Developing a Digital Artifact for the Sustainable Presentation of Marketing Research Results


Abstract
1. Introduction
2. Smart Content Marketing
3. Text Mining Methods
3.1. Data Collection
3.2. Data Analysis
3.2.1. Linguistic Pre-Processing
Example:Pippa O’Connor 30 December 2016YesssOur winter sales on pocobypippa.com and pippacollection.com are ending tomorrow at midnight
They are also happening in the pop-up shop in Dundrum Town Centre too
(From Pippa O’Connor on 30 December 2016)





Text Normalization: Yes Our winter sales on pocobypippa.com and pippacollection.com are ending tomorrow at midnight They are also happening in the pop-up shop in Dundrum Town Centre too
NLTK Tokenization:>>> nltk.word_tokenize(text)>>> ['Yes', 'Our', 'winter', 'sales', 'on', 'pocobypippa.com', 'and', 'pippacollection.com', 'are', 'ending', 'tomorrow', 'at', 'midnight', 'They', 'are', 'also', 'happening', 'in', 'the', 'pop', 'up', 'shop', 'in', 'Dundrum', 'Town', 'Centre', 'too']
NLTK POS:>>> nltk.pos_tag (nltk.word_tokenize (text))>>> [('Yes', 'VB'), ('Our', 'PRP$'), ('winter', 'NN'), ('sales', 'NNS'), ('on', 'IN'), ('pocobypippa.com', 'NN'), ('and', 'CC'), ('pippacollection.com', 'NN'), ('are', 'VBP'), ('ending', 'VBG'), ('tomorrow', 'NN'), ('at', 'IN'), ('midnight', 'NN'), ('They', 'PRP'), ('are', 'VBP'), ('also', 'RB'), ('happening', 'VBG'), ('in', 'IN'), ('the', 'DT'), ('pop', 'NN'), ('up', 'RP'), ('shop', 'NN'), ('in', 'IN'), ('Dundrum', 'NNP'), ('Town', 'NNP'), ('Centre', 'NNP'), ('too', 'RB')]
NLTK NER:>>> nltk.chunk.ne_chunk(nltk.pos_tag (nltk.word_tokenize (text)))>>> Tree ('S', [('Yes', 'VB'), ('Our', 'PRP$'), ('winter', 'NN'), ('sales', 'NNS'), ('on', 'IN'), ('pocobypippa.com', 'NN'), ('and', 'CC'), ('pippacollection.com', 'NN'), ('are', 'VBP'), ('ending', 'VBG'), ('tomorrow', 'NN'), ('at', 'IN'), ('midnight', 'NN'), ('They', 'PRP'), ('are', 'VBP'), ('also', 'RB'), ('happening', 'VBG'), ('in', 'IN'), ('the', 'DT'), ('pop', 'NN'), ('up', 'RP'), ('shop', 'NN'), ('in', 'IN'), Tree ('GPE', [('Dundrum', 'NNP')]), ('Town', 'NNP'), ('Centre', 'NNP'), ('too', 'RB')])
3.2.2. Semantic Analysis
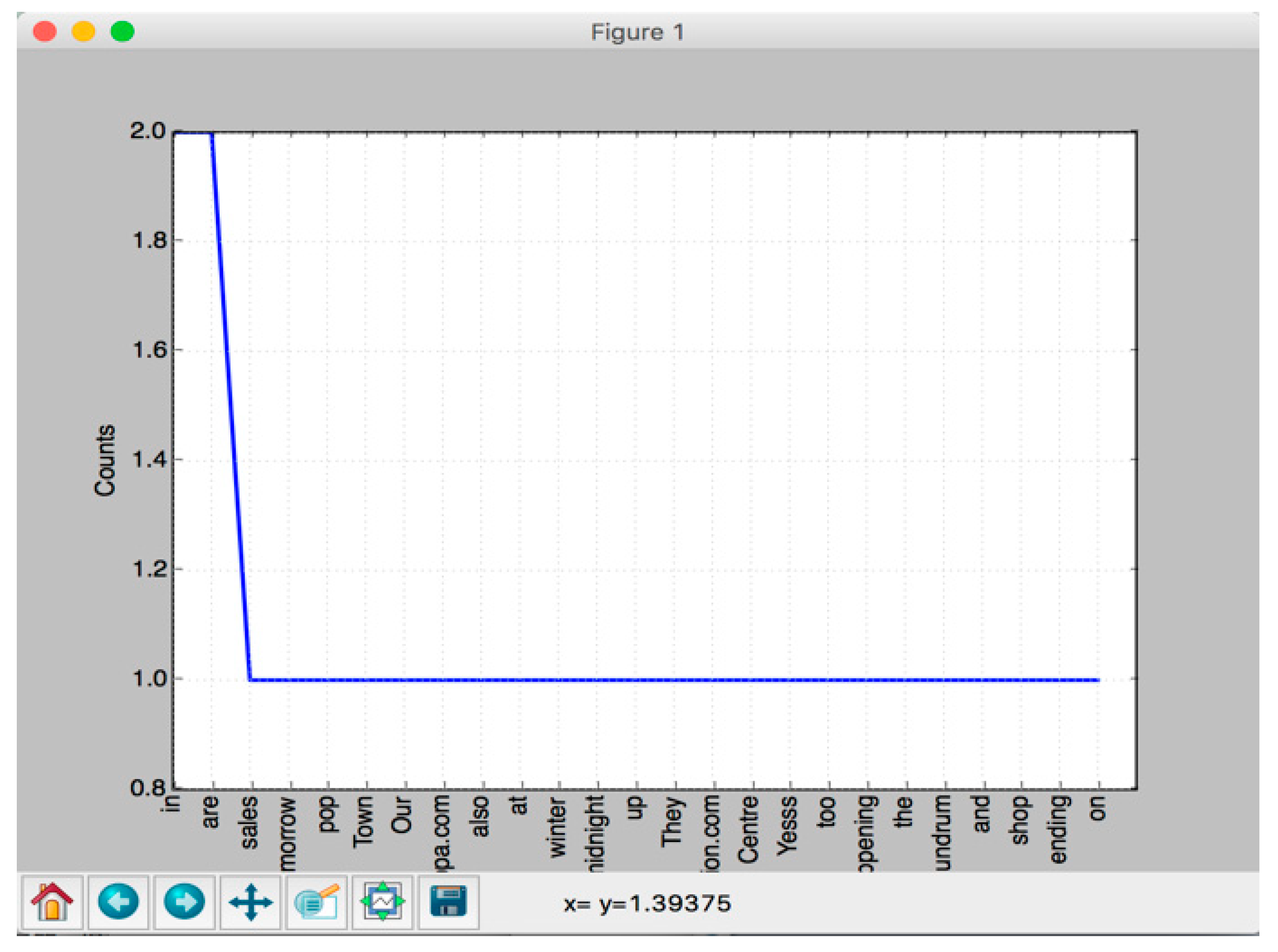
>>> nltk.FreqDist(nltk.tokenize.word_tokenize(text))>>> FreqDist({'in': 2, 'are': 2, 'sales': 1, 'tomorrow': 1, 'pop': 1, 'Town': 1, 'Our': 1, 'pocobypippa.com': 1, 'also': 1, 'at': 1, ...})>>> nltk.FreqDist(nltk.tokenize.word_tokenize(text)).freq('sales')>>> 0.037037037037037035>>> nltk.FreqDist(nltk.tokenize.word_tokenize(text)).plot()>>>
3.3. Data Results
3.3.1. Brands
3.3.2. Products
3.3.3. Occasions
3.3.4. Entertainments
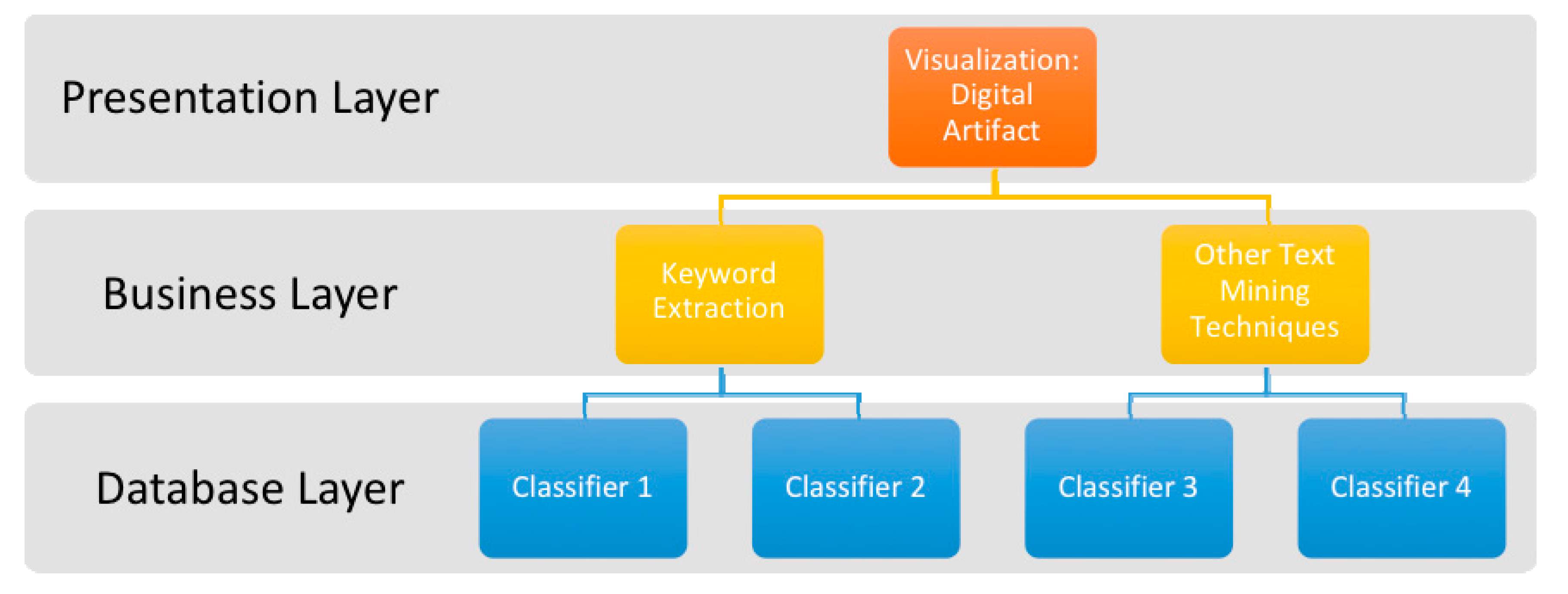
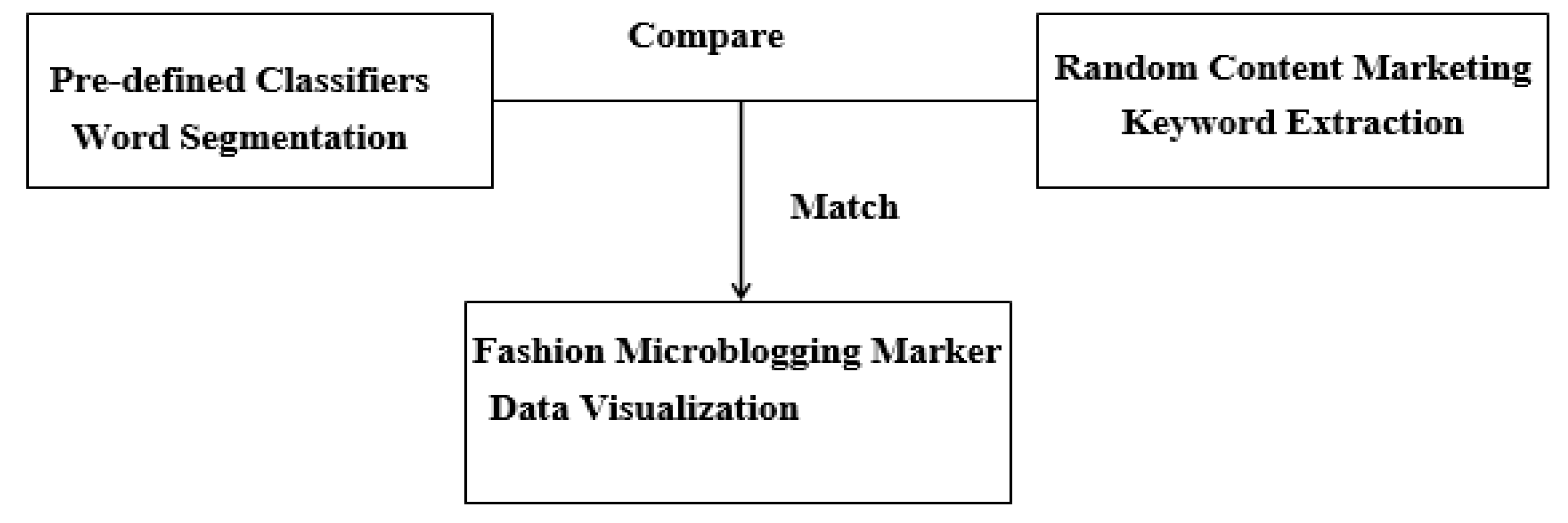
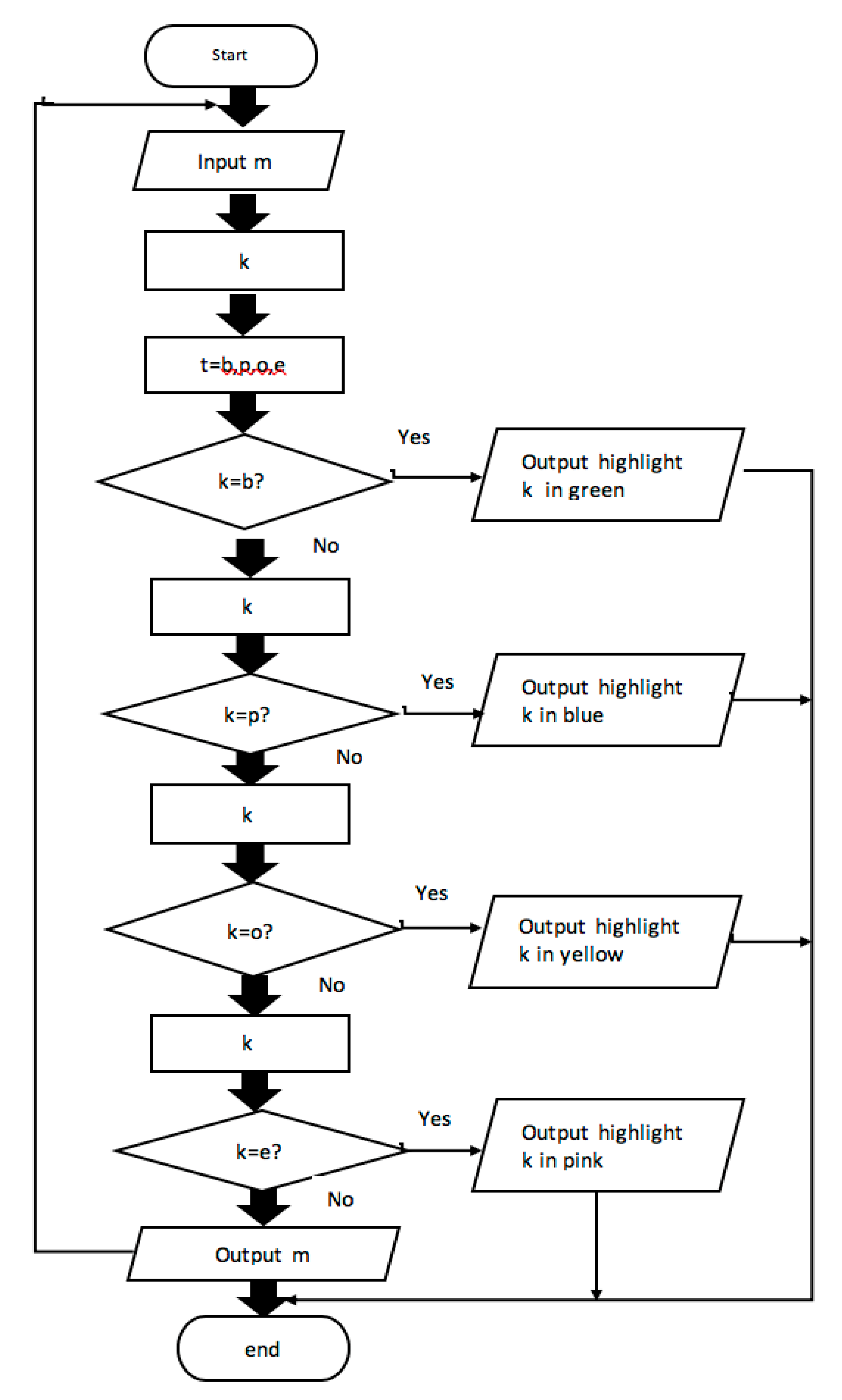
4. The Development of Digital Artifact
Re-trained POS Taggers:>>> import nltk>>> pos={'Louis Vuitton': 'brand'}>>> pos['Louis Vuitton']>>> 'brand'>>> pos={'fishnet': 'product'}>>> pos['fishnet']>>> 'product'>>> pos={'this week': 'occasion'}>>> pos['this week']>>> 'occasion'>>> pos={'Gigi Hadid': 'entertainment'}>>> pos['Gigi Hadid']>>> 'entertainment'
5. Conclusions
5.1. Contributions to Existing Knowledge
5.2. Implications for Practice
5.3. Limitations and Future Research Directions
Author Contributions
Funding
Conflicts of Interest
References
- Belk, W.R.; Llamas, R. Living in a digital world. In The Routledge Companion to Digital Consumption; Belk, W.R., Llamas, R., Eds.; Routledge, Taylor and Francis Group: London, UK, 2013; pp. 3–12. [Google Scholar]
- Hanser, A.; Li, J.L.C. Opting out? gated consumption, infant formula and China’s affluent urban consumers. China J. 2015, 74, 110–128. [Google Scholar] [CrossRef]
- Statista. Fashion Ireland. Available online: https://www.statista.com/outlook/244/117/fashion/china?currency=eur (accessed on 28 April 2019).
- Kim, J.A.; Ko, E. Do social media marketing activities enhance customer equity? an empirical study of luxury fashion brand. J. Bus. 2012, 65, 1480–1486. [Google Scholar] [CrossRef]
- Lenhart, A.; Purcell, K.; Smith, A.; Zickuhr, K. Social Media & Mobile Internet Use among Teens and Young Adults. Pew Research Center. Available online: https://www.pewresearch.org/internet/2010/02/03/social-media-and-young-adults/ (accessed on 19 November 2019).
- Arora, A.; Bansal, S.; Kandpal, C.; Aswani, R.; Dwivedi, Y. Measuring social media influencer index-insights from facebook, twitter and instagram. J. Retail. Consum. Serv. 2019, 49, 86–101. [Google Scholar] [CrossRef]
- Jefferson, S.; Tanton, S. Valuable Content Marketing: How to Make Quality Content Your Key to Success; Kogan Page: London, UK, 2015. [Google Scholar]
- Burley, D.; Silver, N. The impact of ‘smart content’ and metadata from creation to distribution. J. Digit. Media Manag. 2017, 5, 326–335. [Google Scholar]
- Kozinets, R.V. Netnography: The Marketer’s Secret Weapon; NetBase: Santa Clara, CA, USA, 2010. [Google Scholar]
- Araujo, T.; Neijens, P.; Vliegenthart, R. Getting the word out on Twitter: The role of influentials, information brokers and strong ties in building word-of-mouth for brands. Int. J. Advert. 2016, 36, 496–513. [Google Scholar] [CrossRef]
- Barker, M.; Barker, D.; Bormann, N.; Neher, K. Social Media Marketing: A Strategic Approach; South-Western, Cengage Learning: Boston, MA, USA, 2013. [Google Scholar]
- Hughes, C.; Swaminathan, V.; Brooks, G. Driving brand engagement through online social influencers: An empirical investigation of sponsored blogging campaigns. J. Mark. 2019, 83, 78–96. [Google Scholar] [CrossRef]
- Ramirez-de-la-Rosa, G.; Villatoro-Tello, E.; Jimenez-Salazar, H.; Sanchez-Sanchez, C. Towards automatic detection of user influence in Twitter by means of stylistic and behavioural features. In Human-Inspired Computing and Its Applications; Gelbukh, A., Espinoza, G.C., Galicia-Haro, S.N., Eds.; MICAI: Tuxtla Gutierrez, Mexico, 2014; Volume 8856, pp. 245–256. [Google Scholar]
- Moldovan, S.; Muller, E.; Richter, Y.; Tov, E.Y. Opinion leadership in small groups. Int. J. Res. Mark. 2017, 34, 536–552. [Google Scholar] [CrossRef]
- Dubois, E.; Gaffney, D. The multiple facets of influence: Identifying political influentials and opinion leaders on Twitter. Am. Behav. Sci. 2014, 58, 1260–1277. [Google Scholar] [CrossRef]
- Tuarob, S.; Tucker, C.S. Automated discovery of lead users and latent product features by mining large scale social media networks. J. Mech. Des. 2015, 137, 1–11. [Google Scholar] [CrossRef]
- Macskassy, S.A. Contextual linking behavior of bloggers: Leveraging text mining to enable topic-based analysis. Soc. Netw. Anal. Min. 2011, 1, 355–375. [Google Scholar] [CrossRef]
- Basili, C.; Lanzillo, L. Research quality criteria in the evaluation of books. In The Evaluation of Research in Social Sciences and Humanities. Lessons from the Italian Experience; Bonaccorsi, A., Ed.; Springer: Berlin, Germany, 2018; pp. 159–184. [Google Scholar]
- Engels, T.; Starcic, A.I.; Kulczycki, E.; Pölönenm, J. Are book publications disappearing from scholarly communication in the social sciences and humanities? Cent. Sci. Technol. 2018, 70, 774–780. [Google Scholar] [CrossRef]
- Greenwood, S.; Perrin, A.; Duggan, M. Social Media Update 2016. Pew Research Center: Internet & Technology. Available online: http://www.pewinternet.org/2016/11/11/social-media-update-2016/ (accessed on 28 November 2017).
- Alperin, J.P.; Gomez, C.J.; Haustein, S. Identifying diffusion patterns of research articles on Twitter: A case study of online engagement with open access articles. Public Underst. Sci. 2019, 28, 2–18. [Google Scholar] [CrossRef] [PubMed]
- Sugimoto, C.R.; Work, S.; Larivière, V.; Haustein, S. Scholarly use of social media and altimetric: A review of the literature. J. Assoc. Inf. Sci. Technol. 2017, 68, 2037–2062. [Google Scholar] [CrossRef]
- Sterne, J. Artificial Intelligence for Marketing: Practical Applications; John Wiley and Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Davenport, T.; Guha, A.; Grewal, D.; Bressgott, T. How artificial intelligence will change the future of marketing. J. Acad. Mark. Sci. 2019, 1–19. [Google Scholar] [CrossRef]
- Hanlon, A. Digital Marketing: Strategic Planning & Integration; Sage Publications Ltd.: London, UK, 2019. [Google Scholar]
- Hall, J. 7 Marketing Trends to Budget for in 2019. Available online: https://www.forbes.com/sites/johnhall/2018/11/11/7-marketing-trends-to-budget-for-in-2019/#d43ee82511c8 (accessed on 11 November 2018).
- DeMers, J. 5 Ways A Content Marketing Campaign Can Backfire. Available online: https://www.forbes.com/sites/jaysondemers/2015/10/09/5-ways-a-content-marketing-campaign-can-backfire/#aab75065e0b7 (accessed on 9 October 2015).
- Forbes Agency Council. 10 Marketing Tools and Tactics That Will Shake Up the Industry in 2019. Available online: https://www.forbes.com/sites/forbesagencycouncil/2019/01/25/10-marketing-tools-and-tactics-that-will-shake-up-the-industry-in-2019/#2fe47f803412 (accessed on 25 January 2019).
- Lieb, R. Content Marketing; Que Publishing: Indianapolis, Indiana, 2012. [Google Scholar]
- Jerath, K.; Liya, M.; Park, Y.H. Consumer click behaviour at a search engine: The role of keyword popularity. Keller Cent. Res. Rep. 2015, 8, 21–24. [Google Scholar]
- Simonov, A.; Nosko, C. Competition and crowd-out for brand keywords in sponsored search. Mark. Sci. 2018, 37, 177–331. [Google Scholar] [CrossRef]
- Lu, S.J.; Yang, S. Investigating the spillover effect of keyword market entry in sponsored search advertising. Mark. Sci. 2017, 36, 813–1017. [Google Scholar] [CrossRef]
- Terrance, A.R.; Shrivastava, S.; Kumari, A. Importance of search engine marketing in the digital world. Technol. Knowl. Manag. 2018, 14, 155–158. [Google Scholar]
- Harris, J. Road Map to Success: Content Marketing Strategy Essentials. Available online: https://contentmarketinginstitute.com/2018/02/content-strategy-essentials/ (accessed on 20 February 2018).
- Tekin, M.; Etlioglu, M.; Koyuncuoglu, O. Data mining in digital marketing. In Proceedings of the International Symposium for Production Research 2018; Springer: Berlin, Germany, 2018; pp. 44–61. [Google Scholar]
- Bello, O.G.; Jung, J.J.; Camacho, D. Social big data: Recent achievements and new challenges. Inf. Fusion 2016, 28, 45–59. [Google Scholar] [CrossRef]
- Zhang, K.; Stoffel, A.; Behrisch, M.; Mittelstadt, S.; Schreck, T.; Pompl, R.; Weber, S.; Last, H.; Keim, D. Visual analytics for the big data era—A comparative review of state-of-the-art commercial systems. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 14–19 October 2012; pp. 173–182. [Google Scholar]
- Wang, W.; Chen, L.; Thirunarayan, K.P.; Sheth, A. Harnessing twitter ‘big data’ for automatic emotion identification. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Confernece on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; pp. 1–6. [Google Scholar]
- Talib, R.; Hanif, M.K.; Ayesha, S.; Fatima, F. Text mining: Techniques, applications and issues. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 414–418. [Google Scholar] [CrossRef]
- Weiss, S.M.; Indurkhya, N.; Zhang, T.; Damerau, F.J. Text Mining: Predictive Methods for Analyzing Unstructured Information; Springer Science & Business Media: New York, NY, USA, 2010. [Google Scholar]
- Muninger, M.; Hammedi, W.; Mahr, D. The value of social media for innovation: A capability perspective. J. Bus. Res. 2019, 95, 116–127. [Google Scholar] [CrossRef]
- Holzinger, A.; Schantl, J.; Schroettner, M. Biomedical text mining: State-of-the-art, open problems and future challenges. In Knowledge Discovery and Data Mining; Holzinger, A., Jurisica, I., Eds.; Springer-Verlag Berlin Heidelberg: Berlin, Germany, 2014; pp. 271–300. [Google Scholar]
- Glowacki, E.M.; Glowacki, J.B.; Wilcox, G.B. A text-mining analysis of the public’s reactions to the opioid crisis. J. Subst. Abus. 2017, 7, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Bae, J.H.; Song, J.E.; Song, M. Analysis of Twitter for 2012 South Korea presidential election by text mining techniques. J. Intell. Inf. Syst. 2013, 19, 141–156. [Google Scholar]
- Bowers, A.J.; Chen, J.J. Ask and ye shall receive? Automated text mining of michigan capital facility finance bond election proposals to identify which topics are associated with bond passage and voter turnout. J. Educ. Financ. 2015, 41, 164–196. [Google Scholar]
- Hosoi, H.; Yamagata, T.; Ikarashi, Y. Visualization of special features in “The Tale of Genji” by text mining and correspondence analysis with clustering. J. Flow Control Meas. Vis. 2014, 2, 1–6. [Google Scholar] [CrossRef]
- Westergaard, D.; Staerfeldt, H.H.; Tonsberg, C.; Jensen, L.J.; Brunak, S. Text mining of 15 million full-text scientific articles. Biorxiv 2017, 11, 1–28. [Google Scholar]
- Hung, J. Trends of e-learning research from 2000 to 2008: Use of text mining and bibliometrics. Br. J. Educ. Technol. 2012, 43, 5–16. [Google Scholar] [CrossRef]
- Yasuhara, T.; Sone, T.; Konishi, M.; Kushihata, M.; Nishikawa, T.; Yamamoto, Y.; Kurio, W.; Kohno, T. Studies using text mining on the differences in learning effects between the KJ and world café method as learning strategies. J. Pharm. Soc. Jpn. 2015, 135, 753–759. [Google Scholar] [CrossRef][Green Version]
- Mostafa, M.M. More than words: Social networks’ text mining for consumer brand sentiments. Expert Syst. Appl. 2013, 40, 4241–4251. [Google Scholar] [CrossRef]
- Culotta, A.; Cutler, J. Mining brand perceptions from twitter social networks. Mark. Sci. 2016, 35, 1–39. [Google Scholar] [CrossRef]
- Owyang, J.; Lovett, J. Social Marketing Analytics A New Framework for Measuring Results in Social Media. Web Analytics Demystified and Altimeter Group. Available online: https://www.slideshare.net/jlovett/social-marketing-analytics (accessed on 3 October 2019).
- Brown, D.; Fiorella, S. Influence Marketing: How to Create, Manage, and Measure Brand Influencers in Social Media Marketing; Que Publishing: Upper Saddle River, NJ, USA, 2013. [Google Scholar]
- Boerman, S.C. The effects of the standardized instagram disclosure for micro- and meso-influencers. Comput. Hum. Behav. 2020, 103, 199–207. [Google Scholar] [CrossRef]
- Ersun, A.N.; Yildirim, F. Consumer involvement and brand sensitivity of university students in their choice of fashion. Marmara Univ. J. Fac. Econ. Administ 2010, 28, 313–333. [Google Scholar]
- Shephard, A.; Kinley, T.R.; Josiam, B.M. Fashion leadership, shopping enjoyment, and gender: Hispanic versus, Caucasian consumers’ shopping preferences. J. Retail. Consum. Serv. 2014, 21, 277–283. [Google Scholar] [CrossRef]
- Sarathy, P.; Patro, S. The role of opinion leaders in high-involvement purchases: An empirical investigation. S. Asian J. Manag. 2013, 20, 11–53. [Google Scholar]
- Yang, H. Market mavens in social media: Examining young Chinese consumers’ viral marketing attitude, eWOM motive, and behaviour. J. Asia-Pac. Bus. 2013, 14, 154–178. [Google Scholar] [CrossRef]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. A brief survey of text mining: Classification, clustering and extraction techniques. arXiv 2017, arXiv:1707.02919 2017, 1–13. [Google Scholar]
- Farzindar, A.; Inkpen, D. Natural language processing for social media. Synth. Lect. Hum. Lang. Technol. 2017, 10, 1–195. [Google Scholar] [CrossRef]
- Bird, S. Natural Language Processing with Python; O’Reilly Media. H: Sebastopol, CA, USA, 2010. [Google Scholar]
- Gaikwad, V.S.; Chaugule, A.; Patil, P. Text mining methods and techniques. Int. J. Comput. Appl. 2014, 85, 42–45. [Google Scholar]
- Dercynski, L.; Maynard, D.; Rizzo, G.; Erp, M.; Gorrell, G.; Troncy, R.; Petrak, J.; Bontcheva, K. Analysis of named entity recognition and linking for tweets. Inf. Process. Manag. 2015, 51, 32–49. [Google Scholar] [CrossRef]
- Hmeidi, I.; Al-Ayyoub, M.; Abdulla, N.; Almodawar, A.A. Automatic Arabic text categorization: A comprehensive comparative study. J. Inf. Sci. 2014, 41, 1–11. [Google Scholar]
- Wu, X.; Du, Z.K.; Guo, Y.K. A visual attention-based keyword extraction for document classification. Multimed. Tools Appl. 2018, 77, 25355–25367. [Google Scholar] [CrossRef]
- Onan, A.; Korukoglu, S.; Bulut, H. Ensemble of keyword extraction methods and classifiers in text classification. Expert Syst. Appl. 2016, 57, 232–247. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, X.Y. Recognizing opinion leaders based on social network analysis. J. Inf. Sci. 2015, 33, 13–20. [Google Scholar]
- W3Techs. Usage of Content Management Systems for Websites. Available online: https://w3techs.com/technologies/overview/content_management/all/ (accessed on 23 April 2018).
- Epalle, T.E. Mobile social media mining challenges overview: A case study of wechat. Int. J. Comput. Technol. Appl. 2015, 6, 347–351. [Google Scholar]
- Humphreys, A.; Jen-Hui Wang, R. Automated text analysis for consumer research. J. Consum. Res. 2017, 44, 1274–1306. [Google Scholar] [CrossRef]
- Klein, L.F.; Gold, M.K. Debates in the Digital Humanities 2016; University of Minnesota Press: Minneapolis, MN, USA, 2016. [Google Scholar]
- Miltgen, C.L.; Henseler, J.; Gelhard, C.; Popovič, A. Introducing new products that affect consumer privacy: A mediation model. J. Bus. Res. 2016, 69, 4659–4666. [Google Scholar] [CrossRef]
- Krafft, M.; Arden, C.M.; Verhoef, P.C. Permission marketing and privacy concerns—why do customers (not) grant permissions? J. Interact. Mark. 2017, 39, 39–54. [Google Scholar] [CrossRef]
- Rauch, C. AI for Good—How Artificial Intelligence Can Help Sustainable Development. Available online: https://medium.com/@C8215/ai-for-good-how-artificial-intelligence-can-help-sustainable-development-58b47d1c289a (accessed on 4 November 2019).
- Chui, M.; Chung, R.; Heteren, A. Using AI to Help Achieve Sustainable Development Goals. Available online: https://www.undp.org/content/undp/en/home/blog/2019/Using_AI_to_help_achieve_Sustainable_Development_Goals.html (accessed on 4 October 2019).
- Ince, B.K.; Cetecioglu, Z.; Ince, O. Pollution Prevention in the Pulp and Paper Industries. Environmental Management in Practice, 2011. Available online: https://www.intechopen.com/books/environmental-management-in-practice/pollution-prevention-in-the-pulp-and-paper-industries (accessed on 4 October 2019).
- Gavrilescu, D.; Puitel, A.C.; Dutuc, G.; Craciun, G. Environmental impact of pulp and paper mills. Environ. Eng. Manag. J. 2012, 11, 81–85. [Google Scholar] [CrossRef]
- Li, W.J.; Feng, Y.M.; Li, D.J.; Yu, Z.T. Micro-blog topic detection method based on BTM topic model and K-means clustering algorithm. Autom. Control Comput. Sci. 2016, 50, 271–277. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Irish Micro-Influencers | No. of Comments | No. of Reach | No. of Relevant Contents | No. Shares | Active Influence |
|---|---|---|---|---|---|
| Sosueme | 4016 | 605,207 | 11,974 | 5663 | 0.88 |
| Thunder and Threads | 3512 | 569,453 | 11,855 | 4540 | 0.82 |
| Pippa | 3244 | 493,959 | 11,547 | 4505 | 0.81 |
| Help my style | 3303 | 424,584 | 9255 | 4132 | 0.78 |
| Anouska | 3453 | 389,824 | 8090 | 3949 | 0.7 |
| Fluff and Fripperies | 3371 | 390,842 | 7998 | 3988 | 0.7 |
| The Style Fairy | 3200 | 276,472 | 6367 | 3323 | 0.63 |
| What she wears | 3169 | 276,228 | 6163 | 3585 | 0.63 |
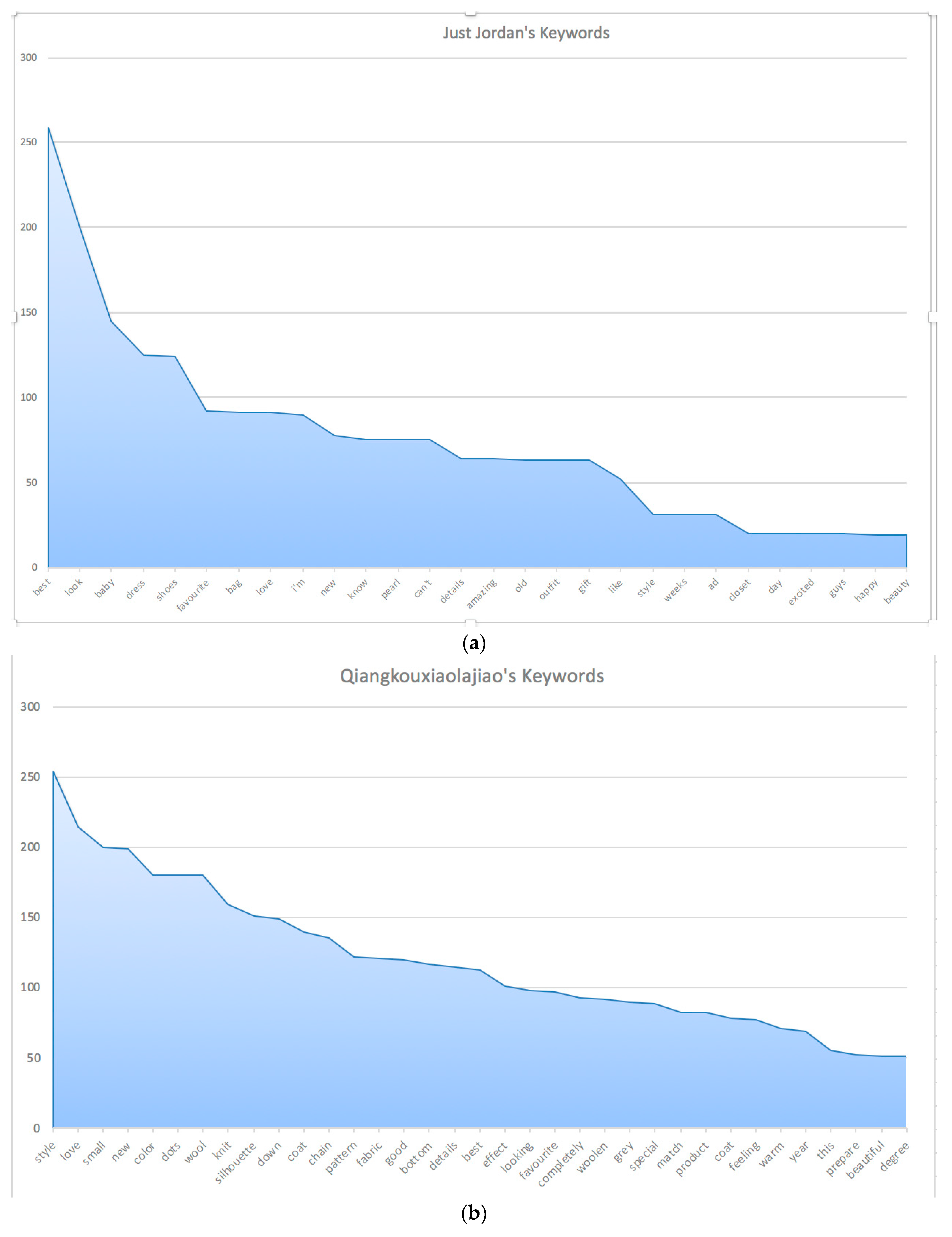
| Just Jordan | 2179 | 195,426 | 5222 | 2340 | 0.57 |
| Love Lauren | 2112 | 174,200 | 5230 | 2255 | 0.53 |
| Chinese micro-Influencers | No. of Comments | No. of Reach | No. of Relevant Contents | No. Shares | Active Influence |
|---|---|---|---|---|---|
| Shiliupobaogao | 22,630 | 9,534,440 | 41,340 | 81,980 | 0.94 |
| Yang Fan Jame | 36,500 | 9,077,270 | 31,908 | 61,790 | 0.89 |
| Han Huohuo | 14,892 | 9,028,789 | 31,056 | 51,914 | 0.87 |
| Chrison | 25,404 | 8,884,001 | 30,156 | 62,791 | 0.86 |
| Peter Xu | 23,215 | 8,490,286 | 23,372 | 51,134 | 0.77 |
| Gogoboi | 24,528 | 8,320,808 | 18,945 | 29,200 | 0.72 |
| Mr. Kira | 12,410 | 5,337,882 | 16,733 | 12,118 | 0.7 |
| Qiangkouxiaolajiao | 29,200 | 5,227,843 | 13,663 | 25,477 | 0.69 |
| Miss Shopping Li | 15,630 | 3,605,081 | 10,079 | 20,300 | 0.68 |
| Boy Mr. K | 17,305 | 1,342,843 | 11,631 | 24,090 | 0.51 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, Z.; de la Garza, A. Developing a Digital Artifact for the Sustainable Presentation of Marketing Research Results. Sustainability 2019, 11, 6554. https://doi.org/10.3390/su11236554
Shen Z, de la Garza A. Developing a Digital Artifact for the Sustainable Presentation of Marketing Research Results. Sustainability. 2019; 11(23):6554. https://doi.org/10.3390/su11236554
Chicago/Turabian StyleShen, Zheng, and Armida de la Garza. 2019. "Developing a Digital Artifact for the Sustainable Presentation of Marketing Research Results" Sustainability 11, no. 23: 6554. https://doi.org/10.3390/su11236554
APA StyleShen, Z., & de la Garza, A. (2019). Developing a Digital Artifact for the Sustainable Presentation of Marketing Research Results. Sustainability, 11(23), 6554. https://doi.org/10.3390/su11236554