The literature review is divided into two parts. We first provide an overview of the work on Sentiment Analysis which is closest to our interests, whereas in the second part we focus on the use of social media for research in the transport domain.
2.1. Sentiment Analysis
The Opinion Mining and Sentiment Analysis fields have seen, in the last 20 years, a huge increase in popularity to automatically determining opinion trends and attitudes about commercial products, companies reputation management, brand monitoring, or to track attitudes by mining social media, etc. These techniques have been particularly useful in addressing the explosion of information produced and shared via the Internet, especially in social media, which means that it is simply not possible to keep up with the constant flow of new information exclusively using manual methods.
Most popular approaches are based on document classification, where the task is to determine the polarity (positive, negative, neutral) of a given document or review similar to Examples (1) and (2) shown above. Well known benchmarks for polarity classification at document level include the Movie Reviews Corpus [
27,
28], the Large Movie Review Dataset [
29], and the Stanford Sentiment Treebank (SST) [
30], although many other corpora and resources have since been developed for many languages and domains [
19,
22,
31].
It should be noted that there is a large body of work also on finer-grained Sentiment Analysis [
31,
32]. This was mostly motivated by the fact that a single review may contain more than one opinion about a variety of aspects or attributes of a given product or topic. Thus, Aspect Based Sentiment Analysis (ABSA) was defined as a task consisting of identifying the following components: the opinion holder, the target, the opinion expression (the textual expression conveying polarity), and the aspects. Aspects are mostly domain-dependent and refer to relevant aspects pertaining to the specific domain. For example, in restaurant reviews relevant aspects would include
food quality,
price,
service, etc. Similarly, if our domain would be that of consumer electronics such as laptops, then relevant aspects would be those referring to
weight,
battery life,
hard drive capacity, etc.
While performing Aspect Based Sentiment Analysis might certainly be of interest for the transport domain, in this paper we focus on presenting the first publicly available dataset to assess transport sustainability in terms Sentiment Analysis at document or review level, leaving the fine-grained aspects for future work.
The techniques most often used to perform sentiment analysis classification at document level can be largely classified into two main approaches: unsupervised methods based on sentiment lexicons and supervised methods which learn classifiers from labeled corpora.
With respect to lexicon-based methods, Sentiment Analysis often relies on the availability of words and phrases annotated according to the positive or negative connotations they express. Thus, words such as
beautiful, and
wonderful would indicate a positive polarity, whereas words such as
bad or
poor refer to a negative polarity. The generation of annotated lists of sentiment words has been addressed by
manual-,
corpus- and
dictionary-based methods. Manually collecting such polarity lexicons is labor intensive and time consuming, and it is usually combined with automated approaches. However, there are very popular sentiment lexicons which have been fully [
33,
34] or at least partially manually created [
35,
36].
Corpus-based methods are mostly used to generate domain-specific polarity lexicons. They are usually built by trying to find related words in a given corpus taking a list of seed words as starting point [
37,
38].
Dictionary-based methods often rely on a lexical knowledge base (LKB) such as WordNet [
39] that contains synonyms and antonyms for each word. Thus, a common technique is to start with some sentiment words as seeds which are taken as the starting point to perform some iterative propagation on the LKB [
40,
41]. Among these, SentiWordNet (SWN) [
20] is perhaps the most commonly used opinion lexicon based on WordNet [
39], although other approaches have shown better performance on intrinsic [
42] and extrinsic [
22] evaluations. WordNet is a lexical resource in which the lexical entries are sets of words that express the same concept, namely, a synset. SWN assigns to each synset in WordNet three scores (positive, negative, and objective) which are normalized to be equal to 1.0, although most previous works that use SentiWordNet calculate aggregate polarity values at word or lemma level from the corresponding synsets [
22,
34].
With respect to supervised approaches, it is possible distinguish between those based on manually-engineered features to train supervised classifiers (classic machine-learning) and recent deep-learning and neural-based approaches.
Overall, most classic machine learning methods employ bag-of-words representations together with manually engineered features based on local information such as n-grams, orthographic features, etc. but also on external information such as morphological tags or polarity features obtained from sentiment lexicons [
19,
27,
29,
31]. The most common machine learning algorithms within this tradition include Naive Bayes, Maximum Entropy [
43] and Support Vector Machines [
44], among others [
45]. Although they are nowadays usually outperformed by deep-learning systems, these methods are still very competitive and much faster and cheaper to run. As a downside, these systems depend on manually coded features.
Recursive neural networks (RNNs) and, more specifically, various variations of Bidirectional Long-Short Term Memory (BiLSTM) networks initialized with vector-based word representations [
46,
47] helped to improve state-of-the-art results on usual Sentiment Analysis datasets, such as SST [
30], which is included in the GLUE benchmark [
48], although many other BiLSTM-based approaches exist [
49,
50,
51].
Current best performing systems for Sentiment Analysis at document level are based on large pretrained language models [
21,
25]. These language models generate rich representations of text based on contextual word embeddings. Instead of generating static word embeddings [
46,
47], namely, unique representations for a given word regardless of the context, the idea is to be able to generate word representations according to the context in which the word occurs. Currently there are many approaches to generate such contextual word representations, but we will focus on those that have had a direct impact in text classification, namely, the models based on the transformer architecture [
52] and of which BERT is perhaps the most popular example [
25].
There are also several multilingual versions of these models. Thus, the multilingual version of BERT [
25] was trained for 104 languages. More recently, XLM-RoBERTa [
21] distributes a multilingual model which contains 100 languages trained on 2.5 TB of filtered Common Crawl text. To put results into perspective, results of BiLSTM based systems are around 90% word accuracy on the SST dataset included in GLUE. These results were hugely improved by the English BERT Large model (94.9 word accuracy) and by XLM-RoBERTa (95%). These results have been further improved by various ensembles of Transformer-based language models (Results and approaches can be found in the GLUE website:
https://gluebenchmark.com, accessed on 7 October 2020).
2.2. Social Media Analysis in the Urban Transport Area
The field of research on modes of transportation has attracted the interest of researchers who already used social, demographic, and sentiment analysis techniques.
Seliverstov et al. [
53] developed a method of automatic review classification based on a sentiment classifier to analyze traffic safety in Russia, according to the reviews published in different transport Internet resources, such as websites that contain new and constantly updating reviews of road conditions, Twitter channels, and VK communities. They used the Naïve Bayes algorithm and a linear classifier model with stochastic gradient descent optimization and obtained a classification accuracy of 71.94%. Ali et al. [
54] propose an ontology and Latent Dirichlet allocation (OLDA)-based topic modeling and word embedding approach for sentiment classification. The proposed approach offers a text classification system that identifies the most relevant transportation texts in social media and analyses them to examine traffic control management and transportation services. It integrates lexicons into a pretrained word embedding model that increases the accuracy of sentiment classification, obtaining 90% accuracy and 88% F1-score.
Serna et al.’s research [
17] focuses on one of the most sustainable transport modes, the bicycle. A statistical model that assesses the connection between public bike share (PBS) use and certain characteristics of the PBS systems is proposed. Their system includes sociodemographic, climate, and positive and negative opinion data (based on SentiWordNet) extracted from social media comments (Facebook, Twitter, and TripAdvisor). In previous works, Serna et al. [
15,
16] demonstrate empirically the feasibility of the automatic identification of the Sustainable Urban Mobility problems by leveraging the SUMO ontology and SentiWordNet in several social media, such as, Minube [
15] and TripAdvisor Traveller Social Network [
16], for two languages (English and Spanish).
Previously, Ruiz Sánchez et al. [
55] propose to collect high quality data from social media that may be used for Transport Planning. Furthermore, Grant-Muller et al. [
13] demonstrate that User Generated Content can complement, improve, and even replace conventional data. They also stress the need to develop automated methods to gather and analyze transport-related data from social media.
Gitto and Mancuso [
56] use sentiment analysis to extract information from blogs with the objective of measuring the level of customer satisfaction on various airports using various software services: KNIME (
https://www.knime.com/, accessed on 7 October 2020), designed for the analysis of web forums and social networks, and Semantria (
https://www.lexalytics.com/semantria, accessed on 7 October 2020).
Twitter data has also gained the interest of researchers. Effendy et al. [
57] use a trained SVM for sentiment analysis to determine which factors are the main cause of the ineligibility and eligibility of public transport use. Their model scores 78.12% in word accuracy. Anastasia and Budi [
58] aim to measure customer satisfaction for online transportation services providers through sentiment analysis of Twitter data using three algorithms, namely Naïve Bayes, SVM, and Decision Trees. In addition, they manually preprocess the tweets and label them, obtaining a sentiment score that correlates with client satisfaction.
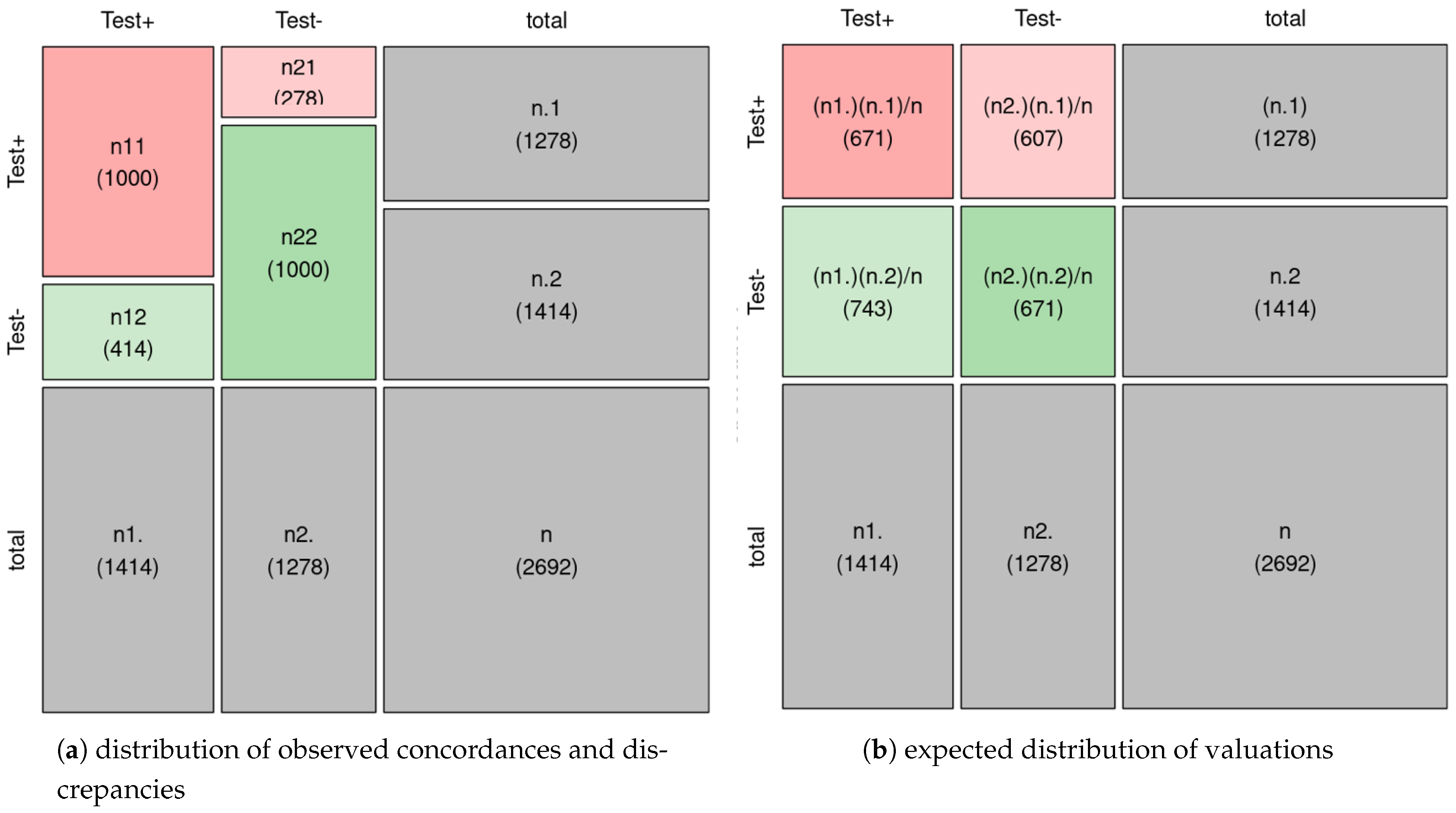
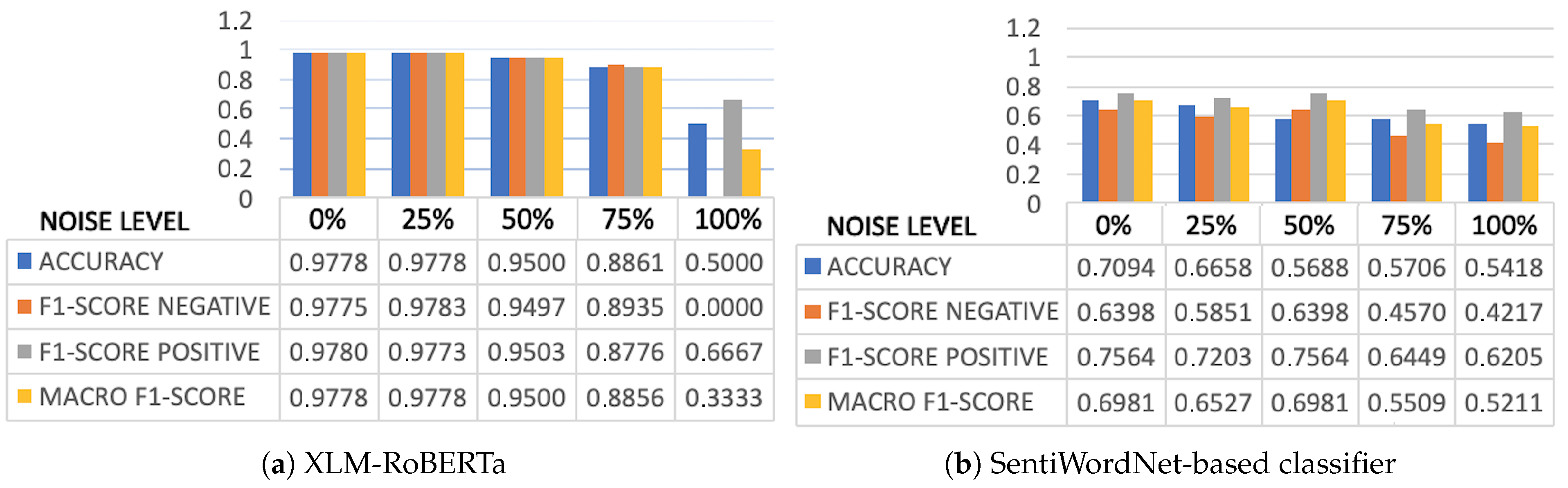
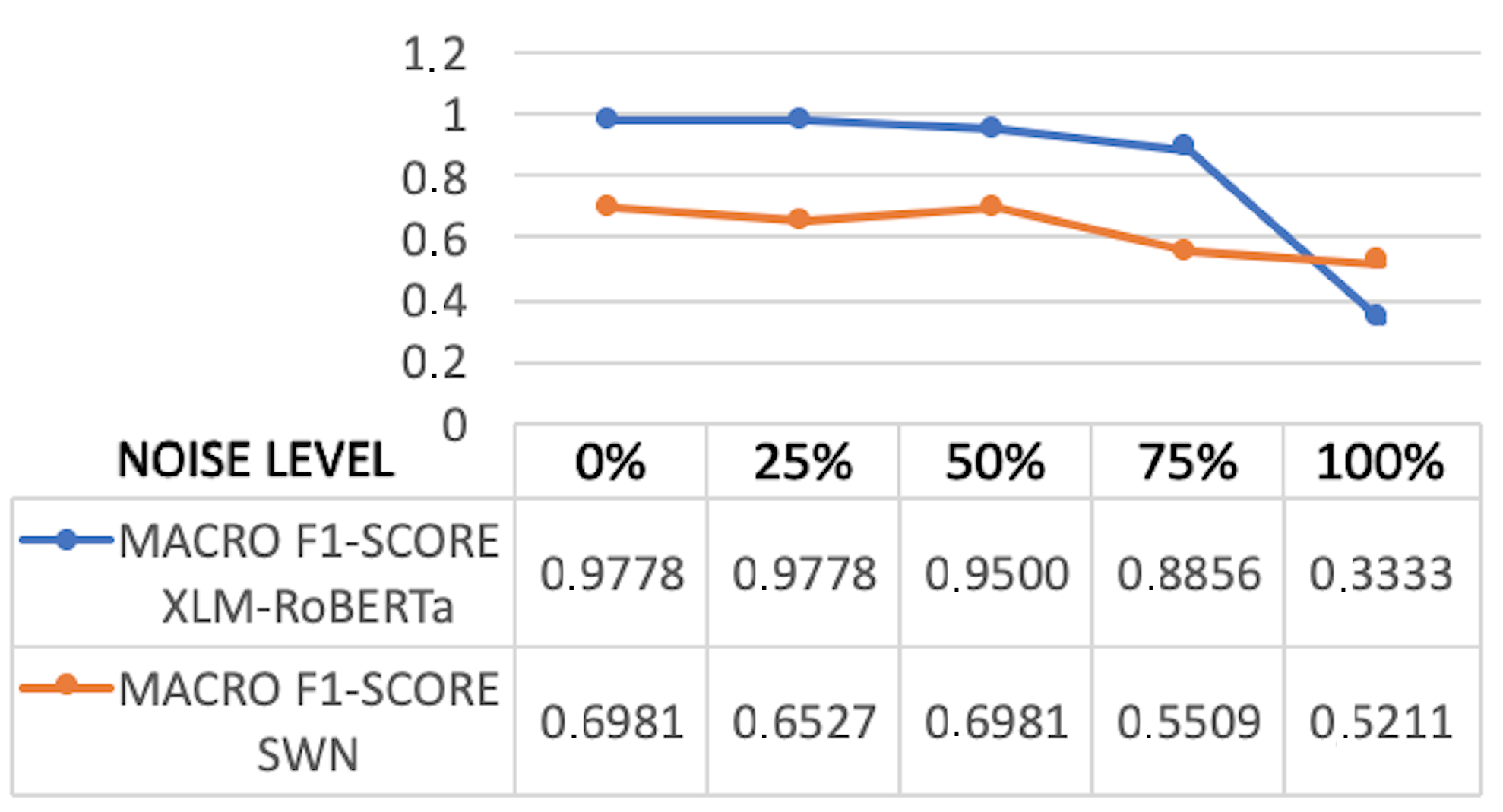
Summarizing, both supervised techniques and lexicon-based methods have been used for analyzing opinions about modes of transportation automatically. However, as far as we know no previous approach exists that has experimented with the latest advances in NLP, such as the Transformer models. Furthermore, previous works did not make the datasets used in their research available, which means that we cannot compare our approach with respect to the state of the art. In order to address this issue, we will generate a new dataset for Sentiment Analysis in the transport domain which we will then use to evaluate the robustness of an unsupervised method based on the SentiWordNet lexicon with respect to the supervised classifiers obtained by fine-tuning XLM-RoBERTa.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}