Abstract
Algal bloom is a typical pollution of urban lakes, which threatens drinking safety and breaks the urban landscape. It is pivotal to select a reasonable governance approach for sustainable management. A decision-making support method was studied in this paper. First, a general framework was designed to organize the rational decision-making processes. Second, quantitative calculation methods were proposed, including expert selection and opinion integration. The methods can determine the vital decision elements objectively and automatically. Third, the method was applied in Yuyuantan Lake in Beijing, China. The monitoring information and decision-making process are presented and the rank of governance alternatives is given. The comparison and discussion show that the group decision-making method is feasible and effective. It can assist the sustainable management of algal bloom.
1. Introduction
Water is pivotal in the ecological environment and is a living resource for human beings. However, the water environment still faces a severe situation due to its limited volume and recurring pollution. Algal bloom is a typical pollution in urban lakes and reservoirs. Taking Beijing, China, as an example, algal bloom has occurred in Beihai Lake, Shichahai Lake, and Beihucheng River in recent years. Today, 30.7% of lakes are in the middle eutrophic degree [1] where algal bloom is highly likely. Algal bloom occurs when the eutrophication level is high. It generates foul smells and toxins which seriously affect the urban landscape and threaten the health of citizens. Various categories of governance approaches have been carried out to clear algal bloom, including physical, chemical, biological, and ecological approaches [2,3]. The advantages and application conditions of each approach are different. It has been a crucial task to select the correct governance approach according to the current conditions and management preferences, which is an issue that has to do with decision making.
In traditional decision making of algal bloom governance, decisions are made by the administrator directly based on his or her personal experience, which is quite subjective and unreliable. For modern sustainable management, a decision-making support system and technique have been developed through extensive research [4,5,6]. Some studies [7,8,9] were conducted on algal bloom governance mainly based on multi-attribute decision making. Moreover, some intelligent methods have been proposed that make use of a correlation analysis and multi-source information fusion [10,11,12]. In these methods, more influence factors are considered for a comprehensive decision. The decision-making process becomes calculable and automatic and therefore, can be applied in information systems.
For the methods mentioned above, the core issue is the source and processing of the decision information. On the one hand, experts are an important decision information source. Many management factors, such as governance efficiency, elimination degree, secondary pollution possibility, etc., are evaluated by experts. The specialization level of experts directly impacts decision making. Group decision making [13] has been proposed to improve the specialized skills of professionals and reduce the impact of personal bias. However, the existing studies do not focus on the rational recognition and selection of experts. On the other hand, decision opinions should reflect experts’ original meaning as much as possible. The decision-making calculation should rely on the original knowledge expression and computable format.
Based on the unresolved problems above, a group decision-making method is proposed. In this method, experts can be classified and selected automatically based on machine learning. Their decision opinions are expressed and calculated in a two-tuple linguistic form. Here, Yuyuantan Lake in Beijing is studied using the proposed method. The decision-making process and result are analyzed and discussed later in this paper.
The rest of this paper is organized as follows. Related works are introduced in Section 2. Section 3 introduces the problem, source information, and the main method. In Section 4, the whole decision-making process is presented, along with the case study of Yuyuantan Lake. The method and results are discussed in Section 5. Finally, the conclusions are presented in Section 6.
2. Related Works
2.1. Algal Bloom Governance and Sustainable Management
As mentioned in the introduction, algal bloom pollution threatens drinking safety and causes damage to the urban landscape. Therefore, modern management methods need to be introduced into the decision-making process related to algal bloom governance.
In a previous study, Wang et al. [7] proposed some constraint conditions to select the algal bloom governance alternatives with the fuzzy Bayes method. Liu et al. [8] introduced information entropy and grey theory into the decision-making computing in order to give the weight to the objective data. Bai et al. [9] used the Vague set to express an evaluation of opinions for multiple management objectives. Most of the proposed methods are based on multi-attribute decision making. In the literature, additional types of information are introduced, including nature language processing and data fusion [10,11].
Sustainable management has also attracted attention [14,15]. Any selected governance approach should be conducted according to sustainable principles, which requires more factors and limitations in management and decision making. With the development of information technology, more techniques can help with modern sustainable management, including machine learning [16,17,18], information fusion [19,20], sensor networks [21,22,23], and Internet of Things [24,25].
The methods and techniques above make it possible for decision making to automatically take place online. The vital issue is the processing of the multi-source information. Various decision information data should be integrated with calculable methods. The decision-making process should also be embedded into information systems. Then, the decision support techniques can help decision makers reach an appropriate conclusion.
2.2. The Decision Support Technique
For rational decision making, various classical methods have been studied, including multi-attribute decision making [6,26] and multi-criteria decision making [27]. The attributes and criteria can be regarded as decision factors; therefore, these two categories are consistent from a theoretical perspective. Because decision making is closely related to human actives, the expression of human thought becomes a vital issue. To address this issue, different formats have been explored, including fuzzy set, grey theory, and linguistic variable [5,28,29]. Meanwhile, the group decision-making [13] has been studied to reduce personal bias impact. The expert library and knowledge management form the new trend.
For decision information processing and understanding, the semantic web can store and evaluate the cyberspace data intelligently [4,30]. Some semantic web standards have been proposed for unified data management. However, much online content does not accord with the rules. It has been a problem to extract semantic information from unstructured and semi-structured data. For the self-learning ability, machine learning develops fast in-text analysis and natural language understanding [11]. Semantic web and machine learning have been applied in the decision support systems.
For the problem in this paper, the experts desired to be classified and selected with their features. The expert scale is not so large, and their feature factors can be transformed into the structured type. Therefore, machine learning was chosen as the primary technique with a more accessible and simpler calculation than the semantic web.
3. Materials and Methods
3.1. Problem Description
For the sustainable governance of algal bloom in urban lakes, a suitable and optimal approach should be selected first. The optimal selection of approaches is the decision-making problem being studied in this paper.
Concretely, a lake can be monitored in real-time, including water quality, hydrologic data, and meteorological status. By judging the monitoring data, the state of algal bloom can be determined. If the algal bloom generates or will occur in a high probability, some experts and administrators are invited to make the decision on how to govern the algal bloom. They give opinions on various aspects, considering the current environment status. The opinions are integrated to form the final decision-making result. The decision-making problem above can be described and expressed as follows.
There are decision experts to be selected and the expert set is . There are governance methods that can be selected and they form the alternative set . Experts will assess the alternatives from multiple aspects, and the elements are named as attributes. The attribute set is . For each expert, opinions can be organized in a decision matrix:
where is the serial number of experts, , , . The matrix element rij denotes the i-th solution’s impact degree on the j-th attribute. Experts give the evaluation degree r in the grade forms. Moreover, the grade in this paper is expressed with 2-tuple linguistic. The 2-tuple linguistic method can reflect the grade with a definite similarity, which will be introduced concretely in Section 3.3.3.
There are two main tasks in this paper. First, experts should be selected quantificationally with their features, which will help to determine their weights. Second, the opinions in the matrix (1) should be integrated for the final decision-making result. The solutions to these two tasks are described in Section 3.3.
3.2. Study Area and Experimental Data
In this paper, Yuyuantan Lake in Beijing was analyzed as an example. The decision-making method can be clear and intuitive with the instance, and it can be applied in other similar management.
Yuyuantan Lake is endowed with the function of a landscape by the Beijing government. Its area is 44 hm2 and the target level of water quality is in the Chinese national standard. It is located at the West-Third-Ring Road in Beijing. The range of Yuyuantan Lake is shown in Figure 1, and the studied area is in the yellow block.
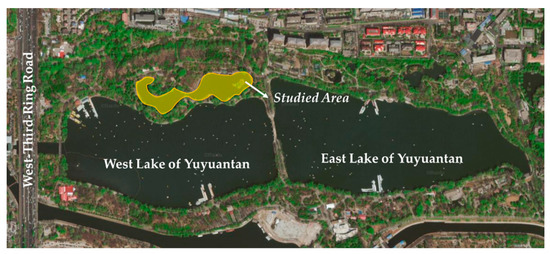
Figure 1.
Studied area and range of Yuyuantan Lake in Beijing, China.
Automatic monitoring equipment was installed on the bank of the studied lake. This consists of a small weather station and a self-integrated water quality sensor (YSI 6600v2 and other independent sensors). These obtain the water quality and hydrologic data once an hour. The real-time data are judged with the local standard of algal bloom [31,32]. An early warning threshold was set for the activation of governance decision-making. The real-time monitoring data of the instance are listed in Table 1. In the monitoring data, DO (Dissolved Oxygen) and Chl_a (Chlorophyll a) are the main character indexes of algal bloom. Decision-making should be conducted once the real-time concentration of DO and Chl_a (at 14:00) has reached the warning threshold.

Table 1.
Real-time monitoring data of the studied area in Yuyuantan Lake on 23rd June, 2015.
For the machine learning method used in this paper, the necessary information of experts was collected manually in the previous research work. The resumes of experts were preprocessed artificially to extract the main factors. In this study, 57 sheets of expert information were collected and converted into the table shown in Table 2. Each expert was described with nine factors, such as education degree, professional title, and number of papers. The meanings of the factors are listed in Table 3.
Table 2.
Structured data of experts to be selected for the formal decision-making process.
Table 3.
Factors and optional values in the structured data of experts.
3.3. Group Decision-Making Method
As mentioned in Section 3.1, there are two main tasks in the decision-making of algal bloom governance. One is the expert selection and the other is the integration of decision opinions. The solutions are introduced in Section 3.3.2 and Section 3.3.3, and the general decision-making framework is interpreted first in Section 3.3.1.
3.3.1. Group Decision-Making Framework
Based on the field research and literature survey [5,13], traditional decision-making usually relies on opinions from one source. It is subjective and prone to be biased because of one’s limited knowledge and experience. Therefore, group decision-making has received attention as it avoids bias. The usual methods lack the objective appraisal and classification of the experts, which brings about the problem of weight definition. The weights are pivotal for decision opinion integration. The experts’ weights should be different according to their professional level. Based on the determination of the experts, the decision-making process can be carried out by providing and integrating opinions. The whole process mentioned above is concluded in Figure 2.
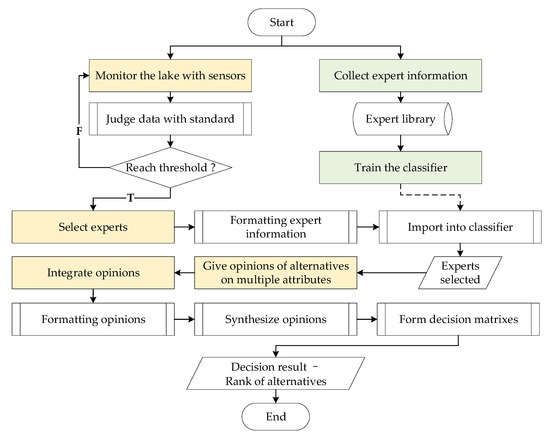
Figure 2.
General process of group decision-making for algal bloom governance.
The decision-making process mainly consists of three parts, namely lake monitoring with sensors, the selection of experts, integration of decision opinions, marked with yellow blocks in Figure 2. The sub-processes of the main actions are in white blocks. For expert selection, the machine learning model includes training and application. The training of the model is shown in the green blocks. The model can be applied in decision-making when it is trained and fixed.
3.3.2. Method of Expert Selection and Weight Definition
As the subjects of decision-making, experts can be described with some factors, as shown in Table 2 and Table 3. The structured variables can contribute to the classification. In this paper, a machine learning method was introduced to classify and select the experts automatically.
For the various classifiers, it was proved that the integration and cross-validation can obtain better results [33,34]. Therefore, scholars put forward integrated learning methods to combine single classifiers. AdaBoost is the most representative method in the Boosting tree classifiers which can improve the weak learning algorithm to a strong learning algorithm. For the studied issue, the input variables are relatively numerous, and the sample scale is not so large. AdaBoost is suitable because of its ensemble learning ability and controllable calculation scale. AdaBoost follows the basic framework of the Boosting algorithm, including the linear addition model and the forward iteration algorithm, as shown in Figure 3.
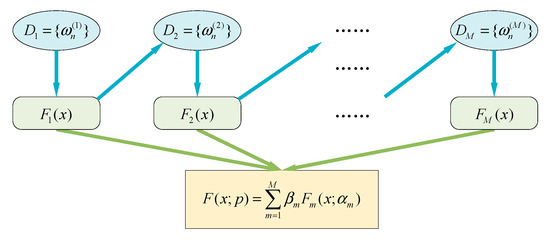
Figure 3.
AdaBoost algorithm framework.
In the algorithm framework in Figure 3, is the distribution of the input samples. and are the single weak classifiers, where is the optimal inner parameter of the classifier, is the weight of the classifier, and is the set of parameters and .
For the linear addition model in AdaBoost, multiple weak classifiers are combined with the weights. The weights are determined mainly by the error of each classifier. The linear addition model is expressed with the green arrow in Figure 3, as well as with the expression:
where the weight of the classifier is defined as
where is the error of the classifier and . is the judgment function. if the judgment condition is true, otherwise .
For the forward iteration algorithm in AdaBoost, the classifiers in the next generation rely on the previous generation, which is expressed with the blue arrow in Figure 3, as well as the expression:
where the exponential loss function is adopted in the iteration.
Based on the AdaBoost classifier, the method of expert selection is proposed. The training algorithm is as follows.
| Algorithm 1: Classifier training for expert selection |
| Input: structured expert information (shown in Table 2), 9 variables of each expert form a sample set . , and is the category label of the expert. is corresponding to the sample set , and the values of 1-5 represent the descending professional grades. Output: classifier used to classify and select experts. Procedure % Initialize the weights of samples for i = 1; i ≤ N; i++ ; % is the initialized sample weight end for % Train weak classifiers iteratively for m = 1; m ≤ M; m++ for i=1; i<=N; i++ end for end for % Obtain the final classifier % sign is the activation function. End Procedure |
The classifier can output the category and professional level of the expert. The result can help to determine the decision experts finally.
Moreover, the weights of the experts are vital in the opinion integration. Based on the output of the classifier, the expert weight can be calculated as
3.3.3. Method of Decision Opinion Integration
Based on Section 3.3.2, some experts can be chosen according to the category result. Following the decision-making framework in Figure 2, the selected experts will provide decision opinions to form the matrix in Equation (1).
The rows of the matrix are the governance alternatives, and the columns are the decision attributes. For the alternative set , seven governance approaches are selected as the alternatives, including aeration oxygenation, water scour, algicide, coagulating sedimentation, electrochemistry, algophagous, hydrophyte, respectively. For the attribute set , five management objectives and decision factors are selected, including the cost, time to take effect, removal degree, impact on the surrounding environment, secondary pollution level, respectively.
The matrix element indicates the impact degree of the i-th alternative on the j-th attribute. The opinions denote the assessment grades, expressed with the two-tuple linguistic form [35] in this paper. The two-tuple linguistic is denoted as , where is the assessment grade, and . The grade is divided into nine levels, and the abbreviations are L for Low, M for Middle, H for High, A for Absolutely, V for Very, R for Relatively, respectively. The sign indicates the similarity degree between the opinion and the grade variables.
For real arithmetic, a transfer function and its inverse function are introduced to convert the two-tuple linguistic and real number in both ways [11]. is set as the real number converted from the two-tuple linguistic, and . is the number of grade variables, and it is equal to 9 in this paper. The transfer function is defined as
where is the serial number of the grade variable, round is the rounding off operator. is the inverse function of , and
The elements in the decision matrix should be integrated into two steps. First, the inner elements in each matrix are integrated. The weighted harmonic average operator (WHA) is introduced to synthesize the elements in the i-th row. Then the general evaluation of alternatives from the expert can be obtained:
where is the weights of decision attributes.
Second, the evaluation values of alternatives from multiple experts are synthesized. The WHA operator can be applied again to integrate the values, and the final evaluation of the alternative is obtained:
where is the weights of experts, calculated following Equation (5).
Finally, can be converted to the real number with the function . The alternatives can be ranked by the evaluation values. The ranking can help the decision of algal bloom governance.
4. Results
As introduced in Section 3.2, the decision-making process starts because the real-time data have reached the warning threshold. Following the proposed decision-making framework, some experts are selected with the classification method first. Then, they provide opinions according to the current lake condition. The opinions are integrated to rank the governance alternatives. The intermediate and final results are presented in this section.
4.1. Expert Selection
In the study of Yuyuantan Lake, 57 sheets of expert information were collected manually beforehand. For the AdaBoost classifier, a training process is needed to build an available model. Therefore, the original samples were divided into two parts, namely the training set (27 sheets) and the test set (30 sheets).
The training samples should be enough for the convergence status of a stable model. The existing 27 samples are extended to 180 samples with Monte Carlo simulation [36]. Monte Carlo simulation can capture the geometric quantities and characteristics of the object data. It uses mathematical methods to simulate the probability distribution of the data. There is a category label corresponding to each sheet of expert information. For the 180 training samples, their categories are shown in Figure 4.
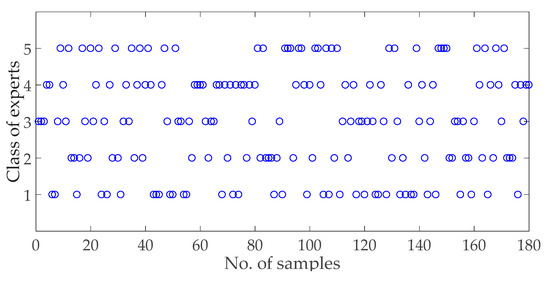
Figure 4.
Categories of the training samples, in which 180 experts are labeled with “1-5” to represent their professional level.
The training algorithm in Section 3.3.2 was conducted to obtain an available AdaBoost classifier. Then the test samples were imported into the classifier. The classification output is shown in Table 4.
Table 4.
Classification result of the experts.
For the results in Table 4, Class 1 is the highest professional level, and Class 5 is the lowest. In the instance, four experts were finally selected from the categories of Class 1 and Class 2. The selected experts include Exp 1, 2, 9, 15. Meanwhile, their weights can be calculated based on their categories. Their weights are 0.278, 0.278, 0.222, 0.222, respectively.
4.2. Opinion Integration
The four experts selected analyzed the current status of Yuyuantan Lake with the monitoring data and base materials. They assessed the alternatives from multiple aspects. As mentioned in Section 3.3.3, the alternatives include aeration oxygenation, water scour, algicide, coagulating sedimentation, electrochemistry, algophagous, hydrophyte. The attributes include the cost, time to take effect, removal degree, impact on the surrounding environment, and secondary pollution level. They are symbolized with and in the following text. Expert opinions are expressed with the two-tuple linguistic , where is the nine evaluation grades, and is the similarity degree between the opinion and the grade variable. The original opinions of the four experts are listed in Table 5.
Table 5.
Decision opinions from the four experts selected.
The decision opinions were integrated internally in each expert matrix following Equation (10). Then, they were synthesized again and converted to the real number following Equation (11). The assessing values of the alternatives are 0.89, 0.95, 0.37, 0.10, 0.35, 0.25, 0.37, respectively. The final rank of the governance alternatives is shown in Figure 5.
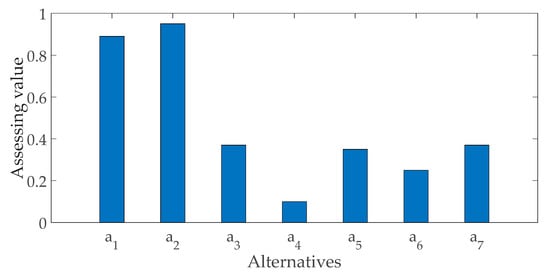
Figure 5.
Rank of the governance alternatives for the algal bloom in Yuyuantan Lake.
The rank of governance alternatives is . Concretely, the governance approaches from the most suitable to the most inappropriate are water scour, aeration oxygenation, algicide, hydrophyte, electrochemistry, algophagous, and coagulating sedimentation. The physical approaches perform better than others, of which the water scour method is the most appropriate. The result above is concluded by considering the approach features and management objectives, such as expenditure, efficiency, and the possibility of secondary pollution.
5. Discussion
5.1. Comparison of Expert Classification
As an essential decision-making component, the selection of experts impacts the decision result severely. The selection and classification of experts should be rational and comprehensive. The performance of the proposed method was compared with other classifiers.
Because AdaBoost is an integration of single classifiers, the typical single classifiers are set as the contrast, including the support vector machine (SVM) [37] and decision tree (DT) [38]. The same training set of 180 samples is used for the classifier construction. A total of 30 samples were tested, and the classification results are shown in Figure 6.
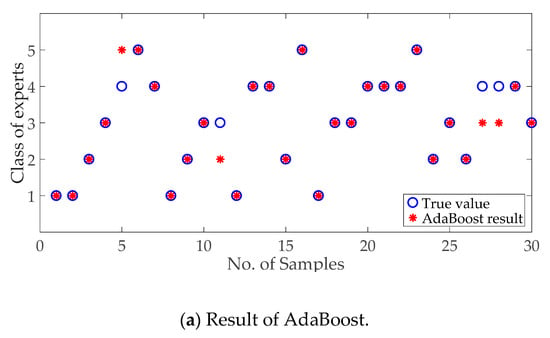
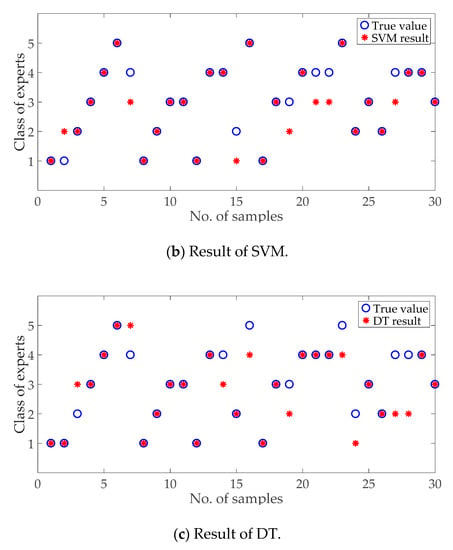
Figure 6.
Expert classification results of the three methods, including AdaBoost proposed in this paper, SVM, and DT.
For the classification results of the 30 samples, the precision ratio is introduced as the evaluation indicator. The precision ratio , where is the number of correct classification samples, and is the total number of samples. The precision ratio of the three methods is shown in Figure 7. Moreover, the mean obfuscation matrix is calculated with the result of the proposed method, shown in Table 6. The matrix means the ratio of one category to another. Concretely, the values indicate the ratio of the categories of rows classified into the categories of columns.
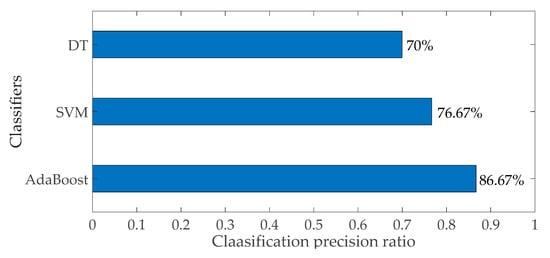
Figure 7.
Precision ratio of expert classification results of the three methods.
Table 6.
Mean obfuscation matrix of the classification results of AdaBoost.
According to the results in Figure 6, the classifications are of a high accuracy because the expert factors selected in this paper have a high correlation with the category. As shown in Figure 7, the classification precisions of various methods are over 70%. The precision of the proposed method is higher than that of the traditional methods because it is a synthesis and improvement of the basic classifiers.
As shown in Figure 6(a), the samples misclassified are in adjacent categories, which means that the proposed method has a certain fault tolerance. The misclassified situation can also be seen from Table 6. Most of the misclassified samples are in one or two adjacent categories. For example, 14.29% of samples in Class 3 are misclassified into Class 2. In total, 20% and 10% of samples in Class 4 are misclassified into Classes 3 and 5. The classification performance of the proposed method is better than the basic classifiers and it can help to select experts with quantized categories.
5.2. Comparison of Decision-Making Results
The proposed decision-making method mainly integrates the opinions from multiple experts. The integrated result was compared with the personal result of each expert, as shown in Figure 8. The grades of results are in different colors. The yellow block on the lines shows the membership degree of the evaluation in the grade.
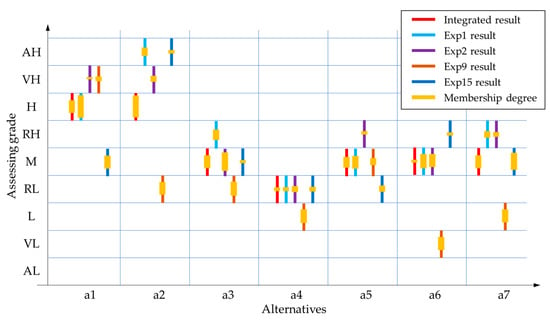
Figure 8.
Integrated decision result and the discrete decision result of each expert.
The red line in Figure 8 shows the integration of the four experts. It can reflect the primary preference trend of different experts. Moreover, it can avoid the bias of an individual expert. For example, the result of Exp 9 differs from others distinctly. The integrated result decreases the effect of Exp 9, and the final result is consistent with most experts’ opinions.
In Figure 8, the yellow block on the lines indicates the membership degree, which is the refined expression of the evaluation. For example, although , and are in the same grade of “M”, their membership degrees are distinct. In general, the group decision result is of high comprehensiveness, which supports the sustainable management of the algal bloom pollution with a quantitative solution.
5.3. Extension and Improvement of Group Decision-Making
In modern management, the governance of water pollution should be professional and sustainable. The group decision-making in this paper provides a feasible solution. For superior and comprehensive management, group decision-making can be improved from the following aspects.
On the one hand, the real-time monitoring information should play a more prominent role in decision support. The experts comprehend the monitoring data in the proposed method. The data can be more direct for the decision-making calculation. Moreover, the prediction of the water quality [39] should be introduced to pre-judge the trend. The prediction models [40,41,42,43] and data estimation methods [44,45] can help data analysis in the aforehand decision-making.
On the other hand, the expression of decision opinions can be more humanized. The grade variable in the paper is relatively convenient and intuitional. However, some details and precise information may lose in the fixed variable frame. The natural language understanding can better comprehend the experts’ thoughts. The technique has been explored in [11] with simple processing. Advanced natural language understanding will help the automatic operation of the decision-making process.
6. Conclusions
Algal bloom is a typical type of pollution in urban lakes, which threatens drinking water safety and destroys the urban landscape. Sustainable governance should be carried out with a professional and rational decision. A group decision-making method is studied in this paper. It realizes the automatic and quantitative selection of experts and comprehensively synthesizes the opinions. The experiment in Yuyuantan Lake of Beijing shows that the classification method can help to determine the expert category and weight. The decision result can meet the water environment condition and management objectives. In future work, more information can be introduced into decision-making, such as real-time and prediction data. The advanced natural language processing can also be studied for intelligent decision support.
Author Contributions
conceptualization, Y.B. and X.W.; methodology, Y.Y. and Y.B.; writing—original draft preparation, Y.Y. and Y.B.; writing—review and editing, X.J.; funding acquisition, L.W. and Q.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Social Science Fund of China No. 19BGL184, Beijing Excellent Talent Training Support Project for Young Top-Notch Team No. 2018000026833TD01, National Natural Science Foundation of China No. 61703008, 61802010, 61673002.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bulletin on Beijing’s Ecological Environment State in 2018. Available online: http://sthjj.beijing.gov.cn/bjhrb/zrqskqzl/849908 (accessed on 9 May 2018). (In Chinese)
- Visser, P.M.; Ibelings, B.W.; Bormans, M.; Huisman, J. Artificial mixing to control cyanobacterial blooms: A review. Aquat. Ecol. 2016, 50, 423–441. [Google Scholar] [CrossRef]
- Sun, R.; Sun, P.; Zhang, J.; Esquivel-Elizondo, S.; Wu, Y. Microorganisms-based methods for harmful algal blooms control: A review. Bioresour. Technol. 2018, 248, 12–20. [Google Scholar] [CrossRef] [PubMed]
- Bose, R.; Sugumaran, V. Semantic web technologies for enhancing intelligent DSS environments. In Decision Support for Global Enterprises; Springer: Boston, MA, USA, 2007; pp. 221–238. [Google Scholar]
- Morente-Molinera, J.A.; Wikström, R.; Herrera-Viedma, E.; Carlsson, C. A linguistic mobile decision support system based on fuzzy ontology to facilitate knowledge mobilization. Decis. Support Syst. 2016, 81, 66–75. [Google Scholar] [CrossRef]
- Bozanic, D.; Tešić, D.; Milićević, J. A hybrid fuzzy AHP-MABAC model: Application in the Serbian Army–The selection of the location for deep wading as a technique of crossing the river by tanks. Decis. Mak. Appl. Manag. Eng. 2018, 1, 143–164. [Google Scholar] [CrossRef]
- Wang, X.; Chen, C.; Liu, Z.; Xu, J.; Hao, Q.; Liu, P. Research on the Emergency Control Decision on Water Bloom in Lake and Reservoir Based on Fuzzy Bayes under Comprehensive Restrictions. In Proceedings of the Second International Conference on IEEE, Sanya, Hainan, China, 6–7 January 2012; pp. 894–898. [Google Scholar]
- Liu, Z.; Li, L.; Wang, X.; Chen, C. Researches of water bloom emergency management decision-making method and system based on fuzzy multiple attribute decision making. Int. J. Comput. Sci. Issues 2012, 9, 48–53. [Google Scholar]
- Bai, Y.; Wang, X.; Wang, L.; Xu, J.; Yu, J.; Shi, Y. The research of decision-making method for multi-objective in water bloom emergency governance based on Vague set theory. J. Comput. Inf. Syst. 2014, 10, 2099–2106. [Google Scholar]
- Bai, Y.-T.; Zhang, B.-H.; Wang, X.-Y.; Jin, X.-B.; Xu, J.-P.; Su, T.-L.; Wang, Z.-Y. A novel group decision-making method based on sensor data and fuzzy information. Sensors 2016, 16, 1799. [Google Scholar] [CrossRef]
- Bai, Y.-T.; Zhang, B.-H.; Wang, X.-Y.; Jin, X.-B.; Xu, J.-P.; Wang, Z.-Y. Expert decision support technique for algal bloom governance in urban lakes based on text analysis. Water 2017, 9, 308. [Google Scholar] [CrossRef]
- Bai, Y.-t.; Jin, X.-b.; Wang, X.-y.; Wang, X.-k.; Xu, J.-p. Dynamic correlation analysis method of air pollutants in spatio-temporal analysis. Int. J. Environ. Res. Public Health 2020, 17, 360. [Google Scholar] [CrossRef]
- Fazlollahtabar, H.; Smailbašić, A.; Stević, Ž. FUCOM method in group decision-making: Selection of forklift in a warehouse. Decis. Mak. Appl. Manag. Eng. 2019, 2, 49–65. [Google Scholar] [CrossRef]
- Sekulić, V.; Pavlović, M. Corporate social responsibility in relations with social community: Determinants, development, management aspects. Ekonomika 2018, 64, 59–69. [Google Scholar] [CrossRef]
- Radukić, S.; Petrović-Ranđelović, M.; Kostić, Z. Sustainability-based goals and achieved results in Western Balkan countries. Econ. Sustain. Dev. 2019, 3, 9–18. [Google Scholar] [CrossRef]
- Jin, X.; Yang, N.; Wang, X.; Bai, Y.; Su, T.; Kong, J. Deep hybrid model based on EMD with classification by frequency characteristics for long-term air quality prediction. Mathematics 2020, 8, 214. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, T.; Wang, X.; Jin, X.; Xu, J.; Yu, J.; Zhang, H.; Zhao, Z. An approach of improved multivariate timing-random deep belief net modelling for algal bloom prediction. Biosyst. Eng. 2019, 177, 130–138. [Google Scholar] [CrossRef]
- Zheng, Y.; Kong, J.; Jin, X.; Wang, X.; Su, T.; Zuo, M. Cropdeep: The crop vision dataset for deep-learning-based classification and detection in precision agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [PubMed]
- Cui, T.; Ding, F.; Jin, X.; Alsaedi, A.; Hayat, T. Joint multi-innovation recursive extended least squares parameter and state estimation for a class of state-space systems. Int. J. Control Autom. Syst. 2020, 17, 1–13. [Google Scholar] [CrossRef]
- Ding, F.; Xu, L.; Meng, D.; Jin, X.; Alsaedi, A.; Hayat, T. Gradient estimation algorithms for the parameter identification of bilinear systems using the auxiliary model. J. Comput. Appl. Math. 2020, 369. [Google Scholar] [CrossRef]
- Wang, F.; Su, T.; Jin, X.; Zheng, Y.; Kong, J.; Bai, Y. Indoor Tracking by RFID Fusion with IMU Data. Asian J. Control 2019, 21. [Google Scholar] [CrossRef]
- Wang, Z.; Jin, X.; Wang, X.; Xu, J.; Bai, Y. Hard decision-based cooperative localization for wireless sensor networks. Sensors 2019, 19, 4665. [Google Scholar] [CrossRef]
- Bai, Y.; Wang, X.; Jin, X.; Su, T.; Kong, J. Adaptive filtering for MEMS gyroscope with dynamic noise model. ISA Trans. 2020. [Google Scholar] [CrossRef]
- Zhao, Z.; Yao, P.; Wang, X.; Xu, J.; Wang, L.; Yu, J. Reliable flight performance assessment of multirotor based on interacting multiple model particle filter and health degree. Chin. J. Aeronaut. 2019, 32, 444–453. [Google Scholar] [CrossRef]
- Wang, X.; Zhou, Y.; Zhao, Z.; Wei, W.; Li, W. Time-delay system control based on an integration of active disturbance rejection and modified twice optimal control. IEEE Access 2019, 7, 130734–130744. [Google Scholar] [CrossRef]
- Pamučar, D.; Božanić, D. Selection of a location for the development of multimodal logistics center: Application of single-valued neutrosophic MABAC model. Oper. Res. Eng. Sci. Theory Appl. 2019, 2, 55–71. [Google Scholar] [CrossRef]
- Hassanpour, M.; Pamucar, D. Evaluation of Iranian household appliance industries using MCDM models. Oper. Res. Eng. Sci. Theory Appl. 2019, 2, 1–25. [Google Scholar] [CrossRef]
- Naeini, A.B.; Mosayebi, A.; Mohajerani, N. A hybrid model of competitive advantage based on Bourdieu capital theory and competitive intelligence using fuzzy Delphi and ism-gray Dematel (study of Iranian food industry). Int. Rev. 2019, 1–2, 21–35. [Google Scholar] [CrossRef]
- Karabašević, D.; Popović, G.; Stanujkić, D.; Maksimović, M.; Sava, C. An approach for hotel type selection based on the single-valued intuitionistic fuzzy numbers. Int. Rev. 2019, 1–2, 7–14. [Google Scholar] [CrossRef]
- Spoladore, D.; Sacco, M. Semantic and dweller-based decision support system for the reconfiguration of domestic environments: RecAAL. Electronics 2018, 7, 179. [Google Scholar] [CrossRef]
- Liu, B.; Cui, L.; Liu, Z. Correlation between chlorophyll a and algal density of surface water in urban of Beijing. Environ. Sci. Technol. 2008, 31, 29–33. (In Chinese) [Google Scholar]
- Wang, X.; Zhou, Y.; Zhao, Z.; Wang, L.; Xu, J.; Yu, J. A novel water quality mechanism modeling and eutrophication risk assessment method of lakes and reservoirs. Nonlinear Dyn. 2019, 96, 1037–1053. [Google Scholar] [CrossRef]
- Collins, M.; Schapire, R.E.; Singer, Y. Logistic regression, AdaBoost and Bregman distances. Mach. Learn. 2002, 48, 253–285. [Google Scholar] [CrossRef]
- Kim, K.; Lin, H.; Jin, Y.C.; Choi, K. A design framework for hierarchical ensemble of multiple feature extractors and multiple classifiers. Pattern Recogn. C 2016, 52, 1–16. [Google Scholar] [CrossRef]
- Wei, G. Some harmonic aggregation operators with 2-tuple linguistic assessment information and their application to multiple attribute group decision making. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2011, 19, 977–998. [Google Scholar] [CrossRef]
- Bonate, P.L. A brief introduction to Monte Carlo simulation. Clin. Pharmacokinet. 2001, 40, 15–22. [Google Scholar] [CrossRef] [PubMed]
- Guenther, N.; Schonlau, M. Support vector machines. Stata J. 2016, 16, 917–937. [Google Scholar] [CrossRef]
- Song, Y.Y.; Ying, L.U. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar]
- Wang, L.; Zhang, T.; Jin, X.; Xu, J.; Wang, X.; Zhang, H.; Yu, J.; Sun, Q.; Zhao, Z.; Xie, Y. An approach of recursive timing deep belief network for algal bloom forecasting. Neural Comput. Appl. 2020, 32, 163–171. [Google Scholar] [CrossRef]
- Jin, X.; Yang, N.; Wang, X.; Bai, Y.; Su, T.; Kong, J. Integrated predictor based on decomposition mechanism for PM2.5 long-term prediction. Appl. Sci. 2019, 9, 4533. [Google Scholar] [CrossRef]
- Bai, Y.; Jin, X.; Wang, X.; Su, T.; Kong, J.; Lu, Y. Compound autoregressive network for prediction of multivariate time series. Complexity 2019, 9107167. [Google Scholar] [CrossRef]
- Bai, Y.; Wang, X.; Sun, Q.; Jin, X.; Wang, X.; Su, T.; Kong, J. Spatio-temporal prediction for the monitoring-blind area of industrial atmosphere based on the fusion network. Int. J. Environ. Res. Public Health 2019, 16, 3788. [Google Scholar] [CrossRef]
- Jin, X.; Yu, X.; Wang, X.; Bai, Y.; Su, T.; Kong, J. Deep Learning Predictor for Sustainable Precision Agriculture Based on Internet of Things System. Sustainability 2020, 12, 1433. [Google Scholar]
- Ding, F.; Lv, L.; Pan, J.; Wan, X.; Jin, X. Two-stage gradient-based iterative estimation methods for controlled autoregressive systems using the measurement data. Int. J. Control Autom. Syst. 2019, 17. [Google Scholar] [CrossRef]
- Bai, Y.-t.; Wang, X.-y.; Jin, X.-b.; Zhao, Z.-y.; Zhang, B.-h. A neuron-based Kalman filter with nonlinear autoregressive model. Sensors 2020, 20, 299. [Google Scholar] [CrossRef] [PubMed]









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).