Machine Learning Approach Using MLP and SVM Algorithms for the Fault Prediction of a Centrifugal Pump in the Oil and Gas Industry


 ,
, 
Abstract
1. Introduction
- Data acquisition and storage [46]. A large amount of data is used in the process of training and learning. In general, more data leads to more reliable models and, consequently, better results. However, data should be representative of the analyzed process. Therefore, the acquisition of relevant data has a strong influence on the ML algorithm performance. Moreover, the processing of large repositories of time series data capturing during the process is necessary to handle them aiming at extracting valuable knowledge and information;
- Selection and design of the ML algorithm [44]. The ML model must be able to estimate machinery condition in a short time interval, aiming at performing proper and agile decision-making. As said before, the growing interest in the field of ML in manufacturing has led to the development of a large number of different ML algorithms or at least variations to adapt their operation according to different situations requiring deep skills and expertise. Although the core principles of ML are now accessible to a wider audience, adequate knowledge and deep technical know-how are required.
2. Methodology Applied to the Case Study
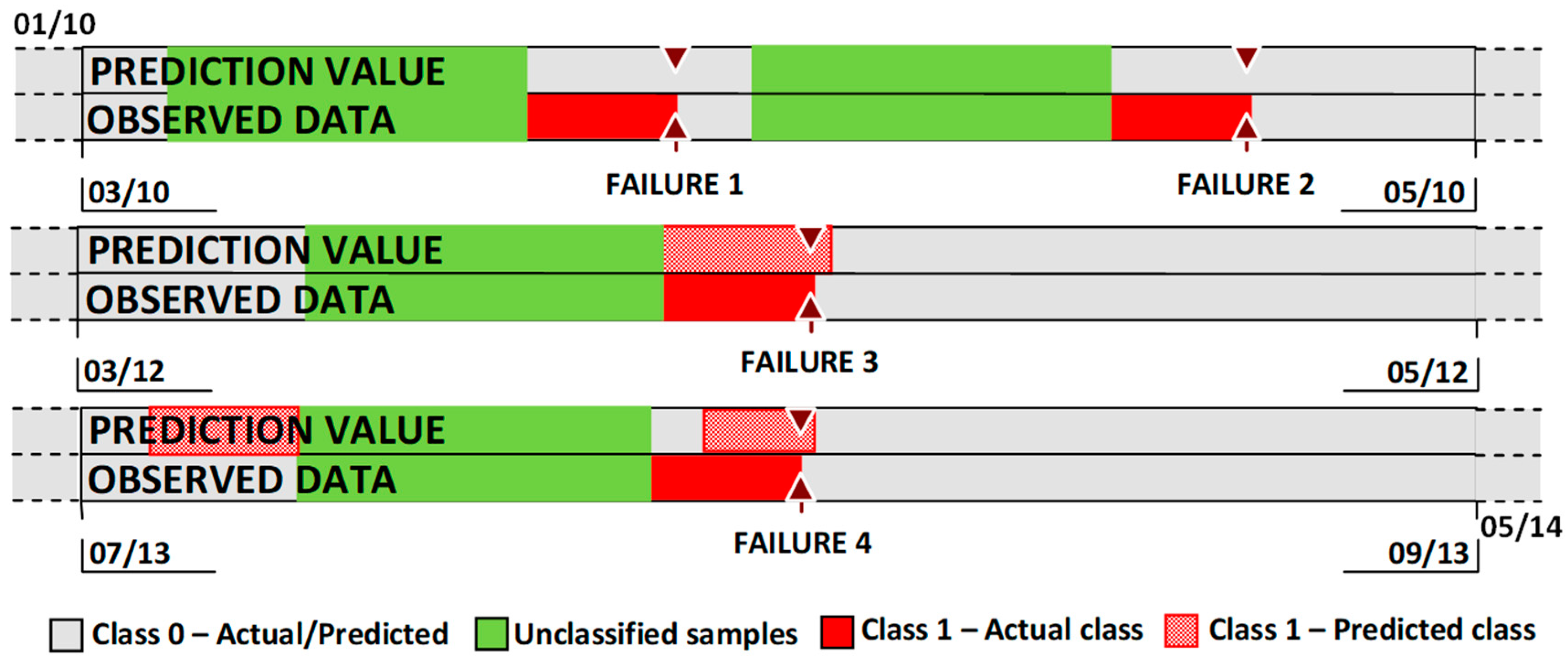
- A classification approach aims at predicting whether the centrifugal pump will fail or not within a future time interval, called failure prediction horizon T in this paper, whose length is determined by various factors, such as management needs and possibilities, domain expert decisions, etc. The parameter T is defined as the minimum lead time required to replace components before a problem occurs and its value is defined in such a way that it would be possible to apply proactively maintenance to avoid the problem.
- A regression approach aims at predicting how much time is left before the next failure event (RUL, Remaining Useful Life prediction) [48].
2.1. Data Acquisition Step
Dataset
2.2. Data Processing Step
2.2.1. Missing Values Treatment
2.2.2. Feature Engineering
2.2.3. Data Cleaning
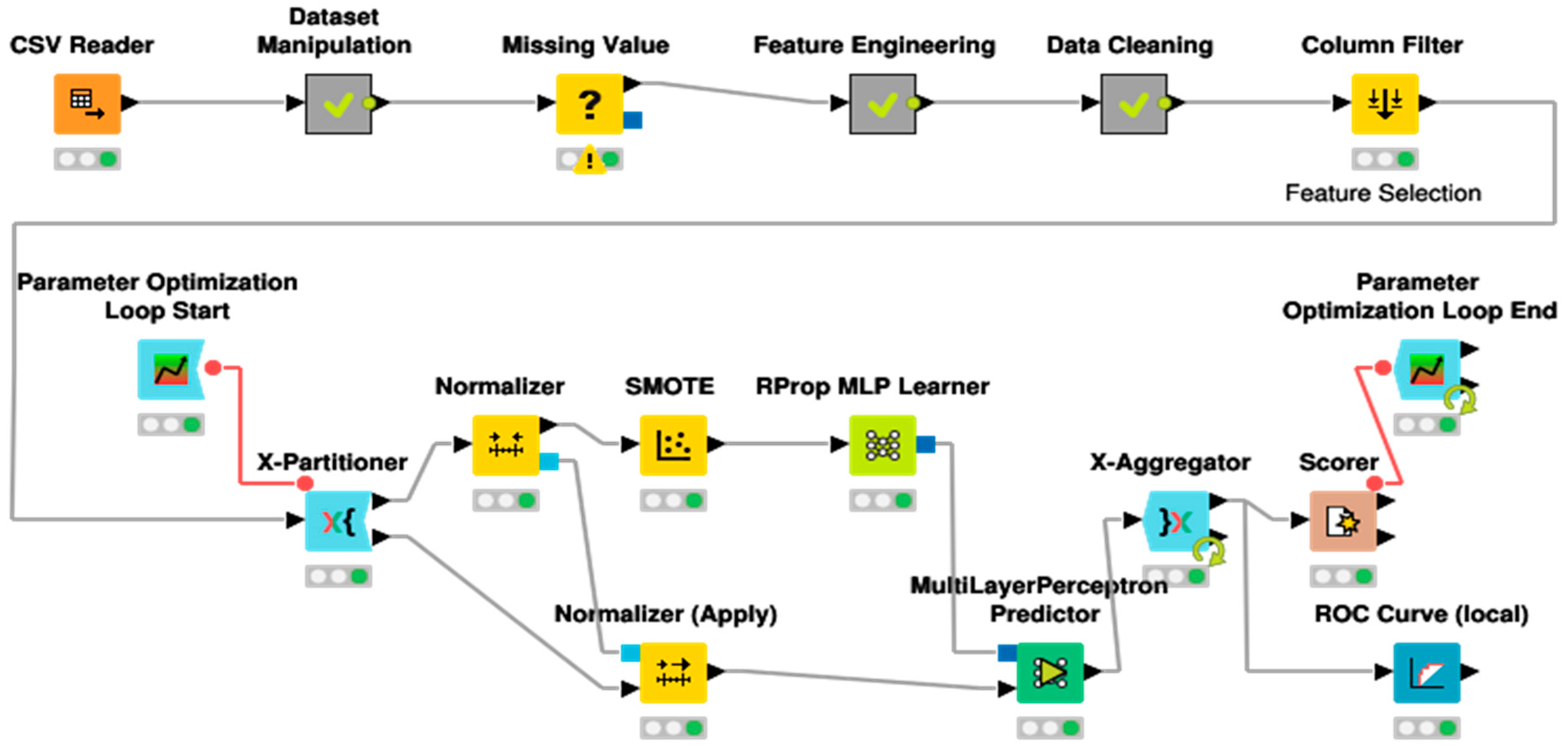
2.3. Model Selection and Validation
2.3.1. Classification Algorithms
2.3.2. Model Evaluation Metrics
3. Results
3.1. Results—Support Vector Machine Algorithm
3.2. Results—Multilayer Perceptron Algorithm
- The failure events register results incomplete and un-standardized.
- The dataset includes just four non-ambiguous fault events, which is a very small number. Consequently, the dataset is highly unbalanced between classes and the algorithm training set contains very few examples of class “1”. By using the SMOTE algorithm, classes are balanced—but still the information quality provided by a “synthetic” sample is not of as high a quality as is provided by real data.
- Inadequate sensory equipment, since the machine parts are not equipped with the most appropriate sensors.
- Sampling frequency has been set to one sample per hour, providing a smaller amount of data to be stored and analyzed.
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Susto, G.A.; Schirru, A.; Pampuri, S.; McLoone, S.; Beghi, A. Machine Learning for Predictive Maintenance: A Multiple Classifier Approach. IEEE Trans. Ind. Inform. 2015, 11, 812–820. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.A.M.N.; Vita, R.; Francisco, R.d.P.; Basto, J.P.; Alcalá, S.G.S. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137. [Google Scholar] [CrossRef]
- Li, K.; Xue, Y.; Cui, S.; Niu, Q. Intelligent Computing in Smart Grid and Electrical Vehicles; Springer: Cham, Switzerland, 2014; Volume 463, ISBN 9783662452851. [Google Scholar]
- Kostrzewski, M.; Varjan, P.; Gnap, J. Solutions dedicated to internal logistics 4.0. In Sustainable Logistics and Production in Industry 4.0; Springer: Cham, Switzerland, 2020; pp. 243–262. ISBN 978-3-030-33368-3. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2010; ISBN 9780262012430. [Google Scholar]
- Pham, D.T.; Afify, A.A. Machine-learning techniques and their applications in manufacturing. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2005, 219, 395–412. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Diez-Olivan, A.; Del Ser, J.; Galar, D.; Sierra, B. Data fusion and machine learning for industrial prognosis: Trends and perspectives towards Industry 4.0. Inf. Fus. 2019, 50, 92–111. [Google Scholar] [CrossRef]
- Costello, J.J.A.; West, G.M.; McArthur, S.D.J. Machine learning model for event-based prognostics in gas circulator condition monitoring. IEEE Trans. Reliab. 2017, 66, 1048–1057. [Google Scholar] [CrossRef]
- Han, Y.; Zhao, D.; Hou, H. Oil-immersed Transformer Internal Thermoelectric Potential Fault Diagnosis Based on Decision-tree of KNIME Platform. Proced. Comput. Sci. 2016, 83, 1321–1326. [Google Scholar] [CrossRef]
- Czwajda, L.; Kosacka-Olejnik, M.; Kudelska, I.; Kostrzewski, M.; Sethanan, K.; Pitakaso, R. Application of Prediction Markets Phenomenon as Decision Support Instrument in Vehicle Recycling Sector. LogForum 2019, 15, 265–278. [Google Scholar] [CrossRef]
- Li, H.; Parikh, D.; He, Q.; Qian, B.; Li, Z.; Fang, D.; Hampapur, A. Improving rail network velocity: A machine learning approach to predictive maintenance. Transp. Res. Part C Emerg. Technol. 2014, 45, 17–26. [Google Scholar] [CrossRef]
- Allah Bukhsh, Z.; Saeed, A.; Stipanovic, I.; Doree, A.G. Predictive maintenance using tree-based classification techniques: A case of railway switches. Transp. Res. Part C Emerg. Technol. 2019, 101, 35–54. [Google Scholar] [CrossRef]
- Sahal, R.; Breslin, J.G.; Ali, M.I. Big data and stream processing platforms for Industry 4.0 requirements mapping for a predictive maintenance use case. J. Manuf. Syst. 2020, 54, 138–151. [Google Scholar] [CrossRef]
- Hajizadeh, Y. Machine learning in oil and gas; a SWOT analysis approach. J. Pet. Sci. Eng. 2019, 176, 661–663. [Google Scholar] [CrossRef]
- Hanga, K.; Kovalchuk, Y. Machine Learning and Multi-Agent Systems in Oil and Gas Industry Applications: A Survey. Comput. Sci. Rev. 2019, 34, 100191. [Google Scholar] [CrossRef]
- Trout, J.N.; Kolodziej, J.R. Reciprocating compressor valve condition monitoring using image-based pattern recognition. In Proceedings of the Annual Conference of the Prognostics and Health Management Society, Denver, CO, USA, 6 October 2016. [Google Scholar]
- Deutsch, J.; He, D. Using Deep Learning-Based Approach to Predict Remaining Useful Life of Rotating Components. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 11–20. [Google Scholar] [CrossRef]
- Kwak, D.S.; Kim, K.J. A data mining approach considering missing values for the optimization of semiconductor-manufacturing processes. Expert Syst. Appl. 2012, 39, 2590–2596. [Google Scholar] [CrossRef]
- Qian, W.; Li, S.; Yi, P.; Zhang, K. A novel transfer learning method for robust fault diagnosis of rotating machines under variable working conditions. Meas. J. Int. Meas. Confed. 2019, 138, 514–525. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ding, Q. Deep residual learning-based fault diagnosis method for rotating machinery. ISA Trans. 2018. [Google Scholar] [CrossRef]
- Su, L.; Li, K.; Xiong, M.; Li, F.; Wu, J. A novel fault diagnosis algorithm for rotating machinery based on a sparsity and neighborhood preserving deep extreme learning machine. Neurocomputing 2019, 350, 261–270. [Google Scholar]
- Qian, W.; Li, S.; Wang, J.; Wu, Q. A novel supervised sparse feature extraction method and its application on rotating machine fault diagnosis. Neurocomputing 2018, 320, 129–140. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, S.; Wang, J.; Xin, Y.; An, Z. General normalized sparse filtering: A novel unsupervised learning method for rotating machinery fault diagnosis. Mech. Syst. Signal Process. 2019, 124, 596–612. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Bilski, P. Application of Support Vector Machines to the induction motor parameters identification. Meas. J. Int. Meas. Confed. 2014, 51, 377–386. [Google Scholar] [CrossRef]
- Jirdehi, M.A.; Rezaei, A. Parameters estimation of squirrel-cage induction motors using ANN and ANFIS. Alex. Eng. J. 2016, 55, 357–368. [Google Scholar] [CrossRef]
- Romeo, L.; Loncarski, J.; Paolanti, M.; Bocchini, G.; Mancini, A.; Frontoni, E. Machine learning-based design support system for the prediction of heterogeneous machine parameters in industry 4.0. Expert Syst. Appl. 2020, 140. [Google Scholar] [CrossRef]
- Giantomassi, A.; Ferracuti, F.; Iarlori, S.; Ippoliti, G.; Longhi, S. Electric Motor Fault Detection and Diagnosis by Kernel Density Estimation and Kullback-Leibler Divergence based on Stator Current Measurements. IEEE Trans. Ind. Electron. 2015, 62, 1770–1780. [Google Scholar] [CrossRef]
- Paolanti, M.; Romeo, L.; Felicetti, A.; Mancini, A.; Frontoni, E.; Loncarski, J. Machine learning approach for predictive maintenance in industry 4.0. In Proceedings of the 14th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications (MESA), Oulu, Finland, 2–4 July 2018; pp. 1–6. [Google Scholar]
- Yang, Y.; Zheng, H.; Li, Y.; Xu, M.; Chen, Y. A fault diagnosis scheme for rotating machinery using hierarchical symbolic analysis and convolutional neural network. ISA Trans. 2019, 91, 235–252. [Google Scholar] [CrossRef]
- Pang, S.; Yang, X.; Zhang, X.; Lin, X. Fault diagnosis of rotating machinery with ensemble kernel extreme learning machine based on fused multi-domain features. ISA Trans. 2019. [Google Scholar] [CrossRef]
- Chen, Z.; Gryllias, K.; Li, W. Mechanical fault diagnosis using Convolutional Neural Networks and Extreme Learning Machine. Mech. Syst. Signal Process. 2019, 133, 106272. [Google Scholar] [CrossRef]
- Zhang, X.L.; Chen, W.; Wang, B.J.; Chen, X.F. Intelligent fault diagnosis of rotating machinery using support vector machine with ant colony algorithm for synchronous feature selection and parameter optimization. Neurocomputing 2015, 167, 260–279. [Google Scholar] [CrossRef]
- Wang, X.B.; Zhang, X.; Li, Z.; Wu, J. Ensemble extreme learning machines for compound-fault diagnosis of rotating machinery. Knowl.-Based Syst. 2019. [Google Scholar] [CrossRef]
- Panda, A.K.; Rapur, J.S.; Tiwari, R. Prediction of flow blockages and impending cavitation in centrifugal pumps using Support Vector Machine (SVM) algorithms based on vibration measurements. Meas. J. Int. Meas. Confed. 2018, 130, 44–56. [Google Scholar] [CrossRef]
- Wang, Z.Y.; Lu, C.; Zhou, B. Fault diagnosis for rotary machinery with selective ensemble neural networks. Mech. Syst. Signal Process. 2018, 113, 112–130. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Tang, S.; Shen, C.; Wang, D.; Li, S.; Huang, W.; Zhu, Z. Adaptive deep feature learning network with Nesterov momentum and its application to rotating machinery fault diagnosis. Neurocomputing 2018, 305, 1–14. [Google Scholar] [CrossRef]
- Yu, S.; Zhao, D.; Chen, W.; Hou, H. Oil-immersed Power Transformer Internal Fault Diagnosis Research Based on Probabilistic Neural Network. Proced. Comput. Sci. 2016, 83, 1327–1331. [Google Scholar] [CrossRef]
- Zenisek, J.; Holzinger, F.; Affenzeller, M. Machine learning based concept drift detection for predictive maintenance. Comput. Ind. Eng. 2019, 137. [Google Scholar] [CrossRef]
- Lee, W.J.; Wu, H.; Yun, H.; Kim, H.; Jun, M.B.G.; Sutherland, J.W. Predictive maintenance of machine tool systems using artificial intelligence techniques applied to machine condition data. Proced. CIRP 2019, 80, 506–511. [Google Scholar] [CrossRef]
- Guedes, A.S.; Silva, S.M.; Cardoso Filho, B.d.J.; Conceição, C.A. Evaluation of electrical insulation in three-phase induction motors and classification of failures using neural networks. Electr. Power Syst. Res. 2016, 140, 263–273. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Ruiz-Sarmiento, J.R.; Monroy, J.; Moreno, F.A.; Galindo, C.; Bonelo, J.M.; Gonzalez-Jimenez, J. A predictive model for the maintenance of industrial machinery in the context of industry 4.0. Eng. Appl. Artif. Intell. 2020, 87, 103289. [Google Scholar] [CrossRef]
- Ruiz-Sarmiento, J.R.; Galindo, C.; Gonzalez-Jimenez, J. Building multiversal semantic maps for mobile robot operation. Knowl.-Based Syst. 2017, 119, 257–272. [Google Scholar] [CrossRef]
- Burkov, A. The Hundred-Page Machine Learning Book, 1st ed.; Publishing Kindle Direct: Seattle, WA, USA, 2019. [Google Scholar]
- Jahnke, P. Machine Learning Approaches for Failure Type Detection and Predictive Maintenance. Master’s Thesis, Technische Universität Darmstadt, Darmstadt, Germany, 19 June 2015. [Google Scholar]
- Lepot, M.; Aubin, J.B.; Clemens, F.H.L.R. Interpolation in time series: An introductive overview of existing methods, their performance criteria and uncertainty assessment. Water 2017, 9, 796. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: Berlin, Germany, 2017. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. Journal of Artificial Intelligence Research. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Ha, T.M.; Bunke, H. Off-line, handwritten numeral recognition by perturbation method. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 535–539. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V.N. Support-Vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory; John Wiley & Sons Inc.: New York, NY, USA, 1998. [Google Scholar]
- Riedmiller, M.; Braun, H. A direct adaptive method for faster backpropagation learning: The RPROP algorithm. In Proceedings of the IEEE International Conference on Neural Networks, San Francisco, CA, USA, 28 March–1 April 1993; pp. 586–591. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class 0 | Class 1 | |
|---|---|---|
| Class 0 | 27,745 | 71 |
| Class 1 | 456 | 175 |
| Class 0 | Class 1 | |
|---|---|---|
| Class 0 | 27,684 | 132 |
| Class 1 | 366 | 265 |
| Recall | Precision | F1 Score | Accuracy | Cohen’s K | |
|---|---|---|---|---|---|
| Class 0 | 99.7% | 98.4% | 99.1% | - | - |
| Class 1 | 27.7% | 71.1% | 39.9% | - | - |
| Overall | - | - | - | 98.1% | 0.392 |
| Recall | Precision | F1 Score | Accuracy | Cohen’s K | |
|---|---|---|---|---|---|
| Class 0 | 99.5% | 98.7% | 99.1% | - | - |
| Class 1 | 42.2% | 66.8% | 51.6% | - | - |
| Overall | - | - | - | 98.2% | 0.507 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Orrù, P.F.; Zoccheddu, A.; Sassu, L.; Mattia, C.; Cozza, R.; Arena, S. Machine Learning Approach Using MLP and SVM Algorithms for the Fault Prediction of a Centrifugal Pump in the Oil and Gas Industry. Sustainability 2020, 12, 4776. https://doi.org/10.3390/su12114776
Orrù PF, Zoccheddu A, Sassu L, Mattia C, Cozza R, Arena S. Machine Learning Approach Using MLP and SVM Algorithms for the Fault Prediction of a Centrifugal Pump in the Oil and Gas Industry. Sustainability. 2020; 12(11):4776. https://doi.org/10.3390/su12114776
Chicago/Turabian StyleOrrù, Pier Francesco, Andrea Zoccheddu, Lorenzo Sassu, Carmine Mattia, Riccardo Cozza, and Simone Arena. 2020. "Machine Learning Approach Using MLP and SVM Algorithms for the Fault Prediction of a Centrifugal Pump in the Oil and Gas Industry" Sustainability 12, no. 11: 4776. https://doi.org/10.3390/su12114776
APA StyleOrrù, P. F., Zoccheddu, A., Sassu, L., Mattia, C., Cozza, R., & Arena, S. (2020). Machine Learning Approach Using MLP and SVM Algorithms for the Fault Prediction of a Centrifugal Pump in the Oil and Gas Industry. Sustainability, 12(11), 4776. https://doi.org/10.3390/su12114776