1. Introduction
Integrated circuit (IC) manufacturing has become an industry-leading area in recent years, and it accordingly receives great attention from researchers. As the demand for production increases, environmental concerns are also elevated [
1], and thus improving on environmental protection and sustainable practices while maintaining productivity are strategic goals for manufacturing firms today [
2]. The IC manufacturing process in particular involves many automatic machining steps, and improving this machining process directly influences sustainability in the manufacturing system [
3]. Thus, reducing the use of resources and optimizing the mostly automated system could be viewed as one of the goals necessary to work towards sustainable manufacturing.
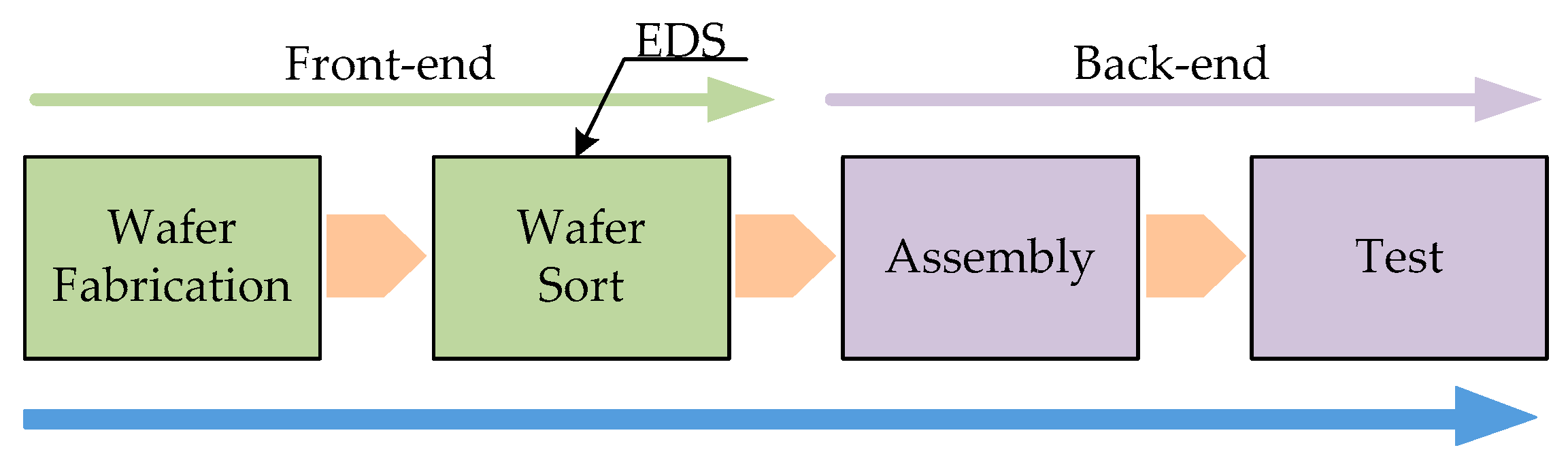
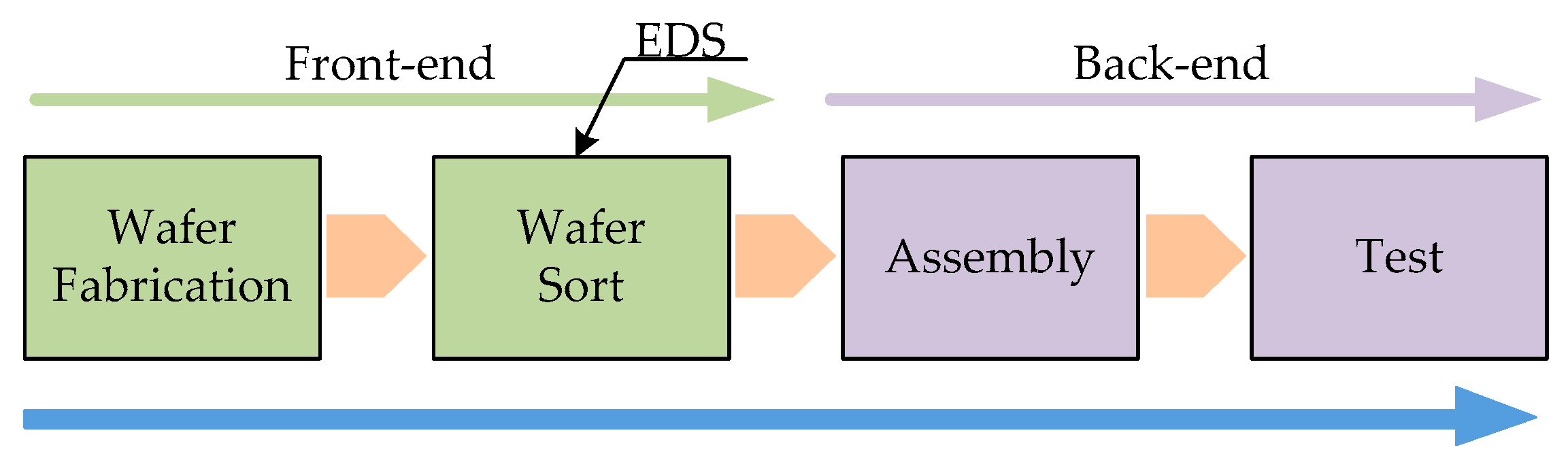
In general, the IC manufacturing process is composed of the following four major phases: wafer fabrication, wafer probing (wafer sort), packaging (assembly), and the final test [
4,
5], as shown in
Figure 1. Wafer fabrication is a highly complex technological process and highly capital-intensive [
3,
4,
5]. In this process, the semiconductor devices are manufactured in a fab, and this is termed as front-end operations [
6]. This requires a long cycle time and takes numerous steps in a clean environment [
3,
4,
6]. The individual chips on the wafers are tested via electrical die sorting (EDS) for functionality at the end of the front-end operation phase. After this process, the wafers move to the assembly stage and final test, which are called back-end operations [
6]. The chips are encapsulated in a plastic or ceramic material to protect them from contamination, and the devices are subsequently inspected to confirm whether they satisfy the required specifications [
2,
6]. In the EDS test, numerous operations should be employed to assess the reliability of the functioning chips on a wafer before that wafer is sent to the next stage. Several kinds of machines are used, and the material flow for the steps is either circular or linear in form. Various scheduling approaches can be used to efficiently job sequence this operation flow. The goals of this scheduling are to shorten the cycle time, increase the throughput, and lower the work in process (WIP). The proper allocation of resources combining the routing of material movements for scheduling would facilitate increased system efficiency.
In this paper, we analyze system performance for the predefined layout of an EDS test facility in several terms, such as time in system and WIP. The layout of the facility includes several cells and stockers. The machines are grouped into a cell for their function or usability and identical machines could be allocated to a different cell for improved system performance. This sort of machine allocation influences the scheduling effect on system performance. The facility configuration in this paper is based on one currently in use. An automatic material handling system (AMHS) controls the front open unified pod (FOUP) intercell and intracell movements. We propose four scheduling policies for intercell schedulers and two for intracell schedulers. The system needs both inter- and intracell movements to complete the test process, and we selected four reasonable combinations of two kinds of operations and investigate their performance. The AutoMod® simulation tool is used to evaluate the performance of the proposed heuristic scheduling policies, and the results are compared to each combination to find the most favorable policy for a given facility.
Figure 2 shows the sample layout of an EDS.
The remainder of the paper is organized as follows.
Section 2 provides a review of the related literature. In
Section 3, the problem is described, and the basic representation of the problem is presented. The proposed heuristic scheduling policies are presented in detail in
Section 4. Specific simulation experiments and experimental comparisons are explained in
Section 5.
Section 6 concludes the research, including a discussion of future work.
2. Literature Review
In semiconductor manufacturing, much research literature since the late 1980s has focused on the scheduling problems of wafer fabrication phase. Regarding the scheduling problems of semiconductor testing facilities, the first research report can be found in the paper by Uzsoy et al. [
6] Uzsoy et al. [
6] characterized the operations in the testing facility as a broad product mix, variable lot sizes and yields, long and variable setup times, and limited test equipment capacity. They first divided the facility, or job shop, into a number of work centers, and represent the job shop using a disjunctive graph to capture interactions between work centers. They insist that the proposed approach is able to efficiently obtain solutions to particular work center subproblem. Then Ovacik and Uzsoy [
7] presented a shift bottleneck algorithm for scheduling of semiconductor testing facility that is composed of work centers. They show that the proposed shifting bottleneck algorithm performs better than dispatching rules by simulation experiments. Later Ovacik and Uzsoy [
8] also presented a decomposition method for scheduling a semiconductor testing facility. They assume that the facility is characterized by different types of work centers, some of which have sequence-dependent setup times and some parallel identical machines. Chen et al. [
9] presented a Lagrangian relaxation approach for the scheduling problems of a wafer test (or wafer probing or wafer sorting) and final test facility with preemptiveness. They formulated the scheduling problem as an integer programming problem and have solved the problem by using the Lagrangian relaxation to minimize the total weighted tardiness. Then, Chen and Hsia [
10] presented a scheduling method for a wafer test and final test facilities with precedence constraints using Lagrangian relaxation technique.
Huang and Lin [
11] present a human–computer interactive scheduler, named the interactive computer-aided scheduling system, to cope with the combinatorial difficulties of scheduling problems with sequence-dependent setup costs and multiple criteria for a wafer test facility. An experiment has been conducted to compare the performance of the proposed scheduling approach with six priority rules. De and Lee [
12] presented a knowledge-based scheduling system for a semiconductor final test facility. They characterized the scheduling problem as a generalized job shop problem with both parallel workstation clusters and batch processors. The proposed scheduling system consists of a knowledge base developed using a frame-based knowledge representation scheme, and a solution strategy based on filtered beam search. Yang and Chang [
13] address a multiobjective scheduling problem for minimizing cycle time and on time delivery in wafer test and final test facilities. The Pareto optimization approach is used and a new scheduling algorithm is proposed to solve the dual problem. Xiong and Zhou [
14] proposed a Petri net-based hybrid heuristic search strategies to cope with the complexities for multiple lot scheduling for a semiconductor test facility. Sivakumar [
15] proposed a simulation-based online near-real-time dynamic scheduling system to reduce cycle time in a final test facility. The proposed scheduling system has been implemented at a semiconductor back-end site. Lee et al. [
16] addressed the wafer testing process, which requires several types of equipment with different capacities. They proposed LP-based heuristic algorithms for monthly production and capacity planning, and daily production planning and scheduling. Pearn et al. [
17] presented a case study on the wafer test scheduling problem, where the jobs are clustered by their product types that are processed on groups of identical parallel machines. They formulated the wafer test scheduling problem, which is a kind of a classical parallel-machine scheduling problem, as an integer programming model to minimize the total machine workload. They demonstrated the applicability of the method using a real-world example in the paper by Pearn et al. [
18] Then, Pearn et al. [
19] addressed the wafer test scheduling problem with due date restriction. Pearn et al. [
20] also presented a case study on the final test scheduling problem with reentry, which is a kind of a variation of the complex flow-shop scheduling problem. They proposed three network algorithms to solve the final test scheduling problem.
Chiang et al. [
21] presented a scheduling method for semiconductor wafer test facility. They have modeled the wafer testing flow using colored-timed petri nets, which are used to simulate the production processes and keep track of the equipment status and lot conditions. Then they presented a genetic algorithm-based approach to solve the scheduling problem, with dispatching policies for lot and equipment selections. Chiang et al. [
22] presented a rule-based scheduling method for a wafer test facility with three due date-base objectives including the tardy rate, total tardiness, and the maximum tardiness. Instead of legacy dispatching rule paradigm, they proposed a new paradigm to better utilize the dispatching rules, in which they use a genetic algorithm to generate appropriate dispatching rules depending on the system status and target performance criteria. Lin at al. [
23] presented a capacity-constrained scheduling method by using the concept of the theory of constraints for a semiconductor final test facility. The addressed scheduling problem is characterized by a broad product mix, variable lot sizes and yields, long and variable setup times, and limited test equipment capacity. Song et al. [
24] addressed the scheduling problem in semiconductor assembly and final test facilities. They focus on the scheduling of the bottleneck stations, since many assembly and final test facilities are designed based on the theory of constraints. They first formulate the bottleneck station scheduling problem and then apply ant colony optimization technique to solve it metaheuristically. They also proposed an ant colony-based scheduling framework and provide the system parameter tuning. Pearn et al. [
25] deal with a multistage wafer test scheduling problem with reentry, which is regarded as the identical parallel-machine scheduling problem. They present sequential and parallel strategies, where the former schedules the jobs at the required stages according to the sequence of manufacturing process and the latter is designed specifically for the reentrant characteristic.
Lee et al. [
26] presented a daily planning and scheduling system for the wafer test facility. They proposed a practical mathematical formulation for the daily planning and heuristic procedure for the scheduling to minimize the test change-over within the daily target. Bang and Kim [
4] addressed a scheduling problem for a semiconductor wafer test facility, where wafer lots are processed on a series of workstation with identical parallel machines. In order to minimize total tardiness, they presented a heuristic algorithm, where a bottleneck-focused scheduling approach was employed, and priority-rule-based algorithms were used for scheduling at the workstations including the bottleneck workstation. Lin et al. [
27] addressed the scheduling problem of a wafer test facility. They presented three meta-heuristic algorithms— an ant colony system algorithm, a genetic algorithm, and a Tabu search algorithm—with total setup time minimization as the primary criterion and the minimization of the number of machines as the secondary criterion. With the identical scheduling problem definition in [
27], Ying [
28] presented a heuristic scheduling method based on the iterated greedy approach [
29]. Doleschal et al. [
30] addressed a scheduling problem of a wafer test facility, which is regarded as a single operation problem with unrelated parallel machines, release dates, setup, and dedications. They presented a scheduling approach, in which a static resource allocation problem is solved by mixed integer programming to remove unnecessary equipment allocations in the dedication scenario, and then feasible scheduling solutions are generated by a discrete event simulation based on the reduced dedication matrices.
Bard et al. [
31] proposed a daily scheduling method of multipass lots in assembly and final test facilities with reentry. They formulated the scheduling problem as a mixed integer programming problem, and presented a multistage scheduling approach using a reactive greedy randomized search procedure. Pearn et al. [
32] addressed the burn-in test scheduling problem that can be found in a semiconductor final test facility and thin film transistor liquid crystal display (TFT-LCD) manufacturing facility. The burn-in test scheduling problem, first proposed by Lee et al. [
33], is regarded as a multidimensional parallel-batch processing machine scheduling problem. The authors formulate the burn-in test scheduling problem as a mixed integer linear programming problem and present two heuristic algorithms to minimize total setup and processing times in the burn-in test processes. Hao et al. [
34] present a cooperative estimation of distribution algorithm to solve a semiconductor final test scheduling problem. The proposed method incorporates a cooperative coevolutionary paradigm to extend the model features and improve the evaluation lead-time of an estimation of distribution algorithms. Zheng et al. [
35] proposed a novel fruit fly optimization algorithm to solve a semiconductor final testing scheduling problem, which is regarded as a simultaneous multiresource flexible job-shop scheduling problem with sequence-dependent setup times, with the objective of minimizing the maximum completion time of all the operations. Bard et al. [
36] presented optimization and simulation approaches for semiconductor assembly and final test facilities. The optimization model is solved with a greedy randomized adaptive search procedure [
31] that is designed to focus on hot lots while taking the cost of changeovers into account. Wang et al. [
37] presented a hybrid estimation distribution algorithm for a semiconductor final testing scheduling problem. They combine the estimation of distribution algorithm with a local search procedure to enhance the exploitation ability of the algorithm. Kim et al. [
38] present agent-based scheduling methods for hybrid cellular production line, which is one of the types of wafer probe centers in the semiconductor industry. They propose heuristic scheduling rules for both intercell and intracell scheduling problems.
Gao et al. [
39] present a three-phase methodology for a scheduling assembly and final test operations for semiconductor devices. In the first phase, the authors solve the assignment of tooling and lots to machines, and in the second phase, the lots are optimally sequenced. Finally, the machines are reset to allow additional lots when tooling is available. The proposed methodology is tested using data provided by the assembly and test facility of a leading manufacture. Jia et al. [
40] showed how the logic of intelligent heuristics can be combined with discrete event simulation software (AutoSched AP) to evaluate various dispatch rules for machine setup and scheduling in the assembly and final test facilities. Three new dispatch rules are presented to configure machines and assigning lots in the facilities. Hur et al. [
41] investigated the setup scheduling problem at the semiconductor assembly and final test facilities in a multimachine and multitooling environment. The objective is to minimize the number of shortages of key devices and to maximize the weighted throughput over a two- to five-day planning horizon. They presented a hierarchical machine setup scheduling model to determine machine setups, lot assignments, and lot sequences using a greedy randomized adaptive search procedure. Jia et al. [
42] statistically compared six dispatch rules for semiconductor assembly and final test facilities. The objectives are to minimize the weighted sum of key device shortages and to maximize the weighted throughput of lots processed. The statistical analyses show that the two rules designed to process as many hot lots as possible offer the best performance in terms of minimizing the weighted shortage.
Wang and Wang [
43] presented a knowledge-based multiagent evolutionary algorithm to solve a semiconductor final testing scheduling problem. Each agent is represented by a solution that is a combination of the operation sequence vector and the machine assignment vector. The agents evolve via mutual learning and competition based on the agent lattice model. Joung et al. [
44] presented a multipass oriented scheduling heuristic algorithm to maximize the throughput of semiconductor final test facilities. The algorithm determines test schedules, machine setups, and job assignments. Sang et al. [
45] proposed a cooperative coevolutionary invasive weed optimization algorithm for a semiconductor final testing scheduling problem. The algorithm iterates with two coupled colonies, one of which addresses the machine assignment problem, while the other deals with the operation sequence problem.
3. Problem Description
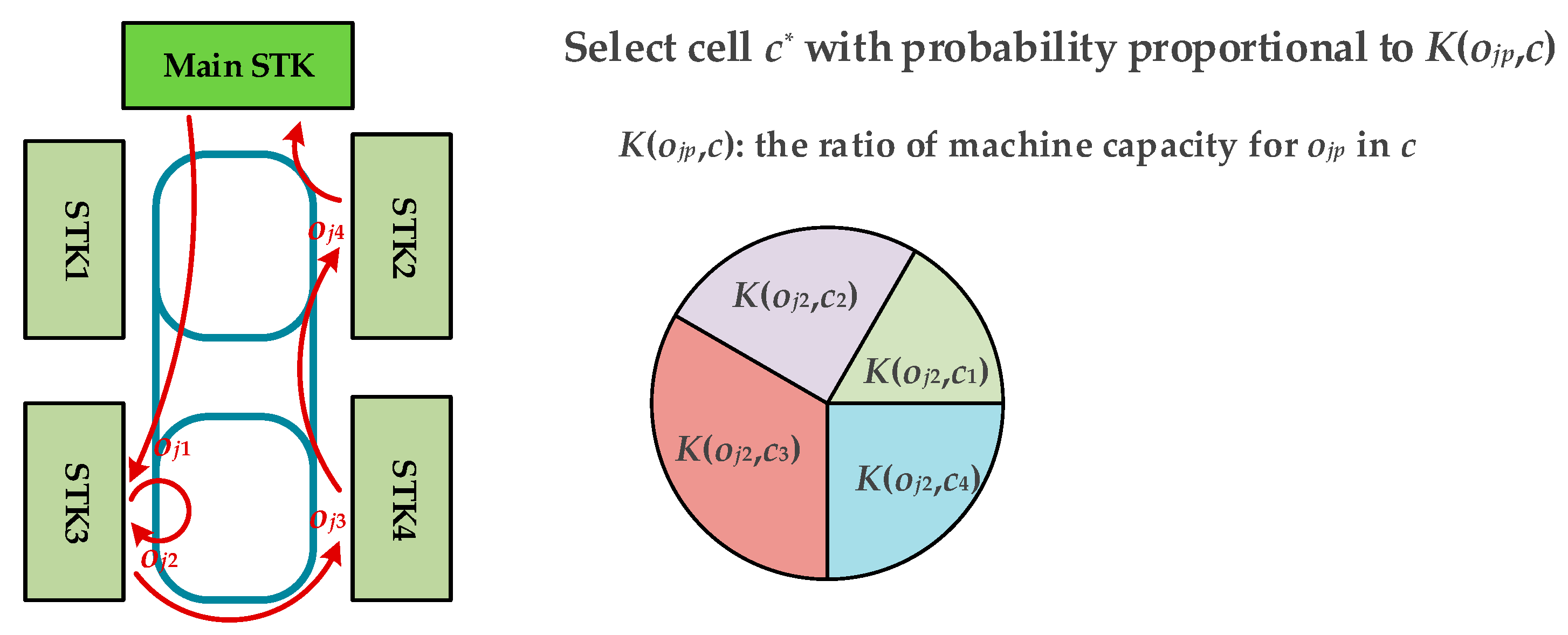
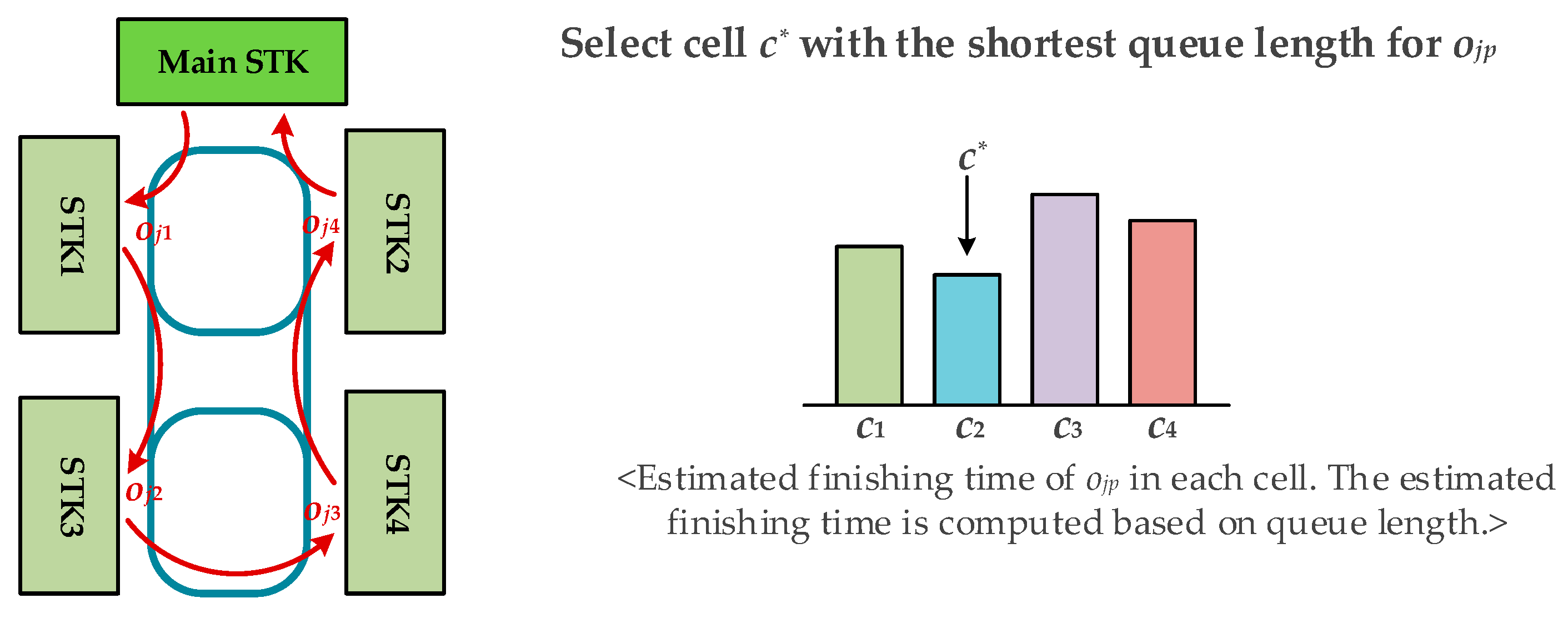
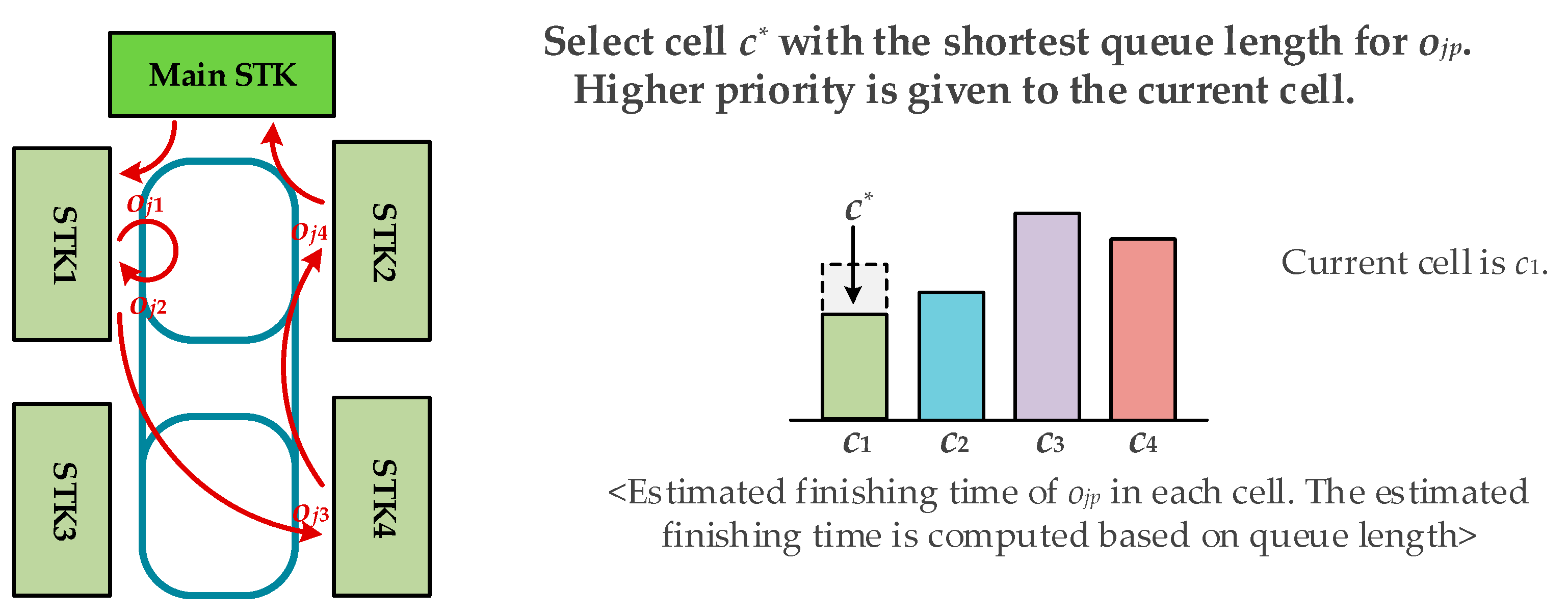
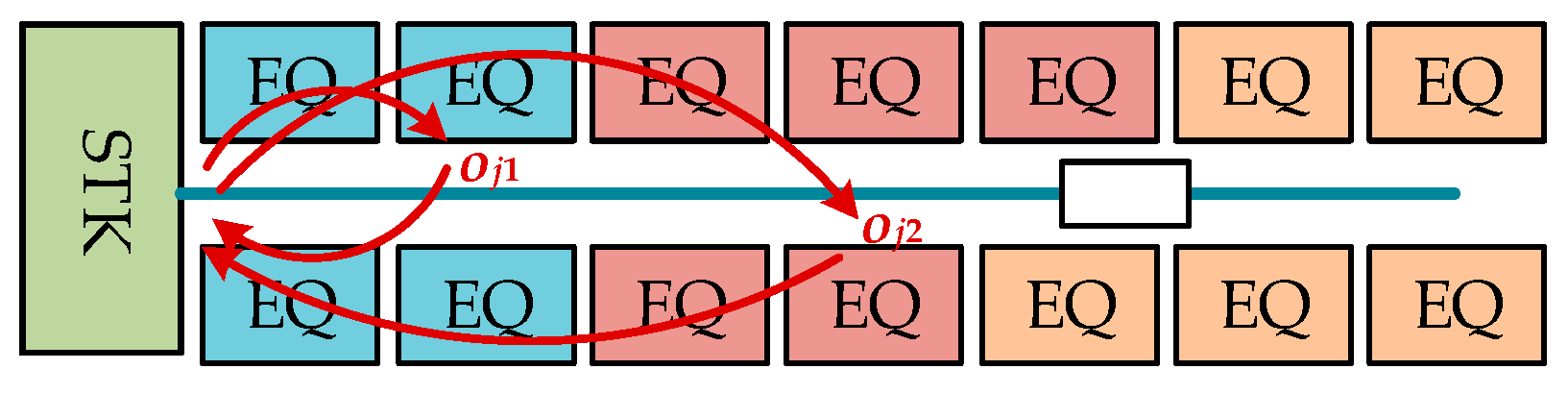
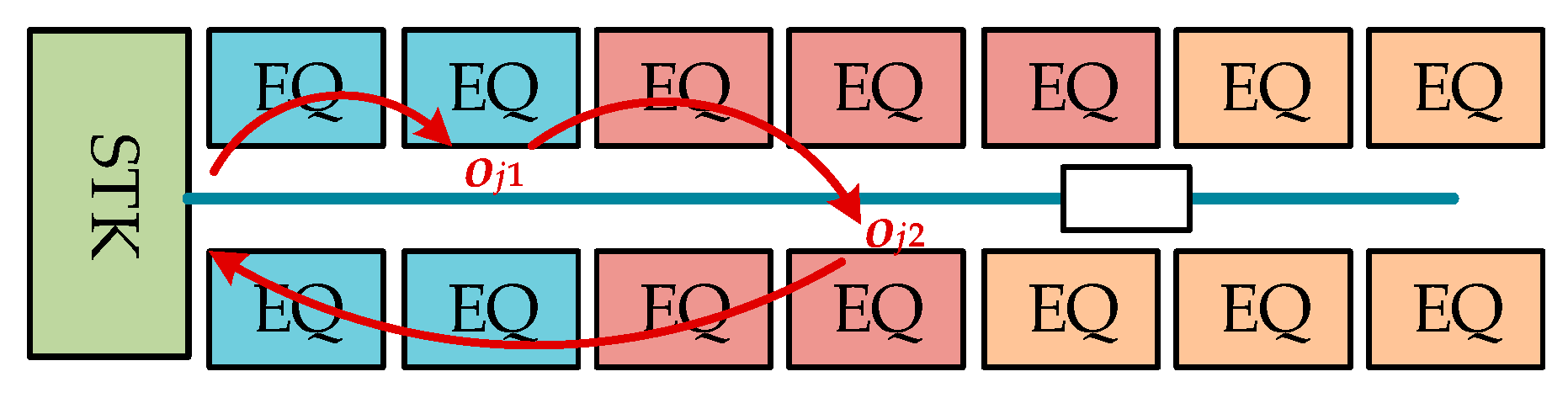
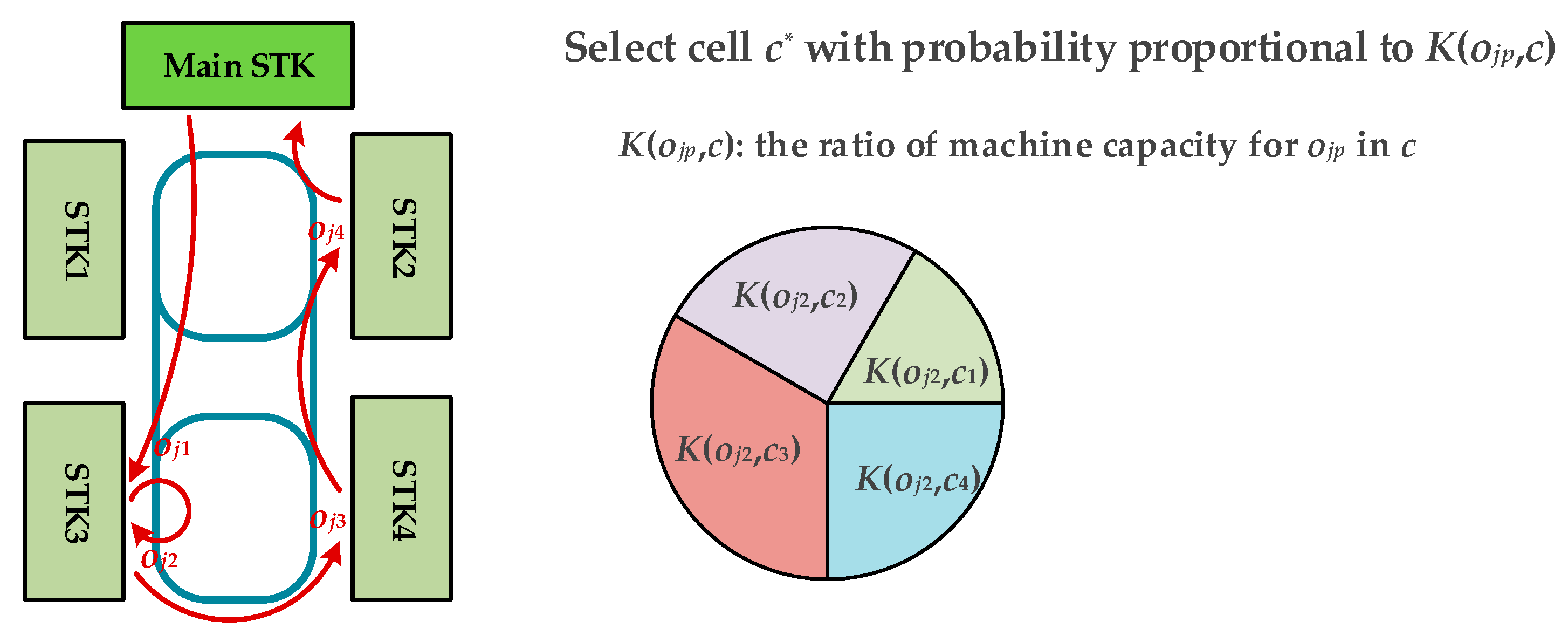
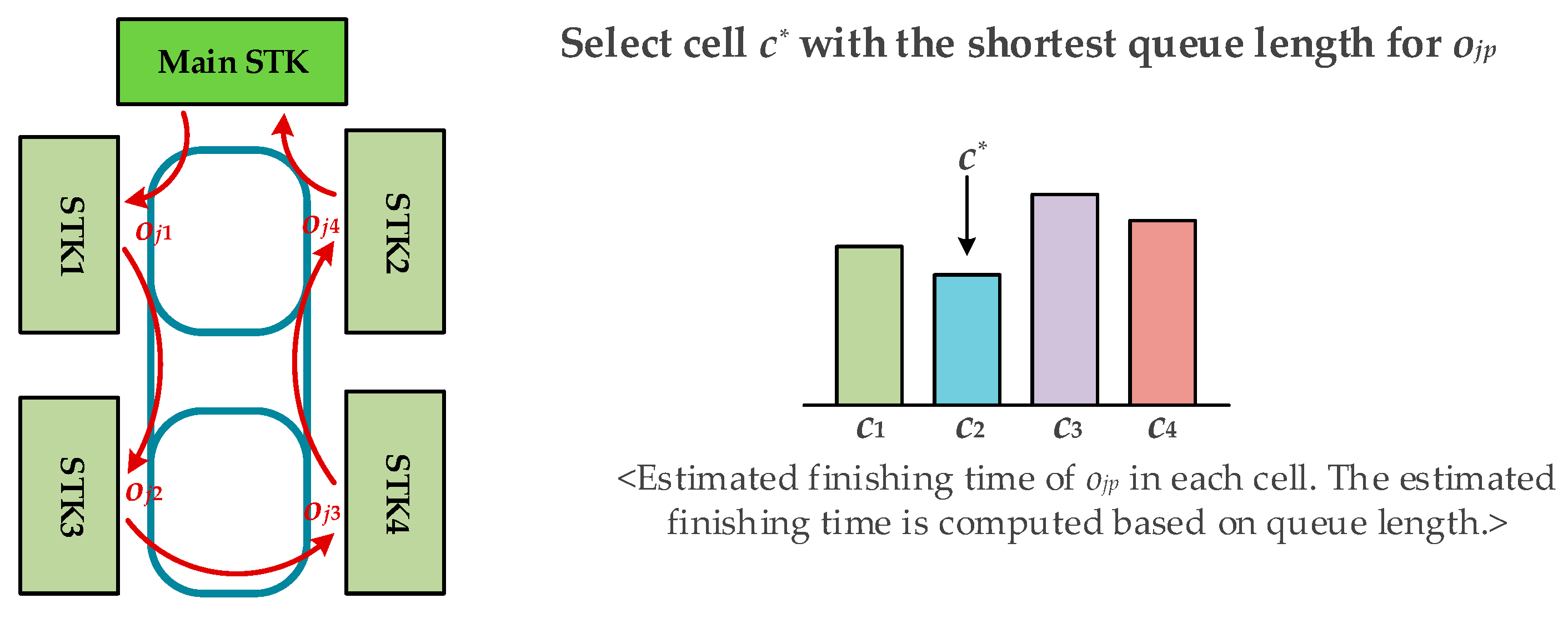
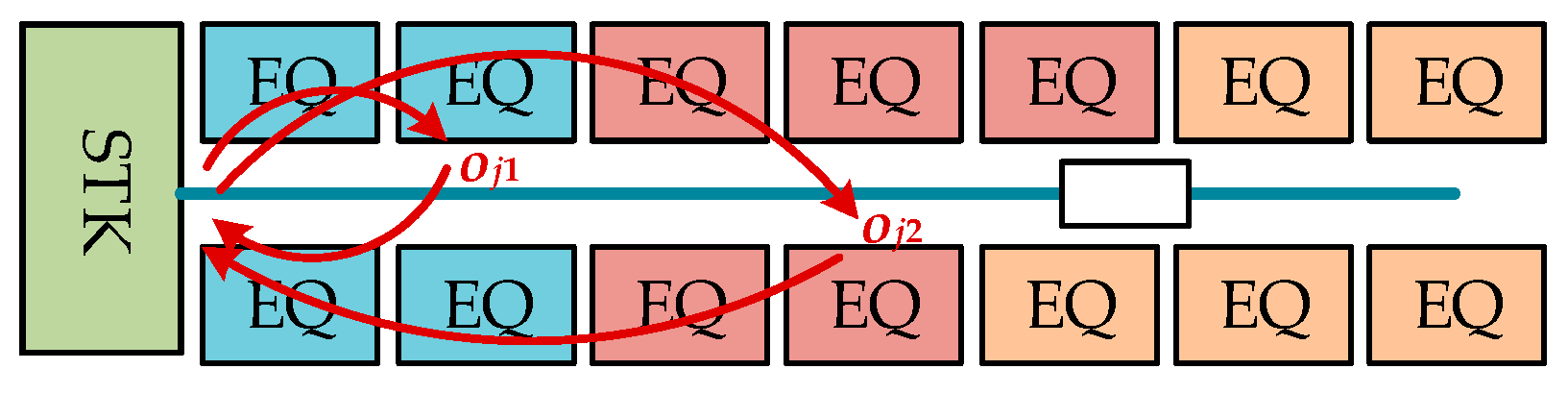
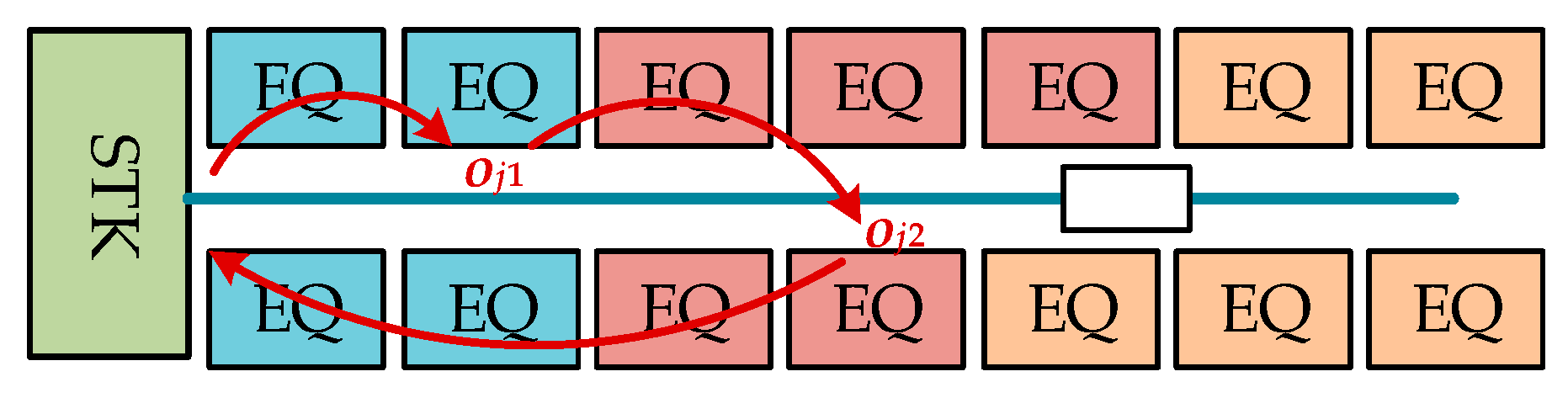
This paper deals with the scheduling of the wafer test facility that is assumed to be a sort of hybrid cellular production line. A wafer test facility consists of cells and each cell is composed of more than one processing machine. There are two kinds of stockers to store jobs. Jobs (or FOUPs) start and end at a main stocker. The other kind of stocker is a cell stocker. Every cell has its own cell stocker to store jobs temporally in cells. There exists an intracell material handling system (Intra-MHS), such as an automated guided vehicle, in each cell to transfer jobs within a cell, and there is an intercell material handling system (Inter-MHS), such as an overhead transfer system, to transfer jobs from cell to cell. For example, a job is firstly released into a main stocker. If the job in the main stocker is allocated to one of cells, an Inter-MHS transfers the job to the cell stocker of the target cell. An Intra-MHS moves the job from the cell stocker to a machine and vice versa. When the whole operations that are to be processed in the cell are finished, the job waits in the cell stocker to be ordered to a next cell for the remaining operations. After completing the whole operations of the job, it goes back to the main stocker. In addition to the above described consideration, this study considers multiple types of jobs with identical operation sequences, which implies that although they have identical operation sequences their processing times may be different depending on the its job type. This is a general situation in a wafer test facility for semiconductor memory.
Selected nomenclature is defined as follows.
is the finite set of jobs.
is the finite set of cells.
is the finite set of machines.
is the finite set of machines in the cell .
is the finite set of machine types.
is the finite sequence of operations of job .
is the partition of operation sequence .
is the machine-to-machine-type function.
is the operation-to-machine-type function.
or is the cell allocation function.
is the machine allocation function.
With respect to the partition of the operation sequence, for instance, let us assume that job j has five operations: . Then, one of the possible partitions of operation sequence is . The machine-to-machine-type function returns the machine type () of machine . The operation-to-machine-type function returns the machine type (), where operation should be processed. The cell allocation function allocates each element of to proper cell. For instance, , , and imply that , , and are processed in cell , , and , where , respectively. The machine allocation function returns the machine, in which operation should be processed. Note that the sequences of operations, the operation-to-machine-type functions, and the machine-to-machine-type functions should be given in advance, whereas the partitions of operation sequences, the cell allocation functions, and the machine allocation functions should be determined by the scheduler.
In addition, time related indices are defined as follows.
is the released time of job .
is the completion time of job .
is the cell starting time of in cell .
is the cell finishing time of in .
is the starting time of in machine .
is the finishing time of in .
is the cell processing time of in .
is the processing time of in .
is the moving time from cell to cell by an Inter-MHS.
is the moving time in a cell by an Intra-MHS.
The released time can be defined as the time when job is released into the main stocker or the time when job in a main stocker is allocated to the first cell. In this paper, the second definition is used. The completion time is the time when job j comes back into the main stocker after completing all its operations. The cell starting time is defined as the time when job j arrives at cell to perform its operation(s) in , and the cell finishing time is the time when job returns to the stocker of after finishing whole operation(s) in . The starting time is defined as the time when operation starts its process in machine , and the finishing time is defined as the time when operation is finished in . The finishing time can be simply computed by . The cell processing time is the time required by to be processed in . The cell processing time includes waiting times in both a stocker and machines, processing times in machines, and moving times by an Intra-MHS. The processing time is the time required by to be processed in .
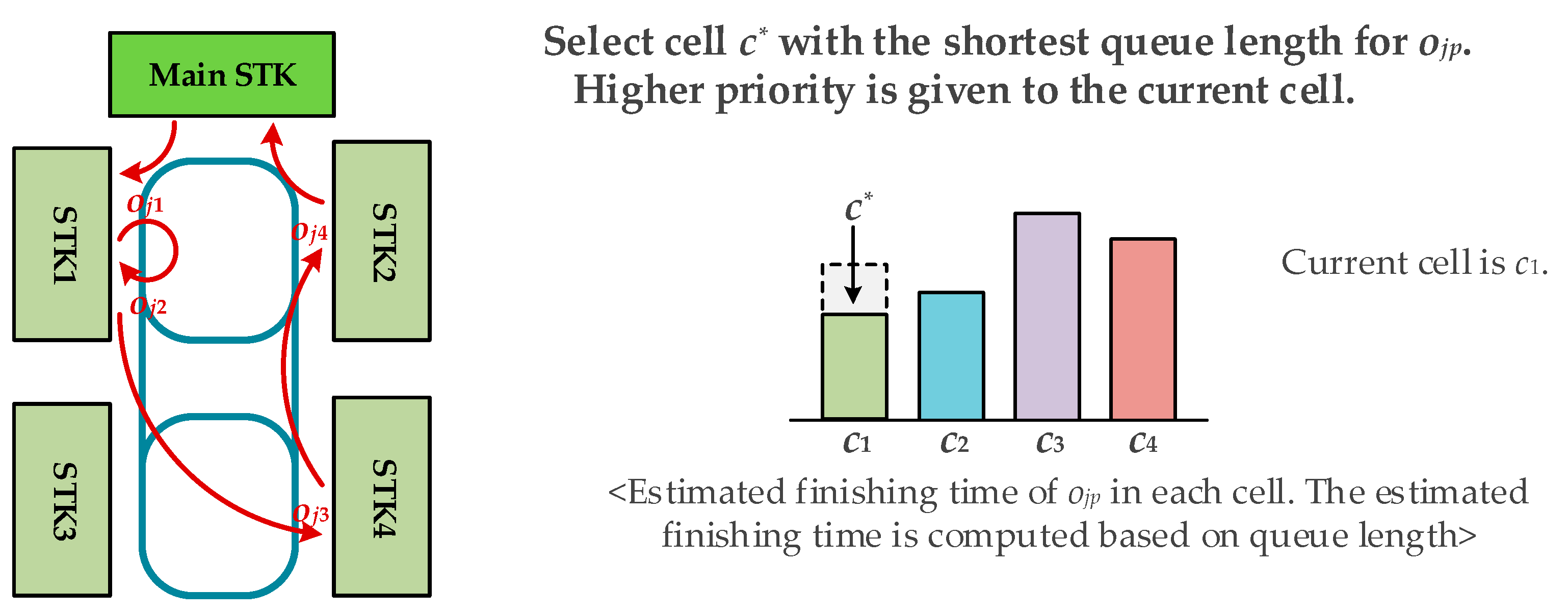
The intercell scheduling problem is to find a proper partition of operation sequence for every job in , and to determine the cell allocation function for every so that a given objective function is minimized. For instance, the objective function to minimize mean cycle time is given by
The completion time of job is obtained as follows. Let is the last element of , i.e., . Then, the completion time is computed by .
Constraints:
If for , then .
, then
If , ; Otherwise, , .
.
The fist constraint implies that every operation of a job should be processed in a different kind of machine type. The second constraint states that there should exist at least one machine in for every operation in . The third constraint ensures the precedence condition of operations for every job, in which is the precedent element of , i.e., and there exists no such that and . The last constraint is to compute the cell finishing time , which is sum of the cell starting time and the cell processing time in .
The intrascheduling problem in cell is to determine the machine allocation function for every such that . For instance, the objective function can be defined as minimization of the total tardiness of all jobs allocated to cell . The tardiness of in is the maximum value between zero and the cell finishing time, , minus its estimated value, . The estimated cell finishing time is anticipated by the intercell scheduler, which will be further discussed in the following section. In this case, the objective function of the intracell scheduling problem is given by
Constraints:
If for , then , .
If , ; Otherwise, , .
, , .
, .
The first constraint of the intracell scheduling is same with that of the intercell scheduling. The second constraint ensures the precedence condition of operations for every job in a cell, where is the precedent element of , i.e., and there exists no such that and . The third constraint states that only one operation should be processed in a machine at a time. The last constraint is to compute the cell finishing time.
5. Simulation Experiments
The performances of the proposed heuristic scheduling policies are evaluated through computer simulation experiments, which re-executed using AutoMod Version 14.0.1 of Applied Materials, Inc. For the simulation experiments, the layout of a wafer test facility and operation flows are redesigned based on a real existing memory wafer test facility. It is assumed that the wafer test facility has six cells and that there is one main stocker and one cell stocker for every cell. Every cell contains 40 processing machines. A FOUP is used to transfer silicon wafers securely and safely for intercell transport and intracell transport. Each FOUP is assumed to have two wafers. Every machine has two input-buffers and two output-buffers to store FOUPs temporally.
Table 1 shows the machine type and the processing time for each operation step of three types of wafers, and
Table 2 shows the number of machines equipped in each cell. In the wafer test facility, machines are equipped functionally or multifunctionally in each cell, which is known as a hybrid cellular production line. Machines’ configurations of cells 1–4 are designed so that a FOUP can execute its whole operation in a single cell, while those of cells 5–6 are designed to balance workloads among machine types. When wafer types and their processing times are fixed in advance, it would be the best machines’ configuration if every cell contains a balanced number of machines for all operations. However, when a new type of wafer is released into the wafer test facility, the workloads’ balance among machine types is broken. Hence, a lot of wafer test facilities adopt hybrid cellular production lines. Although the configuration of machines in each cell significantly affects the manufacturing performance indices such as work in process (WIP), cycle time, utilities of material handling systems, and optimal layout; machine configuration is not within the scope of this study. Thus, the proposed scheduling policies have been tested with the predefined layout and machines’ configuration.
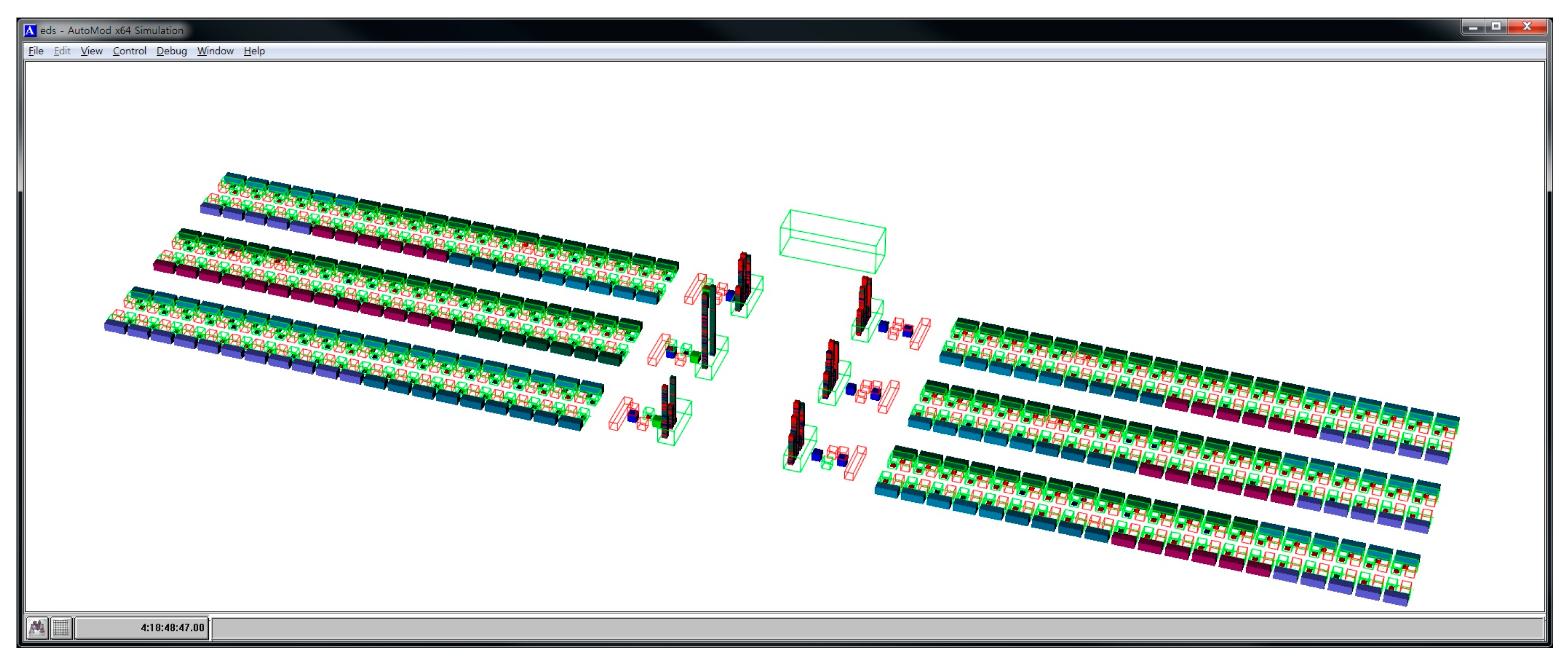
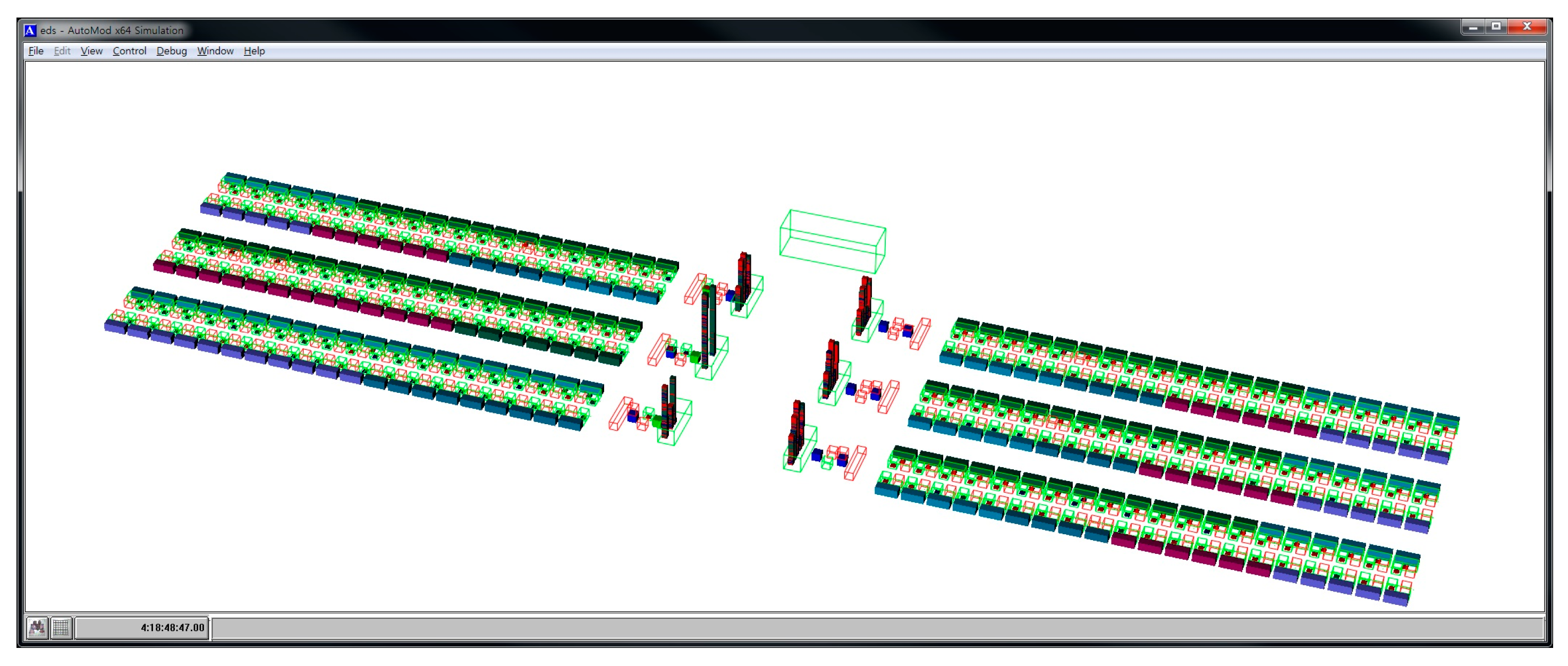
Figure 9 shows a screenshot of Automod’s simulation experiment.
For the simulation experiments, four combinations of intercell and intracell scheduling policies were investigated: BRD+SEQL (or shortly BRD), SSQL+SEQL (or shortly SSQL), M-SSQL+SEQL (or shortly M-SSQL), and MDT+DT (or shortly MDT). The tested combinations of scheduling policies can be classified into two scenario groups. One is the combinations of scheduling policies without consideration given to the machine-to-machine direct transfer in each cell, and the other is those with consideration given to the machine-to-machine direct transfers. For the former group, the BRD, SSQL, and M-SSQL policies are investigated for the intercell scheduling policies. In this scenario group, SEQL is applied for the intracell scheduling policies. On the other hand, for the latter group, the MDT and DT policies are developed and investigated for intercell and intracell scheduling, respectively. The MDT policy is designed to only be compatible with the DT policy. The release of FOUPs is controlled so that the average throughputs of the four scheduling policies meets the near-maximum capacity of the wafer test facility.
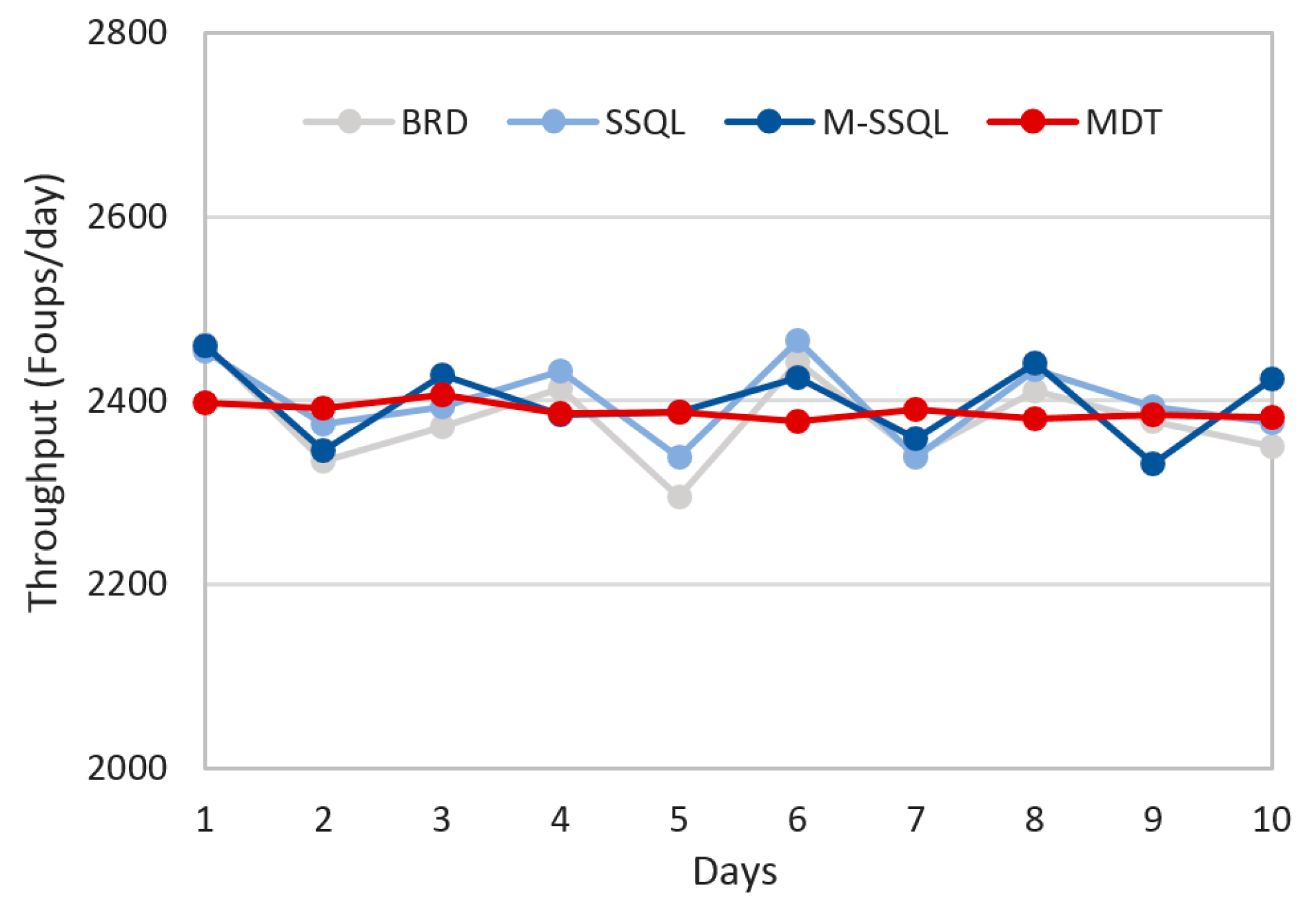
One of the most important indices in manufacturing systems is throughput.
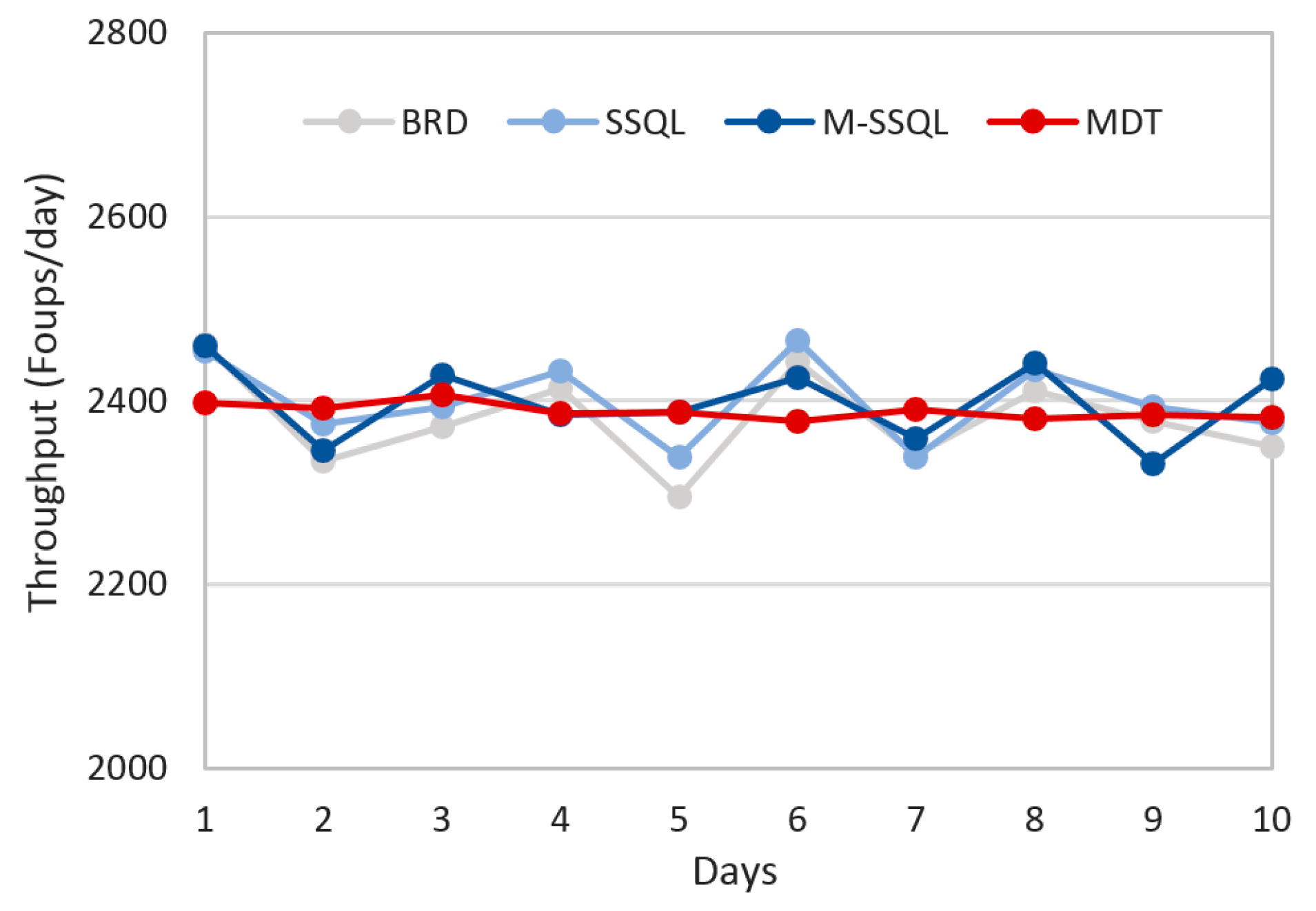
Figure 10 depicts the daily throughput trends of the four scheduling policies for ten days. The average throughputs are 2379.8, 2400.0, 2398.6, and 2388.3 FOUPs/day under BRD, SSQL, M-SSQL, and MDT, respectively. Although there are no significant differences among the average throughputs under the four scheduling policies, as shown in the graph, the daily perturbation of throughputs is the lowest under the MDT policy.
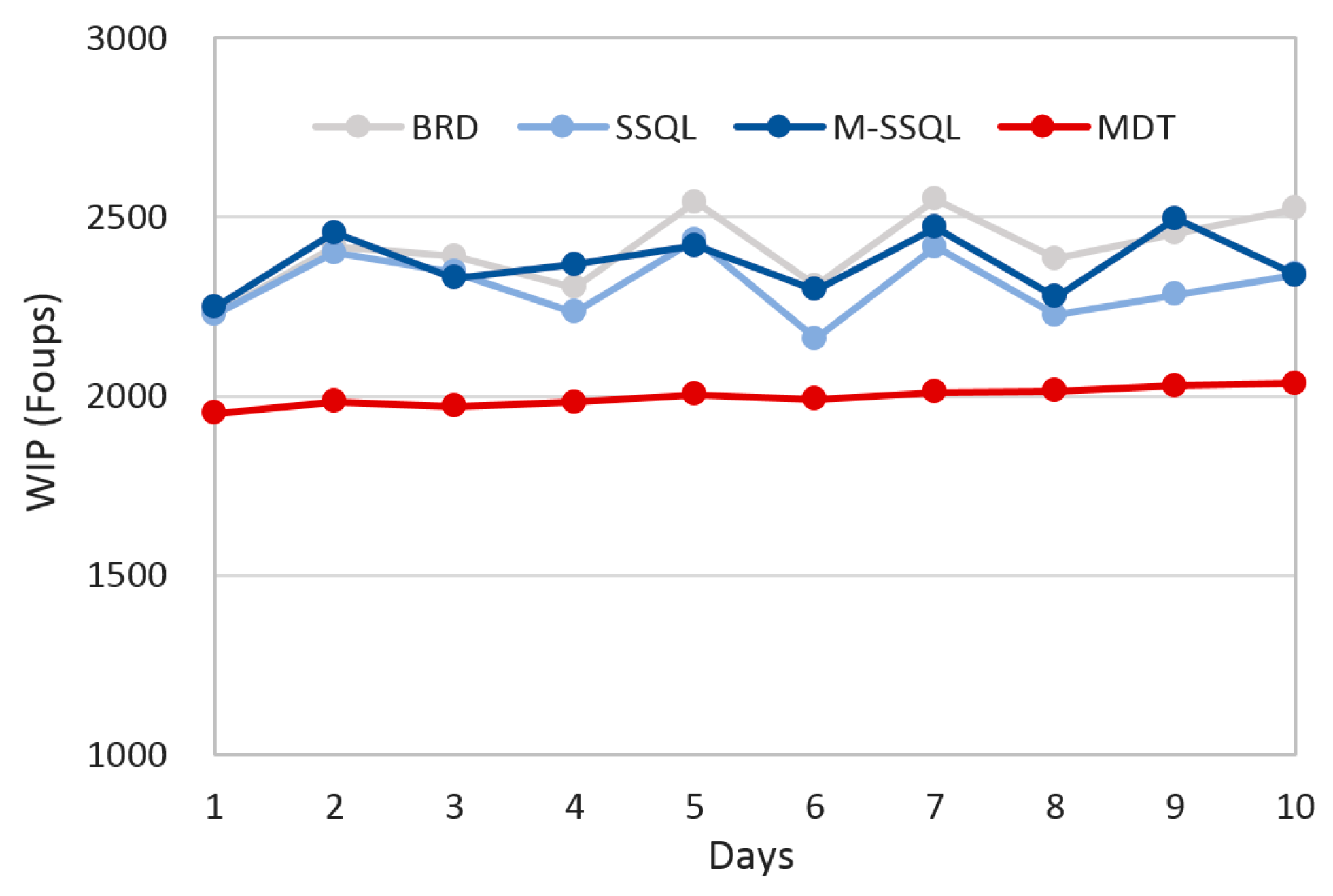
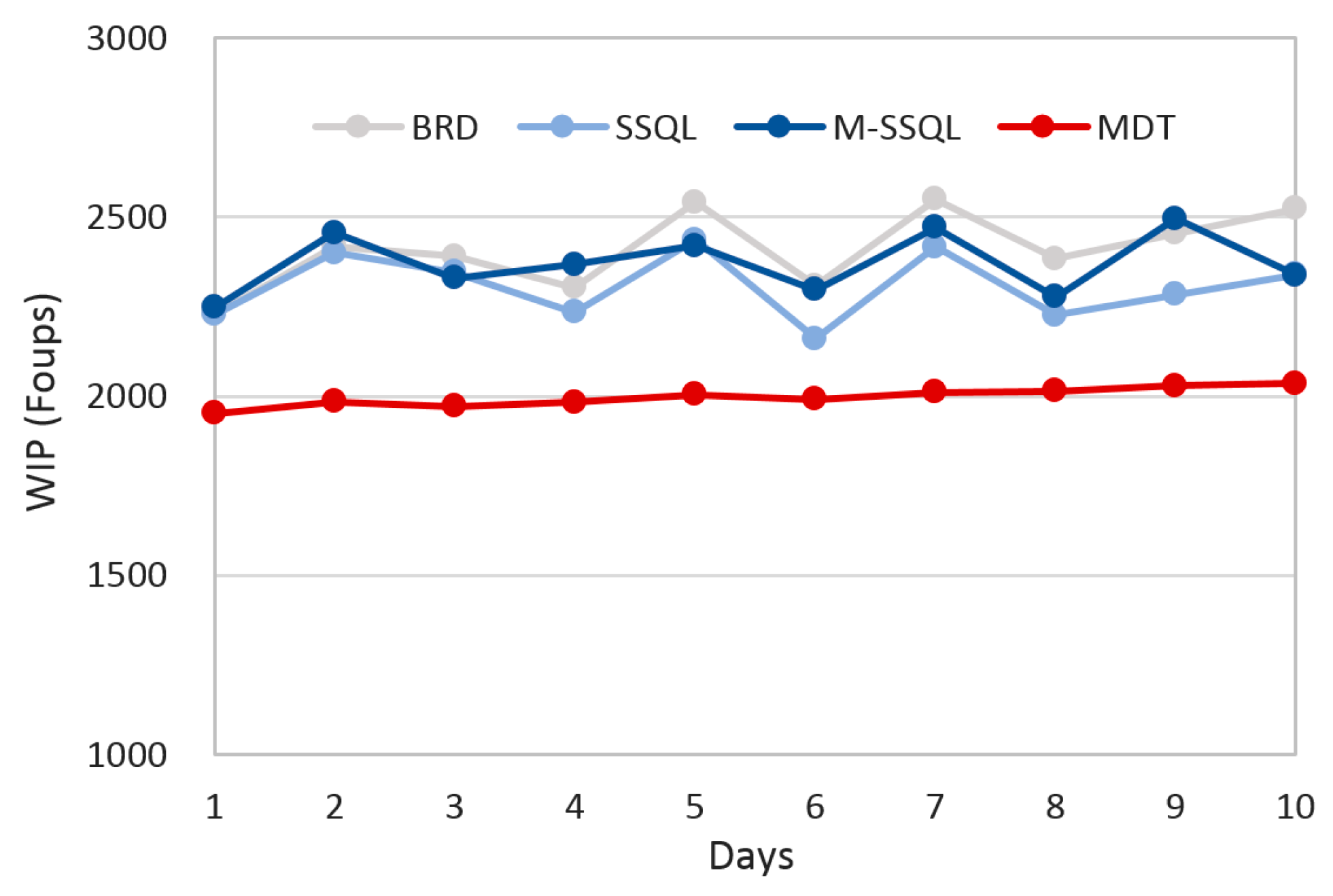
The WIP is another important production index.
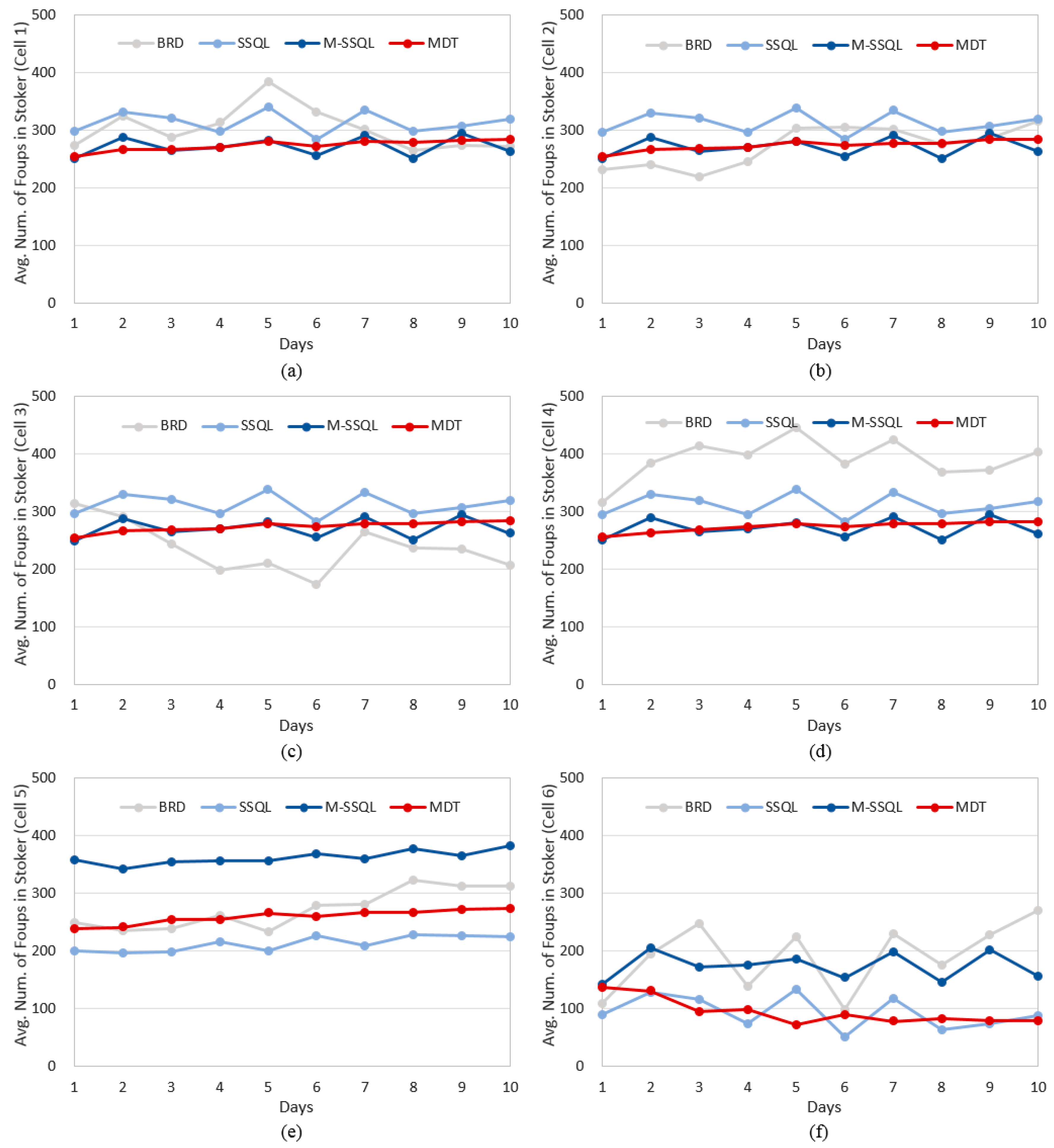
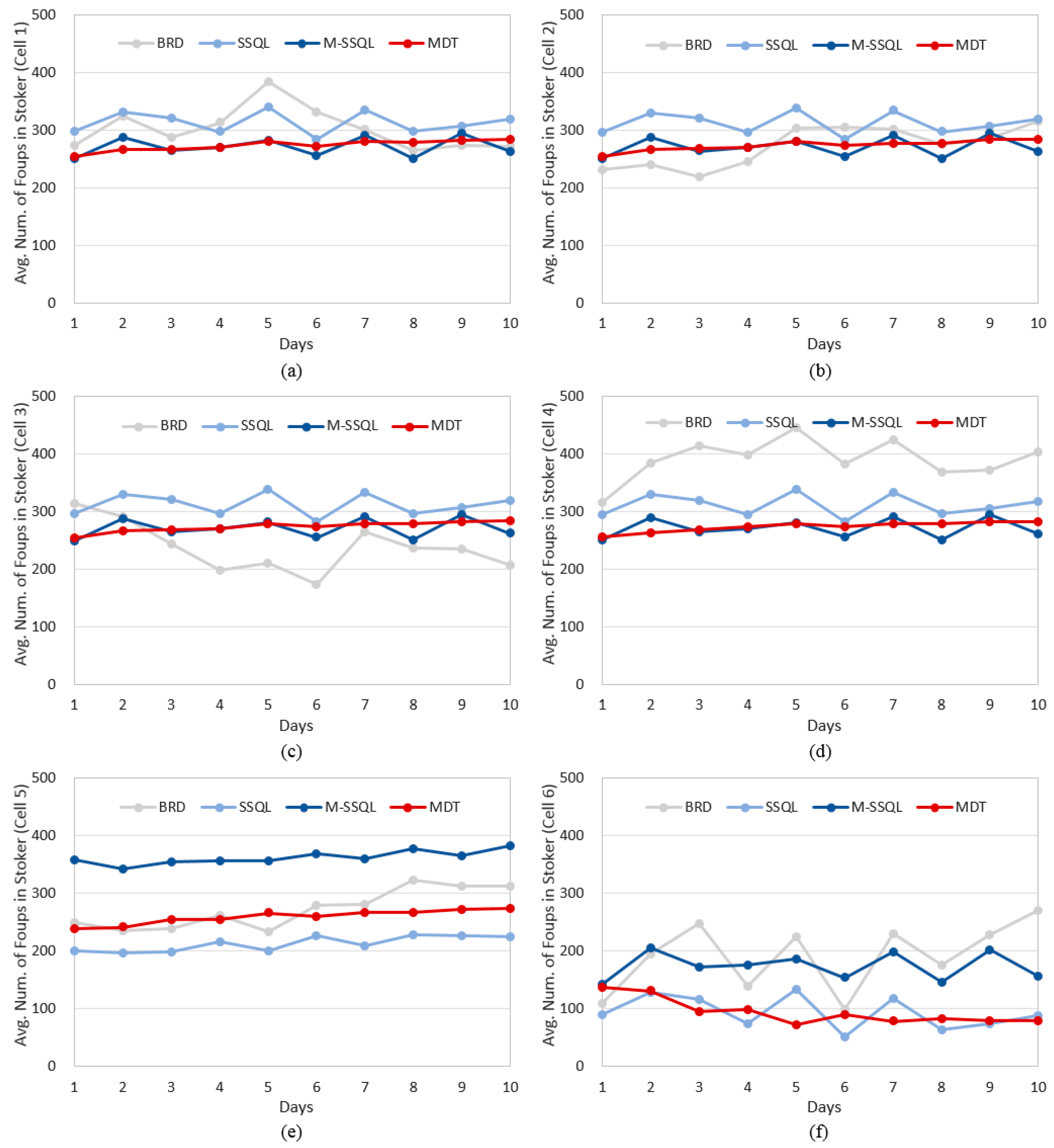
Figure 11 shows the trends of the WIP under the four scheduling policies. The average WIPs are 2410.1, 2307.1, 2369.7, and 1997.3 FOUPs under BRD, SSQL, M-SSQL, and MDT, respectively. There are no significant differences among the average WIPs under BRD, SSQL, and M-SSQL, whereas that under MDT shows the lowest WIP level. In addition, the daily WIP variation is the lowest under the MDT policy. More specifically, the daily average number of FOUPs in each stocker are investigated in
Figure 12. In cells 1 to 3, where the machine configurations are designed so that a FOUP can execute all of its operations in a single cell, there are no significant differences among the average number of FOUPs under the four scheduling policies. However, the MDT shows the lowest daily variation of FOUP numbers. In cells 4 to 6, on the other hand, there are differences among the average number of FOUPs, but the MDT also shows the lowest daily variation of FOUP numbers.
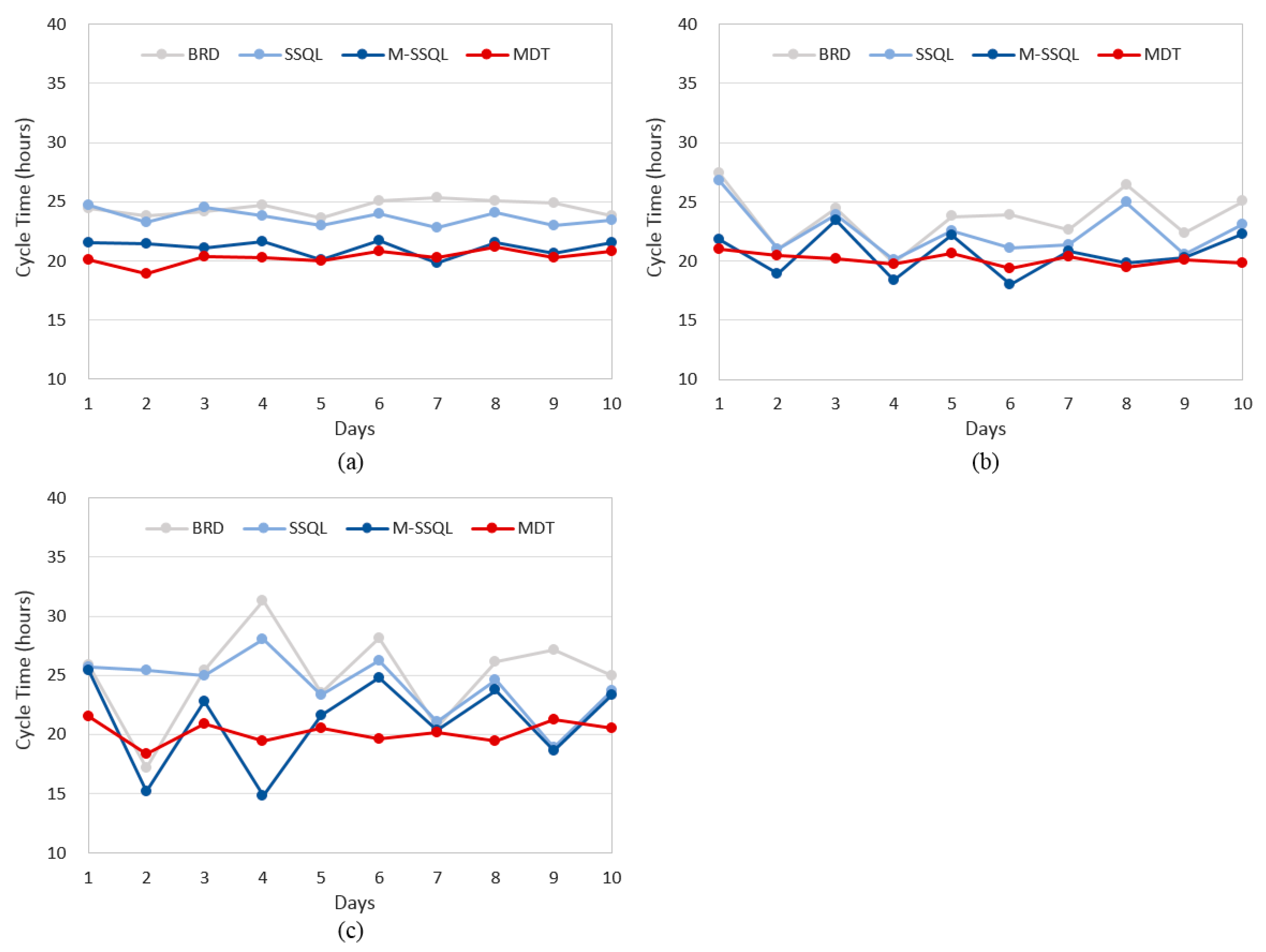
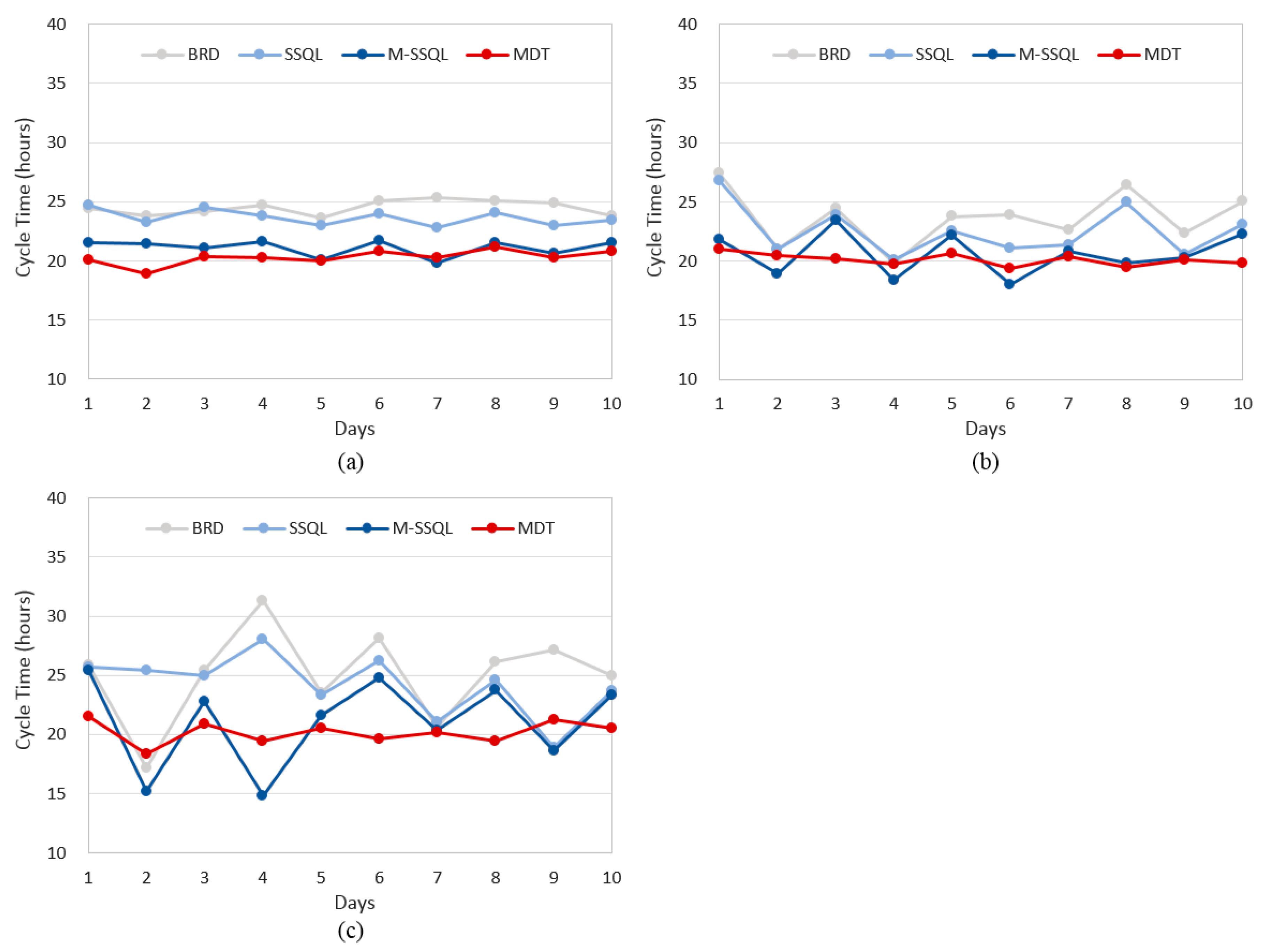
With respect to the daily cycle time, as shown in
Figure 13, the MDT scheduling policy shows the lowest value. For instance, the average cycle times of Wafer Type A under the BRD, SSQL, M-SSQL, and MDT rules are 24.5, 23.7, 21.1, and 20.3 days, respectively, and those of Wafer Type B are 23.7, 22.6, 20.6, and 20.1 days, respectively. The average cycle times for Wafer Type C are 25.0, 24.2, 21.1, and 20.2 days, respectively. The MDT, M-SSQL, SSQL, and BRD rules show lower to higher average cycle times in the listed order. The MDT scheduling policy also shows the lowest variations of daily cycle times among the four scheduling policies. Cycle time variations have recently been considered to be a significant production index in the semiconductor industry because lower daily cycle time variations are helpful in terms of order due dates.
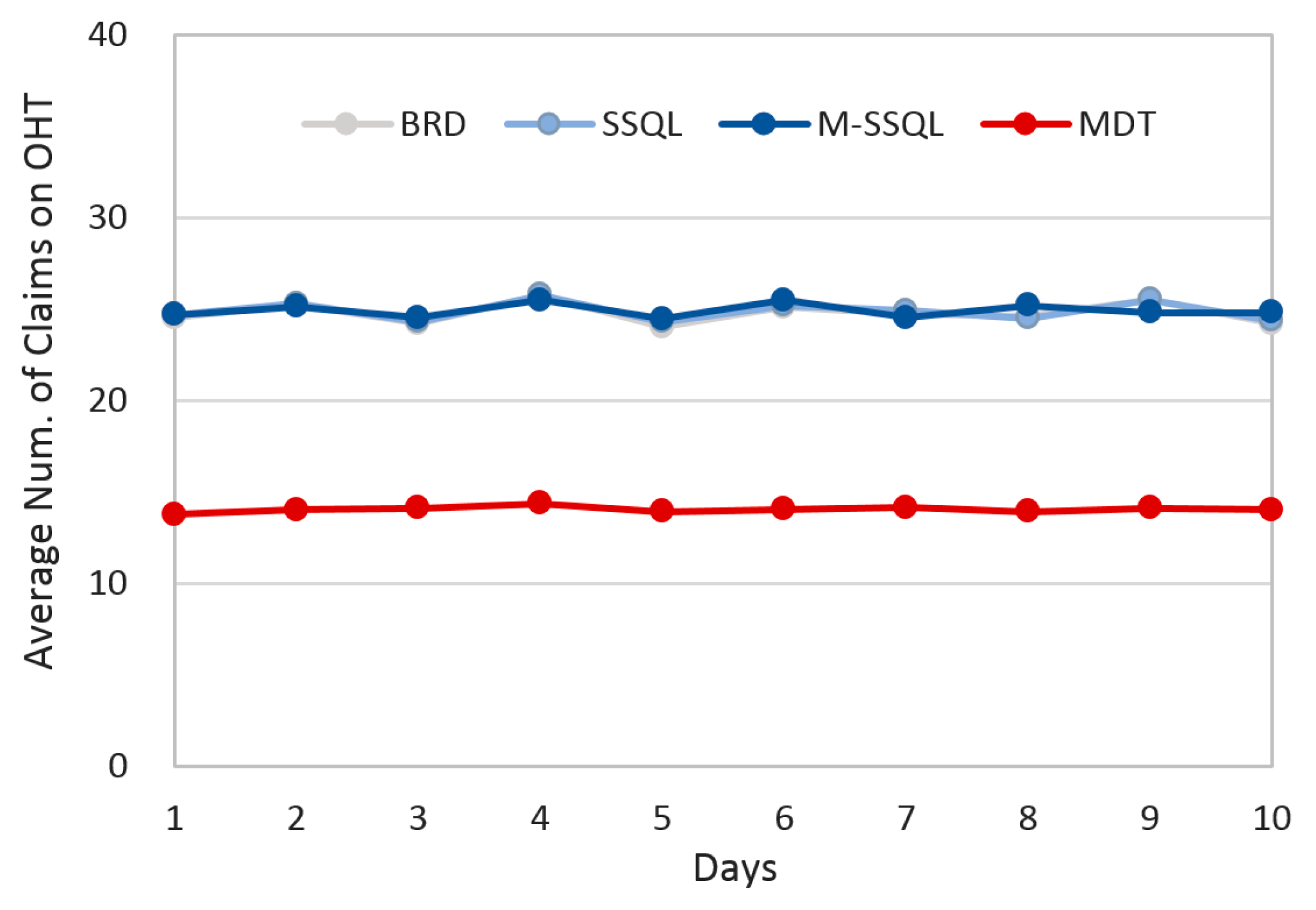
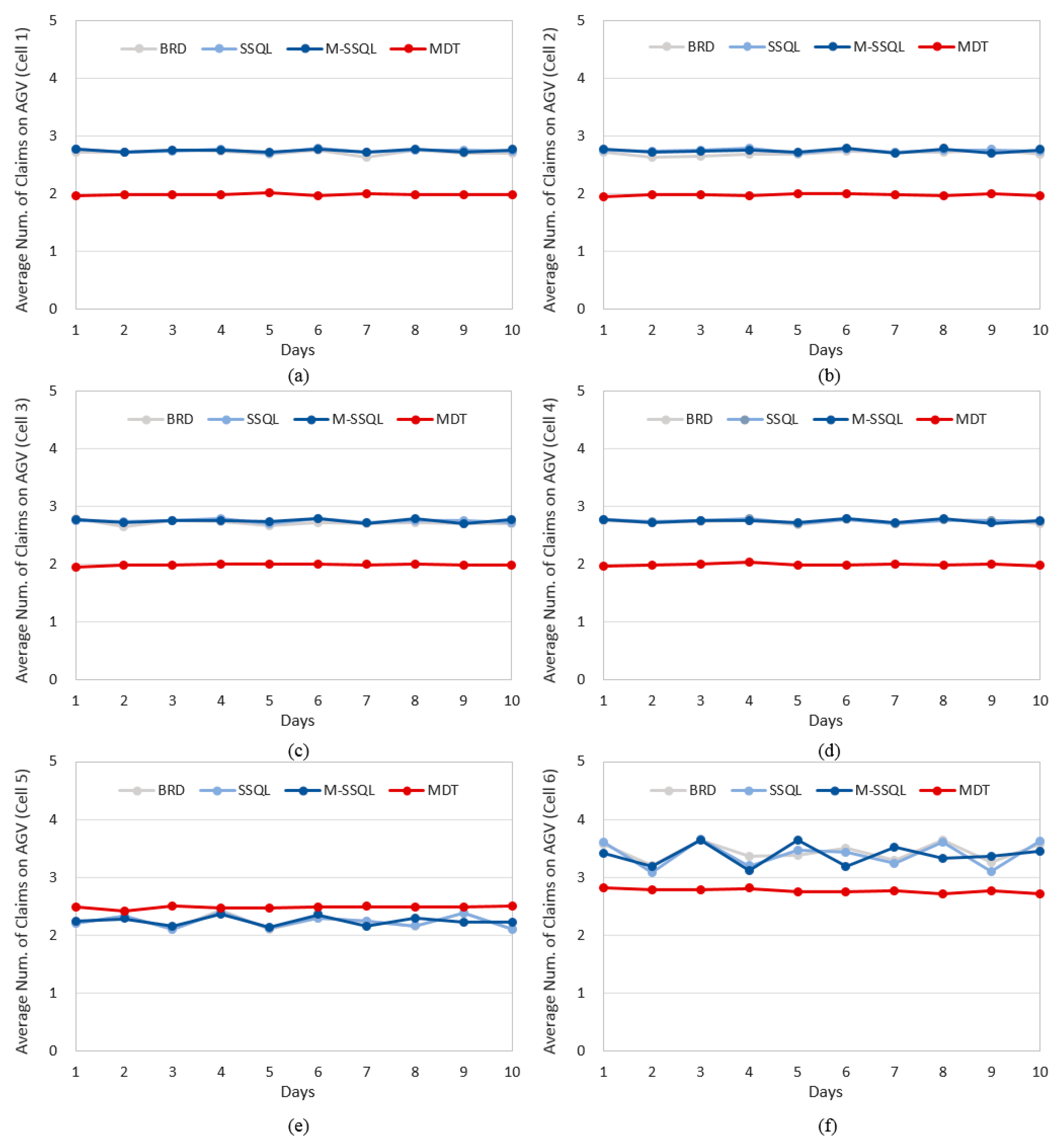
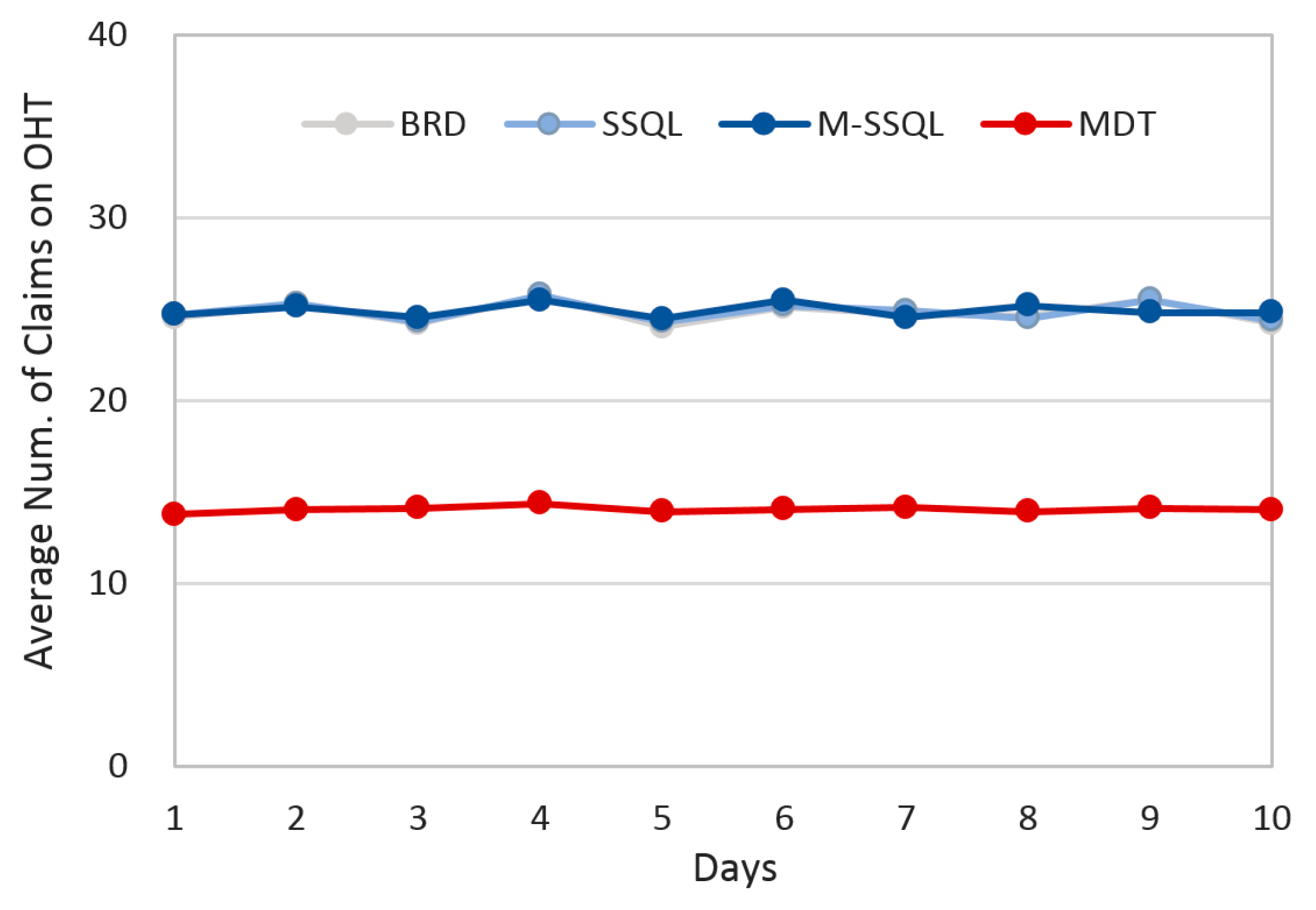
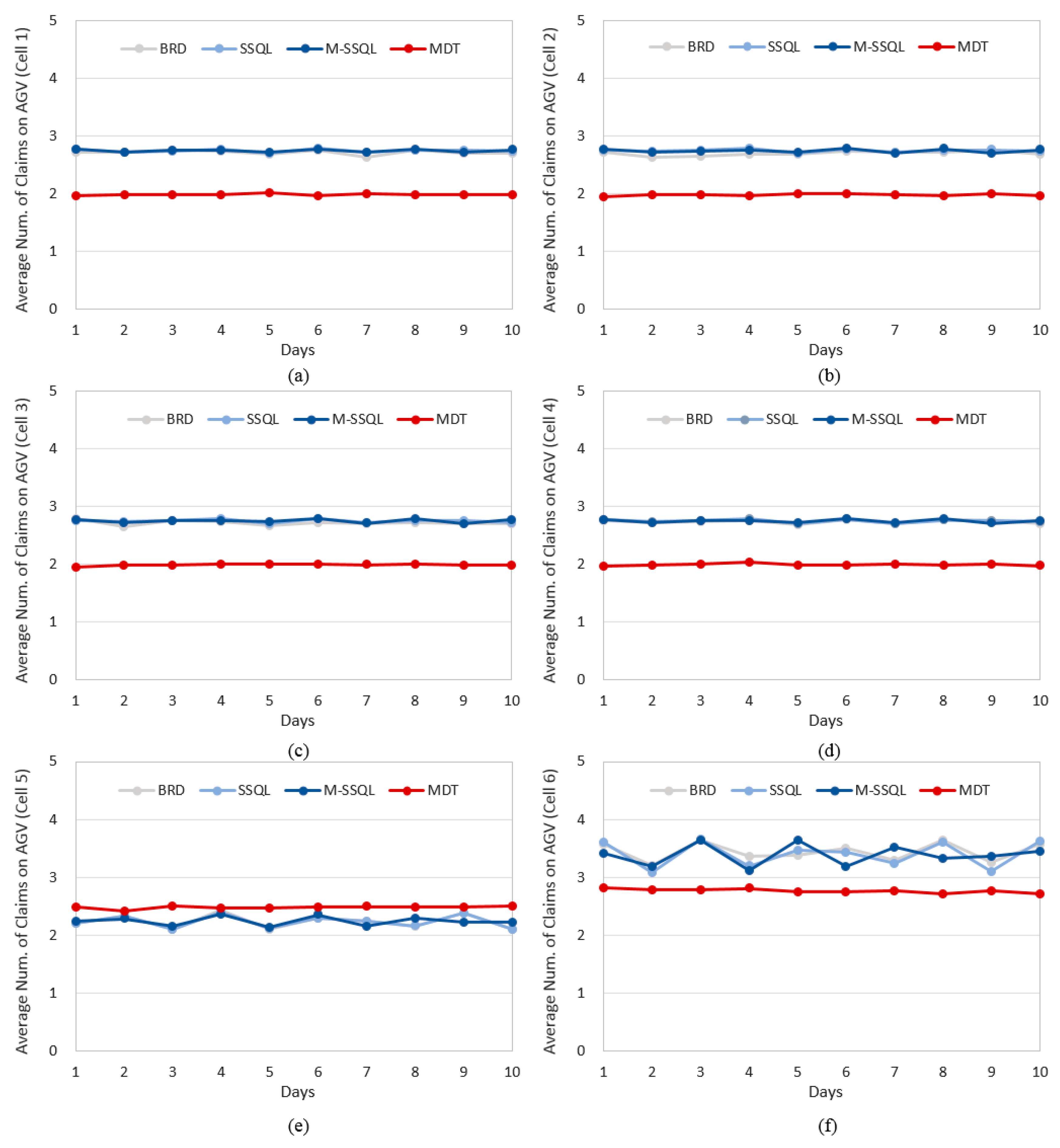
With respect to intercell and intracell material handling systems, graphs showing the daily average number of claims are shown in
Figure 14;
Figure 15, respectively. The daily average number of claims are investigated instead of the utilities of material handling vehicles because the number of material handling vehicles is determined by considering the number of claims in the general semiconductor industry. Lower job claim numbers can reduce the number of material handling vehicles, and fewer variations in job claim numbers can also reduce the number of material handling vehicles.
Figure 14 shows the daily average number of claims on OHT (Overhead Transport), or the intercell material handling system. As anticipated, the MDT scheduling policy significantly reduces the daily average number of claims compared with the BRD, SSQL, and M-SSQL policies. This is because the transfers from cell to cell are reduced by applying the MDT policy. The daily average numbers of claims on OHT are 24.8, 24.9, 24.9, and 14.0 under the BRD, SSQL, M-SSQL, and MDT, respectively.
Figure 15 shows the daily average number of claims on AGV (Automated Guided Vehicle), or the intracell material handling system, in each cell. In cells 1 to 4, where the machine configurations are designed so that a FOUP can execute all of its operations in a single cell, the MDT policy reduces the number of claims by 27.4 to 27.5%. The machine types equipped in cell 5 are MT1 and MT4, and therefore, there is no machine-to-machine direct transfer via the MDT policy. Thus, the average numbers of claims in cell 5 have no significant differences among the four scheduling policies. On the other hand, the machine types equipped in cell 6 are MT2, MT3, and MT5, and therefore, machine-to-machine transfers from MT2 to MT3 are possible under the MDT policies. Thus, the average number of claims under the MDT is lower than those under the other three policies.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}