1. Introduction
The Jupyter notebook (previously known as IPython Notebook) is an open-source tool where users have an interactive programming environment for scientific computing, which allows writing code, text, equations, and multimedia resources [
1]. Due to its increasing usage, it has become the preferred computational notebook in many areas, such as: machine learning, artificial intelligence, data science, among others [
2,
3]. Jupyter notebooks have been recently used as a teaching and learning supporting tool in academic institutions, such as: Universidad Complutense de Madrid [
4], BVB College of Engineering and Technology [
5] and at the University of Illinois at Urbana-Champaign [
6]. They have been used for teaching in different areas like radiology [
7], geography [
8], geology [
9], among others [
10]. Jupyter notebooks have also had a remarkable adoption in engineering and computer science courses [
6,
11]. In addition to their convenience as an interactive handout tool, Jupyter notebooks are used as a mechanism for assigning and collecting homework [
12]. Usually, instructors provide Jupyter Notebooks templates to the students to guide them towards the expected solution, like in the course
Introduction to Data Science at the University of Illinois at Urbana-Champaign [
6]. However, assessing and grading programming activities in a manual way is a tedious and time-consuming task [
13], which may lead to assessment errors and biased grades [
14].
Automatic grading tools for programming activities have been mostly used for competitive programming competitions, like the ICPC (International Collegiate Programming Contest |
https://icpc.global, accessed on: 29 October 2021) or
Codeforces (
http://codeforces.com, accessed on: 29 October 2021). For teaching purposes, many automatic grading tools have been developed, such as: Check50 [
15], Flexible Dynamic Analyzer (FDA) [
16], among others [
17]. However, these tools do not provide automatic grading capabilities for Jupyter notebooks. As a response to the lack of automatic grading tools for Jupyter Notebooks,
nbgrader has been developed by the Jupyter team since 2014 [
18]. It has been widely used by the academic community; by 2018, more than 10,000 notebooks using
nbgrader were located on GitHub and implemented in several universities. For instance, it is used in [
11,
19,
20]. Nevertheless, using
nbgrader requires deploying the JupyterHub server (
https://jupyter.org/hub, accessed on: 29 October 2021) to properly deliver assignments and collect submissions. Other approaches for automatic grading of notebook-based activities include:
OK (
https://okpy.org, accessed on: 29 October 2021), which has been used in Sridhara et al. [
21];
Otter-Grader (
https://otter-grader.readthedocs.io, accessed on: 29 October 2021);
Web-CAT [
22]; and an extended version of
check50 [
15]. Moreover, there are some popular commercial applications providing automatic grading in online learning platforms, such as:
Coursera (
https://www.coursera.org, accessed on: 29 October 2021) and
Vocareum (
https://www.vocareum.com, accessed on: 29 October 2021).
Improving the quality of education is one of the goals of sustainable development. As shown in the works discussed above, automatic grading tools are important assets to improve the quality of education [
23]. They help to provide timely feedback to students during the learning process, help to expand the education system coverage and support the development of systems for autonomous lifelong learning. Many of these systems provide feedback to students with a partial grade, through several ways to collect submissions, having different options to configure and create the assignments. However, various opportunities arise to tackle different limitations of these tools, such as: the assignment configuration can be tedious, as in some cases it must be done manually; in most cases, no graphical user interfaces (GUI) are provided to create tests cases; and more importantly, the feedback given to students on failed submissions does not provide sufficiently detailed information to allow learners not only to find their errors but also to know how to proceed to correct them (i.e., formative feedback [
24]).
The first objective of this paper is to introduce the
UNCode notebook auto-grading tool, where students can obtain detailed and formative feedback instantaneously. The novel tool was built on top of UNCode [
25], which is an educational environment to automatically grade traditional programming activities in introductory programming courses. The second objective is to report the experience of using the UNCode Jupyter notebook auto-grader in two Artificial Intelligence (AI) courses:
Introduction to Intelligent Systems and
Machine Learning. For this purpose, we have analyzed quantitative data from the assignments graded using the tool and also qualitative data related to a survey conducted among students regarding their perception about the tool. This effort is motivated by two main research questions (RQ):
It is worth clarifying what we understand with interaction and perception in this study: interaction refers to the way the students use the UNCode notebook auto-grader, that is, the students’ submissions per activity and the category of the obtained feedback. By perception we refer as how the students assess and judge the utility of the tool and the different features in regard of their learning process, this measured by labeling the students’ answers to open-ended questions regarding this topic. This work contributes to the area of computer science and engineering education in two ways: first, with the proposed self-grading tool itself, which provides instructors with an easy-to-use automatic grader that offers formative feedback to students and its source code is publicly available; second, with the report of the experience of using the tool in an academic context, which offers insights to better understand the potential benefits of the tool for the students’ learning process.
The remainder of this paper is organized as follows:
Section 2 describes related works on automatic grading tools for Jupyter Notebooks and feedback mechanisms on tools that support the students’ learning process.
Section 3 presents the UNCode notebook auto-grader and its technical specifications. Next,
Section 4 details the materials and methods, including descriptions of the AI courses, participants, instruments, procedures, and data analysis.
Section 5 reports the results of the collected data with respect to the students’ interaction with the UNCode notebook auto-grading tool and the conducted survey.
Section 6 discusses the obtained results, and finally,
Section 7 concludes the paper with final remarks and describes future directions of research.
3. UNCode Notebook Auto-Grader
To develop UNCode notebook auto-grader, we add the support for the automatic evaluation of Jupyter notebooks to UNCode. It is an open source educational environment to automatically grade programming assignments [
25], which is built on top of
INGInious [
40]. UNCode is used and maintained by the Universidad Nacional de Colombia, and is deployed at
https://uncode.unal.edu.co (accessed on: 29 October 2021). UNCode facilitates the creation and evaluation of programming activities and provides instantaneous formative feedback [
41]. The supported programming languages are Java, Python, C/C++. Additionally, it supports hardware description languages (HDLs) like Verilog and VHDL. In general, instructors automatically create and deliver assignments to students within the same platform with the help of a graphical user interface to ease the process. Moreover, students access the assignment and solve it following the given specifications, submitting the source code of their solutions. The source code is tested using a variety of test cases, and the students instantly receive feedback, highlighting the failed tests with the associated informative error, as well as the corresponding grade (more information at:
https://juezun.github.io, accessed on: 29 October 2021).
In this context, we developed support to automatically grade Jupyter notebooks on top of UNCode. This tool is called UNCode notebook auto-grader, and it is publicly available under the GNU Affero General Public License v3.0 (AGPL-3.0) (GitHub repository |
https://github.com/JuezUN, accessed on: 29 October 2021). That way, it is not necessary to deploy a new service, and we can take advantage of UNCode for grading Jupyter notebooks. To accomplish this, an easy-to-use user interface was developed for instructors to configure the Jupyter notebook grader. They can create different grading tests using Python code and generate automatically the configuration files. Then, the assignments are delivered to the students on UNCode, where they can either download the students’ version of the notebook and solve it locally in the student’s computer, or open the student’s version in a cloud-based Jupyter notebook execution environment like
Google Colaboratory (Colab |
https://colab.research.google.com, accessed on: 29 October 2021). After solving the assignment, students submit their solution to UNCode and they receive instant feedback along with the grade corresponding to the submission results. This submission is executed in a secure sandbox using
Docker (
https://www.docker.com, accessed on: 29 October 2021), which is in charge of running the submission with the provided tests, with the help of
OK CLI, and the corresponding feedback is generated. We decided to use
OK CLI because this open source tool already has a strong testing system where several test cases can be created, and it provides automatic summative feedback, which is helpful to grade Jupyter notebooks. Therefore, we added complementary information to provide additional formative feedback within UNCode notebook auto-grader.
The presented feedback is marked with different categories: Accepted when the cases are correct, Wrong Answer in case the output is not the expected one, Runtime Error is shown when student’s code throws an exception, Grading Runtime Error is an exception raised by the grading code. In case the submission takes too long, it is categorized as Time Limit, and Memory Limit when it exceeds the allowed memory. In that context, the process can be divided in two big stages: the first stage corresponds to the development of the user interface for instructors; the second stage is related to the execution of the submission and feedback generation. These stages are explained below.
3.1. Automatic Assignment Configuration
The first stage involved developing a user interface for instructors to create and configure the assignments on UNCode. To correctly configure the automatic grader, the student’s notebook version must have been already created, with this, the instructor will be able to create different tests. To start, the instructor has to create a
task on UNCode and fill in the task settings.
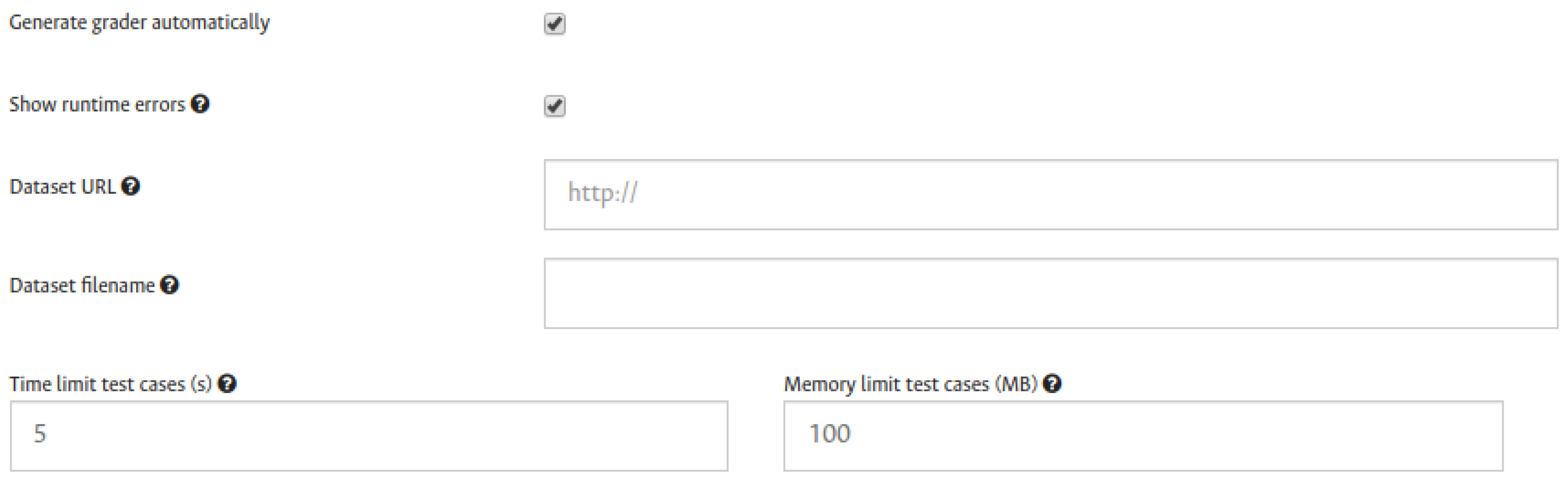
Figure 1 shows some initial general settings for the grader, as explained below:
Generate grader automatically: this is left as optional since the user might want to automatically generate the grader or not. This option is checked by default.
Show runtime errors option is set to choose whether or not to show runtime errors to students when the feedback is given. In case this is checked, additional feedback is shown, such as: Runtime or Memory Limit Errors. Otherwise, the student will receive only Accepted or Wrong Answer results as the feedback.
Dataset URL and Dataset filename options are given in case the assignment requires a dataset. To set an eventual dataset for the automatic grader, there are two options: first, add the dataset URL and filename, informing the grader that a dataset must be downloaded right before each submission is executed. The second option consists of uploading the dataset directly to the task file system.
Grading limits: here the instructor is able to set time and memory limits for each test. This will determine when Time limit or Memory limit errors are shown within the feedback.
After these initial general settings, the grading code can be added. The grader is composed of a group of tests, which aims to grade or evaluate a specific functionality of the assignment. For that, a test is divided into test cases, which grade the target functionality with more granularity. For instance, the student is asked to implement a function that sums two numbers and returns the result, then, a test groups a series of test cases, each test case will then evaluate the function through different parameters. This to finally determine whether the implemented functionality is correct or not. The instructor is free to choose a way the tests and test cases are created and how they evaluate a certain code, all of that depending on the assignment’s goals.
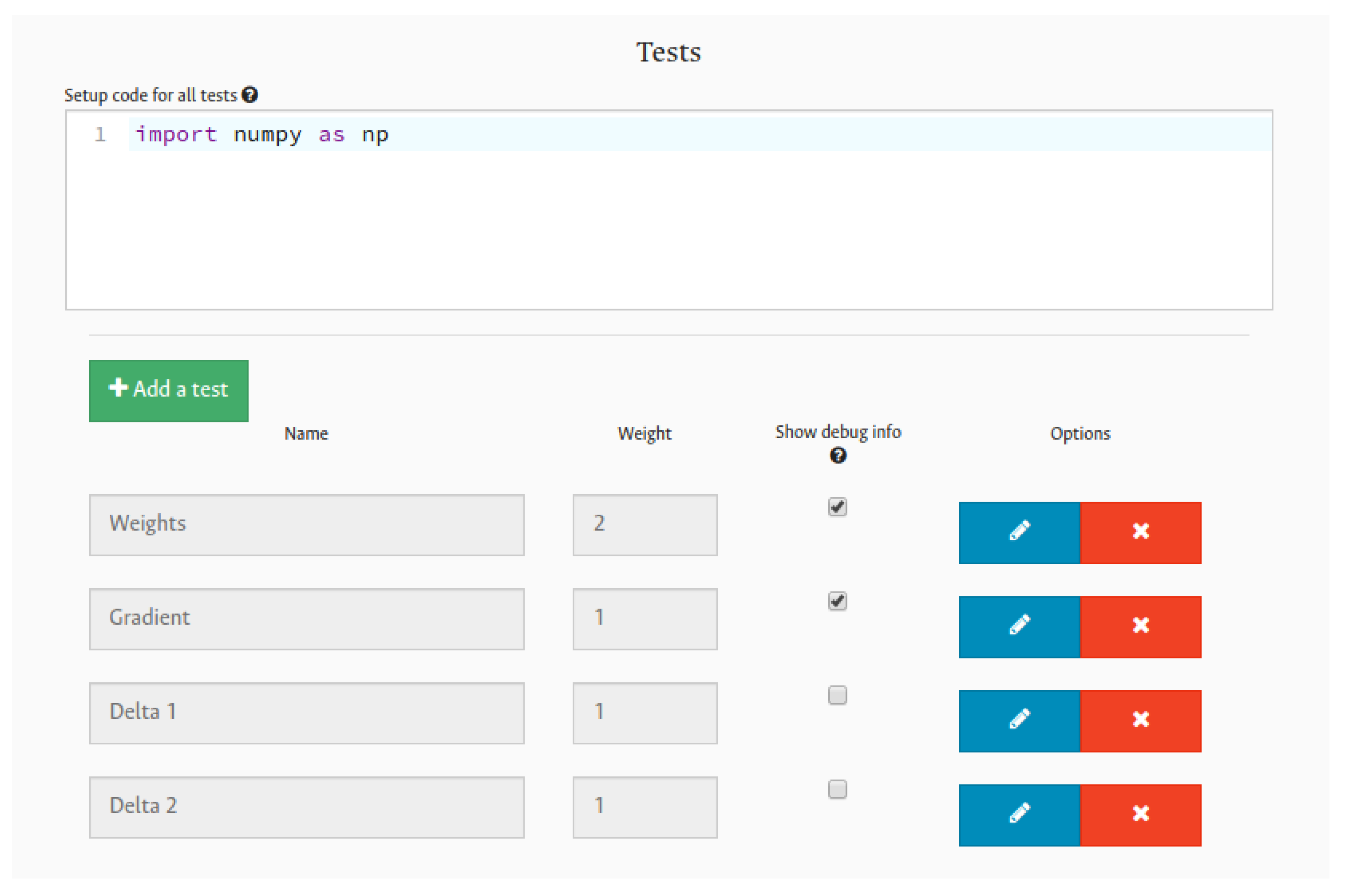
In that context, to create a test, a modal window is displayed with all fields to be filled in as seen in
Figure 2. The different options for the test configuration are described as follows:
Test name: this is used to identify this test among all other tests.
Weight: used to determine the importance of this test among the others when the grade is calculated.
Setup code: code used across all test cases in this specific test. It is intended to help the instructor to reuse the code and facilitate the test creation process when there are several test cases.
Test cases section: the instructor must add all necessary test cases. A test case is composed of the test code and an expected output, which determines the correctness of each test case.
Once the test is saved, it will be added to the
tests section in the grader configuration as shown in
Figure 3. Here, there are four tests that have already been created to evaluate the assignment. Furthermore, these tests can be deleted or edited. Additionally, the instructor may choose which test will show additional information within the feedback to students. This feature aims to help students to debug their code when it fails, showing them the grading code or the raised exception. This is done by activating the option
Show debug info.
After saving the assignment, the OK configuration files are automatically generated, as well as some configuration files necessary to UNCode internals. These files are necessary to execute the submission using the configured tests, and with that, generate the corresponding feedback and grade, as explained in the next section.
3.2. Running Submissions and Generating Feedback
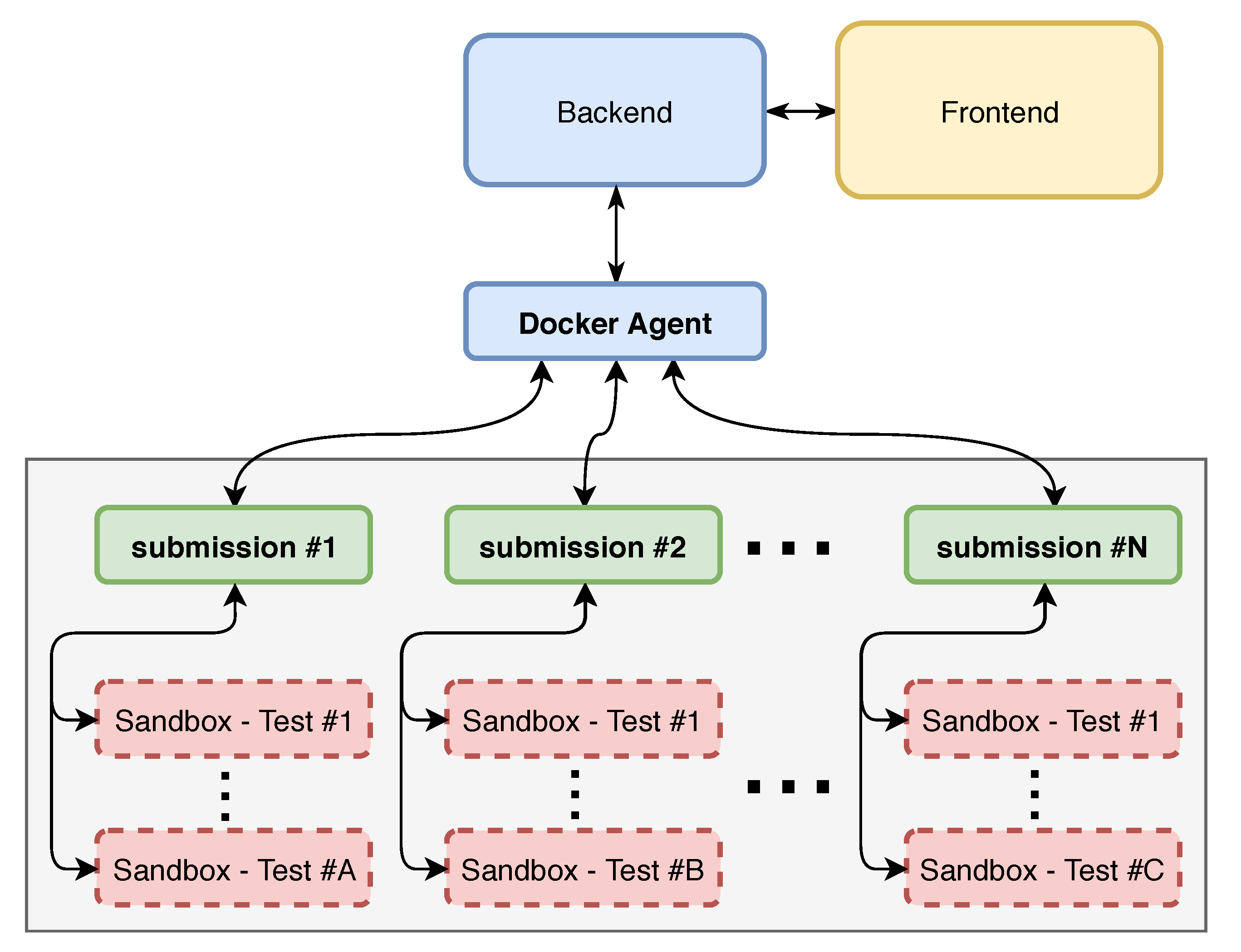
The second stage consisted of developing the environment where submissions are executed, generating the feedback and grade to be delivered to the student. When a student submits a proposal of a solution using UNCode, this submission is managed by the backend, which is in charge of managing all submissions and the corresponding submission queue. This backend sends the submission to another service called the Docker agent, which can be horizontally scaled as well. Then, this service is in charge of running the corresponding submission in a
Docker container, which at the same time, runs each test in an additional docker container, acting as a sandbox to secure the student’s submission. Currently, UNCode supports several grading environments for different kinds of assignments. Additionally, various submissions can be run in parallel to speed up the response time. In this context, the development of the present work was focused on creating a new grading environment for Jupyter notebooks. Therefore, and due to its architectural design, this new grading environment can be easily plugged in to UNCode. This is illustrated in
Figure 4, where the different components are shown.
When this new grading environment or container is started, it already contains the configuration files of the assignment that were created automatically by the grader, as well as the submitted notebook. Additionally, this container already has installed all Python modules that might be necessary to run the student’s code. The installed dependencies are commonly used Python modules in AI courses, for instance, Pandas, Scikit-learn, Keras, among others. On this basis, the student’s notebook is executed inside the container to finally return the feedback and grade to the student in the front-end. To accomplish this, all phases involved within the grading environment are explained in more detail as follows.
3.2.1. Extracting Source Code
Initially, to be able to run the submission, source code is extracted from the submitted notebook; this is done with
nbconvert (
https://nbconvert.readthedocs.io, accessed on: 29 October 2021). This tool automatically allows us to convert
.ipynb files to a Python script containing only the source code.
After the source code is in a Python script, this script is preprocessed. As Jupyter notebooks run over the
IPython interactive environment [
42], they support additional syntax constructs that are not valid under the Python execution environment. Thus, during the conversion process to a script, IPython code is generated. However, only Python code can be executed, and the IPython code must be removed. For instance, a Python module installation syntax needs to be removed from the script to correctly run it under the Python environment. Afterwards, an additional preprocess is accomplished; a
try-except expression is added to enclose all lines of code. This is due to the fact that all the code is in a single script, then, some lines of code may throw exceptions and the grader will evaluate incorrectly the submission as not all tests could be executed. Here is shown an example of a caught exception:
try:
a = 1/0
except
pass:
This way of running notebook submissions has an advantage, students can create as many code cells as they want in the notebook, without the need of using labels or pragmas to indicate to the grader how to parse the code; this gives more flexibility to students when designing the solution. On the other hand, in case the submitted notebook is corrupted or indeed is not a notebook, the process finishes and an error message is shown to the student.
3.2.2. Running Grading Tests
Once the Python script is ready, each test can be executed using the
OK CLI. For that, every test runs in an additional docker container that is launched from the grading container as shown in
Figure 4, for instance,
Sandbox—Test #1. That launched container for each test will act as a sandbox to provide security to the grading system. That way, it avoids the student’s code to interact with the grading code. In addition, the container is created by passing memory and time limit parameters to determine when these types of errors occur during the execution of the tests.
3.2.3. Generating Summative and Formative Feedback
When the sandbox container finishes running the test, the generated standard output and error by OK are collected, then they are parsed to detect the test cases that have failed. In case a test case has failed, the executed code is obtained as well as either the output difference or the thrown runtime exception. This is done to show the student the additional debugging information that may lead them to eventually correct their proposal of solution. This process is done for all test cases. Next are described all possible results or feedback categories that the student may obtain from the generated feedback for each test and test case:
Accepted: all test cases were successful in the given test.
Wrong answer: when the student’s code does not pass a test case and the obtained answer does not coincide with the expected output. The student might be able to see the executed grading code and the output difference in case this test is configured to show this additional debugging information.
Runtime error: this result corresponds to a raised exception while running the student’s code. In case the test is configured to show additional debugging information, the executed grading code and the raised exception are included within the feedback.
Grading runtime error: this type of result is very similar to Runtime error, however, the raised exception occurred while the grading code was running; thus, the raised exception might be due to either there is indeed an error in the grading code that the instructor did not see while creating the task, or the student has not followed the assignment instructions, and the notebook solution does not have the functionality to be tested, for instance, the student has changed the name of a function to be implemented. The executed grading code and the raised exception are sent back within the submission feedback.
Time limit exceeded: the student’s code took more time to finish than the allowed maximum time limit. Then, the whole test is marked with this result.
Memory limit exceeded: a test obtains this error when the test code used more memory than the allowed maximum memory limit for the test.
At the same time the feedback is generated for each test, the grade is also calculated. For that, the number of accepted cases is counted, then the grade of a single test is obtained dividing the total passed test cases by the total of cases in that single test. After all tests have run, the total grade is calculated by the sum of each test weight times the test grade, then divided by the sum of all weights. After all this process, the generated feedback and the grade are sent back to the student. On UNCode notebook auto-grader, the summative feedback corresponds to the feedback category and the obtained grade, and the formative feedback corresponds to the executed code in the test and eventual thrown exceptions, all within the same feedback.
3.3. Bringing All Together
To sum up, initially the instructor creates the student version of the assignment, then, the automatic grader is configured adding all necessary tests and test cases, as well as additional datasets. After that, the student will either download the notebook template and solve it in their local computer, or open it and solve it in a cloud-based Jupyter notebook environment. When the student submits the solution notebook to UNCode notebook, they will instantly receive the feedback and partial grade for the given submission.
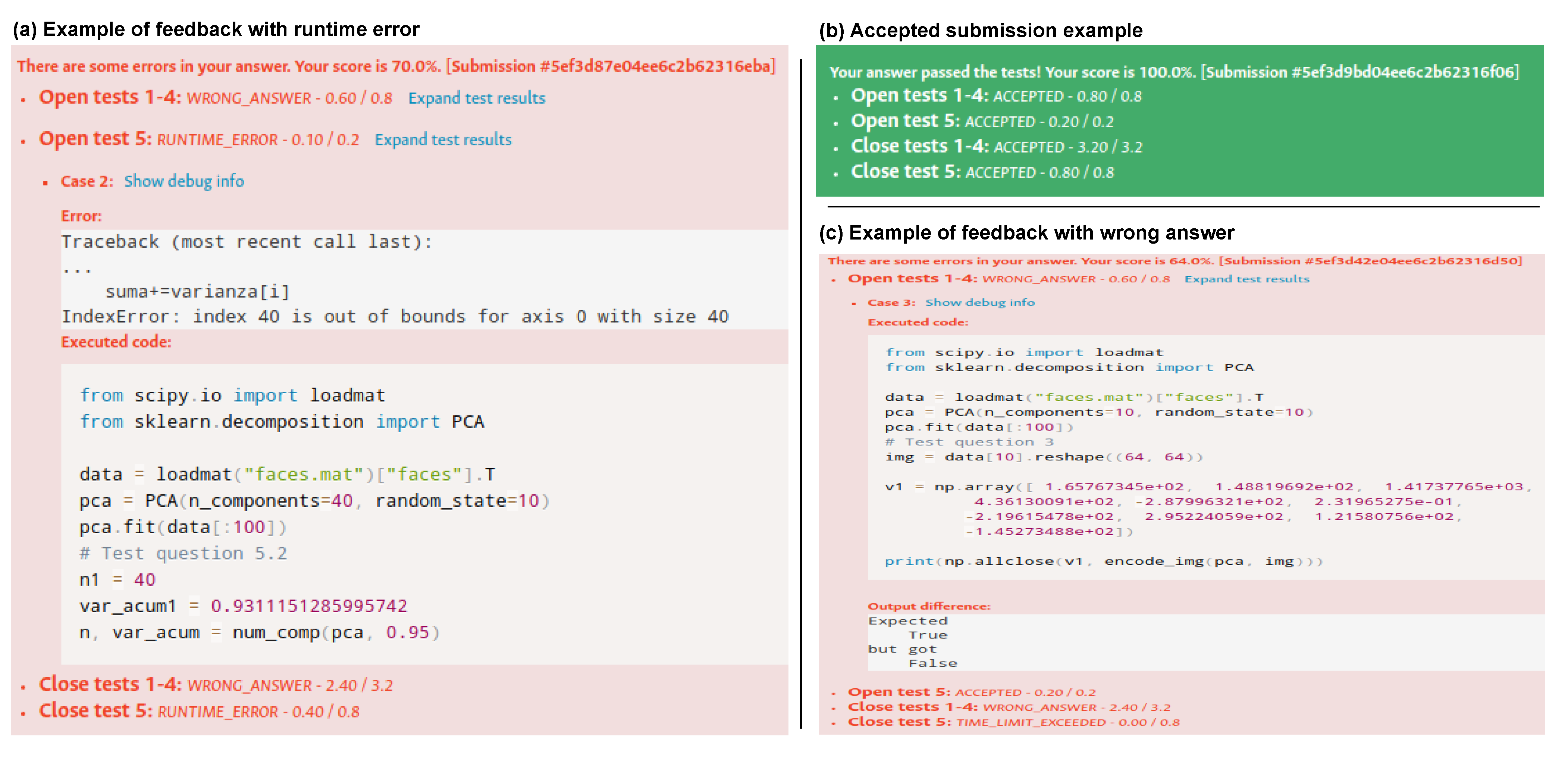
Figure 5 illustrates three different examples of feedback (summative and formative): subfigure (a) shows an example of a submission with grade 70.0% and some tests labeled as WRONG_ANSWER and RUNTIME_ERROR, corresponding to the summative feedback. One of the tests shows feedback with the details of the runtime error, where the grading code and raised exception are shown to the student (formative feedback). It is worth noting that other tests do not show additional details to the student, as the task was configured in that way. Subfigure (b) presents an example of an accepted submission, where all tests passed and the final grade is 100%. For this case, the only presented feedback is summative as all tests were correct and no further formative feedback was necessary. The subfigure (c) illustrates a submission with a grade of 64.0% and several feedback categories for each test in the submission (summative feedback). Here is also presented in more detail a test labeled as WRONG_ANSWER, where the grading code and output difference of the expected output and submission’s output is shown (formative feedback).
3.4. Limitations
Due to the design decisions in the development stage of the proposed tool, UNCode Notebook auto-grader does not allow to use some IPython specific syntax. It is not possible to use magic commands (
https://ipython.readthedocs.io/en/stable/interactive/magics.html, accessed on: 29 October 2021), the integrated shell to execute commands using the exclamation mark character, among other specific syntax introduced by Jupyter Notebooks (Python vs. IPython |
https://ipython.readthedocs.io/en/stable/interactive/python-ipython-diff.html, accessed on: 29 October 2021). Moreover, the students are not allowed to install new modules, as the environment where the submissions run already have all the used and necessary modules to successfully run the student’s notebooks. It is worth noting that in case these features are used in the notebook, the auto-grader will not fail; the tool automatically parses these special command lines before the Python code is executed.
4. Materials and Methods
4.1. Setting
The developed UNCode automatic grader for Jupyter notebooks was employed to evaluate programming activities in two AI related courses at the Universidad Nacional de Colombia in the first semester of 2020: Introduction to Intelligent Systems and Machine Learning, supporting different kinds of in-class or extra-class programming activities. Each course proposed different programming activities to the students on UNCode throughout the courses. These programming activities can be divided in two categories: assignment, which is solved in a period of time of several hours or days and not necessarily solved during the class; Quiz is an examination activity to be solved during the class in short periods of time, generally two hours.
To be able to answer the research questions (RQ1 and RQ2), data was collected from UNCode to understand the students’ interactions with the tool (i.e., students’ submissions). In addition, a survey was conducted in both courses, which contained three multiple-choice and open-ended questions; this survey enabled us to recognize the students’ perceptions about what they think about UNCode notebook auto-grader. Thus, we measured both the students’ interaction with UNCode notebook auto-grader and their judgments about the tool. The collected data from both instruments were analyzed using descriptive statistics.
It is also important to mention that they are traditionally taught in person, although it was necessary to conduct both courses remotely due to COVID-19 pandemic and generalized lockdowns. Next, we explain in more detail the activities carried out per course, and their respective methodology.
4.1.1. Course: Introduction to Intelligent Systems
The course was developed based on two weekly sessions: lecture sessions, where the concepts are presented with the help of presentations and Jupyter notebooks; some sessions were merely practical, where students individually solved quizzes and assignments on UNCode. There were six programming activities supported on UNCode using Jupyter notebooks. These activities are described below in the chronological order that the students were able to start solving them:
Assignment 1: the students were asked to implement various informed search algorithms, such as Breadth First Search.
Assignment 2: the students trained some linear classification models using a benchmark dataset.
Quiz 1: this quiz consisted on implementing from scratch a Decision Tree model and to train it.
Quiz 2: the students implemented a small feed-forward neural network.
Assignment 3: this was related to the topic clustering, where students developed a K-Means model.
Assignment 4: students implemented the algorithm Principal Component Analysis (PCA) for dimensionality reduction for a series of images.
4.1.2. Course: Machine Learning
The methodology of this course is based on two weekly sessions, each session lasts around two hours. In lecture sessions, the concepts are presented with the help of presentations and Jupyter notebooks. Moreover, some sessions were merely practical, where students individually solved quizzes and assignments on UNCode. In that context, four different activities were supported on UNCode using Jupyter notebooks in Python, which are explained below in more detail, in the chronological order they were taken:
Quiz 1: the students trained a logistic regression model using a public dataset.
Assignment 1: the students implemented from scratch a Kernel Ridge Regression model. This homework was solved in three days.
Quiz 2: this quiz consisted on implementing some methods related to the topic of Kernel Logistic Regression.
Quiz 3: the students implemented a small feed-forward neural network from scratch.
4.2. Participants
The first course, Introduction to Intelligent Systems, is taught to undergraduate students in the Department of Systems and Industrial Engineering at the Universidad Nacional de Colombia. The course lasts 16 weeks. The goal of this course is to study the theory and the different methods and techniques used to create rational agents with a strong focus on machine learning. Some of the covered topics during the course include intelligent agents, informed and uninformed search algorithms, supervised learning, linear and nonlinear classification, neural networks and deep learning, and dimensionality reduction. A total of 41 students participated developing activities in UNCode.
The Machine Learning (ML) course is taught in the master’s degree in Systems and Computing Engineering at the Universidad Nacional de Colombia. It also lasts 16 weeks. The main goal of this course is to study the computational, mathematical, and statistical foundations of ML, which are essential for the theoretical analysis of existing learning algorithms, the development of new algorithms, and the well-founded application of ML to solve real-world problems. Some of the covered topics during the course included learning foundations, kernel methods, neural networks, deep learning, and probabilistic programming. A total of 35 students were enrolled in the course.
A total of 55 students from both courses participated in the survey to their perception of UNCode throughout the carried out activities. It is worth noting that the participation in the survey was at the will of each student, hence there are fewer students. On average, the participants were years old at the time this survey was completed, with a standard deviation of years. Most of the participants were male, representing of the participants. Additionally, the students were enrolled in different programs: undergraduate degree in systems and computer engineering (), master’s degree in systems and computer engineering (), undergraduate degree in mechatronics engineering (), master’s degree in bioinformatics (), master’s degree in telecommunications (), undergraduate degree in physics (), undergraduate degree in industrial engineering (), master’s degree in applied mathematics (), and master’s degree in statistics (). A total of 32 (out of 41) students of the Introduction to Intelligent Systems course participated in the survey, and the remainder 23 participants were enrolled in the Machine Learning course (out of 35 students).
4.3. Measurement Instruments
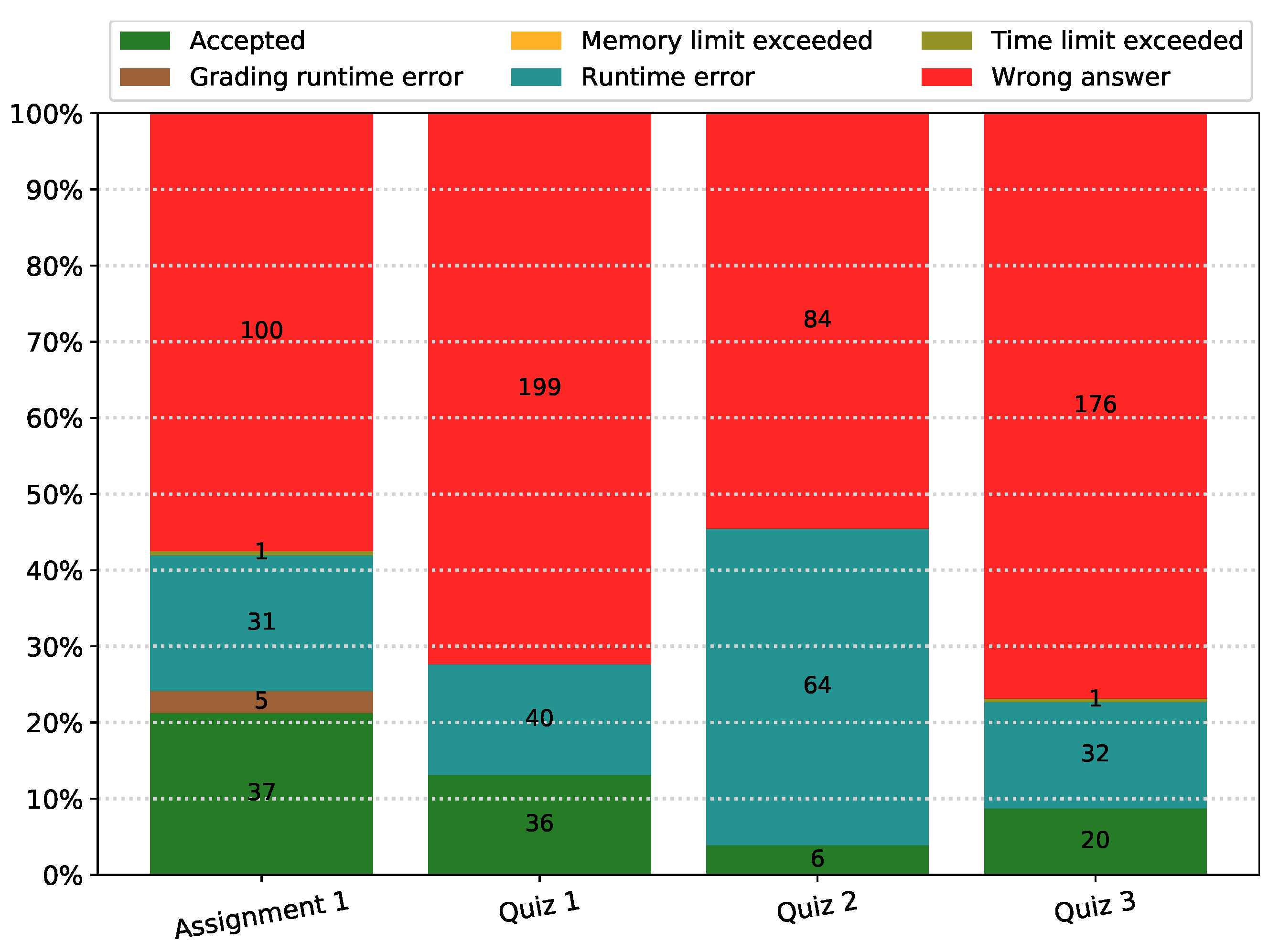
To answer the first research question (RQ1. How students interact with UNCode notebook auto-grader?) quantitative data were collected from UNCode for each one of the programming activities in the courses that were hosted on UNCode. The data collected included: number of participants in the courses and activities, number of submissions, as well as their respective results and the feedback category (e.g., accepted, runtime error, wrong answer). Thus, the tool itself was considered the first measurement instrument of the study.
Regarding to the second research question (RQ2. What is the students’ perception of the tool as a support mechanism for their learning process?), a survey was conducted at the end of the semester. This survey aims to help the authors to understand better the students’ thoughts and receive feedback about the tool, being this survey considered the second measurement instrument. To collect this data, the survey was created using the online tool Google Forms and all students from both courses were asked to complete it, although participation was at the will of each student. Moreover, an informed consent was given at the beginning of the survey to inform the students that the submitted data were treated anonymously, only used for research purposes and the answers did not affect the final course grade. This informed consent must be accepted or rejected by the students.
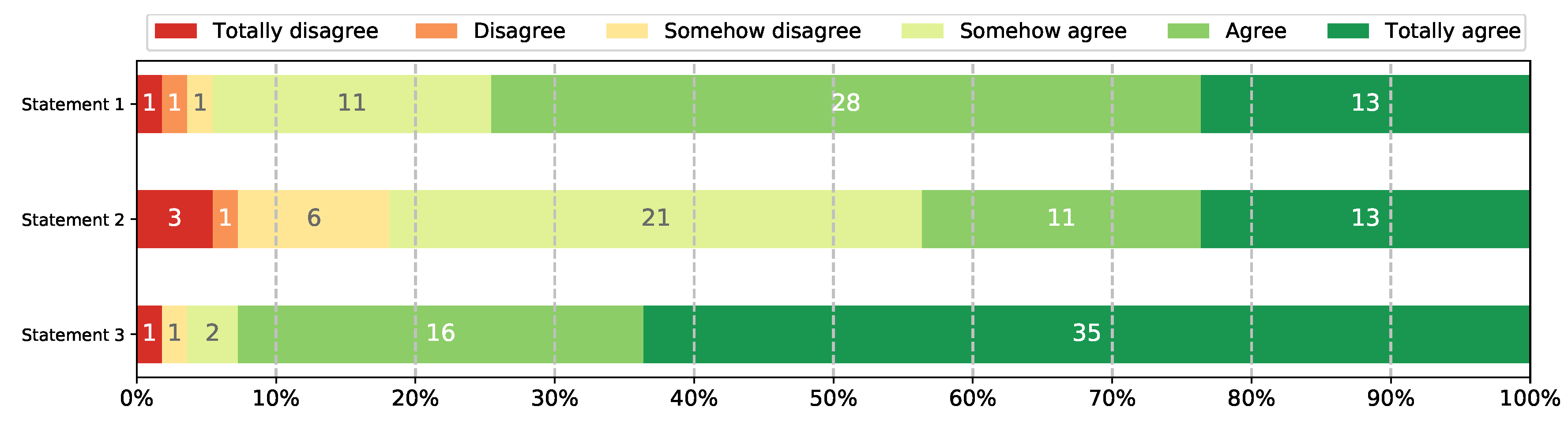
The survey was composed of three multiple-choice and open-ended questions, which were totally focused on the student’s perception and usefulness of UNCode’s Jupyter notebooks automatic grading. Each question was composed of two mandatory-to-answer parts: in the first part, the student selected one option from the Likert scale [
43], which is composed of six levels of agreement/disagreement with respect to a given statement: totally disagree (1), disagree (2), somehow disagree (3), somehow agree (4), agree (5), totally agree (6). The second part was an open-ended question asking the reason they have selected the option of the already mentioned Likert scale. That way, we were able to know different levels of agreement about some features of Jupyter notebooks auto-grader on UNCode, as well as detailed perception and feedback from students. The statements included in the survey were:
Statement 1: I consider that the automatic grader offered by UNCode is a good mechanism to evaluate my performance in the course.
Statement 2: The automatic feedback provided by UNCode is useful to know how to correct errors in the solution to a given programming activity.
Statement 3: The UNCode’s functionality that allows me to see the grading code of a test case is useful to debug my solution to the programming activity.
4.4. Data Analysis
The data collected from UNCode, corresponding to the first measurement instrument, was analyzed through descriptive statistics and the corresponding results are shown in
Section 5.1; some bar charts and tables are presented to help visualization of results related to the students’ interaction.
Moreover, the data collected from the survey was analyzed as follows. The quantitative data from the multiple-choice statements were analyzed via descriptive statistics, with the help of bar charts to visualize the number and percentage of students that selected a given level of agreement in the Likert scale from the survey. In addition, the conducted analysis on the open-ended questions was guided by the widely used framework Grounded Theory for qualitative data analysis, as described by Bryman [
44], which is demonstrated to lead researchers to outstanding results. Following this framework, we encoded each of the answers given by the students, that is, detecting some key words that encode the whole answer. The generated codes work as indicators to detect concepts showing the impact of the UNCode notebook auto-grader on students’ learning process. These concepts refer to labels given to the answers and are determined by grouping the codes by establishing common aspects and links between them, such us patterns of opinions. Nonetheless, it must be noted that an answer (student’s opinion) may be identified not only for a single concept, but various concepts. The process of establishing and analyzing the concepts yields categories, which are at a higher level of abstraction than concepts, enclosing several concepts into one category with common characteristics, and therefore they globally represent students’ perceptions.
The analysis on the open-ended questions was carried out in an iterative process and several times to correctly encode and categorize each answer to give more coherence to the interpretation of the answers. The analysis of the qualitative data was carried out by three of the main researchers in this work with the help of spreadsheets in which the perceptions given by the students were transcribed and ordered. It must be noted that the students’ responses from both courses, in overall, denoted similar categories and opinions, and in consequence it was not pertinent to analyze and present the qualitative results separately for each course, but in a single sample of 55 students from both courses.
6. Discussion
To validate the usefulness of the UNCode notebook auto-grader in an academic context, we designed a study in two AI-related courses at the Universidad Nacional de Colombia. This experience allowed us to answer two research questions: (RQ1) How do students interact with the UNCode notebook auto-grader?; (RQ2) What is the students’ perception of the tool as a support mechanism for their learning process?
Regarding the first research question (RQ1), our findings indicate that there was a great number of submissions in both courses. This is due to the possibility that the students could perform multiple attempts to solve the activities obtaining immediate feedback from the tool; it was advantageous because it allowed them to obtain formative feedback multiple times, which helps them to get close to the solution for the given activities. In the case of obtaining feedback informing an error in the proposed solution, students could identify aspects that need correction, with multiple opportunities to submit new versions of their solution, which is an important benefit. Contrarily, without the UNCode notebook auto-grader, the students would have a limited number of opportunities to submit their solutions for evaluation and the teaching staff would not be able to cope with this amount of submissions to be graded manually, without the support of the automatic tool. In fact, Ala-Mutka [
14] identified that allowing multiple attempts if the student is not satisfied with the results of the programming assignment can be considered as formative assessment. In this case, this might help students by providing feedback on their work and let them improve it. In this way, by using the UNCode Notebook auto-grader, it is possible to effectively provide immediate and formative feedback to the students for a great number of submissions. In addition, the results also indicate the category of feedback assigned to a submission highly depends on how the instructor designs the grading code and the assignment itself, since possible runtime errors can be managed in the grading code and better error messages can be shown; this could be achieved by the instructors with more experience with the tool. Moreover, the succeeding rate of a given activity is contingent upon the difficulty and time restrictions, which influences the kind of feedback the students obtain.
With respect to the students’ perception of UNCode notebook auto-grader, corresponding to the second research question (RQ2), the general opinion of the students regarding the tool is positive. Most of the students agreed that UNCode notebook auto-grader was a good mechanism to evaluate their performance, as well as agreed with the provided formative feedback was quite helpful for solving the programming assignments, and in general, their learning process. Many students mentioned that the feedback helped them to debug and fix their code, highlighting some features, such as: immediate formative and summative feedback, precise and impartial testing, possibility to obtain the grading code, multiple opportunities to submit, among others. In addition, they opined that the tool was useful to identify and solve errors, to guide them towards the solution, and to help them to detect unconsidered test cases, all of this being quite valuable to the practitioners. Although some limitations and a few aspects to improve were detected from negative opinions, such as the need for more detailed feedback, custom feedback and manual grading; it is important to mention that we already have addressed some of these suggestions to improve the system and response better to the learning process of the students, for instance: first, it is now possible for instructors to add custom feedback to the test cases, second, a new feature was developed to add manual reviews to students’ submissions, among other improvements. In this sense, UNCode notebook auto-grader is not only useful as an automatic grading tool that provides summative feedback, but it is also a tool that offers formative feedback through different mechanisms that support the students during their learning process, thus facilitating them to find and correct errors.
Regarding the technical challenges from other automatic grading tools for Jupyter Notebooks identified in
Section 2.1, the proposed tool provides a user interface for instructors to set up the grader and grading code. Unlike other tools (
nbgrader [
18],
Web-CAT [
22],
Vocareum, among others), it does not depend on the JupyterHub Server, which reduces the necessary computational resources and costs to deploy. According to the task configuration selected by the instructor, the tests are generated automatically within the same platform, this in contrast with
Otter-Grader and
OK. Then, students are able to either download the notebook or open it using a development environment, like Colab, to start solving the programming assignment proposed in the notebook. When a student submits an attempt of solution on the online UNCode notebook auto-grader, it is executed in a secure sandboxed environment, which is either not provided by default or it is not used in other systems like nbgrader, OK, Web-CAT, this being important to make sure the students do not interact with the grading code. Afterwards, the feedback and grade are sent back immediately to the student and within the same platform. Therefore, a student can see her or their summative feedback with additional formative information, e.g., the grading code for some test cases. To highlight from the generated summative feedback, this tool addresses some detected lacks in the other generated feedback on tools like OK, as expressed by Sharp et al. [
15],
CoCalc, and
Coursera. This was addressed by labeling the feedback with defined categories, detecting errors in the grading code, showing the raised exceptions, detecting time and memory limit exceeded errors, among others.
Concerning the summative evaluation, as Gordillo [
29] points out, the participants in this experience emphasized that the automatic evaluation of their performance provided them with inputs to increase their practical problem-solving skills. Additionally, they pointed out that automatic grading has characteristics like being accurate, impartial, immediate, allows evaluating the knowledge and level of understanding of the theoretical concepts covered in the courses, and facilitates the permanent monitoring of performance in the subjects. These characteristics indicate specific advantages of including automatic summative assessment tools not only in computer programming learning environments, but also artificial intelligence courses like in this study.
From the analysis of students’ interaction and perception, we see that a formative feedback is essential for the students to support them during their learning process. The participants in this experience pointed out as advantages of the formative evaluation the possibility of identifying errors in the code, making corrections quickly, solving problems correctly, and testing their programs by adding test cases not initially considered. As for the opinions in which the participants highlighted the need to add more information offered by the tool when programs fail, these confirm the need to continue increasing and complementing formative feedback in computer programming learning environments, as pointed out by Keuning et al. [
27]. However, it is also critical, and recommended to the practitioners, to correctly design the test cases and give precise instructions, as this is a key point where students may perceive the grading system as either useful or not. All of this highlights why adopting an auto-grader for Jupyter Notebooks is useful and eases the grading process in computer science courses, either developing a new system or using one of the current grading systems. The Jupyter automatic notebook grading tool presented in this paper provides students with immediate summative and formative feedback, more specifically following the recommendations given by Ullah et al. [
39], as the students are able to instantaneously see the location of their errors, as well as to run the grading code for a better understanding of their errors, which gives students a scaffolding to know how to proceed to correct their errors, which must be taken into account by practitioners and academicians.
7. Conclusions
We presented UNCode notebook auto-grader, where students can obtain not only summative feedback related to programming assignments but also detailed formative feedback in an instantaneous way. We added support to grade automatically Jupyter Notebooks on top of UNCode, the already working auto-grader at the Universidad Nacional de Colombia. To validate this new automatic grading tool, we also reported the experience of using the UNCode Jupyter notebook auto-grader in two AI courses: Introduction to Intelligent Systems and Machine Learning. The results of the study were divided into two parts: students’ interaction with UNCode, and students’ perception and feedback.
The possibility of obtaining summative and formative feedback automatically from an online tool is an important advantage for students when developing their solutions to challenging computer programming tasks in Jupyter Notebooks for AI courses. This was shown in both quantitative and qualitative data analysis conducted in this work. The large number of submissions made by the students, and the feedback obtained automatically guided them towards solving the proposed activities. Otherwise, without the support of an auto-grading tool, students might have a limited number of opportunities for the evaluation of their solutions, and the instructors would not be able to cope with a large number of submissions to be manually graded. Not to mention that, in such case, feedback could be communicated several days/weeks after the submission. Moreover, students’ perceptions indicated that the proposed tool was adopted as a good mechanism to evaluate their performance; the feedback provided was useful not only to identify errors in the proposed solutions, but also to correct them, and the functionality developed to improve debugging information (by showing the grading code of some selected test cases to students) was also useful in the problem-solving process.
This work makes two main contributions to the area of computer science and engineering education: first, we introduce a publicly available Jupyter Notebooks auto-grading tool, which provides instructors with an easy-to-use automatic grader that offers summative and formative feedback to students instantaneously; and second, we provide empirical evidence on the benefits of using the proposed tool in an academic through the reported experience on the use of the tool in two AI courses, where the students expressed how helpful UNCode notebook auto-grader was for their learning process.
It should be noted that since this work presents a case study in two AI courses, the generalization of the results could be limited. Firstly, it is worth noting that the test had some particularities: not all the students in both courses participated in the survey, thus the number of samples was smaller. Secondly, mainly young male with a background in computation participated in the test. Further experimental design studies are recommended to provide solid evidence on the impact of the use of this novel tool on variables, such as academic performance and student motivation. Additionally, a quasi-experimental study can be carried out to compare the students outcomes of an experimental group using UNCode notebook with the results of a control group, and supplementary this might determine other information like whether the students learn more or not and how fast they learn, among others. Furthermore, future studies could focus on evaluating which type of feedback helped students debug their work, determining when they fixed an error (how many submissions they made until they fixed their code), and detecting the occasions the students were able to fix a specific error identified in the feedback. For future work, we plan to explore some of these possibilities. In addition, we will develop new functionalities to the tool to further improve the feedback provided to students, for example, by including some specific hints, pre-configured by the instructors, depending on the specific test case that is failing. Another way to send the notebooks directly from the development environment may also be developed to facilitate the students’ workflow.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}