1. Introduction
A company with sustainable technology can maintain technological competitiveness in the marketplace [
1,
2]. Most companies have tried to find their sustainable areas for technological innovation and new product development. Therefore, sustainable technology is an important issue in the management of technology (MOT) [
3]. Many academics, research institutes, and companies have studied sustainable technologies. Recently, Kim et al. (2018) published a statistical method for sustainable technology analysis [
4]. They considered Bayesian inference and social network analysis for the proposed method and applied their research to the technology domain related to artificial intelligence (AI). They also used the IPC (international patent classification) codes extracted from patent documents as input data for sustainable technology analysis. The IPC is a hierarchical system of technologies for the classification of patents [
5]. For example, the IPC code G06F represents electric digital data processing technology [
6]. In general, IPC codes cover a wide range of technologies. Thus, it is difficult for us to grasp the detailed technological structure of a specific technology field. In order to overcome this problem, we propose a technology analysis method using patent keywords. The keywords are extracted from patent documents related to specific technology through text mining techniques [
7]. Therefore, the technology keyword can represent a more detailed description of a specific technology field than the IPC code for sustainable technology analysis. In addition, we propose a statistical modeling using Bayesian count data analysis for understanding sustainability of a given technology domain. The count of event is the number of times an event occurs [
8]. In this paper, each patent keyword is an event, and we analyzed the count data of patent keywords. We considered the Poisson probability distribution for the proposed statistical patent analysis model, because the count data of patent keywords are nonnegative integer values [
9]. We also combined the Poisson count model with Bayesian regression analysis to build Bayesian count data modeling for finding technological sustainability. In this paper, we looked for sustainable technologies from the predictive keywords that have the most significant impact on the dependent keywords that represent the target technology. For example, if AI (artificial intelligence) is the target technology, ‘artificial’ and ‘intelligence’ become response keywords (variables), and other keywords, except ‘artificial’ and ‘intelligence’, such as ‘learning’, ‘visual’, and ‘language’, are predictive variables. Therefore, we carried out Bayesian count data modeling to find technological sustainability. To show the validity of our modeling, we performed a case study using the patent documents related to AI. The remainder of this paper is organized as follows: In
Section 2, we show the research background related to our study. We explain the proposed modeling for finding technological sustainability in
Section 3. The next section illustrates the result of our case study. In the Conclusions section, we conclude our research and describe our future work related to this paper.
3. Finding Technological Sustainability Using Bayesian Count Data Modeling
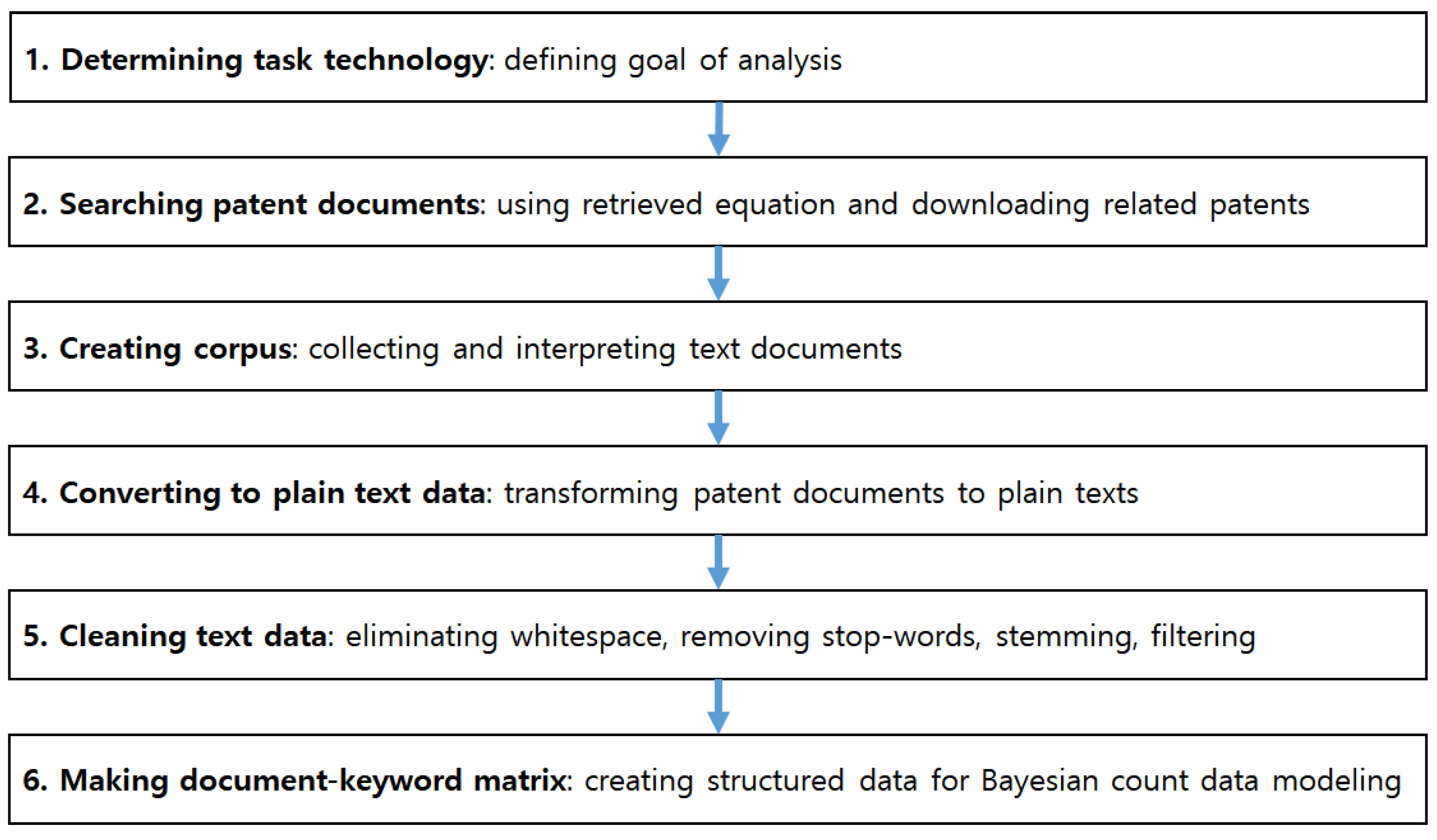
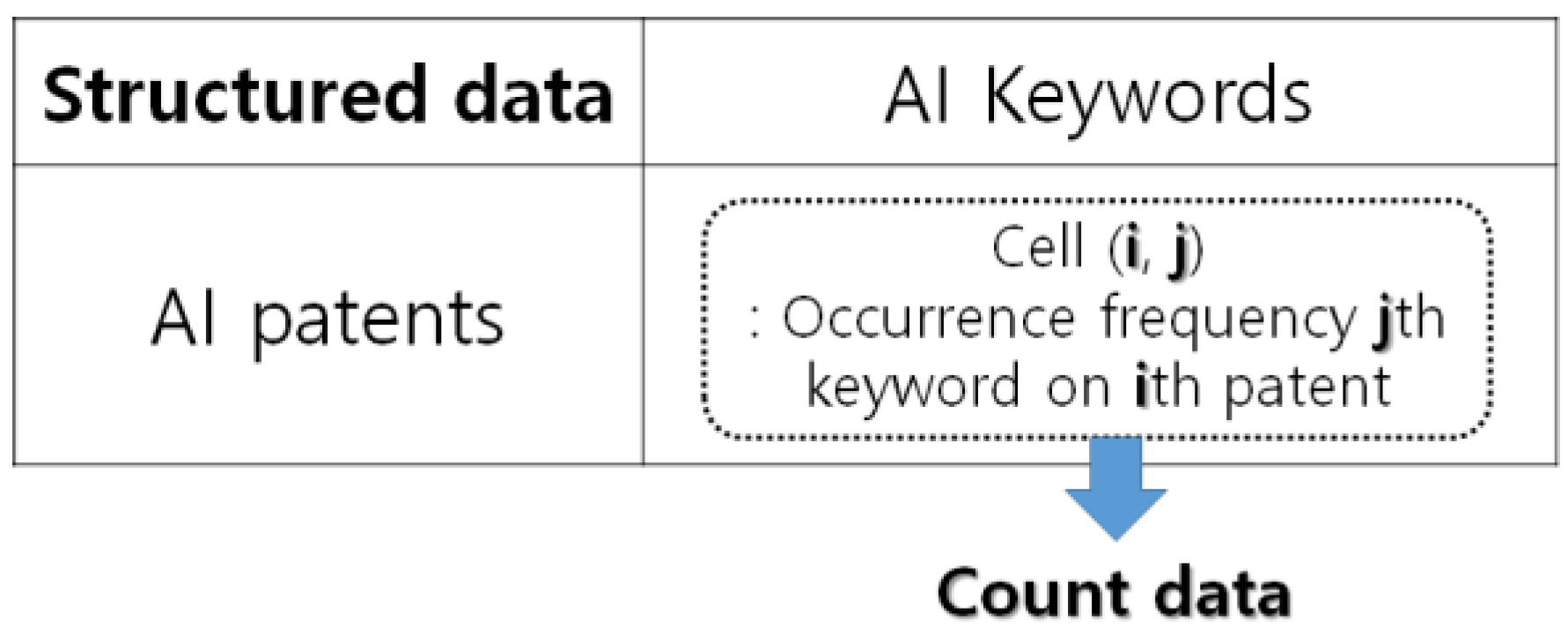
To find the sustainability of a given technology field, we need the structured data applied to Bayesian count data modeling. Therefore, to prepare the structured data, we extracted the patent keywords from the collected patent documents using text mining techniques in
Figure 1.
In our text mining process, first of all, we needed to determine the target technology for statistical analysis. Next, we used a retrieved equation to collect the patent documents related to target technology from the patent databases in the world. It is impossible to analyze the searched patent document data directly, because the data are not suitable for inputting data for statistical analysis, including Bayesian count data modeling. Thus, we tried to make structured data for statistical analysis. The first step in creating structured data is to create a corpus collecting and interpreting text documents. Based on the created corpus, we transformed the patent documents into plain texts, and cleaned the text data by eliminating whitespace, removing step-words (“and”, “for”, “in”, “is”, etc.), stemming, and filtering. Finally, we made the document–keyword matrix as structured data for Bayesian count data modeling. The matrix consisted of patents (rows) and keywords (columns), and its elements were the frequency (count) values of keywords occurring in each patent document. Next, we built a methodology using the Bayesian count data model to analyze the structured data for finding sustainable technology.
In our research, we considered Bayesian count data modeling with a Poisson distribution for finding technological sustainability. The Poisson probability distribution is the most popular model for count data. If the random variable
Y is distributed to Poisson with parameter
λ, its distribution is defined as follows [
9]:
.
where the expectation E(
Y) and variance of
Y are equal to parameter
. In addition, the likelihood function of Poisson random variable
Y is as follows [
18,
19]:
Equation (4) is in the form of
, and this is Gamma distribution with parameters
c and
d. We can therefore select Gamma distribution as conjugate prior for the Poisson parameter. In this paper, the frequency of each patent keyword extracted from patent document data is a Poisson random variable with parameter
as follows:
where m is the number of all keywords. In our modeling, we define the frequency (count) of
ith keyword, the occurring keyword as
, and represent the data set as follows [
9]:
Using this data set, we performed the generalized linear model (GLM) with Poisson probability distribution, no predictors, and log link function as follows:
We determined the response and predictor variables (keywords) by the results of the GLM. The parameter from this constant GLM model with Poisson distribution is similar to the mean of Poisson random variable. In this paper, therefore, we used the Poisson mean value by MLE (maximum likelihood estimator) instead of the constant GLM model. In addition, we considered the full GLM model using all predictor variables as well as the constant model. In our study, we used variables with large coefficient values as response variables and those with small coefficient values as explanatory variables.
In
Figure 2, Bayesian modeling has increasingly been used in diverse data analysis areas, such as regression and classification. This is one of two approaches to statistics. We started Bayesian count data modeling from the following expression [
18]:
where
is the model parameter, and
is the response variable to be predicted.
and
are the prior and posterior probabilities of parameter
respectively.
represents the likelihood function of
given
, respectively. Additionally,
is calculated by the following integration [
19]:
Using Bayesian modeling, we determined the model parameter of posterior distribution. Because we were interested in the mean of the parameters, we had to select a prior distribution to begin Bayesian modeling. In general, noninformative or informative priors can be used for the prior distribution in Bayesian modeling [
9,
19]. In our research, we used the informative prior to get the updated result for the parameter estimation. However, we needed to carry out Bayesian computing such as Markov Chain Monte Carlo (MCMC) for using the informative prior [
19]. To alleviate the computational burden, we were able to use conjugate prior.
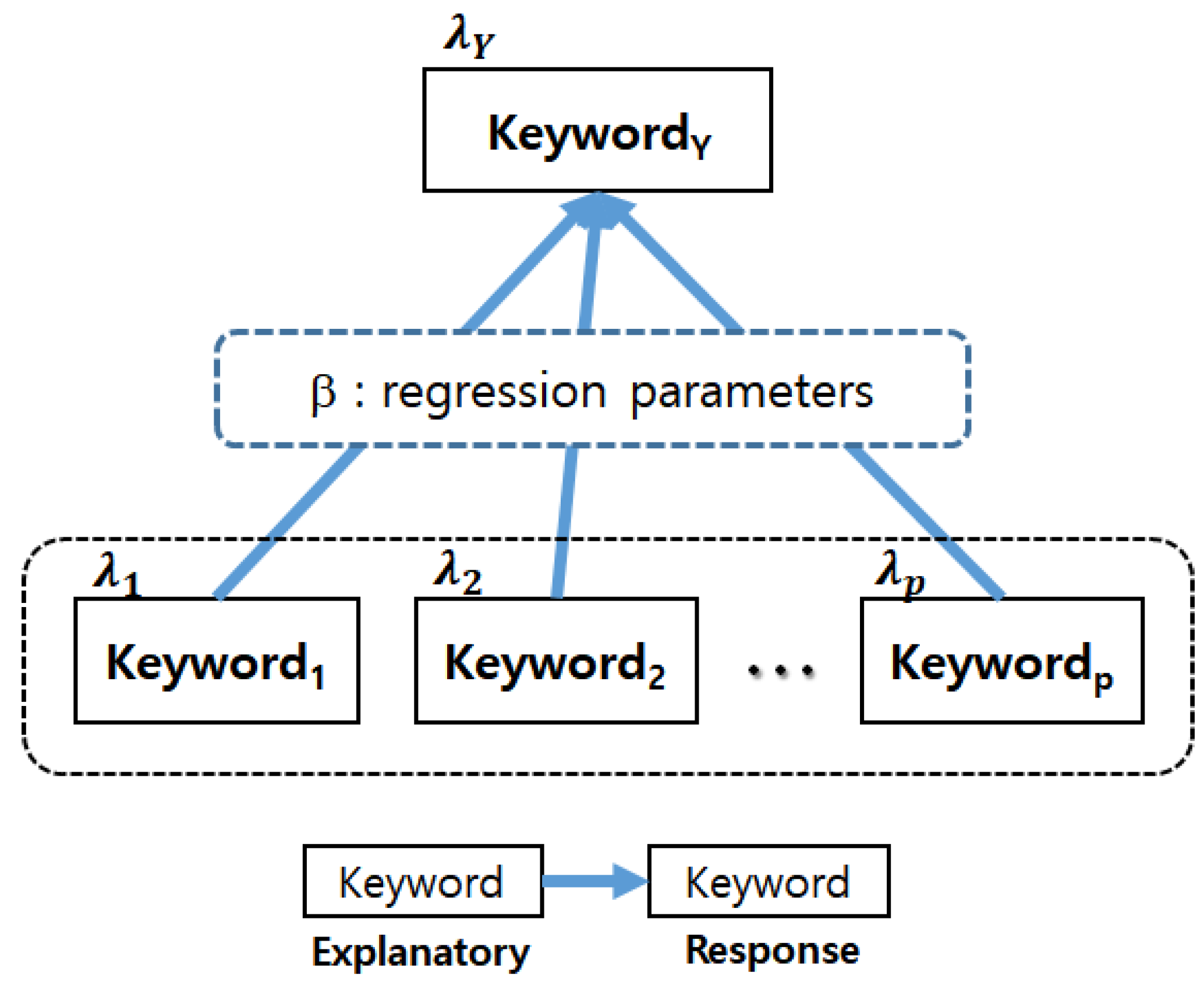
In this paper, we denoted the response variable as
Y, and the explanatory variables as
, where
p is the number of explanatory variables. We selected the keywords representing target technology as response variables, and the remaining keywords, except the response variables, were used as explanatory variables. For example, if our target technology was AI, we selected the keywords ‘Artificial’ and ‘Intelligence’ as response variables. For Bayesian count data modeling, we constructed the Poisson regression model with Gamma distribution as prior. The Poisson regression model is defined as follows [
9,
20]:
where
β is the regression parameter. Additionally, an informative Gamma prior for
is as follows:
where
is Gamma function, and
and
are
and
, respectively. This expression is used for the likelihood in Bayesian count data modeling. Thus, using the likelihood and prior distributions, we show the posterior distribution as follows:
We can ignore the terms not involving
, so we yield the proportional result of posterior distribution as follows:
This expression represents the kernel of the Gamma distribution with parameters
and
. In addition, by the characteristic of Gamma distribution, the posterior mean and variance of
are
and
, respectively. In the Bayesian Poisson regression case,
is distributed Poisson with mean
, where
is the parameter vector of Poisson regression. In our research, (
) is shown as (response keyword | explanatory keywords). Therefore, we get the Bayesian count data modeling as follows:
where
c and
d are defined in Equation (4). The posterior distribution is computed by multiplying given prior and likelihood based on data, and the calculated posterior is used as a prior at the next modeling. Using this modeling, we built a technology structure to understand the target technology from the viewpoint of sustainability in
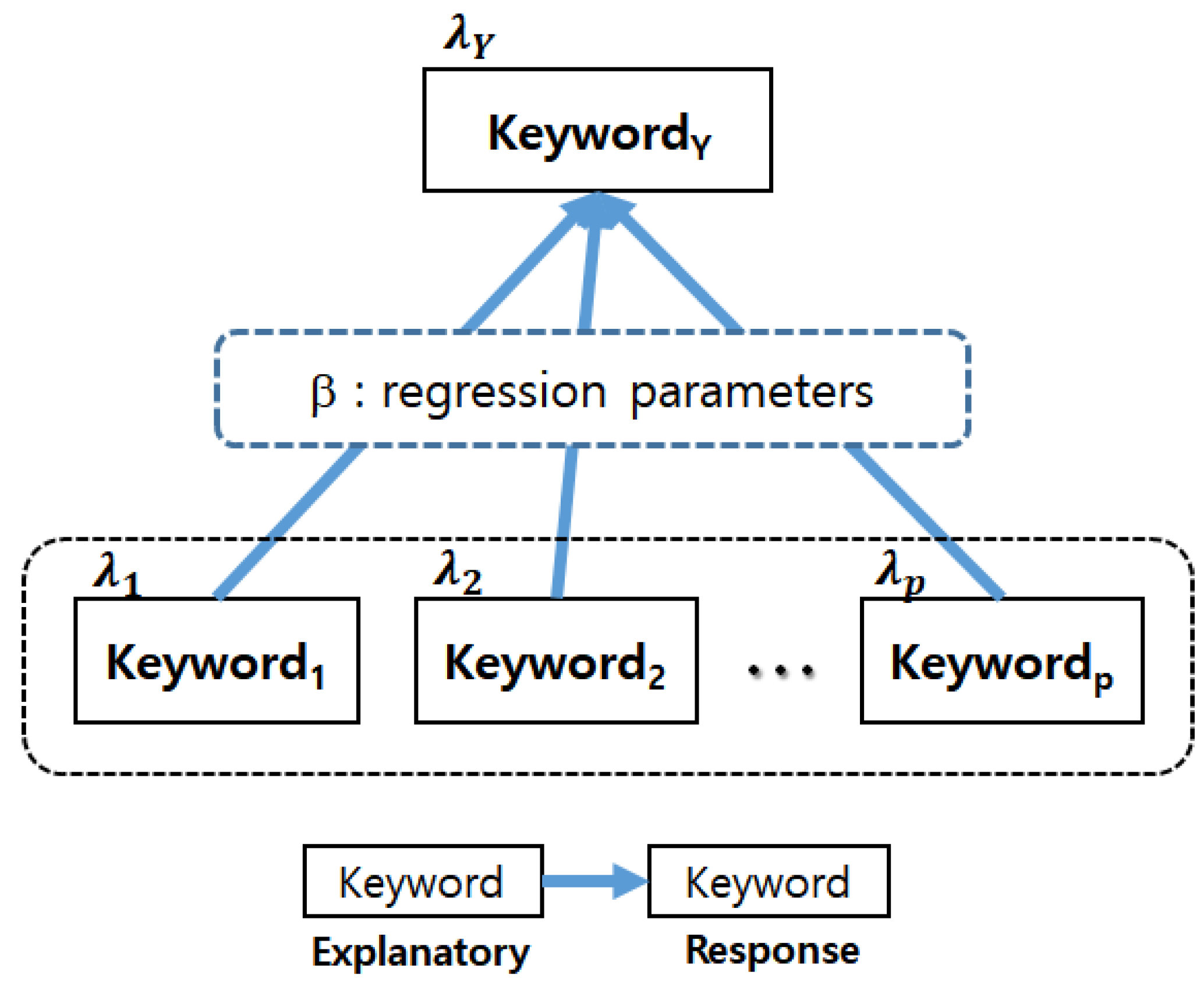
Figure 3.
In our modeling, all keywords except response were used as explanatory keywords. In
Figure 3, the keyword at the beginning of the arrow indicates the explanatory variable, and the keyword at the end of the arrow indicates the response variable. Additionally, each keyword is distributed to Poisson with parameter
. From the final result of Bayesian count data modeling, we got the regression coefficients
β between response and explanatory variables (keywords). Using
β, we built a technological structure of a target domain for sustainable technology management. This description is related to
Figure 3. That is, we selected the keywords with high impact using the Poisson parameter, which is mean value of Poisson random variable (keyword). Next, we extracted the final predictor keywords by comparing probability value (
p-value) of the regression parameters. Therefore, we selected the meaningful predictor variables in two steps. First, the predictor variables with large Poisson parameters were selected. Next, the predictor variables with relatively large regression coefficients were chosen. In order to make the scale of variables equal, we standardized variables before proceeding with Bayesian count data modeling. Bayesian count data modeling is based on the following concept in
Figure 4.
In this paper, we tried to combine the expert’s subjective knowledge and objective result from patent data analysis. That is, the prior represented the domain knowledge of experts, and the likelihood denoted the objective data based on patent documents. The result of multiplying prior and likelihood is posterior; we used this as a predictive model for finding technological sustainability. Therefore, we used the prior probability distribution to reflect the experience and knowledge of the relevant technology experts in the model. The collected patent data were represented by the likelihood function. We got the posterior distribution by multiplying the prior distribution and likelihood function. Finally, these Bayesian probability distributions were applied to the count data regression for the Bayesian count data model. Using this approach, we expect an improved performance of patent technology analysis for sustainable technology. Our model is applicable to multivariate response vector as well as univariate response variables.
This is because, depending on the technology field, there may be more than one response variable. For example, in the AI technology field, the response vector is defined as follows:
We illustrate how this research could be applied to practical problems through a case study in the next section.
4. Case Study
To show how this research could be applied to a practical problem, we performed a case study using the patent documents related to artificial intelligence (AI) technology. We collected the patents applied and registered by 2016 from the WIPSON [
21]. The total number of collected and valid patents was 11,973 cases. First of all, we consulted experts on AI and extracted the keywords related to AI from the collected patent document data [
22]. Next, using text mining techniques, we built structured patent data for performing our case study [
7,
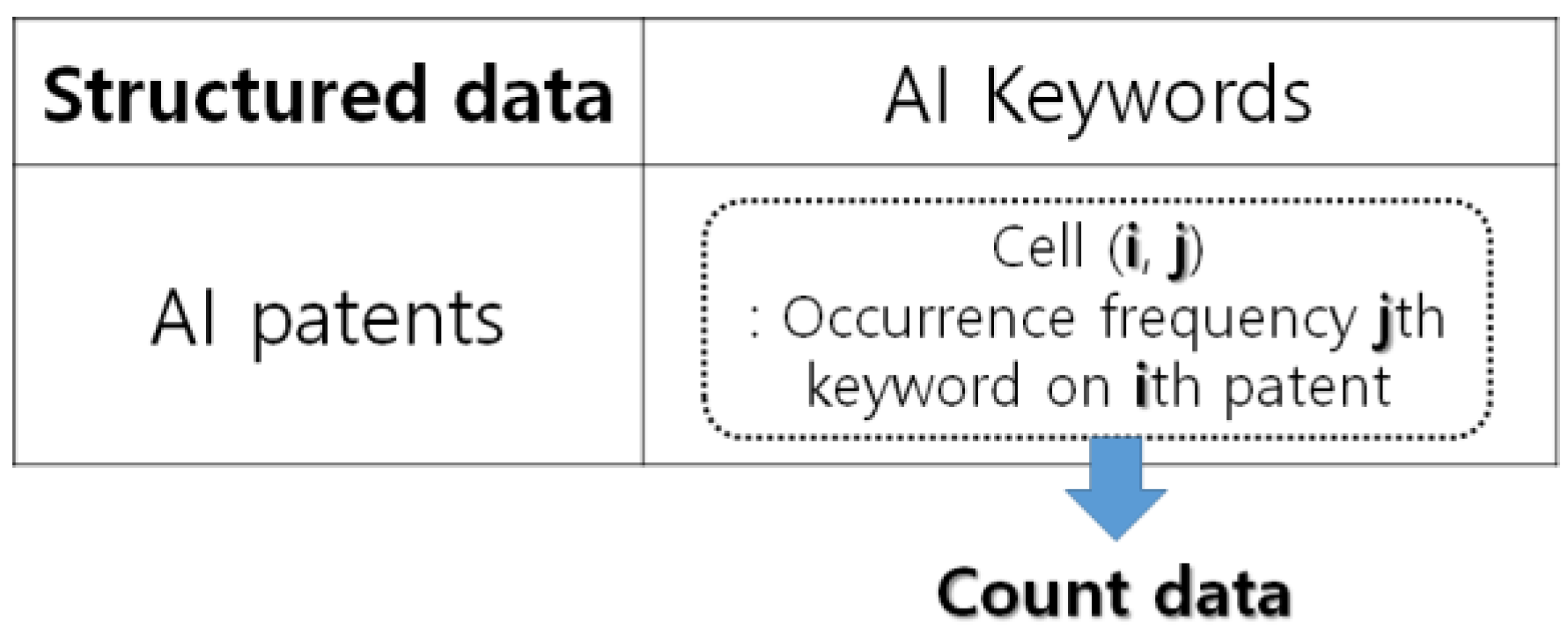
17]. Our structured patent data are shown in
Figure 5.
The row and column of this data matrix are patents and keywords related to AI, and each cell of this matrix represents the occurrence frequency of each keyword on a patent. In this case study, we selected the keywords ‘Artificial’ and ‘Intelligence’ as dependent variables. The remaining keywords, except dependent variables, were used as predictor variables. That is, the structured data contain the keywords in
Table 1 and the keywords ‘Artificial’ and ‘Intelligence’, and each element of the structured data represents the occurrence frequency of each keyword on the AI patents. Based on the structured data, we classified the AI technology as follows:
In
Table 1, we divided AI technology to five subtechnologies as follow: Learning, behavior, language, vision, and neuro. In addition, we showed the patent keywords belonging to each subtechnology. We used this technology tree to retrieve the AI patents and analyze them. First, we estimated the Poisson parameters for the patent keywords using a maximum likelihood estimator (MLE) by the frequency values of the keywords.
Table 2 shows the estimates of Poisson parameters for all patent keywords.
We can compare the relative frequency between the patent keywords in
Table 2. These estimates are the MLE (maximum likelihood estimate) for Poisson parameters of AI keywords [
18].
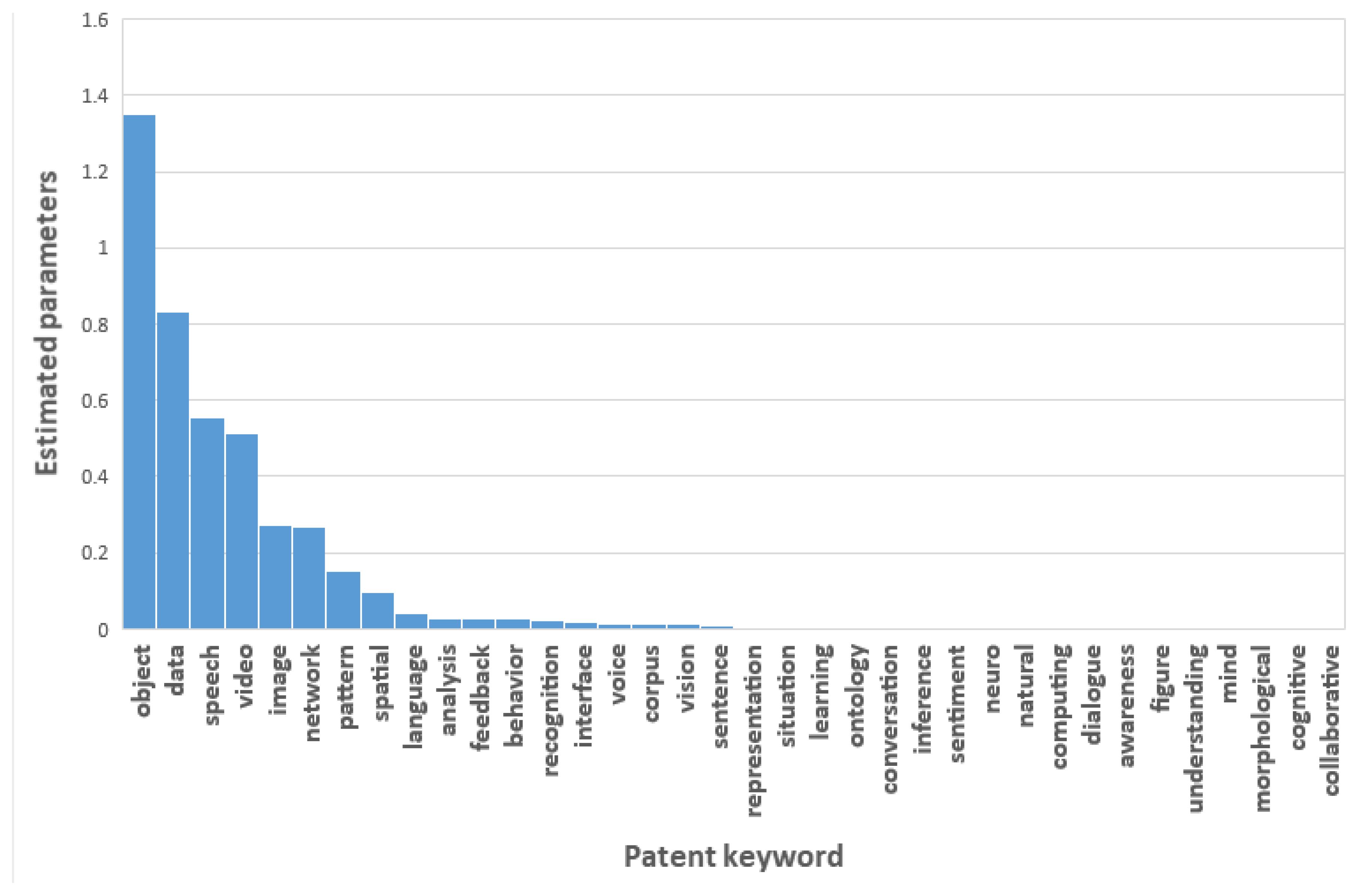
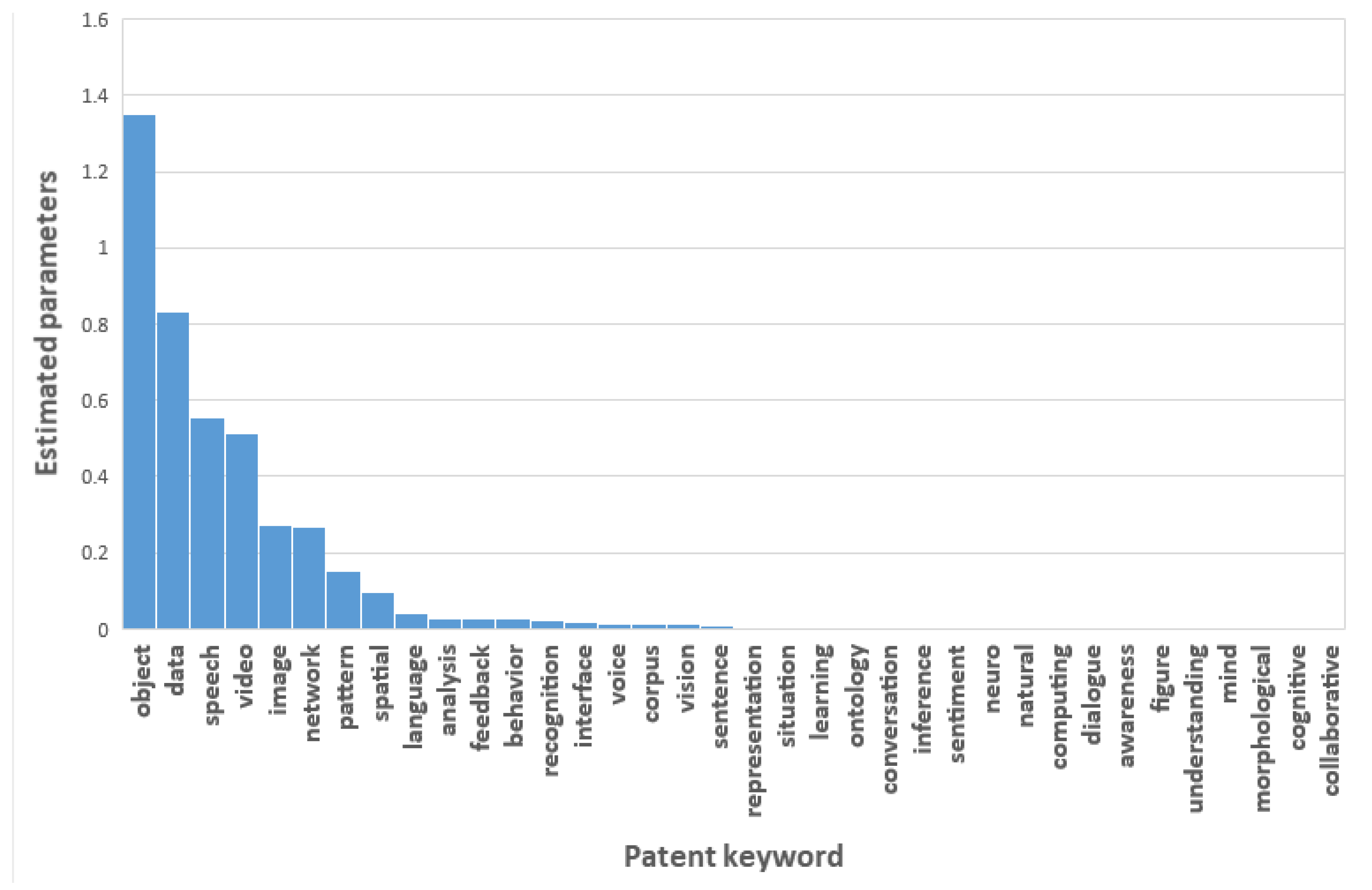
Figure 6 illustrates the MLEs for the Poisson parameters of all patent keywords.
In this figure, we found the MLEs of ‘object’, ‘data’, ‘speech’, ‘video’, ‘image’, ‘network’, ‘pattern’, ‘spatial’, ‘language’, ‘analysis’, feedback’, ‘behavior’, ‘recognition’, ‘interface’, ‘voice’, ‘corpus’, ‘vision’, and ‘learning’ are relatively larger than other keywords. Using the results in
Figure 6, we determined the patent keywords that affect AI technology. A keyword with a larger MLE value will have more impact on AI technology. We also carried out Bayesian count data modeling on the structured patent data matrix.
Table 3 shows the results of the modeling.
We performed the Bayesian regression models by Gaussian, as well as Poisson distributions. To compare the weights of all keywords equally, we standardized the scale of each variable. In addition, the weight in
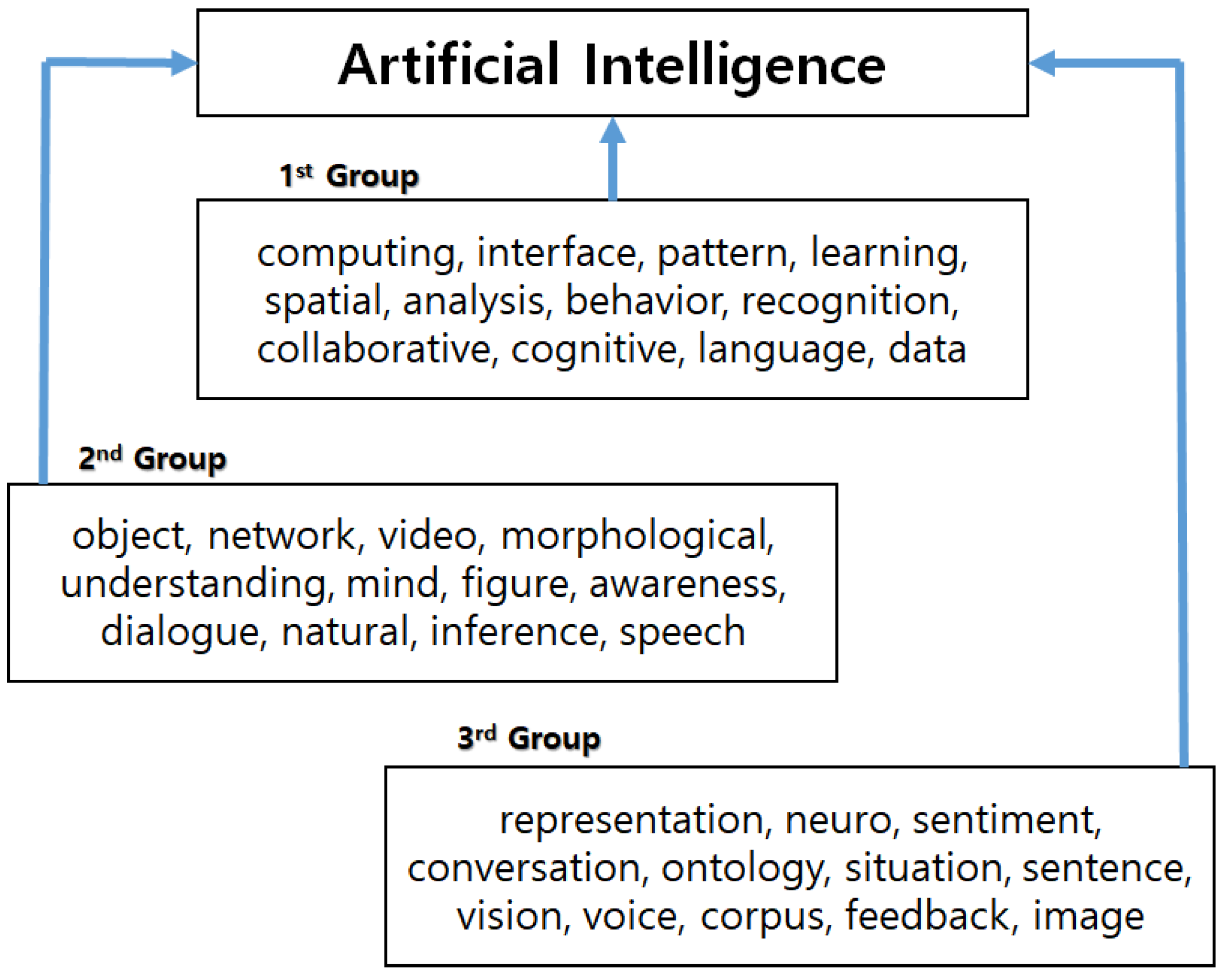
Table 3 is the average value of Poisson and Gaussian parameters. In this paper, we selected the keywords with larger weight values for finding technological sustainability in AI technology. Using the result of
Table 3, we show the patent keyword ranking that influences AI technology in
Figure 7.
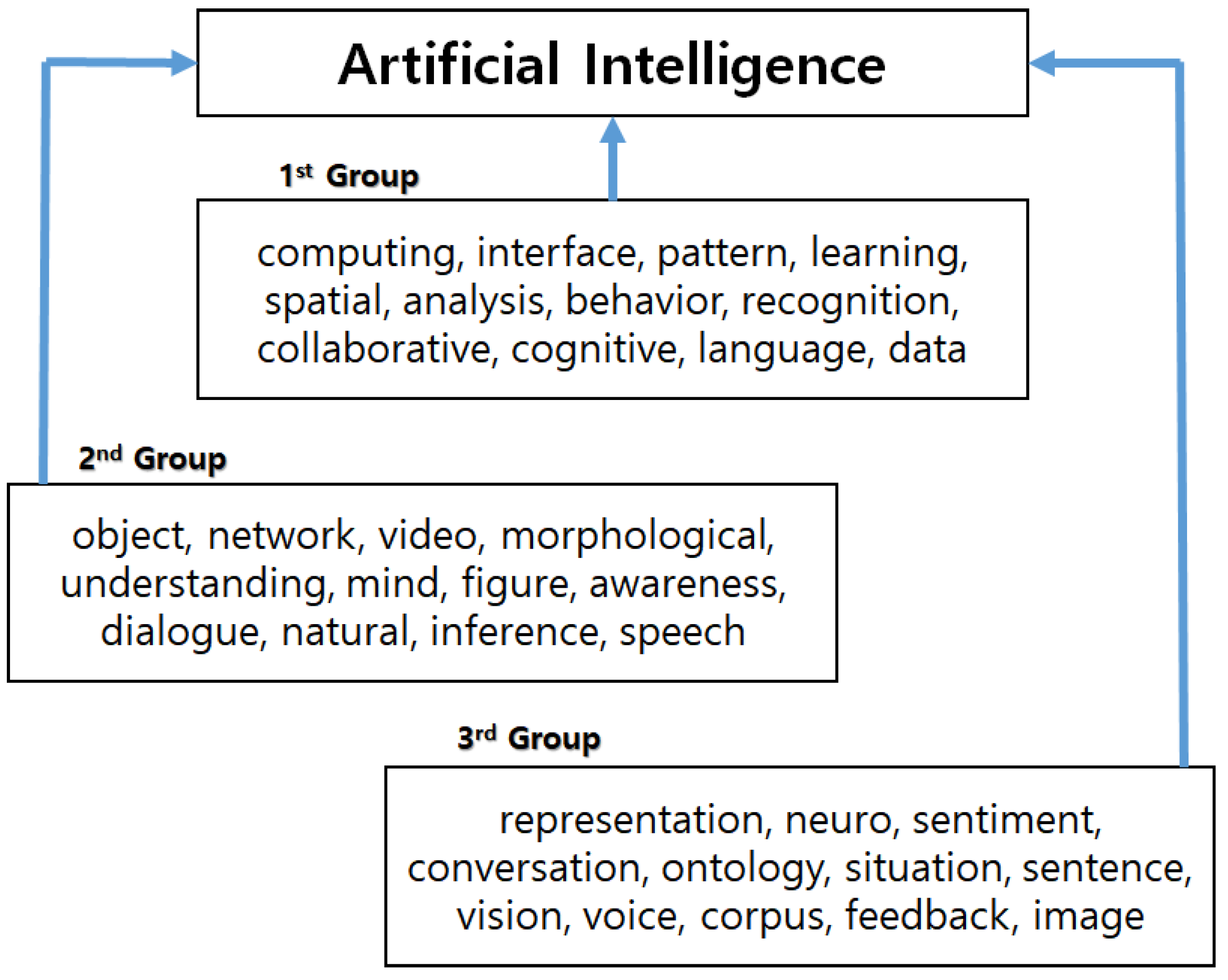
The keywords in the 1st Group have a greater impact on AI technology than in the 2nd Group or the 3rd Group. Using the experimental results of this paper, we made the following technological structure for sustainable AI technology.
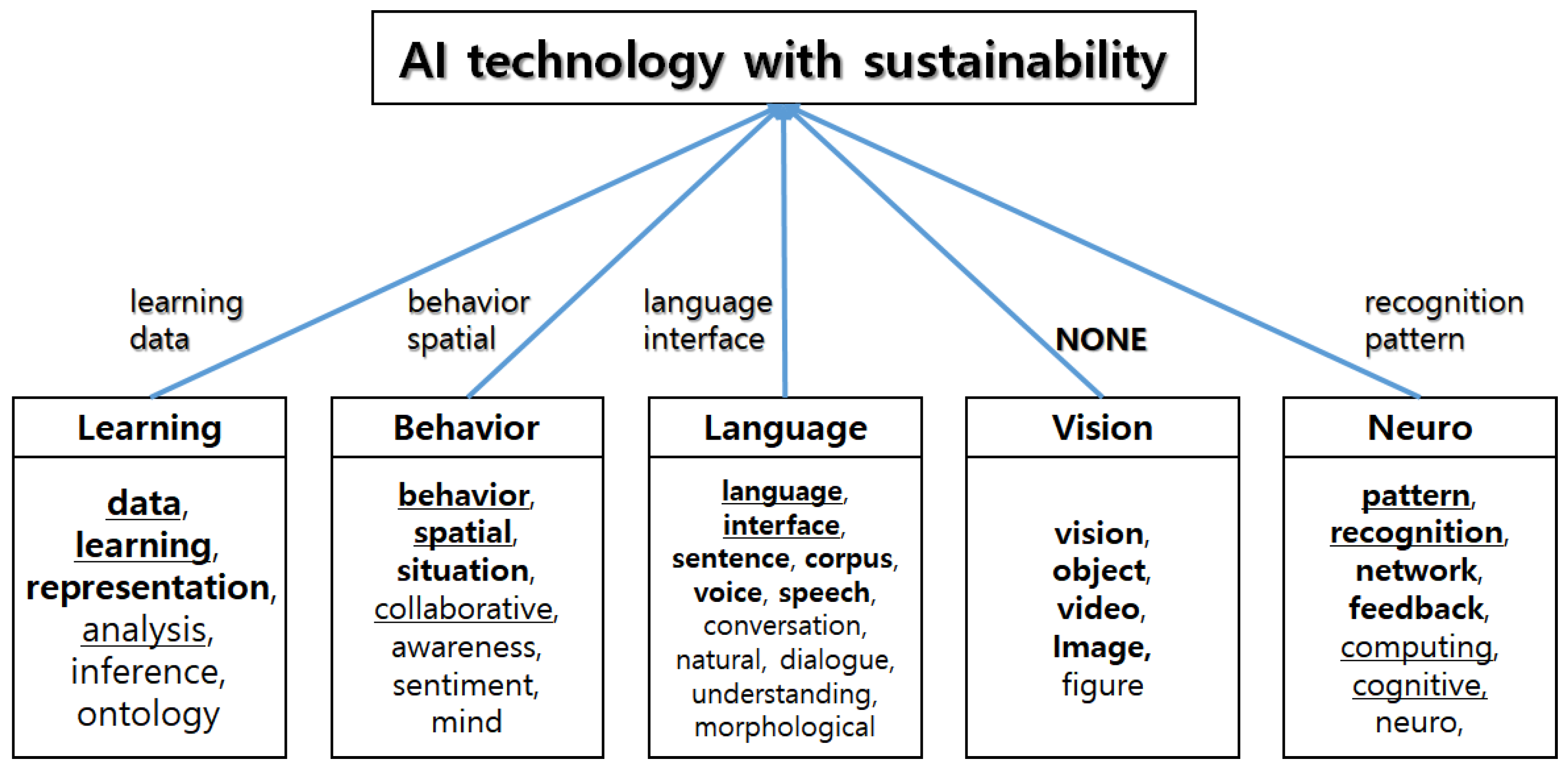
In this paper, we divided the AI technology into five subtechnologies (learning, behavior, language, vision, neuro) in
Table 1. In
Figure 8, each subtechnology contains the keywords that can represent its technology. For example, the keywords of learning, inference, ontology, representation, analysis, and data describe the learning technology for AI. Each keyword is represented by bold or underlined types, depending on its importance from the results of
Table 2 and
Table 3. The keywords in bold type are those that have an impact on AI technology from the results of Poisson MLEs. Additionally, the keywords with underlined lettering affect AI technology, based on the Bayesian regression model. Therefore, we knew that the subtechnologies related to learning, behavior, language, and neuro influence the sustainability of AI technology. However. we found that the subtechnology of vision has a relatively small effect on the technological sustainability of AI compared to other subtechnologies. In this paper, we concluded that the four technologies related to ‘learning data’, ‘behavior spatial’, ‘language interface’, and ‘recognition pattern’ are important to continue the sustainability for AI technology.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}