Bankruptcy or Success? The Effective Prediction of a Company’s Financial Development Using LSTM




Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
- (1)
- Selection and preparation of the data for the calculation.
- (2)
- Division of the data into training and testing data sets.
- (3)
- Creation of a bankruptcy model by means of an experiment using Mathematica Software.
- (4)
- Generation of NN using LSTM networks and other elementwise layers.
- (5)
- Evaluation of the performance of networks in the training and testing data sets, creation of a confusion matrix characterizing the correct classification of companies into “active” and “in liquidation”.
- (6)
- Description of the best NN and discussion on the success rate of the network.
3.1. Data
- AKTIVACELK—total assets, i.e., the result of economic activities carried out in the past. This represents the future economic profit of the company.
- STALAA—fixed assets, i.e., long-term, fixed, non-current items, including property components, used for company activities over the long run (for more than one year) and consumed over time.
- OBEZNAA—current assets characterized by the operating cycle, i.e., they are in constant motion and change form. These include money, materials, semi-finished products, unfinished products, finished products, and receivables from customers.
- KP—short-term receivables with a maturity of less than 1 year, representing the right of the creditor to demand the fulfilment of a certain obligation from the other party. The receivable ceases to exist upon the fulfilment of the obligation.
- VLASTNIJM—equity, i.e., the company’s resources for financing assets in order to create capital. This primarily concerns the contributions of the founders (owners or partners) to the basic capital of the company and those components arising from the company’s activities.
- CIZIZDROJE—borrowed capital, i.e., company debts that have to be repaid within a specified period of time. This represents the company’s liabilities towards other entities.
- KZ—short-term liabilities, i.e., due within 1 year. Together with equity, they ensure the financing of the day-to-day activities of the company. These primarily include bank loans, liabilities to employees and institutions, debts to suppliers or taxes due.
- V—performance, i.e., the results of company activities which are characterized by the main activity of the company—production. This includes the goods and services used for satisfying demands.
- SLUZBY—services, i.e., those activities intended to meet human needs or the needs of a company by means of their execution.
- PRIDHODN—added value, i.e., trademarking, sales, changes in inventory through own activities, or activation reduced by power consumption. This includes both company margin and performance.
- ON—personnel costs, i.e., gross salaries and the employer’s compulsory social and health insurance contributions for each employee.
- PROVHOSP—operating results, i.e., the outcomes and products that reflect the ability of a company to transform production factors.
- NU—interest payable, i.e., the price of borrowed capital.
- HOSPVZUO—economic result for an accounting period, i.e., from operational, financial, and extraordinary activities.
- STAV—target situation, i.e., classification as “active” for companies able to survive potential financial distress, and “in liquidation” for companies that will go bankrupt.
3.2. Methods
- Hyperbolic tangent (Tanh),
- Sinus (Sin),
- Ramp (referred to as ReLU),
- Logistic function (logistic sigmoid).
- Hyperbolic tangent (Tanh),
- Sinus (Sin),
- Ramp (referred to as ReLU),
- Logistic function (logistic sigmoid).
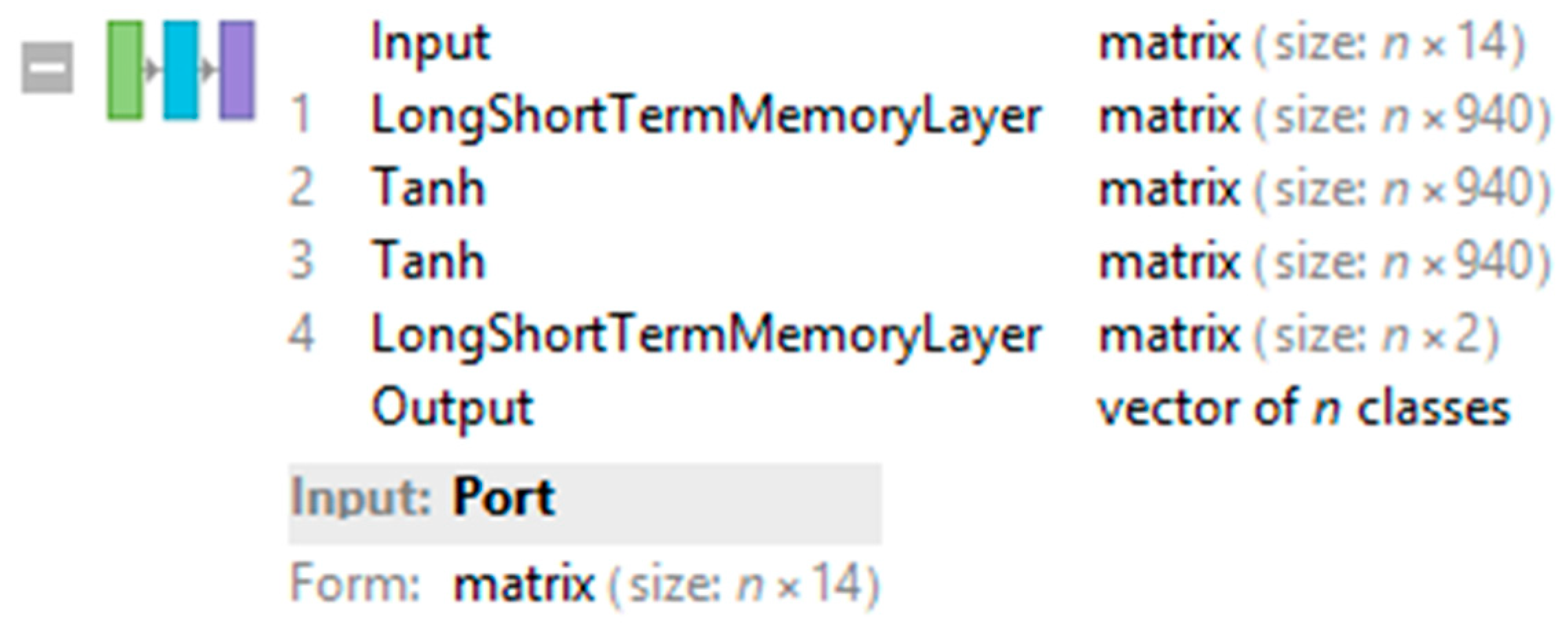
3.3. Long-Short Term Memory Layer
3.4. Elementwise Layer
- 1.
- Hyperbolic tangent (Tanh):
- 2.
- Sinus (Sin):
- 3.
- Ramp (referred to as ReLU):
- 4.
- Logistic function (logistic sigmoid):
3.5. Evaluation of Network Performance
- The performance of the individual networks in the training and testing datasets.
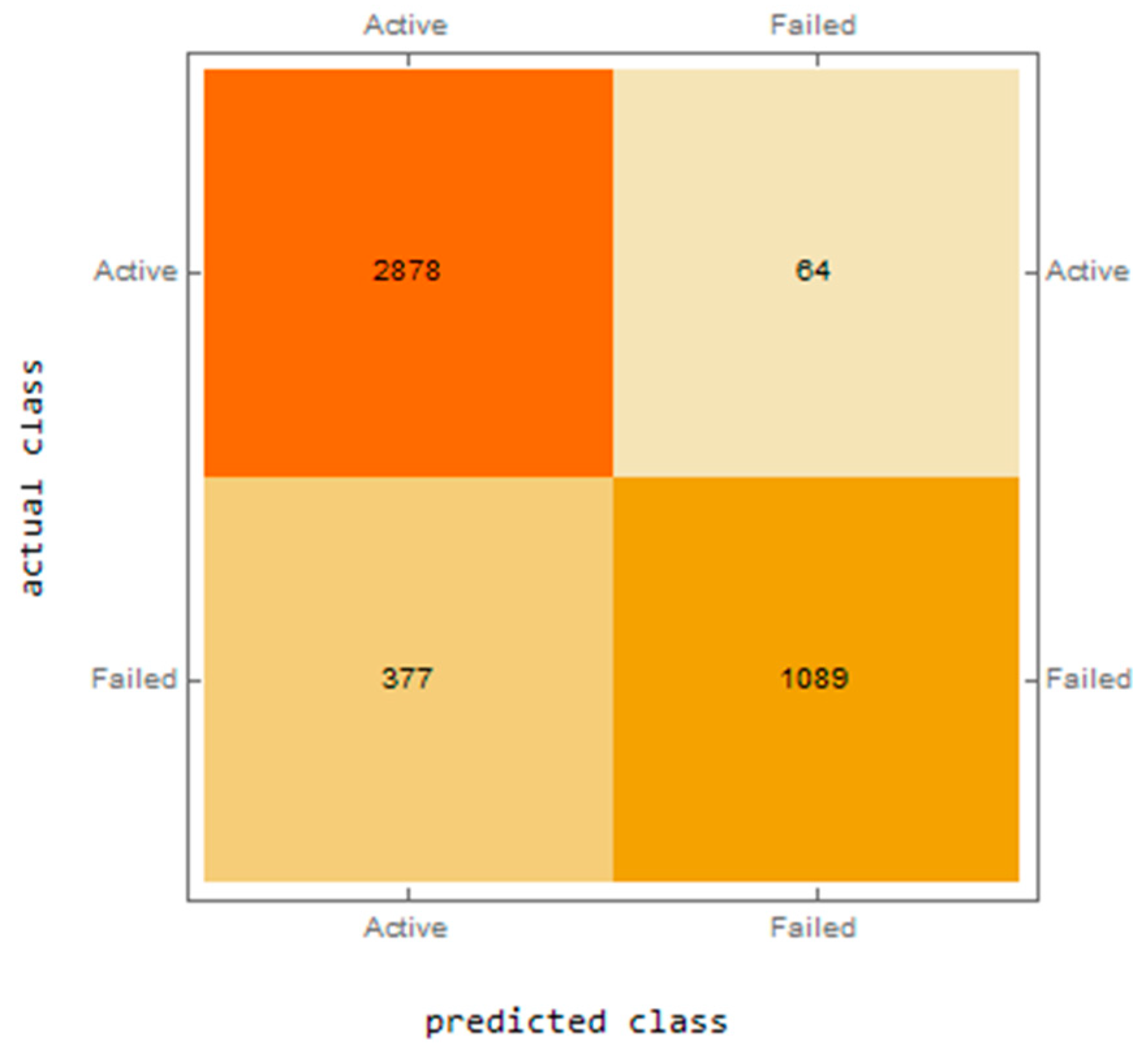
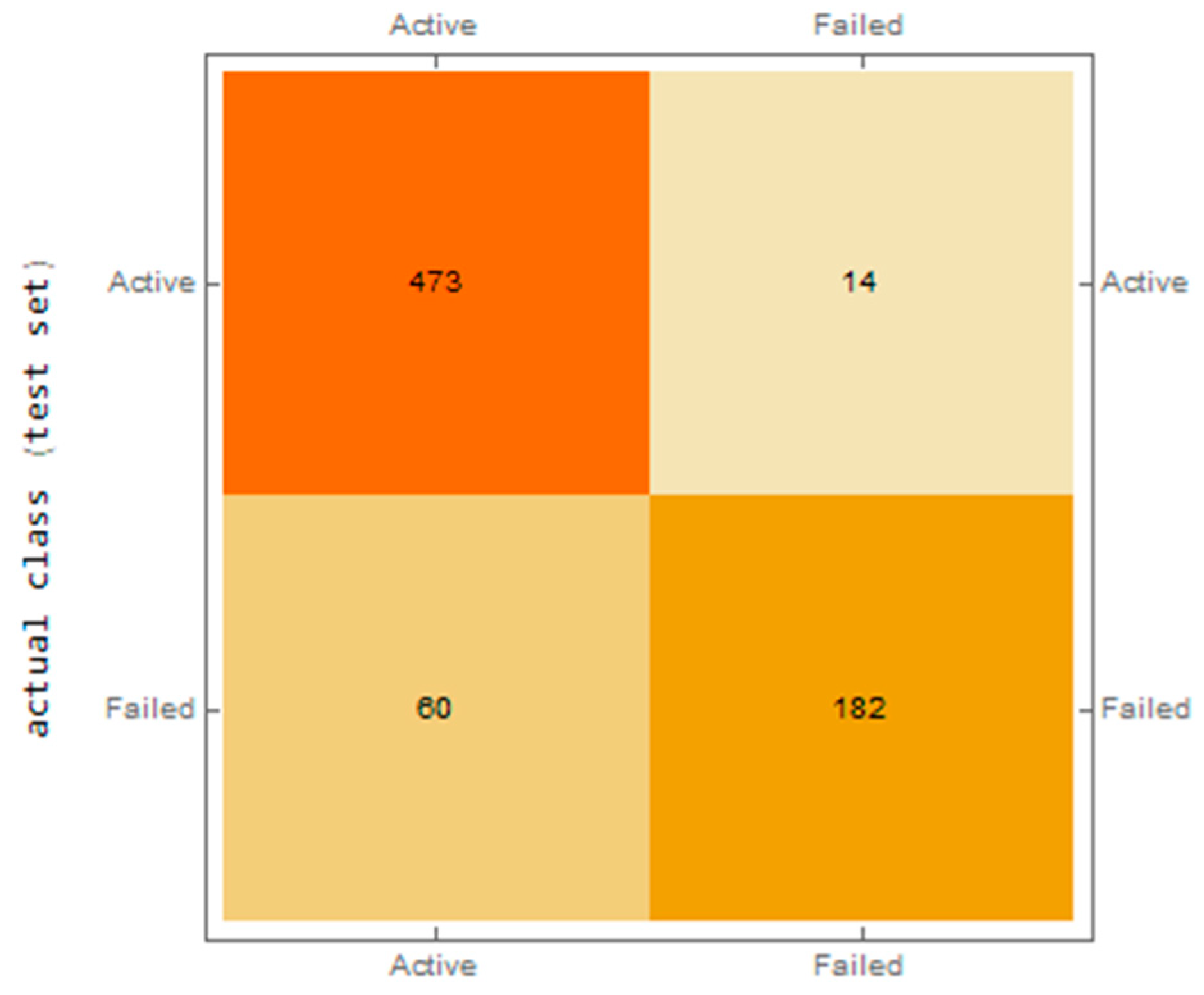
- The confusion matrix characterizing the correct classification of companies into “active” and “in liquidation”. The confusion matrix was created for both the training and testing datasets.
4. Results
- The trained NN in the WLNet format is available from: https://ftp.vstecb.cz
- The training dataset in xlsx format is available from: https://ftp.vstecb.cz
- The testing dataset in xlsx format is available from: https://ftp.vstecb.cz
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tang, Y.; Ji, J.; Zhu, Y.; Gao, S.; Tang, Z.; Todo, Y. A differential evolution-oriented pruning neural network model for bankruptcy prediction. Complexity 2019, 2019, 1–21. [Google Scholar] [CrossRef]
- Kliestik, T.; Misankova, M.; Valaskova, K.; Svabova, L. Bankruptcy prevention: New effort to reflect on legal and social changes. Sci. Eng. Ethics 2018, 24, 791–803. [Google Scholar] [CrossRef] [PubMed]
- Kliestik, T.; Vrbka, J.; Rowland, Z. Bankruptcy prediction in Visegrad group countries using multiple discriminant analysis. Equilib. Q. J. Econ. Econ. Policy 2018, 13, 569–593. [Google Scholar] [CrossRef]
- Horak, J.; Krulicky, T. Comparison of exponential time series alignment and time series alignment using artificial neural networks by example of prediction of future development of stock prices of a specific company. In Proceedings of the SHS Web of Conferences: Innovative Economic Symposium 2018—Milestones and Trends of World Economy (IES2018), Beijing, China, 8–9 November 2018. [Google Scholar] [CrossRef]
- Antunes, F.; Ribeiro, B.; Pereira, F. Probabilistic modeling and visualization for bankruptcy prediction. Appl. Soft Comput. 2017, 60, 831–843. [Google Scholar] [CrossRef]
- Machova, V.; Marecek, J. Estimation of the development of Czech Koruna to Chinese Yuan exchange rate using artificial neural networks. In Proceedings of the SHS Web of Conferences: Innovative Economic Symposium 2018—Milestones and Trends of World Economy (IES2018), Beijing, China, 8–9 November 2018. [Google Scholar] [CrossRef]
- Gavurova, B.; Packova, M.; Misankova, M.; Smrcka, L. Predictive potential and risks of selected bankruptcy prediction models in the Slovak company environment. J. Bus. Econ. Manag. 2017, 18, 1156–1173. [Google Scholar] [CrossRef]
- Nakajima, M. Assessing bankruptcy reform in a model with temptation and equilibrium default. J. Public Econ. 2017, 145, 42–64. [Google Scholar] [CrossRef][Green Version]
- Horak, J.; Machova, V. Comparison of neural networks and regression time series on forecasting development of US imports from the PRC. Littera Scr. 2019, 12, 22–36. [Google Scholar]
- Alaminos, D.; Del Castillo, A.; Fernández, M.A.; Ponti, G. A global model for bankruptcy prediction. PLoS ONE 2016, 11. [Google Scholar] [CrossRef]
- Alaka, H.A.; Oyedele, L.O.; Owolabi, H.A.; Kumar, V.; Ajayi, S.O.; Akinade, O.O.; Bilal, M. Systematic review of bankruptcy prediction models: Towards a framework for tool selection. Expert Syst. Appl. 2018, 94, 164–184. [Google Scholar] [CrossRef]
- Eysenck, G.; Kovalova, E.; Machova, V.; Konecny, V. Big data analytics processes in industrial internet of things systems: Sensing and computing technologies, machine learning techniques, and autonomous decision-making algorithms. J. Self-Gov. Manag. Econ. 2019, 7, 28–34. [Google Scholar] [CrossRef]
- Barboza, F.; Kimura, H.; Altman, E. Machine learning models and bankruptcy prediction. Expert Syst. Appl. 2017, 83, 405–417. [Google Scholar] [CrossRef]
- Horák, J.; Vrbka, J.; Šuleř, P. Support vector machine methods and artificial neural networks used for the development of bankruptcy prediction models and their comparison. J. Risk Financ. Manag. 2020, 13, 3390. [Google Scholar] [CrossRef]
- Vrbka, J.; Rowland, Z. Using artificial intelligence in company management. In Digital Age: Chances, Challenges and Future, 1st ed.; Lecture Notes in Networks and Systems; Ashmarina, S.I., Vochozka, M., Mantulenko, V.V., Eds.; Springer: Cham, Switzerland, 2020; pp. 422–429. [Google Scholar] [CrossRef]
- Zheng, C.; Wang, S.; Liu, Y.; Liu, C.; Xie, W.; Fang, C.; Liu, S. A novel equivalent model of active distribution networks based on LSTM. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2611–2624. [Google Scholar] [CrossRef] [PubMed]
- Rundo, F. Deep LSTM with reinforcement learning layer for financial trend prediction in FX high frequency trading systems. Appl. Sci. 2019, 9, 4460. [Google Scholar] [CrossRef]
- Liu, R.; Liu, L. Predicting housing price in China based on long short-term memory incorporating modified genetic algorithm. Soft Comput. 2019, 23, 11829–11838. [Google Scholar] [CrossRef]
- Chebeir, J.; Asala, H.; Manee, V.; Gupta, I.; Romagnoli, J.A. Data driven techno-economic framework for the development of shale gas resources. J. Nat. Gas Sci. Eng. 2019, 72, 103007. [Google Scholar] [CrossRef]
- Liu, W.; Liu, W.D.; Gu, J. Forecasting oil production using ensemble empirical model decomposition based Long Short-Term Memory neural network. J. Pet. Sci. Eng. 2020, 189, 107013. [Google Scholar] [CrossRef]
- Karevan, Z.; Suykens, J.A.K. Transductive LSTM for time-series prediction: An application to weather forecasting. Neural Netw. 2020, 125, 1–9. [Google Scholar] [CrossRef]
- Sagheer, A.; Kotb, M. Unsupervised pre-training of a deep LSTM-based stacked autoencoder for multivariate time series forecasting problems. Sci. Rep. 2019, 9, 19038. [Google Scholar] [CrossRef]
- Xiao, X.; Zhang, D.; Hu, G.; Jiang, Y.; Xia, S. A Convolutional neural network and multi-head self-attention combined approach for detecting phishing websites. Neural Netw. 2020, 125, 303–312. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, L.; Ma, H.; Wang, H.; Wan, S. Parallel LSTM-Based regional integrated energy system multienergy source-load information interactive energy prediction. Complexity 2019, 2019, 1–13. [Google Scholar] [CrossRef]
- Panigrahi, S.; Behera, S.H. A study on leading machine learning techniques for high order fuzzy time series forecasting. Eng. Appl. Artif. Intell. 2020, 87, 103245. [Google Scholar] [CrossRef]
- Pang, X.; Zhou, Y.; Wang, P.; Lin, W.; Chang, W. An innovative neural network approach for stock market prediction. J. Supercomput. 2020, 76, 2098–2118. [Google Scholar] [CrossRef]
- Au Yeung, J.F.K.; Wei, Z.; Chan, K.Y.; Lau, H.Y.K.; Yiu, K.C. Jump detection in financial time series using machine learning algorithms. Soft Comput. 2020, 24, 1789–1801. [Google Scholar] [CrossRef]
- Ding, G.; Qin, L. Study on the prediction of stock price based on the associated network model of LSTM. Int. J. Mach. Learn. Cybern. 2019, 11, 1307–1317. [Google Scholar] [CrossRef]
- Adeel, A.; Gogate, M.; Hussain, A. Contextual deep learning-based audio-visual switching for speech enhancement in real-world environments. Inf. Fusion 2020, 59, 163–170. [Google Scholar] [CrossRef]
- Roy, P.K.; Singh, J.P.; Banerjee, S. Deep learning to filter SMS Spam. Future Gener. Comput. Syst. 2020, 102, 524–533. [Google Scholar] [CrossRef]
- Tian, Y.; Lai, R.; Li, X.; Xiang, L.; Tian, J. A combined method for state-of-charge estimation for lithium-ion batteries using a long short-term memory network and an adaptive cubature Kalman filter. Appl. Energy 2020, 265. [Google Scholar] [CrossRef]
- Chatterjee, J.; Dethlefs, N. Deep learning with knowledge transfer for explainable anomaly prediction in wind turbines. Wind Energy 2020, 23, 1693–1710. [Google Scholar] [CrossRef]
- Hong, J.; Wang, Z.; Chen, W.; Yao, Y. Synchronous multi-parameter prediction of battery systems on electric vehicles using long short-term memory networks. Appl. Energy 2019, 254. [Google Scholar] [CrossRef]
- Yang, G.; Wang, Y.; Li, X. Prediction of the NO emissions from thermal power plant using long-short term memory neural network. Energy 2020, 192. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, Y.; Li, S.; Xu, S. A weighted auto regressive LSTM based approach for chemical processes modeling. Neurocomputing 2019, 367, 64–74. [Google Scholar] [CrossRef]
- Correa-Jullian, C.; Cardemil, J.M.; López Droguett, E.; Behzad, M. Assessment of deep learning techniques for prognosis of solar thermal systems. Renew. Energy 2020, 145, 2178–2191. [Google Scholar] [CrossRef]
- Wei, N.; Li, C.; Peng, X.; Li, Y.; Zeng, F. Daily natural gas consumption forecasting via the application of a novel hybrid model. Appl. Energy 2019, 250, 358–368. [Google Scholar] [CrossRef]
- Somu, N.; Ramamritham, K. A hybrid model for building energy consumption forecasting using long short term memory networks. Appl. Energy 2020, 261, 114131. [Google Scholar] [CrossRef]
- Zhu, X.; Zeng, B.; Dong, H.; Liu, J. An interval-prediction based robust optimization approach for energy-hub operation scheduling considering flexible ramping products. Energy 2020, 194. [Google Scholar] [CrossRef]
- Liu, Y. Novel volatility forecasting using deep learning–Long Short Term Memory Recurrent Neural Networks. Expert Syst. Appl. 2019, 132, 99–109. [Google Scholar] [CrossRef]
- Qiao, W.; Yang, Z. Forecast the electricity price of U.S. using a wavelet transform-based hybrid model. Energy 2020, 193, 116704. [Google Scholar] [CrossRef]
- Chang, Z.; Zhang, Y.; Chen, W. Electricity price prediction based on hybrid model of ADAM optimized LSTM neural network and wavelet transform. Energy 2019, 187, 115804. [Google Scholar] [CrossRef]
- Xie, X.; Liu, G.; Cai, Q.; Sun, G.; Zhang, M.; Qu, H. An end-to-end functional spiking model for sequential feature learning. Knowl. Based Syst. 2020, 195, 105643. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Yang, Y.; Horng, S.J. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]
- Punia, S.; Nikolopoulos, K.; Singh, S.P.; Madaan, J.K.; Litsiou, K. Deep learning with long short-term memory networks and random forests for demand forecasting in multi-channel retail. Int. J. Prod. Res. 2020, 58, 4964–4979. [Google Scholar] [CrossRef]
- Fong, I.; Li, H.T.; Fong, S.; Wong, R.K.; Tallón-Ballesteros, A.J. Predicting concentration levels of air pollutants by transfer learning and recurrent neural network. Knowl. Based Syst. 2020, 192, 105622. [Google Scholar] [CrossRef]
- Wan, H.; Guo, S.; Yin, K.; Liang, X.; Lin, Y. CTS-LSTM: LSTM-based neural networks for correlated time series prediction. Knowl. Based Syst. 2020, 191, 105239. [Google Scholar] [CrossRef]
- Bandara, K.; Bergmeir, C.; Smyl, S. Forecasting across time series databases using recurrent neural networks on groups of similar series: A clustering approach. Expert Syst. Appl. 2020, 140, 112896. [Google Scholar] [CrossRef]
- Park, H.; Song, M.; Shin, K.S. Deep learning models and datasets for aspect term sentiment classification: Implementing holistic recurrent attention on target-dependent memories. Knowl. Based Syst. 2020, 187, 104825. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for time series classification. Neural Netw. 2019, 116, 237–245. [Google Scholar] [CrossRef]
- Farzad, A.; Hmashayekhi, H.; Hassanpour, H. A comparative performance analysis of different activation functions in LSTM networks for classification. Neural Comput. Appl. 2019, 31, 2507–2521. [Google Scholar] [CrossRef]
- Smyl, S. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. Int. J. Forecast. 2020, 36, 75–85. [Google Scholar] [CrossRef]
- Schönfeld, J.; Kudej, M.; Smrcka, L. Financial health of enterprises introducing safeguard procedure based on bankruptcy models. J. Co. Econ. Manag. 2018, 19, 692–705. [Google Scholar] [CrossRef]
- Affes, Z.; Hentati-Kaffel, R. Forecast bankruptcy using a blend of clustering and MARS model: Case of US banks. Ann. Oper. Res. 2019, 281, 27–64. [Google Scholar] [CrossRef]
- Fu, S.; Li, H.; Zhao, G. Modelling and strategy optimisation for a kind of networked evolutionary games with memories under the bankruptcy mechanism. Int. J. Control 2017, 91, 1104–1117. [Google Scholar] [CrossRef]
- Sant’anna, P.H.C. Testing for Uncorrelated Residuals in Dynamic Count Models with an Application to Corporate Bankruptcy. J. Co. Econ. Stat. 2017, 35, 349–358. [Google Scholar] [CrossRef]
- Hu, Y. A multivariate grey prediction model with grey relational analysis for bankruptcy prediction problems. Soft Comput. 2020, 24, 4259–4268. [Google Scholar] [CrossRef]
- Nyitrai, T.; Virag, M. The effects of handling outliers on the performance of bankruptcy prediction models. Socio-Econ. Plan. Sci. 2019, 67, 34–42. [Google Scholar] [CrossRef]
- Kubenka, M.; Myskova, R. Obvious and hidden features of corporate default in bankruptcy models. J. Bus. Econ. Manag. 2019, 20, 368–383. [Google Scholar] [CrossRef]
- Zhou, L.; Lai, K.K. AdaBoost models for corporate bankruptcy prediction with missing data. Comput. Econ. 2017, 50, 69–94. [Google Scholar] [CrossRef]
- Kim, A.; Yang, Y.; Lessmann, S.; Ma, T.; Sung, M.; Johnson, J.E.V. Can deep learning predict risky retail investors? A case study in financial risk behavior forecasting. Eur. J. Oper. Res. 2020, 283, 217–234. [Google Scholar] [CrossRef]
- Koudjonou, K.M.; Rout, M. A stateless deep learning framework to predict net asset value. Neural Comput. Appl. 2020, 32, 1–19. [Google Scholar] [CrossRef]
- Mai, F.; Tian, S.; Lee, C.; Ma, L. Deep learning models for bankruptcy prediction using textual disclosures. Eur. J. Oper. Res. 2019, 274, 743–758. [Google Scholar] [CrossRef]
- Mihalovic, M. Performance comparison of multiple discriminant analysis and Logit models in bankruptcy prediction. Econ. Sociol. 2016, 9, 101. [Google Scholar] [CrossRef] [PubMed]
- Lin, T. A cross model study of corporate financial distress prediction in Taiwan: Multiple discriminant analysis, logit, probit and neural networks models. Neurocomputing 2009, 72, 3507–3516. [Google Scholar] [CrossRef]
- Unvan, Y.A.; Tatlidil, H. A comparative analysis of Turkish bank failures using logit, probit and discriminant models. Philippines 2013, 22, 281–302. [Google Scholar]
- Lunacek, J. Selection of bankruptcy prediction model for the construction industry—A case study from the Czech Republic. In Proceedings of the 25th International Company Information Management Association Conference—Innovation Vision 2020: From Regional Development Sustainability to Global Economic Growth, IBIMA, Amsterdam, The Netherlands, 7–8 May 2015; pp. 2627–2637. [Google Scholar]
- Iturriaga, F.J.L.; Sanz, I.P. Bankruptcy visualization and prediction using neural networks: A study of US commercial banks. Expert Syst. Appl. 2015, 42, 2857–2869. [Google Scholar] [CrossRef]
- Bateni, L.; Asghari, F. Bankruptcy prediction using logit and genetic algorithm models: A comparative analysis. Comput. Econ. Comput. Econ. 2020, 55, 335–348. [Google Scholar] [CrossRef]
- Altman, E.I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Altman, E.I.; Haldeman, R.G.; Narayanan, P. ZETA analysis: A new model to identify bankruptcy risk of corporations. J. Bank. Financ. 1977, 1, 29–51. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Item | Training | Testing | ||||||
|---|---|---|---|---|---|---|---|---|
| Minimum | Maximum | Mean | Standard Deviation | Minimum | Maximum | Mean | Standard Deviation | |
| Total Assets | 0 | 6,963,568 | 101,794.3 | 421,183.6 | 0 | 62,924,684 | 193,629.3 | 2,402,017 |
| Fixed Assets | −19,065 | 4,558,816 | 49,269.92 | 251,519.4 | 0 | 30,832,576 | 90,484.69 | 1,204,674 |
| Current Assets | 0 | 2,391,855 | 51,801.29 | 182,982.9 | 0 | 32,066,562 | 102,624.7 | 1,222,082 |
| Short Term Receivables | −127 | 1,947,964 | 24,162.22 | 106,237.4 | 0 | 27,683,668 | 65,334.36 | 1,039,648 |
| Equity | −9662 | 1,923,390 | 50,993.7 | 186,972.2 | −206,208 | 53,318,744 | 131,475.4 | 2,004,015 |
| Borrowed Capital | 0 | 5,024,089 | 50,269.76 | 256,551.2 | −21 | 9,605,513 | 61,351.15 | 469,600.1 |
| Short Term Liabilities | 0 | 4,906,382 | 31,905.76 | 204,347.7 | −96 | 7,970,386 | 41,665.4 | 366,137.2 |
| Performance | −40 | 4,180,449 | 97,214.31 | 335,148.6 | −246 | 33,887,311 | 142,956.2 | 1,342,696 |
| Services | 0 | 569,454 | 14,468.57 | 48,754.07 | 0 | 3,038,338 | 19,348.75 | 133,230.2 |
| Added Value | −7788 | 824,345 | 26,734.39 | 76,957.12 | −20,284 | 3,457,583 | 30,516.86 | 167,441.7 |
| Personnel Costs | 0 | 463,685 | 17,940.92 | 46,808.62 | −60 | 2,665,233 | 19,125.81 | 111,284.5 |
| Operating Result | −150,310 | 852,991 | 7316.556 | 44,552.34 | −847,530 | 914,063 | 4213.27 | 63,193.46 |
| Interest Payable | 0 | 187,218 | 744.4554 | 7525.506 | 0 | 52,798 | 494.3265 | 2912.81 |
| Economic Result for Accounting Period (+/−) | −245,135 | 700,092 | 6354.041 | 43,196.58 | −645,493 | 673,179 | 5049.786 | 53,302.32 |
| ID NN | Neural Network | Training Performance | Test Performance | ||||
|---|---|---|---|---|---|---|---|
| Active | Failed | Total | Active | Failed | Total | ||
| 1. | 14-940-Tanh-Tanh-2-1 | 0.978246 | 0.742838 | 0.899955 | 0.971253 | 0.752066 | 0.898491 |
| 2. | 14-1970-Ramp-Tanh-2-1 | 0.978586 | 0.722374 | 0.893376 | 0.967199 | 0.750331 | 0.899863 |
| 3. | 14-1980-Ramp-Sin-2-1 | 0.976547 | 0.718963 | 0.89088 | 0.973306 | 0.747934 | 0.898491 |
| 4. | 14-1990-Sin-Sin-2-1 | 0.973148 | 0.736016 | 0.894283 | 0.975359 | 0.747934 | 0.899863 |
| 5. | 14-1010-Tanh-Sin-2-1 | 0.980625 | 0.734652 | 0.89882 | 0.967146 | 0.772727 | 0.902606 |
| Field | Type of Output | Size of Output |
|---|---|---|
| Input gate input weights | matrix | 940 × 14 |
| Input gate state weights | matrix | 940 × 940 |
| Input gate biases | vector | 940 |
| Output gate input weights | matrix | 940 × 14 |
| Output gate state weights | matrix | 940 × 940 |
| Output gate biases | vector | 940 |
| Forget gate input weights | matrix | 940 × 14 |
| Forget gate state weights | matrix | 940 × 940 |
| Forget gate biases | vector | 940 |
| Memory gate input weights | matrix | 940 × 14 |
| Memory gate state weights | matrix | 940 × 940 |
| Memory gate biases | vector | 940 |
| Field | Type of Output | Size of Output |
|---|---|---|
| Input gate input weights | matrix | 2 × 940 |
| Input gate state weights | matrix | 2 × 2 |
| Input gate biases | vector | 2 |
| Output gate input weights | matrix | 2 × 940 |
| Output gate state weights | matrix | 2 × 2 |
| Output gate biases | vector | 2 |
| Forget gate input weights | matrix | 2 × 940 |
| Forget gate state weights | matrix | 2 × 2 |
| Forget gate biases | vector | 2 |
| Memory gate input weights | matrix | 2 × 940 |
| Memory gate state weights | matrix | 2 × 2 |
| Memory gate biases | vector | 2 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vochozka, M.; Vrbka, J.; Suler, P. Bankruptcy or Success? The Effective Prediction of a Company’s Financial Development Using LSTM. Sustainability 2020, 12, 7529. https://doi.org/10.3390/su12187529
Vochozka M, Vrbka J, Suler P. Bankruptcy or Success? The Effective Prediction of a Company’s Financial Development Using LSTM. Sustainability. 2020; 12(18):7529. https://doi.org/10.3390/su12187529
Chicago/Turabian StyleVochozka, Marek, Jaromir Vrbka, and Petr Suler. 2020. "Bankruptcy or Success? The Effective Prediction of a Company’s Financial Development Using LSTM" Sustainability 12, no. 18: 7529. https://doi.org/10.3390/su12187529
APA StyleVochozka, M., Vrbka, J., & Suler, P. (2020). Bankruptcy or Success? The Effective Prediction of a Company’s Financial Development Using LSTM. Sustainability, 12(18), 7529. https://doi.org/10.3390/su12187529