3.1. Automatic Data Extraction
To better understand the approach used in extracting the data, the Sakai system’s data were used, because the Sakai LMS is specific when the database is brought to the fore. The main reason is that Sakai is an open-source solution, meaning that many developers are continually developing the system and adding more functionalities to it. The module of data management was used to enable natural expansion. That is, whenever the developer wants to add some functionality to the existing Sakai version, he or she must develop adequate PHP pages and tables for the database model that will be used to manage data for the new set of functionalities. This method of adding functions and new modules to the Sakai model complicates how data can be extracted in the future. Bainbridge et al. [
21] and Jayaprakash et al. [
22] give directions on how to extract data for EDM analysis that is based on a series of queries defined in the MySQL database. These two groups of researchers propose two methods for extracting data in the Sakai database structure. The first approach is to monitor the activity log that the Sakai system uses to track the activity of each student. However, there is a challenge that comes with this approach: Sakai is not able to continuously track usage because it is a web-based system that functions on an HTTP request or reply model. Under this model, it is even difficult to determine the time spent on an activity, since activities are listed only when a user performs a click action on a web link.
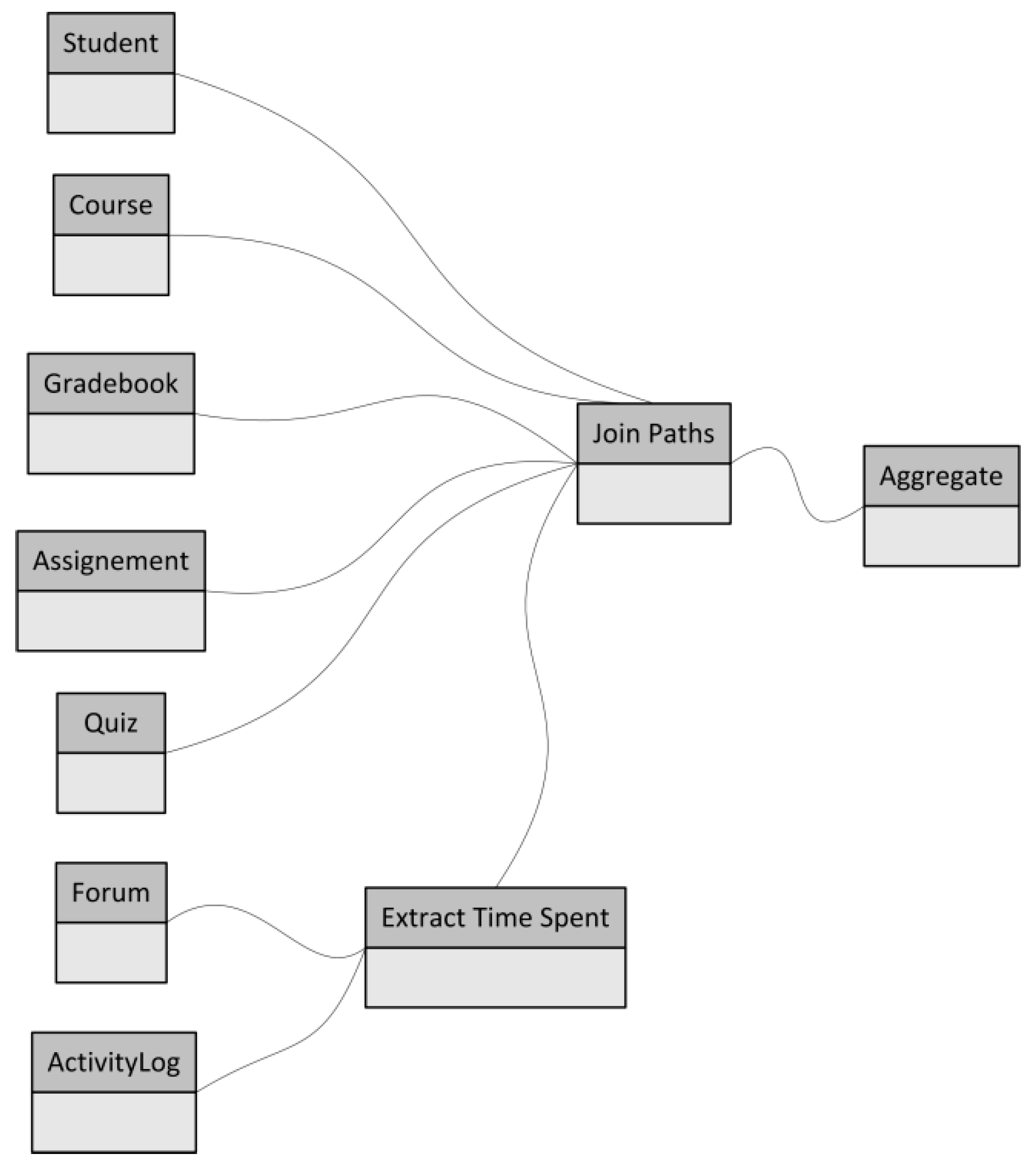
The second approach to extracting data is using a set of tables that are created for each individual module. The data in these tables keep track of students’ significant activities regarding that particular module. For example, when a student performs an assignment, the module in question will keep track of when the student reads the assignment, submits it, and so forth. Nonetheless, these data provide little information on each action a student performs on the Sakai platform. As a way of getting better information, I will utilise data from both approaches, as combining these two types of data is a better foundation for EDM analysis, as highlighted in
Figure 1.
Furthermore,
Table 1 shows a stream of automatic extraction and aggregation of Sakai data for EDM analyses. Preparing data as described in the table, I will first extract the data about students, courses, and grades achieved in every course. Secondly, the data from various modules will be extracted, that is, forum, assignment, and quiz modules. These data define the basic user model to support student performance in UNIR’s methodology framework.
Given that Sakai is an LMS, it faces the common issues of such systems. For instance, the system uses resources from many alternative sources. In addition, Sakai is an open-source system, meaning that the system has no specific developer, and the information sources may use different representations and ways of encoding the data. Vieira, Parsons, and Byrd (2018) suggest that syntactic interoperability can be achieved when compatible forms of encoding and access protocols are used to allow information systems to communicate.
For this analysis, the data were extracted from the standard Sakai module that was developed over a period of time. These data were part of an integrated production issuer of Sakai, which helped to standardise the data and, as a result, avoid data heterogeneity. No system is ever problem-free, and as such, data inconsistency is a common occurrence, but then again, inconsistency is common in any open-source system. However, Sakai happens to be stable and consistent with the data it uses. For example, the time values are always in a stamp format, which simplifies the pre-processing steps. Moreover, this action also enables more comfortable and faster manipulation of the data by subtracting the beginning time from the end time of each activity. The main reason for why most systems fail or generate errors is the improper use of these systems. For instance, when a student does not complete the assignment and upload it and then closes the browser, the assignment will be regarded as still open and the end time will be set to zero. The same will happen when the quiz or assignment page is left open by the educator. In the event that such cases exist in the primary data, they will be eliminated, and I will assume that the assignment was never opened.
On the other hand, a system that has many active users often suffers from data redundancy. For Sakai, the most common redundancy is the duplication of courses or user accounts. I recommend a more centralised approach in the generation of courses and user accounts as a way of dealing with this problem. That is, the system administrator will create a new user account only on request of the educator. Moreover, it is the educators’ responsibility to check for duplications of user details in the system. This process will ensure that no duplications occur in the system. As for the forum module, the main challenge is extracting the data on time spent by users in a particular online session. As a student may spend an unspecified amount of time on a given forum without necessarily giving feedback to the system, it becomes difficult to determine whether the user is active in the forum. In case this happens, I recommend the use of an activity log that will track user activity while the user is online. For instance, it will track every single click the user makes on a link in the system.
Sakai provides a module name as one of the metadata, which makes it easy to track a student’s activities on a given forum. For instance, it is easy to determine the time that a student spends on the forum by monitoring the time between the first and the last click. In the event that a student makes the last click in a forum and is inactive for a prolonged period of time, the system will take the average time between the two clicks in a forum context for all users. The above incident may be caused by various reasons. For instance, a student may not log out of the system properly. In most cases, students merely close the web browser and move on to other activities. Regrettably, in the event that such an incident occurs, the system is unable to get any meaningful data because the user did not leave any feedback when the activity ended. I designed a specific application that integrates the data into a stream and uses these data for the forum module and activity log to calculate the amount of time spent by students on each course forum. The extracted information is grouped based on the students’ course levels.
I used the data about students’ cognitive styles that were gathered from a questionnaire that was administered during the survey on Sakai; this self-report MBTI -Myers–Briggs Type Indicator- questionnaire is the best tool to analyse students’ profiles. The MBTI has 100 forced-choice items that are part of the four bipolar scales, that is, EI (extraversion–introversion), TF (thinking–feeling), SN (sensing–intuition), and JP (judging–perception). Combining the four dimensions results in 16 different types of cognitive functioning. For instance, introverts lean towards internal cues, whereas extroverts lean towards external cues, because of the difference in focusing their psychical energy. They perform different intellectual tasks differently. Further, the sensing mode type tends to perceive data obtained from one of the five senses, as opposed to the intuitive type, who is inclined to lean on inner processes, perceiving the bigger picture, which enables people of this type to concentrate and reveal the unseen implications and possibilities of the matter at hand.
According to Chin et al. [
23], there are two decision-making systems that one must use when assessing the validity of perception, that is, thinking and feeling. There are individual differences in preference for the quality of the environment in which one learns. Moreover, there are two categories of the subject matter: (a) Perceivers, who need to keep options open and are less concerned with deadlines, and (b) judgers, who structure and order in a manner that promotes a predictable surrounding, in which decisions are made fast. The MBTI is an instrument that conceptualises, measures, and evaluates ideas, which I believe will be useful in the case of distance online learning. When the MBTI was put to a reliability test, it emerged that the split-half coefficient goes from 0.56 to 0.89, and the test-retest reliability shows that the results are relatively stable. The records on students will be extended with the attributes derived from their cognitive style.
3.2. Prediction of Students’ Success
This section introduces a classification model that predicts whether students would display excellent performance, that is, whether they attain the highest grades in a given course. The input data for this prediction module are the data used to access a student’s behaviour on the e-learning resources that were highlighted earlier in this paper, namely, forum discussions, posts, quizzes, and assignments. The data set in this category will contain 360 instances. I will first prepare the data by grouping them into main distinct categories, both social or mathematical; then, the normalisation features will be incorporated, and issues with any missing information resolved. The model used to predict students’ performance will utilise binary attributes that separate students with the highest grades from the rest. These categories of students will be assigned a binary value of 1, while the rest will be assigned a binary value of 0. The goal of the model is to predict whether a student will obtain an excellent result based on the input data.
For this model to work, it must identify the students that are performing well on a course in the early stages of teaching. The people who benefit from this model include (a) teachers, who can identify students that will work and are cooperative; (b) students, who are able to see if more efforts are needed for them to achieve better results; and (c) corporate executives and employers, who are able to identify students with top skills early so that that they could be nurtured and absorbed into the job market.
The following algorithms for classification, which have all been proven to yield good results in EDM, were utilised in the paper:
AdaBoost, abbreviated as Boost;
naïve Bayes;
linear discriminant analysis (LDA);
J4.8;
logistic regression;
neural net (NN); and
random forests, abbreviated as Forests.
The results of the algorithms are shown in percentages. Given that the model will be used in the future, a 10-fold cross-validation technique will be used on future data. The technique is useful for preventing the generation of an overtrained model and for assessing the model’s generalisation ability. That is, using stratified sampling, the cross-validation will keep similar class distributions in each fold. In addition, the model also measured other evaluation measures, such as the LIFT ratio and the area under curve (AUC) ratio. In this case, the AUC estimate is interpreted as the probability that the classifier will assign a higher score to a randomly chosen positive example than to a randomly chosen negative example. On the other hand, the LIFT ratio measures the degree to which predictions of classification models are better than randomly generated predictions. Romero-Zaldivar et al. [
24] define LIFT as the ratio of true positives to total positives that result from the classification process compared with the fraction of true positives in the general population. Both measures will be used in the model to complement the evaluation based on accuracy. This approach is necessary because this study deals with imbalanced data [
24].
In dealing with accuracy, there are apparent errors that are generally overlooked; for instance, the classifier’s inability to predict all of the classes singularly when it is focused on only one class. The testing of the model was done using the RapidMiner data mining platform, and default parameters and random seeds were utilised; the results are shown in
Table 2.
From the above results, several algorithms show excellent performance in generating desirable classification models. For instance, AdaBoost, Random Forests, and Neural Net all have results that are comparable with respect to accuracy. Even though Random Forests seems to be the most useful one in terms of accuracy, the AUC evaluation suggests that it is not the best algorithm and, therefore, should be abandoned because it does not have the ability to predict both excellent and other students, which results in lower AUC performance. On the other hand, simple algorithms such as logistic regression, naïve Bayes, and LDA mostly performed poorly. Although LDA and J4.8 seemed to have better accuracy, the performance of the two algorithms is close to the random performance, and the accuracy is mostly attributable to class imbalance. The results also show that the best way to predict excellent students is to use nonlinear models. Generally, both AdaBoost and Neural Net showed good results, rendering quality models that can be used further. Given the results of the cross-validation, the acceptable, successful prediction was nine out of 10 students.
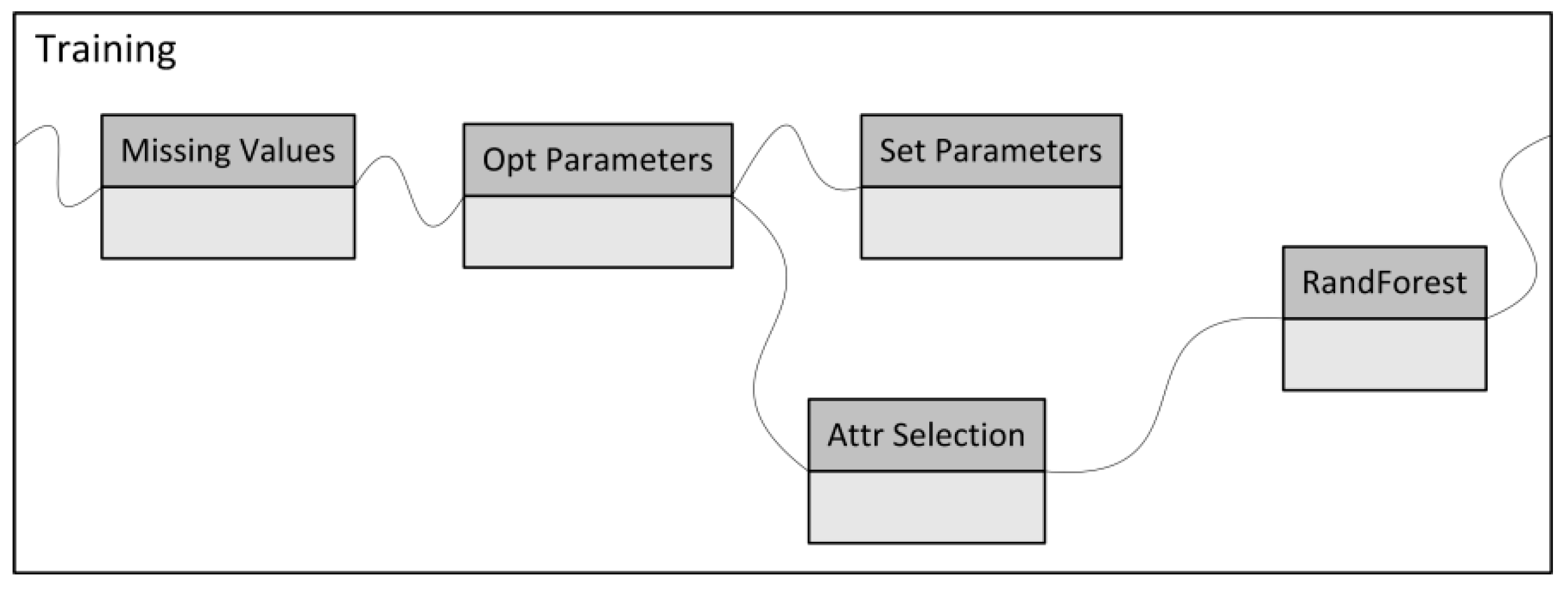
The next step after selecting the most promising algorithms is to improve the performance, as measured by the AUC through conducting different pre-processing and parameter optimisation steps. The setup of the pre-processing is shown in
Figure 2.
The results of applying these steps are shown in
Table 3.
In order to achieve the above result, I followed several steps; that is, for pre-processing, I first averaged out the missing values present in the data—namely, total_time_assignment or total_time_quiz attributes—to better fit the problem at hand. This will improve all three algorithms and should be considered when applying these algorithms. Next, I seek to minimise the noise level in the model by conducting an attribute selection test and removing attributes that bring about redundancy. Elimination of noise will be done manually, and it will remove one attribute at a time until the performance improves. Although after pre-processing the general performance of the model improved, I could not settle on one specific algorithm to use in the model; therefore, I recommend using all three for practical applications.
3.3. Grouping Students
This section will first define clustering models that would detect groupings of students with respect to their cognitive styles and general performance as a way of better understanding and adopting the learning material. In this regard, the students will be described based on their cognitive styles and the scores they achieve on a given course. The data in this model are classified based on the courses, and as such, the individual student profiles can be considered for each course separately. This model enables one to see the profiles of all students, to see which students are having a hard time, and to assess whether students performed poorly in the past. With this information, student mentors should adjust accordingly to enable poor-performing groups to improve on their course performance. To achieve an active clustering, the K-means clustering algorithm was used to group the data according to different categories, and the result is shown in
Figure 3,
Figure 4,
Figure 5 and
Figure 6. For each course, several student profiles are found based on similarities in cognitive style between students.
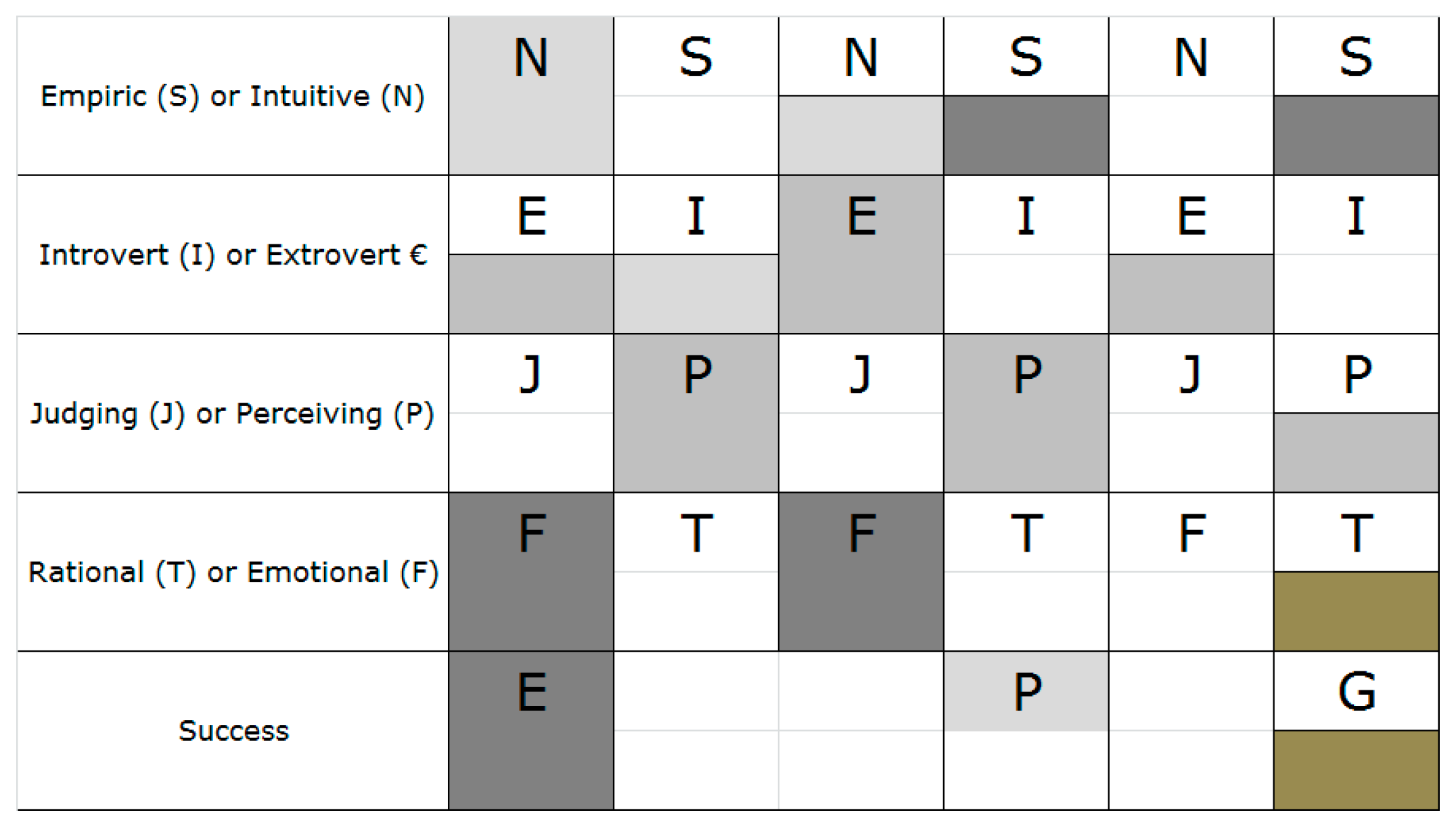
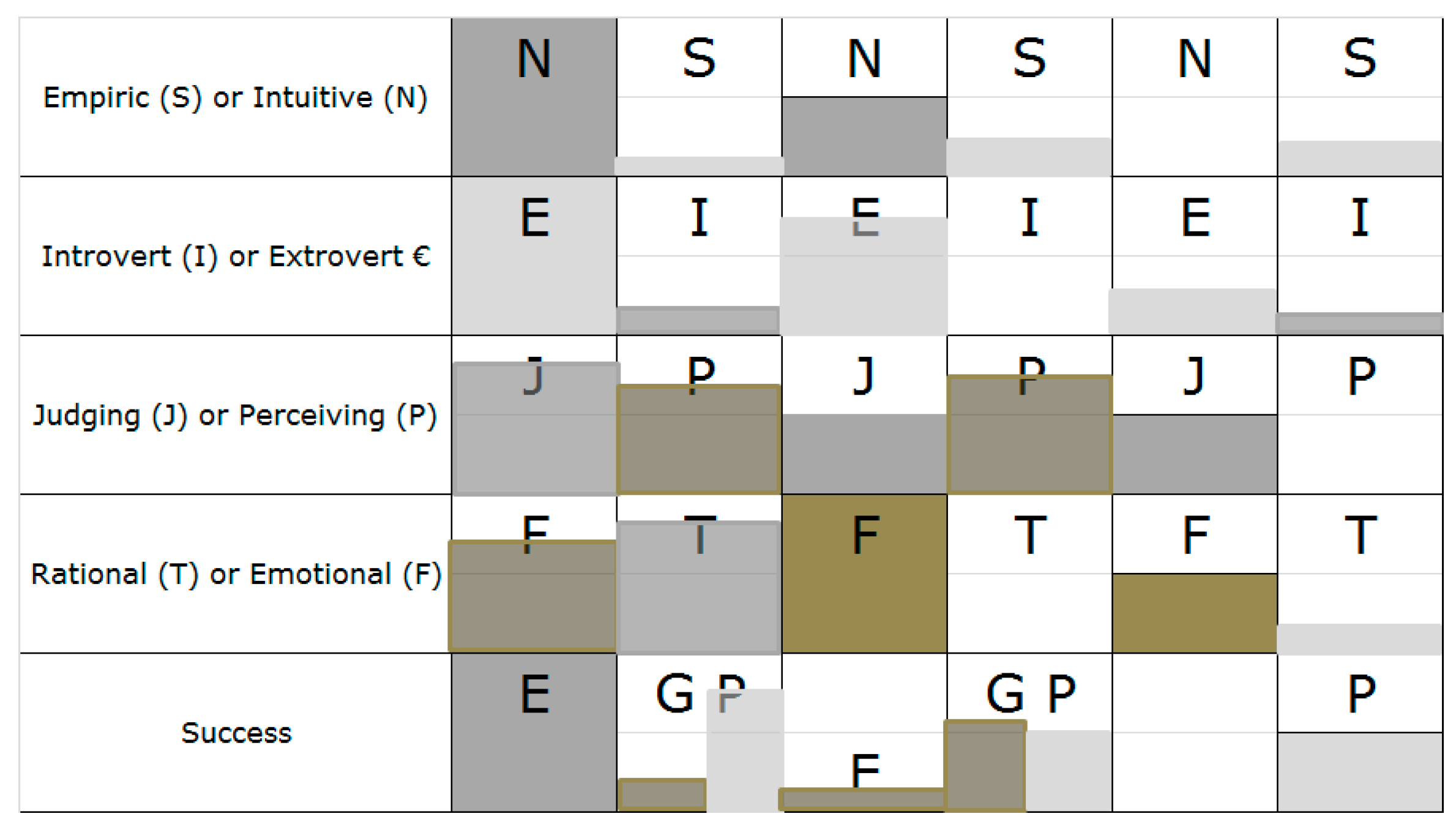
Figure 3 and
Figure 4 present different groups of students in different courses. Each row represents different cognitive properties, as discussed earlier in
Section 3.1, and each column stands for one profile that is a cluster of students with similar cognitive properties. In the figures, the term success represents the success of students of a particular profile, in which P means poor performance, G stands for good performance, and E indicates excellent performance. In this case, I used a three-level categorisation of success instead of a two-level one to achieve a more detailed description of the clusters found. In principle, any number of success levels could be used; however, empirically, the model seeks to detect the highest clarity of cluster interpretations by using three levels. The same is true for the clusters, which were also set to three.
From
Figure 3, for example, students with the profile SEFJ had excellent results, while other profiles have a moderate to good performance. This implies that students with other profiles than SEFJ had trouble delivering the best performance, which may be attributed to several factors.
Nonetheless, since the model has identified the cognitive profiles of these students, it is now the duty of the instructor to formulate course materials that fit the needs of the target groups; for example, from the analysis, the mathematics course is more suitable to empiric and judging cognitive styles. Therefore, the teacher could adopt materials that oppose the cognitive styles; that is, they could try introducing the intuitive and perceiver cognitive style, which might be beneficial to the other cluster of students [
25,
26,
27]. Moreover, the instructor could also adopt a different approach to administering the examination. For instance, they could opt to seek further expertise from a psychologist on how to deal with introverts who have difficulties expressing themselves verbally.
It is expected that different courses will fit different profiles, which is primarily due to preference, different materials, and different areas of research offered by the instructors.
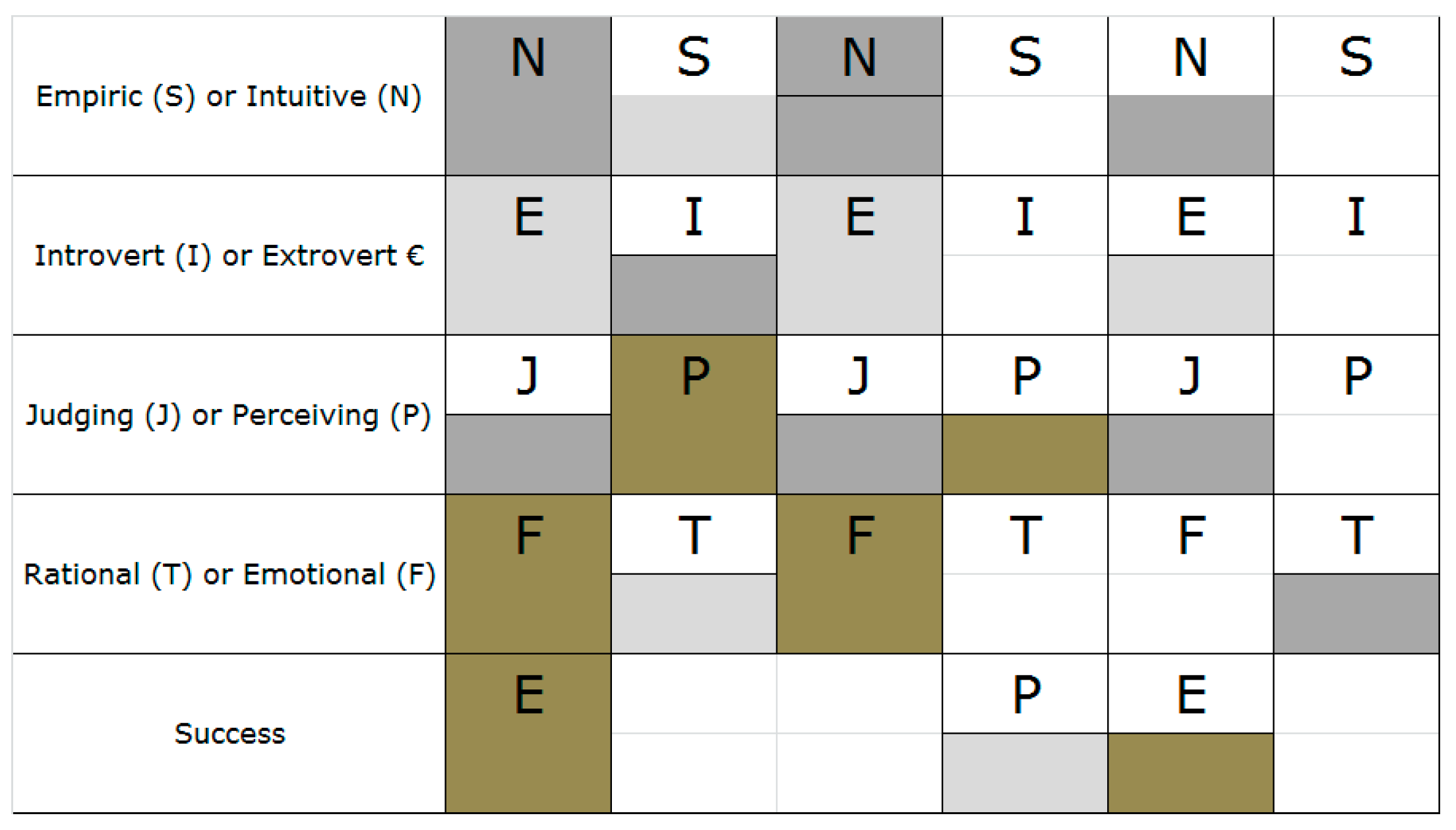
Figure 4 shows profiles for the course on competences, in which the profiles of excellent and poor were almost similar and the profile of good had different cognitive styles. What also stood out from these results is that the introverts were clustered in the excellent group, implying that they understood this course material better.
There are occasions in which it is impossible to isolate the complete cognitive profile of successful students, as shown in
Figure 5. Nonetheless, partial information could be detected. For instance, taking a closer look at the first two cognitive attributes, the empiric and introvert students are only part of the first group of students in the first column. The two types of students all turned out to be excellent by the end of the course.
As for the open education course in
Figure 6, the first cluster contained students with excellent and poor success, whereas the second cluster contained students with good and poor success. The two clusters overlapped in cognitive styles. This confusion was resolved in the third cluster, in which it was determined that students with poor success are empiric and judging, as opposed to in mathematics, in which deductive thinking and reasoning are applied. As a result, I recommend that these students should put more effort into developing a sense of language by listening to conversations between native speakers or by reading learning resources written by native speakers. Alternatively, perceiving and intuitive students have already developed a sense of language, and as a result, they do not need additional activities.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}