Sustainability Analysis and Market Demand Estimation in the Retail Industry through a Convolutional Neural Network

Abstract
:1. Introduction
2. Literature Review
2.1. Sustainability in the Retail Industry
2.2. Estimation of Economic Consumer Demand
2.3. Reflection of Consumer Mobility through CNN
3. Study Area and Data Description
3.1. Study Areas
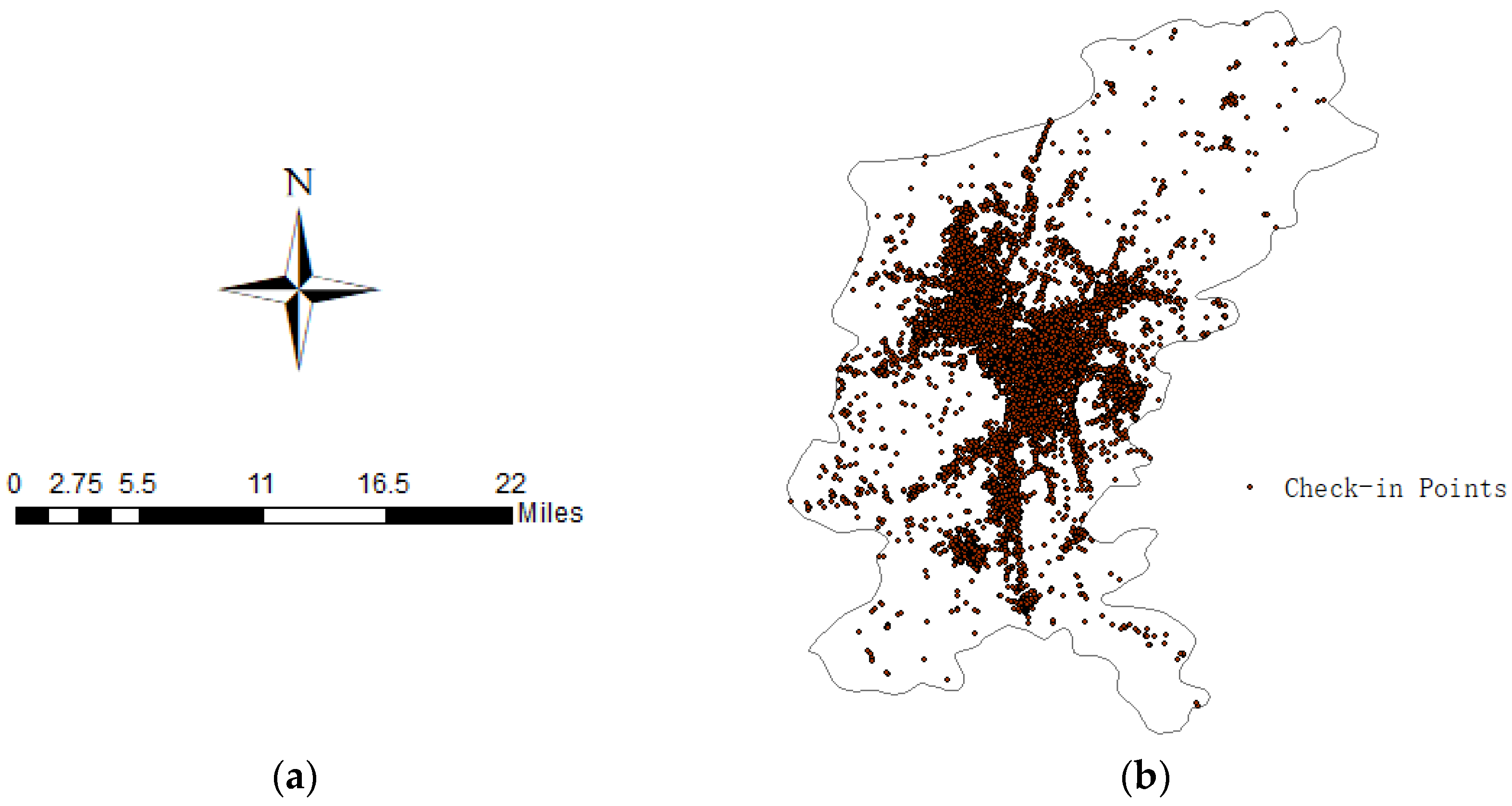
3.2. Data Source
- Mobile check-in data: The media data used in this study are the check-in data from Sina-Weibo, which is the largest blogging platform in China, between January 2016 and December 2016. The check-in data include user ID, location, check-in time, and several attributes, such as comments or pictures. After data cleaning, approximately 55,000 effective check-in data remained. The media data are shown, as follows:
- Retailer data: The retailer data used in this study include the location and monthly sales data of FMCG between 2015 and 2016 from 5614 FMCG retail shops in Guiyang City, China. The data are provided by a local company. These shops are distinguished into three types that are based on their formats: small supermarket; chain convenient store, such as “Today” (a famous convenience chain store in China); and, groceries distributed over each street. Hypermarkets such as WalMart and Carrefour, shopping malls, and vegetable markets were not included in our data source. To improve the accuracy of analysis, retail shops with average monthly sales less than $500/month were not included in our data source. The considered goods were mainly FMCG goods, such as clothes, tobacco, wine, foods, and other daily necessities. Electrical appliance sales were removed from the data source because most retail shops did not sell them. Examples of the information that was obtained from retail shops, such as retail type, retail ID, retail name, monthly sales, and locations, are shown in Table 1.
- External data: The external data include the road network and maps (1:200,000) of Guiyang City as spatial references and a base map.
4. Methods
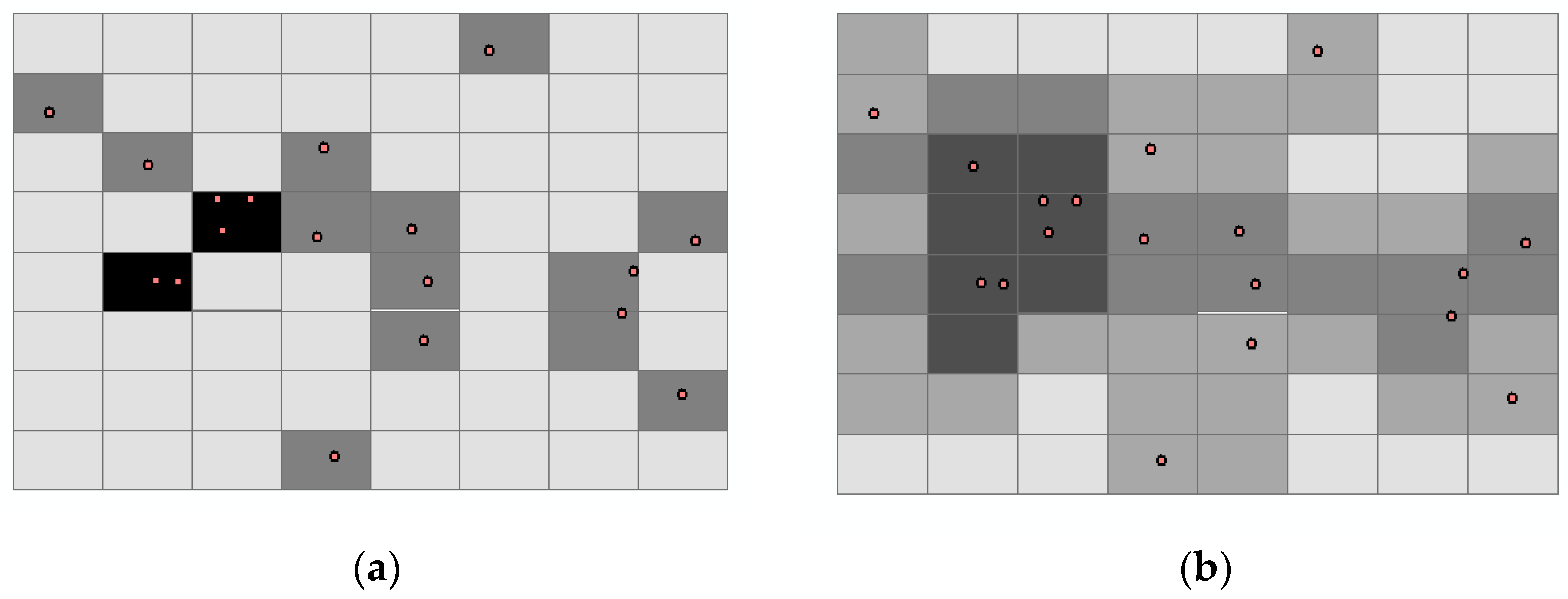
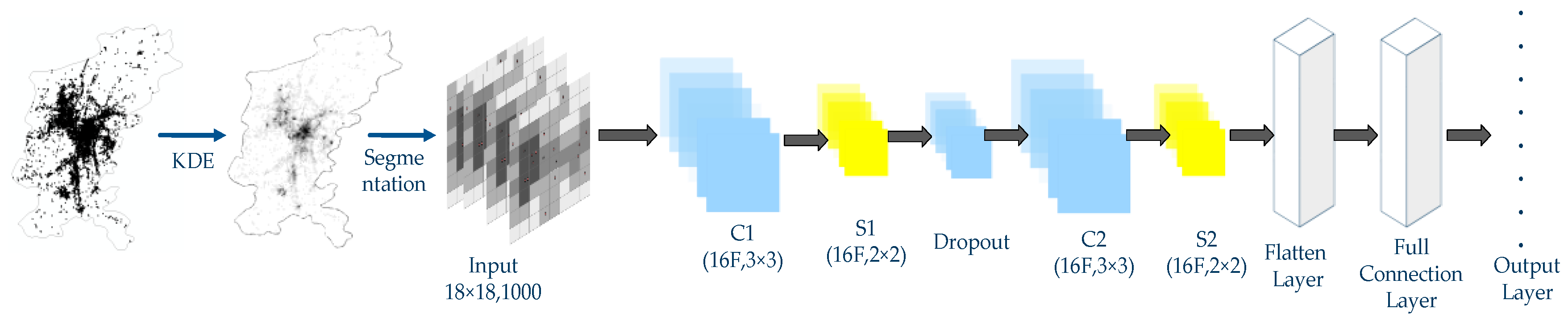
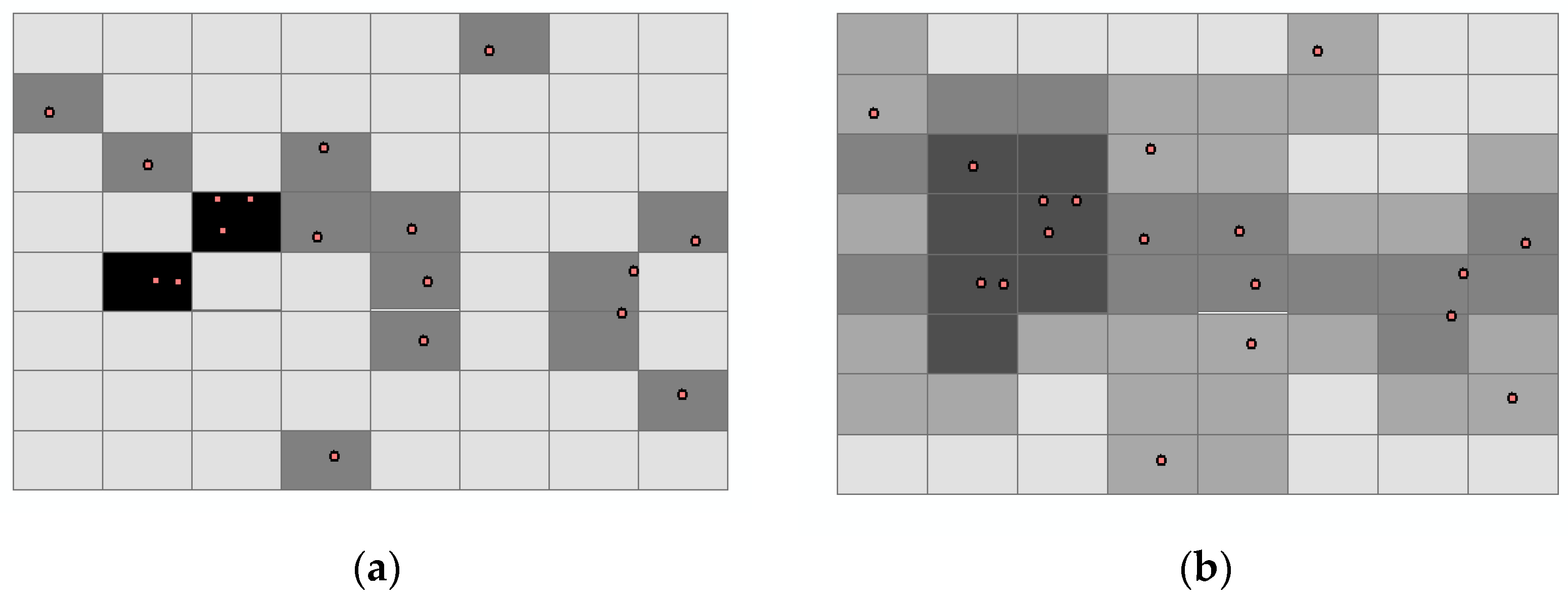
4.1. KDE of Grid Cells
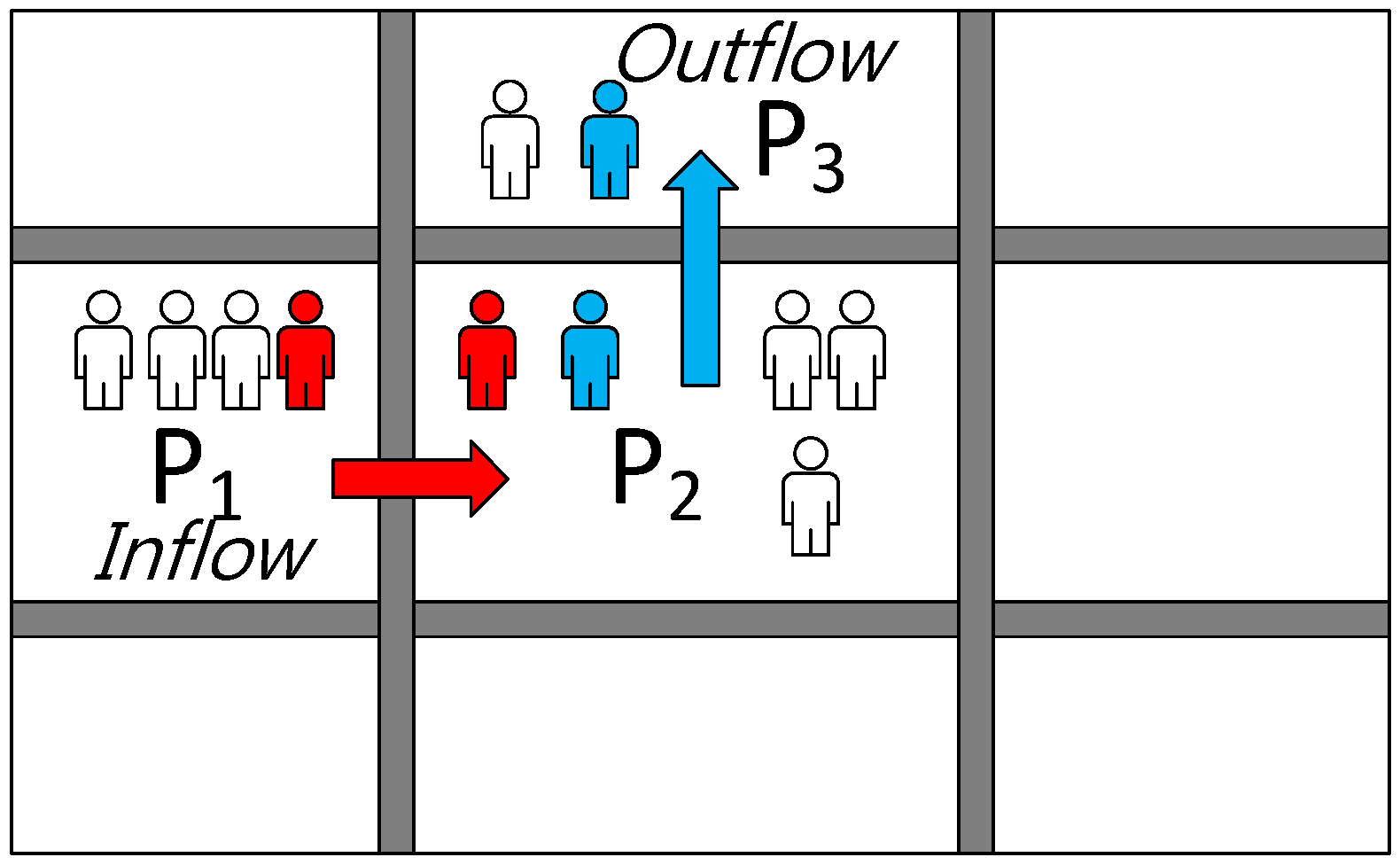
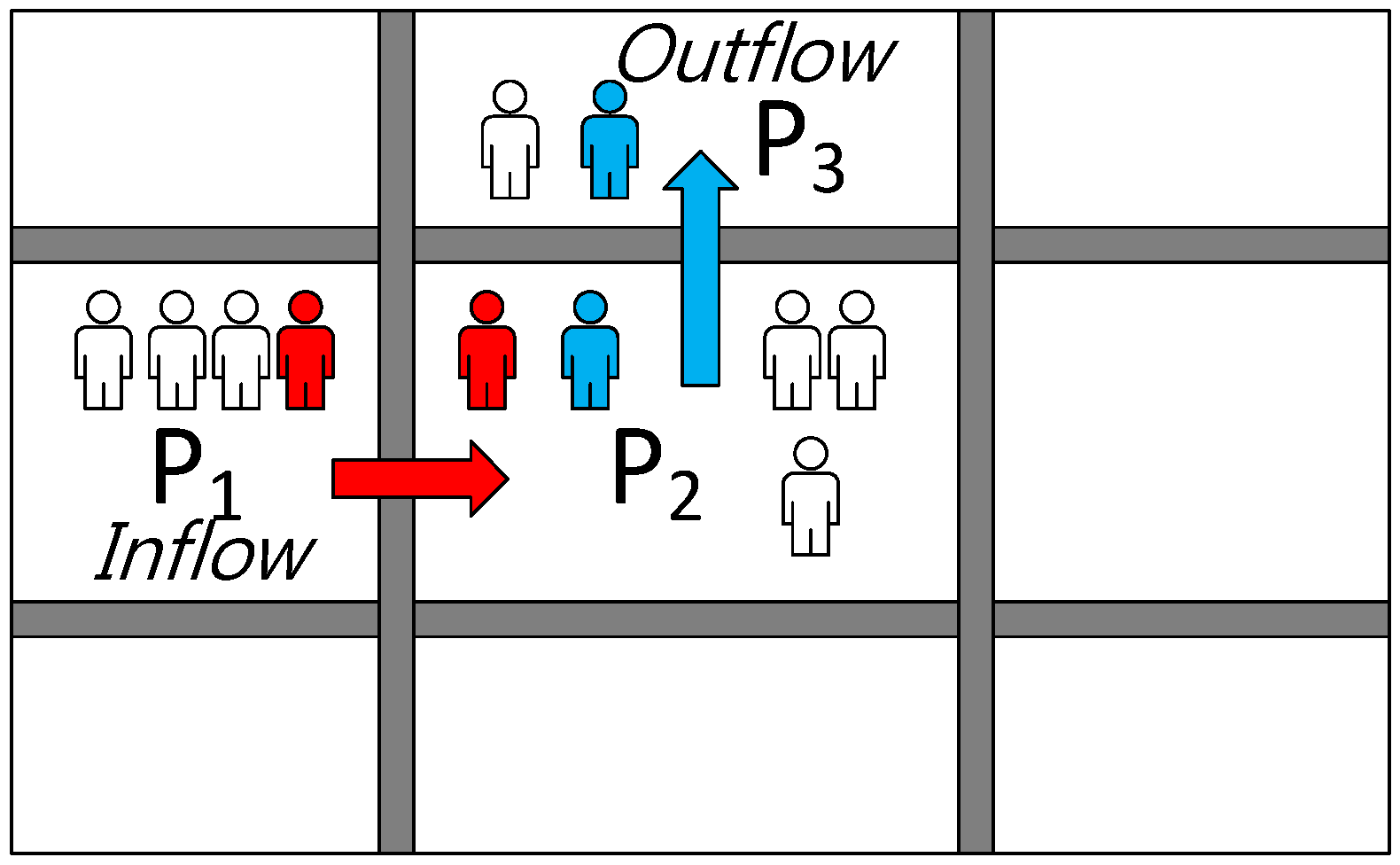
4.2. Sustainability Evaluation Model-Market Stability Assessment
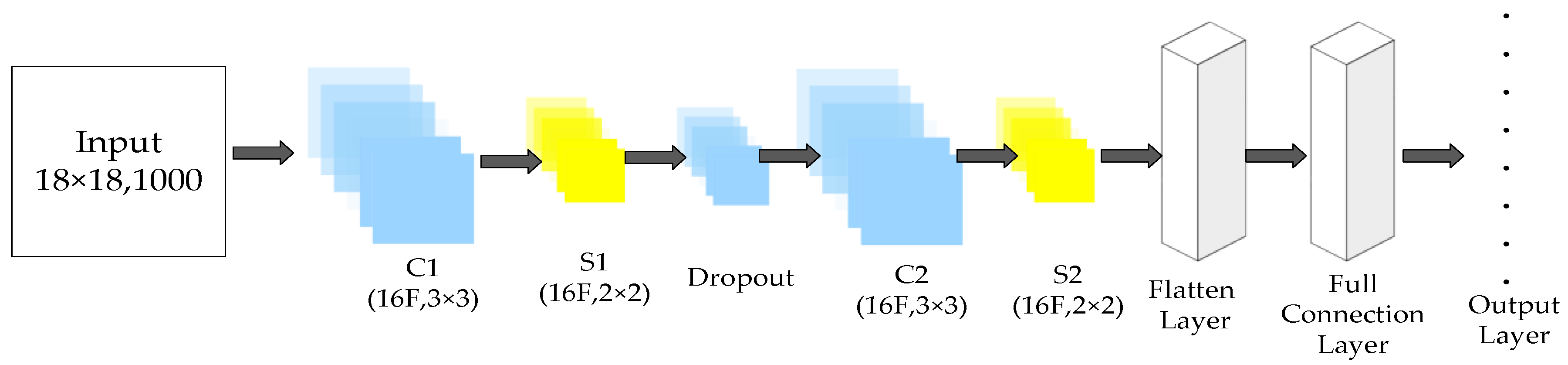
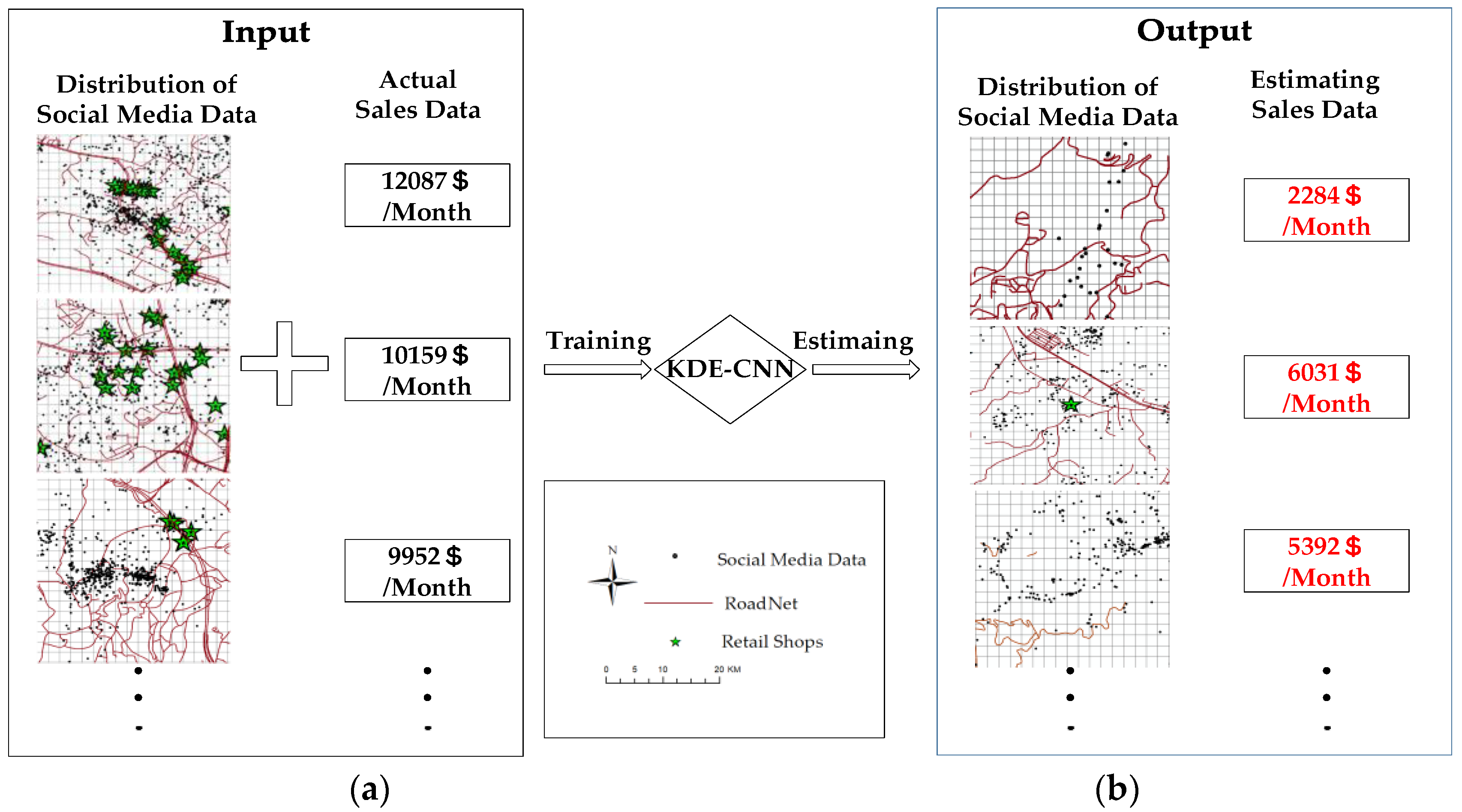
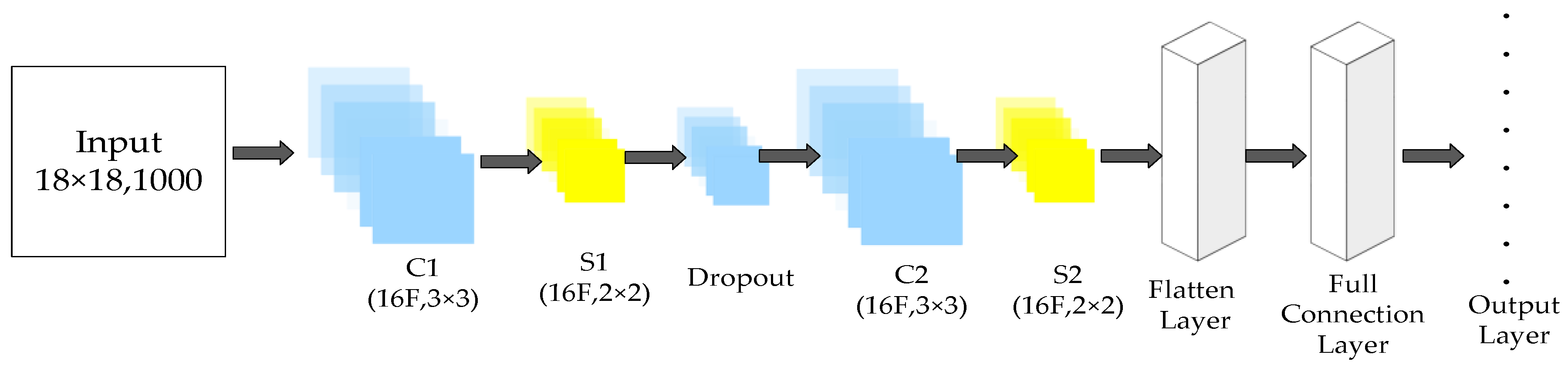
4.3. Consumer Demand Estimation through CNN
- (1)
- Convolution layer: This layer is considered to be an important layer in a CNN to extract the main information of an image. The convolution layer contains a convolution kernel, which is also called a filter. The filter is an matrix that extracts the main information from the original input and reduces its complexity. n is the width of the filter, especially the odd numbers, such as 3 and 5, and x is the channel number of the image. Filter can be recognized as a neuron layer to regroup and simplify the information from previous layers. When the filter goes through the entire image and the pixel values that are covered by the filter are multiplied with the matrix in each channel, the result is the extracted information of pixels. The number of steps the filter moves in each time is called the stride, which is conventionally set to 1. In this way, the size of an image is narrowed to . However, the stride can be other values, such as 2 or 3, when dealing with several large images. For example, the image is narrowed to when the value is set to p. To avoid from becoming an integer, several columns and rows are added to the input, an action that is called padding. Thus, the data volume of the input can be effectively reduced through the convolution layer.
- (2)
- Pooling layer: This layer is also called the sub-sampling layer, which is frequently the next layer of the convolution layer. This layer progressively reduces the data volume of the data from the previous convolution layer. Similar to the filter in the convolution layer, a matrix also exists in the pooling layer that passes through the entire input image. The functions in the matrix can be the average, max, and positive functions. To reduce information loss, each channel is dealt with several pooling layers with different functions. Thus, the channels of the input image increase through the pooling layer.
- (3)
- Full connection layer: This layer is the final layer of a CNN. In this layer, the neurons connect with all of the neurons from the previous layer. After this layer, the input image with multiple dimensions is translated to one-dimensional (1D) data that are used for classification or regression. The CNN structure is shown in Figure 4.
5. Experiment
5.1. Kernel Density of Commercial Activity Points
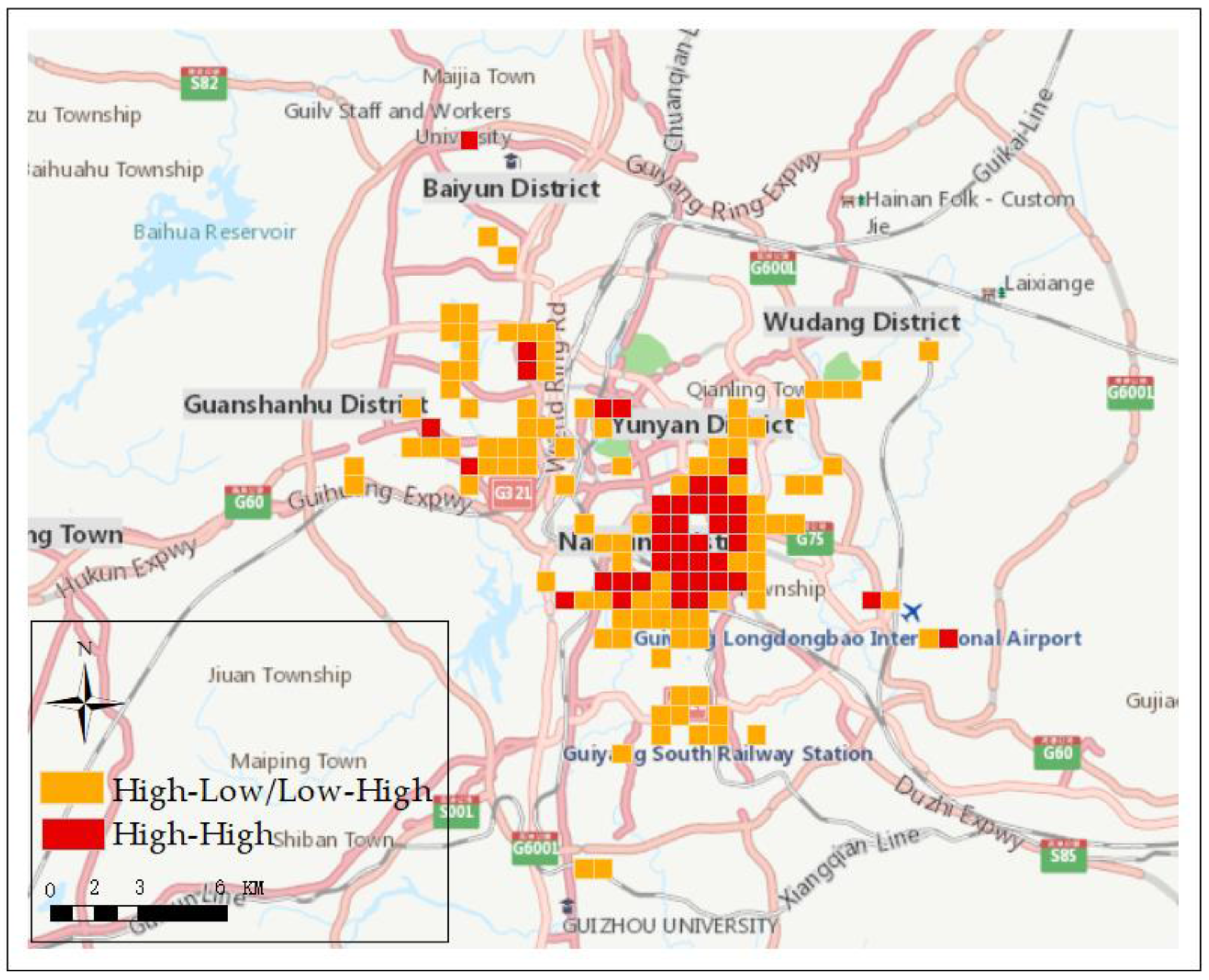
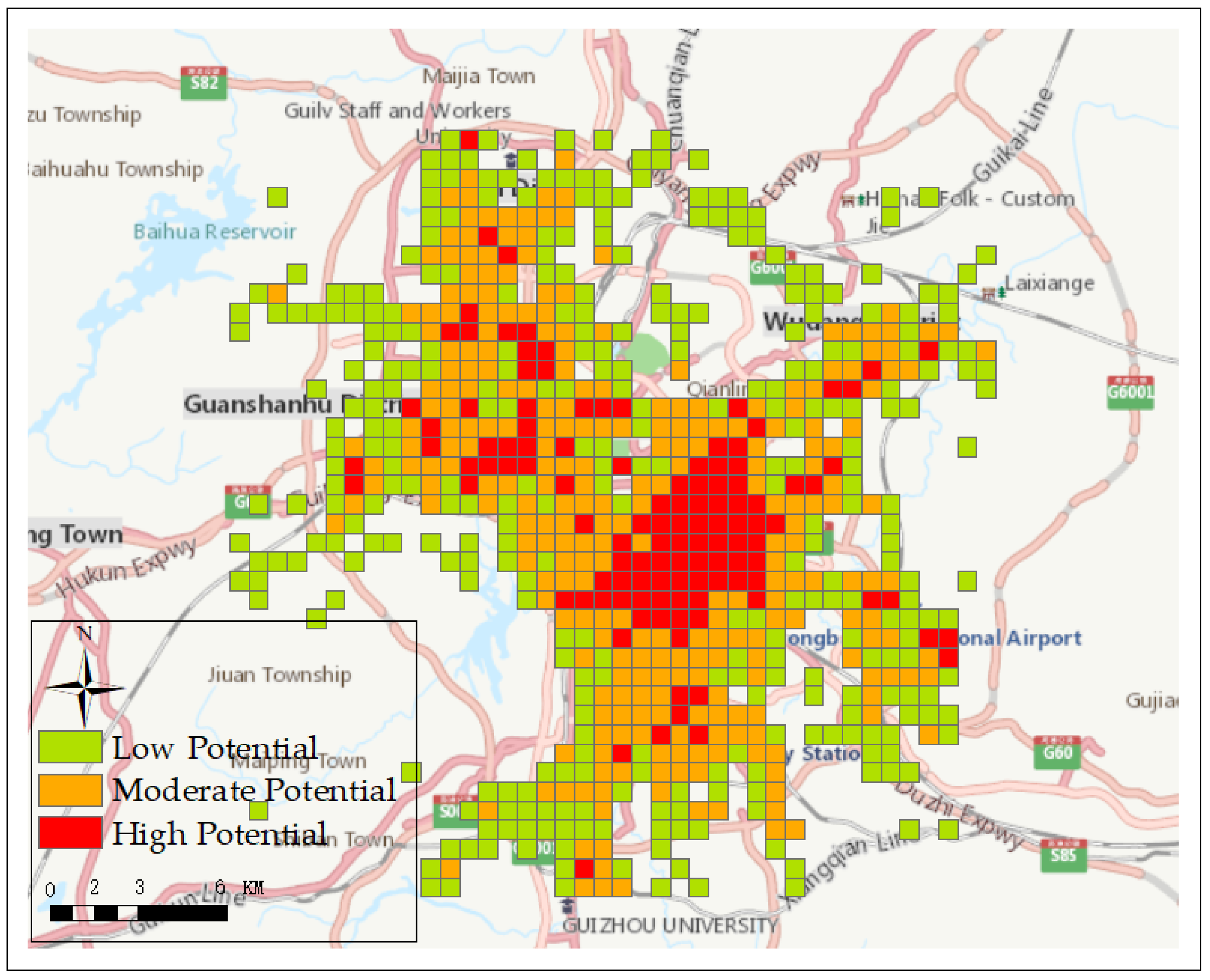
5.2. Market Potential Estimation and Sustainability Evaluation
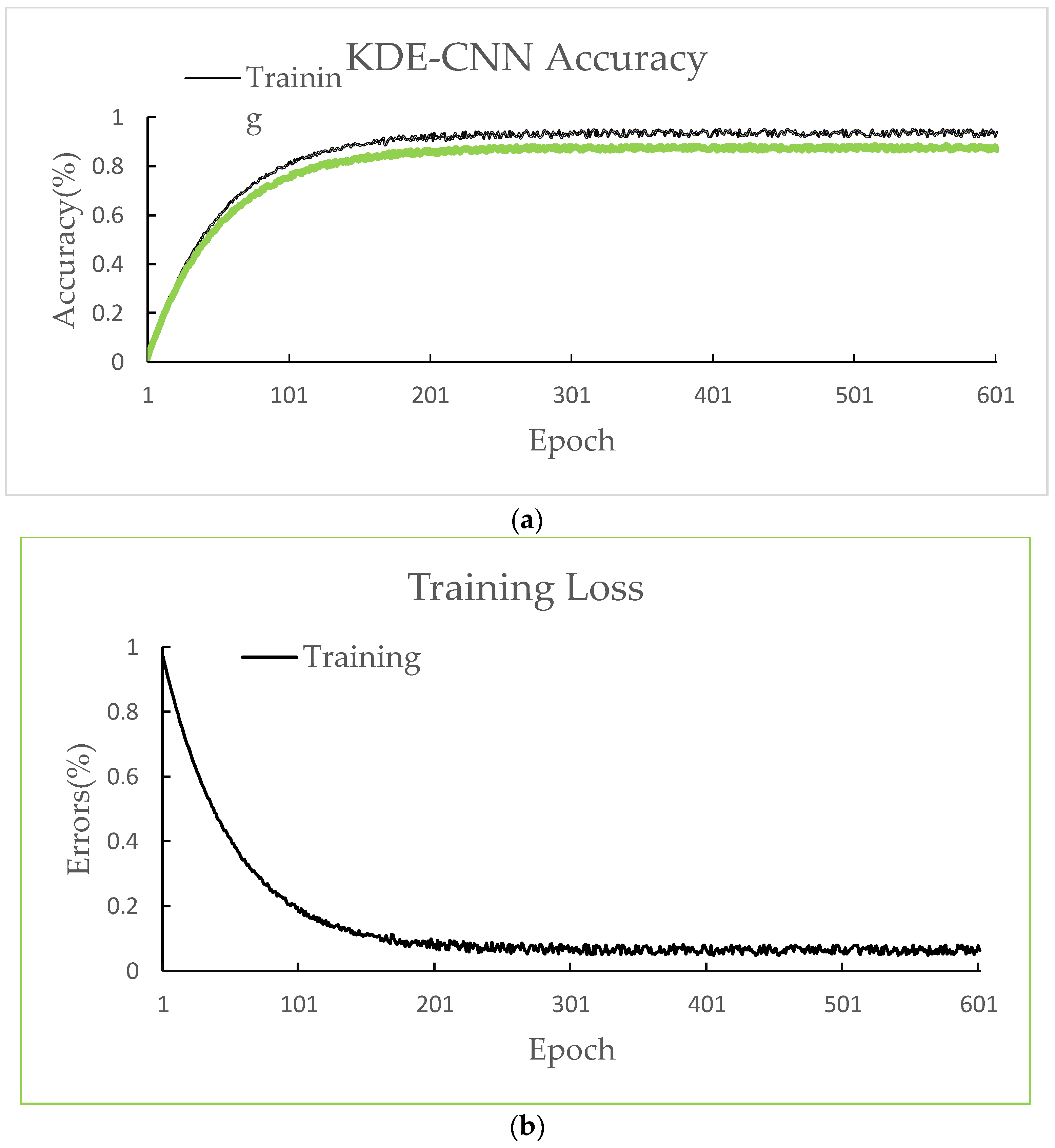
5.3. Accuracy Analysis and Comparison
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mcneill, L.S. The influence of culture on retail sales promotion use in chinese supermarkets. Australas. Mark. J. 2006, 14, 34–46. [Google Scholar] [CrossRef]
- İşlek, İ.; Öğüdücü, Ş.G. A Retail Demand Forecasting Model Based on Data Mining Techniques. In Proceedings of the IEEE International Symposium on Industrial Electronics, Buzios, Brazil, 3–5 June 2015; pp. 55–60. [Google Scholar]
- Li, Y.; Liu, L. Assessing the impact of retail location on store performance: A comparison of wal-mart and kmart stores in cincinnati. Appl. Geogr. 2012, 32, 591–600. [Google Scholar] [CrossRef]
- O’Kelly, M.E. Trade-area models and choice-based samples: Methods. Environ. Plan. A 1999, 31, 613–627. [Google Scholar] [CrossRef]
- Adnan, M.; Leak, A.; Longley, P. A geocomputational analysis of twitter activity around different world cities. ISPRS Int. J. Geo-Inf. 2014, 17, 145–152. [Google Scholar] [CrossRef]
- Sun, Y. Investigating “locality” of intra-urban spatial interactions in new york city using foursquare data. ISPRS Int. J. Geo-Inf. 2016, 5, 43. [Google Scholar] [CrossRef]
- Laylavi, F.; Rajabifard, A.; Kalantari, M. A multi-element approach to location inference of twitter: A case for emergency response. ISPRS Int. J. Geo-Inf. 2016, 5, 56. [Google Scholar] [CrossRef]
- Granell, C.; Ostermann, F.O. Beyond data collection: Objectives and methods of research using vgi and geo-social media for disaster management. Comput. Environ. Urban Syst. 2016, 59, 231–243. [Google Scholar] [CrossRef]
- Qingwu, H.U.; Ming, W.; Qingquan, L.I. Urban hotspot and commercial area exploration with check-in data. Acta Geod. Cartogr. Sin. 2014, 43, 314–321. [Google Scholar]
- Qu, Y.; Zhang, J. Trade area analysis using user generated mobile location data. In Proceedings of the International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1053–1064. [Google Scholar]
- Wang, Y.; Jiang, W.; Liu, S.; Ye, X.; Wang, T. Evaluating trade areas using social media data with a calibrated huff model. ISPRS Int. J. Geo-Inf. 2016, 5, 112. [Google Scholar] [CrossRef]
- Huff, D.L. Defining and estimating a trading area. J. Mark. 1964, 28, 34–38. [Google Scholar] [CrossRef]
- Choi, T.M.; Chiu, C.H. Mean-downside-risk and mean-variance newsvendor models: Implications for sustainable fashion retailing. Int. J. Prod. Econ. 2012, 135, 552–560. [Google Scholar] [CrossRef]
- Mayer, H.; Knox, P.L. Slow cities: Sustainable places in a fast world. J. Urban Aff. 2006, 28, 321–334. [Google Scholar] [CrossRef]
- Zarandi, M.H.F.; Mansour, S.; Hosseinijou, S.A.; Avazbeigi, M. A material selection methodology and expert system for sustainable product design. Int. J. Adv. Manuf. Technol. 2011, 57, 885–903. [Google Scholar] [CrossRef]
- Altug, M.S.; Aydinliyim, T. Counteracting strategic purchase deferrals: The impact of online retailers’ return policy decisions. Soc. Sci. Electron. Publ. 2014, 18, 376–392. [Google Scholar] [CrossRef]
- Bernstein, F.; Federgruen, A. Decentralized supply chains with competing retailers under demand uncertainty. Manag. Sci. 2005, 51, 18–29. [Google Scholar] [CrossRef]
- Lippman, S.A.; Mccardle, K.F. The competitive newsboy. Oper. Res. 1997, 45, 54–65. [Google Scholar] [CrossRef]
- Chien, C.F.; Chen, Y.J.; Peng, J.T. Manufacturing intelligence for semiconductor demand forecast based on technology diffusion and product life cycle. Int. J. Prod. Econ. 2010, 128, 496–509. [Google Scholar] [CrossRef]
- Anderson, E.W.; Fornell, C.; Lehmann, D.R. Customer satisfaction, market share, and profitability: Findings from sweden. J. Mark. 1994, 58, 53–66. [Google Scholar] [CrossRef]
- Rabinovich, E.; Rungtusanatham, M.; Laseter, T.M. Physical distribution service performance and internet retailer margins: The drop-shipping context. J. Oper. Manag. 2008, 26, 767–780. [Google Scholar] [CrossRef]
- Tokatli, N. Global sourcing: Insights from the global clothing industry—The case of ZARA, a fast fashion retailer. J. Econ. Geogr. 2008, 8, 21–38. [Google Scholar] [CrossRef]
- Oppewal, H.; Holyoake, B. Bundling and retail agglomeration effects on shopping behavior. J. Retail. Consum. Serv. 2004, 11, 61–74. [Google Scholar] [CrossRef]
- KhosrowDehnad. Density estimation for statistics and data analysis. Technometrics 2012, 29, 495. [Google Scholar]
- Paralikas, J.; Fysikopoulos, A.; Pandremenos, J.; Chryssolouris, G. Product modularity and assembly systems: An automotive case study. CIRP Ann.-Manuf. Technol. 2011, 60, 165–168. [Google Scholar] [CrossRef]
- Wang, S.Y.; Wang, L.; Liu, M.; Xu, Y. An effective estimation of distribution algorithm for solving the distributed permutation flow-shop scheduling problem. Int. J. Prod. Econ. 2013, 145, 387–396. [Google Scholar] [CrossRef]
- Korpusik, M.; Sakaki, S.; Chen, Y.Y. Recurrent Neural Networks for Customer Purchase Prediction on Twitter; ACM Conference on Recommender Systems (RecSys). 2016. Available online: http://ceur-ws.org/Vol-1673/paper9.pdf (accessed on 28 May 2018).
- Kalogirou, S.A.; Bojic, M. Artificial neural networks for the prediction of the energy consumption of a passive solar building. Energy 2000, 25, 479–491. [Google Scholar] [CrossRef]
- Marvuglia, A.; Messineo, A. Using recurrent artificial neural networks to forecast household electricity consumption. Energy Procedia 2012, 14, 45–55. [Google Scholar] [CrossRef]
- Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biol. 1990, 52, 99. [Google Scholar]
- González, A.G. Artificial intelligence and soft computing: Behavioral and cognitive modeling of the human brain, amit konar. J. Chemom. 2001, 15, 685–687. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Fang, H.; Lv, P.; Cui, L.; Zhang, S.; Zhou, B. D-stc: Deep learning with spatio-temporal constraints for train drivers detection from videos. Pattern Recognit. Lett. 2017. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Françoislavet, V.; Taralla, D.; Ernst, D.; Fonteneau, R. Deep reinforcement learning solutions for energy microgrids management. In Proceedings of the European Workshop on Reinforcement Learning (EWRL 2016), Barcelona, Spain, 3–4 December 2016. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. Adv. Neural Inf. Process. Syst. 2013, 26, 2553–2561. [Google Scholar]
- Triana, N.; Cerquera, A. Computer-aided detection of microcalcifications in digital mammograms to support early diagnosis of breast cancer. In Proceedings of the V International Work-Conference on the Interplay Between Natural and Artificial Computation, Mallorca, Spain, 10–14 June 2013; pp. 293–302. [Google Scholar]
- Ashiquzzaman, A.; Tushar, A.K. Handwritten arabic numeral recognition using deep learning neural networks. In Proceedings of the IEEE International Conference on Imaging, Vision & Pattern Recognition, Dhaka, Bangladesh, 13–14 February 2017; pp. 1–4. [Google Scholar]
- Zhang, J.; Zheng, Y.; Qi, D. Deep spatio-temporal residual networks for citywide crowd flows prediction. arXiv, 2016; arXiv:1610.00081. [Google Scholar]
- Anderson, T.K. Kernel density estimation and k-means clustering to profile road accident hotspots. Accid. Anal. Prev. 2009, 41, 359. [Google Scholar] [CrossRef] [PubMed]
- Tobler, W.R. A computer movie simulating urban growth in the detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Mikelbank, B.A. Quantitative geography: Perspectives on spatial data analysis, by a. S. Fotheringham, c. Brunsdon, and m. Charlton. Geogr. Anal. 2001, 33, 370–372. [Google Scholar] [CrossRef]
- Cai, X.J.; Zhi-Feng, W.U.; Cheng, J. Analysis of road network pattern and landscape fragmentation based on kernel density estimation. Chin. J. Ecol. 2012, 31, 158–164. [Google Scholar]
- Wang, L.; Fan, H.; Gong, T. The consumer demand estimating and purchasing strategies optimizing of fmcg retailers based on geographic methods. Sustainability 2018, 10, 466. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Retail ID | Name | Types | Lon | Lat | Sales (US Dollars/Month) |
|---|---|---|---|---|---|
| 54116864 | Small supermarket | Hualian Supermarket | 106.717 | 26.605 | 68,152 |
| 54116360 | Small supermarket | Yonghui Supermarket | 106.715 | 26.583 | 41,516 |
| 54127706 | Chain convenience store | Hanlejia 24 h chain store | 106.719 | 26.571 | 18,196 |
| 54130581 | Groceries | Youjia Grocery | 106.695 | 26.335 | 7289 |
| Data Types | Description | Data Volume | Time | Source |
|---|---|---|---|---|
| Media data | Web check-in data Section of users | 75,000+ | 2016 | Sina Weibo API |
| Retailer Locations | Longitude and latitude of retailers | 5614 | 2016 | Local Cooperative Enterprises |
| Retailer Sales | FMCG sales of each retailer | 5614 | 2016 | Local Cooperative Enterprises |
| Basic map | Vector map data of Guiyang | Entire City | 2016 | OpenStreetMap (OSM) |
| Colors | Number | Market Potential | Confidence |
|---|---|---|---|
| Red | 40 | H-H | >0.75 |
| Orange | 100 | H-L/L-H | 0.35–0.74 |
| Model | RMSE |
|---|---|
| Arima | 0.275 |
| SArima | 0.301 |
| OLS(ordinary least squares) | 0.162 |
| CNN | 0.117 |
| KDE-CNN(Ours) | 0.065 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Fan, H.; Wang, Y. Sustainability Analysis and Market Demand Estimation in the Retail Industry through a Convolutional Neural Network. Sustainability 2018, 10, 1762. https://doi.org/10.3390/su10061762
Wang L, Fan H, Wang Y. Sustainability Analysis and Market Demand Estimation in the Retail Industry through a Convolutional Neural Network. Sustainability. 2018; 10(6):1762. https://doi.org/10.3390/su10061762
Chicago/Turabian StyleWang, Luyao, Hong Fan, and Yankun Wang. 2018. "Sustainability Analysis and Market Demand Estimation in the Retail Industry through a Convolutional Neural Network" Sustainability 10, no. 6: 1762. https://doi.org/10.3390/su10061762
APA StyleWang, L., Fan, H., & Wang, Y. (2018). Sustainability Analysis and Market Demand Estimation in the Retail Industry through a Convolutional Neural Network. Sustainability, 10(6), 1762. https://doi.org/10.3390/su10061762