Applying Machine Learning and Statistical Approaches for Travel Time Estimation in Partial Network Coverage


Abstract
1. Introduction
2. Literature Review
3. Methodology
3.1. Neighbor Link Allocation
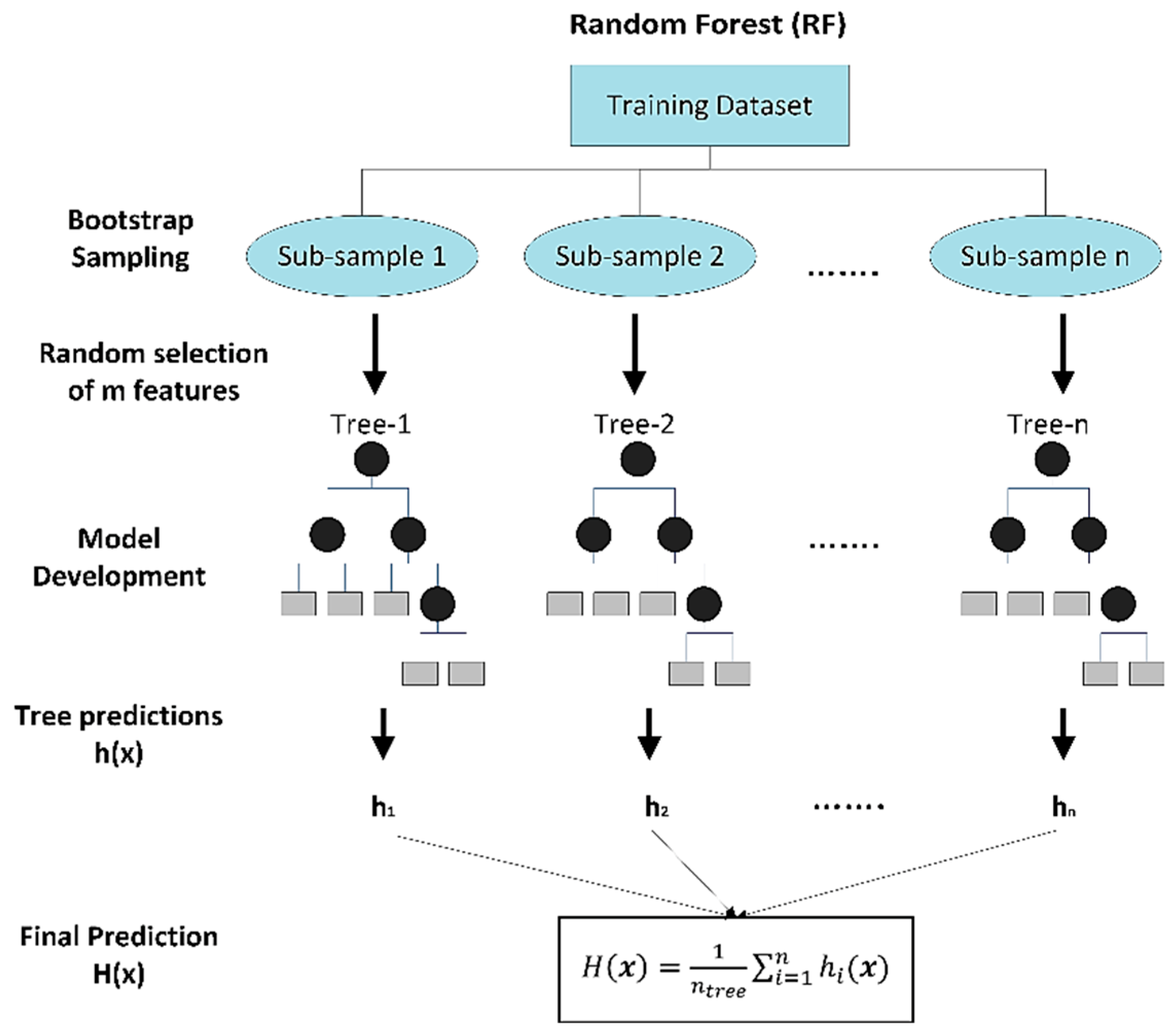
3.2. Random Forest Model
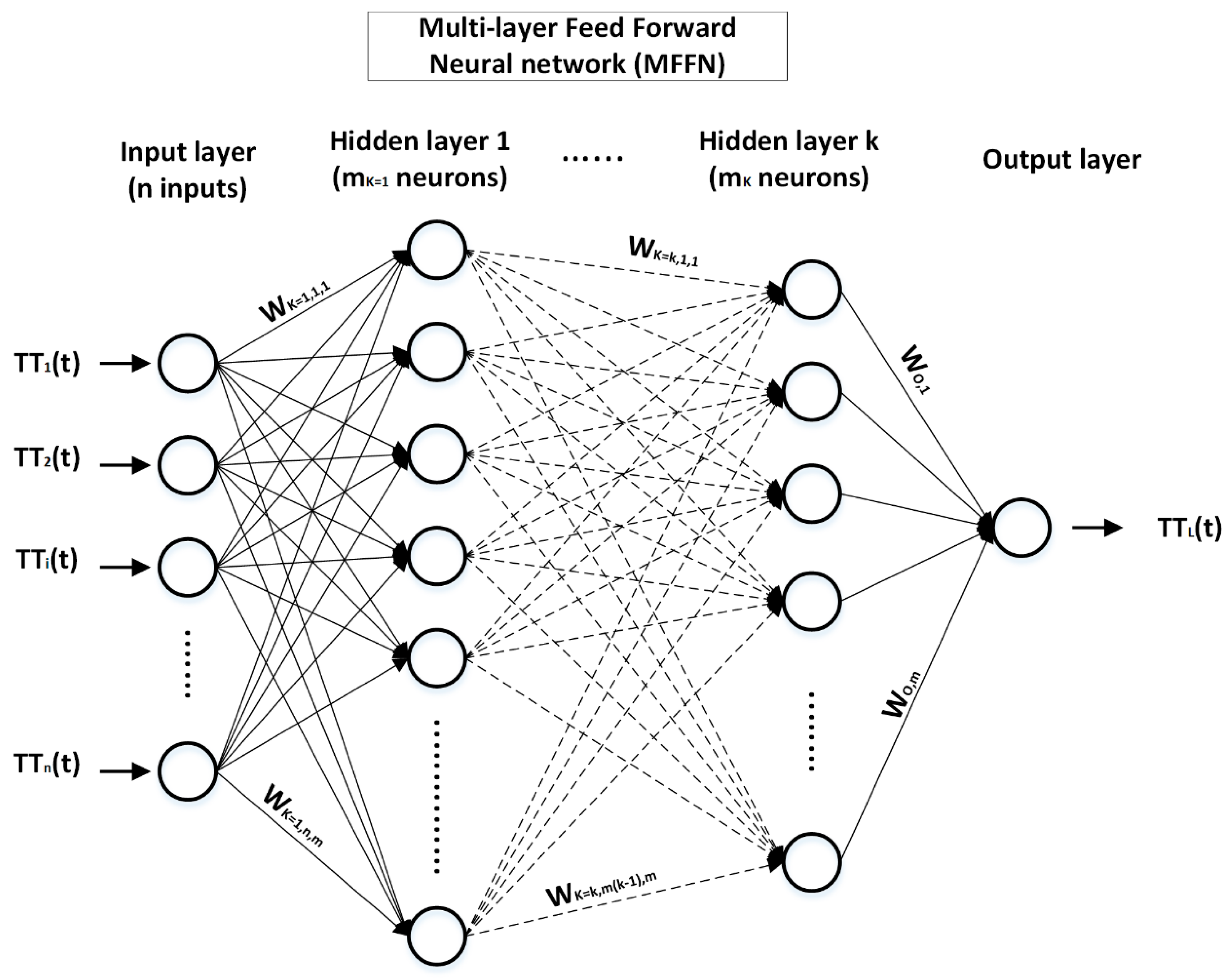
3.3. Artificial Neural Network Model
3.4. Statistical Model
4. Models Application
4.1. Urban Road Network
4.2. Data Preparation
4.2.1. Travel Time Re-Sampling Process
4.2.2. Data for Training and Testing
4.3. Performance Evaluation
5. Results
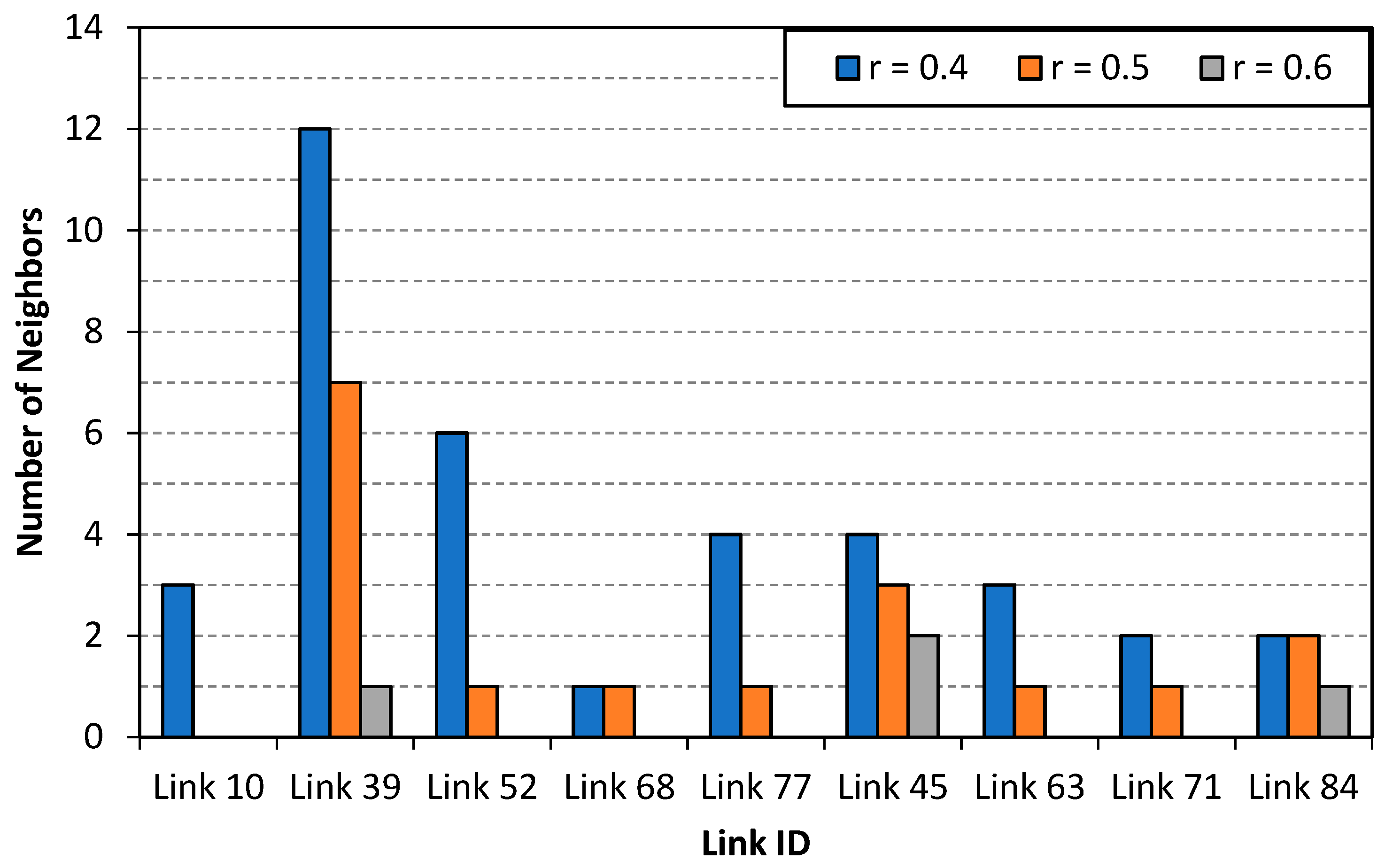
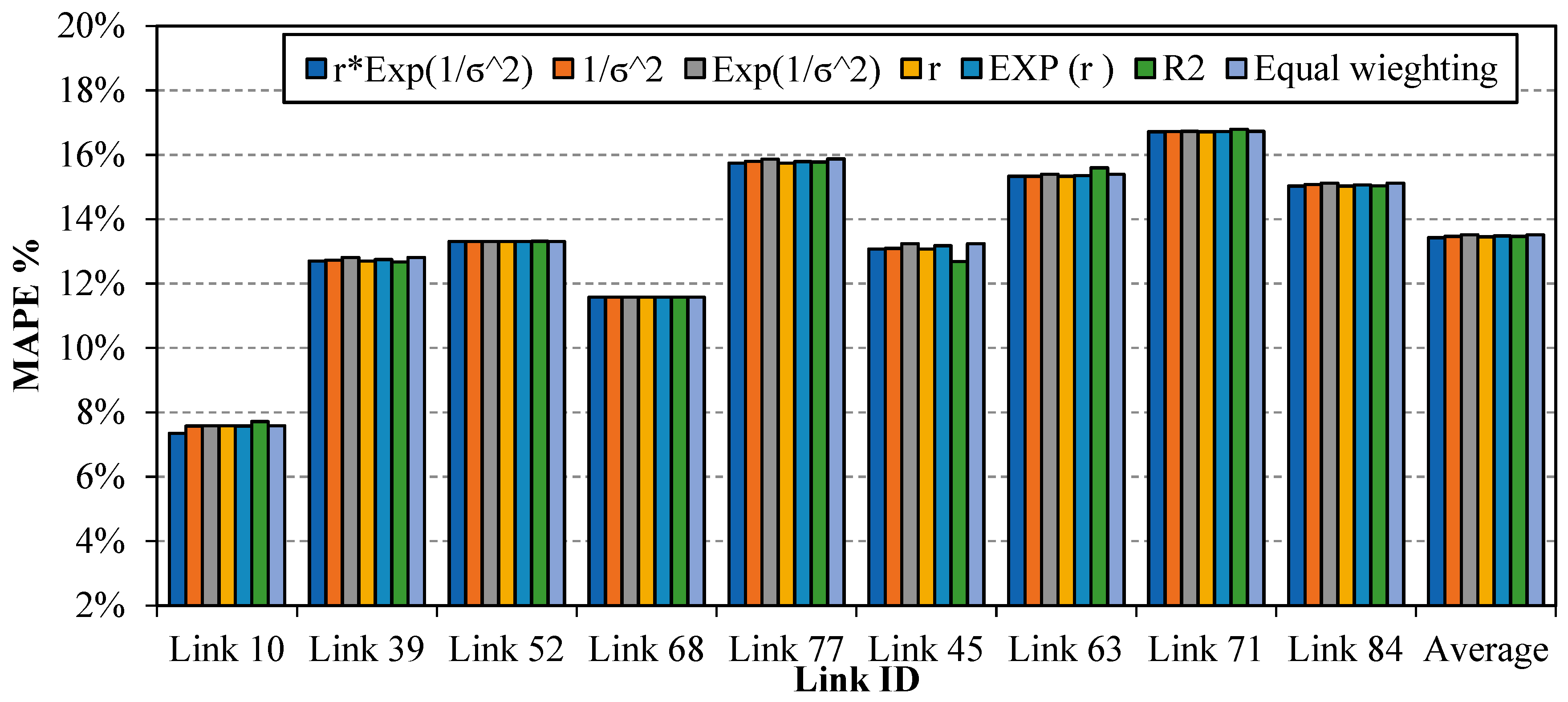
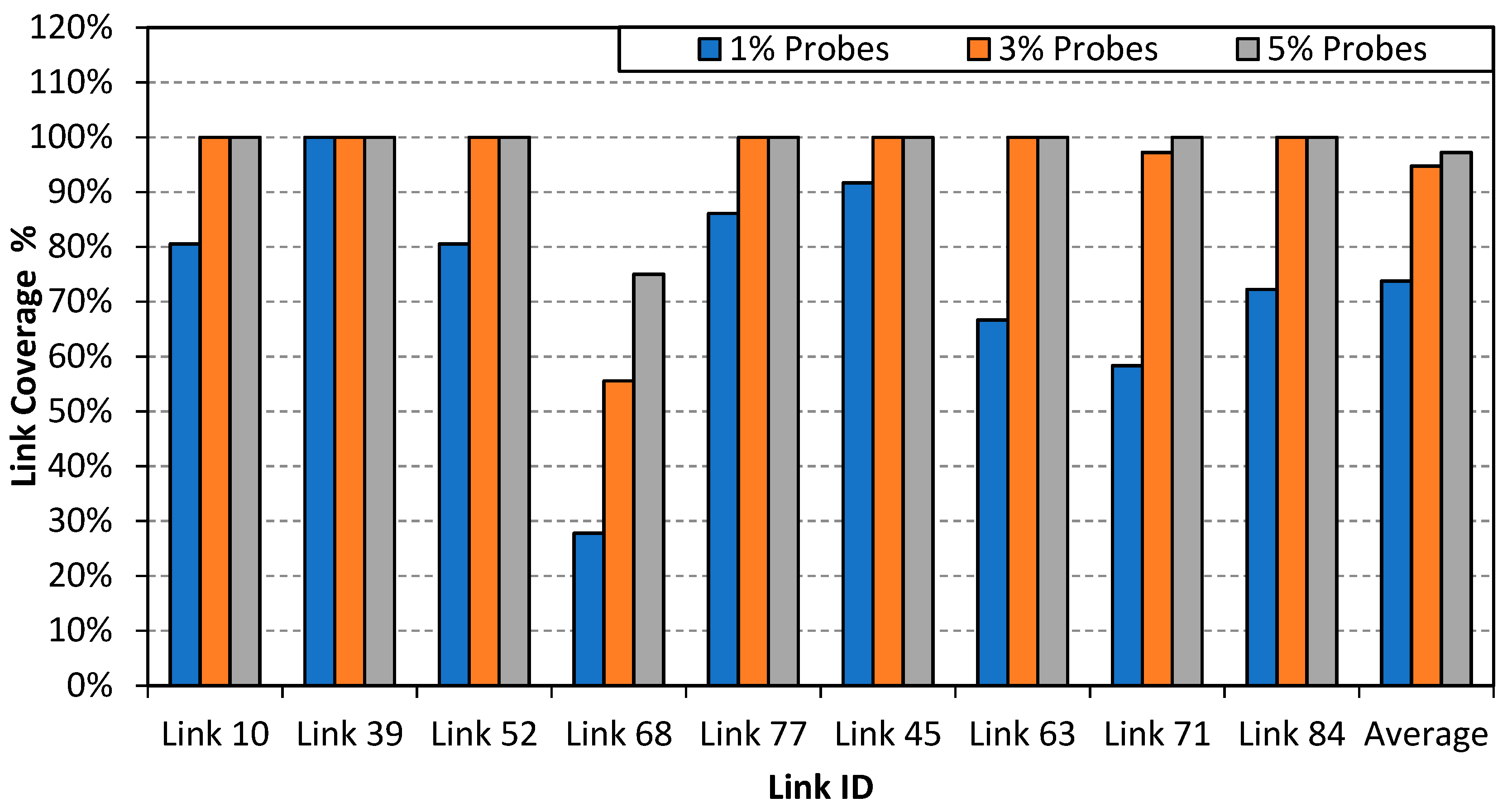
5.1. Link Neighbors Identification
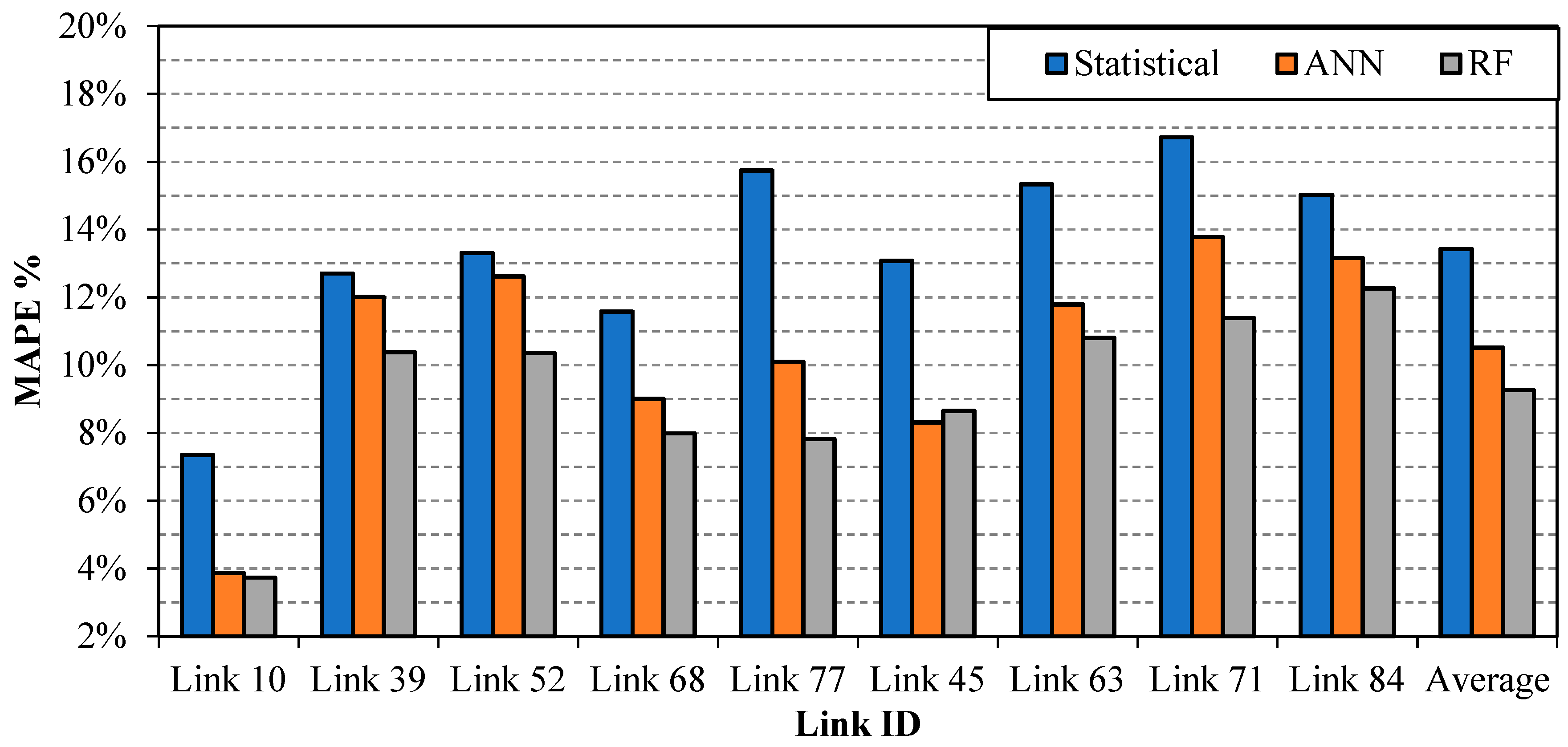
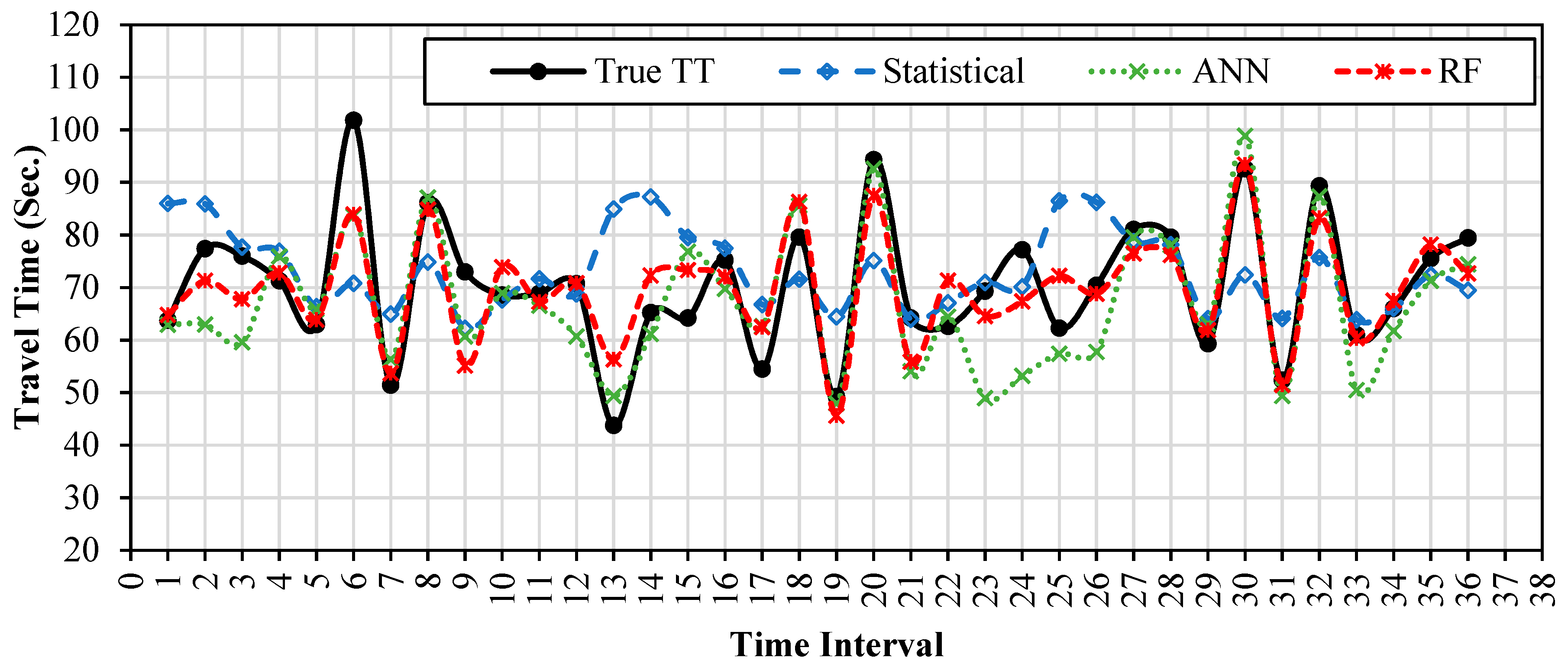
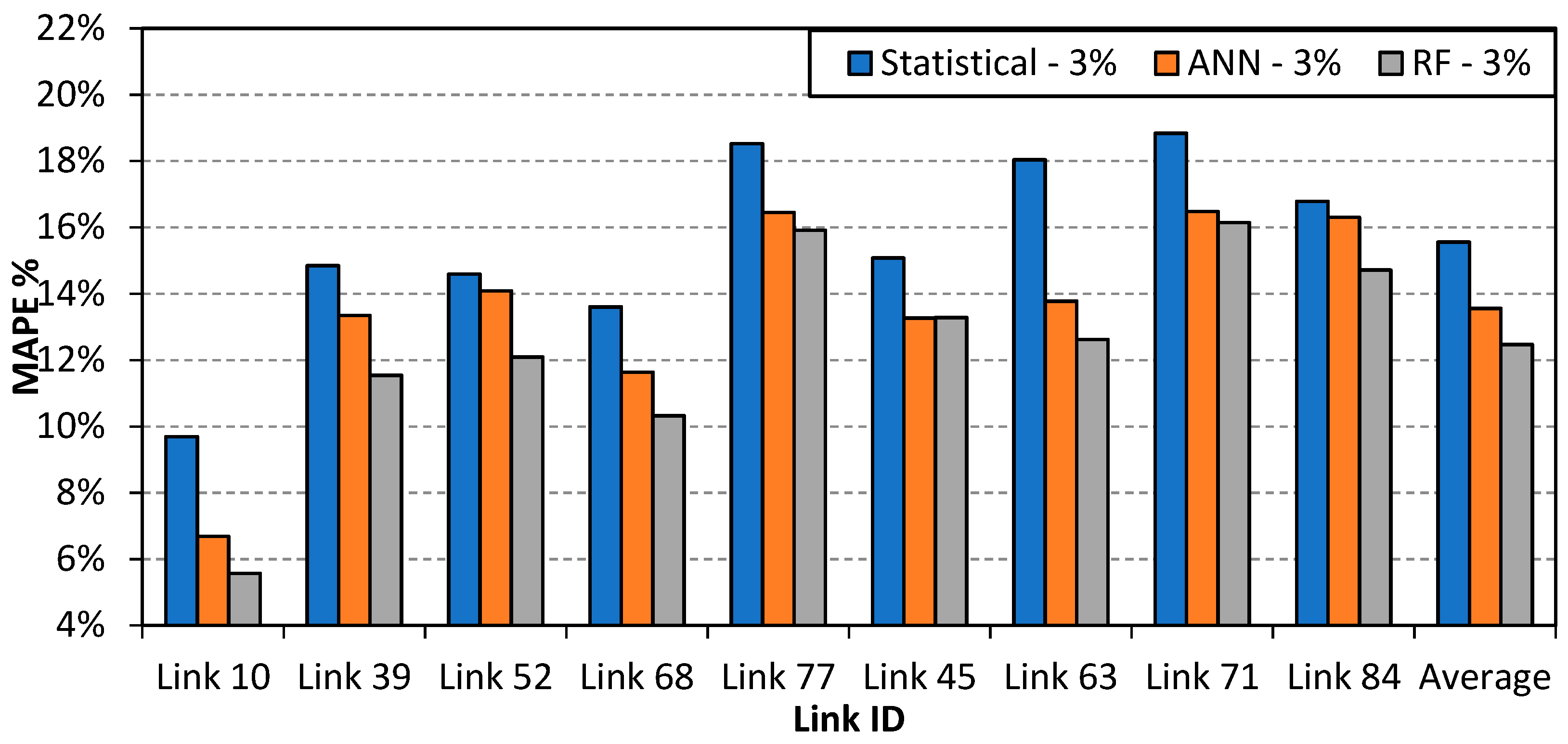
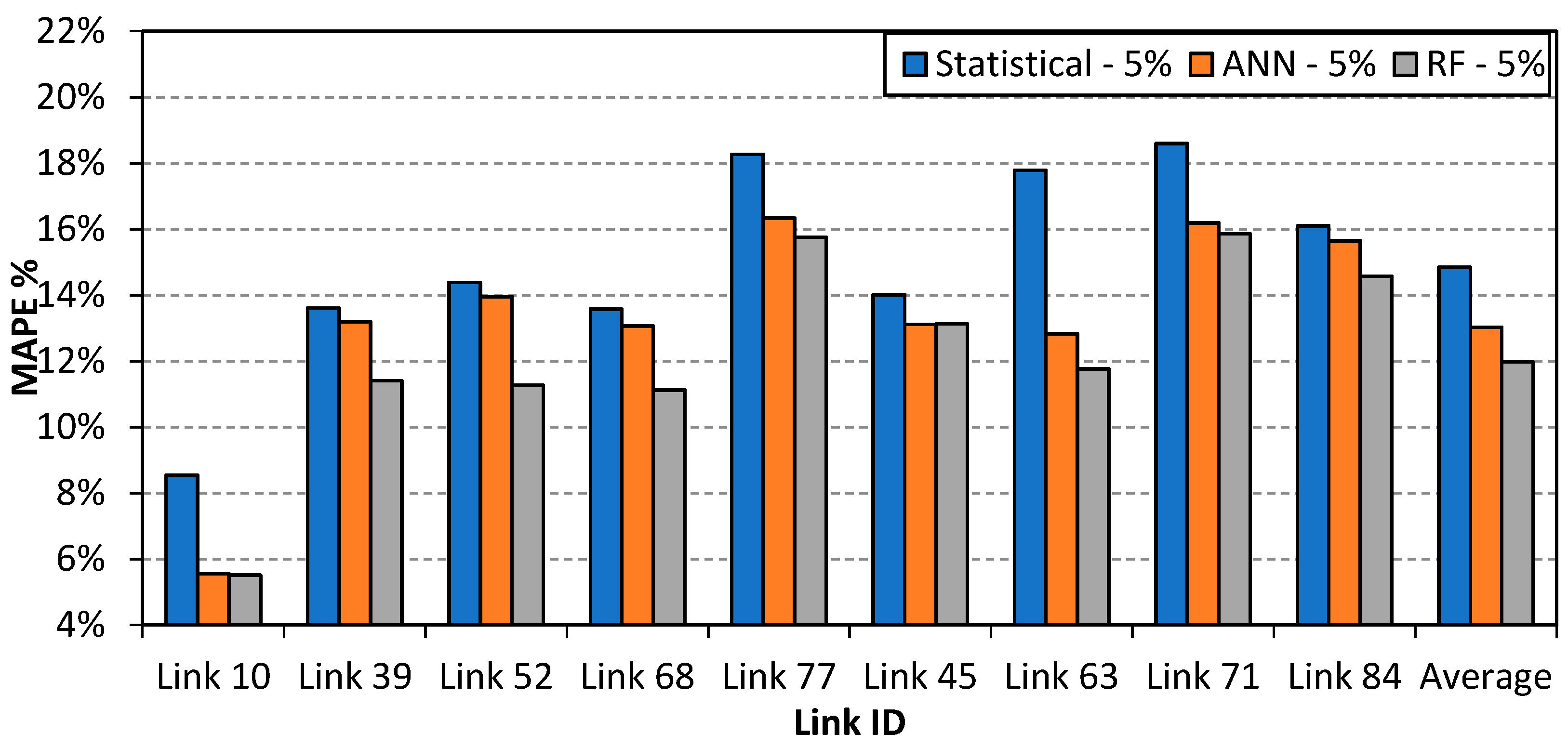
5.2. Travel Time Estimation Models
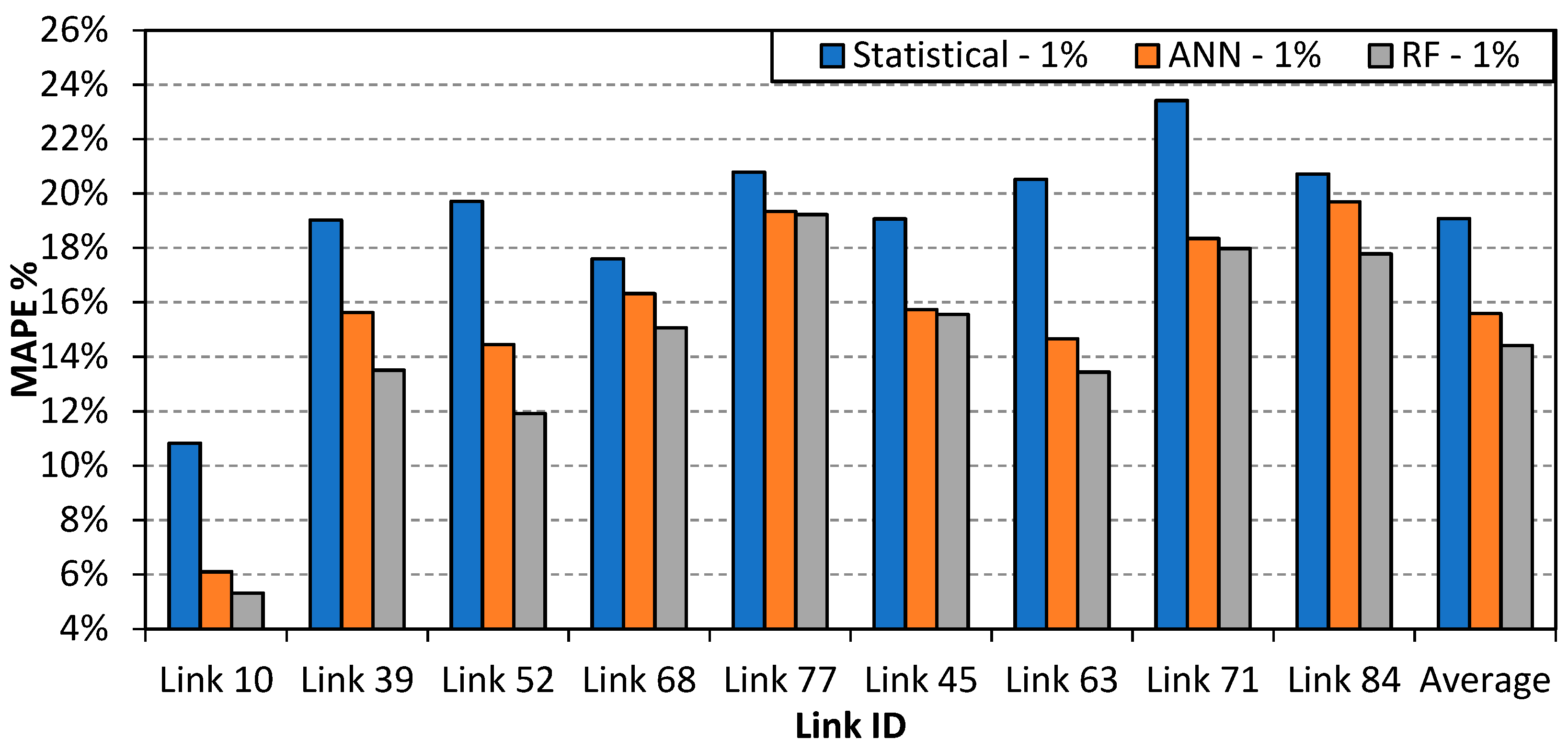
5.3. Model Performance in Partial Network Coverage
6. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, L.; Chen, X.; Li, Z.; Zhang, L. Freeway Travel-Time Estimation Based on Temporal–Spatial Queueing Model. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1536–1541. [Google Scholar] [CrossRef]
- Coifman, B. Estimating travel times and vehicle trajectories on freeways using dual loop detectors. Transp. Res. Part A Policy Pr. 2002, 36, 351–364. [Google Scholar] [CrossRef]
- Zheng, F.; Van Zuylen, H. Urban link travel time estimation based on sparse probe vehicle data. Transp. Res. Part C Emerg. Technol. 2013, 31, 145–157. [Google Scholar] [CrossRef]
- Rahmani, M.; Koutsopoulos, H.N.; Jenelius, E. Travel time estimation from sparse floating car data with consistent path inference: A fixed point approach. Transp. Res. Part C Emerg. Technol. 2017, 85, 628–643. [Google Scholar] [CrossRef]
- Tang, K.; Chen, S.; Liu, Z.; Khattak, A.J. A tensor-based Bayesian probabilistic model for citywide personalized travel time estimation. Transp. Res. Part C Emerg. Technol. 2018, 90, 260–280. [Google Scholar] [CrossRef]
- Sanaullah, I.; Quddus, M.; Enoch, M. Developing Travel Time Estimation Methods Using Sparse GPS Data. J. Intell. Transp. Syst. 2016, 20, 532–544. [Google Scholar] [CrossRef]
- Rilett, L.R.; Park, D. Direct Forecasting of Freeway Corridor Travel Times Using Spectral Basis Neural Networks. Transp. Res. Rec. J. Transp. Res. Board 2001, 1752, 140–147. [Google Scholar] [CrossRef]
- Chen, B.Y.; Lam, W.H.; Sumalee, A.; Li, Z.-L. Reliable shortest path finding in stochastic networks with spatial correlated link travel times. Int. J. Geogr. Inf. Sci. 2012, 26, 365–386. [Google Scholar] [CrossRef]
- Chan, K.S.; Lam, W.H.K.; Tam, M.L. Real time Estimation of Arterial Travel Times with Spatial Travel Time Covariance Relationships. Transp. Res. Rec. J. Transp. Res. Board 2009, 2121, 102–109. [Google Scholar] [CrossRef]
- El Esawey, M.; Sayed, T. Travel time estimation in urban networks using limited probes data. Can. J. Civ. Eng. 2011, 38, 305–318. [Google Scholar] [CrossRef]
- Alrukaibi, F.; Alsaleh, R.; Sayed, T. Real time travel time estimation in partial network coverage: A case study in Kuwait City. Adv. Transp. Stud. 2018, 44, 79–94. [Google Scholar]
- Jenelius, E.; Koutsopoulos, H.N. Travel time estimation for urban road networks using low frequency probe vehicle data. Transp. Res. Part B Methodol. 2013, 53, 64–81. [Google Scholar] [CrossRef]
- Liu, H.X.; Ma, W. A virtual vehicle probe model for time-dependent travel time estimation on signalized arterials. Transp. Res. Part C Emerg. Technol. 2009, 17, 11–26. [Google Scholar] [CrossRef]
- Jula, H.; Dessouky, M.; Ioannou, P.A. Real time Estimation of Travel Times along the Arcs and Arrival Times at the Nodes of Dynamic Stochastic Networks. IEEE Trans. Intell. Transp. Syst. 2008, 9, 97–110. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y.; Chen, P.; He, Z.; Yu, G. Probe data-driven travel time forecasting for urban expressways by matching similar spatiotemporal traffic patterns. Transp. Res. Part C Emerg. Technol. 2017, 85, 476–493. [Google Scholar] [CrossRef]
- Gajewski, B.J.; Rilett, L.R. Estimating link travel time correlation: An application of Bayesian smoothing splines. J. Transp. Stat. 2005, 7, 53–70. [Google Scholar]
- Zeng, W.; Miwa, T.; Wakita, Y.; Morikawa, T. Application of Lagrangian relaxation approach to α -reliable path finding in stochastic networks with correlated link travel times. Transp. Res. Part C Emerg. Technol. 2015, 56, 309–334. [Google Scholar] [CrossRef]
- Seo, T.; Kusakabe, T. Probe vehicle-based traffic state estimation method with spacing information and conservation law. Transp. Res. Part C Emerg. Technol. 2015, 59, 391–403. [Google Scholar] [CrossRef]
- Hellinga, B.; Fu, L. Assessing Expected Accuracy of Probe Vehicle Travel Time Reports. J. Transp. Eng. 1999, 125, 524–530. [Google Scholar] [CrossRef]
- El Esawey, M.; Sayed, T. A framework for neighbour links travel time estimation in an urban network. Transp. Plan. Technol. 2012, 35, 281–301. [Google Scholar] [CrossRef]
- Muknahallipatna, S.; Chowdhury, B.H. Input Dimension Reduction in Neural Network Training-Case Study in Transient Stability Assessment of Large Systems. In Proceedings of the International Conference on Intelligent System Application to Power Systems, Orlando, FL, USA, 28 January–2 February 1996. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.; Franklin, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 12th ed.; Springer Series in Statistics: New York, NY, USA, 2017. [Google Scholar]
- Biau, G. Analysis of a random forests model. J. Mach. Learn. Res. 2012, 13, 1063–1095. [Google Scholar]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How Many Trees in a Random Forest? In Machine Learning and Data Mining in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Laña, I.; Lobo, J.L.; Capecci, E.; Del Ser, J.; Kasabov, N. Adaptive long-term traffic state estimation with evolving spiking neural networks. Transp. Res. Part C Emerg. Technol. 2019, 101, 126–144. [Google Scholar] [CrossRef]
- Torlai, G.; Mazzola, G.; Carrasquilla, J.; Troyer, M.; Melko, R.; Carleo, G. Neural-network quantum state tomography. Nat. Phys. 2018, 14, 447–450. [Google Scholar] [CrossRef]
- Fausett, L. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications; Englewood Cliffs: Prentice-Hall, NJ, USA, 1994. [Google Scholar]
- Levenherg, K. A method for the solution of certain problems in least squares. Quart. Appl. Math. 1994, 2, 164–168. [Google Scholar] [CrossRef]
- Marquardt, D.W. An Algorithm for Least-Squares Estimation of Nonlinear Parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- El Esawey, M.; Sayed, T. Using buses as probes for neighbor links travel time estimation in an urban network. Transp. Lett. 2011, 3, 279–292. [Google Scholar] [CrossRef]
- Sen, A.; Thakuriah, P.; Zhu, X.Q.; Karr, A. Frequency of probe reports and variance of travel time estimates. J. Transp. Eng. 1997, 123, 290–297. [Google Scholar] [CrossRef]
- Alsaleh, R.; Sayed, T.; Zaki, M.H. Assessing the Effect of Pedestrians’ Use of Cell Phones on Their Walking Behavior: A Study Based on Automated Video Analysis. Transp. Res. Rec. J. Transp. Res. Board. 2018, 2672, 46–57. [Google Scholar] [CrossRef]
- Alsaleh, R.; Hussein, M.; Sayed, T. Microscopic Behavioural Analysis of Cyclists and Pedestrians Interactions in Shared Space. Can. J. Civ. Eng. 2019. In press. [Google Scholar] [CrossRef]
- Abduljabbar, R.; Dia, H.; Liyanage, S.; Bagloee, S. Applications of artificial intelligence in transport: An overview. Sustainability 2019, 11, 189. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training dataset: traffic demand levels as a percentage of the pm peak demand | 60%, 65%, 70%, 80%, 90%, 100%, 105% |
| Testing (Validation) dataset: traffic demand levels as a percentage of the pm peak demand | 75%, 85%, 95% |
| Simulation period for each demand level | 60 min |
| Sampling interval | 5 min |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alrukaibi, F.; Alsaleh, R.; Sayed, T. Applying Machine Learning and Statistical Approaches for Travel Time Estimation in Partial Network Coverage. Sustainability 2019, 11, 3822. https://doi.org/10.3390/su11143822
Alrukaibi F, Alsaleh R, Sayed T. Applying Machine Learning and Statistical Approaches for Travel Time Estimation in Partial Network Coverage. Sustainability. 2019; 11(14):3822. https://doi.org/10.3390/su11143822
Chicago/Turabian StyleAlrukaibi, Fahad, Rushdi Alsaleh, and Tarek Sayed. 2019. "Applying Machine Learning and Statistical Approaches for Travel Time Estimation in Partial Network Coverage" Sustainability 11, no. 14: 3822. https://doi.org/10.3390/su11143822
APA StyleAlrukaibi, F., Alsaleh, R., & Sayed, T. (2019). Applying Machine Learning and Statistical Approaches for Travel Time Estimation in Partial Network Coverage. Sustainability, 11(14), 3822. https://doi.org/10.3390/su11143822