Structure of YOLOv5
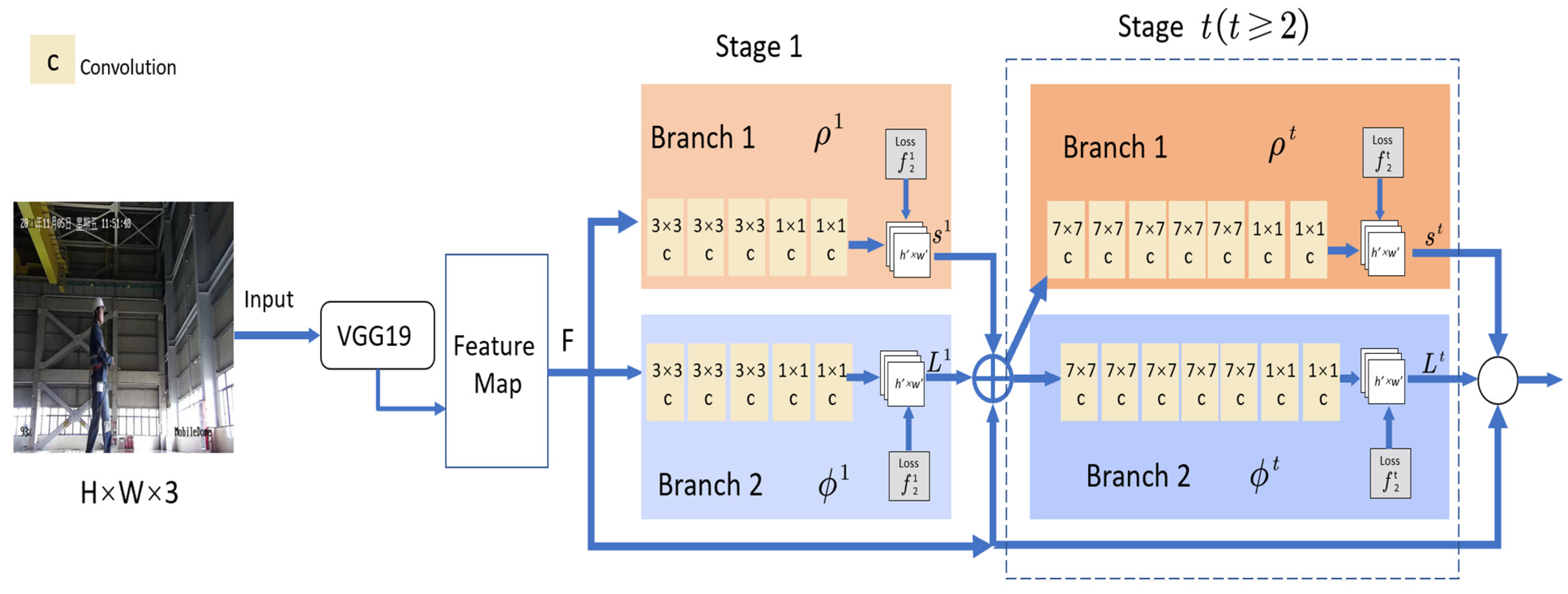
3.3. Acquisition of Information on Key Points of the Human Skeleton
3.4. Criterion for Judging Human Posture
- (1)
- If or , or , , the program determines that the worker’s posture is squatting.
- (2)
- If , , , the program determines that the worker’s posture is bending.
- (3)
- If , , , the program determines that that the worker’s posture is standing.
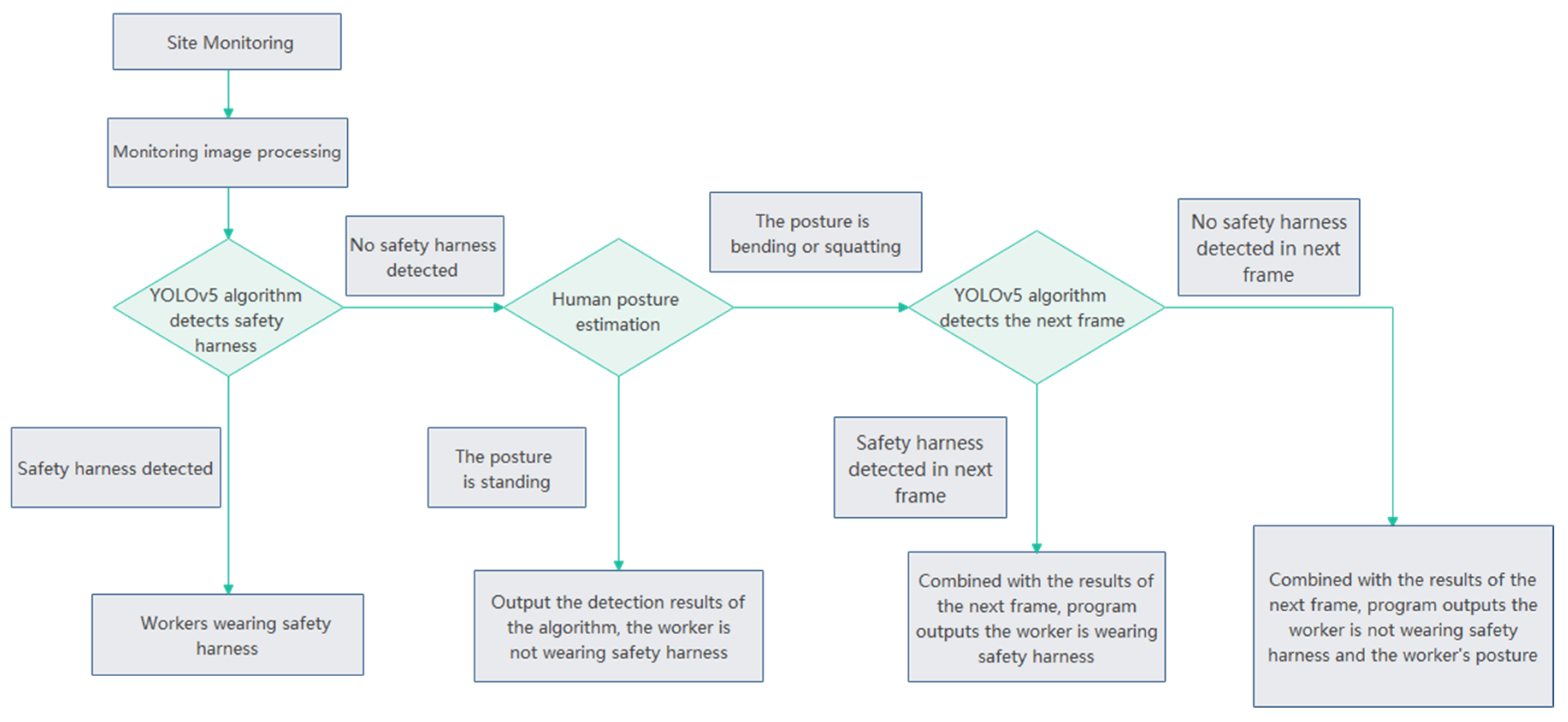
3.5. Program Detection Flow
4. Results and Discussion
4.1. Experimental Environment
4.2. Results and Analysis of Safety Harness Detection
4.3. Human Body Posture Estimation
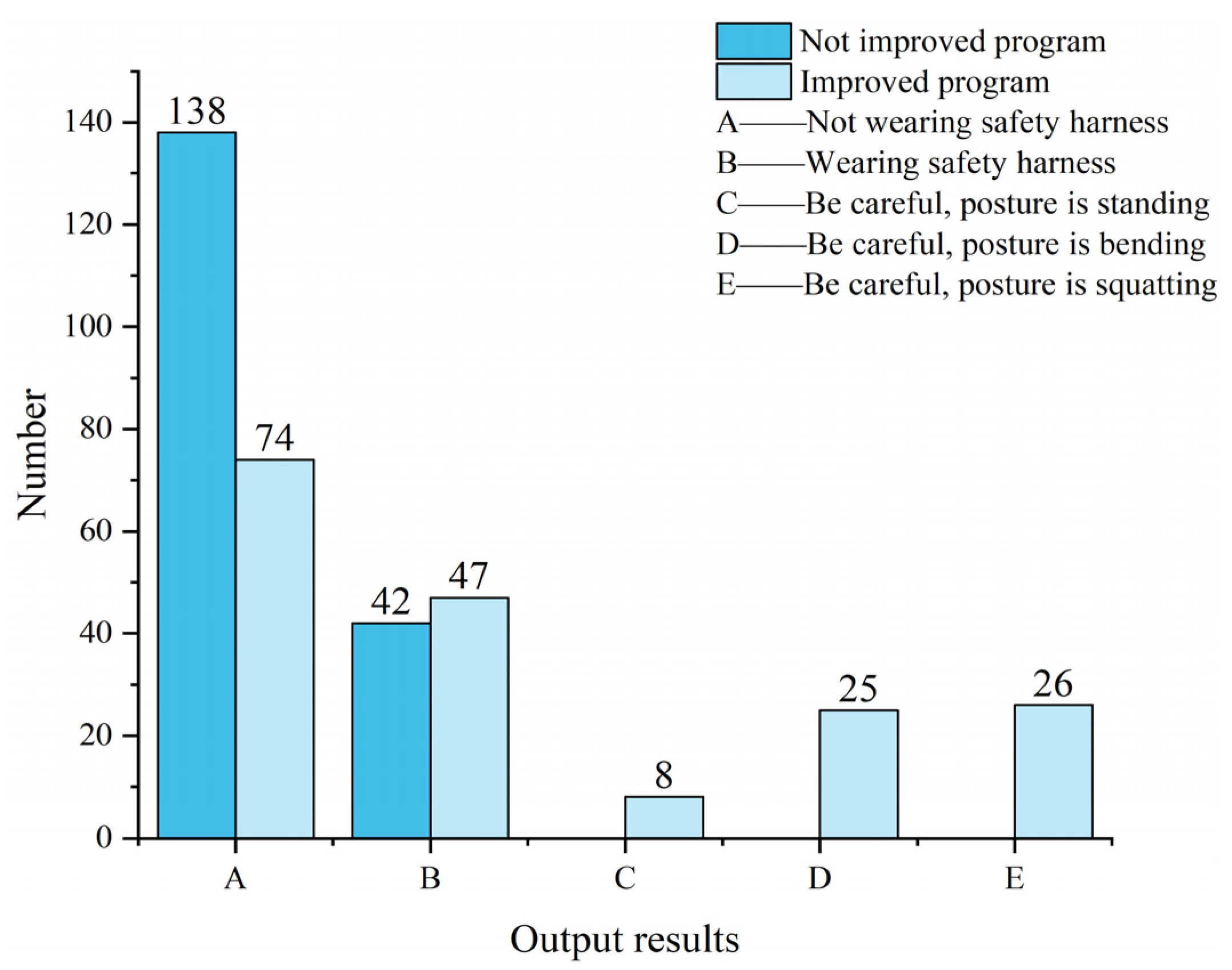
4.4. Detect Safety Harness According to the Program
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, H.; Lin, H.; Zhang, S.; Li, S. Imaged-based seat belt detection. In Proceedings of the 2011 IEEE International Conference on Vehicular Electronics and Safety, Beijing, China, 10–12 July 2011; pp. 161–164. Available online: https://www.researchgate.net/publication/252029744 (accessed on 17 March 2022).
- Feng, Z.; Zhang, W.; Zhen, Z. Mask R-CNN based aerial work harness detection. Comput. Syst. Appl. 2021, 30, 202–207. [Google Scholar] [CrossRef]
- Ghods, A.; Cook, D.J. A survey of deep network techniques all classifiers can adopt. Data Min. Knowl. Discov. 2020, 35, 46–87. [Google Scholar] [CrossRef] [PubMed]
- Fu, C. Research on Seat Belt Detection Method Based on Deep Learning. Master’s Thesis, Huazhong University of Science and Technology, Wuhan, China, 2015. [Google Scholar]
- Jin, Y.; Wu, X.; Dong, H.; Yu, L.; Zhang, L. Helmet wearing detection algorithm based on improved YOLOv4. Comput. Sci. 2021, 48, 268–275. [Google Scholar]
- Wang, Y.; Gu, Y.; Feng, X.; Fu, X.; Zhuang, L.; Xu, S. Research on helmet wearing detection method based on pose estimation. Comput. Appl. Res. 2021, 38, 937–940. [Google Scholar] [CrossRef]
- Tan, L.; Lu, J.; Zhang, X.; Liu, Y.; Zhang, R. Improved gesture interaction system for phantom machines based on lightweight OpenPose. Comput. Eng. Appl. 2021, 57, 159–166. [Google Scholar]
- Wang, Y.; Cao, T.; Cao, T.; Yang, J.; Zheng, Y.; Fang, Z.; Deng, X.; Wu, J.; Lin, J. Research on camouflage target detection technology based on YOLOv5 algorithm. Comput. Sci. 2021, 48, 226–232. [Google Scholar]
- Hao, X.; Meng, X.; Zhang, Y.; Xue, J.; Xia, J. Conveyor Belt Detection Based on Deep Convolution GANs. Intell. Autom. Soft Comput. 2021, 29, 601–613. Available online: http://www.techscience.com/iasc/v30n2/44027 (accessed on 15 March 2022). [CrossRef]
- Wu, J. Research on Visual Inspection for Safety Protection of Construction Site Personnel. Master’s Thesis, Guangdong University of Technology, Gaungzhou, China, 2020. [Google Scholar] [CrossRef]
- Wu, L.; Cai, N.; Liu, Z.; Yuan, A.; Wang, H. A one-stage deep learning framework for automatic detection of safety harnesses in high-altitude operations. Signal Image Video Process. 2022, 4, 15. [Google Scholar] [CrossRef]
- Fang, W.; Ding, L.; Luo, H.; Love, P.E.D. Falls from heights: A computer vision-based approach for safety harness detection. Autom. Constr. 2018, 91, 53–61. Available online: https://www.sciencedirect.com/science/article/pii/S0926580517308403 (accessed on 15 March 2022). [CrossRef]
- Liu, C.; Wu, Y.; Liu, J.; Sun, Z.; Xu, H. Insulator Faults Detection in Aerial Images from High-Voltage Transmission Lines Based on Deep Learning Model. Appl. Sci. 2021, 11, 4647. Available online: https://www.mdpi.com/2076-3417/11/10/4647 (accessed on 16 March 2022). [CrossRef]
- Adibhatla, V.A.; Chih, H.-C.; Hsu, C.-C.; Cheng, J.; Abbod, M.F.; Shieh, J.-S. Applying deep learning to defect detection in printed circuit boards via a newest model of you-only-look-once. Math. Biosci. Eng. 2021, 18, 4411–4428. [Google Scholar] [CrossRef] [PubMed]
- Ren, P.; Wang, L.; Fang, W.; Song, S.; Djahel, S. A novel squeeze YOLO-based real-time people counting approach. Int. J. Bio-Inspired Comput. 2020, 16, 94. [Google Scholar] [CrossRef]
- Zago, M.; Luzzago, M.; Marangoni, T.; De Cecco, M.; Tarabini, M.; Galli, M. 3D Tracking of Human Motion Using Visual Skeletonization and Stereoscopic Vision. Front. Bioeng. Biotechnol. 2020, 8, 181. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Huang, G.; Yu, M.; Guo, Y. Fall prediction based on key points of human bones. Phys. A Stat. Mech. Its Appl. 2020, 540, 123205. Available online: https://www.sciencedirect.com/science/article/pii/S0378437119318011 (accessed on 5 March 2022). [CrossRef]
- Chen, W.; Jiang, Z.; Guo, H.; Ni, X. Fall Detection Based on Key Points of Human-Skeleton Using OpenPose. Symmetry 2020, 12, 744. [Google Scholar] [CrossRef]
- Liu, C.; Wu, Y.; Liu, J.; Han, J. MTI-YOLO: A Light-Weight and Real-Time Deep Neural Network for Insulator Detection in Complex Aerial Images. Energies 2021, 14, 1426. [Google Scholar] [CrossRef]
- Li, N.; Wang, X.; Fu, Y.; Zheng, F.; He, D.; Yuan, S. A traffic police target detection method with optimized YOLO model. J. Graph. 2022, 1, 11. [Google Scholar]
- Lu, J.; Lu, Z.; Zhan, T.; Dai, Y.; Wang, P. Dog face detection algorithm based on YOLO and deep residual hybrid network. Comput. Appl. Softw. 2021, 38, 140–145. [Google Scholar] [CrossRef]
- He, Y.; Li, H. Mask wearing recognition in complex scenes based on improved YOLOv5 model. Microprocessor 2022, 43, 42–46. [Google Scholar]
- Wu, W.; Liu, H.; Li, L.; Long, Y.; Wang, X.; Wang, Z.; Li, J.; Chang, Y. Application of local fully Convolutional Neural Network combined with YOLOv5 algorithm in small target detection of remote sensing image. PLoS ONE 2021, 16, e0259283. [Google Scholar] [CrossRef]
- Palucci Vieira, L.H.; Santiago, P.R.P.; Pinto, A.; Aquino, R.; Torres, R.d.S.; Barbieri, F.A. Automatic Markerless Motion Detector Method against Traditional Digitisation for 3-Dimensional Movement Kinematic Analysis of Ball Kicking in Soccer Field Context. Int. J. Environ. Res. Public Health 2022, 19, 1179. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.-Y.; Liao, H.-Y.M.; Yeh, I.-H.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A New Backbone that can Enhance Learning Capablity of CNN. In Proceedings of the IEEE|CVF Conference on Computer Vision and Pattern Recognition Workshops(CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Guo, K.; He, C.; Yang, M.; Wang, S. A pavement distresses identification method optimized for YOLOv5s. Sci. Rep. 2022, 12, 3542. [Google Scholar] [CrossRef]
- Wu, S.; Yang, J.; Wang, X.; Li, X. IoU-Balanced Loss Functions for Single-stage Object Detection. arXiv 2019, arXiv:abs/1908.05641. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE|CVF Conference on Computer Vision and Pattern Recognition(CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Nakano, N.; Sakura, T.; Ueda, K.; Omura, L.; Kimura, A.; Iino, Y.; Fukashiro, S.; Yoshioka, S. Evaluation of 3D Markerless Motion Capture Accuracy Using OpenPose With Multiple Video Cameras. Front. Sports Act. Living 2020, 2. [Google Scholar] [CrossRef] [PubMed]
- Su, C.; Wang, G. A study of student behavior recognition based on improved OpenPose. Comput. Appl. Res. 2021, 38, 3183–3188. [Google Scholar] [CrossRef]
- Fu, N.; Liu, D.; Cheng, X.; Jing, Y.; Zhang, X. Fall detection algorithm based on lightweight OpenPose model. Sens. Microsyst. 2021, 40, 131–134. [Google Scholar] [CrossRef]
- Lin, C.-B.; Dong, Z.; Kuan, W.-K.; Huang, Y.-F. A Framework for Fall Detection Based on OpenPose Skeleton and LSTM/GRU Models. Appl. Sci. 2020, 11, 329. [Google Scholar] [CrossRef]
- Wang, T.C.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y.; Shao, L. Learning rich features at high-speed for single-shot object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1971–1980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Human Posture | Feature Distance of Y-Direction | Feature Angle |
|---|---|---|
| Standing | 1-8, 8-10 | 1-8-9 |
| Bending | 1-8, 8-10 | 1-8-9 |
| Squatting | 1-8, 8-10 | 8-9-10 |
| Posture | Threshold Value | Threshold Value |
|---|---|---|
| Standing | ||
| Bending | ||
| Squatting |
| Accuracy | Speed of Processing an Image | |
|---|---|---|
| Reference No.2 | 98% | 4 s |
| YOLOv5 | 89% | 0.018 s |
| Posture | Program Output Results | Number of Detected Images |
|---|---|---|
| Standing | The human body posture is standing | 30 |
| Bending | The human body posture is bending | 50 |
| Squatting | The human body posture is squatting | 50 |
| Accuracy | False Alarm Rate | Specificity | |
|---|---|---|---|
| Not improved program | 56.7% | 56.5% | 43.5% |
| Improved program | 92.2% | 18.9% | 81.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, C.; Xiang, H.; Leng, C.; Chen, J.; Yu, Q. Research on Real-Time Detection of Safety Harness Wearing of Workshop Personnel Based on YOLOv5 and OpenPose. Sustainability 2022, 14, 5872. https://doi.org/10.3390/su14105872
Fang C, Xiang H, Leng C, Chen J, Yu Q. Research on Real-Time Detection of Safety Harness Wearing of Workshop Personnel Based on YOLOv5 and OpenPose. Sustainability. 2022; 14(10):5872. https://doi.org/10.3390/su14105872
Chicago/Turabian StyleFang, Chengle, Huiyu Xiang, Chongjie Leng, Jiayue Chen, and Qian Yu. 2022. "Research on Real-Time Detection of Safety Harness Wearing of Workshop Personnel Based on YOLOv5 and OpenPose" Sustainability 14, no. 10: 5872. https://doi.org/10.3390/su14105872
APA StyleFang, C., Xiang, H., Leng, C., Chen, J., & Yu, Q. (2022). Research on Real-Time Detection of Safety Harness Wearing of Workshop Personnel Based on YOLOv5 and OpenPose. Sustainability, 14(10), 5872. https://doi.org/10.3390/su14105872