1. Introduction
Changes in social, economic, technical, and political environments are everywhere in today’s rapidly developing world. Therefore, one of the requirements for modern decision-making systems is the ability to withstand sudden changes. Terms related to sustainability such as ‘maintain’, ‘support’, and ‘endure’ have become very important in such circumstances. Sustainability issues influence business in all industrial sectors and parts of the world, especially in marketing and management [
1,
2].
Financial portfolio management greatly affects industry, social life, and politics. The nature of multidimensional time series is determined by the interaction of millions of economic and financial units. Many unforeseen external consequences of political, environmental, meteorological, and natural disaster events also affect historical time series.
In the portfolio construction problem, people seek to allocate assets (stocks, bonds) in such a manner that it would maximize return given a fixed level of risk or reduce risk given a desired return. Currently, different investors use diverse algorithms for portfolio design. In computerized approaches, instead of assets, investors use automated trading strategies (ATS) as inputs for their portfolios [
3,
4].
There are several dozen formulations of what makes an optimal financial portfolio. Conventionally, a financial portfolio of assets is developed. Trading strategy can have a long, short, or flat position at any time. The position can change at any time during a day and sometimes even several times during the day. Typically, we record profit or loss (PnL) at the end of the trading day when the exchange closes. PnL is the profit difference from the same time in the previous business day. In US terms, that is at 4:00 p.m. Eastern Time. We use mark-to-market profit calculation methodology where we include all unrealized profits in our PnL.
In algorithmic trading, portfolio construction seeks to allocate money to different ATSs so that the resulting risk reward ratio is optimized. The biggest challenge in any portfolio construction is that portfolio results in the future or in the unseen data are often worse than was expected from historical results. This problem is even more acute in algorithmic trading as there is a far greater number of ATS than assets being traded by ATS, and classic portfolio construction methods are not suitable for this task.
This paper deals with the selection of a subset of portfolio inputs from a large investment universe. In the second section of the paper we present definitions and terminology used in the portfolio selection task and a literature review. In the third section we analyze ten types of recent high-dimensional financial time series with the aim of discovering which length of the most recent historical data is best to use for optimal ATSs selection. We discovered that there is no a priori fixed ‘optimal’ length of training history for all portfolio design tasks. It varies between two and 24 months. The most profitable training data length (TDL) can be estimated empirically by examining the prior successes of a set of potentially lucrative lengths. Consequently, we suggested and verified a simple algorithm for determining the optimal length of training history to produce a sustainable portfolio. The varying training data length phenomenon was confirmed in the third section’s analysis of a dozen multi-dimensional synthetic time series generated by an excitable medium model, frequently considered in studies of chaos.
2. Terminology and the Literature Review
The term “portfolio” refers to any combination of financial assets or ATSs. The idea is to put such ATS together so that if one ATS generates a loss during a day there will be other ATS that generates a profit and will compensate the loss of the first one. The main objective of developing a financial portfolio is to determine the
N investment proportions,
w1, …,
wN, where the sum
and all components,
wj, are positive. Denote
r = [
r1,
r2, …,
rN], a
N-dimensional vector of returns (profit or losses) of
N investment assets or ATSs. Thus the portfolio profit is expressed as the weighted sum,
P(
r,
w) =
If
L vectors,
r, are used as a training set, one can seek for the vector’s
w, optimal proportions, where profit and risk are taken into account. We consider the problem of portfolio selection within the classical Markowitz mean-variance framework. To find the investment proportions,
w1, …,
wN, we have to maximize selected performance measure of the portfolio. We used standard mean-variance quality criterion (
MVQC) [
5,
6,
7]
where
mean and
stdev denote a mean and a standard deviation or probability distribution of the returns.
In criterion (1) the profit and risk are taken into account. To evaluate
mean and
stdev one needs to know
N-dimensional mean vector, and
N ×
N-dimensional covariance matrix composed of
N variances and
N × (
N − 1)/2 correlations. Criterion (1) is good when probability distribution of portfolio sums,
P(
r,
w), is Gaussian and one knows the exact values of the means, variances, and correlations. Moreover, these values must not change in time. These requirements are very restrictive. In spite of sub-optimality, after more than half a century since the seminal work by Markowitz [
5], the mean-variance framework remains prevalent and represents the most broadly chosen approach in both industry and academia for portfolio selection (see review [
8]).
To mitigate the restrictive requirements, thousands of modifications of the
mean/
variance rule appear in the literature [
8,
9,
10]. A number of papers were aimed to use other criteria than mean/variance ratio, such as requirements for maximal size of the portfolio, minimum position size, transaction costs, preferences over assets, management costs, etc. Methods were created to take into account the skewness and kurtosis of the asset distribution [
9]. In an attempt to take into account the variability of data, a number of papers have been devoted to efficient managing of temporal information [
11,
12]. Use of meta-heuristics for increasing the speed of optimization methods of ratio (1) in high-dimensional situations have been suggested as well [
10].
In analysis of sustainability it is very important to consider learning set size—portfolio dimensionality effects [
13,
14]. In a previous paper [
14], an expected value of the mean sample
MVQC criterion was investigated in an asymptotic where both the learning set size,
L, and portfolio dimensionality,
N, were increasing, however, ratio
L/
N does remain constant. This approach allowed for the obtaining of an explicit asymptotic equation to calculate the out-of-sample
MVQC criterion
where δ is a limiting value of ratio (1) when
L tends to infinity, however
N is fixed;
Term (3) is responsible for the inexact estimation of the mean vector of returns and term for inexact estimation of correlations
. Theoretical and experimental analysis showed [
14]:
- -
Estimation of variances asymptotically does not affect the value;
- -
if L < N, we cannot estimate CM.
Term (3) demonstrates that estimation of several thousands of components of the mean vector makes the learning set-based portfolio ineffective. Suppose, N = 6000, δ = 0.5, and L→∞. If L = 256, use of term (3) leads to MVQC = 0.052. An extraordinary difference between these values indicates that in an inexact estimation the mean return values reduce the MVQC criterion almost ten times!
Thus, for situations where learning set size is small and dimensionality is high, the classical criterion (1) becomes useless. A number of simplifications for estimation of the covariance matrix have been suggested: regularization, subset resampling, splitting the portfolio inputs matrix into a lot of parts, etc. [
15,
16,
17,
18].
A limiting case for simplification of the portfolio construction is a non-trainable 1/N rule where all
N portfolio inputs are weighted equally. In many cases, the 1/N strategy can become the most effective one [
19]. In this rule, the portfolio optimization (training) consists of selecting a subset of assets or the trading strategies from an investment universe with respect to a given portfolio performance criterion. Nowadays, the selection problem becomes very important since the number of trading strategies and stocks listed on stock markets are continuously increasing [
20]. A number of algorithms and criteria for stock screening and ranking are proposed in the literature [
21,
22,
23].
An important factor in the application of stock screening and ranking algorithms is the size of the data used to estimate numerical effectiveness values. In a previous paper [
24] the authors examined the financial portfolio inputs’ random selection optimization model. We derived an equation to calculate an accuracy of the out-of-sample
MVQC criterion value in dependence of the number of potential asset number of portfolio inputs,
N0, the desirable portfolio size,
N (
N0>>
N0), the sample size
L used to estimate
MVQC criterion and complexity of the random search procedure (a number of times,
m, the portfolio subsets were generated randomly). It was demonstrated that with an increase in portfolio complexity and complexity of optimization procedure,
m, we can observe the over-fitting phenomena in the selection procedure. For this reason, often one employs simple selection rules such as selection of the individually most effective inputs [
20,
23,
25,
26].
Informative learning set size is closely related to environment changes. If environmental changes are frequent, only short historical data segments turn out to be reliable. Hence, the small sample problems are very important in sustainability analysis. To explore and understand the almost chaotic ceaselessly changing environments in financial portfolio management it is necessary to comprehend training data length/complexity relations of portfolio design rules.
To the best of our knowledge, learning set size problems arising in chaotically changing financial data were not considered in the literature. As an exception we can mention an attempt to determine training history length using a relatively small number of potential ATSs (
N0 = 169) [
15]. It was found that the length should be rather short, 500–600 business days. To cognize sustainability issues one needs to analyze regularities of financial chaos by considering not a single, but a wide diversity of real world data sets. In order to better understand stability problems, it is also necessary to use ideas from chaos theory [
27,
28], e.g. explore synthetic purely chaotic multi-dimensional time series in which external unforeseen events do not affect the created time series.
3. The Methodology
Our research is pointed towards designing a sustainable portfolio management strategy that can endure for a long time in the chaotic, ceaselessly changing environment. An important step in our research is to find the training data length to be used to design the financial portfolio. Obviously, it depends on the frequency and magnitude of environmental changes. In
Section 2 we reviewed our earlier analytical results concerning the influence of learning set size on mean-variance principle designed portfolio [
14] and random search based best input selection [
24]. These results were obtained for static situations. For chaotically hanging environments, however, we have no means to perform analytic investigations. For that reason, we need to perform experiments with a large number of diverse types of real world financial data stored in financial databases. In order to expand sustainability issues to wider research disciplines a part of the experiments we performed with synthetic chaotic data.
3.1. Financial Data Used
Automated trading is when a human writes a computer algorithm that can trade in financial markets automatically, by using predefined rules. These algorithms are called Automated Trading Strategies (ATS). For example, ATS can buy and sell Apple stock based on stock price changes. Individual ATS on a given day can make or lose money, though in the long term, the results are positive. The aim is to put several ATS in a sustainable portfolio in such a way that if one ATS loses there will be another to make money on that day. The more independent ATS we put together, the better the result. The problem is to find independent, sustainable, and consistent ATS that do not change their behavior in the future.
Given ATS, one can execute computer algorithms in simulations and see how well the ATS would have performed on historical data. The results of this simulation can be recorded, analyzed, and used to design a portfolio composed of several ATS. Typically, one records daily profit and loss (PnL) of ATS. That is how much money ATS made or lost during that day. We investigated the daily series of PnLs of fifteen years, from 2003 to 2018. This data was given to us by trading firm that uses these ATS in practice.
PnL is the amount of US dollars made or loss during a day. ATS PnL is a series of daily profit and losses from 2003 to 2018. Portfolio PnL refers to a sum of ATS PnLs—every day, we sum profits and losses from all ATS in the portfolio and that constitutes portfolio PnL for one day.
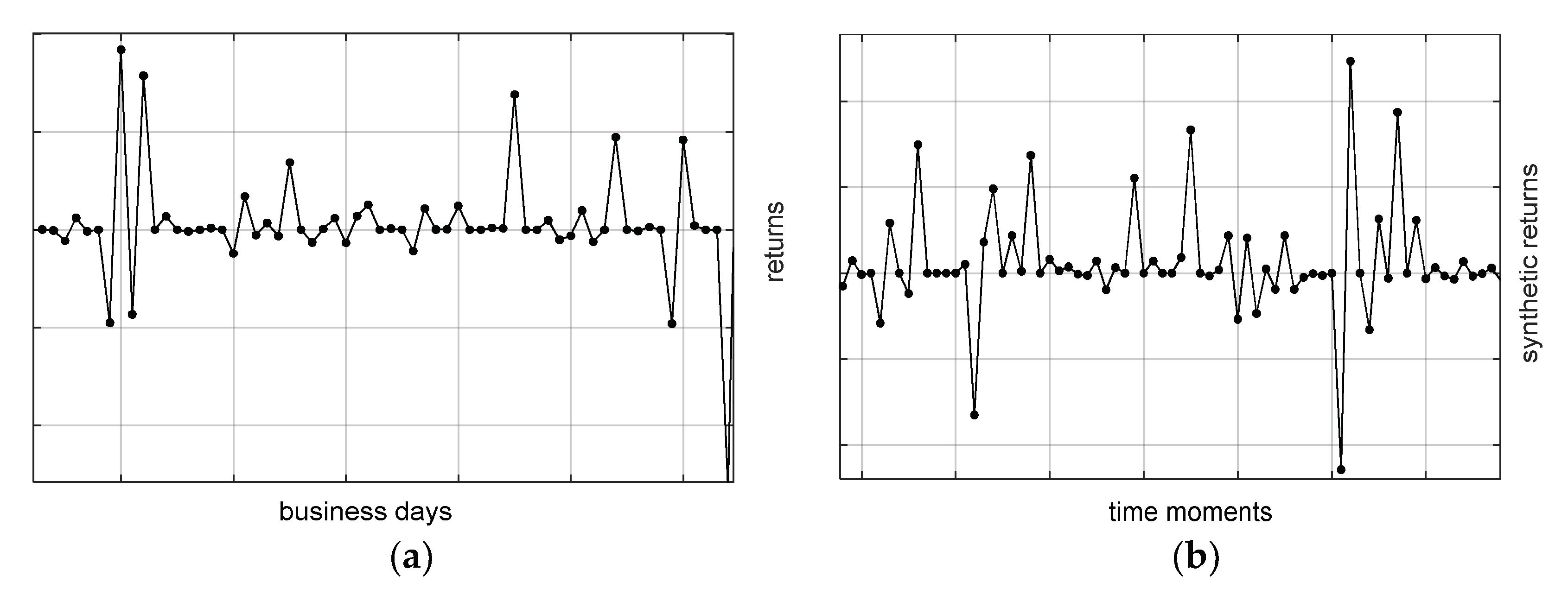
ATS can be very different from each other. There are many different rules that can be put into a computer algorithm. Our data consisted of mainly 3 types of ATS: Mean reversion (MR), Trend following (TF), and Event-based Trend (ET). In automated trading often one uses ATS strategies where strategies differ in the investment risk levels that lead to frequent refusal from investments. In the case of refusal, the next day’s return is equal to zero (see
Figure 1a). For more details about the data see
Appendix A.
3.2. Preparation of the Financial Data and the Experiments’ Design
We consider the algorithmic trading where the number of ATS (a maximal portfolio dimensionality) can be as high as N0 = 258,000. In such situations we are obliged to reduce the dimensionality of the portfolio inputs drastically. At the same time, we have to use only the simplest, the 1/N portfolio rule.
In the investigation of the dynamic portfolio selection scheme, we assigned two years history data allocated for “comparison of diverse lengths of training data”. The next month is assigned for out of sample testing, i.e., for calculating the returns of each day. We aimed to determine the best training data length and to select Nportfolio ATS for the 1/N portfolio design. In the experiments we moved stepwise the 25 month data segment 1 month forwards until the data history end. During each single step we estimated the MVQC ratio for all N0 ATSs M = 6 times with 2, 4, 9, 12, 18, and 24 month training data histories. Then for each training set size we selected Nportfolio = 10 best trading strategies and used them for calculation profits or losses for all business days of the test month.
Procedure “select the individually best ATSs” is the simplest and fastest one among a many selection rules used in data mining tasks. One of heuristic procedures employed in the portfolio selection is a Comgen rule [
15,
29] where the best ATS, say the
j-th one, is selected first, then all
N0 (
N0 − 1)/2 pairs containing the
j-th ATS are compared and then the best pair is selected. The selection process goes on until
Nportfolio ATS are selected. To evaluate performance of the set
Nportfolio trading strategies in the “individual selection” procedure we have to estimate
Nportfolio means and
Nportfolio standard deviations of the returns. A simple matrix algebra shows that in the Comgen procedure it is additionally necessary to estimate
N0 × (
N0 − 1)/2 correlation coefficients. Therefore, the Comgen procedure is more complex and requires longer training set sizes. Theoretical and empirical investigations [
24] show that in a small sample size situation simpler procedures like “select individually the best ATS” are more preferable when sample size is small (two months data, 41 days).
Preliminary experiments showed that often even four month training data can be too long for portfolio selection in frequently changing situations. Often the ATS selection based on two months of data outperformed the portfolio based on four months of data. It is a frustrating truth in the situation when we have 15 years of historical financial data at our disposal. These conclusions prompted us to devise a new approach to employ lengthy historical data.
In an attempt to use the information contained in the older data, we divided the 15 years of data sets into two parts. The first part of the data of each dataset (up to 1 January 2011) was assigned for preliminary subset selection (PSS) used for formation of N1-dimensional subset of the most profitable trading strategies (typically N1<<N0). The conventional way to select N1 best trading strategies is to use the first part of the data to estimate the MVQC ratio of all N0 ATS. Then one selects N1 ATS with the highest MVQC ratio values. This procedure we will name PSS1.
Our novel stepwise procedure (PSS2) is based on an assumption that due to unexpected environmental changes, different ATS should be specific to be profitable at various short time intervals. Contrary, the procedure PSS1 selects nonspecific (indistinct) trading strategies. The procedure PSS2, however, is more complex. Having 8 years (96 months) of historical data we considered 95 two month-length time series sections to estimate the
MVQC ratio of
N0 trading strategies and select
n1 = 70 best of them to be included into subset PSS2. We will have to repeat the selection process many times. Therefore, procedure PSS2 is slower. In columns “Dimension” and “Reduced dim” of
Appendix A,
Table A1 we present values of
N0 and
N1 for ten data sets used in the experiments. For each data set the number
N1 was determined individually using the procedure PP2.
In the experiments with ten data sets we observed high influence of environmental changes on the “optimal” training history time. Therefore, the investor-practitioner is obliged to find most effective training period. Possible algorithms will be presented in the subsequent section.
4. The Analysis of Financial Time Series
To make conclusions authoritative, we prepared ten brand new (until April 2018) large scale sets of the financial data. In the experiments, we examined the successes of M = 6 portfolios based on the training data of six different lengths (2, 4, 9, 12, 18 and 24 months). We fixed the dimension of the portfolio, Nportfolio, a priori. The value Nportfolio = 10 was set up after a large number of previous (2015–2016 years) experiments performed with other sets of financial ATS data.
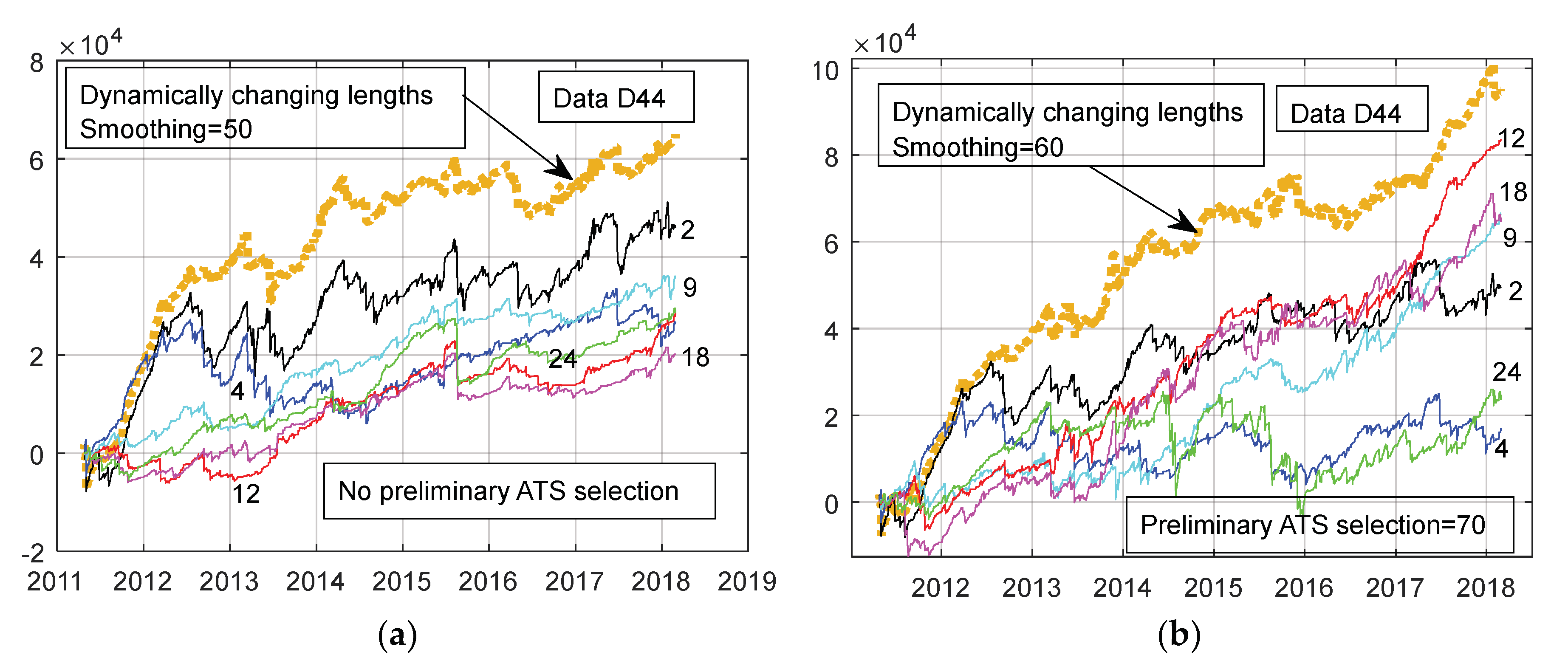
Figure 2a,b show six curves: “variation of the cumulative sums of portfolio PnL in time”,
CS1,
CS2, ...,
CS6. Each of them corresponds to a diverse length of the training data. Curves in
Figure 2a correspond to experiment when the best
Nportfolio ATS were selected out of
N0 = 44,068 original trading strategies of 44,068–D (dimensional) data set D44. We see that the best learning set size was 2 months (curve 2 in the figure). Training set sizes of 12, 18, and 24 months in length resulted in the worst results. Better portfolios were obtained in the situation when, for the final decision making, we selected dynamically from the pool PSS2 of 3533 specific trading strategies (
Figure 1b). The two-month length training set was among the best up to the year 2017. In this time the four months training history was unsuccessful. One may guess that the third and fourth backward shifted training months are harmful for this data. In
Figure 1b we see, however, that the 9–18 backward shifted training months were very useful during the year 2017. These observations lead to the conclusion that the most effective duration of training depends on time. This conclusion was confirmed in experiments with the rest of the data sets. Portfolio performances with nonspecific ATSs (pool PSS1) were similar to that as results without the primary ATS selection.
To design a profitable portfolio for each trading day, we need to know the optimal length of the training data. To fulfill this requirement for the
z-th day we can analyze curves
CS1,
CS2, …,
CS6 up to the
z-th day and decide which training data length was the most profitable during the past time period. To estimate the desirable TDL, we chose the simplest method: we smoothed the return curves with period
Smoothing days, and selected the length corresponding to the highest return value. In practice, however, the best smoothing interval values are unknown. Hence, the investor is forced to examine carefully a history of past successes (the set of different smoothing values in the previous history up to the
z-th day). In
Figure 2a,b, we depicted a variation of cumulative sums of the 10-dimensional portfolio returns, when the length of the learning data was determined dynamically according to the rule described above (bold dark yellow doted curves). We see, in this example the dynamics TSL determination outperforms remaining six curves obtained for the six definite values of TDL. Thus, that the novel simple method works.
Figure 2a,b demonstrates that the preliminary reduction of data D44 dimensionality performed on the basis of 2003–2010 year data lead to a visible increase in the final portfolio performance.
Analyzing the remaining nine arrays of financial data, we found frequent situations in which the two months’ history used to select the set of the most productive ten ATS were the best. Nevertheless, for some financial data, we observed a reverse scheme: the most profitable were the long histories of the training data. In
Figure 3a,b we present such example (257,769-dimensional data set D258). Like in data set (D44) the dimensional reduction method PSS2 was profitable: the portfolio returns increased more than two times. The use of dynamically changing learning data is superior to portfolios that have been trained by 18 or 24 month periods. Data for 4 months of training was again less successful than the data for two months. However, in both cases it was useful to increase the length of the training data further.
Figure 3a shows that in period after June 2015 the dynamic control of the TDL stopped being effective. Recommendation: after observing such a phenomenon in the history of past successes, the investor must choose another, more profitable data set of financial time series immediately. In this example the choice is simple: after the 2016, one needs to use the data set D258 with specific 4023 trading strategies (see
Figure 3b).
Due to the random nature of the data, the cumulative sum of the dynamically controlled portfolio returns, increases in a wavy manner. In the
Appendix A,
Table A1 we present cumulative sums of the
Nportfolio-dimensional portfolio at its maximum and at the last day of the inspected data. It is done for the original
N0-dimensional data and for the PSS2 reduced dimensionality data. In 50% of cases primary dimensionality reduction with procedure PSS2 improved the 10-D portfolio selected directly from original
N0-dimensional data (an interested reader can find figures similar to
Figure 2 and
Figure 3 in a web page of Vilnius university:
https://mif.vu.lt/aistis/2018/sustainability).
We tested the procedure PSS1 to reduce primary dimensionality of the data as well. In all cases, except D56 data, the method PSS2 outperformed method PSS1. For data D56 the PSS1 method resulted in cumulative sums of the portfolio returns 60/52 (60,000 at the maximum, and 52,000 for the last day of the data). It means that the novel stepwise dimensionality reduction procedure, PSS2, is worth investigating further. The results obtained advocate that efficacy of the dimensionality reduction algorithm, PSS2, depends on the data. Therefore, instead of the two-month data interval used to evaluate and select the N1 best trading strategies at each step, shorter or longer time intervals can be used. Possibly, the go-forwards steps ought to be shorter than one month. Diverse values of N1 should be investigated. A problem of improvement of the accuracy of training data length determination procedure is important for future research. One needs to examine the larger number, M, of training data sizes, L, and the smooth empirical curves according to the L direction.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}