Generalizing Predictive Models of Admission Test Success Based on Online Interactions

 , ,
, ,
Abstract
1. Introduction
- O1.
- Analyze the moment in which success on the admission test can be accurately predicted using SPOC activity and in which variables are the best predictors in the developed predictive models;
- O2.
- Analyze to what extent the best predictors of success in the admission test generalize when developing predictive models in other courses;
- O3.
- Analyze to what extent predictive models can be transferred to other courses with the same cohort, to the same courses but different cohorts, and to both different courses and cohorts;
- O4.
- Discuss which conditions have to be met to achieve generalizability of the predictive models.
2. Related Work
2.1. Prediction in Education
2.2. Generalizability and Sustainability of Predictions
3. Materials and Methods
3.1. Context and Data Collection for the Initial Course of Chemistry
3.2. Variables and Techniques
3.3. Courses and Experiments for the Generalization
- Within the same cohort: It consists of building a model using data of one SPOC and of predicting using data of another SPOC taken by the same cohort.
- Within the same course but different cohort: It consists of training using data of one SPOC and of predicting using data of the same SPOC but in a different cohort.
- Using a different course and cohort: It consists of training using data of one SPOC and of predicting using data of another course in a different cohort.
- Using the combination of SPOCs in different cohorts: It consists of training a model with the interactions of the learners in both chemistry and physics SPOCs in the same cohort and of predicting using the interactions of both SPOC in a different cohort.
4. Results
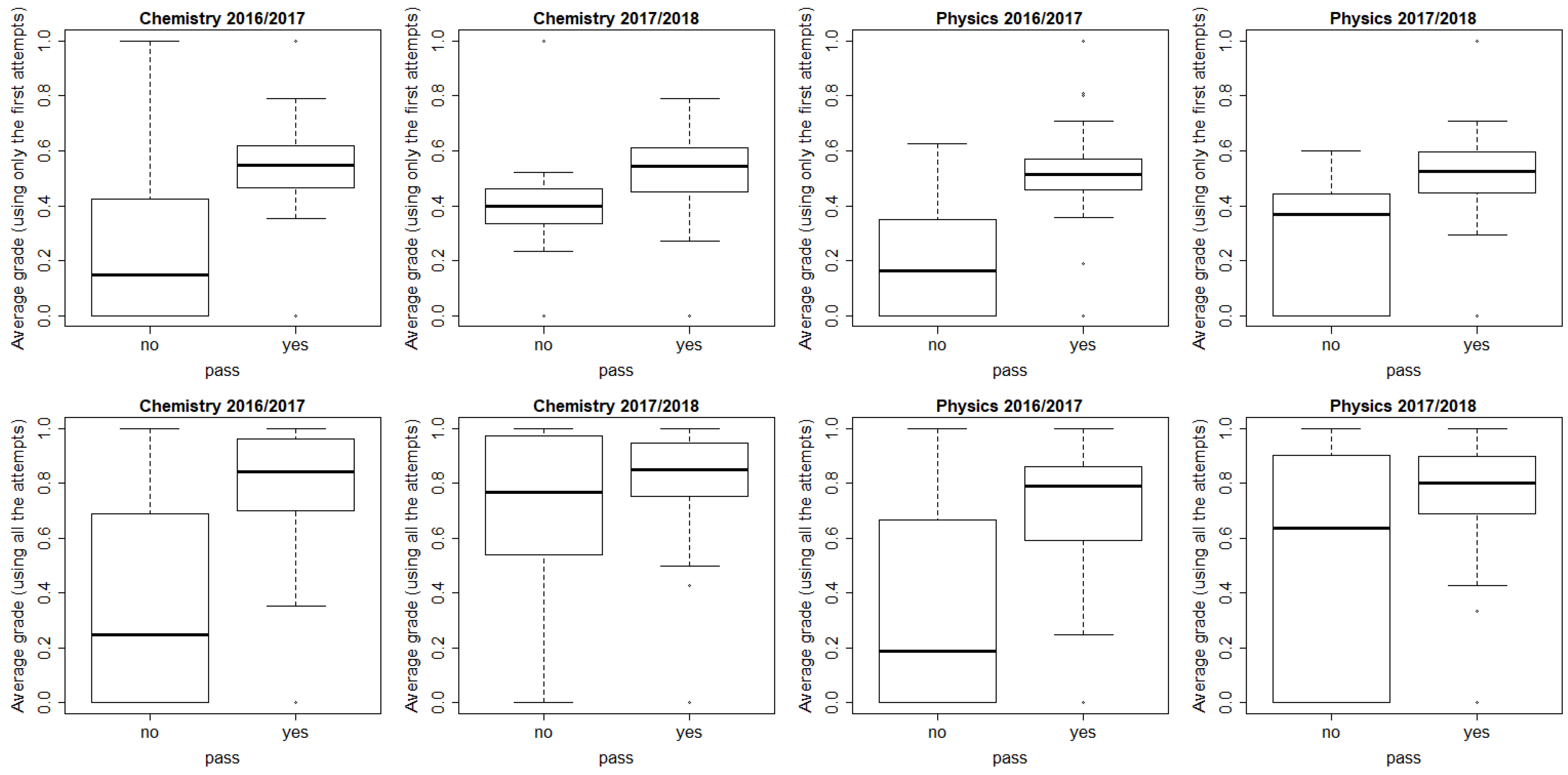
4.1. O1: Anticipation of Grades and Influence of Variables for the Initial Course of Chemistry
4.2. O2: Analysis of the Influence of Variables in Prediction for Different Courses
4.3. O3: Analysis of the Generalizability and Transferrability of the Models
5. Discussion about the Generalizability
- Student characteristics should be as similar as possible: When one model is generated with one course and used in another course with the same students, the predictive power was very high. This may imply that, if students’ behaviors are similar, it is possible to transfer the models. While it is not always possible to use the model with the same cohort, results show that it would be possible because of the high predictive power. However, when changing the cohorts (students), the predictive power is worse but can be still acceptable.
- Courses should be as similar as possible: Results showed that the predictive power dropped considerably when predicting using a model with different students in a different course. This fact can hinder the generalizability, although the predictive power may be acceptable if the course is similar. If the course is the same but in a different edition, it may be possible to achieve a reasonable performance. Therefore, it would be better to generate a model from the same course in another edition (if available) than to use a trained model from another course.
- The methodology: The four SPOCs were taught using blended learning, and they were organized in a similar way. All the SPOCs were run in the same period (from September to the dates of the admission test) each year, and face-to-face sessions were organized following a similar approach for all the SPOCs. With regard to the face-to-face sessions, a positive result in the analyzed SPOCs was that the variables obtained from them were less strong predictors. While this may change in another context and should not be neglected, it can be good if the offline part of the blended program is less important for the generalizability, as it is often harder to measure.
- Delivery mode: All SPOCs were synchronous (instructor paced), which means that materials were released every fortnight. Changes in the delivery mode may affect the way students behave (e.g., students may face more problems in self-regulation in self-paced settings [17]) and thus the generalizability.
- Perceived importance of the course: In this case, all the SPOCs were supporting materials for the admission test, although they were perceived as an important tool for the exam preparation. Even if two courses are the same, there can be differences if the perceived importance of the SPOC is different. For example, if one instructor does not strengthen the importance of the SPOC and only considers it as extra material, results may differ from a similar SPOC in which the instructor encourages its use frequently.
- Course duration: All the SPOCs were launched at the beginning of the academic year, and they were intended to be used until the end of the academic year when the admission test was held.
- Relationship between the dependent variable among courses: The dependent variable in this case is the overall pass/fail result of the sciences part of the exam, which includes both chemistry and physics. That may contribute to the generalizability across courses which are part of the final result.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Roggemans, L.; Spruyt, B. Toelatingsproef (tand) arts: Een sociografische schets van de deelnemers en geslaagden. In Bruss. Onderzoeksgr. Tor Vakgr. Sociol. Vrije Univ. Bruss. (140 Blz.)-Tor; Vrije Universiteit Brussel: Brussel, Belgium, 2014. [Google Scholar]
- Orlando, M.; Howard, L. Setting the Stage for Success in an Online Learning Environment. In Emerging Self-Directed Learning Strategies in the Digital Age, 1st ed.; Giuseffi, F.G., Ed.; IGI Global: Hershey, PA, USA, 2018; pp. 1–9. [Google Scholar]
- Fox, A. From MOOCs to SPOCs. Commun. ACM 2013, 56, 38–40. [Google Scholar] [CrossRef]
- Moreno-Marcos, P.M.; Muñoz-Merino, P.J.; Alario-Hoyos, C.; Estévez-Ayres, I.; Delgado Kloos, C. Analysing the predictive power for anticipating assignment grades in a massive open online course. Behav. Inf. Technol. 2018, 37, 1021–1036. [Google Scholar] [CrossRef]
- Davis, D.; Jivet, I.; Kizilcec, R.F.; Chen, G.; Hauff, C.; Houben, G.J. Follow the successful crowd: Raising MOOC completion rates through social comparison at scale. In Proceedings of the 7th International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada, 13–17 March 2017; pp. 454–463. [Google Scholar]
- Ali, L.; Hatala, M.; Gašević, D.; Jovanović, J. A qualitative evaluation of evolution of a learning analytics tool. Comput. Educ. 2012, 58, 470–489. [Google Scholar] [CrossRef]
- Park, Y.; Jo, I.H. Development of the Learning Analytics Dashboard to Support Students’ Learning Performance. J. Univ. Comput. Sci. 2015, 21, 110–133. [Google Scholar]
- You, J.W. Identifying significant indicators using LMS data to predict course achievement in online learning. Int. High. Educ. 2016, 29, 23–30. [Google Scholar] [CrossRef]
- Gašević, D.; Dawson, S.; Siemens, G. Let’s not forget: Learning analytics are about learning. TechTrends 2015, 59, 64–71. [Google Scholar] [CrossRef]
- Ferguson, R.; Clow, D.; Macfadyen, L.; Essa, A.; Dawson, S.; Alexander, S. Setting learning analytics in context: Overcoming the barriers to large-scale adoption. In Proceedings of the 4th International Conference on Learning Analytics and Knowledge, Indianapolis, IN, USA, 24–28 March 2014; pp. 251–253. [Google Scholar]
- Alharbi, Z.; Cornford, J.; Dolder, L.; De La Iglesia, B. Using data mining techniques to predict students at risk of poor performance. In Proceedings of the 2016 Science and Information Computing Conference, London, UK, 13–15 July 2016; pp. 523–531. [Google Scholar]
- Moreno-Marcos, P.M.; De Laet, T.; Muñoz-Merino, P.J.; Van Soom, C.; Broos, T.; Verbert, K.; Delgado Kloos, C. Predicting admission test success using SPOC interactions. In Proceedings of the 9th International Conference of Learning Analytics & Knowledge, Tempe, AZ, USA, 4–8 March 2019; pp. 924–934. [Google Scholar]
- Romero, C.; Ventura, S. Guest Editorial: Special Issue on Early Prediction and Supporting of Learning Performance. IEEE Trans. Learn. Technol. 2019, 12, 145–147. [Google Scholar] [CrossRef]
- Brooks, C.; Thompson, C.; Teasley, S. Who you are or what you do: Comparing the predictive power of demographics vs. activity patterns in massive open online courses (MOOCs). In Proceedings of the 2nd ACM Conference on Learning@ Scale, Vancouver, BC, Canada, 14–18 March 2015; pp. 245–248. [Google Scholar]
- Ruipérez-Valiente, J.A.; Cobos, R.; Muñoz-Merino, P.J.; Andujar, Á.; Delgado Kloos, C. Early prediction and variable importance of certificate accomplishment in a MOOC. In Proceedings of the 5th European Conference on Massive Open Online Courses, Madrid, Spain, 22–26 May 2017; pp. 263–272. [Google Scholar]
- Moreno-Marcos, P.M.; Alario-Hoyos, C.; Muñoz-Merino, P.J.; Delgado Kloos, C. Prediction in MOOCs: A review and future research directions. IEEE Trans. Learn. Technol. 2018. [Google Scholar] [CrossRef]
- Maldonado-Mahauad, J.; Pérez-Sanagustín, M.; Moreno-Marcos, P.M.; Alario-Hoyos, C.; Muñoz-Merino, P.J.; Delgado Kloos, C. Predicting Learners’ Success in a Self-paced MOOC Through Sequence Patterns of Self-regulated Learning. In Proceedings of the 13th European Conference on Technology Enhanced Learning, Leeds, UK, 3–5 September 2018; pp. 355–369. [Google Scholar]
- Alamri, A.; Alshehri, M.; Cristea, A.; Pereira, F.D.; Oliveira, E.; Shi, L.; Stewart, C. Predicting MOOCs dropout using only two easily obtainable features from the first week’s activities. In Proceedings of the 15th International Conference on Intelligent Tutoring Systems, Kingston, Jamaica, 3–7 June 2019; pp. 163–173. [Google Scholar]
- Aguiar, E.; Chawla, N.V.; Brockman, J.; Ambrose, G.A.; Goodrich, V. Engagement vs performance: Using electronic portfolios to predict first semester engineering student retention. In Proceedings of the 4th International Conference on Learning Analytics and Knowledge, Indianapolis, IN, USA, 24–28 March 2014; pp. 103–112. [Google Scholar]
- Fei, M.; Yeung, D.Y. Temporal models for predicting student dropout in massive open online courses. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop, Atlantic City, NJ, USA, 14–17 November 2015; pp. 256–263. [Google Scholar]
- Polyzou, A.; Karypis, G. Feature Extraction for Next-term Prediction of Poor Student Performance. IEEE Trans. Learn. Technol. 2019, 12, 237–248. [Google Scholar] [CrossRef]
- Okubo, F.; Yamashita, T.; Shimada, A.; Ogata, H. A neural network approach for students’ performance prediction. In Proceedings of the 7th International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 598–599. [Google Scholar]
- Ashenafi, M.M.; Riccardi, G.; Ronchetti, M. Predicting students’ final exam scores from their course activities. In Proceedings of the 45th IEEE Frontiers in Education Conference, El Paso, TX, USA, 21–24 October 2015; pp. 1–9. [Google Scholar]
- Ding, M.; Yang, K.; Yeung, D.Y.; Pong, T.C. Effective Feature Learning with Unsupervised Learning for Improving the Predictive Models in Massive Open Online Courses. In Proceedings of the 9th International Conference on Learning Analytics & Knowledge, Tempe, AZ, USA, 4–8 March 2019; pp. 135–144. [Google Scholar]
- Jiang, F.; Li, W. Who Will Be the Next to Drop Out? Anticipating Dropouts in MOOCs with Multi-View Features. Int. J. Perform. Eng. 2017, 13, 201–210. [Google Scholar] [CrossRef]
- Brinton, C.G.; Chiang, M. MOOC performance prediction via clickstream data and social learning networks. In Proceedings of the 34th IEEE International Conference on Computer Communications, Kowloon, Hong Kong, China, 26 April–1 May 2015; pp. 2299–2307. [Google Scholar]
- Xu, B.; Yang, D. Motivation classification and grade prediction for MOOCs learners. Comput. Intell. Neurosci. 2016. [Google Scholar] [CrossRef] [PubMed]
- Kizilcec, R.F.; Cohen, G.L. Eight-minute self-regulation intervention raises educational attainment at scale in individualist but not collectivist cultures. Proc. Natl. Acad. Sci. USA 2017, 114, 4348–4353. [Google Scholar] [CrossRef] [PubMed]
- Xing, W.; Du, D. Dropout prediction in MOOCs: Using deep learning for personalized intervention. J. Educ. Comput. Res. 2019, 57, 547–570. [Google Scholar] [CrossRef]
- Yu, C. SPOC-MFLP: A Multi-feature Learning Prediction Model for SPOC Students Using Machine Learning. J. Appl. Sci. Eng. 2018, 21, 279–290. [Google Scholar]
- Ruipérez-Valiente, J.A.; Muñoz-Merino, P.J.; Delgado Kloos, C. Improving the prediction of learning outcomes in educational platforms including higher level interaction indicators. Expert Syst. 2018, 35, e12298. [Google Scholar] [CrossRef]
- Feng, M.; Heffernan, N.T.; Koedinger, K.R. Predicting state test scores better with intelligent tutoring systems: Developing metrics to measure assistance required. In Proceedings of the 8th International Conference on Intelligent Tutoring Systems, Jhongli, Taiwan, 26–30 June 2006; pp. 31–40. [Google Scholar]
- Fancsali, S.E.; Zheng, G.; Tan, Y.; Ritter, S.; Berman, S.R.; Galyardt, A. Using embedded formative assessment to predict state summative test scores. In Proceedings of the 8th International Conference on Learning Analytics and Knowledge, Sydney, Australia, 7–9 March 2018; pp. 161–170. [Google Scholar]
- Ocumpaugh, J.; Baker, R.; Gowda, S.; Heffernan, N.; Heffernan, C. Population validity for Educational Data Mining models: A case study in affect detection. Br. J. Educ. Technol. 2014, 45, 487–501. [Google Scholar] [CrossRef]
- Olivé, D.M.; Huynh, D.; Reynolds, M.; Dougiamas, M.; Wiese, D. A Quest for a one-size-fits-all Neural Network: Early Prediction of Students at Risk in Online Courses. IEEE Trans. Learn. Technol. 2019, 12, 171–183. [Google Scholar] [CrossRef]
- Merceron, A. Educational Data Mining/Learning Analytics: Methods, Tasks and Current Trends. In Proceedings of the DeLFI Workshops 2015, München, Germany, 1 September 2015; pp. 101–109. [Google Scholar]
- Strang, K.D. Beyond engagement analytics: Which online mixed-data factors predict student learning outcomes? Educ. Inf. Technol. 2017, 22, 917–937. [Google Scholar] [CrossRef]
- Schneider, B.; Blikstein, P. Unraveling students’ interaction around a tangible interface using multimodal learning analytics. J. Educ. Data Min. 2015, 7, 89–116. [Google Scholar]
- Boyer, S.; Veeramachaneni, K. Transfer learning for predictive models in massive open online courses. In Proceedings of the 17th International Conference on Artificial Intelligence in Education, Madrid, Spain, 22–26 June 2015; pp. 54–63. [Google Scholar]
- He, J.; Bailey, J.; Rubinstein, B.I.; Zhang, R. Identifying at-risk students in massive open online courses. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015; pp. 1749–1755. [Google Scholar]
- Gitinabard, N.; Xu, Y.; Heckman, S.; Barnes, T.; Lynch, C.F. How Widely Can Prediction Models be Generalized? IEEE Trans. Learn. Technol. 2019, 12, 184–197. [Google Scholar] [CrossRef]
- Hung, J.L.; Shelton, B.E.; Yang, J.; Du, X. Improving Predictive Modeling for At-Risk Student Identification: A Multi-Stage Approach. IEEE Trans. Learn. Technol. 2019, 12, 148–157. [Google Scholar] [CrossRef]
- Kidzinsk, L.; Sharma, K.; Boroujeni, M.S.; Dillenbourg, P. On Generalizability of MOOC Models. In Proceedings of the 9th International Conference on Educational Data Mining, Raleigh, NC, USA, 29 June–2 July 2016; pp. 406–411. [Google Scholar]
- Kizilcec, R.F.; Halawa, S. Attrition and achievement gaps in online learning. In Proceedings of the 2nd ACM conference on Learning@ Scale, Vancouver, BC, Canada, 14–18 March 2015; pp. 57–66. [Google Scholar]
- Bote-Lorenzo, M.L.; Gómez-Sánchez, E. An Approach to Build in situ Models for the Prediction of the Decrease of Academic Engagement Indicators in Massive Open Online Courses. J. Univ. Comput. Sci. 2018, 24, 1052–1071. [Google Scholar]
- Whitehill, J.; Mohan, K.; Seaton, D.; Rosen, Y.; Tingley, D. MOOC dropout prediction: How to measure accuracy? In Proceedings of the 4th ACM Conference on Learning@ Scale, Cambridge, MA, USA, 20–21 April 2017; pp. 161–164. [Google Scholar]
- EdX Research Guide. Available online: https://media.readthedocs.org/pdf/devdata/latest/devdata.pdf (accessed on 8 July 2019).
- Pelánek, R. Metrics for evaluation of student models. J. Educ. Data Min. 2015, 7, 1–19. [Google Scholar]
- Jeni, L.A.; Cohn, J.F.; De La Torre, F. Facing Imbalanced Data—Recommendations for the Use of Performance Metrics. In Proceedings of the 5th International Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 245–251. [Google Scholar]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding variable importances in forests of randomized trees. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 431–439. [Google Scholar]
- Moreno-Marcos, P.M.; Muñoz-Merino, P.J.; Alario-Hoyos, C.; Delgado Kloos, C. Analyzing students’ persistence using an event-based model. In Proceedings of the Learning Analytics Summer Institute Spain 2019, Vigo, Spain, 27–28 June 2019. [Google Scholar]
- Gašević, D.; Dawson, S.; Rogers, T.; Gasevic, D. Learning analytics should not promote one size fits all: The effects of instructional conditions in predicting academic success. Int. High. Educ. 2016, 28, 68–84. [Google Scholar] [CrossRef]


{kind=link}
| ID | Variable | Description |
|---|---|---|
| Variables related to accesses to the platform | ||
| 1 | streak_acc | Longest consecutive run of accesses to the platform |
| 2 | ndays | Number of days the student has access to the platform |
| 3 | avg_con | Average number of consecutive days that the student accesses the platform |
| 4 | per_pc | Percentage of accesses from a PC (not from a mobile, tablet, etc.) |
| 5 | per_wk | Percentage of accesses during weekend |
| 6 | per_night | Percentage of accesses during evening/night |
| Variables related to interactions with videos | ||
| 7 | per_vtotal | Viewed percentage of total video time |
| 8 | per_compl | Percentage of completed videos |
| 9 | per_open | Percentage of opened videos |
| 10 | avg_rep | Average number of repetitions per video |
| 11 | avg_pause | Average number of pauses per video |
| Variables related to interactions with exercises | ||
| 12 | per_attempt | Percentage of attempted exercises over the total |
| 13 | avg_grade | Average grade of formative exercises (only using the first attempts) |
| 14 | avg_attempt | Average number of attempts in the exercises attempted |
| 15 | per_correct | Percent of correctness using all attempts (average grade). This variable matches with the percentage of correct exercises over attempted when exercises are binary. |
| 16 | CFA | Number of 100% correct exercises in the first attempt |
| 17 | streak_ex | Longest consecutive run of correct exercises |
| 18 | nshow | Number of times the user asks for the solution of an exercise (without submitting an answer) |
| Course | Year | No. Students | Students Who Watched at Least 1 Video | Students Who Attempted at Least 1 Exercise |
|---|---|---|---|---|
| Chemistry | 2016/2017 | 1062 | 750 | 680 |
| Physics | 730 | 606 | ||
| Chemistry | 2017/2018 | 1131 | 936 | 834 |
| Physics | 856 | 767 |
| Period | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
|---|---|---|---|---|---|---|---|
| End date of the period | 22/10 | 14/01 | 07/04 | 06/05 | 05/07 | 30/08 | |
| Students included | 33 | 79 | 104 | 107 | 113 | 114 | 114 |
| % activity included | 2.2% | 13.4% | 31.0% | 42.6% | 77.6% | 99.8% | 100% |
| RF | 0.46 | 0.45 | 0.70 | 0.78 | 0.84 | 0.87 | 0.87 |
| GLM | 0.59 | 0.71 | 0.72 | 0.73 | 0.74 | 0.77 | 0.77 |
| SVM | 0.55 | 0.51 | 0.72 | 0.73 | 0.84 | 0.85 | 0.85 |
| DT | 0.50 | 0.50 | 0.70 | 0.71 | 0.78 | 0.80 | 0.80 |
| Variable | VI | CR | Variable | VI | CR |
|---|---|---|---|---|---|
| streak_acc | 0.35 | 0.14 | avg_rep | 1.55 | 0.26 |
| ndays | 2.67 | 0.26 | avg_pause | 1.41 | 0.07 |
| avg_con | 0.64 | 0.04 | per_attempt | 1.33 | 0.30 |
| per_pc | 1.08 | 0.12 | avg_grade | 8.42 | 0.44 |
| per_wk | 1.13 | 0.14 | avg_attempt | 1.41 | 0.38 |
| per_night | 1.96 | 0.08 | per_correct | 2.14 | 0.47 |
| per_vtotal | 1.11 | 0.21 | CFA | 1.15 | 0.35 |
| per_compl | 0.62 | 0.19 | streak_ex | 2.12 | 0.40 |
| per_open | 2.10 | 0.24 | nshow | 2.34 | 0.21 |
| Course | AUC | Top 5 Predictors (in Order) |
|---|---|---|
| Chemistry 2016/2017 | 0.87 | avg_grade (100), ndays (29), nshow (25), per_correct (22), streak_ex (22) |
| Physics 2016/2017 | 0.87 | avg_grade (100), avg_pause (29), per_attempt (23), avg_rep (21), per_correct (18) |
| Physics + Chemistry 2016/2017 | 0.88 | avg_grade (100, PH), avg_grade (97, CH), per_correct (33, CH), steak_ex (33, CH), per_open (31, CH) |
| Chemistry 2017/2018 | 0.77 | avg_grade (100), avg_rep (53), avg_attemp (40), CFA (34), ndays (27) |
| Physics 2017/2018 | 0.86 | avg_grade (100), per_correct (54), avg_attempt (35), per_compl (32), CFA (28) |
| Physics + Chemistry 2017/2018 | 0.84 | avg_grade (100, PH), avg_grade (65, CH), avg_rep (41, CH), per_correct (39, PH), avg_attempt (38, CH) |
| Experiment | Course Used for Training | Course Used for Prediction | AUC |
|---|---|---|---|
| (a) Within the same cohort | Chemistry 16/17 | Physics 16/17 | 0.88 |
| Physics 16/17 | Chemistry 16/17 | 0.89 | |
| Chemistry 17/18 | Physics 17/18 | 0.87 | |
| Physics 17/18 | Chemistry 17/18 | 0.83 | |
| (b) Within the same course but different cohort | Chemistry 16/17 | Chemistry 17/18 | 0.79 |
| Physics 16/17 | Physics 17/18 | 0.79 | |
| (c) Using a different course and cohort | Chemistry 16/17 | Physics 17/18 | 0.75 |
| Physics 16/17 | Chemistry 17/18 | 0.63 | |
| (d) Using the combination of SPOCs in different cohorts | Physics + Chemistry 16/17 | Physics + Chemistry 17/18 | 0.74 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moreno-Marcos, P.M.; De Laet, T.; Muñoz-Merino, P.J.; Van Soom, C.; Broos, T.; Verbert, K.; Delgado Kloos, C. Generalizing Predictive Models of Admission Test Success Based on Online Interactions. Sustainability 2019, 11, 4940. https://doi.org/10.3390/su11184940
Moreno-Marcos PM, De Laet T, Muñoz-Merino PJ, Van Soom C, Broos T, Verbert K, Delgado Kloos C. Generalizing Predictive Models of Admission Test Success Based on Online Interactions. Sustainability. 2019; 11(18):4940. https://doi.org/10.3390/su11184940
Chicago/Turabian StyleMoreno-Marcos, Pedro Manuel, Tinne De Laet, Pedro J. Muñoz-Merino, Carolien Van Soom, Tom Broos, Katrien Verbert, and Carlos Delgado Kloos. 2019. "Generalizing Predictive Models of Admission Test Success Based on Online Interactions" Sustainability 11, no. 18: 4940. https://doi.org/10.3390/su11184940
APA StyleMoreno-Marcos, P. M., De Laet, T., Muñoz-Merino, P. J., Van Soom, C., Broos, T., Verbert, K., & Delgado Kloos, C. (2019). Generalizing Predictive Models of Admission Test Success Based on Online Interactions. Sustainability, 11(18), 4940. https://doi.org/10.3390/su11184940