
The Willingness to Pay for Residential PV Plants in Italy: A Discrete Choice Experiment


Abstract
:1. Introduction
2. Related Literature
3. Materials and Method
3.1. Method
3.2. Survey Design and Administration
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- European Commission. 2021. Available online: https://ec.europa.eu/energy/topics/renewable-energy/renewable-energy-directive/overview_it#the-recast-directive-2018-2001-eu (accessed on 9 June 2021).
- Mancò, G.; Guelpa, E.; Colangelo, A.; Virtuani, A.; Morbiato, T.; Verda, V. Innovative renewable technology integration for nearly zero-energy buildings within the Re-cognition project. Sustainability 2021, 13, 1938. [Google Scholar] [CrossRef]
- Barron-Gafford, G.A.; Minor, R.L.; Allen, N.A.; Cronin, A.D.; Brooks, A.E.; Pavao-Zuckerman, M.A. The Photovoltaic Heat Island Effect: Larger solar power plants increase local temperatures. Sci. Rep. 2016, 6, 35070. [Google Scholar] [CrossRef] [Green Version]
- Torlo, M.; Kreso, I.; Edin, Š. Renewable Energy Sources in Construction of Energy Efficient Residential Buildings. In Lecture Notes in Networks and Systems; Springer: Berlin/Heidelberg, Germany, 2020; Volume 128, pp. 709–719. [Google Scholar]
- Colak, H.E.; Memisoglu, T.; Gercek, Y. Optimal site selection for solar photovoltaic (PV) power plants using GIS and AHP: A case study of Malatya Province, Turkey. Renew. Energy 2020, 149, 565–576. [Google Scholar] [CrossRef]
- Li, R.; Leung, G.C.K. The relationship between energy prices, economic growth and renewable energy consumption: Evidence from Europe. Energy Rep. 2021, 7, 1712–1719. [Google Scholar] [CrossRef]
- Fratini, P.; Moretti, E.; Belloni, E. Energy and economic evaluation of solar photovoltaics plants: Influence of different input parameters. In Proceedings of the ECOS 2012-The 25th International Conference on Efficiency, Cost, Optimization, Simulation And Environmental Impact Of Energy Systems, Perugia, Italy, 26–29 June 2012. [Google Scholar]
- Mangan, S.D.; Koçlar Oral, G. Energy, economic and environmental analyses of photovoltaic systems in the energy renovation of residential buildings in Turkey. A/Z ITU J. Fac. Arch. 2016, 13, 5–22. [Google Scholar] [CrossRef]
- Akter, M.N.; Mahmud, M.A.; Amanullah, M.T.O. Comprehensive economic evaluations of a residential building with solar photovoltaic and battery energy storage systems: An Australian case study. Energy Build. 2017, 138, 332–346. [Google Scholar] [CrossRef]
- Minuto, F.D.; Lazzeroni, P.; Borchiellini, R.; Olivero, S.; Bottaccioli, L.; Lanzini, A. Modeling technology retrofit scenarios for the conversion of condominium into an energy community: An Italian case study. J. Clean. Prod. 2021, 282, 124536. [Google Scholar] [CrossRef]
- Bertolini, M.; D’Alpaos, C.; Moretto, M. Do Smart Grids boost investments in domestic PV plants? Evidence from the Italian electricity market. Energy 2018, 149, 890–902. [Google Scholar] [CrossRef]
- D’Alpaos, C.; Moretto, M. Do Smart grid innovations affect real estate market values? AIMS Energy 2019, 7, 141–150. [Google Scholar] [CrossRef]
- D’Alpaos, C.; Bragolusi, P. The market price premium for residential PV plants. In Smart Innovation, Systems and Technologies; Springer: Berlin/Heidelberg, Germany, 2021; Volume 178, pp. 1208–1216. [Google Scholar] [CrossRef]
- Gestore Servizi Energetici (GSE). 2020. Available online: https://www.gse.it/documenti_site/Documenti%20GSE/Rapporti%20statistici/Solare%20Fotovoltaico%20-%20Rapporto%20Statistico%202019.pdf (accessed on 15 June 2021).
- Abdelhafez, M.H.H.; Touahmia, M.; Noaime, E.; Albaqawy, G.A.; Elkhayat, K.; Achour, B.; Boukendakdji, M. Integrating solar photovoltaics in residential buildings: Towards zero energy buildings in hail city, ksa. Sustainability 2021, 13, 1845. [Google Scholar]
- Hu, X.; Xiang, Y.; Zhang, H.; Lin, Q.; Wang, W.; Wang, H. Active–passive combined energy-efficient retrofit of rural residence with non-benchmarked construction: A case study in Shandong province, China. Energy Rep. 2021, 7, 1360–1373. [Google Scholar] [CrossRef]
- Dastrup, S.R.; Graff Zivin, J.; Costa, D.L.; Kahn, M.E. Understanding the Solar Home price premium: Electricity generation and “Green” social status. Eur. Econ. Rev. 2012, 56, 961–973. [Google Scholar] [CrossRef] [Green Version]
- Kok, N.; Miller, N.G.; Morris, P. The Economics of Green Retrofits. J. Sustain. Real Estate 2011, 4, 4–22. [Google Scholar] [CrossRef]
- Kahn, M.E.; Kok, N. The capitalization of green labels in the California housing market. Reg. Sci. Urban Econ. 2014, 47, 25–34. [Google Scholar] [CrossRef]
- Dell’Anna, F.; Bravi, M.; Marmolejo-Duarte, C.; Bottero, M.C.; Chen, A. EPC green premium in two different European climate zones: A comparative study between Barcelona and Turin. Sustainability 2019, 11, 5605. [Google Scholar] [CrossRef] [Green Version]
- Mangialardo, A.; Micelli, E.; Saccani, F. Does sustainability affect real estate market values? Empirical evidence from the office buildings market in Milan (Italy). Sustainability 2018, 11, 12. [Google Scholar] [CrossRef] [Green Version]
- Chegut, A.; Eichholtz, P.; Kok, N. The price of innovation: An analysis of the marginal cost of green buildings. J. Environ. Econ. Manag. 2019, 98, 102248. [Google Scholar] [CrossRef] [Green Version]
- Stanley, S.; Lyons, R.C.; Lyons, S. The price effect of building energy ratings in the Dublin residential market. Energy Efficiency 2016, 9, 875–885. [Google Scholar] [CrossRef] [Green Version]
- Papineau, M. Energy Efficiency Premiums in Unlabeled Office Buildings. Energy J. 2017, 38, 195–212. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, H.; Wu, J. The price premium for green-labelled housing: Evidence from China. Urban Studies 2017, 54, 3524–3541. [Google Scholar] [CrossRef]
- Lee, H.; Lee, M.; Lim, S. Do Consumers Care about the Energy Efficiency of Build-ings? Understanding Residential Choice Based on Energy Performance Certificates. Sustainability 2018, 10, 4297. [Google Scholar] [CrossRef] [Green Version]
- Hoen, B.; Wiser, R.; Thayer, M.; Cappers, P. Residential photovoltaic energy systems in California: The effect on home sales prices. Contemp. Econ. Policy 2013, 31, 708–718. [Google Scholar] [CrossRef] [Green Version]
- Desmarais, L. The Impact of Photovoltaic Systems on Market Value and Marketability: A Case Study of 30 Single-Family Homes in the North and Northwest Denver Metro Area. 2013. Available online: https://www.colorado.gov/pacific/energyoffice/atom/14956 (accessed on 9 June 2021).
- Hoen, B.; Adomatis, S.; Jacksonc, T.; Graff-Zivin, J.; Thayere, M.; Klise, G.T.; Wiser, R. Multi-state residential transaction estimates of solar photovoltaic system premiums. Renew. Energy Focus 2017, 19–20, 90–103. [Google Scholar] [CrossRef] [Green Version]
- Bao, Q.; Honda, T.; El Ferik, S.; Shaukat, M.M.; Yang, M.C. Understanding the role of visual appeal in consumer preference for residential solar panels. Renew. Energy 2017, 113, 1569–1579. [Google Scholar] [CrossRef] [Green Version]
- Qiu, Y.; Wang, Y.D.; Wang, J. Soak up the sun: Impact of solar energy systems on residential home values in Arizona. Energy Econ. 2017, 66, 328–336. [Google Scholar] [CrossRef]
- Glumac, B.; Wissink, T.P. Homebuyers’ preferences concerning installed photovoltaic systems: A discrete choice experiment. J. Eur. Real Estate Res. 2018, 11, 102–124. [Google Scholar] [CrossRef]
- Hille, S.L.; Curtius, H.C.; Wüstenhagen, R. Red is the new blue-The role of colour, building integration and country-of-origin in homeowners’ preferences for residential photovoltaics. Energy Build. 2018, 162, 21–31. [Google Scholar] [CrossRef]
- Baldi, F. Valuing a greenfield real estate property development project: A real options approach. J. Eur. Real Estate Res. 2013, 6, 186–217. [Google Scholar]
- Högberg, L. The impact of energy performance on single-family home selling prices in Sweden. J. Eur. Real Estate Res. 2013, 6, 242–261. [Google Scholar] [CrossRef]
- Vimpari, J.; Junnila, S. Valuing green building certificates as real options. J. Eur. Real Estate Res. 2014, 7, 181–198. [Google Scholar] [CrossRef]
- Rosen, S. Hedonic Prices and Implicit Markets: Product Differentiation in Pure Competition. J. Political Econ. 1974, 82, 34–55. [Google Scholar] [CrossRef]
- Lancaster, E.; Louviere, J. Conducting Discrete Choice Experiments to Inform Healthcare Decision Making. Pharmaco Econ. 2008, 26, 661–677. [Google Scholar]
- McFadden, D. Conditional logit analysis of qualitative choice behaviour. In Frontiers in Econometrics; Zarembka, P., Ed.; Academic Press: New York, NY, USA, 1974; pp. 105–142. [Google Scholar]
- Hanley, N.; Mourato, S.; Wright, R.E. Choice modelling approaches: A superior alternative for environmental valuation? J. Econ. Surv. 2001, 15, 435–462. [Google Scholar] [CrossRef]
- Davidson, D. Experimental Tests of a Stochastic Decision Theory (1959). In Economic Information, Decision, and Prediction; Theory and Decision Library (An International Series in the Philosophy and Methodology of the Social and Behavioral Sciences); Springer: Dordrecht, The Netherlands, 1974; Volume 7, pp. 133–171. [Google Scholar]
- Manski, C.F. The structure of random utility models. Theory Dec. 1977, 8, 229–254. [Google Scholar] [CrossRef]
- Walker, J.; Ben-Akiva, M. Generalized random utility model. Math. Soc. Sci. 2002, 43, 303–343. [Google Scholar] [CrossRef]
- Train, K. Discrete Choice Methods with Simulation; Cambridge University Press: New York, NY, USA, 2009; Available online: https://eml.berkeley.edu/books/choice2.html (accessed on 18 January 2021).
- Alberini, A.; Ščasný, M.; Bigano, A. Policy-v. individual heterogeneity in the benefits of climate change mitigation: Evidence from a stated-preference survey. Energy Policy 2018, 121, 565–575. [Google Scholar] [CrossRef] [Green Version]
- Hanemann, W.M. Welfare evaluations in contingent valuation experiments with discrete responses. Am. J. Agric. Econ. 1984, 66, 332–341. [Google Scholar] [CrossRef]
- Parsons, G.R.; Kealy, M.J. Randomly drawn opportunity sets in a random utility model of lake recreation. Land Econ. 1992, 68, 93–106. [Google Scholar] [CrossRef]
- Carson, R.T.; Louviere, J.J.; Anderson, D.A.; Arabie, P.; Bunch, D.S.; Hensher, D.A.; Johnson, R.M.; Kuhfeld, W.R.; Steinberg, D.; Swait, J.; et al. Experimental analysis of choice. Mark. Lett. 1994, 5, 351–367. [Google Scholar] [CrossRef]
- Huber, J.; Zwerina, K. The importance of utility balance and efficient choice designs. J. Mark. Res. 1996, 33, 307–317. [Google Scholar] [CrossRef]
- Kanninen, B.J. Optimal design for multinomial choice experiments. J. Mark. Res. 2002, 39, 214–217. [Google Scholar] [CrossRef]
- Rose, J.M.; Bliemer, M.C.J. Designing efficient data for stated choice: Accounting for sociodemographic and contextual effects in designing stated choice experiments. In Proceedings of the 11th International Conference on Travel Behaviour Research, Kyoto, Japan, 16–20 August 2006. [Google Scholar]
- Rose, J.M.; Scarpa, R. Designs efficiency for non-market valuation with choice modelling: How to measure it, what to report and why. Aust. J. Agric. Resour. Econ. 2008, 52, 253–282. [Google Scholar]
- Rose, J.M.; Bleimer, M.C.J. Constructing Efficient Stated Choice Experimental Designs. Transp. Rev. 2009, 29, 587–617. [Google Scholar] [CrossRef]
- Bliemer, M.C.J.; Collins, A.T. On determining priors for the generation of efficient stated choice experimental designs. J. Choice Model. 2016, 21, 10–14. [Google Scholar] [CrossRef]
- Istituto Nazionale di Statistica–ISTAT. Edifici E Abitazioni. 2014. Available online: https://www.istat.it/it/files//2014/08/Nota-edifici-e-abitazioni_rev.pdf (accessed on 9 June 2021).
- Osservatorio sul Mercato Immobiliare (NOMISMA). 2021. Available online: https://www.nomisma.it/wp-content/uploads/2021/07/Highlights-2-rapporto-immobiliare-2021.pdf (accessed on 2 August 2021).
- Agenzia Nazionale Per le Nuove Tecnologie, L’energia e lo Sviluppo Economico Sostenibile (ENEA). 2020. Available online: https://www.enea.it/it/Stampa/news/energia-report-enea-iea-tornano-a-crescere-gli-impianti-fotovoltaici-in-italia (accessed on 9 June 2021).
- Istituto Nazionale di Statistica (ISTAT). Indicatori Demografici 2019. 2020. Available online: https://www.istat.it/it/files/2020/02/Indicatori-demografici_2019.pdf (accessed on 15 June 2021).
- Istituto Nazionale di Statistica–ISTAT. Indicatori Demografici 2020. 2021. Available online: https://www.istat.it/it/archivio/indicatori+demografici (accessed on 9 June 2021).
- Istituto Nazionale di Statistica–ISTAT. Indagine Conoscitiva Sulla Riforma Dell’imposta Sul Reddito delle Persone Fisiche E Altri Aspetti del Sistema Tributario. 2021. Available online: https://www.camera.it/application/xmanager/projects/leg18/attachments/upload_file_doc_acquisiti/pdfs/000/004/664/05-bis_Memoria_ISTAT_Allegato_statistico_pdf (accessed on 9 June 2021).


{kind=link}
{kind=link}
| Attribute Levels |
|---|
| NO PV plant |
| PV plant #1 |
| PV plant #2 |
| PV plant #3 |
| PV plant #4 |
| PV plant #5 |
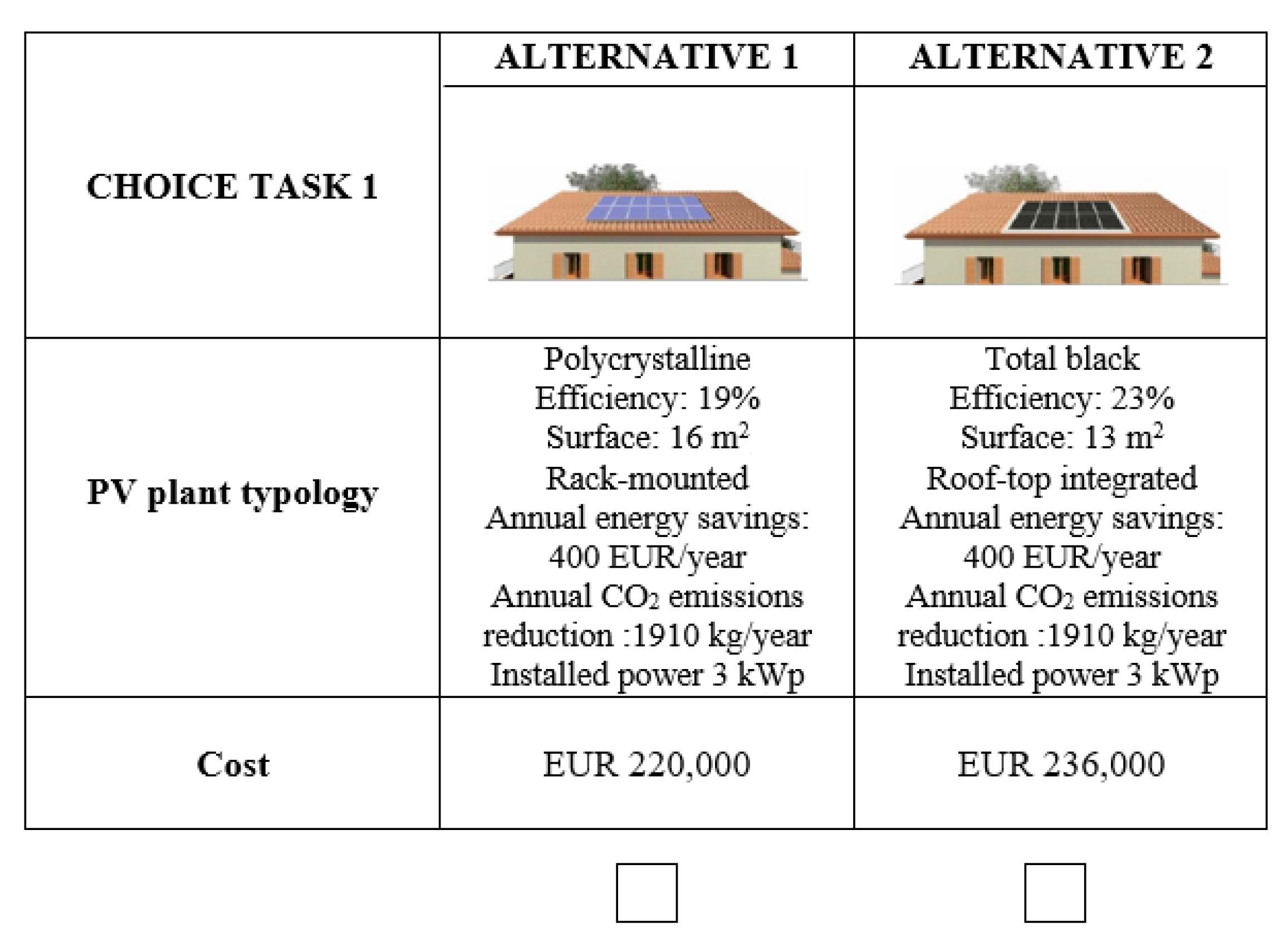
| PV Plant | Technical Characteristics | |
|---|---|---|
| PV plant #1 | Solar cells typology | Polycrystalline |
| Efficiency | 19% | |
| PV plant surface [m2] | 16 | |
| Installation mode | Rack-mounted | |
| Annual energy savings in monetary terms [€/year] | 400 | |
| Annual CO2 emissions reduction [kg/year] | 1910 | |
| Installed power [kWp] | 3 | |
| PV plant #2 | Solar cells typology | Monocrystalline |
| Efficiency | 23% | |
| PV plant surface [m2] | 13 | |
| Installation mode | Rooftop-integrated | |
| Annual energy savings in monetary terms [€/year] | 400 | |
| Annual CO2 emissions reduction [kg/year] | 1910 | |
| Installed power [kWp] | 3 | |
| PV plant #3 | Solar cells typology | Total black |
| Efficiency | 23% | |
| PV plant surface [m2] | 13 | |
| Installation mode | Rooftop-integrated | |
| Annual energy savings in monetary terms [€/year] | 400 | |
| Annual CO2 emissions reduction [kg/year] | 1910 | |
| Installed power [kWp] | 3 | |
| PV plant #4 | Solar cells typology | Polycrystalline |
| Efficiency | 19% | |
| PV plant surface [m2] | 26 | |
| Installation mode | Rooftop-integrated | |
| Annual energy savings in monetary terms [€/year] | 550 | |
| Annual CO2 emissions reduction [kg/year] | 3180 | |
| Installed power [kWp] | 5 | |
| PV plant #5 | Solar cells typology | Polycrystalline |
| Efficiency | 19% | |
| PV plant surface [m2] | 26 | |
| Installation mode | Rack-mounted | |
| Annual energy savings in monetary terms [€/year] | 550 | |
| Annual CO2 emissions reduction [kg/year] | 3180 | |
| Installed power [kWp] | 5 | |
| Market Price [EUR] | Price Premium for the Solar Home |
|---|---|
| 200,000 | 0% |
| 206,000 | 3% |
| 210,000 | 5% |
| 214,000 | 7% |
| 226,000 | 13% |
| 236,000 | 18% |
| 250,000 | 25% |
| Variable | % | |
|---|---|---|
| Gender | M | 47.02% |
| F | 52.98% | |
| Age | 18–29 | 22.84% |
| 30–39 | 10.58% | |
| 40–49 | 15.34% | |
| 50–59 | 16.47% | |
| 60–70 | 34.77% | |
| Educational Attainment | Middle school diploma | 5.56% |
| High school diploma | 35.38% | |
| Bachelor degree | 50.24% | |
| Master degree/PhD | 8.82% | |
| Individual Annual Income | 0–15,000 EUR | 34.35% |
| 15,001 €–28,000 EUR | 37.13% | |
| 28,001 €–55,000 EUR | 23.61% | |
| 55,001 €–75,000 EUR | 2.80% | |
| >75,000 EUR | 2.11% | |
| Coefficient | Estimate | Standard Error | t-Value |
|---|---|---|---|
| 0.3065 | 0.1497 | 2.04 *** | |
| 0.8463 | 0.2898 | 2.92 **** | |
| 0.9178 | 0.2776 | 3.31 **** | |
| 1.4963 | 0.3828 | 3.91 **** | |
| 1.4897 | 0.512 | 3.10 **** | |
| NO PV plant: Reference level (set to 0) | |||
| −0.4936 | 0.096 | −5.14 **** | |
| −0.3691 | 0.1462 | −2.52 **** | |
| PV Plant Typology | mWTP [EUR] | Price Premium [%] |
|---|---|---|
| PV plant #1 | 6209 | 3.10% |
| PV plant #2 | 17,145 | 8.57% |
| PV plant #3 | 18,594 | 9.30% |
| PV plant #4 | 30,314 | 15.16% |
| PV plant #5 | 30,180 | 15.09% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bragolusi, P.; D’Alpaos, C. The Willingness to Pay for Residential PV Plants in Italy: A Discrete Choice Experiment. Sustainability 2021, 13, 10544. https://doi.org/10.3390/su131910544
Bragolusi P, D’Alpaos C. The Willingness to Pay for Residential PV Plants in Italy: A Discrete Choice Experiment. Sustainability. 2021; 13(19):10544. https://doi.org/10.3390/su131910544
Chicago/Turabian StyleBragolusi, Paolo, and Chiara D’Alpaos. 2021. "The Willingness to Pay for Residential PV Plants in Italy: A Discrete Choice Experiment" Sustainability 13, no. 19: 10544. https://doi.org/10.3390/su131910544
APA StyleBragolusi, P., & D’Alpaos, C. (2021). The Willingness to Pay for Residential PV Plants in Italy: A Discrete Choice Experiment. Sustainability, 13(19), 10544. https://doi.org/10.3390/su131910544