
Facial Recognition System for People with and without Face Mask in Times of the COVID-19 Pandemic




Abstract
1. Introduction
2. Materials and Methods
2.1. Description of the Problem
2.2. Requirements
2.3. System Development
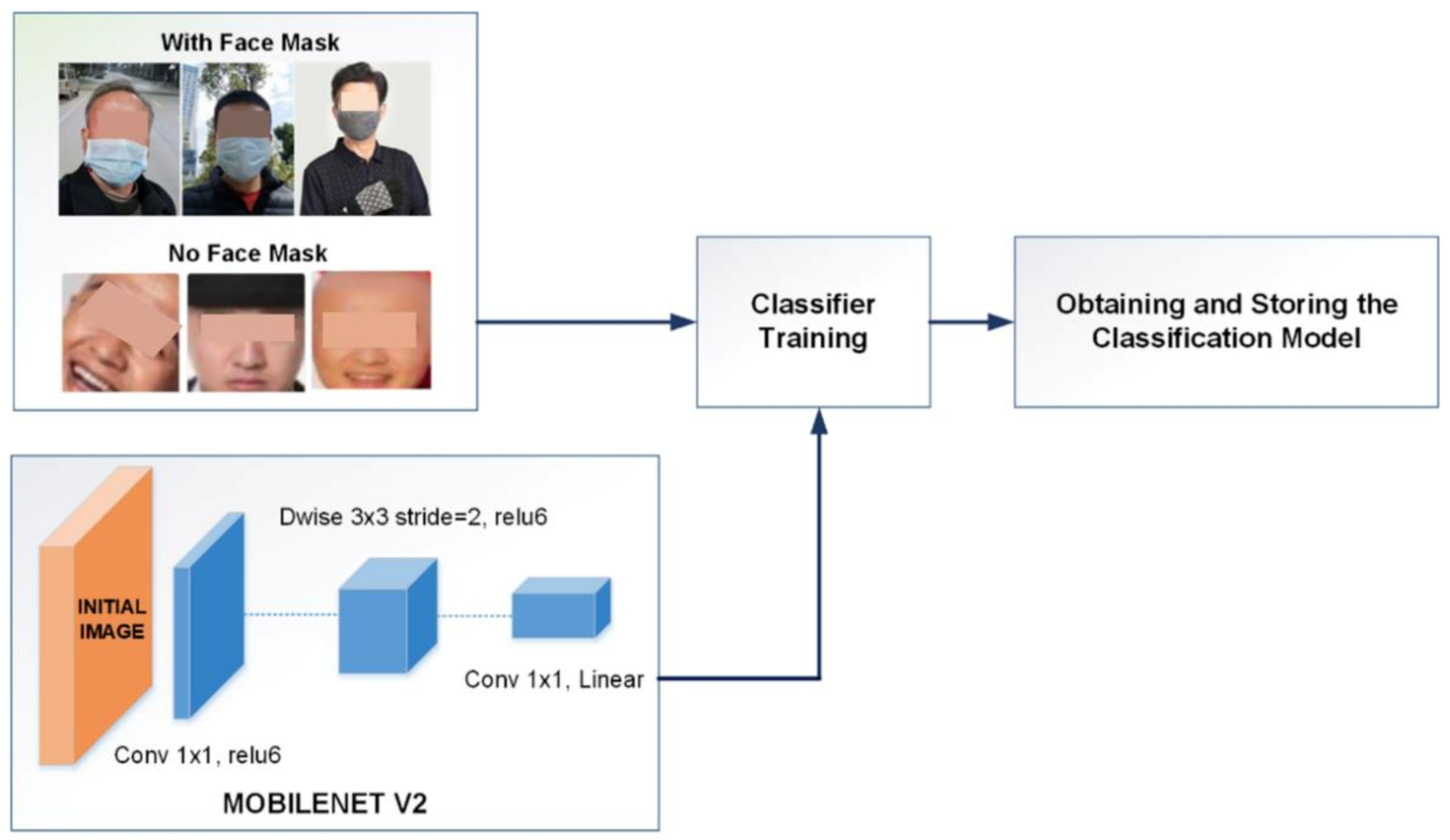
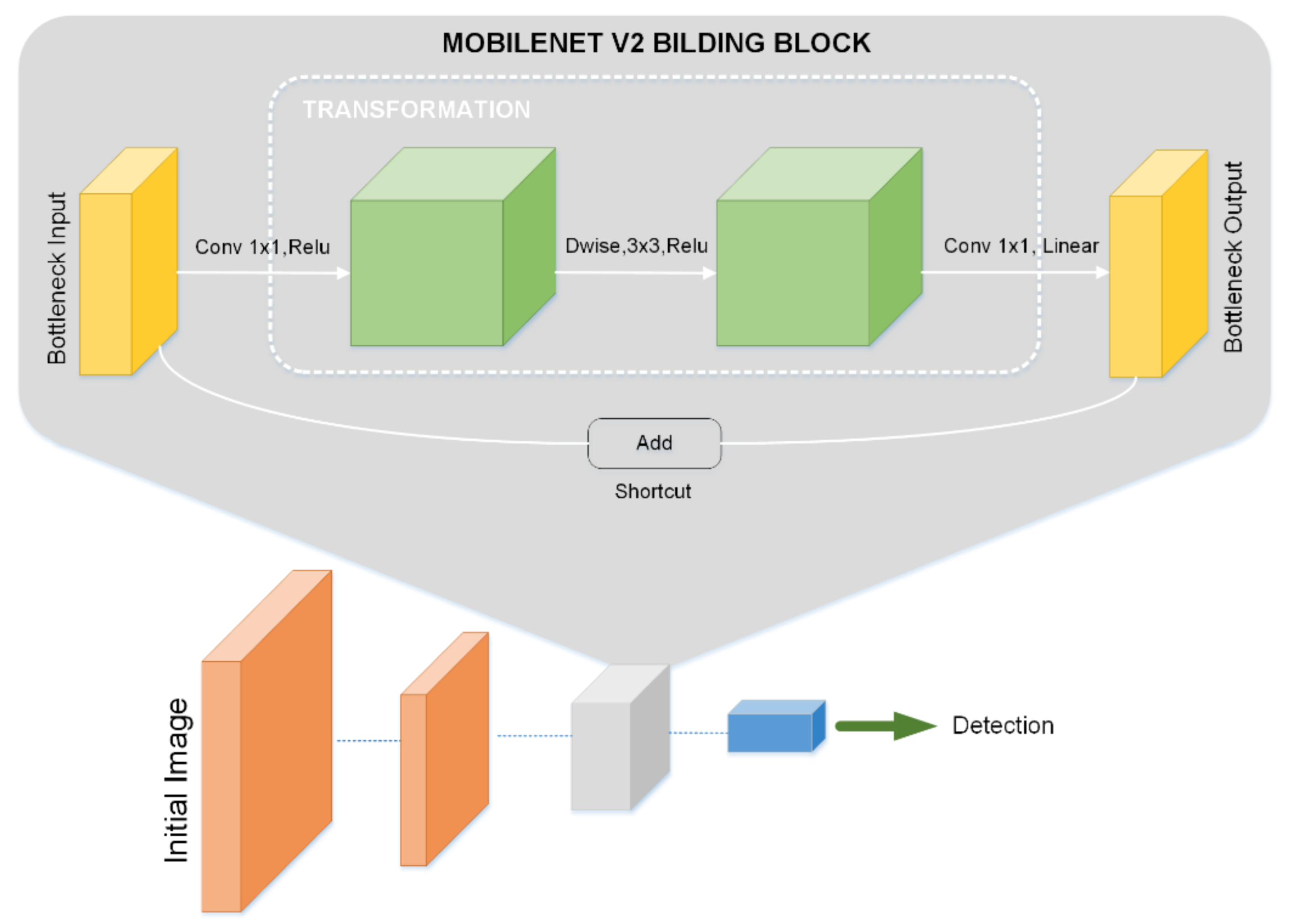
2.3.1. First Stage
2.3.2. Second Stage
2.3.3. Third Stage
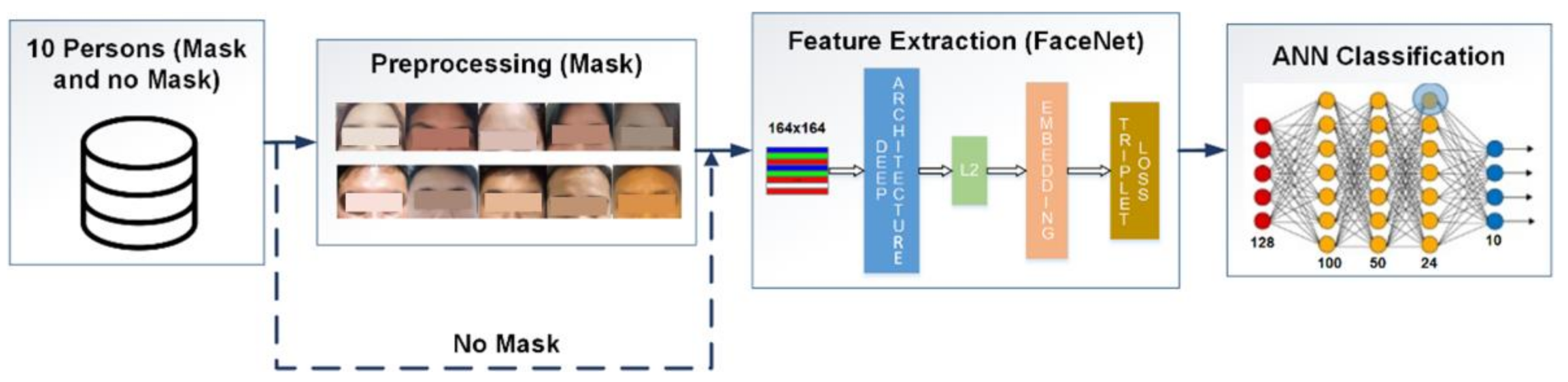
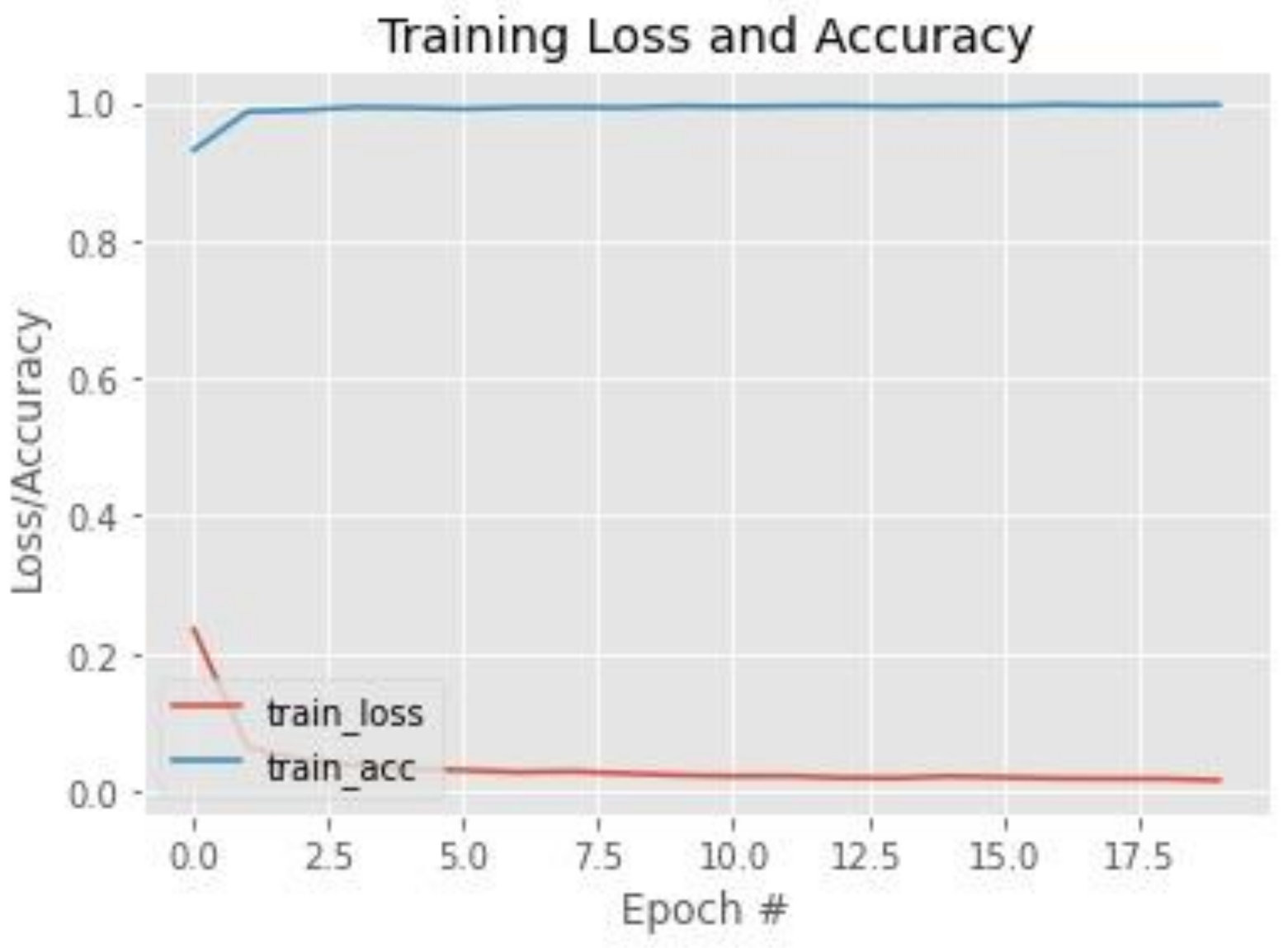
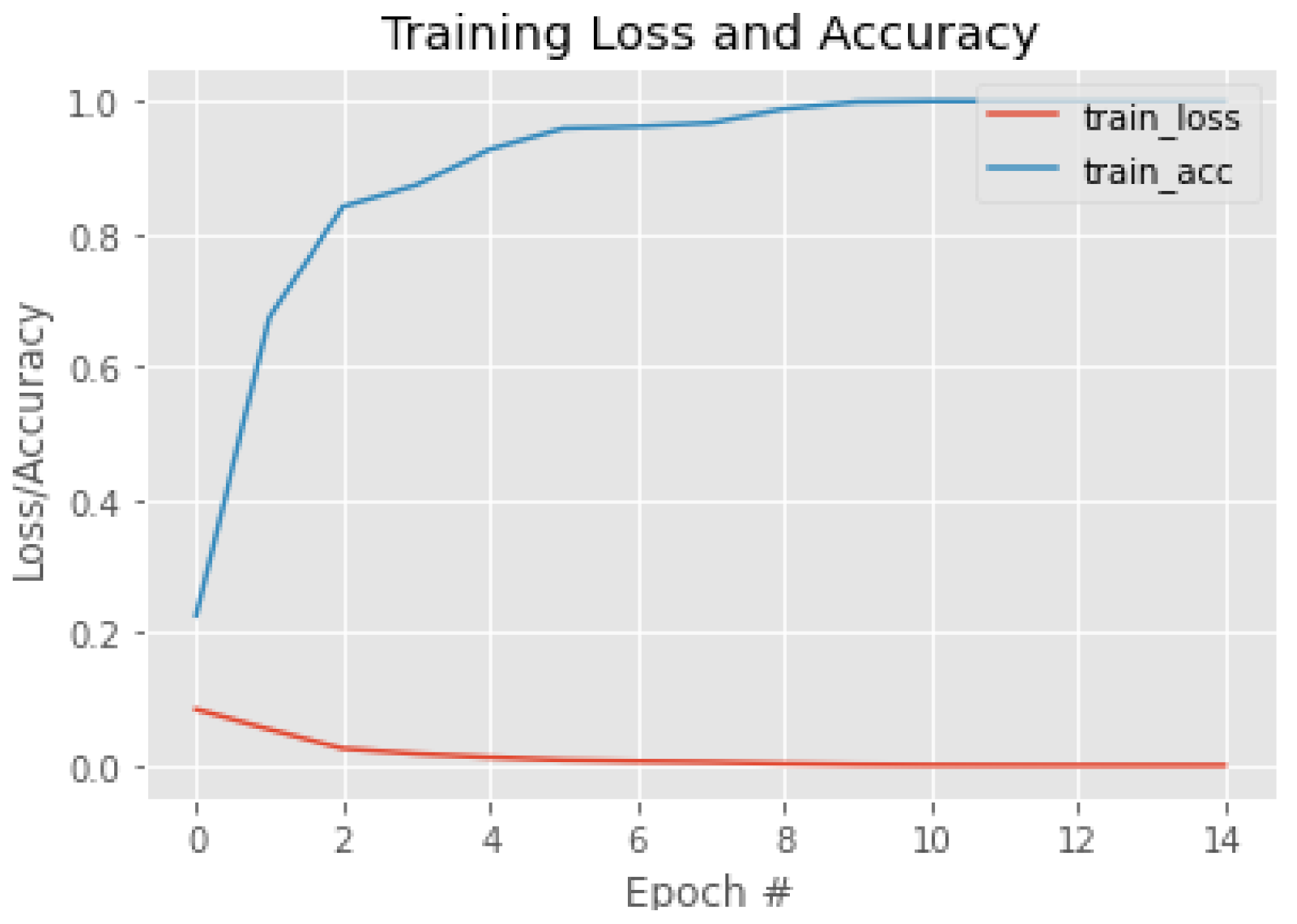
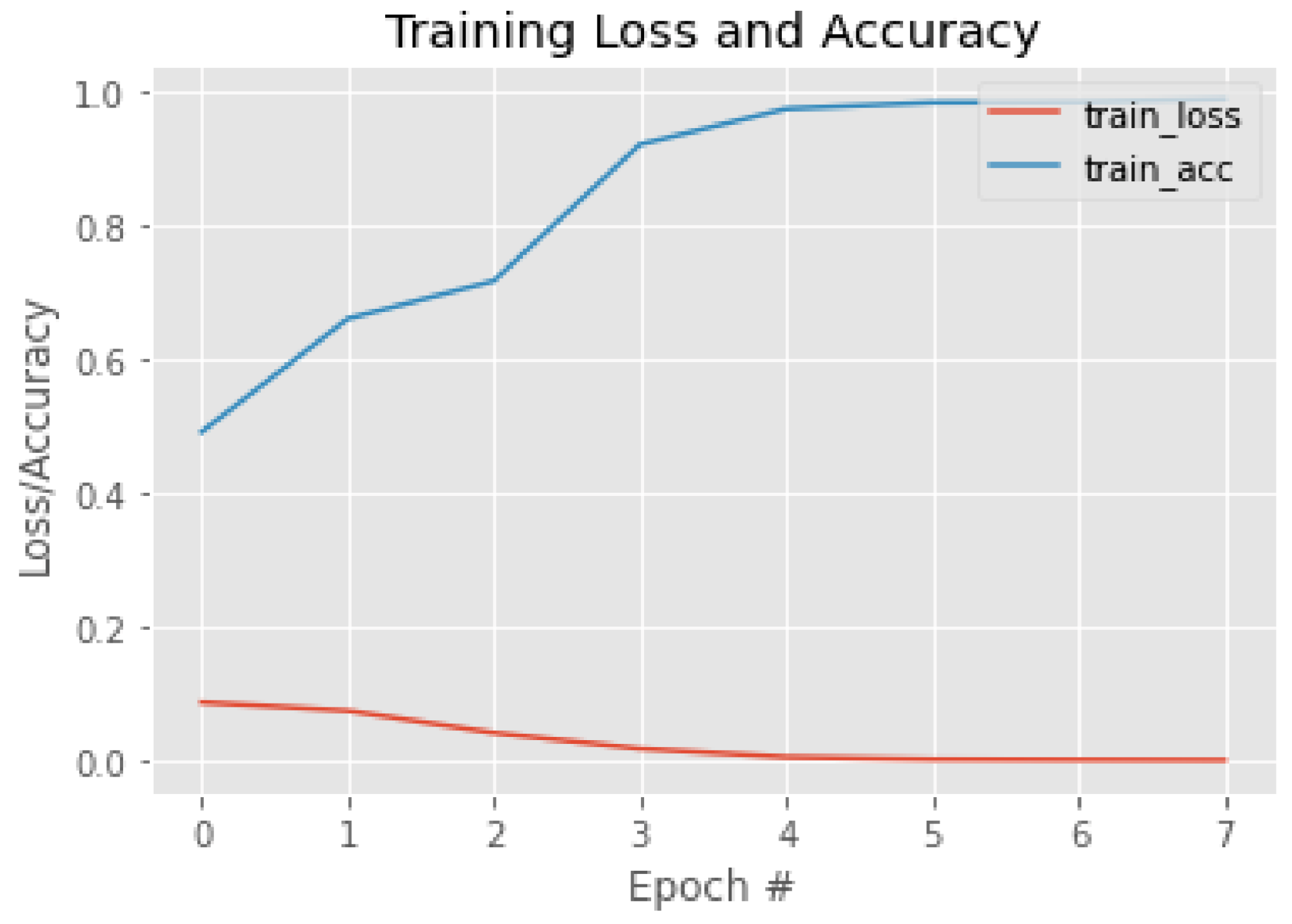
2.4. Training of Facial Recognition Models
- Women: W1, W2, W3, W4, and W5 (Vicky, Mela, Damaris, Ale, and Yaritza, respectively).
- Men: M1, M2, M3, M4, and M5 (Oscar, Jorge, Pablo, John, and Jonathan respectively).

- 128 neurons in the initial layer (size of the feature vector—face embedding)
- 100 neurons in a hidden layer with built-in ReLu activation
- 50 neurons in a hidden layer with built-in ReLu activation
- 24 neurons in a hidden layer with built-in ReLu activation
- 10 neurons in the output layer with a Softmax activation function
- The following configurations are used for classifier training:
- Epochs: 15
- Batch Size: 32
- Optimizer: Adam
- Loss Function: MSE
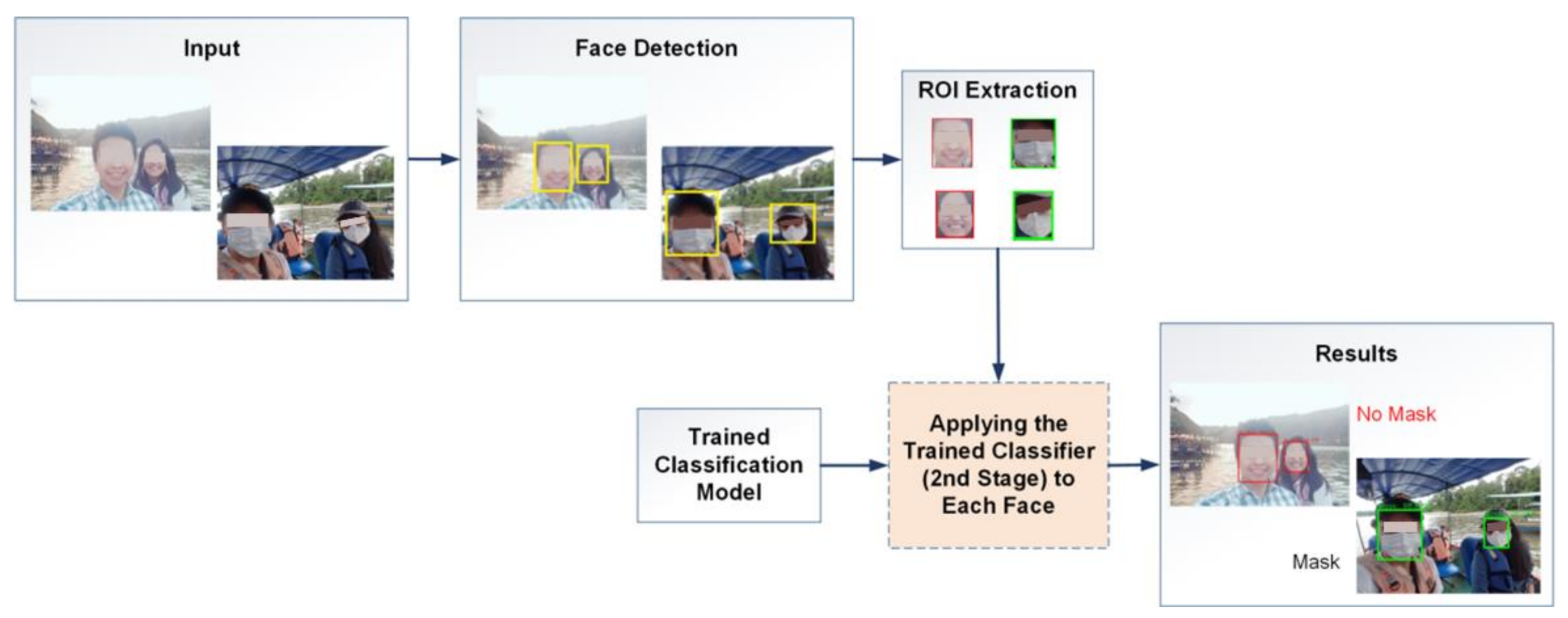
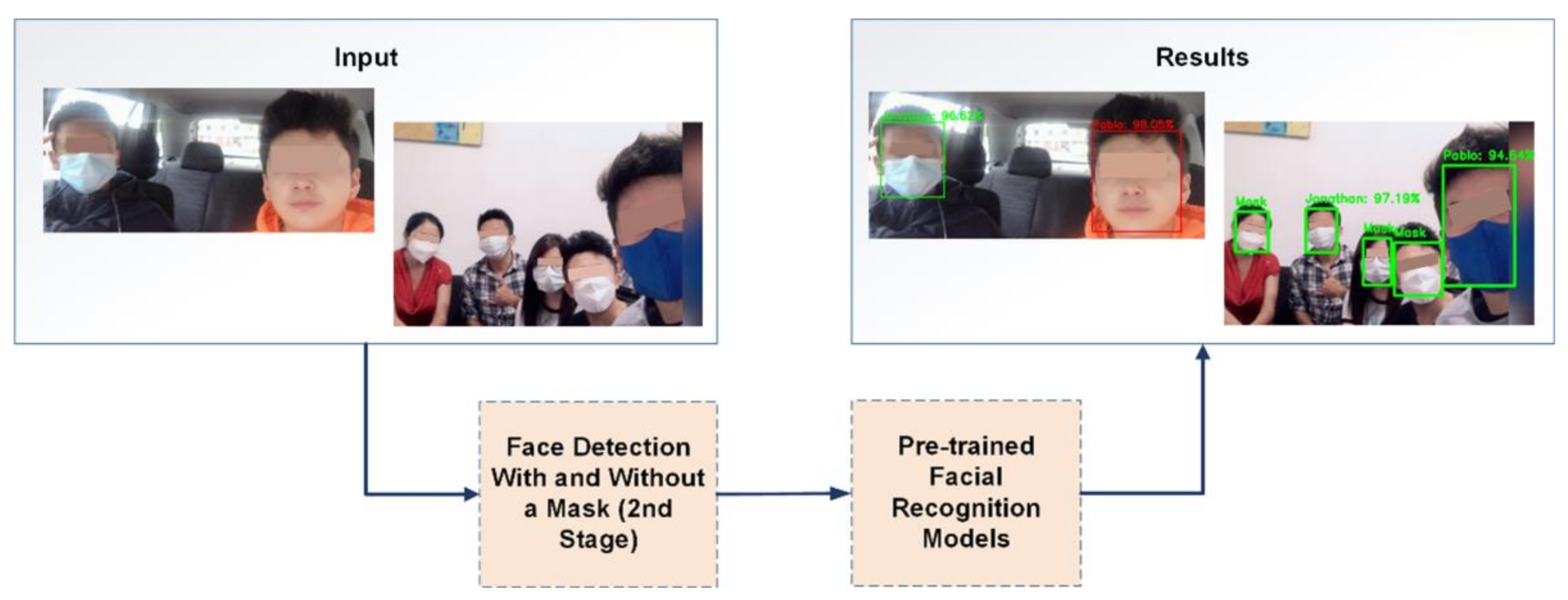
2.5. Application of the Facial Recognition System
2.6. Implementation Costs
- 12 GB RAM
- 50 GB disk
- Duration of 12 h, if it is used for more than 90 min, it disconnects.
- Using a random GPU.
3. Results
3.1. Face Classification—First and Second Stages
3.2. Facial Recognition—Third Stage
4. Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018. [Google Scholar] [CrossRef]
- Chakraborty, B.K.; Sarma, D.; Bhuyan, M.K.; MacDorman, K.F. Review of constraints on vision-based gesture recognition for human-computer interaction. IET Comput. Vis. 2018, 12, 3–15. [Google Scholar] [CrossRef]
- Ko, B.C. A brief review of facial emotion recognition based on visual information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Egger, M.; Ley, M.; Hanke, S. Emotion Recognition from Physiological Signal Analysis: A Review. In Proceedings of the Electronic Notes in Theoretical Computer Science, Yangzhou, China, 14–17 June 2019; Elsevier B.V.: Larnaca, Cyprus, 2019; Volume 343, pp. 35–55. [Google Scholar] [CrossRef]
- Qiu, S.; Liu, Q.; Zhou, S.; Wu, C. Review of artificial intelligence adversarial attack and defense technologies. Appl. Sci. 2019, 9, 909. [Google Scholar] [CrossRef]
- Dang, K.; Sharma, S. Review and comparison of face detection algorithms. In Proceedings of the 7th International Conference Confluence 2017 on Cloud Computing, Data Science and Engineering, Noida, India, 12–13 January 2017; pp. 629–633. [Google Scholar]
- Cook, C.M.; Howard, J.J.; Sirotin, Y.B.; Tipton, J.L.; Vemury, A.R. Demographic Effects in Facial Recognition and Their Dependence on Image Acquisition: An Evaluation of Eleven Commercial Systems. IEEE Trans. Biom. Behav. Identity Sci. 2019, 1, 32–41. [Google Scholar] [CrossRef]
- Dargan, S.; Kumar, M. A comprehensive survey on the biometric recognition systems based on physiological and behavioral modalities. Expert Syst. Appl. 2020, 143, 113114. [Google Scholar] [CrossRef]
- Jeon, B.; Jeong, B.; Jee, S.; Huang, Y.; Kim, Y.; Park, G.H.; Kim, J.; Wufuer, M.; Jin, X.; Kim, S.W.; et al. A facial recognition mobile app for patient safety and biometric identification: Design, development, and validation. JMIR mHealth uHealth 2019, 7, e11472. [Google Scholar] [CrossRef]
- Gonzalez-Sosa, E.; Fierrez, J.; Vera-Rodriguez, R.; Alonso-Fernandez, F. Facial soft biometrics for recognition in the wild: Recent works, annotation, and COTS evaluation. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2001–2014. [Google Scholar] [CrossRef]
- Galterio, M.G.; Shavit, S.A.; Hayajneh, T. A review of facial biometrics security for smart devices. Computers 2018, 7, 37. [Google Scholar] [CrossRef]
- Karthik, K.; Aravindh Babu, R.P.; Dhama, K.; Chitra, M.A.; Kalaiselvi, G.; Alagesan Senthilkumar, T.M.; Raj, G.D. Biosafety Concerns During the Collection, Transportation, and Processing of COVID-19 Samples for Diagnosis. Arch. Med. Res. 2020, 51, 623–630. [Google Scholar] [CrossRef]
- Souza, T.M.L.; Morel, C.M. The COVID-19 pandemics and the relevance of biosafety facilities for metagenomics surveillance, structured disease prevention and control. Biosaf. Heal. 2020, 3, 1–3. [Google Scholar] [CrossRef]
- Ortiz, M.R.; Grijalva, M.J.; Turell, M.J.; Waters, W.F.; Montalvo, A.C.; Mathias, D.; Sharma, V.; Renoy, C.F.; Suits, P.; Thomas, S.J.; et al. Biosafety at home: How to translate biomedical laboratory safety precautions for everyday use in the context of COVID-19. Am. J. Trop. Med. Hyg. 2020, 103, 838–840. [Google Scholar] [CrossRef]
- Mills, M.; Rahal, C.; Akimova, E. Face masks and coverings for the general public: Behavioural knowledge, effectiveness of cloth coverings and public messaging. R. Soc. 2020, 1–37. Available online: https://royalsociety.org/-/media/policy/projects/set-c/set-c-facemasks.pdf?la=en-GB&hash=A22A87CB28F7D6AD9BD93BBCBFC2BB24 (accessed on 5 February 2021).
- Ngan, M.; Grother, P.; Hanaoka, K. Ongoing Face Recognition Vendor Test (FRVT)—Part 6A: Face recognition accuracy with masks using pre-COVID-19 algorithms. Natl. Inst. Stand. Technol. 2020. [Google Scholar] [CrossRef]
- Cheng, V.C.C.; Wong, S.C.; Chuang, V.W.M.; So, S.Y.C.; Chen, J.H.K.; Sridhar, S.; To, K.K.W.; Chan, J.F.W.; Hung, I.F.N.; Ho, P.L.; et al. The role of community-wide wearing of face mask for control of coronavirus disease 2019 (COVID-19) epidemic due to SARS-CoV-2. J. Infect. 2020, 81, 107–114. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhang, S. COVID-19: Face masks and human-to-human transmission. Influenza Other Respi. Viruses 2020, 14, 472–473. [Google Scholar] [CrossRef] [PubMed]
- Rahman, A.; Hossain, M.S.; Alrajeh, N.A.; Alsolami, F. Adversarial Examples—Security Threats to COVID-19 Deep Learning Systems in Medical IoT Devices. IEEE Internet Things J. 2020, 8, 9603–9610. [Google Scholar] [CrossRef]
- Mundial, I.Q.; Ul Hassan, M.S.; Tiwana, M.I.; Qureshi, W.S.; Alanazi, E. Towards facial recognition problem in COVID-19 pandemic. In Proceedings of the 2020 4th International Conference on Electrical, Telecommunication and Computer Engineering, ELTICOM 2020—Proceedings, Medan, Indonesia, 3–4 September 2020; pp. 210–214. [Google Scholar]
- Ting, D.S.W.; Carin, L.; Dzau, V.; Wong, T.Y. Digital technology and COVID-19. Nat. Med. 2020, 26, 459–461. [Google Scholar] [CrossRef]
- Yao, G.; Lei, T.; Zhong, J. A review of Convolutional-Neural-Network-based action recognition. Pattern Recognit. Lett. 2019, 118, 14–22. [Google Scholar] [CrossRef]
- McCann, M.T.; Jin, K.H.; Unser, M. Convolutional neural networks for inverse problems in imaging: A review. IEEE Signal Process. Mag. 2017, 34, 85–95. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Aloysius, N.; Geetha, M. A review on deep convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Communication and Signal Processing, ICCSP 2017, Chennai, India, 6–8 April 2017; Volume 2018, pp. 588–592. [Google Scholar]
- Al-Saffar, A.A.M.; Tao, H.; Talab, M.A. Review of deep convolution neural network in image classification. In Proceedings of the 2017 International Conference on Radar, Antenna, Microwave, Electronics, and Telecommunications, ICRAMET 2017, Jakarta, Indonesia, 23–24 October 2017; Volume 2018, pp. 26–31. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Yang, Z.; Yu, W.; Liang, P.; Guo, H.; Xia, L.; Zhang, F.; Ma, Y.; Ma, J. Deep transfer learning for military object recognition under small training set condition. Neural Comput. Appl. 2019, 31, 6469–6478. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef]
- Schwendicke, F.; Golla, T.; Dreher, M.; Krois, J. Convolutional neural networks for dental image diagnostics: A scoping review. J. Dent. 2019, 91, 103226. [Google Scholar] [CrossRef] [PubMed]
- Van Grinsven, M.J.J.P.; Van Ginneken, B.; Hoyng, C.B.; Theelen, T.; Sánchez, C.I. Fast Convolutional Neural Network Training Using Selective Data Sampling: Application to Hemorrhage Detection in Color Fundus Images. IEEE Trans. Med. Imaging 2016, 35, 1273–1284. [Google Scholar] [CrossRef]
- Zou, L.; Yu, S.; Meng, T.; Zhang, Z.; Liang, X.; Xie, Y. A Technical Review of Convolutional Neural Network-Based Mammographic Breast Cancer Diagnosis. Comput. Math. Methods Med. 2019, 2019. [Google Scholar] [CrossRef]
- Bernal, J.; Kushibar, K.; Asfaw, D.S.; Valverde, S.; Oliver, A.; Martí, R.; Lladó, X. Deep convolutional neural networks for brain image analysis on magnetic resonance imaging: A review. Artif. Intell. Med. 2019, 95, 64–81. [Google Scholar] [CrossRef]
- Hassantabar, S.; Ahmadi, M.; Sharifi, A. Diagnosis and detection of infected tissue of COVID-19 patients based on lung x-ray image using convolutional neural network approaches. Chaos Solitons Fractals 2020, 140, 110170. [Google Scholar] [CrossRef]
- Lalmuanawma, S.; Hussain, J.; Chhakchhuak, L. Applications of machine learning and artificial intelligence for Covid-19 (SARS-CoV-2) pandemic: A review. Chaos Solitons Fractals 2020, 139, 110059. [Google Scholar] [CrossRef]
- Mukherjee, H.; Ghosh, S.; Dhar, A.; Obaidullah, S.M.; Santosh, K.C.; Roy, K. Deep neural network to detect COVID-19: One architecture for both CT Scans and Chest X-rays. Appl. Intell. 2020, 1–13. [Google Scholar] [CrossRef]
- Ardakani, A.A.; Kanafi, A.R.; Acharya, U.R.; Khadem, N.; Mohammadi, A. Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: Results of 10 convolutional neural networks. Comput. Biol. Med. 2020, 121, 103795. [Google Scholar] [CrossRef] [PubMed]
- Marques, G.; Agarwal, D.; de la Torre Díez, I. Automated medical diagnosis of COVID-19 through EfficientNet convolutional neural network. Appl. Soft Comput. J. 2020, 96, 106691. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, N.K.; Rahman, M.M.; Kabir, M.A. PDCOVIDNeT: A parallel-dilated convolutional neural network architecture for detecting COVID-19 from chest X-ray images. Heal. Inf. Sci. Syst. 2020, 8, 27. [Google Scholar] [CrossRef] [PubMed]
- Toraman, S.; Alakus, T.B.; Turkoglu, I. Convolutional capsnet: A novel artificial neural network approach to detect COVID-19 disease from X-ray images using capsule networks. Chaos Solitons Fractals 2020, 140, 110122. [Google Scholar] [CrossRef]
- Panwar, H.; Gupta, P.K.; Siddiqui, M.K.; Morales-Menendez, R.; Singh, V. Application of deep learning for fast detection of COVID-19 in X-Rays using nCOVnet. Chaos Solitons Fractals 2020, 138, 109944. [Google Scholar] [CrossRef]
- Nayak, S.R.; Nayak, D.R.; Sinha, U.; Arora, V.; Pachori, R.B. Application of deep learning techniques for detection of COVID-19 cases using chest X-ray images: A comprehensive study. Biomed. Signal Process. Control 2021, 64, 102365. [Google Scholar] [CrossRef]
- Yu, X.; Lu, S.; Guo, L.; Wang, S.H.; Zhang, Y.D. ResGNet-C: A graph convolutional neural network for detection of COVID-19. Neurocomputing 2020. [Google Scholar] [CrossRef]
- Uddin, M.I.; Shah, S.A.A.; Al-Khasawneh, M.A. A Novel Deep Convolutional Neural Network Model to Monitor People following Guidelines to Avoid COVID-19. J. Sens. 2020, 2020. [Google Scholar] [CrossRef]
- Meivel, S.; Indira Devi, K.; Uma Maheswari, S.; Vijaya Menaka, J. Real time data analysis of face mask detection and social distance measurement using Matlab. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Militante, S.V.; Dionisio, N.V. Real-Time Facemask Recognition with Alarm System using Deep Learning. In Proceedings of the 2020 11th IEEE Control and System Graduate Research Colloquium, ICSGRC 2020—Proceedings, Shah Alam, Malaysia, 8 August 2020; pp. 106–110. [Google Scholar]
- Nagrath, P.; Jain, R.; Madan, A.; Arora, R.; Kataria, P.; Hemanth, J. SSDMNV2: A real time DNN-based face mask detection system using single shot multibox detector and MobileNetV2. Sustain. Cities Soc. 2021, 66, 102692. [Google Scholar] [CrossRef] [PubMed]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. A hybrid deep transfer learning model with machine learning methods for face mask detection in the era of the COVID-19 pandemic. Meas. J. Int. Meas. Confed. 2021, 167, 108288. [Google Scholar] [CrossRef] [PubMed]
- Chowdary, G.J.; Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Face mask detection using transfer learning of inceptionV3. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); In Proceedings of the International Conference on Big Data Analytics, Sonepat, India, 15–18 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 81–90. [Google Scholar]
- Qin, B.; Li, D. Identifying Facemask-Wearing Condition Using Image Super-Resolution with Classification Network to Prevent COVID-19. Sensors 2020, 20, 5236. [Google Scholar] [CrossRef] [PubMed]
- Alonso-Fernandez, F.; Diaz, K.H.; Ramis, S.; Perales, F.J.; Bigun, J. Facial Masks and Soft-Biometrics: Leveraging Face Recognition CNNs for Age and Gender Prediction on Mobile Ocular Images. IET Biom. 2021. [Google Scholar] [CrossRef]
- Kumari, P.; Seeja, K.R. A novel periocular biometrics solution for authentication during Covid-19 pandemic situation. J. Ambient Intell. Humaniz. Comput. 2021, 1, 3. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Wang, X.; Chen, Z.; Wei, B.; Ling, M. Application of Pruning Yolo-V4 with Center Loss in Mask Wearing Recognition for Gymnasiums and Sports Grounds of Colleges and Universities. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications, ICCC 2020, Chengdu, China, 11–14 December 2020; pp. 1373–1377. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Detail |
|---|---|
| Learning rate | 1e-4 |
| Epochs | 20 |
| Batch size | 32 |
| Optimizador: | Adam |
| Loss function | Binary Cross Entropy |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Face mask | 0.99 | 1.00 | 0.99 |
| No face mask | 1.00 | 1.00 | 1.00 |
| Accuracy | 1.00 | ||
| Macro avg | 0.99 | 1.00 | 1.00 |
| Weighted avg | 1.00 | 1.00 | 1.00 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| W4 | 0.99 | 0.98 | 0.98 |
| W3 | 1.00 | 1.00 | 1.00 |
| M4 | 0.99 | 1.00 | 0.99 |
| M5 | 1.00 | 0.99 | 0.99 |
| M2 | 0.99 | 1.00 | 1.00 |
| W2 | 1.00 | 1.00 | 1.00 |
| M1 | 0.99 | 1.00 | 1.00 |
| M3 | 1.00 | 1.00 | 1.00 |
| W1 | 0.97 | 0.99 | 0.98 |
| W5 | 1.00 | 1.00 | 1.00 |
| Accuracy | 1.00 | ||
| Macro avg | 0.99 | 0.99 | 0.99 |
| Weighted avg | 1.00 | 1.00 | 1.00 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| W4 | 1.00 | 0.97 | 0.98 |
| W3 | 1.00 | 1.00 | 1.00 |
| M4 | 1.00 | 1.00 | 1.00 |
| M5 | 1.00 | 1.00 | 1.00 |
| M2 | 1.00 | 1.00 | 1.00 |
| W2 | 1.00 | 1.00 | 1.00 |
| M1 | 1.00 | 1.00 | 1.00 |
| M3 | 1.00 | 1.00 | 1.00 |
| W1 | 0.99 | 1.00 | 1.00 |
| W5 | 1.00 | 1.00 | 1.00 |
| Accuracy | 1.00 | ||
| Macro avg | 1.00 | 1.00 | 1.00 |
| Weighted avg | 1.00 | 1.00 | 1.00 |
| Current Approach | [46] | [47] | [48] | [49] | [50] | [51] | |
|---|---|---|---|---|---|---|---|
| Classification mask and no mask | X | X | X | X | X | X | X |
| Facial recognition | X | ||||||
| Social distance measurement | X | ||||||
| Network type | MobileNetV2 | R-CNN | VGG-16 | MobileNetV2 | SVM | InceptionV3 | SRCNet |
| software | Python | MATLAB | Python | Python | MATLAB | Not specified | MATLAB |
| Prosecution | Google Colab | Not specified | Computer | ||||
| Entry | images | Real time video | images | images | images | images | |
| Image or video capture distance | 0.5 metros | 3 metros | Not specified | Not specified | Not specified | Not specified | Not specified |
| Database size | 13,359 images | Not specified | 12,500 images | 5521 images | 10,000 images | 1570 images | 3835 images |
| Calculation time | 0.84 s | Not specified | Not specified | Not specified | 0.03 s (only classifier) | Not specified | 0.1 s |
| Precision | 99.96% and 99.52% | 93.4% | 96% | 92.64% | 100% | 100% | 98.7% |
| Limitations/Observations | Problems with lighting and programming code that could be optimized. | Problems with white skin tones that are mistaken for the face mask | Adjusting the settings requires a review. | Low performance. | high computational consumption. | Reduced database. It does not have facial recognition. | Reduced database. The images used do not have lighting changes. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Talahua, J.S.; Buele, J.; Calvopiña, P.; Varela-Aldás, J. Facial Recognition System for People with and without Face Mask in Times of the COVID-19 Pandemic. Sustainability 2021, 13, 6900. https://doi.org/10.3390/su13126900
Talahua JS, Buele J, Calvopiña P, Varela-Aldás J. Facial Recognition System for People with and without Face Mask in Times of the COVID-19 Pandemic. Sustainability. 2021; 13(12):6900. https://doi.org/10.3390/su13126900
Chicago/Turabian StyleTalahua, Jonathan S., Jorge Buele, P. Calvopiña, and José Varela-Aldás. 2021. "Facial Recognition System for People with and without Face Mask in Times of the COVID-19 Pandemic" Sustainability 13, no. 12: 6900. https://doi.org/10.3390/su13126900
APA StyleTalahua, J. S., Buele, J., Calvopiña, P., & Varela-Aldás, J. (2021). Facial Recognition System for People with and without Face Mask in Times of the COVID-19 Pandemic. Sustainability, 13(12), 6900. https://doi.org/10.3390/su13126900