LSTM-Based Deep Learning Model for Predicting Individual Mobility Traces of Short-Term Foreign Tourists

Abstract
1. Introduction
2. Related Work
3. Methodology
3.1. Trajectory Pre-Processing
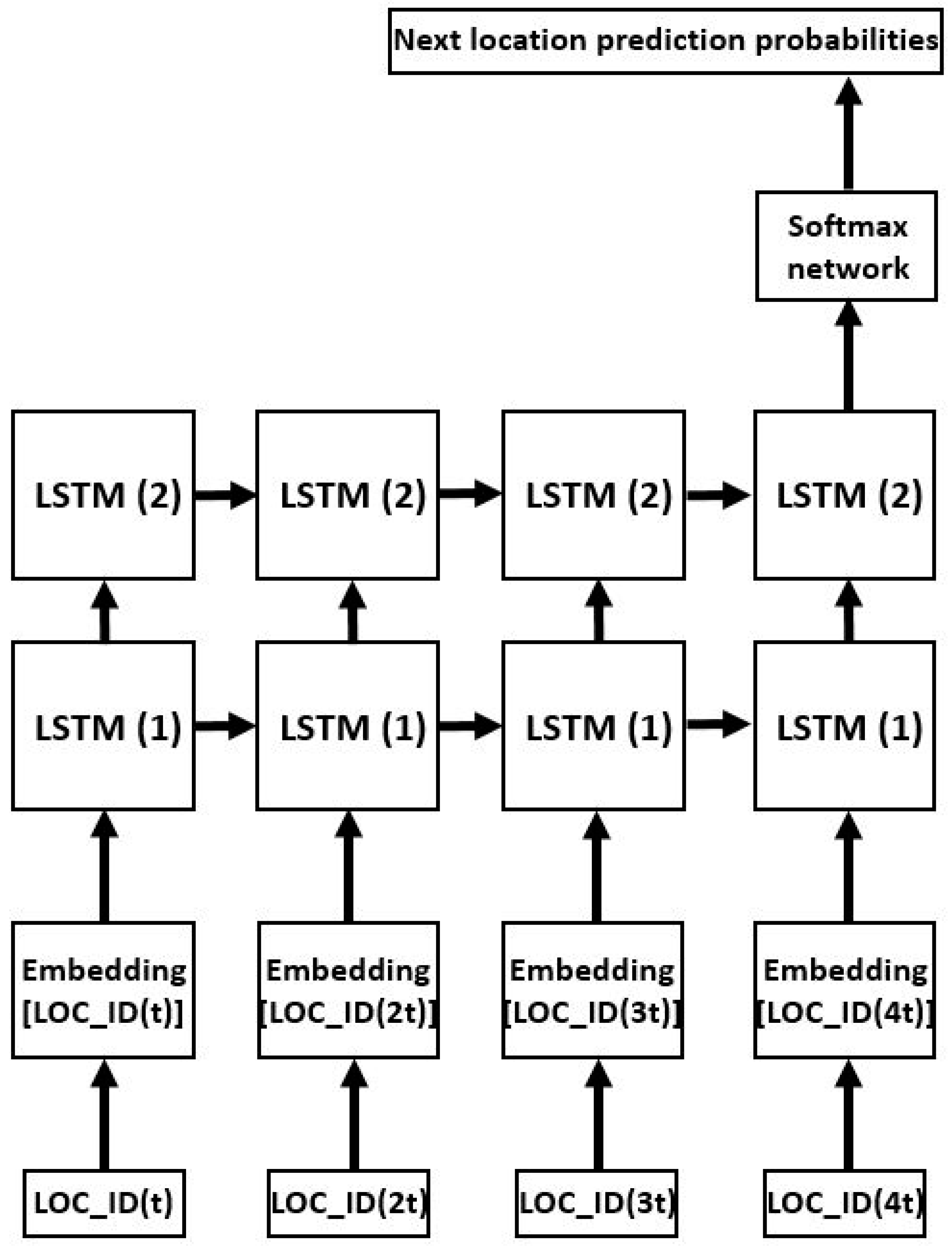
3.2. Deep Learning Model for Trajectory Prediction
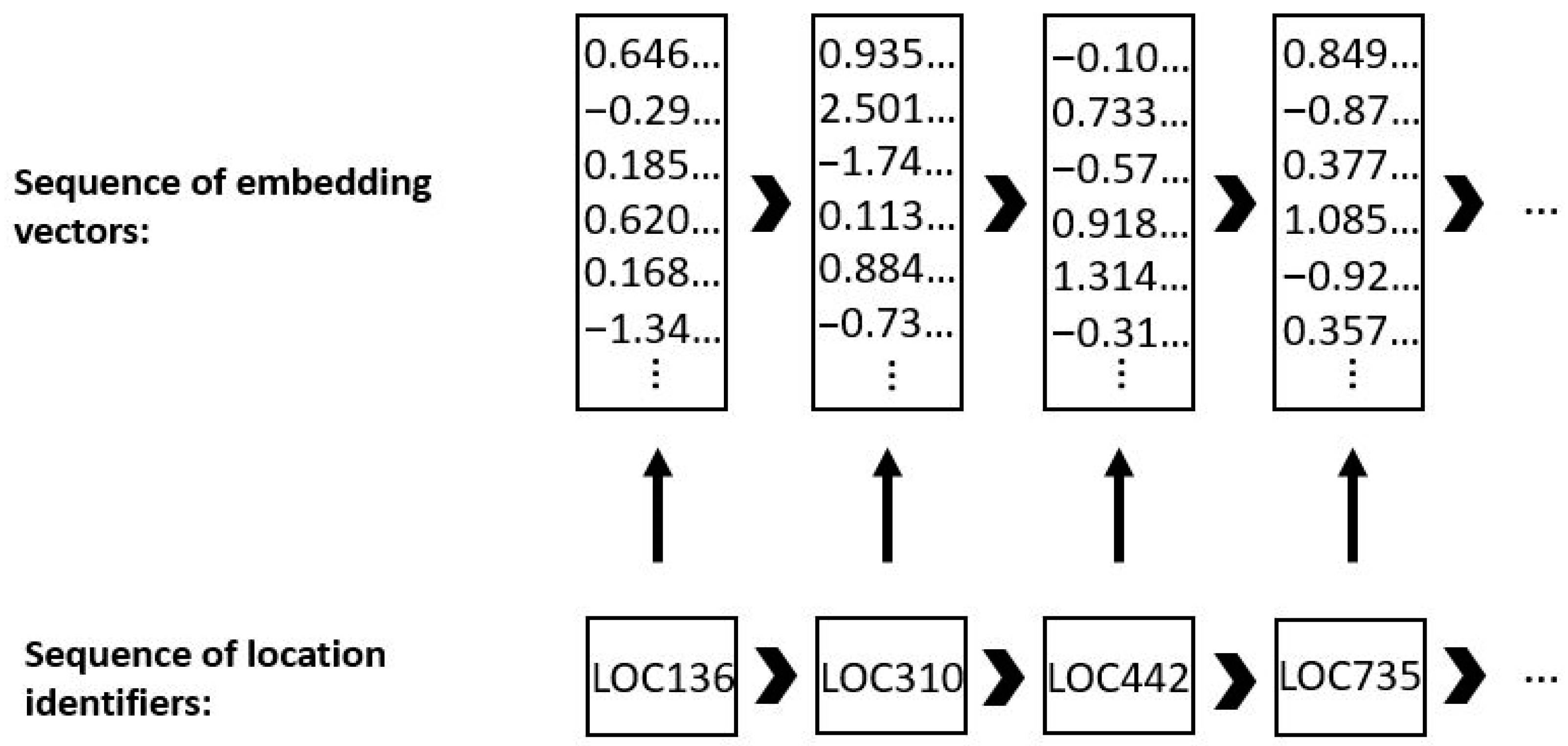
3.2.1. Embedding Layer
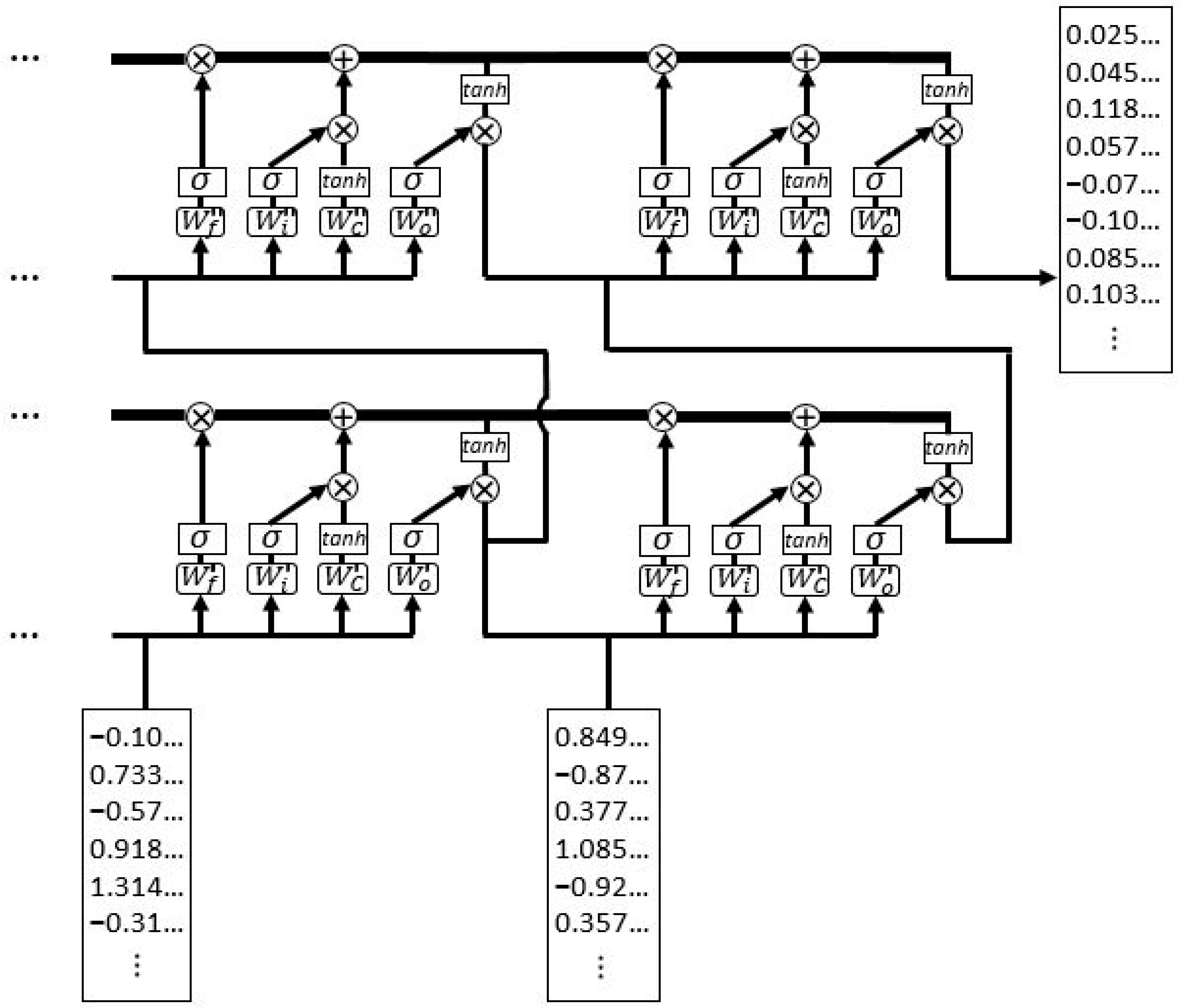
3.2.2. LSTM Block
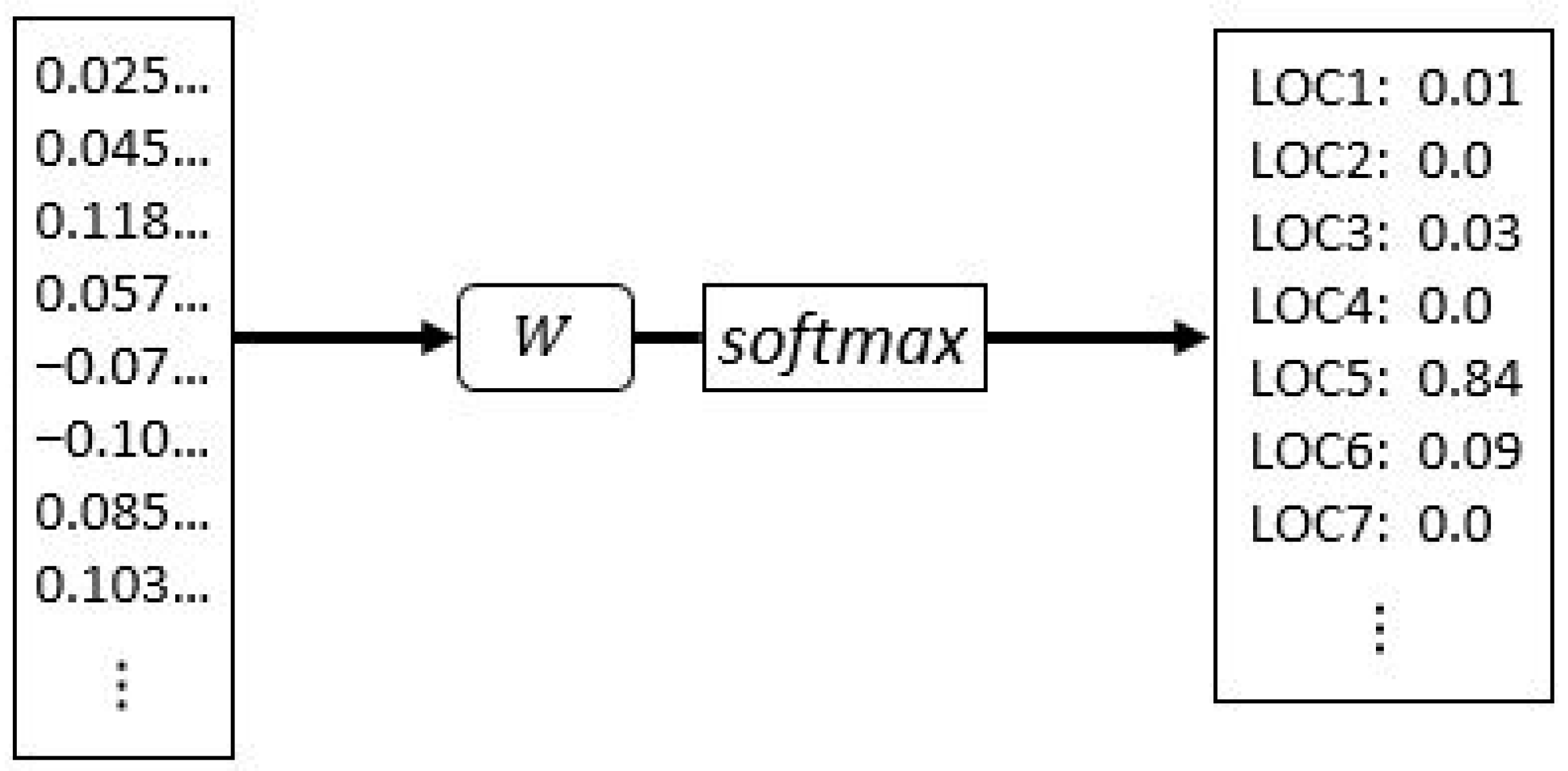
3.2.3. Softmax Layer
3.2.4. Model Training
4. Experiment
4.1. Dataset
4.2. Experimental Settings
- -
- Personal Markov model. Transition probabilities were calculated by counting each single user’s transitions, modeling individual movement patterns.
- -
- Global Markov model. First-order probability distributions were calculated by counting the collective state transitions of all users, modeling collective movement patterns.
- -
- Variable-order global Markov model. The principle of the longest match was applied to select which global Markov model order to adopt to calculate the transition probabilities; for a given location sequence, the collective prediction probability distribution was computed on the set of training sequences matching its longest suffix.
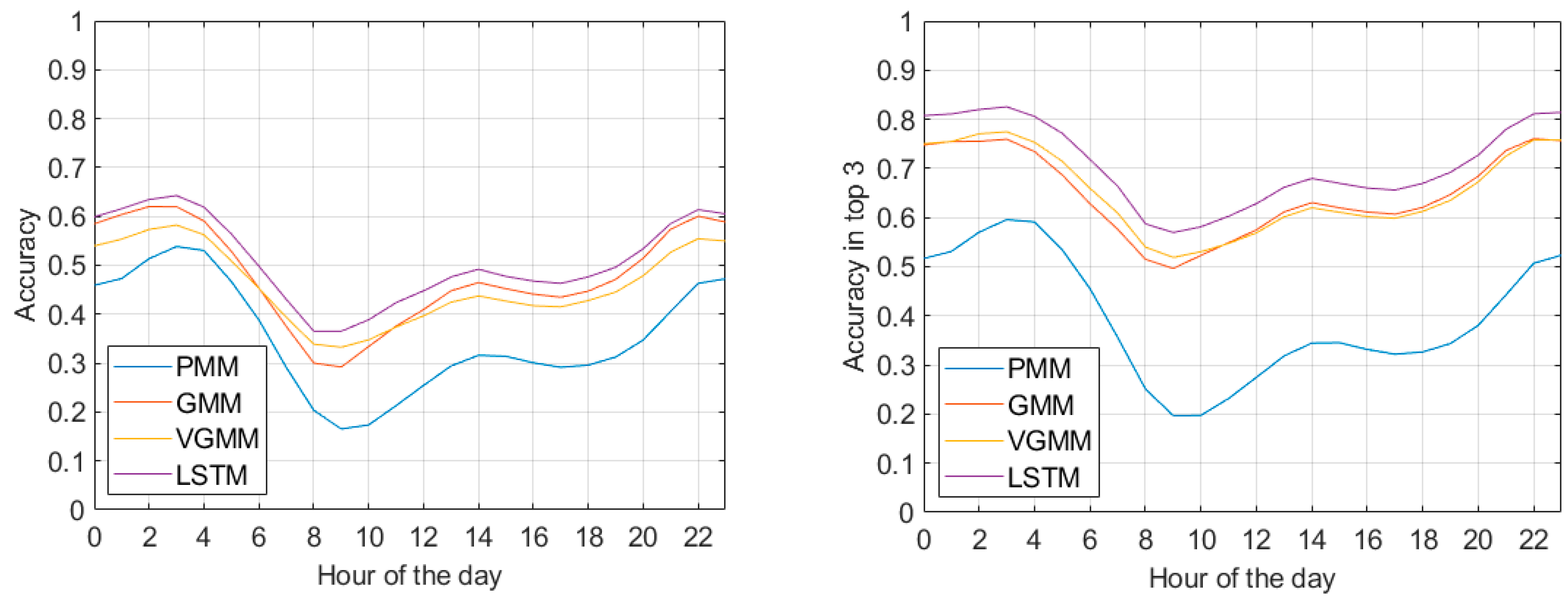
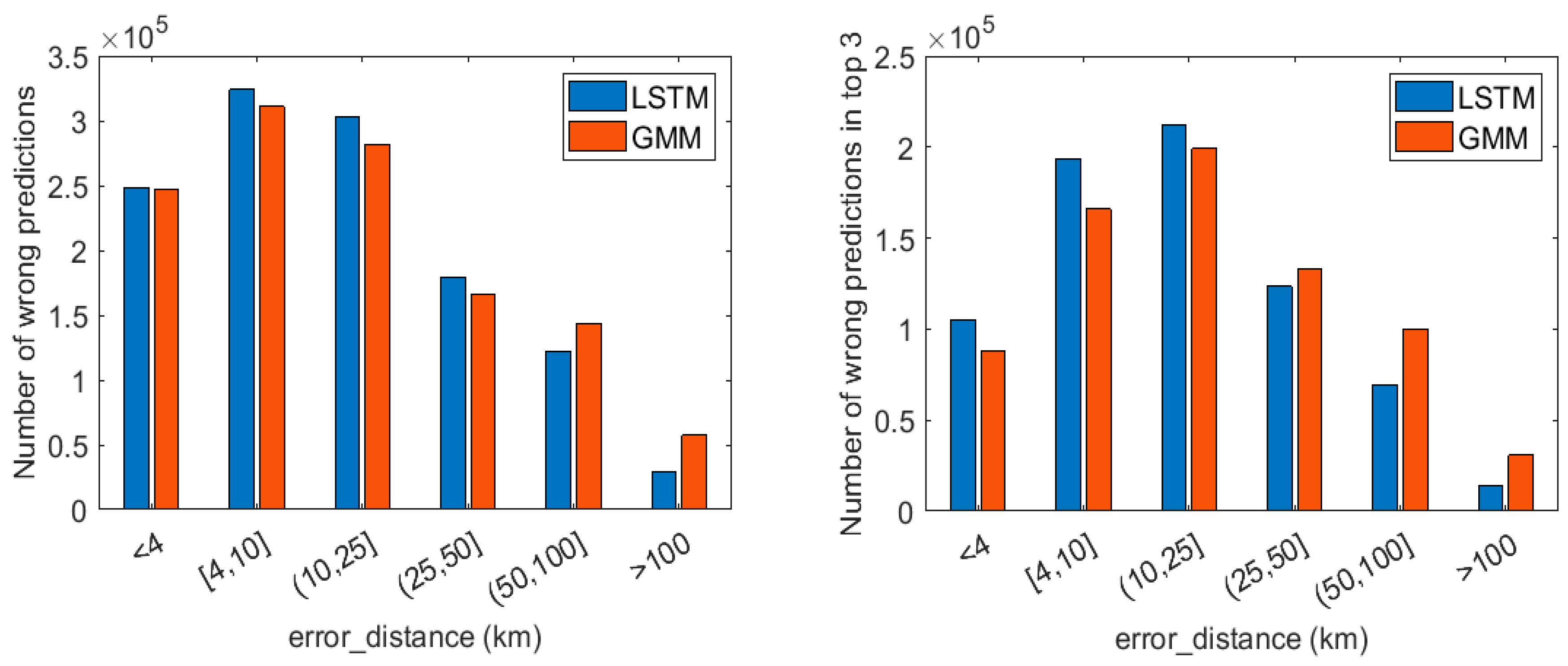
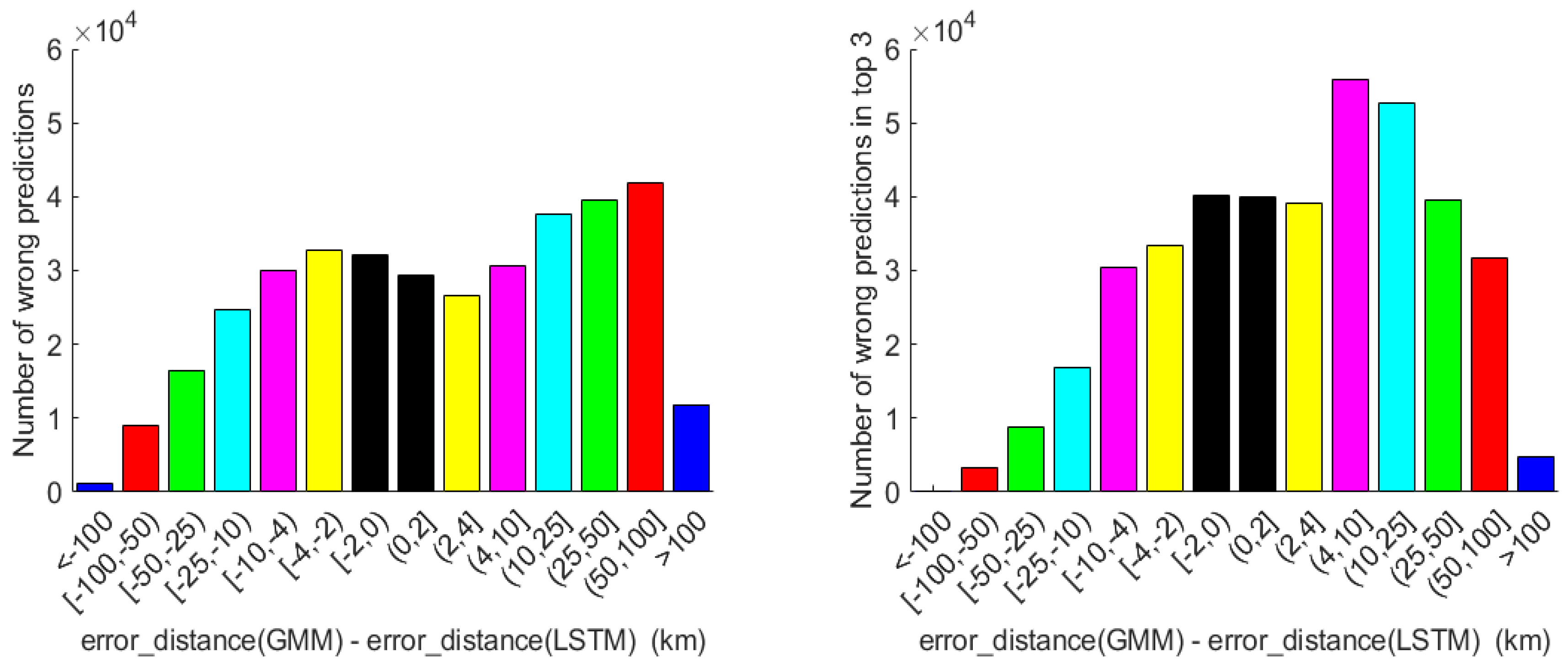
4.3. Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Feng, Z.; Zhu, Y. A survey on trajectory data mining: Techniques and applications. IEEE Access 2016, 4, 2056–2067. [Google Scholar] [CrossRef]
- Zheng, Y. Trajectory data mining: An overview. Acm. Trans. Intell. Syst. Technol. 2015, 6, 1–41. [Google Scholar] [CrossRef]
- Bhargava, P.; Phan, T.; Zhou, J.; Lee, J. Who, what, when, and where: Multi-dimensional collaborative recommendations using tensor factorization on sparse user-generated data. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 130–140. [Google Scholar] [CrossRef]
- Cheng, C.; Yang, H.; Lyu, M.R.; King, I. Where you like to go next: Successive point-of-interest recommendation. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2605–2611. [Google Scholar]
- Semanjski, I.; Gautama, S. Smart city mobility application—Gradient boosting trees for mobility prediction and analysis based on crowdsourced data. Sensors 2015, 15, 15974–15987. [Google Scholar] [CrossRef] [PubMed]
- Crivellari, A.; Beinat, E. Identifying Foreign Tourists’ Nationality from Mobility Traces via LSTM Neural Network and Location Embeddings. Appl. Sci. 2019, 9, 2861. [Google Scholar] [CrossRef]
- Litman, T.; Colman, S.B. Generated traffic: Implications for transport planning. ITE J. 2001, 71, 38–46. [Google Scholar]
- Song, X.; Zhang, Q.; Sekimoto, Y.; Shibasaki, R. Prediction of human emergency behavior and their mobility following large-scale disaster. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 5–14. [Google Scholar] [CrossRef]
- Helbing, D.; Brockmann, D.; Chadefaux, T.; Donnay, K.; Blanke, U.; Woolley-Meza, O.; Moussaid, M.; Johansson, A.; Krause, J.; Schutte, S. Saving human lives: What complexity science and information systems can contribute. J. Stat. Phys. 2015, 158, 735–781. [Google Scholar] [CrossRef]
- Ye, M.; Yin, P.; Lee, W.-C. Location recommendation for location-based social networks. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 458–461. [Google Scholar] [CrossRef]
- Cho, S.-B. Exploiting machine learning techniques for location recognition and prediction with smartphone logs. Neurocomputing 2016, 176, 98–106. [Google Scholar] [CrossRef]
- Gambs, S.; Killijian, M.-O.; del Prado Cortez, M.N. Next place prediction using mobility markov chains. In Proceedings of the First Workshop on Measurement, Privacy, and Mobility, Bern, Switzerland, 10 April 2012. Art. No. 3. [Google Scholar] [CrossRef]
- Miller, R.; Huang, Q. An adaptive peer-to-peer collision warning system. In Proceedings of the IEEE 55th Vehicular Technology Conference, Birmingham, AL, USA, 6–9 May 2002; pp. 317–321. [Google Scholar] [CrossRef]
- Ammoun, S.; Nashashibi, F. Real time trajectory prediction for collision risk estimation between vehicles. In Proceedings of the 2009 IEEE 5th International Conference on Intelligent Computer Communication and Processing, Cluj-Napoca, Romania, 27–29 August 2009; pp. 417–422. [Google Scholar] [CrossRef]
- Broadhurst, A.; Baker, S.; Kanade, T. Monte Carlo road safety reasoning. In Proceedings of the IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005; pp. 319–324. [Google Scholar] [CrossRef]
- Bae, S.J.; Lee, H.; Suh, E.-K.; Suh, K.-S. Shared experience in pretrip and experience sharing in posttrip: A survey of Airbnb users. Inf. Manag. 2017, 54, 714–727. [Google Scholar] [CrossRef]
- Towner, N. How to manage the perfect wave: Surfing tourism management in the Mentawai Islands, Indonesia. Ocean Coast. Manag. 2016, 119, 217–226. [Google Scholar] [CrossRef]
- Atsalakis, G.S.; Atsalaki, I.G.; Zopounidis, C. Forecasting the success of a new tourism service by a neuro-fuzzy technique. Eur. J. Oper. Res. 2018, 268, 716–727. [Google Scholar] [CrossRef]
- Albuquerque, H.; Costa, C.; Martins, F. The use of geographical information systems for tourism Marketing purposes in Aveiro region (Portugal). Tour. Manag. Perspect. 2018, 26, 172–178. [Google Scholar] [CrossRef]
- De Cantis, S.; Ferrante, M.; Kahani, A.; Shoval, N. Cruise passengers’ behavior at the destination: Investigation using GPS technology. Tour. Manag. 2016, 52, 133–150. [Google Scholar] [CrossRef]
- Lew, A.; McKercher, B. Modeling tourist movements: A local destination analysis. Ann. Tour. Res. 2006, 33, 403–423. [Google Scholar] [CrossRef]
- McKercher, B.; Shoval, N.; Ng, E.; Birenboim, A. First and repeat visitor behaviour: GPS tracking and GIS analysis in Hong Kong. Tour. Geogr. 2012, 14, 147–161. [Google Scholar] [CrossRef]
- Shoval, N.; McKercher, B.; Ng, E.; Birenboim, A. Hotel location and tourist activity in cities. Ann. Tour. Res. 2011, 38, 1594–1612. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.-L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef]
- Ashbrook, D.; Starner, T. Using GPS to learn significant locations and predict movement across multiple users. Pers. Ubiquitous Comput. 2003, 7, 275–286. [Google Scholar] [CrossRef]
- Feder, M.; Merhav, N.; Gutman, M. Universal prediction of individual sequences. IEEE Trans. Inf. Theory 1992, 38, 1258–1270. [Google Scholar] [CrossRef]
- Schneider, C.M.; Belik, V.; Couronné, T.; Smoreda, Z.; González, M.C. Unravelling daily human mobility motifs. J. R. Soc. Interface 2013, 10, 20130246. [Google Scholar] [CrossRef]
- Mazimpaka, J.D.; Timpf, S. Trajectory data mining: A review of methods and applications. J. Spat. Inf. Sci. 2016, 13, 61–99. [Google Scholar] [CrossRef]
- Jonietz, D.; Bucher, D. Continuous trajectory pattern mining for mobility behaviour change detection. In Proceedings of the LBS 2018: 14th International Conference on Location Based Services, Zurich, Switzerland, 15–17 January 2018; pp. 211–230. [Google Scholar] [CrossRef]
- De Brébisson, A.; Simon, É.; Auvolat, A.; Vincent, P.; Bengio, Y. Artificial neural networks applied to taxi destination prediction. arXiv 2015, arXiv:1508.00021. [Google Scholar]
- Etter, V.; Kafsi, M.; Kazemi, E. Been there, done that: What your mobility traces reveal about your behavior. In Proceedings of the Mobile Data Challenge by Nokia Workshop, in Conjunction with Int. Conf. on Pervasive Computing, Newcastle, UK, 18–19 June 2012. [Google Scholar]
- Gomes, J.B.; Phua, C.; Krishnaswamy, S. Where will you go? mobile data mining for next place prediction. In Proceedings of the International Conference on Data Warehousing and Knowledge Discovery, Prague, Czech Republic, 26–29 August 2013; pp. 146–158. [Google Scholar] [CrossRef]
- Dong, M.; He, D. Hidden semi-Markov model-based methodology for multi-sensor equipment health diagnosis and prognosis. Eur. J. Oper. Res. 2007, 178, 858–878. [Google Scholar] [CrossRef]
- Lin, L.-Z.; Yeh, H.-R. Analysis of tour values to develop enablers using an interpretive hierarchy-based model in Taiwan. Tour. Manag. 2013, 34, 133–144. [Google Scholar] [CrossRef]
- Chen, L.; Lv, M.; Ye, Q.; Chen, G.; Woodward, J. A personal route prediction system based on trajectory data mining. Inf. Sci. 2011, 181, 1264–1284. [Google Scholar] [CrossRef]
- Vu, T.H.N.; Ryu, K.H.; Park, N. A method for predicting future location of mobile user for location-based services system. Comput. Ind. Eng. 2009, 57, 91–105. [Google Scholar] [CrossRef]
- Yavaş, G.; Katsaros, D.; Ulusoy, Ö.; Manolopoulos, Y. A data mining approach for location prediction in mobile environments. Data Knowl. Eng. 2005, 54, 121–146. [Google Scholar] [CrossRef]
- Liao, L.; Patterson, D.J.; Fox, D.; Kautz, H. Building personal maps from GPS data. Ann. N. Y. Acad. Sci. 2006, 1093, 249–265. [Google Scholar] [CrossRef]
- Lee, S.; Lim, J.; Park, J.; Kim, K. Next place prediction based on spatiotemporal pattern mining of mobile device logs. Sensors 2016, 16, 145. [Google Scholar] [CrossRef]
- Alvarez-Garcia, J.A.; Ortega, J.A.; Gonzalez-Abril, L.; Velasco, F. Trip destination prediction based on past GPS log using a Hidden Markov Model. Expert Syst. Appl. 2010, 37, 8166–8171. [Google Scholar] [CrossRef]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Thalmann, N.M. Time-aware point-of-interest recommendation. In Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 363–372. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Aberer, K.; Miao, C. Personalized point-of-interest recommendation by mining users’ preference transition. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 733–738. [Google Scholar] [CrossRef]
- Zheng, Y.; Xie, X. Learning travel recommendations from user-generated GPS traces. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 2. [Google Scholar] [CrossRef]
- Noulas, A.; Scellato, S.; Lathia, N.; Mascolo, C. Mining user mobility features for next place prediction in location-based services. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 1038–1043. [Google Scholar] [CrossRef]
- Noulas, A.; Shaw, B.; Lambiotte, R.; Mascolo, C. Topological properties and temporal dynamics of place networks in urban environments. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 431–441. [Google Scholar] [CrossRef]
- Chen, M.; Liu, Y.; Yu, X. Nlpmm: A next location predictor with markov modeling. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Tainan, Taiwan, 13–16 May 2014; pp. 186–197. [Google Scholar]
- Hawelka, B.; Sitko, I.; Kazakopoulos, P.; Beinat, E. Collective prediction of individual mobility traces for users with short data history. PLoS ONE 2017, 12, e0170907. [Google Scholar] [CrossRef]
- Do, T.M.T.; Gatica-Perez, D. Where and what: Using smartphones to predict next locations and applications in daily life. Pervasive Mob. Comput. 2014, 12, 79–91. [Google Scholar] [CrossRef]
- Urner, J.; Bucher, D.; Yang, J.; Jonietz, D. Assessing the influence of spatio-temporal context for next place prediction using different machine learning approaches. ISPRS Int. J. Geo-Inf. 2018, 7, 166. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 194–200. [Google Scholar]
- Wu, F.; Fu, K.; Wang, Y.; Xiao, Z.; Fu, X. A spatial-temporal-semantic neural network algorithm for location prediction on moving objects. Algorithms 2017, 10, 37. [Google Scholar] [CrossRef]
- Hoang, M.X.; Zheng, Y.; Singh, A.K. FCCF: Forecasting citywide crowd flows based on big data. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Francisco, CA, USA, 31 October–3 November 2016. Art. No. 6. [Google Scholar] [CrossRef]
- Gunduz, S.; Yavanoglu, U.; Sagiroglu, S. Predicting next location of Twitter users for surveillance. In Proceedings of the IEEE 2013 12th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 4–7 December 2013; Volume 2, pp. 267–273. [Google Scholar] [CrossRef]
- Siła-Nowicka, K.; Vandrol, J.; Oshan, T.; Long, J.A.; Demšar, U.; Fotheringham, A.S. Analysis of human mobility patterns from GPS trajectories and contextual information. Int. J. Geogr. Inf. Sci. 2016, 30, 881–906. [Google Scholar] [CrossRef]
- Yuan, Y.; Raubal, M. Spatio-temporal knowledge discovery from georeferenced mobile phone data. In Proceedings of the 2010 Movement Pattern Analysis, Zurich, Switzerland, 14 September 2010; Volume 14. [Google Scholar]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.Y. Mining interesting locations and travel sequences from GPS trajectories. In Proceedings of the ACM 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 791–800. [Google Scholar] [CrossRef]
- Quercia, D.; Lathia, N.; Calabrese, F.; Di Lorenzo, G.; Crowcroft, J. Recommending social events from mobile phone location data. In Proceedings of the 2010 IEEE international Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 971–976. [Google Scholar] [CrossRef]
- Xia, J.; Zeephongsekul, P.; Arrowsmith, C. Modelling spatio-temporal movement of tourists using finite Markov chains. Math. Comput. Simul. 2009, 79, 1544–1553. [Google Scholar] [CrossRef]
- Xia, J.; Zeephongsekul, P.; Packer, D. Spatial and temporal modelling of tourist movements using Semi-Markov processes. Tour. Manag. 2011, 32, 844–851. [Google Scholar] [CrossRef]
- Xia, J.C.; Evans, F.H.; Spilsbury, K.; Ciesielski, V.; Arrowsmith, C.; Wright, G. Market segments based on the dominant movement patterns of tourists. Tour. Manag. 2010, 31, 464–469. [Google Scholar] [CrossRef]
- Xiao-Ting, H.; Bi-Hu, W. Intra-attraction tourist spatial-temporal behaviour patterns. Tour. Geogr. 2012, 14, 625–645. [Google Scholar] [CrossRef]
- McKercher, B.; Shoval, N.; Park, E.; Kahani, A. The [limited] impact of weather on tourist behavior in an urban destination. J. Travel Res. 2015, 54, 442–455. [Google Scholar] [CrossRef]
- McKercher, B.; Lau, G. Movement Patterns of Tourists within a Destination. Tour. Geogr. 2008, 10, 355–374. [Google Scholar] [CrossRef]
- Ben-Akiva, M.E.; Lerman, S.R.; Lerman, S.R. Discrete Choice Analysis: Theory and Application to Travel Demand; MIT Press: Cambridge, MA, USA, 1985; Volume 9. [Google Scholar]
- Lue, C.-C.; Crompton, J.L.; Fesenmaier, D.R. Conceptualization of multi-destination pleasure trips. Ann. Tour. Res. 1993, 20, 289–301. [Google Scholar] [CrossRef]
- Oppermann, M. A model of travel itineraries. J. Travel Res. 1995, 33, 57–61. [Google Scholar] [CrossRef]
- Li, X.; Meng, F.; Uysal, M. Spatial pattern of tourist flows among the Asia-Pacific countries: An examination over a decade. Asia Pac. J. Tour. Res. 2008, 13, 229–243. [Google Scholar] [CrossRef]
- Yang, Y.; Fik, T.; Zhang, J. Modeling sequential tourist flows: Where is the next destination? Ann. Tour. Res. 2013, 43, 297–320. [Google Scholar] [CrossRef]
- Fennell, D.A. A tourist space-time budget in the Shetland Islands. Ann. Tour. Res. 1996, 23, 811–829. [Google Scholar] [CrossRef]
- Hwang, Y.-H.; Gretzel, U.; Fesenmaier, D.R. Multicity trip patterns: Tourists to the United States. Ann. Tour. Res. 2006, 33, 1057–1078. [Google Scholar] [CrossRef]
- Tideswell, C.; Faulkner, B. Multidestination travel patterns of international visitors to Queensland. J. Travel Res. 1999, 37, 364–374. [Google Scholar] [CrossRef]
- Chang, Y.-W.; Tsai, C.-Y. Apply deep learning neural network to forecast number of tourists. In Proceedings of the 2017 31st International Conference on Advanced Information Networking and Applications Workshops (WAINA), Taipei, Taiwan, 27–29 March 2017; pp. 259–264. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- De Montjoye, Y.-A.; Quoidbach, J.; Robic, F.; Pentland, A. Predicting Personality Using Novel Mobile Phone-Based Metrics. In Proceedings of the Social Computing, Behavioral-Cultural Modeling and Prediction, Washington, DC, USA, 2–5 April 2013; pp. 48–55. [Google Scholar] [CrossRef]
- Lu, X.; Bengtsson, L.; Holme, P. Predictability of population displacement after the 2010 Haiti earthquake. Proc. Natl. Acad. Sci. USA 2012, 109, 11576–11581. [Google Scholar] [CrossRef]
- Crivellari, A.; Beinat, E. From Motion Activity to Geo-Embeddings: Generating and Exploring Vector Representations of Locations, Traces and Visitors through Large-Scale Mobility Data. ISPRS Int. J. Geo-Inf. 2019, 8, 134. [Google Scholar] [CrossRef]
- Sundsøy, P.; Bjelland, J.; Reme, B.A.; Iqbal, A.M.; Jahani, E. Deep learning applied to mobile phone data for individual income classification. In Proceedings of the 2016 International Conference on Artificial Intelligence: Technologies and Applications, Bangkok, Thailand, 24–25 January 2016. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lytras, M.D.; Visvizi, A.; Sarirete, A. Clustering smart city services: Perceptions, expectations, responses. Sustainability 2019, 11, 1669. [Google Scholar] [CrossRef]
- Lytras, M.D.; Raghavan, V.; Damiani, E. Big data and data analytics research: From metaphors to value space for collective wisdom in human decision making and smart machines. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2017, 13, 1–10. [Google Scholar] [CrossRef]
- Angelidou, M.; Psaltoglou, A.; Komninos, N.; Kakderi, C.; Tsarchopoulos, P.; Panori, A. Enhancing sustainable urban development through smart city applications. J. Sci. Technol. Policy Manag. 2018, 9, 146–169. [Google Scholar] [CrossRef]
- Lytras, M.; Visvizi, A. Who uses smart city services and what to make of it: Toward interdisciplinary smart cities research. Sustainability 2018, 10, 1998. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Accuracy in Top 3 | |
|---|---|---|
| PMM | 0.3373 | 0.3717 |
| GMM | 0.4822 | 0.6508 |
| VGMM | 0.4553 | 0.6445 |
| LSTM | 0.5076 | 0.7013 |
| Trav. Dist. = | ≤10 km | 10–25 km | 25–50 km | 50–100 km | ≥100 km |
|---|---|---|---|---|---|
| PMM | 0.4645 (0.5088) | 0.4240 (0.4901) | 0.3260 (0.3639) | 0.2613 (0.2796) | 0.1665 (0.1689) |
| GMM | 0.5495 (0.7805) | 0.5648 (0.7412) | 0.4988 (0.6534) | 0.4494 (0.5845) | 0.3391 (0.4582) |
| VGMM | 0.5788 (0.7945) | 0.5033 (0.7201) | 0.4312 (0.6270) | 0.3979 (0.5656) | 0.3212 (0.4630) |
| LSTM | 0.5938 (0.8172) | 0.5696 (0.7933) | 0.5061 (0.7036) | 0.4633 (0.6293) | 0.3803 (0.5270) |
| ROG = | ≤3 km | 3–10 km | 10–32 km | ≥32 km |
|---|---|---|---|---|
| PMM | 0.4539 (0.5213) | 0.3650 (0.4078) | 0.2974 (0.3089) | 0.1880 (0.1899) |
| GMM | 0.5496 (0.7859) | 0.5246 (0.6880) | 0.4719 (0.6038) | 0.3548 (0.4729) |
| VGMM | 0.5661 (0.7923) | 0.4578 (0.6668) | 0.4218 (0.5846) | 0.3371 (0.4781) |
| LSTM | 0.5891 (0.8229) | 0.5299 (0.7480) | 0.4849 (0.6426) | 0.3955 (0.5404) |
| Amount of Data: | ≥0.5% | 0.1–0.5% | 0.05–0.1% | ≤0.05% |
|---|---|---|---|---|
| PMM | 0.5169 (0.5485) | 0.3809 (0.4147) | 0.3280 (0.3600) | 0.2624 (0.2986) |
| GMM | 0.6872 (0.9305) | 0.5398 (0.7659) | 0.4745 (0.6511) | 0.3925 (0.5095) |
| VGMM | 0.7172 (0.9146) | 0.5448 (0.7624) | 0.4462 (0.6456) | 0.3336 (0.5049) |
| LSTM | 0.7372 (0.9459) | 0.6024 (0.8210) | 0.5039 (0.7151) | 0.3925 (0.5660) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Crivellari, A.; Beinat, E. LSTM-Based Deep Learning Model for Predicting Individual Mobility Traces of Short-Term Foreign Tourists. Sustainability 2020, 12, 349. https://doi.org/10.3390/su12010349
Crivellari A, Beinat E. LSTM-Based Deep Learning Model for Predicting Individual Mobility Traces of Short-Term Foreign Tourists. Sustainability. 2020; 12(1):349. https://doi.org/10.3390/su12010349
Chicago/Turabian StyleCrivellari, Alessandro, and Euro Beinat. 2020. "LSTM-Based Deep Learning Model for Predicting Individual Mobility Traces of Short-Term Foreign Tourists" Sustainability 12, no. 1: 349. https://doi.org/10.3390/su12010349
APA StyleCrivellari, A., & Beinat, E. (2020). LSTM-Based Deep Learning Model for Predicting Individual Mobility Traces of Short-Term Foreign Tourists. Sustainability, 12(1), 349. https://doi.org/10.3390/su12010349