
Crash Severity Analysis of Highways Based on Multinomial Logistic Regression Model, Decision Tree Techniques, and Artificial Neural Network: A Modeling Comparison

Abstract
1. Introduction
2. Literature Review
3. Research Method
3.1. Data Description
3.2. MLR Model
3.3. ANN-MLP Model
3.4. DT Techniques
3.4.1. C5.0 DT Technique
3.4.2. CHAID DT Technique
3.5. Performance Evaluation of Classifier Accuracy
4. Results
4.1. Correlation Analysis of Independent Variables
4.2. Results of the MLR Model
4.3. Testing Goodness of Fit on the Models
4.4. DT Techniques and the ANN-MLP Model
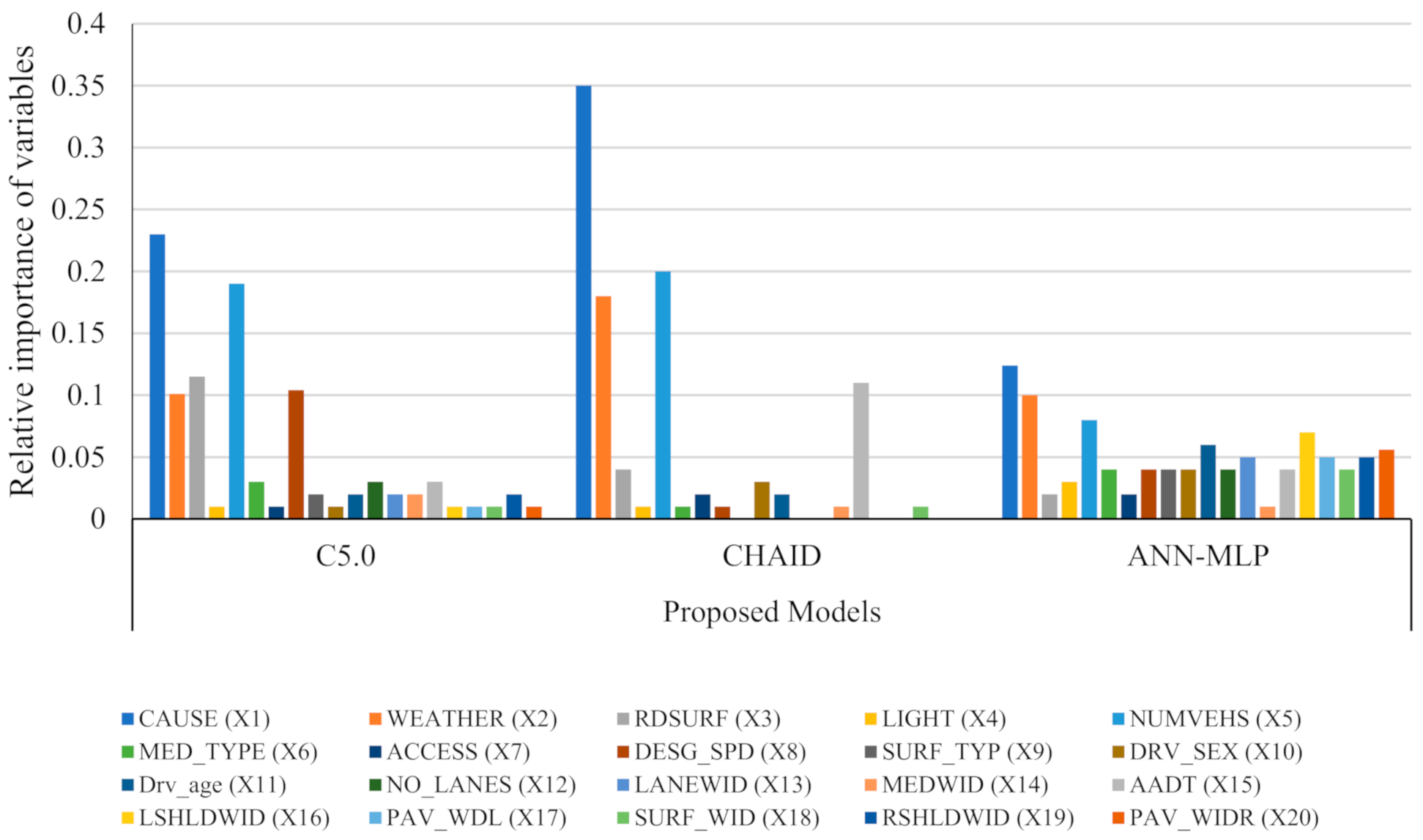
4.5. Sensitivity Analysis
5. Conclusions
- (1)
- Using MLR models, it was observed that independent variables of the cause of the crash (X1), weather conditions (X2), road surface conditions (X3), lighting conditions (X4), the number of vehicles (X5), design speed (X8), and from the driver’s aspect and age (X11) showed significant correlations in crash severity. In addition, regarding the lower values of the AIC, BIC, and χ2 in comparison with other variables, it was found that driver’s age (X11) accounts for a larger proportion of traffic crash severity among the independent variables.
- (2)
- The use of C5.0 and CHAID models indicated that the cause of the crash (CAUSE(X1)) and the number of vehicles (NUMVEHS(X5)) were the most important variables involved in the occurrence of crashes.
- (3)
- The ANN-MLP model indicated that CAUSE (X1) and WEATHER (X2) were as the most influential variables in crash severity.
- (4)
- When using the DT model (C5.0), the prediction accuracy was 94.53%, 76.87%, 83.26%, 89.10%, and 90.33% for the entire applied dataset as a training set with 10-fold cross-validation and after resampling for PDO, fatal, severe injury, other visible injuries, and complaint of pain, respectively. For the CHAID classifier, the prediction accuracy was reported 88.61%, 76.60%, 45.78%, 65.90%, and 76.89% for the entire used dataset as the training set, with 10-fold cross-validation and after resampling for PDO, fatality, severe injury, other visible injuries, and complaint of pain, respectively. For the ANN-MLP classifier, the prediction accuracy for the entire applied dataset as a training set, with 10-fold cross-validation and after resampling for PDO, fatality, severe injury, other visible injuries, and complaint of pain was 88.61%, 85.67%, 78.90%, 82.38%, and 85.57%, respectively. Finally, sensitivity analysis showed that the C5.0 model was selected as the best predictive model with five variables regarding predicting road crash severity since it demonstrated the highest accuracy rate for training and the validation set compared to CHAID, ANN-MLP, and MLR models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Global Status Report on Road Safety; World Health Organization (WHO): Geneva, Switzerland, 2015.
- Zong, F.; Zhang, H.; Xu, H.; Zhu, X.; Wang, L. Predicting Severity and Duration of Road Traffic Accident. Math. Probl. Eng. 2013, 2013, 1–9. [Google Scholar] [CrossRef]
- Hasheminezhad, A.; Hadadi, F.; Shirmohammadi, H. Investigation and prioritization of risk factors in the collision of two passenger trains based on fuzzy COPRAS and fuzzy DEMATEL methods. Soft Comput. 2021, 25, 4677–4697. [Google Scholar] [CrossRef]
- Afandizadeh, S.; Hassanpour, S. Evaluating the Effect of Roadway and Development Factors on the Rural Road Safety Risk Index. Adv. Civ. Eng. 2020, 2020, 7820565. [Google Scholar] [CrossRef]
- HSIS. Highway Safety Information System. 2017. Available online: https://www.hsisinfo.org. (accessed on 15 October 2018).
- Mannering, F.L.; Bhat, C.R. Analytic methods in accident research: Methodological frontier and future directions. Anal. Methods Accid. Res. 2014, 1, 1–22. [Google Scholar] [CrossRef]
- Ratanavaraha, V.; Suangka, S. Impacts of accident severity factors and loss values of crashes on ex-pressways in Thailand. IATSS Res. 2014, 37, 130–136. [Google Scholar] [CrossRef]
- Mafi, S.; Abdelrazig, Y.; Doczy, R. Machine Learning Methods to Analyze Injury Severity of Drivers from Different Age and Gender Groups. Transp. Res. Rec. 2018, 2672, 171–183. [Google Scholar] [CrossRef]
- Hazaa, M.A.; Saad, R.M.; Alnaklani, M.A. Prediction of Traffic Accident Severity Using Data Mining Techniques in IBB Province, Yemen. Int. J. Softw. Eng. Comput. Syst. 2019, 5, 77–92. [Google Scholar] [CrossRef]
- Mokoatle, M. Road Traffic Accident Analysis Using Machine Learning Techniques for Soshanguve, Pretoria. Ph.D. Thesis, North-West University, Potchefstroom, South Africa, 2019. [Google Scholar]
- Abdel-Aty, M. Analysis of driver injury severity levels at multiple locations using ordered probit models. J. Saf. Res. 2003, 34, 597–603. [Google Scholar] [CrossRef]
- Abdel-Aty, M.A.; Abdelwahab, H.T. Predicting Injury Severity Levels in Traffic Crashes: A Modeling Comparison. J. Transp. Eng. 2004, 130, 204–210. [Google Scholar] [CrossRef]
- Milton, J.C.; Shankar, V.N.; Mannering, F.L. Highway accident severities and the mixed logit model: An exploratory empirical analysis. Accid. Anal. Prev. 2008, 40, 260–266. [Google Scholar] [CrossRef]
- Anjana, S.; Anjaneyulu, M.V.L.R. Development of safety performance measures for urban roundabouts in India. J. Transp. Eng. 2015, 141, 04014066. [Google Scholar] [CrossRef]
- Campos, C.I.D.; Santos, M.C.D.; Pitombo, C.S. Characterization of municipalities with high road traffic fatality rates using macro level data and the CART algorithm. J. Appl. Res. Technol. 2018, 16, 79–94. [Google Scholar] [CrossRef]
- Kashani, A.T.; Mohaymany, A.S. Analysis of the traffic injury severity on two-lane, two-way rural roads based on classification tree models. Saf. Sci. 2011, 49, 1314–1320. [Google Scholar] [CrossRef]
- Mansouri, M.; Kargar, M.J. Analysis and Monitoring of the Traffic Suburban Road Accidents Using Data Mining Techniques; A Case Study of Isfahan Province in Iran. Open Transp. J. 2014, 8, 39–49. [Google Scholar] [CrossRef][Green Version]
- Wang, S.; Li, Z. Exploring the mechanism of crashes with automated vehicles using statistical modeling approaches. PLoS ONE 2019, 14, e0214550. [Google Scholar] [CrossRef]
- Rezapour, M.; Molan, A.M.; Ksaibati, K. Application of Multinomial Regression Model to Identify Parameters Impacting Traffic Barrier Crash Severity. Open Transp. J. 2019, 13, 57–64. [Google Scholar] [CrossRef]
- Wahab, L.; Jiang, H. A multinomial logit analysis of factors associated with severity of motorcycle crashes in Ghana. Traffic Inj. Prev. 2019, 20, 521–527. [Google Scholar] [CrossRef]
- Rezapour, M.; Ksaibati, K. Application of multinomial and ordinal logistic regression to model injury severity of truck crashes, using violation and crash data. J. Mod. Transp. 2018, 26, 268–277. [Google Scholar] [CrossRef]
- Pradipta, P.; Siregar, M.L.; Kusuma, A. Modelling of severity level causes factors in the traffic accident victims in the province of West Nusa Tenggara. IOP Conf. Ser. 2020, 426, 012027. [Google Scholar] [CrossRef]
- Vajari, M.A.; Aghabayk, K.; Sadeghian, M.; Shiwakoti, N. A multinomial logit model of motorcycle crash severity at Australian intersections. J. Saf. Res. 2020, 73, 17–24. [Google Scholar] [CrossRef]
- Abdulhafedh, A. Incorporating the Multinomial Logistic Regression in Vehicle Crash Severity Modeling: A Detailed Overview. J. Transp. Technol. 2017, 7, 279–303. [Google Scholar] [CrossRef]
- Shirmohammadi, H.; Hadadi, F. Assessment of drowsy drivers by fuzzy logic approach based on multinomial logistic regression analysis. Int. J. Comput. Sci. Netw. Secur. 2017, 17, 298. [Google Scholar]
- Gholizadeh, P.; Esmaeili, B. Developing a Multi-variate Logistic Regression Model to Analyze Accident Scenarios: Case of Electrical Contractors. Int. J. Environ. Res. Public Health 2020, 17, 4852. [Google Scholar] [CrossRef]
- Chen, Z.; Fan, W.D. A multinomial logit model of pedestrian-vehicle crash severity in North Carolina. Int. J. Transp. Sci. Technol. 2019, 8, 43–52. [Google Scholar] [CrossRef]
- Abdelwahab, H.T.; Abdel-Aty, M.A. Development of Artificial Neural Network Models to Predict Driver Injury Severity in Traffic Accidents at Signalized Intersections. Transp. Res. Rec. 2001, 1746, 6–13. [Google Scholar] [CrossRef]
- Shirmohammadi, H.; Hadadi, F.; Saeedian, M. Clustering analysis of drivers based on behavioral characteristics regarding road safety. Int. J. Civ. Eng. 2019, 17, 1327–1340. [Google Scholar] [CrossRef]
- Shirmohammadi, H.; Najib, A.S.; Hadadi, F. Identification of Road Critical Segments Using Wavelet Theory and Multi-Criteria Decision-Making Method. Eur. Transp. 2018, 68, 1–14. [Google Scholar]
- Alkheder, S.; Taamneh, M.; Taamneh, S. Severity Prediction of Traffic Accident Using an Artificial Neural Network. J. Forecast. 2017, 36, 100–108. [Google Scholar] [CrossRef]
- Taamneh, M.; Taamneh, S.; Alkheder, S. Clustering-based classification of road traffic accidents using hierarchical clustering and artificial neural networks. Int. J. Inj. Control Saf. Promot. 2017, 24, 388–395. [Google Scholar] [CrossRef]
- Mokhtarimousavi, S.; Anderson, J.C.; Azizinamini, A.; Hadi, M. Improved Support Vector Machine Models for Work Zone Crash Injury Severity Prediction and Analysis. Transp. Res. Rec. 2019, 2673, 680–692. [Google Scholar] [CrossRef]
- Wahab, L.; Jiang, H. A comparative study on machine learning based algorithms for prediction of motorcycle crash severity. PLoS ONE 2019, 14, e0214966. [Google Scholar] [CrossRef]
- Amiri, A.M.; Sadri, A.; Nadimi, N.; Shams, M. A comparison between artificial neural network and hybrid intelligent genetic algorithm in predicting the severity of fixed object crashes among elderly drivers. Accid. Anal. Prev. 2020, 138, 105468. [Google Scholar] [CrossRef]
- Ooi, S.Y.; Tan, S.C.; Cheah, W.P. Temporal Sleuth Machine with decision tree for temporal classification. Soft Comput. 2018, 22, 8077–8095. [Google Scholar] [CrossRef]
- Banerjee, A.; Raoniar, R.; Maurya, A.K. Pedestrian overpass utilization modeling based on mobility friction, safety and security, and connectivity using machine learning techniques. Soft Comput. 2020, 24, 17467–17493. [Google Scholar] [CrossRef]
- Mondal, A.R.; Bhuiyan, A.E.; Yang, F. Advancement of weather-related crash prediction model using nonparametric machine learning algorithms. SN Appl. Sci. 2020, 2, 1–11. [Google Scholar] [CrossRef]
- Chang, L.-Y.; Chien, J.-T. Analysis of driver injury severity in truck-involved accidents using a non-parametric classification tree model. Saf. Sci. 2013, 51, 17–22. [Google Scholar] [CrossRef]
- Chong, M.M.; Abraham, A.; Paprzycki, M. Traffic accident analysis using decision trees and neural networks. arXiv 2004, arXiv:cs/0405050. [Google Scholar]
- Beshah, T.; Hill, S. Mining road traffic accident data to improve safety: Role of road-related factors on accident severity in Ethiopia. In AAAI Spring Symposium: Artificial Intelligence for Development; The AAAI Press: Menlo Park, CA, USA, 2010; Volume 24, pp. 1173–1181. [Google Scholar]
- O′Connor, A. An Analysis of the Predictive Capability of C5. 0 and Chaid Decision Trees and Bayes Net in the Classification of fatal Traffic Accidents in the UK. Master′s Thesis, Technological University, Dublin, Ireland, 2015. [Google Scholar]
- Sut, N.; Simsek, O. Comparison of regression tree data mining methods for prediction of mortality in head injury. Expert Syst. Appl. 2011, 38, 15534–15539. [Google Scholar] [CrossRef]
- Prati, G.; Pietrantoni, L.; Fraboni, F. Using data mining techniques to predict the severity of bicycle crashes. Accid. Anal. Prev. 2017, 101, 44–54. [Google Scholar] [CrossRef]
- Hezaveh, A.M.; Azad, M.; Cherry, C.R. Pedestrian Crashes in Tennessee: A Data Mining Approach. Presented at the Transportation Research Board 97th Annual Meeting, Washington, DC, USA, 7–11 January 2018. [Google Scholar]
- Saracoglu, A.; Ozen, H. Estimation of Traffic Incident Duration: A Comparative Study of Decision Tree Models. Arab. J. Sci. Eng. 2020, 45, 8099–8110. [Google Scholar] [CrossRef]
- Behbahani, H.; Amiri, A.M.; Imaninasab, R.; Alizamir, M. Forecasting accident frequency of an urban road network: A comparison of four artificial neural network techniques. J. Forecast. 2018, 37, 767–780. [Google Scholar] [CrossRef]
- Amiri, A.M.; Nadimi, N.; Ragland, D.R.; Imaninasab, R. Predicting Crash Severity Based on Its Related Collision Type Using Five Data Mining Techniques. Presented at the Transportation Research Board 97th Annual Meeting, Washington DC, USA, 7–11 January 2018. [Google Scholar]
- Iranitalab, A.; Khattak, A. Comparison of four statistical and machine learning methods for crash severity prediction. Accid. Anal. Prev. 2017, 108, 27–36. [Google Scholar] [CrossRef] [PubMed]
- Singh, G.; Pal, M.; Yadav, Y.; Singla, T. Deep neural network-based predictive modeling of road accidents. Neural Comput. Appl. 2020, 32, 12417–12426. [Google Scholar] [CrossRef]
- Al-Ghamdi, A.S. Using logistic regression to estimate the influence of accident factors on accident severity. Accid. Anal. Prev. 2002, 34, 729–741. [Google Scholar] [CrossRef]
- Xi, J.; Liu, H.; Zhao, Z.; Ding, T. Correlation Analysis of Driver Factors to Traffic Accident Severity. In Proceedings of the ICTE 2013: Safety, Speediness, Intelligence, Low-Carbon, Innovation, Chengdu, China, 19–20 October 2013. [Google Scholar]
- Eboli, L.; Forciniti, C.; Mazzulla, G. Factors influencing accident severity: An analysis by road accident type. Transp. Res. Procedia 2020, 47, 449–456. [Google Scholar] [CrossRef]
- McCullagh, P.; Nelder, J. Generalized Linear Models, 2nd ed.; Chapman & Hall: London, UK, 1989. [Google Scholar]
- Çamdeviren, H.; Yazici, A.; Akkus, Z.; Bugdayci, R.; Sungur, M. Comparison of logistic regression model and classification tree: An application to postpartum depression data. Expert Syst. Appl. 2007, 32, 987–994. [Google Scholar] [CrossRef]
- Zeng, P. Neural Computing in Mechanics. Appl. Mech. Rev. 1998, 51, 173–197. [Google Scholar] [CrossRef]
- Priddy, K.L.; Keller, P.E. Artificial Neural Networks: An Introduction; SPIE Press: Bellingham, WS, USA, 2005. [Google Scholar]
- Ghorbani, M.A.; Zadeh, H.A.; Isazadeh, M.; Terzi, O. A comparative study of artificial neural network (MLP, RBF) and support vector machine models for river flow prediction. Environ. Earth Sci. 2016, 75, 1–14. [Google Scholar] [CrossRef]
- Shamsashtiany, R.; Ameri, M. Road accidents prediction with multilayer perceptron MLP modelling case study: Roads of Qazvin, Zanjan and Hamadan. J. Civ. Eng. Mater. Appl. 2018, 2, 181–192. [Google Scholar]
- Meireles, M.; Almeida, P.; Simoes, M. A comprehensive review for industrial applicability of artificial neural networks. IEEE Trans. Ind. Electron. 2003, 50, 585–601. [Google Scholar] [CrossRef]
- Wilkinson, L. Tree structured data analysis: AID, CHAID and CART. In Proceedings of the Sawtooth/SYSTAT Join Software Conference, Idaho, ID, USA, 1992; 10p. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, S.; Liu, Z.; Cui, G.; Wang, Y. Influencing factors analysis of side right-angle collisions severity at intersections based on decision tree. Int. J. Crashworthiness 2020, 1–11. [Google Scholar] [CrossRef]
- Pandya, R.; Pandya, J. C5. 0 Algorithm to Improved Decision Tree with Feature Selection and Reduced Error Pruning. Int. J. Comput. Appl. 2015, 117, 18–21. [Google Scholar] [CrossRef]
- Milanović, M.; Stamenković, M. CHAID Decision Tree: Methodological Frame and Application. Econ. Themes 2016, 54, 563–586. [Google Scholar] [CrossRef]
- Kass, G.V. An Exploratory Technique for Investigating Large Quantities of Categorical Data. J. R. Stat. Soc. Ser. C 1980, 29, 119. [Google Scholar] [CrossRef]
- Atti, A.; Dodo, D. Chi-Square Automatic Interaction Detection (Chaid) Analysis for Home Quality Status Segmentation. Am. J. Eng. Res. 2018, 7, 183–188. [Google Scholar]
- Althuwaynee, O.F.; Pradhan, B.; Park, H.J.; Lee, J.H. A novel ensemble decision tree-based CHi-squared Automatic Interaction Detection (CHAID) and multivariate logistic regression models in landslide susceptibility mapping. Landslides 2014, 11, 1063–1078. [Google Scholar] [CrossRef]
- Cruz, A.P.D. Predicting the relapse category in patients with tuberculosis: A chi-square automatic interaction detector (CHAID) decision tree analysis. Open J. Soc. Sci. 2018, 6, 29. [Google Scholar] [CrossRef]
- Susanti, Y.; Zukhronah, E.; Pratiwi, H.; Respatiwulan; Sulistijowati, H.S. Analysis of Chi-square Automatic Interaction Detection (CHAID) and Classification and Regression Tree (CRT) for Classification of Corn Production. J. Phys. Conf. Ser. 2017, 909, 12041. [Google Scholar] [CrossRef]
- Šimundić, A.-M. Measures of Diagnostic Accuracy: Basic Definitions. EJIFCC 2009, 19, 203–211. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Abbreviation | Variable Symbol | Data Type | Code/Unit | Description | Percentage of Total Crashes (%) | ||
|---|---|---|---|---|---|---|---|---|
| 2012 | 2013 | 2014 | ||||||
| Cause of crash | CAUSE | X1 | Qualitative | 1 | Driving under influence | 6.7 | 8.7 | 10.6 |
| 2 | Following too closely | 1.9 | 7.41 | 4.9 | ||||
| 3 | Failure to yield | 2.9 | 7.34 | 2.50 | ||||
| 4 | Improper turn | 16.7 | 14.59 | 13.99 | ||||
| 5 | Speeding | 46.9 | 39.79 | 50.82 | ||||
| 6 | Other violations (Hazardous) | 19.9 | 17.77 | 11.89 | ||||
| 7 | Other improper driving | 0.2 | 1.2 | 0.9 | ||||
| 8 | Alcohol/drug use | 4.8 | 2.5 | 3.2 | ||||
| 9 | Fell asleep | 0 | 0.7 | 1.2 | ||||
| Weather condition | WEATHER | X2 | Qualitative | 1 | Clear | 79.4 | 63.80 | 54.32 |
| 2 | Cloudy | 15.9 | 19.89 | 35.88 | ||||
| 3 | Raining | 3.7 | 9.73 | 5.1 | ||||
| 4 | Snowing | 0.3 | 3.18 | 2.7 | ||||
| 5 | Fog | 0.3 | 2.8 | 1.6 | ||||
| 6 | Wind | 0 | 0 | 0 | ||||
| 7 | Other | 0.1 | 0.6 | 0.3 | ||||
| 8 | Not stated | 0.3 | 0 | 0.1 | ||||
| Road surface condition | RDSURF | X3 | Qualitative | 1 | Dry | 88.7 | 77.89 | 67.21 |
| 2 | Wet | 10 | 19.45 | 28.14 | ||||
| 3 | Snowy or icy | 0.8 | 2.06 | 3.7 | ||||
| 4 | Slippery or muddy | 0.1 | 0.6 | 0.95 | ||||
| 5 | Not stated | 0.4 | 0 | 0 | ||||
| Lighting conditions | LIGHT | X4 | Qualitative | 1 | Daylight | 69 | 78 | 84.52 |
| 2 | Dusk—Dawn | 3.4 | 5.8 | 3.7 | ||||
| 3 | Dark—Street Lights | 15 | 11 | 9.18 | ||||
| 4 | Dark—No Street Lights | 12.1 | 2.9 | 1.7 | ||||
| 5 | Dark—Street Lights Not Functioning | 0.3 | 1.9 | 0.9 | ||||
| 6 | Not stated | 0.3 | 0.4 | 0 | ||||
| Number of vehicles | NUMVEHS | X5 | Qualitative | 1–9 | 1 to 9 vehicles involved in a crash | 22.7; 60.5; 12.9; 3; 0.7; 0.2; 0; 0. | 26.7; 59.5; 10.9; 1.7; 0.8; 0.4; 0; 0 | 18.87; 47.8; 19.9; 11.63; 0.9; 0.3; 0.6; 0. |
| 10–15 | 10 to 15 vehicles involved in a crash | 0; 0; 0; 0; 0; 0. | 0; 0; 0; 0; 0; 0. | 0; 0; 0; 0; 0; 0. | ||||
| Median type | MED_TYPE | X6 | Qualitative | 1 | Undivided, Not Separated or Striped | 0.1 | 0.3 | 0.2 |
| 2 | Undivided, Striped | 10.4 | 7.97 | 12.6 | ||||
| 3 | Undivided, Reversible Peak Hour Lane (S) | 0 | 0 | 0 | ||||
| 4 | Divided, Two-Way Left Turn Lane | 0.9 | 0.4 | 0.7 | ||||
| 5 | Divided, Continuous Left-Turn Lane | 2.2 | 1.9 | 0.8 | ||||
| 6 | Divided, Paved Median | 49.8 | 59.68 | 48.89 | ||||
| 7 | Divided, Unpaved Median | 17.2 | 16.66 | 20.51 | ||||
| 8 | Divided, Separate Grades | 3.8 | 1.9 | 2.9 | ||||
| 9 | Divided, Separate Grades with Retaining Wall | 0.1 | 0 | 0 | ||||
| 10 | Divided, Sawtooth (Paved) | 0 | 0 | 0 | ||||
| 11 | Divided, Separate Structure | 14.5 | 10.7 | 13.4 | ||||
| 12 | Divided, Railroad or Rapid Transit | 0.3 | 0.5 | 0 | ||||
| 13 | Divided, Bus Lanes | 0 | 0 | 0 | ||||
| 14 | Divided, Other | 0.6 | 0 | 0 | ||||
| Facility access | ACCESS | X7 | Qualitative | 1 | Conventional—No Access Control | 20.3 | 29.78 | 20.97 |
| 2 | Expressway—Partial Access Control | 8.1 | 6.53 | 4.8 | ||||
| 3 | Freeway—Full Access Control | 71.1 | 63.69 | 74.23 | ||||
| 4 | One-Way City Street—No Access Control | 0.4 | 0 | 0 | ||||
| Design speed | DESG_ SPD | X8 | Qualitative | 1 | <30 mile/h | 0.2 | 0.1 | 0 |
| 2 | 30 mile/h | 0.4 | 0.7 | 0.8 | ||||
| 3 | 35 mile/h | 0.7 | 1.3 | 0.9 | ||||
| 4 | 40 mile/h | 1.8 | 3.8 | 1.7 | ||||
| 5 | 45 mile/h | 3.2 | 2.9 | 1.5 | ||||
| 6 | 50 mile/h | 3.9 | 1.9 | 4.5 | ||||
| 7 | 55 mile/h | 2.7 | 2.01 | 3.90 | ||||
| 8 | 60 mile/h | 8.3 | 5.7 | 8.7 | ||||
| 9 | 65 mile/h | 8.8 | 10.6 | 9.04 | ||||
| 10 | >70 mile/h | 70.1 | 70.99 | 68.96 | ||||
| Surface type | SURF_TYP | X9 | Qualitative | 1 | PCC, Bridge Deck | 27.9 | 19.91 | 20.89 |
| 2 | PCC, Concrete | 36.4 | 32.78 | 37.89 | ||||
| 3 | Unpaved-Earth | 0 | 0 | 0 | ||||
| 4 | Unpaved-Undetermined | 0 | 0 | 0 | ||||
| 5 | AC, Base & Surface 7” Thick | 33.3 | 43.86 | 34.67 | ||||
| 6 | AC, Base & Surface < 7” Thick | 1.2 | 2.66 | 3.7 | ||||
| 7 | AC, Oiled Earth-Gravel | 0.1 | 0 | 0.55 | ||||
| 8 | AC, Bridge Deck (2” Or Greater) | 0 | 0 | 0 | ||||
| 9 | Not stated | 1 | 0.8 | 2.3 | ||||
| Gender | DRV_SEX | X10 | Qualitative | 1 | Male | 59.8 | 65.21 | 69.89 |
| 2 | Female | 33.8 | 34.79 | 30.11 | ||||
| 3 | Not stated | 6.4 | 0 | 0 | ||||
| Driver’s age | DRV_AGE | X11 | Quantitative | 0 | Age from 16 to 25 | 17.56 | 22.67 | 28.17 |
| 1 | 26 to 35 | 47.80 | 56.07 | 49.96 | ||||
| 2 | 36 to 45 | 22.13 | 11.63 | 13.71 | ||||
| 3 | above 46 | 12.51 | 9.63 | 8.16 | ||||
| Number of lanes | NO_ LANES | X12 | Quantitative | - | ||||
| Lane width | LANEWID | X13 | Quantitative | Ft | ||||
| Median width | MEDWID | X14 | Quantitative | Ft | ||||
| Annual Average Daily Traffic | AADT | X15 | Quantitative | (Veh/year) | ||||
| Left shoulder width | LSHLDWID | X16 | Quantitative | Ft | ||||
| Left paved shoulder width | PAV_WDL | X17 | Quantitative | Ft | ||||
| Surface width | SURF_WID | X18 | Quantitative | Ft | ||||
| Right shoulder width | RSHLDWID | X19 | Quantitative | Ft | ||||
| Right paved shoulder width | PAV_WIDR | X20 | Quantitative | Ft | ||||
| Variables | Mean | Median | Std. Deviation | Range | Min. | Max. |
|---|---|---|---|---|---|---|
| Drv_age | 37.55 | 36 | 15.311 | 84 | 15 | 99 |
| No_LANES | 6.13 | 6 | 2.667 | 12 | 2 | 14 |
| LANEWID | 40.96 | 42 | 18.692 | 86 | 3 | 89 |
| MEDWID | 32.63 | 22 | 31.851 | 99 | 0 | 99 |
| AADT | 11,866.69 | 91,500 | 85,212.204 | 354,772 | 0 | 354,772 |
| LSHLDWID | 4.83 | 5 | 3.874 | 26 | 0 | 26 |
| PAV_WID | 4.53 | 4 | 3.874 | 26 | 0 | 26 |
| SURF_WID | 37.11 | 36 | 16.519 | 83 | 0 | 83 |
| RSHLDWID | 7.05 | 8 | 3.916 | 20 | 0 | 20 |
| PAV_WIDR | 6.81 | 8 | 4.009 | 20 | 0 | 20 |
| Classifier | Parameter | Description | Values |
|---|---|---|---|
| C5.0 | Binary splits | Whether to use binary splits on nominal attributes when building the trees | False |
| Min Num Obj | Minimum number of instance per leaf | 2 | |
| Num folds | Determination of the amount of data used for reduced-error pruning | 3 | |
| Confidence factor | The confidence factor used for pruning | 0.25 | |
| Unpruned | Whether pruning is performable | False | |
| CHAID | Binary splits | Whether to use binary splits on nominal attributes when building the trees | False |
| Min Num Obj | Minimum number of instance per leaf | 2 | |
| Num folds | Determination of the amount of data used for reduced error pruning | 3 | |
| Confidence factor | The confidence factor used for pruning | 0.25 | |
| Unpruned | Whether pruning is performable | False | |
| ANN-MLP | Hidden layers | The number of hidden layers | a (i.e., one hidden layer with 10 nodes) |
| Learning rate | The amount of the weights is updated | 0.3 | |
| Momentum | Momentum applied to the weights during updating | 0.2 | |
| Normalize attributes | This will normalize the attributes | True | |
| Reset | This will allow the network to reset with a lower learning rate | True |
| Decision Tree Techniques | Class Attribute | Number of Rules | Generated Rules | Total Number of Instances/Misclassified Instances |
|---|---|---|---|---|
| C5.0 | PDO | 12 | CAUSE (X1) = Other Violations (Hazardous) AND NUMVEHS (X5) = Two vehicles involved in a crash AND RDSURF (X3) = Dry AND DESG_SPD (X8) = 60 mile/h AND WEATHER (X2) = Clear AND Drv_age (X11) = 36 to 45 | 10 |
| Fatal | 25 | CAUSE (X1) = Speeding AND NUMVEHS (X5) = Two vehicles involved in a crash AND RDSURF (X3) = Dry | 25.0/3.0 | |
| CAUSE (X1) = Speeding AND NUMVEHS (X5) = Two vehicles involved in a crash AND DESG_SPD (X8) = >70 mile/h AND WEATHER (X2) = Clear AND Drv_age (X11) = 26 to 35 | 23.0/8.0 | |||
| Severe injury | 96 | CAUSE (X1) = Speeding AND NUMVEHS (X5) = Two vehicles involved in a crash AND RDSURF (X3) = Dry AND DESG_SPD (X8) = >70 mile/h AND Drv_age (X11) = 26 to 35 And LIGHT (X4) = Daylight And DRV_SEX (X10) = Male | 18.0/5.0 | |
| CAUSE (X1) = Speeding AND NUMVEHS (X5) = Two vehicles involved in a crash AND WEATHER (X2) = Clear AND DRV_SEX (X10) = Female | 15.0/4.0 | |||
| CAUSE (X1) = Speeding AND NUMVEHS (X5) = Two vehicles involved in a crash AND WEATHER (X2) = Cloudy AND Drv_age (X11) = 26 to 35 AND DRV_SEX (X10) = Male | 11.0/3.0 | |||
| Other visible injuries | 135 | CAUSE (X1) = Other Violations (Hazardous) AND NUMVEHS (X5) = Two vehicles involved in a crash AND DESG_SPD (X8) >65 mile/h AND Drv_age (X11) = 26 to 35 | 87.0/12.0 | |
| DESG_SPD (X8) = >65 mile/h AND LIGHT (X4) = Dark − Street Lights AND ACCESS (X7) = Conventional − No Access Control | 66.0/11.0 | |||
| NUMVEHS (X5) = Two vehicles involved in a crash AND DESG_SPD (X8) = >65 mile/h AND DRV_SEX (X10) = Male | 43.0 | |||
| DESG_SPD (X8) = >65 mile/h AND Drv_age (X11) = 26 to 35 AND RDSURF (X3) = Dry | 37.0/7.0 | |||
| CAUSE (X1) = Other Violations (Hazardous) AND NUMVEHS (X5) = Two vehicles involved in a crash AND DESG_SPD (X8) = >65 mile/h | 55.0/9.0 | |||
| Complain of pain | 189 | CAUSE (X1) = Other Violations (Hazardous) AND Drv_age (X11) = 36 to 45 | 45.0/6.0 | |
| NUMVEHS (X5) = Two vehicles involved in a crash AND DESG_SPD (X8) = >65 mile/h AND AADT (X15) AND DRV_SEX (X10) = Male | 78.0/21.0 | |||
| NUMVEHS (X5) = Three vehicles involved in a crash AND SURF_TYP = PCC, Bridge Deck AND Drv_age (X11) =36 to 45 | 123.0/34.0 | |||
| CAUSE (X1) = Improper turn AND NUMVEHS (X5) = Two vehicles involved in a crash AND LIGHT (X4) = Daylight | 98.0/33.0 | |||
| CHAID | PDO | 23 | CAUSE (X1) = Other Violations (Hazardous) AND NUMVEHS (X5) = Two vehicles involved in a crash WEATHER(X2) = Dry | 20.0/2.0 |
| Fatal | 35 | CAUSE (X1) = Speeding AND NUMVEHS(X5) = Two vehicles involved in a crash WEATHER(X2) = Dry AND AADT (X15) | 30.0/3.0 | |
| CAUSE (X1) = Speeding AND NUMVEHS(X5) = Two vehicles involved in a crash AND DRV_SEX (X10) = Male | 19.0/2.0 | |||
| Severe injury | 110 | CAUSE (X1) = Speeding AND NUMVEHS(X5) = Two vehicles involved in a crash WEATHER(X2) = Dry AND Drv_age (X11) = 26 to 35 | 88.0/7.0 | |
| CAUSE (X1) = Speeding AND NUMVEHS (X5) = Two vehicles involved in a crash AND DESG_SPD (X8) = >65 mile/h AND DRV_SEX (X10) = Male | 65.0/12.0 | |||
| DESG_SPD (X8) = >70 mile/h AND WEATHER (X2) = Clear AND LIGHT(X4) = Daylight | 40.0/9.0 | |||
| Other visible injuries | 145 | CAUSE (X1) = Other Violations (Hazardous) AND NUMVEHS (X5) = Two vehicles involved in a crash AND DRV_SEX (X10) = Male | 121.0/13.0 | |
| CAUSE (X1) = Other Violations (Hazardous) AND NUMVEHS (X5) = Two vehicles involved in a crash AND WEATHER (X2) = Raining | 76.0/15.0 | |||
| SURF_TYP = PCC, Concrete AND Drv_age (X11) = 26 to 35 AND RDSURF (X3) = Wet | 59.0/13.0 | |||
| DRV_SEX = Male AND LIGHT (X4) = Dark − Street Lights AND Drv_age (X11) = 26 to 35 | 33.0/4.0 | |||
| Complain of pain | 198 | CAUSE (X1) = Other Violations (Hazardous) AND Drv_age (X11) = 36 to 45 | 134.0/22.0 | |
| NUMVEHS (X5) = Two vehicles involved in a crash AND AADT (X15)And LIGHT (X4) = Daylight AND DRV_SEX (X10) = Male | 89.0/13.0 | |||
| NUMVEHS (X5) = One vehicle involved in a crash AND SURF_TYP (X9) = PCC, Concrete AND Drv_age (X11) = 36 to 45 AND AADT (X15) | 64.0/18.0 | |||
| CAUSE (X1) = Other Violations (Hazardous) AND NUMVEHS (X5) = Three vehicles involved in a crash AND Drv_age (X11) = 36 to 45 | 46.0/11.0 | |||
| CAUSE (X1) = Improper turn AND NUMVEHS (X5) = Two vehicles involved in a crash AND DESG_SPD (X8) = >65 mile/h | 38.0 |
| True Class | Predicted Class | |
|---|---|---|
| Positive | Negative | |
| Positive | TP | FN |
| Negative | FP | TN |
| Model Type | Description | Simulating Performance | Accuracy Rate (%) |
|---|---|---|---|
| MLR Main | In the proposed models, all sets of the variable are applied. | Training | 68.21% |
| Validation | 59.37% | ||
| MLR Inter | Training | 82.34% | |
| Validation | 44.27% | ||
| MLR Poly | Training | 55.10% | |
| Validation | 38.61% | ||
| MLR Main Inter | In the proposed models, considering two factors interaction for class variable sets used are included. | Training | 91.56% |
| Validation | 34.77% | ||
| MLR Main Poly | Training | 74.29% | |
| Validation | 54.44% | ||
| MLR Inter Poly | Training | 66.10% | |
| Validation | 44.89% | ||
| MLR Main Inter Poly | Poly Term is in the model polynomial which terms up to the degree specified for all interval variables used. Poly Degree specifies the polynomial degree when the term is included in the proposed model | Training | 77.22% |
| Validation | 51.98% |
| Variable | AIC * | BIC * | Simplified Model Negative Twice Logarithmic Likelihood Values | χ2 | Df * | Significance Level |
|---|---|---|---|---|---|---|
| Effect of the intercept | 1.20 × 104 | 1.43 × 104 | 1.03 × 104 | 0 | 0 | --- |
| X1 | 1.23 × 104 | 1.40 × 104 | 1.08 × 104 | 18 | 3 | 0.018 |
| X2 | 1.24 × 104 | 1.42 × 104 | 1.12 × 104 | 15 | 6 | 0.001 |
| X3 | 1.25 × 104 | 1.44 × 104 | 1.16 × 104 | 26 | 9 | 0.004 |
| X4 | 1.28 × 104 | 1.47 × 104 | 1.13 × 104 | 37 | 5 | 0.011 |
| X5 | 1.32 × 104 | 1.52 × 104 | 1.24 × 104 | 28 | 2 | 0.026 |
| X6 | 1.36 × 104 | 1.58 × 104 | 1.29 × 104 | 17 | 8 | 0.189 |
| X7 | 1.28 × 104 | 1.66 × 104 | 1.22 × 104 | 18 | 7 | 0.870 |
| X8 | 1.21 × 104 | 1.55 × 104 | 1.14 × 104 | 45 | 10 | 0.005 |
| X9 | 1.24 × 104 | 1.45 × 104 | 1.17 × 104 | 34 | 4 | 0.086 |
| X10 | 1.26 × 104 | 1.61 × 104 | 1.18 × 104 | 22 | 6 | 0.177 |
| X11 | 1.12 × 104 | 1.22 × 104 | 1.16 × 104 | 14 | 5 | 0.031 |
| X12 | 1.29 × 104 | 1.68 × 104 | 1.21 × 104 | 23 | 3 | 0.121 |
| X13 | 1.20 × 104 | 1.38 × 104 | 1.13 × 104 | 54 | 7 | 0.091 |
| X14 | 1.19 × 104 | 1.37 × 104 | 1.12 × 104 | 31 | 11 | 0.220 |
| X15 | 1.30 × 104 | 1.50 × 104 | 1.23 × 104 | 25 | 17 | 0.178 |
| X16 | 1.18 × 104 | 1.36 × 104 | 1.11 × 104 | 27 | 12 | 0.101 |
| X17 | 1.17 × 104 | 1.34 × 104 | 1.09 × 104 | 21 | 1 | 0.231 |
| X18 | 1.20 × 104 | 1.35 × 104 | 1.10 × 104 | 17 | 3 | 0.183 |
| X19 | 1.15 × 104 | 1.32 × 104 | 1.05 × 104 | 19 | 2 | 0.224 |
| X20 | 1.22 × 104 | 1.39 × 104 | 1.14 × 104 | 16 | 2 | 0.351 |
| Crash Severity | MLR Model | Variable |
|---|---|---|
| PDO | X1 = 5; X2 = 1; X3 = 1; X4 = 1; X5 = 5; X8 = 9; X11 = 1; | |
| Fatality | X1 = 5; X2 = 1; X3 = 1; X4 = 1; X5 = 2; X8 = 10; X11 = 0; | |
| Severe injuries | X1 = 4; X2 = 1; X3 = 2; X4 = 1; X5 = 1; X8 = 9; X11 = 0; | |
| Other visible injuries | X1 = 6; X2 = 2; X3 = 2; X4 = 2; X5 = 3; X8 = 10; X11 = 0; | |
| Complaint of pain | X1 = 5; X2 = 1; X3 = 1; X4 = 1; X5 = 4; X8 = 9; X11 = 1; |
| Statistical Parameter | χ2 | df | Significance Level |
|---|---|---|---|
| Pearson | 13,764.64 | 12,948.01 | 0.076 |
| Deviation | 12,100.38 | 12,948.01 | 0.083 |
| Algorithm | Sample | Crash Severity | Correctly Classified Instances | Incorrectly Classified Instances | Accuracy (Recall) | AUCs | Time (Seconds) |
|---|---|---|---|---|---|---|---|
| C5.0 | Using training set | PDO = 1 | 93,099 | 14,257 | 86.72% | 0.923 | 0.05 |
| Fatal = 2 | 32 | 103 | 23.67% | 0.912 | |||
| Severe injury = 3 | 83 | 126 | 39.65% | 0.907 | |||
| Other visible injury = 4 | 384 | 304 | 55.78% | 0.915 | |||
| Complaint of pain = 5 | 1690 | 731 | 69.80% | 0.956 | |||
| Overall | 95,288 | 12,883 | 88.09% | 0.950 | |||
| Cross validation (10-fold) | PDO = 1 | 70,620 | 19,273 | 78.56% | 0.782 | 0.03 | |
| Fatal = 2 | 182 | 1500 | 10.82% | 0.678 | |||
| Severe injury = 3 | 210 | 993 | 17.45% | 0.699 | |||
| Other visible injury = 4 | 631 | 1882 | 25.11% | 0.641 | |||
| Complaint of pain = 5 | 885 | 1048 | 45.78% | 0.781 | |||
| Overall | 89,761 | 34,767 | 72.08% | 0.832 | |||
| Resampled training set | PDO = 1 | 89,920 | 5203 | 94.53% | 0.967 | 0.87 | |
| Fatal = 2 | 378 | 114 | 76.87% | 0.954 | |||
| Severe injury = 3 | 529 | 106 | 83.26% | 0.938 | |||
| Other visible injury = 4 | 841 | 103 | 89.10% | 0.977 | |||
| Complaint of pain = 5 | 1434 | 154 | 90.33% | 0.981 | |||
| Overall | 93,102 | 10,981 | 89.45% | 0.985 |
| Algorithm | Sample | Crash Severity | Correctly Classified Instances | Incorrectly Classified Instances | Accuracy (Recall) | AUCs | Time (Seconds) |
|---|---|---|---|---|---|---|---|
| CHAID | Using training set | PDO = 1 | 85,502 | 13,082 | 86.73% | 0.953 | 0.76 |
| Fatal = 2 | 901 | 2906 | 23.67% | 0.932 | |||
| Severe injury = 3 | 2930 | 5036 | 36.78% | 0.920 | |||
| Other visible injury = 4 | 3841 | 576 | 68.95% | 0.921 | |||
| Complaint of pain = 5 | 35 | 284 | 10.99% | 0.928 | |||
| Overall | 93,209 | 27,512 | 77.21% | 0.945 | |||
| Cross validation (10-fold) | PDO = 1 | 82,032 | 38,621 | 67.99% | 0.621 | 1.59 | |
| Fatal = 2 | 3456 | 16,509 | 17.31% | 0.634 | |||
| Severe injury = 3 | 4897 | 16,666 | 22.71% | 0.678 | |||
| Other visible injury = 4 | 1230 | 2413 | 35.76% | 0.731 | |||
| Complaint of pain = 5 | 89 | 912 | 8.89% | 0.760 | |||
| Overall | 91,704 | 86,189 | 51.55% | 0.794 | |||
| Resampled training set | PDO = 1 | 86,134 | 11,072 | 88.61% | 0.983 | 0.78 | |
| Fatal = 2 | 2409 | 736 | 76.60% | 0.985 | |||
| Severe injury = 3 | 3080 | 3648 | 45.78% | 0.871 | |||
| Other visible injury = 4 | 897 | 464 | 65.90% | 0.890 | |||
| Complaint of pain = 5 | 128 | 39 | 76.89% | 0.850 | |||
| Overall | 92,648 | 22,457 | 80.49% | 0.961 |
| Algorithm | Sample | Crash Severity | Correctly Classified Instances | Incorrectly Classified Instances | Accuracy (Recall) | AUCs | Time (Seconds) |
|---|---|---|---|---|---|---|---|
| ANN-MLP | Using training set | PDO = 1 | 90,971 | 51,907 | 63.67% | 0.763 | 179.0 |
| Fatal= 2 | 761 | 897 | 45.89% | 0.785 | |||
| Severe injury = 3 | 158 | 82 | 65.81% | 0.943 | |||
| Other visible injury = 4 | 303 | 745 | 28.90% | 0.952 | |||
| Complaint of pain = 5 | 922 | 4652 | 16.54% | 0.955 | |||
| Overall | 93,115 | 39,509 | 70.21 | 0.876 | |||
| Cross validation (10-fold) | PDO = 1 | 87,591 | 48,801 | 64.22% | 0.567 | 379 | |
| Fatal = 2 | 83 | 186 | 30.89% | 0.618 | |||
| Severe injury = 3 | 34 | 101 | 25.10% | 0.721 | |||
| Other visible injury = 4 | 199 | 836 | 19.23% | 0.745 | |||
| Complaint of pain = 5 | 784 | 7682 | 9.26% | 0.789 | |||
| Overall | 88,691 | 76,162 | 53.80% | 0.804 | |||
| Resampled training set | PDO = 1 | 79,210 | 101,182 | 88.61% | 0.921 | 384 | |
| Fatal = 2 | 2634 | 440 | 85.67% | 0.935 | |||
| Severe injury = 3 | 1289 | 345 | 78.90% | 0.956 | |||
| Other visible injury = 4 | 3140 | 672 | 82.38% | 0.867 | |||
| Complaint of pain = 5 | 4320 | 728 | 85.57% | 0.892 | |||
| Overall | 90,593 | 28,233 | 76.24% | 0.926 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shiran, G.; Imaninasab, R.; Khayamim, R. Crash Severity Analysis of Highways Based on Multinomial Logistic Regression Model, Decision Tree Techniques, and Artificial Neural Network: A Modeling Comparison. Sustainability 2021, 13, 5670. https://doi.org/10.3390/su13105670
Shiran G, Imaninasab R, Khayamim R. Crash Severity Analysis of Highways Based on Multinomial Logistic Regression Model, Decision Tree Techniques, and Artificial Neural Network: A Modeling Comparison. Sustainability. 2021; 13(10):5670. https://doi.org/10.3390/su13105670
Chicago/Turabian StyleShiran, Gholamreza, Reza Imaninasab, and Razieh Khayamim. 2021. "Crash Severity Analysis of Highways Based on Multinomial Logistic Regression Model, Decision Tree Techniques, and Artificial Neural Network: A Modeling Comparison" Sustainability 13, no. 10: 5670. https://doi.org/10.3390/su13105670
APA StyleShiran, G., Imaninasab, R., & Khayamim, R. (2021). Crash Severity Analysis of Highways Based on Multinomial Logistic Regression Model, Decision Tree Techniques, and Artificial Neural Network: A Modeling Comparison. Sustainability, 13(10), 5670. https://doi.org/10.3390/su13105670