1. Introduction
For decades, a classical problem has been how to describe the dynamics of stock prices. The most basic model used to describe stock prices is geometric Brownian motion (GBM), which was first used by Black and Scholes [
1]. However, there are many empirical features of market data that cannot be captured by GBM. Many researchers have proposed different approaches to modeling phenomenon in the market. For example, Merton [
2] proposed a jump-diffusion process to capture the extraordinary magnitude changes of the asset price and Hamilton [
3] introduced regime switching to capture structural changes in time series data. In this paper, we focus on another market phenomenon, which is called long-duration asset prices or price clustering. This phenomenon has been observed by some researchers. Sonnemans [
4] found that the price of the stocks on the Dutch stock market tended to cluster at round numbers (e.g., 10, 20, 30, etc. or 5, 15, 25, etc.) and were affected by the round number price barriers (prices passed less frequently round numbers than other numbers). Similar phenomenon was also observed in China (Brown and Mitchell [
5]; Hu et al. [
6]) and Japan (Aşçioǧlu et al. [
7]). The phenomenon can be described by the skew diffusion process. Itô and McKean [
8] first introduced the skew Brownian motion (SBM), a process that behaves similarly to the conventional Brownian motion before arriving at the skew level. Once it hits a skew level
a, its excursion from
a has a probability of
p to go upward and a probability of
to go downward. Due to this property of skew process, it is very suitable for describing the price clustering phenomenon. We notice that skew processes can also illustrate the strength of the phenomenon through the skew probability
p. It is a more precise characterization of the phenomenon than price clustering. Thus, we name the phenomenon described by the skew process as skew phenomenon.
The mathematics of the SBM was explored, for instance, by Walsh [
9], Le Gall [
10], Barlow et al. [
11], Ouknine [
12], Lejay and Martinez [
13], Ramirez et al. [
14], Ramirez [
15], and Appuhamillage and Sheldon [
16]. The diverse applications of SBM in many fields have been investigated, such as in geophysics (Appuhamillage et al. [
17]; Atar and Budhiraja [
18]; Song et al. [
19]), molecular biology (Bossy et al. [
20]), population ecology (Cantrell and Cosner [
21]; Min et al. [
22]; Barahona et al. [
23]), and so on. The SBM has also been applied to financial modeling by several scholars; for example, Corns and Satchell [
24] and Gairat and Shcherbakov [
25] used them to model the dynamics of the underlying asset and price derivatives. Although Rossello [
26] argued that there is arbitrage in SBM models, Zhu and He [
27] demonstrated that, by carefully choosing a risk-neutral measure, the SBM could be consistent with no-arbitrage property.
In the existing literature on SBM, much effort has been made in exploring the mathematical properties of SBM or applying them to model the underlying asset and price derivatives. However, empirical testing of SBM has received much less attention. Is there, indeed, the skew phenomenon present in the market? Can skew geometric Brownian motion (SGBM) outperform other models when applied to modeling the dynamics of asset price? We attempt to answer these questions in this paper. The contributions of this paper are four-fold. First, we apply a Bayesian estimation approach to estimate the parameters. To do this, the local time in the model is removed by a piecewise transform. Second, we test whether skew phenomenon is present in the global stock markets by checking whether the skew probability p is significantly different from 0.5. Third, we compare the performance of SGBM with three other models, the basic GBM model, GBM-jump model (GBM-J) and Markov regime switching GBM model (GBM-MRS). Fourth, we show that the skew phenomenon and the price clustering phenomenon can confirm with each other; the skew phenomenon is also related to the herd behavior. In this point, we try to explain why the skew phenomenon exists.
The remaining part of this paper is organized as follows.
Section 2 presents the SGBM model and its piecewise transform.
Section 3 specifies the methods for evaluating the model’s performance.
Section 4 describes the data and empirical results. In
Section 5, we try to find some theories to explain the existence of skew phenomenon. Finally, the conclusion is presented in
Section 6.
2. The Model
Let
be the stock price at time
t. Assume that
follows the SGBM
where
is the symmetric local time of the process
at the “skew level”
a, and the skew probability
p is the probability of moving upward when
hits the level
a. If we set
and
, then we get that
follows
It is not difficult to obtain that
is the symmetric local time of the process
and the “skew level” of
is
. To remove the local time, similar to Harrison and Shepp [
28], we define a function
by
Then, we obtain its inverse function
as
Consider
. Then,
The inverse transform
can be expressed as
As the function
is the difference of two convex functions, we apply the generalized Itô formula to
to obtain:
The discretized version of Equation (
7) can be expressed as:
where
and
are independent and standard normally distributed. Denote
(respectively,
) as the set in which the sample value is bigger (respectively, smaller) than the skew level
(i.e.,
and
). Let
,
be the number of
i included in the set
and
, respectively. Obviously,
. Define
. Then, the likelihood function of Equation (
8) can be written as:
where
is the set of all parameters
in Equation (
8) and
X represents the sample data.
3. Model Performance Evaluation
3.1. Significance Test of Skew Probability p
As SBM reduces to standard Brownian motion when
, the skew model does not make any sense if the estimated
is not significantly different from 0.5. Thus, we need to test the significance of the estimated skew probability
. The null hypothesis
is
, and the alternative hypothesis
is
. The other parameters are assumed to be the same under the two hypotheses. Under the null hypothesis, the likelihood function is
The likelihood ratio is defined as follows:
where
X is the sample data,
is the likelihood function under
, and
is the likelihood function under
. When
is large enough, we reject
and accept
; then, we can consider the alternative model to be better than the null model.
We need to know the distribution of under in order to decide whether to accept the null hypothesis or reject it at a specified significance level; however, it is difficult to obtain an analytical solution of the distribution. Thus, we apply the bootstrap method to obtain an approximation of the distribution. First, we get the parameters of standard BM model by maximum likelihood estimation. Then, a simulated sample can be obtained using the estimated model and, thus, we can calculate a value of based on . Repeat this process 10,000 times, we can get 10,000 . Finally, we can get the p-value of , which is the probability that is bigger than .
3.2. Comparison of Model Performance
After verifying previous procedure, in this part, we compare the SGBM defined by Equation (
1) with the commonly-used models, to see which model fits the best. We focus on the following three models.
GBM-J:
where
,
is a Poisson process with intensity
, and
,
and
are independent of each other.
GBM-MRS:
where
is a two state continuous-time Markov process which is independent of
.
The null hypothesis is that the GBM (respectively, GBM-J and GBM-MRS) is suitable for fitting the data, and the alternative hypothesis is that the SGBM fits the data better. The test statistic
defined by Equation (
11) is also adopted. We obtain the
p-value from 10,000 bootstrap samples. If the
p-value is less than 10%, we have the evidence that the SGBM fits the data better. If the
p-value is less than 5%, we have very strong evidence against the commonly-used models.
4. Empirical Analysis
4.1. Data
The closing prices of the AEX (Netherlands, AEX), BEL 20 (Belgium, BFX), DAX (Germany, GDAXI), CAC 40 (France, FCHI), FTSE 100 (UK, FTSE), Shanghai Shenzhen CSI 300 (China, CSI 300), Nikkei 225 (Japan, N225), SMI (Switzerland, SSMI), and S&P 500 (U.S., SPX) indices are used in the empirical study. The stock markets considered represent nine of the most important stock markets internationally; all of them are mature capital markets (except for Chinese market). As a representative of an emerging market, the Chinese market has been rapidly developing and has had an important influence on the world economy; for these reasons, we also take it into account. The data are taken from the Wind Database. The sample period of eight mature markets is from 1 January 2000 to 31 December 2017, while the starting sample period of CSI 300 is 1 January 2002, as it is the first day that the data are available. First, we use the weekly data over the whole sample period to check the skew phenomenon in stock markets in the long-run. Then, we use daily data in each year to check the skew phenomenon over a year. By rolling forward the data quarterly, we obtain 61 groups of data for Chinese market and 69 groups for the other markets.
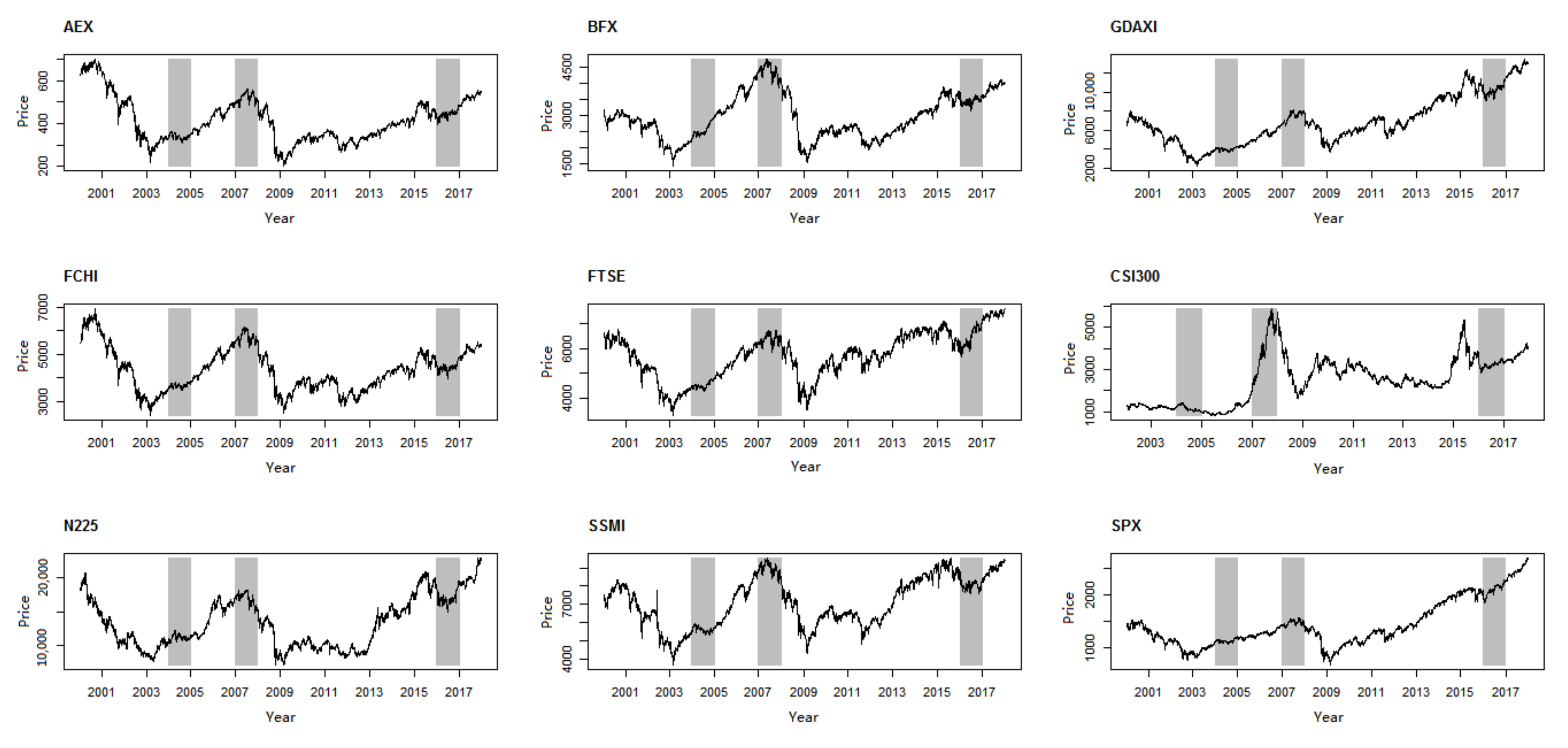
Figure 1 and
Table 1 illustrate the price series under consideration and show their descriptive statistics, respectively. In
Figure 1, we can observe that all stock indices display very similar patterns. For example, during 2004, 2007, and 2016, the indices all clustered at a certain level. It is likely that skew phenomenon exists over these periods.
In
Table 1, according to the coefficient of variation (C.V.), we can see that Shanghai Shenzhen CSI 300 index is the most volatile of the indices, while the FTSE 100 is the most stable.
Table 2 shows that the nine stock markets are highly correlated, which coincides with the results in
Figure 1. The correlation coefficient between the S&P 500 and DAX is the highest, while the correlation coefficient between AEX and CSI 300 is the lowest.
4.2. Empirical Results
4.2.1. Weekly Data of the Whole Sample Period
We estimate the parameters of SGBM model and test the skew phenomenon using the weekly closing prices of the nine stock indices over the whole sample period. For more details of parameter estimation approach, see
Appendix A.
Table 3 gives the results of parameter estimation for the nine indices. We focus on the estimated skew probability
. For the nine stock indices, the skew probabilities
are 0.3343, 0.3669, 0.3754, 0.3204, 0.2748, 0.4715, 0.2984, 0.2712, and 0.3187, respectively. The corresponding skew levels are 329.4386, 2664.4319, 5540.7140, 3921.4128, 4788.8800, 3303.4179, 10,543.1285, 6589.6171, and 1066.8168, respectively. According to the significance test of the skew probability
p, all these estimates are statistically significantly different from 0.5 at 5% level, other than the
of CSI 300, indicating that there are significant skew phenomena in the eight stock markets. According to
Table 1, since C.V. is used to measure the dispersion of data, it is not abnormal that the skew phenomenon does not exist in the Chinese market over the whole sample period. Coinciding with the correlation shown in
Table 2, all the
values are smaller than 0.5, which means that it is more likely for the dynamics of indices to move downward than upward when hitting the skew level
a. However, the likelihood ratio test gives different conclusions. There are only four markets on which SGBM model strictly significantly outperforms the other three models at the 10% level, while there are four markets on which SGBM does not outperform them. The
p-values of likelihood ratio tests in Japanese market is 0.100 against GBM and 0.074 against GBM-J, reaching a significant margin. It is hard to say whether SGBM outperforms these two models, since the
p-values are at such a marginal level. Therefor, we try to find some clues from the graph of the index.
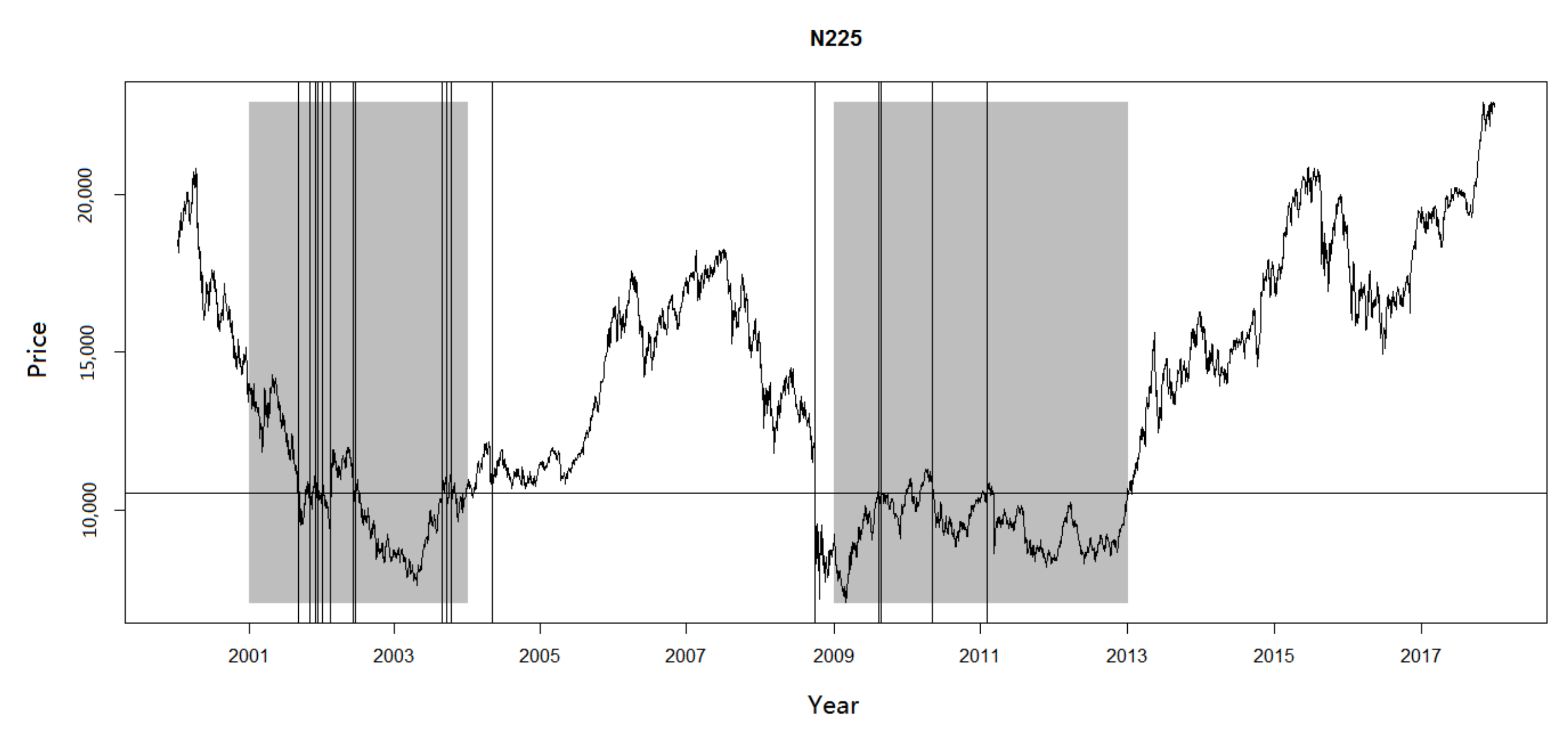
Figure 2 shows the historical price data and skew level of Nikkei 225 index, which is 10,543.1285, as shown in
Table 3. In
Figure 2, we can see that there are two major time intervals during which the skew phenomenon is very significant. The first interval is from 2001 to 2003, during which the process walks through the skew level several times, but the major part is below it. The second interval is from 2009 to 2013. The vertical lines indicate the dates when the extreme price movements occur. It is obvious that extreme price movements occur frequently when the index is near the skew level. As many researchers have devoted considerable effort to correlation between extreme price movement and herding, the herding may be conducive to the explanation of skew phenomenon.
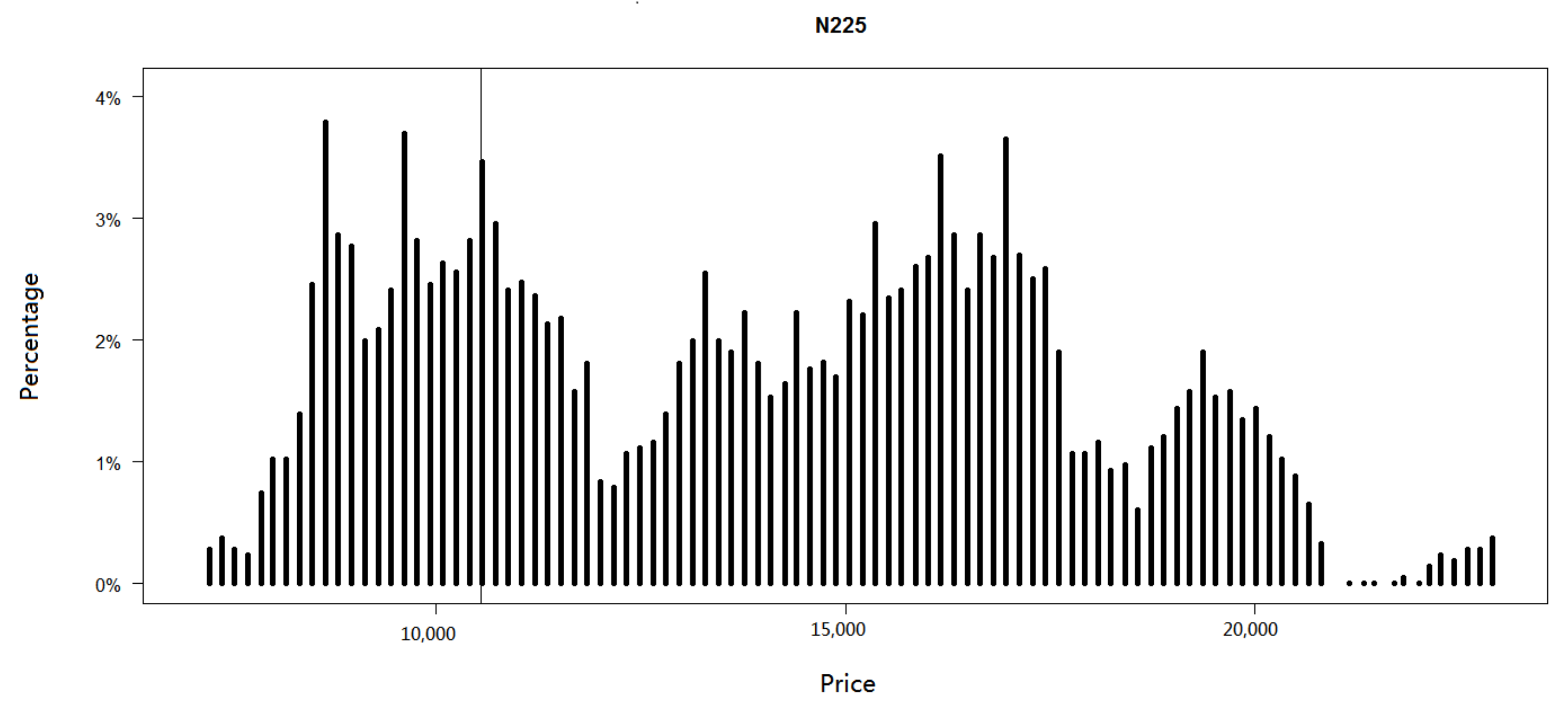
Figure 3 shows the price clustering during 2000–2017, in Nikkei 225 index. As the observations of the index are discrete, it is difficult to find that the dynamic hits a specific level precisely. Thus, we use a small interval around it to stand for the level. Sonnemans [
4] was interested in the number of times crossing a level. Besides that, we also consider the number of times reflecting from a level. The difference between “crossing” and “reflecting” is whether the previous price and the following price are on the same side of the level. In
Figure 3 we notice that the data exhibit price clustering on some scales. After signalling the skew level in
Figure 3 by a straight line, it is obvious that the skew level is one of the points at which the indices cluster. The total number of times hitting the skew level is 53. In addition to three times crossing the skew level from above and three times from below, there are also 17 times reflected by the skew level upward and 30 times downward. For convenience, we assume that, after hitting the skew level, whether the dynamic goes up or goes down can be described by a Bernoulli random variable with probability
p. The result of hypothesis test shows that the
p is rejected to be greater than or equal to 0.5. We can conclude that there is a big chance for Nikkei 225 index to move down when price series hits 10,543.1285, the process goes down in most cases once it touches the skew level.
We can notice that skew level does not need to be a very high level for the skew probability p to be smaller than 0.5, or to be at a very low level for the skew probability p to be bigger than 0.5. In fact, the skew levels we estimate in the empirical study are all lower than both the means and medians in the eight mature stock markets. However, the skew levels need to be the levels at which the dynamic crosses several times and has a preference for moving upward or downward. Overall, the skew probabilities p are different from 0.5 with statistical significance in the eight markets and the SGBM model does not underperform the standard GBM model, GBM-J model, and GBM-MRS model, proving that skew phenomenon exists broadly in stock markets all around the world.
4.2.2. Daily Data over One Year Period
After investigating the skew phenomenon over the whole sample period, we study the skew phenomenon over a one-year period. We obtain 61 subsamples of the CSI 300 index and 69 subsamples of the other eight stock indices. We estimate the parameters and check the skew phenomenon by testing the significance of the skew probability
p.
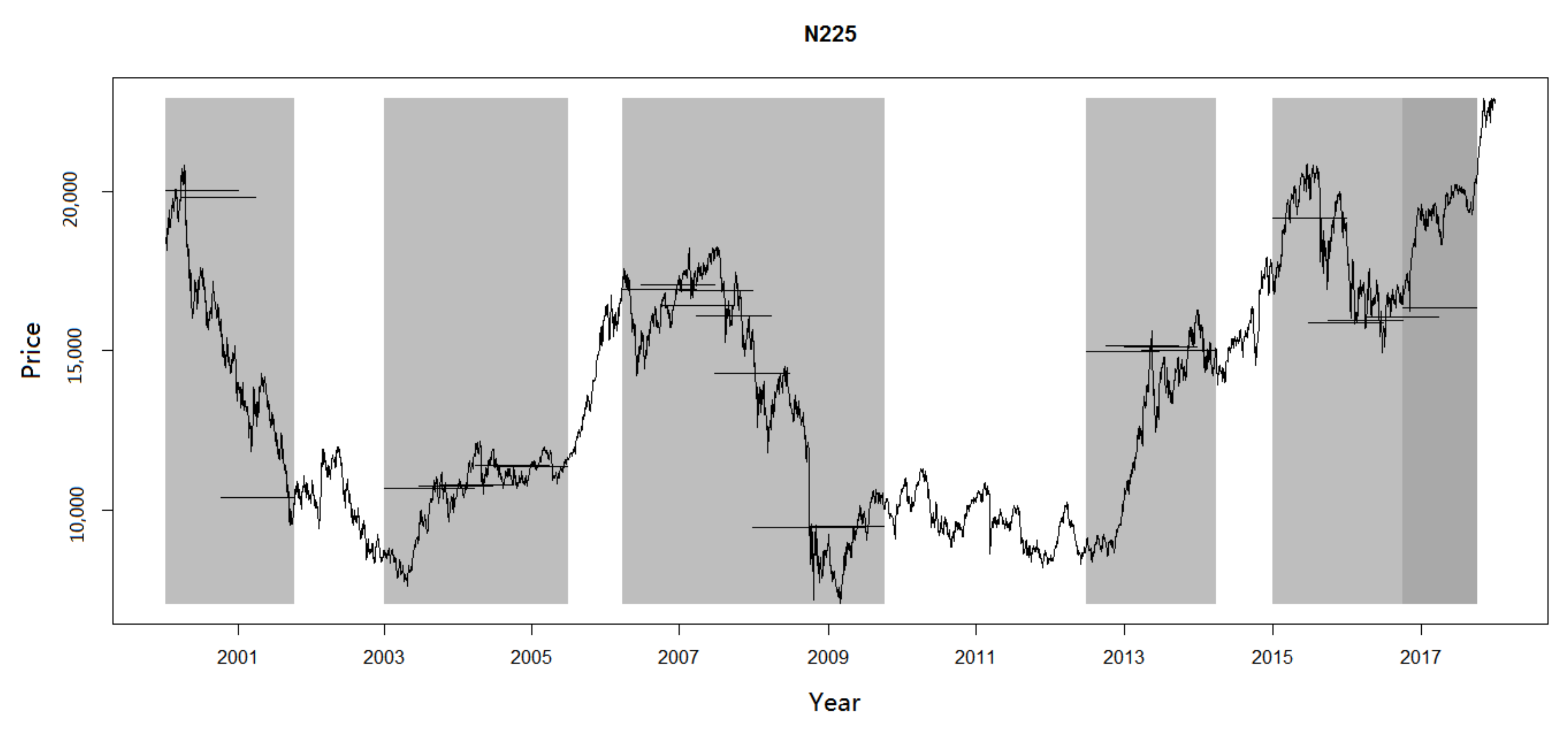
Table 4 and
Figure 4 show the results for the Nikkei 225 index. The detailed results of other indices are available upon request. For simplicity, we only show the results of subsamples whose skew probability
p is significantly different from 0.5 at the 10% level. Furthermore, we define the subsamples in which the skew phenomenon exists as skew subsamples.
There are 28 subsamples in which the skew phenomenon exists, accounting for about 40% of the total subsamples. Almost all the skew probabilities
are smaller than 0.5, indicating that these skew levels are resistance levels. The only subsample in which the
is bigger than 0.5 is from the fourth quarter of 2016 to the third quarter of 2017, with the corresponding skew level
of 16,336.7533. Similar to the weekly data, the skew level of each subsample can be seen as the scale at which the index clusters. Taking the subsample from the second quarter of 2003 to the first quarter of 2004 as an example,
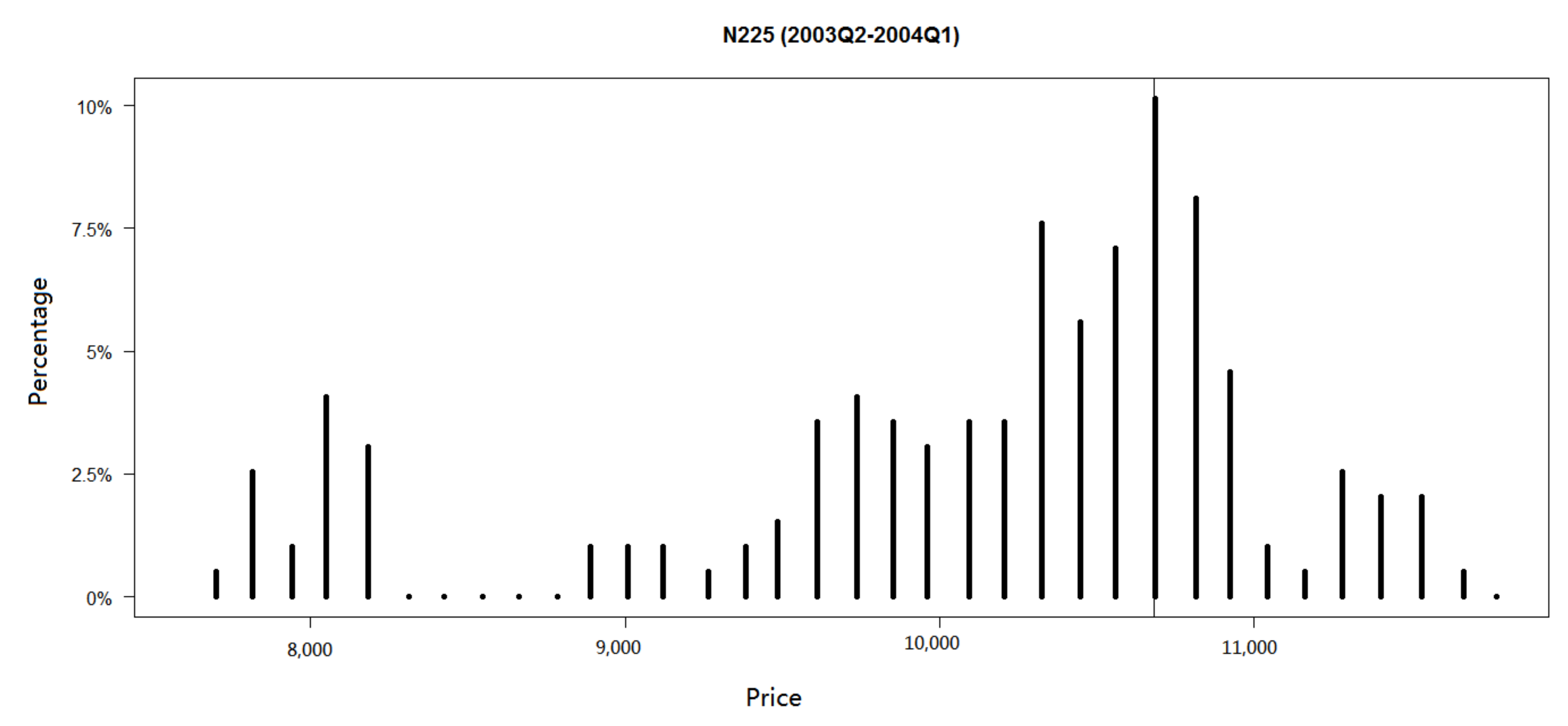
Figure 5 shows the conclusion clearly. The skew level we estimate is 10,742.4626. The price clustering phenomenon is also most foremost on the level. Therefore, our skew phenomenon and price clustering phenomenon can confirm with each other.
Table 5 shows the results of the comparison of
p-values and MSEs for each model. The third column of
Table 5 shows that the SGBM model clearly works better than the GBM model in most cases. In detail, the SGBM model wins 19 (67.86%) of the subsamples. The SGBM model also beats the GBM-J model, which is exhibited in the fifth column of
Table 5; the SGBM model wins 18 (64.29%) of the subsamples. However, the results indicate that there may not be a noticeable difference between the SGBM model and GBM-MRS model for fitting the data. In fact, the two models capture different characteristics of the dynamic. A combination of them may outperform all the models mentioned here, and this is one of our future works.
Table 6 summarizes the results of all the nine indices. It can be easily observed in
Table 6 that the SMI has the most skew subsamples among all the indices, followed by the Nikkei 225, while FTSE 100 has the fewest skew subsamples. Since the market behaviors of the different indices vary, it is reasonable that there are more skew subsamples in some markets while fewer in others. Although the numbers of skew subsamples in all markets are fewer than half of total subsamples, the percentages are still noticeable. Collectively, all the numbers in
Table 6 confirm that the skew phenomenon exists in subsamples of daily data over the period of a year. The skew probability
p is smaller than 0.5 in most skew subsamples, which means that there are more resistance levels than support levels; this is consistent with the investor psychology: as investors are more sensitive to decline of stock price, stock price will sometimes move downward with a bigger probability when hitting a specific level.
Although there are some markets in which the long-run skew phenomenon does not exist and the percentage of short-run skew subsamples is smaller than 50%, we should not ignore skew phenomenon when modeling asset prices. As a skew model can be reduced to a conventional model, the skew model can be used in both kinds of markets: the markets in which skew phenomenon exists and the markets in which skew phenomenon does not exist. For those markets in which skew phenomenon does not exist, the skew probability will simply be 0.5. However, the conventional model cannot capture skew features, and there will be bias if we use the conventional model to describe markets in which skew phenomenon is present. Thus, it is necessary to introduce the skew model and consider skew phenomenon when modeling asset dynamics.
5. Why the Skew Phenomenon Exists
As the market behavior is uncertain and confusing, many researchers try to find some reasons to explain different market phenomena. In this section, we try to explain why the skew phenomenon exists.
As shown in
Figure 3 and
Figure 5, the skew levels are consistent with the levels that the indices cluster at. Thus, the explanations for price clustering phenomenon can help us to understand the reason for the existence of skew phenomenon. Donaldson and Kim [
29] pointed out that the DJIA’s rise and fall was indeed restrained by “support” and “resistance” levels; these “support” and “resistance” levels are known as psychological barriers. The existence of such psychological barriers in different markets has been proven in many empirical studies. Sonnemans [
4] found that round numbers could act as price barriers for individual stocks. Westerhoff [
30] claimed the psychological barriers existed in foreign exchange market. Dowling et al. [
31] tested the presence of psychological barriers in WTI and Brent oil futures and found them present in the Brent prices but not in the WTI prices. Skew level is similar to, but not identical to, a psychological barrier. Psychological barriers exist in markets due to investor’s perceptions that the fundamental asset value is anchored to a nearest round number. The skew level can be viewed as a psychological barrier, although it is not a round number. Both ideas describe the unusual behavior of asset dynamics when hitting a special level.
According to the empirical results in
Table 1 and
Table 3, the skew probability
is smaller than 0.5 and the skew level is lower than the mean in each market. This may be not consistent with what we should expect. Usually, we expect a high skew level
a when
p is small. However, “running after rising and falling” phenomenon can often be seen in stock markets, which can be connected with herding behavior and positive feedback trading strategies.
Figure 2 illustrates that the skew phenomenon is closely related to extreme price movements. During periods of extreme market movements, the herd behavior is universal in the markets. Devenow and Welch [
32] conducted a literature review on the economics of rational herding in financial markets, demonstrating that irrational investors usually disregard their prior beliefs and follow other investors blindly. Chang et al. [
33] examined the investor behavior within different international markets (i.e., US, Hong Kong, Japan, South Korea, and Taiwan) and found significant evidence of herding in the two emerging markets (Korea and Taiwan). Perhaps the existence of a low skew level with a small skew probability can be explained by positive feedback trading. When there is a stock market downturn, many investors expect a high probability to keep moving downward. Therefore, a low skew level sometimes correspond to a small skew probability.
Additionally, skew phenomenon may be the result of government regulation. There is less government regulation in stock markets than interest markets or foreign exchange markets, but it does not mean that the government will leave the stock market alone. Stock prices are usually considered to react to external forces. Chen et al. [
34] proved that stock returns were exposed to systematic economic news, where many macroeconomic variables would systematically affect stock market returns. To stabilize the stock markets, a government may take some measures and give guidance to markets. Chang et al. [
33] proved that, in the emerging market, herd behavior could result due to a relatively high degree of government intervention. In June 2015, the Chinese stock market lost over
$3.2 trillion in value, Chinese government took unprecedented steps to prevent stocks from falling further. Authorities suspended initial public offerings (IPOs), limited bearish bets though CSI 300 Index Futures, and encouraged financial firms to buy more shares. The empirical results show that there was indeed skew phenomenon in 2015. When the stock index hits a specific level, the government will try to guide the trend of market, causing the occurrence of a skew level.
In the end, it is noteworthy that the Chinese market is the only one in which the p is not significantly different from 0.5. As an emerging market, the Chinese stock market started relatively late compared with other developed countries and is still immature. Therefore, it is not abnormal that the long-run skew phenomenon existing in the other mature capital markets can not be found in the Chinese market. Another reason may be that the interest rate in China is relatively high compared with other developed countries. The U.S. held a zero interest rate for seven years, and Europe and Japan have been holding zero or negative interest rate since 2016. However, the interest rate in China was between 4% and 6% during 2000–2018, which was much higher than the interest rates in other areas. Thus, it is inappropriate to ignore time value in the Chinese market. The trend of the dynamic is influenced by the interest rate more significantly in Chinese stock market than in other stock markets. Therefore, the long-run skew phenomenon is also affected by the interest rates, the skew level should be an oblique line rather than a straight line, as the sample period spanned 17 years. When we move to one-year sample period, there is still short-run skew phenomenon in the Chinese market.
6. Conclusions
This study tests for the skew phenomenon in nine international stock markets, based on the SGBM model, and find that skew phenomenon is common worldwide. For the weekly data over the whole sample period, the skew probabilities p are significantly different from 0.5 at the 5% level in eight markets. Furthermore, we test the goodness-of-fit of SGBM model and three commonly-used models using the likelihood ratio test. SGBM significantly outperforms other models in four markets: the Dutch market, British market, Swiss market and American market. In the Japanese market, the p-value of likelihood ratio test is 0.1, reaching a significant margin. The graph of historical prices show that the Nikkei 225 index goes downward at most times when it hits the skew level. Thus, we can consider the Japanese market to be a skew market as well. Overall, we can say that skew phenomenon exists broadly in the global stock markets.
For the daily data over the one-year period, there are 61 subsamples for the CSI 300 and 69 subsamples for the other indices. There are 15, 19, 14, 20, 13, 23, 27, 29, and 20 skew subsamples in each market, respectively. The Swiss market has the most skew subsamples while the British market has the fewest skew subsamples. The proportion of skew subsamples, out of the total subsamples, is noticeable. The skew probability is smaller than 0.5 in most skew subsamples, indicating that there are more resistance levels than support levels.
In addition, we attempt to explain why the skew phenomenon exists in stock markets. As the skew levels can be viewed as the barriers at which the indices cluster, psychological barriers of stock price may be one of the reasons. Herding behavior and positive feedback trading strategy may provide another reason, as a skew probability smaller than 0.5 corresponds to a skew level lower than the sample mean in the empirical test. Government regulation can cause the occurrence of skew phenomenon as well.
For the above explanations of the skew phenomenon, an important investment implication is that, besides the characteristics such as jump and regime switching, the skew phenomenon is also noteworthy. In the financial markets with skew phenomenon, the value of skew levels and skew probabilities are great assistance to investors in judging the indices trends. For the government, testing the skew phenomenon is a method to examine whether the intervention is effective. The value of skew levels and skew probabilities are the evidence of the effect of intervention.
Author Contributions
All authors have read and agree to the published version of the manuscript. Conceptualization, Y.B. and Z.G.; methodology, Y.B.; software, Y.B.; formal analysis, Y.B.; investigation, Z.G.; data curation, Z.G.; writing—original draft preparation, Z.G.; writing—review and editing, Y.B. and Z.G.
Funding
This research was funded by National Natural Science Foundation of China grant number No. 71532001 and No. 11631004.
Acknowledgments
The authors are indebted to the participants in the seminar on Stochastic Processes and Financial Engineering at Nankai University for their valuable comments and discussions.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Bayesian Estimation of Skew Brownian Motion Model
We introduce the parameter estimation method in this appendix. If we assume
to be the set of all parameters
and the joint prior density function of
to be
, the posterior density function of the model is:
In Bayesian inference, the inference which we want to conduct can be evaluated from the expectation of a certain function
:
To avoid the complexity of multiple integrals, the Monte Carlo method is adopted in this paper. Let
be the samples generated from the posterior density function
; then, Equation (
A2) is approximated by:
However, due to the difficulty in generating the samples
directly, we employ the Gibbs sampler, which provides an exercisable way to generate these samples. In fact, the Gibbs sampler always uses the full set of univariate conditionals to define the iteration. In our case, instead of generating
from
by
directly, we get the
with the conditional probability densities as follows:
To make the Gibbs sampler computationally efficient, the priors are chosen such that the conditional posterior distributions are easy to simulate. According to convention, conjugate priors are used to obtain simple analytical forms. For the resulting posterior distributions, see Chen and Li [
35].
For each parameter in SGBM model, the estimation is presented as follows:
Appendix A.1. Estimation of the Instantaneous Return
Conditional on
,
p, and
a, the proper prior distribution of
should be a normal distribution
. With the likelihood function in Equation (10), we get the proposal distribution of
:
where
Appendix A.2. Estimation of the Volatility
Conditional on
,
p and
a, the posterior distribution of
is
. Then, the proposal distribution of
is:
where
Appendix A.3. Estimation of the Skew Level
Conditional on
,
, and
p, we can hardly find the conjugate priors of
a to be its prior distribution. Normally, we employ the Griddy–Gibbs sampler according to Ritter and Tanner [
36]. Assume that
a is uniform on a predetermined interval
by observation. Conditional on
,
, and
p, the density of
a is developed:
We get the cumulative density
through the
n grid points
and right part of Equation (
A7). Then, together with a uniform random number
and preselected values
,
and the new grid points (i.e., used in the next iteration) are obtained as
and
.
Appendix A.4. Estimation of the Skew Probability
Analogous to the estimation of the skew level, we assume
p to be uniform on
and the grid points to be
. For each
, conditional on
,
, and
a, and from the transforms in Equations (
5) and (
7), we calculate density of
p as:
Then, we get the cumulative density . The other procedure is the same as what is done to estimate the skew level. Finally, we demonstrate that equals and the new grid points are .
Appendix A.5. Simulations
To evaluate the performance of our SGBM model and estimation approach, we conduct a set of simulations. The simulation results are presented in the following.
We set the parameter values at
,
,
, and
, which are the same as the estimates that we obtain using the price series of Nikkei 225 index, as analyzed in
Section 4. For the skew model, the
is generated as specified in Equation (
1) for the samples of size 1000. As the skew phenomenon is set to exist in the simulated sample, the parameters are expected to be biased if the presence of skew phenomenon is ignored. For the simulated sample, we compare the estimates of SGBM model using the Bayesian approach and the estimates of conventional GBM model using maximum likelihood estimation. the absolute relative error (ARE) of the estimates, between the calculated value and experimental value, is defined as
where
is used as a generic notation to denote each parameter in the model. The simulation results are presented in
Table A1.
Table A1.
Simulation Results.
Table A1.
Simulation Results.
| | | | a | p | p-Value
(Likelihood Ratio Test) | p-Value
(Significance Test of p) |
|---|
| SGBM | 0.0593 | 0.2109 | 10,367.3596 | 0.3034 | 0.04 | 0.0000 |
| | (0.0063) | (0.0049) | (83.2747) | (0.0370) | | |
| ARE | 11.75% | 1.26% | 1.67% | 1.65% | | |
| GBM | 0.0227 | 0.2152 | | | | |
| ARE | 66.22% | 0.75% | | | | |
For the simulated sample, the parameters are estimated to be , , , and under the SGBM assumption, and the parameters are estimated to be and under the GBM assumption. We can see that the absolute relative error reached as high as 66.22% between the real value of and estimated value of under the GBM model, while the absolute relative error is much smaller under the SGBM assumption. As for , the ARE is small for both models. It turns out to be true that skew phenomenon, if ignored, can yield a substantial bias in the estimates of parameters.
Finally, we consider testing for the presence of skew phenomenon on the basis of the likelihood ratio test and significance test of skew probability
p. As shown in
Table A1, the skew probability is significantly different from 0.5, thus there is skew phenomenon present in the simulated sample. The
p-value of the likelihood ratio test shows that the SGBM model outperforms the GBM model. We can see that skew phenomenon plays an important role in the dynamics of stock prices, such that it is essential to take into consideration when modeling stock prices.
References
- Black, F.; Scholes, M. The pricing of options and corporate liabilities. J. Political Econ. 1973, 81, 637–654. [Google Scholar] [CrossRef]
- Merton, R.C. Option pricing when underlying stock returns are discontinuous. J. Financ. Econ. 1976, 3, 125–144. [Google Scholar] [CrossRef]
- Hamilton, J.D. A new approach to the economic analysis of nonstationary time series and the business cycle. Econometrica 1989, 57, 357–384. [Google Scholar] [CrossRef]
- Sonnemans, J. Price clustering and natural resistance points in the dutch stock market: A natural experiment. Eur. Econ. Rev. 2006, 50, 1937–1950. [Google Scholar] [CrossRef]
- Brown, P.; Mitchell, J. Culture and stock price clustering: Evidence from The Peoples’ Republic of China. Pac. Basin Financ. J. 2008, 16, 95–120. [Google Scholar] [CrossRef]
- Hu, B.; Jiang, C.; McInish, T.; Zhou, H. Price clustering on the shanghai stock exchange. Appl. Econ. 2017, 49, 2766–2778. [Google Scholar] [CrossRef]
- Aşçioǧlu, A.; Comerton-Forde, C.; McInish, T.H. Price clustering on the Tokyo stock exchange. Financ. Rev. 2007, 42, 289–301. [Google Scholar] [CrossRef]
- Itô, K.; Mckean, H.P. Diffusion Processes and Their Sample Paths; Springer: Berlin/Heidelberg, Germany, 1965. [Google Scholar]
- Walsh, J.B. A diffusion with a discontinuous local time. Astérisque 1978, 52, 37–45. [Google Scholar]
- Le Gall, J.F. One-dimensional stochastic differential equations involving the local times of the unknown process. In Stochastic Analysis and Applications; Springer: Berlin/Heidelberg, Germany, 1984; pp. 51–82. [Google Scholar]
- Barlow, M.T.; Pitman, J.; Yor, M. On Walsh’s Brownian motions. Sémin. Probab Strasbg. 1989, 23, 275–293. [Google Scholar]
- Ouknine, Y. Le “skew-Brownian motion” et les processus qui en dérivent. Theory Probab. Appl. 1990, 35, 173–179. [Google Scholar]
- Lejay, A.; Martinez, M. A scheme for simulating one-dimensional diffusion processes with discontinuous coefficients. Ann. Appl. Probab. 2006, 16, 107–139. [Google Scholar] [CrossRef]
- Ramirez, J.M.; Thomann, E.A.; Waymire, E.C.; Chastanet, J.; Wood, B.D. A note on the theoretical foundations of particle tracking methods in heterogeneous porous media. Water Resour. Res. 2008, 44, 186–192. [Google Scholar] [CrossRef]
- Ramirez, J.M. Multi-skewed Brownian motion and diffusion in layered media. Proc. Am. Math. Soc. 2011, 139, 3739–3752. [Google Scholar] [CrossRef]
- Appuhamillage, T.; Sheldon, D. Ranked excursion heights and first passage time of skew Brownian motion. J. Appl. Probab. 2010, 49, 685–696. [Google Scholar] [CrossRef]
- Appuhamillage, T.; Bokil, V.; Thomann, E.; Waymire, E.; Wood, B. Occupation and local times for skew Brownian motion with applications to dispersion across an interface. Ann. Appl. Probab. 2011, 21, 183–214. [Google Scholar] [CrossRef]
- Atar, R.; Budhiraja, A. On the multi-dimensional skew Brownian motion. Stoch. Process. Appl. 2015, 125, 1911–1925. [Google Scholar] [CrossRef]
- Song, S.; Wang, S.; Wang, Y. On some properties of reflected skew Brownian motions and applications to dispersion in heterogeneous media. Phys. A 2016, 456, 90–105. [Google Scholar] [CrossRef]
- Bossy, M.; Champagnat, N.; Maire, S.; Talay, D. Probabilistic interpretation and random walk on spheres algorithms for the Poisson-Boltzmann equation in molecular dynamics. Math. Model. Numer. Anal. 2010, 44, 997–1048. [Google Scholar] [CrossRef]
- Cantrell, R.S.; Cosner, C. Diffusion models for population dynamics incorporating individual behavior at boundaries: applications to refuge design. Theor. Popul. Biol. 1999, 55, 189. [Google Scholar] [CrossRef]
- Min, A.; Reeve, J.D.; Xiao, M.; Xu, D. Identification of diffusion coefficient in nonhomogeneous landscapes. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2012; pp. 290–297. [Google Scholar]
- Barahona, M.; Rifo, L.; Sepúlveda, M.; Torres, S. A simulation-based study on Bayesian estimators for the skew Brownian motion. Entropy 2016, 18, 241. [Google Scholar] [CrossRef]
- Corns, T.R.A.; Satchell, S.E. Skew Brownian motion and pricing European options. Eur. J. Financ. 2007, 13, 523–544. [Google Scholar] [CrossRef]
- Gairat, A.; Shcherbakov, V. Density of skew Brownian motion and its functionals with application in finance. Math. Financ. 2017, 27, 1069–1088. [Google Scholar] [CrossRef]
- Rossello, D. Arbitrage in skew Brownian motion models. Insur. Math. Econ. 2012, 50, 50–56. [Google Scholar] [CrossRef]
- Zhu, S.P.; He, X.J. A new closed-form formula for pricing european options under a skew Brownian motion. Eur. J. Financ. 2017, 24, 1–13. [Google Scholar] [CrossRef]
- Harrison, J.M.; Shepp, L.A. On skew Brownian motion. Ann. Probab. 1981, 9, 309–313. [Google Scholar] [CrossRef]
- Donaldson, R.G.; Kim, H.Y. Price barriers in the dow jones industrial average. J. Financ. Quant. Anal. 1993, 28, 313–330. [Google Scholar] [CrossRef]
- Westerhoff, F. Anchoring and psychological barriers in foreign exchange markets. J. Behav. Financ. 2003, 4, 65–70. [Google Scholar] [CrossRef]
- Dowling, M.; Cummins, M.; Lucey, B.M. Psychological barriers in oil futures markets. Energy Econ. 2016, 53, 293–304. [Google Scholar] [CrossRef]
- Devenow, A.; Welch, I. Rational herding in financial economics. Eur. Econ. Rev. 1996, 40, 603–615. [Google Scholar] [CrossRef]
- Chang, E.C.; Cheng, J.W.; Khorana, A. An examination of herd behavior in equity markets: An international perspective. J. Bank. Financ. 2000, 24, 1651–1679. [Google Scholar] [CrossRef]
- Chen, N.F.; Roll, R.; Ross, S.A. Economic forces and the stock market. J. Bus. 1986, 59, 383–403. [Google Scholar] [CrossRef]
- Chen, R.; Li, T.H. Blind restoration of linearly degraded discrete signals by gibbs sampling. IEEE Trans. Signal Process. 1995, 43, 2410–2413. [Google Scholar] [CrossRef]
- Ritter, C.; Tanner, M.A. Facilitating the Gibbs sampler: The Gibbs stopper and the griddy-Gibbs sampler. J. Am. Stat. Assoc. 1992, 87, 861–868. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




