
Customer Satisfaction of Recommender System: Examining Accuracy and Diversity in Several Types of Recommendation Approaches



Abstract
1. Introduction
2. Literature Review
2.1. Recommender Systems in E-Commerce
2.2. Methodologies in Recommender Systems
2.3. EDT and Customer Satisfaction
3. Research Hypotheses
3.1. Hypothesis 1: Accuracy of Recommendation
3.2. Hypothesis 2: Diversity of Recommendation
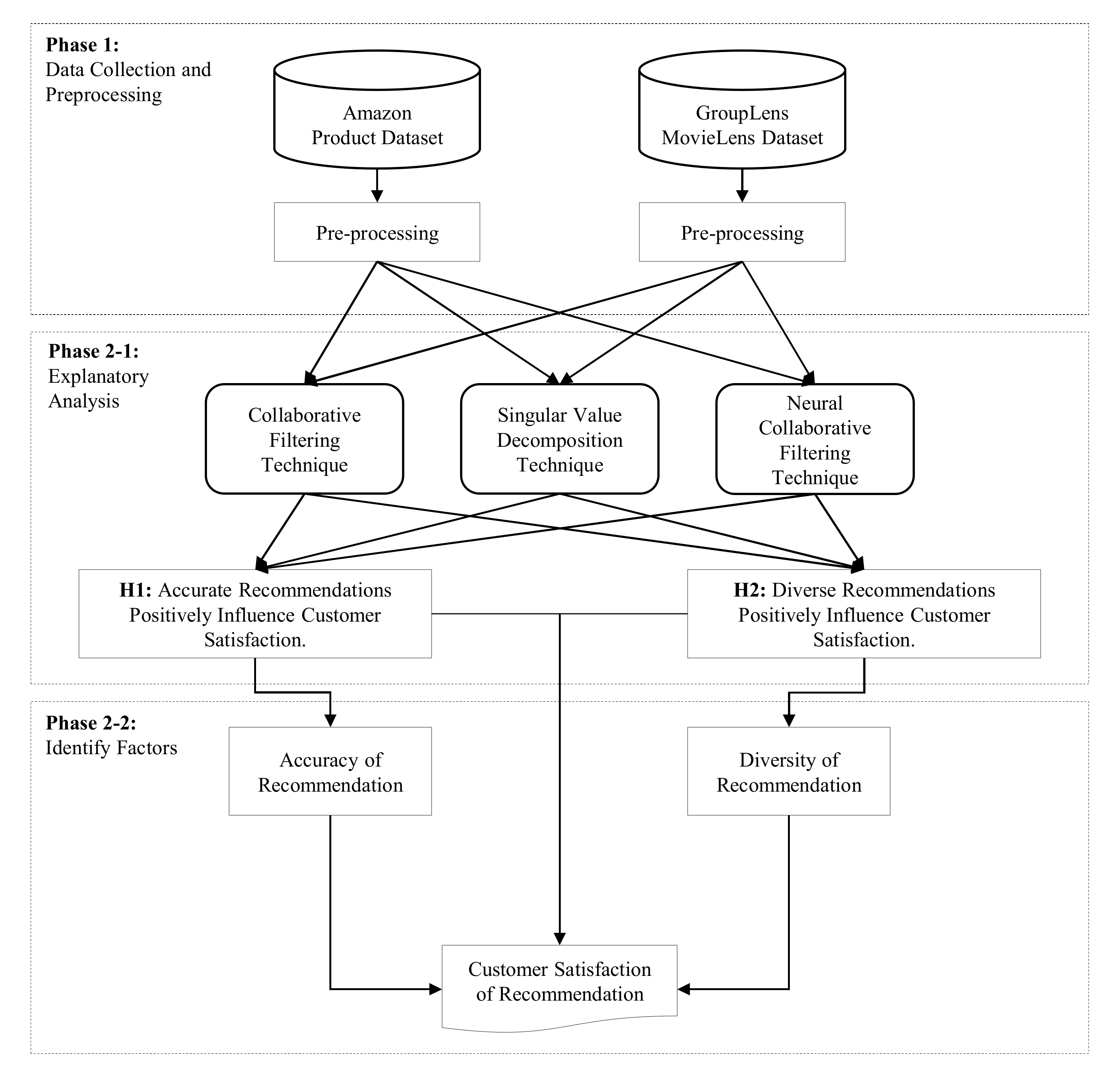
4. Dataset and Evaluation Criteria
4.1. Dataset Collection and Pre-Processing
4.2. Evaluation Criteria of Accuracy, Diversity, and Customer Satisfaction
5. Exploratory Analysis
5.1. Build Several Types of Recommender System
5.1.1. ItemKNN
5.1.2. SVD
5.1.3. NCF
5.2. Experiment 1: Movielens Dataset
5.2.1. Impact of Predictive Factor Size
5.2.2. Impact of Number of Recommendation List
5.2.3. Experimental Results
5.3. Experiment 2: Amazon Dataset
5.3.1. Impact of Predictive Factor Size
5.3.2. Impact of Number of Recommendation List
5.3.3. Experimental Results
6. Conclusions
6.1. Results and Discussion
6.2. Theoretical Contributions and Practical Implications
6.3. Limitations and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cho, Y.H.; Kim, J.K. Application of Web usage mining and product taxonomy to collaborative recommendations in e-commerce. Expert Syst. Appl. 2004, 26, 233–246. [Google Scholar] [CrossRef]
- Linden, G.; Smith, B.; York, J. Amazon.com recommendation—Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Bennett, J.; Lanning, S. The netflix prize. In Proceedings of the KDD Cup and Workshop, San Jose, CA, USA, 12 August 2007; p. 35. [Google Scholar]
- Das, A.S.; Datar, M.; Garg, A.; Rajaram, S. Google news personalization: Scalable online collaborative filtering. In Proceedings of the 16th International Conference on World Wide Web 2007, Banff, AB, Canada, 8–12 May 2007; pp. 271–280. [Google Scholar]
- Kim, H.K.; Kim, J.K.; Ryu, Y.U. Personalized Recommendation over a Customer Network for Ubiquitous Shopping. IEEE Trans. Serv. Comput. 2009, 2, 140–151. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 1–35. [Google Scholar]
- Kim, H.K.; Ryu, Y.U.; Cho, Y.; Kim, J.K. Customer-driven content recommendation over a network of customers. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 42, 48–56. [Google Scholar] [CrossRef]
- Zhou, T.; Kuscsik, Z.; Liu, J.-G.; Medo, M.; Wakeling, J.R.; Zhang, Y.-C. Solving the apparent diversity-accuracy dilemma of recommender systems. Proc. Natl. Acad. Sci. USA 2010, 107, 4511–4515. [Google Scholar] [CrossRef]
- Silveira, T.; Zhang, M.; Lin, X.; Liu, Y.; Ma, S. How good your recommender system is? A survey on evaluations in recommendation. Int. J. Mach. Learn. Cybern. 2019, 10, 813–831. [Google Scholar] [CrossRef]
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Bag, S.; Ghadge, A.; Tiwari, M.K. An integrated recommender system for improved accuracy and aggregate diversity. Comput. Ind. Eng. 2019, 130, 187–197. [Google Scholar] [CrossRef]
- Smyth, B.; McClave, P. Similarity vs. diversity. In Proceedings of the International Conference on Case-Based Reasoning, Vancouver, BC, Canada, 30 July–2 August 2001; pp. 347–361. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Choi, I.Y.; Oh, M.G.; Kim, J.K.; Ryu, Y.U. Collaborative filtering with facial expressions for online video recommendation. Int. J. Inf. Manag. 2016, 36, 397–402. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Riedl, J. Explaining collaborative filtering recommendations. In Proceedings of the 2000 ACM Conference on Computer Supported Cooperative Work, Philadelphia, PA, USA, 2–6 December 2000; pp. 241–250. [Google Scholar]
- Unger, M.; Tuzhilin, A.; Livne, A. Context-Aware Recommendations Based on Deep Learning Frameworks. ACM Trans. Manag. Inf. Syst. (TMIS) 2020, 11, 1–15. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Context-aware recommender systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 217–253. [Google Scholar]
- Colace, F.; De Santo, M.; Lombardi, M.; Santaniello, D. CHARS: A cultural heritage adaptive recommender system. In Proceedings of the 1st ACM International Workshop on Technology Enablers and Innovative Applications for Smart Cities and Communities, New York, NY, USA, 10 November 2019; pp. 58–61. [Google Scholar]
- Colace, F.; Lemma, S.; Lombardi, M.; Pascale, F. A Context Aware Approach for Promoting Tourism Events: The Case of Artist’s Lights in Salerno. In Proceedings of the 19th International Conference on Enterprise Information Systems (ICEIS (2)), Porto, Portugal, 26–29 April 2017; pp. 752–759. [Google Scholar]
- Hurley, N.; Zhang, M. Novelty and diversity in top-n recommendation—Analysis and evaluation. ACM Trans. Internet Technol. (TOIT) 2011, 10, 1–30. [Google Scholar] [CrossRef]
- Adomavicius, G.; Kwon, Y. Improving aggregate recommendation diversity using ranking-based techniques. IEEE Trans. Knowl. Data Eng. 2011, 24, 896–911. [Google Scholar] [CrossRef]
- Zhang, L.; Wei, Q.; Zhang, L.; Wang, B.; Ho, W.-H. Diversity balancing for two-stage collaborative filtering in recommender systems. Appl. Sci. 2020, 10, 1257. [Google Scholar] [CrossRef]
- Kotkov, D.; Veijalainen, J.; Wang, S. How does serendipity affect diversity in recommender systems? A serendipity-oriented greedy algorithm. Computing 2020, 102, 393–411. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Recommender Systems; Springer: Cham, Switzerland, 2016; Volume 1. [Google Scholar]
- Lathia, N.; Hailes, S.; Capra, L.; Amatriain, X. Temporal diversity in recommender systems. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 23 July 2010; pp. 210–217. [Google Scholar]
- Beel, J.; Langer, S.; Genzmehr, M.; Gipp, B.; Breitinger, C.; Nürnberger, A. Research paper recommender system evaluation: A quantitative literature survey. In Proceedings of the International Workshop on Reproducibility and Replication in Recommender Systems Evaluation, Hong Kong, China, 12 October 2013; pp. 15–22. [Google Scholar]
- Isufi, E.; Pocchiari, M.; Hanjalic, A. Accuracy-diversity trade-off in recommender systems via graph convolutions. Inf. Process. Manag. 2021, 58, 102459. [Google Scholar] [CrossRef]
- Eskandanian, F.; Mobasher, B. Using Stable Matching to Optimize the Balance between Accuracy and Diversity in Recommendation. In Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization, Genoa, Italy, 12–18 July 2020; pp. 71–79. [Google Scholar]
- Adomavicius, G.; Kwon, Y. Overcoming accuracy-diversity tradeoff in recommender systems: A variance-based approach. In Proceedings of the 18th Workshop on Information Technology and Systems (WITS), Paris, France, 13–14 December 2008. [Google Scholar]
- Abdel-Hafez, A.; Tang, X.; Tian, N.; Xu, Y. A reputation-enhanced recommender system. In Proceedings of the International Conference on Advanced Data Mining and Applications, Guilin, China, 19–21 December 2014; pp. 185–198. [Google Scholar]
- Christoffel, F.; Paudel, B.; Newell, C.; Bernstein, A. Blockbusters and wallflowers: Accurate, diverse, and scalable recommendations with random walks. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 163–170. [Google Scholar]
- McNee, S.M.; Riedl, J.; Konstan, J.A. Being accurate is not enough: How accuracy metrics have hurt recommender systems. In Proceedings of the CHI’06 Extended Abstracts on Human Factors in Computing Systems, Montréal, QC, Canada, 22–27 April 2006; pp. 1097–1101. [Google Scholar]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Pu, P.; Chen, L.; Hu, R. A user-centric evaluation framework for recommender systems. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 157–164. [Google Scholar]
- Kaminskas, M.; Bridge, D. Diversity, serendipity, novelty, and coverage: A survey and empirical analysis of beyond-accuracy objectives in recommender systems. ACM Trans. Interact. Intell. Syst. (TIIS) 2016, 7, 1–42. [Google Scholar] [CrossRef]
- Elkhani, N.; Bakri, A. Review on “expectancy disconfirmation theory”(EDT) Model in B2C E-Commerce. J. Inf. Syst. Res. Innov. 2012, 2, 95–102. [Google Scholar]
- Liao, C.; Liu, C.-C.; Liu, Y.-P.; To, P.-L.; Lin, H.-N. Applying the expectancy disconfirmation and regret theories to online consumer behavior. CyberpsychologyBehav. Soc. Netw. 2011, 14, 241–246. [Google Scholar] [CrossRef]
- Park, D.H.; Kim, H.K.; Choi, I.Y.; Kim, J.K. A literature review and classification of recommender systems research. Expert Syst. Appl. 2012, 39, 10059–10072. [Google Scholar] [CrossRef]
- Kim, J.K.; Kim, H.K.; Oh, H.Y.; Ryu, Y.U. A group recommendation system for online communities. Int. J. Inf. Manag. 2010, 30, 212–219. [Google Scholar] [CrossRef]
- Guo, Y.; Yin, C.; Li, M.; Ren, X.; Liu, P. Mobile e-commerce recommendation system based on multi-source information fusion for sustainable e-business. Sustainability 2018, 10, 147. [Google Scholar] [CrossRef]
- Van Den Oord, A.; Dieleman, S.; Schrauwen, B. Deep content-based music recommendation. In Proceedings of the Neural Information Processing Systems Conference (NIPS 2013), Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Quadrana, M.; Karatzoglou, A.; Hidasi, B.; Cremonesi, P. Personalizing session-based recommendations with hierarchical recurrent neural networks. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 130–137. [Google Scholar]
- Hu, Y.; Da, Q.; Zeng, A.; Yu, Y.; Xu, Y. Reinforcement learning to rank in e-commerce search engine: Formalization, analysis, and application. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 368–377. [Google Scholar]
- Park, K.; Lee, J.; Choi, J. Deep neural networks for news recommendations. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 2255–2258. [Google Scholar]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Ekstrand, M.D.; Riedl, J.T.; Konstan, J.A. Collaborative Filtering Recommender Systems; Now Publishers Inc: Delft, The Netherlands, 2011. [Google Scholar]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. (CSUR) 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar]
- Cheng, H.-T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Okura, S.; Tagami, Y.; Ono, S.; Tajima, A. Embedding-based news recommendation for millions of users. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1933–1942. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Bhattacherjee, A. Understanding information systems continuance: An expectation-confirmation model. MIS Q. 2001, 25, 351–370. [Google Scholar] [CrossRef]
- Roca, J.C.; Chiu, C.-M.; Martínez, F.J. Understanding e-learning continuance intention: An extension of the Technology Acceptance Model. Int. J. Hum. Comput. Stud. 2006, 64, 683–696. [Google Scholar] [CrossRef]
- Oliver, R.L. A cognitive model of the antecedents and consequences of satisfaction decisions. J. Mark. Res. 1980, 17, 460–469. [Google Scholar] [CrossRef]
- McKinney, V.; Yoon, K.; Zahedi, F.M. The measurement of web-customer satisfaction: An expectation and disconfirmation approach. Inf. Syst. Res. 2002, 13, 296–315. [Google Scholar] [CrossRef]
- Lin, H.-F. The impact of website quality dimensions on customer satisfaction in the B2C e-commerce context. Total Qual. Manag. Bus. Excell. 2007, 18, 363–378. [Google Scholar] [CrossRef]
- Nevo, D.; Chan, Y.E. A temporal approach to expectations and desires from knowledge management systems. Decis. Support Syst. 2007, 44, 298–312. [Google Scholar] [CrossRef]
- Doong, H.-S.; Lai, H. Exploring usage continuance of e-negotiation systems: Expectation and disconfirmation approach. Group Decis. Negot. 2008, 17, 111–126. [Google Scholar] [CrossRef]
- Calvo-Porral, C.; Levy-Mangin, J.P. Switching behavior and customer satisfaction in mobile services: Analyzing virtual and traditional operators. Comput. Hum. Behav. 2015, 49, 532–540. [Google Scholar] [CrossRef]
- Shani, G.; Gunawardana, A. Evaluating recommendation systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 257–297. [Google Scholar]
- Lee, H.I.; Choi, I.Y.; Moon, H.S.; Kim, J.K. A Multi-Period Product Recommender System in Online Food Market based on Recurrent Neural Networks. Sustainability 2020, 12, 969. [Google Scholar] [CrossRef]
- Liang, T.P.; Lai, H.J.; Ku, Y.C. Personalized content recommendation and user satisfaction: Theoretical synthesis and empirical findings. J. Manag. Inf. Syst 2006, 23, 45–70. [Google Scholar] [CrossRef]
- McGinty, L.; Smyth, B. On the role of diversity in conversational recommender systems. In Proceedings of the International Conference on Case-Based Reasoning, Trondheim, Norway, 23–26 June 2003; pp. 276–290. [Google Scholar]
- Ziegler, C.-N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving recommendation lists through topic diversification. In Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 22–32. [Google Scholar]
- Bradley, K.; Smyth, B. Improving recommendation diversity. In Proceedings of the Twelfth Irish Conference on Artificial Intelligence and Cognitive Science, Maynooth, Ireland, 5–7 September 2001; pp. 141–152. [Google Scholar]
- Chen, R.; Hua, Q.; Chang, Y.-S.; Wang, B.; Zhang, L.; Kong, X. A survey of collaborative filtering-based recommender systems: From traditional methods to hybrid methods based on social networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar] [CrossRef]
- Cho, Y.H.; Kim, J.K.; Kim, S.H. A personalized recommender system based on web usage mining and decision tree induction. Expert Syst. Appl. 2002, 23, 329–342. [Google Scholar] [CrossRef]
- Panniello, U.; Tuzhilin, A.; Gorgoglione, M. Comparing context-aware recommender systems in terms of accuracy and diversity. User Modeling User Adapt. Interact. 2014, 24, 35–65. [Google Scholar] [CrossRef]
- Castells, P.; Hurley, N.J.; Vargas, S. Novelty and Diversity in Recommender Systems. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Eds.; Springer: Boston, MA, USA, 2015; pp. 881–918. [Google Scholar] [CrossRef]
- Susan, M.M.; David, S. What makes a helpful online review? A study of customer reviews on amazon.com. MIS Q. 2010, 34, 185–200. [Google Scholar]
- Pujahari, A.; Sisodia, D.S. Pair-wise preference relation based probabilistic matrix factorization for collaborative filtering in recommender system. Knowl. Based Syst. 2020, 196, 105798. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Vozalis, M.G.; Margaritis, K.G. Using SVD and demographic data for the enhancement of generalized collaborative filtering. Inf. Sci. 2007, 177, 3017–3037. [Google Scholar] [CrossRef]
- Paterek, A. Improving regularized singular value decomposition for collaborative filtering. In Proceedings of the KDD Cup and Workshop, San Jose, CA, USA, 12 August 2007; pp. 5–8. [Google Scholar]
- Batmaz, Z.; Yurekli, A.; Bilge, A.; Kaleli, C. A review on deep learning for recommender systems: Challenges and remedies. Artif. Intell. Rev. 2019, 52, 1–37. [Google Scholar] [CrossRef]
- Chen, W.; Cai, F.; Chen, H.; Rijke, M.D. Joint neural collaborative filtering for recommender systems. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 1–30. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | User | Item | Rating | Sparsity |
|---|---|---|---|---|
| MovieLens | 6040 | 3706 | 1,000,209 | 95.53% |
| Amazon | 1,210,271 | 249,274 | 2,023,070 | 99.99% |
| Methods | Variables | Mean | Std. Deviation |
|---|---|---|---|
| ItemKNN | Accuracy Diversity Customer satisfaction | 0.51461 1.05600 0.4820 | 0.39460 0.47720 0.1831 |
| SVD | Accuracy Diversity Customer satisfaction | 0.52531 1.15400 0.5848 | 0.37280 0.42300 0.1497 |
| NCF | Accuracy Diversity Customer satisfaction | 0.69271 1.16280 0.6204 | 0.28320 0.40580 0.2964 |
| Methods | SE | t | p | Result | ||
|---|---|---|---|---|---|---|
| ItemKNN | H1 | 0.662 | 0.23 | 28.930 | ** | Supported |
| H2 | −0.001 | 0.009 | −0.069 | Rejected | ||
| SVD | H1 | 0.067 | 0.006 | 10.3967 | ** | Supported |
| H2 | −0.027 | 0.005 | −5.389 | ** | Rejected | |
| NCF | H1 | 1.023 | 0.023 | 43.672 | ** | Supported |
| H2 | 0.025 | 0.010 | 2.579 | * | Supported | |
| = 0.143, = 0.019, = 0.257 | ||||||
| Subscale and Source | SS | df | MS | F |
|---|---|---|---|---|
| Accuracy of recommendation | ||||
| Between groups | 5.782 | 2 | 1.471 | 2.002 * |
| Within groups | 75.824 | 16,614 | 0.063 | |
| Diversity of recommendation | ||||
| Between groups | 5.671 | 2 | 2.336 | 13.873 ** |
| Within groups | 125.104 | 16,614 | 0.168 | |
| Customer Satisfaction | ||||
| Between groups | 13.322 | 2 | 4.441 | 4.428 * |
| Within groups | 352.277 | 16,614 | 0.960 |
| Methods | Variables | Mean | Std. Deviation |
|---|---|---|---|
| ItemKNN | Accuracy Diversity Customer satisfaction | 0.77970 0.68260 0.6748 | 0.24720 0.31180 0.2652 |
| SVD | Accuracy Diversity Customer satisfaction | 0.67970 0.68780 0.6550 | 0.37280 0.30170 0.2464 |
| NCF | Accuracy Diversity Customer satisfaction | 0.73180 0.71620 0.6911 | 0.28320 0.31830 0.2544 |
| Methods | SE | t | p | Result | ||
| ItemKNN | H1 | 0.731 | 0.019 | 38.585 | ** | Supported |
| H2 | 0.023 | 0.016 | 1.427 | Rejected | ||
| SVD | H1 | 0.753 | 0.025 | 30.215 | ** | Supported |
| H2 | 0.001 | 0.018 | 0.055 | Rejected | ||
| NCF | H1 | 0.392 | 0.021 | 39.789 | * | Supported |
| H2 | 0.664 | 0.054 | 2.144 | * | Supported | |
| = 0.359, = 0.292, = 0.167 | ||||||
| Subscale and Source | SS | df | MS | F |
|---|---|---|---|---|
| Accuracy of recommendation | ||||
| Between groups | 0.010 | 2 | 0.005 | 0.170 ** |
| Within groups | 225.262 | 8025 | 0.028 | |
| Diversity of recommendation | ||||
| Between groups | 4.889 | 2 | 1.154 | 1.265 * |
| Within groups | 156.012 | 8025 | 0.998 | |
| Customer Satisfaction | ||||
| Between groups | 22.758 | 2 | 0.005 | 6.170 ** |
| Within groups | 108.765 | 8025 | 0.028 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Choi, I.; Li, Q. Customer Satisfaction of Recommender System: Examining Accuracy and Diversity in Several Types of Recommendation Approaches. Sustainability 2021, 13, 6165. https://doi.org/10.3390/su13116165
Kim J, Choi I, Li Q. Customer Satisfaction of Recommender System: Examining Accuracy and Diversity in Several Types of Recommendation Approaches. Sustainability. 2021; 13(11):6165. https://doi.org/10.3390/su13116165
Chicago/Turabian StyleKim, Jaekyeong, Ilyoung Choi, and Qinglong Li. 2021. "Customer Satisfaction of Recommender System: Examining Accuracy and Diversity in Several Types of Recommendation Approaches" Sustainability 13, no. 11: 6165. https://doi.org/10.3390/su13116165
APA StyleKim, J., Choi, I., & Li, Q. (2021). Customer Satisfaction of Recommender System: Examining Accuracy and Diversity in Several Types of Recommendation Approaches. Sustainability, 13(11), 6165. https://doi.org/10.3390/su13116165